خلاصه
کلید واژه ها:
کشف همسفر ; استخراج مسیر مکانی-زمانی ; چارچوب ; تجزیه و تحلیل انجمن ; خوشه بندی ; استراتژی تنظیم پارامتر
۱٫ معرفی
-
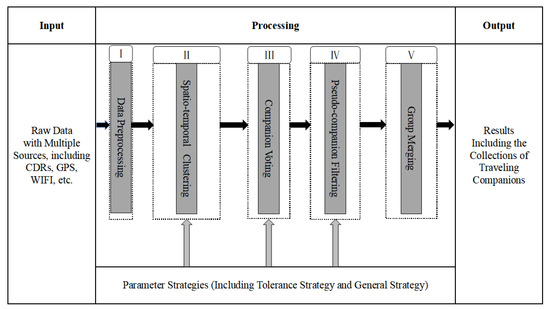
چارچوبی برای کشف همسفر به نام GroupSeeker پیشنهاد شده است. از طریق یک جریان پردازش پنج مرحله ای، GroupSeeker می تواند همراهان بالقوه سفر را در حجم عظیمی از داده های مسیر با عملکرد و دقت بالا بیابد.
-
استراتژی های تنظیم پارامتر ذاتاً در GroupSeeker تعبیه شده است. مراحل اولیه می توانند پارامترهای خود را با توجه به ویژگی مجموعه داده ها تعیین کنند، که این چارچوب را بسیار کاربردی تر و کاربردی تر می کند.
-
یک روش جدید خوشهبندی مکانی-زمانی برای مقابله با دادههای مسیر برشهای زمانی بلندمدت و حل مشکل حذف نامزدهای همراه ناشی از تقسیمبندی زمان کوتاهمدت نامناسب در کار قبلی استفاده میشود.
-
نتایج تجربی بر روی مجموعه داده های واقعی و شبیه سازی شده نشان می دهد که هزینه زمانی GroupSeeker در سطح مطلوبی است. داده های مسیر برای بیست و چهار ساعت را می توان در عرض یک ساعت و نیم پردازش کرد، به این معنی که GroupSeeker را می توان در کارهای نظارتی در همه شرایط آب و هوایی استفاده کرد.
۲٫ کارهای مرتبط
۲٫۱٫ خوشه بندی مسیر
۲٫۲٫ کشف الگوی همراه
۳٫ مواد و روشها
۳٫۱٫ بیان مسأله
۳٫۱٫۱٫ مشکل حذف کاندیدای همراه
-
سیگنالهای دادههای موقعیتیابی در دنیای واقعی ممکن است در حین اکتساب و انتقال مسدود شوند. دلیل مسدود کردن این است که کاربران می توانند به طور فعال دستگاه ها را خاموش کنند یا خدمات مکان را خاتمه دهند و انتقال اطلاعات مکان ممکن است توسط محیط های اطراف تداخل یا مسدود شود.
-
به دلیل تفاوت در روشهای نمونهگیری و از دست دادن انتقال دادهها، دادههای مسیر در طول جمعآوری دادهها پراکنده یا تا حدی از بین خواهند رفت.
۳٫۱٫۲٫ تعریف مشکل
-
تعریف ۱ (مجموعه عکس فوری): مجموعه عکس لحظه ای زمانی اس={س۱،س۲،…،سn}مجموعه ای از مجموعه ای از عکس های فوری کوتاه مدت است. که می تواند به عنوان یک پسوند برای یک عکس فوری کوتاه مدت دیده شود.
-
تعریف ۲ (گروه رکورد): یک گروه رکورد آر={r1،r2،…،rn}مجموعه ای از تمام رکوردهای شی متحرک در یک مجموعه عکس فوری است اس={س۱،س۲،…،سn}، n تعداد اجسام متحرک در مجموعه زمانی را نشان می دهد. برای یک جسم متحرک oj، تعداد رکوردها rjاست ک، و rj={r1j،r2j،…،rکj}
-
تعریف ۳ (کاندیدا بالقوه محلی (LPC)): یک مجموعه نامزد سی={ج۱،ج۲،…،جمتر}مجموعه ای به عنوان مجموعه ای از نامزدهای همراه است که بر اساس اطلاعات مکان خوشه بندی شده اند، جایی که m تعداد خوشه ها را نشان می دهد. این مقاله از الگوریتم خوشهبندی مبتنی بر چگالی استفاده میکند. برخی از پارامترها باید تعریف شوند. δسبه عنوان آستانه اندازه خوشه بندی تعریف می شود، εبه عنوان آستانه فاصله استفاده می شود. فرمول فاصله پیشفرض چندین الگوریتم خوشهبندی بر اساس فرمول فاصله اقلیدسی است که میتواند مزایای کارایی خاصی را ارائه دهد. با این حال، به منظور تسهیل تنظیم پارامترهای داده کاوی مسیر و بهبود دقت نتایج داده کاوی مسیر، فرمول فاصله در اینجا ممکن است با فرمول فاصله ای جایگزین شود که نیازهای صحنه را بهتر برآورده کند. مجموعه کاندیدای بالقوه مکانی یک مجموعه خوشه ای است که wrt را راضی می کند δسو ε.
-
تعریف ۴ (نامزد بالقوه زمان و مکان (TLPC)): بر اساس نامزدهای بالقوه برای موقعیت، خوشههای کاندیداها بر اساس زمان خوشهبندی را برآورده میکنند تا خوشهها را تشکیل دهند. مجموعه اشیاء در این خوشه ها به عنوان کاندیدای بالقوه زمان و مکان در نظر گرفته می شود. در میان آنها، δستیبه عنوان حداقل اندازه خوشه تعریف می شود. علاوه بر این، چون HDBSCAN برای تضعیف پارامتر فاصله دیگری استفاده می شود، در اینجا تعریف نشده است.
-
تعریف ۵ (نامزد همراه مسافر (ATCC)): مترمنn_ستوپحداقل آستانه حمایت برای تجزیه و تحلیل انجمن و مترمنn_جonfحداقل آستانه اطمینان است. نامزد مجموعه م={متر۱،متر۲،…،مترq}یک فرهنگ لغت قوانین انجمن را برآورده می کند دبلیو. جفت کلید-مقدار فرهنگ لغت دبلیومربوط به آیتم مکرر و پشتیبانی آن است. متریک مورد مکرر است که پشتیبانی آن کمتر از حداقل پشتیبانی نیست. کلید قانون انجمن یک مورد مکرر است مبا اطمینان آن کمتر از حداقل اطمینان نیست.
-
تعریف ۶ (سناریوهای شبه همراه): سناریوهای شبه همراه به سناریوهایی اطلاق می شود که قبلاً بالقوه همراهی دارند در حالی که برخی از ویژگی های مهم به طور کامل با الگوی همراه مطابقت ندارند.
-
تعریف ۷ (استراتژی تحمل): هنگام انجام داده کاوی مسیری در یک مجموعه داده پراکنده، برخی از پارامترها را نمی توان به طور دقیق تنظیم کرد. در غیر این صورت یافتن اشیاء تحقیقی که شرایط مربوطه را داشته باشند مشکل خواهد بود. به همین دلیل، برای کشف اجسام متحرک باید یک استراتژی تحمل در نظر گرفته شود.
-
تعریف ۸ (همسفر (TC)): س={q1،q2،…،qn}مجموعه ای از همسفر، که در آن یک گروه همراه در سفر است qمنگروهی است که ارضای تعداد رکوردهای ارضا کننده وضعیت همراه بالقوه بیشتر از آستانه فرکانس است. δf، و نسبت رکوردهای رضایت بخش بیشتر از آستانه درصد است δrدر بازه زمانی S.
۳٫۲٫ روش شناسی
۳٫۲٫۱٫ چارچوب
۳٫۲٫۲٫ پیش پردازش داده ها
۳٫۲٫۳٫ خوشه بندی مکانی-زمانی
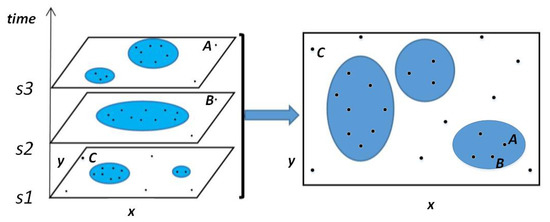
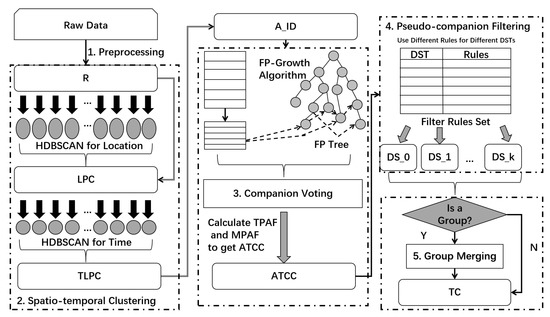
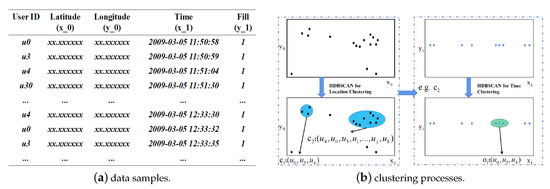
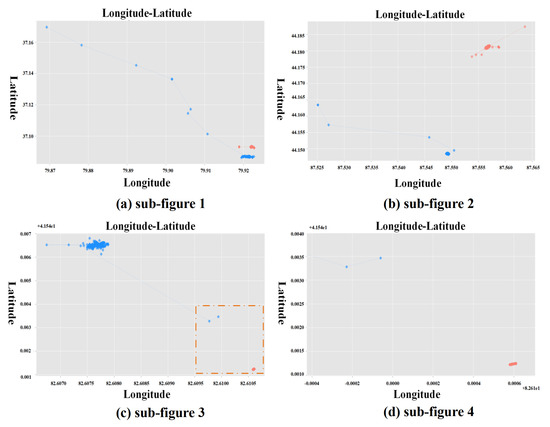
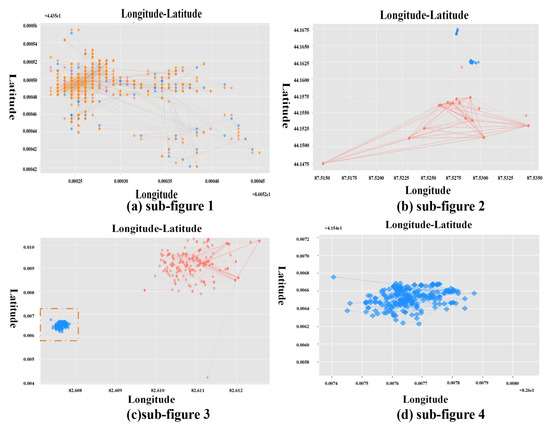
شکل ۳ فرآیند خوشه بندی را به تفصیل نشان می دهد. در این پردازش، HDBSCAN برای کشف نامزد بالقوه مکان (LPC) و زمان و مکان نامزد بالقوه (TLPC) استفاده می شود. LPC شباهت را در ویژگی های مکان نشان می دهد. بر این اساس، TLPC به تشابه در بعد زمانی به شدت نیاز دارد. شکل ۴ نمونه ای از یک فرآیند خاص برای ترکیب فیلدهای داده را نشان می دهد. در شکل ۴الف، مجموعه ای از نمونه داده ها ارائه می شود که چندین فیلد (User ID، Latitude، Longitude، Time) فیلدهای باقی مانده پس از پیش پردازش هستند و فیلد Fill برای این رکوردها به عنوان LPC اضافه می شود. برای کشف LPC، از دو پارامتر برای محدود کردن حداقل اندازه خوشه و آستانه فاصله همسایگی استفاده میشود، که باعث میشود HDBSCAN نتایج ثابت و مؤثری را برای کشف LPC و فیلتر کردن مقداری نویز که نمیتوان خوشهبندی کرد، دریافت کند. یک فیلد Fill به مجموعه LPC افزایش مییابد تا ابعاد مورد نیاز را برآورده کند. مقدار فیلد FILL روی ۱ تنظیم می شود تا محاسبه ساده شود. در هر خوشه LPC، HDBSCAN یک بار برای یافتن TLPC، از جمله ویژگیهای مشابه زمان و مکان، و فیلتر کردن برخی رکوردهای نویز اجرا میشود. شکل ۴ب این روند را به صورت بصری نشان می دهد. در الگوریتم ۱، مراحل ۴ تا ۸ مرحله را از سطح الگوریتم نشان می دهد. قابل ذکر است که تعداد این رکوردهای فیلتر شده می تواند بر ارتقای رکوردهای رضایت بخش تأثیر بگذارد. برای اهداف تحقیقاتی مختلف، ارزش آنها متفاوت است.
| الگوریتم ۱: الگوریتم فضایی-زمانی Clusteirng و Companion Voting. |
 |
۳٫۲٫۴٫ رای همراه
اگر دو رکورد از کاربر X و Y که بخواهند TPAF را تجزیه و تحلیل کنند، TPAF مربوطه است :
برای X و Y ، MPAF به صورت زیر به دست می آید:
۳٫۲٫۵٫ فیلتر شبه همراه
۳٫۲٫۶٫ ادغام گروه
هدف Stage V کشف همراهان مسافرتی است که شامل چندین کاربر میشود، نه فقط یک جفت شامل دو کاربر. مجموعه شامل چندین کاربر به عنوان یک گروه در نظر گرفته می شود. شکل ۳فرآیند ادغام گروه را با جزئیات نشان می دهد. لازم است تشخیص داده شود که آیا وضعیت همراه گروه وجود دارد و تصمیم به ادغام آنها گرفته شود. در مرحله III برای کشف نامزد همراه مسافر (ATCC)، ترفندی برای بهینهسازی سربار محاسباتی برای کاهش زمان همگرایی استفاده میشود که منجر به بحث در مورد سناریوهای تحقیقاتی بین دو کاربر میشود. با این حال، تعداد مجازی کاربران همراه ممکن است چندگانه باشد، مانند گروه های توریستی، شرکت کنندگان در فعالیت های گروهی یک خانواده سه نفره در خرید و غیره. -وضعیت کاربری که ممکن است در میان کاندیدای همراهی که قبلاً کشف شده بود وجود داشته باشد. اگر این کاربران در فیلتر شبه همراه فیلتر شده و باقی بمانند، آنها باید با استفاده از زیر مجموعه های رایج موجود ادغام شوند. به عنوان مثال، برای مجموعه {{تو۰،تو۳}،{تو۳،تو۴}}، زیرا دو مورد از زیرمجموعه ها دارای یک زیر مجموعه مشترک هستند {تو۳}، دو زیرمجموعه را ادغام می کنیم و زیر مجموعه های واقعی دیگر را حذف می کنیم. در نهایت، مجموعه به تغییر می کند {{تو۰،تو۳،تو۴}}. در الگوریتم ۲، مراحل ۱۹-۲۵ این فرآیند را در آخرین مرحله نشان می دهد.
| الگوریتم ۲: فیلترینگ شبه همراه و الگوریتم ادغام گروه. |
 |
۳٫۲٫۷٫ استراتژی تنظیم پارامتر
-
استراتژی کلی: استراتژی کلی در اینجا به منظور برجسته کردن استراتژی تحمل توضیح داده شده است. اول، فرمول هارسین فرمولی است که به ویژه برای فاصله بین دو نقطه از طریق طول و عرض جغرافیایی آنها محاسبه می شود. بسیاری از الگوریتمهای خوشهبندی شامل پارامتری به نام متریک هستند که میتوان آن را بهعنوان «haversine» تنظیم کرد. ثانیاً، برای کشف همسفران، حداقل تعداد خوشهبندی شده برای خوشهبندی باید بزرگتر از ۳ باشد تا تعداد خوشهها کاهش یابد. علاوه بر این، برای تنظیم حمایت و اطمینان، جدول ۴یک مطابقت اولیه بین مشارکت و سطح اطمینان را نشان می دهد. امیدواریم سطح اطمینان بالاتری را تضمین کنیم، بنابراین مقدار اطمینان پیشفرض تعیین شده در این مطالعه ۰٫۶ است. برای سطح پشتیبانی، ما به طور همزمان روی فرکانس شی هدف تمرکز خواهیم کرد و لزوماً نیازی به دریافت نسبت نداریم. در نهایت، برای ثبات نتایج یک مجموعه داده برای اطمینان از پارامتر آستانه فاصله مهم است. به عنوان مثال، برای εو δد، با توجه به دقت نمونه برداری در مراحل مختلف روی یک مقدار تنظیم می شوند. قطعاً، اگر هدف برنامهها نیاز به فیلتر کردن سختگیرانهتری داشته باشد، باید پارامتر دوم را کوچکتر تنظیم کند.
-
استراتژی تحمل: در مقایسه با سختگیری استراتژی کلی، استراتژی تحمل پشتیبانی خوبی برای مجموعه دادهها از برخی منابع داده خاص، مانند CDRها فراهم میکند. علاوه بر این، ارائه یک محدوده ارزش واضح برای برخی پارامترها برای مجموعه دادههای مختلف دشوار است، در حالی که استراتژی تحمل پیشنهادی میتواند کاربران را راهنمایی کند تا برخی از ایدههای تنظیم پارامتر را از هدف کاوی تضعیف کنند. هدف اصلی این استراتژی این است که برای نمونههای دادهای با پراکندگی بالاتر، محدودیتهای آستانه سختی الزامی است تا مجموعه نتایج را تا حد امکان کوچک کند. در واقع تنظیم این استراتژی بیشتر از عملی بودن نتایج حاصل می شود. در این زمینه، پراکندگی داده های مسیر همیشه یک چالش بزرگ بوده است. همزمان، جمع آوری اطلاعات داده های همه کاربران در یک منطقه جغرافیایی خاص در مدت زمان طولانی برای برخی منابع داده خاص دشوار است. این منجر به پراکندگی داده های دنیای واقعی می شود که منطقی و اجتناب ناپذیر است. به همین دلیل، محققان باید امیدوار باشند که از هر اطلاعات ثبت شده (به جز نویز آشکار) استفاده کامل کنند. به طور خاص، برای برخی سناریوهای مهم، مانند استخراج الگوهای رفتاری گروههای خاص و افراد خاص برای کشف الگوی همسفر، گاهی اوقات عوامل مختلفی فرآیند جمعآوری را مختل میکنند به طوری که این دادهها پراکنده میشوند. در این حالت، استراتژی تلورانس بهتر می تواند از فیلتر شدن شدید برخی رکوردها جلوگیری کند که احتمال بیشتری برای یافتن سایر اجسام متحرک مرتبط وجود دارد. در مطالعه ما، برای این منجر به پراکندگی داده های دنیای واقعی می شود که منطقی و اجتناب ناپذیر است. به همین دلیل، محققان باید امیدوار باشند که از هر اطلاعات ثبت شده (به جز نویز آشکار) استفاده کامل کنند. به طور خاص، برای برخی سناریوهای مهم، مانند استخراج الگوهای رفتاری گروههای خاص و افراد خاص برای کشف الگوی همسفر، گاهی اوقات عوامل مختلفی فرآیند جمعآوری را مختل میکنند به طوری که این دادهها پراکنده میشوند. در این حالت، استراتژی تلورانس بهتر می تواند از فیلتر شدن شدید برخی رکوردها جلوگیری کند که احتمال بیشتری برای یافتن سایر اجسام متحرک مرتبط وجود دارد. در مطالعه ما، برای این منجر به پراکندگی داده های دنیای واقعی می شود که منطقی و اجتناب ناپذیر است. به همین دلیل، محققان باید امیدوار باشند که از هر اطلاعات ثبت شده (به جز نویز آشکار) استفاده کامل کنند. به طور خاص، برای برخی سناریوهای مهم، مانند استخراج الگوهای رفتاری گروههای خاص و افراد خاص برای کشف الگوی همسفر، گاهی اوقات عوامل مختلفی فرآیند جمعآوری را مختل میکنند به طوری که این دادهها پراکنده میشوند. در این حالت، استراتژی تلورانس بهتر می تواند از فیلتر شدن شدید برخی رکوردها جلوگیری کند که احتمال بیشتری برای یافتن سایر اجسام متحرک مرتبط وجود دارد. در مطالعه ما، برای محققان باید امیدوار باشند که از هر اطلاعات ثبت شده (به جز نویز آشکار) استفاده کامل کنند. به طور خاص، برای برخی سناریوهای مهم، مانند استخراج الگوهای رفتاری گروههای خاص و افراد خاص برای کشف الگوی همسفر، گاهی اوقات عوامل مختلفی فرآیند جمعآوری را مختل میکنند به طوری که این دادهها پراکنده میشوند. در این حالت، استراتژی تلورانس بهتر می تواند از فیلتر شدن شدید برخی رکوردها جلوگیری کند که احتمال بیشتری برای یافتن سایر اجسام متحرک مرتبط وجود دارد. در مطالعه ما، برای محققان باید امیدوار باشند که از هر اطلاعات ثبت شده (به جز نویز آشکار) استفاده کامل کنند. به طور خاص، برای برخی سناریوهای مهم، مانند استخراج الگوهای رفتاری گروههای خاص و افراد خاص برای کشف الگوی همسفر، گاهی اوقات عوامل مختلفی فرآیند جمعآوری را مختل میکنند به طوری که این دادهها پراکنده میشوند. در این حالت، استراتژی تلورانس بهتر می تواند از فیلتر شدن شدید برخی رکوردها جلوگیری کند که احتمال بیشتری برای یافتن سایر اجسام متحرک مرتبط وجود دارد. در مطالعه ما، برای گاهی اوقات عوامل مختلفی فرآیند جمع آوری را مختل می کند به طوری که این داده ها پراکنده می شوند. در این حالت، استراتژی تلورانس بهتر می تواند از فیلتر شدن شدید برخی رکوردها جلوگیری کند که احتمال بیشتری برای یافتن سایر اجسام متحرک مرتبط وجود دارد. در مطالعه ما، برای گاهی اوقات عوامل مختلفی فرآیند جمع آوری را مختل می کند به طوری که این داده ها پراکنده می شوند. در این حالت، استراتژی تلورانس بهتر می تواند از فیلتر شدن شدید برخی رکوردها جلوگیری کند که احتمال بیشتری برای یافتن سایر اجسام متحرک مرتبط وجود دارد. در مطالعه ما، برای δfو δrدر منبع داده D1 تحمل را در نظر بگیرید. این دو پارامتر را می توان روی مقادیر بزرگتر تنظیم کرد تا سناریوهای سردرگمی را محدود کند، مثلاً تعداد کمی از رکوردها به هم مرتبط هستند و بیشتر رکوردها از هم فاصله دارند یا تعداد رکوردهای یک شی به قدری کم است که باید فیلتر شود. بیرون
۴٫ آزمایش و نتایج
۴٫۱٫ مجموعه داده ها
-
فرکانس نمونه برداری
-
تعداد سوابق برای افراد
-
مدت زمان موثر
-
دوره جمع آوری داده ها
-
D1 (مجموعه داده کاربران مسافر): این مجموعه داده از کاربران واقعی در منطقه خاصی از چین بین ۱۶ نوامبر ۲۰۱۴ تا ۱۸ نوامبر ۲۰۱۴ جمع آوری شده است که توسط یک ارائه دهنده ارتباطات در چین ارائه شده است. مکان ها از سایت های سلولی هستند که با تلفن های زیادی متصل هستند. دادههای خط سیر فضایی خام عمدتاً شامل مختصات طول و عرض جغرافیایی، مهر زمان و اطلاعات کاربر است. هنگامی که ما این مجموعه داده را دریافت کردیم، اطلاعات حساس شخصی در مجموعه داده ناشناس شد و اطلاعات مختصات توسط این ارائه دهنده برای حفاظت از حریم خصوصی مجدداً تنظیم شد.
-
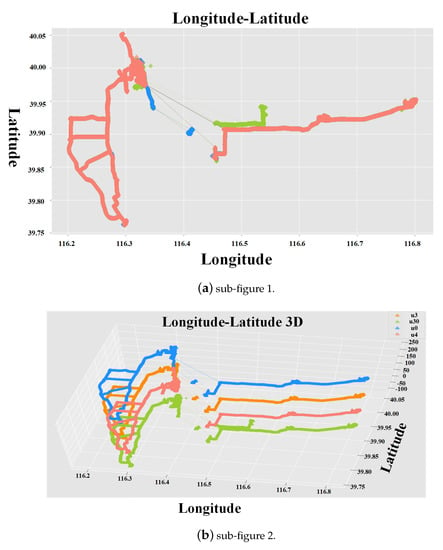
D2 (مسیر Geolife): این مجموعه داده در پروژه Geolife (Microsoft Research Asia) از ۱۸۲ کاربر بین آوریل ۲۰۰۷ و اوت ۲۰۱۲ جمع آوری شد [ ۵۱ ، ۵۲ ، ۵۳ ]. یک مسیر GPS از آن مجموعه با دنباله ای از نقاط مهر زمانی نشان داده می شود که حاوی اطلاعاتی در مورد طول و عرض جغرافیایی، طول و ارتفاع است. ۹۱٫۵%از مسیرها در یک نمایش متراکم هستند، به عنوان مثال، هر ۱-۵ ثانیه یا هر ۵-۱۰ متر در هر نقطه، نمای کلی این مجموعه داده در شکل ۵ نشان داده شده است :
۴٫۲٫ نمایش فیلترینگ سناریوهای شبه همراه
۴٫۳٫ نتایج کشف و اعتبارسنجی همراهان مسافرتی
۴٫۳٫۱٫ اندازه گیری زمان سربار
۴٫۳٫۲٫ تجزیه و تحلیل نتایج مهم
۵٫ نتیجه گیری و بحث
اختصارات
در این نسخه از اختصارات زیر استفاده شده است:
| ANPR | تشخیص خودکار پلاک |
| ATCC | نامزد همراه مسافر |
| CDR ها | تماس با سوابق جزئیات |
| DBSCAN | انطباق فضایی مبتنی بر چگالی کاربرد با نویز |
| DENCLUE | خوشه بندی مبتنی بر چگالی |
| DTS | منبع داده های مختلف |
| DTWD | فاصله زمانی تابش پویا |
| HDBSCAN | خوشه بندی فضایی مبتنی بر چگالی سلسله مراتبی برنامه های کاربردی با نویز |
| HD-FIM | یک رویکرد ترکیبی توزیع شده وسعت اول و عمق اول با استخراج مجموعه آیتم های مکرر |
| IT ها | سیستم هوشمند |
| LBS | سرویس مبتنی بر مکان |
| LPC | کاندیدای بالقوه مکان |
| MBB | جعبه محدود کننده حداقل |
| MBR | حداقل مستطیل مرزی |
| MPAF | ارتقای متقابل فرکانس همراه |
| اپتیک | ترتیب نقاط برای شناسایی ساختار خوشه بندی |
| TLPC | زمان و مکان نامزد بالقوه |
| TC | همسفر |
| TPAF | نسبت کل فرکانس همراه |
منابع
- دفتر ملی آمار چین، بیانیه آماری جمهوری خلق چین در مورد توسعه ملی اقتصادی و اجتماعی در سال ۲۰۱۹٫ در دسترس آنلاین: http://www.stats.gov.cn/tjsj/zxfb/202002/t20200228_1728913.html (در دسترس ۲۸ فوریه ۲۰۲۰).
- گائو، کیو. ژانگ، فلوریدا؛ وانگ، RJ; ژو، اف. داده های بزرگ مسیر: مروری بر فناوری های کلیدی در پردازش داده ها. Ruan Jian Xue Bao/J. نرم افزار ۲۰۱۷ ، ۲۸ ، ۹۵۹-۹۹۲٫ (به زبان چینی) [ Google Scholar ]
- Elragal، A. تجزیه و تحلیل داده های مسیر در حمایت از مدیریت ترافیک. لکت. یادداشت ها محاسبه. علمی ۲۰۱۵ ، ۸۵۵۷ ، ۱۷۴-۱۸۸٫ [ Google Scholar ]
- انامی، س. Shiomoto، K. پیشبینی تحرک فضایی-زمانی انسان بر اساس دادهکاوی مسیر برای مدیریت منابع در شبکههای ارتباطی سیار. در مجموعه مقالات کنفرانس بین المللی IEEE در مورد سوئیچینگ و مسیریابی با عملکرد بالا، شی آن، چین، ۲۶ تا ۲۹ مه ۲۰۱۹؛ IEEE: Piscataway، نیوجرسی، ایالات متحده آمریکا، ۲۰۱۹؛ صص ۱-۶٫ [ Google Scholar ]
- کین، تی. شانگگوان، دبلیو. آهنگ، جی. تانگ، جی. استخراج روتین فضایی-زمانی روی داده های تلفن همراه. ACM Trans. بدانید. کشف کنید. داده ۲۰۱۸ ، ۱۲ ، ۵۶٫۱–۵۶٫۲۴٫ [ Google Scholar ] [ CrossRef ]
- لی، اچ. گو، ی. دادههای حسگر موبایل استخراج برای رفتارهای اجتماعی. در مجموعه مقالات دومین کارگاه بین المللی سنجش اجتماعی، پیتزبورگ، PA، ایالات متحده آمریکا، ۲۱ آوریل ۲۰۱۷٫ [ Google Scholar ]
- چن، ی. کرسپی، ن. Ortiz، AM; شو، ال. کاوی واقعیت: یک الگوریتم پیش بینی برای پویایی بیماری بر اساس داده های بزرگ تلفن همراه. Inf. علمی بین المللی J. ۲۰۱۷ ، ۳۷۹ ، ۸۲-۹۳٫ [ Google Scholar ] [ CrossRef ]
- لیو، ایکس. تیان، ی. ژانگ، ایکس. Wan, Z. شناسایی مناطق عملکردی شهری در چنگدو بر اساس دادههای سری زمانی مسیر تاکسی. بین المللی J. Geo-Inf. ۲۰۲۰ ، ۹ ، ۱۵۸٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- ژنگ، ی. داده کاوی مسیر: مروری. ACM Trans. هوشمند سیستم تکنولوژی ۲۰۱۵ ، ۶ ، ۲۹:۱-۲۹:۴۱٫ [ Google Scholar ] [ CrossRef ]
- تانگ، ال. ژنگ، ی. یوان، جی. هان، جی. لئونگ، آ. پنگ، دبلیو. Porta, TFL چارچوبی برای کشف همسفر در جریان داده های مسیر. ACM Trans. هوشمند سیستم تکنولوژی ۲۰۱۳ ، ۵ ، ۳:۱-۳:۳۴٫ [ Google Scholar ] [ CrossRef ]
- زو، ام ال. لیو، سی. وانگ، X.-B. هان، ی.-بی. رویکردی برای کشف الگوی همراه بر اساس جریان داده anpr. Ruan Jian Xue Bao/J. نرم افزار ۲۰۱۷ . (به زبان چینی) [ Google Scholar ]
- زو، ایکس. سان، تی. یوان، اچ. هو، ز. میائو، جی. بررسی الگوی حرکت گروهی از طریق داده های سلولی: مطالعه موردی گردشگران در هاینان. ISPRS Int. J. Geo-Inf. ۲۰۱۹ ، ۸ ، ۷۴٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- گودموندسون، جی. van Kreveld، MJ محاسبات طولانی ترین گله های طول مدت در داده های مسیر. در مجموعه مقالات چهاردهمین سمپوزیوم بین المللی ACM در سیستم های اطلاعات جغرافیایی، ACM-GIS 2006، آرلینگتون، VA، ایالات متحده آمریکا، ۱۰-۱۱ نوامبر ۲۰۰۶٫ de By, RA, Nittel, S., Eds. ACM: نیویورک، نیویورک، ایالات متحده آمریکا، ۲۰۰۶; صص ۳۵-۴۲٫ [ Google Scholar ]
- تانگ، ال. ژنگ، ی. یوان، جی. هان، جی. لئونگ، آ. هونگ، سی. پنگ، دبلیو. درباره کشف همراهان مسافر از مسیرهای جریانی. در مجموعه مقالات بیست و هشتمین کنفرانس بین المللی IEEE در مهندسی داده (ICDE 2012)، واشنگتن، دی سی، ایالات متحده آمریکا، ۱ تا ۵ آوریل ۲۰۱۲٫ Kementsietsidis, A., Salles, MAV, Eds. انجمن کامپیوتر IEEE: واشنگتن، دی سی، ایالات متحده آمریکا، ۲۰۱۲; ص ۱۸۶-۱۹۷٫ [ Google Scholar ]
- ژانگ، ی. جی، جی. ژائو، بی. ژانگ، بی. الگوریتمی برای استخراج الگوی خوشه های شی متحرک تدریجی از جریان های مسیر. CMC-Comput. ماتر ادامه ۲۰۱۹ ، ۵۹ ، ۸۸۵–۹۰۱٫ [ Google Scholar ] [ CrossRef ]
- یائو، آر. وانگ، اف. Chen, S. TCoD: روش کشف همراه مسافر بر اساس تجزیه و تحلیل خوشهبندی و انجمن. در مجموعه مقالات کنفرانس مشترک بین المللی شبکه های عصبی (IJCNN)، بوداپست، مجارستان، ۱۴ تا ۱۹ ژوئیه ۲۰۱۹؛ IEEE: Piscataway، نیوجرسی، ایالات متحده آمریکا، ۲۰۱۹؛ صص ۱-۷٫ [ Google Scholar ]
- مکینز، ال. هیلی، جی. Astels, S. hdbscan: خوشه بندی مبتنی بر چگالی سلسله مراتبی. جی. ترش باز. نرم افزار ۲۰۱۷ ، ۲ ، ۲۰۵٫ [ Google Scholar ] [ CrossRef ]
- آگراوال، آر. فالوتسوس، سی. سوامی، یک جستجوی کارآمد تشابه در پایگاههای داده توالی . Springer: برلین/هایدلبرگ، آلمان، ۱۹۹۳٫ [ Google Scholar ]
- فالوتسوس، سی. رانگاناتان، ام. Manolopoulos، Y. تطبیق سریع دنبالهای در پایگاههای داده سری زمانی. در مجموعه مقالات کنفرانس بین المللی ACM SIGMOD 1994 در مدیریت داده ها، مینیاپولیس، MN، ایالات متحده، ۲۴-۲۷ مه ۱۹۹۴٫ صص ۴۱۹-۴۲۹٫ [ Google Scholar ]
- چان، ک. Fu، AW تطبیق سری های زمانی کارآمد توسط موجک ها. در مجموعه مقالات پانزدهمین کنفرانس بین المللی مهندسی داده (Cat. No.99CB36337)، سیدنی، استرالیا، ۲۳-۲۶ مارس ۱۹۹۹٫ صص ۱۲۶-۱۳۳٫ [ Google Scholar ]
- النکاوه، س. آخرین، م. Maimon، O. خوشه بندی افزایشی اشیاء متحرک. در مجموعه مقالات کنفرانس بین المللی IEEE در کارگاه مهندسی داده، ICDE 2007، استانبول، ترکیه، ۱۵-۲۰ آوریل ۲۰۰۷٫ صص ۵۸۵-۵۹۲٫ [ Google Scholar ]
- De Vries، GKD; Van Someren، M. خوشهبندی مسیرهای کشتی با هستههای تراز تحت فشردهسازی مسیر. در مجموعه مقالات یادگیری ماشین و کشف دانش در پایگاههای داده، کنفرانس اروپایی، ECML PKDD 2010، بارسلون، اسپانیا، ۲۰-۲۴ سپتامبر ۲۰۱۰٫ جلد ۶۳۲۱، ص ۲۹۶–۳۱۱٫ [ Google Scholar ]
- هایتاور، جی. Borriello، G. فیلترهای ذرات برای تخمین مکان در محاسبات همه جا حاضر: مطالعه موردی. در مجموعه مقالات UbiComp 2004: همه جا محاسباتی: ششمین کنفرانس بین المللی، ناتینگهام، انگلستان، ۷ تا ۱۰ سپتامبر ۲۰۰۴٫ جلد ۳۲۰۵، صص ۸۸–۱۰۶٫ [ Google Scholar ]
- استر، ام. کریگل، اچ. ساندر، جی. Xu, X. الگوریتمی مبتنی بر چگالی برای کشف خوشهها در پایگاههای داده فضایی بزرگ با نویز. Kdd ۱۹۹۶ ، ۹۶ ، ۲۲۶-۲۳۱٫ [ Google Scholar ]
- پیپی، ز. چینگهای، دی. هایبو، ال. Xinglin، H. تشخیص دورتر مسیر بر اساس الگوریتم خوشهبندی DBSCAN. مهندسی لیزر مادون قرمز ۲۰۱۷ , ۴۶ , ۵۲۸۰۰۱٫ [ Google Scholar ] [ CrossRef ]
- آنکرست، م. برونیگ، MM; کریگل، اچ. Sander, J. OPTICS: نقاط ترتیب برای شناسایی ساختار خوشه بندی. SIGMOD 1999. در مجموعه مقالات ACM SIGMOD کنفرانس بین المللی مدیریت داده ها، فیلادلفیا، PA، ایالات متحده آمریکا، ۱-۳ ژوئن ۱۹۹۹٫ صص ۴۹-۶۰٫ [ Google Scholar ]
- هینهبورگ، ای. Keim, DA یک رویکرد کلی برای خوشه بندی در پایگاه های داده بزرگ با نویز. بدانید. Inf. سیستم ۲۰۰۳ ، ۵ ، ۳۸۷-۴۱۵٫ [ Google Scholar ] [ CrossRef ]
- هینهبورگ، ای. گابریل، HH DENCLUE 2.0: خوشه بندی سریع بر اساس تخمین چگالی هسته. در مجموعه مقالات پیشرفت در تجزیه و تحلیل داده های هوشمند VII، هفتمین سمپوزیوم بین المللی تجزیه و تحلیل داده های هوشمند، IDA 2007، لیوبلیانا، اسلوونی، ۶-۸ سپتامبر ۲۰۰۷٫ جلد ۴۷۲۳، ص ۷۰–۸۰٫ [ Google Scholar ]
- یانگ، ی. کای، جی. یانگ، اچ. ژانگ، جی. Zhao، X. TAD: یک الگوریتم خوشهبندی مسیر بر اساس تحلیل چگالی مکانی-زمانی. سیستم خبره Appl. ۲۰۲۰ , ۱۳۹ , ۱۱۲۸۴۶٫ [ Google Scholar ] [ CrossRef ]
- گائو، ی. ژنگ، بی. چن، جی. Li, Q. الگوریتمهایی برای جستوجوهای محدود به نزدیکترین همسایه بر روی مسیرهای حرکت جسم. Geoinformatica ۲۰۱۰ ، ۱۴ ، ۲۴۱-۲۷۶٫ [ Google Scholar ] [ CrossRef ]
- گودموندسون، جی. Valladares، N. یک رویکرد GPU برای خوشهبندی زیر مسیر با استفاده از فاصله Fréchet. در مجموعه مقالات کنفرانس بینالمللی SIGSPATIAL 2012 در مورد پیشرفتها در سیستمهای اطلاعات جغرافیایی (که قبلاً GIS نامیده میشد)، SIGSPATIAL’12، Redondo Beach، CA، ایالات متحده آمریکا، ۷-۹ نوامبر ۲۰۱۲٫ صص ۲۵۹-۲۶۸٫ [ Google Scholar ]
- دنگ، ز. هو، ی. زو، ام. هوانگ، ایکس. Du, B. یک اپتیک مقیاس پذیر و سریع برای خوشه بندی کلان داده های مسیر. خوشه. محاسبه کنید. ۲۰۱۵ ، ۱۸ ، ۵۴۹-۵۶۲٫ [ Google Scholar ] [ CrossRef ]
- یوان، جی. سان، پ. ژائو، جی. لی، دی. وانگ، سی. مروری بر الگوریتمهای خوشهبندی مسیر جسم متحرک. آرتیف. هوشمند Rev. ۲۰۱۷ , ۴۷ , ۱۲۳-۱۴۴٫ [ Google Scholar ] [ CrossRef ]
- شیائو، ایکس. ژنگ، ی. لو، کیو. Xie، X. یافتن کاربران مشابه با استفاده از تاریخچه مکان مبتنی بر دسته. در مجموعه مقالات هجدهمین سمپوزیوم بین المللی ACM SIGSPATIAL در مورد پیشرفت ها در سیستم های اطلاعات جغرافیایی، ACM-GIS 2010، سان خوزه، کالیفرنیا، ایالات متحده آمریکا، ۳ تا ۵ نوامبر ۲۰۱۰٫ صص ۴۴۲-۴۴۵٫ [ Google Scholar ]
- یینگ، JJC; لی، WC; Weng، TC; Tseng، VS استخراج مسیر معنایی برای پیشبینی مکان. در مجموعه مقالات نوزدهمین سمپوزیوم بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، ACM-GIS 2011، شیکاگو، IL، ایالات متحده آمریکا، ۱-۴ نوامبر ۲۰۱۱٫ صص ۳۴-۴۳٫ [ Google Scholar ]
- لیو، حیله گر؛ Ni، LM به سمت خوشه بندی مبتنی بر تحرک. در مجموعه مقالات شانزدهمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، واشنگتن، دی سی، ایالات متحده آمریکا، ۲۵ تا ۲۸ ژوئیه ۲۰۱۰٫ ص ۹۱۹-۹۲۸٫ [ Google Scholar ]
- آندرینکو، جی. آندرینکو، ن. فوکس، جی. گارسیا، مسیرهای خوشهبندی JMC توسط قطعات مربوطه برای تجزیه و تحلیل ترافیک هوایی. IEEE Trans. Vis. محاسبه کنید. نمودار. ۲۰۱۸ ، ۲۴ ، ۳۴-۴۴٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- زیتون، X. موریو، جی. خوشهبندی مسیر جریانهای ترافیک هوایی در اطراف فرودگاهها. هوانوردی علمی تکنولوژی ۲۰۱۹ ، ۸۴ ، ۷۷۶-۷۸۱٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گودموندسون، جی. Kreveld، MJV محاسبات طولانیترین گلهها در دادههای مسیر. در مجموعه مقالات چهاردهمین سمپوزیوم بین المللی ACM در سیستم های اطلاعات جغرافیایی، ACM-GIS 2006، آرلینگتون، VA، ایالات متحده آمریکا، ۱۰–۱۱ نوامبر ۲۰۰۶٫ [ Google Scholar ]
- جونگ، اچ. Yiu، ML; ژو، ایکس. جنسن، CS; شن، اچ تی کشف کاروان ها در پایگاه داده های مسیر. Proc. VLDB Enddow. ۲۰۰۸ ، ۱ ، ۱۰۶۸-۱۰۸۰٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژنهوی، ال. بولین، دی. هان، جی. ازدحام: استخراج خوشههای شی متحرک زمانی آرام. Proc. VLDB Enddow. ۲۰۱۰ ، ۳ ، ۷۲۳-۷۳۴٫ [ Google Scholar ]
- کای، ز. یو، ز. یوان، نیوجرسی؛ Shang, S. در مورد کشف الگوهای جمع آوری از مسیرها. در مجموعه مقالات بیست و نهمین کنفرانس بین المللی IEEE در مهندسی داده، ICDE 2013، بریزبن، استرالیا، ۸ تا ۱۲ آوریل ۲۰۱۳٫ ص ۲۴۲-۲۵۳٫ [ Google Scholar ]
- وانگ، ز. او، SY; لئونگ، ی. استفاده از داده های تلفن همراه برای تحقیقات رفتار سفر: مروری بر ادبیات. رفتار سفر. Soc. ۲۰۱۷ ، ۱۱ ، ۱۴۱-۱۵۵٫ [ Google Scholar ] [ CrossRef ]
- فن، سی. کاوالارو، A. تشخیص تعاملات گروهی توسط انجمن آنلاین داده های مسیر. در مجموعه مقالات کنفرانس بین المللی IEEE 2013 در مورد آکوستیک، پردازش گفتار و سیگنال، ونکوور، BC، کانادا، ۲۶-۳۱ مه ۲۰۱۳٫ صفحات ۱۷۵۴-۱۷۵۸٫ [ Google Scholar ]
- ژانگ، جی. لی، جی. وانگ، اس. لیو، ز. یوان، Q. Yang, F. در مورد بازیابی اشیاء متحرک الگوهای جمع آوری از داده های مسیر از طریق نمودار فضایی-زمانی. در مجموعه مقالات کنگره بین المللی IEEE در سال ۲۰۱۴ در مورد داده های بزرگ، انکوریج، AK، ایالات متحده، ۲۷ ژوئن تا ۲ ژوئیه ۲۰۱۴٫ صص ۳۹۰-۳۹۷٫ [ Google Scholar ]
- Puntheeranurak، S. شین، تی تی. امامورا، ام. کشف کارآمد همراه مسافر از جریان داده سیر تکاملی. در مجموعه مقالات چهل و دومین کنفرانس سالانه نرم افزار و برنامه های کامپیوتری IEEE 2018، توکیو، ژاپن، ۲۳ تا ۲۷ ژوئیه ۲۰۱۸؛ جلد ۱، ص ۴۴۸-۴۵۳٫ [ Google Scholar ]
- زو، ام. چن، ال. وانگ، جی. وانگ، ایکس. Han, Y. یک رویکرد خدمات پسند برای کشف همراهان مسافر بر اساس جریان داده ANPR. در مجموعه مقالات کنفرانس بین المللی IEEE در محاسبات خدمات، SCC 2016، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، ۲۷ ژوئن تا ۲ ژوئیه ۲۰۱۶٫ صص ۱۷۱-۱۷۸٫ [ Google Scholar ]
- شیا، دی. لو، ایکس. لی، اچ. وانگ، دبلیو. لی، ی. Zhang، Z. الگوریتم رشد الگوی مکرر موازی مبتنی بر کاهش نقشه برای تجزیه و تحلیل انجمن مکانی-زمانی داده های بزرگ مسیر موبایل. پیچیدگی ۲۰۱۸ ، ۲۰۱۸ ، ۲۸۱۸۲۵۱:۱–۲۸۱۸۲۵۱:۱۶٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Wen-Bo، HU; هوانگ، دبلیو. Guo-Chao، HU تحلیل الگوی ضمیمه مسیر بر اساس تجزیه و تحلیل خوشهبندی و انجمن اپتیک. محاسبه کنید. مد. ۲۰۱۷ . (به زبان چینی) [ Google Scholar ] [ CrossRef ]
- البادوی، ع. لانگ، ز. ژانگ، ز. الحبیب، م. Alsabahi, K. یک رویکرد یکپارچه جدید برای کشف وسیله نقلیه همراه بر اساس استخراج مکرر مجموعه موارد در Spark. عرب J. Sci. مهندس ۲۰۱۹ ، ۴۴ ، ۹۵۱۷–۹۵۲۷٫ [ Google Scholar ] [ CrossRef ]
- ژنگ، ی. ژانگ، ال. Xie، X. Ma، W. استخراج مکان های جالب و توالی سفر از مسیرهای GPS. در مجموعه مقالات کنفرانس بین المللی وب جهانی، مادرید، اسپانیا، ۲۰-۲۴ آوریل ۲۰۰۹; صص ۷۹۱-۸۰۰٫ [ Google Scholar ]
- ژنگ، ی. لی، کیو. چن، ی. Xie، X. Ma, W. درک تحرک بر اساس داده های GPS. در مجموعه مقالات Ubicomp: Ubiquitous Computing، کنفرانس بین المللی، Ubicomp، سئول، کره، ۲۱-۲۴ سپتامبر ۲۰۰۸٫ صص ۳۱۲-۳۲۱٫ [ Google Scholar ]
- ژنگ، ی. Xie، X. Ma، W. GeoLife: یک سرویس شبکه اجتماعی مشترک بین کاربر، مکان و مسیر. مهندسی (پایه) IEEE گاو نر ۲۰۱۰ ، ۳۳ ، ۳۲-۳۹٫ [ Google Scholar ]