۱٫ مقدمه
در چند سال گذشته، علاقه فزاینده ای به رانندگی خودران افزایش یافته است، زیرا وسایل نقلیه خودکار پتانسیل حذف خطای انسانی در تصادفات رانندگی را دارند که به محافظت از رانندگان و مسافران و کاهش آسیب های اقتصادی کمک می کند. با این حال، راه درازی باقی مانده است تا رانندگی خودران به طور کامل جایگزین رانندگی انسان شود. محیط جاده به دلیل تعامل بین عوامل راه مانند خودروها، کامیون ها و عابران پیاده بسیار پویا و پیچیده است. برای رانندگی ایمن و کارآمد، وسایل نقلیه خودران باید اشیاء دیگر را شناسایی و شناسایی کنند و رفتار این اشیاء در آینده کوتاه مدت مانند انسان ها را پیش بینی کرده و به آن واکنش نشان دهند. بنابراین، پیشبینی مسیر سایر عوامل جادهای برای تصمیمگیری عاقلانه وسیله نقلیه خودران ضروری است.
پیشبینی مسیر به دلایل زیر یک مشکل نسبتاً چالش برانگیز است. اولاً، یک وابستگی متقابل بین وسایل نقلیه وجود دارد که در آن رفتارهای یک وسیله نقلیه بر رفتار دیگران تأثیر می گذارد [ ۱]. به عنوان مثال، یک راننده انسانی معمولاً هنگامی که وسیله نقلیه جلو در حال ترمز است، سرعت ماشین خود را کاهش می دهد. بنابراین، برای پیشبینی دقیق مسیر یک وسیله نقلیه، یک مدل پیشبینی مسیر باید مسیرهای همسایه این وسیله نقلیه را نیز پیشبینی کند و تعاملات احتمالی آینده را بین آنها در نظر بگیرد. دوم، انباشته شدن خطاها. مدلهای پیشبینی مسیر معمولاً موقعیت بعدی خودرو را بر اساس موقعیت فعلی و قبلی آن پیشبینی میکنند. در نتیجه، مدل خطاها را در هر مرحله جمع میکند که منجر به عملکرد ضعیف در پیشبینی مسیر بلندمدت میشود. سوم، به دلیل تصمیمات راننده [ ۲ ]، مسیر در طول زمان بسیار غیرخطی است، که چالشی جدی برای مدلهای دینامیکی سنتی و مدلهای یادگیری ماشین ایجاد میکند.
اکثر مطالعات اخیر در مورد پیش بینی مسیر از روش های یادگیری عمیق استفاده می کنند. برای مدلسازی تعاملات بین وسایل نقلیه، مطالعات قبلی تلاش کردهاند اطلاعات فضایی وسایل نقلیه را بهعنوان تانسورهای اجتماعی مبتنی بر خط یا ساختارهای نمودار نشان دهند و لایههای ادغام را برای به دست آوردن رمزگذاری بافت اجتماعی اعمال کنند. اگرچه این روشها تعامل فضایی مسیرهای تاریخی وسیله نقلیه هدف و همسایگان آن را در مرحله رمزگذاری ثبت میکنند، آنها فقط مسیر آینده خودروی هدف را هنگام رمزگشایی پیشبینی میکنند و تعاملات احتمالی آینده بین وسیله نقلیه هدف و همسایگانش را نادیده میگیرند. در حالی که ترانسفورماتور [ ۳]، یک شبکه مبتنی بر توجه چند سر، توانایی قابل توجه خود را در بسیاری از وظایف مدلسازی دنبالهای (مثلاً ترجمه ماشینی در پردازش زبان طبیعی) نسبت به RNN نشان داده است، در پیشبینی مسیر چندان مورد بررسی قرار نگرفته است. علاوه بر این، کارهای قبلی معمولاً از دو لایه ترانسفورماتور برای مدلسازی جداگانه وابستگی زمانی مسیر و وابستگی متقابل فضایی وسایل نقلیه استفاده میکنند [ ۴ ، ۵ ].
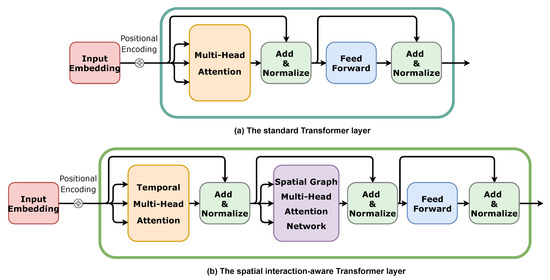
در این مقاله، ما یک مدل مبتنی بر ترانسفورماتور مبتنی بر تعامل فضایی را ارائه میکنیم. برخلاف لایه ترانسفورماتور استاندارد که فقط یک ماژول خودتوجهی چند سر دارد، ترانسفورماتور جدید آگاه از تعامل فضایی (SIT) شامل دو ماژول خودتوجهی چند سر است. به طور خاص، این دو ماژول توجه دو ماسک توجه متفاوت دارند، یکی برای گرفتن وابستگی های زمانی مسیرها و دیگری برای مدل سازی تعاملات فضایی بین وسایل نقلیه. SIT پیشنهادی یک راه حل منظم و کارآمد برای ادغام اطلاعات زمینه زمانی و مکانی تنها بر اساس مکانیسم توجه به خود ارائه می دهد. با انباشتن چندین لایه SIT، مدل ما میتواند اطلاعات زمانی و مکانی پیچیدهتر و انتزاعیتری را ثبت کند. علاوه بر این، مدل پیشنهادی شامل یک ماژول رمزگذار-رمزگشا مبتنی بر GRU در بالای لایههای SIT برای پیشبینی نهایی است. هنگام رمزگشایی، برای هر مرحله زمانی، رمزگشا به آخرین حالت های مخفی خروجی همه وسایل نقلیه مشاهده شده دسترسی پیدا می کند و از یک ماژول خودتوجهی چند سر برای هدایت پیام رسانی و مدل سازی تعاملات احتمالی آینده بین این وسایل نقلیه استفاده می کند.
ما روش خود را بر روی مجموعه داده های عمومی NGSIM US-101 و I-80 ارزیابی می کنیم. نتایج تجربی نشان میدهد که روش ما با بهبود عملکرد قابل توجهی از سایر خطوط پایه بهتر عمل میکند. ما بیشتر مطالعات فرسایشی انجام می دهیم تا برتری روش خود را نسبت به انواع آن نشان دهیم که از لایه های ترانسفورماتور استاندارد یا رمزگذار-رمزگر استاندارد GRU استفاده می کنند.
مشارکت های اصلی این کار به شرح زیر خلاصه می شود:
-
یک مدل مبتنی بر ترانسفورماتور مبتنی بر تعامل فضایی برای ضبط و ادغام موثر وابستگیهای زمانی مسیرها و تعاملات فضایی بین وسایل نقلیه پیشنهاد شدهاست.
-
رمزگشایی که ارسال پیام را برای همه وسایل نقلیه در نظر می گیرد برای مدل سازی تعاملات احتمالی آینده بین وسایل نقلیه مشاهده شده استفاده می شود.
۲٫ بررسی ادبیات
۲٫۱٫ پیش بینی توالی
RNN ها، به عنوان مثال، GRU [ ۶ ] و LSTM [ ۷ ]، به موفقیت های زیادی در کارهای پیش بینی توالی، به عنوان مثال، تشخیص گفتار، ترجمه ماشینی، تصمیم گیری ربات، و غیره دست یافته اند. RNN ها همچنین کاربردهای گسترده ای در مدل سازی الگوهای حرکت زمانی وسایل نقلیه دارند. [ ۲ , ۸ , ۹ , ۱۰ , ۱۱ , ۱۲ ] و عابران پیاده [ ۱۳ , ۱۴ , ۱۵ , ۱۶ , ۱۷]. پیشبینیکنندههای مسیر مبتنی بر RNN معمولاً دارای معماری رمزگذار-رمزگشا هستند. با توجه به محدودیت در مدلسازی تعامل فضایی، که برای پیشبینی مسیر ضروری است، RNNها معمولاً نیاز به همکاری با یک ساختار اضافی، مانند شبکههای عصبی کانولوشنال (CNN) [ ۲ ، ۱۸ ، ۱۹ ]، مکانیسم توجه [ ۴ ، ۱۸ ] و شبکه های عصبی نموداری (GNN) [ ۸ ، ۲۰ ، ۲۱ ].
ترانسفورماتورها، بر اساس مکانیسم های توجه، در سال های اخیر بر پردازش زبان طبیعی (NLP) تسلط داشته اند [ ۲۲ ، ۲۳ ، ۲۴ ، ۲۵ ، ۲۶ ]. به دلیل عدم وجود تکرار، این معماری نسبت به RNN ها توانایی بیشتری در مدل سازی وابستگی طولانی مدت و آموزش موازی سازی دارد. یو و همکاران [ ۴ ] دو ترانسفورماتور جداگانه را به ترتیب برای استخراج فعل و انفعالات مکانی و زمانی بین عابران پیاده اعمال کنید. با این حال، معماری ترانسفورماتور در پیش بینی مسیر خودرو چندان مورد بررسی قرار نگرفته است.
۲٫۲٫ مدل سازی تعامل فضایی
رویکردهای مرسوم [ ۲۷ ، ۲۸ ، ۲۹ ] معمولاً مسیر آینده شی هدف را تنها بر اساس وضعیت فعلی و تاریخچه مسیر پیش بینی می کنند. با این حال، در یک محیط جاده شلوغ، تنها تکیه بر تاریخچه مسیر هدف ممکن است منجر به نتایج پیشبینی نادرست، به ویژه برای پیشبینیهای بلندمدت شود [ ۱ ]. برای مدلسازی تعامل فضایی بین وسایل نقلیه یا عابران پیاده، برخی از مطالعات تاریخچه مسیر هدف و اشیاء اطراف آن را به پیشبینیکننده میخورند و از CNN [ ۲ ، ۱۸ ، ۱۹ ]، مکانیسم توجه [ ۴ ، ۱۸ ، ۳۰ ، ۳۱ ] استفاده میکنند.] یا GNN [ ۸ ، ۲۰ ، ۲۱ ] برای پیاده سازی ارسال پیام از میان این اشیا.
الهی و همکاران [ ۱۳ ] LSTMهای همسایه را از طریق استراتژی ادغام اجتماعی به هم متصل می کنند، که به LSTMهای نزدیک به فضایی اجازه می دهد تا اطلاعات را با یکدیگر به اشتراک بگذارند. دیو و همکاران [ ۲ ] اشیاء همسایه را با یک تانسور اجتماعی نشان میدهد و یک ادغام اجتماعی کانولوشنال را برای بهبود روش ادغام اجتماعی پیشنهاد شده در [ ۱۳ ] پیشنهاد میکند.
در مقایسه با روش های ادغام، مکانیسم توجه می تواند اهمیت همسایگان مختلف را برای یک شی معین تخمین بزند. ژانگ و همکاران [ ۱۴ ] یک دروازه حرکتی و یک ماژول توجه عابر پیاده را برای تمرکز سازگارانه بر مفیدترین اطلاعات همسایه و هدایت پیام در عبور پیشنهاد دهید. یو و همکاران [ ۴ ] تعاملات مکانی-زمانی را توسط دو ترانسفورماتور مکانی و زمانی جداگانه ثبت کنید.
در یک محیط رانندگی، میتوان وسایل نقلیه یا عابران پیاده و برهمکنشهای آنها را نموداری در نظر گرفت که گرهها و لبهها به ترتیب بیانگر اجسام و تعاملات فضایی بین آنها هستند. از آنجایی که GNN ها به طور طبیعی برای داده های ساختاریافته گراف مناسب هستند، برای مدل سازی تعامل فضایی نیز استفاده می شوند. لی و همکاران [ ۲۰ ] از یک نمودار برای نشان دادن تعاملات اشیاء همسایه استفاده کنید و چندین بلوک کانولوشنی گراف را برای استخراج ویژگی ها اعمال کنید. یو و همکاران [ ۴ ] و پانگ و همکاران. [ ۵ ] از یک ترانسفورماتور فضایی برای مدلسازی اشیاء مجاور بهعنوان یک نمودار استفاده کنید و یک پیچیدگی گراف گذر پیام مبتنی بر ترانسفورماتور را برای ثبت تعاملات اجتماعی اعمال کنید. پنگ و همکاران [ ۳۲] از توجهات روابط اجتماعی برای مدل سازی تعاملات فضایی بر اساس موقعیت نسبی عابران پیاده استفاده می کند. برای اجتناب از مدلسازی مسیرهای چند عاملی در ابعاد زمانی و اجتماعی به طور جداگانه، یوان و همکاران. [ ۳۳ ] یک ترانسفورماتور آگاه از عامل را پیشنهاد میکند تا از نمایش دنبالهای از مسیرهای چند عاملی با مسطح کردن ویژگیهای مسیر در طول زمان و عوامل استفاده کند.
اگرچه این مطالعات تعاملات بین اشیاء همسایه را با مدلسازی روابط فضایی آنها تشخیص میدهند، اما فقط تعاملات بین مسیرهای مشاهدهشده را در نظر میگیرند و برهمکنشهای بالقوه بین مسیرهای آینده وسیله نقلیه هدف و همسایگان آن را در مرحله پیشبینی نادیده میگیرند.
۳٫ فرمول مسئله
این کار مشکل پیشبینی مسیر را بهعنوان پیشبینی مسیر آینده همه اشیاء در یک صحنه مشاهدهشده بر اساس سیر تاریخی آنها فرموله میکند. با توجه به اینکه پیشبینی سرعت یک جسم آسانتر از پیشبینی مکان آن است [ ۲۰ ]، مکانها و سرعتهای تاریخی را به مدل خود وارد میکنیم و به مدل اجازه میدهیم سرعتهای آینده را پیشبینی کند. سپس، سرعت های پیش بینی شده و آخرین مکان های مشاهده شده را جمع آوری می کنیم تا پیش بینی مکان نهایی را بدست آوریم.
همانطور که در بالا توضیح داده شد، ورودی های X مدل ما، مسیرها و سرعت های تاریخی همه وسایل نقلیه مشاهده شده هستند. مراحل زمانی:
جایی که
مختصات را نشان می دهد و سرعت ها از تمام وسایل نقلیه در صحنه مشاهده شده در زمان t . n تعداد وسایل نقلیه مشاهده شده است. خروجیهای Y مدل ما، سرعتهای آینده پیشبینیشده همه وسایل نقلیه مشاهدهشده از مرحله زمانی است به ، و افق پیش بینی شده است:
جایی که
به دنبال [ ۲ ، ۲۰ ]، وسایل نقلیه در ۹۰ فوت از مرکز وسیله نقلیه مورد نظر مشاهده می شوند.
۴٫ روش شناسی
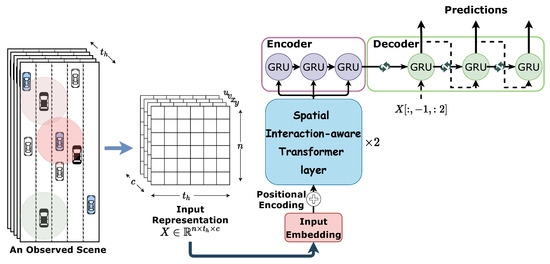
شکل ۱ مدل پیشنهادی ما را نشان می دهد که از سه جزء تشکیل شده است: یک ماژول پیش پردازش ورودی، لایه های ترانسفورماتور آگاه از تعامل فضایی، و یک مدل پیش بینی مسیر.
۴٫۱٫ ماژول پیش پردازش ورودی
۴٫۱٫۱٫ نمایش ورودی
به دنبال [ ۲۰ ]، برای محاسبات کارآمد بعدی، ما مستقیماً داده های سیر خام اشیاء را به مدل خود وارد نمی کنیم. با توجه به یک صحنه ترافیک، با فرض وجود n شیء در گذشته مشاهده شده است مراحل زمانی، داده های خام را به یک تانسور سه بعدی از قبل پردازش می کنیم همانطور که در شکل ۱ نشان داده شده است. تنظیم کردیم برای علامت گذاری مختصات یک شی و سرعت در یک گام زمانی، و همه مختصات و سرعت ها را به محدوده .
۴٫۱٫۲٫ ساخت نمودار فضایی
در سناریوهای ترافیکی، حرکت یک وسیله نقلیه تا حد زیادی تحت تأثیر وسایل نقلیه اطراف آن است. بنابراین، ما فکر می کنیم که نشان دادن وابستگی های متقابل بین وسایل نقلیه به عنوان نمودارهای غیر جهت دار کارآمد است. به طور خاص، برای هر مرحله زمانی مشاهده شده t ، یک گراف بدون جهت می سازیم ، که در آن گره ها و لبه ها به ترتیب نشان دهنده اشیاء و تعاملات فضایی بین آنهاست. گره تنظیم شده در مرحله زمانی t به صورت تعریف شده است ، در حالی که لبه مجموعه در زمان گام t به عنوان نشان داده می شود .
در هر مرحله زمانی t ، یک برهمکنش فضایی تنها زمانی اتفاق می افتد که فاصله فعلی بین دو جسم از یک آستانه کوتاهتر باشد. و این دو شی در خطوط مجاور هستند، به عنوان مثال، . برای کارایی محاسبات، میتوانیم نشان دهیم به عنوان یک ماتریس مجاورت . بنابراین، در هر مرحله زمانی t ،
که در آن n تعداد وسایل نقلیه مشاهده شده است. با توجه به n وسیله نقلیه مسیر مشاهده شده با طول مراحل زمانی، ما می توانیم ماتریس های مجاورت را بدست آوریم همانطور که در بالا توضیح داده شد. این ماتریس های مجاورت بخشی از ورودی های مدل ما هستند.
۴٫۲٫ ترانسفورماتور آگاه از تعامل فضایی
با توجه به داده های ورودی به دست آمده از ماژول پیش پردازش، ابتدا دو عملیات زیر را انجام می دهیم:
۴٫۲٫۱٫ جاسازی
علامت گذاری می کنیم و این شبکه جاسازی را اعمال کنید نقشه برداری ، که وضعیت جسم i را در مرحله زمانی t ، به یک نمایش پنهان نشان می دهد ، که در آن مختصات و سرعت با هم متحد می شوند تا کار مدل سازی زمینه بعدی آسان شود:
جایی که وزن تعبیه شده است. این مقاله از یک پرسپترون چند لایه (MLP) به عنوان شبکه جاسازی استفاده می کند .
۴٫۲٫۲٫ رمزگذاری موقعیتی
اگرچه معماری ترانسفورماتور میتواند وابستگیهای دنبالهای طولانیتر را ثبت کند و با اجتناب از روش مکانیزم تکرار RNN، سرعت زیادی را هنگام آموزش به دست آورد، اما هیچ حس نظمی برای هر عنصر در یک دنباله ندارد. در نتیجه، الحاق ترتیب عناصر ورودی به مدل ترانسفورماتور، حیاتی است، به خصوص زمانی که دادههای سری زمانی، به عنوان مثال، دادههای مسیر را مدیریت میکنیم. بنابراین، در این مقاله، هر ورودی تعبیه شده است با اضافه کردن یک بردار رمزگذاری موقعیتی، با زمان t خود مهر زمان میشود شکل دادن . هر دو و دارای ابعاد یکسانی هستند . برای سادگی، بردارهای رمزگذاری موقعیتی را به عنوان یک ماتریس مقداردهی اولیه می کنیم ، که در آن بردار هر ردیف بردار رمزگذاری موقعیتی مرحله زمانی t را نشان می دهد. بدین ترتیب، . این یک مهر زمانی منحصر به فرد را برای هر مکان تاریخی یک شی تضمین می کند. هنگام آموزش ، ماتریس P در شرکت با مدل بهینه می شود.
با انجام دو عمل فوق بر روی هر کدام برای و ، می توانیم بدست آوریم ، که ورودی اولین لایه ترانسفورماتور آگاه از تعامل فضایی است.
برخلاف لایه رمزگذار استاندارد ترانسفورماتور، که فقط در مدلسازی وابستگی زمانی مناسب است، لایه ترانسفورماتور آگاه از تعامل فضایی پیشنهادی (SIT) میتواند وابستگیهای زمانی مسیرها و تعاملات فضایی بین وسایل نقلیه را ضبط و ادغام کند. همانطور که در شکل ۲ نشان داده شده است ، در مقایسه با لایه ترانسفورماتور استاندارد، SIT ما همچنین حاوی یک شبکه توجه چند سر نمودار فضایی است که برای ثبت تعاملات فضایی بین وسایل نقلیه بسته بر اساس ماتریسهای مجاورت A استفاده میشود . محتوای زیر توضیح می دهد که چگونه یک لایه SIT وابستگی های زمانی مسیرها و تعاملات فضایی بین وسایل نقلیه را با استفاده از ماژول توجه چند سر زمانی و شبکه توجه چند سر نمودار فضایی مدل می کند.
۴٫۲٫۳٫ ماژول توجه چند سر زمانی
مشابه لایه رمزگذار ترانسفورماتور استاندارد، SIT از یک ماژول توجه چند سر پوشانده استفاده می کند تا وابستگی زمانی مسیر هر وسیله نقلیه را به طور مستقل ثبت کند. این ماژول توجه پوشانده مانع از حضور مراحل بعدی در مراحل بعدی می شود. با توجه به ورودی ، ماژول توجه ابتدا ماتریس های پرس و جو را محاسبه می کند ، ماتریس های کلیدی و ماتریس های مقدار . برای i- امین وسیله نقلیه، ما محاسبه می کنیم
جایی که ، و توابع مربوط به پرس و جو، کلید و ارزش به اشتراک گذاشته شده توسط وسایل نقلیه هستند ; و ، . برای مسیر وسیله نقلیه i ، همانطور که در شکل ۳ a نشان داده شده است، پیام عبور از مرحله زمانی s به t را به صورت تعریف می کنیم.
سپس، توجه پوشانده شده را برای وسیله نقلیه i در مرحله زمانی t به صورت زیر محاسبه می کنیم:
جایی که نشان می دهد که مرحله فعلی فقط می تواند به مراحل قبلی خود دسترسی داشته باشد. به طور مشابه، ما می توانیم توجه چند سر پوشانده شده ( k سر) را برای وسیله نقلیه i برای گام زمانی t بدست آوریم :
جایی که یک لایه کاملا متصل است که اطلاعات k heads را ادغام می کند. پس از محاسبه توجه چند سر برای هر وسیله نقلیه و هر مرحله زمانی ، ما بدست می آوریم ، که حاوی اطلاعات زمانی استخراج شده از مسیرهای تاریخی است.
۴٫۲٫۴٫ شبکه توجه چند سر نمودار فضایی
بر اساس به دست آمده و ماتریس های مجاورت A ، یک گراف فضایی شبکه توجه چند سر برای استخراج تعاملات فضایی بین وسایل نقلیه مشاهده شده اعمال می شود.
مکانیسم توجه به خود را می توان به عنوان پیامی در نظر گرفت که روی یک گراف کاملاً متصل بدون جهت می دهد. برای یک گام زمانی t ، می توانیم n ویژگی وسیله نقلیه را بدست آوریم از T و بردار پرس و جو متناظر، بردار کلید و بردار مقدار را به ترتیب نشان می دهد ، و . مشابه بخش ۴٫۲٫۳ ، ما محاسبه می کنیم
و پیام عبور از وسیله نقلیه j به i را در نمودار کاملاً متصل به صورت تعریف کنید
سپس توجه در مرحله زمانی t را می توان به صورت محاسبه کرد
با این حال، در نظر گرفتن تعاملات فضایی بین وسایل نقلیه به عنوان یک نمودار کاملاً متصل ناکارآمد است. بنابراین، ما از ماتریسهای مجاورت A برای جایگزینی نمودار کاملاً متصل بالا استفاده میکنیم، که تضمین میکند پیام از وسیله نقلیه j به i در یک مرحله زمانی t تنها زمانی که فاصله فعلی این دو وسیله کوتاهتر از یک آستانه باشد، منتقل میشود. و دو وسیله نقلیه در خطوط مجاور هستند، همانطور که در شکل ۳ ب نشان داده شده است. سپس می توانیم محاسبه توجه وسیله نقلیه i را در مرحله زمانی t بازنویسی کنیم :
جایی که مجموعه همسایه وسیله نقلیه i را نشان می دهد. به طور مشابه، ما می توانیم توجه چند سر ( k سر) وسیله نقلیه i را برای گام زمانی t بدست آوریم :
جایی که یک لایه کاملا متصل است که اطلاعات k heads را ادغام می کند. پس از محاسبه توجه چند سر برای هر وسیله نقلیه و هر مرحله زمانی ، ما بدست می آوریم که حاوی اطلاعات تعامل استخراج شده بین خودروهای مشاهده شده است. ما چندین لایه SIT را برای گرفتن اطلاعات زمانی و مکانی پیچیدهتر و انتزاعیتر روی هم قرار میدهیم.
۴٫۳٫ ماژول پیش بینی مسیر
ما یک ماژول رمزگذار-رمزگشا مبتنی بر GRU را برای پیش بینی مسیرهای آینده همه وسایل نقلیه مشاهده شده اعمال می کنیم. خروجی های آخرین لایه SIT به رمزگذار GRU وارد می شود. در اولین مرحله رمزگشایی، هم ویژگی پنهان رمزگذار و هم سرعت تمام اجسام در آخرین مرحله زمانی مشاهده شده برای پیش بینی سرعت وسایل نقلیه به رمزگشا وارد می شود. برای مراحل رمزگشایی زیر، رمزگشا هم ویژگی پنهان خود و هم سرعت های پیش بینی شده همه اشیاء در مرحله زمانی قبلی را به عنوان ورودی برای پیش بینی می گیرد.
با این حال، چنین فرآیندهای رمزگشایی، تعاملات بالقوه در مسیرهای آینده وسایل نقلیه مشاهده شده را نادیده می گیرند. برای مدلسازی آن تعاملات بالقوه، برای هر مرحله رمزگشایی، رمزگشای ما به ویژگیهای پنهان مرحله قبل وسایل نقلیه دسترسی پیدا میکند و از یک ماژول خودتوجهی چند سر برای هدایت پیام در میان آن وسایل نقلیه استفاده میکند. سپس، رمزگشا، ویژگیهای پنهان تعامل شده را به جای ویژگیهای پنهان مبدا به عنوان ورودی میگیرد تا پیشبینی نهایی را انجام دهد، همانطور که در شکل ۱ نشان داده شده است.
۴٫۴٫ جزئیات پیاده سازی
پیرو لی و همکاران [ ۸ ]، یک صحنه ترافیک را در داخل پردازش می کنیم فوت و تمامی وسایل نقلیه در این صحنه در آینده مشاهده و پیش بینی می شود.
هنگام ساخت ماتریس های مجاورت A ، تنظیم می کنیم پا. در لایههای ترانسفورماتور آگاه از تعامل فضایی، اجازه میدهیم ; تعداد سر ماژول های توجه چند سر ۴ است. و تعداد لایه های SIT 2 است.
در ماژول رمزگشای رمزگذار مبتنی بر GRU، هر دو رمزگذار و رمزگشا یک GRU دو لایه هستند. تعداد واحدهای پنهان GRU را برابر با ۶۰ قرار می دهیم و a را اعمال می کنیم عملکرد فعال سازی برای تغییر مقیاس خروجی رمزگشا به محدوده .
کد ما با استفاده از کتابخانه PyTorch [ ۳۴ ] پیاده سازی می شود، ما مدل خود را به عنوان یک کار رگرسیونی آموزش می دهیم. زیان کلی را می توان به صورت زیر محاسبه کرد:
جایی که تعداد مرحله زمانی است که باید در آینده پیش بینی شود، و به ترتیب موقعیت ها و حقیقت زمین در گام زمانی t پیش بینی می شوند. ما با استفاده از مدل آموزش می دهیم [ ۳۵ ] بهینه ساز با ، ، و . میزان یادگیری است . تنظیم کردیم در طول آموزش ما برای تسریع در همگرایی از اجبار معلم در آموزش استفاده می کنیم.
۵٫ ارزیابی تجربی
۵٫۱٫ تنظیمات آزمایشی
این بخش ارزیابی مدل پیشنهادی را ارائه می دهد. برای مقایسه منصفانه با روشهای دیگر، مدل ما بر روی دو مجموعه داده در دسترس عموم آموزش و ارزیابی شد. ما آزمایشها را روی دسکتاپ با Ubuntu 18.04 با پردازنده ۲٫۵۰ گیگاهرتزی Intel Xeon E5-2678، حافظه ۳۲ گیگابایتی و کارت گرافیک NVIDIA 1080Ti انجام میدهیم.
۵٫۱٫۱٫ مجموعه داده
مدل پیشنهادی با استفاده از مجموعه دادههای عمومی NGSIM US-101 و I-80 آموزش و ارزیابی شد. هر دو مجموعه داده در فرکانس ۱۰ هرتز در مدت ۴۵ دقیقه ضبط و به سه دوره ۱۵ دقیقه ای تقسیم شدند. این دورهها شرایط ترافیکی ملایم، متوسط و شلوغ را نشان میدهند. این دو مجموعه داده شامل مسیرهای وسایل نقلیه در ترافیک آزادراه واقعی است. مسیر هر وسیله نقلیه به بخش های ۸ ثانیه ای تقسیم شد که ۳ ثانیه اول به عنوان تاریخچه مسیر مشاهده شده استفاده می شود و ۵ ثانیه باقی مانده افق پیش بینی است. پیروی از Deo et al. [ ۲]، داده های مسیر برای ۱۰ هرتز تا ۵ هرتز، یعنی پنج فریم در ثانیه نمونه برداری شدند. دو مجموعه داده فوق در یک مجموعه داده ادغام می شوند که به طور تصادفی مخلوط شده و به مجموعه آموزشی، مجموعه اعتبار سنجی و مجموعه تست با نسبت ۷:۱:۲ تقسیم می شود. ارزیابی های تجربی زیر بر روی مجموعه آزمون انجام می شود. کد پیش پردازش داده ها و تقسیم بندی داده ها را می توان در GitHub بارگیری کرد ( https://github.com/nachiket92/conv-social-pooling ، در ۱۰ اکتبر ۲۰۲۱ قابل دسترسی است).
۵٫۱٫۲٫ معیارهای ارزیابی
ما از معیارهای ارزیابی مشابه با روشهای دیگر استفاده میکنیم [ ۲ ، ۱۸ ] و نتایج ارزیابی خود را بر اساس ریشه میانگین مربعات خطا گزارش میکنیم. ) از مسیرهای آینده پیش بینی شده برای هر مرحله زمانی در افق پیش بینی ۵ ثانیه. را در مرحله زمانی t را می توان به صورت زیر محاسبه کرد:
که در آن m تعداد وسایل نقلیه در مجموعه داده آزمایشی است، و به ترتیب موقعیت ها و حقیقت زمین در گام زمانی t پیش بینی می شوند.
۵٫۲٫ مطالعه ابلیشن
۵٫۲٫۱٫ آزمایشهای فرسایشی روی آستانههای همسایه
همانطور که در بخش ۴٫۱٫۲ ذکر شد ، ما دو آستانه را برای ساختن گراف همسایه معرفی می کنیم: آستانه فاصله همسایه و حد اختلاف خط .
در این بخش، دو آزمایش را برای ارائه تأثیرات مختلف انجام می دهیم و متنوع در مدل SIT-ID ما. محدوده از ما در آزمایش های فرسایشی خود اعمال می کنیم ، در حالی که مقادیری که انتخاب می کنیم ۰، ۳۰، ۵۰، ۷۰ و ۹۰ فوت هستند. همانطور که در شکل ۴ الف نشان داده شده است، هنگامی که ما تعمیر می کنیم ، عملکرد بهتری نسبت به سایر آستانه های فاصله همسایه دارد. از شکل ۴ ب، می توانیم ببینیم که حد بهینه اختلاف خط ۱ اگر است . بنابراین، در نظر گرفتن بیش از حد وسایل نقلیه همسایه یا عدم توجه به وسایل نقلیه همسایه، عملکرد مدل را کاهش می دهد. بر اساس این مشاهدات، در این مقاله، مجموعه ای از پا و به عنوان تنظیمات پیش فرض ما، مگر اینکه طور دیگری مشخص شده باشد.
۵٫۲٫۲٫ آزمایشهای فرسایشی در مدل پیشنهادی
در این بخش، ما سه آزمایش فرسایش را بر روی مدل پیشنهادی SIT-ID انجام میدهیم. ابتدا، لایههای SIT پیشنهادی و لایه ترانسفورماتور استاندارد (ST) را مقایسه میکنیم تا بررسی کنیم که آیا شبکه توجه چند سر نمودار فضایی ما میتواند دقت را با گرفتن تعامل فضایی بهبود بخشد یا خیر. ST-GD و SIT-GD هر دو از یک ماژول رمزگذار رمزگشای استاندارد GRU برای پیش بینی استفاده می کنند. لایه ST مورد استفاده در اینجا فقط می تواند وابستگی زمانی مسیر تاریخی هر وسیله نقلیه را نشان دهد. همانطور که در جدول ۱ نشان داده شده است ، مدل SIT-GD از نظر عملکرد بهتر از مدل ST-GD عمل می کند. ارزش ها، به ویژه در پیش بینی های بلند مدت آینده. لایه های SIT کاهش می یابد ارزش ۲۵٫۸٪ در مقایسه با لایه های ترانسفورماتور استاندارد. این نتیجه نشان میدهد که لایه SIT پیشنهادی میتواند اطلاعات مفیدتری را برای پیشبینی مسیر با استفاده از شبکه توجه چند سر نمودار فضایی برای مدلسازی تعاملات بین وسایل نقلیه همسایه، که اهمیت تعاملات فضایی بین وسایل نقلیه در پیشبینی مسیر را تأیید میکند، دریافت کند.
دوم، برای بررسی اثربخشی رمزگذار GRU در چارچوب ما، این دو مدل را با هم مقایسه میکنیم: SIT-GD و SIT-WoE. SIT-WoE مدلی بدون رمزگذار GRU است و رمزگشای GRU آن مستقیماً حالت پنهان آخرین مرحله لایه های SIT را به عنوان ورودی می گیرد. SIT-GD از یک رمزگذار-رمزگر استاندارد GRU برای پیش بینی استفاده می کند. همانطور که در جدول ۱ نشان داده شده است ، SIT-GD کمی بهتر از SIT-WoE است مقادیر دو مدل هستند و ، به ترتیب. این نتیجه کارایی رمزگذار GRU را تایید می کند. با این حال، ما فکر میکنیم رمزگذار GRU را میتوان حذف کرد اگر بتوانیم راه بهتری برای استفاده از حالتهای پنهان لایههای SIT، مانند اتخاذ مکانیسمهای توجه یا روشهای ادغام پیدا کنیم. آن را برای مطالعه آینده می گذاریم.
سوم، برای تایید اثر در نظر گرفتن فعل و انفعالات بالقوه در مسیرهای آینده وسایل نقلیه مشاهده شده در رمزگشایی، ما رمزگشای GRU آگاه از تعامل پیشنهادی و رمزگشای استاندارد GRU را مقایسه میکنیم. SIT-GD و SIT-ID هر دو از دو لایه SIT برای گرفتن وابستگی های زمانی و مکانی استفاده می کنند، اما اولی از رمزگذار-رمزگر GRU استاندارد برای پیش بینی استفاده می کند، در حالی که دومی از یک رمزگذار استاندارد GRU و یک رمزگشای GRU آگاه از تعامل فضایی استفاده می کند. همانطور که در جدول ۱ نشان داده شده است ، دومی بهبود می بخشد مقادیر پیشبینیهای آینده بلندمدت (به عنوان مثال، و ) همچنان بیشتر، که ثابت می کند که در نظر گرفتن فعل و انفعالات بالقوه بین وسایل نقلیه در رمزگشایی نیز برای پیش بینی مسیر، به ویژه پیش بینی مسیر طولانی مدت، ضروری است.
برای برجسته کردن اهمیت مدلسازی تعامل فضایی، نتایج این سه مدل را در صحنههای ترافیکی شلوغ گزارش میکنیم. ما فکر می کنیم یک صحنه ترافیک زمانی شلوغ است که تعداد وسایل نقلیه مشاهده شده آن مساوی یا بیشتر باشد . شکاف ST-GD در صحنه های ترافیکی شلوغ، در مقایسه با صحنه های ترافیکی غیر متراکم. در صحنه های شلوغ ترافیک، SIT-GD شکاف را از ۲۵٫۸ درصد به ۳۸٫۶ درصد افزایش داد، در حالی که SIT-ID از ۳۱٫۷ درصد به ۴۰٫۳ درصد افزایش یافت.
۵٫۳٫ مدل های مقایسه شده
ما مدل پیشنهادی را با خطوط پایه زیر مقایسه می کنیم:
-
سرعت ثابت (CV) [ ۲ ]: این روش به سادگی از فیلتر کالمن با سرعت ثابت برای پیش بینی مسیرها استفاده می کند.
-
Vanilla LSTM (V-LSTM) [ ۲ ]: این رویکرد تعاملات را در نظر نمی گیرد و از ساختار رمزگذار-رمزگر مبتنی بر LSTM برای پیش بینی استفاده می کند.
-
LSTM با ادغام اجتماعی کاملاً متصل (S-LSTM) [ ۱۳ ]: متفاوت از V-LSTM، این کار مسیرهای تاریخی وسایل نقلیه اطراف هدف را در بر می گیرد و از یک لایه کاملاً متصل برای ترکیب نمایش های رمزگذاری شده وسیله نقلیه هدف و اطراف آن استفاده می کند. وسایل نقلیه در رمزگشایی
-
LSTM با ادغام اجتماعی کانولوشنال (CS-LSTM) [ ۲ ]: این روش از لایه ادغام اجتماعی کانولوشنی برای در نظر گرفتن تعاملات بین هدف و وسایل نقلیه اطراف آن بر اساس یک شبکه فضایی استفاده می کند. خروجی توزیع مسیر تک وجهی است.
-
CS-LSTM(M) [ ۲ ]: متفاوت از CS-LSTM، این مدل توزیع مسیر چندوجهی مبتنی بر مانور را خروجی میدهد. حالت با بیشترین احتمال برای ارزیابی استفاده می شود.
-
شبکه توجه آگاه از متن پویا و ایستا (DSCAN) [ ۱۸ ]: این روش از مکانیزم توجه برای تصمیم گیری اینکه کدام وسایل نقلیه اطراف برای وسیله نقلیه هدف اهمیت بیشتری دارند استفاده می کند و با استفاده از یک شبکه محدودیت، اطلاعات محیط را در نظر می گیرد.
۵٫۴٫ نتایج مقایسه شده
جدول ۳ نشان می دهد مقادیر مدل های مقایسه شده ما دریافتیم که CV و V-LSTM بازده بسیار بالاتری دارند مقادیر نسبت به سایر مدل ها این دو مدل فقط از تاریخچه مسیر وسیله نقلیه مورد نظر استفاده می کنند، در حالی که مدل های دیگر از اطلاعات حرکت وسایل نقلیه اطراف استفاده می کنند. این نتیجه نشان می دهد که در نظر گرفتن فعل و انفعالات بین وسیله نقلیه برای پیش بینی مسیر ضروری است.
ما توجه می کنیم که CS-LSTM(M) به بالاتر منجر می شود مقادیر نسبت به CS-LSTM. همانطور که در [ ۲ ] ذکر شد، این می تواند تا حدی به دلیل مانورهای طبقه بندی نادرست باشد.
همچنین توجه داریم که SIT-ID ما کمتر تولید می کند مقادیر در مقایسه با S-LSTM، CS-LSTM و DSCAN، به ویژه برای پیش بینی های طولانی مدت، به عنوان مثال، و . S-LSTM، CS-LSTM و DSCAN تعاملات بالقوه را در رمزگشایی در نظر نمی گیرند. این نتیجه نشان می دهد که در نظر گرفتن فعل و انفعالات بالقوه بین وسایل نقلیه در رمزگشایی نیز به طور قابل توجهی بر پیش بینی مسیر تأثیر می گذارد، به ویژه برای پیش بینی های مسیر طولانی مدت.
۵٫۵٫ تجسم نتایج پیش بینی
ما یک مورد پیشبینی خوب و بد را که از مجموعه آزمون انتخاب شده است، به ترتیب در شکل ۵ a و شکل ۵ b تجسم میکنیم. پس از مشاهده ۳ ثانیه مسیر تاریخ، SIT-ID ما مسیرهای بیش از ۵ ثانیه را در آینده پیش بینی می کند. ما از رنگ های مختلف برای تشخیص وسایل نقلیه مختلف استفاده می کنیم. خط جامد نشان دهنده مسیرهای مشاهده شده است، در حالی که نشانگرهای “+” و “•” به ترتیب بیانگر حقیقت زمین در آینده و نتایج پیش بینی شده هستند. رنگ های قرمز مربوط به اتومبیل های واقع در وسط است که هدف CS-LSTM [ ۲ ] و DSCAN [ ۱۸ ] است.] سعی کنید پیش بینی کنید. مورد خوب نشان می دهد که مدل ما می تواند دقیقاً مسیر همه وسایل نقلیه را در یک صحنه مشاهده شده به طور همزمان پیش بینی کند. اما، همانطور که از مورد بد مشاهده می شود، مدل ما در صورت تغییر خط اضطراری که بلافاصله پس از مرحله مشاهده اتفاق می افتد، عملکرد ضعیفی دارد. ما فکر میکنیم که این عمدتاً به این دلیل است که نمونههای موجود در مجموعه داده NGSIM حاوی تغییرات خط اضطراری بسیار کم هستند. بنابراین، در آینده نزدیک، میخواهیم مدل خود را بر روی سایر مجموعههای داده، به عنوان مثال، مجموعه دادههای Apollo [ ۱۰ ]، که در آن دادهها نه تنها در بزرگراه، بلکه از مناطق شهری نیز گرفته میشود، ارزیابی کنیم.
۵٫۶٫ تجزیه و تحلیل توزیع توجه
ماژول توجه چند سر زمانی (TMHA) و شبکه توجه چند سر نمودار فضایی (SGMA) بر اساس مکانیسم توجه هستند. توجه در یادگیری عمیق را می توان به طور گسترده به عنوان بردار وزن های اهمیت تفسیر کرد که نشان می دهد یک عنصر چقدر با عناصر دیگر همبستگی دارد. بنابراین، برای تجزیه و تحلیل بیشتر مکانیسم مدل خود، توزیع توجه تولید شده توسط TMHA و SGMA آخرین لایه SIT مدل خود را تجسم می کنیم.
شکل ۶ نمونه ای از توزیع توجه زمانی محاسبه شده توسط ماژول TMHA را نشان می دهد. ما از مکانیسم های توجه k -head در TMHA و SGMA و مجموعه استفاده می کنیم ، بنابراین چهار توزیع مختلف به ترتیب مربوط به سرهای توجه مختلف وجود دارد. با بررسی توزیع توجه هد ۲ در شکل ۶ ، توجه می کنیم که برای هر مرحله زمانی، توجه آن عمدتاً به جریان و چند مرحله قبلی توزیع می شود و هر چه از نظر زمان دورتر باشد، وزن توجه کمتر می شود. این مکانیسم شبیه به انسان است. در هنگام رانندگی، یک راننده انسانی حرکت وسیله نقلیه همسایه را معمولاً بر اساس مکانهای اخیر این وسیله نقلیه پیشبینی میکند و مکانهای مربوط به مدتها قبل را در نظر نمیگیرد.
شکل ۷ نمونه ای از توزیع توجه فضایی محاسبه شده توسط SGMA را نشان می دهد. مقادیر موجود در شبکه، فاصله اقلیدسی بین وسایل نقلیه مربوطه در واحد پا است. توجه می کنیم که وزن های توجه در امتداد قطر کمی متقارن هستند. علاوه بر این، این وزن ها به طور خطی با فواصل اقلیدسی مرتبط هستند، یعنی فاصله کوچکتر معمولاً وزن توجه قابل توجهی دارد. این توزیع توجه نیز مشابه انسان است. با توجه به یک گام زمانی، یک راننده انسان باید توجه بیشتری به وسایل نقلیه نزدیک به خود داشته باشد.
تجزیه و تحلیل فوق نشان می دهد که TMHA و SGMA مورد استفاده در SIT پیشنهادی ما می توانند به طور موثر وابستگی های زمانی مسیرها و تعاملات فضایی وسایل نقلیه را ضبط کنند.
۶٫ نتیجه گیری
در صحنه های ترافیکی بسیار پویا، حرکات بعدی وسیله نقلیه تحت تأثیر فعل و انفعالات وسایل نقلیه اطراف آن قرار می گیرد. در نظر گرفتن تعاملات بین وسایل نقلیه، هم در رمزگذاری مسیر تاریخی و هم در مراحل رمزگشایی مسیر آینده، برای پیشبینی مسیر ضروری است. بنابراین، این مقاله یک مدل مبتنی بر ترانسفورماتور مبتنی بر تعامل فضایی را پیشنهاد میکند. در مرحله رمزگذاری، لایههای ترانسفورماتور آگاه از تعامل فضایی (SIT) پیشنهادی برای به دست آوردن اطلاعات زمینه مفید برای پیشبینی مسیر استفاده میشوند. لایه SIT شامل دو ماژول کلیدی است: ماژول توجه چند سر زمانی و شبکه توجه چند سر نمودار فضایی، که به ترتیب برای ثبت وابستگی های زمانی مسیرها و تعاملات فضایی بین وسایل نقلیه اعمال می شوند. در مرحله رمزگشایی، یک ماژول رمزگذار-رمزگشا مبتنی بر GRU برای انجام پیشبینیهای نهایی اعمال میشود. برای در نظر گرفتن فعل و انفعالات بالقوه آینده، برای هر مرحله رمزگشایی، رمزگشا ابتدا به آخرین حالات همه وسایل نقلیه مشاهده شده دسترسی پیدا می کند و بر اساس مکانیسم توجه چند سر، انتقال پیام را از بین آنها کنترل می کند، سپس برای هر وسیله نقلیه پیش بینی می کند.
مدل پیشنهادی با استفاده از مجموعه دادههای عمومی NGSIM US-101 و I-80 مورد ارزیابی قرار گرفت. مزایای اصلی مدل پیشنهادی به شرح زیر است:
-
مدل مبتنی بر SIT پیشنهادی میتواند مسیر را با دقت بیشتری نسبت به سایر خطوط پایه، به ویژه برای پیشبینی بلندمدت و در موقعیتهای بسیار تعاملی پیشبینی کند. زیرا تعاملات بین وسایل نقلیه را هم در مرحله رمزگذاری و هم در مرحله رمزگشایی در نظر می گیرد.
-
لایههای SIT پیشنهادی میتوانند به طور موثر وابستگیهای زمانی مسیرها و تعاملات فضایی بین وسایل نقلیه را هنگام رمزگذاری ضبط و ادغام کنند. در مطالعه فرسایشی، لایههای SIT کاهش میدهند ارزش ۲۵٫۸٪ در مقایسه با لایه های ترانسفورماتور استاندارد.
با توجه به مجموعه دادههای مورد استفاده در کار شامل بخشهای بزرگراه، که سادهتر از صحنههای ترافیکی معمولی هستند، به عنوان مثال، صحنههای ترافیک شهری، نتایج ما محدودیتهای خاصی در تعمیم دارند. برای انطباق با محیط های پیچیده و ترکیب اطلاعات ترافیکی، مانند انواع خطوط و چراغ های راهنمایی، به طور قابل توجهی باید کار بیشتری انجام شود.