۱٫ مقدمه
نقشه برداری از مکان ها و شرایط تصادفات جدی در یک شهر بزرگ، با میلیون ها وسیله نقلیه در حال تردد روزانه، وظیفه ای است که می تواند به طور موثری به نجات جان انسان ها کمک کند. بیشتر زمانی که این تلاش در یک ابتکار آزمایشگاه زنده مدیریت دولتی ادغام شود، تضمین می کند که دانش تولید شده به دارندگان داده بازگردانده می شود. این مقاله به طور مفصل کاربرد چندین تکنیک را توصیف می کند که مقدار و تنوع منابع داده های مختلف را جمع آوری و تجزیه و تحلیل می کند که در مطالعات موردی قبلی یافت نشده است.
سیستمهای اطلاعات جغرافیایی (GIS) به محققان اجازه میدهد تا از روشها و ابزارهای محاسباتی مختلف برای ترکیب دادههای جغرافیایی، آماری و نقشهبرداری برای شناسایی ویژگیهای فضایی یک کانون استفاده کنند [ ۱ ]. به گفته استیوز [ ۲]، «GIS ابزارهای محاسباتی هستند که امکان یکپارچه سازی و دستکاری انواع مختلف اطلاعات را فراهم می کند، به ویژه برای متغیرهای فضایی با ماهیت جهانی، منطقه ای یا محلی مناسب است. آنها یک سیستم پشتیبانی تصمیم هستند که شامل یکپارچه سازی داده های جغرافیایی در یک محیط مشکل گرا، به ویژه در محیط هایی که جزء فضایی به شدت وجود دارد، است. شناسایی این نقاط بحرانی از طریق GIS بسیار مهم است، زیرا درک علل و عوامل مرتبط با حوادث را ممکن میسازد و امکان تصمیمگیری منسجم توسط بخش تحرک شورای شهر را فراهم میکند. برای آن، شناسایی وجود الگوی خوشههای فضایی در دادههای تصادف ضروری است. در این کار این با استفاده از دو الگوریتم تحلیل فضایی زیر به دست می آید [ ۳]: (۱) تخمین چگالی هسته (KDE) تکنیکی برای درونیابی و تحلیل الگوهای فضایی نقاط است. مجموعه ای از نقاط شناخته شده، شدتی را که یک متغیر معین در فضا رخ می دهد، مشخص می کند. برای فرمولبندی توضیحات و نشان دادن نتیجهگیری ایدهآل است و برای غیرریاضیدانان یک روش آماری به راحتی قابل درک است. با GIS می توان غلظت فرآیندها را تجسم کرد و تغییرات فرآیند را در سطح محلی توصیف کرد. (۲) تجزیه و تحلیل نقطه داغ در یک بافت محله، که بر اساس محاسبه آماری Getis-Ord Gi است، مقادیر خوشهبندی بالا (نقطه داغ) و پایین (نقطه سرد) را ارائه میکند که منجر به z-score (تعداد انحرافات استاندارد میشود). از میانگین نقطه اطلاعاتی) و ص– مقدار (احتمال به دست آوردن نتایج مشاهده شده یک آزمون، با فرض صحت فرضیه صفر). منطقه ای با مقدار p بالا لزوما یک نقطه مهم آماری نیست. یک نقطه باید ارزش بالایی داشته باشد و توسط نقاط دیگر با مقادیر به همان اندازه بالا احاطه شود تا یک نقطه مهم آماری باشد [ ۴ ]. مجموع محلی یک مکان و همسایگان آن به نسبت مجموع تمام نقاط مقایسه می شود. زمانی که مجموع محلی کاملاً متفاوت از مجموع محلی مورد انتظار باشد، و اگر این تفاوت خیلی زیاد باشد، یک مقدار z آماری معنیدار رخ میدهد [ ۵ ].
هدف این مطالعه از یک چالش با استفاده از دادههای واقعی، برگرفته از شهرداری، بر اساس دادههای موجود دفتر تحرک شورای شهر لیسبون استخراج شد. این ابتکار شامل شهرداری و آکادمی در جستجوی راه حل از طریق تجزیه و تحلیل داده ها برای مشکلات واقعی شهر است. این چالش مستلزم شناسایی مناطق مستعد حوادث ترافیکی (نقاط داغ) در شهرداری لیسبون و علل آن بود.
چالش ” Lisboa Inteligente ” با هدف ارائه اطلاعات لازم به مقامات شهرداری مسئول تحرک و مدیریت حفاظت و نجات است. اطلاعات لازم برای بهبود برنامه ریزی و مدیریت ترافیک شهر را فراهم می کند و امکان شناسایی و اجرای اقدامات کاهشی را فراهم می کند که تعداد تصادفات و قربانیان را در این نقاط حادثه خیز محدود می کند.
بنابراین، و برای دستیابی به هدفی که اکنون محقق شده است، یک تحلیل فضا-زمان چند متغیره از تصادفات جادهای که بین سالهای ۲۰۱۰ و ۲۰۱۹ رخ دادهاند، برای شناسایی مکان کانونهای آن انجام شد.
کار با مجموعهای از دادههای ارائهشده توسط شهرداری لیسبون (CML) به مؤسسه دانشگاهی لیسبون (ISCTE-IUL) آغاز شد که شامل یک پایگاه داده از رخدادهای هنگ آتشنشانی (RSB) برای سال ۲۰۱۹ و برخی فایلهای شکل با موقعیت جغرافیایی بود. داده های شهرداری، یعنی مقادیر شیب چراغ های راهنمایی، تقاطع ها و ارتفاع سنجی. به نظر می رسید از ابتدا و پس از تجزیه و تحلیل داده ها ارائه شده است که از نیازهای واقعی برای تحقیق در این ماهیت فاصله دارد. بنابراین یک فرآیند دقیق برای جمع آوری داده های لازم برای امکان تجزیه و تحلیل قوی و کارآمد آغاز شد. این فرآیند امکان ادغام دادهها از شش نهاد مختلف را فراهم میآورد که اطلاعات بیشتر و احتمالات متفاوتی را برای نتیجهگیری نسبت به هر مطالعه قبلی شناخته شده در این موضوع ارائه میدهد.
۲٫ بررسی ادبیات
اهداف تحقیق ما عمدتاً کشف نتایج حاصل از ترکیب داده ها و تجزیه و تحلیل داده های بزرگ برای استخراج دانش از چندین مجموعه داده پراکنده و بزرگ است. ما معتقدیم که این ادغام در کنار تکنیک مناسب تجسم داده ها به ما امکان می دهد مکان ها و شرایطی را که احتمال تصادف را افزایش می دهد درک کنیم. شناسایی نقاط کانونی RTA و مشخص کردن عوامل ایجاد کننده آنها درخواستی از سوی شهرداری لیسبون بود.
یک رویکرد ترکیبی ترکیبی از دو روش برای انجام مرور ادبیات سیستماتیک استفاده شد. بیانیه PRISMA—موارد گزارش برگزیده برای بررسی های سیستماتیک و متاآنالیزها [ ۶ ]، که هدف آن اطمینان از اینکه بررسی های سیستماتیک (SR) و متاآنالیزها به شیوه ای کامل، واضح و دقیق انجام می شود. و به طور مکمل، روش نمونهگیری گلوله برفی (نمونهگیری غیر احتمالی با استفاده از زنجیرههای مرجع)، تکنیکی که به دنبال منابع جدید اطلاعات بر اساس منابع مورد استفاده توسط اسنادی است که از نظر علمی این مطالعه را پشتیبانی میکنند.
بنابراین، جستجوی سیستماتیک در سه موتور جستجوی دانشگاهی انجام شد: Scopus [ ۷ ]، Biblioteca do Conhecimento Online [ ۸ ] و Web of Science [ ۹ ]. فاصله زمانی در نظر گرفته شده برای این مقالات، تاریخ انتشار بین سال های ۲۰۱۰ تا ۲۰۲۰ بود. مکان مقالات مورد نیاز برای این مطالعه از طریق ترکیب های مختلف از گروه های کلیدواژه تعیین شد. از طریق آنها محتویات موجود در پایگاه های مربوطه استخراج و فیلتر شد:
(“حوادث ترافیک جاده ای” و “تحلیل” و پرتغال و الگوی فضایی).
(RTA و تصادف و نقشه برداری و تجزیه و تحلیل فضایی و زمانی)؛
(حادثه ترافیکی و GIS، و تخمینگر چگالی هسته و KDE+ یا “Getis-Ord Gi”)؛
(لیسبون و RTA و “GIS”؛ (KDE و KDE+)) و (تجزیه و تحلیل نقاط داغ). (Lisboa AND Acidentes de transito); (عوامل انسانی و تصادفات جاده ای).
نتایج بهدستآمده بر اساس منطق اعمال شده در Covidence [ ۱۰ ] فیلتر شدند] ابزار بررسی نظام مند ادبیات، شامل سه مرحله: (۱) معیارهای واجد شرایط بودن – در این مرحله، نتایج بر اساس معیارهای زیر تأیید یا رد می شوند: زبان (فقط مقالاتی که به زبان انگلیسی یا پرتغالی نوشته شده اند پذیرفته می شوند). تاریخ انتشار مقاله بین سالهای ۲۰۱۰ تا ۲۰۲۰؛ (۲) ادبیات علمی منحصراً از مقالات یا بررسی های علمی، جدا از ادبیات خاکستری از شورای شهر لیسبون، سازمان ملی ایمنی جاده ها و کمیسیون اروپا. این طرحهای مداخله، اسناد فنی (مثلاً طرح اضطراری شهرداری حفاظت مدنی لیسبون) و گزارشها، نمیتوانند در جامعه علمی منتشر شوند. و مقاله The CRISP-DM Model: The New Blueprint for Data Mining، به دلیل عدم رعایت معیار تاریخ انتشار.
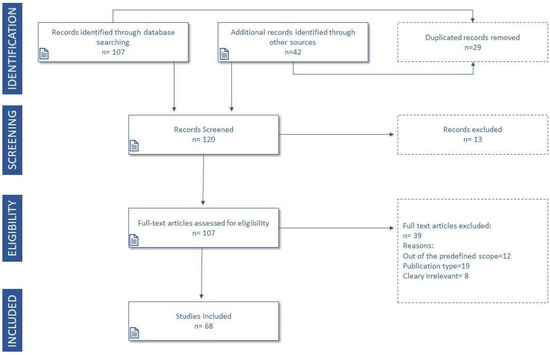
پس از تجزیه و تحلیل و فیلتر کردن نتایج، مقادیر به دست آمده در شکل ۱ نشان داده شده است.
این نقشه بهطور مشهودی عبارت «GIS» را بهعنوان مفهوم اصلی پیوندها و روابط ایجاد شده، و پس از آن عبارت «ایمنی جادهای»، حوادث ترافیکی و نقاط داغ برجسته میکند.
یکی از مؤلفههای مهم کاهش تصادفات جادهای، تجزیه و تحلیل مکانهای تصادف است. تصادفات جاده ای تصادفی رخ نمی دهد. آنها مستعد تجمع در مکانهای خاص به دلایلی هستند که میتوان آنها را با شرایط مختلفی توضیح داد که به آنها «عوامل تأثیرگذار» میگویند. این خوشهها یا غلظتهای RTA که معمولاً در ادبیات به عنوان «نقاط داغ» نامیده میشوند، به عنوان مکانهایی توصیف میشوند که «تعداد تصادفات بیشتری نسبت به سایر نقاط مشابه به دلیل عوامل خطر محلی دارند» [ ۱۱]. این مفهوم به این مفهوم اشاره دارد که نقاط حساس مناطق مستعدی هستند که هندسه و طراحی ترافیک (به عنوان مثال، تقاطع های شلوغ، منحنی های تیز، و سیگنال دهی عمودی ناکارآمد) نقش مهمی در تصادفات ایفا می کنند، که در صورت شناسایی عوامل تأثیرگذار می توان آن را کاهش داد. توسط مقامات تصحیح شد. هیچ تعریف قابل قبول و دقیقی از نقاط حادثه خیز [ ۱۲ ] وجود ندارد، زیرا تعاریف در بین محققان متفاوت است و متناسب با ویژگی های هر کشور و اهداف دولتی تطبیق داده شده است. Rune Elvik تعاریف هات اسپات را در کشورهای اروپایی [ ۱۳ ] جمع آوری کرد تا تفاوت ها را نشان دهد.
با توجه به بررسی ادبیات و مقایسه رویکردها برای تعریف نقاط داغ، هیچ کشور اروپایی روش شناسی یکسانی را برای تعیین نقاط داغ به طور کامل اتخاذ نکرده است که در جدول ۱ نشان داده شده است. روش های کاربردی شناسایی، که هر کدام دارای نقاط قوت و ضعف متمایز در زمینه کاربرد خود هستند، در مکان یابی نقاط حساس مفید هستند. با توجه به موارد فوق، این مطالعه از تعریف نقطه داغ ارائه شده توسط سازمان ملی ایمنی راه پرتغال (ANSR) استفاده می کند: «یک امتداد جاده با طول حداکثر ۲۰۰ متر، که در آن حداقل پنج تصادف با قربانیان در سال رخ داده است. تحت بررسی» [ ۱۴ ].
دنیای دانشگاهی از مدل های آماری مختلفی برای طبقه بندی نقاط حساس استفاده کرده است. این موضوع در ربع آخر قرن بیستم، به ویژه در اواخر دهه ۱۹۷۰ شتاب بیشتری گرفت. رگرسیون گاوسی، رگرسیون پواسون چند متغیره و مدلهای دوجملهای منفی با در نظر گرفتن تصادفی بودن رویدادها در فضا و زمان [ ۱۵ ، ۱۶ ] در چندین مطالعه به کار گرفته شد. نتایج مدلهای ذکر شده نادرست بود زیرا آنها ویژگیهای فضایی یک RTA را برای یک دوره معین ثابت در نظر میگرفتند که لاکشمی [ ۱] زمانی اتفاق می افتد که این فرض که میانگین و واریانس باید برابر باشند نقض شود. هنگامی که داده های تصادف بیش از حد پراکنده شوند (واریانس از میانگین بیشتر است) یا کم پراکنده شوند (میانگین از واریانس بیشتر باشد)، منجر به استنتاج اشتباه از پارامترهایی می شود که فرکانس تصادف را تعیین می کند. شناسایی یک نقطه داغ نیازمند تجزیه و تحلیل بسیار دقیق تری از علل و عوامل است – به عنوان مثال، شدت تصادف، شرایط جاده، شرایط وسیله نقلیه، و عوامل آب و هوایی موجود/موجود هنگام وقوع تصادفات [ ۱۲ ، ۱۳ ، ۱۴ ]. , ۱۵ , ۱۶ , ۱۷ ].
امروزه، محققان در حال ترکیب GIS و تکنیکهای تحلیل فضایی برای بررسی توزیع فضایی و وابستگی فضایی رویدادهای RTA در یک فضای مسطح دوبعدی (۲D) با استفاده از شاخصهای جهانی مانند Global Moran’s I (خودهمبستگی فضایی)، Getis-Ord G، و Getis-Ord G*، که محققان را قادر می سازد نقاط داغ، نقاط سرد و نقاط پرت فضایی را شناسایی کنند. علاوه بر این، شاخصهای محلی مانند KDE و Local Anselin Moran میتوانند برای شناسایی مکانهای فضایی خوشههای RTA استفاده شوند. سیستمهای اطلاعات جغرافیایی (GIS) به دلیل ویژگیها و کاربردهای متعدد، خود را به عنوان ابزاری حیاتی و قدرتمند برای تحلیل دادههای مکانی در طول زمان معرفی کردهاند. این سیستمها ذخیره، مدلسازی، تجزیه و تحلیل و تجسم دادههای جغرافیایی ارجاعشده را امکانپذیر میسازند.
خان گیانگ لی و همکاران [ ۱۸ ] از ترکیبی از تکنیکهای KDE و COMAP (فرایند ارزیابی جامع کاهش) برای شناسایی نقاط مهم RTA استفاده کرد. هر دو تجزیه و تحلیل نقاط حساس نسبتا مشابهی را تعیین کردند، اما رتبه بندی برخی از نقاط حساس به دلیل ادغام شاخص شدت متفاوت بود. در این ارزیابی، Khanh Giang Le ثابت میکند که علاوه بر فراوانی تصادف، سطح شدت تصادف نیز ضروری است، زیرا به برجسته کردن حوادثی که شامل خسارت قابل توجهی هستند کمک میکند. کایگز و همکاران [ ۱۹] تجزیه و تحلیل مکانی – زمانی از تصادفات رانندگی در بزرگراه های ترکیه انجام داد. با توجه به کیفیت داده ها، تنها بزرگراه آناتولی جنوبی به صورت عددی مورد بررسی قرار گرفت. هر دو تکنیک KDE و Network KDE برای شناسایی نقاط مهم مورد استفاده قرار گرفتند، که عمدتاً در تابستان اتفاق می افتاد. شایع ترین انواع تصادفات در منطقه مورد مطالعه، برخورد از عقب، برخورد اجسام ثابت و روان آب بود.
با استفاده از داده های تصادفات از پنسیلوانیا بین سال های ۱۹۹۶ و ۲۰۰۰، آگوئرو والورده و جووانیس [ ۲۰ ] فراوانی سالانه تصادفات در ایالات متحده را در سطح شهرستان بر اساس مدل های سلسله مراتبی تقریب زدند. داده های جمعیت شناختی اجتماعی، شرایط آب و هوایی، زیرساخت های حمل و نقل و زمان سفر از جمله عناصر در نظر گرفته شده بودند. آنها کشف کردند که پارامترهایی مانند فقر کم، محدوده سنی (به ویژه ۰ تا ۲۴ سال و بالای ۶۴ سال)، طول جاده و تراکم جریان ترافیک در افزایش احتمال تصادفات جاده ای نقش دارند.
ایاندا [ ۲۱] از یک روش هموارسازی برای پیش بینی دو سال حوادث جاده ای بر اساس RTA تاریخی قبلی در تمام ۳۶ ایالت و قلمرو فدرال نیجریه استفاده کرد. این مطالعه از موران I، یک آماره همبستگی فضایی، برای تعیین میزان تصادفی بودن شدت RTA در بین ۳۶ حالت استفاده کرد. همچنین از شاخص محلی Anselin از ارتباط فضایی (LISA) استفاده کرد که آماری را برای هر مکان با ارزیابی اهمیت ارائه میکند و یک رابطه متناسب بین مجموع آمارهای محلی و یک آمار جهانی مربوطه برقرار میکند. بر اساس یافتهها، بخش شمالی نیجریه دارای بالاترین شدت RTA در مقایسه با ایالتهای جنوبی است. تحقیقات محلی نشان می دهد که این خوشه ها در قسمت شمالی نیجریه به طور تصادفی رخ نداده اند. الگوهای جغرافیایی به طور قابل توجهی خوشه ای هستند.
تخمین چگالی هسته یک تکنیک فضایی به طور گسترده مورد استفاده و تثبیت شده برای تخمین شدت تصادف و شناسایی نقاط داغ است [ ۱۲ ، ۲۲ ، ۲۳ ]. این روش مجموعهای از رویدادهای نقطهای را به یک سطح پیوسته تبدیل میکند که چگالی آنها را نشان میدهد و محققین را قادر میسازد تا واریانس مقدار میانگین رویداد مورد مطالعه را در منطقه مورد مطالعه بررسی کنند – یعنی اینکه رویدادها چگونه در فضا توزیع میشوند.
اردوغان و همکاران [ ۲۴ ] نقاط حادثه خیز را بررسی کرد و مناطق ناامن را در بزرگراه ها در شهر افیون ترکیه شناسایی کرد. KDE و تجزیه و تحلیل تکرارپذیری برای تجزیه و تحلیل داده ها استفاده شد. هر دو ارزیابی مکانهای تقریباً یکسانی را به عنوان نقاط داغ شناسایی کردند. اکثر آنها در اطراف نقاط تقاطع، چهارراه ها و مسیرهای دسترسی به روستاها و شهرها بودند. آنها همچنین دریافتند که تعداد تصادفات در تابستان و زمستان به ویژه در ماه اوت و دسامبر افزایش می یابد. آخر هفته ها نیز فرکانس های بالاتری داشتند. علاوه بر این، آنها دریافتند که اکثر تصادفات مرگبار بعد از نیمه شب رخ داده است. اندرسون [ ۱۲] استفاده از GIS و KDE را برای بررسی الگوهای منطقه ای، مانند نقاط داغ تصادف آسیب، و سپس ادغام داده ها با تکنیک های خوشه بندی را توصیه می کند.
پراساناکومار و همکاران [ ۳ ] ۱۴۶۸ تصادف را مورد مطالعه قرار داد که در سال ۲۰۰۸ به پلیس در Thiruvananthapuram هند گزارش شد. برخلاف بسیاری از گزارشهای کاری دیگر، این گزارشها مختصات هر رویداد را ارائه کردند. برای انجام این تحقیق، محققان روشهای خودهمبستگی فضایی موران I، شاخص آماری Getis-Ord Gi* و KDE را مقایسه کردند.
هنگامی که Getis-Ord Gi* و KDE اعمال شدند، Moran I نشان داد که داده ها تمایل دارند در مناطق زمانی خاص خوشه شوند [ ۲۵ ]. علاوه بر این، با استفاده از روشهایی مانند موران I، تحلیل نقطهای حساس و KDE، آقاجانی و همکاران. [ ۲۵] ارتباط معنی داری بین تراکم تصادف، توپوگرافی و نقشه های بارندگی کشف کرد – یعنی مناطق کوهستانی و مکان های با بارندگی بیشتر تراکم تصادف بالاتری دارند. از مطالعاتی که در بالا توضیح داده شد، تعداد کمی استراتژی های پیشگیری از تصادف را پیشنهاد می کنند. در عوض، آنها فقط بر فرآیند کشف نقاط حساس و ارائه یک تحلیل توصیفی تمرکز می کنند. با در نظر گرفتن این سناریو، ما یکپارچه سازی داده ها را از منابع اطلاعاتی مختلف انجام دادیم تا این فرآیند تجزیه و تحلیل داده ها را غنی کنیم. این رویکرد می تواند برای هر شهر هوشمند با داده های موجود اعمال شود. این داده ها امکان کشف دانش مهمی را فراهم می کند که بر اساس آن مقامات محلی می توانند عمل کنند.
۳٫ مواد و روشها
برای اجرای این مطالعه، ما تماس هایی را با ANSR و Instituto Português do Mar e da Atmosfera (IPMA) برای به دست آوردن داده های لازم آغاز کردیم. از این تماس ها یک پروتکل همکاری بین ISCTE و ANSR ایجاد شد که به سایر دانشجویان و محققان اجازه می دهد تا به یک منبع ارزشمند اطلاعات دسترسی داشته باشند.
پس از تجزیه و تحلیل جدید، متوجه شدیم که هنوز اندازه گیری حجم ترافیک در جاده های لیسبون در زمان حادثه امکان پذیر نیست. IMTT و TomTom برای دریافت این پاسخ ضروری بودند.
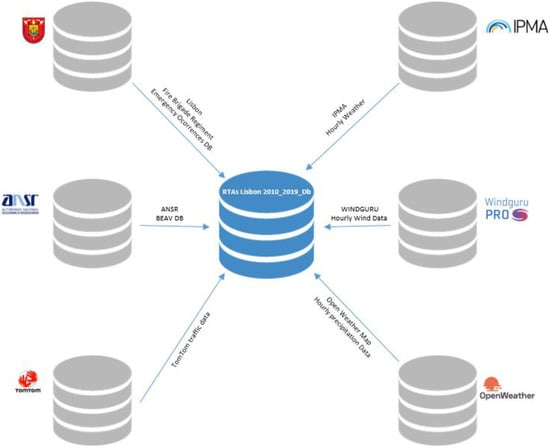
پس از جمع آوری داده های لازم، اقدام به پاکسازی و تهیه داده ها از ۶ منبع مختلف با اطلاعات جغرافیایی و در قالب های مختلف، انجام کل فرآیند مهندسی ویژگی برای تبدیل و ساخت داده های مشتق شده و غیره کردیم.
یک مجموعه داده واحد ایجاد شد که به صورت تکراری برای مجموعهای از دادههای درخواست شده به نهادهای مختلف، مانند
-
داده های هواشناسی از IPMA [ ۲۶ ]؛
-
اطلاعات باد از Windguru [ ۲۷ ];
-
مشاهدات بارش ساعتی از API تاریخچه نقشه آب و هوا [ ۲۸ ]؛
-
دادههای گزارشهای بولتن آماری حوادث ترافیکی از ANSR [ ۲۹ ]؛
-
حوادث اضطراری هنگ آتش نشانی لیسبون؛
-
آمار ترافیک تاریخی از TomTom [ ۳۰ ].
تمام منابع داده های مختلف ذکر شده در این مطالعه تحقیقی در شکل ۲ نشان داده شده است.
در مورد ۱، سوابق موجود در این مجموعه دادهها چندین تناقض را نشان میدهند، به ویژه در مورد ثبت سرعت و جهت باد (عدم وجود) و بارش. چندین رکورد بارش دارای مقدار “۹۹۰-” (مقدار بیان شده بر حسب میلی متر در ساعت) بودند که در ابتدا به عنوان یک پدیده طبیعی شناخته شده به عنوان بارندگی منفی شناخته شد، اما بعدا توسط متخصصان IPMA به عنوان یک خطای کد ایستگاه هواشناسی (سنسور کار نمی کند) مشخص شد. ).
در ۲ و ۳، رکوردهای موجود در مجموعه داده شامل ۸۷۸۲۹ خط اطلاعات ساعتی سرعت و جهت باد (برای ۲) و اطلاعات آب و هوا (در رابطه با ۳) با داده های بسیار کمی از دست رفته است.
برای مجموعه داده شماره ۴، مجموعه داده از ۲۲۷۲۵ رکورد تصادف تشکیل شده است. در این مجموعه داده ما فقط از دادههای مربوط به حوادثی که قربانیان ایجاد کردهاند (مرگ، مجروح جدی، آسیب سبک) استفاده کردیم.
در مورد ۵، مجموعه داده های او شامل ۱۰۰۹۷ رکورد از تمام رخدادهای مربوط به سه ماهیت مرتبط با RTA بود – (۱) تصادفات مربوط به وسایل نقلیه، (۲) تصادفات مربوط به عملیات بیرون آوردن، و (۳) تصادفات مربوط به عابران پیاده.
در نهایت، برای ۶، به دلیل بار مالی که این اکتساب نشان میدهد، نمیتوان دادههایی را برای کل دوره مورد تجزیه و تحلیل به دست آورد، بنابراین تصمیم گرفته شد که کسب به یک دوره یک ساله محدود شود (۲۰۱۹؛ سازماندهی شده در مجموعه دادههای ماهانه به تفکیک شده به داده های روزهای هفته و آخر هفته). با توجه به هزینه به دست آوردن داده ها برای یک بازه ۱۰ ساله، به همراه کارشناسان برای اهداف این مطالعه فرض شد که مقادیر به دست آمده به اندازه کافی نماینده پویایی ترافیک لیسبون هستند. بنابراین، نتایج دادهها در گستره کامل مجموعه داده اعمال شد.
پس از این مرحله و داشتن یک مجموعه داده جدید که دادههای لازم برای مطالعه را در اختیار ما قرار میداد، کار تجزیه و تحلیل دادههای آماری، شناسایی الگوها و انحرافها و جستجوی توجیهی برای برخی از نتایجی که چالشبرانگیز بودند را آغاز کردیم.
پس از اتمام ETL، ما با استفاده از ArcGIS PRO نسخه ۲٫۸ و کاربرد الگوریتم های خودهمبستگی فضایی، یعنی تخمین چگالی هسته، شاخص Moran I و تجزیه و تحلیل Hotspot getis ord gi*، به تمام پردازش و تحلیل جغرافیایی پرداختیم.
هدف ما بر اساس داده های تصادف با استفاده از GPS شناسایی نقاط داغ است. برای آن، از موران I جهانی برای ارزیابی دادهها برای خودهمبستگی فضایی استفاده شد. سپس از تخمینگر تراکم هسته برای شناسایی نقاط حادثهای استفاده کردیم، زیرا این یک روش پرکاربرد است که کاربرد و پیادهسازی آن ساده است و نتایج بصری جذابی را ایجاد میکند [ ۳۱ ] شبیه به نتایج به دست آمده توسط نویسندگان ذکر شده در بالا [ ۱۲ , ۲۱ , ۲۲ , ۲۳ ]. ]. علاوه بر این، هنگامی که با تجزیه و تحلیل نقاط داغ (Getis-Ord Gi *) ترکیب می شود، امکان شناسایی نقاط حساس در شبکه جاده لیسبون را فراهم می کند. مقادیر شاخص موران از -۱ تا ۱ متفاوت است، با مقدار نزدیک به ۱٫۰ نشان دهنده خوشه بندی، مقدار نزدیک به -۱٫۰ نشان دهنده پراکندگی [ ۳۲]، و مقدار “۰” نشان دهنده تصادفی کامل جغرافیایی [ ۳۳ ] است.
۳٫۱٫ گلوبال موران I
Global Moran’s I یک شاخص خودهمبستگی فضایی است که به طور گسترده مورد استفاده قرار می گیرد. معیار اولیه در خود همبستگی فضایی برای تصادفات ترافیکی جاده ای در این مطالعه Global Moran’s I بود. ما از Global Moran’s I برای شناسایی خوشه ای، پراکندگی یا تصادفی بودن الگوی خروجی فضایی و همچنین سطوح غلظت استفاده کردیم [ ۳ ]. فرضیه صفر بیان می کند که مقادیر ویژگی به طور تصادفی در سراسر منطقه تحقیق توزیع می شود. مقادیر شاخص موران از -۱ تا ۱ متفاوت است، با مقدار نزدیک به +۱٫۰ نشان دهنده خوشه بندی، مقدار نزدیک به -۱٫۰ نشان دهنده پراکندگی [ ۳۴ ]، و مقدار “۰” نشان دهنده تصادفی کامل جغرافیایی [ ۳۵ ].
p – value احتمالی است که نشان می دهد آیا مقادیر مشاهده شده توسط فرآیندهای تصادفی یا سایر فعالیت های جغرافیایی ایجاد شده اند. زمانی که مقادیر z-score ضروری ۱٫۶۵۵ در سطح اطمینان ۹۰% و p-value بیش از ۰٫۱۰ (>0.10) باشد، فرضیه صفر را می توان پذیرفت. فرضیه صفر را می توان رد کرد که مقادیر مهم z-score از ۱٫۶۵ در سطح اطمینان ۹۰% معنی دارتر باشند و p-value کمتر از ۰٫۱۰ (۰٫۱۰) باشد. این به این دلیل است که خوشه بندی قابل توجهی فراتر از این منطقه وجود دارد [ ۲۴ ]. در انتهای توزیع نرمال، امتیازهای z بسیار بالا (۲٫۵۸+) یا بسیار پایین (۲٫۵۸-) کشف میشوند که با p بسیار کوچک مرتبط هستند.– مقادیر (۰٫۰۱) و نشان دهنده خوشه بندی یا پراکندگی در سطح اطمینان ۹۹ درصد است. نقاط داغ قابل توجه (سایه های قرمز در تصویر ۳٫۲) با امتیازهای z بالا مرتبط با مقادیر p کوچک نشان داده می شوند، در حالی که نقاط سرد قابل توجه با امتیازهای z پایین همراه با مقادیر p کوچک نشان داده می شوند [ ۳۶ ].
ابزار خودهمبستگی فضایی برای هر تکرار با معیارهای فاصله تعریف شده توسط خودهمبستگی فضایی افزایشی ArcGIS انجام شد. فاصله مستقیم بین دو نقطه برای تعیین نزدیکی مکانی رویدادهای داده استفاده شد، در حالی که رویکرد وزن دهی معکوس فاصله برای تعیین نزدیکی مکانی نقاط همسایه استفاده شد. از آنجایی که هر نقطه داده بر حسب همسایگان خود، تعیین شده توسط آستانه فاصله، تجزیه و تحلیل می شود، مهم است که آستانه فاصله ای را انتخاب کنید که همبستگی مکانی را به حداکثر برساند [ ۳ ]. شاخص جهانی Moran I با استفاده از معادله زیر محاسبه می شود:
۳٫۲٫ تخمینگر تراکم هسته برای تجزیه و تحلیل تصادفات جاده ای
یکی از محبوب ترین تکنیک ها برای شناسایی نقاط حساس، تحلیل الگوی نقطه فضایی است و روش های مختلفی برای انجام این کار وجود دارد. ما از توصیه [ ۱۲ ] برای استفاده از GIS و KDE برای بررسی الگوها همانطور که در وضعیت هنر توضیح داده شده است پیروی کرده ایم. این ها را می توان به دو دسته تقسیم کرد [ ۲۵ ]: روش های مرتبه اول، که تغییرات مقدار میانگین فرآیند را اندازه گیری می کنند، مانند شمارش ربع یا KDE، و روش های مرتبه دوم، که وابستگی مکانی نقاط را بررسی می کنند و از توابع استفاده می کنند. این سطح از وابستگی فضایی را توضیح دهد.
همانطور که قبلاً گفته شد، KDE پرکاربردترین روش آماری ناپارامتریک برای هموارسازی داده ها است زیرا درک و پیاده سازی آن ساده است. برای محاسبه مقدار چگالی مجموعهای از رویدادهای نقطهای ( n ) در یک ناحیه معین، از یک هسته، K(x) با مرکز در محل تخمین ( Xi ) استفاده میکند ، آنها را درونیابی میکند و سطحی پیوسته و کمابیش صاف ایجاد میکند. . هسته یک تابع وزنی است که می تواند ماهیت گاوسی، درجه دوم یا مخروطی داشته باشد. به عبارت دیگر، تابع تعداد نقاط یک منطقه تحت تأثیر را می شمارد و آنها را بر اساس فاصله آنها از مکان مورد نظر وزن می کند. پهنای باند h ناحیه نفوذ را تعیین می کند.
معادله (۲) تابع چگالی کرنل f را بیان می کند :
هسته انتخاب شده و پهنای باند دو پارامتری هستند که می توانند بر نتیجه نهایی تأثیر بگذارند. با این حال، به گفته چندین نویسنده، از جمله Wand و Jones [ ۳۵ ]، نتیجه نهایی نسبتاً تحت تأثیر نوع هسته مورد استفاده قرار نمی گیرد. پهنای باند حیاتی ترین پارامتر است و بیشترین تأثیر را در نتیجه نهایی دارد. صافی سطح تولید شده را تعیین می کند. نوارهایی که خیلی کوچک هستند نتایج غیر یکنواختی ایجاد می کنند، در حالی که باندهای خیلی پهن اثر معکوس دارند. از آنجا که با منطقه و داده های مورد مطالعه متفاوت است و گاهی اوقات در هنگام اعمال نیاز به قضاوت ذهنی دارد، هیچ فرمول جهانی برای تعیین این پارامتر وجود ندارد.
این مطالعه از روش KDE در ArcGIS PRO 2.8 [ ۳۴ ] با پسوند Spatial Analyst استفاده کرد. پس از آزمایش چند پهنای باند، پهنای باند ۵۰۰ متر انتخاب شد. نقاط داغ بخش بزرگی از منطقه مورد مطالعه را با نوارهای بزرگتر پوشانده اند، که تعیین مکان تمرکز نقاط داغ در جاده های خاص را غیرممکن می کند. در مقایسه، تنها چند نقطه حساس با باندهای کوچکتر شناسایی شدند، که منجر به یک سطح ناهموار شد که برای دستیابی به آن نیاز به تلاش های متعدد داشت [ ۳۶ ].
۳٫۳٫ تجزیه و تحلیل نقطه اتصال (Getis-Ord Gi*)
Getis-Ord Gi* گروهی از آمارها با چندین ویژگی هستند که آنها را برای کمی کردن وابستگی در یک متغیر توزیع شده جغرافیایی جذاب می کند، به ویژه هنگامی که با I انسلی موران ترکیب می شود [ ۳۷ ].
Getis-Ord Gi* شواهدی از الگوهای فضایی را تجزیه و تحلیل میکند، به گفته خالقان Getis و Ord [ ۴ ]، « دانش فرآیندی را که منجر به وابستگی فضایی میشود را عمیقتر میکند و تشخیص بستههای محلی وابستگی را که ممکن است شناسایی نشوند افزایش میدهد. هنگام استفاده از آمار جهانی “.
در این مطالعه از محاسبات آماری Getis-Ord Gi* برای تعیین محل وقوع خوشههای فضایی (نقاط داغ) تصادفات جادهای با قربانیان در منطقه مورد مطالعه استفاده میشود. علاوه بر شناسایی این خوشه ها، الگوریتم از مقادیر z-score و p – value برای تعیین محل وقوع بالاترین/پایین ترین مقادیر برای خوشه های فضایی استفاده می کند.
تجزیه و تحلیل خوشه فضایی Getis-Ord Gi* ویژگی های هر وقوع تصادفات جاده ای با قربانیان را تجزیه و تحلیل می کند، به هر رکورد در یک بافت محله دسترسی پیدا می کند و به دنبال فاصله ای است که تضمین می کند هر رکورد (تصادف) حداقل یک همسایه دارد. یک رویداد با ارزش بالا لزوماً به معنای منطقه گرم نیست.
برای اینکه از نظر آماری معنادار باشد، باید ارزش بالایی داشته باشد و با اتفاقات با ارزش بالا احاطه شود.
مجموع یک مشخصه، [تصادف] با همسایگانش به نسبت مجموع همه صفات مقایسه می شود. هنگامی که مجموع محلی به طور قابل توجهی با آنچه پیش بینی می شود متفاوت است، و این تفاوت یک نتیجه تصادفی نیست، یک z-score با اهمیت آماری تولید می شود.
جایی که: Gi* آمار همبستگی مکانی یک رویداد i بر روی n رویداد است. اصطلاح xj مقدار مشخصه ویژگی j است، wi ، j وزن فضایی بین ویژگی i و j است، n برابر با تعداد کل ویژگی ها است.
پس از محاسبه، t مقدار تعیین شده یک امتیاز z است، و هر چه امتیاز بیشتر باشد، خوشه بندی مقادیر بالا (نقطه داغ) قوی تر است. هنگامی که عدد z-score منفی است (مقدار کم)، مقادیر بیشتری از نقاط سرد خوشه بندی می شوند.
۴٫ خروجی های عمده اعمال شده برای داده های شهر لیسبون
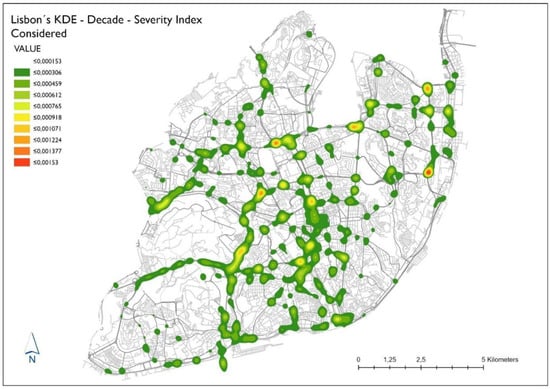
استفاده از یک تکنیک به کمک GIS (ArcGIS Pro) برای شناسایی نقاط حادثه خیز در ناحیه شهرداری لیسبون به شناسایی علل کمک می کند و به شورای شهر و بخش های آن در اجرای اقدامات کاهشی برای ایمن کردن رانندگی در این مناطق کمک می کند. تخمین چگالی هسته ( KDE ) و Getis-Ord Gi*تجزیه و تحلیل نقاط داغ برای شناسایی نقاط داغ تصادفات جاده ای با قربانیان در منطقه شهر لیسبون بر اساس موقعیت و ویژگی های تصادف جاده ای استفاده شد. با استفاده از تجزیه و تحلیل چگالی هسته و تجزیه و تحلیل نقاط داغ Getis-Ord Gi*، چگالی ها و سطوح مختلف اطمینان برای داده های هر سال تعیین شد. نقشه تولید شده توسط تجزیه و تحلیل چگالی هسته و تجزیه و تحلیل نقاط داغ Getis-Ord Gi* از دهه ۲۰۱۰-۲۰۱۹ در شکل ۳ نشان داده شده است.. چندین منطقه کانونی در منطقه مورد مطالعه به طور مداوم در طول دوره مطالعه رخ داده است. داده ها برای همبستگی خودکار فضایی با استفاده از Moran’s I جهانی قبل از انجام تجزیه و تحلیل نقطه اتصال KDE و Getis-Ord Gi* بررسی شدند تا اطمینان حاصل شود که داده ها حاوی خوشه بندی فضایی مورد نیاز برای تجزیه و تحلیل هات اسپات هستند. تعاریف ANSR (5 قربانی، ۲۰۰ متر) از یک هات اسپات جمعآوری شد و برای تعیین فاصله شعاع جستجوی مناسب برای KDE و Getis-Ord Gi* استفاده شد.
به منظور به دست آوردن پارامترهای مورد نیاز برای ادامه تجزیه و تحلیل هات اسپات، داده های دوسالانه در ArcGis Pro 2.8 با استفاده از یک پرس و جوی SQL انتخاب شدند که به ما امکان می داد فقط تصادفات جاده ای با قربانیان را برای سال های مورد بررسی (۲۰۱۰-۲۰۱۱) انتخاب کنیم. ۲۰۱۲-۲۰۱۳؛ ۲۰۱۴-۲۰۱۵؛ ۲۰۱۶-۲۰۱۷؛ و ۲۰۱۸-۲۰۱۹)، پس از آن، پنج دوسالانه هر کدام تحت محاسبه Moran I قرار گرفتند تا وجود خوشه های RTA را ارزیابی کنند. فاصله معکوس و روش فاصله اقلیدسی برای مفهوم سازی روابط فضایی معرفی شدند. هیچ آستانه ای استفاده نشده است. نتایج بهدستآمده نشاندهنده خوشهای قوی از Padron تصادفات، با شاخص موران مثبت ۰٫۹۹، z-score 65 و p است.– مقدار ۰٫۰۱، به ما کمتر از ۱% احتمال برای نتیجه الگوی خوشهبندی شانس تصادفی میدهد. بنابراین، می توانیم فرضیه صفر را رد کنیم.
گام بعدی پس از شناسایی خوشهبندی فضایی تصادفات جادهای در سالهای ۲۰۱۰ و ۲۰۱۱، انجام تخمین تراکم هسته (KDE) در ArcGis 2.8 با استفاده از ابزار تحلیل فضایی ابزار بود. اندرسون [ ۱۲ ] اندازه سلول و شعاع جستجو (پهنای باند) را به عنوان دو عنصر مهم موثر بر تکنیک KDE شناسایی می کند. به گفته چندین متخصص، پهنای باند حیاتی ترین پارامتر برای تعیین بهترین سطح چگالی است [ ۳۸ ]. در نتیجه، انتخاب پهنای باند تأثیر قابل توجهی بر نتیجه هات اسپات ها خواهد داشت. به طور خاص، هر چه پهنای باند کمتر باشد، نقاط مهم کوچکتر است.
مقدار پهنای باند بر صافی سطح چگالی تأثیر می گذارد. هرچه سطح چگالی صاف تر باشد، پهنای باند بزرگتر است. در نتیجه، انتخاب یک پهنای باند ایده آل بسیار مهم است.
برای تعیین پهنای باند مورد نظر، از مطالعه فومیا [ ۳۹ ] استفاده کردیم، که پیشنهاد میکند پرشهای ۵۰ متری افزایشی را انجام دهیم تا زمانی که نمودار هاتاسپات به تعادل برسد، یعنی باندهای بزرگتر، نقاط داغ بخش بزرگی از منطقه مورد مطالعه را پوشش میدهند و شناسایی آن را چالش برانگیز میکند. نقاط تمرکز نقاط داغ در جاده های خاص به درستی. در مقایسه، تنها چند نقطه حساس با نوارهای کوچکتر شناسایی میشوند که در نتیجه سطحی ناهموار ایجاد میشود. در مورد ما به تعادل در پهنای باند ۲۵۰ متر رسیدیم.
دوسالانه ۲۰۱۸-۲۰۱۹ دومین نقطه پرت در داده های ما را ارائه می دهد. کاهش در تعداد و مکان کانون ها وجود دارد، به ویژه در مرکز شهر، نقاطی که قبلاً در جاده های سطح ۳، سطح ۴ و ۵ پخش شده بودند، عملاً وجود ندارند. اگر در سالهای ۲۰۱۲-۲۰۱۳ بحران اقتصادی کاهش ترافیک و در نتیجه کاهش تصادفات با قربانیان را توجیه کرد، دوسالانه کنونی نمیتواند همین را توجیه کند. بر اساس توریسم پرتغال، پرتغال در کل رشد اقتصادی دارد [ ۴۰]، و لیسبون یکی از شهرهای اروپایی با بیشترین تقاضا است که تنها در سال ۲۰۱۸ تعداد گردشگران را به ترتیب ۷٫۵ میلیون نفر ثبت کرده است. برای درک این پدیده، از حفاظت مدنی شهرداری لیسبون و پلیس شهرداری لیسبون پرسیدیم که چه چیزی می تواند این کاهش را توجیه کند. . نتیجه ای که به آن رسیدیم هم تعجب آور و هم آشکار کننده است. بار دیگر با تبیین پایان نامه دفاع شده در این پژوهش که بدون شک عوامل انسانی مهم ترین عامل در تصادفات جاده ای با قربانیان است.
با مقایسه شکل ۴ ، با دهه بعد از شکل ۳ ، کاهش قابل توجهی در تعداد و مکان کانون ها، به ویژه در مرکز شهر مشاهده می شود.
این پدیده از آنجایی توضیح داده شده است که در سال ۲۰۱۹، پلیس شهری لیسبون (PML)، علاوه بر ۲۱ دوربین کنترل سرعت ثابت، شروع به کنترل سرعت با دوربینهای سرعت سیار به صورت استراتژیک در مناطقی که محدودیت سرعت ۳۰ کیلومتر در ساعت (سطح ۴) است، کرد. و جاده های سطح ۵) مانند مناطق مسکونی یا مدارس. کنترل سرعت سیار در شهرداری به PML اجازه داد تا رکورد تعداد تخلفات را با مجموع ۶۱۵۴۰ تخلف شدید ثبت کند که ده برابر بیشتر از سال ۲۰۱۵ (۶۸۴۲) است. این دادهها و مطالعه میانگین سرعتهای ثبتشده توسط TomTom نشان داد که رانندگان سرعت خود را تا حد تعیینشده توسط قانون عمدتاً در جادههای ذکر شده در بالا تنظیم میکنند که منجر به کاهش واضح تصادفات جادهای میشود.
تجزیه و تحلیل فصلی انجام شد و شکل ۵ مطالعه زمانی تراکم هسته را برای فصول سال تصادفات با قربانیان نشان می دهد، که به ما امکان می دهد تشخیص دهیم که در فصل بهار، غلظت کمتری از نقاط داغ در مناطق دورافتاده وجود دارد. شهر در مقایسه با سایر فصول سال، قابل مشاهده بودن مرکز شهر و همچنین منطقه مرکز شهر در اطراف میدان Marquês de Pombal که تصادفات را متمرکز می کند، نمونه ای از آن Avenida da República ، Avenida Fontes Pereira de Melo هستند. و Avenida Liberdade . در فصل تابستان، افزایش تصادفات و تکرار تصادفات در محدوده مرکزی شهر، در محدودهEixo Norte-Sul ، به پل ۲۵ de Abril ، خیابان General Norton de Matos با جاده بنفیکا ، و در انتهای A5 به سمت پلراه Duarte Pacheco در خروجی پل دسترسی دارد. جادههای فوقالذکر همچنان در طول پاییز و زمستان نقاط داغ هستند. با این حال، تمرکز تصادفات بیشتر در حومه لیسبون، به طور خاص همراه با Avenida General Norton de Matos و Eixo Norte-Sul ، با بیشترین تمرکز تصادفات در منطقه ای که روی Avenida Engenheiro Duarte Pacheco همپوشانی دارد، وجود دارد .
برای اینکه بتوانیم یک ارزیابی و شناسایی نقاط داغ تصادفات رانندگی با قربانیان موجود در منطقه شهرداری لیسبون انجام دهیم که منعکس کننده مشکلات واقعی است بدون اینکه متحمل تأثیرات یا انحرافاتی شود که ممکن است در تحلیلهای زمانی- مکانی پایینتر زمانی وجود داشته باشد. ما همانند تحلیلهای دوسالانه، تجزیه و تحلیل KDE را از تمام تصادفات جادهای با قربانیانی که الزامات خوشه نقطه کانونی ANSR را برآورده میکردند (۵ قربانی، ۲۰۰ متر) انجام دادیم. نتایج بهدستآمده یک الگوی خوشهای قوی از تصادفات را نشان میدهد، با شاخص موران مثبت ۰٫۹۹، z-score 200، و p-value ۰٫۰۰۰۱، که کمتر از ۱٪ احتمال برای نتیجه الگوی خوشهبندی شانس تصادفی به ما میدهد.
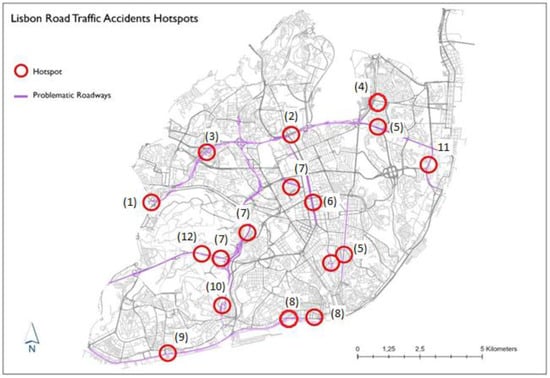
بنابراین، میتوانیم فرضیه صفر را رد کنیم. تحلیل Getis-Ord Gi*. تجزیه و تحلیل قبلی (KDE) امکان شناسایی نقاط RTA را فراهم کرد. با این حال، همانطور که قبلا گفته شد، تکنیک KDE فاقد ارزیابی اهمیت آماری نقاط حساس کشف شده است. در نتیجه، بررسی اهمیت آماری کانون و شناسایی مستعدترین مناطق با اهمیت آماری بسیار مهم است. به گفته بسیاری از محققان، ترجیح داده می شود که ارزش آماری کانون کشف شده به طور عینی و پیشگیرانه تعیین شود [ ۲۴ ].]. روش ارزیابی آماری معنی دار ما با این فرضیه صفر آغاز شد: “تصادفات در یک بخش جاده به طور تصادفی رخ داده است.” همانطور که قبلاً گفته شد، ما در ابتدا از آزمون موران I جهانی خود همبستگی فضایی برای تأیید آزمون آماری برای فرضیه صفر و تعیین اینکه آیا نقاط RTA در خوشه هایی با مقادیر یکسان سازماندهی شده اند استفاده کردیم. بر این اساس، پراساناکومار [ ۳ ]، این یک مرحله ضروری قبل از انجام تجزیه و تحلیل Hotspot (Getis-Ord Gi*) در ArcGIS PRO است. به این ترتیب و برای شناسایی نقاط داغ تصادفات جاده ای با قربانیان در شهرداری لیسبون، Hotspot Analysis Getis-Ord Gi* در پایگاه داده ما اعمال شد و خوشه ای از مقادیر بالا (نقاط داغ) را با سطح اطمینان ۹۹ ارائه کرد. ٪ همانطور که در شکل ۶ نشان داده شده استبرای مکانهای زیر: Avenida Dom João II، Eixo Norte-Sul، Avenida General Norton de Matos، Avenida Marechal Craveiro Lopes، Avenida Eusébio da Silva Ferreira، Itinerário Complementar 17، Estrada de Monsanto، A5، Acesso de Penonida da Ponte ابریل، آونیدا وینته و کواترو د جولهو، کامپو دوس مارتیرس دا پاتریا، روآ خواکیم آنتونیو د آگویار، تونل مارکوئس . در فاصله اطمینان ۹۵% به عنوان نقاط داغ آماری شناسایی شدند: Avenida Fontes Pereira de Melo، Rua Sousa Lopes، Avenida da República، Avenida Álvaro Pais، Avenida General Roçadas، Avenida Mouzinho de Albuquerque، Avenida Mouzinho de Albuquerque، Avenida Da República، Avenida Álvaro Pais. هندوستان _
شناسایی هات اسپات و خصوصیات آن در شکل ۷ نشان داده شده است . پس از شناسایی مکان نقاط مهم آماری که توسط الگوریتم تجزیه و تحلیل Hotspot Getis-Ord Gi* انجام شد، نتایج مورد تجزیه و تحلیل قرار گرفت و انتخابی از فعال ترین نقاط بر اساس تعداد تصادفات و شدت قربانیان ترتیب داده شد. اگر شهرداری لیسبون قبلاً از شاخص ایمنی جاده شهری (ISRM) استفاده کرده بود، میتوانستیم این طبقهبندی را با طبقهبندی محاسبهشده توسط CML مقایسه کنیم.
داده ها نشان می دهد که بخش سگوندا مشکل سازترین جاده در این مطالعه است. این شامل سه خیابان است: Avenida General Norton de Matos، Avenida Marechal Craveiro Lopes، و Avenida Eusébio da Silva Ferreira ، که اخیراً فقط از سال ۲۰۱۵ به بعد وجود دارد.
یافته های اصلی از این فرآیند تجزیه و تحلیل داده های بزرگ داده های شهر
تجزیه و تحلیلی در رابطه با نقاط داغ نشان داده شده در نقشه شکل ۷ انجام شد و خلاصه ای در جدول ۲ انجام شد که در هر مکان شماره شناسایی نقاط مهم در نقشه را داریم. جدول ۲دانش اصلی استخراجشده از دادههای شهر هوشمند را به شهرداری محلی خلاصه میکند تا به آنها در مقابله با افزایش تعداد تصادفات کمک کند. رشد شبکه شهری و تراکم جمعیت با توسعه یا اندازه زیرساخت جاده در لیسبون همراه نبوده است. این یک واقعیت است که تعداد و شدت تصادفات جاده ای در پرتغال طی سی سال گذشته رو به کاهش بوده است و ما را به میانگین اروپا نزدیکتر کرده است. با این حال، با وجود این واقعیت ها، وضعیت همچنان منبع نگرانی است. برای کمک به مقابله با این مشکلات، داده های مربوط به تصادفات جاده ای شروع به ارجاع جغرافیایی کرده اند تا درک بهتری از الگوهای مکانی و عوامل خطر ایجاد شود. در این بخش یک فرآیند تجزیه و تحلیل داده ها به این داده ها جمع آوری شده تا اطلاعات مفیدی برای مدیریت محلی استخراج شود.
در طول تجزیه و تحلیل ما و در مورد Avenida Eusébio da Silva Ferreira (نقطه داغ ۱)، به طور متوسط تنها ۱۰۰ روز بارندگی در سال وجود داشت و این شرایط (باران) تنها با ۱۷٪ از موارد RTAs در مطالعه ما مطابقت دارد.
از جدول ۲ ، ما معتقدیم که علل اصلی وجود این کانون بدون شک عوامل انسانی هستند که در ترکیب با شرایط جوی، وقوع RTA را در این مکان ها تشدید می کنند.
با توجه به Segunda Circular ، به عنوان یک پیشنهاد و گسترش مفهوم به بقیه مکان ها، ما معتقدیم که کاهش سرعت از ۸۰ کیلومتر در ساعت به ۵۰ کیلومتر در ساعت همراه با وجود دوربین های سرعت متوسط (واقع در نزدیکی فرودگاه، Campo Grande ) ویاداکت و پس از خروج به بنفیکا/بوراکا ) تعداد تصادفات در این جاده را به شدت کاهش می دهد.
علت اصلی تصادفات جاده ای ناشی از عوامل انسانی است که در eixo norte-sul (Hotspot 7) ترکیبی بین این عوامل انسانی و محیطی (راه با زهکشی نامناسب و شرایط جوی) وجود دارد.
۵٫ نتیجه گیری ها
ما تشخیص دادیم که یک دوره ایدهآل برای جمعآوری دادهها هنگام انجام یک مطالعه در مورد تصادفات جادهای باید بین ۵ تا ۱۰ سال متوالی باشد، زیرا این فاصله نشاندهنده سازش بین تعداد سالهای مورد نیاز برای داشتن یک نمونه معقول از الگوهای فصلی است و هنوز در مرحله پردازش قرار دارد. دامنه.
بنابراین، اولین کار ترکیب شش پایگاه داده اصلی با داده های مرتبط برای این کار بود. این ترکیب داده ها امکان بهبود استخراج دانش را فراهم می کند. پس از جمع آوری داده های لازم، آنها پاکسازی و آماده شدند. استفاده از روشهای تجسم دادهها بر روی این ادغام، دیدگاه جدیدی را در مورد محل حادثه و شرایط در لیسبون فراهم میکند.
پس از این مرحله، مرحله اکتشاف داده های لازم و سپس کار پردازش و تحلیل جغرافیایی با استفاده از ArcGIS PRO نسخه ۲٫۸ و کاربرد الگوریتم های خودهمبستگی فضایی، یعنی تخمین چگالی هسته، شاخص موران I و تحلیل Hotspot Getis را انجام دادیم. -اُرد گی*.
نتایج به ما این امکان را می دهد تا دوازده خیابان مشکل زا و موقعیت چهارده نقطه حادثه رانندگی در شهرداری را شناسایی کنیم. تجزیه و تحلیل آمار هر نقطه داغ به ما اجازه داد تا بیان کنیم که عامل اصلی تصادفات رانندگی در شهر لیسبون عامل انسانی است که از جدول ۲ نتیجه گیری می شود. اکثریت قریب به اتفاق، اگر نگوییم مجموع علل RTA در مکان های مورد بررسی، به دلیل سرعت بیش از حد یا بی احترامی به علائم راهنمایی و رانندگی و علائم راهنمایی و رانندگی است. شهرداری محلی از این اطلاعات جغرافیایی نقطه داغ برای مکان یابی رادارهای سرعت جدید در شهر استفاده کرد. حدود ۲۲ رادار سرعت جدید با استفاده از این اطلاعات نقطه داغ قرار داده شد.
ما دیده ایم که عوامل محیطی (آب و هوا) تأثیر کمی بر تصادفات جاده ای در منطقه مورد مطالعه دارد، به استثنای دو مورد شناسایی شده، یعنی در یک منطقه مستعد سیل واقع در محور شمال-جنوب، در نزدیکی راهرو Duarte Pacheco . و در بخش Segunda در انتهای Avenida Eusébio de Silva Ferreira ، در نزدیکی خروجی IC19. به استثنای این عوامل، ما نتوانستیم هیچ عامل دیگری را شناسایی کنیم که می تواند یک حادثه رانندگی را تشدید کند. این نمونه دیگری از اطلاعات مفیدی است که از این فرآیند تجزیه و تحلیل داده ها بر روی داده های همجوشی شهر هوشمند تولید می شود.
از آنجایی که محصول یک مصنوع دیجیتال، یک خروجی و نه یک چارچوب است، باید اعتبارسنجی میشد، بنابراین کل فرآیند با پانل چهار متخصص از شاخههای مختلف مرتبط با حوزه پروژه همراه بود. چندین تکرار انجام شد و همچنین تغییرات/اصلاحاتی پیشنهاد شد.
مطالعاتی مانند این باید به طور منظم انجام شود و از وجود یک پایگاه داده یکپارچه با منابع داده استفاده شده و همچنین سایر منابع بهره مند شود.
به منظور تصحیح مشکلات پیش آمده در فرآیند بررسی داده ها برای داشتن یک پایگاه داده منسجم، تدوین مجموعه ای از توصیه ها برای پر کردن شکاف های اطلاعاتی شناسایی شده در فرآیند بررسی داده ها ضروری است:
-
ادغام بین IPMA و ANSR، به طوری که وقتی حادثه در پایگاه داده ANSR وارد می شود، مقادیر هواشناسی برای آن تاریخ، زمان و مکان به طور خودکار به BEAV اضافه می شود.
-
ادغام بین ANSR و دادههای جغرافیایی ارجاعشده برنامه کاربردی امن الکترونیکی اخیر از انجمن بیمهگران پرتغال [ ۴۰ ] اجازه میدهد مختصات حادثه با موارد ثبتشده توسط نیروهای امنیتی و ثبتشده در BEAV مقایسه شود.
-
علل تصادف را نیز می توان تجزیه و تحلیل کرد، به عنوان مثال، متراکم کردن داده های شناسایی علت تصادف: آیا رانندگان تحت تأثیر الکل بودند؟ آیا علت حواس پرتی تصادف به خاطر حضور آنها در تلفن همراه بوده است؟ چرا عابر پیاده با ماشین برخورد کرد؟ آیا او هدفون به سر داشت یا با تلفن همراه؟ این سؤالات و سؤالات دیگر به محققان این امکان را می دهد که در آینده مطالعات دقیق تری را با توجه به واقعیت تصادفات جاده ای با قربانیان در شهرداری لیسبون توسعه دهند.