۱٫ مقدمه
در بازسازی محیط های داخلی، ابرهای نقطه اسکن لیزری به طور کلی استفاده شده است، که اطلاعات مکانی با دقت بالا و غنی را برای مدل سازی اطلاعات ساختمان بعدی (BIM) فراهم می کند [ ۱ ]. با این وجود، بخش بندی معنایی موثر باید قبل از بازیابی موجودیت های هندسی انجام شود. این می تواند درک بهتر صحنه و مدل سازی مبتنی بر موجودیت با دقت بالا را تقویت کند [ ۲ ، ۳ ].
در چند سال گذشته، عملیات بخشبندی عمدتاً بر طراحی ویژگیهای دست ساز متمرکز شده است [ ۴ ، ۵ ، ۶] با استفاده از دانش تجربی در مورد هندسه یا تقارن فضایی. آنها نسبتاً محدود به سناریوهای خاص با موارد اولیه هندسی خاص هستند. با این حال، موجودیتهای داخلی ترکیبی، مانند میز، صندلی، قفسه کتاب و غیره، ساختارهای هندسی نامنظم یا اطلاعات فیزیکی متفاوتی را نشان میدهند و به سختی میتوان آنها را از نظر معنایی با ویژگیهای دست ساز تقسیم کرد. علاوه بر این، برخی از اطلاعات پنهان غیربصری پنهان در ویژگیهای سطح بالا ممکن است نادیده گرفته شوند، و تمایز بین دستههای مختلف اشیاء با تفاوتهای حاشیهای را دشوار میسازد. علاوه بر این، چیدمان پیچیده محیط های داخلی منجر به مسدود شدن و ناقص شدن ابرهای نقطه ای می شود. ممکن است طراحی ویژگی مصنوعی را مختل کند و دقت بخشبندی را کاهش دهد. در همین حال،۷ ، ۸ ] و بینایی کامپیوتری [ ۹ ، ۱۰ ]، بسیاری از تحقیقات اکتشافی تلاش کردند تا مستقیماً شبکه عصبی کانولوشن دوبعدی (CNN) از قبل بالغ شده را برای اشاره به ابرها برای استخراج خودکار ویژگیهای با ابعاد بالا برای طبقهبندی شکل، تقسیمبندی، و تشخیص اشیا اعمال کنند. ردیابی [ ۱۱ ، ۱۲ ]. با توجه به ویژگیهای نامنظم، ناهموار و بدون ساختار ابرهای نقطهای، اکثر روشها تمایل داشتند تا ابر نقطهای را به ساختارهای دادهای منظم بهعنوان نمایش میانی برای کاربرد CNN دو بعدی سازماندهی کنند. از سوی دیگر، این پیشبینی داده منجر به فرآیندهای تبدیل زائد و زمانبر و فضای ذخیرهسازی قابلتوجهی میشود.
اخیراً، PointNet [ ۱۳ ]، یک کار پیشگام، استخراج ویژگی نقطهای را بدون تغییر دادههای ورودی انجام داد. این شامل چندین عملیات ثابت جایگشت مشترک، لایههای پرسپترون چندلایه (MLP) و یک لایه max-pooling است. با این حال، نمایش کارآمد و مختصر یادگیری ویژگی نقطهای نمیتواند ساختارهای محلی را در صحنههای پیچیدهتر به تصویر بکشد. یک شبکه کارآمد و قوی، PointNet++ [ ۱۴]، برای گرفتن ساختارهای هندسی از مقیاس های چندگانه با اعمال بازگشتی PointNet به ساختارهای سلسله مراتبی پیشنهاد شده است. ساختار سلسله مراتبی از مجموعه ای از سطوح انتزاعی تشکیل شده است. در هر سطح، لایه نمونهگیری و لایه گروهبندی را پیادهسازی میکند تا نقاطی را بهطور تصادفی از نقاط ورودی انتخاب کرده و محلههای منطقهای آنها را بسازد، و به دنبال آن یک لایه PointNet برای یادگیری ویژگیهای هندسی محلی. با انباشتن این سطوح انتزاعی مجموعه، ویژگیهای هندسی محلی لایه به لایه جمع میشوند و در نهایت ویژگیهای جهانی به تدریج استخراج میشوند تا کل صحنه پیچیده را نشان دهند. سپس، استفاده از PointNet++ الهام بخش بسیاری از شبکه های پیشرفته بعدی شد. آنها عملیات نقطهای را در محلههای محلی انجام میدهند و در عین حال ویژگیهای جهانی را به صورت سلسله مراتبی در سراسر کل ابر نقطهای در مقیاس بزرگ جمعآوری میکنند. با این وجود، بر خلاف ارتباط فضایی طبیعی بین پیکسل های مجاور منظم تصاویر، اطلاعات بالقوه روابط توپولوژیکی فضایی بین نقاط مختلف را نمی توان به طور کامل در میان نقاط نامرتب همسایه یاد گرفت. در نتیجه، شبکه های مبتنی بر نمودار [۱۵ ، ۱۶ ، ۱۷ ، ۱۸ ] پیشنهاد شده است که هر نقطه را به عنوان یک راس در ساختار نمودار در نظر گرفته و ویژگی آن را بر اساس اطلاعات زمینه ای بین لبه ها و رئوس متصل به روز کند. با این حال، ساختن یک ساختار نمودار جهانی در میان ابرهای عظیم نقطه، فرآیند تقسیمبندی را پیچیده میکند.
در همین حال، طیف وسیعی از شبکههای ترانسفورماتور [ ۱۹ ] که در اصل برای ترجمه ماشینی طراحی شده بودند، ظرفیت بیشتری را برای مدلسازی وابستگیهای متنی نسبت به CNN و شبکههای عصبی بازگشتی (RNN) با ارتباط صریح موقعیتهای مختلف یک دنباله نشان دادهاند. بسیاری از انواع Transformer کاربردهای خود را در زمینه بینایی کامپیوتر گسترش داده اند. با این حال، در مورد ابرهای نقطه، مکانیسم توجه کامل ناکارآمدی خود را در محاسبه بی رویه امتیازات توجه در بین نقاط عظیم نشان می دهد.
به طور کلی، محدودیت های فعلی روش های مبتنی بر CNN در جهت های زیر نهفته است:
-
ویژگیهای ابعادی بالا بر اساس نقاط منطقهای، که میتوانند اشیاء مختلف را با ویژگیهای مشابه اما موقعیتهای متمایز تشخیص دهند، به طور کامل در هستههای پیچشی طراحیشده استفاده نمیشوند.
-
اطلاعات متنی به دست آمده از ساختار نمودار کاملاً متصل برای همه نقاط، نه تنها کارایی را کاهش می دهد، بلکه بر تعمیم تعامل جهانی تأثیر منفی می گذارد.
برای متعادل کردن الزامات برای اطلاعات ویژگیهای غنی و کارایی بالا، ما یک شبکه پیچیدگی گراف مبتنی بر توجه تعاملی (IAGC) جدید را پیشنهاد میکنیم تا به طور انتخابی به ویژگیهای قابل توجه در هر مجموعه خوشهبندی همگن که ابرنقطهها نامیده میشوند [ ۲۰ ] توجه شود. و سپس، با توجه به نمودار جهانی ساخته شده توسط سوپرنقاط، ما به تدریج جاسازی را با پیوست کردن ویژگی های ابرنقطه متصل به ابرنقطه مرکزی ورودی، به روز می کنیم. به طور مشخص، با الهام از ایده gMLPs [ ۲۱]، یک معماری gMLP با توجه تعاملی اکتشافی و سبک (IAG-MLP) طراحی شده است تا به صورت پویا وزنهای توجه مناسب را به بخشهایی از کانالهای ویژگی برای یادگیری ویژگیهای محلی در سوپرپوینتها اختصاص دهد، که میتواند موثرتر از Transformers باشد. علاوه بر این، با یکپارچهسازی جهانی ویژگیهای دیگر ابرنقطهها، یک تغییر سادهشده از معماری حافظه بلند مدت (LSTM) [ ۲۲ ]، که به عنوان واحد بازگشتی دردار (GRU) [ ۲۳ ] شناخته میشود، میتواند در معنایی سطح ابرنقطه پیادهسازی شود. استنتاج
بنابراین، سهم اصلی الگوریتم پیشنهادی به شرح زیر خلاصه می شود:
-
یک نوع ترانسفورماتور متقاطع دوگانه، به نام IAG-MLP، پیشنهاد شده است که مستقیماً به سوپرنقطههایی که از ابرهای نقطه خام به بخشهای همگن مبتنی بر هندسه و مبتنی بر رنگ سازماندهی مجدد میشوند، جهتگیری شود و توانایی ثبت تصاویر با ابعاد بالا را افزایش دهد. وابستگیهای زمینهای در تعبیههای محلی با یادگیری توجه موقعیت متقاطع و توجه بین کانالی.
-
با انتشار پیامهای متنی از طریق ابرنقطههای مجاور و سوپر لبههای مرتبط، یک شبکه گراف سرتاسر ساخته میشود تا به تدریج ویژگیهای جاسازیشده ابرنقطهها را بهروزرسانی کند، و در نهایت استنتاج معنایی سطح ابرنقطه را به استنتاج ریزدانه سطح نقطه تبدیل کند.
-
ما تحلیلهای نظری و تجربی معماری پیشنهادی IAGC و همچنین آزمایشهای کمی و کیفی را در سه معیار داخلی ارائه میکنیم که نشاندهنده اثربخشی و عملکرد قابل توجه آن است.
ادامه مقاله به شرح زیر تدوین شده است. بخش ۲ به بررسی مختصری از کار مرتبط میپردازد. بخش ۳ جزئیات روش تقسیم بندی معنایی پیشنهادی را شرح می دهد. بخش ۴ نتایج تجربی کمی و کیفی را برای اعتبار سنجی رویکرد تقسیم بندی پیشنهادی ارائه می دهد و بخش ۵ چندین نکته پایانی را نشان می دهد.
۲٫ کارهای مرتبط
رویکرد کلاسیک برای برچسبگذاری معنایی ابرهای نقطهای در مقیاس بزرگ، سازماندهی مجدد ابرهای نقطهای به یک ساختار منظم برای یک تابع پیچشی فشرده است. در همین حال، بسیاری از توابع تجمع بر اساس ساختار گراف در حال حاضر برای گرفتن ارتباطات زیربنایی بین نقاط مختلف پیشنهاد شدهاند. این بخش عمدتاً روشهای تقسیمبندی معنایی را برای ابرهای نقطه، ساختار دادههای ابرهای نقطهای که به شبکههای مبتنی بر یادگیری عمیق تغذیه میشوند، انواع ترانسفورماتور غالب، و پیچیدگیهای نمودار برای درک زمینهای را بررسی میکند.
۲٫۱٫ تقسیم بندی معنایی برای ابرهای نقطه ای
از نظر تقسیم بندی معنایی برای درک بهتر صحنه های داخلی، می توان آنها را به رویکردهای مدل محور، دانش محور و داده محور تقسیم کرد. رویکردهای مبتنی بر مدل ابتدا مدلهای بالقوه اولیههای هندسی (مثلاً خطوط، صفحات، مکعبها و استوانهها) را تولید میکنند و سپس بزرگترین خوشهای را پیدا میکنند که به بهترین شکل با حدسهای هندسی مطابقت دارد [ ۲۴ ]. آنها می توانند به طور مکرر فرضیه و روش های تأیید را برای یافتن چندین اولیه پیاده سازی کنند، اما به دلیل عملکرد ضعیف تقسیم بندی در هندسه های بدون ساختار، به صورت محلی در محیط های پیچیده داخلی بهینه هستند.
به منظور تحقق راهحلهای بهینهسازی جهانی برای اشیاء مختلف، رویکردهای دانش محور، یعنی هستیشناسی محور، انتخاب بهینه الگوریتمها را برای هندسههای خاص با ایجاد یک هستیشناسی که ویژگیهای داده، الگوریتمهای بالقوه و دانش قبلی صریح را ادغام میکند، افزایش میدهد. به طور خاص، اطلاعات خارجی مدل هستیشناسی را به اعمال الگوریتمهای مختلف بر اساس ویژگیهای نقطهای مختلف هدایت میکند، و نتایج تقسیمبندی به طور معکوس شکاف ویژگی را در بین دستههای مختلف در فرآیند اکتساب اولیه افزایش میدهد [ ۲۵ ، ۲۶ ]. بنابراین، هستی شناسی به عنوان یک نمودار متا برای به اشتراک گذاری و استفاده مجدد از دانش خارجی در کل گردش کار عمل می کند و در نهایت به بهینه سازی جهانی کمک می کند.
از سوی دیگر، رویکردهای مبتنی بر دادههای پیشرفته بر طراحی شبکههای یادگیری عمیق معقول و بهبود کیفیت دادههای آموزشی تمرکز دارند. از نظر تئوری، ویژگیهای ابرهای نقطهای را میتوان به طور ضمنی به شبکههای عصبی چندلایه بدون تداخل دانش خارجی نگاشت و قادر به تقسیمبندی دستههای مختلف اشیاء، بهویژه برای موجودیتهای مرکب و پرت باشد.
۲٫۲٫ شبکه های یادگیری عمیق برای تقسیم بندی معنایی
روشهای یادگیری عمیق موجود برای تقسیمبندی معنایی را میتوان با توجه به دانهبندی ابرهای نقطهای که استخراج ویژگی بر روی آنها انجام میشود، به دو جنبه طبقهبندی کرد: شبکههای مبتنی بر طرح ریزی و شبکههای مبتنی بر نقطه. اغلب شبکههای مبتنی بر پیشبینیشده معمولاً عملیات کانولوشن را اعمال میکنند، که عملکرد عالی را بر روی تصاویر دو بعدی یا توالیهای متنی منظم و فشرده، به ابرهای نقطهای نامرتب و بدون ساختار با نمایش آنها به نمایشهای منظم متوسط، مانند نمایش مبتنی بر وکسل، اعمال میکنند [ ۲۷ ] ، نمایش مبتنی بر Multiview [ ۲۸ ]، یا نمایش شبکه با ابعاد بالاتر [ ۲۹ ]]. به طور معمول، این روشها نه تنها منجر به مصرف غیرضروری حافظه و محاسباتی میشوند، بلکه ارتباط فضایی طبیعی میان ابرهای نقطهای را نیز مختل میکنند. در مقابل، روشهای نقطهای، ویژگیهای یادگیری مستقیم را در ابرهای نقطه خام بدون ایجاد تبدیل دادههای اضافی امکانپذیر میکنند. بیشتر شبکههای بعدی قابلیتهای خود را در مدلسازی ساختارهای محلی با شبکه بستر مبتنی بر نقطه، PointNet بهبود بخشیدند. برای مثال، PointNet++ [ ۱۴ ] از Furthest Point Sampling (FPS) برای کاهش سلسله مراتبی ابرهای نقطهای و استخراج مکرر ویژگیها از PointNet در هر لایه نمونهبرداری استفاده کرد. به منظور توصیف صحنههای مقیاس بزرگ از وضوحهای چندگانه، MSSCN [ ۳۰ ] ویژگیهای نقطهای را با تراکمهای مختلف، PointSIFT [ ۳۱ ] به هم متصل کرد.] به رمزگذاری هر دو جهت گیری و چند مقیاس برای جزئیات محلی توجه کرد و PointCNN [ ۳۲ ] از یک شبکه نقطه کاملاً کانولوشن با یک سری لایه های انتزاعی، یادگیرندگان ویژگی در مقیاس های مختلف و یک لایه ادغام استفاده کرد. هنگامی که استراتژی نمونهگیری تصادفی در صحنههای بزرگ زمانبر است، زیرا روی نقاط اصلی کار میکند، استفاده از سوپروکسلها [ ۳۳ ]]، که از سوپرپیکسل ها در پردازش تصویر دو بعدی الهام گرفته شده اند، تعداد نقاط را تا حد زیادی کاهش می دهد و نمایش طبیعی و فشرده تری را برای عملیات محلی ارائه می دهد. با این وجود، وضوح ثابت سوپروکسلها ممکن است منجر به تقسیمبندی نادرست در نواحی حاشیهای چندین اشیا شود، زیرا همسایگی محلی آنها کلاسهای مختلفی از نقاط را مشخص میکند، و در مورد اشیایی با مساحتهای بزرگ، مانند دیوار، سقف یا کف، غیرضروری است. در همان زمان، با توجه به بهینه سازی انرژی جهانی، ابر نقطه [ ۲۰] با تقسیمبندی هندسی و حتی فیزیکی ابرهای نقطهای بدون از پیش تعریف کردن تعداد بخشها ساخته شد، که بخشبندی غیرضروری اشیاء با مساحتهای بزرگ را به حداقل میرساند اما روابط توپولوژیکی بین ابرنقطهها را با ساختن یک نمودار جهانی حفظ میکند. بعداً، ساخت ابرنقطهها با ایجاد یک فقدان سازگاری برچسب بین برچسبهای واقعی نقاط و شبه برچسبهای ابرنقطه در یک شبکه انتها به انتها بهبود یافت [ ۳۴ ]. علاوه بر این، شبکه غیر محلی آبشاری [ ۳۵] ابرنقطه ها را به عنوان واحدهای اساسی پذیرفت و یک عملیات غیرمحلی با سه سطح دانه بندی، شامل سطح همسایگی، سطح ابرنقطه و سطح جهانی ساخت. در نتیجه، زمینه سازی در میان نقاط مختلف مختلف به صورت سلسله مراتبی از طریق انباشته شدن تعدادی از ماژول های غیر محلی تجمیع شد.
۲٫۳٫ شبکه های ترانسفورماتور مبتنی بر توجه
معماری ترانسفورماتور که به طور گسترده در پردازش زبان طبیعی پذیرفته شده است، بر ایجاد روابط متنی در ساختار متوالی رمزگذار-رمزگشا متمرکز است، که معمولاً از چندین ماژول خودتوجهی چند سر پشتهای، یک شبکه پیشخور (FFN) و یک اتصال باقیمانده در هر رمزگذار تشکیل شده است. یا بلوک رمزگشا به عنوان یک عنصر مهم ترانسفورماتور، توجه به خود با هدف تولید وزنهای دینامیکی از روابط زوجی ورودیها و یادگیری نمایشهای وابسته به زمینه برای هر نشانه در یک دنباله است.
از آنجایی که شبکه ترانسفورماتور انقلابی پیشرفت چشمگیری در زمینه بینایی کامپیوتر داشته است، مانند Vision Transformer (ViT) اخیر [ ۳۶ ]، استفاده از آن برای یادگیری عمیق در ابرهای نقطه اجتناب ناپذیر است. با این وجود، وقتی صحبت از مجموعه داده های سطح صحنه بزرگتر می شود، ساختار ترانسفورماتور برای ابرهای نقطه سه بعدی نسبتاً گران است زیرا هزینه محاسبات با اندازه ورودی به طور درجه دوم افزایش می یابد. برای پرداختن به این محدودیتها، چندین مدل مشتق شده با استفاده از مکانیسم مهم توجه به خود، اطلاعات متنی محلی را یاد میگیرند و وابستگیهای دوربرد را در فضای ابر نقطه سه بعدی ایجاد میکنند. به عنوان مثال، به جای یک لایه MLP ساده یا لایه max-pooling در PointNet، PointTransformer [ ۳۷] از خود توجهی مبتنی بر برداری همراه با تفریق رابطه و اضافه کردن کدگذاری موقعیت برای انتقال سلسله مراتبی به پایین در رمزگذاری ویژگی و انتقال به بالا در رمزگشایی ویژگی استفاده کرد. PointCloudTansformer (PCT) [ ۳۸ ] از یک ترانسفورماتور توجه افست فقط با ماژول های کدگذاری شده برای بهبود یادگیری ویژگی برای طبقه بندی شکل و بخش بندی استفاده کرد. Pointformer [ ۳۹ ] برای مدلسازی تعاملات بین نقاط در منطقه محلی با ترانسفورماتورهای محلی چند مقیاسی (LT) و RandLA-Net [ ۴۰ ] با توجه به نقاط نمونهبرداری تصادفی با کارایی بالا، پیشنهاد شده است. تحقیق در [ ۴۱] از همجوشی دروازهای در ساختارهای منطقهای و توجه فضایی و کانالی در ساختارهای جهانی بهرهبرداری کرد. به طور کلی، انجام مکانیسم توجه در صحنههای مقیاس بزرگ ممکن است به حجم کار محاسباتی قابلتوجهی برای وزنهای توجه زوجی منجر شود، بنابراین ادغام خود توجهی در بین ساختارهای منطقهای و وابستگیهای دوربرد در یک نمودار جهانی میتواند مؤثرتر باشد.
۲٫۴٫ پیچیدگی نمودار
شبکه پیچیدگی گراف (GCN) [ 42 ، ۴۳ ، ۴۴ ] به دلیل توانایی فزاینده برجسته آن در پردازش داده های بدون ساختار، بدون شک در پردازش ابرهای نقطه ای به کار می رود و به طور کلی به دو گروه طبقه بندی می شود: روش مبتنی بر طیف و روش مبتنی بر فضایی. روش. رویکردهای مبتنی بر طیف با تبدیل نمایشهای راس به حوزه طیفی با تبدیل فوریه یا پسوندهای آن، کانولاسیون را انجام میدهند [ ۴۵ ، ۴۶ ]. در مقابل، رویکردهای مبتنی بر فضایی به طور مستقیم کانولوشن را بر اساس توپولوژی گراف انجام می دهند. به عنوان مثال، PyramNet [ ۴۷] ماتریس کوواریانس را در یک گراف غیر چرخهای جهتدهی شده برای کشف ارتباطات منطقهای بین نقاط فرمولبندی کرد و یک شبکه توجه هرمی را برای استخراج ویژگیهایی با شدت معنایی مختلف پیشنهاد کرد. علاوه بر این، گراف توجه گراف (GAC) [ ۱۸ ] شکل هسته پیچیدگی را با محاسبه وزن توجه در میان نقاط همسایه در یک نمودار متصل تعریف کرد تا اهمیت بخشهای مربوطه را نشان دهد. به منظور گسترش زمینههای دریافتی، MS-RRFSegNet [ ۴۸ ] تقسیمبندی ویژگی در سطح سوپروکسل را انجام داد تا زمینههای توصیفی بیشتری را به دست آورد. با این حال، این شبکههای ذکر شده در بالا، نمودارهای محلی را بر اساس توزیع منطقهای نقاط همسایه ساختند و ذاتاً اطلاعات زمینهای منطقهای را ضبط میکنند.
۳٫ روش شناسی
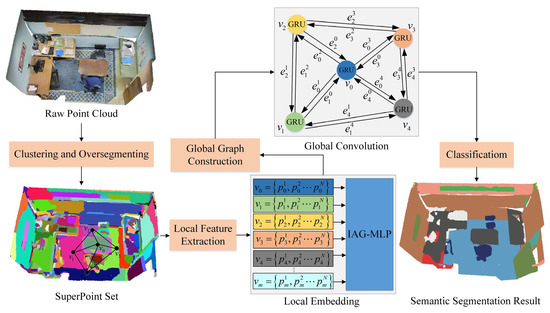
در این مقاله، ما یک شبکه گراف جدید برای تقسیمبندی معنایی برای ابرهای نقطهای در مقیاس بزرگ در صحنههای داخلی پیشنهاد میکنیم. به طور خاص، ما ابتدا ابرنقطههای بهدستآمده از تقسیمبندی بیش از حد ابرهای نقطه را معرفی میکنیم و سپس ماژول IAG-MLP انباشته شده خود را برای تعبیه یادگیری نمایش سطح ابرنقطه نشان میدهیم. در نهایت، با ماژول پیچیدگی مکرر، یک نمودار جهتدار جهانی برای بهروزرسانی مکرر جاسازیهای ویژگی قبلی ارائه میشود.
۳٫۱٫ تولید بیش از حد سوپرپوینت
با توجه به مصرف محاسبات در پردازش میلیونها نقطه در یک صحنه داخلی در مقیاس بزرگ، ابرهای نقطهای به نقاط همگن هندسی و فیزیکی تقسیم میشوند، به عنوان مثال، ابرنقاطها را میتوان به عنوان واحدهای عملیاتی اساسی برای شبکههای یادگیری عمیق مشاهده کرد. به این ترتیب، تعداد ابرنقطهها در یک صحنه و تعداد نقاط موجود در یک ابرنقطه از قبل تعریف نمیشوند، که حداقل مقدار و حداکثر تکمیل ساختاری بخشهای ساده را برای یادگیری ویژگی محلی تضمین میکند. در این مورد، ما فرض میکنیم که نقاط یک ابرنقطه باید ویژگیهای مشابهی داشته باشند و در نتیجه برچسب کلاس یکسانی را به اشتراک بگذارند. بر اساس تجزیه و تحلیل اجزای اصلی (PCA) [ ۴۹] الگوریتم، ویژگی های شکل محاسبه شده بر روی نمودار مجاورت بهینه K نزدیکترین همسایگی را می توان با ساخت یک ماتریس کوواریانس و تجزیه مقادیر ویژه آن، که مثبت و مرتب هستند، بازیابی کرد، به عنوان مثال، ۰ <λ۱<λ۲<λ۳. سپس، PCA سه جهت اصلی را توصیف می کند که ویژگی های حجمی، مسطح و خطی محله را نشان می دهد.
ویژگی پراکندگی متراسبه شکل بیضی همسانگرد محله، مسطح بودن اشاره دارد مترپمیانگین فاصله در اطراف مرکز ثقل و خطی بودن را تعریف می کند مترLتشریح می کند که مجاورت چقدر کشیده است. علاوه بر این، عمودی بودن مترVهمچنین می توان برای تشخیص اشیاء در توزیع عمودی مختلف، که در آن تو۱، تو۲، تو۳سه بردار ویژه مرتبط با λ۱، λ۲، λ۳، به ترتیب.
به منظور خوشهبندی نقاط همگن با ویژگیهای مشابه، ویژگیهای هندسی ذکر شده در بالا و ویژگیهای فیزیکی مانند رنگ را میتوان برای مسئله پارتیشن حداقلی تعمیمیافته در نظر گرفت، که با تقریب ثابت تکهای تابع انرژی جهانی مورد مطالعه قرار میگیرد [ ۲۰ ] :
برای هر نقطه من ∈ Vشکل محله محلی آن با ویژگی های ترکیبی مشخص می شود f∈آر۷ × V، که شامل ۴ ویژگی هندسی و ۳ ویژگی فیزیکی است. اولین بخش از این تابع انرژی، فرمول وفاداری است، که تضمین می کند که بخش های ثابت از g∗مطابق با مقدار همگن است f. بخش دوم تابع منظم شده است که برای هر یال که دو بخش با مقادیر متفاوت را به هم متصل می کند، یک محدودیت اضافه می کند. علاوه بر این، δ( ⋅ ≠ ۰ )به براکت آیورسون اشاره دارد و قدرت منظمسازی درشتی پارتیشن حاصل و همچنین دانهبندی نمودار ابرنقطه، یعنی تعداد کل بخشها را مشخص میکند. در واقع، اگرچه مسئله بهینهسازی یک تابع غیرمحدب و غیرپیوسته است که نمیتوان آن را به سادگی حل کرد، ل۰الگوریتم تعقیب برش [ ۵۰ ] میتواند از برشهای نمودار برای تقسیم بازگشتی مجموعههای سطح یک راهحل کاندید ثابت تکهای استفاده کند. در عمل، همانطور که در شکل ۱ نشان داده شده است ، بخش های استنباط کننده مربوط به ابرنقطه ها به دلیل ویژگی های هندسی و فیزیکی به اندازه ها و اشکال مختلف تقسیم می شوند.
در نهایت، تا زمانی که ابرهای نقطه توسط نمودار ابرنقطه با ابرنقطهها به همراه لبههای متصل آنها بازسازی میشوند، ویژگیهای موقعیت مکانی (موقعیت فضایی، موقعیت نرمال شده، ارتفاع)، ویژگیهای هندسی (پراکندگی، مسطح بودن، خطی بودن، عمودی) را به هم متصل میکنیم. و ویژگی های رنگی (مقادیر RGB) سوپرنقاط به عنوان ویژگی های ورودی برای شبکه استخراج ویژگی محلی پیشنهادی ما. به طور خاص، ارتفاع برای تشخیص اجسام در ارتفاعات مختلف نسبت به کف داخلی معرفی شده است که به شرح زیر تعریف می شود:
۳٫۲٫ IAG–MLP
استخراج ویژگی های محلی برای عملیات جمع آوری گرافیک جهانی بعدی بسیار مهم است. با این حال، گرفتن خودکار ویژگی های ساختاری محلی بر اساس منطقه همسایه هنوز چالش برانگیز است. در واقع، بیشتر شبکههای پیشرفته کنونی به PointNet ساده و مختصر برای اجرای توابع کانولوشن با تغییر ناپذیری جایگشت نقاط در منطقه محلی متوسل میشوند. با این وجود، عملیات جمعآوری حداکثری نهایی در PointNet به عنوان مکانیزم «حداکثر توجه» عمل میکند که تنها شاخصترین ویژگیها مانند خطوط نقاط در فضای ویژگی را در نظر میگیرد و همبستگیهای ساختاری بین نقاط داخلی باقیمانده را نادیده میگیرد. با ویژگی یادگیری متفاوت است.
برای مقابله با اطلاعات مهم نادیده گرفته شده در عملیات پیچیدگی محلی ناشی از PointNet، ترانسفورماتور با مکانیزم خودتوجهی که به منطقه با اطلاعات غنی توجه می کند، می تواند به عنوان یک الگوریتم یادگیری ویژگی جدید استفاده شود. ما ابتدا مکانیسم توجه به خود را که توسط معروف ترین ترانسفورماتور وانیلی [ ۱۹ ] اعمال می شود (به شکل ۲ مراجعه کنید ) در زمینه ترجمه ماشینی بررسی می کنیم. با توجه به ویژگی ورودی، توجه به خود به صورت خطی ویژگی ورودی را در یک ماتریس پرس و جو طرح می کند س، یک ماتریس کلیدی کو یک ماتریس مقدار V، که می تواند به صورت زیر فرموله شود:
جایی که آماتریس توجهی است که پیوند زوجی را در میان نشانههای یک دنباله و به عنوان یک عامل مقیاسپذیر نشان میدهد، دکبعد ماتریس است ک.
با این حال، هنگامی که برای پردازش ابر نقطه ای اعمال می شود، به دلیل بار محاسباتی بالای آن با محاسبه توجه نقطه-محصول در بین نقاط در هر لایه رمزگذار یا رمزگشا، اجرای مستقیم حالت رمزگذار-رمزگشا انباشته روی ابرهای نقطه عظیم غیرممکن است. علاوه بر این، از آنجایی که بعد بالا برای نمایش بهتر در سطح بالا ضروری است، استفاده جداگانه از یک ترکیب خطی از مقادیر دوتایی به عنوان وزن های خودتوجهی برای بهبود ویژگی های ورودی در هر کانال ویژگی ممکن است مصرف حافظه را در بعد بالا افزایش دهد. بنابراین، با الهام از ترانسفورماتور وانیلی و gMLP [ ۲۱]، ما یک شبکه جدید IAG-MLP را پیشنهاد میکنیم که مستقیماً به سوپرنقطهها جهتگیری شده است، که میتواند به طور خودکار نمایش تعبیهشده هر ابرنقطه را با یک معماری دروازهای تعاملی سبک وزن، تحت تأثیر قرار دهد و رمزگذاری کند.
طرح کلی در شکل ۳ نشان داده شده است . با توجه به یک ابرنقطه همراه با ویژگیهای هر نقطه (به عنوان مثال، RGB خام، مختصات فضایی، مکان عادی، ارتفاع، و ویژگیهای هندسی ذکر شده در بالا)، این واحد کدگذاری محلی ابتدا نمونهبرداری میکند. ننقاط داخلی و جاسازی آنها از این ویژگی های دست ساز در ویژگی های با ابعاد بالا، به طوری که توجه متقابل را می توان با دو ویژگی تقسیم شده با ابعاد بالا برای یادگیری ساختار محلی پیچیده محاسبه کرد. پس از آن، بلوک IAG پیشنهادی ما تعاملات فضایی با واحد حافظه مشترک را برای توجه موقعیت متقاطع به تصویر میکشد و ارتباطات کانال را در عملیات دروازه برای توجه بین کانالی گسترش میدهد. در عمل، بر خلاف مکانیسم توجه به خود، که پیچیدگی محاسباتی بالایی دارد ای (n2د)مکانیسم توجه متقاطع امکان تبدیل فضایی قابل یادگیری با پیچیدگی محاسباتی کمتر را می دهد ای (n2د۲)، جایی که nتعداد نقاط منطقه ای و دابعاد ویژگی ورودی را نشان می دهد.
به طور خاص، این بلوک IAG شامل مراحل زیر است:
- (۱)
-
عملیات انقباضی. برای فعال کردن تعامل متقابل کانال، لازم است یک عملیات انقباض در کل بعد ویژگی وجود داشته باشد. روش مختصر با اعمال یک طرح ریزی خطی همراه با یک تابع عادی سازی قدامی و یک تابع فعال سازی خلفی است که می تواند به صورت زیر فرموله شود:
که در آن ویژگی ورودی ایکسبه روش دسته ای نرمال می شود [ ۵۱ ]، که برای همگرایی یادگیری ضروری است. سپس یک طرح خطی با ضرب ماتریس اجرا می شود دبلیو∈آر۲ د× ۲ روزکه برای آن اندازه از ۲ دابعاد ویژگی پیش بینی شده است. علاوه بر این، بو σبه یک بایاس مراجعه کنید که می تواند یک ماتریس یا اسکالر و یک تابع فعال سازی مانند R EL U[ ۵۲ ].
برای محاسبه توجه متقاطع بین ابعاد کانال به طور موثر، تقسیم کردیم fدبلیو، ب( X)به دو جزء مستقل، f1( X)و f2( X)، در امتداد کانال ویژگی و برهمکنش فضایی مبتنی بر عنصر پیاده سازی شده است که به عنوان تابع دروازه شناخته می شود و نشان داده شده است که در واحدهای خطی دروازه ای (GLUs) امکان پذیر است [ ۵۳ ، ۵۴ ]. در واقع، ما توجه موقعیت متقاطع و توجه متقابل کانال را در آن پیاده سازی می کنیم f1( X)و f2( X)به ترتیب، و آنها را در تابع دروازه جمع کنید تا مشکل گرادیان ناپدید شدن را کاهش دهید. توجه داشته باشید، ما از ساختار چند سر برای محاسبه توجه استفاده نمیکنیم زیرا بعد ابرهای نقطه در مقایسه با بعد توالیهای متن بسیار کوچک است، و غیرضروری است که ویژگیها را در شبکه تعبیه محلی برای یادگیری عمیق در سطح ابرنقطه تقسیم کنیم. .
- (۲)
-
موقعیت متقاطع توجه. توجه به خود معمولاً به عنوان یک الگوریتم طرح ریزی خطی در نظر گرفته می شود که از ارزش های خود نمونه های داده برای بهبود ویژگی های خود استفاده می کند، اما این ن× Nماتریس توجه به خود فقط می تواند رابطه متقابل بین نقاط در مجموعه داده آموزشی مشابه را توضیح دهد و مشخص نیست که آیا همبستگی خاصی بین نمونه داده ها در یک صحنه وجود دارد یا خیر. علاوه بر این، با وجود مقدار کمی از پارامترهای درگیر در ماژول توجه به خود، محاسبه توجه زوجی را نمی توان نادیده گرفت. بنابراین، ما یک واحد توجه تعاملی فضایی، با الهام از شبکه توجه خارجی [ ۵۵ ] طراحی کردیم]، برای محاسبه توجه موقعیت متقاطع بین ویژگی های با ابعاد بالا و یک واحد حافظه خارجی، که مستقل از ویژگی ورودی است و اطلاعات را در کل مجموعه داده آموزشی به اشتراک می گذارد. به طور خاص، ما واحد تعامل فضایی را با ساختار الگوی لایه خودتوجهی ترانسفورماتور وانیلی میسازیم و در ابتدا آن را به روشی مشابه PCT [ ۳۸ ] با روش نرمالسازی مضاعف عادی میکنیم، که به طور تجربی پایداری شبکههای تعبیهشده محلی را بهبود میبخشد. .
سپس با توجه به ساختار ترانسفورماتور وانیلی، واحد حافظه خارجی م_ k e y∈آرن× Nخدمت بر روی ماتریس کلید کمی تواند به تدریج اطلاعات متنی را در بین نقاط منطقه ای در عملیات ضرب ماتریس ثبت کند ⊗با ضرب در دو نرمال شده f1(ایکس۱) ∈آرن× dبا اشاره به ماتریس پرس و جو س.
- (۳)
-
توجه بین کانالی برخلاف وزنهای خودتوجهی که از توجه زوجی در بین نقاط به دست میآیند، واحد توجه متقابل کانالی را میتوان به عنوان مکانیزم توجه متقابل برای تعدیل نمایش نقطهای با استفاده از سیگنال فضایی مشاهده کرد. به طور خاص، نقشه توجه متقابل کانال از تولید نقطه استنباط می شود f2( X)و ماتریس وزن توجه موقعیت متقاطع اف:
را ⊙نشان دهنده ضرب عنصر است که به سرعت بزرگی هر عنصر را تنظیم می کند ایکسبه صورت جفتی ویژگی در واقع، این یک مکانیسم دروازهای است، یعنی عملکرد محصول نقطهای خروجی لایه کانولوشن بدون تبدیل غیرخطی و خروجی لایه کانولوشن با تبدیل غیرخطی در واحد IAG-MLP ما، اما هم موقعیت متقاطع و هم کانال متقاطع. توجه در این مکانیسم دروازه ای در واحد IAG-MLP ما محاسبه و ترکیب می شود.
علاوه بر این، برای به کارگیری یک ارتباط باقیمانده بین ویژگی ورودی و نقشه توجه، نقشه توجه را به یک ۲ دابعاد و آن را به ویژگی ورودی اضافه کنید.
- (۴)
-
بلوک اتصال باقیمانده از نظر تئوری، یک شبکه یادگیری عمیق با متغیرهای بیشتر باید بهتر بتواند وظایف چالش برانگیز را انجام دهد، اما ثابت شده است که عمیق کردن لایه ها، آموزش شبکه را سخت تر می کند، که به آن مشکل انحطاط می گویند. از این رو، با توجه به مشکل انحطاط یک شبکه یادگیری عمیق با افزایش لایه ها به عنوان ماژول های IAG-MLP بیشتر، بلوک اتصال باقیمانده برای ایجاد یک میانبر مختصر ارائه می شود که در آن ورودی پیش بینی شده در بلوک IAG قرار می گیرد و از چندین لایه عبور می کند. تا در نهایت با نقشه توجه پیش بینی شده ادغام شود.
با توجه به نیاز به نمایش ویژگی محلی، عملیات حداکثر ادغام برای تشکیل یک بردار ویژگی برای جمعآوری ویژگی نسبتاً جهانی یک ابر نقطه از نقاط نمونهبرداری شده انجام میشود. در نهایت، ما ویژگیهای ورودی را بر اساس بعد فضایی بهجای بعد کانال بهروزرسانی میکنیم، فقط با چندین لایه MLP ساده برای بیان ویژگی ابعاد بالاتر و بلوکهای IAG انباشته برای سیگنال ویژگی پیشرفته.
۳٫۳٫ شبکه کانولوشن گراف توجه تعاملی (IAGC)
برای یک صحنه داخلی در مقیاس بزرگ، روابط توپولوژیکی فضایی بین انواع مختلف اشیاء میتواند به عنوان اطلاعات زمینهای در سطح شی مورد استفاده قرار گیرد تا نمایش تعبیهشده را در سطح جهانی بهبود بخشد. به منظور بهبود عملکرد بخشبندی معنایی با تجمیع زمینهسازی در سطح بخش، پیچیدگی نمودار از پیچیدگی شرط لبه (ECC) [ ۵۶ ] مشتق شده است.] ویژگیهای تعبیهشده در سطح ابرنقطه و اطلاعات متنی را در نمودار سراسری برای بهروزرسانی تدریجی استنتاج تقسیمبندی معنایی ترکیب میکند. از این رو، در این کار، ما یک شبکه تقسیمبندی معنایی مبتنی بر ابرنقطه پایان به انتها پیشنهاد میکنیم که ابتدا نقاط همگن هندسی و فیزیکی را بهعنوان نمایشهای میانی و همچنین ابرنقطههایی برای استخراج ویژگیهای محلی در شبکه محلی IAG-MLP خوشهبندی میکند و سپس آن را میسازد. نمودار جهانی SuperPoint (SPG) برای به روز رسانی سلسله مراتبی و جهانی نمایش های تعبیه شده با لبه های متصل.
به طور خاص، برای توضیح بیشتر کل معماری IAGC پیشنهادی ما، شکل ۴ استنتاج تقسیم بندی معنایی از یک صحنه ابر نقطه خام به نمودار مبتنی بر ابرنقطه را نشان می دهد. G = ( V، ای)، جایی که Vمجموعه فوق نقطه و را نشان می دهد Eمجموعه لبه های نسبت داده شده جهت دار است. هنگامی که ویژگی محلی در ابرنقطه جاسازی می شود، ECC به طور مکرر عملیات پیچیدگی را روی هر ابرنقطه بدون پردازش در کل ساختار نمودار انجام می دهد.
به عنوان مثال، برای یک نقطه فوق العاده Vمنو ابر نقطه متصل آن Vj، فرض کن که Ejمنلبه متصل بین ابرنقاط است منو jبا ویژگی های جهت دار در رابطه با نسبت ویژگی های هندسی، نسبت تعداد نقاط، و روابط فضایی مرکزها. پس از آن، اطلاعات متنی کلی هر راس در SPG را می توان با تابع تجمع میانگین زیر به عنوان یک پیام جهانی فرموله کرد:
جایی که دبلیوبه پارامترهای ایجاد شده به صورت پویا از شبکه فیلتر پویا اشاره دارد [ ۵۷ ]، که در اصل یک لایه MLP بدون بایاس است، به طوری که بعد ویژگی ویژگی های لبه با بعد ویژگی تعبیه نقطه فوق العاده یکسان است. v، که ضرب عنصر را تسهیل می کند ( ⋅ ). علاوه بر این، ۱نjسهم سایر نقاط ابرنقطه را در گراف جهانی متصل به ابرنقطه عادی و میانگین می کند.
در مرحله بعد، با توجه به قابلیت مدیریت ورودی متوالی برای پردازش اطلاعات متنی، GRU، که دارای پارامترهای کمتری است اما به اندازه LSTM موثر است، برای ساخت و بهروزرسانی مکرر یک حالت پنهان که توسط نمایش تعبیه شده و پیام متنی جهانی یکپارچه شده است، استفاده میشود. در امتداد لبه های متصل پخش می شود. در این حالت حالت پنهان را تعریف می کنیم ساعتمنهمانطور که با جاسازی مقداردهی اولیه شد vمنو تجمیع جهانی بین پیش بینی شده را انجام دهید ساعتو پیام جهانی متربا ضرب عنصر:
با توجه به مکانیزم گیتینگ در ماژول GRU، ابتدا ورودی جریان را به صورت خطی طرح ریزی می کنیم ایکستیمنو حالت پنهان قبلی ساعتt – ۱منبه یک جاسازی با ابعاد بالاتر ایکس¯تیمنو حالت پنهان ساعت¯t – ۱منکه در تی= tتکرارها
همانطور که در شکل ۵ نشان داده شده است ، ایکس¯تیمنو ساعتt – ۱منبا جمع بردار به هم متصل می شوند و به یک تابع سیگموئید منتقل می شوند تا مقادیر خود را بین ۰ و ۱ قرار دهند، جایی که ۰ به معنای ویژگی های نامربوط برای دور ریختن و ۱ به معنای ویژگی های مفید برای حفظ است. بنابراین، این عملیات فیلتر کردن به گیت به روز رسانی کمک می کند تومنو گیت را ریست کنید rمن.
جایی که توتیمنویژگی های نامربوط را دور می اندازد و اطلاعات جدید را اضافه می کند و rتیمنتصمیم گرفت چه مقدار از ویژگی های گذشته را در عملیات بعدی فراموش کند. سپس، یک کاندیدای دولت پنهان جدید ساعت⃗ تیمنبرای تأکید بر ابعاد شدیداً همبسته و نادیده گرفتن ابعاد همبسته ضعیف با استفاده از تابع tanh برای تنظیم مقادیر به هم پیوسته ساخته شده است. rتیمن، ساعت¯t – ۱من، و ایکس¯تیمنبین -۱ و ۱٫
پس از آن، به روز رسانی حالت پنهان ساعتتیمنبرای تکرار فعلی را می توان با دو جزء به شرح زیر ساخت:
جایی که ( ۱- _توتیمن) ⊙ساعت⃗ تیمنجریان اطلاعات وضعیت پنهان فعلی را تعیین می کند ساعتتیمن، و توتیمن⊙ساعت¯t – ۱منقبلی را تعیین می کند ساعت¯t – ۱مناز طریق گیت آپدیت توتیمن. در نهایت، زمینه سازی جهانی در ویژگی های ابعادی بالا که با توالی های طولانی حالت های پنهان به هم پیوسته اند، گنجانده می شود.
۴٫ آزمایشات
در این بخش ابتدا جزئیات تنظیمات آزمایشی را معرفی می کنیم. ثانیا، ما مطالعات فرسایشی را برای تأیید کارایی اجزای جداگانه IAGC پیشنهادی خود در سه مجموعه داده داخلی سه بعدی، از جمله مجموعه داده SceneNN، مجموعه داده فضای داخلی سه بعدی مقیاس بزرگ استنفورد (S3DIS) و مجموعه داده ScanNet (V2) انجام میدهیم. در نهایت، ما شبکه خود را با چندین شبکه پیشرفته مقایسه می کنیم و در نهایت به ارزیابی کمی و کیفی عملکرد آنها می پردازیم.
۴٫۱٫ مجموعه داده ها
مجموعه داده S3DIS در ۶ منطقه داخلی در مقیاس بزرگ که از ۳ ساختمان اداری مختلف سرچشمه می گیرد، جمع آوری شده است که بیش از ۶۰۰۰ متر مربع با ۲۷۱ اتاق را پوشش می دهد. هر نقطه با ویژگی های هندسی و فیزیکی مانند مختصات فضایی XYZ و ویژگی های RGB در ۱۳ کلاس معنایی طبقه بندی می شود. با توجه به استقرار و پیکربندی مجموعه داده، اکثر روشهای پیشرفته مدلهای خود را در منطقه ۵ آزمایش میکنند، زیرا از یک ساختمان متفاوت میآیند، اما عموماً عملکرد ضعیفی در چندین دسته از جمله تیر، ستون و تخته نشان میدهند. ویژگی ها با اشیاء مربوطه در مناطق دیگر متفاوت است. از این رو، به منظور تأیید جامع مدل خود، نتایج Area-4 برابر و نتایج ۶ برابر اعتبار متقاطع را ارائه می دهیم.
- ۲٫
-
ScanNet (V2) [ ۵۹ ]
ScanNet شامل ۱۶۱۳ صحنه داخلی است که از بازسازی RGB-D مشتق شده است، و نقاط آن در ۲۰ کلاس حاشیه نویسی شده است، که در آن ۱۵۱۳ صحنه به ترتیب برای آموزش و اعتبارسنجی به ۱۲۰۱ و ۳۱۲ تقسیم می شوند و ۱۰۰ صحنه باقی مانده بدون برچسب به عنوان آزمایش مشاهده می شوند. مجموعه دادههای ارائه شده در رقابت چالشی معیار باز برای تأیید. و با این حال، ما مجموعه داده اعتبار سنجی را به دو مجموعه داده برای اعتبارسنجی و آزمایش در یک مطالعه فرسایشی برای بررسی وکسل سازی بهینه ابرهای نقطه خام و تعداد مناسب ابرنقاط برای تجمع نمودار تقسیم کردیم.
- ۳٫
-
SceneNN [ ۶۰ ]
مجموعه داده SceneNN یک مجموعه داده مش صحنه متشکل از ۷۶ اتاق داخلی برای تقسیم بندی معنایی و نمونه است. به طور خاص، برچسبگذاری معنایی آنها با NYU-D v2 مطابقت دارد [ ۶۱استاندارد دسته بندی با ۴۰ کلاس معنایی که از ساختارهای ساختمانی مانند دیوارها، کف و سقف تا مبلمان مختلف را شامل می شود، اما تقریباً ۸ دسته به ندرت به نقاط متصل می شوند که ذاتاً بر عملکرد کلی کل دسته ها تأثیر می گذارد. با این حال، تنوع طبقات معنایی می تواند تعمیم مدل ما را تأیید کند. بنابراین، در کار خود، آنها را در آزمایشهای فرسایشی خود به کار میبریم تا هم اثربخشی و هم تعمیم مدلهایمان را با تقسیم کردن آنها به سه ناحیه بررسی کنیم، که تقریباً از تقسیم اتاق ۵۱/۱۵/۱۰ برای آموزش، اعتبارسنجی و آزمایش پیروی میکند.
۴٫۲٫ جزئیات پیاده سازی
تمام آزمایشات طراحی شده با Pytorch روی یک سرور با کارایی بالا مجهز به پردازنده گرافیکی ۱۲ گیگابایتی NVIDIA Tesla K80 پیاده سازی شده است. از آنجایی که هدف مدل IAGC طراحی شده ما، تقسیم معنایی در ساختمان سناریوهای داخلی با نقاط سه بعدی عظیم است، به منظور سرعت بخشیدن به راندمان محاسبات و بهبود عملکرد بخشبندی در طول فرآیند آموزش، ابرهای نقطهای را با فاصله ۰٫۰۳ متر برای S3DIS و SceneNN پیش پردازش میکنیم. و به خصوص ۰٫۰۲ متر برای ScanNet به دلیل محیط پیچیده و اجسام مختلف. علاوه بر این، برای هر ابرنقطه، ۱۲۸ نقطه برای یادگیری توزیع فضایی در یک شبکه محلی زیرنمونهبرداری میشود و حداکثر ۵۱۲ ابرنقطه بهطور تصادفی برای تکرارهای زمینهسازی جهانی در پیچیدگیهای نمودار انتخاب میشوند. ما در طول فرآیند آموزش از بهینه ساز ADAM با نرخ اولیه ۰ استفاده می کنیم. ۰۱ و نرخ پوسیدگی ۰٫۷٫ همچنین، از آنجایی که کل نمودار ابرنقطه یک صحنه را در یک زمان آموزش میدهیم، اندازه دستهای به ترتیب برای S3DIS، SceneNN و ScanNet به ۲ کاهش مییابد. علاوه بر این، معیارهای ارزیابی مانند میانگین کلاس تقاطع بیش از اتحاد (mIoU)، دقت متوسط کلاس (mAcc) و دقت کلی (OA) به صورت متناسب بیان میشوند و برای ارزیابی کمی نتایج تقسیمبندی استفاده میشوند.
در این مورد، ما از ابرنقطه های از پیش پردازش شده به عنوان واحد پایه خود برای یادگیری عمیق استفاده می کنیم، به طوری که نقاط مشابه هندسی و فیزیکی متعلق به یک دسته را می توان در یک ابر نقطه دسته بندی کرد، که یادگیری تعبیه شده را با نقاط همگن تر تقویت می کند. به طور خاص، ما روش IAGC خود را با معماری نشان داده شده در شکل ۶ می سازیم .
۴٫۳٫ مطالعات و تجزیه و تحلیل فرسایش
ما چندین مطالعه فرسایشی انجام دادیم تا کارایی شبکه پیشنهادی خود را با جایگزینی شبکه جاسازی محلی و کار انباشتگی جهانی با همتایان شبکههای پیشرفته فعلی و تنظیم مقدار بلوکهای IAG روی هم در شبکه IAG-MLP انجام دهیم. . علاوه بر این، ما دانه بندی نمودار ابرنقطه را با پیش پردازش ابرهای نقطه در فواصل مختلف نمونه برداری و از پیش تعریف کردن حداکثر تعداد ابرنقطه برای پیچیدگی نمودار تنظیم کردیم تا ساختار گرافیکی بهینه برای یادگیری عمیق را بررسی کنیم.
۴٫۳٫۱٫ تست Ablation تابع جاسازی محلی
برای نشان دادن اثربخشی شبکه استخراج ویژگی محلی خود، ما مدل ها را با چیدن ۱، ۲، ۳، ۴، ۵ بلوک IAG در IAG-MLP، یعنی ۱-IAG-MLP، ۲-IAG-MLP، ۳-IAG- آموزش دادیم. MLP، ۴-IAG-MLP، و ۵-IAG-MLP. سپس عملکرد آنها را با دو شبکه مختلف مقایسه کردیم، از جمله شبکه کانولوشن رایج PointNet و شبکه سنتی وانیلی خود توجه.
علاوه بر این، PointNet را به یک معماری سبک وزن که در SPG [ ۱۶ ] اتخاذ شده است، تنظیم کردیم، که از یک شبکه ترانسفورماتور (یعنی T-Net، که کاملاً با شبکه ترانسفورماتور وانیلی متفاوت است)، چندین MLP متوالی با ۲۵۶ نهایی تشکیل شده است. ویژگی ابعاد، و یک لایه حداکثر استخر نهایی با بردار ویژگی ۳۲ بعدی. در شبکه وانیلی ترانسفورماتور، به جای افزودن آنها به ویژگی های ورودی، از رمزگذاری های موقعیت به هم پیوسته با سایر ویژگی های هندسی استفاده کردیم.
بر اساس نتایج عددی مربوطه در جدول ۱(پانل سمت چپ)، می بینیم که اگرچه پوینت نت بهترین OA را با ۶۴٫۱۳ درصد به دست آورد، اما کمترین IoU را در مقایسه با سایر شبکه ها از نظر بلوک های تعبیه محلی ارائه می دهد. از نظر تئوری، اشیاء بزرگ مانند دیوارها یا کف معمولاً بخش زیادی از فضای داخلی ساختمان را به خود اختصاص می دهند، و متریک OA عموماً توسط اجسام بزرگ، حاوی مقادیر زیادی از نقاط، تسلط دارد، در حالی که mIoU ارتباط نزدیکی با همه دسته ها دارد. در نتیجه، میتوان نتیجه گرفت که شبکههای مبتنی بر توجه دوگانه نسبت به PointNet نسبت به اهداف کوچک حساستر هستند، زیرا اکثر شبکههای IAG-MLP انباشته شده عملکرد بهتری نسبت به دو روش دیگر در mIoU نشان میدهند، که نشاندهنده توانایی بهتر برای تشخیص چندین کلاس است، به ویژه مناسب برای محیط های داخلی با ساختارهای پیچیده معماری و تجهیزات متمایز. به طور مشخص،شکل ۷ a منحنی های معیارهای تقسیم بندی معنایی را در شبکه های IAG-MLP انباشته شده مختلف نشان می دهد، و نشان می دهد که با افزایش بلوک IAG پشته ای، IAG-MLP با بلوک های IAG کمتر باعث عدم تناسب می شود در حالی که IAG-MLP با بلوک های IAG بیشتر، بیش از حد برازش را نشان می دهد. که به عملکرد بهینه ۲-IAG-MLP نسبت به سایر شبکه ها در mIoU کمک می کند. از سوی دیگر، ترانسفورماتور سنتی وانیلی عملکرد ضعیفی نسبت به IAG-MLP های انباشته در هر دو OA و mIoU داشت، زیرا توجه متقابل به کار رفته در IAG-MLP روابط سطح بالایی را در کانال های غیر از توجه به خود جلب می کند.
با توجه به پیچیدگی محاسباتی، ما از Gflop برای اندازه گیری تعداد عملیات ممیز شناور ۱ میلیارد بار در ثانیه در طول فرآیند آموزش استفاده کردیم. میبینیم که اگرچه مدل PointNet بیشترین تعداد پارامتر را در مقایسه با شبکههای Transformer و ۲-IAG-MLP دارد، اما کمترین پیچیدگی محاسباتی را دارد زیرا محاسبه وزن توجه در شبکه مبتنی بر توجه پیچیدهتر از عملیات کانولوشنی در شبکه است. PointNet.
۴٫۳٫۲٫ آزمون فرسایشی تابع تجمع جهانی
به منظور تایید اثربخشی مکانیسم راهاندازی RNN در بلوک تجمع جهانی، ما ابتدا سه شبکه استخراج ویژگی منطقهای که در بالا ذکر شد در GRU [ ۲۳ ] برای کانولوشن گراف ادغام کردیم. از هر دو صفحه سمت راست بالای جدول ۱ قابل مشاهده استکه تمام شبکههای محلی ادغام شده با GRU برای تجمیع جهانی بهبود عملکرد را به دست آوردند، و به ویژه، ۲-IAG-MLP ادغام شده با GRU، یعنی ۲-IAG-MLP + GRU، بهترین عملکرد mIoU و OA را با ۱۶٫۰۵٪ به دست آورد. و ۷۳٫۰۳ درصد. اگرچه Transformer + GRU بهبود قابل توجهی در mAcc ارائه می دهد، عملکرد ضعیف آن در mIoU آن را بدترین در OA می کند، که نشان دهنده عملکرد بخش بندی عالی آن در دسته های خاص است اما نه همه دسته ها.
ثانیا، ما ماژول RNN ساده شده، یعنی GRU، را با ماژول RNN پیچیده تر، یعنی LSTM مقایسه کردیم تا شبکه نموداری بهینه برای استراتژی تجمیع جهانی را بررسی کنیم. همانطور که می بینیم، اگرچه LSTM به طور عالی با سه گیت برای به روز رسانی حالت پنهان ساخته شده است، ۲-IAG-MLP + GRU با دو گیت به بهبودی بالاتر از ۲-IAG-MLP + LSTM با ۳٫۱۹٪ و ۲٫۴۴٪ در OA و mIoU دست یافت. . ما همچنین IAG-MLP خود را با سایر استراتژیهای گرافیکی مانند شبکه توجه نمودار (GAT) ترکیب کردیم [ ۶۲]. همانطور که مشاهده میشود، در GAT اصلی، الحاق ویژگیهای تعبیهشده به صورت زوجی مورد استفاده در محاسبه وزنهای توجهی، منجر به هزینه محاسباتی هنگفتی میشود و در نتیجه، برای کارایی بالا، آنها را با لبههای نسبت داده شده در ECC جایگزین کردیم. می بینیم که ۲-IAG-MLP + GAT حتی بدتر از ۲-IAG-MLP عمل می کند، عمدتاً به این دلیل که تخصیص بی رویه وزن توجه سراسری سایر ابرنقطه ها به هر ابرنقطه در نمودار ابرنقطه ممکن است نمایش ویژگی را مختل کند، که این امر ضرورت مکانیسم دروازه در LSTM و GRU برای حذف مکرر و انتخابی اطلاعات نامربوط و جذب اطلاعات مهم در طول توالی طولانی.
علاوه بر این، ما چهار شبکه با بهترین عملکرد را در بلوک تجمع جهانی برای آموزش در مجموعه داده S3DIS انتخاب کردیم تا تعمیم شبکه خود را ثابت کنیم. فرآیندهای آموزشی خاص Area 4-fold در شکل ۷ نشان داده شده است، که از آن می توانیم نشان دهیم که روش های مبتنی بر IAG-MLP بهترین تناسب را با توزیع داده ها دارند، جایی که آنها کمی بهتر از PointNet + GRU در ۲۵۰ دوره اول عمل می کنند و ادامه می دهند. به طور پیوسته رشد کند در حالی که PointNet + GRU یک روند نزولی بزرگ در ۱۰۰ دوره گذشته نشان می دهد. علاوه بر این، نتایج آزمایش در منطقه ۴ در جدول ۲(پانل سمت چپ) نشان می دهد که با افزایش مجموعه داده های آموزشی، شکاف بین IAGC ما و سه شبکه دیگر به طور قابل توجهی گسترده تر است، جایی که ۲-IAG-MLP + GRU بهترین عملکرد را در تمام معیارها دارد، به خصوص بیش از ۱۰٫۷٪ و ۱۳٫۳٫ درصد بالاتر از سه مدل دیگر در mIoU و mAcc بود. علاوه بر این، نتایج اعتبارسنجی متقابل ۶ برابری نیز در جدول ۲ (پانل پایین سمت راست) ارائه شده است تا ثابت کند که روش پیشنهادی مبتنی بر IAG-MLP ما میتواند به دقت رقابتی با روشهای مبتنی بر MLP دست یابد و حتی از آنها بهتر عمل کند.
۴٫۳٫۳٫ تست ابلیشن دانه بندی گراف ابرنقطه ای
با توجه به بار محاسباتی عظیم ماژول تجمع گراف با GRU برای سوپرنقاط، لازم است تعداد بهینه ابرنقطه ها و ساختار گرافیکی بهینه برای پیاده سازی ماژول GRU بررسی شود. بنابراین، ما تأثیر دانهبندی نمودار ابرنقطه را بر نتایج تقسیمبندی معنایی در مجموعه داده ScanNet با پیادهسازی ۲-IAG-MLP در اندازههای مختلف نمونهبرداری فرعی، دانهبندیهای پارتیشنبندی و حداکثر تعداد ابرنقطهها برای انباشتگی جهانی تحلیل کردیم. مجموعه داده Scannet برای آموزش، اعتبارسنجی و آزمایش به صحنه های ۱۲۰۱/۱۵۶/۱۵۶ تقسیم شد. به طور خاص، ما روی ابرهای نقطهای برچسبگذاری شده برای ۵۰ دوره در عرضهای وکسلسازی مختلف، نقاط قوت منظمسازی و حداکثر ابرنقطهها (مشخص شده به عنوان v، μ، و max _ s p)، جایی که vبازه نمونه برداری فرعی و تعداد نقاط هر ابرنقطه را تعیین می کند و μ، که در تابع انرژی جهانی در معادله (۳) نقل شده است، بر تعداد ابرنقطه ها در هر نمودار ابرنقطه غالب است و max _ s pحداکثر تعداد سوپرنقطه را برای عملیات جمع آوری جهانی توصیف می کند. به عنوان مثال، شکل ۸ رویههای پیش پردازش ابرهای نقطهای را در محاسبه ویژگیهای هندسی، پارتیشنبندی مبتنی بر هندسه و رنگ، و مراحل ساخت نمودار سراسری نشان میدهد، که ساختار داده را از ابرهای نقطهای بینظم اولیه تا نمودارهای ابرنقطه نهایی سازماندهی مجدد میکند. باید توجه داشته باشیم که ویژگی های هندسی مانند پراکندگی، مسطح بودن و خطی بودن به ترتیب به رنگ های قرمز، سبز و آبی نسبت داده می شود. ابرنقطه ها به طور تصادفی رنگ می شوند و خطوط خاکستری لبه های نسبت داده شده در نمودارهای ابرنقطه را نشان می دهند.
از سوی دیگر، همانطور که در جدول ۳ نشان داده شده است ، با افزایش فاصله وکسل سازی، تقسیم بندی با v0.03 = در مقایسه با نتایج متناظر با آنها کاهش یافته است v= 0.02، که ممکن است زمینه ساز این واقعیت باشد که نمونه برداری بیش از حد ممکن است منجر به نقاط ناکافی در سوپرنقطه برای یادگیری تعبیه محلی شود. علاوه بر این، پارتیشن بندی با بزرگتر μاندازه ابرنقطهها را افزایش داد و به اشتباه نقاطی را با ویژگیهای مشابه اما برچسبهای متفاوت در یک ابرنقطه خوشهبندی کرد که منجر به استنباط تقسیمبندی نادرست معمولاً در لبه مجاور دو شی از دستههای مختلف میشود.
علاوه بر این، به منظور متعادل کردن هزینه راندمان محاسباتی و دقت تقسیمبندی، عملکرد تجمع جهانی را با توجه به حداکثر تعداد ابرنقطهها بررسی کردیم. لازم به ذکر است که ابرهای نقطه خام پارتیشن بندی شده با μ> 0.05 معمولاً از کمتر از ۵۱۲ ابرنقطه تشکیل شده است، و در نتیجه، ما فقط حداکثر ۱۰۲۴ ابرنقطه را برای تجمع جهانی در { v= 0.02، μ= ۰٫۰۳}، { v= 0.02، μ= ۰٫۰۵} و { v= 0.03، μ= ۰٫۰۳} و حداکثر ۵۱۲ ابرنقطه برای سایر آزمایشات مقایسه ای.
قابل توجه، در مقایسه با آزمایشات با W، کسانی که با max _ s p= 512 به نتایج بخش بندی بهتری دست یافتند زیرا ابرنقاط بیش از حد شرکت کننده در به روز رسانی اطلاعات متنی جهانی منجر به توانایی ضعیف در بازیابی معتبر اطلاعات موجود در طول تکرارهای محدود شد. همانطور که در شکل ۹ مشاهده می شود ، ما نتایج تقسیم بندی معنایی را در مجموعه داده ScanNet مشاهده می کنیم، که در حداکثر تعداد مختلف ابرنقطه با max _ s p= 512 و max _ s p= 1024، به ترتیب. در نتیجه، آزمایش با { v= 0.02، μ= ۰٫۰۳، max _ s p= 512} در تمام معیارها بهترین ها را به دست آورد، و ما از نتایج تقسیم بندی آن برای مقایسه با چندین روش پیشرفته در ScanNet در آزمایش های زیر استفاده کردیم.
۴٫۴٫ نتایج تقسیم بندی
در این بخش، IAGC پیشنهادی خود را با چندین روش پیشرفته فعلی مقایسه کردیم تا عملکرد بخشبندی شبکه خود را در دو معیار باز متفاوت، یعنی S3DIS و ScanNet بررسی و ارزیابی کنیم.
۴٫۴٫۱٫ نتایج مربوط به مجموعه داده S3DIS
با توجه به مجموعه داده S3DIS، ما آنها را با همان نقاط زیر نمونه (۰٫۰۳ متر) با توجه به ابرهای نقطه خام متراکم و عظیم آن آموزش دادیم. ما یک اعتبارسنجی متقابل ۶ برابری را در سراسر مناطق به جای ساختمانها انجام دادیم تا توانایی IAGC خود را برای تشخیص چندین کلاس ثابت کنیم. معیارهای ارزیابی نتایج میانگین miro میانگین mioU و میانگین دقت کلی بیش از ۱۳ کلاس در ابرهای نقطه خام است.
ما IAGC خود را با چندین روش تقسیمبندی معنایی ابر نقطهای پیشرفته، از جمله PointNet [ ۱۳ ]، PointNet++ [ ۱۴ ]، SPG [ ۱۶ ] و GAC [ ۱۸ ] مقایسه کردیم. نکته قابل توجه، PointNet و GAC به ترتیب تنها شبکههای محلی را با MLP و انحراف توجه گراف اجرا کردند، در حالی که هر دو PointNet++ و SPG تجمیع جهانی را با تعبیههای محلی مشتق شده از PointNet پیادهسازی کردند. به عنوان جدول ۴نشان می دهد، mIoU IAGC در مقایسه با PointNet و GAC حداقل ۱۷٫۹٪ بالاتر بود، که به تعامل نمودار بین ابرنقاط نسبت داده می شود. به همین ترتیب، در مقایسه با دو شبکه جهانی دیگر، mIoU به طور قابل توجهی افزایش یافته است، به ویژه در اشیاء با ساختار پیچیده مانند تیرها، قفسهها و مبلها، در IAGC با حداقل ۱۲٫۳٪، ۷٫۲٪ و ۱۱٫۴٪ بهبود مشاهده می شود. با این حال، mIoU دسته برد ۲۰٫۹٪ و سپس ۳۰٫۹٪ کمتر از بهترین عملکرد PointNet است. این شکاف عملکرد بزرگ در دسته تخته احتمالاً از سازماندهی داده های اولیه ابرهای نقطه ناشی می شود زیرا PointNet در شبکه های وکسل سه بعدی معمولی تقسیم بر توزیع فضایی پیاده سازی می شود.
ما در ادامه نمونههای تجسم سه صحنه را در مدلهای مختلف ارائه کردیم. همانطور که در شکل ۱۰ مشاهده می شود ، IAGC پیشنهادی ما می تواند با دقت بیشتری در تمام سازه های ساختمانی و اکثر مبلمان پیش بینی کند، و لبه های تقسیم بندی متمایز را بین دسته های مختلف نشان می دهد، در حالی که PointNet و PointNet++ اشکال نامنظمی از اشیاء قطعه بندی شده و نقاط به اشتباه تقسیم شده را در توزیع های گسسته ارائه می دهند، که نتیجه می شود. در لبه های تقسیم بندی مبهم و عملکرد پایین تقسیم بندی معنایی.
۴٫۴٫۲٫ نتایج مربوط به مجموعه داده ScanNet
در مورد مجموعه داده ScanNet، ما IAGC را در مجموعه داده های آموزشی آموزش دادیم و نتایج پیش بینی را روی مجموعه داده آزمایشی بدون برچسب به سرور آزمایش ارسال کردیم. به طور کلی، روشهای پیشرفتهای که به سرور آزمایشی ارسال میشوند، عمدتاً بر اساس دستههای کانولوشن و انواع دادههای ورودی طبقهبندی میشوند. همانطور که در جدول ۵ نشان داده شده است ، برخی از شبکه ها مانند ۳DMV [ ۶۳ ]، PFCNN [ ۶۴ ] و Convolution مماس [ ۶۵ ]] برچسب های معنایی را از اطلاعات دوبعدی و سه بعدی بازیابی کرد، در حالی که سایر شبکه های فهرست شده در زیر تنها با داده های ورودی سه بعدی آموزش دیدند و می توان آنها را به پیچیدگی نقطه ای و پیچیدگی نمودار تقسیم کرد. برای مقایسه قانع کننده، ما عمق شبکه IAG-MLP را برای اطمینان از ظرفیت قابل مقایسه مدل IAGC با خط پایه پیچیدگی نقطه تنظیم کردیم.
بدیهی است که در ScanNet مقوله های معنایی بیشتری نسبت به S3DIS وجود دارد که منجر به کاهش کل mIoU می شود. با این حال، روش ما که صرفاً از دادههای ورودی سهبعدی استفاده میکند، همچنان به امتیاز ۵۳٫۴% mIoU دست مییابد که در مقایسه با شبکههایی که با اطلاعات دوبعدی و سه بعدی آموزش دیدهاند، به افزایش عملکرد قابلتوجهی دستکم ۵ درصدی دست مییابد. به طور مشابه، سازههای ساختمانی دائمی، که در S3DIS نیز دیده میشوند، مانند دیوارها، کفها و درها، همچنان عملکرد بالایی داشتند. علاوه بر این، اکثر مبلمان، از جمله تخت، کابینت، صندلی، مبل، میز و توالت، میانگین IoU 56.03٪ را به دست آوردند که با اختلاف زیادی (۷٫۴٪) از روش های مبتنی بر پیچش نقطه ای بهتر عمل کردند و سایر مبلمان، مانند به عنوان وان حمام، قفسه کتاب، پیشخوان، و یخچال، نتایج تقسیم بندی رقابتی در مقایسه با روش های پیچش نقطه ای به دست آوردند. از نظر روشهای مبتنی بر نمودار، هر دو IAGC و SPG ما کانولوشن گراف جهانی را با GRU پیادهسازی کردند، اما استراتژیهای جاسازی محلی متفاوتی داشتند، و IAGC ما ۸٫۳٪ بالاتر از SPG در mIoU بود. به طور کلی، مکانیسم دروازه همراه با تعامل توجه کانال منجر به یک ماژول توجه اضافی برای گرفتن روابط فضایی بیشتری نسبت به پیچیدگی نقطهای معمولی با یک فیلتر خاص کانال میشود.
۴٫۴٫۳٫ تجزیه و تحلیل نتایج
به طور کلی، IAG-MLP پیشنهادی ما عملکرد رقابتی را در کار تعبیه نمایش محلی در مقایسه با شبکههای کانولوشن نقطهای رایج ارائه میدهد و ترکیب شبکههای کانولوشن گراف IAG-MLP و جهانی حتی از سایر شبکههای مبتنی بر MLP یا ترانسفورماتور بهتر عمل میکند. وظیفه تقسیم بندی معنایی بر این اساس، ما این بهبودها را به دو عامل اساسی نسبت می دهیم. اول از همه، IAG-MLP یک مکانیسم توجه تعاملی را اجرا میکند که در آن جاسازیها میتوانند توسط ویژگیهای تقویتشده از ترکیب کانالهای ویژگی متعدد در روند بهبود تولید نقطهای تحت سلطه قرار گیرند، که برای اشیایی که مبتنی بر هندسه متمایز و متمایز را نشان میدهند مفید است. ویژگی های مبتنی بر رنگ (به عنوان مثال، صندلی، مبل، و میز). به دلیل ویژگی های مرتبه بالا که در کانال ویژگی های سطح بالا پخش شده است، اشیاء با هندسه مشابه اما رنگ های متفاوت با اشیاء اطراف (یعنی تخته و پنجره) و اشیاء با رنگ مشابه اما هندسه متفاوت (یعنی تیر و ستون) می توانند به وضوح متمایز شود علاوه بر این، نمایشهای متمایز به دست آمده از شبکه IAG-MLP تعامل اطلاعات زمینهای را در بین ابرنقاط تسهیل میکند. در عمل، با در نظر گرفتن تأثیر اشیاء مجاور مانند مبلمان داخلی و دیوارهای اطراف، کف را از سقف متمایز می کند. در مقابل، کف و سقف ممکن است به طور متقابل تقسیم بندی مبلمان داخلی را افزایش دهند. به طور کلی،
۵٫ نتیجه گیری و بحث
در این مقاله، ما یک معماری عمیق سهبعدی جدید برای تقسیمبندی معنایی در صحنههای درب، به نام پیچیدگی گراف مبتنی بر توجه تعاملی (IAGC) ارائه میکنیم. ما ابتدا ابرهای نقطه خام را به ابرنقطه های همگن بر اساس اطلاعات مبتنی بر هندسه و رنگ سازماندهی کردیم تا به طور موثر پیچیدگی محاسباتی را کاهش دهیم و در عین حال ویژگی های اشیاء هر ابرنقطه را تا حد زیادی حفظ کنیم. در عین حال، استفاده از سوپرنقاط به عنوان واحد داده ورودی ممکن است به طور قابل توجهی میدان دریافت را برای به دست آوردن اطلاعات غنی تر گسترش دهد. در نتیجه، با هدف رسیدگی به مشکل یادگیری ویژگیهای محلی ناکافی توسط PointNet، که بستری برای اکثر شبکههای پیشرفته است، ما یک ماژول توجه دوگانه، MLP دروازهای توجه تعاملی، یعنی IAG-MLP، پیشنهاد کردیم. که برای ثبت کامل ویژگیهای سطح بالا در سوپرنقطهها توسط فیلترهای توجه متقاطع و متقابل کانالی جهتگیری میکند. علاوه بر این، ما یک معماری RNN دیگر به نام GRU را پیادهسازی کردیم که بر روی کل مجموعه سوپرنقطهها برای استخراج اطلاعات متنی جهانی به منظور بهروزرسانی تعبیه محلی ابرنقاط و تقویت استنتاج نهایی از نظر معنایی انجام میشود. در نهایت، آزمایشهای گسترده بر روی معیارهای باز چالشبرانگیز نشان میدهد که روش پیشنهادی ما میتواند یک شبکه محلی بالقوه با قابلیت قوی در بیان ویژگیهای قویتر برای ابرهای نقطه سهبعدی باشد. ما امیدواریم که کار ما الهامبخش تحقیقات بیشتر در مورد ایده تقویت معماری MLP با مکانیزم توجه تعاملی، طراحی شبکههای مبتنی بر ابرنقطه و تقسیمبندی نمونه یا قطعه باشد.