۱٫ مقدمه
محوطههای باستانشناسی بقایای فعالیتهای انسان باستانی هستند که حاوی اطلاعات انسانی و اجتماعی غنی و قانون پیشرفت تمدن هستند. متون محوطه باستانی به متون توصیف کننده اطلاعات محوطه های باستانی اشاره دارد که حامل مهمی از اطلاعات ویژگی سایت است. به طور رسمی، اغلب به صورت مجزا در قالبهای مختلف ثبت میشود، برای مثال، گزارشهای کاوشهای باستانشناسی، جلسات توجیهی کاوشهای باستانشناسی و فرهنگهای باستانشناسی و مدخلهای دایرهالمعارفی به شیوهای بدون ساختار. از نظر کمیت، با پیشرفت مداوم در کار باستان شناسی، داده های متنی در باستان شناسی در حال افزایش است و اطلاعات بیشتر و بیشتری در مورد سایت های باستان شناسی در حال انباشته شدن است. از نظر محتوا، درجه جزئیات در انواع مختلف متون سایت باستان شناسی متفاوت است، اما همه آنها اطلاعات اولیه سایت را توصیف می کنند (از جمله نام، مکان، سلسله، نوع فرهنگی و سایر عناصر کلیدی)، که یک کانون داده مهم برای تحقیق و تجزیه و تحلیل باستان شناسی است. . به عنوان یک قاعده، محتوای متون سایت باستان شناسی در درجه اول شامل دو دیدگاه است: زمان و مکان. همانطور که باستان شناس اسکاولدینگ در کتاب منتشر شده خود در سال ۱۹۶۰ گفت: “به طور خلاصه، باستان شناسی علمی است که بر شکل، زمان و توزیع مکانی بقایای باستانی تمرکز می کند.” محتوای متون محوطه باستان شناسی در درجه اول شامل دو دیدگاه است: زمان و مکان. همانطور که باستان شناس اسکاولدینگ در کتاب منتشر شده خود در سال ۱۹۶۰ گفت: “به طور خلاصه، باستان شناسی علمی است که بر شکل، زمان و توزیع مکانی بقایای باستانی تمرکز می کند.” محتوای متون محوطه باستان شناسی در درجه اول شامل دو دیدگاه است: زمان و مکان. همانطور که باستان شناس اسکاولدینگ در کتاب منتشر شده خود در سال ۱۹۶۰ گفت: “به طور خلاصه، باستان شناسی علمی است که بر شکل، زمان و توزیع مکانی بقایای باستانی تمرکز می کند.”۱ ]. برای باستان شناسی، زمان و مکان از ویژگی های اساسی همزیستی با فرم بقایای بقایا هستند [ ۲]. مطالب متقابل موجود در متون مختلف محوطه باستان شناسی که در بالا ذکر شد، شرح اطلاعات ضروری مکانی-زمانی در مورد سایت است. در متون باستان شناسی، اطلاعات زمانی، تصویری از دوره تاریخی محوطه است که ممکن است به عنوان یک یا چند سلسله یا برخی از انواع فرهنگی که محوطه به آن تعلق دارد، توصیف شود. چنین توصیفهایی از زمان یکسان نیستند و ممکن است دقیق یا مبهم باشند، بنابراین تعیین دوره بقایای از متن محوطه باستانشناسی یک وظیفه حیاتی و اساسی است. اطلاعات مکانی موقعیت جغرافیایی سایت ممکن است به صراحت به عنوان یک مختصات شناسایی شده، نام منطقه اداری یا حتی یک مکان نسبی مبهم توصیف شود. بنابراین انتظار می رود که در استخراج اطلاعات به طور یکسان شناسایی، تفسیر و بیان شود.
متون محوطه باستانی مبنای تحقیقات محوطه باستانی است که حاوی اطلاعات و ارزش تحقیقاتی غنی است. بنابراین، به منظور تحقق بهرهبرداری مؤثر از متون محوطه باستانشناسی، ادغام و استفاده از اطلاعات سایتهای باستانشناسی و استخراج دانش کلیدی و ارزشمند باستانشناسی بسیار حیاتی است. روش سنتی شناسایی دستی برای به دست آوردن اطلاعات سایت از اسناد حجیم وقت گیر و ناکارآمد است و نتایج ساختاری داده ها ممکن است به دلیل سطوح ناهماهنگ کارکنان مختلف متفاوت باشد که برای استخراج اطلاعات از متون انبوه سایت غیر قابل اجرا است. تا به امروز، این مشکل در ادبیات تحقیقاتی توجه کمی داشته است، بنابراین مطالعات کمی وجود دارد که متون محوطه باستانی را مورد تحقیق قرار داده باشد. از این رو، چگونگی استخراج اطلاعات یکپارچه سایت از تعداد زیادی متون پراکنده، مفصل یا مختصر بدون ساختار سایت باستان شناسی، نکته اصلی تحقق دیجیتالی شدن و استفاده جامع از متون سایت باستان شناسی است. در سال های اخیر، با پیشرفت روزافزون فناوری هوش مصنوعی، روش های استخراج اطلاعات و کاربردهای زبان طبیعی پیشرفت زیادی داشته است. به گفته کاوی، استخراج اطلاعات را میتوان به صورت زیر تعریف کرد: «استخراج اطلاعات (IE) نامی است که به هر فرآیندی داده میشود که به طور انتخابی دادههایی را که در یک یا چند متن یافت میشوند، صریحاً بیان یا ضمنی میسازد و ترکیب میکند». متون دقیق یا مختصر بدون ساختار محوطه باستان شناسی محور تحقق دیجیتالی شدن و استفاده همه جانبه از متون محوطه باستان شناسی است. در سال های اخیر، با پیشرفت روزافزون فناوری هوش مصنوعی، روش های استخراج اطلاعات و کاربردهای زبان طبیعی پیشرفت زیادی داشته است. به گفته کاوی، استخراج اطلاعات را میتوان به صورت زیر تعریف کرد: «استخراج اطلاعات (IE) نامی است که به هر فرآیندی داده میشود که به طور انتخابی دادههایی را که در یک یا چند متن یافت میشوند، صریحاً بیان یا ضمنی میسازد و ترکیب میکند». متون دقیق یا مختصر بدون ساختار محوطه باستان شناسی محور تحقق دیجیتالی شدن و استفاده همه جانبه از متون محوطه باستان شناسی است. در سال های اخیر، با پیشرفت روزافزون فناوری هوش مصنوعی، روش های استخراج اطلاعات و کاربردهای زبان طبیعی پیشرفت زیادی داشته است. به گفته کاوی، استخراج اطلاعات را میتوان به صورت زیر تعریف کرد: «استخراج اطلاعات (IE) نامی است که به هر فرآیندی داده میشود که به طور انتخابی دادههایی را که در یک یا چند متن یافت میشوند، صریحاً بیان یا ضمنی میسازد و ترکیب میکند».۳ ]. مجموعه تحقیقات موجود در مورد استخراج اطلاعات نشان می دهد که این فناوری معنادار و امیدوارکننده است. با تجزیه و تحلیل تحقیقات موجود در زمینه استخراج اطلاعات متن باستانشناسی، مشاهده میشود که این مطالعات اساساً بر پیکره انگلیسی متمرکز شدهاند، در حالی که مطالعات چینی عموماً مبتنی بر قوانین است که قابلیت حمل و نقل ضعیف و هزینه اجرای بالایی دارد. تحقیق در مورد استخراج اطلاعات چینی در متون سایت باستان شناسی، که با مشکلاتی مانند حاشیه نویسی پیکره و تقسیم بندی کلمات چینی محدود شده است. در عین حال، کمبودهایی در این مطالعات وجود دارد، مانند منابع داده های منحصر به فرد، فرآیندهای ساخت و ساز پراکنده و غیره.
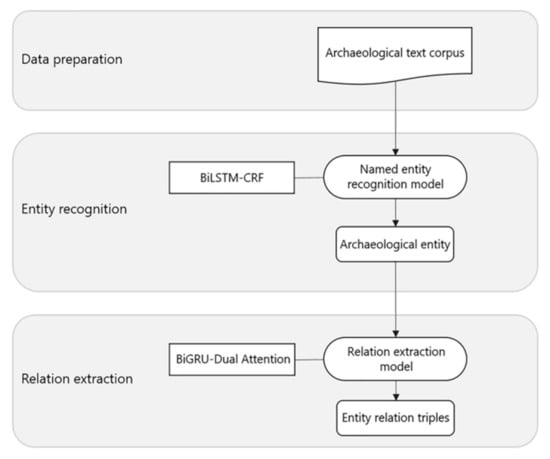
تحت این مبنا، این مقاله بر استخراج اطلاعات مکانی-زمانی از متون سایت باستان شناسی تمرکز دارد. آزمایش استخراج اطلاعات عمدتاً به دو بخش تقسیم میشود: شناسایی موجودیت و استخراج رابطه. هدف اصلی آنها شناسایی موجودیت ها از متون و استخراج روابط معنایی بین موجودیت ها است. برای یک جمله ورودی معین، شناسایی موجودیت شامل تقسیم بندی موجودیت و نوع موجودیت می شود. هدف استخراج رابطه شناسایی روابط معنایی بین جفت موجودیت متقارن از متون سایت باستان شناسی بدون ساختار و بیان آنها بر اساس شکل ساختار یافته یک سه گانه (e1, r, e2) است که در آن e1 و e2 نمایانگر نهاد اول و موجودیت دوم هستند. به ترتیب، و r نشان دهنده نوع رابطه بین آنها است. سرانجام، اطلاعات زمانی و مکانی سایت نیز در این فرم ارائه خواهد شد. در پردازش زبان طبیعی سنتی، شناسایی موجودیت و استخراج رابطه دو وظیفه مستقل هستند. مدل تشخیص موجودیت در این مقاله، با نام حافظه کوتاه مدت دو جهته با زمینه های تصادفی شرطی (BiLSTM-CRF)، محتوای برنامه را در پردازش زبان طبیعی ترکیب می کند.۴ ] و برخی تحقیقات را در مورد پیش پردازش داده ها و تجزیه و تحلیل داده ها انجام می دهد. از طریق استفاده از مدل BiLSTM-CRF، می تواند به طور موثر اطلاعات زمینه را به خاطر بسپارد و رابطه وابستگی بین برچسب های مجاور را به دست آورد تا نتایج بهینه برچسب گذاری یک موجود باستان شناسی را به دست آورد. در تکلیف استخراج رابطه، مدل واحدهای بازگشتی دردار دوطرفه با توجه دوگانه (BiGRU-Dual Attention) که در این مطالعه اتخاذ شده است، یک روش ترکیبی بر اساس مطالعات قبلی است [ ۵ ، ۶ ]]. برای وظیفه استخراج روابط چینی، کلمات چینی، به عنوان اساسی ترین واحد در زبان چینی، حاوی مقدار زیادی اطلاعات معنایی مهم است. بنابراین، اطلاعات سطح کلمه در نمونه های آموزشی چینی برای استخراج روابط چینی بسیار مهم است. با اثر بهینه سازی خوب، معرفی مکانیزم توجه می تواند به طور کامل اطلاعات زمینه متون باستان شناسی را استخراج کند تا اثر استخراج را تقویت کند. مکانیسم توجه سطح کلمه و مکانیسم توجه سطح جمله در مدل می تواند وزن را بهتر تخصیص دهد، نویز را حذف کند و دقت تشخیص استخراج رابطه موجودیت را بهبود بخشد. با بهرهگیری از یک شبکه عصبی، مدل توجه دوگانه BiGRU میتواند مشکلات دقت پایین و پایداری ضعیف مدلهای استخراج رابطه سنتی را حل کند.
به طور خلاصه، هدف خاص این مطالعه شناسایی سریع و خودکار و به دست آوردن اطلاعات هدف از حجم زیادی از متون سایت باستان شناسی بدون ساختار با استفاده از فناوری جدید بود، در نتیجه زمان پیش پردازش استخراج اطلاعات باستان شناسی را تا حد زیادی کاهش داد. علاوه بر این، دادههای این مطالعه از چندین حامل تا حد امکان جامع جمعآوری شد که ایدهها و روشهای جدیدی را برای مطالعه اطلاعات مکانی-زمانی سایتهای باستانشناسی ارائه میدهد. استخراج اطلاعات از متن سایت باستان شناسی کمک مهمی به ذخیره، مدیریت، استفاده و به اشتراک گذاری دانش باستان شناسی می کند و ارزش متن سایت باستان شناسی را به حداکثر می رساند.
۲٫ کارهای مرتبط
همانطور که در بالا اشاره شد، استخراج اطلاعات فناوری کلیدی استخراج خودکار اطلاعات از متون سایت باستان شناسی است. در اوایل دهه ۱۹۶۰، تحقیق در مورد فناوری استخراج اطلاعات مطرح شد، و این تکنیک به دستیابی سریع اطلاعات هدف از متون بیساختار فراوان قدرت میدهد و استفاده بیشتر از اطلاعات را به همراه میآورد. روشهای استخراج اطلاعات عموماً شامل روشهای مبتنی بر قانون، مبتنی بر آمار و مبتنی بر یادگیری عمیق است [ ۷ ]. سیستم نمونه LaSIE-II (استخراج اطلاعات در مقیاس بزرگ) به قوانین معنایی برای تحقق استخراج اطلاعات وابسته است [ ۸ ]]. با این حال، این روش مبتنی بر قانون محدودیتهای خاص خود را دارد، مانند فرآیند ساخت قوانین به صورت دستی پیچیده و جهانی بودن ضعیف. در نتیجه تحقیقات بعدی به تدریج به روشی مبتنی بر آمار روی آورد. در مطالعه ای که توسط چمبرز انجام شد، نشان داده شد که الگوریتم یادگیری آماری می تواند قوانین را از متون ساده بیاموزد و کار استخراج اطلاعات را بدون اطلاع از ساختار الگو انجام دهد [ ۹ ]]. در مطالعات بعدی، محققان دریافتند که یک روش مبتنی بر آمار نسبت به روش قبلی قابل اجراتر است، اما هزینه کار و زمان بسیار بالا است زیرا علاوه بر این به حاشیه نویسی دستی با دانش حرفه ای نیاز دارد. اخیراً، مدلهای شبکه عصبی مبتنی بر یادگیری عمیق میتوانند به طور خودکار اطلاعات ویژگی را از تعداد زیادی متون بدست آورند که پشتیبانی مستقیم از تکنیکهای استخراج اطلاعات را فراهم میکند. مدل مبتنی بر یادگیری عمیق بسیار بهتر از روشهای مرسوم در کارایی و دقت عمل میکند و متعاقباً به طور گسترده به کار گرفته شد و به تدریج جریان اصلی در وظایف استخراج اطلاعات را اشغال کرد. چندین مطالعه در مورد استخراج اطلاعات مبتنی بر یادگیری عمیق، نتایج مثمر ثمری را به همراه داشته است. کیو و همکاران۱۰ ]. ژانگ و همکاران دوره ساختار یافته اطلاعات موجودات زمین شناسی را با استفاده از یک شبکه عصبی عمیق اجرا کرد [ ۱۱ ]. ژائو مکانیسم توجه را با لایه برچسبگذاری و فیلتر در مدل واحدهای بازگشتی دردار دوطرفه (Bi-GRU) ترکیب کرد، که به طور قابلتوجهی بر استخراج رابطه متن نیاز در صنعت نرمافزار تأثیر میگذارد [ ۱۲ ]. از وضعیت فعلی تحقیقات، شبکههای عصبی و روشهای CRF به استانداردی تبدیل شدهاند که برخی از بهترین گزینهها را برای روشهای استخراج اطلاعات نشان میدهد.
حوزه کاربرد استخراج اطلاعات با توسعه فناوری آن به تدریج گسترش یافته است. تحقیقات اولیه عمدتاً بر مطالعه وظایف استخراج اطلاعات متنی در حوزههای همه منظوره، مانند تشخیص نام افراد و نام سازمانها [ ۱۳ ، ۱۴ ] متمرکز بود. بر اساس بهینهسازی ثابت در حوزه عمومی در طول سالها، توسعه استخراج اطلاعات از متون را به سمت زمینههای بیشتری از جمله پزشکی، ارتش، کشاورزی و غیره ارتقا داده است [ ۱۵ ، ۱۶ ، ۱۷ ].]. به طور همزمان، استخراج اطلاعات نیز به سمت مرحله بالاتری مانند استخراج رابطه، استخراج رویداد و سایر وظایف پیچیده تر توسعه یافته است.۱۸ ، ۱۹ ]. امروزه مشاهده می شود که فناوری استخراج اطلاعات در تاریخ و علوم انسانی نیز مورد کاوش و کاربرد قرار گرفته است. به عنوان مثال، Sprugnoli یک روش عصبی با حاشیه نویسی دستی را پیشنهاد کرد که در تشخیص نام مکان متون گردشگری تاریخی انگلیسی استفاده شد [ ۲۰ ]. علاوه بر این، پترسون و همکاران. ابزار آنلاینی به نام HistSearch را ارائه کرد که می تواند به طور مؤثر اطلاعات مفیدی را از متون تاریخی در مدت کوتاهی استخراج کند [ ۲۱ ]]. بر اساس مطالعه بر روی گزارش های باستان شناسی انگلیسی در مرحله قبل، Vlachidis و همکاران. سیستم شناسایی موجودیت نامگذاری شده از اسناد خاکستری باستان شناسی هلندی را توسعه داد که توانست به حاشیه نویسی معنایی گزارش های باستان شناسی دست یابد و به طور خودکار ابرداده تولید کند [۲۲ ]. با استناد به ادبیات و کدهای موجود، بیشتر برای مجموعه انگلیسی هستند و معمولاً از وکتورهای کلمه برای آموزش استفاده می کنند.
مطالعه استخراج اطلاعات متن چینی عمدتاً به شناسایی موجودیت نامگذاری شده در مرحله اولیه توجه داشت. پس از آن، به تدریج به وظایف مربوط به رابطه و استخراج رویداد گسترش یافت. در این میان، حوزه استخراج اطلاعات به تدریج به دامنه وسیع تری گسترش یافت. از نظر داده کاوی متون باستان شناسی چینی، نسبتاً دیر شروع شده است، در حالی که نتایج تحقیقاتی نیز به دست آمده است. به عنوان مثال، ژانگ از دانش دامنه برای استخراج داده ها از متون باستان شناسی استفاده کرد [ ۲۳]. با این حال، یادگیری الگوهای متنی کافی برای این روش مبتنی بر الگو دشوار است و با تعداد زیادی توالی کلمات بی معنی مخلوط می شود. برای کاری که این روش را اتخاذ می کند، معمولاً باید با تأیید و فیلتر پیچیده ترکیب شود. لو پیشنهاد یک پلت فرم طراحی خلاقانه برای آثار فرهنگی کوره چانگشا را ارائه کرد و ویژگی های متنی عناصر بقایای فرهنگی کوره چانگشا را با استفاده از مدل BiLSTM-CRF استخراج کرد [ ۲۴ ].]. در نتیجه، به ساخت پایگاه دانش فرهنگی کوره چانگشا دست یافت. این پلتفرم بر اساس فناوری یادگیری عمیق، طراحی مجدد عناصر بقایای فرهنگی را محقق کرد که توسعه یکپارچه فرهنگ و فناوری را ارتقا داد. ژانگ با ترکیب تقسیمبندی کلمات چینی با شناسایی موجودیت، به طور موثر استخراج اطلاعات از دادههای متن باستانشناسی را درک کرد [ ۲۵ ]. با این حال، او فقط آزمایش هایی را روی داده های سایت Liangzhu انجام داد که فاقد محبوبیت و جهانی بود. از طریق استفاده از فناوری استخراج اطلاعات، لیو مدل BiLSTM-CRF را برای شناسایی موجودیت هایی مانند نام شخص، نام مکان و زمان در بیست و چهار تاریخ اتخاذ کرد [ ۲۶ ]]. پس از آن، او گراف دانش را ساخت و دانش استخراج شده را از طریق پایگاه داده گراف neo4j ذخیره کرد، که تابع بازیابی معنایی را محقق کرد. با این حال، در هنگام آموزش مدلهای تحلیل نحوی وابسته، هنوز به کار دستی زیادی نیاز دارد که در طبقهبندی جملات منفرد و پیچیده وجود دارد، که باعث میشود ساخت مدل فاقد اتوماسیون کافی باشد. در مجموع، این مطالعات نشان میدهد که فناوری استخراج اطلاعات مبتنی بر یادگیری عمیق در زمینه متون سایت باستانشناسی چینی مورد مطالعه قرار گرفته است، اما مطالعات کمی توانستهاند از تحقیقات سیستماتیک در کل فرآیند استفاده کنند. در همین حال، چنین مطالعاتی در کانون توجه محدود باقی می مانند و تنها به یک موضوع خاص بدون کلیت می پردازند. علاوه بر این، یادگیری عمیق در حال حاضر روش اصلی است و دستاوردهای آن قابل توجه بوده است.
به طور خلاصه، مطالعه استخراج اطلاعات چندین دهه از تشخیص الگو تا یادگیری ماشینی تا یادگیری عمیق، از حوزه عمومی تا حوزه حرفه ای، از متن استاندارد معمولی تا متن معمولی را طی کرده است و دستاوردهای آن قابل توجه است. بر اساس تجزیه و تحلیل فوق، تحقیق در مورد استخراج اطلاعات در باستان شناسی چینی که توسط شناسایی موجودیت نامگذاری شده و استخراج روابط ارائه شده است، پیشرفت زیادی داشته است، اما هنوز هم فضای گسترده ای برای بهبود در فناوری و روش ها دارد. اولاً، در مقایسه با زمینه عمومی، متون باستان شناسی از نظر منابع غنی هستند، اما اطلاعات موجود پیچیده است. تعداد زیادی نهاد اختصاصی در زمینه باستان شناسی وجود دارد و شناسایی آنها دشوار است. بنابراین تحقیق استخراج اطلاعات بر اثربخشی و اتوماسیون آن متمرکز است. علاوه بر این، متون باستانشناسی به دلیل نحو پیچیده و توزیع متراکم جفتهای موجود با روابط همپوشانی فراوان، الزامات بالاتری را برای دقت استخراج رابطه مطرح میکنند. بنابراین، با توجه به پیچیدگی و ویژگی دامنه بالای متون باستانشناسی چینی، این مقاله از روشهای پردازش زبان طبیعی و یادگیری عمیق برای مطالعه شناخت موجودیت و استخراج رابطه در متون سایت باستانشناسی چینی استفاده میکند. علاوه بر این، امید است که این روش بتواند پردازش دادههای متنی چند منبعی را محقق کند، استقرار از مجموعه به نمودار دانش را تکمیل کند و تبدیل از دادههای غیرساختیافته به ساختاریافته را واقعاً کامل کند. با توجه به نیازهای عملی باستان شناسی، شناسایی موجودیت نامگذاری شده توسط مدل BiLSTM-CRF انجام میشود و استخراج رابطه موجودیت توسط مدل BiGRU-Dual Attention تکمیل میشود. در نهایت، روشها و تکنیکهای قابل استفاده برای متون محوطه باستانشناسی به صورت تجربی مورد آزمایش قرار گرفتند و مدل استخراج اطلاعات برای متن سایت باستانشناسی ساخته شد. مطالعه فوق روش جدیدی را برای کسب اطلاعات در باستان شناسی ارائه می دهد که دارای ارزش تحقیقاتی مهم و اهمیت کاربردی برای ارتقاء اطلاعات باستان شناسی است. و مدل استخراج اطلاعات برای متن سایت باستان شناسی ساخته شد. مطالعه فوق روش جدیدی را برای کسب اطلاعات در باستان شناسی ارائه می دهد که دارای ارزش تحقیقاتی مهم و اهمیت کاربردی برای ارتقاء اطلاعات باستان شناسی است. و مدل استخراج اطلاعات برای متن سایت باستان شناسی ساخته شد. مطالعه فوق روش جدیدی را برای کسب اطلاعات در باستان شناسی ارائه می دهد که دارای ارزش تحقیقاتی مهم و اهمیت کاربردی برای ارتقاء اطلاعات باستان شناسی است.
۳٫ مواد و روشها
۳٫۱٫ داده ها
باستان شناسی چینی دارای مجموعه بی نظیری از مواد ارزشمند است. متون سایت باستان شناسی وسیله اولیه برای ارائه نتایج و تبادلات آکادمیک در باستان شناسی هستند و کمیت آن با توسعه حرفه باستان شناسی چینی به سرعت افزایش یافته است. با این حال، هیچ مجموعه ای در دسترس عموم در زمینه باستان شناسی چینی وجود ندارد. متعاقباً، با در نظر گرفتن متون سایت باستانشناسی چینی به عنوان منبع دادههای تحقیق، این مقاله ۶۲۵ مدخل بایدو بایک از سایتها [ ۲۷ ]، ۳۰۰ گزارش کاوشهای باستانشناسی از CNKI [ ۲۸ ]، و ۲۳۲۵ مدخل از فرهنگ لغت باستانشناسی چینی اصلی را جمعآوری و سازماندهی میکند. داده [ ۲۹]. در پی تنظیم و جمعبندی این دادهها، مجموعه متنی از سایتهای باستانشناسی چینی ساختیم. در طول زمان صرف شده برای تحقیق، مشاهده کردیم که داده های متنی در باستان شناسی در مقایسه با داده های متنی در سایر زمینه ها ویژگی های خاص خود را دارند. از نظر شکل متنی، اولاً، نامهای مناسبی وجود دارد که کمتر در سایر متون چینی دیده میشوند، مانند «鬶» (پارچ با سه پایه)، «盉» (رگ گرد با دهانه بسته)، «甗’ (ظروف سفالی) و غیره ثانیاً به دلیل روشهای مختلف کاوش در مؤسسات باستان شناسی منطقه ای، حجم کار و شرایط کار متفاوت است. به طور همزمان، ضبط کننده های مختلف باستان شناسی سبک های ضبط متفاوتی دارند. با توجه به این ویژگی ها، ما باید بر روی روش های استخراج اطلاعات مناسب برای پردازش آنها تمرکز کنیم.
اطلاعات زمانی و مکانی برای تحقیقات باستان شناسی ارزش زیادی دارد. تا آنجا که به ویژگیهای زمانی مربوط میشود، هر محوطه باستانشناسی دوره خاص خود را دارد، اما خود محوطهها (بهویژه مکانهای ماقبل تاریخ) اغلب فاقد شناسایی زمانی مشخص هستند، بنابراین سال اکثر محوطهها را نمیتوان دقیقاً تعیین کرد. در چارچوب گاهشماری باستان شناسی کنونی، عبارات گاهشماری باستان شناسی عموماً شامل سن مطلق و سن نسبی است. با توجه به تجزیه و تحلیل به موقع در متن سایتهای باستانشناسی چینی، مشاهده میشود که ترجیح داده میشود اطلاعات زمانی به روش سن نسبی ثبت شود (مانند عصر پارینه سنگی، عصر نوسنگی و سلسله ژو غربی و غیره). علاوه بر این، متن سایت نیز از فرهنگ باستان شناسی (مانند فرهنگ یانگ شائو، فرهنگ هنگشان و غیره) به عنوان مهر زمانی برای ثبت قدمت سایت. فرهنگ باستانشناسی به مکانهای فرهنگی متعلق به یک دوره اطلاق میشود که در یک منطقه پراکنده شده و دارای مجموعهای از آثار و بقایای فرهنگی مشخص هستند. در پرتو این، چارچوب فضا-زمان اساسی و روشی برای ساختن روایت های تاریخی از باستان شناسی ایجاد کرده است. در نتیجه، این پژوهش به استخراج نوع فرهنگی در متون به عنوان اطلاعات زمانی سایت ها می پردازد. از نظر ویژگی مکانی، شناسایی موقعیت جغرافیایی در متون سایت است. از ترسیم اطلاعات مکانی می توان آن را به دو دسته توصیف دقیق و توصیف فازی تقسیم کرد. در توضیحات دقیق، مختصات جغرافیایی سایت در متن ثبت شده است. که به صورت مستقیم به عنوان اطلاعات مکانی سایت قابل استخراج است. در توصیف فازی، از زبان طبیعی برای توصیف موقعیت مکانی استفاده میکند که عمدتاً شامل نام مناطق اداری است. این نوع اطلاعات فضایی دارای یک سلسله مراتب اداری و روابط فرعی است و معمولاً برای روستا دقیق است. با توجه به تحلیل فوق از متون باستان شناسی چینی، این مطالعه با ادغام سن نسبی و نوع فرهنگی در متون، اطلاعات زمانی محوطه را تعیین می کند. در این میان نام مکان اداری به عنوان اطلاعات مکانی محوطه باستانی استخراج می شود. روش خاص به شرح زیر است. عمدتاً شامل نام مناطق اداری است. این نوع اطلاعات فضایی دارای یک سلسله مراتب اداری و روابط فرعی است و معمولاً برای روستا دقیق است. با توجه به تحلیل فوق از متون باستان شناسی چینی، این مطالعه با ادغام سن نسبی و نوع فرهنگی در متون، اطلاعات زمانی محوطه را تعیین می کند. در این میان نام مکان اداری به عنوان اطلاعات مکانی محوطه باستانی استخراج می شود. روش خاص به شرح زیر است. عمدتاً شامل نام مناطق اداری است. این نوع اطلاعات فضایی دارای یک سلسله مراتب اداری و روابط فرعی است و معمولاً برای روستا دقیق است. با توجه به تحلیل فوق از متون باستان شناسی چینی، این مطالعه با ادغام سن نسبی و نوع فرهنگی در متون، اطلاعات زمانی محوطه را تعیین می کند. در این میان نام مکان اداری به عنوان اطلاعات مکانی محوطه باستانی استخراج می شود. روش خاص به شرح زیر است. این مطالعه با ادغام سن نسبی و نوع فرهنگی در متون، اطلاعات زمانی سایت را تعیین می کند. در این میان نام مکان اداری به عنوان اطلاعات مکانی محوطه باستانی استخراج می شود. روش خاص به شرح زیر است. این مطالعه با ادغام سن نسبی و نوع فرهنگی در متون، اطلاعات زمانی سایت را تعیین می کند. در این میان نام مکان اداری به عنوان اطلاعات مکانی محوطه باستانی استخراج می شود. روش خاص به شرح زیر است.
۳٫۲٫ روش شناسی
از نظر روششناسی، فناوری استخراج اطلاعات برای استخراج اطلاعات خاص از دادههای متنی عظیم باستانشناسی اتخاذ میشود. متون بدون ساختار پردازش شده و به اطلاعات ساختاریافته تبدیل می شوند. با توجه به مدل استخراج اطلاعات برای متن سایت باستانشناسی در این مطالعه، عمدتاً BiLSTM-CRF، به نام مدل شناسایی موجودیت، و مدل استخراج رابطه توجه دوگانه BiGRU را پوشش میدهد. آموزش مدل شناسایی موجودیت نامگذاری شده به مقدار زیادی از داده های حاشیه نویسی نیاز دارد. از آنجایی که داده های تجربی نمی توانند از پایگاه داده حاشیه نویسی عمومی در اینترنت استفاده کنند، حاشیه نویسی متن سایت باستان شناسی با YEDDA تکمیل می شود [ ۳۰]. پس از انجام تکالیف پاکسازی داده ها مانند حذف نمادهای استثنایی و URL های بیهوده و حفظ علائم نگارشی مهم، داده های متنی به صورت دستی حاشیه نویسی می شوند. با توجه به تحلیل فوق از متون باستان شناسی، ابتدا به تعریف نهاد باستان شناسی پرداختیم. ما کلمات یا عبارات با اهمیت توصیفی در مورد سایت مانند نام سایت، نوع فرهنگی، موقعیت جغرافیایی و سلسله تاریخی را در متن به عنوان موجودیت باستان شناسی انتخاب می کنیم، زیرا همه آنها مطالبی با معنای خاص در زمینه باستان شناسی هستند. استراتژی BIO برای حاشیه نویسی داده ها استفاده می شود. در فرآیند برچسبگذاری، کاراکتر حداقل واحد برچسبگذاری است. BIO نشان دهنده رده و موقعیت موجودیت باستان شناسی است، B به رئیس نهاد، I نشان دهنده موقعیت میانی موجودیت به جز رئیس است، O نشان می دهد که این کاراکتر به هیچ دسته موجودیتی تعلق ندارد و X به دسته موجودیت اشاره دارد. با توجه به این استراتژی، هر کاراکتر می تواند به عنوان “BX”، “IX” یا “O” علامت گذاری شود. برچسب های مربوط به چهار دسته از موجودیت ها در متن سایت باستان شناسی در نشان داده شده استجدول ۱ .
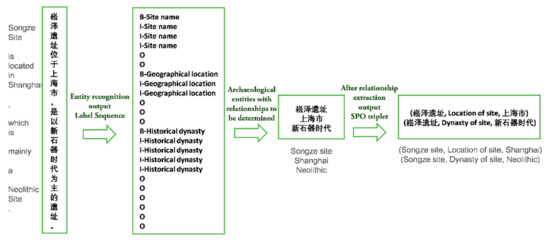
با توجه به ارتباط بین چهار موجود باستان شناسی فوق، ما چهار رابطه باستان شناسی را تعریف کرده ایم که عبارتند از: فرهنگ محوطه، موقعیت مکانی، سلسله محوطه و هیچ. در فرآیند انجام آزمایش های استخراج اطلاعات، در درجه اول به دو بخش تقسیم می شود. در ابتدا، متن باستان شناسی جمله به جمله در مدل شناسایی موجودیت نامگذاری شده وارد می شود. مدل آموزشدیده میتواند موجودیتهای باستانشناختی مقولههای از پیش تعیینشده را شناسایی کند و جملات حاوی موجودیتها را خروجی دهد. سپس، نتیجه فوق به مدل استخراج رابطه وارد می شود، که در نهایت سه گانه رابطه موجودیت (e1, r, e2) را به دست می آورد که به عنوان «سه گانه SPO (موضوع، محمول، مفعول)» نیز شناخته می شود. به عنوان مثال، نمایش استخراج اطلاعات در متن سایت باستان شناسی در نشان داده شده استشکل ۱ .
شناسایی موجودیت نامگذاری شده یک وظیفه ضروری برای استخراج اطلاعات است. این به شناسایی موجودیت های هدف در متن و طبقه بندی آنها به عنوان معیارهای از پیش تعریف شده اشاره دارد. در این آزمایش، مدل BiLSTM-CRF برای شناسایی موجودیت نامگذاری شده در متون سایت باستانشناسی چینی استفاده میشود که یک تفکر و روش جدید برای شناسایی موجودیت در زمینه باستانشناسی چینی ارائه میدهد. استخراج رابطه موجودیت به این معنی است که پس از شناخت موجودیت های حیاتی در یک جمله، روابط معنایی موجود بین موجودیت ها مشخص می شود. در نتیجه، در پرتو شناخت موجودیت، این مقاله یک مدل توجه دوگانه BiGRU برای متون سایت باستانشناسی میسازد. این مدل از BiGRU برای یادگیری اطلاعات متنی کلمات استفاده میکند تا ویژگیهای دقیقتری را به دست آورد. از طریق مکانیسم توجه در سطح کلمه می توان وزن کلماتی را که برای طبقه بندی رابطه قطعی هستند افزایش داد. به طور همزمان، با استفاده از مکانیسم توجه در سطح جمله، میتوانیم ویژگیهای بیشتر جملات را بیاموزیم و وزن جملات پر سر و صدا را کاهش دهیم، در نتیجه به طور موثر مشکل برچسبگذاری نادرست را حل کرده و اثر طبقهبندی کننده را بهبود میبخشیم. روند کلی روش این مقاله در نشان داده شده استشکل ۲ .
۳٫۲٫۱٫ مدل شناسایی موجودیت با نام BiLSTM-CRF
LSTM نوعی شبکه عصبی بازگشتی (RNN) برای مدلسازی دادههای سری زمانی متنی است. BiLSTM یک LSTM دو طرفه است که از یک LSTM رو به جلو و یک LSTM عقب تشکیل شده است. با این حال، BiLSTM فقط می تواند رابطه بین دنباله متن و تگ را پیش بینی کند و نمی تواند رابطه بین برچسب ها را پیش بینی کند، بنابراین به ماتریس انتقال در CRF نیاز دارد. در تقابل با LSTM، CRF میتواند حالتهای پنهان را مدلسازی کند و ویژگیهای دنبالههای حالت را بیاموزد، اما نیاز به استخراج دستی ویژگیهای دنباله دارد. بنابراین، مدل BiLSTM-CRF برای به دست آوردن نقاط مثبت هر دو مرجع قبلی ساخته شده است.
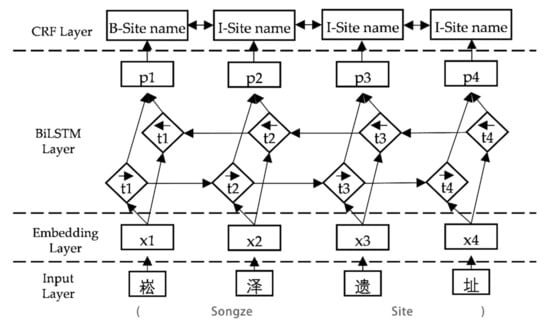
مدل BiLSTM-CRF ساخته شده برای شناسایی موجودیت های باستان شناسی نامگذاری شده شامل چهار لایه است: لایه ورودی، لایه جاسازی، لایه BiLSTM و لایه CRF. ساختار خاص مدل شناسایی موجودیت در شکل ۳ نشان داده شده است .
لایه اول لایه ورودی است که متن سایت باستان شناسی چینی را به صورت کلمات به عنوان ورودی اولیه می گیرد و جمله ای حاوی n کلمه به صورت یادداشت می شود. ، شامل یک فرهنگ لغت، که در آن شناسه i -امین کلمه جمله در فرهنگ لغت است و بعد اندازه فرهنگ لغت است که تعداد کلمات است.
لایه دوم لایه embedding است که از طریق ابزار word2vec تبدیل داده های متنی به ماتریس های برداری قابل پردازش توسط کامپیوتر را انجام می دهد. هر کلمه با استفاده از یک ماتریس تصادفی اولیه در این لایه به یک بردار کلمه نگاشت می شود. برای یک دنباله متن معین از سایتهای باستانشناسی بدون ساختار، کلمه بردار به دست آمده است.
در لایه BiLSTM که از دو لایه LSTM تشکیل شده است، ویژگیهای معنایی جلو و عقب با توجه به ورودی کلمه برداری در هر مرحله زمانی استخراج میشوند. به دلیل تفاوت در ترتیب ترتیب پردازش برداری، دو لایه LSTM به ترتیب مثبت به لایه جلو و به ترتیب معکوس به لایه عقب تقسیم می شوند. لایه پنهان جلو وظیفه استخراج خصوصیات هر کلمه در متن و به دست آوردن حالت مخفی خروجی را بر عهده دارد. از هر کلمه لایه پنهان عقب مسئول استخراج ویژگی معکوس و حالت پنهان خروجی است به دست آمده است. شکل ۳ روند انتشار به جلو و عقب و مسیر را از طریق جهت فلش نشان می دهد. در همان زمان، شبکه BiLSTM امتیازهای پیشبینی برچسبها را به لایه CRF خروجی میدهد، یعنی: . هر بعد از را می توان به عنوان امتیاز طبقه بندی کلمه در نظر گرفت به برچسب j- ام.
لایه چهارم لایه CRF است که رابطه بین کلمات جلو و عقب را برای کنترل ترتیب خروجی حاشیه نویسی در نظر می گیرد. با فرض اینکه جمله ورودی W یک دنباله تگ پیش بینی به دست می آورد ، امتیاز پیش بینی به صورت زیر تعریف می شود:
جایی که احتمال این است که خروجی BiLSTM موقعیت i -ام باشد ، و احتمال انتقال از است به . امتیاز کل دنباله مجموع امتیازات هر موقعیت است. امتیاز هر موقعیت به طور مشترک توسط و ماتریس انتقال A از CRF. نمره از تمام توالی های حاشیه نویسی ممکن y از W توسط الگوریتم Viterbi به دست می آید و پس از آن، تمام امتیازات توسط تابع softmax نرمال می شوند. در نهایت احتمال دنباله y به صورت زیر بدست می آید:
در حین آموزش مدل، برای دنباله ورودی جمله X ، تابع ضرر تنظیم شده است تا لگاریتم احتمال دنباله نشانه گذاری واقعی هدف Y را بگیرد. برای به حداکثر رساندن احتمال مربوط به دنباله نشانگر واقعی، استراتژی گرفتن یک مقدار منفی و سپس به حداقل رساندن آن اتخاذ میشود و الگوریتم نزول گرادیان برای حل پارامترها معرفی میشود. تابع حداکثر کردن log درستنمایی به شرح زیر است:
در فرآیند پیشبینی، امتیازهای S مربوط به تمام توالیهای y ممکن توسط پارامترهای آموزشدیده شده محاسبه میشوند و از الگوریتم Viterbi برای حل مسیر بهینه استفاده میشود. نتیجه پیش بینی شده به صورت ثبت می شود :
۳٫۲٫۲٫ مدل استخراج رابطه توجه دوگانه BiGRU
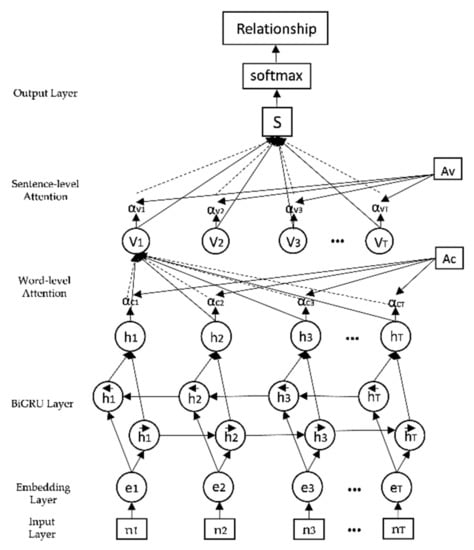
GRU گونه ای از LSTM است که بر اساس LSTM ساده شده است. از آنجایی که GRU یک جهته ارتباط بین متون را نادیده می گیرد، BIGRU برای انجام این ارتباط در این مطالعه استفاده می شود. علاوه بر این، این مقاله مکانیسم توجه دوگانه در سطح کلمه و جمله را معرفی میکند که میتواند تداخل نویز را بهتر از بین ببرد و دقت را در مقایسه با مکانیسم توجه تک لایه بهبود بخشد. مدل BiGRU-Dual Attention به شش قسمت تقسیم می شود. ساختار مدل در شکل ۴ نشان داده شده است .
برای شروع، نمونه آموزش ورودی به دنباله برداری کلمه تبدیل می شود از طریق لایه جاسازی سپس، GRU برای ادغام اطلاعات زمینه استفاده می شود. در مقایسه با شبکه یک طرفه GRU، BiGRU یک لایه مخفی دیگر اضافه می کند که دنباله متن را در جهت جلو و عقب به مدل وارد می کند و حالت های لایه پنهان را در هر دو جهت به لایه خروجی متصل می کند. در این زمان، خروجی شبکه مربوط به نویسه چینی i- امین است:
جایی که خروجی لایه فوروارد شبکه GRU با کلمه برداری است به عنوان ورودی، خروجی لایه معکوس است و ⊕ نشان دهنده اضافه شدن عنصر به عنصر است. برای کلمه ماتریس برداری خروجی توسط شبکه BiGRU، که در آن T تعداد کاراکترهای چینی موجود در نمونه رابطه است.
وکتور هر کلمه با معرفی وزن توجه در سطح کلمه وزن می شود :
که در آن V بردار نتیجه محاسبه شده است و می توان با تابع softmax محاسبه کرد:
جایی که پارامتر مورد استفاده برای آموزش در مدل است که در فرآیند آموزش به دست می آید.
مکانیسم توجه در سطح جمله خروجی لایه مکانیسم توجه کلمه را به عنوان ورودی می گیرد. با محاسبه درجه تطابق بین هر جمله حاوی جفت موجودیت و رابطه پیش بینی شده، ماتریس وزن سطح جمله ساخته می شود و در نهایت بردار بیانگر جمله به دست می آید. جریان الگوریتم خاص به شرح زیر است:
که در آن S بردار خروجی لایه مکانیسم توجه در سطح جمله است و وزن هر بردار جمله است . کارکرد نشان دهنده درجه تطابق بین هر جمله است و رابطه پیش بینی r ، و A ماتریس قطری وزن است.
سپس، احتمال شرطی رابطه پیش بینی از طریق تابع softmax محاسبه می شود:
که در آن R ماتریسی است که از همه بردارهای رابطه تشکیل شده است و b بردار افست است. در نهایت، از تابع argmax برای به دست آوردن رابطه پیش بینی نهایی استفاده می شود:
بر اساس تنسورفلو، این مقاله مدل استخراج رابطه را در پرتو مکانیسم توجه دوگانه درک میکند، از آنتروپی متقاطع به عنوان تابع از دست دادن در طول تمرین استفاده میکند و منظمسازی L2 را برای محدود کردن اندازه پارامترها برای کاهش مشکل اضافه برازش در فرآیند تمرین ترکیب میکند. محاسبه تابع ضرر به صورت زیر است:
جایی که تمام پارامترهای مدل را نشان می دهد، m تعداد مجموعه های نمونه را نشان می دهد. برچسب رابطه واقعی است و ضریب تنظیم L2 است. سپس تابع ضرر توسط الگوریتم آدام به حداقل می رسد تا آموزش و به روز رسانی پایدار پارامترها در مدل محقق شود. علاوه بر این، برای جلوگیری از برازش بیش از حد، حذف به لایه BiGRU اضافه می شود.
۴٫ نتایج تجربی
۴٫۱٫ راه اندازی آزمایشی
همانطور که در بخش ۳٫۲ اشاره شد ، این مطالعه چهار موجودیت باستان شناسی شامل نام سایت، نوع فرهنگی، موقعیت جغرافیایی و سلسله های تاریخی را شناسایی کرده است. سپس، آزمایش شناسایی موجودیت نامگذاری شده با پیکره برچسبگذاری شده دستی بالا انجام میشود. در مجموع ۲۱۸۰۰ پیکره از متون ۸۰۰ سایت به عنوان مجموعه آزمایشی آزمایش شناسایی موجودیت نامگذاری شده انتخاب شد. از این میان ۸۰ درصد برای پیکره آموزشی، ۱۰ درصد برای پیکره تأیید و ۱۰ درصد برای پیکره آزمون استفاده می شود. آمار موجودیت ها در مجموعه داده ها در جدول ۲ نشان داده شده است.
تا آنجا که وظیفه شناسایی موجودیت نامگذاری شده متن سایت باستانشناسی، آزمایشها بر اساس چارچوب یادگیری عمیق Pytorch انجام شد و تنظیمات پارامتر مدل در آموزش در جدول ۳ نشان داده شده است.
بر اساس شناخت موجودیت، استخراج رابطه موجودیت های باستان شناسی انجام می شود. برای استخراج رابطه موجودیت در زمینه متون باستان شناسی، ۸۱۲۰ پیکره از نتایج شناسایی موجودیت انتخاب شده است که ۸۰ درصد به عنوان پیکره های آموزشی، ۱۰ درصد به عنوان پیکره های تأیید و ۱۰ درصد به عنوان پیکره های آزمایشی انتخاب شده اند. روابط موجود درگیر به چهار دسته تقسیم می شود که شامل فرهنگ سایت، موقعیت مکانی سایت، سلسله سایت و هیچ کدام است. آمار روابط موجود در مجموعه داده ها در جدول ۴ نشان داده شده است.
در این مقاله، مدل توجه دوگانه BiGRU برای متون باستان شناسی بر اساس چارچوب یادگیری عمیق تنسورفلو ساخته شده است و تنظیمات پارامترهای مدل در آموزش در جدول ۵ نشان داده شده است.
ارزیابی یک کار ضروری در زمینههای یادگیری ماشین، پردازش زبان طبیعی، بازیابی اطلاعات و غیره است و معیارهای ارزیابی معمولاً به شرح زیر است: دقت، یادآوری و مقدار F1. بنابراین، مدل استخراج اطلاعات برای متون محوطه باستانشناسی در این مطالعه از مقادیر دقیق P، Recall R و F1 به عنوان شاخص ارزیابی استفاده میکند. می توان آن را به صورت زیر محاسبه کرد:
در جایی که مثبت های واقعی نشان دهنده داده هایی هستند که واقعاً پیش بینی شده اند، مثبت های کاذب نشان دهنده داده هایی هستند که به اشتباه پیش بینی شده اند و منفی های کاذب نشان دهنده داده هایی هستند که باید به درستی پیش بینی شوند اما پیش بینی نشده اند.
۴٫۲٫ نتایج شناسایی موجودیت
مدل شناسایی موجودیت BiLSTM-CRF با استفاده از متن سایت باستانشناسی برچسبگذاری شده آموزش داده شد. به منظور ارزیابی اثربخشی مدل شناسایی موجودیت BiLSTM-CRF در متون سایت باستانشناسی، آزمایشهای مقایسهای بر روی یک مدل مارکوف پنهان (HMM، یک مدل آماری کلاسیک اولیه)، یک مدل BiLSTM با دادههای تجربی مشابه انجام شد. نتایج تجربی در جدول ۶ نشان داده شده است.
از تجزیه و تحلیل آزمایش مقایسه ای، تأثیر مدل BiLSTM-CRF ساخته شده در این مقاله، با نرخ دقت ۹۴٫۵۱ درصد، نرخ فراخوان ۸۲٫۱۰ درصد و مقدار F1 87.87 درصد، نسبت به روش های دیگر برتر است. این نشان میدهد که سازگاری خوبی در وظیفه شناسایی موجودیت متن سایت باستانشناسی دارد و میتواند به طور موثر مدلسازی انتزاعی متون باستانشناسی را انجام دهد. از نظر سه معیار، مدل در این مقاله با بهبود در دقت، در یادآوری و در مقدار F1 از مدل HMM بهتر عمل میکند. این نشان می دهد که عملکرد مدل متکی به یک شبکه عصبی بدیهی است بهتر از مدل آماری اولیه، با بهبود قابل توجهی. مدل در این مقاله دقت، فراخوانی و مقدار F1 را در مقایسه با BiLSTM بهبود می بخشد.
در ادامه، تجزیه و تحلیل بیشتر در مورد نتیجه شناسایی مدل BiLSTM-CRF برای انواع مختلف موجودیت ها در جدول ۷ نشان داده شده است .
مشاهده می شود که این مدل می تواند به طور نسبی چهار نوع موجودیت را در متن سایت باستان شناسی تشخیص دهد که مقادیر F1 موقعیت جغرافیایی و نوع فرهنگی بالای ۹۰ درصد است. از تجزیه و تحلیل نتایج تجربی، می توان مشاهده کرد که دقت موجودیت های نوع فرهنگی بالاترین است. این ممکن است به شناسایی واضح «فرهنگ» و «نوع» در متون سایت باستانشناسی چینی مرتبط باشد، که برای بهبود ظرفیت تشخیص مدل مفید است. برعکس، توصیف سلسله تاریخی در زبان چینی پیچیدهتر است، بنابراین این مدل در یافتن یک بیان قاعده کلی مشکل دارد و نتیجه شناخت نسبتاً ضعیفی را به همراه دارد.
۴٫۳٫ نتایج استخراج رابطه
در آزمایش استخراج رابطه موجودیت، از دقت P، مقدار فراخوان R و F1 نیز برای ارزیابی عملکرد مدل استفاده میشود. به منظور تأیید عملکرد مدل توجه دوگانه BiGRU در دقت و یادآوری، نتیجه تجربی استخراج رابطه از موجودیتهای متن باستانشناسی تحلیل و با مدل BiLSTM-توجه مقایسه میشود. نتایج در جدول ۸ نشان داده شده است.
نتایج تجربی نشان میدهد که مدل توجه دوگانه BiGRU عملکرد بهتری نسبت به مدل BiLSTM-توجه بدون افزایش پیچیدگی مدل به دست میآورد. مدل BiGRU-Dual Attention مقداری بهبود در عملکرد، با پیشرفت در دقت، در یادآوری و در مقدار F1 را نشان میدهد. در این میان، مشاهده میشود که استفاده از مکانیسم توجه دوگانه تأثیر مثبتی بر بهبود عملکرد مدل و دستیابی به دقت بالاتر در استخراج رابطه دارد. به منظور تجزیه و تحلیل بیشتر تفاوت در اثر استخراج روابط مختلف موجودیت، نتایج ارزیابی روابط مختلف، همانطور که در جدول ۹ نشان داده شده است، تجزیه و تحلیل می شود .
همراه با توزیع موجودیت مجموعه داده نمونه برچسبگذاری شده، از جدول ۴ قابل مشاهده استکه رابطه مکان سایت بیشترین نسبت را در مجموعه آزمایشی به خود اختصاص می دهد، در حالی که رابطه هیچکدام کمترین نسبت را به خود اختصاص می دهد. به طور نسبی، مقولههای رابطه با حجم زیادی از دادهها، نرخ فراخوانی بالاتری در طول آزمون دارند. از تجزیه و تحلیل فوق، می توان دریافت که در کار استخراج رابطه متن، در مقایسه با بهبود الگوریتم مدل، کیفیت مجموعه نیز حیاتی است. هر چه کیفیت مجموعه های آموزشی و یادگیری مدل یادگیری عمیق بالاتر باشد، اثر تشخیص مدل دقیق تر خواهد بود. از نظر اثربخشی و امکانسنجی، نتایج تجربی جامع نشان میدهد که مدل توجه دوگانه BiGRU تأثیر مثبتی بر استخراج رابطه در متون سایت باستانشناسی چینی دارد.
هدف از آزمایش فوق، امکان سنجی کاربرد استخراج اطلاعات در زمینه متون محوطه باستان شناسی و یافتن روشی مناسب است. از طریق تأمل در نتایج آزمون، میتواند به افزایش مجموعه دادهها و مدلها در تحقیقات بعدی کمک کند. به طور کلی، مدل BiLSTM-CRF می تواند به طور موثر چهار نوع موجودیت را که به اطلاعات مکانی-زمانی سایت ها مربوط می شوند، شناسایی کند. با این حال، یادآوری کمی دارد که ناشی از تغییرپذیری الگوهای جملات در متون سایت باستانشناسی چینی است. بعداً، پیکره با برچسب نهاد را برای بهبود توانایی تشخیص مدل اضافه می کنیم. بر اساس آزمایش شناسایی موجودیت، مشخص شده است که مدل توجه دوگانه BiGRU در وظیفه استخراج رابطه سایت باستان شناسی به خوبی عمل می کند، که کارایی آموزشی آزمایش را بیشتر افزایش می دهد. علاوه بر این، دلیل تشخیص نادرست رابطه موجودیت عمدتاً به فقدان پیکره حاشیهنویسی مربوط میشود و در نتیجه توانایی استخراج رابطه مدل وجود ندارد. در تحقیقات آینده، مجموعه متون حاشیه نویسی رابطه ای گسترش خواهد یافت. ما امیدواریم که بتوانیم توانایی استخراج مدل را بهبود بخشیم تا مرجعی برای ساخت نمودار دانش محوطه های باستانی ارائه کنیم. منجر به عدم توانایی استخراج رابطه مدل می شود. در تحقیقات آینده، مجموعه متون حاشیه نویسی رابطه ای گسترش خواهد یافت. ما امیدواریم که بتوانیم توانایی استخراج مدل را بهبود بخشیم تا مرجعی برای ساخت نمودار دانش محوطه های باستانی ارائه کنیم. منجر به عدم توانایی استخراج رابطه مدل می شود. در تحقیقات آینده، مجموعه متون حاشیه نویسی رابطه ای گسترش خواهد یافت. ما امیدواریم که بتوانیم توانایی استخراج مدل را بهبود بخشیم تا مرجعی برای ساخت نمودار دانش محوطه های باستانی ارائه کنیم.
۴٫۴٫ مثال کاربردی
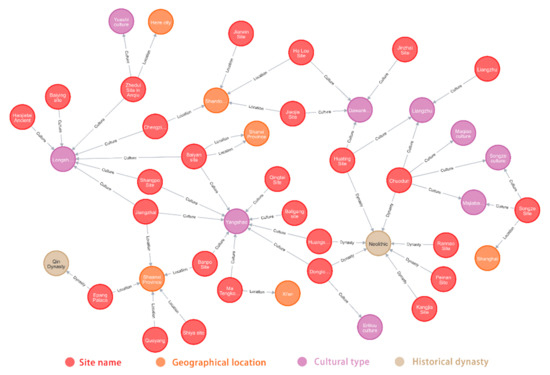
با پیشرفت رایانه ها و اینترنت در طول سال ها، می توان دریافت که فناوری نمودار دانش توجه گسترده ای را به خود جلب کرده است. نمودارهای دانش دارای مزایای طبیعی برای تجزیه و تحلیل، نمایش و استفاده از نتایج استخراج اطلاعات هستند. به عنوان پایگاه دانش معنایی ساختاریافته، نمودارهای دانش می توانند به طور موثر حجم عظیمی از اطلاعات را پردازش، مدیریت و ادغام کنند. استخراج اطلاعات بر اساس سه گانه ساختاریافته گام مهمی در فرآیند ساخت نمودارهای دانش است. پس از آزمایش استخراج اطلاعات فوق، سه گانه ها را از متون سایت باستان شناسی به دست می آوریم. با ذخیره سه گانه ها در پایگاه داده رابطه ای، می توانیم یک نمودار دانش پایه به دست آوریم و تبدیل از متون بدون ساختار به متون ساختاریافته را کامل کنیم. در راستای فرآیند ساخت نمودار دانش، توسعه و ذخیره نمودارهای دانش سایت باستان شناسی بر اساس Neo4j محقق می شود. این نمودار در مجموع شامل ۳۳۱۸ گره و ۸۱۲۰ یال است.شکل ۵نمودار دانش جزئی از سایت های باستانی را نشان می دهد. اساساً، این مقاله با هدف استخراج اطلاعات مکانی-زمانی ساختاریافته از دادههای متنی مختلف باستانشناسی و رسمیسازی آنها با یک نمایش سهگانه یکپارچه است. آنها از دسترسی به زبان پرس و جو گرافیکی پشتیبانی می کنند، به طوری که می توان دانش عمیق را به دست آورد. معرفی نمودارهای دانش نسبتاً جدید است و مطالعات کمی کاربرد آنها را در زمینه باستان شناسی بررسی کرده است. در آینده، پیوند دانش محوطه باستانشناسی را از منابع مختلف در نظر میگیریم، و استفاده از این دانش مرتبط، کشف دانش باستانشناسی را بیشتر تقویت میکند. با ساخت نمودار دانش محوطه باستان شناسی، نه تنها دانش محوطه باستان شناسی را غنی می کند، بلکه باستان شناسی را برای عموم رایج می کند. در همین حال،
۵٫ بحث و نتیجه گیری
متن محوطه باستانی به عنوان هدف تحقیق در این پژوهش انتخاب شده است. با توجه به موضوع اطلاعات غنی با دانش پراکنده در زمینه متون محوطه باستان شناسی چینی، ویژگی ها و الزامات کاربردی آن به عنوان نقطه شروع در نظر گرفته شده است. ما از روش استخراج اطلاعات برای استخراج اطلاعات مکانی-زمانی از متن سایت باستان شناسی استفاده می کنیم. نتایج نشان می دهد که برای کارهای مربوطه مناسب است. در مقایسه با سایر مطالعات موجود، ما متن منابع داده بیشتری را بررسی میکنیم و طبیعتاً آنها را با هم ادغام میکنیم. این مطالعه داده های چند منبعی مانند کتاب های باستان شناسی، گزارش های کاوش ها و متون آنلاین را به دست آورده است. این مزیت به دست آوردن اطلاعات با کیفیت بالاتر و پوشش خوب زمینه های محوطه باستان شناسی است. که برای کشف و کسب دانش حیاتی است. ما ثابت میکنیم که فناوری استخراج اطلاعات برای حوزه باستانشناسی چینی مناسب است، نه اینکه فقط یک شی متن واحد را مورد بحث قرار دهد. در مقایسه با ژانگ [۲۵ ]، تحت معیارهای ارزیابی یکسان، P، R و F1 آزمایش استخراج اطلاعات ما به طور جزئی کمتر هستند، اساساً با توجه به این واقعیت که دادههای ورودی در مطالعه او نیمهساختارمند هستند، در حالی که دادههای ورودی ما ساختاریافته هستند و میآیند. از منابع مختلف عملکرد مدل شناسایی موجودیت نامگذاری شده مشابه لیو است [ ۲۶] اما با دقت بالاتر و یادآوری کم. با ظهور مداوم موجودیتهای جدید، برای تضمین کیفیت شناسایی موجودیت نامگذاری شده، نیاز به حفظ فرهنگ لغت داریم. زمانی که دیکشنری ها مفصل نیستند یا قوانین دامنه کامل نیستند، اغلب ویژگی های دقت بالا و یادآوری کم وجود دارد. به طور همزمان، همچنین مشاهده می شود که توزیع نامتعادل روابط موجود در متن محوطه های باستانی وجود دارد. در یک متن، اغلب توصیف های بیشتری از مکان و کمتر توصیفی از فرهنگ یا سلسله وجود دارد. بنابراین، در مورد انطباق الگوریتم مدل، افزایش موثر دادهها انتظار میرود که توزیع روابط موجودیت را متعادل کند تا اثر کلی استخراج اطلاعات بهبود یابد. امروزه رسانه های مختلف به اشتراک گذاری اطلاعات دانش مفیدی را ارائه می دهند. بنابراین ایجاد یک پایگاه دانش نهایی و کامل دشوار است. با این حال، منابع مختلف دانش می توانند مکمل یکدیگر باشند. در مقایسه با روش جریان توصیف استفاده شده توسط ژانگ [۲۳ ]، سه قلوها می توانند دانش را از منابع مختلف به هم متصل کرده و آنها را به صورت یکپارچه منتشر کنند. در همان زمان، ما نمودارهای دانش را معرفی کردیم و یک کاوش اولیه را انجام دادیم. این به کاربران اجازه می دهد تا پرس و جوهای پیچیده ای را در نمودار دانش ایجاد کنند تا ارتباط و اشتراک دانش را ارتقا دهند. بر این اساس، میتواند برای محققین مربوطه پشتیبانی داده و ایدههای جدیدی برای بازیابی اطلاعات سنتی ارائه دهد.
مطالعه روش استخراج اطلاعات مکانی-زمانی و تأیید اثربخشی آن در متون سایت باستانشناسی چینی در این مقاله انجام شده است. این مطالعه با استفاده کامل از دادههای متنی سایت باستانشناسی چند منبعی و ناهمگون در اینترنت، حاشیهنویسی دادهها را انجام میدهد که در ابتدا ساخت مجموعه سایت باستانشناسی چینی را تکمیل میکند. از آنجایی که هیچ مجموعه یا مجموعه داده حاشیه نویسی عمومی در زمینه باستان شناسی چینی وجود ندارد، از طریق تجزیه و تحلیل متون سایت باستان شناسی چینی، این مطالعه تعریف مناسبی از سلسله مراتب رابطه موجودیت در مورد اطلاعات مکانی-زمانی سایت ارائه می دهد. بر این اساس، پایه داده ای را برای استخراج دانش از محوطه های باستانی ایجاد می کند. با تکیه بر روش یادگیری عمیق که نیازی به استخراج دستی ویژگی ندارد، BiLSTM-CRF، به نام مدل شناسایی موجودیت، و مدل استخراج رابطه توجه دوگانه BiGRU برای استخراج اطلاعات مکانی-زمانی در سایت ساخته شدهاند. پس از آن، این مطالعه آزمایشهای مقایسهای انجام داد که نتایج تجربی نسبتاً خوبی به دست آورد. این نتایج امکان بکارگیری این روش استخراج اطلاعات را در متون محوطه باستان شناسی نشان می دهد. برای تأیید بیشتر نتایج استخراج از رابطه موجودیت سه گانه از سایت های باستان شناسی، نمونه ای از یک نمودار دانش تکمیل شد. بنابراین روش جدیدی برای ذخیره و نمایش دانش محوطه باستان شناسی سنتی ارائه شده است. با توجه به نتایج مطالعه، می تواند تحقیقات مربوطه در زمینه کاوش اطلاعات مکانی-زمانی را در سایت ها ترویج کند و زمینه را برای ساخت نمودارهای دانش در باستان شناسی فراهم کند. علاوه بر این، برای ارتقای نوآوری روشهای تحقیق باستانشناسی و کاوش مشکلات باستانشناسی در عصر اطلاعات، ارزش مرجع زیادی دارد. در کار بعدی، در نظر گرفته شده است که نهادهای باستان شناسی بیشتری (از جمله مصنوعات حفاری شده، محوطه سایت و غیره) حاشیه نویسی شود تا مجموعه را گسترش دهد، که تلاش می کند ساخت نمودارهای دانش را در زمینه باستان شناسی چینی کامل کند و مفهوم را غنی کند. از دانش در عین حال، ما به توسعه و تحقیق جستجوی معنایی، پرسش و پاسخ هوشمند و سایر برنامههای کاربردی سطح بالا بر اساس نمودار دانش سایت باستانشناسی چینی ادامه خواهیم داد. برای ارتقای نوآوری روش های تحقیق باستان شناسی و کاوش در مشکلات باستان شناسی در عصر اطلاعات، ارزش مرجع زیادی دارد. در کار بعدی، در نظر گرفته شده است که نهادهای باستان شناسی بیشتری (از جمله مصنوعات حفاری شده، محوطه سایت و غیره) حاشیه نویسی شود تا مجموعه را گسترش دهد، که تلاش می کند ساخت نمودارهای دانش را در زمینه باستان شناسی چینی کامل کند و مفهوم را غنی کند. از دانش در عین حال، ما به توسعه و تحقیق جستجوی معنایی، پرسش و پاسخ هوشمند و سایر برنامههای کاربردی سطح بالا بر اساس نمودار دانش سایت باستانشناسی چینی ادامه خواهیم داد. برای ارتقای نوآوری روش های تحقیق باستان شناسی و کاوش در مشکلات باستان شناسی در عصر اطلاعات، ارزش مرجع زیادی دارد. در کار بعدی، در نظر گرفته شده است که نهادهای باستان شناسی بیشتری (از جمله مصنوعات حفاری شده، محوطه سایت و غیره) حاشیه نویسی شود تا مجموعه را گسترش دهد، که تلاش می کند ساخت نمودارهای دانش را در زمینه باستان شناسی چینی کامل کند و مفهوم را غنی کند. از دانش در عین حال، ما به توسعه و تحقیق جستجوی معنایی، پرسش و پاسخ هوشمند و سایر برنامههای کاربردی سطح بالا بر اساس نمودار دانش سایت باستانشناسی چینی ادامه خواهیم داد. در نظر گرفته شده است که نهادهای باستان شناسی بیشتری (از جمله مصنوعات حفاری شده، محوطه سایت و غیره) را برای گسترش مجموعه، که تلاش می کند ساخت نمودارهای دانش در زمینه باستان شناسی چینی را کامل کند و مفهوم دانش را غنی کند، حاشیه نویسی کند. در عین حال، ما به توسعه و تحقیق جستجوی معنایی، پرسش و پاسخ هوشمند و سایر برنامههای کاربردی سطح بالا بر اساس نمودار دانش سایت باستانشناسی چینی ادامه خواهیم داد. در نظر گرفته شده است که نهادهای باستان شناسی بیشتری (از جمله مصنوعات حفاری شده، محوطه سایت و غیره) را برای گسترش مجموعه، که تلاش می کند ساخت نمودارهای دانش در زمینه باستان شناسی چینی را کامل کند و مفهوم دانش را غنی کند، حاشیه نویسی کند. در عین حال، ما به توسعه و تحقیق جستجوی معنایی، پرسش و پاسخ هوشمند و سایر برنامههای کاربردی سطح بالا بر اساس نمودار دانش سایت باستانشناسی چینی ادامه خواهیم داد.