

- مقاله
- دسترسی آزاد
- منتشر شده:
یک گردش کار همکاری انسان و هوش مصنوعی برای شناسایی سایتهای باستانشناسی
گزارشهای علمی حجم ۱۳ ، شماره مقاله: ۸۶۹۹ ( ۲۰۲۳ )
چکیده
این مقاله نتایج بهدستآمده با استفاده از مدلهای یادگیری عمیق قطعهبندی معنایی از پیش آموزشدیده برای تشخیص مکانهای باستانی در محیط دشتهای سیلابی بینالنهرین را نشان میدهد. مدلها با استفاده از تصاویر ماهوارهای در دسترس عموم و اشکال برداری حاصل از مجموعهای بزرگ از حاشیهنویسیها (یعنی مکانهای بررسیشده) تنظیم دقیق شدند. یک آزمایش تصادفی نشان داد که بهترین مدل به دقت تشخیص در حدود ۸۰٪ میرسد. ادغام تخصص حوزه برای تعریف نحوه ساخت مجموعه دادهها و نحوه ارزیابی پیشبینیها بسیار مهم بود، زیرا تعریف اینکه آیا یک ماسک پیشنهادی به عنوان یک پیشبینی محسوب میشود یا خیر، بسیار ذهنی است. علاوه بر این، حتی یک پیشبینی نادرست نیز میتواند زمانی مفید باشد که در متن قرار گیرد و توسط یک باستانشناس آموزشدیده تفسیر شود. با توجه به این ملاحظات، مقاله را با چشماندازی برای گردش کار همکاری انسان و هوش مصنوعی به پایان میرسانیم. با شروع از یک مجموعه داده حاشیهنویسیشده که توسط متخصص انسانی اصلاح میشود، مدلی به دست میآوریم که پیشبینیهای آن یا میتوانند برای ایجاد یک نقشه حرارتی ترکیب شوند، یا روی تصاویر ماهوارهای و/یا هوایی قرار گیرند، یا میتوانند به صورت برداری درآیند تا تجزیه و تحلیل بیشتر در یک نرمافزار GIS آسانتر و خودکار شود. در عوض، باستانشناسان میتوانند پیشبینیها را تجزیه و تحلیل کنند، بررسیهای میدانی خود را سازماندهی کنند و مجموعه دادهها را با حاشیهنویسیهای جدید و اصلاحشده اصلاح کنند.
محتوای مشابه توسط دیگران مشاهده میشود
مقدمه
این مقاله نتایج همکاری بین دانشمندان داده و باستانشناسان را با هدف ایجاد یک سیستم هوش مصنوعی (AI) که قادر به کمک به تشخیص مکانهای باستانی بالقوه از تصاویر هوایی یا در مورد ما، تصاویر ماهوارهای باشد، مستند میکند. استفاده از مدلهای تقسیمبندی معنایی به ما این امکان را داد که خطوط کلی دقیقی ترسیم کنیم و ارزیابی انسان در حلقه نشان داد که دقت تشخیص در حدود ۸۰٪ است.
این روش در حوزه سنجش از دور (RS) قرار میگیرد که به عمل شناسایی و/یا نظارت بر یک نقطه مورد نظر از راه دور اشاره دارد. در دنیای باستانشناسی، این عملیات با در دسترس بودن تصاویر بیشتر و بهتر از ماهوارهها که میتوانند با منابع اطلاعاتی قدیمیتر (مثلاً تصاویر ماهوارهای CORONA) ترکیب شوند، برای شناسایی تعداد بیشتری از مکانهای باستانی و همچنین ردیابی تخریب متوالی آنها به دلیل عوامل انسانی، بسیار ارزشمند شده است . بسته به منطقه مورد بررسی و اندازه ویژگیهای باستانشناسی مورد بررسی، تلاش لازم، به ویژه از نظر زمان، میتواند برای محقق بسیار زیاد باشد.
این همکاری با هدف حل دقیق همین مسئله با استفاده از مدلهای یادگیری عمیق برای سادهسازی، اما نه کاملاً خودکارسازی، این فرآیند انجام شد. بنابراین، با شروع از یک مجموعه داده از اشکال برداری برای تمام مکانهای ثبتشده باستانشناسی در دشت سیلابی جنوب بینالنهرین (که نشاندهنده یک منطقه ژئومورفولوژیکی به اندازه کافی منسجم است)، ما مدلی را برای شناسایی و تقسیمبندی مکانها در یک تصویر ورودی مشخص آموزش دادیم. با ادامه پروژه، تعدادی از مسائل پدیدار شدند که حل این مشکل را به ویژه دشوار میکنند و منجر به تأمل مهمی در مورد استفاده از یادگیری عمیق به طور کلی و ارتباط آن با متخصصان انسانی میشوند. این مجموعه داده، اگرچه ممکن است برای باستانشناسی شرق نزدیک با تقریباً ۵۰۰۰ مکان، بسیار بزرگ در نظر گرفته شود، اما به سختی برای آموزش مدلی به بزرگی مدلهای پیشرفتهای که امروزه در حال استفاده میبینیم، کافی است و شاید مهمتر از آن، شامل موارد زیادی است که فقط در تصاویر قدیمی خاصی قابل مشاهده هستند. اولین مسئله معمولاً از طریق یادگیری انتقالی ۲ حل میشود . این تکنیک شامل شروع از یک مدل است که از قبل روی یک مجموعه داده بزرگ و عمومی (مثلاً imagenet ۳ ) آموزش دیده است و سپس تنظیم دقیق آن روی یک مجموعه داده کوچکتر اما خاصتر، با استفاده از مهارتهایی که قبلاً آموخته است تا وظیفه جدید را قابل مدیریتتر کند. با این حال، مورد دوم، هم آموزش و هم ارزیابی را در معرض خطر قرار میدهد، زیرا مدل در طول آموزش به سمت طبقهبندیهای اشتباه سوق داده میشود و حتی اگر نمایشهای قوی را یاد گرفته باشد که نمونههای بد را نادیده میگیرند، در آن صورت تشخیص اینکه آیا اشتباه از مدل است یا از برچسبها، برای ما دشوار خواهد بود.
ما معتقدیم که تنها راه برونرفت از این معضل، رویکرد انسان در حلقه است . به همین دلیل، در سراسر مقاله بر اهمیت ادغام تخصص در حوزه مورد نظر در طول مرحله آموزش و ارزیابی آزمایشهایمان تأکید میکنیم، زیرا این امر در بهبود مجموعه دادههای مورد استفاده و به نوبه خود، مدل بسیار مهم بود. نتیجه نهایی این فرآیند تکراری، مدلی است که قادر به دقت تشخیص حدود ۸۰٪ است.
بر اساس این نتایج امیدوارکننده، ما ابزاری را برای همکاری انسان و هوش مصنوعی پیشبینی میکنیم تا از باستانشناسان در عملیات سنجش از دور پشتیبانی کند (به جای اینکه جایگزین آنها شود) و نوع جدیدی از گردش کار را پیشنهاد میدهیم که هم وظیفه آنها و هم مدل را با ارائه دادههای بهبود یافته پس از هر بار استفاده، بهبود میبخشد. ۴ ، ۵٫ تمام نتایج با استفاده از نرمافزارها و مدلهای منبع باز و همچنین دادههای در دسترس (تصاویر، حاشیهنویسیها) و منابع محاسباتی (Google Colab) به دست آمده است که این نوع کار را حتی در محیطهای تحقیقاتی با منابع محدود، بسیار قابل دسترسی و تکرارپذیر میکند. تمام کدها، دادهها و منابع ذکر شده در GitHub ( https://bit.ly/NSR_floodplains ) موجود است.
پیشینه تحقیق
دشت سیلابی بین النهرین
دشت سیلابی جنوب بینالنهرین منطقهای حیاتی برای درک تعامل پیچیده بین خوشهبندی فضایی جوامع انسانی و توسعه زمینهای کشاورزی آبیاریشده در محیطی نیمهخشک است .۶ بررسیهای رابرت مککورمیک آدامز در منطقه ۷ ، ۸ ، ۹ طبق استانداردهایی انجام شد که برای آن زمان بینظیر بودند: او از مجموعهای از عکسهای هوایی سال ۱۹۶۱ برای مکانیابی مکانهای بالقوه و نقشهبرداری از کانالهایی که آثار آنها روی سطح قابل مشاهده بود، استفاده کرد. او در ثبت مکانهایی که از هزاره هفتم پیش از میلاد تا دوره عثمانی را شامل میشدند، سیستماتیک عمل میکرد. مهمتر از همه، او به شدت از پتانسیل تاریخنگاری کار بررسی خود آگاه بود، که منجر به تفسیر قدرتمندی از الگوهای سکونت و فعالیتهای هیدرولیکی شد .۸
پس از یک وقفه طولانی در کار میدانی ناشی از بیثباتی سیاسی، تحقیقات باستانشناسی در جنوب عراق در سالهای اخیر از سر گرفته شد، برای مرور کلی به ۱۰ مراجعه کنید . در این منطقه، مکانها معمولاً با کلمه عربی «تل» برای تپه شناخته میشوند. رنگ و شکل این تپهها باعث میشود که آنها به ویژه از تصاویر هوایی و ماهوارهای قابل مشاهده باشند، که منجر به استفاده از سنجش از دور به عنوان یک استراتژی مناسب برای کشف موقعیت مکانی آنها شد.
همانطور که تونی ویلکینسون میگوید: «تلها شامل لایههای متعددی از سطوح ساختمانی و زبالههای انباشته شده در طول زمان هستند، که تا حدودی به این دلیل است که محل سکونت ثابت مانده است. سکونتگاههای تل اغلب توسط یک دیوار بیرونی تعریف میشوند که هم مواد انباشته شده را در بر میگیرد و هم آنها را محدود میکند و در نتیجه گسترش آنها را محدود میکند […]. تل به هیچ وجه محل فروش سکونت نیست […]. شهرهای بیرونی یا پایینتر […] اغلب به صورت برآمدگیهای کم ارتفاع یا صرفاً پراکندگی مصنوعات در اطراف تلها ظاهر میشوند و میتوانند کل مساحت اشغال شده یک سایت را چندین برابر گسترش دهند. » ۱۱
در بینالنهرین، تپههای تل اغلب فقط کمی مرتفعتر از حومه اطراف هستند و در چنین مواردی اغلب مستعد تسطیح مصنوعی برای به دست آوردن مناطق کشاورزی قابل آبیاری هستند. بنابراین، تشخیص خودکار مکانها در چنین محیط پویایی، عملیاتی بسیار پیچیده است، اگرچه تضادها به اندازه کافی مشخص هستند که این تلاش را توجیه کنند.
سنجش از دور
سنجش از دور میتواند به استفاده از هر حسگری (مثلاً دما، رطوبت، فراطیفی، تصاویر ماهوارهای و غیره) برای تشخیص یا پایش یک نقطه مورد نظر بدون نیاز به مشاهده مستقیم اشاره داشته باشد. این رویکرد برای زمینههای مختلفی مرتبط است، اما راهحلهایی که در یک حوزه کار میکنند ممکن است برای سایر حوزهها قابل تعمیم نباشند.
مکانیابی مکانهای باستانی از راه دور، حتی قبل از ظهور فناوری مدرن رایانهای با استفاده از عکسهای هوایی و نقشههای توپوگرافی منطقه مورد بررسی، قطعاً امکانپذیر بود، اما امروزه ترکیب چندین منبع، با استفاده از حسگرهایی با ماهیت متفاوت یا از نقاط زمانی مختلف، برای دستیابی به تصویر کاملتری از محیط، بهویژه از آنجایی که میتواند به دلیل عوامل طبیعی یا انسانی در حال تغییر باشد، آسانتر است. ۱۲ ، ۱۳ ، ۱۴٫ بسته به ویژگیهای مکانها، نمایشهای خاصی میتوانند مفید باشند، مانند مدلهای ارتفاعی بهدستآمده از تصاویر استریوسکوپی یا استفاده از بخشهایی از طیف الکترومغناطیسی غیر از نور مرئی مانند امواج مادون قرمز یا رادیویی. ۱۵ ، ۱۶٫ تشخیص و مسافتیابی نور (LiDAR) نیز به دلیل ارائه تصاویر با وضوح بالا و رضایتبخش، محبوبیت پیدا کرده است، اما استفاده از آن میتواند دشوار باشد، زیرا اغلب نیاز به نصب بر روی نوعی وسیله پرنده مانند پهپادها دارد . ۱۷٫ مشکل این نوع منابع این است که ممکن است برای هر مکانی در دسترس نباشند یا وضوح کافی برای کار مورد نظر را نداشته باشند. از سوی دیگر، تصاویر RGB با کیفیت خوب و متنباز تقریباً از هر مکانی روی کره زمین، به ویژه به دلیل محبوبیت سرویسهای آنلاین مانند نقشههای گوگل یا نقشههای بینگ، به راحتی در دسترس هستند. به طور خاص، در این پروژه، ما از تصاویر ماهوارهای از سرویس نقشههای بینگ استفاده میکنیم که برای منطقه مورد تجزیه و تحلیل، دید بسیار خوبی از آثار انسانی که روی آنها تمرکز داریم، ارائه میدهد: میگوید.
یادگیری عمیق برای سنجش از دور و باستانشناسی
یادگیری عمیق کاربردهای متعددی در هر زمینه کاربردی پیدا کرده است و باستانشناسی نیز از این قاعده مستثنی نیست. این فناوری میتواند در طبقهبندی اشیاء و متن، یافتن شباهتها، ساخت مدلهای سهبعدی و همانطور که این مقاله نیز نشان میدهد، در تشخیص مکانها کمک کند. ۱۸ ، ۱۹ ، ۲۰ ، ۲۱ ، ۲۲. یکی از دشواریهای کار با چنین مدلی این است که نیاز به همکاری متخصصان حوزه باستانشناسی و یادگیری عمیق دارد، اما ممکن است به میزان دادههای موجود نیز بستگی داشته باشد. شبکههای عصبی به شدت تشنه دادهها هستند و باستانشناسی همانطور که بیکلر گفته است، یک حوزه «داده کند» است . ۲۳. با این وجود، اخیراً چند نمونه از یادگیری عمیق وجود دارد که با موفقیت در تشخیص مکان در سناریوهای مختلف به کار گرفته شدهاند. ۲۴ ، ۲۵ ، ۲۶ ، ۲۷. اکثر برنامهها یا از شبکه عصبی برای انجام یک کار طبقهبندی، تشخیص یا تقسیمبندی استفاده میکنند. مورد اول از کاشیهای نمونهبرداری شده از نقشههایی استفاده میکند که به عنوان حاوی مکان مورد نظر یا غیر آن علامتگذاری شدهاند. در عوض، روش دوم شامل پیشبینی یک کادر مرزی در اطراف یک شیء و طبقهبندی آن در صورت نیاز است؛ در روش سوم، پیکسلهای منفرد طبقهبندی میشوند و نتیجه، پیشبینی شکلی متناظر با محل مورد نظر است. در این مقاله، ما از رویکرد دوم، همانطور که در زیر توضیح داده شده است، استفاده میکنیم.
تقسیمبندی معنایی
تقسیمبندی معنایی وظیفه تقسیم یک تصویر به بخشهایی است که با واحدهایی با معنای خاص مطابقت دارند. این بخشها میتوانند با یک موضوع خاص (مثلاً طرح کلی افراد، وسایل نقلیه و غیره) یا با یک دسته کلی که شامل چندین موجودیت (مثلاً ساختمانها، پسزمینهها و غیره) است، مطابقت داشته باشند. در متن این مقاله، ما فقط دو دسته داریم: یکی برای مکانهای تپهای (تل) و دیگری برای هر چیز دیگری. تقسیمبندی را میتوان با تکنیکهای مختلفی که طبقهبندی در سطح پیکسل را انجام میدهند، انجام داد. یک رویکرد بسیار رایج از ویژگیهای از پیش محاسبه شده، استخراج شده توسط برخی الگوریتمها یا مهندسی دستی استفاده میکند که سپس توسط یک الگوریتم جنگل تصادفی ۲۸ طبقهبندی میشوند . وضعیت فعلی هنر توسط سیستمهای سرتاسری مبتنی بر یادگیری عمیق با شبکههای عصبی کانولوشنی نشان داده میشود. برای این رویکرد، معرفی U-Net توسط روننبرگر در زمینه تصویربرداری پزشکی، یک نقطه عطف ۲۹ بود . این کار از معماری جدیدتری به نام MA-Net ۳۰ بهره میبرد که میتوان آن را به عنوان ارتقاء معماری U-Net با گنجاندن مکانیسم خود-توجهی که در معماریهای محبوب Transformer ۳۱ پیشنهاد شده است، در نظر گرفت . این امر به مدل اجازه میدهد تا ویژگیهای نهفته مختلف را بسته به محتوا وزندهی کند و به صورت مجازی مشخص کند که برای یادگیری بهتر، در این فضای نهفته به کجا «توجه» کند. اگرچه این معماری در زمینه تصویربرداری پزشکی توسعه یافته است، اما در وظایف سنجش از دور نیز کاربرد دارد . در بخش « مواد و روشها » در زیر، جزئیات بیشتری ارائه میدهیم.
کارهای قبلی و محدودیتها
در مقاله قبلی سعی کردیم با استفاده از یک رویکرد طبقهبندی تصویر که در آن نقشه به کاشیهای ۳۴ تقسیم شده بود، به همین مشکل بپردازیم . با این حال، در آن آزمایش، مجموعه دادهها یک مرتبه کوچکتر بود و ما مجبور شدیم برای افزایش عملکرد به تقویت دادههای تهاجمی متوسل شویم. بهترین مدل امتیاز AUC حدود ۷۰٪ را به دست آورد، اما هنگامی که روی بخشی دیده نشده از نقشه آزمایش شد، محدودیتهای خود را نشان داد، زیرا بسیاری از موارد مثبت کاذب را پیشبینی میکرد در حالی که برخی از سایتها را نیز از دست میداد. بزرگترین مشکل این رویکرد طبقهبندی مبتنی بر کاشی، بین اندازه کاشیها و دانهبندی پیشبینیها با مربعهای بزرگتر است که کاربردیتر هستند اما منجر به از دست رفتن جزئیات میشوند. همچنین مشکل برخورد با سایتهایی که در لبه یک کاشی قرار میگیرند، وجود دارد. راه حلی که ما امتحان کردیم، ایجاد یک مجموعه داده توفال با کاشیهای بینابینی برای پر کردن شکافها بود. با این حال، این امر میزان پیشبینی ایجاد شده را به میزان زیادی افزایش داد. در نهایت، اکثر مدلهای طبقهبندی تصویر به استفاده از اندازه ثابت ورودی محدود میشوند که میتواند هنگام کار با نقشهها محدودیت بزرگی باشد. در این آزمایش جدید، با توجه به افزایش اندازه مجموعه دادهها، تصمیم گرفتیم از مدلهای قطعهبندی تصویر با لایههای کاملاً کانولوشنی استفاده کنیم که هم محدودیتهای اندازه ورودی و هم بدهبستان دانهبندی را برطرف میکنند.
مواد و روشها
در این بخش، ابتدا مجموعه داده مورد استفاده را که با استفاده از منابع آزاد موجود ساخته شده است، شرح میدهیم و سپس مدلهای متنبازی را که بر روی آن مجموعه داده تنظیم کردهایم، معرفی میکنیم.
اشکال برداری برای سایتهای باستانشناسی
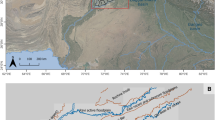
ما با مجموعهای از اشکال برداری زمینمرجعشده مطابق با خطوط تراز محوطههای تپهای شناختهشده در منطقه بررسیشده پروژه Floodplains که ۶۶۰۰۰ کیلومتر مربع را در بر میگیرد، همانطور که در شکل ۱ نشان داده شده است، شروع کردیم . این مجموعه دادهها – که در دانشگاه بولونیا با ثبت تمام بررسیهای باستانشناسی منتشر شده در منطقه و زمینمرجعسازی مجدد محوطههای فهرستشده در آن ( https://floodplains.orientlab.net ) توسعه داده شده است – شامل ۴۹۳۴ شکل است، بنابراین همه به محوطههایی اشاره دارند که توسط دادههای زمینی و مطالعه مرتبط با پراکندگی سطحی مصنوعات تأیید شدهاند.

منطقه تحقیقاتی. نقاط نارنجی نشاندهنده مکانهای بررسیشده در دشت سیلابی بینالنهرین هستند. مستطیل قرمز پررنگ یک منطقه آزمایشی انتخابشده در میسان است. تمام دادههای نمایش دادهشده تحت شرایط استفاده منصفانه از دادههای جغرافیایی برای اهداف دانشگاهی قرار میگیرند. فهرست تمام ارائهدهندگان دادهها/نرمافزار مربوطه به شرح زیر است: (۱) ایجاد نقشههای اولیه تحت بخش ۵ شرایط استفاده از APIهای پلتفرم نقشههای بینگ مایکروسافت ( https://www.microsoft.com/en-us/maps/product/print-rights )؛ (۲) نمایش نقشهها با یک نرمافزار متنباز، تحت مجوزهای GNU QGIS ( https://qgis.org/en/site/ ) و QuickMapsServices ( https://github.com/nextgis/quickmapservices )؛ (۳) بسط نهایی نقشهها با نرمافزاری که توسط نویسندگان توسعه داده شده و در ( https://bit.ly/NSR_floodplains ) موجود است، انجام شده است.
از آنجایی که مجموعه دادهها به عنوان یک منبع جامع اطلاعات برای باستانشناسان گردآوری شده بود، نه به طور خاص برای آموزش یک مدل یادگیری عمیق، ما نیاز داشتیم برخی از نمونههایی را که هیچ اطلاعاتی ارائه نمیدادند و در واقع میتوانستند فرآیند یادگیری را مختل کنند، فیلتر کنیم. ما با حذف ۲۰۰ محوطه برتر بر اساس مساحت شروع کردیم، زیرا این محوطهها به طور قابل توجهی بزرگتر از بقیه مجموعه دادهها بودند و بازرسی بصری تأیید کرد که آنها از شکل مناطقی پیروی میکنند که صرفاً تپه نیستند. عدد ۲۰۰ از توجه به این نکته ناشی میشود که این محوطهها مساحتی بزرگتر از ناحیه مربعی دارند که ما به عنوان ورودی استفاده میکنیم و بنابراین میتواند منجر به یک ماسک تقسیمبندی کاملاً کامل شود که خیلی مفید نخواهد بود. پس از بحث بین دانشمندان داده و باستانشناسان، به این نتیجه رسیدیم که این یک راه حل اکتشافی خوب است.
علاوه بر این، ما ۶۸۴ محوطه را که یا مساحتی بسیار کوچک برای تل بودن داشتند یا توسط باستانشناسان به عنوان محوطههای تخریبشده مشخص شده بودند، فیلتر کردیم. به طور خاص، آستانه اندازه حدود ۱۰۰۰ متر مربع تعیین شد که مربوط به دایرهای به قطر ۳۰ متر است. این محوطههای بسیار کوچک در واقع با یک حاشیهنویسی عمومی برای محوطههای شناختهشده با اندازه یا مکان دقیق ناشناخته مطابقت دارند.
تنظیم تصاویر ورودی
برای تولید مجموعهای از تصاویر جهت تنظیم دقیق مدل از پیش آموزشدیدهمان، اشکال فوقالذکر را به QGIS، یک نرمافزار متنباز GIS ، وارد کردیم و با استفاده از یک اسکریپت پایتون، مربعی به طول L با مرکز ثقل سایت که فقط شامل تصاویر ماهوارهای از نقشههای بینگ است (که مستقیماً در محیط GIS از طریق افزونه QuickMapService نمایش داده میشود و امکان دسترسی به تصاویر ارائه شده توسط سرویسهای آنلاین مختلف، از جمله نقشههای بینگ را فراهم میکند)، ذخیره کردیم. سپس همان تصویر را بدون نقشه پایه، اما با خطوط تراز سایت که به صورت شکلی پر شده با رنگ ثابت نمایش داده شده است، ذخیره کردیم تا به عنوان ماسکهای واقعیت زمینی عمل کند.
بنابراین، در طول آموزش، شبکه عصبی ما یاد میگیرد که شکل سایت را از روی تصویر واقعی زمین، تنها با نگاه کردن به تصویر ماهوارهای RGB، بازتولید کند؛ در طول استنتاج، میتوانیم در صورت وجود، سایتهای جدید را در یک تصویر ورودی مشخص شناسایی و ترسیم کنیم.
در آزمایشهای اول، L را برابر با ۱۰۰۰ متر قرار دادیم، اما تصور کردیم که افزایش اندازه ناحیه پیشبینی میتواند به دلیل گنجاندن یک زمینه بزرگتر مفید باشد. در نتیجه، ما همچنین از L = ۲۰۰۰ متر استفاده کردیم و به طور کلی عملکرد بهبود یافتهای را به دست آوردیم.
از تصویر مربعی شروع، به صورت تصادفی یک مربع به طول L/2 را برش میدهیم تا به عنوان ورودی استفاده شود. این کار تضمین میکند که مدل نمایش جانبدارانهای را که برای آن مکانها همیشه در مرکز ورودی ظاهر میشوند، یاد نمیگیرد و علاوه بر این، به عنوان تقویت داده نیز عمل میکند. در کنار این برش، ما همچنین مجموعه دادهها را با اعمال چرخش و آینهسازی تصادفی و همچنین تغییر جزئی در روشنایی و کنتراست، تقویت میکنیم و همه این عملیات در هر تکرار آموزش به شیوهای متفاوت اعمال میشوند. هنگام استخراج از QGIS، تصاویر را با وضوح حدود ۱ پیکسل در هر متر ذخیره کردیم (۱۰۲۴ پیکسل برای ۱۰۰۰ متر، دو برابر آن برای مدل با اندازه ورودی افزایش یافته) اما ورودیها سپس به نصف آن کاهش یافتند تا نیازهای محاسباتی را کاهش دهند و در عین حال تأثیر کمی بر عملکرد کلی داشته باشند ۳۶ .
در نهایت، ما ۱۱۵۵ تصویر با ماسکهای خالی (بدون مکان برای پیشبینی) را که از مکانهای پیشنهادی باستانشناسان نمونهبرداری شده بودند، معرفی کردیم. این مکانها شامل مناطق بسیار شهری، مناطق کشاورزی فشرده، مکانهای در معرض سیل (یعنی دریاچهها و حوضههای مصنوعی) و تپهها و کوههای سنگی میشوند.
این تعداد به صورت دلخواه و با در نظر گرفتن اندازه هر ناحیه پیشنهادی و اندازه کاشیها انتخاب شد. بنابراین تعداد نهایی تصاویر ۵۰۲۵ است. ما مجموعه دادهها را به یک مجموعه آموزشی ۹۰٪ و یک مجموعه آزمایشی ۱۰٪ تقسیم کردیم و تصاویر «خالی» اضافه شده را طبقهبندی کردیم. ۱۰٪ از مجموعه آموزشی نیز به صورت تصادفی انتخاب شد تا به عنوان مجموعه اعتبارسنجی استفاده شود.
ما سعی کردیم تصاویر CORONA را به عنوان یک ورودی اضافی ۳۷ ادغام کنیم ، همانطور که در گردش کار معمول باستانشناسی، تصاویر تاریخی بسیار مفید هستند (زیرا به موقعیتی اشاره دارند که بسیار کمتر تحت تأثیر توسعه قرار گرفته است) و اغلب با نقشههای پایه ماهوارهای و نقشههای توپوگرافی ترکیب میشوند (اما از آنجایی که CORONA در اینجا به عنوان مکمل استفاده شده است، ما تشخیص خودکار را فقط روی آنها دنبال نکردیم و بنابراین مکانهای تخریب شده پس از دهه ۱۹۷۰ از تجزیه و تحلیل حذف شدهاند). پس از وارد کردن تصاویر به QGIS، ما همان رویه را برای ایجاد ورودیها دنبال کردیم و اطمینان حاصل کردیم که عملیات برش برای تصاویر Bing و CORONA برابر است.
مدلهای تقسیمبندی معنایی
این پروژه به عنوان آزمایشی برای بررسی قابلیت مدلهای قطعهبندی معنایی از پیش آموزشدیده به عنوان ابزاری برای تشخیص مکانها آغاز شد. به همین دلیل، تصمیم گرفتیم مدلهای متنباز از پیش آموزشدیده که به عنوان بخشی از یک کتابخانه نوشته شده در PyTorch در دسترس هستند را مقایسه کنیم. این کتابخانه به فرد اجازه میدهد تا یک شبکه عصبی کانولوشنی رمزگذار برای استخراج ویژگی و یک معماری قطعهبندی را به طور مستقل انتخاب کند، و همچنین تعدادی تابع زیان مختلف ۳۸ را ارائه میدهد .
در یک مقاله مقدماتی قبلی، ما با انتخابهای مختلف معماری، رمزگذارها و توابع تلفات ۳۶ آزمایش کردیم . ما U-Net را در مقابل MA-net، Resnet18 را در مقابل Efficientnet-B3 و Dice Loss را در مقابل Focal Loss مقایسه کردیم. تفاوتهای عملکرد کوچک بودند، در بهترین حالت در حد چند درصد، که میتوان آن را به خوبی با نوسانات ناشی از افزایش تصادفی دادهها توضیح داد.
با این وجود، ما بهترین مدل را که از MA-net، Efficientnet-B3 و Focal Loss استفاده میکند، انتخاب کردیم و آن را برای ۲۰ دوره آموزش دادیم. ما همچنین اثرات روش فیلترینگ خود را (که کمی نسبت به کار قبلی بهبود یافته بود) آزمایش کردیم و علاوه بر این، با معرفی تصاویر CORONA آزمایشهایی انجام دادیم و اندازه ورودی را افزایش دادیم.
تپههای تپه در ازبکستان
ما همچنین یک آزمایش اضافی روی مجموعه داده بزرگ دیگری ( https://www.orientlab.net/samark-land/ ) که توسط پروژه باستانشناسی ازبکستان-ایتالیا در سمرقند ۳۹ تهیه شده بود، انجام دادیم . با توجه به شباهت بین تل بینالنهرین و تپه ازبکستانی، میخواستیم ببینیم که آیا مدل قادر است بدون نیاز به آموزش مجدد اضافی، آن مکانها را شناسایی کند یا خیر.
این مجموعه دادهها شامل ۲۳۱۸ حاشیهنویسی نقطهمانند است که به روشهای مختلف طبقهبندی شدهاند و دارای ویژگیهایی مربوط به وضعیت حفظشدهی خود نیز میباشند. ما فقط مکانهایی را انتخاب کردیم که به صورت Tepa یا Low Mound طبقهبندی شدهاند و برچسب Well-preserved (خوب حفظشده) دارند . تعداد نهایی مکانها به ۲۱۵ میرسد: ۱۴۸ Tepa و ۶۷ Mound. تصاویر واقعی مجموعه آزمایش با پیروی از همان روشی که در بالا توضیح داده شد، ایجاد شدند.
نتایج
بین النهرین
ابتدا، نتایج را بر اساس میانگین امتیاز تقاطع روی اجتماع (IoU) در مجموعه داده آزمایشی ارائه میدهیم. معیارها را به صورت زیر تعریف میکنیم: که P نشان دهنده شکل پیشبینی شده و G شکل واقعیت پایه است. IoU نشان دهنده میزان تطابق بین شکل پیشبینی شده و حاشیه نویسی در مجموعه داده است. اگرچه این به ما ایدهای از نحوه رفتار مدل میدهد و به ما در انتخاب بهترین مدل کمک میکند، اما باید بدانیم که نشان نمیدهد چند مکان شناسایی شدهاند یا نشدهاند، که هدف اصلی ماست.
جدول ۱ نتایج مربوط به تمام مدلهای موجود در مجموعه دادههای holdout را، همانطور که در بخش روشها توضیح داده شده است، خلاصه میکند. توجه داشته باشید که برای هر مدل، ما یک امتیاز میانگین و انحراف معیار مرتبط را گزارش میکنیم. این به این دلیل است که ما یک برش تصادفی روی تصاویر، حتی در مجموعه آزمایش، انجام میدهیم و بنابراین ده آزمایش با برشهای مختلف انجام میدهیم تا این اثر را میانگین بگیریم.
اولین چیزی که میتوان به آن اشاره کرد، بهبود قابل توجه حاصل از افزایش اندازه ورودی است. ما تصور میکنیم که ناحیه بزرگتر، زمینه بیشتری برای پیشبینیها فراهم میکند و مدل را دقیقتر میکند. به همان اندازه، روش فیلترینگ که در بالا توضیح داده شد، مهم است که سعی میکند مکانهای کوچک و غیرقابل تشخیص را حذف کند و در نتیجه صرف نظر از اندازه ورودی، عملکرد را افزایش دهد.
در نهایت، استفاده از تصاویر CORONA کمی بحثبرانگیز است. برای اندازه ورودی کوچکتر، به نظر میرسد هیچ مزیتی ندارد (نمره خطای پایینتر در حاشیه خطا است) و میتوانیم فرض کنیم که این به دلیل وضوح پایین این تصاویر است. در عوض، با مناطق بزرگتر، به نظر میرسد که افزایش عملکرد را فراهم میکنند، شاید دوباره به دلیل زمینه بزرگتر. با این حال، بررسی پیشبینی، عدم وجود تفاوت قابل توجه را نشان داد، شاید به این معنی که IoU درست در نتیجه خطوط کانتور کمی دقیقتر در حال افزایش است.
دقت تشخیص
برای ارزیابی بیشتر نتایج، به سراغ دقت تشخیص رفتیم. ابتدا، پیشبینیهای رستری از مدل را با استفاده از کتابخانهی شناختهشدهی GDAL ۴۰ به اشکال برداری تبدیل کردیم و سپس به دنبال تقاطع بین حاشیهنویسیهای سایت و پیشبینیها گشتیم. برای به دست آوردن اشکال نرمتر، قبل از تبدیل، ابتدا یک محوشدگی گاوسی به رسترهای پیشبینی اعمال کردیم و سپس مقادیر بالاتر از یک آستانهی مشخص (۰٫۵، اما این عدد را میتوان برای یک مدل کمحساستر یا حساستر تغییر داد) را به ۱٫۰ کاهش دادیم، در حالی که سایر موارد روی ۰٫۰ تنظیم شدند.
این ارزیابی خودکار نتایج خوب اما نه چندان هیجانانگیزی ارائه میدهد، با امتیاز دقت ۶۲.۵۷٪ برای مدل ۵ و ۶۰.۰۸٪ برای مدل ۶. مدلی که بتواند دو از سه مکان را پیدا کند، نقطه شروع خوبی برای تجزیه و تحلیل انسانی خواهد بود. با این حال، باستانشناسان باید تأییدی بر پیشبینیها ارائه دهند و مواردی را که مدل اشتباهات مناسبی مرتکب میشود از مواردی که اشتباهات موجهی مرتکب میشود که یک انسان نیز مرتکب میشود، متمایز کنند. ۴۱ ، ۴۲ ، ۴۳ .
اول از همه، تعداد قابل توجهی از مکانها وجود دارند که دیگر از تصاویر ماهوارهای امروزی قابل مشاهده نیستند و از مجموعه دادهها فیلتر نشدهاند. این امر قابل انتظار بود زیرا تنها نیمی از حاشیهنویسیها اطلاعات اضافی داشتند و حتی کمتر شامل نشانههایی از قابل مشاهده بودن آنها بودند. هر تصویر ورودی که فقط شامل مکانهایی باشد که دیگر قابل مشاهده نیستند، اگر مدل هیچ کانتور تولید نکند، باید به عنوان منفی واقعی در نظر گرفته شود، نه منفی کاذب.
وقتی صحبت از پیشبینیهایی میشود که به عنوان مثبت کاذب (False Positive) مشخص شدهاند، گاهی اوقات مدل، سایت دیگری را در نزدیکی پیشبینی میکند، نه سایتی که در حال آزمایش است. این میتواند بسته به ماهیت سایت “از دست رفته” اشتباه یا غیر اشتباه در نظر گرفته شود. در صورتی که سایت از دست رفته یکی از سایتهایی باشد که دیگر قابل مشاهده نیستند، اما ما یک سایت تقریباً قابل مشاهده را تشخیص میدهیم، پیشبینی در واقع یک مثبت واقعی (True Positive) است. از سوی دیگر، سایت از دست رفته میتواند سایتی باشد که هنوز قابل مشاهده است اما شاید کمتر از سایت دیگری در تصویر قابل مشاهده باشد. در این شرایط، میتوانیم هم منفی کاذب (False Negative) و هم مثبت واقعی (True Positive) را در نظر بگیریم، یا فقط به عنوان یک مثبت واقعی در نظر بگیریم، با توجه به اینکه در یک سناریوی دنیای واقعی، نزدیکی به سایتهای دیگر منجر به پیشنهاد مفیدی به عنوان متخصص انسانی میشود که میتواند همه آنها را بازیابی کند. از طرف دیگر، میتوانیم از در نظر گرفتن سایتهای غیر قابل مشاهده به طور کلی خودداری کنیم، اما تفاوت حداقل خواهد بود (دقت ۷۸.۳۷٪ و فراخوانی ۸۲.۰۱٪).
در نهایت، برخی پیشبینیها در واقع در خروجیها وجود داشتند اما برای آستانهی حد آستانهای که ما اعمال کردیم، بسیار ضعیف بودند. ما این خطاها را تنظیم نکردیم، اما آنها یک رویکرد ممکن برای تعامل را نشان میدهند: استفاده از پیشبینیها به عنوان پوشش و بررسی دستی نقشه. به طور جایگزین، تنظیم آستانهی پایینتر میتواند مشکل را حل کند.
این تنظیم، دقت و فراخوانی را به حدود ۸۰ افزایش میدهد و ایدهای عینیتر از عملکرد واقعی مدل ارائه میدهد.
جدول ۲ نتایج ارزیابی خودکار و مقادیر تنظیمشده پس از ارزیابی انسانی که مکانهای غیرقابل مشاهده را برجسته کرد، خلاصه میکند. معادلات زیر معیارهای مورد استفاده را بر حسب درست/غلط، مثبت/منفی تعریف میکنند. ما دقت، دقت، فراخوانی و ضریب همبستگی متیوز را انتخاب کردیم.
جالب است که ببینیم مدل ۶ که امتیاز IoU بالاتری داشت، چگونه اکنون عملکرد بدتری دارد. با نگاهی به تصاویر، به نظر میرسد که این مدل کمی محتاطتر و محتاطتر است و در نتیجه پیشبینیهای مثبت کمتری و در نتیجه مثبت کاذب کمتری دارد. در عوض، این میتواند منجر به IoU بالاتر شود زیرا عبارت Union را کاهش میدهد و اگر مناطق کمی دقیقتر باشند، حتی عبارت Intersection را نیز افزایش میدهد. با این حال، برای تشخیص، به جای تطابق کامل، به وجود یک تقاطع نیاز داریم و در این شرایط، تعداد کمتر مثبتها آزاردهنده است. در مجموع، تفاوت در دقت بیش از حد نیست، بنابراین هر دو مدل مفید هستند و میتوانند به صورت موازی استفاده شوند، اما باید پیچیدگی و هزینه اضافی استفاده از دو مجموعه تصویر ورودی را نیز در نظر بگیریم که مدل ۶ را کمی دست و پا گیر میکند. به همین دلیل، ما فقط از مدل ۵ استفاده کردیم.
این زیربخش را با شکل ۲ به پایان رساندیم که شامل چند مثال از مجموعه دادههای آزمایشی برای نمایش کیفیت خروجیهای مدل است. توجه داشته باشید که چگونه رنگها با مقادیر احتمال مطابقت دارند و نواحی کمرنگ با آستانه ۰.۵ که در ایجاد اشکال برداری استفاده میکنیم، حذف میشوند. این مدل در ردیابی خطوط کلی سایت بسیار دقیق است و در برخی موارد (یعنی ستون اول در شکل ۲ ) این خطوط حتی از واقعیت زمینی با توجه به تصاویر ماهوارهای فعلی دقیقتر هستند.

چند نمونه پیشبینی از مجموعه تست. در سمت چپ، ماسک هدف روی تصویر ورودی قرار دارد. در سمت راست، خروجی مدل. نوار رنگی مربوط به احتمال طبقهبندی است. توجه داشته باشید که مدل چگونه قادر به تطبیق دقیق طرح کلی سایت است. تمام دادههای نمایش داده شده تحت شرایط استفاده منصفانه از دادههای جغرافیایی برای اهداف دانشگاهی قرار میگیرند. لیست تمام ارائهدهندگان دادهها/نرمافزار مربوطه به شرح زیر است: (i) ایجاد نقشههای اصلی تحت بخش ۵ شرایط استفاده از APIهای پلتفرم نقشههای بینگ مایکروسافت ( https://www.microsoft.com/en-us/maps/product/print-rights )؛ (ii) نمایش نقشهها با یک نرمافزار متنباز، تحت مجوزهای GNU QGIS ( https://qgis.org/en/site/ ) و QuickMapsServices ( https://github.com/nextgis/quickmapservices )؛ (iii) بسط نهایی نقشهها با نرمافزاری که توسط نویسندگان توسعه داده شده و در ( https://bit.ly/NSR_floodplains ) موجود است، انجام شده است .
آزمایشی در استان میسان
پس از ارزیابی عملکرد تشخیص، میخواستیم مدل را روی یک منطقه مستطیلی در استان میسان که نقشهبرداری نشده بود و برای آن سنجش از دور انجام داده بودیم، امتحان کنیم. هدف این آزمایش ارزیابی تعداد موارد مثبت کاذب پیشبینیشده توسط مدل و ارائه نمونهای از اشتباهاتی بود که مدل در یک سناریوی عملیاتی مرتکب میشود.
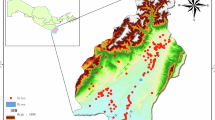
منطقهای که ما انتخاب کردیم شامل ۲۰ مکان ادعایی است و ۱۰۴ کیلومتر مربع را در بر میگیرد . شکل ۳ منطقه را به همراه توضیحات باستانشناس و پیشبینی مدل نشان میدهد. همانطور که مشاهده میشود، مدل قادر است ۱۷ مورد از ۲۰ مکان را بازیابی کند و در عین حال حدود ۲۰ شکل دیگر (یا کمتر، بسته به اینکه چه چیزی یک نمونه واحد در نظر گرفته میشود) را نیز پیشنهاد دهد. اکثر این پیشنهادها مفید نیستند، اما با توجه به اندازه یا موقعیت مکانی آنها، به راحتی و به سرعت توسط یک متخصص، به ویژه در زمینه، غربال میشوند.

منطقه آزمایشی استان میسان (صورتی، خط چین) با مکانهایی که از راه دور توسط باستانشناسان شناسایی شدهاند (آبی، نقطهچین) و پیشبینیهای مدل (زرد، خطچین). مکانهایی که توسط چشم آموزشدیده و مدل شناسایی شدهاند معادل هستند و از همه مهمتر، مدل قادر به نادیده گرفتن مناطقی است که ویژگیهای قابل توجهی ندارند. تمام دادههای نمایش داده شده تحت شرایط استفاده منصفانه از دادههای جغرافیایی برای اهداف دانشگاهی قرار میگیرند. لیست تمام ارائهدهندگان دادهها/نرمافزار مربوطه به شرح زیر است: (۱) ایجاد نقشههای اصلی تحت بخش ۵ شرایط استفاده از APIهای پلتفرم نقشههای بینگ مایکروسافت ( https://www.microsoft.com/en-us/maps/product/print-rights )؛ (۲) نمایش نقشهها با یک نرمافزار متنباز، تحت مجوزهای GNU از QGIS ( https://qgis.org/en/site/ ) و QuickMapsServices ( https://github.com/nextgis/quickmapservices )؛ (iii) جزئیات نهایی نقشهها با نرمافزاری که توسط نویسندگان توسعه داده شده و در ( https://bit.ly/NSR_floodplains ) موجود است، انجام شده است.
در عوض ، شکل ۴ یک پوشش ایجاد شده با کنار هم قرار دادن پیشبینیهای مختلف و استفاده از مقادیر احتمالات به عنوان نوعی نقشه حرارتی را نشان میدهد. رنگهای «داغتر» مربوط به احتمالات بالاتر هستند در حالی که رنگ سیاه نشاندهنده عدم وجود یک مکان است. توجه داشته باشید که پالت رنگی همان پالتی است که در شکل ۲ دیده میشود ، با رنگهای بنفش تیره که نشاندهنده احتمال نسبتاً کم (کمتر از ۰.۵) هستند. شفافیت از طریق استفاده از فیلتر پوششی در QGIS به دست میآید.

لایه احتمالات پیشبینی منطقه آزمایشی میسان به عنوان لایه برتر در QGIS تجسم شده است. این تجسم به کاربر اجازه میدهد تا به جای تکیه بر یک مقدار آستانه از پیش تعریف شده، تصمیم بگیرد که به کجا نگاه کند. تمام دادههای نمایش داده شده تحت شرایط استفاده منصفانه از دادههای جغرافیایی برای اهداف دانشگاهی قرار میگیرند. لیست تمام ارائهدهندگان (یا ارائهدهندگان) دادهها/نرمافزار مربوطه به شرح زیر است: (i) ایجاد نقشههای اولیه تحت بخش ۵ شرایط استفاده از APIهای پلتفرم نقشههای بینگ مایکروسافت ( https://www.microsoft.com/en-us/maps/product/print-rights )؛ (ii) نمایش نقشهها با یک نرمافزار متنباز، تحت مجوزهای GNU QGIS ( https://qgis.org/en/site/ ) و QuickMapsServices ( https://github.com/nextgis/quickmapservices )؛ (iii) توسعه نهایی نقشهها با نرمافزاری که توسط نویسندگان توسعه داده شده و در ( https://bit.ly/NSR_floodplains ) موجود است، انجام شده است.
ازبکستان
متأسفانه، ارزیابی انسانی از خروجیها نشان داد که مدل بسته به نحوه انتخاب آستانهها، قادر است تنها حدود ۲۵ تا ۳۰ درصد از مکانهای این منطقه را به درستی شناسایی کند. بخش باقیمانده شامل مکانهایی است که کاملاً از قلم افتادهاند یا مکانهایی که به نحوی یا خیلی کمرنگ یا در داخل یک منطقه بزرگ که بیمعنی به نظر میرسد، به آنها اشاره شده است.
دلیل این افت شدید عملکرد، به احتمال زیاد به دلیل ماهیت متفاوت چشمانداز منطقه است که در برخی مکانها به نظر میرسد بسیار شهریتر است و به طور کلی پوشش گیاهی بیشتری دارد: بنابراین، همه محیطهای دشت سیلابی به اندازه کافی مشابه نیستند که بتوان آنها را مستقیماً با هم مقایسه کرد. علاوه بر این، قراردادهایی که در پشت حاشیهنویسیهای مجموعه دادههای ازبکستان وجود دارد، ممکن است کاملاً با حاشیهنویسیهای بینالنهرین همسو نباشند و این امر وضعیت را پیچیدهتر میکند.
این نقص جزئی باید در یک زمینه بررسی شود، زیرا ما معتقدیم که روش ما میتواند در طیف وسیعی از محیطهای مشابه در آسیا و فراتر از آن که دارای تاریخچههای سکونت چند دورهای هستند، اعمال شود: تنها راه مقابله با این مشکل در اینجا، ایجاد یک مجموعه داده کوچک از سایتهای منتخب Tepa و انجام یک دور اضافی از یادگیری انتقالی است تا مدل بتواند زمینه و ویژگیهای جدید منطقه مورد نظر را درک کند.
بحث
نتایج بهدستآمده را میتوان رضایتبخش دانست، حتی اگر معیار IoU، در مقایسه با سایر برنامههای تقسیمبندی معنایی، خیلی بالا نباشد. با این حال، هنگام آزمایش عملکرد تشخیص، متوجه شدیم که این مدل هنوز قادر به تشخیص اکثر سایتهای موجود در مجموعه دادهها است و انتظارات خوبی برای استفاده از آن در سایر بخشهای منطقه مورد بررسی داریم. با این حال، همانطور که آزمایش ازبکستان نشان میدهد، وقتی صحبت از مناطق جدید با سایتهای مشابه اما در زمینهای متفاوت میشود، عملکرد ممکن است به شدت کاهش یابد. این موضوع انتقالپذیری، همانطور که در باستانشناسی به آن اشاره میشود، یک موضوع تحقیقاتی فعال است. امیدواریم یک مرحله آموزش مجدد، حتی با یک مجموعه داده کوچکتر، بتواند این مشکل را برطرف کند و کارهای آینده ممکن است این مسیر تحقیقاتی را بررسی کنند.
لازم به ذکر است که چگونه معیارهای ارزیابی در این کار، وقتی با این واقعیت مواجه میشوند که بر اساس حاشیهنویسیهایی محاسبه میشوند که اغلب همگن نیستند و حاوی برچسبهای جعلی مختلفی هستند، به بنبست میرسند ۴۴. در مورد ما، ما با این واقعیت کنار آمدیم که بسیاری از سایتها فقط در برخی از عکسها یا نقشههای تاریخی که بخشی از مجموعه دادهها هستند، قابل مشاهده هستند، حتی اگر نمونههای مفیدی ارائه ندهند. خوشبختانه، به نظر میرسد که این مدل به اندازه کافی قوی است تا مفاهیم مفید را یاد بگیرد و این نقاط داده گیجکننده را نادیده بگیرد. با این حال، یک مجموعه داده کوچکتر و تمیزتر میتواند عملکرد را به طور چشمگیری بهبود بخشد و در عین حال بار محاسباتی را نیز کاهش دهد. بدیهی است که چنین عملیات پاکسازی از نظر زمانی یک سرمایهگذاری عظیم خواهد بود و باستانشناسان ترجیح میدهند آن را صرف جستجوی فعال خود سایتها کنند.
با این حال، مدل ما این امکان را فراهم میکند که به طور خودکار مناطق از قبل بررسی شده را بررسی کنیم و سپس فهرستی از پیشبینیها را تولید کنیم که با حاشیهنویسیهایی که باید به صورت دستی بررسی شوند، در تضاد باشد. متعاقباً یک مجموعه داده جدید و تمیزتر میتواند توسط باستانشناسان جمعآوری شود و یک مدل بهبود یافته جدید آموزش داده شود. برای مثالی با استفاده از علوم شهروندی به Lambers و همکاران مراجعه کنید ۴۵. همین رویه در کاربردهای مناطق جدید نیز کار میکند، جایی که پیشبینیهای جدید میتوانند به صورت دستی بررسی شده و به مرور زمان به یک مجموعه داده جدید اضافه شوند.
علاوه بر رویه خودکار، این مدل میتواند برای تولید یک پوشش برای هدایت چشم باستانشناس در داخل نرمافزار GIS نیز استفاده شود. این رویکرد گرافیکی به کاربران اجازه میدهد تا پوشش را با نقشههای دیگری که ممکن است استفاده کنند نیز مقایسه کنند و از تخصص خود برای استنباط وجود یک سایت بر اساس تمام اطلاعات زمینهای که دارند استفاده کنند ۴۶ ، ۴۷٫ ما این رویکرد را فقط در یک منطقه کوچک همانطور که در شکل ۴ نشان داده شده است، امتحان کردیم ، اما محاسبه را میتوان به راحتی برای پوشش مناطق بزرگ افزایش داد، زیرا تولید خروجی کمتر از یک ثانیه طول میکشد و نیازی به تکمیل عملیات در یک مرحله نیست. تنها نقص این روش، عدم تطابق آشکار در مرز بین تصاویر ورودی مختلف است که به پوشش ظاهری موزاییک مانند میدهد. در تئوری، تقسیمبندی معنایی میتواند با ورودیهایی با اندازه دلخواه کار کند، اما انجام این کار نیاز به مقدار زیادی حافظه دارد که ممکن است در دسترس نباشد. یک راه حل میتواند ایجاد نقشههای پیشبینی همپوشانی باشد که سپس میانگینگیری میشوند و زمان محاسباتی را برای افزایش دقت مبادله میکنند.
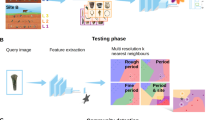
شکل ۵ خلاصهای از کاربرد مدلی که توصیف کردیم را نشان میدهد، که مشابه راهحلهای مشابه ۴۸ ، ۴۹ است . با شروع از مجموعه دادهها، مدل ماسکهای پیشبینی تولید میکند که میتوانیم از طریق پسپردازش آنها را دستکاری کنیم تا یک فایل شکل برداری به دست آوریم که میتواند برای ارزیابی و تشخیص خودکار مکانها استفاده شود. در این مرحله، کاربر امکان انتخاب آستانه برای قطع پیشبینی و استفاده از تکنیکهایی برای هموار کردن شکلهای خروجی، مانند تار کردن یا بافر کردن بردارها، را دارد. به طور مشابه، میتوان با انتخاب نمایشهای گرافیکی مختلف به طور مستقیم در نرمافزار GIS، پوشش نقشه را تنظیم کرد. هدف در این مورد، شناسایی مکانهایی است که ممکن است توسط مقایسه خودکار شناسایی نشوند، زیرا احتمال آنها کمتر از آستانه است، در حالی که هنوز برای انسان قابل تشخیص هستند. هر بار که از مدل استفاده میشود، به هر طریقی، کاربران پس از بررسی خروجیها میتوانند یا مجموعهای جدید از حاشیهنویسیها یا فهرستی از مکانهایی که باید حذف یا برچسبگذاری مجدد شوند را به دست آورند. اگر چنین گردش کاری توسط بیش از یک تیم استفاده شود، میتواند تلاشهای جستجو را نیز تا حد زیادی سرعت بخشد: استفاده از فناوریهای باز در این مورد، به اشتراکگذاری نتایج بین گروههای تحقیقاتی را آسانتر میکند، که میتواند به باستانشناسی به عنوان یک حوزه تحقیقاتی کمک زیادی کند .

یک گردش کار انسانی در حلقه مبتنی بر مدل ما. یک مدل از تصاویر حاشیهنویسی شده آموزش داده میشود و ماسکهای پیشبینی را ارائه میدهد. ماسکها میتوانند به عنوان یک پوشش یا بردار استفاده شوند. ارزیابی انسانی روی خروجیها انجام میشود و به نوبه خود میتوان یک مجموعه داده اصلاحشده برای بهبود مدل ایجاد کرد.
آزمایشها با تصاویر CORONA همچنین به امکان ترکیب مدلهای بیشتر، شاید آموزش دیده با نقشههای پایه مختلف یا ترکیبی از آنها، و مقایسه پیشبینی ارائه شده توسط همه اینها اشاره دارد. به خصوص اگر تصاویر تاریخی وجود داشته باشند، میتوانیم در نهایت به مجموعه دادهای برسیم که شامل اطلاعات زمانی در مورد زمان قابل مشاهده بودن یک مکان و زمان غیرقابل تشخیص بودن آن نیز باشد. این جنبه اخیر کاملاً جدید است و نشاندهنده یک پیشرفت بالقوه در سنجش از دور خودکار است. استفاده از تصاویر استریوسکوپی برای ایجاد مدلهای ارتفاعی نیز میتواند در این کار مفید باشد، اگر وضوح کافی برای برجسته کردن تپههای کم ارتفاع مورد نظر ما وجود داشته باشد.
نتیجهگیری
ما یک مدل یادگیری عمیق برای شناسایی مکانهای باستانی تپهای در دشت سیلابی بینالنهرین ارائه دادیم. این مدل با استفاده از مدلهای از پیش آموزشدیده برای تقسیمبندی معنایی، تنظیم دقیق روی تصاویر ماهوارهای و ماسکهای شکل مکانها از یک مجموعه داده حاوی تقریباً ۵۰۰۰ نمونه، پیادهسازی شد.
نتیجه آزمایشهای ما مدلی است که امتیاز IoU برابر با ۰٫۸۱۵۴ را در مجموعه دادههای آزمایشی به دست میآورد و مکانها را با ۸۰٪ دقت تشخیص میدهد. با این حال، این دقت آماری برای تعداد قابل توجهی از مکانهایی که به دلیل عدم مشاهده در تصاویر ماهوارهای مدرن، برچسبگذاری نادرستی دارند، تنظیم شده است. در حالی که ما مجموعه دادهها را تا حد امکان پاکسازی کردیم، بسیاری از مکانهای غیرقابل تشخیص هنوز باقی مانده بودند. با این حال، به نظر میرسد که این مدل کاملاً قوی است.
پس از این نتیجه، ما یک گردش کار برای باستانشناسان پیشنهاد میکنیم که در آن شیوههای سنجش از دور از پیش تثبیتشده آنها با استفاده از مدلی مانند مدل ما پشتیبانی و بهبود مییابد. خروجیها را میتوان هم برای تشخیص خودکار بسیار سریع، با آگاهی از اشتباهاتی که این امر میتواند ایجاد کند، و هم برای ایجاد یک پوشش گرافیکی برای هدایت توجه کاربر به مناطق خاص، استفاده کرد. به نوبه خود، استفاده از این مدل منجر به ایجاد فایلهای شکل و حاشیهنویسیهای جدیدی میشود که میتوانند برای آموزش مجدد و بهبود مدل و همچنین امکان تجزیه و تحلیلهای بیشتر مورد استفاده قرار گیرند. کاربردهای بالقوه این روش بسیار گسترده است و نه تنها به سرعت آن مربوط میشود: بلکه باید به عنوان یک مکمل ضروری برای تفسیر عکس سنتی مبتنی بر متخصص در نظر گرفته شود و در بسیاری از موارد، ویژگیهای سایت را که ممکن است نادیده گرفته شوند اما احتمالاً قابل توجه هستند، به دومی اضافه کند.
در دسترس بودن دادهها
علاوه بر اطلاعات خاص ارائه شده در مقاله، تمام کدها، دادهها و منابع مختلف در GitHub ( https://bit.ly/NSR_floodplains ) موجود است. در مورد دادههای جغرافیایی، تمام دادههای نمایش داده شده تحت شرایط استفاده منصفانه از دادههای جغرافیایی برای اهداف دانشگاهی قرار میگیرند. لیست تمام ارائهدهندگان دادهها/نرمافزار مربوطه به شرح زیر است: (i) ایجاد نقشههای اصلی تحت بخش ۵ شرایط استفاده از APIهای پلتفرم نقشههای بینگ مایکروسافت ( https://www.microsoft.com/en-us/maps/product/print-rights )؛ (ii) نمایش نقشهها با یک نرمافزار متنباز، تحت مجوزهای GNU QGIS ( https://qgis.org/en/site/ ) و QuickMapsServices ( https://github.com/nextgis/quickmapservices )؛ (iii) توسعه نهایی نقشهها با نرمافزاری که توسط نویسندگان توسعه داده شده و در ( https://bit.ly/NSR_floodplains ) موجود است، انجام شده است.
منابع
-
ورشوف-ون در وارت، دبلیو بی و لانداور، جی. استفاده از کارکاسوننت برای شناسایی و ردیابی خودکار جادههای گود در دادههای لیدار از هلند. مجله کالت. هریت. ۴۷ ، ۱۴۳-۱۵۴٫ https://doi.org/10.1016/j.culher.2020.10.009 (۲۰۲۱).
-
توری، ال. و شاولیک، جی. یادگیری انتقالی. در کتابچه راهنمای تحقیق در مورد کاربردها و روندهای یادگیری ماشین: الگوریتمها، روشها و تکنیکها (ویراستاران توری، ال. و شاولیک، جی.) ۲۴۲–۲۶۴ (IGI Global، ۲۰۱۰).
-
دنگ، جی. و همکاران . ImageNet: یک پایگاه داده تصویر سلسله مراتبی در مقیاس بزرگ. در کنفرانس IEEE 2009 در مورد بینایی کامپیوتر و تشخیص الگو ۲۴۸-۲۵۵ (۲۰۰۹).
-
Traviglia، A.، Cowley، D. و Lambers، K. یافتن زمینههای مشترک: بینایی انسان و کامپیوتر در کاوشهای باستانشناسی. خبرنامه AARGnews. باستانشناسی هوایی. گروه Res. ۵۳ ، ۱۱–۲۴ (۲۰۱۶).
-
پالمر، ر. سرمقاله. AARGnews (۲۰۲۱).
-
ویلکینسون، تی.جی، گیبسون، ام. و ویدل، ام. مدلهایی از چشماندازهای بینالنهرین: چگونه فرآیندهای کوچکمقیاس در رشد تمدنهای اولیه نقش داشتند (آرکئوپرس، ۲۰۱۳).
-
آدامز، آر. ام. زمین پشت بغداد: تاریخچه سکونت در دشتهای دیاله (انتشارات دانشگاه شیکاگو، ۱۹۶۵).
-
آدامز، آر. ام. قلب شهرها: بررسی سکونتگاههای باستانی و کاربری زمین در دشت سیلابی مرکزی فرات (انتشارات دانشگاه شیکاگو، ۱۹۸۱).
-
آدامز، آر. ام. و نیسن، اچ. جی. حومه اوروک: محیط طبیعی جوامع شهری (انتشارات دانشگاه شیکاگو، ۱۹۷۲).
-
مارچتی، ن. و همکاران. ظهور مناظر شهری در بینالنهرین: نتایج بررسی یکپارچه QADIS و تفسیر مناظر تاریخی چندلایه. Z. Assyriol. Vorderasiat. Archäol. ۱۰۹ ، ۲۱۴-۲۳۷٫ https://doi.org/10.1515/za-2019-0016 (۲۰۱۹).
-
ویلکینسون، تی.جی. مناظر باستانی خاور نزدیک (انتشارات دانشگاه آریزونا، ۲۰۰۳).
-
لیونز، تی. آر. و هیچکاک، آر. کی. تکنیکهای سنجش از دور هوایی در باستانشناسی (مرکز چاکو، ۱۹۷۷).
-
کوچوکایا، ای. جی. فتوگرامتری و سنجش از دور در باستانشناسی. مجله کمیت. طیفسنجی. تابش. ترجمه. ۸۸ ، ۸۳–۸۸ (۲۰۰۴).
-
کارامیترو، آ.، استورت، اف.، بوگیاتزیس، پی. و برسفورد-جونز، دی. به سوی استفاده از شبکههای یادگیری عمیق هوش مصنوعی برای شناسایی مکانهای باستانشناسی. Surf. Topogr. Metrol. Prop. ۱۰ , ۰۴۴۰۰۱ (۲۰۲۲).
-
هندریکس، م. و همکاران. استفاده از تصاویر استریوسکوپی گرفته شده از یک میکروپهپاد برای مستندسازی میراث – نمونهای از تپههای تدفین توئکتا در آلتای روسیه. مجله باستانشناسی. علوم. ۳۸ ، ۲۹۶۸–۲۹۷۸ (۲۰۱۱).
-
کوچوک دمیرچی، م. و ساریس، ا. پردازش و تفسیر دادههای GPR مبتنی بر رویکردهای هوش مصنوعی: چشماندازهای آینده برای کاوشهای باستانشناسی. سنجش از دور. ۱۴ ، ۳۳۷۷ (۲۰۲۲).
-
بالسی، م. و همکاران. بررسی مقدماتی محوطههای باستانشناسی با استفاده از لیدار پهپادی: مطالعه موردی. سنجش از دور. ۱۳ ، ۳۳۲ (۲۰۲۱).
-
آسائل، وای. و همکاران. بازیابی و انتساب متون باستانی با استفاده از شبکههای عصبی عمیق. نیچر ۶۰۳ ، ۲۸۰–۲۸۳ (۲۰۲۲).
-
ورشوف-وان در وارت، دبلیو بی، لمبرز، ک.، کوالچیک، دبلیو. و بورژوا، کیو پی. ترکیب یادگیری عمیق و رتبهبندی مبتنی بر مکان برای کاوشهای باستانشناسی در مقیاس بزرگ دادههای لیدار از هلند. ISPRS Int. J. Geo Inf. ۹ ، ۲۹۳ (۲۰۲۰).
-
Trier، Ø. D.، Cowley، DC & Waldeland، AU استفاده از شبکههای عصبی عمیق بر روی دادههای اسکن لیزری هوایی: نتایج حاصل از مطالعه موردی نقشهبرداری نیمهخودکار توپوگرافی باستانشناسی در آران، اسکاتلند. Archaeol. Prospect. ۲۶ ، ۱۶۵–۱۷۵ (۲۰۱۹).
-
آنیچینی، اف. و همکاران. تشخیص خودکار سرامیکها تنها از یک عکس: برنامه ArchAIDE. مجله علمی باستانشناسی، شماره ۳۶ ، شماره ۱۰۲۷۸۸ (۲۰۲۱).
-
مانتوان، ل. و نانی، ل. کامپیوتری شدن باستانشناسی: بررسی تکنیکهای هوش مصنوعی. SN Comput. Sci. ۱ ، ۱-۳۲ (۲۰۲۰).
-
بیکلر، اس اچ. یادگیری ماشینی وارد باستانشناسی میشود. Adv. Archaeol. Pract. ۹ ، ۱۸۶–۱۹۱ (۲۰۲۱).
-
Guyot، A.، Lennon، M.، Lorho، T. و Hubert-Moy، L. تشخیص و قطعهبندی ترکیبی ساختارهای باستانشناسی از دادههای LiDAR با استفاده از رویکرد یادگیری عمیق. J. Comput. Appl. Archaeol. ۴ ، ۱ (۲۰۲۱).
-
تریِر، اُ. دی.، سالبرگ، اِی.-بی. و پیلو، اِل. اچ. نقشهبرداری نیمهخودکار از کورههای زغالسنگ از دادههای اسکن لیزری هوایی با استفاده از یادگیری عمیق. در CAA2016: اقیانوس دادهها. مجموعه مقالات چهل و چهارمین کنفرانس کاربردهای رایانه و روشهای کمی در باستانشناسی، ۲۱۹-۲۳۱ (آرکئوپرس، ۲۰۱۸).
-
بیکلر، اس اچ و جونز، بی. گسترش یادگیری عمیق برای شناسایی مکانهای خاکریز در ته تای توکرو، نورثلند، نیوزیلند. باستانشناسی ۱۶ ، ۱ (۲۰۲۱).
-
کاسپاری، جی. و کرسپو، پی. شبکههای عصبی کانولوشنی برای تشخیص مکانهای باستانی – یافتن مقبرههای «شاهزادهوار». مجله علمی باستانشناسی. ۱۱۰ ، ۱۰۴۹۹۸ (۲۰۱۹).
-
اورنگو، اچ.ای و همکاران. تشخیص خودکار تپههای باستانشناسی با استفاده از طبقهبندی یادگیری ماشینی دادههای ماهوارهای چندحسگره و چندزمانه. مجموعه مقالات ملی آکادمی علوم. ۱۱۷ ، ۱۸۲۴۰–۱۸۲۵۰٫ https://doi.org/10.1073/pnas.2005583117 (۲۰۲۰).
-
رونبرگر، او.، فیشر، پی. و بروکس، تی. یو-نت: شبکههای کانولوشن برای قطعهبندی تصاویر زیستپزشکی. در کنفرانس بینالمللی محاسبات تصاویر پزشکی و مداخله به کمک کامپیوتر، صفحات ۲۳۴-۲۴۱ (اسپرینگر، ۲۰۱۵).
-
فن، تی.، وانگ، جی.، لی، وای. و وانگ، اچ. MA-Net: یک شبکه توجه چندمقیاسی برای قطعهبندی کبد و تومور. IEEE Access ۸ ، ۱۷۹۶۵۶–۱۷۹۶۶۵٫ https://doi.org/10.1109/ACCESS.2020.3025372 (۲۰۲۰).
-
واسوانی، آ. و همکاران. توجه تنها چیزی است که نیاز دارید. در پیشرفتها در سیستمهای پردازش اطلاعات عصبی (ویراستاران واسوانی، آ. و همکاران ) ۵۹۹۸–۶۰۰۸ (انتشارات MIT، ۲۰۱۷).
-
دا کوستا، البی و همکاران. تقسیمبندی معنایی عمیق برای تشخیص جنگلهای کاشتهشده اکالیپتوس در قلمرو برزیل با استفاده از تصاویر سنتینل-۲. Geocarto Int. ۳۷ ، ۶۵۳۸–۶۵۵۰ (۲۰۲۲).
-
لی، آر. و همکاران. شبکه چندتوجهی برای تقسیمبندی معنایی تصاویر سنجش از دور با وضوح خوب. IEEE Trans. Geosci. Remote Sens. ۶۰ ، ۱-۱۳ (۲۰۲۱).
-
روچتی، ام. و همکاران . پتانسیلها و محدودیتهای طراحی یک مدل یادگیری عمیق برای کشف مکانهای باستانی جدید: موردی با دشت سیلابی بینالنهرین. در مجموعه مقالات ششمین کنفرانس بینالمللی EAI در مورد اشیاء هوشمند و فناوریها برای خیر اجتماعی ۲۱۶–۲۲۱ (انجمن ماشینآلات محاسباتی، ۲۰۲۰).
-
تیم توسعه QGIS. سیستم اطلاعات جغرافیایی QGIS (انجمن QGIS، ۲۰۲۲).
-
کاسینی، ل.، اورو، و.، روچتی، م. و مارچتی، ن. وقتی ماشینها مکانهایی را برای باستانشناسان پیدا میکنند: یک مطالعه مقدماتی با تقسیمبندی معنایی اعمال شده بر روی تصاویر ماهوارهای دشت سیلابی بینالنهرین. در مجموعه مقالات کنفرانس ACM 2022 در مورد فناوری اطلاعات برای خیر اجتماعی ۳۷۸-۳۸۳ (۲۰۲۲).
-
کازانا، جی. و کاترن، جی. پروژه اطلس CORONA: تصحیح قائم تصاویر ماهوارهای CORONA و کاوشهای باستانشناسی در مقیاس منطقهای در خاور نزدیک. در کتاب نقشهبرداری از مناظر باستانشناسی از فضا (ویراستاران: کامر، دیسی و هاروور، امجی) ۳۳–۴۳ (اسپرینگر، ۲۰۱۳).
-
ایکوبوفسکی، پ. مدلهای قطعهبندی در پایتون. مخزن گیتهاب (۲۰۱۹).
-
مانتلینی، س. و بردیمورادوف، AE ارزیابی تأثیر انسان بر چشمانداز باستانشناسی سمرقند (ازبکستان): ارزیابی در زمانی منطقه تایلاک با استفاده از سنجش از دور، بررسی میدانی و دانش محلی. Archaeol. Res. Asia ۲۰ ، ۱۰۰۱۴۳٫ https://doi.org/10.1016/j.ara.2019.100143 (۲۰۱۹).
-
همکاران GDAL/OGR. کتابخانه نرمافزاری انتزاع دادههای مکانی GDAL/OGR (بنیاد مکانی متنباز، ۲۰۲۲).
-
بائزا-یتس، ر. و استوز-المنزار، م. ارتباط خطاهای غیرانسانی در یادگیری ماشین. در EBeM’22: کارگاه ارزیابی هوش مصنوعی فراتر از معیارها (۲۰۲۲).
-
کاولی، دیسی، با جدید، کنار قدیمی؟ استخراج خودکار برای باستانشناسی سنجش از دور. در سنجش از دور اقیانوس، یخ دریا، آبهای ساحلی و مناطق آبی بزرگ ۲۰۱۲، صفحات ۳۷-۴۵ (SPIE، ۲۰۱۲).
-
گالوی، جی.، ایر، ام.، تانکینز، ام. و کوگان، جی. بازگرداندن لیدار قمری به زمین: نقشهبرداری از میراث صنعتی ما از طریق یادگیری انتقالی عمیق. Remote Sens. ۱۱ ، ۱۹۹۴٫ https://doi.org/10.3390/rs11171994 (۲۰۱۹).
-
فیوروچی، م. و همکاران. یادگیری عمیق برای تشخیص اشیاء باستانی در لیدار: معیارهای ارزیابی و بینشهای جدید. سنجش از دور. ۱۴ ، ۱۶۹۴٫ https://doi.org/10.3390/rs14071694 (۲۰۲۲).
-
Lambers، K.، Verschoof-van der Vaart، WB & Bourgeois، QPJ ادغام سنجش از دور، یادگیری ماشین و علم شهروندی در کاوش باستانشناسی هلند. Remote Sens. ۱۱ , ۷۹۴٫ https://doi.org/10.3390/rs11070794 (۲۰۱۹).
-
ورشوف-ون در وارت، WB، یادگیری نگاه به لیدار: ترکیب تشخیص اشیاء مبتنی بر CNN و GIS برای کاوشهای باستانشناسی در دادههای سنجش از دور (دانشگاه لیدن، ۲۰۲۲).
-
ورشوف-وان در وارت، دبلیو بی و لمبرز، کی. به کارگیری تشخیص خودکار اشیاء در عمل باستانشناسی: مطالعه موردی از جنوب هلند. Archaeol. Prospect. ۲۹ ، ۱۵-۳۱٫ https://doi.org/10.1002/arp.1833 (۲۰۲۲).
-
هرفورت، ب. و همکاران. نقشهبرداری از سکونتگاههای انسانی با دقت بالاتر و تلاشهای داوطلبانه کمتر با ترکیب جمعسپاری و یادگیری عمیق. سنجش از دور. ۱۱ ، ۱۷۹۹٫ https://doi.org/10.3390/rs11151799 (۲۰۱۹).
-
پونتی، م. و سردکو، آ. ادغام یادگیری انسان-ماشین و تخصیص وظایف در علوم شهروندی. Humanit. Soc. Sci. Commun. ۹ ، ۱-۱۵٫ https://doi.org/10.1057/s41599-022-01049-z (۲۰۲۲).
-
مارچتی، ن. و همکاران. NEARCHOS. علوم باز باستانشناسی شبکهای: پیشرفت در باستانشناسی از طریق تجزیه و تحلیل میدانی و اشتراکگذاری جامعه علمی. مجله باستانشناسی. پژوهشها. ۲۶ ، ۴۴۷–۴۶۹ (۲۰۱۸).
بودجه
این بودجه توسط کمیسیون اروپا (CSOLA/2016/382-631)، بنیاد فولکس واگن (پروژه کلام) و دانشگاه تورنتو (پروژه CRANE 2.0) تأمین شده است.
اعلامیههای اخلاقی
منافع رقابتی
نیکولو مارکتی توسط پروژههای زیر تأمین مالی شده است: (۱) پروژه «EDUU — آموزش و ارتقای میراث فرهنگی برای انسجام اجتماعی در عراق»، که توسط EuropeAid (CSOLA/2016/382–۶۳۱)، www.eduu.unibo.it تأمین مالی شده است ، که در چارچوب آن پروژه FloodPlains توسعه یافته است، https://floodplains.orientlab.net/ ؛ (۲) پروژه «KALAM. تجزیه و تحلیل، حفاظت و توسعه مناظر باستانی در عراق و ازبکستان از طریق فناوری اطلاعات و ارتباطات و رویکردهای مبتنی بر جامعه»، که توسط بنیاد فولکس واگن تأمین مالی شده است، www.kalam.unibo.it ؛ (۳) پروژه CRANE 2.0 دانشگاه تورنتو، که سرورهای مکانی را که FloodPlains روی آنها اجرا میشود، فراهم کرده است. سایر نویسندگان هیچ گونه تضاد منافعی را اعلام نمیکنند.
اطلاعات تکمیلی
یادداشت ناشر
اشپرینگر نیچر در مورد ادعاهای مربوط به صلاحیت قضایی در نقشههای منتشر شده و وابستگیهای سازمانی بیطرف باقی میماند.
حقوق و مجوزها
دسترسی آزاد این مقاله تحت مجوز بینالمللی Creative Commons Attribution 4.0 منتشر شده است که استفاده، اشتراکگذاری، اقتباس، توزیع و تکثیر در هر رسانه یا قالبی را مجاز میداند، مادامی که به نویسنده(گان) اصلی و منبع، ارجاع مناسب داده شود، پیوندی به مجوز Creative Commons ارائه شود و در صورت ایجاد تغییرات، مشخص شود. تصاویر یا سایر مطالب شخص ثالث در این مقاله در مجوز Creative Commons مقاله گنجانده شدهاند، مگر اینکه در خط اعتباری مطلب، خلاف آن ذکر شده باشد. اگر مطلبی در مجوز Creative Commons مقاله گنجانده نشده باشد و استفاده مورد نظر شما طبق مقررات قانونی مجاز نباشد یا از حد مجاز تجاوز کند، باید مستقیماً از دارنده حق چاپ اجازه بگیرید. برای مشاهده نسخهای از این مجوز، به http://creativecommons.org/licenses/by/4.0/ مراجعه کنید .
درباره این مقاله

به این مقاله استناد کنید
کاسینی، ل.، مارچتی، ن.، مونتانوچی، آ . و همکاران. یک گردش کار همکاری انسان و هوش مصنوعی برای شناسایی مکانهای باستانی. Sci Rep ۱۳ ، ۸۶۹۹ (۲۰۲۳). https://doi.org/10.1038/s41598-023-36015-5
- دریافت شده
- پذیرفته شده
- منتشر شده
- نسخه رکورد
- DOIhttps://doi.org/10.1038/s41598-023-36015-5
این مقاله مورد استناد قرار گرفته است
-
مدلسازی پیشبینی برای بررسی باستانشناسی هدفمند محوطههای دوره اشکانی در منطقه مرزی ایران دره رود ارس
مجله روش و نظریه باستانشناسی (۲۰۲۶)
-
روندهای بلندمدت شهری و جمعیتی در دشتهای سیلابی جنوب بینالنهرین
مجله تحقیقات باستانشناسی (۲۰۲۵)
-
وضعیت و روندهای فعلی فناوری، روشها و کاربردهای تعامل هوشمند انسان و کامپیوتر (HCII): یک پژوهش کتابسنجی
ابزارها و برنامههای چندرسانهای (۲۰۲۴)
-
شبکه تبدیل گراف مکانی-زمانی برای تقسیمبندی عمل زمانی مبتنی بر اسکلت
ابزارها و برنامههای چندرسانهای (۲۰۲۳)