

- مقاله
- دسترسی آزاد
- منتشر شده:
نقشهبرداری از داراییهای زیرساخت حمل و نقل در معرض خطر با استفاده از روشهای آماری و یادگیری ماشینی
گزارشهای علمی حجم ۱۶ ، شماره مقاله: ۴۳۱۳ ( ۲۰۲۶ )
چکیده
داراییهای ژئوتکنیکی مانند خاکریزها و شیبهای بزرگراه (HWS) برای یکپارچگی زیرساختهای حمل و نقل حیاتی هستند. با این حال، آنها تا حد زیادی توسط برنامههای مدیریت داراییهای حمل و نقل در ایالات متحده نادیده گرفته میشوند. HWS در برابر رانش زمین ناشی از عوامل مختلفی از جمله وقوع مکرر بارندگیهای شدید آسیبپذیر است. بنابراین، نقشهبرداری از HWS آسیبپذیر و ایجاد یک فهرست موجودی به طور قابل توجهی به مدیریت داراییهای زیرساخت کمک خواهد کرد. برای این منظور، این تحقیق سیستمهای اطلاعات جغرافیایی اثبات شده مبتنی بر روشهای نقشهبرداری از حساسیت زمین لغزش را که معمولاً برای دامنههای تپه اعمال میشود، اتخاذ کرد و روشی برای نقشهبرداری از داراییهای HWS در معرض خطر توسعه داده شد. چندین مدل طبقهبندی یادگیری ماشینی (ML) تحت نظارت برای نقشهبرداری دقیق HWS در معرض خطر در منطقه مورد مطالعه مرکز میسیسیپی توسعه داده و ارزیابی شدند. مدلهای ارتفاعی دیجیتال (DEM) ایجاد شده از دادههای سنجش از دور به دست آمده از ماهوارهها، حسگرهای پهپادی و LiDAR زمینی برای توسعه عوامل ایجاد کننده رستری شده استفاده شدند. عوامل مؤثر مورد استفاده شامل موارد زیر بودند: ویژگیهای ژئوتکنیکی و ژئومورفولوژیکی، مانند شیب، جهت، انحنا، ارتفاع، شاخص پوشش گیاهی نرمال شده (NDVI)، ترکیب خاک و زمین از DEM؛ و عوامل هیدرولوژیکی، از جمله بارندگی، فاصله از رودخانه، عمق آبهای زیرزمینی و شاخص رطوبت توپوگرافی. مکانهای شناخته شده HWS خراب و خراب نشده انتخاب و رستری شدند و پیکسلها به عنوان دادههای واقعیت زمینی استخراج شدند. عوامل مؤثر رستری شده به عنوان ویژگیهای مستقل برای آموزش مدلهای طبقهبندی ML برای پیشبینی حساسیت به شکست HWS مورد استفاده قرار گرفتند. مدلها با توسعه ماتریسهای سردرگمی و استفاده از معیارهای احتمالی مانند نمره سطح زیر منحنی (AUC)، نمره F-1 و نمرات دقت ارزیابی شدند. جنگل تصادفی نسبت به سایر مدلها (نمرات AUC، F1 و دقت ۱٫۰) عملکرد بهتری داشت. تنظیم آستانه احتمال بر روی مدل جنگل تصادفی انجام شد و نقشههای حساسیت با آستانههای مختلف ارزیابی شدند. یک آستانه بهینه ۰.۷۵ برای ایجاد تعادل بین نتایج منفی کاذب و مثبت کاذب در نتایج پیشبینیشده استفاده شد و شناسایی قابل اعتمادتری از دامنههای مستعد خطر را تضمین کرد. مدل RF آموزشدیده نشان داد که ارتفاع، فاصله از نهرها، NDVI و بارندگی چهار عامل اصلی مؤثر بر خرابیهای HWS در این مطالعه بودند. این روش امکان شناسایی آسان HWSهای آسیبپذیر را در مناطق جغرافیایی وسیع فراهم میکند. این روش با انجام مداخلات هدفمند و تلاشهای پیشگیرانه در زمینه نگهداری، به استفاده مؤثر از بودجه کمک میکند. سازمانهای حمل و نقل میتوانند این روش را در HWS در هر مکانی پیادهسازی کنند تا تلاشهای مدیریت داراییهای ژئوتکنیکی را استراتژیک کنند.
محتوای مشابه توسط دیگران مشاهده میشود

مقدمه
داراییهای ژئوتکنیکی مانند HWS، در میان سایر سازههای جغرافیایی، بخش جداییناپذیر زیرساخت حمل و نقل چندوجهی هستند. هنگامی که آنها دچار نقص یا مشکل میشوند، کل زیرساخت رو به زوال میرود. تعمیرات سالانه شیبهای آسیبدیده، درصد قابل توجهی از بودجه نگهداری بسیاری از آژانسهای حمل و نقل، از جمله وزارت حمل و نقل میسیسیپی (MDOT) و سپاه مهندسان ارتش ایالات متحده را تشکیل میدهد و عدم اقدام، هزینههای نگهداری را افزایش داده و منجر به خرابیهای فاجعهبار بدون هشدار قبلی میشود. با این وجود، برنامههای مدیریت دارایی حمل و نقل عمدتاً بر پلها و روسازیها تمرکز دارند. ۱ ، ۲ ، ۳ .
مخاطرات طبیعی و بارندگیهای شدید و مکرر، وخامت زیرساختهای حمل و نقل را تشدید میکنند. طوفانهایی مانند هاروی (۲۰۱۷)، فلورانس (۲۰۱۸)، آیدا (۲۰۲۱) و ایان (۲۰۲۲) شدیدتر از طوفانهای قبلی بودند و منجر به اثرات مخربتری از جمله ایجاد رانش زمین و تأثیر بر زیرساختهای حمل و نقل شدند. شبکه زیرساخت حمل و نقل میسیسیپی در سال ۲۰۲۱ به شدت تحت تأثیر طوفان آیدا و در سال ۲۰۲۲ شاهد بارندگیهای سیلآسای بیسابقهای بود [۴] . علاوه بر تلفات جانی، آوارگی جوامع و خسارت به اموال، بارندگیهای شدید همچنین باعث خطرات جغرافیایی قابل توجهی از جمله رانش زمین و آبگرفتگیهایی شد که بر زیرساختهای حمل و نقل تأثیر گذاشت. انتظار میرود وقوع رانش زمین به دلیل شهرنشینی، جنگلزدایی و تغییرات بارندگی ۵ که بر سیستمهای زیرساخت حمل و نقل تأثیر میگذارند، در سطح جهان افزایش یابد.
این سیستمهای حمل و نقل برای توسعه اقتصادی و اتصال منطقهای بسیار مهم هستند. اختلالات ناشی از رانش زمین، جریانهای آوار و ریزش سنگ نه تنها مانع تحرک میشوند، بلکه منجر به خسارات اقتصادی قابل توجهی میشوند، امنیت عمومی را به خطر میاندازند و تلاشهای واکنش اضطراری را پیچیده میکنند.
تأثیرات آبشاری این رویدادها بر روی شکست شیبها و خاکریزها عمیق است و اغلب زیرساختهای حیاتی جغرافیایی را فلج کرده و سیستمهای ضروری مانند حمل و نقل، انرژی و تأمین آب را مختل میکند. جوامع با مشکلات شدیدی روبرو میشوند و دسترسی به تأسیسات حیاتی مانند بیمارستانها، پناهگاهها و سایر زیرساختهای حیاتی را از دست میدهند.
نقشهبرداری حساسیت زمینلغزش (LSM) با استفاده از سیستم اطلاعات جغرافیایی (GIS) یک روش اثباتشده برای درک و پیشبینی اثرات رویدادهای مهم آب و هوایی بر روی شیبهای شیبدار تپهها است. مطالعات متعددی از مدلهای آماری مانند روش نسبت فراوانی (FR) ۶ ، ۷ ، ۸ ، روش وزن شواهد (WOE) ۸ ، ۹ و فرآیند سلسله مراتبی تحلیلی (AHP) ۱۰ ، ۱۱ برای LSM استفاده کردهاند. WOE و AHP شامل اختصاص امتیاز به هر عامل مؤثر، چه به صورت تصادفی و چه بر اساس تجربه، هستند. با این حال، این روشها بر فرضیهسازی وزن عوامل مؤثر قبل از مدلسازی بر اساس استنتاج نظری و نه مشاهدات تجربی متکی هستند. برای جلوگیری از چنین تخصیص وزن تصادفی، مطالعات متعددی تکنیکهای یادگیری ماشین ۱۲ ، ۱۳ مانند ماشینهای بردار پشتیبان، درختان تصمیمگیری و جنگلهای تصادفی را برای ارزیابی حساسیت زمینلغزش ۱۴ ، ۱۵ ، ۱۶ ، ۱۷ ، ۱۸ پیادهسازی کردهاند .
اخیراً، با دسترسی آسان به دادههای سنجش از دور، محققان به طور فزایندهای از روشهای GIS و ML برای مطالعه حساسیت زمین لغزش استفاده کردهاند. برخی از مطالعات انجام شده در مقالات که LSM را با استفاده از GIS و ML در سراسر جهان پیادهسازی کردهاند، شامل منطقه ارتفاعات کامرون در مالزی ۱۱ ، استان اصفهان در ایران ۱۹ ، دامنههای کوهستانی بزرگراه قراقروم در پاکستان ۲۰ ، شهرستان چینگچوان در چین ۲۱ و موارد دیگر است. ۲۲ نقش حیاتی ML را در استفاده از دادههای سنجش از دور برای LSM و مدیریت ریسک بلایا برجسته میکند. ما و همکاران ۲۳ همچنین یک کاربرد نوآورانه از یادگیری ماشینی خودکار (AutoML) را به عنوان ابزاری کاربرپسند و آماده ارائه میدهند که برای LSM بسیار مفید است. با این حال، بسیاری از مطالعات LSM مناطق کوهستانی را هدف قرار دادهاند و بر رانش زمین در دامنههای تپههای طبیعی یا بریده شده در سراسر جهان تمرکز دارند ۱۱ ، ۱۹ ، ۲۰ ، ۲۱ . از جمله استثنائات قابل توجه میتوان به کریگ و آگوستو فیلهو [ ۲۴] اشاره کرد که روشهای تعادل حدی را برای انجام ارزیابی پایداری شیب در مقیاس بزرگ در امتداد دامنههای بزرگراه در سائوپائولو، برزیل، در مقیاس درشت و سپس در مقیاس ریزتر، پیادهسازی کردند. آچور و پورقاسمی [ ۲۵] مطالعهای انجام دادند که پتانسیل LSM مبتنی بر یادگیری ماشین را برای شناسایی مناطق پرخطر در امتداد زیرساختهای حیاتی بزرگراه در مناطق کوهستانی الجزایر برجسته کرد. مطالعه آنها نشان داد که جنگل تصادفی (Random Forest) عملکرد بهتری (AUC = 0.97) نسبت به سایر مدلهای LSM داشته است.
با این حال، توجه نسبتاً کمی به ناپایداریهای شیب که بر شیبها در زمینهای کمارتفاع یا مسطح تأثیر میگذارند، شده است. به ویژه، شکاف قابل توجهی در ادبیات مربوط به شکستهای شیب خاکریز که بر زیرساختهای حمل و نقل، مانند بزرگراهها، راهآهن و شبکههای حمل و نقل بینوجهی تأثیر میگذارند، وجود دارد. این شکاف به ویژه در مناطقی مانند میسیسیپی، که در آن رسهای منبسطشونده و الگوهای متناوب بارندگی شدید و خشکسالی، که اغلب توسط طوفانها تشدید میشوند، به چرخههای انقباض-تورم کمک میکنند که پایداری خاکریزهای بزرگراهها و راهآهن را تضعیف میکنند، برجسته است. این ناپایداریهای ژئوتکنیکی عملکرد، ایمنی و قابلیت سرویسدهی بلندمدت داراییهای زیرساختی را تهدید میکنند و نیاز فوری به مدلسازی حساسیت هدفمند را برجسته میکنند. با وجود اهمیت آنها، شیبهای خاکریز خاکی همچنان در تحقیقات اصلی LSM کمتر مورد توجه قرار میگیرند.
اگرچه تعداد فزایندهای از محققان اکیداً اجرای دادههای سنجش از دور را برای نظارت و مدیریت داراییهای زیرساختهای ژئوتکنیکی و حمل و نقل مانند خاکریزها و شیبهای بزرگراه توصیه میکنند [۲۶ ، ۲۷ ، ۲۸ ، ۲۹ ، ۳۰ ]. با این حال، مطالعات کمی در مورد اجرای LSM با تمرکز بر شیبهای بزرگراه با استفاده از GIS و تکنیکهای سنجش از دور انجام شده است. در این عصر اطلاعات و هوش مصنوعی، محققان باید تکنیکهای سنجش از دور را با هوش مصنوعی برای نظارت بر داراییهای ژئوتکنیکی مانند شیبهای خاکریز و به تبع آن، زیرساختهای حمل و نقل به کار گیرند.
بنابراین، در این مطالعه فعلی، ما به شکاف تحقیقاتی پرداخته و با استفاده از GIS و یک چارچوب مبتنی بر ML، یک نقشه حساسیت به شکست HWS در امتداد دامنههای کریدور بزرگراه میسیسیپی تهیه میکنیم. این تحقیق به دنبال پر کردن شکافهای دانش موجود با انجام ارزیابی دقیق خاکریزهای بزرگراه و آسیبپذیری آنها در برابر شکست شیب در میسیسیپی است. این فرآیند شامل ایجاد فهرستی از شیبهای بزرگراه شکست خورده و دست نخورده و به دنبال آن استفاده از تکنیکهای ML برای نقشهبرداری حساسیت است. مدلهای مختلف ML تحت نظارت، از جمله جنگل تصادفی، طبقهبندیکنندههای ساده بیز، طبقهبندیکننده بردار پشتیبان و رگرسیون لجستیک، برای تعیین اثربخشی آنها در پیشبینی خاکریز بزرگراه و حساسیت به شکست شیب ارزیابی میشوند. اگرچه هیچ اجماعی در مورد اینکه کدام مدل ML باید برای انجام LSM ۳۱ استفاده شود، وجود ندارد ، مدلهای مورد استفاده در این مطالعه به طور گسترده توسط سایر مطالعات LSM مورد استفاده قرار گرفتهاند. مدلها با مقایسه دقت، امتیاز F-1 و نمرات AUC که معیارهای عملکرد محبوب برای مدلهای طبقهبندی LSM ۳۲ هستند، ارزیابی شدند .
منابع دادهای مختلفی برای توسعه عوامل مؤثر، از جمله DEM های ایجاد شده از روشهای سنجش از دور مانند ماهوارهها و LiDAR هوایی، مورد استفاده قرار گرفتند. LSM متمرکز بر شیبهای بزرگراه با هدف کمک به افزایش تابآوری زیرساختها با فراهم کردن امکان نظارت پیشگیرانه، هشدار اولیه و مدیریت داراییهای آگاه از ریسک از طریق ادغام تجزیه و تحلیل مکانی، سنجش از دور و مدلسازی پیشبینی، طراحی شده است.
عوامل مؤثر در نظر گرفته شده در این مطالعه شامل ویژگیهای ژئوتکنیکی و ژئومورفولوژیکی، مانند زاویه شیب، جهت شیب، انحنا، شاخص پوشش گیاهی نرمال شده (NDVI) و نوع خاک بود. عوامل هیدرولوژیکی، از جمله بارندگی، فاصله از نهرها، شاخص رطوبت توپوگرافی (TWI) و عمق آبهای زیرزمینی نیز در نظر گرفته شدند. عوامل مؤثر انتخاب شده به طور مداوم در مطالعات مدلسازی زمین لغزش و حساسیت به خطرات زمینلرزه توسط چندین مطالعه ۱۰ ، ۱۱ ، ۳۳ ، ۳۴ ، ۳۵ ، ۳۶ مورد استفاده قرار گرفتهاند . بحث مفصلتر در مورد انتخاب عوامل مؤثر در بخش روشها ارائه شده است.
عوامل ایجادکننده به عنوان ویژگیهای مستقل برای آموزش مدلهای طبقهبندی ML جهت پیشبینی شیبها و خاکریزهای آسیبپذیر بزرگراهها مورد استفاده قرار گرفتند. نتایج این مطالعه میتواند با ارائه بینشهای ارزشمند برای هدف قرار دادن تلاشهای تعمیر و نگهداری پیشگیرانه در داراییهای ژئوتکنیکی و کاهش خرابیهای فاجعهبار ناشی از بارندگیهای قابل توجه و رویدادهای آب و هوایی در شبکههای جادهای و شیبهای بزرگراه، به طور قابل توجهی به کار آژانسها و مقامات حمل و نقل کمک کند.
اگرچه توسعه مدلهای حساسیت به شکست با استفاده از GIS همراه با مدلهای ML یک تکنیک اثباتشده است، اما به ندرت برای نقشهبرداری از شیبهای ناپایدار خاکریز بزرگراهها به کار گرفته شده است. تکنیک مدلسازی حساسیت مبتنی بر GIS که در این مطالعه پیشنهاد شده است، در توسعه فهرستی از داراییهای شیب بزرگراه در معرض خطر، مفید خواهد بود. چارچوب این مطالعه کاربردهای وسیعتری دارد و به خاکریزهای راهآهن و سایر زیرساختهای ژئوتکنیکی حیاتی، مانند خاکریزها و سدهای خاکی، که اجزای اساسی سیستمهای حمل و نقل چندوجهی را تشکیل میدهند، گسترش مییابد.
روشها
این مطالعه در مراحل زیر انجام شد: (۱) توسعه یک پایگاه داده موجودی شیبهای خاکی شکست خورده و شکست نخورده؛ (۲) تعیین عوامل ایجاد کننده؛ (۳) ساخت و مقایسه مدلهای طبقهبندی یادگیری ماشین برای پیشبینی شکست، از جمله جنگل تصادفی، رگرسیون لجستیک، بیز ساده و SVC؛ (۴) تولید نقشه حساسیت به شکست شیبها و خاکریزهای ناپایدار با استفاده از بهترین مدل یادگیری ماشین.
این روش ابتدا با تهیه نقشههای عامل مسبب در قالب رستری انجام شد، که روشی محبوب و از نظر محاسباتی کارآمد برای انجام LSM ۲۳ است . این روش در شماتیک ارائه شده در شکل ۱ شرح داده شده است .

طرح کلی روششناسی برای نقشهبرداری از آسیبپذیری HWS. توجه : تصاویر ماهوارهای لندست ۹ شماره ۳۷ که از سازمان زمینشناسی ایالات متحده (earthexplorer.usgs.gov/) دریافت شده است، توسط نویسنده اول (RS) برای ایجاد رستر NDVI استفاده شد. تمام عوامل مسبب رستری شده و نقشههای آسیبپذیری HWS در نرمافزار ArcGIS Pro توسط Esri، نسخه ۳.۰ ( https://www.esri.com/arcgis ) توسط نویسنده اول (RS) ایجاد شدند.
برای تهیه نقشه حساسیت، مراحل زیر طی شد.
- مرحله ۱: فهرستی از خاکریزهای خراب و سالم در منطقه مورد مطالعه تهیه شد. مکان خاکریزها در Google Earth به صورت برداری و به صورت فایل kmz ذخیره شد، سپس در ArcGIS وارد شد، به چندضلعیهای خراب و سالم تبدیل شد و در نهایت به صورت رستری نمایش داده شد.
- مرحله ۲: عوامل مؤثر بر شکست به صورت رستری توسعه داده شدند. عوامل توپوگرافی، ژئومورفولوژیکی و هیدرولوژیکی با استفاده از DEM های به دست آمده از منابع مختلف توسعه داده شدند.
- مرحله ۳: دادهها تجزیه و تحلیل شدند، مدلها توسعه داده شدند و نتایج آزمون طبقهبندی از مدلهای مختلف یادگیری ماشینی مقایسه شدند.
- مرحله ۴. مدل با عملکرد بهتر (جنگل تصادفی) برای تولید نقشههای حساسیت به شکست شیبهای خاکریز بزرگراه در امتداد کریدور شبکه اصلی میسیسیپی استفاده شد.
نرمافزار مورد استفاده برای تمرینهای نقشهبرداری حساسیت شامل نرمافزار ArcGIS Pro از شرکت Esri، نسخه ۳.۰ ( www.esri.com/arcgis )، کتابخانههای پایتون متنباز از جمله کتابخانه Pandas نسخه ۱.۵.۳ بود.
(pandas.pydata.org)، Scikit-learn نسخه ۱.۲.۲ (sklearn، scikit-learn.org/) و کتابخانه انتزاع دادههای مکانی “GDAL” نسخه ۳.۲.۴ (gdal.org) استفاده شد. همه تحلیلها در پایتون در JupyterLab 3.6.3 (jupyter.org)، یک محیط توسعه تعاملی مبتنی بر وب در پلتفرم توزیع Anaconda Navigator نسخه ۲.۵.۰ ( www.anaconda.com ) انجام شد. DEM های مبتنی بر LiDAR هوایی از سیستم اطلاعات منابع خودکار میسیسیپی (MARIS، maris.mississippi.edu/) که توسط ایالت میسیسیپی در دسترس عموم قرار گرفته است، تهیه شدند. DEM ها با استفاده از دادههای جمعآوریشده توسط ماموریتهای نقشهبرداری هوایی LiDAR که طی سالهای ۲۰۰۵ تا ۲۰۱۷ انجام شده بود، توسعه داده شدند. DEM در سیستم تصویر افقی بود: NAD 1983 (2011)، UTM 15N و ۱۶N، داده عمودی: NAVD88 GEOID12b، با وضوح یا فاصله پیکسلی تقریباً ۰٫۷ متر (یا ۳ فوت). چنین DEM های با وضوح بالا به ویژه ارزشمند هستند زیرا جزئیات مکانی دقیق تری ارائه می دهند و می توانند دقت نقشه های حساسیت ۳۸ را در مقایسه با داده های ماهواره ای با وضوح پایین تر، مانند وضوح ۳۰ متر یا ۹۸ فوت از Landsat 9، افزایش دهند.
منطقه مورد مطالعه و مجموعه دادهها
موجودی خاکریز و شیب بزرگراه
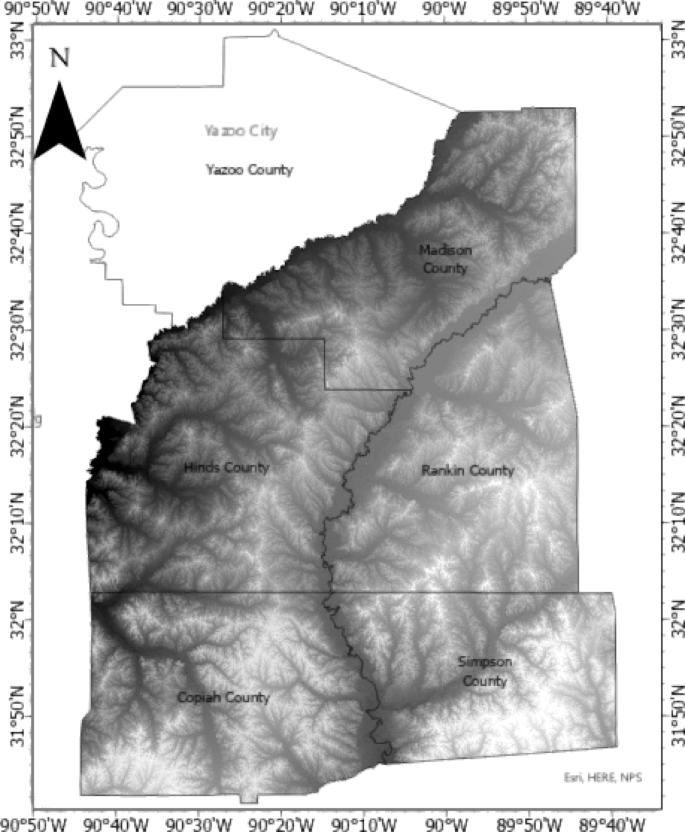
دامنههای شکست خورده مورد بررسی در این مطالعه از هشت شهرستان در میسیسیپی بودند. تقریباً ۶۴۰۰۰ پیکسل از مناطق شیب شکست خورده با وضوح ۰٫۹ متر × ۰٫۹ متر وجود داشت که مساحتی معادل ۰٫۸۳ متر مربع در هر پیکسل را نشان میداد. تقریباً دو برابر تعداد پیکسلهایی که مناطق غیر شکست خورده را نشان میدادند، به طور تصادفی در منطقه مورد مطالعه انتخاب شدند تا مدلهای پیشبینی حساسیت به شکست توسعه داده شوند. مکانهای HWS شکست خورده و غیر شکست خورده در شکل ۲ ارائه شده است . HWS غیر شکست خورده که توسط چندضلعیها مشخص شده است، به دلیل مقیاس بزرگ نقشه، در نقشه شکل ۲ قابل مشاهده نیست. تعداد دامنههای شکست خورده در مقابل غیر شکست خورده در شکل ۳ ارائه شده است .

نقشه موقعیت منطقه مورد مطالعه و موجودی HWS که در نرمافزار ArcGIS Pro (Esri، نسخه ۳.۰، www.esri.com/arcgis ) توسط نویسنده اول (RS) تهیه شده است.

توزیع موجودی دامنهها.
آمادهسازی مجموعه دادههای عوامل سببی
مهمترین مرحله در توسعه مدل برای نقشه برداری از حساسیت به شکست شیب، تهیه مجموعه داده عوامل ایجاد کننده است که به عنوان ویژگی هایی برای آموزش و اعتبارسنجی مدل استفاده می شود. به طور کلی، دقت مدل ها تحت تأثیر استراتژی های نمونه برداری از داده ها قرار دارد. شیب های خاکریز شکست خورده به عنوان سلول های شبکه ای نمونه برداری شدند، روشی اثبات شده که برای مدل سازی حساسیت به مخاطرات طبیعی، از جمله رانش زمین ۳۹ استفاده می شود . چندضلعی های شیب خاکریز شکست خورده با فرمت kmz وارد شده و در ArcGIS Pro به رستر تبدیل شدند. سپس، رستر به اندازه شبکه پیکسلی ۳′ × ۳′ نمونه برداری شد. از ۲۶ محل شیب شکست خورده در منطقه مورد مطالعه هشت شهرستان (شکل ۲ )، که شامل ۲۹۴۶۹ سلول شبکه ای است، برای مدل سازی حساسیت استفاده شد. مکان های شیب خاکریز شکست نخورده با نسبت ۱:۲ (یا دو برابر تعداد شیب های شکست خورده) به طور تصادفی در منطقه مورد مطالعه انتخاب شدند. به شیبهای شکستخورده امتیاز ۱ و به پیکسلهای شیب بدون شکست امتیاز ۰ اختصاص داده شد. از رسترهای شیب شکستخورده و بدون شکست برای نمونهبرداری از عوامل ایجادکننده استفاده شد. با انجام این کار، یک مجموعه داده متشکل از ۱۴ ستون ویژگیها و یک ستون هدف از طبقهبندی شکست با مقدار ۰ یا ۱ ایجاد شد. پس از پاکسازی و بهینهسازی دادهها، شکل کل مجموعه داده شامل ۳۲۲۱۷ ردیف و ۱۵ ستون بود. عوامل ایجادکننده و آمادهسازی مجموعه داده در ArcGIS Pro و رابط JupyterLab در Anaconda Navigator با استفاده از پایتون و کتابخانه GDAL انجام شد.
انتخاب عوامل مؤثر بر اساس بررسی گسترده منابع علمی انجام شد، همانطور که در جدول ۱ شرح داده شده است . رایجترین و مرتبطترین عوامل مؤثر، یعنی ارتفاع، شیب و غیره، انتخاب شدند. ۳۸ نفر دریافتند که افزایش تعداد عوامل مؤثر از ۱۲ به ۱۵، دقت پیشبینی را کمی افزایش میدهد. بنابراین، ما با استفاده از ۱۵ عامل مؤثر، یعنی: ارتفاع، شیب، جهت، انحنا، انحنای سطح، انحنای پروفیل، NDVI، TWI، فاصله از نهرها، تجمع جریان، عمق سطح ایستابی و نوع خاک، شروع کردیم. عوامل مؤثر رایج در سایر مطالعات که از بررسی منابع علمی به دست آمدهاند، در جدول ۱ شرح داده شدهاند . هر عامل مؤثر مورد استفاده در این مطالعه در بخش بعدی مورد بحث قرار گرفته است.
ارتفاع
ارتفاع از سطح دریا یک عامل مؤثر و حیاتی است که اغلب در ارزیابی حساسیت به رانش زمین مورد استفاده قرار میگیرد . ۵۰٫ مدل رقومی ارتفاع (DEM) منطقه مورد مطالعه وضوح مکانی ۰٫۷ متر را نشان میدهد. شکل ۴ مدل رقومی ارتفاع (DEM) مشتق شده از MARIS را برای منطقه مورد مطالعه نشان میدهد.
DEM برای منطقه مورد مطالعه (وضوح = ۰٫۷ متر یا ۲٫۳ فوت). منبع دادهها: DEM هوایی مبتنی بر LiDAR که به صورت عمومی از MARIS (maris.mississippi.edu) در دسترس است.
کریدورهای بزرگراه ملی، بزرگراههای ایالتی و جادهها انتخاب و در گوگل ارث برداری شدند و یک چندضلعی حائل تا ۴۲۷ متر در دو طرف جادهها ایجاد شد. متعاقباً، با استفاده از منطقه حائل به عنوان چندضلعیها، DEM برای ایجاد نمایش رستری خاکریز بزرگراه، همانطور که در شکل ۵ نشان داده شده است، برش داده شد . ارتفاع از ۲۷ تا ۱۹۳ متر متغیر بود. این DEM خاکریز بزرگراه برای ایجاد سایر عوامل مؤثر رستری، از جمله شیب، جهت، TWI، انحنا، انحناهای پلان و پروفیل، تجمع جریان و فاصله از نهر استفاده شد.

رستر ارتفاعی (متر).
شیب
شیب (یا درجه) میزان شیب یا شیب سطح زمین است. این پارامتر نقش محوری در تأثیرگذاری بر پایداری و آسیبپذیری زمین دارد و پارامتری حیاتی در درک رفتار مناظر و سازندهای زمینشناسی است. زاویه شیب معمولاً بر حسب درجه یا رادیان اندازهگیری میشود و عامل مهمی در محیطهای مختلف طبیعی و مهندسی است. رستر شیب بر حسب درجه در شکل ۶ ارائه شده است .

رستر شیب (درجه).
جنبه
وجه، جهت شیب را نشان میدهد. این شاخص، جهتگیری تندترین مسیر سرازیری روی یک شیب را اندازهگیری میکند و اغلب بر حسب درجه بیان میشود و جهت شیب را نسبت به شمال نشان میدهد. این یک جزء اساسی در تحلیل زمین است و با تأثیر بر میزان قرار گرفتن در معرض نور خورشید، تغییرات دما، تبخیر و تعرق، تأثیر بارندگی و فرسایش، بر حساسیت زمین لغزش تأثیر میگذارد . وجهها معمولاً در جهات اصلی (شمال، جنوب، شرق یا غرب) طبقهبندی میشوند یا بر حسب درجه مشخص میشوند که اطلاعات ارزشمندی را برای کاربردهای مختلف، از جمله کشاورزی، جنگلداری، هیدرولوژی و مهندسی ژئوتکنیک ارائه میدهد. رستر وجه در شکل ۷ ارائه شده است .

رستر جنبه.
انحنا
انحنا به میزان تغییر شیب در امتداد یک سطح اشاره دارد. این یک عامل کلیدی در درک ژئومورفولوژی است، زیرا نشان میدهد که آیا یک سطح مقعر است یا محدب و بینشی در مورد شکل کلی زمین ارائه میدهد. دو نوع اصلی انحنا وجود دارد: انحنای صفحه و انحنای پروفیل. رستر انحنا برای منطقه مورد مطالعه در شکل ۸ ارائه شده است .
- انحنای صفحه: انحنای صفحه که به عنوان انحنای خطوط تراز نیز شناخته میشود، انحنای عمود بر جهت شیب را نشان میدهد و نشان میدهد که چگونه یک سطح هنگام حرکت موازی با خطوط تراز، انحنا پیدا میکند. انحنای صفحه مثبت نشان دهنده تحدب است، در حالی که انحنای صفحه منفی نشان دهنده تقعر در امتداد خطوط تراز است. رستر انحنای صفحه برای منطقه مورد مطالعه در شکل ۹ ارائه شده است .
- انحنای پروفیل: انحنای پروفیل، انحنای موازی با شیب یا در امتداد تندترین جهت شیب را نشان میدهد. انحنای پروفیل مثبت، انحنای رو به بالا (تقعر به بالا) را نشان میدهد، در حالی که انحنای پروفیل منفی، انحنای رو به پایین (تقعر به پایین) را نشان میدهد. رستر انحنای پروفیل برای منطقه مورد مطالعه در شکل ۱۰ ارائه شده است .

رستر انحنا (متر).

انحنای نقشه شطرنجی (متر).

رستر انحنای پروفیل (متر).
شاخص پوشش گیاهی نرمال شده تفاضلی (NDVI)
NDVI یک شاخص گیاهی پرکاربرد در سنجش از دور است و به ویژه برای ارزیابی سلامت و تراکم پوشش گیاهی ارزشمند است. پوشش گیاهی سالم به این معنی است که ریشهها قوی هستند و خاک نزدیک به سطح را در کنار هم نگه میدارند و مقاومت برشی خاک را بهبود میبخشند. NDVI میتواند یک عامل تأثیرگذار بر شکست خاکریز و شیب باشد. فرمول NDVI در معادله ( ۱ ) ارائه شده است.
که در آن، NIR = بازتاب مادون قرمز نزدیک، و Red = مقدار بازتاب قرمز
تصاویر ماهوارهای لندست ۹ ۳۷ که از سازمان زمینشناسی ایالات متحده (earthexplorer.usgs.gov/) به دست آمده است، برای ایجاد رستر NDVI استفاده شد. باندهای طیفی متعدد لندست ۹، از جمله باندهای قرمز و مادون قرمز نزدیک، در ArcGIS Pro استخراج شدند و NDVI با استفاده از معادله فوق محاسبه شد. مقادیر NDVI معمولاً از ۱- تا ۱+ متغیر است؛ آبها نزدیک به ۱- هستند؛ مناطق بایر، سنگها یا محیطهای ساخته شده نزدیک به ۰ هستند؛ و مقادیر ۰ تا ۱ به مناطقی اختصاص داده میشود که بر اساس پوشش گیاهی متراکم و سالم، به طور فزایندهای در حال افزایش هستند. رستر NDVI توسعه یافته برای منطقه مورد مطالعه در شکل ۱۱ ارائه شده است .

رستر NDVI.
شاخص رطوبت توپوگرافی (TWI)
شاخص رطوبت توپوگرافی یک شاخص بدون بعد است که از DEM ها محاسبه میشود. این شاخص، شیب هر سلول و مساحت مؤثر در یک منطقه مورد مطالعه را در نظر میگیرد. مقادیر بالاتر TWI عموماً مناطقی را نشان میدهد که پتانسیل تجمع آب در آنها بیشتر است، در حالی که مقادیر پایینتر نشاندهنده زهکشی بهتر هستند. مناطقی با TWI بالاتر ممکن است بیشتر مستعد اشباع و افزایش فشار آب منفذی باشند که به طور بالقوه در ناپایداری شیب یا شکست خاکریز نقش دارد. TWI اغلب با استفاده از فرمول معادله ( ۲ ) محاسبه میشود.
که در آن، a مساحت مشخص مشارکتکننده (ناحیه بالادست که به نقطهای در واحد طول خطوط تراز زهکشی میشود) و β شیب بر حسب رادیان است. رستر TWI در شکل ۱۲ ارائه شده است .

رستر TWI.
تجمع جریان
تجمع جریان به تعداد سلولهایی اشاره دارد که در یک شبکه رستری، جریان را به یک سلول خاص اختصاص میدهند. هر سلول مقداری را نشان میدهد که نشاندهنده تعداد کل سلولهایی است که به داخل سلول زهکشی میشوند. در زمینه هیدرولوژی، این مقدار نشاندهنده مساحت بالادست انباشته شده است که به داخل هر سلول زهکشی میشود و نشاندهنده جریان یا رواناب بالقوه است. رستر تجمع جریان در شکل ۱۳ ارائه شده است .

رستر تجمع جریان.
بارش
بارش عامل مهمی در وقوع رانش زمین و شکست سیستمهای گرمایشی و سرمایشی (HWS) است. دادههای بارش بین سالهای ۲۰۱۱ تا ۲۰۲۰ از وبسایت دسترسی به دادههای ناسا برای هشت شهرستان میسیسیپی در منطقه مورد مطالعه دانلود و میانگینها محاسبه شدند. مقادیر میانگین بارش (بر حسب متر) با انجام درونیابی تجربی کریجینگ بیزی، رستری شدند و مقادیر بارش برای هر پیکسل در منطقه مورد مطالعه تولید شد. رستر بارش در شکل ۱۴ ارائه شده است .

رستر بارش (متر).
فاصله از نهر
فاصله از نهر به اندازهگیری مکانی فاصله یک مکان یا عارضه خاص از یک نهر یا رودخانه اشاره دارد. شیبها و خاکریزهای نزدیک نهرها میتوانند به دلیل اشباع خاک یا تغییرات سطح آبهای زیرزمینی بیشتر تحت تأثیر قرار گیرند. با استفاده از DEM، حوزههای آبخیز در منطقه مورد مطالعه برای شناسایی نهرها مشخص شدند. سپس، فواصل بر اساس روش اقلیدسی با استفاده از ArcGIS محاسبه و نتایج رستری شدند. فاصله از رستر نهر در شکل ۱۵ ارائه شده است .

فاصله از رستر رودخانه (متر). این نمایش مکانی با استفاده از تجمع جریان و آستانهگذاری رودخانه از DEM استخراج شد؛ سپس فاصله از رودخانه با استفاده از فاصله اقلیدسی محاسبه شد. تمام این فرآیندها توسط نویسنده اول (RS) با استفاده از نرمافزار ArcGIS Pro (Esri، نسخه ۳٫۰، www.esri.com/arcgis ) انجام شد. DEM مورد استفاده از دادههای هوایی LiDAR بود که به طور عمومی از MARIS (maris.mississippi.edu) در دسترس است.
عمق سطح ایستابی و نوع خاک
آب زیرزمینی عامل مهمی است که بر فشار آب منفذی، مقاومت برشی مؤثر و چگالی خاک تأثیر میگذارد؛ بنابراین، عمق سطح آب زیرزمینی به عنوان یک عامل مؤثر در شکست خاکریز در نظر گرفته شد. مجموعه دادههای USA Soils از Living Atlas Library ارائه شده توسط ESRI دانلود شد. عمق سطح آب زیرزمینی و نوع خاک طبقهبندی شده بر اساس نمادشناسی ESRI از مجموعه دادهها استخراج، رستری شده و به ترتیب در شکلهای ۱۶ و ۱۷ ارائه شدهاند .

عمق سفره آب زیرزمینی (سانتیمتر) در نمودار شطرنجی.

رستر نوع خاک (نامگذاری نمادشناسی ESRI).
بهینهسازی انتخاب ویژگی
انتخاب ویژگی نقش مهمی در بهبود عملکرد مدل برای نقشهبرداری حساسیت زمینلغزش و شکست شیب ایفا میکند. در این مطالعه چندین تکنیک بهینهسازی ویژگی برای شناسایی مرتبطترین متغیرها و حذف نویز یا اطلاعات اضافی پیادهسازی شد. انتخاب ویژگی بهینه به جلوگیری از بیشبرازش کمک میکند و توانایی مدل را برای تعمیم بهتر در مجموعه دادههای متنوع افزایش میدهد ۵۱٫ در این مطالعه، سه الگوریتم انتخاب ویژگی، افزایش اطلاعات، تحلیل مؤلفههای اصلی (PCA) و ماتریس شباهت یا همبستگی، برای سادهسازی فرآیند انتخاب ویژگی پیادهسازی شدند. این الگوریتمها با موفقیت توسط محققانی مانند ۵۱ و ۳۲ برای انتخاب ویژگیهای بهینه برای پیشبینی زمینلغزش استفاده شدهاند . روشهای انتخاب ویژگی و کاهش ابعاد از نظر استفاده از متغیر هدف، نوع یادگیری و هدف آنها متفاوت هستند.
تحلیل مؤلفههای اصلی (PCA)
PCA یک تکنیک بدون نظارت است که به متغیر هدف متکی نیست و برای کاهش ابعاد و در عین حال حفظ هرچه بیشتر واریانس دادهها استفاده میشود. PCA به شناسایی مؤلفههایی که بیشترین تغییرپذیری را در مجموعه دادهها توضیح میدهند، کمک میکند. PC1 تقریباً همیشه بیشترین توضیح را میدهد، زیرا PCA مؤلفهها را با کاهش واریانس توضیح داده شده مرتب میکند. ویژگیهایی با مقادیر بارگذاری مطلق بالا که در یک مؤلفه اصلی نقش دارند، تأثیر بیشتری بر نتیجه دارند. به عنوان مثال، در جدول ۲ ، PC1 20٪ از واریانس را توضیح میدهد و TWI و Precipitation بارهای مطلق بالایی دارند و تأثیرگذارترین عوامل ایجادکننده هستند.
همبستگی
تحلیل همبستگی با استفاده از ضریب پیرسون، که به عنوان ماتریس شباهت نیز شناخته میشود، یک روش بدون نظارت است که یک تکنیک انتخاب ویژگی محسوب میشود. این روش به شناسایی و حذف ویژگیهای اضافی یا با همبستگی بالا کمک میکند. نقشه حرارتی همبستگی پیرسون (شکل ۱۸ ) همبستگی قوی بین انحنا و انحنای صفحه را نشان میدهد.

نقشه حرارتی همبستگی ویژگیها با استفاده از ضریب پیرسون.
چندین همبستگی بالای قابل توجه (مثبت و منفی یا معکوس) در بین ویژگیها مشاهده شد. ارتفاع و فاصله از آبراهه همبستگی منفی نسبتاً بالاتری معادل -۰٫۶۳ نشان دادند که نشان میدهد ارتفاعات بالاتر عموماً از آبراههها دورتر هستند. انحنای سطح و انحنا همبستگی مثبت قوی معادل ۰٫۸۰ نشان دادند. در مقابل، انحنای نیمرخ و انحنا همبستگی منفی قوی در -۰٫۹۴ داشتند که منطقی است زیرا انحنای نیمرخ مثبت نشاندهنده انحنای رو به بالا (تقعر به بالا) است. در مقابل، انحنای نیمرخ منفی نشاندهنده انحنای رو به پایین (تقعر به پایین) است. علاوه بر این، شاخص رطوبت توپوگرافی (TWI) همبستگی منفی قوی با شیب (-۰٫۷۵) و جهت (-۰٫۶۱) نشان داد، که با توجه به اینکه TWI با استفاده از شیب و مساحت حوضه آبریز استخراج میشود، انتظار میرفت، با وجود اینکه در اینجا به عنوان یک شاخص هیدرولوژیکی برای اطلاعرسانی در مورد مناطقی که میتوانند مرطوب شوند، استفاده میشود.
در مدلهای طبقهبندی (به عنوان مثال، RF، SVC و غیره که در این مطالعه استفاده شدهاند) با متغیرهای هدف دستهبندیشده، همخطی چندگانه بین ویژگیها عموماً کمتر از مدلهای رگرسیون خطی مشکلساز است. در حالی که ویژگیهای همبسته ممکن است به دلیل واریانس مشترک، اهمیت ویژگیهای منفرد را کاهش دهند، این امر معمولاً دقت مدل را به شدت کاهش نمیدهد. در چنین مواردی، مقدار پیشبینی واقعی ممکن است در بین متغیرهای همبسته توزیع شود و باعث شود اهمیت ویژگیهای منفرد کم به نظر برسد، حتی اگر آنها با هم در پیشبینی مدل بسیار تأثیرگذار باشند. با این حال، اهمیت ویژگی را میتوان از طریق تفسیر آگاهانه با کمک نقشه همبستگی ماتریس شباهت ویژگی ارائه شده در شکل ۱۸ درک کرد .
افزایش اطلاعات
بهره اطلاعات یک روش نظارتشده است که برخلاف دو الگوریتم انتخاب ویژگی قبلی، شامل هدف برای ارزیابی و انتخاب ویژگیهایی است که بیشترین پیشبینی را از نتیجه دارند. این روش میزان کاهش عدم قطعیت (آنتروپی) در مورد هدف توسط یک ویژگی را کمّی میکند. بهره اطلاعات هر ۱۵ ویژگی با مقادیر هدف ارزیابی شد و نتایج در قالب نمودار در شکل ۱۹ ارائه شده است .

کسب اطلاعات از عوامل ایجاد کننده
از نتایج PCA و افزایش اطلاعات، مشخص شد که آلبدوی خاک و تجمع جریان دارای بارگذاری مطلق پایین (جدول ۲ ) و کمترین افزایش اطلاعات (شکل ۱۹ ) هستند. از این رو، آنها از مجموعه دادههای ویژگیها حذف شدند. علاوه بر این، انحنای سطح نیز به دلیل مشکلات همخطی چندگانه (شکل ۱۸ ) و افزایش اطلاعات پایین (شکل ۱۹ ) از لیست ویژگیها حذف شد.
مدلهای یادگیری ماشین ارزیابی شدند
چندین مدل یادگیری ماشین، یعنی جنگل تصادفی، بیز ساده، طبقهبندی کننده بردار پشتیبان و رگرسیون لجستیک، برای دقت آنها در طبقهبندی خرابیهای HWS مورد آزمایش قرار گرفتند.
جنگل تصادفی (RF)
جنگل تصادفی (RF) یک روش یادگیری گروهی است. در این روش، چندین درخت تصمیم در فرآیند آموزش ساخته میشوند که حالتهای خروجی تعریف شده توسط وظایف طبقهبندی را تولید میکنند. این روش به دلیل استحکام، دقت بالا و مقاومت در برابر بیشبرازش شناخته شده است، که آن را برای مجموعه دادههای پیچیده با ویژگیهای متعدد مناسب میکند. این روش پیشبینیهای درختان منفرد را برای تولید یک طبقهبندی قابل اعتمادتر و پایدارتر ترکیب میکند و پیشبینی کلی ترکیبی از پیشبینیهای درختان منفرد است. عبارت احتمال پیشبینیشده کلاس P(yi) برای نمونه i در یک سناریوی طبقهبندی دودویی در معادله ( ۳ ) شرح داده شده است.
که در آن N تعداد درختان در جنگل و Pj ( yi ) احتمال پیشبینیشده از درخت j ام برای کلاس y i است .
لانگ و همکارانش ۳۲ دریافتند که مدل RF با تصاویر ماهوارهای و مقایسه آن برای تشخیص خودکار زمینلغزش در یک دوره ده ساله، دقت بالایی ارائه میدهد. RF به دلیل عملکرد قابل اعتماد اثبات شدهاش انتخاب شد و از آنجایی که به طور مداوم برای مسائل طبقهبندی مانند LSM ۱۲ ، ۱۴ ، ۱۶ ، ۵۲ بهتر از سایر مدلهای ML عمل میکند .
بیز ساده (NB)
بیز ساده (NB) یک طبقهبندیکننده احتمالاتی مبتنی بر قضیه بیز با فرض “ساده” استقلال بین ویژگیها است. این روش از نظر محاسباتی کارآمد و بهویژه برای طبقهبندی متن و فیلتر کردن هرزنامه مؤثر است. NB احتمال هر کلاس از یک مجموعه مشخص از ویژگیها را محاسبه میکند و کلاسی را با بالاترین احتمال به عنوان برچسب پیشبینیشده انتخاب میکند. احتمال پسین، برای یک مسئله طبقهبندی دودویی، برای کلاس ویژگیهای X دادهشده با استفاده از معادله ( ۴ ) محاسبه میشود .
که در آن درستنمایی، احتمال پیشین کلاس و شواهد است.
طبقهبندیکننده ماشین بردار پشتیبان (SVC)
طبقهبندیکننده ماشین بردار پشتیبان (SVC) یک الگوریتم یادگیری ماشین تحت نظارت است که برای مسائل رگرسیون و طبقهبندی مناسب است. SVC با شناسایی ابرصفحهای که به بهترین نحو کلاسهای مختلف را در فضای ویژگی از هم جدا میکند و در عین حال حاشیه بین آنها را به حداکثر میرساند، کار میکند. SVC در فضاهای با ابعاد بالا مؤثر است و قادر به مدیریت روابط غیرخطی از طریق استفاده از توابع هسته است. برای یک مسئله طبقهبندی دودویی، یک SVC خطی ابرصفحهای را که با w*x + b = نشان داده میشود، پیدا میکند که در آن w بردار وزن، x بردار ورودی و b بایاس است. تابع تصمیمگیری توسط معادله ( ۵ ) داده شده است.
کلاس پیشبینیشده با علامت f(x) تعیین میشود، که در آن f(x) > 0 مربوط به یک کلاس و f(x) < مربوط به کلاس دیگر است.
رگرسیون لجستیک (LR)
رگرسیون لجستیک (LR) یک مدل خطی است که احتمال تعلق یک نمونه به یک کلاس خاص را تخمین میزند و برای مسائل طبقهبندی دودویی مناسب است. LR رابطه بین متغیر دودویی وابسته و یک یا چند متغیر مستقل را با استفاده از تابع لجستیک مدلسازی میکند. این مدل ساده، قابل تفسیر و برای سناریوهایی با مرزهای تصمیمگیری تقریباً خطی مناسب است. برای LR دودویی، از تابع لجستیک (سیگموئید) برای مدلسازی رابطه بین متغیرهای مستقل، X، و لگاریتم شانس متغیر وابسته، Y، استفاده میشود. تابع لجستیک همانطور که در معادله ( ۶ ) نشان داده شده است، تعریف میشود.
که در آن ضرایب هستند.
معیارهای عملکرد مدل
معیارهای زیر برای آزمایش عملکرد مدل استفاده شدند. توابع Sklearn برای محاسبه معیارها استفاده شدند.
ضریب تعیین (R2_Score): ضریب تعیین (R2_Score) یک آماره کلیدی است که برای اندازهگیری میزان موفقیت یک مدل رگرسیون در پیشبینی متغیر وابسته بر اساس متغیرهای مستقل استفاده میشود. R2_score نسبت واریانس در متغیر هدف را که مدل میتواند توضیح دهد، نشان میدهد. فرمول امتیاز R2 در معادله ( ۷ ) آمده است. اساساً، این ضریب، برازش پیشبینیهای مدل با دادههای واقعی را ارزیابی میکند. مقدار R2 از ۰ تا ۱ متغیر است، که در آن امتیاز ۱ نشاندهنده پیشبینی کامل متغیر هدف است و امتیاز ۰ به این معنی است که مدل نمیتواند هیچ واریانسی را در هدف در نظر بگیرد.
که در آن y i مقدار پیشبینیشده، x i مقدار واقعی، x mean مقدار میانگین متغیرهای واقعی و n تعداد کل متغیرها است.
ماتریس سردرگمی: یک ماتریس سردرگمی، عملکرد یک الگوریتم طبقهبندی را در مجموعهای از دادهها با مقادیر واقعی شناخته شده ارزیابی میکند. این ماتریس، تجزیه و تحلیل دقیقی از پیشبینیهای مدل ارائه میدهد و موارد طبقهبندیهای صحیح و نادرست را برجسته میکند. ماتریس سردرگمی به ارزیابی عملکرد یک مدل طبقهبندی کمک میکند و به ویژه برای مسائل طبقهبندی دودویی و چندکلاسی مفید است. این ماتریس معمولاً از چهار جزء تشکیل شده است: مثبت واقعی (TP)، زمانی که مدل به درستی یک ناحیه شکست خورده را به عنوان شکست خورده پیشبینی میکند؛ مثبت کاذب (FP)، زمانی که مدل به اشتباه یک ناحیه غیر شکست خورده را به عنوان شکست خورده پیشبینی میکند؛ منفی واقعی (TN)، زمانی که مدل به درستی نواحی غیر شکست خورده را به عنوان غیر شکست خورده پیشبینی میکند؛ و منفی کاذب (FN)، زمانی که مدل به اشتباه نواحی شکست خورده را به عنوان غیر شکست خورده پیشبینی میکند. چندین معیار عملکرد دیگر که میتوان از نتایج ماتریس سردرگمی استخراج کرد، در معادلات ( ۸-۱۲ ) فهرست شدهاند .
ویژگی: ویژگی، نرخ منفی واقعی (TNR) است و فرمول آن در معادله ( ۸ ) شرح داده شده است.
دقت: دقت، دقت پیشبینیهای مثبت یک مدل را اندازهگیری میکند و نسبت پیشبینیهای مثبت واقعی از کل پیشبینیهای مثبت را نشان میدهد. به عبارت ساده، دقت، تعداد کل پیشبینیهای مثبت صحیح را نشان میدهد که در این مورد، وقوع شکست شیب هستند. این مورد در معادله ( ۱۰ ) شرح داده شده است.
یادآوری: یادآوری که به آن حساسیت نیز گفته میشود، نرخ مثبت واقعی (TPR) است. این معیاری برای سنجش کامل بودن پیشبینیهای مثبت است. نسبت نمونههای مثبت پیشبینیشده به درستی به تعداد کل نمونههای مثبت واقعی، یادآوری را فراهم میکند. فرمول یادآوری یا TPR در معادله ( ۱۱ ) آمده است.
امتیاز F1: امتیاز F1 میانگین هارمونیک دقت و یادآوری است و زمانی که هم مثبت کاذب و هم منفی کاذب مهم هستند، یک معیار ارزیابی متعادل ارائه میدهد. این معیار زمانی مفید است که مدلها بتوانند به دقت بالا اما یادآوری پایین دست یابند، یا برعکس. امتیاز F1 عدم تعادل شدید بین این دو را جریمه میکند. امتیاز F1 بالا نشان دهنده عملکرد کلی قوی در شناسایی مثبتهای واقعی بدون ایجاد مثبتهای کاذب بیش از حد است. امتیاز F1 را میتوان با استفاده از معادله ( ۱۲ ) محاسبه کرد.
دقت: دقت، تعداد دفعاتی را که پیشبینیهای یک مدل درست هستند، صرف نظر از اینکه پیشبینیهای مثبت یا منفی باشند، اندازهگیری میکند. به عبارت دیگر، این نشاندهنده صحت پیشبینی مدل طبقهبندی کننده است که شامل پیشبینیهای مثبت واقعی و منفی واقعی میشود. روش محاسبه دقت، تقسیم کل پیشبینیهای صحیح بر کل پیشبینیها است، همانطور که در معادله ( ۱۳ ) ارائه شده است.
منحنی مشخصه عملیاتی گیرنده (ROC): منحنی ROC یک نمایش گرافیکی است که عملکرد یک مدل طبقهبندی دودویی را در آستانههای طبقهبندی مختلف نشان میدهد. منحنی ROC، بده بستان بین نرخ مثبت واقعی (حساسیت) و نرخ مثبت کاذب (۱-ویژگی) را ارزیابی میکند. منحنی ROC با رسم دو پارامتر مهم با نرخهای مثبت کاذب (۱-ویژگی) روی محور x و نرخهای مثبت واقعی (مقدار حساسیت) روی محور y بدست میآید.
امتیاز مساحت زیر منحنی (AUC): مساحت زیر منحنی ROC (AUC) به عنوان یک معیار کلیدی برای ارزیابی دقت یک مدل عمل میکند. امتیاز AUC برابر با ۱.۰ نشان دهنده دقت کامل است، در حالی که امتیاز نزدیک به ۰.۵ نشان میدهد که مدل تنها اندکی بهتر از حدس تصادفی عمل میکند و نشاندهنده دقت پایینتر است.
توسعه مدل
توسعه، بهینهسازی و انتخاب مدل مطابق با طرح گردش کار ارائه شده در شکل ۲۰ برای نقشهبرداری حساسیت به شکست HWS انجام شد .
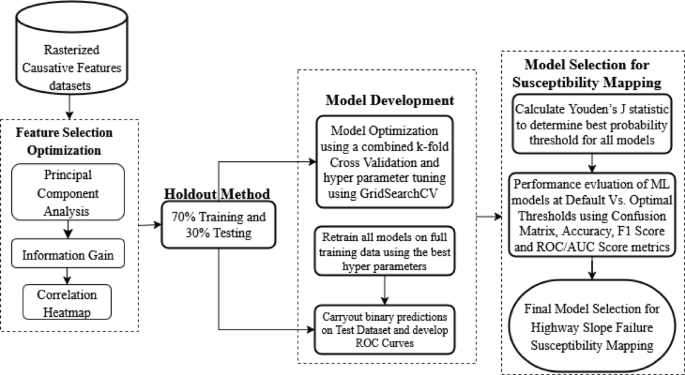
گردش کار طبقهبندی ML برای نقشهبرداری حساسیت به شکست شیب بزرگراه.
روش نگهداشتن
روش holdout برای توسعه مدلهای پیشبینی حساسیت به شکست HWS به کار گرفته شد. این روش شامل تقسیم مجموعه دادهها به دو بخش، ۷۰٪ برای آموزش و ۳۰٪ برای آزمایش بود. مجموعه دادهها به طور تصادفی به ۷۰٪ برای آموزش مدلها و ۳۰٪ برای آزمایش عملکرد مدل و بررسی بیشبرازش و دقت تقسیم شدند. روش تقسیم train-test در کتابخانه sklearn برای تقسیم تصادفی مجموعه دادهها استفاده شد. سپس مدلها بر روی دادههای آموزشی آموزش داده شدند تا روابط بین عوامل سببی و کلاسهای طبقهبندی هدف را یاد بگیرند. متعاقباً، مدلها بر روی مجموعه آزمون آزمایش شدند تا عملکرد آنها با استفاده از معیارهایی مانند دقت، صحت، یادآوری و امتیاز F1 ارزیابی شود.
بهینهسازی مدل
تنظیم هایپرپارامتر و اعتبارسنجی متقابل k-fold به طور مشترک در طول فرآیند آموزش مدل انجام شد تا عملکرد پیشبینیکننده بهینه شود و قابلیت تعمیم مدلها افزایش یابد. یک اعتبارسنجی متقابل طبقهبندیشده پنجگانه برای اطمینان از اینکه نسبتهای کلاس در بین لایههای آموزش و اعتبارسنجی ثابت باقی میمانند، پیادهسازی شد و در نتیجه خطر ارزیابی مدل مغرضانه کاهش یافت. برای شناسایی پیکربندیهای با بهترین عملکرد، هر معماری مدل تحت جستجوی شبکهای، یک رویکرد تنظیم هایپرپارامتر سیستماتیک و رایج ۳۲ قرار گرفت . این روش تمام ترکیبات ممکن از مقادیر هایپرپارامتر را در محدودههای از پیش تعریفشده ارزیابی میکند. با ترکیب جستجوی شبکهای با اعتبارسنجی متقابل، ارزیابی هر تنظیم هایپرپارامتر بر اساس عملکرد متوسط آن در تمام لایهها انجام شد و در نتیجه یک فرآیند انتخاب قویتر و قابل اعتمادتر تضمین شد. هر مدل یادگیری ماشین با استفاده از چندین ترکیب هایپرپارامتر خاص مدل ارزیابی شد. لیست کامل محدودههای هایپرپارامتر بررسی شده برای هر مدل در جدول ۳ خلاصه شده است .
آستانه احتمال سفارشی برای بهینهسازی مدل
به حداقل رساندن نتایج منفی کاذب و مثبت کاذب هنگام انجام نقشهبرداری از آسیبپذیری سازههای هیدرولیکی (HWS) به یک اندازه مهم است. نادیده گرفتن مناطق مستعد میتواند منجر به خرابیهای فاجعهبار شود، در حالی که طبقهبندی نادرست بسیاری از مناطق پایدار به عنوان مناطق پرخطر میتواند منجر به استفاده ناکارآمد از بودجههای مهندسی محدود فعلی برای کاهش خطرات ژئوتکنیکی شود. بنابراین، تکیه بر یک آستانه ثابت ۰٫۵، که در آن پیشبینی در صورت احتمال ≥ ۰٫۵ به عنوان خرابی شیب طبقهبندی میشود و در غیر این صورت هیچ خرابی وجود ندارد، ممکن است برای شناسایی دقیق آسیبپذیری سازههای هیدرولیکی (HWS) ایدهآل نباشد.
برای پرداختن به این تعادل، از ضریب J یودن برای تعیین آستانه بهینه با به حداکثر رساندن حساسیت و ویژگی به طور مشترک، و تضمین یک روش طبقهبندی متعادل و مؤثر، استفاده شد. ضریب J یودن طبق معادله ( ۱۴ ) محاسبه میشود.
نتایج
نتایج عملکرد مدل
نتایج اعتبارسنجی متقابل
مدلهای پیادهسازی شده برای طبقهبندی حساسیت به شکست با مقایسه معیارهای عملکرد آنها ارزیابی شدند. از دادههای آزمایشی دیده نشده یا ۳۰٪ برای به دست آوردن نتایج طبقهبندی و مقایسه آنها با دادههای واقعی استفاده شد. در نهایت، منحنیهای مشخصه عملکرد گیرنده (ROC) و امتیاز سطح زیر منحنی (AUC) برای ارزیابی عملکرد مدلها توسعه داده شدند.
عملکرد مدل در طول مرحله اعتبارسنجی متقابل در جدول ۴ ارائه شده است که میانگین معیارهای عملکرد را نشان میدهد: امتیاز F1، دقت و نمرات AUC از اعتبارسنجی متقابل k-fold مدلهایی با بهترین ابرپارامترها. نتایج به وضوح نشان میدهد که RF بهترین مدل از نظر عملکرد بوده و SVC با اختلاف کمی در رتبه دوم قرار دارد.
از نتایج بهینهسازی مدل، RF و SVC به عنوان دو مدل برتر با بهترین عملکرد ظاهر شدند و پس از آنها به ترتیب LR و NB قرار گرفتند. لازم به ذکر است که معیارهای عملکرد LR و NB پس از بهینهسازی انتخاب ویژگی به طور قابل توجهی بهبود یافتند.
متعاقباً، کل مجموعه دادهها به ۷۰٪ برای آموزش و ۳۰٪ برای آزمایش تقسیم شد و مدلهای جدید (RF، SVC، LR و NB) با بهترین ابرپارامترها ساخته شده و روی کل مجموعه دادههای آموزشی آموزش داده شدند.
عملکرد مدلهای آموزشدیده با استفاده از نتایج آنها بر روی دادههای آزمایشی دیده نشده، با معیارهایی مانند امتیاز F1، دقت و AUC برای ارزیابی ارزیابی شد.
برای افزایش بیشتر عملکرد مدل، نتایج طبقهبندی با استفاده از آستانه احتمال پیشفرض ۰.۵ در مقابل نتایج بهدستآمده با آستانههای سفارشی بهینه ارزیابی شدند.
آستانههای احتمال سفارشی
با استفاده از روش Youden’s J، مقادیر آستانه سفارشی بهینه برای هر مدل در جدول ۵ ارائه شده است.
ماتریسهای سردرگمی از نتایج بهدستآمده از مدلهای طبقهبندیکننده توسعه داده شدند و برای مقادیر آستانه پیشفرض در مقابل مقادیر آستانه بهینه مورد ارزیابی بیشتر قرار گرفتند. ماتریسهای سردرگمی مدلهای طبقهبندی یادگیری ماشین، RF، SVC، LR و NB، به ترتیب در شکلهای ۲۱ ، ۲۲ ، ۲۳ ، ۲۴ ارائه شدهاند .

ماتریسهای درهمریختگی از طبقهبندی RF روی مجموعه دادههای آزمایشی برای: ( الف ) آستانه پیشفرض (۰٫۵)، ( ب ) آستانه سفارشی بهینه (۰٫۷۵).

ماتریسهای درهمریختگی از طبقهبندی SVC روی مجموعه دادههای آزمایشی برای: ( الف ) آستانه پیشفرض (۰٫۵)، ( ب ) آستانه سفارشی بهینه (۰٫۲۹).

ماتریسهای درهمریختگی از طبقهبندی LR روی مجموعه دادههای آزمون برای: ( الف ) آستانه پیشفرض (۰٫۵)، ( ب ) آستانه سفارشی بهینه (۰٫۳۳).
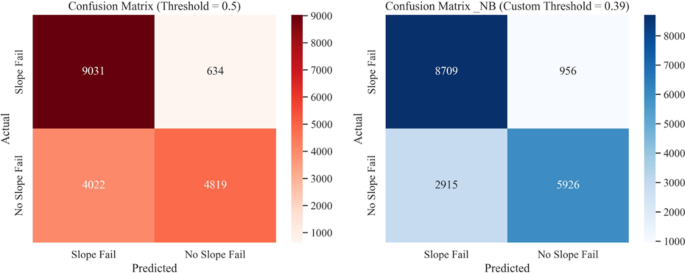
ماتریسهای درهمریختگی از طبقهبندی NB روی مجموعه دادههای آزمایشی برای: ( الف ) آستانه پیشفرض (۰٫۵)، ( ب ) آستانه سفارشی بهینه (۰٫۳۹).
مقایسه معیارهای عملکرد مدلهای مختلف در آستانههای احتمال پیشفرض و بهینه در شکل ۲۵ ارائه شده است . دقت و نمرات F1 چهار مدل (RF، SVC، LR و NB) با استفاده از آستانه پیشفرض (۰٫۵) و آستانه بهینه (۰٫۷۵ از روش Youden’s J) مقایسه شدند. آستانه احتمال بهینه، معیارهای عملکرد هر مدل را بهبود بخشید. اگرچه فضای زیادی برای بهبود در مدلهای RF و SVC وجود نداشت، که حتی با آستانه احتمال پیشفرض ۰٫۵ نیز عملکرد خوبی داشتند، اما آستانه سفارشی همچنان نتایج طبقهبندی بهتری را ارائه داد. از سوی دیگر، بهبود عملکرد مدلهای LR و NB هنگام استفاده از آستانههای سفارشی در مقایسه با آستانههای پیشفرض بسیار مشهود بود.

معیارهای عملکرد مدلهای یادگیری ماشین در آستانههای پیشفرض در مقابل آستانههای بهینه: ( الف ) مقایسه امتیاز دقت، ( ب ) مقایسه امتیاز F1.
منحنی مشخصه عملکرد گیرنده (ROC)
منحنی ROC یک نمایش گرافیکی است که عملکرد یک مدل طبقهبندی دودویی را در آستانههای طبقهبندی مختلف نشان میدهد. منحنی ROC، بده بستان بین نرخ مثبت واقعی (حساسیت) و نرخ مثبت کاذب (۱-ویژگی) را ارزیابی میکند. منحنی ROC با رسم دو پارامتر مهم با نرخهای مثبت کاذب (۱-ویژگی) روی محور x و نرخهای مثبت واقعی (مقدار حساسیت) روی محور y بدست میآید. مدلی که عملکرد بهتری از احتمال تصادفی نداشته باشد، منحنی ROC در امتداد خط مورب (از گوشه پایین سمت چپ تا گوشه بالا سمت راست) خواهد داشت. مدلی با مساحت زیر منحنی (AUC) بالاتر، نزدیکتر به ۱، عموماً نشاندهنده طبقهبندی بهتر برای آستانه تعیین شده است. مقایسه منحنیهای ROC برای همه مدلهای یادگیری ماشینی که در این مطالعه آزمایش شدهاند، در شکل ۲۶ ارائه شده است که به وضوح نشان میدهد که RF بهترین مدل با بالاترین AUC (1.0) است. SVC مدل بعدی با بهترین عملکرد با AUC 0.94 بود. بر اساس ارزیابی چهار مدل ML، RF بهترین عملکرد را داشت و از این رو برای پیشبینی حساسیت به شکست HWS انتخاب شد.

منحنی ROC و AUC برای مدلهای یادگیری ماشین.
نقشه برداری از حساسیت به خرابی HWS
نتایج طبقهبندی جنگل تصادفی
با توجه به وضوح بالای دادههای رستری (۰٫۹۱ متر × ۰٫۹۱ متر)، کل منطقه مورد مطالعه شامل ۸ شهرستان، حجم عظیمی از دادهها (۴۵۰ میلیون ردیف یا پیکسل) را تولید کرد. پردازش برای طبقهبندی هر پیکسل از نظر محاسباتی بسیار پرهزینه شد. در نتیجه، پیشبینی حساسیت به شکست HWS بر روی یک منطقه مورد توجه (AOI) متمرکز از کریدور بزرگراه ملی در امتداد I-55 و I-20 در منطقه شهری جکسون، میسیسیپی انجام شد. بخش عمدهای از این AOI قبلاً در طول توسعه مدل استفاده نشده بود، بنابراین مدل RF آموزشدیده، اگنوستیک بود.
علاوه بر این، نقشههای حساسیت به شکست HWS (HWS-FSM) با استفاده از مدل طبقهبندی آموزشدیده، RF، تحت دو شرط تولید شدند. دو شرط، استراتژیهای آستانهگذاری بودند: اول، استفاده از آستانه پیشفرض (۰٫۵) و دوم، استفاده از یک آستانه سفارشی بهینه (۰٫۷۵) مشتق شده از آماره J یودن برای به حداکثر رساندن عملکرد طبقهبندی. سپس این احتمالات با استفاده از آستانههای پیشفرض و بهینه سفارشی، همانطور که به ترتیب در شکلهای ۲۷ الف و ب ارائه شده است، به نقشههای حساسیت به شکست دودویی طبقهبندی شدند. این نقشههای حساسیت با طبقهبندیهای دودویی، حساسیت به شکست بزرگراه را نشان میدهند. آستانه پیشفرض یک طبقهبندی دودویی پایه ارائه میدهد، در حالی که آستانه سفارشی، تعادل متعادلتری بین مثبتهای کاذب و منفیهای کاذب ارائه میدهد. به عنوان مثال، HWS_FSM مبتنی بر آستانه پیشفرض (شکل ۲۷ الف) به وضوح مناطق بیشتری را با طبقهبندی شکست نشان میدهد. با این حال، آستانه سفارشی بهینه HWS-FSM (شکل ۲۷ ب) مناطق کمتری را به عنوان شکستهای بالقوه طبقهبندی میکند.

نقشههای حساسیت به شکست شیب بزرگراه با طبقهبندی دودویی برای AOI در MS مرکزی که توسط مدل RF با استفاده از: ( الف ) آستانه پیشفرض ۰٫۵ و ( ب ) آستانه بهینه سفارشی ۰٫۷۵ تولید شدهاند.
شش شیب بزرگراه که قبلاً توسط نویسندگان با شرایط شناخته شده مورد مطالعه قرار گرفته بودند، برای اعتبارسنجی نقشه حساسیت RF مورد استفاده قرار گرفتند. این شش شیب بزرگراه از آموزش و آزمایش مدل حذف شدند. هم نقشههای آستانه پیشفرض و هم نقشههای آستانه سفارشی حساسیت به شکست HWS نشان دادند که شیبهای ۲، ۳ و ۴ که قبلاً دچار شکست شده بودند و نشانههایی از حرکت قریبالوقوع را نشان میدادند، دقیقاً با مناطقی که در نقشه به عنوان مستعد شکست شناسایی شدهاند، مطابقت دارند. شیب ۱ کمتر مستعد شکست بود. برعکس، شیب ۶ که دست نخورده باقی مانده و از نظر تاریخی با مناطقی که مستعد شکست تلقی نمیشوند، همسو است.
علاوه بر این، دو نقشه حساسیت دیگر با طبقهبندی احتمالات پیشبینیشده به پنج دسته – خیلی کم، کم، متوسط، زیاد و خیلی زیاد – با استفاده از آستانه پیشفرض (۰٫۵) و آستانه سفارشی بهینه ۰٫۷۵ مشتق شده از آماره Youden’s J تهیه شدند. به جای طبقهبندی دودویی، این رویکرد طیف کامل احتمالات پیشبینیشده توسط مدل را حفظ کرد و امکان نقشهبرداری جزئیتر از خطر رانش زمین را فراهم کرد. نسخه اصلاحشده نقشههای حساسیت شکست HWS با پنج دسته طبقهبندی تهیهشده با اعمال آستانههای بهینه پیشفرض و سفارشی به ترتیب در شکل ۲۸ الف و ب ارائه شده است. دستههای طبقهبندی در ابتدا بر اساس شکستهای طبیعی در توزیع احتمال تعریف شدند، اما سپس برای ترسیم بهتر و تفسیرهای سازگار در نقشهها، کمی به صورت دستی تنظیم شدند. این روش امکان بیان حساسیت را بر روی یک طیف ریسک پیوسته فراهم کرد و ارتباط بهتر ریسک و اولویتبندی مداخلات بر اساس شدت را تسهیل نمود.

نقشههای حساسیت به خرابی HWS با پنج دسته برای AOI در شهرستانهای مرکزی MS، که توسط مدل RF آموزشدیده با استفاده از: ( الف ) آستانه پیشفرض ۰٫۵، و ( ب ) آستانه بهینه سفارشی ۰٫۷۵ تولید شدهاند.
مقایسه خروجیهای طبقهبندی آستانه پیشفرض و سفارشی نشان داد که تنظیم آستانه طبقهبندی، توانایی مدل را در تشخیص مناطق مستعد و غیر مستعد به طور قابل توجهی بهبود میبخشد. طبقهبندی مبتنی بر آستانه پیشفرض، یک تقسیم نقطه میانی مرسوم را با احتمال ۰٫۵۰ ارائه میدهد. با این حال، طبقهبندی مبتنی بر آستانه سفارشی، حساسیت (یا یادآوری) و ویژگی مدل را با تغییر حد آستانه به نقطه تصمیمگیری بهینه شناسایی شده از منحنی ROC برای مدل RF بهبود میبخشد. این رویکرد با کاهش طبقهبندی نادرست و همسو کردن پیشبینیهای مدل با خطرات شکست شیب در دنیای واقعی، قابلیت اطمینان مدیریت داراییهای زیرساخت را افزایش میدهد.
تحلیل حساسیت و اهمیت ویژگیها
برای ارزیابی بیشتر تأثیر ویژگیهای مختلف بر پیشبینی، یک تحلیل حساسیت بر روی مدل RF پیشرو انجام شد. نمودارهای وابستگی جزئی (PDP) ایجاد شدند تا نشان دهند که چگونه پیشبینیها با تغییر ویژگیهای فردی تغییر میکنند، در حالی که سایر متغیرها ثابت میمانند. PDPها بینش ارزشمندی در مورد نحوه واکنش مدلهای یادگیری ماشین به تغییرات در ورودیهای خاص ارائه میدهند و آنها را به ویژه برای تفسیر حساسیت در LSM مفید میکنند. هدف از این تحلیل ارزیابی میزان پاسخگویی پیشبینیهای مدل به هر متغیر ورودی بود. شکل ۲۹ PDPها را برای مدل RF با عملکرد برتر نشان میدهد. نمودارها تأثیر هر ویژگی را بر حساسیت به خرابی HWS در حالی که سایر متغیرها ثابت نگه داشته میشوند، نشان میدهند.

نمودارهای وابستگی جزئی (PDP) که اثرات ویژگیهای منفرد را بر احتمال پیشبینیشده وقوع خرابی HWS بر اساس طبقهبندیکننده RF آموزشدیده نشان میدهند. محور Y نشاندهنده میانگین پاسخ مدل (وابستگی جزئی) است، در حالی که محور X مقادیر ویژگیها را نشان میدهد.
تحلیل وابستگی جزئی نشان داد که ارتفاع، NDVI، فاصله از نهرها و نوع خاک، پیشبینیکنندههای کلیدی مؤثر بر حساسیت به لغزش زمین هستند. این مدل کاهش شدیدی در احتمال پیشبینیشده در ارتفاع بالاتر از حدود ۲۵۰ فوت نشان میدهد که نشاندهنده خطر بالاتر در ارتفاعات پایینتر است. این امر شواهد میدانی را تأیید میکند که در آن پنجههای شیب، شکستهای بیشتری نسبت به تاج شیب تجربه میکنند. به طور مشابه، مناطقی با مقادیر NDVI پایین (یعنی پوشش گیاهی پراکنده) با خطر بالاتر مرتبط هستند، در حالی که افزایش فاصله از نهرها، احتمالاً به دلیل کاهش فرسایش و اشباع پنجه، حساسیت را به طور قابل توجهی کاهش میدهد. انواع خاصی از خاک نیز تغییرات واضحی در پاسخ نشان میدهند که نشاندهنده تأثیر قابل توجه بر پایداری شیب است. در مقابل، ویژگیهایی مانند شیب، انحنا، جهت و بارندگی، PDPهای نسبتاً مسطحی را نشان دادند، که نشان میدهد آنها محرکهای کلیدی شکست نیستند یا میتوانند با سایر ویژگیهای مؤثر در مجموعه دادهها همبستگی داشته باشند، که کاملاً محتمل است.
علاوه بر این، معیارهای اهمیت ویژگی از نتایج طبقهبندی مدل RF استخراج و در شکل ۳۰ ارائه شدهاند . یافتههای PDPها بیشتر توسط معیارهای اهمیت ویژگی ارائه شده در شکل ۳۰ تأیید میشوند . پنج عامل مؤثر شناسایی شده عبارتند از ارتفاع، فاصله از نهرها، NDVI، بارندگی و نوع خاک. وجود خاکهای رسی منبسطشونده در سراسر منطقه مورد مطالعه، که به شدت مستعد تغییرات حجمی در طول چرخههای آب و هوایی مرطوب و خشک هستند، احتمالاً به اهمیت نوع خاک به عنوان یک ویژگی پیشبینیکننده کمک میکند.

اهمیت ویژگی های جنگل تصادفی
بحث
مدل RF با داشتن سطح زیر منحنی (AUC) چشمگیر ۱.۰، به عنوان مؤثرترین طبقهبندیکننده در مطالعه ما ظاهر شد. این معیار که نشاندهنده توانایی مدل در تمایز بین نمونههای مثبت و منفی است، عملکرد قوی، دقت برتر، یادآوری قوی و معیارهای امتیاز f-1 الگوریتم RF را برجسته کرد و جایگاه آن را به عنوان مدل برتر در تحلیل ما تثبیت کرد. مدل RF پس از بررسی جزئیات پیشبینی خرابیهای HWS، چهار عامل تأثیرگذار را مشخص کرد: ارتفاع (در وهله اول)، و پس از آن فاصله از جریان آب، NDVI و بارندگی. این یافتهها متغیرهای حیاتی مؤثر در آسیبپذیری HWS را روشن میکند و بینشهای عملی برای استراتژیهای مؤثر کاهش ریسک ارائه میدهد.
در این مطالعه، بهینهسازی دقیق مدل، از جمله بهینهسازی انتخاب ویژگی، انتخاب آستانه سفارشی بهینه، تنظیم فراپارامتر و اعتبارسنجی متقابل k-fold انجام شد. این رویکرد یکپارچه از انتخاب ویژگی بهینه و تنظیم فراپارامتر به افزایش عملکرد پیشبینی و تعمیمپذیری کمک کرد و بینشهایی را در مورد عوامل کلیدی مؤثر بر رانش زمین ارائه داد ۵۱ . استفاده از گروه بهینه ویژگیها برای افزایش عملکرد طبقهبندی مدل مهم است ۳۲ . انتخاب ویژگی به شناسایی مرتبطترین متغیرها، کاهش نویز و بیشبرازش کمک کرد، در حالی که تنظیم فراپارامتر پیچیدگی مدل را کنترل و تعمیمپذیری را به مجموعه دادههای دیده نشده بهبود بخشید.
علاوه بر این، یک آستانه بهینه سفارشی ضروری تلقی شد زیرا هدف، ایجاد تعادل مناسب بین منفیهای کاذب (از دست دادن شیب مستعد خطر) و مثبتهای کاذب (شکستهای شیب بیش از حد پیشبینیشده برای محدود کردن هزینهها برای منابع پرهزینه) بود. انتخاب مقدار آستانه ۰٫۷۵ برای طبقهبندی حساسیت به شکست HWS، هم تفاوتهای ظریف مجموعه دادهها و هم ویژگیهای مدل RF را منعکس میکند. به عنوان مثال، اگر شکستهای HWS یک اتفاق نادر در مجموعه دادهها باشند، مدل تمایل دارد احتمالات پایینی را به اکثر نمونهها اختصاص دهد و برای حفظ ویژگی و جلوگیری از مثبتهای کاذب، آستانه بالاتری را ضروری میداند. در نتیجه، آستانه بالاتر بهینه تشخیص داده شد، و مدل قبل از برچسبگذاری یک مورد به عنوان مثبت، به یک سیگنال قوی نیاز دارد.
مطالعه حساسیت، شامل PDP و تحلیل اهمیت ویژگیها، ارتفاع، فاصله از نهرها، NDVI، بارندگی و نوع خاک را به عنوان مهمترین پیشبینیکنندههای شکست HWS شناسایی کرد. اهمیت نوع خاک با شیوع خاکهای رسی منبسطشونده در منطقه مورد مطالعه که مستعد رفتار انقباض-تورم در شرایط رطوبتی متغیر هستند، همسو است. در حالی که بارندگی از نظر اهمیت ویژگیها رتبه بالایی دارد، تأثیر محدود آن در PDPها نشان میدهد که اثر آن ممکن است هنگام تعامل با سایر متغیرها به جای عملکرد مستقل، برجستهتر باشد.
با تکیه بر این بینشها، روش مدلسازی حساسیت به شکست ایجاد شده، در ارزیابی شیبها و خاکریزهای ناپایدار برای پشتیبانی از مدیریت داراییهای ژئوتکنیکی مؤثر واقع شد. این روش، که با عملکرد بالای مدل RF تأیید شده است، به عنوان ابزاری ارزشمند برای شناسایی مناطق مستعد شکست و هدایت مداخلات هدفمند برای افزایش تابآوری زیرساختها عمل میکند.
ادغام نگاشت حساسیت به شکست HWS در چارچوب GAM
قانون MAP-21 (2012) همه آژانسهای حمل و نقل ایالتی ایالات متحده را ملزم به اتخاذ برنامههای مدیریت دارایی مبتنی بر ریسک برای سیستم بزرگراه ملی کرد ۵۳٫ در پاسخ، اکثر آژانسها برنامههای مدیریت دارایی حمل و نقل (TAM) را که عمدتاً بر روسازیها و پلها متمرکز بودند، اجرا کردند. با این حال، مدیریت دارایی ژئوتکنیکی (GAM) همچنان توسعه نیافته است، و HWS اغلب به دلایل متعدد، احتمالاً از جمله بودجه، منابع و آگاهی محدود، در برنامه مدیریت دارایی گنجانده نمیشود ۹ ، ۵۴ ، ۵۵ ، ۵۶ .
علیرغم پتانسیل اثباتشدهی یادگیری ماشینی برای پیشبینی شکست، چنین تکنیکهایی به ندرت در HWS اعمال میشوند. این مطالعه با معرفی یک رویکرد مقیاسپذیر و دادهمحور برای نقشهبرداری از آسیبپذیری HWS با استفاده از یادگیری ماشینی، این شکاف را برطرف میکند. روش پیشنهادی، غربالگری سریع مناطق جغرافیایی بزرگ با حداقل منابع را امکانپذیر میکند و آن را به ویژه برای سازمانهای دولتی که تحت محدودیتهای بودجه فعالیت میکنند، مفید میسازد. با شناسایی داراییهای زیرساختی حیاتی در معرض خطر مانند HWS، این رویکرد میتواند به عنوان اولین گام مهم در اولویتبندی داراییهای ژئوتکنیکی برای ارزیابی دقیقتر عمل کند.
وقتی نقاط حساس به زلزله شناسایی میشوند، سازمانها میتوانند از فناوریهای سنجش هدفمند مانند لیدار و فتوگرامتری مبتنی بر پهپاد برای ارزیابی تغییر شکل سطح استفاده کنند. اگر این ارزیابیها نشاندهنده بیثباتی مداوم یا بالقوه باشند، میتوان آنها را با بررسیهای ژئوفیزیکی و ژئوتکنیکی برای ارزیابی شرایط زیرسطحی و تعیین دقیق مکانیسمهای خرابی دنبال کرد. این فرآیند بررسی روشمند و چند مرحلهای، سازمانها را قادر میسازد تا منابع را به طور مؤثرتری تخصیص دهند و در صورت لزوم، به ویژه برای داراییهای حیاتی برای شبکههای حمل و نقل چندوجهی، اقدامات پیشگیرانه کاهش خطر را انجام دهند. این رویکرد چند مرحلهای از تصمیمات به موقع و مبتنی بر داده و کاهش ریسک مقرون به صرفه پشتیبانی میکند.
علاوه بر این، مدل آموزشدیده میتواند در یک چارچوب هوشمند GAM تعبیه شود و نظارت مداوم بر عملکرد و هشدارهای اولیه را ارائه دهد. شکل ۳۱ نحوه ادغام نقشهبرداری حساسیت در گردشهای کاری مدیریت ریسک GAM و زیرساخت را نشان میدهد.

آسیبپذیری HWS را در GAM و چارچوب ارزیابی ریسک زیرساخت ادغام کنید.
محدودیتها
علیرغم ارزیابی جامع منطقه مورد مطالعه، این مطالعه هنوز محدودیتهای متعددی دارد. به عنوان مثال، دقت مدل به کیفیت و وضوح مجموعه دادههای ورودی، از جمله DEM مورد استفاده برای تولید چندین عامل ایجادکننده و NDVI تولید شده از دادههای ماهوارهای لندست و میزان بارندگی از مقادیر میانگین روزانه، که ممکن است از نظر مکانی متفاوت باشند، بستگی دارد. فهرست زمین لغزش مورد استفاده برای آموزش ممکن است ناقص یا متمایل به سمت رویدادهای اخیر یا قابل دسترس باشد، که به طور بالقوه بر تعمیمپذیری تأثیر میگذارد. این عوامل ایجادکننده استاتیک، تغییرپذیری زمانی عوامل تحریککننده مانند بارندگی شدید در مدت زمان کوتاه یا تغییرات پوشش زمین را در بر نمیگیرند. خروجیهای دودویی ممکن است حساسیت را در شرایط پیچیده زمین بیش از حد ساده کنند، اگرچه بهینهسازی آستانه، طبقهبندی را بهبود میبخشد.
علاوه بر این، علیرغم استفاده از PDPها و تحلیل اهمیت متغیرها، ممکن است تعاملات ویژگیها به طور کامل ثبت نشده باشد و قابلیت تفسیر مدل همچنان محدود باشد. جزئیات حیاتی مختص زیرساختها مانند زهکشی و تقویت شیب در نظر گرفته نشده است که ممکن است بر پایداری شیب تأثیر بگذارد. در نهایت، این مدل ممکن است مختص منطقه باشد و بدون کالیبراسیون مجدد به خوبی به سایر زمینههای جغرافیایی قابل انتقال نباشد، اما این موضوع نیاز به ارزیابی بیشتر دارد.
کارهای آینده
این مطالعه، کاربرد رو به رشد یادگیری ماشینی (ML) را در پایش ژئومورفولوژیکی بلندمدت و ارزیابی ریسک بلایا برجسته میکند و نشان میدهد که چگونه مدلهایی مانند RF میتوانند از دادههای ماهوارهای بینش استخراج کرده و روشهای مقیاسپذیر برای تجزیه و تحلیل تکامل رانش زمین از خطرات طبیعی مختلف ارائه دهند. راههای بیشتری برای پیادهسازی این روش متناسب با سایر نیروهای جوی، از جمله رویدادهای لرزهای، طوفانها، بارانهای شدید و غیره، بررسی خواهد شد. علاوه بر این، میتوان با اعمال آن به HWS در مناطق جغرافیایی مختلف، استحکام مدل آموزشدیده را بیشتر ارزیابی کرد و امکان ارزیابی قابلیت انتقال و تعمیمپذیری آن را در زمینهای مختلف فراهم نمود.
تحقیقات آینده بر توسعه مدلهای ترکیبی یادگیری ماشین (ML) متمرکز خواهد بود که تکنیکهای بهینهسازی مورد استفاده گسترده در نقشهبرداری حساسیت زمینلغزش (LSM)، مانند الگوریتمهای الهام گرفته از طبیعت که توسط لیو و همکاران شرح داده شده است را ادغام میکنند. ۵۷٫ این رویکردها برای افزایش عملکرد مدل و پیشبینی دقیقتر الگوهای جابجایی استفاده خواهند شد.
علاوه بر این، حوزه دیگری از کاوش شامل تحلیل مقایسهای بین رویکردهای نقشهبرداری واحد شیب و واحد رستری ۲۳ و همچنین گسترش مجموعه دادهها برای پشتیبانی از تحلیلهای حساسیت قوی خواهد بود. این تحلیلها تأثیر ویژگیهای منفرد و ترکیبی را بر پیشبینیهای مدل ارزیابی میکنند. مدلهای آینده متغیرهای ورودی مشتق شده از مشاهدات InSAR و LiDAR، مانند حرکت زمین، تغییر شکل سری زمانی و نشست، را همراه با دادههای سنگشناسی، هیدرولوژیکی و محیطی در بر خواهند گرفت. هدف، توسعه نقشههای حساسیت با وضوح بالا است که مستقیماً برای ساخت محیطها و زیرساختهای حمل و نقل قابل استفاده هستند و سیستمهای هشدار اولیه و تابآوری زیرساختها را افزایش میدهند.
نتیجهگیری
داراییهای ژئوتکنیکی مانند خاکریزها و شیبهای بزرگراه (HWS) نقش مهمی در پایداری و عملکرد زیرساختهای حمل و نقل دارند، اما اغلب در برنامههای مدیریت داراییهای حمل و نقل (TAM) کمتر مورد توجه قرار میگیرند. شناسایی و نقشهبرداری اولیه از HWSهای آسیبپذیر برای تابآوری زیرساختها حیاتی است. این مطالعه با تطبیق تکنیکهای نقشهبرداری از حساسیت به لغزش زمین که معمولاً برای دامنههای طبیعی یا بریده شده تپهها اعمال میشود، یک چارچوب نقشهبرداری از حساسیت به شکست HWS مبتنی بر سیستم اطلاعات جغرافیایی (GIS) ایجاد کرد. مدلهای ML نظارت شده، شامل جنگل تصادفی (RF)، طبقهبندی کننده بردار پشتیبان (SVC)، رگرسیون لجستیک (LR) و بیز ساده (NB)، با استفاده از DEMهای مشتق شده از سنجش از دور و ویژگیهای ژئوتکنیکی، ژئومورفولوژیکی و هیدرولوژیکی رستری شده آموزش داده شدند.
در میان مدلهای آزمایششده، RF عملکرد برتر را در تمام معیارهای ارزیابی، با AUC، امتیاز F1 و امتیاز دقت هر کدام ۱.۰، نشان داد. SVC با امتیاز AUC = ۰.۹۴، امتیاز F1 و امتیاز دقت هر کدام = ۰.۸۸، برای هر دو آستانه احتمال پیشفرض و سفارشی، در رتبه دوم قرار گرفت. کاهش ویژگی از طریق PCA و Information Gain با حذف عوامل (ویژگیهای) کماثر مانند آلبدو خاک، تجمع جریان و انحنای صفحه، کارایی مدل را بیشتر افزایش داد. مقایسهها با استفاده از آستانه احتمال پیشفرض (۰.۵) و یک آستانه بهینه سفارشی (۰.۷۵)، که از طریق آماره J یودن به دست آمده است، دقت طبقهبندی بهبود یافتهای را در تمام مدلها، بهویژه برای SVC، LR و NB نشان داد که ارزش تنظیم آستانه در نقشهبرداری حساسیت را تأیید میکند. نقشههای حساسیت حاصل، امکان اولویتبندی داراییهای پرخطر در مناطق بزرگ با منابع محدود را فراهم میکنند و تخصیص تلاشهای کاهشی را بهبود میبخشند. پنج عامل مؤثر شناساییشده عبارت بودند از ارتفاع، فاصله از نهرها، شاخص پوشش گیاهی نرمالشده (NDVI)، بارندگی و نوع خاک. وجود خاکهای رسی منبسطشونده در سراسر منطقه مورد مطالعه، که در طول چرخههای آب و هوایی مرطوب و خشک بسیار مستعد تغییرات حجمی هستند، احتمالاً به اهمیت نوع خاک به عنوان یک ویژگی پیشبینیکننده کمک میکند. اگرچه مدل RF بارندگی را به عنوان یک ویژگی مهم برای طبقهبندی شناسایی کرد، نمودارهای وابستگی جزئی (PDPs) تأثیر فردی ضعیفتری را نشان دادند. این نتیجه تا حدودی خلاف شهود است، زیرا بارندگی به طور گسترده به عنوان یک عامل اصلی رانش زمین و حرکت زمین شناخته میشود. این اختلاف ممکن است نشان دهد که عوامل خاص از طریق تعاملات یا ترکیبات، تأثیر بیشتری دارند، نه به عنوان متغیرهای مستقل.
علاوه بر این، اعتبارسنجی با استفاده از شش سایت شناخته شده HWS، توافق مکانی قوی بین پیشبینیهای مدل و شرایط خرابی مشاهده شده را نشان داد. این مطالعه یک رویکرد نوآورانه مبتنی بر داده را معرفی کرد که یادگیری ماشین، سنجش از دور و تحلیل مکانی را برای مدرنسازی نظارت سنتی بر داراییها ادغام میکند. برخلاف روشهای مرسوم که به شدت به خرابیهای تاریخی یا بازرسیهای دستی متکی هستند، چارچوب پیشنهادی، مدیریت داراییهای ژئوتکنیکی (GAM) خودکار، مقیاسپذیر و پیشگیرانه را امکانپذیر میکند. با ترکیب طبقهبندی احتمالی و آستانههای بهینه، روش پیشنهادی، اولویتبندی هشدار اولیه، بازرسیهای هدفمند و تصمیمگیری دقیقتر را امکانپذیر میکند. این مزایا میتواند به طور قابل توجهی نگهداری و برنامهریزی زیرساختها را بهبود بخشد. علاوه بر این، مدلسازی حساسیت به خرابی HWS، ارزیابی ریسک داراییهای ژئوتکنیکی را ساده کرده و از استراتژیهای بلندمدت برای مدیریت زیرساختهای حمل و نقل پشتیبانی میکند.
در دسترس بودن دادهها
مجموعه دادههای مورد استفاده و/یا تحلیلشده در طول مطالعهی حاضر، در صورت درخواست معقول، از نویسندهی مسئول در دسترس قرار خواهد گرفت.
منابع
-
طرح مدیریت داراییهای ژئوتکنیکی تامپسون، اداره توسعه شهری . (گزارش شماره STP000S(802)(B)). آلاسکا. اداره حمل و نقل و تأسیسات عمومی. تحقیق و انتقال فناوری. https://rosap.ntl.bts.gov/view/dot/36139/dot_36139_DS1.pdf (۲۰۱۷).
-
اندرسون، س.، شافر، وی آر و نیکولز، اس سی، طبقهبندی برای داراییها، عناصر و ویژگیهای ژئوتکنیکی. در نود و پنجمین نشست سالانه هیئت تحقیقات حمل و نقل (هیئت تحقیقات حمل و نقل، ۲۰۱۶).
-
وسلی، ام. و همکاران. مدیریت داراییهای ژئوتکنیکی برای آژانسهای حمل و نقل، جلد ۲: راهنمای اجرا . (۲۰۱۹) https://doi.org/10.17226/25364 .
-
روپرت، تی. و اسنایدر، بی. بزرگراه جنوبی میسیسیپی پس از بارندگی شدید فرو ریخت. WLOX (۲۰۲۱).
-
مینا، اس. آر و همکاران. نقشهبرداری سریع از رانش زمین در رشتهکوههای گهات غربی (هند) که در اثر بارندگی شدید موسمی سال ۲۰۱۸ رخ داده است با استفاده از رویکرد یادگیری عمیق. رانش زمین ۱۸ ، ۱۹۳۷-۱۹۵۰ (۲۰۲۱).
-
پاتاک، ال. و دوکوتا، کی. سی. ارزیابی حساسیت زمین لغزش در حوزه آبخیز رانگون خولا در غرب نپال. مجله زمین شناسی نپال. https://doi.org/10.3126/jngs.v63i01.50827 (۲۰۲۲).
-
آدیتیان، آ.، کوبوتا، ت. و شینوهارا، ی. مقایسه مدلهای حساسیت زمینلغزش مبتنی بر GIS با استفاده از نسبت فراوانی، رگرسیون لجستیک و شبکه عصبی مصنوعی در منطقه درجه سه آمبون، اندونزی. ژئومورفولوژی ۳۱۸ ، ۱۰۱-۱۱۱ (۲۰۱۸).
-
دینگ، کیو.، چن، دبلیو. و هونگ، اچ. کاربرد مدلهای نسبت فراوانی، وزن شواهد و تابع باور شواهد در نقشهبرداری حساسیت زمینلغزش. Geocarto. Int. https://doi.org/10.1080/10106049.2016.1165294 (۲۰۱۶).
-
اندرسون، س.، وسلی، م.، داولینگ، س. و کارتر، ر. مدیریت داراییهای ژئوتکنیکی برای شیبها . (شماره شناسایی WisDOT: 0092-21-06). دفتر خدمات فنی، وزارت حمل و نقل ویسکانسین. https://wisconsindot.gov/documents2/research/0092-21-06-final-report.pdf (۲۰۲۲).
-
عبدی، ا.، بوعمران، ا.، کارچ، ت.، دهری، ن. و کائوچی، ا. نقشهبرداری حساسیت زمینلغزش با استفاده از منطق فازی مبتنی بر GIS و رویکرد فرآیندهای سلسله مراتبی تحلیلی: مطالعه موردی در قسطنطنیه (شمال شرقی الجزایر). ژئوتکنیک. مهندسی زمین. ۳۹ ، ۵۶۷۵–۵۶۹۱ (۲۰۲۱).
-
شهابی، ح. و هاشم، م. نقشهبرداری حساسیت زمینلغزش با استفاده از مدلهای آماری مبتنی بر GIS و دادههای سنجش از دور در محیط گرمسیری. Sci. Rep. ۵ ، ۹۸۹۹ (۲۰۱۵).
-
گوتز، جی. ان.، برنینگ، ای.، پتشکو، اچ. و لئوپولد، پی. ارزیابی تکنیکهای یادگیری ماشین و پیشبینی آماری برای مدلسازی حساسیت زمینلغزش. Comput. Geosci. ۸۱ ، ۱–۱۱ (۲۰۱۵).
-
تین بویی، دی.، توان، تی.ای.، کلمپه، اچ.، پرادان، بی. و روهاگ، آی. مدلهای پیشبینی مکانی برای خطرات رانش زمین کمعمق: ارزیابی مقایسهای اثربخشی ماشینهای بردار پشتیبان، شبکههای عصبی مصنوعی، رگرسیون لجستیک هسته و درخت مدل لجستیک. رانش زمین ۱۳ ، ۳۶۱-۳۷۸ (۲۰۱۶).
-
چن، دبلیو و همکاران. مطالعه تطبیقی مدلهای درخت مدل لجستیک، جنگل تصادفی و درخت طبقهبندی و رگرسیون برای پیشبینی مکانی حساسیت زمینلغزش. Catena (Amst) ۱۵۱ ، ۱۴۷–۱۶۰ (۲۰۱۷).
-
سونگن، ای.، کوکامان، اس.، نفسلیوغلو، اچ. ای. و گوکچئوغلو، سی. یک رویکرد ارزیابی عملکرد جدید با استفاده از تکنیکهای فتوگرامتری برای نقشهبرداری حساسیت زمینلغزش با رگرسیون لجستیک، شبکه عصبی مصنوعی و جنگل تصادفی. حسگرها ۱۹ ، ۳۹۴۰ (۲۰۱۹).
-
Orhan, O., Bilgilioglu, SS, Kaya, Z., Ozcan, AK & Bilgilioglu, H. ارزیابی و نقشهبرداری حساسیت زمین لغزش با استفاده از روشهای مختلف یادگیری ماشین. ژئوکارتو بین المللی ۳۷ ، ۲۷۹۵-۲۸۲۰ (۲۰۲۲).
-
سونگن، ای.، کوکامان، اس.، نفسلیوغلو، اچ. ای. و گوکچئوغلو، سی. ای. یک رویکرد ارزیابی عملکرد جدید با استفاده از تکنیکهای فتوگرامتری برای نقشهبرداری حساسیت زمینلغزش با رگرسیون لجستیک، شبکه عصبی مصنوعی و جنگل تصادفی. حسگرها ۱۹ ، ۳۹۴۰ (۲۰۱۹).
-
کاتانی، ف.، لاگومارسینو، د.، سگونی، س. و طوفانی، و. تخمین حساسیت زمین لغزش با استفاده از تکنیک جنگلهای تصادفی: مسائل حساسیت و مقیاسبندی. مجله خطر ملی. ۱۳ ، ۲۸۱۵–۲۸۳۱ (۲۰۱۳).
-
آذرافزا، م.، آذرافزا، م.، آکگون، ح.، اتکینسون، پی. ام. و درخشانی، ر. نقشهبرداری حساسیت زمینلغزش مبتنی بر یادگیری عمیق. مجله علمی پژوهشی شماره ۱۱ ، شماره ۲۴۱۱۲ (۲۰۲۱).
-
حسین، س. و همکاران. تشخیص زمینلغزش و بهروزرسانی فهرست با استفاده از رویکرد InSAR سری زمانی در امتداد بزرگراه قراقروم، شمال پاکستان. Sci. Rep. ۱۳ ، ۷۴۸۵ (۲۰۲۳).
-
لو، ایکس. و همکاران. پیوند مدل درختی لجستیک و زیرفضای تصادفی برای پیشبینی مناطق مستعد لغزش زمین با در نظر گرفتن عدم قطعیت ویژگیهای محیطی. مجله علمی پژوهشی شماره ۹ ، ۱۵۳۶۹ (۲۰۱۹).
-
لانگ، وای. و همکاران. مطالعه تطبیقی روشهای طبقهبندی نظارتشده برای بررسی تکامل زمینلغزش در حوضه رودخانه میانیوان، چین. مجله علوم زمین. ۳۴ ، ۳۱۶-۳۲۹ (۲۰۲۳).
-
ما، س.، شائو، خ. و شو، س. نقشهبرداری حساسیت زمینلغزش بر اساس واحد شیب یا واحد رستری، کدام بهتر است؟. مجله علوم زمین. ۳۴ ، ۳۸۶–۳۹۷ (۲۰۲۳).
-
کریگ، ایدی و آگوستو فیلهو، او. نقشهبرداری حساسیت زمینلغزش دامنههای بزرگراه، با استفاده از تحلیلهای پایداری و روشهای GIS. Soils Rocks ۴۳ ، ۷۱–۸۴ (۲۰۲۰).
-
آخور، ی. و پورقاسمی، اچ آر. چگونه تکنیکهای یادگیری ماشین به افزایش دقت نقشههای حساسیت زمین لغزش کمک میکنند؟. علوم زمین. فرانت. ۱۱ ، ۸۷۱–۸۸۳ (۲۰۲۰).
-
پاور، سی. و ابوت، اس. مقدمهای بر ریسک مرتبط با زمین برای زیرساختهای حمل و نقل. QJ Eng. Geol. Hydrogeol. ۵۲ ، ۲۸۰-۲۸۵٫ https://doi.org/10.1144/qjegh2019-016 (۲۰۱۹).
-
هوپ، ای. و همکاران. پایش زیرساختهای حمل و نقل با استفاده از سنجش از دور ماهوارهای . (۲۰۱۴).
-
کین، ی.، هوپه، ای. و پریسین، دی. پایش خطر شیب با استفاده از سنجش از دور ماهوارهای با وضوح بالا: درسهایی از یک مطالعه موردی. ISPRS Int J Geoinf ۹ ، (۲۰۲۰).
-
بوعلی، ایوایوای، اکسکوبار-ولف، آر. و اومن، تی. پایش عوارض زمینی با استفاده از تصاویر ماهوارهای. ژئواستراتا، موسسه ژئو انجمن مهندسان عمران آمریکا ۵۲-۵۷ (۲۰۱۵).
-
ولف، آر.ای و همکاران. GAM پایدار در امتداد زیرساخت حمل و نقل با استفاده از سنجش از دور . (۲۰۱۵).
-
هوانگ، ف.، شیونگ، ه.، ژو، خ.، کاتانی، ف. و هوانگ، ج. مدلسازی عدم قطعیتها و تحلیل حساسیت پیشبینی حساسیت زمینلغزش تحت روشهای مختلف ارتباط عوامل محیطی و مدلهای یادگیری ماشین. KSCE J. Civ. Eng. ۲۸ ، ۴۵–۶۲ (۲۰۲۴).
-
ما، جی. و همکاران. نقشهبرداری خودکار حساسیت زمینلغزش مبتنی بر یادگیری ماشین برای منطقه مخزن سه دره، چین. Math. Geosci. ۵۶ ، ۹۷۵–۱۰۱۰ (۲۰۲۴).
-
کلانتر، ب. و همکاران. ارزیابی نقشهبرداری حساسیت زمینلغزش با استفاده از دادههای سنجش از دور و الگوریتمهای یادگیری ماشین در ایران. سالنامههای ISPRS از فتوگرامتری، سنجش از دور و علوم اطلاعات مکانی IV-2/W5 ، ۵۰۳–۵۱۱ (۲۰۱۹).
-
چن، ایکس. و چن، دبلیو. ارزیابی حساسیت زمین لغزش مبتنی بر GIS با استفاده از روشهای ترکیبی بهینه یادگیری ماشین. Catena (Amst) ۱۹۶ ، ۱۰۴۸۳۳ (۲۰۲۱).
-
ژو، ایکس اچ و وانگ، وای اچ، سرمقاله شماره ویژه سازههای با عملکرد بالا. مهندسی ۵ ، ۱۸۳. https://doi.org/10.1016/j.eng.2019.02.002 (۲۰۱۹).
-
ماندال، ک.، ساها، س. و ماندال، س. بهکارگیری الگوریتمهای یادگیری عمیق و یادگیری ماشین معیار برای مدلسازی حساسیت زمینلغزش در حوضه رودخانه روراچو در سیکیم هیمالیا، هند. Geosci. Front. ۱۲ ، ۱۰۱۲۰۳ (۲۰۲۱).
-
مرکز رصد و علوم منابع زمین (EROS). تصویرگر عملیاتی زمین/سنسور مادون قرمز حرارتی لندست ۸-۹ سطح ۲، مجموعه ۲. سازمان زمینشناسی ایالات متحده. https://doi.org/10.5066/P9OGBGM6 (۲۰۲۰).
-
گایدزیک، ک. و رامیرز-هررا، ام. تی. اهمیت دادههای ورودی در نقشهبرداری از حساسیت زمینلغزش. مجله علمی-پژوهشی شماره ۱۱ ، ۱۹۳۳۴ (۲۰۲۱).
-
بویی، دیتی، لافمن، او.، روهاگ، آی. و دیک، او. تحلیل حساسیت زمینلغزش در استان هوابین ویتنام با استفاده از شاخص آماری و رگرسیون لجستیک. مجله خطرات طبیعی، شماره ۵۹ ، صفحات ۱۴۱۳ تا ۱۴۴۴ (۲۰۱۱).
-
چانگ، ز. و همکاران. پیشبینی حساسیت زمینلغزش با استفاده از مدلهای یادگیری ماشین مبتنی بر واحد شیب با در نظر گرفتن ناهمگونی عوامل مؤثر. مجله مهندسی مکانیک سنگ، ۱۵ ، ۱۱۲۷–۱۱۴۳ (۲۰۲۳).
-
هو، م.، لیو، کیو. و لیو، پ. ارزیابی حساسیت زمین لغزش در منطقه آلپاین-کانیون با استفاده از چندین مدل مبتنی بر GIS. مجله علوم طبیعی دانشگاه ووهان، شماره ۲۴ ، صفحات ۲۵۷-۲۷۰ (۲۰۱۹).
-
ون وستن، سیجی، رنگرز، ان. و سوترز، آر. استفاده از اطلاعات ژئومورفولوژیکی در ارزیابی غیرمستقیم حساسیت زمینلغزش. مجله خطرات طبیعی، شماره ۳۰ ، صفحات ۳۹۹-۴۱۹ (۲۰۰۳).
-
ژانگ، تی. و همکاران. ارزیابی مدلهای مختلف یادگیری ماشین و الگوریتم جدید مبتنی بر یادگیری عمیق برای نقشهبرداری حساسیت زمینلغزش. Geosci. Lett. ۹ ، (۲۰۲۲).
-
کاستانزو، دی.، روتیلیانو، ای.، ایریگاری، سی.، خیمنز-پرالوارز، جی. دی. و چاکون، جی. انتخاب عوامل در مدلسازی حساسیت زمینلغزش در مقیاس بزرگ با استفاده از روش ماتریس gis: کاربرد در حوضه رودخانه بیرو (اسپانیا). مجله خطر ملی. ۱۲ ، ۳۲۷-۳۴۰ (۲۰۱۲).
-
قربانزاده، ا. و همکاران. ارزیابی روشهای مختلف یادگیری ماشین و شبکههای عصبی کانولوشنی یادگیری عمیق برای تشخیص رانش زمین. سنجش از دور. (بازل) ۱۱ ، ۱۹۶ (۲۰۱۹).
-
ما، س.، ما، م.، هوانگ، ز.، هو، ی. و شائو، ی. تحقیقی در مورد بهبود رفتار نفوذپذیری باران در شیب خاک منبسطشونده با محافظت از پوشش ضد آب پلیمری. Soils Foundations ۶۳ ، (۲۰۲۳).
-
قربانزاده، ا. و همکاران. ارزیابی روشهای مختلف یادگیری ماشین و شبکههای عصبی کانولوشنی یادگیری عمیق برای تشخیص رانش زمین. سنجش از دور. (بازل) ۱۱ ، (۲۰۱۹).
-
گارسیا-رویز، جی. ام. و همکاران. جنگلزدایی باعث رانش زمین در کمربندهای کوهستانی و نیمهآلپی کوههای اوربین، رشتهکوه ایبری، شمال اسپانیا میشود. ژئومورفولوژی ۲۹۶ ، ۳۱-۴۴ (۲۰۱۷).
-
گلید، تی. وقوع زمین لغزش به عنوان پاسخی به تغییر کاربری زمین: مروری بر شواهد نیوزیلند. Catena (Amst) ۵۱ ، ۲۹۷–۳۱۴ (۲۰۰۳).
-
ژائو، ب.، لی، دبلیو.، سو، ل.، وانگ، ی. و وو، ه. بینشهایی در مورد رانشهای زمین ناشی از زلزله لوشان ام اس ۶.۱ در سال ۲۰۲۲: توزیع مکانی و کنترلها. سنجش از دور. (بازل) ۱۴ ، ۴۳۶۵ (۲۰۲۲).
-
عباس، ف. و همکاران. نقشهبرداری حساسیت زمینلغزش: تحلیل تکنیکهای مختلف انتخاب ویژگی با شبکه عصبی مصنوعی تنظیمشده توسط الگوریتمهای بیزی و فراابتکاری. سنجش از دور. (بازل) ۱۵ ، ۴۳۳۰ (۲۰۲۳).
-
امبرسون، آر.ای، کیرشباوم، دی.بی و استنلی، تی. مدلسازی خطر رانش زمین و مواجهه با آن در مناطق فقیر از نظر داده: نمونهای از اردوگاههای پناهندگان روهینگیا در بنگلادش. Earths Future ۹ ، (۲۰۲۱).
-
استنلی، دی. و پیرسون، ال. مدیریت داراییهای ژئوتکنیکی شیبها: شاخصهای وضعیت و معیارهای عملکرد. ۱۶۵۱–۱۶۶۰ (۲۰۱۳). https://doi.org/10.1061/9780784412787.166 .
-
وسلی، م. چارچوب مبتنی بر ریسک برای مدیریت داراییهای ژئوتکنیکی . (گزارش شماره STP000S(802)(C)). وزارت حمل و نقل و تأسیسات عمومی آلاسکا. تحقیق و انتقال فناوری. https://rosap.ntl.bts.gov/view/dot/36140/dot_36140_DS1.pdf (۲۰۱۷).
-
اندرسون، س.، وسلی، م. ج. و اورتیز، ت. ارتباط و مدیریت ریسکهای ژئوتکنیکی برای اهداف عملکرد حمل و نقل. در ۲۷۹-۲۹۰ (انجمن مهندسان عمران آمریکا (ASCE)، ۲۰۱۷). https://doi.org/10.1061/9780784480724.026 .
-
تامپسون، پیدی و همکاران. طرح مدیریت داراییهای ژئوتکنیکی: تحلیل هزینه و ریسک چرخه عمر. Transp. Res. Rec. ۲۵۹۶ , ۳۶–۴۳ (۲۰۱۶).
-
لیو، ز. و همکاران. به سوی پیشبینی قابل اعتماد جابجایی زمین لغزش مخزن با استفاده از رگرسیون بردار پشتیبان بهینه شده با الگوریتم بهینهسازی کرم خاکی (EOA-SVR). Nat. Hazards ۱۲۰ ، ۳۱۶۵–۳۱۸۸ (۲۰۲۴).
تقدیرنامهها
این کار تا حدودی توسط بنیاد ملی علوم (NSF) تحت کمک هزینه ۲۰۴۶۰۵۴ اعطا شده به SK پشتیبانی شد. ما مایلیم از وزارت حمل و نقل میسیسیپی (MDOT) برای اجازه دسترسی به سایتهای شیبدار تشکر کنیم.
اعلامیههای اخلاقی
منافع رقابتی
نویسندگان هیچ گونه تضاد منافعی را اعلام نمیکنند.
اطلاعات تکمیلی
یادداشت ناشر
اشپرینگر نیچر در مورد ادعاهای مربوط به صلاحیت قضایی در نقشههای منتشر شده و وابستگیهای سازمانی بیطرف باقی میماند.
حقوق و مجوزها
دسترسی آزاد این مقاله تحت مجوز بینالمللی Creative Commons Attribution 4.0 منتشر شده است که استفاده، اشتراکگذاری، اقتباس، توزیع و تکثیر در هر رسانه یا قالبی را مجاز میداند، مادامی که به نویسنده(گان) اصلی و منبع، ارجاع مناسب داده شود، پیوندی به مجوز Creative Commons ارائه شود و در صورت ایجاد تغییرات، مشخص شود. تصاویر یا سایر مطالب شخص ثالث در این مقاله در مجوز Creative Commons مقاله گنجانده شدهاند، مگر اینکه در خط اعتباری مطلب، خلاف آن ذکر شده باشد. اگر مطلبی در مجوز Creative Commons مقاله گنجانده نشده باشد و استفاده مورد نظر شما طبق مقررات قانونی مجاز نباشد یا از حد مجاز تجاوز کند، باید مستقیماً از دارنده حق چاپ اجازه بگیرید. برای مشاهده نسخهای از این مجوز، به http://creativecommons.org/licenses/by/4.0/ مراجعه کنید .
درباره این مقاله

به این مقاله استناد کنید
سالونک، ر.، خان، س. نقشهبرداری از داراییهای زیرساخت حمل و نقل در معرض خطر با استفاده از روشهای آماری و یادگیری ماشین. Sci Rep ۱۶ ، ۴۳۱۳ (۲۰۲۶). https://doi.org/10.1038/s41598-025-18440-w
- دریافت شده
- پذیرفته شده
- منتشر شده
- نسخه رکورد
- DOIhttps://doi.org/10.1038/s41598-025-18440-w
کلمات کلیدی
- حساسیت
- شیب بزرگراهها
- یادگیری ماشینی
- سیستم اطلاعات جغرافیایی
- جنگل تصادفی
- زیرساخت
- مدیریت داراییهای ژئوتکنیکی