
خلاصه
کلید واژه ها:
وندالیسم ؛ OpenStreetMap ; اطلاعات جغرافیایی داوطلبانه یادگیری ماشینی تحت نظارت ؛ جنگل تصادفی ; کیفیت
۱٫ معرفی
-
چگونه میتوانیم مجموعهای را که موارد مختلف خرابکاری را در مناطق مختلف نقشه پوشش میدهد، بدست آوریم یا تولید کنیم؟
-
از چه ویژگی هایی می توانیم از OSM برای ساخت مجموعه داده های یادگیری استفاده کنیم؟
-
آیا طبقهبندیکنندهای که در بخشی از یک منطقه جغرافیایی خاص آموزش دیده است، میتواند به طور خودکار خرابکاری OSM را در سایر بخشهای این منطقه خاص شناسایی کند؟
-
آیا همان طبقه بندی کننده می تواند خرابکاری OSM را در هر منطقه ای از جهان تشخیص دهد؟
-
اگر یک مجموعه داده یادگیری را در نظر بگیریم، با در نظر گرفتن چندین منطقه، آیا مدل ساخته شده بر روی آن بهتر است تا خرابکاری OSM را در هر منطقه ای از نقشه تشخیص دهد؟
۲٫ کارهای مرتبط
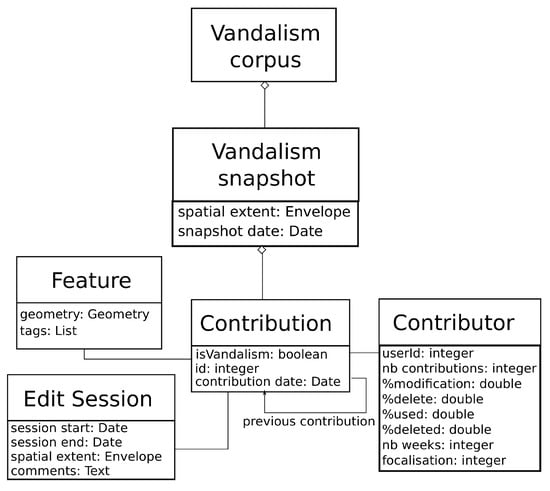
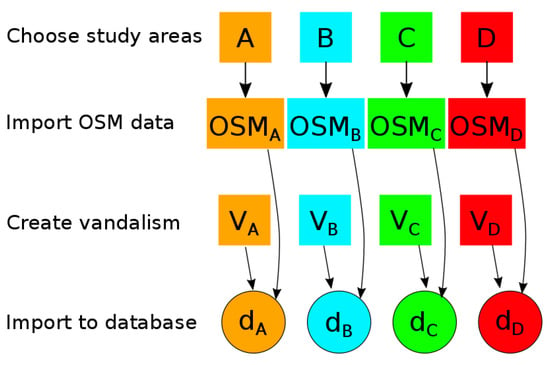
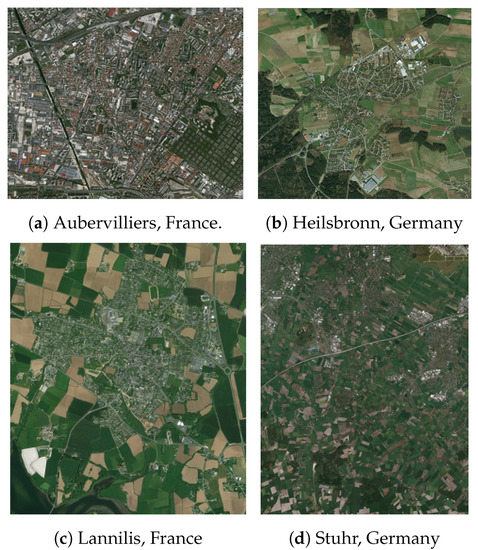
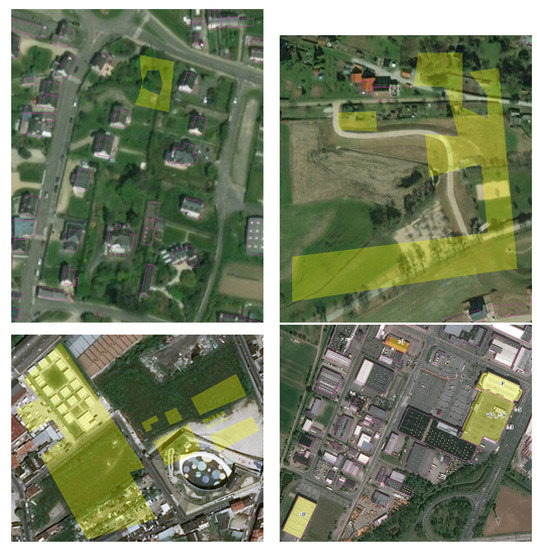
۳٫ مجموعه ای از خرابکاری در OpenStreetMap
۳٫۱٫ مدل بدنه
۳٫۲٫ خط لوله ساختمان کورپوس
۳٫۳٫ عکس های فوری انتخاب شده
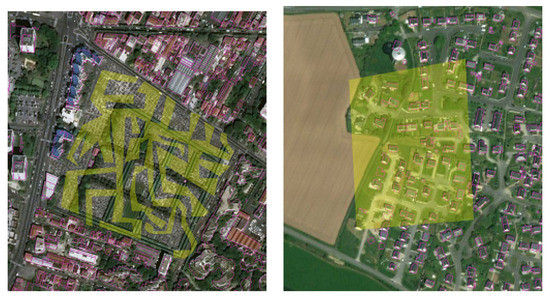
۳٫۴٫ خرابکاری مجموعه داده
۴٫ روش برای استفاده از یادگیری ماشین برای تشخیص خرابکاری
۴٫۱٫ اصول اصلی
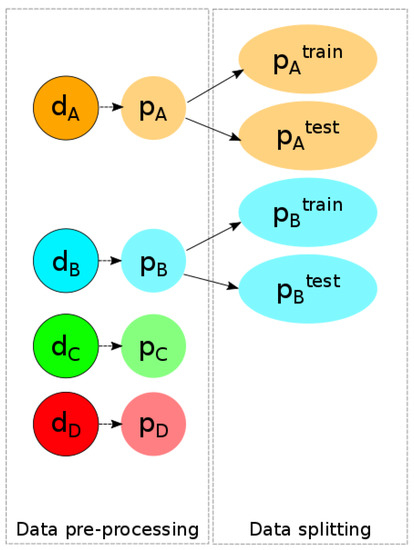
۴٫۲٫ ساخت مجموعه داده های یادگیری
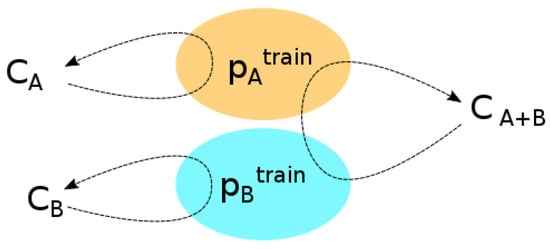
۴٫۳٫ آموزش Classifier
داده های پردازش شده به مجموعه داده های آموزشی و آزمایشی تقسیم می شوند:
جایی که پایکستیrآمنnمجموعه آموزشی از ناحیه x و استپایکستیهستیمجموعه تست مجموعه تست باید حاوی داده هایی باشد که طبقه بندی کننده در مرحله آموزش با آنها مواجه نشده است. از این رو:
۴٫۴٫ ارزیابی سناریوها
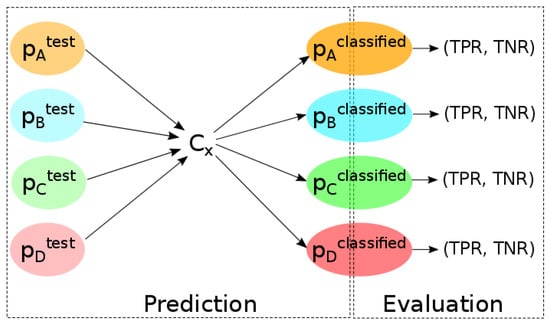
۴٫۵٫ معیارهای ارزیابی
معیارهای مورد استفاده برای ارزیابی طبقهبندیکنندههای مختلف، نرخ مثبت واقعی (همچنین به عنوان فراخوان یا نرخ ضربه شناخته میشود) و نرخ منفی واقعی هستند. این نرخها در پایان یک پیشبینی محاسبه میشوند تا عملکرد یک طبقهبندی کننده را کمی کنند. نرخ مثبت واقعی ( TPR ) بخشی از پیش بینی های خوب را در بین اشیایی که واقعاً خرابکاری هستند اندازه گیری می کند. نرخ منفی واقعی ( TNR ) بخشی از پیشبینیهای خوب مثبتهای واقعی (TPs) را اندازهگیری میکند – در میان مشارکتهای واقعاً غیر وندالیسم. انتظار میرود مدلی که در تشخیص وندالیسم OSM بهطور خودکار عملکرد خوبی داشته باشد، در مرحله پیشبینی آزمایش ، TPR و TNR بالایی داشته باشد.
که در آن مثبتهای واقعی (TPs) دادههای خرابکاری شدهای هستند که توسط طبقهبندیکننده شناسایی میشوند و منفیهای کاذب (FNs) دادههای تخریبشده کشفنشده هستند، و
که در آن منفی های واقعی (TN) داده های OSM هستند که به درستی به عنوان غیر وندالیسم طبقه بندی می شوند.
۵٫ OSMWatchman: طبقه بندی جنگل تصادفی برای تشخیص خرابکاری
۵٫۱٫ ویژگی های تشخیص خرابکاری
۵٫۱٫۱٫ ویژگی های محتوا
در سطح معنایی، دادههای نقشهبرداری OSM دارای برچسبهایی هستند که جفتهای کلید-مقدار هستند که عناصر جغرافیایی را توصیف میکنند. نشان می دهیم n_تیآgس=|تی|به عنوان یک ویژگی که تعداد تگ های توصیف کننده یک عنصر OSM را شمارش می کند، که در آن T مجموعه ای از برچسب هایی است که یک عنصر OSM را توصیف می کند. اجازه دهید تیآgکهyمجموعه کلیدهای برچسب عنصر OSM و تیآgvآلتوهمجموعه مقادیر مربوطه بیشتر مشارکتهای خرابکارانه OSM در جایی که یک شی ایجاد میشود، حاوی تعداد بسیار کمی از برچسبها [ ۹ ] است، بنابراین این ویژگی باید مفید باشد.
برای ثبت خرابکاری در برچسبهای OSM، ویژگیای را در نظر میگیریم که حداکثر نرخ کاراکترهای خاص را در یک مشارکت OSM تعیین میکند. این ویژگی از ویژگی های سطح کاراکتر پیشنهاد شده در [ ۸ ] الهام گرفته شده است. کمی کردن میزان کاراکترهای ویژه برای پوشش هر نوع خرابکاری که ممکن است در تگ های OSM اتفاق بیفتد کافی نیست، اما حداقل می تواند به شناسایی یک مورد خاص از خرابکاری کمک کند: به عنوان مثال، یکی از کاربران ممنوعه OSM تخلف خود را با علامت گذاری کرده است. صورتک ها به عنوان مقادیر برای نام تگ [ ۵ ]. این ویژگی شخصیت به صورت زیر تعریف می شود:
جایی که n_سپهجمنآل_جساعتآrتعداد کاراکترهای خاص در v و the استلهngتیساعتتابع اندازه کل v را می دهد .
۵٫۱٫۲٫ ویژگی های زمینه
از آنجایی که داده های OSM عناصر جغرافیایی هستند، از نظر فضایی با یکدیگر مرتبط هستند [ ۱۸ ]. علاوه بر این، از آنجایی که وندالیسم داستانی و هنری از عناصر نگاشت بر عناصر موجود تشکیل شده است، مهم است که ویژگیهای توپولوژیکی را در نظر بگیریم که همپوشانیهای بالقوه بین انواع مختلف دادههای جغرافیایی را که معمولاً اتفاق نمیافتند، کمیت میدهند [۱۹ ] . نشان می دهیم بتومنلدمنngبه عنوان هندسه یک شی ساختمان OSM و Oاسمnآتیتوrآلبه عنوان مجموعه ای از اشیاء OSM که مطابق با عناصر جغرافیایی طبیعی است که در آن هیچ ساختمانی (آب، چمنزار، جنگل و غیره) نباید وجود داشته باشد. ما دو ویژگی توپولوژیکی را تعریف می کنیم:
۵٫۱٫۳٫ ویژگی های کاربر
-
تیoتیآل_جonتیrمنبتوتیمنonس: تعداد کل مشارکتهای کاربر. با جمع کردن تعداد مشارکتها در مجموعههای تغییرات ایجاد شده در منطقه مورد مطالعه، که شامل ویرایش حداقل یک ساختمان OSM است، به دست میآید.
-
پ_مترoدمنfمنجآتیمنon: بخشی از مشارکت های کاربر که تغییرات داده است.
-
پ_دهلهتیه: بخشی از مشارکت های کاربر که سرکوب داده ها هستند.
-
پ_منس_توسهد: بخشی از مشارکت های کاربر که توسط سایر مشارکت کنندگان مجددا استفاده می شود [ ۲۹ ].
-
پ_منس_هدمنتیهد: بخشی از مشارکت های کاربر که پس از آن توسط سایر مشارکت کنندگان اصلاح شد.
-
پ_منس_دهلهتیهد: بخشی از مشارکت های کاربر که پس از آن توسط سایر مشارکت کنندگان حذف شد.
-
nبدبلیوههکس: تعداد هفته هایی که در طی آن یک مشارکت کننده پایگاه داده OSM را ویرایش کرده است. این مربوط به سن کاربر است که در مورد خرابکاری Pokemon GO بسیار مهم است [ ۹ ].
-
foجآلمنسآتیمنon: این ویژگی هندسه ناحیه ای را که مشارکت کننده ویرایش های خود را روی آن انجام داده است در مقایسه با هندسه منطقه مورد مطالعه ارزیابی می کند. مقدار آن بین صفر تا یک است. زمانی که منطقه مشارکت گسترده تر از منطقه مورد مطالعه است، به سمت صفر و زمانی که منطقه مشارکت عمدتاً در داخل منطقه مورد مطالعه باشد به سمت یک می رود. احتمال کمتری دارد که یک خرابکار به یک منطقه بزرگ کمک کند.
۵٫۲٫ طبقه بندی داده ها
۵٫۳٫ نتایج
۶٫ بحث
-
تعریف ویژگی های جدید یا نرمال شده که حساسیت کمتری نسبت به تغییرات چشم اندازها و منابع داده دارند.
-
از یادگیری انتقال برای تنظیم دقیق یک مدل آموزشدیده برای مناظر خاص استفاده کنید، شاید فقط با مشارکتهای غیر تخریبی، که حاشیهنویسی بسیار آسانتر است.
-
نسخه های مختلف OSMWatchman را آموزش دهید، که هر کدام برای برخی از انواع مناظر تخصصی هستند.
۷٫ نتیجه گیری و کار آینده
منابع
- Zaveri، M. New York City به طور خلاصه در Snapchat و سایر برنامه ها “Jewtropolis” نامگذاری شده است. نیویورک تایمز ، ۳۰ اوت ۲۰۱۸٫ [ Google Scholar ]
- گارلینگ، سی. کارگران گوگل در حال «تخریب» نقشههای منبع باز دستگیر شدند. Wired ۲۰۱۲ . در دسترس آنلاین: https://www.wired.com/2012/01/osm-google-accusation/ (در ۲۱ ژوئن ۲۰۲۰ قابل دسترسی است).
- آیا میتوانیم هر تغییری را در OSM تأیید کنیم ؟ وضعیت نقشه: ۲۰۱۸٫ در دسترس آنلاین: https://2018.stateofthemap.org/2018/T079-Can_we_validate_every_change_on_OSM_/ (در ۲۱ ژوئن ۲۰۲۰ قابل دسترسی است).
- بالاتور، A. تخریب نقشه: وندالیسم نقشهکشی در عوام دیجیتال. کارتوگر. J. ۲۰۱۴ ، ۵۱ ، ۲۱۴-۲۲۴٫ [ Google Scholar ] [ CrossRef ]
- Truong، QT; تویا، جی. De Runz, C. Towards Towardism Vandalism Detection in OpenStreetMap از طریق یک رویکرد مبتنی بر داده. در مجموعه مقالات دهمین کنفرانس بین المللی علوم اطلاعات جغرافیایی (GIScience 2018)، ملبورن، استرالیا، ۲۸ تا ۳۱ اوت ۲۰۱۸٫ [ Google Scholar ] [ CrossRef ]
- کوین، اس. Bull, F. درک تهدیدها برای کیفیت دادههای جغرافیایی جمعسپاری شده از طریق مطالعه ممنوعیتهای مشارکتکننده OpenStreetMap. در استفاده از سیستم اطلاعات جغرافیایی در سازمان های عمومی – چگونه و چرا باید از GIS در بخش عمومی استفاده شود . Valcik, N., Dean, D., Eds. تیلور و فرانسیس: نیویورک، نیویورک، ایالات متحده آمریکا، ۲۰۱۹؛ صص ۸۰-۹۶٫ [ Google Scholar ]
- چانه، SC; خیابان، WN; سرینیواسان، پ. آیشمن، دی. تشخیص خرابکاری ویکیپدیا با یادگیری فعال و مدلهای زبانی آماری. در مجموعه مقالات چهارمین کارگاه آموزشی اعتبار اطلاعات، WICOW ’10، رالی، NC، ایالات متحده آمریکا، ۲۷ آوریل ۲۰۱۰; ACM: نیویورک، نیویورک، ایالات متحده آمریکا، ۲۰۱۰; صص ۳-۱۰٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هایندورف، اس. پوتاست، ام. استاین، بی. انگلس، جی. تشخیص وندالیسم در ویکی داده. در مجموعه مقالات بیست و پنجمین کنفرانس بین المللی ACM در مورد مدیریت اطلاعات و دانش – CIKM ’16، ایندیاناپولیس، IN، ایالات متحده آمریکا، ۲۴ تا ۲۸ اکتبر ۲۰۱۶٫ ACM: نیویورک، نیویورک، ایالات متحده آمریکا، ۲۰۱۶؛ صص ۳۲۷-۳۳۶٫ [ Google Scholar ] [ CrossRef ]
- جوهاز، ال. نواک، تی. Hochmair، HH; Qiao، S. خرابکاری نقشهکشی در عصر بازیهای مبتنی بر مکان – مورد OpenStreetMap و Pokémon GO. ISPRS Int. J. Geo-Inf. ۲۰۲۰ ، ۹ ، ۱۹۷٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- چن، جی. Zipf، A. یادگیری عمیق با تصاویر ماهواره ای و اطلاعات جغرافیایی داوطلبانه. در تکنیک ها و کاربردهای علم داده های جغرافیایی ; CRC Press: بوکا راتون، فلوریدا، ایالات متحده آمریکا، ۲۰۱۷؛ پ. ۲۷۴٫ [ Google Scholar ]
- تویا، جی. ژانگ، ایکس. Lokhat, I. آیا یادگیری عمیق عامل جدیدی برای تعمیم نقشه است؟ بین المللی جی. کارتوگر. ۲۰۱۹ ، ۱-۱۶٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ایدیانوزی، سی. مک آردل، جی. پارادایم یادگیری انتقال برای شبکه های فضایی. در مجموعه مقالات سی و چهارمین سمپوزیوم ACM/SIGAPP در محاسبات کاربردی، SAC ’19، لیماسول، قبرس، ۸ تا ۱۲ آوریل ۲۰۱۹؛ ACM: نیویورک، نیویورک، ایالات متحده آمریکا، ۲۰۱۹؛ صص ۶۵۹-۶۶۶٫ [ Google Scholar ] [ CrossRef ]
- Ho، TK جنگلهای تصمیم تصادفی. در مجموعه مقالات سومین کنفرانس بین المللی تجزیه و تحلیل و شناسایی اسناد، مونترال، QC، کانادا، ۱۴-۱۶ اوت ۱۹۹۵٫ انجمن کامپیوتر IEEE: واشنگتن، دی سی، ایالات متحده آمریکا، ۱۹۹۵; جلد ۱، ص. ۲۷۸٫ [ Google Scholar ]
- نیس، پ. گوتز، ام. Zipf، A. Towards Automatic Vandalism Detection در OpenStreetMap. ISPRS Int. J. Geo-Inf. ۲۰۱۲ ، ۱ ، ۳۱۵-۳۳۲٫ [ Google Scholar ] [ CrossRef ]
- هایندورف، اس. پوتاست، ام. استاین، بی. انگلس، جی. به سوی کشف وندالیسم در پایگاه های دانش. در مجموعه مقالات سی و هشتمین کنفرانس بین المللی ACM SIGIR در مورد تحقیق و توسعه در بازیابی اطلاعات – SIGIR ’15، سانتیاگو، شیلی، ۹ تا ۱۳ اوت ۲۰۱۵٫ صص ۸۳۱-۸۳۴٫ [ Google Scholar ] [ CrossRef ]
- Potthast، M. جمع سپاری مجموعه تخریب ویکی پدیا. در مجموعه مقالات سی و سومین کنفرانس بین المللی ACM SIGIR در مورد تحقیق و توسعه در بازیابی اطلاعات – SIGIR ’10، ژنو، سوئیس، ۱۹ تا ۲۳ ژوئیه ۲۰۱۰٫ ACM: نیویورک، نیویورک، ایالات متحده آمریکا، ۲۰۱۰; صص ۷۸۹-۷۹۰٫ [ Google Scholar ] [ CrossRef ]
- خو، ی. چن، ز. زی، ز. Wu, L. ارزیابی کیفیت دادههای ردپای ساختمان با استفاده از یک شبکه رمزگذار خودکار عمیق. بین المللی جی. جئوگر. Inf. علمی ۲۰۱۷ ، ۳۱ ، ۱۹۲۹-۱۹۵۱٫ [ Google Scholar ] [ CrossRef ]
- Goodchild، MF; Li, L. اطمینان از کیفیت اطلاعات جغرافیایی داوطلبانه. تف کردن آمار ۲۰۱۲ ، ۱ ، ۱۱۰-۱۲۰٫ [ Google Scholar ] [ CrossRef ]
- تویا، جی. براندو، سی. تشخیص تناقضات سطح جزئیات در مجموعه دادههای اطلاعات جغرافیایی داوطلبانه. کارتوگر. بین المللی جی. جئوگر. Inf. جئوویس. ۲۰۱۳ ، ۴۸ ، ۱۳۴-۱۴۳٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بگین، دی. دیویلر، آر. Roche, S. چرخه زندگی مشارکت کنندگان در جوامع آنلاین مشترک – مورد OpenStreetMap. بین المللی جی. جئوگر. Inf. علمی ۲۰۱۸ ، ۳۲ ، ۱۶۱۱-۱۶۳۰٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بگین، دی. دیویلر، آر. روشه، اس. ارزیابی کیفیت اطلاعات جغرافیایی داوطلبانه (VGI) بر اساس رفتارهای نقشه برداری مشارکت کنندگان. در مجموعه مقالات هشتمین سمپوزیوم بین المللی کیفیت داده های مکانی، هنگ کنگ، چین، ۳۰ مه تا ۱ ژوئن ۲۰۱۳٫ جلد XL-2/W1، صص ۱۴۹-۱۵۴٫ [ Google Scholar ]
- مونی، پی. Corcoran, P. OpenStreetMap چقدر اجتماعی است؟ در مجموعه مقالات کنفرانس بین المللی AGILE’2012 در علم اطلاعات جغرافیایی، آوینیون، فرانسه، ۲۴ تا ۲۷ آوریل ۲۰۱۲٫ [ Google Scholar ]
- Truong، QT; د رانز، سی. Touya, G. تجزیه و تحلیل شبکه های همکاری در OpenStreetMap از طریق کاوی چند گراف اجتماعی وزن دار. بین المللی جی. جئوگر. Inf. علمی ۲۰۱۹ ، ۳۳ ، ۱۶۵۱-۱۶۸۲٫ [ Google Scholar ] [ CrossRef ]
- مونی، پی. Corcoran, P. فرآیند حاشیه نویسی در OpenStreetMap. ترانس. GIS ۲۰۱۲ ، ۱۶ ، ۵۶۱-۵۷۹٫ [ Google Scholar ] [ CrossRef ]
- کسلر، سی. de Groot، RTA Trust به عنوان یک معیار پراکسی برای کیفیت اطلاعات جغرافیایی داوطلبانه در مورد OpenStreetMap. در علم اطلاعات جغرافیایی در قلب اروپا ; یادداشت های سخنرانی در اطلاعات جغرافیایی و نقشه برداری. Vandenbroucke, D., Bucher, B., Crompvoets, J., Eds. انتشارات بین المللی Springer: برلین، آلمان، ۲۰۱۳; ص ۲۱-۳۷٫ [ Google Scholar ] [ CrossRef ]
- قهوهای مایل به زرد، CH; آگیشتاین، ای. ایپیروتیس، پ. Gabrilovich، E. Trust, but Verify: Predicting Contribution Quality for Knowledge Base Construction and Curation. در مجموعه مقالات هفتمین کنفرانس بین المللی ACM در جستجوی وب و داده کاوی – WSDM ’14، نیویورک، نیویورک، ایالات متحده آمریکا، ۲۴-۲۸ فوریه ۲۰۱۴; صص ۵۵۳-۵۶۲٫ [ Google Scholar ] [ CrossRef ]
- D’Antonio، F. فوگلیارونی، پ. Kauppinen، T. VGI تاریخچه ویرایش، اعتماد به داده ها و شهرت کاربر را آشکار می کند. در مجموعه مقالات هفدهمین کنفرانس AGILE در علم اطلاعات جغرافیایی، Castellón، اسپانیا، ۳-۶ ژوئن ۲۰۱۴٫ [ Google Scholar ]
- لودیجیانی، سی. Melchiori، M. مدل شهرت مبتنی بر رتبه صفحه برای داده های VGI. Procedia Comput. علمی ۲۰۱۶ ، ۹۸ ، ۵۶۶-۵۷۱٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Truong، QT; تویا، جی. de Runz, C. ایجاد شبکههای اجتماعی در جوامع داوطلبانه اطلاعات جغرافیایی: آنچه رفتارهای مشارکتکننده در مورد کیفیت دادههای جمعسپاری آشکار میکنند. در یادداشت های سخنرانی در اطلاعات جغرافیایی و کارتوگرافی، مجموعه مقالات کارگاه ها و پوسترها در سیزدهمین کنفرانس بین المللی نظریه اطلاعات فضایی (COSIT 2017)، لاکویلا، ایتالیا، ۴ تا ۸ سپتامبر ۲۰۱۷ ؛ Springer: برلین، آلمان، ۲۰۱۷٫ [ Google Scholar ] [ CrossRef ]
- استین، ک. کرمر، دی. Schlieder, C. شبکه های همکاری فضایی OpenStreetMap. در OpenStreetMap در GIScience ; یادداشت های سخنرانی در اطلاعات جغرافیایی و نقشه برداری. جوکار ارسنجانی، ج.، زیپف، ع.، مونی، پ.، هلبیچ، م.، ویرایش. انتشارات بین المللی Springer: برلین، آلمان، ۲۰۱۵; صص ۱۶۷-۱۸۶٫ [ Google Scholar ] [ CrossRef ]
- یانگ، آ. فن، اچ. Jing، N. آماتور یا حرفه ای: ارزیابی تخصص مشارکت کنندگان اصلی در OpenStreetMap بر اساس رفتارهای مشارکتی. ISPRS Int. J. Geo-Inf. ۲۰۱۶ ، ۵ ، ۲۱٫ [ Google Scholar ] [ CrossRef ]
- رابرتسون، سی. Feick, R. تعریف کارشناسان محلی: تخصص جغرافیایی به عنوان مبنایی برای کیفیت اطلاعات جغرافیایی . کلمنتینی، ای.، دانلی، ام.، یوان، م.، کری، سی.، فوگلیارونی، پی.، بالاتوره، آ.، ویرایش. Schloss Dagstuhl–Leibniz-Zentrum fuer Informatik: Dagstuhl، آلمان، ۲۰۱۷٫ [ Google Scholar ]
- هالفاکر، ا. کیتور، آ. Riedl, J. Don’T Bite the Newbies: How Reverts روی کمیت و کیفیت کار ویکیپدیا تأثیر میگذارد. در مجموعه مقالات هفتمین سمپوزیوم بین المللی ویکی ها و همکاری باز، WikiSym ’11، Mountain View، CA، ایالات متحده آمریکا، ۳–۵ اکتبر ۲۰۱۱; ACM: نیویورک، نیویورک، ایالات متحده آمریکا، ۲۰۱۱; صص ۱۶۳-۱۷۲٫ [ Google Scholar ] [ CrossRef ]
- نیس، پ. Zipf، A. تجزیه و تحلیل فعالیت مشارکت کننده یک پروژه داوطلبانه اطلاعات جغرافیایی – مورد OpenStreetMap. ISPRS Int. J. Geo-Inf. ۲۰۱۲ ، ۱ ، ۱۴۶-۱۶۵٫ [ Google Scholar ] [ CrossRef ]
- بریمن، ال. جنگل های تصادفی. ماخ فرا گرفتن. ۲۰۰۱ ، ۴۵ ، ۵-۳۲٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گاما، ج. ژلیوبایته، آی. بیفت، ا. پچنیزکی، م. Bouchachia، A. نظرسنجی در مورد انطباق رانش مفهومی. کامپیوتر ACM. Surv. (CSUR) ۲۰۱۴ ، ۴۶ ، ۱-۳۷٫ [ Google Scholar ] [ CrossRef ]
- LeCun، Y.; بنژیو، ی. هینتون، جی. یادگیری عمیق. Nature ۲۰۱۵ ، ۵۲۱ ، ۴۳۶٫ [ Google Scholar ] [ CrossRef ]
- خو، ی. وو، ال. زی، ز. Chen, Z. استخراج ساختمان در تصاویر سنجش از دور با وضوح بسیار بالا با استفاده از یادگیری عمیق و فیلترهای هدایت شده. Remote Sens. ۲۰۱۸ , ۱۰ , ۱۴۴٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژانگ، ز. لیو، کیو. وانگ، Y. استخراج جاده توسط Deep Residual U-Net. IEEE Geosci. سنسور از راه دور Lett. ۲۰۱۷ ، ۱۵ ، ۷۴۹-۷۵۳٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
|
در دسترس بودن نمونه: نمونه ها از نویسندگان در دسترس است.
|





بدون دیدگاه