۱٫ مقدمه
کاتالوگ های مکانی سیستم های کشف و دسترسی هستند که از فراداده به عنوان هدف برای جستجو در منابع مکانی استفاده می کنند [ ۱ ]. آنها معمولاً یا مجموعه داده های قابل دانلود مستقیم (مجموعه های قابل شناسایی از داده ها) یا خدماتی برای تجسم و دسترسی به این مجموعه داده ها هستند. فراداده نشان دهنده هدف، کیفیت، به موقع بودن، مکان، موضوعات و روابطی است که امکان کشف، ارزیابی و کاربرد منابع مکانی را در درون و فراتر از اهداف ارائه دهنده داده مبدأ فراهم می کند [ ۲ ].
هدف هر سیستم ذخیره سازی کاتالوگ این است که منابع موجود را قابل یافتن، در دسترس، قابل استفاده و قابل استفاده مجدد قرار دهد، که معمولاً به عنوان اصل FAIR شناخته می شود [ ۳ ]. با توجه به قابلیت یافتن، رویکرد رایج برای جستجوی داده های مکانی در کاتالوگ های مکانی، پرس و جو “مفهوم در مکان در زمان” است [ ۴ ]. یعنی کاربران انتظار دارند که کاتالوگ های مکانی اطلاعاتی را بر اساس ارتباط مفهومی، مکانی و زمانی خود با توجه به یک پرس و جو بازگردانند. این رویکرد طبیعی است، اما شناخته شده است که در دنیای واقعی بدون بهبود مؤلفههای مختلف فهرست مکانی با روشهای هوشمندسازی ابرداده یا استفاده از موتورهای جستجوی پیشرفته، بیاثر است [ ۵ ].]. آثار متعددی در ادبیات وجود دارد که بهبودهای جستجو را در تحقق اصول FAIR از طریق افزودن معناشناسی و هستیشناسی به ابرداده، استفاده از الگوریتمهای رتبهبندی جدید، یا تقویت ذخیرهسازی داده پیشنهاد میکنند [ ۶ ، ۷ ، ۸ ، ۹ ].
با این حال، هیچ یک از این پیشنهادات به عدم تطابق بین ماهیت پیوسته اطلاعات مکانی و ماهیت گسسته تولید داده ها نمی پردازد. هنگامی که یک پرس و جو به یک کاتالوگ جغرافیایی درباره مفهومی که گستره فضایی وسیعی را پوشش می دهد ارسال می شود، احتمالاً هیچ یک از منابع بازیابی شده کل وسعت را پوشش نخواهد داد (بیشتر نتایج فقط بخش های کوچکی از این گستره را پوشش می دهند). به عنوان مثال، یک تحلیلگر می تواند داده های مربوط به رفتار هیدرولوژیکی در یک رشته کوه معین را در یک فهرست جستجو کند. با این حال، مجموعه داده های حوضه رودخانه معمولاً یک حوضه واحد را پوشش می دهند، زیرا هر حوضه از نظر توپوگرافی از حوضه های مجاور توسط یک رشته کوه جدا می شود که یک شکاف زهکشی را تشکیل می دهد. از این رو، یک پرس و جو برای رودخانه ها (مفهومی) که رشته کوه (موقعیت) را پوشش می دهد، مجموعه ای از مجموعه داده ها را نشان می دهد که همه حوضه های رودخانه را توصیف می کند که در آن رشته کوه به عنوان تقسیم زهکشی در میان بسیاری دیگر که حاوی مفاهیم رودخانه و رشته کوه هستند، عمل می کند. اگر هیچ منبع واحدی حاوی تمام اطلاعات درخواستی وجود نداشته باشد، تحلیلگر مجبور است تمام نتایج جستجو را بررسی کند تا نتایجی را که حاوی اطلاعات مرتبط هستند پیدا کند و محتوای آنها را ادغام کند.
ما فکر می کنیم که یکی از منابع اصلی این مشکل عدم همسویی بین نیازهای کاربر و اهداف تولید کننده داده است. تولیدکنندگان داده منابع را بر اساس حوزه مسئولیت خود ایجاد می کنند. کاربران کاتالوگ ها را بر اساس حوزه های مورد علاقه خود جستجو می کنند. این حوزههای مورد علاقه ممکن است با موضوعاتی تعریف شوند که یک پیوستار فضایی را از دیدگاه کاربر پوشش میدهند، که لزوماً با حوزههای مسئولیت تولیدکنندگان داده مطابقت ندارد. بنابراین، کاتالوگ های مکانی اغلب ممکن است منابعی را که تا حدی منطقه پرس و جو را پوشش می دهند، بدون اطلاعات زمینه ای مفید برای کشف مجموعه هایی از نتایج که به عنوان یک مجموعه دیده می شوند، کل منطقه پرس و جو را پوشش می دهند، برگردانند. ما در نتایج به این مشکل به عنوان تکه تکه شدن داده ها اشاره می کنیم. این مشکل را می توان با شناسایی مجموعه منابعی که از نظر مفهومی به همان لایه موضوعی تعلق دارند، حل کرد. از طرف ارائهدهنده، یک راهحل برای این چالش استفاده از مجموعههای داده مکانی است که مجموعهای از مجموعه دادههای مکانی هستند که ویژگیهای مشابهی از موضوع، مقیاس یا هدف را به اشتراک میگذارند.۱۰ ]. با این حال، از دیدگاه کاربران، آنها کافی نیستند زیرا دادههای مربوط به یک منطقه میتوانند در مجموعههای داده مکانی مختلف از ارائهدهندگان دادههای مختلف پراکنده شوند. بنابراین، یک راه حل کلی تر برای شناسایی روابط موضوعی در منابع یک کاتالوگ جغرافیایی، ایجاد مجموعه داده های فضایی مجازی از آنها، و بازگرداندن آنها به عنوان بخشی از مجموعه های نتایج پرس و جوی مرتبط مورد نیاز است.
اهداف و مشارکت
پیشنهاد ما برای مقابله با تکه تکه شدن داده ها تغییر روش ارائه نتایج در کاتالوگ های مکانی است. مشکل بازیابی اطلاعات توصیف شده (IR) به طور خاص به انتخاب یک الگوریتم IR مربوط نمی شود، زیرا همه منابع را می توان تا حدی مرتبط در نظر گرفت، بلکه به نحوه ارائه قطعات اطلاعات (منابع فردی) به کاربران مربوط می شود. بهجای فهرستی از نتایج منفرد که بخشهایی از ناحیه درخواستشده را پوشش میدهد، فکر میکنیم که بهتر است این نتایج بر اساس سازگاری مکانی با توجه به وسعت مکانی مشخصشده در درخواست کاربر گروهبندی شوند. یعنی منابع سازگاری که به طور مشترک پاسخ بهتری به درخواست کاربر ارائه می دهند باید به صورت مجموعه ای نشان داده شوند.
برای تولید این مجموعهها، ما پیشنهاد میکنیم که رکوردهای فراداده را خوشهبندی کنیم تا مجموعههایی از منابع مشابه از ارائهدهندگان مختلف را که یک موضوع را توصیف میکنند شناسایی کنیم. به دلیل ایجاد ناهمگون، این منابع ممکن است فرمت، وضوح یا دانه بندی داده متفاوتی داشته باشند. با این حال، از آنجایی که آنها موضوع یکسانی دارند و اتحادیه آنها مناطق وسیع تری را نسبت به هر منبع جداگانه پوشش می دهد، این مجموعه ها می توانند توسط کاربران به عنوان پاسخی معتبر به جستجوی آنها درک شوند. ما میتوانیم این مجموعهها را بهعنوان مجموعه دادههای شبه فضایی نام ببریم، زیرا میتوان آنها را به عنوان مجموعههای مجازی از مجموعه دادههای فضایی توصیف کرد که برخی از ویژگیهای منتسب به سری دادهها را به اشتراک میگذارند. یعنی این مجموعه ها مجموعه ای از مجموعه داده های فضایی با مشخصات محصول نزدیک هستند. این سری ها بر اساس شباهت، منابعی را که سازگار هستند، جمع می کنند، از نیاز کاربر به انجام این تحلیل جلوگیری می کند. این مجموعهها احتمالاً حاوی منابعی با وضوح متفاوت، مناطق همپوشانی یا گستره زمانی متفاوت خواهند بود، اما، از دیدگاه کاربر، منابعی را جمعآوری میکنند که میتوان آنها را بهطور کلی به روشی مشابه با مجموعه دادهها مشاهده کرد. در مورد مجموعه دادهها، همگنی آنها باعث میشود یکپارچهسازی مستقیم آنها انجام شود، در حالی که مجموعه دادههای شبه مکانی پیشنهادی به هماهنگی محتوای آنها نیاز دارد. ما یکپارچه سازی داده ها را در این کار انجام نمی دهیم، اما این گام طبیعی بعدی پیشنهاد ارائه شده در این مقاله خواهد بود. به این ترتیب، کاربر می تواند اطلاعات موجود در مجموعه داده های شبه مکانی تعریف شده را به طور همگن به دست آورد. نواحی همپوشانی یا گستره زمانی متفاوت، اما از دیدگاه کاربر، منابعی را که میتوان به صورت کلی به روشی مشابه به مجموعه دادهها مشاهده کرد، جمعآوری میکند. در مورد مجموعه دادهها، همگنی آنها باعث میشود یکپارچهسازی مستقیم آنها انجام شود، در حالی که مجموعه دادههای شبه مکانی پیشنهادی به هماهنگی محتوای آنها نیاز دارد. ما یکپارچه سازی داده ها را در این کار انجام نمی دهیم، اما این گام طبیعی بعدی پیشنهاد ارائه شده در این مقاله خواهد بود. به این ترتیب، کاربر می تواند اطلاعات موجود در مجموعه داده های شبه مکانی تعریف شده را به طور همگن به دست آورد. نواحی همپوشانی یا گستره زمانی متفاوت، اما از دیدگاه کاربر، منابعی را که میتوان به صورت کلی به روشی مشابه به مجموعه دادهها مشاهده کرد، جمعآوری میکند. در مورد مجموعه دادهها، همگنی آنها باعث میشود یکپارچهسازی مستقیم آنها انجام شود، در حالی که مجموعه دادههای شبه مکانی پیشنهادی به هماهنگی محتوای آنها نیاز دارد. ما یکپارچه سازی داده ها را در این کار انجام نمی دهیم، اما این گام طبیعی بعدی پیشنهاد ارائه شده در این مقاله خواهد بود. به این ترتیب، کاربر می تواند اطلاعات موجود در مجموعه داده های شبه مکانی تعریف شده را به طور همگن به دست آورد. همگنی آنها باعث می شود که ادغام آنها مستقیم باشد، در حالی که مجموعه داده های شبه مکانی پیشنهادی نیاز به هماهنگی محتوای آنها دارد. ما یکپارچه سازی داده ها را در این کار انجام نمی دهیم، اما این گام طبیعی بعدی پیشنهاد ارائه شده در این مقاله خواهد بود. به این ترتیب، کاربر می تواند اطلاعات موجود در مجموعه داده های شبه مکانی تعریف شده را به طور همگن به دست آورد. همگنی آنها باعث می شود که ادغام آنها مستقیم باشد، در حالی که مجموعه داده های شبه مکانی پیشنهادی نیاز به هماهنگی محتوای آنها دارد. ما یکپارچه سازی داده ها را در این کار انجام نمی دهیم، اما این گام طبیعی بعدی پیشنهاد ارائه شده در این مقاله خواهد بود. به این ترتیب، کاربر می تواند اطلاعات موجود در مجموعه داده های شبه مکانی تعریف شده را به طور همگن به دست آورد.
این کار ارزیابی میکند که آیا فرآیندهای خوشهبندی پیشرفته میتوانند به طور موثر منابع مکانی را در مجموعه دادههای شبه فضایی جمعآوری کنند یا خیر، تنها با استفاده از اطلاعات متنی از عناصر موجود در سوابق فراداده مرتبط خود. برای شناسایی اینکه کدام فرآیند خوشهبندی برای این کار مناسبتر است، عملکرد بهدستآمده با استفاده از تمیز کردن دادههای مختلف، مدلهای نمایش ویژگی و الگوریتمهای خوشهبندی را مقایسه میکنیم. ارزیابی با مجموعهای از ۶۳۰ رکورد ابرداده بهدستآمده از کاتالوگ منتشر شده در IDEE (زیرساخت ملی دادههای فضایی اسپانیا)، یک زیرساخت پیشرو دادههای مکانی ملی در اروپا، انجام شده است. این رکوردها مطابق با استاندارد فراداده جغرافیایی ISO 19115 [ ۲]، حاوی اطلاعات متنی توصیفی در مورد طیف وسیعی از موضوعات مانند کاداستر، محیط زیست و زیرساخت ها است.
مشارکتهای این مقاله بر دو حوزه متمرکز است: مطالعه مشکل IR کاتالوگهای مکانی فعلی و مقایسه گزینههای مختلف خوشهبندی که میتواند این مشکل را کاهش دهد. به سوالات تحقیق زیر می پردازد:
- RQ1
-
چه چیزی باعث ناکارآمدی سیستمهای IR فهرست مکانی فعلی میشود و چگونه میتوان آنها را بهبود بخشید؟ برای پاسخ به این سوال، وضعیت فعلی فهرستهای مکانی را تحلیل میکنیم و مشکلات IR مربوط به ناهماهنگی بین ماهیت پیوسته اطلاعات مکانی و ساختار مبتنی بر کتابخانه دیجیتال این فهرستهای فراداده را توصیف میکنیم. بهعنوان راهحلی برای کاهش این مسائل IR، ما تولید مجموعههایی از منابع مرتبط را پیشنهاد میکنیم، که آنها را مجموعههای داده شبه فضایی مینامیم، که برای بهبود نمایش نتایج پرس و جو تعریف شدهاند.
- RQ2
-
آیا تکنیکهای خوشهبندی فعلی میتوانند مجموعه دادههای شبه فضایی با کیفیت خوبی تولید کنند؟ در اینجا، ما مجموعهای از رکوردهای فراداده را با مجموعه دادههای شبه مکانی برچسبگذاری شده دستی به عنوان خط پایه ایجاد کردهایم. سپس، آزمایشهایی را با پیکربندیهای فرآیند خوشهبندی چندگانه انجام دادهایم تا مشخص کنیم که آیا آنها میتوانند به طور خودکار مجموعهها را شناسایی کنند. ما انواع مختلفی از تمیز کردن داده های منبع را انجام می دهیم و نتایج را با استفاده از نمایش ویژگی کلاسیک TF-IDF با توجه به جاسازی های مدرن (Word2Vec، GloVe، FastText، ELMo، Sentence BERT و Universal Sentence Encoder) مقایسه می کنیم. به عنوان الگوریتم های خوشه بندی، ما K-Means، DBSCAN، OPTICS و خوشه بندی Agglomerative را مقایسه کرده ایم.
- RQ3
-
کدام فرآیندهای خوشه بندی برای این کار مناسب هستند؟ فرآیندهای مختلف انجام شده با توجه به مجموعههای برچسبگذاری شده دستی با استفاده از V-measure و Adjusted-Mutual-Information مقایسه میشوند. جدای از شناسایی بهترین پیکربندیها، ما همچنین به دنبال راهحلهای کلی هستیم (راهحلهایی که متن ورودی را به هیچ وجه از قبل پردازش نمیکنند) تا مشخص کنیم که آیا آنها به اندازه کافی خوب هستند که توسط یک کاتالوگ استفاده شوند یا خیر.
این مقاله به صورت زیر سازماندهی شده است: بخش ۲ آخرین تکنیکهای خوشهبندی را برای تولید مجموعه دادههای شبه فضایی مورد نظر توصیف میکند. بخش ۳ مشکلاتی را که باعث تکه تکه شدن داده ها در کاتالوگ های مکانی می شود معرفی می کند. بخش ۴ ویژگی های فرآیندهای خوشه بندی مورد استفاده در آزمایش ها را توضیح می دهد. سپس، بخش ۵ مجموعه داده ها و تنظیمات آزمایشی مورد استفاده برای آزمایش ها را ارائه می دهد و بخش ۶ نتایج به دست آمده را با توجه به مجموعه مرجع انتخاب شده مقایسه می کند. مقاله با بحث در مورد نتایج، نتیجهگیری و چشماندازی در مورد کار آینده به پایان میرسد.
۲٫ کارهای مرتبط
در زمینه کاتالوگ جغرافیایی، کارهای متعددی وجود داشته است که سعی در بهبود فرآیندهای جستجو به طرق مختلف دارد. لارسون و فرانتیرا [ ۱۱ ] مقایسه ای از چندین الگوریتم رتبه بندی برای اشیاء جغرافیایی ارجاع داده شده از جمله همپوشانی ساده، توپولوژیکی و وسعت انجام می دهند، سپس یک رتبه بندی فضایی احتمالی بر اساس رگرسیون لجستیک پیشنهاد می کنند که از مساحت همپوشانی به عنوان عامل تشابه اصلی استفاده می کند. ژان و همکاران [ ۱۲ ] یک مدل توصیف معنایی برای اطلاعات جغرافیایی پیشنهاد میکند که با استفاده از هستیشناسیها میتواند با مشکلات ناهمگونی در توصیفها مقابله کند. این پیشنهاد بر این متمرکز است که به کاربر اجازه می دهد تا معنای سؤالات خود را بیان کند تا نتایج به دست آمده بهبود یابد. ژانگ و همکاران [ ۱۳] رویکردی برای استخراج دادههای مکانی از منابع متعدد، مدلسازی آن بهعنوان RDF برای حذف ناهمگونی و پیوند آن با استفاده از یک الگوریتم تطبیق معنایی نشان میدهد. د آندراد و همکاران [ ۱۴ ] محدودیتهایی را که یافتن دادههای مکانی را در فهرستهای کنونی جغرافیایی دشوار میسازد، ذکر میکنند. برخی از مشکلات شناسایی شده استفاده از یک رکورد واحد برای توصیف انواع ویژگی در یک سرویس، فقدان معنایی در توضیحات و فقدان رتبه بندی مناسب برای سازماندهی نتایج در یک پرس و جو است. آنها چارچوبی با معیارهای رتبه بندی برای بهبود پرس و جوهای مکانی، معنایی، زمانی و چند بعدی پیشنهاد می کنند. لی و همکاران [ ۱۵] یک فرآیند بازیابی اطلاعات را برای کاتالوگ های مکانی توصیف می کند که از تحلیل نهفته معنایی برای بهبود اثربخشی موتورهای جستجو استفاده می کند. این امکان کشف معنایی بین الگوهای کلمه را فراهم می کند که امکان شناسایی منابع مرتبط را فراهم می کند که مستقیماً شامل عبارات پرس و جو نیستند. فوگازا و همکاران [ ۱۶ ] و Fugazza و همکاران. [ ۱۷ ] روشی را برای افزودن ویژگیهای معنایی به ابردادهها پیشنهاد میکند که امکان تفویض ابرداده را فراهم میکند و شناسایی روابط را تسهیل میکند و مدیریت تکامل آنها را ساده میکند. میائو و همکاران [ ۱۸ ] نشان می دهد که چگونه می توان اثربخشی کشف داده های مکانی را با استفاده از یک مدل اندازه گیری شباهت مکانی-زمانی بهبود بخشید. در نهایت لی و همکاران [ ۱۹] یک راه حل یادگیری عمیق را برای بهبود رتبه بندی جستجوی داده های مکانی با استفاده از گزارش های تعاملات قبلی کاربر در کاتالوگ توصیف می کند. آنها ارتباط داده ها را با توجه به تعامل کاربر مدل می کنند و از یک مدل رتبه بندی یادگیری عمیق برای تعیین ترتیب نتایج برای پرس و جوها استفاده می کنند. آنها یک معیار تشابه پیشنهاد می کنند که از حداکثر فاصله معنایی بین هر جفت گره در هستی شناسی مورد استفاده برای تطبیق و فاصله وزنی از پایین ترین گره جد مشترک تا گره ریشه استفاده می کند.
در زمینه کتابخانههای دیجیتال، خوشهبندی اغلب برای تولید مجموعهای از منابع مرتبط که جستجو و مرور را تسهیل میکنند، استفاده شده است. آگاروال و ژای [ ۲۰ ] مجموعه ای دقیق از تکنیک های کلاسیک خوشه بندی برای سازماندهی، مرور، خلاصه سازی و طبقه بندی اسناد می سازند. رکوردهای فراداده را می توان به عنوان اسناد کوتاهی در نظر گرفت که در آنها توضیحات نقش محتوای سند را ایفا می کند و بنابراین می توان بر اساس شباهت آنها خوشه بندی کرد.
یک جنبه اساسی خوشه بندی، نمایش ویژگی است. فرکانس سند، نمایه سازی معنایی پنهان، و فاکتورسازی ماتریس غیر منفی راه حل های کلاسیک برای این کار هستند [ ۲۰ ]. تعبیه کلمه یک نمایش کلمه اخیر است که برای خوشه بندی نیز مناسب است [ ۲۱ ، ۲۲ ]. کلمات را به یک مدل فضای برداری چند بعدی نگاشت می کند تا کلمات مشابه/مرتبط معنایی در آن فضا نزدیک باشند. چندین معماری شبکه عصبی وجود دارد که می تواند این تعبیه ها را ایجاد کند. Word2Vec [ ۲۳ ]، GloVe [ ۲۴ ]، یا FastText [ ۲۵ ]، ELMo [ ۲۶ ]، BERT [ ۲۷ ]، یا GPT-3 [ ۲۸ ]] از محبوب ترین ها هستند. آنها از معماری های مستقل از زمینه به معماری های وابسته به متن تبدیل شده اند که نتایج بهتری را برای درک معنایی کلمات ایجاد می کنند. از آنجایی که تعبیه کلمات بازنمایی کلمات هستند، برای نشان دادن جملات متنی، Arora و همکارانش. [ ۲۹ ] معانی مختلفی برای واژه جاسازی کلمات در یک جمله پیشنهاد کنید. جاسازی جملات تکامل جاسازی های کلمه برای رمزگذاری جملات کامل در نمایش های برداری است. آنها این مزیت را دارند که به طور مستقیم یک جمله را بدون در نظر گرفتن هر کلمه به طور مستقل در نظر بگیرند. محبوب ترین معماری ها Doc2Vec [ ۳۰ ]، Sentence BERT [ ۳۱ ]، InferSent [ ۳۲ ] و رمزگذار جمله جهانی [ ۳۳ ] هستند.]. نمونه ای از استفاده از embedding ها در خوشه بندی کوسنر و همکاران است. [ ۳۴ ]، که از حداقل فاصله بین جاسازی اسناد خود به عنوان معیار فاصله استفاده می کنند. به طور مشابه، ژانگ و همکاران. [ ۳۵ ] تولید طبقه بندی های طبقه بندی از اسناد را با استفاده از جاسازی کلمه محتوای سند توصیف می کند. آنها یک ماژول جاسازی را تعریف می کنند که تعبیه های متمایز را در سطوح مختلف طبقه بندی می آموزد. هو و همکاران [ ۳۶ ] تکامل موضوعات در مقالات علمی را از طریق نمایش آنها به عنوان تعبیههای Word2Vec و اندازهگیری همبستگی فضایی آنها در فضای تعبیهها تحلیل میکنند. آنها می سنجید که چگونه محبوبیت برخی از کلمات کلیدی بر کلیدواژه های اطراف تأثیر می گذارد. دیاز و همکاران [ ۳۷] تعبیه داده های متنی مکانی-زمانی را در نمایشی پیشنهاد می کند که امکان شناسایی الگوهای مرتبط با زمان و مکان فعالیت های انسانی توصیف شده به عنوان متن را فراهم می کند. مدل آنها اجازه می دهد تا دوره ها یا مکان های مرتبط با یک جمله و بالعکس را پیشنهاد کنند. لی و همکاران [ ۳۸ ] خوشه بندی متن را با استفاده از جمله BERT به عنوان رمزگذاری جملات متنی، یک لایه وزنی برای افزایش ارتباط جملات به عنوان تابعی از موجودیت های نام برده شده و K-means به عنوان الگوریتم خوشه بندی انجام می دهد. آرناس مارکز و همکاران [ ۳۹] استفاده از یک شبکه عصبی کانولوشن را برای شناسایی موضوعات مورد علاقه در مجموعه ای از پیام های TripAdvisor با استفاده از جاسازی Word2Vec از کلمات در اسناد به عنوان ورودی توصیف می کند. آنها این رویکرد را با توجه به کدگذاری نهفته تخصیص دیریکله متون و میانگین Word2Vec مقایسه می کنند.
الگوریتمهای خوشهبندی چندگانه میتوانند از این نمایشهای ویژگی استفاده کنند. الگوریتمهای پرکاربرد راهحلهای مبتنی بر فاصله مانند K-means، خوشهبندی فضایی مبتنی بر چگالی برنامههای کاربردی با نویز (DBSCAN)، یا نقاط ترتیب برای شناسایی ساختار خوشهبندی (OPTICS) و موارد احتمالی مانند Indexing معنایی پنهان احتمالی (PLSI) هستند. ) [ ۲۰ ]. کار زولا و همکاران. [ ۴۰ ] نمونه خوبی از این است که چگونه برخی از این تکنیک های خوشه بندی در حال حاضر در زمینه داده های مکانی برای شناسایی الگوها در مجموعه های متنی استفاده می شوند. آنها مکان کاربر توییتر را بر اساس توییتهایشان با استفاده از فرکانسهای Google Trends از اسمهای توییت و خوشهبندی برای شناسایی محتملترین مکان تخمین میزنند. نیومن و همکاران [ ۴۱] نشان میدهد که چگونه مدلهای موضوعی آماری مجموعهای از رکوردهای فراداده را به صورت موضوعی طبقهبندی میکنند و جستجوی وجهی را ارائه میکنند. لاکاستا و همکاران [ ۴۲ ] یک فرآیند خوشه بندی را برای ابرداده ها توصیف می کند که از ساختار سلسله مراتبی مفاهیم موجود در سیستم های سازماندهی دانش (KOS) برای بهبود نتایج خوشه بندی استفاده می کند. توماس و خان [ ۴۳ ] یک فرآیند خوشه بندی را برای اسناد پیشنهاد می کنند که از اطلاعات فراداده مرتبط با هر سند برای بهبود کیفیت خوشه ها استفاده می کند. راجان و همکاران [ ۴۴ ] یک فرآیند خوشهبندی را برای تجمیع توصیفات ثبت اختراع در گروههای مشابه برای تسهیل فرآیند جستجو در پایگاههای اطلاعاتی ثبت اختراع به تصویر میکشد. رکیب و همکاران [ ۴۵] یک روش طبقه بندی تکراری پیشنهاد می کند که خوشه بندی متون کوتاه را بهبود می بخشد. این کار با شناسایی نقاط پرت در طول فرآیند خوشه بندی و تغییر خوشه هایی که به آنها اختصاص داده شده اند انجام می شود. آنها این بهبود را برای انواع مختلف K-means و انواع خوشه بندی انبوه سلسله مراتبی اعمال می کنند تا قابلیت کاربرد در الگوریتم های خوشه بندی چندگانه را تعیین کنند. کای و همکاران [ ۴۶ ] الگوریتم خوشهبندی تطبیقی DBSCAN را پیشنهاد میکند، یک نوع DBSCAN برای مقابله با مسائل مربوط به اتصالات خطی بین خوشههای هدف و پیچیدگی پارامترسازی. از یک تقسیم کننده داده و ادغام هماهنگ در مراحل خوشه بندی محلی و جهانی استفاده می کند. این اجازه می دهد تا به صورت پویا خوشه ها را از محلی به جهانی کشف کنید. لو و همکاران [ ۴۷] تکامل روش های تحقیق در جامعه علم اطلاعات چین را تجزیه و تحلیل کند. چندین ویژگی، مانند زمان انتشار، سن محقق، تازگی یا تنوع مقاله، برای تجزیه و تحلیل در نظر گرفته شده است. برای شناسایی شباهتها بر اساس دوره، موضوع یا محقق، آنها آثار موجود در مجموعه تحلیلشده را با استفاده از شباهت فاصله اقلیدسی، تقسیمبندی حول Medoids و K-means خوشهبندی میکنند. Misztal-Radecka و Indorkhya [ ۴۸] یک الگوریتم خوشهبندی سلسله مراتبی آگاه از تعصب را برای بهبود سیستمهای توصیه با شناسایی خوشههایی از کاربران با توصیههای نامناسب توصیف میکند. این یک تغییر از K-means است که در آن تقسیم به جای واریانس حداقل به بایاس های بالا بستگی دارد. آنها این راه حل را با توجه به سایر گونه های K-means، خوشه بندی تجمعی، BDSCAN سلسله مراتبی و فاکتور دورافتاده محلی بین راه حل های دیگر مقایسه می کنند.
کار ارائه شده در این مقاله مشابه کارهای توصیف شده قبلی است که از تکنیک های خوشه بندی برای شناسایی شباهت ها در مجموعه های کتابخانه دیجیتال استفاده می کنند. با این حال، در مورد ما، ما خوشههایی را در توضیحات فراداده جستجو میکنیم که میتوانند بهعنوان مجموعه دادههای شبه مکانی طبقهبندی شوند، که محدودیتهایی در نحوه انجام فرآیند خوشهبندی ایجاد میکند. برای تجزیه و تحلیل مناسب بودن تکنیک ها و مدل های مختلف، مجموعه ای از تکنیک های خوشه بندی کلاسیک و مدرن را با هم مقایسه می کنیم. این شامل فرآیندهای مختلف پاکسازی داده ها، مدل های نمایش ویژگی و پارامترسازی الگوریتم های خوشه بندی می شود.
۳٫ کاتالوگ های جغرافیایی و زنجیره داده های مکانی
کاتالوگ های مکانی مخازن منابع مکانی هستند که توسط چندین ارائه دهنده تعریف شده و از طریق ابرداده توصیف شده اند. ارائه دهندگان داده به دلیل تعهدات قانونی، محدودیت های اقتصادی و تغییر اهداف در طول زمان بر حوزه های خاصی تمرکز می کنند.
این فهرستها از نظر فنآوری شبیه به کتابخانههای دیجیتال هستند، زیرا محتوای خود را مانند هر منبع دیجیتال مجزا دیگری (مثلاً یک عکس، یک کتاب یا یک ویدیو) مدیریت میکنند. با این حال، بعد فضایی باعث میشود محتوای کاتالوگ جغرافیایی مجموعهای از مناطق روی سطح زمین در مورد موضوعات ناهمگن باشد. احمد و علی [ ۴۹ ] مجموعه ای جامع از خدمات را با ۱۵۳ کاتالوگ فعال نشان می دهند که داده های مکانی را در سراسر جهان ارائه می دهند که از این رویکرد پیروی می کنند. در میان آنها، چند نمونه مرتبط عبارتند از کاتالوگ پان-اروپایی INSPIRE ( https://inspire-geoportal.ec.europa.eu/ ، دسترسی به ۲۶ نوامبر ۲۰۲۱) و کاتالوگ های ملی ایالات متحده آمریکا (GeoPlatform) ( https:// www.geoplatform.gov/، قابل دسترسی در ۲۶ نوامبر ۲۰۲۱)، اسپانیا (IDEE) ( https://www.idee.es/es ، مشاهده شده در ۲۶ نوامبر ۲۰۲۱)، بریتانیا (Data.Gov) ( https://data.gov.uk ، در ۲۶ نوامبر ۲۰۲۱، و کانادا (GeoDiscovery) ( https://geodiscover.alberta.ca/geoporta ، در ۲۶ نوامبر ۲۰۲۱ قابل دسترسی است).
این کاتالوگ ها راه حل ساده ای برای انتشار منابع ارائه می دهند، اما نحوه ارائه نتایج، قابلیت استفاده آنها را محدود می کند. اطلاعات جغرافیایی زنجیرهای را در اطراف زمین تشکیل میدهد که با موقعیت مکانی (نقطه، خط یا چندضلعی) و مضمون مشخص میشود، که انتزاعی مفهومی از ماهیت/هدف دادههای ارائهشده است. حتی انواع جغرافیایی گسسته، مانند مکانهای درختی، رودخانهها یا خیابانها، بخشی از مجموعه بزرگتری هستند که تمام سطح زمین را پوشش میدهند (مثلاً همه درختان، رودخانهها یا خیابانهای روی زمین). هر گونه تقسیم این پیوستار مصنوعی است و مدیریت داده ها را پیچیده تر می کند، زیرا پیوستار باید بازسازی شود تا اطلاعات توزیع شده در چند قطعه به دست آید. این به طور غیرمستقیم عملکرد هر سیستم جستجویی را با استفاده از این رویکرد کاهش می دهد زیرا نتایج داده های جزئی به عنوان نتایج کامل ارائه می شوند. این باعث می شود که نتایج جستجوهای “مفهوم در مکان در زمان” ناقص باشد، زیرا در بیشتر موارد، ناحیه مورد نظر کاربران با پارتیشن دلخواه داده های مکانی مطابقت ندارد. گویی هر منبع مکانی یک «صفحه کتاب» است که نویسنده، عنوان صفحه، تاریخ ایجاد، یا ناشر موجود در ابرداده میتواند به تصمیمگیری درباره اینکه کدام «صفحه کتاب» با نیازهای کاربر بهتر است، کمک کند، حتی اگر اطلاعات مورد نیاز ممکن است در تمام “کتاب” یافت می شود. تکه تکه شدن داده های مکانی چالش های موجود در مورد تولید، به روز رسانی و بهبود فراداده را افزایش می دهد. منطقه ای که توسط کاربران درخواست می شود با پارتیشن دلخواه داده های مکانی مطابقت ندارد. گویی هر منبع مکانی یک «صفحه کتاب» است که نویسنده، عنوان صفحه، تاریخ ایجاد، یا ناشر موجود در ابرداده میتواند به تصمیمگیری درباره اینکه کدام «صفحه کتاب» با نیازهای کاربر بهتر است، کمک کند، حتی اگر اطلاعات مورد نیاز ممکن است در تمام “کتاب” یافت می شود. تکه تکه شدن داده های مکانی چالش های موجود در مورد تولید، به روز رسانی و بهبود فراداده را افزایش می دهد. منطقه ای که توسط کاربران درخواست می شود با پارتیشن دلخواه داده های مکانی مطابقت ندارد. گویی هر منبع مکانی یک «صفحه کتاب» است که نویسنده، عنوان صفحه، تاریخ ایجاد، یا ناشر موجود در ابرداده میتواند به تصمیمگیری درباره اینکه کدام «صفحه کتاب» با نیازهای کاربر بهتر است، کمک کند، حتی اگر اطلاعات مورد نیاز ممکن است در تمام “کتاب” یافت می شود. تکه تکه شدن داده های مکانی چالش های موجود در مورد تولید، به روز رسانی و بهبود فراداده را افزایش می دهد.۵۰ ] و حفظ ابرداده های کامل، به روز و مفید را دشوار می کند. این امر باعث ناهمگونی و عدم هماهنگی در توصیفات حتی در نسخه های همان منبع می شود که یکی از دلایل عملکرد ضعیف آنها است [ ۵ ]. در نهایت، از آنجایی که نتایج ارائه شده تنها تا حدی مرتبط هستند، ارائه آنها به روشی مناسب برای کاربران دشوار است. یک لیست متوالی از نتایج زمانی گیج کننده است که نتایج ارائه شده تنها قطعاتی از داده ها در یک موضوع خاص باشد.
شکل ۱برخی از مشکلات تکه تکه شدن فضایی را به روشی ساده نشان می دهد. این پوشش منابع LIDAR در جنوب اسپانیا از ارائه دهندگان مختلف (شورای استانی مالاگا، کادیز، و هوئلوا) را نشان می دهد. آنها حاوی محتوای معادل هستند، اما هیچ ارتباطی بین آنها وجود ندارد. در کاتالوگهای جغرافیایی فعلی، یک پرس و جو که تمام جنوب اسپانیا را پوشش میدهد، فهرستی حاوی سه نتیجه (در میان سایر موارد) را نشان میدهد، زیرا آنها تا حدی نیازهای کاربر را پوشش میدهند. سپس، کاربر باید کل لیست نتایج را به صورت دستی بررسی کند تا مواردی را که نیازهای او را پوشش می دهد شناسایی کند. این ممکن است ساده به نظر برسد، اما اگر صدها منبع با مسائل مشابه وجود داشته باشد، یافتن منابع مرتبط میتواند زمانبر باشد. به عنوان مثال، یک پرس و جو در مورد تصویربرداری لیزری (LIDAR) در کاتالوگ اسپانیایی ۳۰۵ نتیجه را در مورد موضوعاتی مانند پوشش زمین ارائه می دهد. اطلاعات جنگل، آب، یا سواحل، از جمله. آنها بدون هیچ ترتیبی ارائه می شوند که بتواند شناسایی مواردی را که به طور ضمنی مرتبط هستند، ساده کند.
مشکل اینجاست که نیازهای فضایی کاربر با سازمان کلاسیک مبتنی بر کتابخانه دیجیتال سازگار نیست. به دلیل تقسیم بندی داده های مکانی، منبعی که داده های مورد نیاز کاربر را پوشش می دهد ممکن است حتی وجود نداشته باشد. در این زمینه، برای ارائه قابلیتهای جستجوی خوب و بهبود رضایت کاربر، باید کاتالوگهای مکانی را از سیستمهای IR برای تولیدکنندگان داده که با سوابق فرادادهای مستقل با ویژگیهای فضایی سروکار دارند، به سیستمهای IR برای مصرفکنندگان داده که با لایههای محتوای پیوسته سر و کار دارند، توسعه دهیم. هنیگ و بلگی [ ۵۱ ] و ماسو و همکاران. [ ۵۲] قبلاً نیاز به ساخت SDI های کاربر محور به جای تمرکز بر محصولات یا فرآیندها را برجسته کرده است. به طور خاص، آنها نیاز به بهبود توضیحات فراداده در کاتالوگ های مکانی را برای تمرکز بر نیازهای کاربر و جلوگیری از قطع ارتباط بین داده ها و توضیحات فراداده توصیف می کنند.
برنامههایی مانند Google Maps ( https://www.google.com/ ، دسترسی به ۲۶ نوامبر ۲۰۲۱) یا Open Street Map ( https://www.openstreetmap.org/ ، مشاهده شده در ۲۶ نوامبر ۲۰۲۱) نشان میدهند که لایههای پیوسته اطلاعات مکانی تجربه کاربر را در برخی سناریوها بهبود می بخشد. آنها لایه های یکپارچه اطلاعات را برای چند نوع داده مانند نقشه برداری، جاده ها و تجارت تجاری ارائه می دهند، به طوری که کاربران می توانند مستقیماً اطلاعات را در هر نقطه از کره زمین انتخاب، تجسم یا کپی کنند. این فرآیند جستجو را ساده می کند و مستقل از منطقه درخواستی، تمام اطلاعات در یک منبع واحد با فرمت و کیفیت یکسان است.
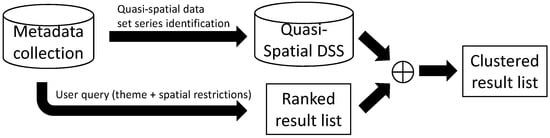
تعریف چنین لایه های پیوسته در حال حاضر قابل اجرا نیست. علاوه بر هزینه هنگفت تمیز کردن، هماهنگ سازی و یکپارچه سازی داده های موجود، مدیریت دستی و به روز رسانی منابع ایجاد شده توسط چندین ارائه دهنده با علایق مختلف بسیار دشوار خواهد بود. یک جایگزین برای این کار دستی، توسعه فرآیندی برای شناسایی خودکار منابع سازگار با موضوع است، به طوری که آنها می توانند به عنوان مجموعه ای در لیست های نتایج ارائه شوند. مجموعههای قابل شناسایی منابع مرتبط با موضوع، لایههای پیوسته نیستند، اما میتوانند نزدیکترین نمایش ممکن با ابردادههای موجود باشند. در آن شکل، برای کاربر سادهتر خواهد بود که تمام منابع مورد نیاز برای پاسخ به سؤال خود را به دست آورد. این ایده از مفهوم مجموعه داده های فضایی ناشی می شود. هنگامی که یک ارائه دهنده یک مجموعه داده مکانی از مجموعه ای از منابع یکنواخت و مشابه ایجاد می کند، کاربر می تواند آنها را به عنوان یک منبع واحد مدیریت کند. مجموعههایی را که میخواهیم شناسایی کنیم، میتوان بهعنوان مجموعه دادههای شبه فضایی نامگذاری کرد، زیرا، همانطور که قبلاً اشاره شد، مجموعهای از مجموعه دادههای مکانی با مشخصات محصول نزدیک هستند که میتوانند به سیستمهای IR برای ارائه نتایج فشردهتر کمک کنند.
فرآیند IR بهبود یافته برای کاتالوگ های مکانی با استفاده از این مجموعه داده های شبه مکانی در شکل ۲ نشان داده شده است . همه الگوریتمها و روشهای مورد استفاده در فرآیند جستجوی کاتالوگهای مکانی فعلی، فهرست رتبهبندیشدهای از نتایج را برمیگردانند. پیشنهاد ما شناسایی روابط بین مجموعه داده ها (سری داده های شبه فضایی) و استفاده از آنها برای خوشه بندی لیست نتایج در مرحله پس از پردازش پرس و جو است. این کار شامل گروه بندی منابع در لیست نتایج است که بخشی از همان مجموعه داده های شبه مکانی هستند و آنها را در بهترین موقعیت های رتبه بندی شده مجموعه نتایج قرار می دهد. میز ۱نشان می دهد که چگونه این تغییر سازمانی لیست نتایج را بهبود می بخشد. به دنبال مثال قبلی LIDAR، جدول زیرمجموعه انتخابی از ۳۰۵ نتیجه یک پرس و جو را با عبارت LIDAR نشان می دهد که طبق تعریف ما از مجموعه داده های شبه فضایی به کاتالوگ مکانی اسپانیایی ارسال شده است. نتایج برای اهداف توضیحی سادهسازی شدهاند تا نشان دهند که چگونه یک فهرست خوشهای از نتایج، روابطی را نشان میدهد که اگر فهرست سازماندهی نشده بود، پنهان میشدند. چند محصول چندین بار در لیست نتایج برای یک نوع داده در مناطق مختلف مانند نقاط LIDAR برای بخشهای اداری، Photogrammetric-LIDAR برای حوضه رودخانهها یا مدلهای ارتفاعی دیجیتالی رودخانهها و سواحل وجود دارد. گروه های نشان داده شده شباهت هایی در عناوین خود دارند، اما در بسیاری از موارد این کافی نیست. زیرا ممکن است توضیحات نشان دهد که محتوای آنها بسیار متفاوت است (به عنوان مثال، ابر نقاط آتش سوزی Cerro Muriano و حوضه رودخانه Guadalete-Barbate)، یا عناوین آنها ممکن است متفاوت باشد حتی اگر توضیحات آنها مشابه باشد. همچنین مهم است که توجه داشته باشید که خوشه های نشان داده شده فقط تا حدی سازگار هستند. آنها مربوط به سال های مختلف هستند و اگر عمیقاً مشاهده شوند، ممکن است فرمت ها، وضوح یا سایر جنبه های فنی ناسازگار متفاوتی داشته باشند. با این حال، از دیدگاه کاربر، دانستن آسان انواع منابع در دسترس یک پیشرفت مرتبط است، زیرا بخش یکپارچهسازی میتواند توسط او بر روی زیرمجموعه انتخابی نهایی که نیازهای او را برآورده میکند، انجام دهد. همچنین مهم است که توجه داشته باشید که خوشه های نشان داده شده فقط تا حدی سازگار هستند. آنها مربوط به سال های مختلف هستند و اگر عمیقاً مشاهده شوند، ممکن است فرمت ها، وضوح یا سایر جنبه های فنی ناسازگار متفاوتی داشته باشند. با این حال، از دیدگاه کاربر، دانستن آسان انواع منابع در دسترس یک پیشرفت مرتبط است، زیرا بخش یکپارچهسازی میتواند توسط او بر روی زیرمجموعه انتخابی نهایی که نیازهای او را برآورده میکند، انجام دهد. همچنین مهم است که توجه داشته باشید که خوشه های نشان داده شده فقط تا حدی سازگار هستند. آنها مربوط به سال های مختلف هستند و اگر عمیقاً مشاهده شوند، ممکن است فرمت ها، وضوح یا سایر جنبه های فنی ناسازگار متفاوتی داشته باشند. با این حال، از دیدگاه کاربر، دانستن آسان انواع منابع در دسترس یک پیشرفت مرتبط است، زیرا بخش یکپارچهسازی میتواند توسط او بر روی زیرمجموعه انتخابی نهایی که نیازهای او را برآورده میکند، انجام دهد.
شناسایی این مجموعه دادههای شبه مکانی کار آسانی نیست زیرا منابع موجود به طور یکنواخت توزیع نشدهاند و ویژگیهای متفاوتی دارند. توضیحات در فراداده آنها حاوی اصطلاحات حوزه فنی، مانند مقیاس، وضوح، یا قالب است. نام مکان های متنی که مکمل جعبه های مرزبندی فضایی عددی هستند. و اطلاعات مختلف در مورد موضوعات متعدد داده های توصیف شده (به عنوان مثال، کشاورزی، محیط زیست، آلودگی، یا کاداستر).
ادبیات آثاری در این زمینه دارد. به عنوان مثال، لاکاستا و همکاران. [ ۵۳ ] یک فرآیند IR را برای کاتالوگ های داده های جغرافیایی توصیف می کند که بر حل این مشکل تکه تکه شدن با شناسایی روابط فضایی/موضوعی ضمنی بین نتایج پرس و جو تمرکز می کند. فرآیند آنها بر یافتن منابعی که از نظر مکانی و موضوعی با پرس و جوی کاربر سازگار هستند و شناسایی موضوع و همپوشانی فضایی آنها متمرکز است. مجموعههای نتایجی که به این ترتیب ساخته شدهاند، درخواستهای کاربر را بهتر از هر منبع بهصورت جداگانه انجام میدهند (بخش بزرگتری از منطقه مورد نیاز برای کلمات کلیدی مورد نیاز را پوشش میدهند). با این حال، نیاز به ساخت پویا مجموعه نتایج تجمیع شده از هر پرس و جو انجام شده و پیچیدگی انتخاب نتایج سازگار موضوعی، کاربرد آن را پیچیده می کند. پیش از این، Latre و همکاران. [۵۴ ] فرآیندی را برای ادغام دادههای هیدرولوژیکی با ادغام هستیشناسیهایی که مدلهای آنها را نشان میدهند، پیشنهاد کرد. این فرآیند به بهای ایجاد هستیشناسیهای پیچیده که دادهها را توصیف میکند، امکان ارائه یک نمای واحد از مجموعههای دادههای تکهتکهشده را فراهم میکند.
ما فکر میکنیم که خوشهبندی یک رویکرد مناسب برای وظایف تجمیع دادهها مانند آنچه در این مقاله پیشنهاد شده است. با این حال، داده های مکانی دارای ویژگی هایی هستند که این فرآیند را دشوار می کند. اولاً، منابع باید بر اساس شباهت موضوعی و نه با ابعاد دیگر مانند مکان، قالب یا وضوح بین سایرین تجمیع شوند. علاوه بر این، تعداد مجموعه ها و ابعاد آنها ممکن است ناهمگن باشد و بسیاری از منابع ممکن است هیچ ارتباط موضوعی با بقیه نداشته باشند (آنها مستقل هستند). حل این مسائل ممکن است، اما نیاز به فرآیندهایی دارد که با داده های تجزیه و تحلیل شده سازگار شوند که ممکن است به مجموعه های دیگر تعمیم داده نشود. با توجه به این ملاحظات، هدف ما شناسایی نه تنها بهترین راه حل خوشه بندی، بلکه بهترین راه حل بین راه حل هایی بدون پیش پردازش داده ها بوده است.
۴٫ چارچوب ارزیابی
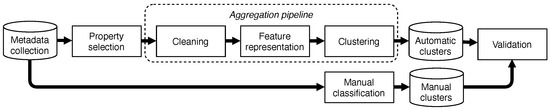
برای شناسایی مجموعه دادههای شبه مکانی در یک کاتالوگ جغرافیایی، اطلاعات متنی را در رکوردهای فراداده موجود خوشهبندی میکنیم. شکل ۳ جزئیات این فرآیند را نشان می دهد. پاکسازی ویژگیهای فراداده انتخابی را انجام میدهد، آنها را به ویژگیها تبدیل میکند و آنها را در مجموعه دادههای شبه مکانی خوشهبندی میکند. برای هر مرحله، ما راه حل های مختلف مورد استفاده در ادبیات را مقایسه کرده ایم. خط لوله توسعه یافته شامل فرآیندهای کلاسیک برای حذف عناصر نامطلوب است که بر نتایج تأثیر می گذارد. با این حال، از آنجایی که مراحل تمیز کردن مختص دادههای پردازش شده است، پیکربندیهای فرآیند را نیز بدون تمیز کردن آزمایش کردهایم.
۴٫۱٫ انتخاب ملک
مرحله اولیه انتخاب ویژگی های ابرداده برای پردازش است.
ما تصمیم گرفتهایم روی ویژگیهایی تمرکز کنیم که بهعنوان عنوان و چکیده عمل میکنند، زیرا آنها عناصر اصلی ابرداده هستند که با متن آزاد در رکوردهای ابرداده پر شدهاند. استفاده از عناصر کلیدواژه، اگرچه به مفاهیم اشاره دارد، اما جایگزین مناسبی نیست زیرا فقط شامل یک یا دو کلمه است که نمایش TF-IDF یا تعبیه کلمه به مفاهیم کلی اشاره دارد و احتمالاً خوشههای بزرگ و ناهمگن ایجاد میکند (ممکن است وجود داشته باشد). هزاران مجموعه داده به عنوان “پوشش زمین” طبقه بندی شوند). با توجه به طرحواره ابرداده، ویژگی عنوان دارای نام متمایز منبع است و ممکن است خلاصهای حداقلی از محتویات آن را بیان کند، در حالی که ویژگی انتزاعی محتویات منبع را با جزئیات بیشتری توصیف میکند. به طور کلی، اطلاعات بیشتری برای یک تکنیک خوشه بندی در دسترس است، بهتر می تواند شباهت منابع را شناسایی کند. با این حال، ما خوشهبندی حداکثر شباهت را نمیخواهیم، زیرا میخواهیم از خوشهبندی بر اساس مکان، مقیاس یا سایر جنبههایی که در سوابق فراداده که موضوع نیستند، توضیح داده شده اجتناب کنیم. در این زمینه، افزودن محتوای متنی بیشتر ممکن است منجر به تجمیعهای نادرست شود (یعنی خوشههایی از دادهها در مورد یک مکان اما موضوع متفاوت). برای ارزیابی تأثیر بالقوه این امکان، ما سه سناریو را ارزیابی کردهایم: استفاده از ویژگی عنوان به عنوان ورودی خوشهبندی، استفاده از تنها ویژگی انتزاعی به عنوان ورودی، و استفاده از هر دو ویژگی به عنوان ورودی. افزودن محتوای متنی بیشتر ممکن است منجر به تجمیعهای نادرست شود (به عنوان مثال، خوشههایی از دادهها در مورد یک مکان اما موضوع متفاوت). برای ارزیابی تأثیر بالقوه این امکان، ما سه سناریو را ارزیابی کردهایم: استفاده از ویژگی عنوان به عنوان ورودی خوشهبندی، استفاده از تنها ویژگی انتزاعی به عنوان ورودی، و استفاده از هر دو ویژگی به عنوان ورودی. افزودن محتوای متنی بیشتر ممکن است منجر به تجمیعهای نادرست شود (به عنوان مثال، خوشههایی از دادهها در مورد یک مکان اما موضوع متفاوت). برای ارزیابی تأثیر بالقوه این امکان، ما سه سناریو را ارزیابی کردهایم: استفاده از ویژگی عنوان به عنوان ورودی خوشهبندی، استفاده از تنها ویژگی انتزاعی به عنوان ورودی، و استفاده از هر دو ویژگی به عنوان ورودی.
۴٫۲٫ تمیز کردن
متن انتخاب شده به کلمات (توکن) تبدیل می شود و نشانه هایی که ممکن است بر نتایج خوشه بندی تأثیر منفی بگذارند حذف می شوند. برای این کار، ما مجموعه ای از فرآیندهای عادی سازی و تمیز کردن اولیه را از ادبیات برای افزایش یکنواختی توکن ها ارزیابی کرده ایم [ ۵۵ ]. به طور خاص، ما تمام ترکیبهای ممکن از فرآیندهای تمیز کردن زیر را آزمایش کردهایم: تبدیل به حروف کوچک، حذف کلمات توقف، حذف نام مکانها، حذف متن درون پرانتز، و کاهش فرمهای کلمه به ریشه. حذف کلمات توقف و نام مکان به لطف استفاده از فهرست کلمات انجام می شود. عبارات منظم برای حذف متن درون پرانتز استفاده می شود. در نهایت، ما از الگوریتم گلوله برفی برای پایه گذاری استفاده می کنیم [ ۵۶ ].
۴٫۳٫ نمایش ویژگی
مرحله بعدی توکن های پاک شده رکورد ابرداده را به ویژگی هایی تبدیل می کند که ورودی الگوریتم های خوشه بندی خواهند بود. به عنوان نمایش ویژگی، جاسازی های کلمه، جاسازی جملات و نمایش ماتریس کلاسیک TF-IDF را به عنوان خط پایه مقایسه کرده ایم.
نمایش ویژگی TF-IDF یک ماتریس سند-ترم است که در آن هر موقعیت است ( د، تی )حاوی بسامد یک عبارت t در رکورد d است که در فراوانی سند معکوس عبارت t در مجموعه D ضرب می شود . از انواع مختلف TF-IDF، ما از شکل نشان داده شده در معادله ( ۱ ) استفاده می کنیم. ارتباط یک اصطلاح موجود در یک سند را اندازه گیری می کند. عبارت فرکانس تعداد دفعات این عبارت در سند را در نظر می گیرد و فراوانی سند معکوس نشان می دهد که این عبارت در مجموعه چقدر نادر و آموزنده است تا ارزش TF-IDF اصطلاحات رایج را کاهش دهد. فراوانی عبارت t در یک رکورد ابرداده d تعداد دفعات آن عبارت است تیfتی ، دتقسیم بر تعداد کل عبارات در رکورد ابرداده ( s i ze ( د)). فراوانی ترم معکوس یک عبارت t در مجموعه، لگاریتم تعداد رکوردهای فراداده در مجموعه ( N ) تقسیم بر تعداد رکوردهای فراداده حاوی t در مجموعه است. دfتی).
تعبیههای کلمه، کلمات را بهعنوان یک مدل فضای برداری چندبعدی نشان میدهند، به گونهای که کلمات مشابه/مرتبط معنایی به عنوان نقاط نزدیک در آن فضا نشان داده میشوند. بسته به معماری شبکه عصبی استفاده شده و داده های آموزشی، پیاده سازی های متعددی از جاسازی کلمه وجود دارد. ما نمیتوانیم مستقیماً از این جاسازیهای کلمه استفاده کنیم، زیرا باید شباهت جملات کامل را با هم مقایسه کنیم تا مشخص کنیم آیا آنها در مورد یک موضوع هستند یا خیر. بنابراین، ما آنها را از طریق خلاصه کردن به یک نمایش جمله تبدیل می کنیم. برای این تبدیل، ما استفاده از میانگین وزنی جاسازی کلمه و میانگین وزنی جاسازی کلمه را در هر جمله مقایسه کرده ایم همانطور که در Arora و همکاران نشان داده شده است. [ ۲۹]. معنی جاسازی کلمه از میانگین جاسازی های مختلف هر سند به عنوان نمایش سند استفاده می کند. میانگین وزنی جاسازیهای کلمه از TF-IDF برای تنظیم وزن هر جاسازی استفاده میکند. نمایش جمله یک رکورد ابرداده ( d ) با استفاده از یک کلمه جاسازی شده ( s e→( د)( w e→(تیمن)) تقسیم بر تعداد عبارت های مختلف در رکورد ابرداده ( s i ze ( دمن s t i n c t (تیمن∈ د) )) (به معادله ( ۲ ) مراجعه کنید). هدف نمایش جمله میانگین وزنی ( s w e→( د)) برای اصلاح اختلاف فراوانی کلمات در مجموعه است، بنابراین عبارات رایج در میانگین وزن کمتری نسبت به موارد غیر معمول دارند. مانند معادله قبلی محاسبه میشود، اما با ضرب نمایش جاسازیهای کلمه هر عبارت مختلف در رکوردهای فراداده توسط TF-IDF چنین عبارتی در مجموعه (به معادله ( ۳ ) مراجعه کنید) محاسبه میشود. ما همچنین جاسازیهای جملات خالص را به عنوان نمایش ویژگی آزمایش کردهایم. این سیستم ها به طور مستقیم جملات را به عنوان یک مدل فضای برداری چند بعدی نشان می دهند و از نیاز به خلاصه کردن اجتناب می کنند.
به طور خاص، ما جاسازیهای زیر را که با مجموعههای متنی اسپانیایی (زبان دادههای آزمایش ما) ایجاد شدهاند، آزمایش کردهایم. به عنوان جاسازی کلمه، ما از Word2Vec [ ۵۷ ]، GLoVe [ ۲۴ ]، FastText [ ۲۵ ] تولید شده با مجموعه متن پیشنهادی توسط Cardellino [ ۵۷ ] و تعبیههای چند زبانه ELMo [ ۵۸ ] استفاده کردهایم. به عنوان جاسازی جملات، از جمله BERT [ ۳۱ ] و Universal Sentence Encoder [ ۳۳ ] استفاده کرده ایم.
۴٫۴٫ خوشه بندی
با توجه به ماهیت فدرال کاتالوگ های جغرافیایی، آنها شامل داده هایی از دولت ها و سازمان های ملی تا محلی هستند. دولت ها و سازمان های سطح بالا مجموعه داده هایی را منتشر می کنند که مناطق وسیعی را تحت صلاحیت خود پوشش می دهد. اینها، به نوبه خود، اغلب به واحدهای کوچکتر تقسیم می شوند که همچنین داده های مربوط به مناطق تحت صلاحیت خود را منتشر می کنند. در بسیاری از موارد، اما نه همیشه، مجموعه دادههای واحدهای کوچکتر را میتوان برای تشکیل مجموعه دادههای شبه مکانی جمع کرد. یعنی می توان آنها را به صورت خوشه ای دسته بندی کرد. برای مثال، میتوان با جمعآوری آدرسهای منتشر شده توسط دولتهای محلی، برای یک هدف خاص، یک روزنامه آدرس به صورت دستی ایجاد کرد. این مورد در مورد مجموعه داده های سطح بالایی نیست، زیرا آنها مجموعه های کامل هستند. یعنی خوشه های تک عنصری هستند. مثلا،
این ویژگی برای بسیاری از الگوریتمهای کلاسیک خوشهبندی مشکل است، زیرا آنها معمولاً قادر به شناسایی خوشههای تک عنصری نیستند. ما K-means [ ۵۹ ]، DBSCAN [ ۶۰ ]، OPTICS [ ۶۱ ] را مقایسه کردیم.] و خوشه بندی تجمعی. K-means، DBSCAN و OPTICS برخی از پرمصرفترین تکنیکهای خوشهبندی در ادبیات هستند، اما در خوشههای تک عنصری دارای اشکالاتی هستند. K-means خوشه های یک عنصری را تولید می کند، اما نیاز به انتخاب تعداد مورد نظر از خوشه ها به صورت دستی دارد و یافتن آن در هر مجموعه نیاز به آزمایش زیادی دارد. DBSCAN بسته به پیکربندی میتواند آنها را تولید کند، اما تنظیم پارامترهای بیش از حد آنها دشوار است. OPTICS کاملاً پایدار است، اما قادر به تولید خوشه های تک عنصری نیست. عناصر جدا شده را به خوشه های دیگر اختصاص می دهد یا آنها را به عنوان داده های جعلی علامت گذاری می کند. در نهایت، ما یک فرآیند خوشهبندی تجمعی را آزمایش کردهایم که مستقیماً امکان تولید خوشههای تک عنصری را فراهم میکند. این فرآیند سادهسازی یک الگوریتم خوشهبندی تجمعی است [ ۶۲] که ساختن درخت خوشه را متوقف می کند زمانی که شباهت بین تمام عناصر خوشه های مختلف کمتر از یک آستانه معین باشد. شباهت بین دو رکورد فراداده را با استفاده از فاصله کسینوس محاسبه میکند و جفتی را با بیشترین مقدار شباهت، یعنی حاصل ضرب نقطهای بین نمایشهای برداری رکوردهای فراداده تقسیم بر حاصلضرب هنجارهای آنها، جمعآوری میکند. این فرآیند تا زمانی تکرار می شود که بیشترین شباهت یافت شده کمتر از مقدار انتخاب شده باشد.
در این الگوریتمهای خوشهبندی، فراپارامترهای مربوط به حداقل اندازه خوشه به حداقل ممکن برای تسهیل شناسایی رکوردهای فراداده بدون هیچ رابطه یا خوشههای کوچک انتخاب شدهاند. مقادیر پارامترهای باقیمانده از طریق یک جاروی ارزش انجام شده با داده های آزمایش به دست آمده است. فاصله بین نمونهها در DBSCAN روی ۱٫۰۵ برای فاصله اقلیدسی و ۰٫۰۹ برای فاصله کسینوس تنظیم شده است زیرا مقادیر دیگر تعداد خوشههای ناهمگن یا تقسیم خوشههای یکنواخت را افزایش میدهند. به طور مشابه، در راه حل تجمعی، مقدار شباهت انتخاب شده برای تشخیص اینکه آیا دو منبع در یک خوشه هستند، ۰٫۹۸ تنظیم شده است. مقادیر بزرگتر تعداد زیادی مجموعه یکنواخت را تقسیم کردند و مقادیر پایین تر، مقادیر ناهمگن اضافی ایجاد کردند.
۴٫۵٫ اعتبارسنجی نتایج
ما نتایج هر رویکرد را با توجه به طبقهبندی دستی دادههای آزمایشی که توسط هیئتی متشکل از ۵ متخصص در زیرساختهای دادههای مکانی انجام شده است، مقایسه کردهایم. معیارهای کیفیت نتیجه مورد استفاده، امتیاز V-Measure [ ۶۳ ] و Adjusted-Mutual-Information (AMI) [ ۶۴ ] است.]. V-Measure میانگین هارمونیک بین همگنی و کامل بودن خوشه ها را محاسبه می کند. یک خوشه اگر فقط شامل اعضای یک کلاس باشد همگن است و اگر همه اعضای کلاس در خوشه باشند کامل است. پارتیشنهای دقیق هم همگن و هم کامل هستند و دارای امتیاز ۱ هستند. با توجه به AMI، وابستگی متقابل بین دو مجموعه از خوشهها را با توجه به اطلاعاتی که آنها به اشتراک میگذارند کمیت میکند. یعنی اندازه گیری می کند که چگونه یکی از مجموعه های خوشه اجازه می دهد از دیگری مطلع شویم. اطلاعات متقابل بین دو پارتیشن به عنوان مجموع احتمالاتی که هر منبع مجموعه برای تعلق داشتن به هر جفت خوشه دارد در لگاریتم نسبت مشاهده شده/انتظار شده تعلق به خوشه ها محاسبه می شود. سپس این متریک به گونه ای تنظیم می شود که مقادیری بین ۱ برای شباهت کامل و ۰ برای عدم تشابه کامل بگیرد. در هر دو مورد، ما معیارهای مقایسه خوشههای تولید شده در هر آزمایش را با توجه به خوشههای ایجاد شده در طبقهبندی دستی محاسبه میکنیم.
۵٫ توضیحات مجموعه داده
زیرساخت ملی داده های مکانی اسپانیا (IDEE) نهاد رسمی است که همکاری زیرساخت های داده های مکانی را که توسط ادارات دولتی در سطح ملی، منطقه ای و محلی راه اندازی شده است، هماهنگ می کند. در سال ۲۰۲۱، همکاری دولتهای ۱۹ منطقه خودمختار، ۱۴ آژانس ملی و ۳۹ شورای شهر ( https://www.idee.es/resources/documentos/Responsables_nodos_IDE.pdf ، دسترسی به ۲۶ نوامبر ۲۰۲۱) را ادغام میکند. از طریق ژئوپورتال IDEE (نامی که به پورتال این نوع زیرساخت داده شده است)، دسترسی به هزاران منبع (مجموعه داده و خدمات) در مورد هزاران موضوع با پوششی که از کل کشور تا یک شهرداری را شامل می شود، امکان پذیر است.
ما این مجموعه را انتخاب کردهایم زیرا حاوی مجموعه کاملی از منابع جغرافیایی منتشر شده در اسپانیا است. به طور خاص، این مجموعه از طریق یک فرآیند برداشت انجام شده است که محتویات کاتالوگ های در حال اجرا در طرح های مختلف SDI را که متعلق به دفاتر دولتی ملی یا دولت های منطقه ای است، بازیابی می کند.
ما ۴۸۲۴ رکورد فراداده را دانلود کردیم که این منابع را توصیف میکردند، اما همه آنها برای تجزیه و تحلیل در این مقاله مناسب نبودند. برای مقایسه بین فرآیندهای توصیف شده قبلی، ما زیر مجموعه ای از ۶۳۰ رکورد ابرداده را انتخاب کرده ایم که مجموعه داده ها را در این زیرساخت توصیف می کند. این رکوردها مطابق با استاندارد فراداده جغرافیایی ISO 19115 [ ۲]، حاوی اطلاعات متنی توصیفی در مورد طیف وسیعی از موضوعات مانند کاداستر، محیط زیست و زیرساخت ها است. آنها به این دلیل انتخاب شدهاند که همه آنها به زبان اسپانیایی هستند (سوابق دیگر زیادی وجود دارد که از زبانهای رسمی اسپانیایی مختلف استفاده میکنند)، و هیچ یک از آنها به عنوان بخشی از یک سریال صریح برچسبگذاری نشده است. در این زیرمجموعه، بسیاری از منابع حوزه های کوچکی را در مورد مضامین معادل پوشش می دهند، اما از آنجایی که توسط ارائه دهندگان مختلف ایجاد شده اند، هیچ رابطه صریحی در ابرداده خود ندارند. به این معنی که شامل مجموعههای منابع زیادی است که میتوانند بهعنوان مجموعه دادههای شبه فضایی سازماندهی شوند، که آن را برای مقایسه الگوریتمهایی که سعی در شناسایی چنین سریهایی دارند بسیار مناسب میسازد. علاوه بر این، اندازه مجموعه به تجزیه و تحلیل دستی آن اجازه می دهد تا یک خط پایه برای مقایسه نتایج ارائه دهد.
جدول ۲ برخی از ویژگی های مربوط به عنوان و ویژگی های انتزاعی ۶۳۰ رکورد ابرداده مورد استفاده در آزمایش ها را نشان می دهد. میانگین کلمات در هر فیلد و انحراف معیار نشان می دهد که بیشتر مقادیر متن تحلیل شده کوتاه هستند. اگرچه طولانی ترین چکیده شامل ۷۱۲ کلمه است، اکثریت آنها کمتر از ۲۵۰ کلمه و یک مجموعه مرتبط کمتر از ۱۰ کلمه دارند.
شکل ۴ نمونه ای از یک رکورد ابرداده اصلی در قالب XML و ترجمه شده به انگلیسی را نشان می دهد. همانطور که نشان داده شده است، معمولاً چنین توصیفاتی حاوی اطلاعات موضوعی در مورد ماهیت یا هدف داده ها همراه با عوامل دیگر مانند فرمت ها، مراجع مکانی و سایر مشخصات فنی داده ها است. بسیاری از عباراتی که اغلب در این توصیفات استفاده میشوند، رایج هستند، اما هیچ ارتباطی با انباشت موضوعی مورد نظر ندارند، بنابراین میتوانند باعث ایجاد خوشهبندیهای نامطلوب شوند.
عملکرد هر آزمایش با توجه به طبقهبندی دستی انجام شده توسط هیئتی از کارشناسان که ۸۰ سری مجموعه دادههای شبه مکانی را شناسایی کردهاند، ارزیابی شده است. بزرگترین خوشه دستی شامل ۱۱۹ عنصر است و ۱۱۱ رکورد ابرداده بدون رابطه وجود دارد. این طبقه بندی در یک فرآیند دو مرحله ای انجام شد. ابتدا ابرداده منابع به صورت دستی بررسی و بر اساس شباهت در توضیحات آنها گروه بندی شد (محتوای آنها معادل است). سپس، دادههای مربوط به هر خوشه شناسایی شده برای تعیین نحوه توزیع مکانی منابع موجود به تصویر کشیده شده است. تصمیم گیری در مورد صحت مجموعه های شناسایی شده با اجماع هیئت کارشناسی صورت گرفته است. ما شناسایی کرده ایم که موضوعات اصلی منابع مربوط به حفاظت از طبیعت است (پوشش گیاهی، فرسایش خاک، سیل، آب و هوا)، فعالیت های کشاورزی (زراعت، گاو، جنگلداری، هیدروگرافی، سدها، آبیاری)، صنعت (توزیع، آلودگی) و سازمان سیاسی (تقسیمات اداری، کاربری های اراضی). برخی از خوشههای شناساییشده مجموعهای از تصاویر هواشناسی از ماهواره LINDE هستند که شهرداریهای مختلف اسپانیا را پوشش میدهند، مجموعهای از فشارها که ورود زبالههای دریایی را در هر مرزبندی مختلف دریای اسپانیا ایجاد میکند، یا خوشهای با مناطق خطر سیل در رودخانهها و سواحل
۶٫ نتایج تجربی
این بخش نتایج تکنیک های مختلف خوشه بندی را با هم مقایسه می کند. به دلیل تعداد آزمایشها، ما پیکربندیهای فرآیند را با بهترین عملکرد برای هر الگوریتم نمایش ویژگی و خوشهبندی مختلف و فهرستی از ده بهترین آنها نشان میدهیم. علاوه بر این، از آنجایی که یکی از اهداف ما این بود که تشخیص دهیم آیا یک راه حل کلی بدون پاک کردن داده ها قابل اجرا است یا خیر، ما همچنین بهترین نتایج چنین تنظیماتی را نشان می دهیم.
جدول ۳پیکربندی های آزمایش استفاده شده و مخفف های نشان داده شده در جداول نتیجه را برای نشان دادن یک پیکربندی خاص خلاصه می کند. در مجموع، ۵۷۶۰ پیکربندی فرآیند آزمایش شده است. آنها همه ترکیبات ممکن از عناصر زیر هستند: “منبع داده” مورد استفاده در آزمایش ها عنوان، چکیده یا عنوان و چکیده با هم بوده است. فرآیندهای “تمیز کردن” مورد استفاده عبارتند از: حذف متن درون پرانتز (PT)، تبدیل تمام مقادیر متن به حروف کوچک (CS)، حذف کلمات توقف (SW)، حذف مکانها (P) و اعمال ریشه (ST) . این پنج فرآیند تمیز کردن ۳۲ ترکیب مختلف تمیز کردن را ایجاد می کنند. بهعنوان «مدل ویژگی»، از موارد زیر استفاده کردهایم: Word2Vec، GloVe، و ELMo جاسازیشده کلمه با استفاده از میانگین (M) و میانگین وزنی (WM) و TF-IDF، جمله BERT، و رمزگذار جملات جهانی که مستقیماً بازنمایی جملات را ارائه می دهد. در نهایت، الگوریتمهای «خوشهبندی» عبارتند از: خوشهبندی DBSCAN و OPTICS که با فاصله کسینوس (Cos) و اقلیدسی (Eucl)، KMEANS و خوشهبندی تجمعی (AG) محاسبه شدهاند. در مورد K-Means، تعداد خوشه هایی که باید ایجاد شوند به صورت دستی به تعداد مشخص شده در طبقه بندی دستی تنظیم شده است.
جدول ۴ بهترین پیکربندی را برای هر تکنیک نمایش ویژگی و خوشه بندی نشان می دهد. ستون ترتیب رتبه آزمایش را بر حسب نتیجه V-Measure نشان می دهد. نتایج دارای ترتیب تقریباً یکسانی با هر دو معیار و مقادیر شباهت بالا هستند. آنها نشان میدهند که امکان شناسایی خودکار مجموعه دادههای شبه مکانی در دادههای مجموعه با دقت بالا وجود دارد، اگرچه بسته به نمایش ویژگی و تکنیک خوشهبندی مورد استفاده، کیفیت نتایج متفاوت است.
در حالی که Word2Vec و GloVe با خوشهبندی تجمعی بهترین راهحلها هستند، نمایش کلاسیک TF-IDF و راهحلهای خوشهبندی مانند DBSCAN، OPTICS یا KMEANS در همه موارد بدتر عمل میکنند. تعجب آور نیست که نمایش جاسازی کلمه بهتر از TF-IDF کار می کند زیرا آنها بازنمایی های غنی تری هستند، اما توجه به این نکته مهم است که چگونه راه حل های جاسازی جملات خالص بدتر از خلاصه سازی کلمات جاسازی می شوند. ما فکر می کنیم که علت این امر تفاوت بین مجموعه های مورد استفاده برای آموزش تعبیه ها و اصطلاحات مورد استفاده در مجموعه آزمایشی است. از آنجایی که برخی از اصطلاحات مکانی تخصصی و فنی هستند، ممکن است در دادههای آموزشی مدلهای جاسازی جملات مورد استفاده در آزمایش ظاهر نشوند. نتایج خوشهبندی انباشته همانطور که انتظار میرفت بود، زیرا به صراحت طراحی شده بود تا مانند تکنیکهای دیگر از وارد کردن عناصر منفرد در داخل یک خوشه جلوگیری کند. با این حال، زمان اجرا بسیار بزرگتر از تکنیک های دیگر است. با استفاده از پردازنده i5-4590، DBSCAN میانگین هزینه ۰٫۰۳ ثانیه، K-means 0.16 ثانیه، OPTICS 0.83 ثانیه و خوشه بندی تجمعی ۳۰٫۷۷ ثانیه داشت. خوشهبندی انباشتهای دارای هزینهای سه مرتبه بزرگتر از سریعترین راهحل است، که با مجموعههای ابرداده بزرگ به یک مسئله مرتبط تبدیل میشود. و خوشهبندی تجمعی ۳۰٫۷۷ ثانیه. خوشهبندی انباشتهای دارای هزینهای سه مرتبه بزرگتر از سریعترین راهحل است، که با مجموعههای ابرداده بزرگ به یک مسئله مرتبط تبدیل میشود. و خوشهبندی تجمعی ۳۰٫۷۷ ثانیه. خوشهبندی انباشتهای دارای هزینهای سه مرتبه بزرگتر از سریعترین راهحل است، که با مجموعههای ابرداده بزرگ به یک مسئله مرتبط تبدیل میشود.
علاوه بر این، توجه به این نکته مهم است که در بیشتر موارد، استفاده از عناوین رکوردهای فراداده از نظر نتایج مرتبط نیست. محتوای آنها تمایل دارد تأثیر منفی بر نتایج داشته باشد. ما فکر می کنیم که این ناشی از اصطلاحات آنها است. حتی اگر توصیفها بسیار متفاوت باشند، عناوین مشابه هستند و اصطلاحات مشابهی در بسیاری از منابع تکرار میشوند. این امر باعث ایجاد اعوجاج های کوچک در خوشه های تولید شده می شود که نتایج به دست آمده را بدتر می کند. در نهایت، مراحل پاکسازی نشان میدهد که کلمات توقف و نام مکانها عناصری در ابرداده هستند که بهطور بیشتر بر خوشههای تولید شده تأثیر میگذارند. این نیز طبیعی است زیرا آنها کلمات رایج در تمام رکوردهای فراداده هستند، بنابراین بر نوع تجمع ایجاد شده تأثیر میگذارند (به عنوان مثال، خوشهبندی بر اساس مکان به جای موضوع).
جدول ۵۱۰ بهترین پیکربندی را بدون تمیز کردن داده ها نشان می دهد. می توان مشاهده کرد که تمیز کردن نتایج را بهبود می بخشد، اما تفاوت کم است. هشت پیکربندی اول از یک نمایش جاسازی کلمه و یک خوشهبندی تجمعی استفاده میکنند. دو مورد آخر از DBSCAN با فاصله اقلیدسی استفاده می کنند. در این مورد، ELMO، FastText و Word2Vec نتایج مشابهی دارند که هر دو معیار تفاوتهای کوچکی در ترتیب دارند. این واقعیت که دو نتیجه بهترین ELMO از تعبیههای میانگین (M) به جای میانگین وزنی (WM) استفاده میکنند، نشان میدهد که بافت کلمه در ELMO به تصحیح نمایش بیش از حد اصطلاحات رایج کمک میکند، که، در بقیه تکنیکها، با استفاده از میانگین وزنی جاسازی ها تنظیم می شود. دو نتیجه آخر از نظر عملکرد کمی با بقیه فاصله دارند،
در نهایت، جدول ۶ ۱۰ پیکربندی فرآیند را با بالاترین امتیاز V-Measure در بین تمام آزمایش های انجام شده نشان می دهد. می توان مشاهده کرد که چگونه استفاده از Word2Vec از GloVe با خوشه بندی انباشته همیشه بهترین نتایج را مستقل از مراحل دیگر ایجاد می کند. اگرچه ترتیب امتیاز AMI کمی متفاوت است، تغییر در ترتیب حداقل است.
۷٫ بحث
ما راهحلهای خوشهبندی چندگانه را روی یک مجموعه برچسبگذاری شده دستی آزمایش کردهایم تا تعیین کنیم که آیا مجموعه دادههای شبه فضایی مورد نظر میتواند به طور خودکار تولید شود یا خیر. نتایج چندین پیکربندی مناسب با عملکرد مشابه را نشان داده است.
میتوانیم بیان کنیم که استفاده از نمایش جاسازیهای کلمه، تولید مجموعه دادههای شبه فضایی مورد نظر را با توجه به TF-IDF کلاسیک، حتی زمانی که هیچ پاکسازی دادهای انجام نمیشود، بهبود میبخشد. به طور مشابه، جاسازیهای جملات میتوانند برای نمایش ویژگیها با کاهش اندک عملکرد استفاده شوند. نتایج بهدستآمده با نمایشهای جاسازی کلمه و جاسازی جملات همیشه بهتر از نمایشهای TF-IDF معادل است. این نشان می دهد که آنها اطلاعات موجود در رکوردهای ابرداده را بهتر بیان می کنند. با این حال، همچنین باید مراقب این راهحلها بود، زیرا ثابت شده است که جاسازیهای جملات به دادههای آموزشی وابسته هستند و تعیین نحوه رفتار آنها با مجموعههای دیگر با اصطلاحات متفاوت را دشوار میکند.
با توجه به خوشهبندی، حتی اگر خوشهبندی تجمعی از بقیه تکنیکهای تحلیلشده بهتر عمل میکند و به خوبی با مشکل خوشههای تک عنصری برخورد میکند، زمان اجرای آن ممکن است استفاده از آن را برای مجموعههای بزرگ منصرف کند. در این موارد، DBSCAN سریعتر است و ثابت کرده است که عملکرد نزدیکی دارد.
تولید سری دادههای شبه فضایی پیشنهادی محدودیتهایی را ارائه میکند که باید در نتایج بهدستآمده در نظر گرفته شوند. اولاً، فرآیند کاملاً به کیفیت ابرداده بستگی دارد. این نیاز به شرح کامل منابع دارد، بنابراین شباهت در تعاریف قابل محاسبه است. این ممکن است بدیهی به نظر برسد، اما در حال حاضر مجموعههای ابردادههای مکانی زیادی با توضیحات کوتاه وجود دارد که فرآیند پیشنهادی را نمیتوان اعمال کرد. ثانیاً به دلیل ماهیت الگوریتمها، اگرچه کیفیت تجمیعهای تولید شده خوب است، اما کامل نیست. بنابراین، نتایج باید توسط کاربران تفسیر شود تا مشخص شود که آیا آنها منطقی هستند یا خیر. در نهایت، پیشنهاد فعلی هیچ گونه ترتیب درون خوشه ای نتایج را ارائه نمی دهد. زیرا قادر به شناسایی ماهیت خوشه های شناسایی شده نیست. یک خوشه ممکن است حاوی منابعی باشد که در امتداد فضا توزیع شده و حاوی محتوای مشابه است، بر روی یک منطقه متمرکز اما با زمان های ایجاد متفاوت، یا هر دوی آنها به طور همزمان باشد. راه حلی برای این مشکل باید در کارهای آینده بررسی شود.
۸٫ نتیجه گیری
این مقاله نشان داده است که چگونه تکه تکه شدن فضایی در کاتالوگهای مکانی میتواند باعث ناکارآمدی در جستجوهای “مفهوم در مکان” شود. ما مشکلات IR موجود را خلاصه کرده و ناهماهنگی موجود بین ماهیت پیوسته اطلاعات مکانی و ساختار مبتنی بر کتابخانه دیجیتالی این فهرستهای فراداده را شرح دادهایم. برای حل این مشکل، ما شناسایی خودکار مجموعه دادههای شبه فضایی را پیشنهاد کردهایم تا نتایج انباشتهای را ارائه کنیم که میتواند برای بهبود فهرستهای نتایج پرس و جو استفاده شود.
ما نشان دادهایم که چگونه میتوان از تکنیکهای خوشهبندی فعلی برای تولید مجموعه دادههای شبه مکانی با کیفیت خوب با استفاده از مجموعه ابرداده اسپانیایی که به صورت دستی برچسبگذاری شده است، استفاده کرد. نتایج به وضوح نشان میدهد که استفاده از جاسازیهای کلمه با خوشهبندی تجمعی بهترین راهحل است، اما اگر زمان اجرا عامل مرتبط باشد، میتوان آن را با DBSCAN جایگزین کرد.
به عنوان کار آینده، ما می خواهیم رویکرد پیشنهادی را در جهت ارائه راه حل لایه پیوسته گسترش دهیم. مجموعه دادههای شبه مکانی شناساییشده را میتوان با استفاده از ابزار اتوماسیون ابرداده فضایی به سیستم IR کاتالوگ مربوطه اضافه کرد. به این ترتیب، آنها می توانند به عنوان نتایج پرس و جو ارائه شوند که یافتن داده هایی را برای کاربران آسان تر می کند که نیازهای آنها را برآورده می کند. برای این منظور، ما قصد داریم یک خط لوله غنیسازی ایجاد کنیم که امکان ادغام منابع ناهمگن مجموعه دادههای شبه مکانی را در یک منبع واحد فراهم میکند. این نه تنها برای بهبود قابلیت های جستجوی کاتالوگ های مکانی، بلکه برای تجزیه و تحلیل داده ها نیز مفید خواهد بود. به عنوان مثال، این لایههای یکپارچه شناسایی مناطق بدون دادهای در مورد یک موضوع یا یافتن مناطقی با کیفیت داده بهتر یا بدتر را ممکن میسازد. مشکلی معادل تقسیم بندی فضایی، تکه تکه شدن زمانی داده ها است. با توجه به ارتباط بیشتر جنبههای فضایی، ما فقط بر تکه تکه شدن فضایی تمرکز کردهایم، اما میخواهیم مشکل مدیریت زمانی را تجزیه و تحلیل کنیم تا مشخص کنیم که آیا همان راهحلهای پیشنهادی برای جنبههای فضایی قابل اعمال است یا خیر. به عنوان بخشی از این فرآیند، تحلیل اینکه آیا میتوان از عناصر فراداده اضافی استفاده کرد و نحوه برخورد با فهرستهای چندزبانه، ضروری است. یکی دیگر از زمینه های بهبود، شناسایی ماهیت خوشه ها و ارائه نتایج است. اگر بتوان رابطه مکانی یا زمانی موجود در هر خوشه را شناسایی کرد، محتوای هر خوشه را می توان به روشی منظم ارائه کرد که کار تجزیه و تحلیل محتوای نتایج را ساده می کند. با توجه به ارتباط بیشتر جنبههای فضایی، ما فقط بر تکه تکه شدن فضایی تمرکز کردهایم، اما میخواهیم مشکل مدیریت زمانی را تجزیه و تحلیل کنیم تا مشخص کنیم که آیا همان راهحلهای پیشنهادی برای جنبههای فضایی قابل اعمال است یا خیر. به عنوان بخشی از این فرآیند، تحلیل اینکه آیا میتوان از عناصر فراداده اضافی استفاده کرد و نحوه برخورد با فهرستهای چندزبانه، ضروری است. یکی دیگر از زمینه های بهبود، شناسایی ماهیت خوشه ها و ارائه نتایج است. اگر بتوان رابطه مکانی یا زمانی موجود در هر خوشه را شناسایی کرد، محتوای هر خوشه را می توان به روشی منظم ارائه کرد که کار تجزیه و تحلیل محتوای نتایج را ساده می کند. با توجه به ارتباط بیشتر جنبههای فضایی، ما فقط بر تکه تکه شدن فضایی تمرکز کردهایم، اما میخواهیم مشکل مدیریت زمانی را تجزیه و تحلیل کنیم تا مشخص کنیم که آیا همان راهحلهای پیشنهادی برای جنبههای فضایی قابل اعمال است یا خیر. به عنوان بخشی از این فرآیند، تحلیل اینکه آیا میتوان از عناصر فراداده اضافی استفاده کرد و نحوه برخورد با فهرستهای چندزبانه، ضروری است. یکی دیگر از زمینه های بهبود، شناسایی ماهیت خوشه ها و ارائه نتایج است. اگر بتوان رابطه مکانی یا زمانی موجود در هر خوشه را شناسایی کرد، محتوای هر خوشه را می توان به روشی منظم ارائه کرد که کار تجزیه و تحلیل محتوای نتایج را ساده می کند. اما ما می خواهیم مشکل مدیریت زمانی را تجزیه و تحلیل کنیم تا مشخص کنیم که آیا همان راه حل های ارائه شده برای جنبه های مکانی را می توان اعمال کرد یا خیر. به عنوان بخشی از این فرآیند، تحلیل اینکه آیا میتوان از عناصر فراداده اضافی استفاده کرد و نحوه برخورد با فهرستهای چندزبانه، ضروری است. یکی دیگر از زمینه های بهبود، شناسایی ماهیت خوشه ها و ارائه نتایج است. اگر بتوان رابطه مکانی یا زمانی موجود در هر خوشه را شناسایی کرد، محتوای هر خوشه را می توان به روشی منظم ارائه کرد که کار تجزیه و تحلیل محتوای نتایج را ساده می کند. اما ما می خواهیم مشکل مدیریت زمانی را تجزیه و تحلیل کنیم تا مشخص کنیم که آیا همان راه حل های ارائه شده برای جنبه های مکانی را می توان اعمال کرد یا خیر. به عنوان بخشی از این فرآیند، تحلیل اینکه آیا میتوان از عناصر فراداده اضافی استفاده کرد و نحوه برخورد با فهرستهای چندزبانه، ضروری است. یکی دیگر از زمینه های بهبود، شناسایی ماهیت خوشه ها و ارائه نتایج است. اگر بتوان رابطه مکانی یا زمانی موجود در هر خوشه را شناسایی کرد، محتوای هر خوشه را می توان به روشی منظم ارائه کرد که کار تجزیه و تحلیل محتوای نتایج را ساده می کند. یکی دیگر از زمینه های بهبود، شناسایی ماهیت خوشه ها و ارائه نتایج است. اگر بتوان رابطه مکانی یا زمانی موجود در هر خوشه را شناسایی کرد، محتوای هر خوشه را می توان به روشی منظم ارائه کرد که کار تجزیه و تحلیل محتوای نتایج را ساده می کند. یکی دیگر از زمینه های بهبود، شناسایی ماهیت خوشه ها و ارائه نتایج است. اگر بتوان رابطه مکانی یا زمانی موجود در هر خوشه را شناسایی کرد، محتوای هر خوشه را می توان به روشی منظم ارائه کرد که کار تجزیه و تحلیل محتوای نتایج را ساده می کند.