۱٫ مقدمه
یک کار اساسی در بینایی کامپیوتری، تشخیص هدف است که ناحیه مورد نظر در تصویر ورودی را در یک کادر محدود قاب میکند. با ادامه پیشرفت فناوری فضایی، تصاویر سنجش از راه دور با وضوح فوق العاده اهمیت فزاینده ای پیدا می کنند. با این حال، تشخیص هدف در تصویربرداری سنجش از دور همچنان یک چالش بزرگ است و بنابراین توجه تحقیقاتی فزاینده ای را به خود جلب می کند. با توجه به باندهای مختلف تصویربرداری، سنجش از راه دور را می توان به سنجش از راه دور نوری، سنجش از راه دور مادون قرمز، SAR (رادار دیافراگم مصنوعی) و دسته های دیگر تقسیم کرد. تشخیص هدف در تصاویر سنجش از دور نوری نقش مهمی در طیف وسیعی از کاربردها مانند پایش محیطی، تشخیص خطرات زمینشناسی، نقشهبرداری کاربری/پوشش زمین (LULC)، بهروزرسانی سیستم اطلاعات جغرافیایی (GIS)، کشاورزی دقیق،۱ ].
در تصویربرداری سنجش از دور نوری، اهداف معمولاً به دلیل تفاوت در نماهای بالای سر، جهت گیری های مختلفی دارند. بنابراین، اهداف در تصاویر سنجش از راه دور نوری، تعداد کمی از پیکسلهای هدف را مصرف میکنند که به طور گسترده در جهات مختلف توزیع شدهاند، و باعث میشوند به راحتی تحت تأثیر محیط اطراف قرار گیرند. برای مثال، همانطور که در شکل ۱ نشان داده شده است، وسایل نقلیه در تصاویر سنجش از راه دور نوری اغلب توسط سایه ها پنهان می شوند . این عوامل کار دشوار تشخیص هدف در تصاویر سنجش از دور نوری را به یک اولویت تحقیقاتی تبدیل می کند.
در چند سال اخیر، افزایش یادگیری عمیق کمک زیادی به توسعه تشخیص هدف کرده است. نتایج خوبی از یک سری الگوریتم های قدرتمند تشخیص هدف، مانند RCNN [ ۲ ]، Fast RCNN [ ۳ ]، Faster RCNN [ ۴ ]، SSD [ ۵ ]، YOLO [ ۶ ، ۷ ] و ResNet [ ۸ ] به دست آمده است. ]. با این حال، عملکرد این الگوریتمها هنگام اعمال تصویربرداری هوایی رضایتبخش نیست.
در بسیاری از مدلهای شبکه کانولوشن، شبکه ستون فقرات اغلب برای استخراج ویژگیهای هدف، مانند رنگ، بافت و مقیاس استفاده میشود. شبکه ستون فقرات میتواند چندین ترکیب از اندازههای میدان حسی و گامهای مرکزی را برای برآوردن نیازهای تشخیص هدف مقیاسها و کلاسهای مختلف فراهم کند [ ۹ ]. برخی از شبکه های ستون فقرات که معمولاً برای کارهای مختلف بینایی رایانه استفاده می شوند عبارتند از VGG [ ۱۰ ]، ResNet [ ۸ ]، MobileNet [ ۱۱ ، ۱۲ ، ۱۳ ] و DarkNet [ ۶ ، ۷ ].
برای شناسایی اهداف کوچک، شبکه ستون فقرات نقش مهمی ایفا می کند. یک شبکه ستون فقرات خوب اطلاعات ویژگی های بیشتری را استخراج می کند، اما استخراج اطلاعات ویژگی از اهداف کوچک دشوارتر است. با این حال، در تصویربرداری سنجش از دور نوری، اهداف خودرو ممکن است کمتر از ۱۰ پیکسل به دلیل زاویه شلیک مصرف کنند. برای شناسایی آن اهداف در تصاویر سنجش از دور نوری، گزارههای زیر را مطرح کردیم:
- ۱٫
-
تحت تأثیر RepVgg [ ۱۴ ]، ما یک شبکه ستون فقرات به نام «RepDarkNet» پیشنهاد کردیم که دقت آموزش و سرعت تشخیص را ترکیب میکند. آزمایشها نشان میدهند که RepDarkNet در مقایسه با YOLOv3 و YOLOv4 با سبک DarkNet بهعنوان ستون فقرات، هنگام اعمال بر مجموعه دادههای Dior بهتر عمل میکند.
- ۲٫
-
ما یک شبکه همگرای چندلایه برای اهداف کوچک در تصاویر سنجش از دور نوری پیشنهاد کردیم. این شبکه شامل شبکههای تشخیص چند لایه و ویژگی فیوژن است.
- ۳٫
-
علاوه بر این، ورودی بزرگتر و GIoU [ ۱۵ ] برای بهبود تشخیص اهداف بسیار کوچک استفاده شد و به طور جداگانه با اعمال آنها بر روی مجموعه داده Dior-vehicle آزمایش شد.
ادامه این مقاله به شرح زیر سازماندهی شده است: بخش ۱ تحقیقات مرتبط در مورد تشخیص در تصاویر سنجش از دور نوری را معرفی می کند. بخش ۲ روش پیشنهادی برای شناسایی اهداف کوچک را تشریح می کند. بخش ۳ طرح آزمایشی و جزئیات آزمایشی را تشریح می کند و بخش ۴ نتایج تجربی و تجزیه و تحلیل را شرح می دهد. در نهایت، ما این مطالعه را در بخش ۵ نتیجه میگیریم .
۲٫ کارهای مرتبط
معمولاً از روش تشخیص هدف جعبه مرزی افقی (HBB) برای صحنه های عمومی و برای تشخیص هدف سنجش از دور نوری استفاده می شود. رابی و همکاران [ ۹ ] از GAN (شبکه های متخاصم مولد) برای تبدیل تصاویر به تصاویر با وضوح فوق العاده و استخراج اطلاعات ویژگی از تصاویر برای بهبود تشخیص اهداف کوچک استفاده کرد. ژانگ و همکاران [ ۱۶ ] یک شبکه عصبی کانولوشنال قوی سلسله مراتبی (CNN) را پیشنهاد کرد و یک مجموعه داده تشخیص هدف با وضوح بالا به نام HRSSD ساخت. آدام و همکاران [ ۱۷ ] YOLT را پیشنهاد کرد که تصاویر ماهوارهای با اندازه دلخواه را با سرعتی بیش از ۰٫۵ کیلومتر بر ثانیه ارزیابی میکند و اهداف کوچک (۵ پیکسل) را با وضوح بالا تعیین میکند.
تصاویر سنجش از راه دور نوری شامل اهدافی با توزیع متراکم جهت گیری های دلخواه است. بنابراین، اهداف مبتنی بر HBB ممکن است به طور قابل توجهی همپوشانی داشته باشند. جعبه های براکتی جهت دار اغلب برای شناسایی اهداف در حال چرخش هنگام مشخص کردن اهداف در تصاویر هوایی استفاده می شوند. دینگ و همکاران [ ۱۸ ] یک یادگیرنده چرخشی منطقه مورد علاقه را برای تبدیل مناطق افقی مورد علاقه به مناطق چرخشی مورد علاقه پیشنهاد کرد. بر اساس مناطق حساس به چرخش، یک ماژول هم ترازی منطقه حساس به موقعیت چرخش (RPS-RoI-Align) برای استخراج ویژگیهای تغییرناپذیر چرخش از مناطق حساس به چرخش و در نتیجه تسهیل طبقهبندی و رگرسیون بعدی پیشنهاد شد. یانگ و همکاران [ ۱۹] یک آشکارساز چرخشی چند کلاسه SCRDet برای اهداف کوچک، با جهت گیری تصادفی و به شدت توزیع شده در تصاویر هوایی پیشنهاد کرد، که حساسیت به اهداف کوچک را از طریق یک شبکه همجوشی نمونهبرداری که ویژگیهای چند لایه را با نمونهبرداری لنگر ترکیب میکند، بهبود میبخشد. در نهایت، ژو و همکاران. [ ۲۰ ] یک آشکارساز هدف سنجش از دور نوری با مختصات قطبی بدون لنگر (P-RSDet) پیشنهاد کرد که دقت تشخیص رقابتی را با استفاده از یک مدل نمایش هدف سادهتر و پارامترهای رگرسیون کمتر فراهم میکند.
در مورد وسایل نقلیه در تصاویر سنجش از دور نوری، محققان متعددی ویژگیهای اهداف خودرو را بررسی کردهاند. اودبرت و همکاران [ ۲۱ ] یک شبکه عمیق و کاملاً پیچیده در ISPRS Potsdam و مجموعه دادههای NZAM/ONERA کرایستچرچ آموزش داد و از نمودار معنایی آموختهشده برای استخراج بخشهای دقیق خودرو استفاده کرد، در نتیجه وسایل نقلیه را با استخراج ساده قطعات متصل شناسایی کرد. ژانگ و همکاران [ ۲۲ ] یک شبکه مبتنی بر YOLOv3 با هدایت توجه عمیق و قابل تفکیک برای تشخیص بلادرنگ اهداف وسایل نقلیه کوچک در تصاویر سنجش از دور نوری پیشنهاد کرد. شی و همکاران [ ۲۳] یک روش تشخیص بدون لنگر تک مرحله ای برای تشخیص وسایل نقلیه در جهت های دلخواه پیشنهاد کرد. این روش تشخیص وسیله نقلیه را به یک مشکل یادگیری چندوظیفه ای تبدیل می کند که نیاز به استفاده از یک شبکه کانولوشن کامل برای پیش بینی مستقیم ویژگی های سطح بالای خودرو دارد.
۳٫ مواد و روشها
این بخش به معرفی شبکه اصلی RepDarkNet می پردازد که یک آشکارساز چند لایه و شبکه فیوژن ویژگی است. علاوه بر این، ما برخی از روشهای رایج را برای بهبود میزان تشخیص اهداف کوچک آزمایش کردیم.
۳٫۱٫ دلایل انتخاب سبک DarkNet
ما ساختار DarkNet را انتخاب کردیم زیرا دقت و سرعت را با هم ترکیب می کند. در حال حاضر، شبکه های ستون فقرات به دقت طراحی شده اند تا ساختار چند شاخه ای را شامل شوند، مانند MobileNet [ ۱۱ ، ۱۲ ، ۱۳ ]، Inception [ ۲۴ ]، یا DenseNet [ ۲۵ ]. آنها ویژگی های مشترکی دارند. برای مثال، DenseNet با اتصال لایههای پایینتر به بسیاری از لایههای بالاتر، توپولوژی را پیچیدهتر میکند، و در حالی که یک شبکه تبدیل با کارایی بالا ارائه میکند، این کار را به قیمت انبوهی از GPU انجام میدهد.
Darknet53 یک شبکه دو شاخه ای ساده است که شاخه ها را در یک فرآیند کانولوشن از بالا به پایین اضافه می کند. این عمدتا از یک سری بلوک های باقیمانده کاملاً طراحی شده تشکیل شده است. همانطور که در شکل ۲ مشاهده می شود ، بلوک باقیمانده خروجی دو پیچیدگی به اضافه خروجی یک اتصال پرش را با هم به عنوان اطلاعات ورودی برای لایه بعدی کانولوشن بارگذاری می کند. لایه شبکه پیچیده DarkNet تشخیص سریع و شگفت آور ایجاد می کند.
در یک ساختار شبکه چند شاخه ای، مسیرهای بین شاخه ها به شدت به یکدیگر وابسته نیستند، بنابراین ساختار را می توان به عنوان مجموعه ای از مسیرهای بسیاری مشاهده کرد [ ۲۶ ]. در مقیاس کوچک، شبکه به سبک DarkNet از چندین نتیجه بلوک باقیمانده تشکیل شده است، در حالی که در مقیاس بزرگتر، می توان آن را به صورت پنج لایه مشاهده کرد، مانند شکل ۲ ، که در آن شبکه ستون فقرات را به یک ساختار پنج بلوکی تقسیم می کنیم. R ۱ – R5). در زمینه تشخیص هدف، ساختارهای شبکه عمیقتر نسبت به سازههای کم عمق قویتر هستند، اگرچه ساختن ساختارهای انشعاب چندگانه در هر لایه باقیمانده، زمان آموزش و زمان تشخیص را افزایش میدهد و منابع محاسباتی قابل توجهی را در ازای دقت ضعیف هدر میدهد. بنابراین، پیاده سازی چنین ساختارهای شبکه در یک ماژول بزرگ راه خوبی برای بهبود آنها است. بنابراین YOLOv4 پیشرفتی در دقت ایجاد میکند، بنابراین ما در شبکه اصلی CSPDarkNet پیشرفت میکنیم.
۳٫۲٫ مروری بر شبکه ستون فقرات به سبک DarkNet
RepVGG پیشنهادی (پارامترسازی مجدد VGG) [ ۱۴ ] باعث می شود VGG دوباره در وظایف طبقه بندی بدرخشد. این یک ساختار شبکه عصبی ساده و در عین حال قدرتمند است. برای تشخیص هدف، DarkNet یک چارچوب عالی و سریع است، اما دقت چیزی است که بسیاری از محققان اکنون روی آن تمرکز میکنند. در این کار، ساختار ساده DarkNet را ادامه میدهیم و یک شبکه اصلی RepDarkNet با شاخههای مختلف طراحی میکنیم (ساختار انشعاب دارکنت را مجدداً برنامهریزی میکنیم)، که جزئیات آن در شکل ۲ آمده است. نشان دهنده یک ماژول چهار شاخه ای در RepDarkNet است. در ماژول SPP، سه لایه maxpool به ترتیب در اندازه های ۵، ۹ و ۱۳ هستند.
CSPDarkNet یکی از شبکه های ستون فقرات ماژول CSP (Cross-Stage-Partial-connections) [ ۷ ] است. اگر CSPDarkNet یک ساختار دو شاخه ای است، RepDarkNet یک ساختار سه شاخه ای ساده، اما قدرتمند است. در مقایسه با CSPDarkNet، تنها یک لایه شاخه در هر لایه اضافه می کند و یک ماژول با اطلاعات تشکیل می دهد. ، جایی که را می توان به صورت زیر بیان کرد:
جایی که خروجی لایه قبلی است، اطلاعات وزن است، پیچیدگی را نشان می دهد، B عملیات عادی سازی دسته ای است، و تابع Relu است. توضیح دادن ، ما به عنوان مثال R2 را در نظر می گیریم که شامل دو ماژول باقیمانده است که هر کدام را می توان به صورت زیر بیان کرد:
با توجه به یک مقدار ورودی ، سپس اولین خروجی باقی مانده است:
به طور مشابه، نتیجه پیچیدگی دوم است ، بنابراین:
در فرآیند کانولوشن، CNN ها به تدریج اطلاعات ویژگی های اهداف کوچک را از دست می دهند، در حالی که ماژول چند شاخه ای ساخته شده است تا اطلاعات لایه بالایی را مستقیماً به لایه عمیق ارسال کند و اطلاعات ویژگی های شبکه لایه عمیق را، به ویژه برای کوچک، غنی کند. اهداف نتایج تجربی همچنین نشان میدهد که RepDarkNet اهداف کوچک را بهتر از سایر الگوریتمها تشخیص میدهد.
۳٫۳٫ شبکه فیوژن متقابل
شبکه همجوشی متقاطع از دو بخش تشکیل شده است: یک آشکارساز چند لایه متقاطع و یک شبکه فیوژن ویژگی گردن.
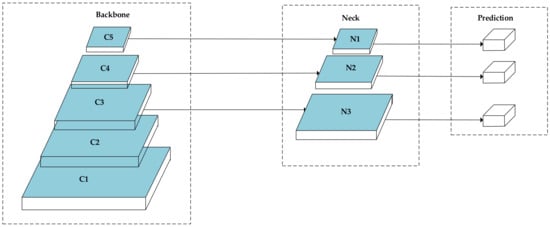
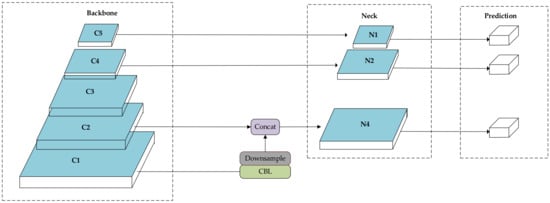
در شبکه YOLOv4، هد YOLO معمولا تصویر را به دو قسمت تقسیم می کند ، ، و شبکه ها با این حال، در تصاویر سنجش از دور نوری، اهداف کوچک معمولا کوچکتر از ۳۰ یا حتی ۲۰ پیکسل هستند. بنابراین، افزودن یک سر تشخیص در سطح کم عمق راه خوبی برای بهبود دقت تشخیص اهداف کوچک است و مطالعات نشان میدهد که این امر امکانپذیر است [ ۲۷ ]. برای شناسایی اهداف کوچک، همانطور که در شکل ۳ نشان داده شده است ، N3 به خوبی کار نمی کند. تقسیم بندی الف تصویر پیکسل به یک شبکه تشخیص را بر اساس اطلاعات ویژگی موجود دشوار می کند. بنابراین، یک آشکارساز چند لایه متقاطع طراحی شد که اندازه شبکه و زمان استنتاج را در نظر می گیرد. آشکارساز فقط از لایه های N1، N2 و N4 استفاده می کند و تصویر را به سه مقیاس تقسیم می کند. ، ، و برای شناسایی اهداف بزرگ و کوچک در تصویر در حین استنتاج. آزمایشات نشان می دهد که آشکارساز چند لایه متقاطع بسیار مؤثرتر است، به ویژه در شناسایی اهداف کوچک. شکل ۴ ساختار شبکه آن را نشان می دهد.
با الهام از لیم و همکاران. [ ۲۸ ]، ما نقشههای ویژگی سطح بالاتر را از لایه ویژگی هدف ادغام کردیم تا زمینه را برای یک نقشه مشخصه مشخص از هدف فراهم کنیم. به عنوان مثال، در RepDarkNet، با توجه به ویژگی های هدف از R ۲، ویژگی های متنی از لایه R ۱ می آیند، همانطور که در شکل ۴ نشان داده شده است. با این حال، R ۱ و R ۲ ابعاد متفاوتی دارند، بنابراین کانالهای شبکه با استفاده از نمونههای پایین مقیاس کوچک میشوند تا اطمینان حاصل شود که اندازه اطلاعات ویژگی در هر دو طرف قبل از ترکیب ویژگیها یکسان است و اطلاعات ویژگی ذوب شده برای تشخیص در هم میپیچد. توسط یک آشکارساز چند لایه متقاطع.
۳٫۴٫ گزینه هایی برای بهبود دقت تشخیص هدف کوچک
۳٫۴٫۱٫ GIoU
به عنوان از دست دادن رگرسیون Bbox، GIoU [ ۱۵ ] (تقاطع عمومی بر روی اتحاد) همیشه کمتر یا برابر با IoU [ ۲۹ ] (تقاطع روی اتحادیه) است، که در آن و . وقتی دو شکل دقیقاً منطبق شوند، GIoU = IoU = 1. GIoU و IoU را می توان به صورت زیر بیان کرد:
جایی که و اشکال دلخواه هستند در این الگوریتم، و شناسایی جعبه نشانگر در تصویر، و الگوریتم جعبه انتخاب لنگر را پیش بینی می کند. حداقل شکل بسته است.
هر دو IoU و GIoU به عنوان فاصله بین آنها عمل می کنند و ; اگر ، سپس IoU( ، ) = ۰، بنابراین IoU نشان نمی دهد که این دو شکل نزدیک یا دور هستند.
۳٫۴٫۲٫ اندازه ورودی بزرگتر
اندازه ورودی بزرگتر اندازه ناحیه هدف را افزایش می دهد و حفظ ویژگی های اهداف کوچکتر را آسان تر می کند. با این حال، افزایش اندازه ورودی در طول تمرین حافظه بیشتری را اشغال می کند. در آزمایشهایمان، حداکثر اندازه ورودی را فقط از افزایش دادیم به به دلیل محدودیت های تجربی ما همچنین میتوانیم اندازه ورودی را افزایش دهیم در حالی که مقدار دستهای را کاهش میدهیم، اگرچه این به طور قابل توجهی زمان آموزش را افزایش میدهد.
۴٫ آزمایش ها، نتایج، و بحث
این بخش مجموعه داده ای را که استفاده کردیم، معیارهای ارزیابی، جزئیات آزمایش ها و نتایج را معرفی می کند. محیط آزمایشی این کار بر اساس سیستم عامل اوبونتو ۱۶٫۰۴ است. پلتفرم سخت افزاری اینتل (R) Xeon(R) Silver 4114 CPU @ 2.2 GHz و Quadro P4000 8 GB * 2 GPU بود.
در فرآیند آموزش، تکانه روی ۰٫۹۴۹، نرخ یادگیری اولیه روی ۰٫۰۰۱۳ و دسته ای روی ۶۴ تنظیم شده است. تعداد تکرارهای متفاوتی برای مجموعه داده های مختلف برای آموزش وجود دارد. در مجموعه داده Dior-vehicle، زمانی که تعداد تکرارهای آموزشی ۳۲۰۰ و ۳۶۰۰ باشد، نرخ یادگیری به ترتیب به ۰٫۰۰۰۱۳ و ۰٫۰۰۰۰۱۳ تنظیم می شود. ما ۴۰۰۰ بار از این الگوریتم را تکرار کرده ایم. در نهایت در این محیط سخت افزاری زمان آموزش حدود ۱۲ ساعت می باشد.
۴٫۱٫ مجموعه داده
Dior [ ۳۰ ] و NWPU VHR-10 [ ۳۰ ] مجموعه داده هایی بودند که برای آزمایش روش ما استفاده شدند. برای نشان دادن شهودی بیشتر نتایج الگوریتم برای شناسایی اهداف کوچک، مجموعه داده Dior-vehicle [ ۳۱ ] را با استفاده از روش آزمایش فرسایش آزمایش کردیم.
۴٫۱٫۱٫ مجموعه داده Dior-Vehicle
Dior-vehicle یک کلاس جداگانه از وسایل نقلیه در Dior است. مجموعه داده عمدتاً دارای اهداف کوچک است و اهداف خودرویی که کمتر از ۱۰ پیکسل مصرف می کنند علامت گذاری می شوند. در اینجا، COCO [ ۳۲ ] را برای طبقه بندی اندازه شی، که مساحت اشیاء کوچک کمتر از ۳۲ × ۳۲ پیکسل است، دنبال می کنیم. مجموعه داده Dior-vehicle دارای ۶۴۲۱ تصویر و بیش از ۳۲۰۰۰ هدف است. در آزمایشهای خود، مجموعههای آموزشی و آزمایشی را به نسبت ۶:۴ تقسیم میکنیم. سپس امکانسنجی روش پیشنهادی را از طریق آزمایش فرسایش آزمایش میکنیم [ ۴ ].
۴٫۱٫۲٫ مجموعه داده دیور
Dior یک مجموعه داده معیار مقیاس بزرگ برای تشخیص هدف در تصاویر سنجش از دور نوری است که از ۲۳۴۶۳ تصویر و ۱۹۰۲۸۸ نمونه تشکیل شده است. این شامل ۲۰ دسته است. در آزمایشهای گزارششده در اینجا، از تصاویر «trainval» برای آموزش و از تصاویر آزمون برای آزمایش استفاده میکنیم. “trainval” یک سند TXT است. نویسنده مجموعه داده دیور نام تصویری را که برای آموزش استفاده می شود در این سند نوشته است.
علاوه بر این، اندازه اشیاء در محدوده وسیعی متفاوت است، نه تنها از نظر وضوح فضایی، بلکه از نظر تنوع اندازه بین و درون طبقاتی بین اشیا. در مرحله بعد، تصاویر در شرایط مختلف تصویربرداری، آب و هوا، فصول و کیفیت تصویر به دست آمدند، بنابراین تفاوت های زیادی در اهداف موجود در آن وجود دارد. برخی از تصاویر ممکن است نویز داشته باشند و برخی از اهداف در حال حرکت تار شوند. در نهایت، از درجه بالایی از شباهت بین طبقاتی و تنوع درون طبقاتی برخوردار است. این ویژگی ها تا حد زیادی دشواری تشخیص را افزایش می دهد.
اگر میخواهید اطلاعات بیشتری درباره مجموعه دادهها بیابید، لطفاً به http://www.escience.cn/people/gongcheng/DIOR.html مراجعه کنید ، که در ۷ اکتبر ۲۰۲۰ قابل دسترسی است.
۴٫۱٫۳٫ مجموعه داده NWPU VHR-10
مجموعه داده NWPU VHR-10 یک مجموعه داده عمومی فقط تحقیقاتی است که شامل ۱۰ کلاس است. NWPU VHR-10 دارای ۶۵۰ تصویر نوری مثبت و ۱۵۰ تصویر نوری منفی است. در آزمایشهایمان، ۶۵۰ تصویر نوری مثبت را با حاشیهنویسی با نرخ ۵:۵ تقسیم کردیم تا یک مجموعه آموزشی و یک مجموعه آزمایشی تولید کنیم. اگر میخواهید اطلاعات بیشتری درباره مجموعه داده بیابید، لطفاً http://www.escience.cn/people/gongcheng/NWPU-VHR-10.html (در ۱۰ مه ۲۰۲۱ در دسترس قرار گرفته است).
۴٫۲٫ استانداردهای ارزیابی
امتیاز F1، دقت، فراخوانی و IoU نیز در اندازه گیری ما در آزمایش فرسایش برای آزمایش مجموعه داده Dior-vehicle در نظر گرفته شده است. فرمول IoU در معادله (۱) آورده شده است و امتیاز F1، دقت و یادآوری را می توان به صورت زیر بیان کرد:
، ، و به ترتیب تعداد مثبت واقعی، مثبت کاذب و منفی کاذب است. در این مقاله از AP (دقت متوسط) و mAP (دقت متوسط متوسط) برای ارزیابی همه روشها استفاده میکنیم. این موارد را می توان به صورت زیر بیان کرد:
هنگام آزمایش نتایج، یک مقدار آستانه برای IoU تنظیم می شود، مانند ۰٫۵ یا ۰٫۷۵٫ هنگامی که کادر شناسایی شده و کادر حاشیه نویسی واقعی از این آستانه فراتر رود، آنها مثبت واقعی در نظر گرفته می شوند. در غیر این صورت، آنها مثبت کاذب هستند. وقتی کادر شناسایی شده در حاشیه نویسی واقعی وجود نداشته باشد، آنها منفی کاذب هستند.
۴٫۳٫ نتایج تجربی و تجزیه و تحلیل
۴٫۳٫۱٫ نتایج Dior-Vehicle و تجزیه و تحلیل
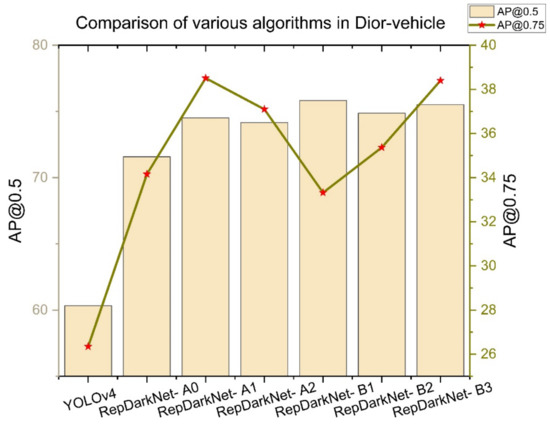
برای بررسی تاثیر روشی که در نتایج تشخیص استفاده کردیم، از آزمایش فرسایش برای آزمایش مجموعه داده استفاده کردیم. همانطور که در جدول ۱ نشان داده شده است ، “a” نشان دهنده ستون فقرات Rep، “b” ورودی بزرگتر، “c” GIoU، “d” آشکارساز چند لایه متقاطع، و “e” شبکه فیوژن ویژگی است. به عنوان مثال، RepDarkNet-A2 از هر دو “a” و “c” استفاده می کند. RepDarknet-B3 از تمام روش ها استفاده می کند و الگوریتم نهایی ما است.
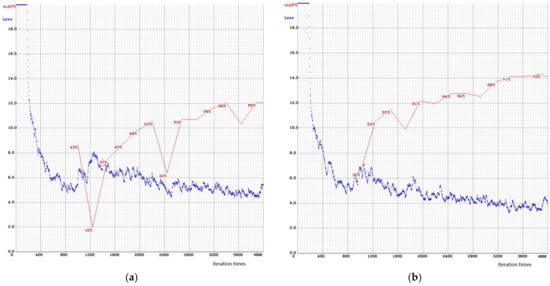
در مرحله اول، RepDarkNet-A0، تنها ستون فقرات RepDarkNet را در بالای الگوریتم YOLOv4 اضافه می کنیم. همانطور که در جدول ۱ مشاهده می شود ، AP بسیار بهبود یافته است (۶۰٫۳۳-۷۱٫۵۸٪). در مرحله بعد، از ورودی بزرگتر و ستون فقرات RepDarkNet استفاده می کنیم و AP ۲٫۹۳٪ افزایش می یابد. ثالثاً، ما از GIoU و RepDarkNet backbone استفاده می کنیم و در مقایسه با RepDarkNet-A0، AP ۲٫۵۸٪ افزایش یافته است. سپس، از ستون فقرات RepDarkNet و آشکارساز چند لایه متقاطع استفاده می کنیم و در مقایسه با RepDarkNet-A0، AP4.24 درصد افزایش یافته است. این بالاترین روش تبلیغاتی غیر از ستون فقرات RepDarkNet است. در مرحله پنج، از ستون فقرات RepDarkNet، آشکارساز چند لایه متقابل و شبکه فیوژن فیچر استفاده میکنیم. در مقایسه با RepDarkNet-B1، AP @۵۰ ۰٫۹۵٪ کمتر است، اما AP @۷۵ ۲٫۰۵٪ بیشتر است. در نهایت همه روش ها را اضافه کردیم. روش پیشنهادی به بهترین عملکرد برای مجموعه داده Dior-vehicle در هر دو مورد AP @۵۰ و AP @۷۵ نزدیک میشود. شکل ۵ مقایسه تلفات و mAP بین YOLOv4 و RepDarkNet-B3 را نشان می دهد. مشاهده می شود که مقدار ضرر RepDarkNet-B3 پس از ۱۲۰۰ بار تکرار کمتر از YOLOv4 است. در همان زمان، mAPمقدار بالاتر از YOLOv4 است. علاوه بر این، شکل ۶ تغییرات AP @۵۰ و AP @۷۵ را برای هر روش نشان می دهد.
همانطور که در شکل ۷ مشاهده می شود (a1,a2,b1,b2)، الگوریتم YOLOv4 به اشتباه کشتی را به عنوان یک ماشین تشخیص می دهد، در حالی که RepDarkNet به طور دقیق اهداف ماشین تصاویر را قاب می کند. از شکل ۷ (a3,a4,b3,b4) مشخص است که RepDarkNet اهداف کوچک را بسیار بهتر از YOLOv4 شناسایی می کند. نتایج در جدول ۱ و جدول ۲ بهبود واضح ارائه شده توسط روش پیشنهادی برای اهداف کوچک را نشان می دهد. شکل ۷ (a5,a6) نشان می دهد که الگوریتم YOLOv4 به اشتباه علائم جاده را به عنوان اتومبیل تشخیص می دهد، در حالی که RepDarkNet به درستی علائم جاده را نادیده می گیرد. با در نظر گرفتن علائم نامحسوس تشخیص اشتباه در شکل ۷(a5,a6)، آن را با دایره زرد علامت گذاری کرده ایم تا خواننده سریعتر متوجه این اطلاعات شود. این نشان می دهد که RepDarkNet از YOLOv4 قوی تر است.
علاوه بر این، وسایل نقلیه ویژه تری مانند کامیون ها وجود دارد که ویژگی های آنها با خودروهای معمولی متفاوت است. در مجموعه داده، اگرچه کامیون ها نیز برچسب گذاری شده اند، تعداد کامیون ها در داده ها نسبتاً کمتر است. همانطور که در شکل ۷ نشان داده شده است (c1,d1)، دقت تشخیص الگوریتم پیشنهادی ما بالاتر از YOLOv4 برای کامیون ها است.
البته الگوریتم ما کاستی هایی هم دارد. با نگاه کردن به شکل ۷ (c2,c3,d2,d3)، میتوانیم ببینیم که به راحتی میتوان کانتینرها را بدون توجه به RepDarkNet یا YOLOv4 به عنوان خودرو اشتباه گرفت. این مشکلی است که ما می خواهیم در تحقیقات آینده خود آن را حل کنیم.
در نهایت، برای آزمایش کلیت آشکارساز پیشنهادی، ما مستقیماً کلاس وسیله نقلیه را در مجموعه داده HRRSD [ ۱۶ ] بدون هیچ آموزشی با استفاده از وزنهای Dior تشخیص میدهیم. نتیجه تشخیص نهایی از به دست آمد. اگرچه دور از انتظار است، اما این بسیار فراتر از نتیجه است بدست آمده توسط YOLOv4. البته، ما همچنین امیدواریم که در تحقیقات آینده، پیشرفت بیشتری در عملکرد عمومی آشکارساز حاصل شود.
۴٫۳٫۲٫ نتایج مجموعه داده دیور و تجزیه و تحلیل
همانطور که در جدول ۳ نشان داده شده است ، برای نمایش بهتر نتایج، هر دسته را در مجموعه داده شماره گذاری می کنیم.
جدول ۴ به وضوح نشان می دهد که الگوریتم پیشنهادی بهترین عملکرد را برای مجموعه داده دیور دارد، و عملکرد بسیار بهتری از الگوریتم های دیگر برای تشخیص اهداف کوچک، مانند ماشین ها یا کشتی ها دارد. برای اهداف نسبتاً بزرگ، مانند پل ها یا زمین های بسکتبال، دقت تشخیص نیز نسبت به سایر الگوریتم ها کمی بهبود یافته است که کاربرد قوی الگوریتم پیشنهادی را نشان می دهد. در مقایسه با الگوریتم YOLOv4، اکثر کلاسهای تست ما دقیقتر هستند، که به طور قانعکنندهای نشان میدهد که RepDarkNet یک الگوریتم تشخیص هدف عالی است.
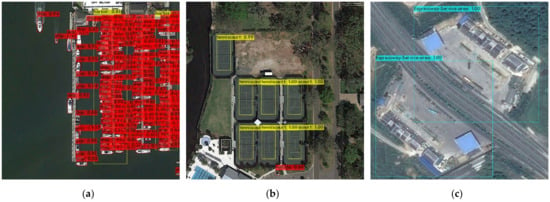
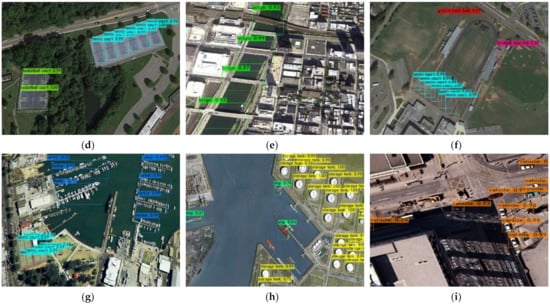
شکل ۸ a-i نتایج تجسم روش پیشنهادی اعمال شده در مجموعه داده دیور را نشان می دهد. RepDarkNet نه تنها برای اهداف کوچک مانند کشتی ها، هواپیماها و مخازن ذخیره سازی در مجموعه داده ها، بلکه برای کلاس های دیگر مانند زمین های تنیس و بسکتبال نیز عملکرد خوبی دارد. نتایج جدول ۴ نیز نشان می دهد که علاوه بر سد، ایستگاه عوارض بزرگراه، زمین تنیس و ایستگاه قطار، رویکرد پیشنهادی بهترین نتایج را در مقایسه با سایر الگوریتم ها ایجاد می کند. فقط در سد، ایستگاه عوارضی بزرگراه و زمین تنیس، YOLOv4 بهتر از RepDarkNet است.
۴٫۳٫۳٫ نتایج NWPU VHR-10 و تجزیه و تحلیل
جدول ۵ و شکل ۹ a-i عملکرد RepDarkNet را در مقایسه با سایر روش های منتشر شده در هنگام اعمال به مجموعه داده NWPU VHR-10 نشان می دهد. ابتدا اختصارات کلاس ها را در جدول ۵ معرفی می کنیم. دسته بندی ها عبارتند از: هواپیما (PL)، کشتی (SP)، مخزن ذخیره سازی (ST)، الماس بیسبال (BD)، زمین تنیس (TC)، زمین بسکتبال (BC)، زمین پیست زمینی (GT)، بندر (HB)، پل (BR) و وسیله نقلیه (VH).
روش پیشنهادی تولید می کند ، که بهترین عملکرد را در بین تمام روش ها دارد. توجه داشته باشید که هیچ هدف کوچکی در مجموعه داده ظاهر نمی شود و کلاس های SH، BD، TC و VE که در جدول ۵ پررنگ شده اند، بالاترین دقت را در نتایج تجربی دارند. به طور کلی، mAP نیز بالاترین است، که شاهد خوبی از کاربرد قوی روش ما است.
۵٫ نتیجه گیری ها
ما یک شبکه استخراج ویژگی ستون فقرات جدید به نام “RepDarkNet” را پیشنهاد می کنیم که با در نظر گرفتن توان عملیاتی شبکه و زمان محاسبات، تشخیص هدف را بهبود می بخشد. علاوه بر این، برای اهداف کوچک در کلاس وسایل نقلیه تصاویر سنجش از دور نوری، ما یک آشکارساز چند لایه چند لایه و شبکه همجوشی را پیشنهاد میکنیم. در نهایت، در آزمایشات، RepDarkNet به دست آورد و ، که هر دو تقریباً بهینه هستند و مجموعه ای از آزمایشات ابلیشن رویکرد ما را توجیه می کند. در آزمایش های گسترده، RepDarkNet در حال اجرا تحت Quadro P4000 به دست می آید هنگامی که به مجموعه داده دیور و هنگامی که به مجموعه داده NWPU VHR-10 اعمال می شود، عملکرد بهتری از سایر الگوریتم ها دارد و کاربرد گسترده الگوریتم پیشنهادی را نشان می دهد. برای آزمایش الگوریتم برای ردیف های تعمیم یافته، به دست آوردیم عملکرد در مجموعه داده HRRSD با استفاده از وزنهای آموزشی مجموعه داده Dior-vehicle بدون هیچ آموزش اضافی دیگری. تحت همین شرایط، YOLOv4 به دست می آید کارایی. بنابراین، از نظر کلی، RepDarkNet بسیار بهتر از YOLOv4 است. با بهینهسازی و ارزیابی مدلهای شبکه هدف کوچک پیشنهادی تحت سه مجموعه داده (Dior-vehicle، Dior، و NWPU VHR-10)، این نتایج پیامدهای عملی برای بهبود تکنیکهای تشخیص مبتنی بر تصاویر سنجش از دور نوری دارند.