

- مقاله
- دسترسی آزاد
- منتشر شده:
پیشبینی سیل ناگهانی در آینده نزدیک در یک منطقه خشک تحت تأثیر تغییرات اقلیمی
گزارشهای علمی حجم ۱۴ ، شماره مقاله: ۲۵۸۸۷ ( ۲۰۲۴ )
چکیده
سیلهای ناگهانی تهدیدی قابل توجه هستند که باعث ایجاد بلایای طبیعی شدید میشوند و منجر به خسارات گسترده به املاک و زیرساختها میشوند که به نوبه خود منجر به از دست رفتن جان انسانها و خسارات اقتصادی قابل توجه میشود. در این مطالعه، یک رویکرد آماری جامع برای پیشبینی سیل آینده در حوضه ساحلی شمال الابطینه، عمان به کار گرفته شد. در این زمینه، گام اولیه شامل تجزیه و تحلیل هجده مدل گردش عمومی (GCM) برای شناسایی مناسبترین مدل است. متعاقباً، چهار سناریوی CMIP6 را برای تجزیه و تحلیل بارندگی آینده ارزیابی کردیم. در مرحله بعد، الگوریتمهای مختلف یادگیری ماشین (ML) از طریق H2O-AutoML برای شناسایی بهترین مدل برای کوچکمقیاس کردن پیشبینیهای بارندگی آینده به کار گرفته شدند. سپس چهل تابع توزیع بر روی بارندگی روزانه آینده برازش داده شد و بهترین مدل برای پیشبینی منحنیهای شدت-مدت-فراوانی (IDF) آینده انتخاب شد. در نهایت، مدل ابزار ارزیابی خاک و آب (SWAT) با گامهای زمانی زیر روزانه برای پیشبینی دقیق سیل ناگهانی در منطقه مورد مطالعه استفاده شد. یافتهها نشان میدهد که IITM-ESM در بین مدلهای GCM مؤثرترین است. علاوه بر این، استفاده از مدل ML با رویکرد ترکیبی، قابل اعتمادترین روش در کوچکمقیاسسازی بارشهای آینده بود. علاوه بر این، این مطالعه نشان داد که سیلابهای ورودی به مناطق شهری میتواند تحت سناریوهای بدبینانه در طول رویدادهای بارش با دوره بازگشت ۱۰۰ و ۲۰۰ ساله، به ترتیب به ۲۰.۳۳ و ۲۰.۷۰ متر مکعب بر ثانیه برسد. این رویکرد جامع سلسله مراتبی با استفاده از مؤثرترین مدل در هر مرحله، نتایج قابل اعتمادی را ارائه میدهد و بینش عمیقی در مورد پیشبینی سیل ناگهانی آینده ارائه میدهد.
محتوای مشابه توسط دیگران مشاهده میشود

مقدمه
تغییرات اقلیمی چرخه هیدرولوژیکی را تشدید میکند که به نوبه خود منجر به افزایش بارندگیهای شدید میشود، روندی که انتظار میرود در آینده نیز ادامه یابد ۱ ، ۲ ، ۳٫ این تغییرات در الگوهای اقلیمی مستقیماً بر روند بارندگی محلی تأثیر میگذارند، بنابراین بر جریان رودخانهها و فراوانی سیلهای ناگهانی تأثیر میگذارند ۴ ، ۵٫ سیل، به عنوان یک خطر طبیعی شدید تاریخی، خطرات قابل توجهی را برای جمعیتهای انسانی، به ویژه در مناطق پرجمعیت ۶ ، ۷ ، ۸ ، ایجاد میکند که متعاقباً خطرات اجتماعی-زیستمحیطی را افزایش میدهد ۹٫ پارامترهای بارندگی مانند مدت زمان، مقدار کل، شدت و توزیع زمان-مکان از عوامل اصلی مؤثر بر وقوع سیل ناگهانی هستند ۱۰ ، ۱۱ ، ۱۲٫ همچنین، این عوامل بر پیشبینی بارندگی آینده تأثیر میگذارند که برای طراحی تأسیسات قابل اعتماد مدیریت سیل بسیار مهم است ۱۳٫ برای مقابله با این چالش، میتوان از منحنیهای شدت-مدت-فراوانی (IDF) برای تخمین شدت بارندگی آینده در یک دوره بازگشت و مدت زمان خاص ۱۴ ، ۱۵ استفاده کرد . در این راستا، منحنیهای IDF برای استان ریزه، ترکیه، از سال ۲۰۱۳ تا ۲۰۹۹ در یک مطالعه ایجاد شدهاند [۱۶] . مطالعه آنها بر اهمیت ارزیابی مجدد طوفانهای طراحی گذشته با استفاده از منحنیهای IDF در سراسر جهان تأکید دارد [۱۶] .
از آنجایی که تغییرات اقلیمی میتواند به طور قابل توجهی بر الگوهای بارندگی و جریان رودخانه تأثیر بگذارد ۱۷ ، ۱۸ ، ۱۹ ، پیشبینی منحنیهای IDF باید در تحلیل بارندگی و شبیهسازی سیل گنجانده شود. تجزیه و تحلیل تغییرات در بارندگیهای شدید آینده یا منحنیهای IDF به پیشبینیهای مدلهای گردش عمومی (GCM) متکی است ۲۰ ، ۲۱ ، ۲۲ ؛ با این حال، وضوح تقریبی این پیشبینیها، اثربخشی آنها را برای کاربردهای در مقیاس حوضه محدود میکند ۲۳ . برای حل این مشکل، میتوان از تکنیکهای کوچکمقیاسسازی برای تولید دادهها در مقیاس محلیتر و دقیقتر استفاده کرد ۱ ، ۲۴ ، ۲۵٫ در این زمینه، دو گروه کلیدی از تکنیکهای کوچکمقیاسسازی وجود دارد: (الف) کوچکمقیاسسازی دینامیکی (DD)، که از مدلهای اقلیمی منطقهای (RCM) برای کوچکمقیاسسازی متغیرهای GCM استفاده میکند؛ (ب) کوچکمقیاسسازی آماری (SD)، که یک رابطه آماری یا تجربی بین متغیرهای جوی بزرگمقیاس (پیشبینیکنندهها) و متغیرهای منطقهای (پیشبینیکنندهها) برقرار میکند ۲۶ . رویکردهای SD در مقایسه با رویکردهای DD روشهای مناسبتری هستند زیرا دقت قابل اعتماد، پیادهسازی آسان و هزینه محاسباتی کمتری ارائه میدهند ۲۷ ، ۲۸٫ بنابراین، تکنیکهای SD ممکن است برای مطالعاتی که بر کوچکمقیاسسازی و پیشبینی بارندگی در مقیاس حوضه و محلی تمرکز دارند مفید باشند ۲۹٫ این روشها به دو گروه اصلی طبقهبندی میشوند: پیشبینی کامل (PP) و آمار خروجی مدل (MOS) ۲۶ ، ۳۰ .
روشهای PP و MOS تفاوتهای ذاتی در فرآیند کوچکمقیاسسازی خود دارند. اگرچه رویکردهای PP رابطه آماری بین یک متغیر اقلیمی مشاهدهشده به عنوان پیشبینیکننده و دادههای مشاهدهشده در مقیاس بزرگ به عنوان پیشبینیکننده ایجاد میکنند، در MOS، رابطه با پیشبینیکننده مشاهدهشده با استفاده از پیشبینیکنندههای مبتنی بر GCM توسعه مییابد. از آنجایی که کوچکمقیاسسازی آماری با استفاده از رویکردهای PP به پیشبینی دقیق پیشبینیکنندههای در مقیاس بزرگ متکی است، کاربرد چنین روشهایی میتواند منجر به عدم قطعیت شود ۲۶٫ به عنوان یک جایگزین، MOS میتواند برای در نظر گرفتن صریح خطاها و سوگیریهای GCMها در تحلیل آنها ۳۱ به کار گرفته شود . این روش با داشتن یک پایگاه داده قابل توجه از الگوهای گذشته، ابزاری قابل اعتماد برای پیشبینیهای تغییرات اقلیمی بوده و میتواند مزایای بیشتری نسبت به PP برای پرداختن به پیشبینیهای مقیاس محلی آینده ارائه دهد ۳۲ ، ۳۳ ، ۳۴٫ علاوه بر این، با ترکیب بارندگی و دما با دادههای گردش خون به عنوان پیشبینیکننده، روشهای MOS میتوانند کنترل پویای تخمینهای بارندگی را بهبود بخشند ۳۵ .
با توجه به پیچیدگی روابط مکانی-زمانی بین متغیرهای اقلیمی، روشهای ساده سنتی نمیتوانند به طور مؤثر این تعاملات را ثبت کنند و در نتیجه، کوچکمقیاسسازی با اطمینان کمتری انجام میشود . ۳۰٫ برای پرداختن به این موضوع، تحقیقات اخیر از تکنیکهای یادگیری ماشین (ML) به عنوان رویکردهای مبتنی بر MOS برای بهبود دقت دادههای کوچکمقیاسشده استفاده کردهاند . ۳۴ ، ۳۶٫ به عنوان مثال، جورج و آتیرا (۲۰۲۳) از یک روش تصادفی چند مرحلهای با استفاده از مدل ماشین بردار ارتباط (RVM) برای کوچکمقیاسسازی بارندگی در حوضه رودخانه بهاراتاپوژا، هند استفاده کردند . ۳۷٫ علاوه بر این، نیازکار و همکاران (۲۰۲۳) از برنامهریزی ژنتیکی چند ژنی (MGGP) و شبکههای عصبی مصنوعی (ANN) برای کوچکمقیاسسازی مدلهای تغییر اقلیم برای پیشبینی دما در استان کهگیلویه و بویراحمد، ایران استفاده کردند . ۳۸٫ مطالعات فوقالذکر نشان داد که رویکردهای ML نتایج رضایتبخشی در کوچکمقیاسسازی متغیرهای اقلیمی نشان دادهاند.
با توجه به تنوع الگوریتمهای یادگیری ماشین، ارزیابی عملکرد آنها در یادگیری الگوهای تاریخی متغیرهای اقلیمی برای شناسایی و انتخاب مناسبترین الگوریتم برای کوچکمقیاسسازی ضروری است. در این زمینه، پلتفرم H2O-AutoML ابزاری ارزشمند برای خودکارسازی فرآیند آموزش و اعتبارسنجی دادهها است. این پلتفرم وظایف مختلفی از جمله پیشپردازش دادهها، انتخاب ویژگی، انتخاب مدل و تنظیم ابرپارامتر ۳۹ را در بر میگیرد . H2O-AutoML با کاهش نیاز به مداخله انسانی و دانش تخصصی، ابزاری کارآمد و سریع برای ایجاد روابط بین بارندگی و متغیرهای اقلیمی ارائه میدهد.
پس از کوچکمقیاسسازی و پیشبینی بارندگی آینده، یک رویکرد پسپردازش برای تولید منحنیهای IDF مرتبط تحت سناریوهای مختلف مورد نیاز است. در این زمینه، چندین محقق منحنیهای IDF را با استفاده از توابع توزیع مختلف، مانند مقادیر حدی تعمیمیافته (GEV) ۴۰ ؛ توزیع گامبل ۴۱ ؛ لوگ پیرسون نوع III ۴۲ ؛ و توزیع بتای بیزی ۱۴ ، ساختهاند که هر کدام برای ارائه منحنیهای IDF به کار گرفته شدهاند.
پس از ایجاد منحنیهای IDF آینده و تعیین میزان بارندگی طراحی، باید از ابزاری قوی برای تدوین شرایط هیدرولوژیکی منطقه مورد مطالعه و تعیین ویژگیهای سیلهای ناگهانی تحت سناریوهای مختلف تغییر اقلیم استفاده شود. در حال حاضر، مدلهای عددی کمی میتوانند فرآیندهای هیدرولوژیکی را در مقیاس حوضه آبریز تحت گامهای زمانی زیر روزانه به طور دقیق تجزیه و تحلیل کنند، که این یک الزام کلیدی برای شبیهسازی پاسخ هیدرولوژیکی حوضههای تمرکز کوتاه مدت است ۷ ، ۴۳ ، ۴۴ ، ۴۵٫ در این راستا، مدل ابزار ارزیابی خاک و آب (SWAT) ۴۶ ، ۴۷ میتواند دقت مکانی را در سطح واحد پاسخ هیدرولوژیکی (HRU) ارائه دهد، که آن را به ابزاری مناسب برای ارزیابی تأثیر کاربری اراضی بر خروجیها تبدیل میکند. علاوه بر این، مدل SWAT طیف گستردهای از کاربردها را در حوضههای بدون آمار ۴۸ ، ۴۹ دارد .
اگرچه مطالعات اخیر، تحلیل سناریوهای GCM، توابع توزیع و مدلهای یادگیری ماشینی را در تخمین بارندگی و رواناب نادیده گرفتهاند، این مطالعه یک چارچوب جدید و جامع را معرفی میکند که برای اولین بار، پلتفرم H2O-AutoML را با مدل هیدرولوژیکی SWAT برای پیشبینی سیلهای ناگهانی آینده ادغام میکند. این چارچوب سلسله مراتبی، دقت پیشبینیهای سیل ناگهانی آینده را در هر مرحله از فرآیند به طور قابل توجهی افزایش میدهد. به عبارت دیگر، نوآوری این تحقیق در سازماندهی استراتژیک سطوح سلسله مراتبی و کاربرد روشهای قوی و متنوع نهفته است که به پیشبینیهای بسیار دقیقی برای وقایع سیل آینده منجر میشود. در مرحله اول مطالعه، مدلهای گردش عمومی جوی-اقیانوسی (AOGCMs) برای شناسایی دقیقترین مدل برای نمایش بارندگی تاریخی در شمال الباطنه مورد تجزیه و تحلیل قرار میگیرند. پس از این، سناریوهای بارندگی آینده پیشبینی شده توسط مدل انتخاب شده با استفاده از H2O-AutoML بررسی و کوچکمقیاس میشوند. پیشبینی منحنیهای IDF آینده با برازش توابع توزیع مختلف حاصل میشود. در نهایت، میزان بارندگی مشخص شده به مدل SWAT وارد میشود تا ویژگیهای سیل ناگهانی آینده تعیین شود.
در بخشهای بعدی مطالعه، بخش « روششناسی » به جزئیات مواد و روشها میپردازد، بخش « مطالعه موردی » ویژگیهای مطالعه موردی را شرح میدهد و بخش « نتایج و بحث » نتایج را ارائه میدهد. علاوه بر این، بخش ماقبل آخر نوآوریها را توضیح میدهد و تحقیقات فعلی را مورد بحث قرار میدهد و بخش « بحث » به طور جامع نتیجهگیریها را توضیح میدهد.
روششناسی
این بخش شرح مفصلی از روشهای به کار رفته در این چارچوب را ارائه میدهد. مراحل رویهای به صورت بصری در شکل ۱ نشان داده شده است و ساختار سلسله مراتبی چارچوب به شرح زیر است:
- ۱.بخش « پیشبینیهای تغییرات اقلیمی » توضیح جامعی از مدلهای AOGCM ارائه میدهد و اطلاعات لازم برای انتخاب مناسبترین مدل برای تحلیلهای بعدی را روشن میکند.
- ۲.بخش « ریزمقیاسنمایی بارش مبتنی بر یادگیری ماشین » توضیح کاملی از H2O-AutoML ارائه میدهد و نقش آن را در ریزمقیاسنمایی سناریوهای بارش آینده تشریح میکند.
- ۳.بخش « تولید منحنیهای شدت-مدت-فراوانی آینده » جزئیات پیشبینی منحنیهای IDF آینده را برای پرداختن به فرآیند تعیین الگوهای بارش طوفان در آینده توضیح میدهد.
- ۴.بخش « شبیهسازی هیدرولوژیکی » مروری دقیق بر مدل SWAT و اجزای آن و همچنین فرآیند محاسبه سیلابهای ناگهانی ارائه میدهد.

نمودار جریان چارچوب پیشنهادی.
پیشبینیهای تغییرات اقلیمی
استفاده از مدلهای گردش عمومی جو-اقیانوس (AOGCM) با گنجاندن عناصری مانند پوشش گیاهی و شیمی جو، توانایی ما را در پیشبینی الگوهای اقلیمی تا حد زیادی افزایش داده است. با این حال، ضروری است که اذعان کنیم این مدلها نیز محدودیتهای خود را دارند، از جمله عدم قطعیت در پارامترسازی، اتکا به دادههای تاریخی و سوگیریهای بالقوه در پیشبینیهای اقلیمی که میتوانند بر دقت و قابلیت اطمینان آنها تأثیر بگذارند . ۲۳٫ گروه چند مدلی پروژه مقایسه متقابل مدل جفتشده فاز ۶ (CMIP6) بر اساس یافتههای فاز ۵ قبلی خود ساخته شده و از یک رویکرد جامع برای تجزیه و تحلیل مکانیسمهای پیچیده سیستم اقلیمی استفاده میکند. ۵۰ و با در نظر گرفتن سناریوهای احتمالی آینده، پیشبینیهای اقلیمی را تولید میکند . ۵۱٫ این مدل، مسیرهای اجتماعی-اقتصادی مشترک (SSP) و مسیرهای تمرکز نماینده (RCP) را ترکیب میکند تا درک دقیقی از چگونگی تأثیر این عوامل بر آب و هوای سیاره ما ارائه دهد. در واقع، بررسی سناریوهای SSP درک ارزشمندی از اثرات بالقوه ناشی از تحولات اجتماعی-اقتصادی قابل توجه ارائه میدهد . ۵۲ . پیشبینیهای مدل کمی با گنجاندن SSPها به طور قابل توجهی بهبود یافته است. در این مطالعه، چهار سناریوی CMIP6 شامل SSP1-2.6، SSP2-4.5، SSP3-7.0 و SSP5-8.5 برای ارزیابی تغییرات بارندگی آینده در منطقه مورد مطالعه استفاده شده است.
کوچکمقیاسسازی بارش مبتنی بر یادگیری ماشین
همبستگی بین بارش محلی و متغیرهای AOGCM اغلب به دلیل تعامل عوامل مختلف اقلیمی پیچیده است ۵۳ ، ۵۴٫ در این زمینه، ساخت یک مدل مؤثر برای پیشبینیهای آینده، مستلزم در نظر گرفتن متغیرهای مرتبط است. با توجه به وجود متغیرهای جوی بزرگمقیاس در پیشبینی بارش آینده تحت سناریوهای مختلف، ما مدلی را برای کوچکمقیاس کردن و افزایش دقت شبیهسازیهای بارش و سیل توسعه میدهیم. این مدل از بارش مشاهدهشده به عنوان متغیر خروجی (پیشبینیکننده) استفاده میکند و از متغیرهای جوی بزرگمقیاس مشتقشده از مدلهای تاریخی AOGCM از سال ۱۹۹۵ تا ۲۰۱۴ به عنوان ورودی یا پیشبینیکننده استفاده میکند. این تحقیق از متغیرهای AOGCM، از جمله رطوبت ویژه (hus)، میانگین دمای هوا و شار بارش (pr) به عنوان پیشبینیکنندههای مهم استفاده میکند. این متغیرها به دلیل در دسترس بودن آنها در مدل CMIP6 انتخاب شدند. پس از تعیین پیشبینیکنندهها و پیشبینیکنندهها، مدل کوچکمقیاسسازی با استفاده از H2O-AutoML توسعه داده شد. بخش زیر H2O-AutoML و کاربرد آن در انتخاب قابل اعتمادترین مدلهای یادگیری ماشین را معرفی میکند.
کاربرد H2O-AutoML در ریزمقیاسنمایی تغییرات اقلیمی
هدف این مطالعه، استفاده از مدلهای یادگیری ماشینی برای کوچکمقیاسنمایی بارشهای آینده با استفاده از ابزار H2O-AutoML است. H2O-AutoML، یک ابزار یادگیری ماشینی متنباز، پلتفرمی مؤثر است که از طریق زبانهای برنامهنویسی مختلف مانند پایتون و برنامهنویسی R ۳۹ قابل دسترسی است . این پلتفرم برای مجموعه دادههای جدولی طراحی شده است که میتواند انواع مختلفی از مسائل، از جمله مسائل رگرسیون و طبقهبندی چند کلاسه را پشتیبانی کند. همچنین، H2O-AutoML قابلیت امتیازدهی سریعی دارد که به مدلهای متعدد اجازه میدهد پیشبینیهای سریعی انجام دهند ۵۵٫ یکی دیگر از مزایای H2O-AutoML، ارائه رابطهای برنامهنویسی کاربردی (API) به زبانهای مختلف است که ادغام و کاربرد گسترده در زمینهها و مسائل مختلف را تسهیل میکند. علاوه بر این، عملکرد مؤثری را در پردازش و شبیهسازی مجموعه دادههای پیچیده نشان میدهد.
H2O مقیاسبندی ویژگیها، تنظیم فراپارامتر و بهینهسازی را از طریق جستجوهای تصادفی شبکه خودکار میکند و به آن اجازه میدهد مدلهای متعددی تولید کند که بر اساس معیارهای عملکرد مختلف ارزیابی میشوند. از این رو، این مطالعه یک چارچوب با زمان کارآمد ایجاد میکند که به سرعت مدل بهینه را بدون نیاز به آزمون و خطای دستی شناسایی میکند. برای بهینهسازی عملکرد مدل، فراپارامترهای مدل به دقت تنظیم شدند تا خطاهای پیشبینی به حداقل برسند و سطح عملکرد رضایتبخشی تضمین شود. با پیروی از اصل آزمایش روی دادههایی که قبلاً در طول آموزش در نظر گرفته نشدهاند، از یک روش اعتبارسنجی متقابل K-fold استفاده کردیم.
این مطالعه از شش مدل یادگیری برای ریزمقیاسنمایی بارش استفاده میکند، از جمله جنگل تصادفی توزیعشده (DRF)، ماشین تقویتکننده گرادیان (GBM)، یادگیری جمعی انباشتهشده، مدل خطی تعمیمیافته (GLM)، شبکههای عصبی عمیق (NN) و درختان بهشدت تصادفی (XRT). توضیحات بیشتر در مورد این مدلها در جدول ۱ ارائه شده است .
ارزیابی مدلها
در این مطالعه، ۸۰٪ از مجموعه دادههای تاریخی CMIP6، شامل رطوبت ویژه، دمای هوا و شار بارندگی به عنوان ورودی، همراه با دادههای بارش مشاهدهشده به عنوان خروجی، برای آموزش مدلهای H2O-AutoML استفاده شد. متعاقباً، مدلهای یادگیری ماشین در مجموعه دادههای پیشپردازششده با استفاده از توابع آموزشی H2O آموزش داده شدند. روش آموزش شامل بهینهسازی تکراری پارامترهای مدل است. برای تجزیه و تحلیل عملکرد مدلهای ML، از معیارهای ارزیابی مختلفی از جمله جذر میانگین مربعات خطای لگاریتمی (RMSLE)، میانگین مربعات خطا (MSE)، جذر میانگین مربعات خطا (RMSE)، میانگین خطای مطلق (MAE) و میانگین انحراف باقیمانده استفاده میشود. در این راستا، ۲۰٪ از مجموعه دادهها برای آزمایش و ارزیابی عملکرد مدلها اختصاص داده شده است. با پیروی از این روش، مدل بهینه یادگیری ماشینی بر اساس معیارهای عملکرد انتخاب شده و سپس برای کوچکمقیاسسازی بارندگی در طول دوره ۲۰۲۳ تا ۲۰۴۲ مورد استفاده قرار میگیرد. از این طریق، هدف اصلی توسعه یک مدل یادگیری ماشینی است که بتواند بارندگی روزانه آینده را بر اساس سناریوهای CMIP6 به طور دقیق پیشبینی کند.
تولید منحنیهای شدت-مدت-فرکانس آینده
منحنی IDF آینده را میتوان با برازش یک تابع توزیع احتمال (PDF) بر دادههای بارشهای شدید برای رویدادها و مدت زمانهای مختلف ۱۴ ساخت . در این فرآیند، شدت بارندگی در مدت زمانها و دورههای بازگشت مورد نظر را میتوان بر اساس روابط برازش شده برای دوره مورد نظر (۲۰۲۳-۲۰۴۲) محاسبه کرد. همچنین، منحنیهای IDF را میتوان با برازش یک تابع توزیع احتمال بر حداکثر بارش سالانه با مدت زمانهای مختلف (مثلاً ۵ دقیقه، ۳۰ دقیقه، ۱ ساعت، ۲ ساعت) ساخت. این امر امکان محاسبه چندکهای بارندگی مربوط به هر دوره بازگشت (مثلاً ۱۰، ۲۵، ۵۰، ۱۰۰ و ۲۰۰ سال) را فراهم میکند.
انتخاب بهترین توزیع احتمال برازش داده شده به حداکثر بارش سالانه بسیار مهم است، زیرا میتواند به طور قابل توجهی بر کوانتیلهای بارش تخمینی برای دورههای بازگشت مختلف تأثیر بگذارد. در این مطالعه، توابع توزیع مختلفی از جمله لوگ-نرمال، نمایی، گاما، نرمال، وایبول نمایی، مقادیر حدی تعمیمیافته (GEV)، لوگ-لاپلاس، نرمال تعمیمیافته، گاوسی معکوس، لوگ-پیرسون III، گاما و توان نمایی و غیره اعمال شده و بر حداکثر بارش سالانه روزانه تحت سناریوهای SSP1-2.6، SSP2-4.5، SSP3-7.0 و SSP5-8.5 برازش داده میشوند . ۲۴ علاوه بر این، هر تابع توزیع بر سری دادههای بارش برازش داده میشود و بر اساس رویکرد تخمین حداکثر درستنمایی (MLE)، پارامترهای مرتبط تخمین زده میشوند . ۵۷ همچنین، معیار اطلاعات هانان-کویین (HQIC) برای هر تابع توزیع بر اساس لگاریتم درستنمایی و تعداد پارامترها محاسبه میشود . HQIC معیاری است که برای تحلیل عملکرد برازش توابع توزیع استفاده میشود و تعادلی بین نیکویی برازش و پیچیدگی مدل ایجاد میکند. در واقع، این معیار مدلهای مختلف را با ارزیابی برازش آنها با دادهها و در عین حال جریمه کردن پیچیدگی مدل، مقایسه میکند. همچنین میتوان آن را مشابه انجام آزمون نسبت درستنمایی در نظر گرفت، که در آن مدلها نه تنها بر اساس نیکویی برازش، بلکه بر اساس تعداد پارامترهایی که دارند نیز ارزیابی میشوند. در این راستا، میتوانیم تصمیمات آگاهانهتری برای انتخاب بهترین مدل(ها) بگیریم، که به ما کمک میکند تا مطمئن شویم مدلی را انتخاب میکنیم که برازش خوبی با دادهها دارد. مقدار HQIC را میتوان از معادله ( ۱ ) تخمین زد.
که در آن نشان دهنده لگاریتم درستنمایی، و n به ترتیب تعداد پارامترها و تعداد نمونهها هستند. همچنین، مقدار HQIC پایینتر نشان دهنده مصالحه ترجیحیتر بین خوبی برازش و پیچیدگی PDF در ارزیابی PDFهای مختلف است. در نتیجه، انتخاب PDF با حداقل HQIC بهترین تابع برازش برای مجموعه دادهها است.
شبیهسازی هیدرولوژیکی
مدل SWAT
مدل SWAT یک مدل هیدرولوژیکی پیوسته و نیمه توزیعی است که به طور گسترده برای ارزیابی اثرات برنامههای مدیریتی متنوع بر کیفیت و کمیت آب در مقیاسهای مختلف استفاده میشود ۵۹ ، ۶۰٫ مدل SWAT از عناصر مختلفی از جمله پارامترهای آب و هوایی، پوشش زمین، ویژگیهای خاک و یک ماژول محصول تشکیل شده است. برای فرموله کردن مسئله هیدرولوژیکی، ابزار ArcSWAT ابتدا منطقه مورد مطالعه را بر اساس یک آستانه مشخص به زیرحوضههای مجزا تقسیم میکند. سپس این زیرحوضهها به واحدهای پاسخ هیدرولوژیکی (HRU) مختلف تفکیک میشوند که شامل بخشهای زمینی با نوع پوشش زمین، درصد شیب و کلاس خاک یکسان ۶۱ ، ۶۲ هستند . در مرحله بعد، خروجیهای کلیدی مدل، مانند رواناب و تبخیر و تعرق (ETa) ابتدا در مقیاس HRU محاسبه میشوند. سپس این خروجیها به سطح زیرحوضه تجمیع شده و به خروجی حوضه آبریز هدایت میشوند. فرآیندهای هیدرولوژیکی در مدل SWAT برای هر واحد منابع آب (HRU) در گامهای زمانی روزانه، بر اساس روش بیلان آب ۶۱ مدلسازی میشوند .
در این تحقیق، از شماره منحنی (CN) برای تحلیل توزیع بارندگی در لایه خاک و تمایز بین نفوذ و رواناب استفاده شده است. همچنین، از تکنیک هارگریوز برای تخمین ETa در منطقه مورد مطالعه ۶۳ استفاده شده است .
در این مطالعه، مدل SWAT با استفاده از ماژول رواناب زیر روزانه بر اساس گامهای زمانی ۱ ساعته اجرا شد. این گام زمانی خاص برای پوشش دقیق توسعه سریع رویدادهای سیل انتخاب شد . ۶۴. برای توضیحات بیشتر در مورد ماژول زیر روزانه SWAT و اطلاعات بیشتر، به مطالعات انجام شده توسط ۷ ، ۶۵ مراجعه کنید .
مطالعه موردی
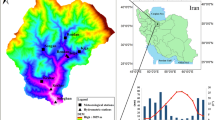
الباطنه، منطقهای خشک در شمال شرقی عمان، از غرب با کوههای حجر غربی و از شمال با دریای عمان هممرز است. دشت ساحلی الباطنه در لبههای شمال غربی و جنوب شرقی خود باریکتر است و در مرکز به وسیعترین بخش خود، تقریباً ۵۰ کیلومتر، گسترش مییابد. این دشت شامل مخروطافکنههای پیوستهای است که رسوبات را از کوهها به ساحل و دشت منتقل میکنند. این دشت دومین منطقه پرجمعیت عمان است که تنها پس از مسقط، پایتخت، قرار دارد . منطقه ساحلی مسطح و حاصلخیز الباطنه، که بیش از ۹۰٪ خط ساحلی را پوشش میدهد، به مرکزی برای سکونت انسان تبدیل شده است. در طول چهار دهه گذشته، توسعه متمرکز، فعالیتهای اجتماعی-اقتصادی مختلفی از جمله شهرنشینی فشرده و آغاز پروژههای گردشگری ساحلی را به پیش برده است. زیرساختهای قابل توجهی، شامل جادههای اصلی، کورنیشها، بازارها، بنادر ماهیگیری و کارخانههای نمکزدایی، به طور استراتژیک برای حمایت و تقویت زندگی ساحلی ایجاد شدهاند. این منطقه مستعد سیلهای ناگهانی و بارندگیهای شدید است که نمونههایی از آن رویدادهای مهمی مانند سیل ناشی از طوفان گرمسیری گونو در سال ۱۸۹۰ در ژوئن ۲۰۰۷، سیل شاهین بین ۱ تا ۴ اکتبر ۲۰۲۱، سیل فت در ژوئن ۲۰۱۰ و سیل کیار در اکتبر ۲۰۱۹ است که منجر به خسارات اقتصادی و انسانی قابل توجهی شده است .
در این مطالعه، منطقهای شامل سه وادی (جدول ۲ ) – وادی الشفان، وادی الصرامی و وادی السخین – در شمال الباطنه برای پیشبینی سیل آینده مورد تجزیه و تحلیل قرار گرفته است (شکل ۲ ).

موقعیت شمال الباطنه به عنوان منطقه مورد مطالعه (ArcMap 10.1).
نتایج و بحث
انتخاب یک مدل AOGCM توانمند
برای افزایش قابلیت اطمینان پیشبینیهای تغییرات اقلیمی، این بخش عملکرد مدلهای مختلف AOGCM را برای شناسایی مناسبترین مدل برای منطقه مورد مطالعه ارزیابی میکند. با توجه به اینکه مدلهای پیشبینی مختلف میتوانند در مناطق و سلولهای محاسباتی عملکرد متفاوتی داشته باشند، انتخاب مدل مناسب برای به حداقل رساندن عدم قطعیتها و اطمینان از پیشبینیهای دقیق آینده بسیار مهم است . ۱٫ در این راستا، یک تحلیل عمیق برای مقایسه میانگین بارش ماهانه بلندمدت پیشبینیشده توسط GCM برای دوره پایه (تاریخی) با دادههای مشاهدهشده انجام شد. این میتواند به طور مؤثر عملکرد هر مدل CMIP6 را در پیشبینی الگوهای تاریخی روشن کند. این ارزیابی شامل ارزیابی ۱۸ مدل AOGCM با استفاده از شاخصهای ارزیابی مختلف، از جمله MSE ۶۷ ، NMSE ۶۸ ، NSE ۶۹ ، AE ۷۰ ، RMSE ۷۱ ، KGE ۷۲ بود. با ارزیابی این مدلها در برابر دادههای بارش مشاهدهشده از سال ۱۹۹۵ تا ۲۰۱۴، مدل IITM-ESM به عنوان دقیقترین مدل در نمایش بارش تاریخی ظاهر شد. جدول ۳ عملکرد مدلهای مختلف AOGCM را خلاصه میکند. در نتیجه، سناریوهای آینده با استفاده از مدل IITM-ESM محاسبه خواهند شد که عملکرد برتر در تخمین دادههای تاریخی را نشان داده است.
تحلیل ریزمقیاسنمایی بارش با استفاده از H2O-AutoML
پس از انتخاب مناسبترین مدل پیشبینی، این بخش بر کوچکمقیاس کردن پیشبینیهای آن تحت چهار سناریوی SSP، شامل SSP1-2.6، SSP2-4.5، SSP3-7.0 و SSP5-8.5 تمرکز دارد. مدلهای GCM، اگرچه در ثبت الگوهای اقلیمی در مقیاس بزرگ قدرتمند هستند، اما اغلب فاقد وضوح لازم برای انعکاس دقیق شرایط اقلیمی محلی هستند. در این بخش، با پالایش این پیشبینیها به مقیاسی دقیقتر، هدف ما تولید پیشبینیهای اقلیمی دقیقتر و مختص منطقه است که برای ارزیابی تأثیرات بالقوه سناریوهای اقلیمی آینده بسیار مهم هستند. برای انجام این کار، پس از شناسایی IITM-ESM به عنوان بهترین مدل برای منطقه مورد مطالعه، پیشبینیهای آن با استفاده از H2O-AutoML کوچکمقیاس میشوند. این پلتفرم مدلها را با استفاده از دادهها، از جمله رطوبت ویژه (hus)، میانگین دمای هوا و شار بارش (pr) آموزش میدهد و همچنین مدل بهینه ML را برای کوچکمقیاس کردن پیشبینیهای بارندگی آینده شناسایی میکند. شکل ۳ عملکرد مدلهای ML را در پلتفرم H2O نشان میدهد. نتایج نشان میدهد که الگوریتم Stacked Ensemble که با شناسه مدل ‘StackedEnsemble_AllModels_6’ شناسایی میشود، بالاترین عملکرد را در طول آموزش مجموعه دادهها نشان داده است. این مدل که تمام مدلهای پایه – GBM، یادگیری عمیق و DRF – را با یک فرایادگیرنده GLM که با ۵ K-fold بهینهسازی شده است، ترکیب میکند، به نتایج برتر دست یافت. به طور خاص، به معیارهای عملکرد زیر دست یافت: RMSE برابر با ۲٫۲۸۱، MSE برابر با ۲٫۲۰۲، MAE برابر با ۰٫۳۶۲، RMSLE برابر با ۰٫۳۲۵ و میانگین انحراف باقیمانده برابر با ۵٫۲۰۲٫ دومین مدل با بهترین عملکرد، ‘GBM_grid_1_model_6’، که یک مدل طبقهبندی سه کلاسه با استفاده از توزیع چندجملهای است، به ترتیب به RMSE، MSE، MAE، RMSLE و میانگین انحراف باقیمانده ۲٫۲۸۲، ۵٫۲۰۷، ۰٫۳۶۶، ۰٫۳۳۰ و ۵٫۲۰۷ دست یافت.

عملکرد مدلهای یادگیری ماشینی جدول امتیازات.
جدول ۴ نشان میدهد که در نتایج اعتبارسنجی متقابل برای H2O-AutoML، لایه اول بالاترین عملکرد را در طول اعتبارسنجی نشان میدهد. این نشان میدهد که مدلهای آموزشدیده روی زیرمجموعه دادههای مربوط به لایه اول، در این بخش خاص از مجموعه دادهها عملکرد مؤثرتری دارند.
پس از شناسایی مدل بهینه یادگیری ماشین، گام بعدی کوچکمقیاس کردن پیشبینیهای بارندگی از سال ۲۰۲۳ تا ۲۰۴۲ با استفاده از این مدل انتخاب شده است. برای دستیابی به این هدف، پیشبینیهای CMIP6، شامل رطوبت ویژه، بارندگی و دمای هوا تحت سناریوهای SSP1-2.6، SSP2-4.5، SSP3-7.0 و SSP5-8.5، جمعآوری و به مدل ‘StackedEnsemble_AllModels_6’ وارد شدند. هدف این فرآیند، تولید پیشبینیهای کوچکمقیاستر و دقیقتر از بارندگی آینده است.
پس از پیشبینی بارندگی آینده توسط H2O، دادههای بارندگی روزانه کوچکمقیاسشده، نمای دقیقی از تغییرات احتمالی بارندگی ارائه میدهند که میتوان آنها را برای ارزیابی روندها در مقیاسهای زمانی بزرگتر، مانند ماهانه و سالانه، تجمیع کرد. شکل ۴ الف، بارندگی ماهانه و سالانه کوچکمقیاسشده برای منطقه مورد مطالعه را نشان میدهد. تجزیه و تحلیل الگوهای بارندگی ماهانه آینده نشان میدهد که پیشبینی میشود ژوئن، ژوئیه، اوت و سپتامبر کمترین بارندگی را تجربه کنند. در مقابل، پیشبینی میشود که مارس بیشترین بارندگی را در تمام سناریوهای ارزیابیشده CMIP6 داشته باشد. علاوه بر این، همانطور که در این شکل نشان داده شده است، پیشبینی میشود که بارندگی آینده تحت تمام سناریوهای SSP در مقایسه با سطوح تاریخی افزایش یابد.
علاوه بر این، بررسی الگوهای بارندگی سالانه (شکل ۴ ب) تفاوتهای بین سناریوهای مختلف را برجسته میکند و بر لزوم سناریوهای متعدد برای ارزیابی کامل طیف وسیعی از شرایط احتمالی آینده تأکید دارد. گنجاندن این سناریوهای متنوع در برنامهریزی آینده برای تدوین استراتژیهای قوی برای مدیریت تأثیرات بالقوه تغییرات اقلیمی بر الگوهای بارندگی در منطقه ضروری است.

( الف ) مقایسه بارندگی تجمعی ماهانه بین دادههای تاریخی (۱۹۹۵-۲۰۱۴) و سناریوهای آینده SSPs (2023-2042). ( ب ) بارندگی تجمعی سالانه برای سناریوهای مختلف SSPs (2023-2042).
پیشبینی آینده ارتش اسرائیل
پس از انتخاب و کوچکمقیاسسازی مناسبترین مدل اقلیمی با استفاده از الگوریتم یادگیری ماشین با بهترین عملکرد، گام مهم بعدی شامل فرمولبندی منحنیهای IDF برای منطقه مورد مطالعه است. با استخراج این منحنیها تحت هر سناریوی SSP ارزیابیشده، هدف ما درک عمیقتری از چگونگی تغییر رویدادهای بارندگی شدید در آینده است که برای طراحی زیرساختها و برنامهریزی استراتژیهای کاهش سیل بسیار مهم است.
در ابتدا، توابع توزیع احتمال (PDF) مختلفی بر روی دادههای بارش روزانه ریزمقیاسشده اعمال شد تا تغییرپذیری و مقادیر حدی مرتبط با هر سناریو ثبت شود. پارامترهای این PDFها با استفاده از روش تخمین حداکثر درستنمایی (MLE) تخمین زده شدند، یک رویکرد آماری که مقادیر پارامتر را شناسایی میکند و تابع درستنمایی را به حداکثر میرساند. با انجام این کار، اطمینان حاصل میکنیم که تابع ارزیابیشده به بهترین وجه با دادههای مشاهدهشده برازش دارد. عملکرد این PDFها با استفاده از معیار اطلاعات هانان-کویین (HQIC)، معیاری که برازش مدل را با پیچیدگی متعادل میکند، ارزیابی شد. HQIC مدلهای پیچیدهتر را جریمه میکند و مدلهایی را که بدون پیچیدگی غیرضروری به برازش خوبی دست مییابند، ترجیح میدهد. مقدار HQIC پایینتر نشان دهنده یک مدل ارجحتر است که به طور مؤثر دقت و سادگی را متعادل میکند. همانطور که در شکل ۵ نشان داده شده است ، نتایج نشان میدهد که توزیع وایبل بهترین برازش را برای SSP1-2.6 دارد، Log-Pearson III برای SSP2-4.5، Gamma برای SSP3-7.0 و Exponential power برای SSP5-8.5 مناسبتر است. این توابع به عنوان مناسبترین توابع برای تولید منحنیهای IDF تحت سناریوهای مربوطه در نظر گرفته میشوند. این روش، توسعه منحنیهای IDF را که برای مدیریت سیل بسیار مهم هستند، تضمین میکند و بینشهای ضروری در مورد وقایع بارندگی شدید ارائه میدهد.
متعاقباً، منحنیهای IDF آینده با محاسبه کوانتیل تجربی برای یک دوره بازگشت معین و نرمالسازی آن بر اساس مدت بارندگی مربوطه تولید شدند. شکل ۶ منحنیهای IDF را برای هر سناریوی SSP نشان میدهد. تجزیه و تحلیل بصری این منحنیها، شدت بارندگی به طور قابل توجهی بالاتر را تحت سناریوهای SSP2-4.5 و SSP5-8.5 در مقایسه با SSP1-2.6 و SSP3-7.0 نشان میدهد. جالب توجه است که منحنیهای IDF برای SSP2-4.5 و SSP5-8.5 به شدت همسو هستند، در حالی که SSP1-2.6 و SSP3-7.0 شدت بارندگی مشابه اما نسبتاً کمتری را نشان میدهند.

مقایسه توابع توزیع برای برازش دادههای بارندگی روزانه آینده.

منحنیهای IDF آینده برای بارندگی با دورههای بازگشت ۵، ۱۰، ۲۵، ۵۰، ۱۰۰ و ۲۰۰ ساله.
شبیهسازی سیل ناگهانی آینده با استفاده از مدل SWAT
پس از استخراج منحنیهای IDF، این بخش بر فرمولبندی شرایط هیدرولوژیکی منطقه مورد مطالعه و شبیهسازی سیلهای ناگهانی تحت سناریوهای مختلف SSP تمرکز دارد. برای درک تأثیرات بالقوه تغییر الگوهای بارندگی بر ویژگیهای سیل، یک ابزار مدلسازی قابل اعتماد ضروری است. در این زمینه، از مدل SWAT برای ارزیابی این تأثیرات استفاده شده است.
تحلیل حساسیت و کالیبراسیون مدل SWAT با استفاده از الگوریتم SUFI-2 انجام میشود، روشی که به طور گسترده برای کالیبراسیون مدل ادغام شده در SWAT-CUP ۷۳ استفاده میشود . در مرحله اول، تحلیل حساسیت برای شناسایی پارامترهایی که به طور قابل توجهی بر خروجیهای مدل تأثیر میگذارند، از جمله جریان پایه و جریان رودخانه انجام میشود. عوامل حساس کلیدی عبارتند از شماره منحنی رواناب SCS، مقدار مانینگ برای کانال اصلی و پارامترهای رطوبت خاک. درک این پارامترها برای شبیهسازی دقیق و نتایج قابل اعتماد بسیار مهم است. مطالعات دیگر نیز حساسیت مدل به پارامترهای جریان کانال را برجسته کردهاند ۷۴٫ با این حال، در مطالعه موردی تحت تأثیر سیل ناگهانی، پارامترهای جریان پایه حساسیتی به کالیبراسیون نشان نمیدهند. در این راستا، مدل با استفاده از پارامترهای فوق الذکر، با تمرکز بر جریان رودخانه (cms) کالیبره شد.
در مرحله بعد، کالیبراسیون در گام زمانی روزانه برای سه ایستگاه DS1، DS2 و DS3، از سال ۲۰۱۸ تا ۲۰۲۰ انجام شد. لازم به ذکر است که فقدان دادههای ساعتی مناسب و رویدادهای سیل، چالشهای قابل توجه و پیچیدهای را در طول فرآیند کالیبراسیون ایجاد کرد. برای ارزیابی دقت نتایج دبی شبیهسازی شده در هر مرحله، از مقادیر ضریب تعیین (R2) و نش-ساتکلیف (NS) استفاده شد. نتایج قابل قبول بودند و معیارهای توصیه شده توسط ۷۵ را برآورده میکردند . در مرحله بعد، مدل برای یک رویداد سیل شدید ارزیابی شد و در نهایت ایستگاه DS1 به عنوان ایستگاه ارزیابی شده در بالادست منطقه شهری انتخاب شد (جدول ۵ ).
پس از اطمینان از اعتبار مدل برای منطقه مورد مطالعه، SWAT از پارامترهای مشتق شده از بارندگی IDF آینده، به ویژه برای مدت زمان ۱۵ و ۶۰ دقیقه و دوره بازگشت ۱۰۰ و ۲۰۰ سال، برای پیشبینی وقوع سیل در آینده استفاده میکند.
برای شروع این فرآیند، شدت بارندگی با استفاده از منحنیهای IDF تحت شرایط مشخص شده محاسبه میشود. متعاقباً، دو سناریو – بدبینانه و خوشبینانه – بر اساس شرایط بارندگی متغیر آینده، همانطور که در جدول ۶ به تفصیل آمده است، انتخاب میشوند .
در مرحله بعد، کل بارندگی آینده بر اساس شدت بارندگی محاسبه شده تعیین میشود. با توجه به تحقیقات انجام شده توسط ۴۴ ، فرض بر این است که الگوی بارندگی آینده، منعکس کننده رویدادهای تاریخی در چنین شرایطی است.
برای تجزیه و تحلیل و تفکیک بارندگیهای آینده، از روشی که توسط ۷۶ توسعه داده شده است ، استفاده میشود. در ابتدا، بارندگی تجمعی تاریخی بر بارندگی در گامهای زمانی مشخص تقسیم میشود. این منجر به ضرایبی میشود که به هر گام زمانی اختصاص داده میشوند که نشان دهنده نسبت کل بارندگی به مقدار رخ داده در آن بازه زمانی است. در واقع، کل بارندگی در ضرایب مربوطه اختصاص داده شده به هر گام زمانی ضرب میشود تا الگوی بارندگی آینده تعیین شود. این رویکرد درک جامعی از توزیع زمانی بارندگیهای آینده بر اساس الگوهای بارندگی تاریخی را تسهیل میکند. به ویژه، برای مدت بارندگی ۶۰ دقیقه و دوره بازگشت مشخص، از ضرایب مشتق شده از وقایع تاریخی با همان مدت استفاده میشود. به عبارت دیگر، بارندگی با مدت ۶۰ دقیقه، تحت دوره بازگشت مشخص، در ضرایب مشتق شده از یک رویداد تاریخی با همان مدت (۶۰ دقیقه) ضرب میشود. این روش جامع به طور مؤثر شدت و زمینه تاریخی را ادغام میکند تا ما را قادر به تجزیه و تحلیل الگوهای بارندگی آینده و پیامدهای آنها برای شبیهسازی سیل سازد.
تحلیل سیلهای آینده
پس از شناسایی الگوهای بارش تفکیکی، در این بخش پایانی، نتایج پیشبینیهای سیل ناگهانی برای شمال الباطنه، برگرفته از شبیهسازیهای مدل SWAT را ارائه میدهیم. نقشه مدل ارتفاعی رقومی (DEM) و شبکههای جریان، امکان تقسیم شمال الباطنه به ۱۵۴ زیرحوضه را فراهم کردند. با استفاده از نقشه کاربری اراضی آژانس فضایی اروپا (ESA) همراه با نقشه خاک سازمان غذا و کشاورزی (FAO)، ArcSWAT 493 واحد واکنش هیدرولوژیکی (HRU) تولید کرد. زیرحوضههای حاصل، شبکه جریان و مکان ایستگاههای تخلیه در شکل ۷ نشان داده شده است .
پس از کالیبراسیون مدل SWAT، شبیهسازیها برای رویدادهای بارندگی ۱ ساعته مربوط به دورههای بازگشت ۱۰۰ و ۲۰۰ ساله انجام شد و سناریوهای خوشبینانه و بدبینانه بررسی شدند (شکل ۸ ). به طور خاص، شکلهای ۸ الف و ب هیدروگراف رویداد بارندگی پیشبینیشده را با دوره بازگشت ۱۰۰ ساله تحت هر دو حالت خوشبینانه و بدبینانه نشان میدهند، در حالی که شکلهای ۸ ج و د هیدروگراف رویدادهای بارندگی آینده را با دورههای بازگشت ۲۰۰ ساله نشان میدهند.
یافتهها نشان میدهد که تحت سناریوهای بدبینانه، سیلهای بالادست منطقه شهری شمال الباطنه میتواند در طول بارندگیهای با دوره بازگشت ۱۰۰ و ۲۰۰ سال به ترتیب به ۲۰.۳۳ و ۲۰.۷۰ متر مکعب بر ثانیه افزایش یابد. در مقابل، در سناریوی خوشبینانه، جریان برای بارندگیهای با دوره بازگشت ۱۰۰ و ۲۰۰ سال به ترتیب ۱۶.۵۶ و ۱۶.۸۵ متر مکعب بر ثانیه است.
گنجاندن سناریوهای خوشبینانه و بدبینانه در شبیهسازیهای سیل، استحکام چارچوب تحلیلی ما را تقویت میکند. این رویکرد دوگانه امکان بررسی کامل شرایط مرزی را فراهم میکند که برای استراتژیهای مؤثر مدیریت سیل بسیار مهم است. با ارزیابی حداکثر بارندگیها تحت سناریوهای مختلف، میتوانیم خطرات بالقوه را شناسایی کرده و برای طیف وسیعی از پیامدهای احتمالی آماده شویم.

موقعیت حوضه آبریز شمالی الباطنه به همراه زیرحوضهها، شبکه رودخانهها، خروجیها و ایستگاههای تخلیه آن.

هیدروگراف سیل آینده با در نظر گرفتن الگوی بارندگی در ایستگاه دبی DS1.
بحث
مطالعه حاضر یک چارچوب جامع و جدید را معرفی میکند که نه تنها دیدگاه جدیدی در مورد پیشبینی سیل ناگهانی ارائه میدهد، بلکه شامل حجم کاری دقیق و پیچیدهای نیز میشود. با توجه به عدم قطعیتهای ذاتی در هر مرحله از پیشبینی سیل ناگهانی، استفاده از ابزارهای قابل اعتمادی که خطاها را در هر مرحله از محاسبات به حداقل میرسانند، بسیار مهم است. برای مقابله با این مشکل، دیدگاه پیشنهادی تضمین میکند که حتی اگر این فرآیند بتواند توسط طیف گستردهای از مدلها در مطالعات موردی مختلف دنبال شود، همچنان قابل اعتماد باقی بماند. در مرحله اول مطالعه، بهترین مدل GCM از بین هجده مدل تغییر اقلیم CMIP6 انتخاب شد. این میتواند خطر انتخاب یک مدل پیشبینی نامناسب را به طور قابل توجهی کاهش دهد. پلتفرم H2O-AutoML، با ارائه امکاناتی مانند بهینهسازی فراپارامتر و مدلهای مختلف ML، برای کوچکمقیاس کردن بارندگی آینده با بالاترین دقت ممکن استفاده شد. در مرحله بعد، برای ساخت مناسبترین منحنیهای IDF برای هر سناریو، چهل تابع توزیع بر دادههای بارندگی روزانه آینده تحت هر سناریوی SSP برازش داده شد. در ادامه، از ماژول زیرروزانه SWAT برای شبیهسازی سیلهای ناگهانی آینده در منطقه مورد مطالعه استفاده شد. در نتیجه، این چارچوب نه تنها حوزه مدلسازی هیدرولوژیکی را پیش میبرد، بلکه استاندارد جدیدی را برای دقت و سازگاری در پیشبینی سیل، به ویژه در مناطقی که با تأثیرات فزاینده تغییرات اقلیمی مواجه هستند، توسعه میدهد.
برای برجسته کردن نوآوریهای مطالعه حاضر در هر مرحله، اطلاعات دقیق در زیر توضیح داده شده است:
مرحله ۱ انتخاب مناسبترین مدل CMIP6
مطالعات مختلف، مدلهای GCM را برای ارزیابی پیشبینی بارندگی و سیل در آینده به کار گرفتهاند. به عنوان مثال ، ۷۷ ، از مدلهای CMIP6 خاصی برای تحلیل سیل شهری استفاده کردند، اما عملکرد آنها را برای بارندگی تاریخی در مطالعه موردی خود ارزیابی نکردند. به طور مشابه، ۴ ، ۷۸ ، CMIP5 را برای تخمین بارندگی آینده به کار گرفتند و ملاحظات اجتماعی-اقتصادی ارائه شده توسط سناریوهای CMIP6 را نادیده گرفتند و ارزیابی نحوه عملکرد مدلهای انتخاب شده در پیشبینی بارندگی تاریخی را نادیده گرفتند. این موضوع، از جمله عدم توجه به جنبههای اجتماعی-اقتصادی در سناریوهای اقلیمی آینده و غفلت از ارزیابی اثربخشی مدلهای اقلیمی در دورههای تاریخی، میتواند عدم قطعیتهایی را در لایههای مختلف پیشبینی سیل ناگهانی ایجاد کند و به طور بالقوه طراحی استراتژیهای کنترل سیل و تصمیمگیری را مختل کند.
مرحله ۲: استفاده از H2O-AutoML برای ریزمقیاسنمایی بارش .
در این مطالعه، برای اولین بار از H2O AutoML برای کوچکمقیاسسازی بارندگی استفاده شد، اما نوآوری این مرحله فراتر از آن است، زیرا عملکرد مدل آماری پیشنهادی از مطالعات اخیر پیشی میگیرد. در مقایسه با مطالعات انجام شده توسط ۷۹ ، ۸۰ ، ۸۱ که از مدلهای ML برای کوچکمقیاسسازی سناریوهای مبتنی بر CMIP6 برای پیشبینی بارندگی آینده استفاده کردند، مدل پیشنهادی ما عملکرد بهتری را نشان داد. دلایل این امر را میتوان به استفاده از مدلهای ML با قدرت کمتر در آن مطالعات یا نظارت بالقوه بر فرآیندهای حیاتی در مرحله ۱ نسبت داد.
مرحله ۳: بهکارگیری طیف گستردهای از توابع توزیع برای ساخت منحنیهای IDF .
اگرچه مطالعات متعددی برای ساخت منحنیهای IDF برای بارندگیهای آینده انجام شده است، اما برخی فرضیات معمول برای سادهسازی محاسبات در نظر گرفته شده است که میتواند دقت را به خطر بیندازد. به عنوان مثال ، ۸۲ و ۸۳ از تابع توزیع GEV برای ایجاد منحنیهای IDF تحت سناریوهای CMIP6 و CMIP5 استفاده کردند، بدون در نظر گرفتن این احتمال که سایر توابع ممکن است دادههای بارندگی آینده را بهتر تفسیر کنند. اکنون در تحقیقات ما آشکار است که سایر توابع توزیع میتوانند عملکرد بهتری در برازش دادههای بارندگی آینده ارائه دهند، همانطور که توسط عامل HQIC تأیید شده است. برای ارائه مروری بر مطالعات مورد بحث، جدول ۷ ادبیات مرتبط را خلاصه میکند. این جدول رویکردهای اتخاذ شده توسط مطالعات قبلی را با چارچوب جامع معرفی شده در تحقیق فعلی که نوآوریهای ما را برجسته میکند، مقایسه میکند.
نتیجهگیری
در این مطالعه، ما از یک چارچوب آماری سلسله مراتبی برای پیشبینی سیلهای آینده در البطینه، عمان، منطقهای خشک که به طور قابل توجهی تحت تأثیر تغییرات اقلیمی قرار دارد، استفاده کردیم. این مطالعه یک رویکرد استراتژیک برای دستیابی به دقیقترین پیشبینی سیل اتخاذ میکند. برای این منظور، گام اولیه شامل انتخاب مناسبترین مدل AOGCM بر اساس معیارهای ارزیابی مختلف بود. یافتهها نشان داد که مدل IITM-ESM بهترین تخمین را از الگوهای بارندگی تاریخی ارائه میدهد و برای پیشبینی بارندگیهای آینده قابل اعتمادتر خواهد بود. بنابراین، تجزیه و تحلیل بعدی با استفاده از مدل IITM-ESM تحت چهار سناریوی SSP، شامل SSP1-2.6، SSP2-4.5، SSP3-7.0 و SSP5-8.5 انجام شد.
در مرحله بعد، برای کوچکمقیاس کردن پیشبینیهای با وضوح درشت از مدل اقلیمی انتخابشده، مدلهای مختلف یادگیری ماشین از طریق پلتفرم H2O-AutoML ارزیابی شدند تا مناسبترین مدل برای منطقه مورد مطالعه شناسایی شود. با انجام این کار، الگوریتم ترکیبی انباشتهشده عملکرد بهینهای را در فرآیند کوچکمقیاسسازی برای پیشبینی بارندگی تاریخی نشان داد و بنابراین، برای پیشبینی بارندگی روزانه آینده از سال ۲۰۲۳ تا ۲۰۴۲ به کار گرفته شد. پس از این، از توابع توزیع مختلف برای شناسایی مؤثرترین آنها برای پیشبینی منحنیهای IDF آینده استفاده شد.
پس از تحلیل حساسیت و کالیبراسیون مدل SWAT، سناریوهای بارندگی آینده برای دورههای بازگشت و مدت زمانهای مختلف برای ارزیابی پتانسیل وقوع سیل ناگهانی بررسی شدند. مدل SWAT کالیبره شده که در منطقه مورد مطالعه اعمال شد، نشان داد که تحت یک سناریوی بدبینانه، جریان سیل در ورودی منطقه شهری در شمال الباطنه میتواند به ترتیب در طول بارندگیهای با دوره بازگشت ۱۰۰ و ۲۰۰ ساله به ۲۰.۳۳ و ۲۰.۷۰ متر مکعب بر ثانیه برسد. با توجه به نزدیکی منطقه شهری شمال الباطنه به اقیانوس، این وضعیت میتواند منجر به خطر قابل توجه خسارات انسانی و اقتصادی شود.
این مطالعه ابزارها و روشهای متنوعی را برای ارائه یک چارچوب جامع برای پیشبینی سیل ناگهانی در یک منطقه خشک ادغام میکند. این رویکرد دادههای ۱۸ AOGCM را در بر میگیرد، از شش مدل یادگیری ماشین استفاده میکند و ۴۰ تابع توزیع را بررسی میکند. با ترکیب این عناصر، هدف این مطالعه افزایش دقت و قابلیت اطمینان پیشبینیهای سیل ناگهانی است.
با توجه به اینکه مدلهای GCM میتوانند دادههای تاریخی را با درجات مختلفی از دقت تفسیر کنند، عملکرد این چارچوب ممکن است در مناطق مورد مطالعه متفاوت باشد. در این راستا، به دلیل عدم دسترسی به طیف وسیعی از دادهها از نقاط مختلف زمین با ویژگیهای اقلیمی متفاوت، در گسترش این چارچوب با محدودیتهایی مواجه شدیم. بنابراین، چارچوب سلسله مراتبی پیشنهادی باید تخصصی باشد و با مطالعات موردی مختلف تطبیق داده شود تا ویژگیهای منحصر به فرد هر منطقه مورد مطالعه را در نظر بگیرد.
علاوه بر این، این تحقیق با دو مورد از اهداف اصلی توسعه پایدار (SDGs) همسو بوده و به آنها کمک میکند. در درجه اول، این کار با بهبود درک ما از الگوهای بارندگی آینده و تأثیرات آنها بر خطرات سیل تحت سناریوهای مختلف تغییر اقلیم، از اقدام اقلیمی (SDG 13) پشتیبانی میکند. این مطالعه با شناسایی مناسبترین مدلها و تکنیکهای کوچکمقیاسسازی، قابلیتهای پیشبینی را افزایش میدهد و به جوامع کمک میکند تا برای رویدادهای شدید آب و هوایی آماده شوند و اثرات بالقوه تغییرات اقلیمی را کاهش دهند. علاوه بر این، توسعه منحنیهای دقیق IDF و شبیهسازی شرایط هیدرولوژیکی مستقیماً با شهرها و جوامع پایدار به عنوان یازدهمین SDG مرتبط هستند. این تحقیق با ارائه بینش در مورد خطرات سیل آینده، از طراحی و اجرای زیرساختهای تابآور پشتیبانی میکند، که به نوبه خود تضمین میکند که جوامع شهری و روستایی برای مقابله با رویدادهای شدید آب و هوایی مجهزتر هستند. این سهم برای برنامهریزی شهری پایدار و کاهش خطر بلایا بسیار مهم است و تابآوری شهرها و جوامع را در مواجهه با خطرات مرتبط با آب و هوا ارتقا میدهد.
با توجه به آسیبپذیری شمال الباطنه در پاییندست رودخانه، تصمیمگیرندگان درگیر در مدیریت سیل در عمان باید به این مسئله حیاتی بپردازند. آنها باید استراتژیهایی را برای کاهش تأثیر سیلها و بارندگیهای آینده در منطقه اجرا کنند. ما توصیه میکنیم که برای مطالعات آینده، شیوههای مدیریت سیل در منطقه مانند سدهای تأخیری برای کاهش و تسکین خسارات سیل و همچنین ترویج توسعه پایدار در مناطق پاییندست شمال الباطنه اجرا شود. چنین اقدامات و برنامهریزیهایی میتواند در به حداقل رساندن پیامدهای احتمالی سیلهای ناگهانی بسیار مهم باشد.
در دسترس بودن دادهها
دادههایی که از یافتههای این مطالعه پشتیبانی میکنند، بنا به درخواست معقول، از نویسنده مسئول در دسترس هستند.
منابع
-
حسنی، م. ر.، نیکسخن، م. ح.، جانبسرایی، س. ف. م. و نیکو، م. ر. تصمیمگیری چندهدفه استوار برای پیادهسازی LIDها تحت تغییرات اقلیمی. مجله هیدرولوگرافیک. ۶۱۷ ، ۱۲۸۹۵۴ (۲۰۲۳).
-
طبری، ح. تأثیر تغییرات اقلیمی بر سیل و بارشهای شدید با افزایش دسترسی به آب افزایش مییابد. Sci. Rep. ۱۰ ، ۱۳۷۶۸ (۲۰۲۰).
-
نیاوپانه، ن.، تاکور، ب.، کالرا، آ. و احمد، س. ارزیابی سناریوهای سیل آینده با استفاده از پیشبینیهای اقلیمی CMIP5. آب ۱۰ ، ۱۸۶۶ (۲۰۱۸).
-
ژو، ک.، ژوانگ، ی.، بین، ل.، وانگ، س. و تیان، ف. ارزیابی تأثیر تغییرات اقلیمی بر سیل مرکب در یک شهر ساحلی. مجله هیدرول. ۶۱۷ ، ۱۲۹۱۶۶ (۲۰۲۳).
-
لیو، دبلیو. و همکاران. ارزیابی احتمالاتی خطر سیل شهری و تأثیرات تغییرات اقلیمی آینده. مجله هیدرول. ۶۱۸ ، ۱۲۹۲۶۷ (۲۰۲۳).
-
جانبسرایی، SFM، نیکسخن، MH، حسنی، MR و اردستانی، M. تصمیمگیری چندهدفه مبتنی بر نظریههای بازی مشارکتی و انتخاب اجتماعی برای تشویق اجرای شیوههای توسعه کماثر. مجله مدیریت محیط زیست. ۳۳۰ ، ۱۱۷۲۴۳ (۲۰۲۳).
-
بویتیاس، ل. و همکاران. شبیهسازی سیلابهای ناگهانی در گام زمانی ساعتی با استفاده از مدل SWAT. آب ۹ ، ۹۲۹ (۲۰۱۷).
-
محمود، ام. آی، الغیب، ان. ای، هورن، اف. و سعد، اس. ای. درسهای آموختهشده از اثرات سیل ناگهانی خارطوم: یک ارزیابی یکپارچه. Sci. Total Environ. ۶۰۱ ، ۱۰۳۱–۱۰۴۵ (۲۰۱۷).
-
de Andrade, MMN & Szlafsztein, CF ارزیابی آسیبپذیری شامل اجزای ملموس و ناملموس در ترکیب شاخص: مطالعه موردی سیل و طغیان ناگهانی در آمازون. Sci. Total Environ. ۶۳۰ ، ۹۰۳–۹۱۲ (۲۰۱۸).
-
جودار-آبلان، آ.، والدس-آبلان، ج.، پلا، سی. و گوماریز-کاستیلو، ف. تأثیر تغییرات کاربری اراضی بر پیشبینی سیل ناگهانی با استفاده از مدل SWAT زیر-روزانه در پنج حوزه آبخیز مدیترانهای بدون آمار (جنوب شرقی اسپانیا). Sci. Total Environ. ۶۵۷ ، ۱۵۷۸–۱۵۹۱ (۲۰۱۹).
-
وانگ، ایکس.، ژای، ایکس.، ژانگ، وای. و گوئو، ال. ارزیابی قابلیت شبیهسازی سیل ناگهانی با توجه به تغییرات زمانی بارندگی در یک حوضه آبریز کوهستانی کوچک. مجله علوم زمین. ۳۳ ، ۲۵۳۰–۲۵۴۸ (۲۰۲۳).
-
محتر، WHMW، عبدالله، J.، مولود، KNA و محمد، NS شاخص سیل ناگهانی شهری بر اساس وقایع بارندگی تاریخی. پایدار. انجمن شهرها. ۵۶ ، ۱۰۲۰۸۸ (۲۰۲۰).
-
کوون، اچ اچ، مون، وای و خلیل، ای اف. شبیهسازی ناپارامتری مونت کارلو برای استخراج منحنی فراوانی سیل: کاربردی در یک حوزه آبخیز کرهای. ۱٫ مجله منابع آب جاورا، شماره ۴۳ ، ۱۳۱۶-۱۳۲۸ (۲۰۰۷).
-
لیما، سی اچ، کوون، اچ اچ و کیم، جی وای. یک مدل توزیع بتای بیزی برای تخمین منحنیهای IDF بارندگی در یک اقلیم در حال تغییر. مجله هیدرول. ۵۴۰ ، ۷۴۴-۷۵۶ (۲۰۱۶).
-
شلف، کی ای و همکاران. گنجاندن غیرایستایی ناشی از تغییرات اقلیمی در منحنیهای فراوانی بارندگی و شدت-مدت-فراوانی (IDF). مجله هیدرول. ۶۱۶ ، ۱۲۸۷۵۷ (۲۰۲۳).
-
شن، او. و کاهیا، ای. تأثیرات تغییرات اقلیمی بر منحنیهای شدت-مدت-فراوانی در پربارانترین شهر ترکیه (ریزه). Theoret. Appl. Climatol. ۱۴۴ ، ۱۰۱۷–۱۰۳۰ (۲۰۲۱).
-
برگ، پ.، موزلی، س. و هارتر، ج. او. افزایش شدید بارش همرفتی در پاسخ به دماهای بالاتر. Nat. Geosci. ۶ ، ۱۸۱–۱۸۵ (۲۰۱۳).
-
کیم، بی. اس.، کیم، بی. کی. و کوون، اچ. اچ. ارزیابی تأثیر تغییرات اقلیمی بر رژیم جریان حوضه رودخانه هان با استفاده از شاخصهای تغییر هیدرولوژیکی. Hydrol. Process. ۲۵ ، ۶۹۱–۷۰۴ (۲۰۱۱).
-
مددگر، س. و مرادخانی، ح. تحلیل خشکسالی تحت تغییرات اقلیمی با استفاده از توابع مفصل. مجله مهندسی آب. ۱۸ ، ۷۴۶-۷۵۹ (۲۰۱۳).
-
کروولین، وی.، حسنزاده، ای. و بوردو-گولت، اس. سی.، ترسیم منحنیهای شدت-مدت-فرکانس برای کانادا با استفاده از پیشبینیهای CMIP6 و رویکرد کوچکمقیاسسازی مبتنی بر چندک. در چکیدههای نشست پاییزی AGU (جلد صفحات H42I-06) (2021). (2021).
-
یان، ال. و همکاران. بهروزرسانی منحنیهای شدت-مدت-فراوانی برای طراحی زیرساختهای شهری تحت شرایط محیطی متغیر. Wiley Interdiscip. Rev. Water ۸ ، e1519 (2021).
-
تایسی، اچ. و اوزگر، ام. تجزیه و تحلیل مدلهای گردش عمومی جو آینده برای تولید منحنیهای IDF برای ارزیابی سیلابهای شهری. مجله آب و هوا. تغییر ۱۳ ، ۶۸۴-۷۰۶ (۲۰۲۲).
-
میثمی، ر. و نیکسخن، م.ح. ارزیابی پایداری تخصیص بار پسماند تحت تغییرات اقلیمی با استفاده از تصمیمگیری چندهدفه. مجله هیدرولوگرافیک. ۵۸۸ ، ۱۲۵۰۹۱ (۲۰۲۰).
-
روزبهانی، ع.، بهزادی، پ. و بوانی، ع. م. تحلیل معیارهای عملکرد و شاخص پایداری در سیستمهای آبهای سطحی شهری تحت تأثیر تغییرات اقلیمی. مجله پاک. شماره ۲۷۱ ، شماره ۱۲۲۷۲۷ (۲۰۲۰).
-
دوری، آ.، سوموت، س.، گادات، س.، ریبز، آ. و کور، ل. شبیهساز مدل اقلیمی منطقهای مبتنی بر یادگیری عمیق: مفهوم و اولین ارزیابی یک رویکرد جدید کوچکمقیاسسازی ترکیبی. Clim. Dyn. ۶۰ ، ۱۷۵۱–۱۷۷۹ (۲۰۲۳).
-
مارائون، دی. و همکاران. کوچکمقیاسسازی بارش تحت تأثیر تغییرات اقلیمی: پیشرفتهای اخیر برای پر کردن شکاف بین مدلهای دینامیکی و کاربر نهایی. Rev. Geophys. ۴۸ ، RG3003 (2010).
-
کلر، ای.ای.، گارنر، کی.ال.، رائو، ان.، نیپینگ، ای. و توماس، جی. رویکردهای کوچکمقیاسنمایی پیشبینیهای تغییرات اقلیمی برای مدلسازی حوزه آبخیز: مروری بر ملاحظات نظری و عملی. PLoS WaterBold”>1 ، e0000046 (2022).
-
فلینت، الای و فلینت، ایال، کوچکمقیاسسازی سناریوهای اقلیمی آینده به مقیاسهای دقیق برای مدلسازی و تحلیل هیدرولوژیکی و اکولوژیکی. فرآیندهای اکولوژیکی ۱ ، ۱–۱۵ (۲۰۱۲).
-
ژو، آر.، چن، ان.، چن، وای. و چن، زی. کوچکمقیاسسازی و پیشبینی بارش چند سانتیمتری-۵ با استفاده از روشهای یادگیری ماشین در حوضه رودخانه هان علیا. مجله هواشناسی پیشرفته. ۱-۱۷ (۲۰۲۰). (۲۰۲۰).
-
پور، اس اچ، شاهد، اس.، چانگ، ای اس و وانگ، ایکس جی، کوچکمقیاسسازی آمار خروجی مدل با استفاده از ماشین بردار پشتیبان برای پیشبینی تغییرات مکانی و زمانی بارندگی بنگلادش. Atmos. Res. ۲۱۳ ، ۱۴۹–۱۶۲ (۲۰۱۸).
-
اشتاینینگر، م. و همکاران. ConvMOS: آمار خروجی مدل CLImate با یادگیری عمیق. Data Min. Knowl. Disc. ۳۷ ، ۱۳۶–۱۶۶ (۲۰۲۳).
-
ادن، جی. ام. و ویدمن، ام. کوچکمقیاسسازی بارش شبیهسازیشده توسط مدلهای گردش عمومی جو با استفاده از آمار خروجی مدل. مجله اقلیم. ۲۷ ، ۳۱۲–۳۲۴ (۲۰۱۴).
-
Turco, M., Quintana-Seguí, P., Llasat, MC, Herrera, S. & Gutiérrez, JM تست کاهش مقیاس بارش MOS برای مدل های آب و هوایی منطقه ای ENSEMBLES در اسپانیا. جی. ژئوفیز. Res. اتمس. ۱۱۶ ، D18109 (2011).
-
باستر، جی.، بنتون، بی. ان.، گلاز، ای. و کینگ، آر. ان. هواشناسی با وضوح بالا با اثرات تغییرات اقلیمی از دادههای مدل جهانی آب و هوا با استفاده از یادگیری ماشین مولد. نات. انرژی ۹ ، ۱–۱۳ (۲۰۲۴).
-
مقیم، س. و براس، آر. ال. تصحیح بایاس دما و بارش مدلسازیشده اقلیمی با استفاده از شبکههای عصبی مصنوعی. مجله هیدرومتئورول. ۱۸ ، ۱۸۶۷–۱۸۸۴ (۲۰۱۷).
-
خیمنز اوسوریو، دی.ای.، مناپیس، ای.، زانفی، ای.، دی آندراد پینتو، ای.جی. و برنتان، بی. روشهای کوچکمقیاسسازی آماری و یادگیری ماشینی برای ارزیابی تغییرات میزان و فراوانی بارندگی در زمینه تغییرات اقلیمی-CMIP 6. پیش از چاپ در (۲۰۲۳). https://doi.org/10.5194/hess-2023-55
-
جورج، جی. و آتیرا، پی. یک رویکرد تصادفی چند مرحلهای برای کوچکمقیاسسازی آماری بارندگی. مدیریت منابع آب. ۳۷ ، ۵۴۷۷–۵۴۹۲ (۲۰۲۳).
-
نیازکار، م.، گودرزی، م. ر.، فاتحیفر، ا. و عابدی، م. ج. ریزمقیاسنمایی مبتنی بر یادگیری ماشین: کاربرد برنامهریزی ژنتیک چند ژنی برای ریزمقیاسنمایی دمای روزانه در دوگنبدان، ایران، تحت سناریوهای CMIP6. Theoret. Appl. Climatol. ۱۵۱ ، ۱۵۳–۱۶۸ (۲۰۲۳).
-
لیدل، ای. و پویریر، اس. H2O automl: یادگیری ماشینی خودکار مقیاسپذیر. در مجموعه مقالات کارگاه AutoML در ICML جلد. ICML. (2020). (2020).
-
شریف، م.، المولا، م.، شتی، ا. و چودوری، ر. ک. تحلیل بارندگی، حداکثر بارندگی قابل تحمل (PMP) و خشکسالی در امارات متحده عربی. مجله بینالمللی اقلیمشناسی. ۳۴ ، ۱۳۱۸–۱۳۲۸ (۲۰۱۴).
-
العنازی، ک. ک. و السباعی، آی. اچ. توسعه روابط شدت-مدت-فرکانس برای شهر ابها در عربستان سعودی. مجله بینالمللی محاسبات مهندسی. پژوهش. ۳ ، ۵۸-۶۵ (۲۰۱۳).
-
العمری، ن.س. و سوبیانی، ای.ام. تولید منحنیهای شدت، مدت و فراوانی بارندگی (IDF) برای مکانهای فاقد آمار در مناطق خشک. Earth Syst. Environ. ۱ ، ۱–۱۲ (۲۰۱۷).
-
لی، دی. و همکاران. توسعه و ادغام قابلیت مدلسازی سیلاب زیر روزانه در مدل SWAT و مقایسه آن با مدل XAJ. آب ۱۰ ، ۱۲۶۳ (۲۰۱۸).
-
روزالیس، س.، مورین، ای.، یایر، ی. و پرایس، س. پیشبینی سیل ناگهانی با استفاده از یک مدل هیدرولوژیکی کالیبره نشده و دادههای بارندگی راداری در یک حوضه آبخیز مدیترانهای تحت شرایط هیدرولوژیکی متغیر. مجله هیدرول. ۳۹۴ ، ۲۴۵-۲۵۵ (۲۰۱۰).
-
یانگ، ایکس.، لیو، کیو.، هی، وای.، لوئو، ایکس. و ژانگ، ایکس. مقایسه مدلهای SWAT روزانه و زیرروزانه برای شبیهسازی جریان روزانه در حوضه رودخانه هوای بالایی چین. Stoch. Env. Res. Risk Assess. ۳۰ ، ۹۵۹–۹۷۲ (۲۰۱۶).
-
نیتش، اس. ال.، آرنولد، جی. جی.، کینیری، جی. آر. و ویلیامز، جی. آر. ابزار ارزیابی خاک و آب، مستندات نظری، نسخه ۲۰۰۹ (موسسه منابع آب تگزاس، ۲۰۱۱).
-
وینچل، م.، سرینیواسان، ر.، دی لوزیو، م. و آرنولد، ج. رابط ArcSWAT برای SWAT2012: راهنمای کاربر. Blackland Res. Cent. Tex. AgriLife Res. Coll. Stn. ، ۱–۴۶۴ (۲۰۱۳).
-
بونگالینگ، CGK، فاستینو-اسلاوا، DV و لانسیگان، FP مدلسازی تأثیرات تغییر کاربری اراضی بر هیدرولوژی و استفاده از معیارهای چشمانداز به عنوان ابزاری برای مدیریت حوزه آبخیز: مورد یک حوزه آبخیز فاقد آمار در فیلیپین. Land. Policy ۷۲ ، ۱۱۶–۱۲۸ (۲۰۱۸).
-
گاسمن، پی. دبلیو، صادقی، ای. ام و سرینیواسان، آر. کاربردهای مدل SWAT بخش ویژه: مرور کلی و بینشها. مجله محیط زیست. کیفیت. ۴۳ ، ۱-۸ (۲۰۱۴).
-
تیلور، کی ای، استوفر، آر جی و میهل، جی ای. مروری بر CMIP5 و طراحی آزمایش. بول. امریکن. متئورول. انجمن صنفی. ۹۳ ، ۴۸۵–۴۹۸ (۲۰۱۲).
-
ایرینگ، وی. و همکاران. مروری بر طراحی و سازماندهی آزمایش فاز ۶ پروژه مقایسه متقابل مدل جفتشده (CMIP6). Geosci. Model Dev. ۹ ، ۱۹۳۷–۱۹۵۸ (۲۰۱۶).
-
اونیل، بی سی و همکاران. جادههای پیش رو: روایتهایی برای مسیرهای مشترک اجتماعی-اقتصادی که آینده جهان را در قرن بیست و یکم توصیف میکنند. گلوب. انویرون. تغییر ۴۲ ، ۱۶۹–۱۸۰ (۲۰۱۷).
-
چن، کالیفرنیا، هسو، اچ اچ، لیانگ، اچ سی، چیو، پی جی و تو، سی وای. تغییرات آینده در بارشهای شدید در بهار شرق آسیا و فصلهای می-یو در دو AGCM با وضوح بالا. Weather Clim. Extremes ۳۵ ، ۱۰۰۴۰۸ (۲۰۲۲).
-
گیورگی، اف. و رافائل، اف. وابستگی پیشبینیهای تغییرات اقلیمی سطحی منطقهای مبتنی بر مدلهای گردش عمومی جو (GCM) به سوگیریهای مدل، وضوح و حساسیت اقلیمی. پیشچاپ https://doi.org/10.21203/rs.3.rs-703062/v1 (۲۰۲۱).
-
ویلا، وی. و همکاران. چارچوب یادگیری ماشین برای نگهداری پایدار از تأسیسات ساختمانی. پایداری ۱۴ ، ۶۸۱ (۲۰۲۲).
-
جین، اچ.، سونگ، کیو. و هو، ایکس. اتو-کراها: یک سیستم جستجوی معماری عصبی کارآمد. در مجموعه مقالات بیست و پنجمین کنفرانس بینالمللی ACM SIGKDD در مورد کشف دانش و دادهکاوی (صفحات ۱۹۴۶-۱۹۵۶) (۲۰۱۹).
-
کاسلا، جی. و برگر، آر. ال. استنباط آماری (داکسبری، ۱۹۹۰).
-
Hannan, EJ & Quinn, BG تعیین ترتیب یک خودرگرسیون. جی.روی. آمار Soc.: Ser. روش B. ۴۱ ، ۱۹۰-۱۹۵ (۱۹۷۹).
-
آرنولد، جی. جی.، سرینیواسان، آر.، موتیا، آر. اس. و ویلیامز، جی. آر. مدلسازی و ارزیابی هیدرولوژیکی مناطق بزرگ، بخش اول: توسعه مدل ۱. مجله منابع آب جاورا، شماره ۱ ، صفحات ۷۳-۸۹ (۱۹۹۸).
-
عینی، م. ر.، جوادی، س.، دلاور، م.، گاسمن، پ. دبلیو. و جاریانی، ب. توسعه مدلهای جایگزین مبتنی بر SWAT برای شبیهسازی اجزای بیلان آب و جریان رودخانه برای یک حوزه آبخیز تحت تأثیر کارست. Catena ۱۹۵ ، ۱۰۴۸۰۱ (۲۰۲۰).
-
گاسمن، پی. دبلیو، ریس، ام. آر، گرین، سی. اچ و آرنولد، جی. جی. ابزار ارزیابی خاک و آب: توسعه تاریخی، کاربردها و جهتگیریهای تحقیقاتی آینده. ترجمه. ASABE . ۵۰ ، ۱۲۱۱–۱۲۵۰ (۲۰۰۷).
-
عینی، م. ر.، جوادی، س.، دلاور، م.، مونتیرو، ج. ا. و دارند، م. دقت بالای بازتحلیلهای بارش منجر به شبیهسازیهای خوب دبی رودخانه در یک حوضه نیمهخشک شد. مهندسی محیط زیست. ۱۳۱ ، ۱۰۷–۱۱۹ (۲۰۱۹).
-
هارگریوز، جی اچ و آلن، آر جی. تاریخچه و ارزیابی معادله تبخیر و تعرق هارگریوز. مجله مهندسی آب و زهکشی، شماره ۱۲۹ ، صفحات ۵۳ تا ۶۳ (۲۰۰۳).
-
کینگ، کی دبلیو، آرنولد، جی جی و بینگر، آر ال. مقایسه روشهای گرین-آمپت و شماره منحنی در حوزه آبخیز گودوین کریک با استفاده از SWAT. ترانس. ASABE ۴۲ ، ۹۱۹-۹۲۵ (۱۹۹۹).
-
باو، آ.، تیدمن، س.، کاله، پ. و لنارتز، ب. آیا تفکیک زمانی ورودی بارش بر اجزای هیدرولوژیکی شبیهسازی شده با استفاده از مدل SWAT تأثیر میگذارد؟. مجله منابع آب آمریکا. ۵۳ ، ۹۹۷–۱۰۰۷ (۲۰۱۷).
-
الرحیلی، ای. ام. داستانی از پیامدهای طوفان شاهین در شهر الخابوره، عمان. آب ۱۴ ، ۳۴۰ (۲۰۲۲).
-
باتالیا، جی. جی. میانگین مربعات خطا. AMP J. Technol. ۵ ، ۳۱-۳۶ (۱۹۹۶).
-
پولی، ای.ای. و سیریلو، ام.سی. در مورد استفاده از میانگین مربعات خطای نرمالشده در ارزیابی عملکرد مدل پراکندگی. محیط جوی. بخش. عمومی. بالا. ۲۷ ، ۲۴۲۷–۲۴۳۴ (۱۹۹۳).
-
نش، جی.ای. و ساتکلیف، جی.وی. پیشبینی جریان رودخانه از طریق مدلهای مفهومی، بخش اول – بحثی در مورد اصول. مجله هیدرول. ۱۰ ، ۲۸۲–۲۹۰ (۱۹۷۰).
-
چای، تی. و دراکسلر، RR، جذر میانگین مربعات خطا (RMSE) یا میانگین خطای مطلق (MAE)؟ – استدلالهایی علیه اجتناب از RMSE در مقالات. Geosci. Model Dev. ۷ ، ۱۲۴۷–۱۲۵۰ (۲۰۱۴).
-
بارنستون، ای.جی. تناظر بین همبستگی، RMSE و معیارهای تأیید پیشبینی هایدک؛ اصلاح امتیاز هایدک. پیشبینی آب و هوا. ۷ ، ۶۹۹–۷۰۹ (۱۹۹۲).
-
گوپتا، اچ. وی، کلینگ، اچ.، ییلماز، کی. کی. و مارتینز، جی. اف. تجزیه میانگین مربعات خطا و معیارهای عملکرد NSE: پیامدهایی برای بهبود مدلسازی هیدرولوژیکی. مجله هیدرول. ۳۷۷ ، ۸۰-۹۱ (۲۰۰۹).
-
عباسپور، کی سی و سوات – برنامه کالیبراسیون و عدم قطعیت SWAT – راهنمای کاربر ، ۱-۱۰۰ (۲۰۱۳). (۲۰۱۲).
-
بریگنتی، تیام و همکاران. دو روش کالیبراسیون برای مدلسازی جریان رودخانه و رسوب معلق با مدل swat. مجله مهندسی محیط زیست، شماره ۱۲۷ ، صفحات ۱۰۳ تا ۱۱۳ (۲۰۱۹).
-
Moriasi, D., Gitau, M., Pai, N. & Daggupati, P. مدلهای هیدرولوژیکی و کیفیت آب: معیارهای عملکرد و معیارهای ارزیابی. Trans. ASABE (Am. Soc. Agric. Biol. Eng.) ۵۸ ، ۱۷۶۳–۱۷۸۵ (۲۰۱۵).
-
بینش، ن.، نیکسخن، م.ح.، سارنگ، ا. و راچ، دبلیو. بهبود پایداری سیستمهای زهکشی شهری برای سازگاری با تغییرات اقلیمی با استفاده از بهترین شیوههای مدیریتی: مطالعه موردی تهران، ایران. مجله علوم آب و خاک. ۶۴ ، ۳۸۱-۴۰۴ (۲۰۱۹).
-
اویلاکین، ر.، یانگ، دبلیو. و کربس، پ. تحلیل خطر سیل شهری با پیشبینیهای اقلیمی CMIP5 و CMIP6. آب . ۱۶ ، ۴۷۴ (۲۰۲۴).
-
ساتریگاسا، ام سی، تونگدینوک، پی. و کاوجامپا، ان. ارزیابی تأثیر تغییرات اقلیمی بر پیشبینی سیلابهای آینده با استفاده از مدل SWAT و HEC-RAS تحت پیشبینی اقلیمی CMIP5 در حوزه آبخیز علیای تایلند. پایداری ۱۵ ، ۵۲۷۶ (۲۰۲۳).
-
اقبال، ز. و همکاران. مدل هیدرولوژیکی توزیعشده مبتنی بر الگوریتم یادگیری ماشین: ارزیابی تأثیر تغییرات اقلیمی بر سیل. پایداری ۱۴ ، ۶۶۲۰ (۲۰۲۲).
-
کریمیزاده، ک. و یی، ج. مدلسازی پاسخهای هیدرولوژیکی حوزه آبخیز تحت سناریوهای تغییر اقلیم با استفاده از تکنیکهای یادگیری ماشین. مدیریت منابع آب. ۳۷ ، ۵۲۳۵–۵۲۵۴ (۲۰۲۳).
-
مسگری، ای.، حسینی، اس. ای.، همسی، ام. اس.، هوشیار، ام. و پرتو، ال. جی. ارزیابی عملکرد مدلهای CMIP6 و پیشبینی بارش بر اساس سناریوهای SSP در منطقه MENAP. مجله تغییرات اقلیمی آب. ۱۳ ، ۳۶۰۷–۳۶۱۹ (۲۰۲۲).
-
Crévolin, V., Hassanzadeh, E. & Bourdeau-Goulet, S. C. Updating the intensity-duration-frequency curves in major Canadian cities under changing climate using CMIP5 and CMIP6 model projections. Sustain. Cities Soc. ۹۲, ۱۰۴۴۷۳ (۲۰۲۳).
-
Noor, M., Ismail, T., Shahid, S., Asaduzzaman, M. & Dewan, A. Projection of rainfall intensity-duration-frequency curves at ungauged location under climate change scenarios. Sustainable Cities Soc. ۸۳, ۱۰۳۹۵۱ (۲۰۲۲).
Acknowledgements
The authors thank Sultan Qaboos University (SQU) and Diwan of Royal Court for the financial support under His Majesty (HM) grant number SR/DVC/CESR/22/01.
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
دسترسی آزاد این مقاله تحت مجوز بینالمللی Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 منتشر شده است که هرگونه استفاده، اشتراکگذاری، توزیع و تکثیر غیرتجاری را در هر رسانه یا قالبی مجاز میداند، مادامی که به نویسنده(گان) اصلی و منبع، اعتبار کافی بدهید، پیوندی به مجوز Creative Commons ارائه دهید و مشخص کنید که آیا محتوای دارای مجوز را اصلاح کردهاید یا خیر. شما تحت این مجوز اجازه اشتراکگذاری محتوای اقتباسشده برگرفته از این مقاله یا بخشهایی از آن را ندارید. تصاویر یا سایر مطالب شخص ثالث در این مقاله در مجوز Creative Commons مقاله گنجانده شدهاند، مگر اینکه در خط اعتباری مطلب، طور دیگری ذکر شده باشد. اگر مطلبی در مجوز Creative Commons مقاله گنجانده نشده باشد و استفاده مورد نظر شما طبق مقررات قانونی مجاز نباشد یا از استفاده مجاز فراتر رود، باید مستقیماً از دارنده حق چاپ اجازه بگیرید. برای مشاهده نسخهای از این مجوز، به http://creativecommons.org/licenses/by-nc-nd/4.0/ مراجعه کنید .
درباره این مقاله

به این مقاله استناد کنید
الرواوس، گ.، نیکو، م. ر.، جانبسرایی، س. و همکاران. پیشبینی سیل ناگهانی در آینده نزدیک در یک منطقه خشک تحت تأثیر تغییرات اقلیمی. Sci Rep ۱۴ ، ۲۵۸۸۷ (۲۰۲۴). https://doi.org/10.1038/s41598-024-76232-0
- دریافت شده
- پذیرفته شده
- منتشر شده
- نسخه رکورد
- DOIhttps://doi.org/10.1038/s41598-024-76232-0
کلمات کلیدی
موضوعات
این مقاله مورد استناد قرار گرفته است
-
نقش دینامیک وارونگی مداوم زمستانی و شرایط خشکسالی بر غلظت PM10 در استانبول، ترکیه
پایش و ارزیابی زیستمحیطی (۲۰۲۵)
-
ارزیابی ریسک سیل ایستگاههای حمل و نقل ریلی شهری بر اساس تحلیل عدم قطعیت
تحقیقات زیستمحیطی تصادفی و ارزیابی ریسک (۲۰۲۵)
-
مدلسازی GIS جغرافیایی-زیستمحیطی برای پیشبینی خطر سیل در بارشهای سنگین منطقه هیمالیا شرقی: یک اقدام احتیاطی در جهت کاهش خطر بلایا
پایش و ارزیابی زیستمحیطی (۲۰۲۵)