کلید واژه ها:
جمع سپاری فضایی ; تکلیف آنلاین ؛ الگوریتم راهزن چند مسلح ; الگوریتم بچینگ ریزدانه
۱٫ مقدمه
-
ما یک الگوریتم تخصیص کار مبتنی بر بچینگ ریز (FGBTA) برای مشکل تخصیص آنلاین در حالت دسته ای (OAPB) برای دستیابی به دسته بندی دقیق و بهبود کارایی تخصیص پیشنهاد می کنیم.
-
ما تنظیمات غیر ثابت را برای در نظر گرفتن تغییرات دینامیکی محیط معرفی میکنیم و از دو رانش مفهومی (پدیدهای که متغیر هدف در طول زمان تغییر میکند) برای تأیید اثربخشی الگوریتم در آزمایشها استفاده میکنیم.
-
ما اثربخشی و کارایی الگوریتم را بر روی داده های مصنوعی و داده های واقعی تأیید می کنیم. نتایج تجربی نشان میدهد که روش ما از نظر کاربرد کلی و زمان انتظار نسبت به روشهای مقایسه شده برتری دارد.
۲٫ کارهای مرتبط
۲٫۱٫ جمع سپاری و جمع سپاری اطلاعات جغرافیایی
۲٫۲٫ تخصیص آنلاین در حالت دسته ای
۲٫۳٫ راهزن چند مسلح (MAB)
۳٫ بیان مشکل
۳٫۱٫ تعاریف مربوط به تخصیص SC
تعریف ۱
تعریف ۲
-
نشان دهنده مهر زمانی است که در آن ظاهر می شود مختصات جغرافیایی با توجه به اینکه در کاربردهای عملی، کارگران (مانند رانندگان تاکسی) تمایل به حرکت پویا دارند و مختصات جغرافیایی آنها دائماً در حال تغییر است، فرض میکنیم که اگر در مدت معینی به کارگری تکلیف مناسبی محول نشود، کارگر باید به روز شود. موقعیت جغرافیایی او و زمان ظهور مربوطه ، و سپس به عنوان یک کارگر جدید روی سکو ظاهر می شود، یعنی ناپدید می شود و ظاهر می شود.
-
سرعت حرکت کارگران به محل کار را نشان می دهد.
-
و به ترتیب نشان دهنده طول و عرض جغرافیایی موقعیت جغرافیایی کارگران در .
-
به این معنی است که کارگران جمع سپاری نزدیک به مختصات جغرافیایی هستند در این دوره، و هنوز هم می توانند از این مختصات برای بیان موقعیت جغرافیایی خود استفاده کنند. شایان ذکر است که اگر کارگران جمع سپاری نتوانند وظیفه مناسبی را برای مطابقت در طول آن بیابند ، آنها مجدداً در فرآیند تطبیق پلت فرم در یک مهر زمانی جدید و یک مکان جدید شرکت خواهند کرد.
-
نشان دهنده شعاع سفارش قابل قبول برای کارگران جمع سپاری است. اگر فاصله سفارش از شعاع قابل قبول بیشتر شود، فکر می کنیم که موقعیت وظیفه خیلی دور است و ارسال بی پروا تجربه هر دو طرف را به شدت کاهش می دهد.
تعریف ۳
-
نشان دهنده زمان انتشار وظیفه است، یعنی زمانی که کار به سرور می رسد.
-
و نشان دهنده طول و عرض جغرافیایی موقعیت جغرافیایی کار است.
-
مدت زمان کار را نشان می دهد و مهر زمان انقضای کار است.
-
نشان دهنده توصیف خاص وظیفه فضایی است. در کاربرد ارسال سفارش تاکسی، توضیحات خاص آن عمدتاً از مقصد مشتری تشکیل شده است. ، جایی که نشان دهنده عرض جغرافیایی مقصد کار و طول جغرافیایی مقصد کار را نشان می دهد.
تعریف ۴
۳٫۲٫ تعاریف مسئله
تعریف ۵
تعریف ۶
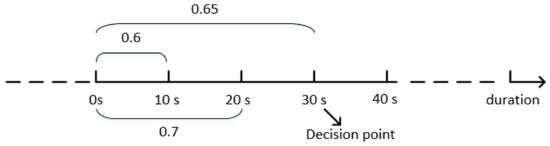
زمان انتظار درخواست کننده از دو بخش تشکیل شده است: (۱) زمان انتظار برای تعیین تکلیف، یعنی تفاوت بین زمان تعیین تکلیف و زمان انتشار به صورت بیان می شود. . (۲) زمان دریافت انتظار مصرف شده توسط کارگران جمع سپاری برای دریافت درخواست کنندگان، یعنی نسبت فاصله مکانی به سرعت، به صورت بیان شده است. . نشان دهنده فاصله بین وظیفه فضایی و کارگر است. بنابراین، کل زمان انتظار درخواست کننده به صورت تعریف می شود
تعریف ۷
(پاداش سفارش) . پاداش سفارش به سودی اشاره دارد که کارگران جمع سپاری می توانند هنگام تکمیل کار فضایی به دست آورند. در کاربرد راید-هیلینگ، پاداش کارگران اغلب با فاصله تا مقصدشان مرتبط است. بنابراین، ما از فاصله برای بیان پاداش سفارش استفاده می کنیم که با نمایش داده می شود
تعریف ۸
تعریف ۹
-
زمان انتظار کاربر:
-
پاداش سفارش:
-
میزان موفقیت تطبیق:
-
عملکرد عادی سازی زمان انتظار :
-
تابع عادی سازی پاداش سفارش :
-
میزان موفقیت تطبیق تابع عادی سازی :
امتیاز سودمندی یک مسابقه با فرمول زیر محاسبه می شود:
نمره کل سودمندی با فرمول زیر محاسبه می شود که در آن مطلوبیت متوسط است و وزن است .
تعریف ۱۰
(مشکل تخصیص آنلاین در حالت دسته ای، OAPB) . در یک سناریوی ایستا (همچنین به عنوان سناریوی آفلاین نیز شناخته میشود)، فرض بر این است که پلتفرم از ابتدا تمام اطلاعات مکانی-زمانی شرکتکنندگان، از جمله زمان رسیدن و مکان وظایف و کارگران را میداند. متفاوت از یک سناریوی آفلاین، یک سناریوی آنلاین بیشتر سناریوهای واقعی جمعسپاری فضایی را نشان میدهد، که در آن وظایف مکانی و کارگران جمعسپاری به صورت پویا وارد میشوند و اطلاعات مکانی و زمانی آنها را نمیتوان از قبل قبل از پایان زمان به دست آورد. با توجه به اطلاعات محدود به دست آمده توسط الگوریتم حریصانه تطبیق فوری، ما جریان زمانی را به مجموعه برش دادیم. با پردازش دسته ای هدف یک مشکل تخصیص آنلاین در حالت دسته ای یافتن مجموعه ای از جفت های منطبق است برای به حداکثر رساندن ابزار تطبیق .
۴٫ الگوریتم تخصیص وظایف مبتنی بر دسته بندی ریز (FGBTA)
۴٫۱٫ ایده پایه
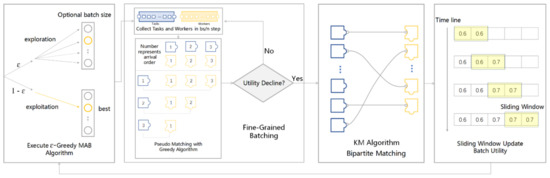
-
اجرای الگوریتم ϵ -greedy MAB: الگوریتم اندازه دسته اختیاری را با احتمال ϵ بررسی می کند و از اندازه دسته بهینه با احتمال ۱- ϵ استفاده می کند. کادر مستطیلی خاکستری در کادر الگوریتم ϵ -greedy MAB فهرستی از اندازه دسته اختیاری ذخیره شده را نشان می دهد. دایره نشان دهنده اندازه دسته اختیاری و دایره زرد نشان دهنده اندازه دسته بهینه است. الگوریتم یک اندازه دسته ای را برمی گرداند به عنوان ورودی الگوریتم بعدی.
-
الگوریتم بچینگ ریز دانه را اجرا کنید:
-
اولین مرحله تقسیم اندازه دسته به دست آمده است به قطعات.
-
مرحله دوم، هر بار که از این مرحله می گذرد، الگوریتم منتظر می ماند چند ثانیه برای ورود به وظایف فضایی جدید و کارگران جمع سپاری. جعبه کوچک در گوشه سمت چپ بالای جعبه بچینگ ریز دانه این فرآیند را بیان می کند. هر قطعه پازل آبی در صف سمت چپ نشان دهنده یک کار فضایی است و هر قطعه پازل زرد رنگ در صف سمت راست نشان دهنده یک کارگر جمع سپاری است.
-
مرحله سوم استفاده از الگوریتم حریص برای انجام شبه تطبیق و محاسبه مطلوبیت است. در فرآیند تطبیق شبه، ما از اصل اولین خدمت برای یافتن کارگران جمع سپاری مناسب برای وظایف استفاده می کنیم. جعبه در گوشه سمت چپ پایین جعبه بچینگ ریز دانه این فرآیند را بیان می کند. قسمت بالای جعبه نشان دهنده وظایف و کارگران موجود است و اعداد ترتیبی در قطعات پازل نشان دهنده ترتیب رسیدن آنها به سکو است. قسمت پایین روند تطبیق الگوریتم را نشان می دهد. وظیفه ۱ ابتدا می رسد، ابتدا انتخاب می کند و کارگر جمع سپاری ۳ را انتخاب می کند. سپس، هنوز دو گزینه برای کار ۲ وجود دارد و کارگر جمع سپاری ۲ را انتخاب می کند. در نهایت، تنها کارگر جمع سپاری ۱ برای کار ۳ موجود است و فقط می تواند جمع سپاری را انتخاب کند. کارگر ۱٫
-
مرحله چهارم، اگر ابزار دسته ای محاسبه شده کاهش نیابد، به این معنی که وظایف و کارگران جمع سپاری بیشتری را می توان در دسته ذخیره کرد، به مرحله دوم باز می گردد. اگر کاربرد دسته کاهش یابد، داده های جمع سپاری بیشتری را نمی توان در دسته ذخیره کرد و الگوریتم بعدی وارد می شود. این فرآیند در جعبه قضاوت در سمت راست جعبه بچینگ ریز دانه بیان میشود، که برای قضاوت در مورد کاهش کاربرد دستهای استفاده میشود. اگر نه، به مرحله دوم بازگردید. در غیر این صورت الگوریتم بعدی را وارد کنید.
-
-
اجرای الگوریتم KM: اجرای الگوریتم KM: این یک فرآیند تطبیق دو بخشی است. قطعات پازل آبی سمت چپ در کادر KM وظایف فضایی موجود را نشان میدهند و قطعات پازل زرد در سمت راست نشاندهنده کارگران جمعسپاری موجود هستند. یک قطعه کمتر از پازل در سمت راست برای نشان دادن اینکه تعداد گره های چپ و راست در صحنه تخصیص کار واقعی اغلب نابرابر است استفاده می شود.
-
اجرای الگوریتم SW برای بهروزرسانی ابزار دستهای: برای یک محیط غیر ثابت، روش SW امتیازهای ابزار کوتاهمدت دستهها را حفظ میکند تا اثرات نامطلوب ناشی از کاربرد تاریخی را حذف کند. خط زمانی سمت چپ در SW نشان دهنده گذر زمان است. با گذشت زمان، ابزار جدید وارد صف می شود. جعبه متحرک زرد نشان دهنده پنجره کشویی و طول جعبه متحرک نشان دهنده طول پنجره کشویی است. لغزش پنجره به سمت راست به معنای دریافت داده های جدیدتر است.
۴٫۲٫ الگوریتم دسته بندی ریز دانه
از نظر دانه بندی ریز، مجموعه ای از اندازه های دسته ای قابل انتخاب را با توجه به زمان انقضا طراحی می کنیم از وظیفه از آنجایی که حداقل فاصله زمانی یک ثانیه است، وجود دارد انواع دسته هایی که می توانند انتخاب شوند اگر طراحی هر یک ثانیه انجام شود، که بسیار گران است. بنابراین، ما دسته های اختیاری را در فواصل زمانی مشخص تنظیم می کنیم. با فرض اینکه طول فاصله است ، مجموعه ای از اندازه دسته اختیاری است . سپس از الگوریتم MAB برای پیشبینی اندازه دسته مناسب استفاده میکنیم و آن را به چند دوره زمانی تقسیم کنید . با گذشت زمان در دنیای واقعی، پلتفرم وظایف فضایی و کارگران جمعسپاری را جمعآوری میکند، از تطبیق شبه الگوریتم ۱ استفاده میکند و سودمندی را با توجه به نتایج شبه تطبیق محاسبه میکند. در این مقاله، کاربرد دسته ای، امتیاز سودمندی اندازه دسته است. روند محاسبه ابزار دسته ای به شرح زیر است:
جایی که امتیاز سودمندی تطبیق یک جفت است، نشان دهنده امتیاز ابزار اندازه دسته است، نشان دهنده تمام جفت های منطبق تشکیل شده در این دسته است، نشان دهنده تعداد تمام جفت های منطبق است، نشان دهنده اندازه دسته این دسته است، یک پارامتر قابل تنظیم است.
در نهایت، زمانی که مطلوبیت افزایش مییابد و شروع به کاهش میکند، به طور کلی، ما فکر میکنیم که نقطه تصمیمگیری بهینه گذشته است و در اینجا نزدیکترین موقعیت موجود به نقطه بهینه است. بنابراین، تطبیق واقعی الگوریتم KM را در این مرحله انجام می دهیم.
| الگوریتم ۱ تطبیق شبه با الگوریتم حریص |
| ورودی : یک مجموعه از ترتیب وظایف بر اساس مُهر زمانی، مجموعه ای از کارگران خروجی : مقدار کاربرد اندازه دسته ای ۱: مجموعه تطبیق اولیه درون دسته ای ; ۲: برای که در : ۳: کارگر پیدا کنید برای به حداکثر رساندن امتیاز سودمندی از جانب ۴: حذف کنید از جانب ۵: ۶: مقدار ابزار اندازه دسته را محاسبه کنید با ست کبریت ; ۷: بازگشت ; |
۴٫۳٫ استفاده از رویکرد پنجره کشویی (SW) برای مقابله با تنظیمات غیر ثابت
ما از یک صف اندازه استفاده می کنیم (در اینجا مسیر داغ نامیده می شود) در هر اندازه دسته برای ذخیره امتیاز ابزار اخیر . هنگام انتخاب اندازه دسته بهینه، مقدار متوسط از امتیاز سودمندی برای نشان دادن ابزار فعلی اندازه دسته استفاده می شود تا بچ بهینه را در نقطه زمانی فعلی ردیابی کند. فرمول محاسبه از است:
در نهایت FGBTA را در الگوریتم ۲ ارائه می کنیم.
| الگوریتم ۲ الگوریتم تخصیص وظایف مبتنی بر دسته بندی ریزدانه با در نظر گرفتن تنظیمات غیر ثابت |
| ورودی : یک مجموعه از وظایف، یک مجموعه از کارگران، مهر زمانی تنظیم شده است ، نرخ اکتشاف ، پارامتر قابل تنظیم , خروجی : ردیابی انتخاب اندازه دسته ای کل جریان داده ۱: مقدار اولیه اکتشاف ، مجموعه وظایف خالی است ، کارگران خالی مجموعه ، اندازه دسته = ۰، مجموعه دسته ای اختیاری ; ۲: مقدار اولیه ردیابی داغ در هر اندازه اختیاری برای ثبت اخیر مقدار ابزار اندازه دسته ای، مجموعه مسابقات ; ۳: هنگام دریافت مهر زمانی انجام دهید : ۴: اگر سپس : ۵: کاوش: ; ۶: else ۷: اندازه دسته بهینه را با میانگین مقدار ردیابی داغ پیدا کنید ; ۸: بهره برداری: ; ۹: پایان ۱۰: مجموعه فاصله: ; ۱۱: مقداردهی اولیه ، ; ۱۲: برای فاصله در : ۱۳: جمع آوری وظایف و کارگران از جانب ; ۱۴: الگوریتم ۱ را اجرا کنید و مقدار ابزار اندازه دسته ای را دریافت کنید با فرمول (۷) و (۸)؛ ۱۵: اگر : ۱۶: ۱۷ : شکستن ۱۸: else : ۱۹: ; ۲۰: پایان ۲۱: برای کارهای ورودی و کارگران ورودی که در do : ۲۲: جمع آوری وظایف و کارگران: ; ۲۳: اجرای الگوریتم انتساب وظیفه و ، ; ۲۴: اندازه دسته ای را پیدا کنید کدام نزدیک به پله ۲۵: مقدار کاربرد اندازه دسته ای را دریافت کنید با فرمول (۷) و (۸)؛ ۲۶: ۲۷: اگر : ۲۸: حذف اولین عنصر از ۲۹: پایان ۳۰: ; |
۵٫ مطالعه تجربی
۵٫۱٫ راه اندازی آزمایشی
-
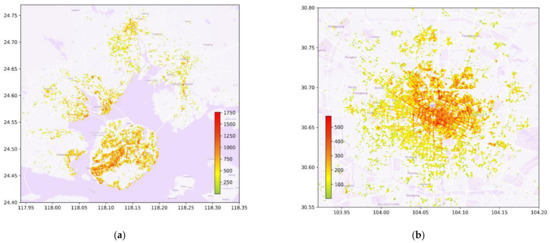
دادههای سفارش آنلاین غیرحساسیتزدایی شده خودرو از رقابت برنامههای باز و نوآورانه امنیت داده بزرگ Xiamen [ ۷۱ ] آمده است. بازه زمانی از ۳۱ مه ۲۰۱۹ تا ۹ ژوئن ۲۰۱۹، و محدوده مکانی از عرض جغرافیایی ۲۴٫۲ درجه تا ۲۴٫۸ درجه، طول جغرافیایی ۱۱۷٫۷ درجه تا ۱۱۸٫۷ درجه، با کل داده ۳,۰۲۷,۴۸۸ قطعه است. با توجه به اطلاعات سفارش آنلاین خودرو در Xiamen در تاریخ ۱ ژوئن ۲۰۱۹، ما نقشه حرارتی توزیع سفارش را ترسیم کردیم. هرچه رنگ در افسانه قرمزتر باشد، عدد بزرگتر است، که نشان دهنده تراکم سفارش بالاتر است. نقشه حرارتی در شکل ۳ الف نشان داده شده است.
-
داده های سفارش تاکسی حساسیت زدایی شده از طرح بازگشایی داده های Gaia [ ۷۲ ] آمده است. محدوده زمانی از ۱ نوامبر ۲۰۱۶ تا ۳۰ نوامبر ۲۰۱۶ است. محدوده فضا از عرض جغرافیایی ۳۰٫۵۷۱۵۳۲ درجه تا ۳۰٫۷۹۱۹۱۹ درجه و طول جغرافیایی ۱۰۳٫۹۳۸۲۱۵ درجه تا ۱۰۴٫۲۱۵۳۴ درجه است. مقدار کل داده ها ۶۸۴۴۲۵۳ است. طبق داده های سفارش تاکسی ها در چنگدو در تاریخ ۱ نوامبر ۲۰۱۶، ما یک نقشه حرارتی از توزیع سفارش رسم کردیم که در آن هر چه رنگ در افسانه قرمزتر باشد، عدد بزرگتر است، به این معنی که بیشتر است. تراکم سفارش نقشه حرارتی در شکل ۳ نشان داده شده استب شایان ذکر است که دو شکل از حداکثر چگالی و حداقل چگالی متفاوت استفاده می کنند، بنابراین رنگ یکسان به معنای تراکم ترتیب یکسان نیست. تشخیص سفارش آنلاین خودرو یا سفارش کروز از ویژگیهای سفارش تاکسی دشوار است، بنابراین ما سفارشهای تاکسی را به همین ترتیب انجام میدهیم، خواه سفارشات آنلاین خودرو باشند یا نه، زیرا اطلاعات ویژگی دیگری وجود نداشت که به ما کمک کند تشخیص دهیم. آیا این یک سفارش سفر دریایی بود یا نه.
-
الگوریتم حریص (GR). این الگوریتم کمی با الگوریتم ۱ در این مقاله متفاوت است. این یک الگوریتم بلادرنگ ساده است که مؤثرترین تطابق را برای کارهای فضایی یا جمعسپاری کارگران بدون دستهبندی انتخاب میکند. در یک مورد سفارش متوسط، این یک الگوریتم رقابتی است.
-
الگوریتم دسته ای ثابت (FB). اندازه دسته ای الگوریتم یک مقدار ثابت است. در محیط غیر ثابت، اندازه بهینه دسته ثابت با ورود ورودیهای جدید تغییر میکند. بنابراین، اندازه دسته بهینه را برای هر آزمایش آزمایش می کنیم. تطبیق درون دسته ای از الگوریتم KM استفاده می کند.
-
ϵ-الگوریتم MAB حریص (G-MAB). این الگوریتم از استراتژی ϵ-greedy برای متعادل کردن اکتشاف و بهره برداری، همراه با الگوریتم MAB استفاده می کند تا دسته مناسبی را برای جریان ورودی در طول زمان انتخاب کند تا حداکثر سود ممکن را به دست آورد.
-
ϵ-MAB حریص با اکتشاف متغیر (GV-MAB). این الگوریتم به صورت پویا نرخ کاوش را بر اساس الگوریتم قبلی تنظیم میکند، که میتواند کارایی تخصیص وظیفه پویا را در کل بهبود بخشد و سازگاری خوبی را نشان دهد [ ۲۴ ].
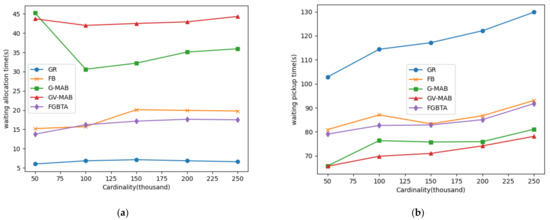
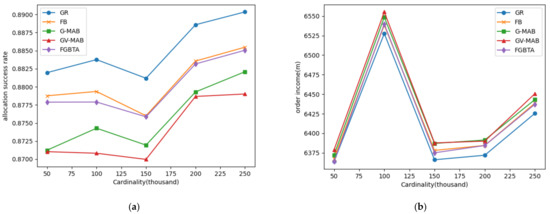
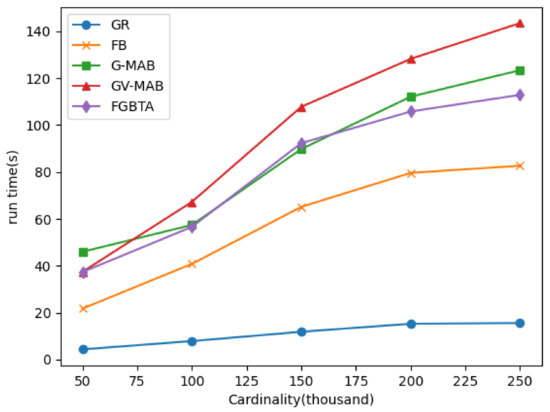
۵٫۲٫ نتایج تجربی
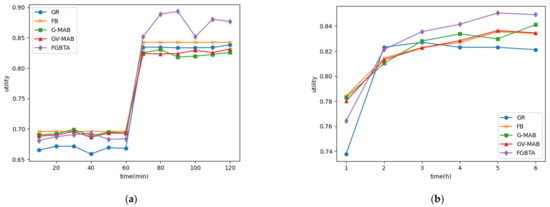
۵٫۲٫۱٫ عملکرد الگوریتم در مجموعه داده های مصنوعی
تاثیر دریفت مفهومی
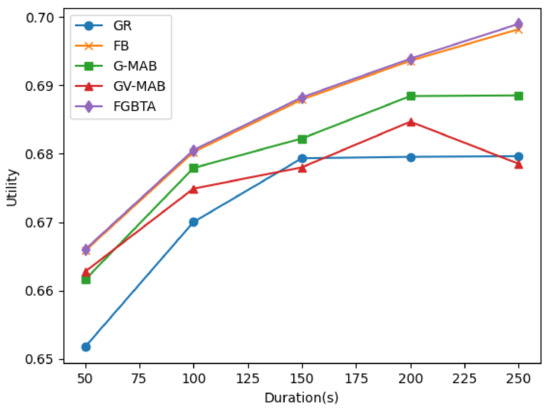
تاثیر مدت زمان
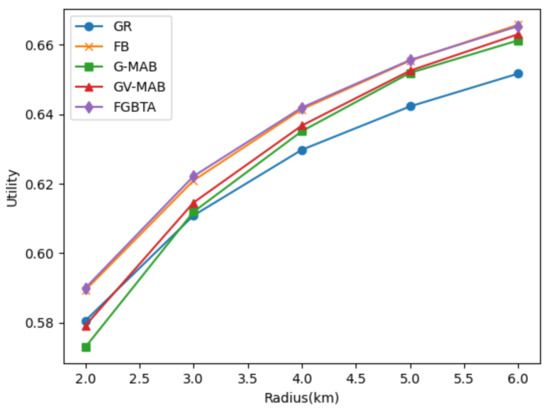
تاثیر شعاع
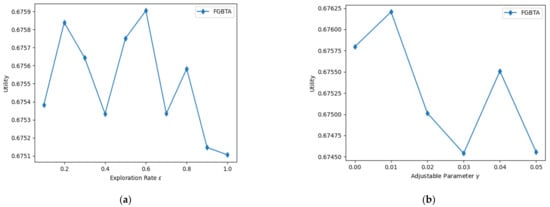
تاثیر نرخ کاوش و پارامتر قابل تنظیم
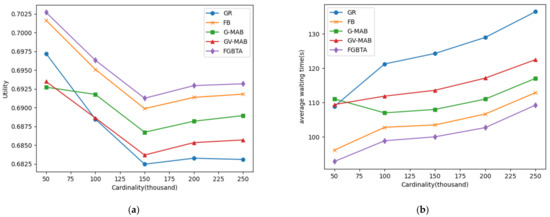
۵٫۲٫۲٫ عملکرد الگوریتم در مجموعه داده های واقعی
۶٫ بحث
-
در تحقیق [ ۲۱ ]، پلت فرم سواری میتواند از ساختار استراتژی آموختهشده بهعنوان جدول جستجو برای تصمیمگیری تطبیقی در مورد زمان استفاده از استراتژی تطبیق تاخیر و مدت زمان این تأخیرهای تطبیق استفاده کند. اطلاعات آفلاین یک ساختار استراتژی آموخته شده است.
-
در تحقیق [ ۴۶ ]، این مقاله یادگیری Q محدود (RQL) را طراحی کرد که یک الگوریتم مبتنی بر یادگیری تقویتی است و می تواند یک استراتژی پردازش دسته ای تقریباً بهینه تولید کند. اطلاعات آفلاین یک استراتژی پردازش دسته ای است که در جدول Q ذخیره می شود.
-
در تحقیق [ ۴۷ ]، روشی با ترکیب یادگیری عمیق و یادگیری تقویتی پیشنهاد شد. با در نظر گرفتن داده های تاریخی، مدل GRU برای پیش بینی تعداد وظایف آینده آموزش داده می شود. الگوریتم مجارستانی به صورت دسته ای پذیرفته شد. دانش آفلاین تعداد پیشبینیشده کارهای آینده است.
-
در تحقیق [ ۴۸ ]، با هدف مشکل تطبیق گلوگاه آنلاین با تاخیر، نویسنده یک استراتژی نگهداری تطبیقی را پیشنهاد میکند که مبتنی بر یادگیری تقویتی است و روشی به نام تطبیقی-h را در بالای استراتژی نگهداری جدید توسعه میدهد. دانش آفلاین استراتژی نگهداری است که به خوبی آموخته شده است.
۷٫ نتیجه گیری و کار آینده
منابع
- تانگ، YX; ژو، ZM; Zeng، YX; چن، ال. شهابی، ج. جمع سپاری فضایی: بررسی. VLDB J. ۲۰۲۰ ، ۲۹ ، ۲۱۷-۲۵۰٫ [ Google Scholar ] [ CrossRef ]
- عبدالله، ن.ا. رحمان، م.م. رحمان، م.م. Ghauth، KI چارچوبی برای انتخاب بهینه کارگر در جمع سپاری فضایی با استفاده از شبکه بیزی. دسترسی IEEE ۲۰۲۰ ، ۸ ، ۱۲۰۲۱۸–۱۲۰۲۳۳٫ [ Google Scholar ] [ CrossRef ]
- علوفی، ا. الحارتی، ر. زهدی، م. الصولامی، د. الرشدی، ط. اولاوویین، آر. یک رویکرد کارآمد برای انتساب وظایف در جمع سپاری فضایی. در مجموعه مقالات کنفرانس بین المللی IOT، الکترونیک و مکاترونیک IEEE (IEMTRONICS)، ونکوور، هند، ۱۲ سپتامبر ۲۰۲۰؛ صص ۶۱۹-۶۲۳٫ [ Google Scholar ]
- بهاتی، اس اس. فن، جی اچ. وانگ، KR؛ گائو، XF؛ وو، اف. چن، GH یک الگوریتم تقریبی برای مسئله انتساب کار محدود در جمع سپاری فضایی. IEEE. ترانس. اوباش محاسبه کنید. ۲۰۲۱ ، ۲۰ ، ۲۵۳۶-۲۵۴۹٫ [ Google Scholar ] [ CrossRef ]
- لی، ال. وانگ، LL; Lv، WF تطبیق تنگناهای بلادرنگ در جمع سپاری فضایی. علمی چین-اینف. علمی ۲۰۲۱ ، ۶۴ ، ۲٫ [ Google Scholar ] [ CrossRef ]
- لی، YH; چانگ، ال. لی، ال. بائو، XG; Gu، TL TASC-MADM: تکلیف در جمع سپاری فضایی بر اساس تصمیم گیری چند ویژگی. امن اشتراک. شبکه ۲۰۲۱ ، ۲۰۲۱ ، ۱۴٫ [ Google Scholar ] [ CrossRef ]
- اوگبی، م. لوجالا، ص. جمع سپاری فضایی در مدیریت درآمد منابع طبیعی. منبع. خط مشی ۲۰۲۱ ، ۷۲ ، ۱۱٫ [ Google Scholar ] [ CrossRef ]
- وانگ، ز. لی، YB; ژائو، ک. شی، دبلیو. Lin, LL; ژائو، JZ Worker برآورد گروهی مشارکتی در جمعسپاری فضایی. محاسبات عصبی ۲۰۲۱ ، ۴۲۸ ، ۳۸۵-۳۹۱ . [ Google Scholar ] [ CrossRef ]
- گممیدی، SRB; Xie، XK; Pedersen, TB A Survey of Spatial Crowdsourcing. ACM Trans. سیستم پایگاه داده ۲۰۱۹ ، ۴۴ ، ۴۶٫ [ Google Scholar ] [ CrossRef ]
- اوبر. در دسترس آنلاین: https://www.uber.com/ (دسترسی در ۲۰ دسامبر ۲۰۲۱).
- ویز. در دسترس آنلاین: https://www.waze.com/ (دسترسی در ۲۰ دسامبر ۲۰۲۱).
- گراب هاب. در دسترس آنلاین: https://www.grubhub.com/ (دسترسی در ۲۰ دسامبر ۲۰۲۱).
- گیگووالک. در دسترس آنلاین: https://www.gigwalk.com/ (دسترسی در ۲۰ دسامبر ۲۰۲۱).
- Xu، ZT; یین، YF; بله، JP در منحنی عرضه سیستم های سواری-تگرگ. ترانسپ Res. قسمت B-روش. ۲۰۲۰ ، ۱۳۲ ، ۲۹-۴۳٫ [ Google Scholar ] [ CrossRef ]
- آهنگ، TH; خو، ک. لی، JN; Li، YM; تانگ، YX تکلیف چند مهارتی آگاهانه در جمع سپاری فضایی بلادرنگ. Geoinformatica ۲۰۲۰ ، ۲۴ ، ۱۵۳-۱۷۳٫ [ Google Scholar ] [ CrossRef ]
- چنگ، ی.آر. لی، توسط; ژو، XM; یوان، ی. وانگ، GR; Chen, L. تطبیق متقابل آنلاین در زمان واقعی در جمع سپاری فضایی. در مجموعه مقالات سی و ششمین کنفرانس بین المللی IEEE در مهندسی داده (ICDE)، دالاس، TX، ایالات متحده، ۲۰-۲۴ آوریل ۲۰۲۰؛ صص ۱-۱۲٫ [ Google Scholar ]
- کاظمی، ل. شهابی، سی. Geocrowd: فعال کردن پاسخ پرس و جو با جمع سپاری فضایی. در مجموعه مقالات بیستمین کنفرانس بین المللی پیشرفت در سیستم های اطلاعات جغرافیایی، ردوندو بیچ، کالیفرنیا، ایالات متحده آمریکا، ۶-۹ نوامبر ۲۰۱۲٫ ص ۱۸۹-۱۹۸٫ [ Google Scholar ]
- به، اچ. شهابی، ج. کاظمی، L. یک چارچوب جمع سپاری فضایی اختصاص داده شده به سرور. ACM Trans. تف کردن سیستم الگوریتم ۲۰۱۵ ، ۱ ، ۱-۲۸٫ [ Google Scholar ] [ CrossRef ]
- که، جی. شیائو، اف. یانگ، اچ. Ye, J. یادگیری تأخیر در سیستمهای منبعیابی سواری: چارچوب یادگیری تقویتی عمیق چند عاملی. در IEEE Transactions on Knowledge and Data Engineering ; IEEE: Piscataway Township، NJ، ایالات متحده، ۲۰۲۰؛ پ. ۱٫ [ Google Scholar ] [ CrossRef ]
- یانگ، اچ. Qin، XR; Ke، JT; بله، JP بهینه سازی بازه زمانی تطبیق و شعاع تطبیق در بازارهای بر اساس تقاضای سواری. ترانسپ Res. قسمت B-روش. ۲۰۲۰ ، ۱۳۱ ، ۸۴-۱۰۵٫ [ Google Scholar ] [ CrossRef ]
- Qin، GY; لو، کیو. یین، YF; سان، ج. بله، JP بهینه سازی فواصل زمانی تطبیق برای خدمات سواری-تگرگ با استفاده از یادگیری تقویتی. ترانسپ Res. قسمت C-Emerg. تکنولوژی ۲۰۲۱ ، ۱۲۹ ، ۱۸٫ [ Google Scholar ] [ CrossRef ]
- آذر، ی. گانش، ع. جنرال الکتریک، آر. پانیگراهی، دی. سرویس آنلاین با تاخیر. ACM Trans. الگوریتم ها ۲۰۲۱ ، ۱۷ ، ۳۱٫ [ Google Scholar ] [ CrossRef ]
- اشلگی، آی. برق، م. دوتا، سی. Jaillet، P. صابری، ع. Sholley، C. حداکثر وزن مطابق آنلاین با ضرب الاجل.arXiv ۲۰۱۸ , arXiv:1808.03526. [ Google Scholar ]
- کیان، ال. لیو، جی اف. زو، اف. Li، ZX; وانگ، ی. لیو، الف. افزایش تجربه کاربر از انتساب وظایف در جمع سپاری فضایی: یک رویکرد دستهای خود تطبیقی. IEEE Access ۲۰۱۹ ، ۷ ، ۱۳۲۳۲۴–۱۳۲۳۳۲٫ [ Google Scholar ] [ CrossRef ]
- نوو، دی. Kotlarsky، J. جمع سپاری به عنوان یک پدیده استراتژیک منبع یابی است: بررسی انتقادی و بینش برای تحقیقات آینده. جی. استراتژی. Inf. سیستم ۲۰۲۰ ، ۲۹ ، ۱۰۱۵۹۳٫ [ Google Scholar ] [ CrossRef ]
- دسایی، ع. وارنر، جی. کودرر، ن. تامپسون، ام. نقاش، سی. لیمن، جی. Lopes, GJNC Crowdsourcing یک پاسخ بحران برای COVID-19 در انکولوژی. نات. سرطان ۲۰۲۰ ، ۱ ، ۴۷۳-۴۷۶٫ [ Google Scholar ] [ CrossRef ]
- پاندی، اس آر. تران، NH; بنیس، م. تون، YK; منظور، ع. Hong, CS چارچوب جمع سپاری برای یادگیری فدرال روی دستگاه. IEEE Trans. سیم. اشتراک. ۲۰۲۰ ، ۱۹ ، ۳۲۴۱-۳۲۵۶٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- وانگ، ی. گائو، ی. لی، ی. تانگ، XJCN یک مکانیسم تشویقی برای انتخاب کارگر برای بهینهسازی سیستمهای جمعسپاری موبایل مبتنی بر پلتفرم. شبکه کامپیوتری ۲۰۲۰ , ۱۷۱ , ۱۰۷۱۴۴٫ [ Google Scholar ] [ CrossRef ]
- مدرس نژاد، م. ایر، ال. پالویا، پی. تاراس، فناوری اطلاعات VJIP (IT) جمع سپاری را فعال کرد: یک چارچوب مفهومی. Inf. روند. ۲۰۲۰ ، ۵۷ ، ۱۰۲۱۳۵٫ [ Google Scholar ] [ CrossRef ]
- هاو، جی. ظهور جمع سپاری. مگ سیمی ۲۰۰۶ ، ۱۴ ، ۱-۴٫ [ Google Scholar ] [ CrossRef ]
- بهاتی، اس اس. گائو، ایکس. چارچوب کلی چن، GJJoS، فرصتها و چالشها برای تکنیکهای جمعسپاری: یک نظرسنجی جامع. جی. سیست. نرم افزار ۲۰۲۰ , ۱۶۷ , ۱۱۰۶۱۱٫ [ Google Scholar ] [ CrossRef ]
- مقدس، م. رجبی فرد، ع. فکته، ا. Kötter, T. چارچوبی برای مقیاس بندی تاب آوری تحول آفرین شهری از طریق استفاده از اطلاعات جغرافیایی داوطلبانه. ISPRS Int. J. Geo-Inf. ۲۰۲۲ ، ۱۱ ، ۱۱۴٫ [ Google Scholar ] [ CrossRef ]
- هرولد، اچ. بهنیش، م. هچت، ر. لیک، SJIIJoG-I. رویکردهای مدلسازی جغرافیایی به سکونتگاههای تاریخی و تحلیل منظر. ISPRS Int. J. Geo-Inf. ۲۰۲۲ ، ۱۱ ، ۷۵٫ [ Google Scholar ] [ CrossRef ]
- هاکار، MJIIJoG-I. تجزیه و تحلیل رفتار داوطلبان OpenStreetMap در نقشه برداری چند ضلعی های ساختمان با استفاده از رویکرد یادگیری ماشینی. ISPRS Int. J. Geo-Inf. ۲۰۲۲ ، ۱۱ ، ۷۰٫ [ Google Scholar ] [ CrossRef ]
- کائو، اس. دو، اس. یانگ، اس. Du, S. طبقهبندی عملکردی پارکهای شهری بر اساس منطقه عملکردی شهری و دادههای جغرافیایی با منبع جمعیت. ISPRS Int. J. Geo-Inf. ۲۰۲۱ ، ۱۰ ، ۸۲۴٫ [ Google Scholar ] [ CrossRef ]
- Goodchild، MF; Glennon، JA جمع سپاری اطلاعات جغرافیایی برای واکنش به بلایا: یک مرز تحقیقاتی. بین المللی جی دیجیت. زمین ۲۰۱۰ ، ۳ ، ۲۳۱-۲۴۱٫ [ Google Scholar ] [ CrossRef ]
- الوود، اس. Goodchild، MF; Sui, D. چشم انداز تحقیقات VGI و پارادایم چهارم در حال ظهور. که در جمع سپاری دانش جغرافیایی ; Springer: برلین/هایدلبرگ، آلمان، ۲۰۱۳; صص ۳۶۱-۳۷۵٫ [ Google Scholar ]
- لی، دبلیو. باتی، م. Goodchild، MF GIS بلادرنگ برای شهرهای هوشمند. بین المللی جی. جئوگر. Inf. علمی ۲۰۲۰ ، ۳۴ ، ۳۱۱-۳۲۴٫ [ Google Scholar ] [ CrossRef ]
- بصیری، ع. هاکلی، م. فودی، جی. Mooney, P. کیفیت دادههای جغرافیایی جمعسپاری شده: چالشها و مسیرهای آینده. بین المللی جی. جئوگر. Inf. علمی ۲۰۱۹ ، ۳۳ ، ۱۵۸۸-۱۵۹۳٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هاکلی، ام. دانش شهروندی و اطلاعات جغرافیایی داوطلبانه: بررسی اجمالی و گونهشناسی مشارکت. در جمع سپاری دانش جغرافیایی ; Springer: برلین/هایدلبرگ، آلمان، ۲۰۱۳; صص ۱۰۵-۱۲۲٫ [ Google Scholar ]
- خواجوال، AB; نوشادروان، الف. چارچوبی آگاه از عدم قطعیت برای ارزیابی قابل اعتماد آسیب بلایا از طریق جمع سپاری. بین المللی J. کاهش خطر بلایا. ۲۰۲۱ ، ۵۵ ، ۱۰۲۱۱۰٫ [ Google Scholar ] [ CrossRef ]
- وربیک، دی. Lábus, V. جمع سپاری نام های نامی رایج: نحوه جمع آوری و حفظ نام های نامی در استفاده گفتاری. بین المللی J. Geo-Inf. ۲۰۲۱ ، ۱۰ ، ۳۰۳٫ [ Google Scholar ] [ CrossRef ]
- ژئو-ویکی. در دسترس آنلاین: https://www.geo-wiki.org/ (در ۱ مارس ۲۰۲۲ قابل دسترسی است).
- مدل جهانی زلزله (GEM). در دسترس آنلاین: https://www.globalquakemodel.org/ (در ۱ مارس ۲۰۲۲ قابل دسترسی است).
- ClickWorkers. در دسترس آنلاین: http://www.nasaclickworkers.com/ (در ۱ مارس ۲۰۲۲ قابل دسترسی است).
- وانگ، YS; تانگ، YX; لانگ، سی. خو، پی. خو، ک. Lv، WF تطبیق گراف پویا دو جانبه تطبیقی: یک رویکرد یادگیری تقویتی. در مجموعه مقالات سی و پنجمین کنفرانس بین المللی IEEE در مهندسی داده (ICDE)، ماکائو، چین، ۸ تا ۱۱ آوریل ۲۰۱۹؛ ص ۱۴۷۸-۱۴۸۹٫ [ Google Scholar ]
- Sun، LJ; یو، XJ; Guo, JC; یان، ی. یو، ایکس. یادگیری تقویتی عمیق برای انتساب وظایف در جمع سپاری و سنجش فضایی. IEEE Sens. J. ۲۰۲۱ , ۲۱ , ۲۵۳۲۳–۲۵۳۳۰٫ [ Google Scholar ] [ CrossRef ]
- وانگ، ک. لانگ، سی. تانگ، ی. ژانگ، جی. Xu, Y. برگزاری تطبیقی برای تطبیق گلوگاه آنلاین با تاخیر. در مجموعه مقالات کنفرانس بین المللی SIAM 2021 در مورد داده کاوی (SDM)، آنلاین، ۲۹ آوریل تا ۱ مه ۲۰۲۱؛ صص ۲۳۵-۲۴۳٫ [ Google Scholar ]
- Manome, N.; شینوهارا، س. سوزوکی، ک. توموناگا، ک. Mitsuyoshi, S. الگوریتم راهزن چند مسلح موجود در محیط های ثابت یا غیر ثابت با استفاده از نقشه های خودسازماندهی. در مجموعه مقالات بیست و هشتمین کنفرانس بین المللی شبکه های عصبی مصنوعی (ICANN)، مونیخ، آلمان، ۱۷ سپتامبر ۲۰۱۹؛ صص ۵۲۹-۵۴۰٫ [ Google Scholar ]
- رحمان، AU; قاتک، گ. De Domenico، A. یک الگوریتم آنلاین برای بارگذاری محاسباتی در محیط های غیر ثابت. IEEE Commun. Lett. ۲۰۲۰ ، ۲۴ ، ۲۱۶۷-۲۱۷۱٫ [ Google Scholar ] [ CrossRef ]
- ژائو، YP; کیان، اچ. کانگ، ک. جین، YL استراتژی راهزن غیر ثابت برای تطبیق نرخ با بازخورد تاخیری. دسترسی IEEE ۲۰۲۰ ، ۸ ، ۷۵۵۰۳–۷۵۵۱۱٫ [ Google Scholar ] [ CrossRef ]
- Xia، WC; Quek، TQS؛ گوو، ک. Wen، WL; یانگ، اچ. زو، HB برنامه ریزی مشتری مبتنی بر راهزن چند مسلح برای یادگیری فدرال. IEEE Trans. سیم. اشتراک. ۲۰۲۰ ، ۱۹ ، ۷۱۰۸-۷۱۲۳٫ [ Google Scholar ] [ CrossRef ]
- لیو، XC; درخشانی، م. لامبوتاران، اس. van der Schaar، M. راهزنان چند مسلح آگاه از خطر با محدودیت های بالای اطمینان. فرآیند سیگنال IEEE Lett. ۲۰۲۱ ، ۲۸ ، ۲۶۹-۲۷۳٫ [ Google Scholar ] [ CrossRef ]
- روی، ک. ژانگ، Q. گاور، م. شیت، الف. دانش، گرادیانهای خطمشی را با مرز اطمینان بالایی برای راهزنان رابطهای ایجاد کرد. در مجموعه مقالات کنفرانس اروپایی یادگیری ماشین و اصول و تمرین کشف دانش در پایگاههای داده (ECML PKDD)، آنلاین، ۱۳ تا ۱۷ سپتامبر ۲۰۲۱؛ صص ۳۵-۵۰٫ [ Google Scholar ]
- رادوویچ، ن. Erceg، M. اجرای سختافزار الگوریتم کران اعتماد بالا برای یادگیری تقویتی. محاسبه کنید. برق مهندس ۲۰۲۱ ، ۹۶ ، ۹٫ [ Google Scholar ] [ CrossRef ]
- واسوانی، س. محرابیان، ع. دوراند، ع. کوتون، بی. سگ قدیمی ترفندهای جدیدی یاد می گیرد: UCB تصادفی برای مشکلات راهزن. در مجموعه مقالات بیست و سومین کنفرانس بین المللی هوش مصنوعی و آمار (AISTATS)، آنلاین، ۲۶ تا ۲۸ اوت ۲۰۲۰٫ [ Google Scholar ]
- تامپسون، WRJB با توجه به شواهد دو نمونه، احتمال اینکه یک احتمال مجهول بیشتر از دیگری باشد. Biometrika ۱۹۳۳ ، ۲۵ ، ۲۸۵-۲۹۴٫ [ Google Scholar ] [ CrossRef ]
- زو، زی؛ هوانگ، LS; Xu، HL مشارکتی تامپسون نمونه برداری. شبکه موبایل. Appl. ۲۰۲۰ ، ۲۵ ، ۱۳۵۱-۱۳۶۳٫ [ Google Scholar ] [ CrossRef ]
- زو، زی؛ هوانگ، LS; Xu، HL خود شتاب نمونه تامپسون با حد بالایی پشیمانی نزدیک به بهینه. محاسبات عصبی ۲۰۲۰ ، ۳۹۹ ، ۳۷-۴۷٫ [ Google Scholar ] [ CrossRef ]
- مرادی پری، ع. علیزاده، م. ترامپولیدیس، سی. نمونه برداری خطی تامپسون تحت محدودیت های خطی ناشناخته. در مجموعه مقالات کنفرانس بین المللی IEEE در مورد آکوستیک، گفتار و پردازش سیگنال، بارسلون، اسپانیا، ۴ تا ۸ مه ۲۰۲۰؛ صص ۳۳۹۲–۳۳۹۶٫ [ Google Scholar ]
- بانجویچ، دی. نمونه برداری کیم، ام جی تامپسون برای کنترل تصادفی: مورد پارامتر پیوسته. IEEE Trans. خودکار کنترل ۲۰۱۹ ، ۶۴ ، ۴۱۳۷–۴۱۵۲٫ [ Google Scholar ] [ CrossRef ]
- کائو، ی. ون، ز. کوتون، بی. Xie, Y. رویه تطبیقی تقریباً بهینه با تشخیص تغییر برای راهزن تکه ای-ایستا. در مجموعه مقالات بیست و دومین کنفرانس بین المللی هوش مصنوعی و آمار (AISTATS)، ناها، ژاپن، ۱۶ تا ۱۸ آوریل ۲۰۱۹؛ ص ۴۱۸-۴۲۷٫ [ Google Scholar ]
- تروو، اف. پالادینو، اس. رستلی، م. Gatti، N. نمونه برداری از پنجره کشویی تامپسون برای تنظیمات غیر ثابت. جی آرتیف. هوشمند Res. ۲۰۲۰ ، ۶۸ ، ۳۱۱-۳۶۴٫ [ Google Scholar ] [ CrossRef ]
- کاونقی، ای. سوتوکورنولا، جی. استلا، اف. زنکر، ام. راهزن چند مسلح غیر ثابت: ارزیابی تجربی یک مفهوم جدید الگوریتم رانش آگاه. Entropy ۲۰۲۱ , ۲۳ , ۳۸۰٫ [ Google Scholar ] [ CrossRef ]
- گالمئانو، اچ. Andonie, R. انطباق دریفت مفهومی با SVM افزایشی-کاهشی. Appl. علمی ۲۰۲۱ ، ۱۱ ، ۹۶۴۴٫ [ Google Scholar ] [ CrossRef ]
- ژنگ، XL; لی، پی پی; هو، XG; Yu, K. طبقه بندی نیمه نظارت شده در جریان داده با رانش مفهومی تکرارشونده و تکامل مفهوم. سیستم مبتنی بر دانش ۲۰۲۱ ، ۲۱۵ ، ۱۶٫ [ Google Scholar ] [ CrossRef ]
- هالستد، بی. Koh، YS; ریدل، پ. گلابی، ر. پچنیزکی، م. بیفت، ا. اولیوارس، جی. Coulson, G. تجزیه و تحلیل و تعمیر انطباق رانش مفهومی در طبقه بندی جریان داده. ماخ فرا گرفتن. ۲۰۲۱ ، ۱-۳۵٫ [ Google Scholar ] [ CrossRef ]
- Wan، JSW; Wang, SD Concept Drift Detection بر اساس پیش خوشه بندی و آزمایش آماری. J. فناوری اینترنت. ۲۰۲۱ ، ۲۲ ، ۴۶۵-۴۷۲٫ [ Google Scholar ] [ CrossRef ]
- گوئل، ک. Batra, S. یادگیری آنلاین تطبیقی برای طبقه بندی تحت رانش مفهومی. بین المللی جی. کامپیوتر. علمی مهندس ۲۰۲۱ ، ۲۴ ، ۱۲۸-۱۳۵٫ [ Google Scholar ] [ CrossRef ]
- محمود، ح. کوستاکوس، پ. کورتس، ام. آناگنوستوپولوس، تی. پیرتیکانگاس، اس. گیلمن، ای. تکنیکهای تطبیق دریفت مفهومی در محیط توزیعشده برای جریانهای داده در دنیای واقعی. شهرهای هوشمند ۲۰۲۱ ، ۴ ، ۳۴۹–۳۷۱٫ [ Google Scholar ] [ CrossRef ]
- رقابت برنامه نوآوری باز امنیت داده بزرگ Xiamen. در دسترس آنلاین: https://data.xm.gov.cn/opendata-contest/#/ (در ۲۰ دسامبر ۲۰۲۱ قابل دسترسی است).
- طرح بازگشایی داده گایا. در دسترس آنلاین: https://outreach.didichuxing.com/research/opendata/ (در ۲۰ دسامبر ۲۰۲۱ قابل دسترسی است).