


تجزیه و تحلیل جغرافیایی ۲: داده های رستری
پس از بررسی تجزیه و تحلیل دادههای ویژگی و برداری، حالا نوبت به تجزیه و تحلیل دادههای رستری میرسد که یکی از ابزارهای قدرتمند دادهکاوی در اختیار جغرافیدانان است. دادههای رستری بهویژه برای انواع خاصی از تجزیه و تحلیلها مناسب هستند، مانند پردازش جغرافیایی پایه (بخش “پردازش جغرافیایی پایه با رسترها”)، تجزیه و تحلیل سطح (بخش “مقیاس تجزیه و تحلیل”) و نقشهبرداری زمین (بخش “تحلیل سطح: درونیابی فضایی”). اگرچه همیشه اینطور نیست، اما دادههای رستری میتوانند بسیاری از انواع تحلیلهای فضایی را سادهسازی کنند؛ بهویژه در مواردی که انجام این تحلیلها بر روی مجموعه دادههای برداری پیچیده و زمانبر خواهد بود. در این پست، برخی از رایجترین این تکنیکها معرفی شده است.
پردازش جغرافیایی پایه با رستر
هدف یادگیری
هدف این پست، آشنایی با تکنیکهای اولیه پردازش جغرافیایی رستری تکلایه و چندلایه است.
مانند ابزارهای پردازش جغرافیایی موجود برای استفاده در مجموعه دادههای برداری (بخش “پردازش جغرافیایی پایه با رسترها”)، دادههای رستری نیز میتوانند عملیات فضایی مشابهی را انجام دهند. اگرچه محاسبات واقعی این عملیات بهطور قابلتوجهی با همتایان برداری آنها متفاوت است، اما زیربنای مفهومی آنها مشابه است. تکنیکهای پردازش جغرافیایی پوشش دادهشده در اینجا شامل عملیات تکلایه (پست “تجزیه و تحلیل تک لایه”) و چندلایه (بخش “تحلیل چند لایه”) میباشد.
تجزیه و تحلیل تک لایه
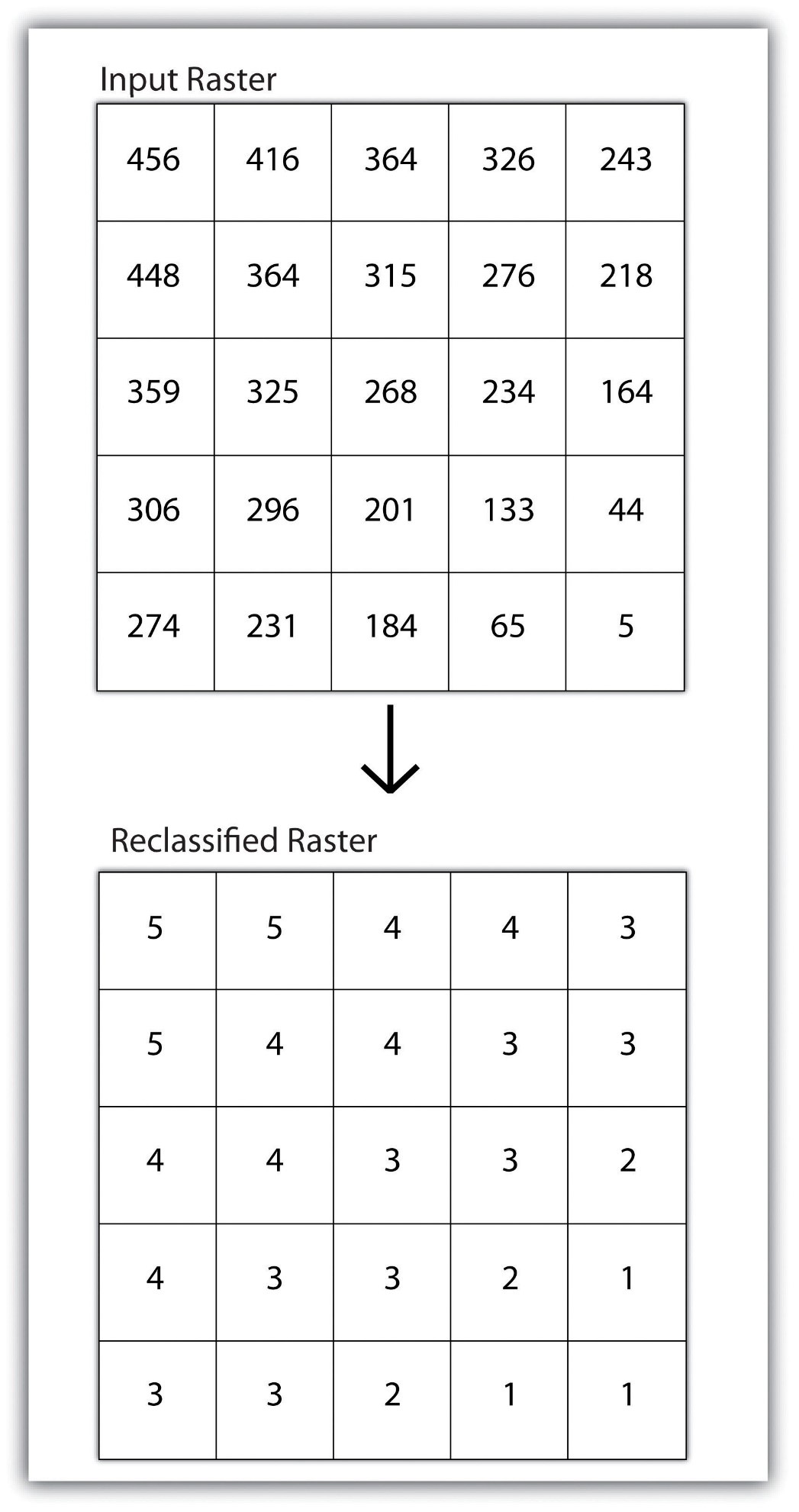
طبقهبندی مجدد یا کدگذاری مجدد یک مجموعه داده معمولاً یکی از اولین مراحل در تجزیه و تحلیل رستری است. طبقهبندی مجدد اساساً فرآیند تخصیص یک مقدار کلاس یا محدوده جدید به تمام پیکسلها در مجموعه داده بر اساس مقادیر اصلی آنها است (شکل ۸٫۱ “تجدید طبقهبندی رستری”). به عنوان مثال، یک شبکه ارتفاع معمولاً حاوی مقادیر متفاوتی برای تقریباً هر سلول داخل خود است. این مقادیر میتوانند با تجمیع هر پیکسل در چند کلاس مجزا سادهسازی شوند (مثلاً ۰-۱۰۰ = “۱”، ۱۰۱-۲۰۰ = “۲”، ۲۰۱-۳۰۰ = “۳” و غیره). سادهسازی مقادیر منحصربهفرد، نیاز به ذخیرهسازی کمتری را فراهم میکند و هزینههای ذخیرهسازی را کاهش میدهد. علاوه بر این، این لایههای طبقهبندیشده اغلب به عنوان ورودی در تحلیلهای ثانویه استفاده میشوند، مانند تحلیلهایی که در ادامه این بست به آنها پرداخته خواهد شد.
شکل ۸٫۱ طبقه بندی مجدد رستری
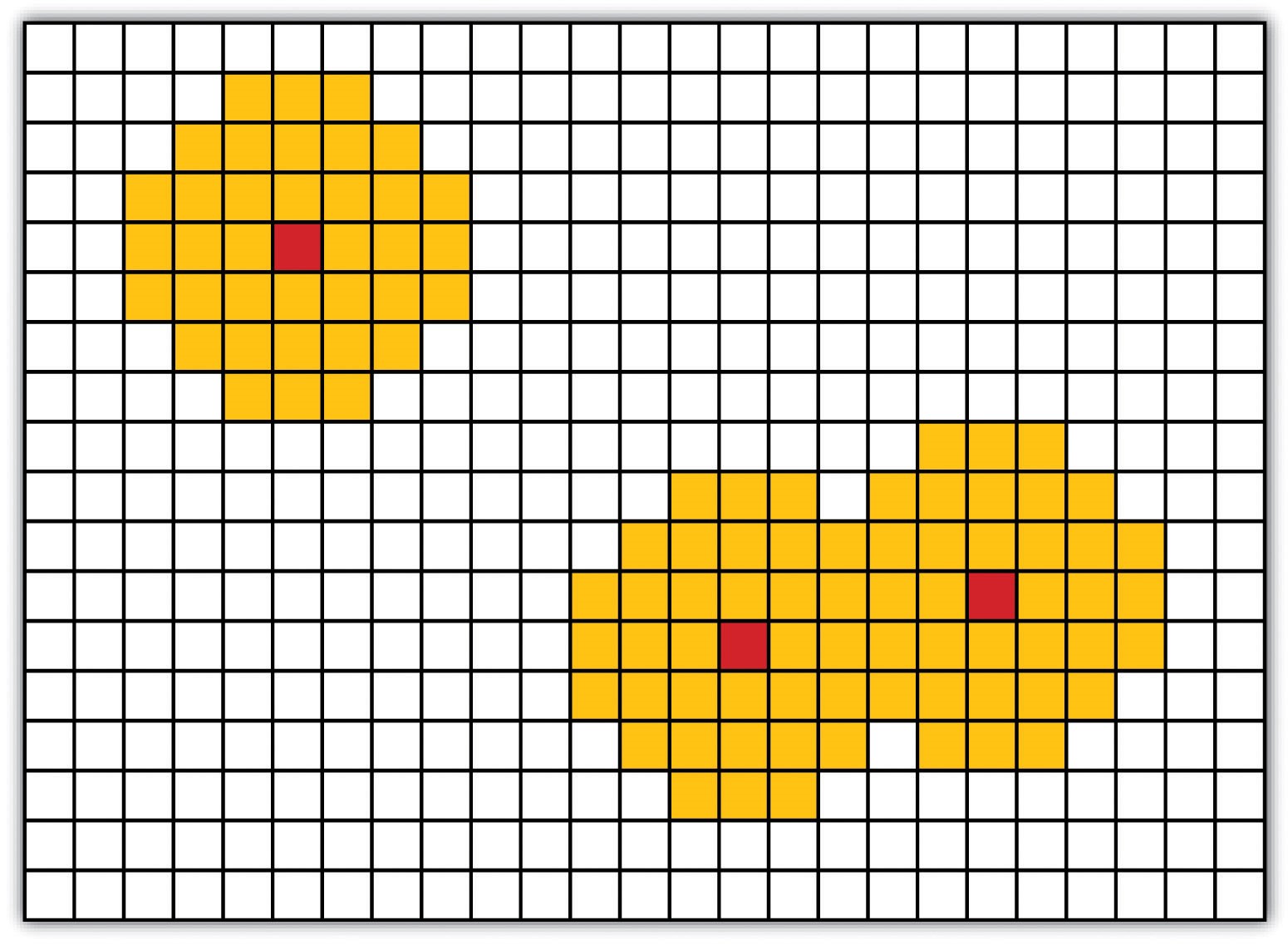
همانطور که در پست “تحلیل مکانی ۱: عملیات برداری” توضیح داده شد، بافر فرآیند ایجاد یک مجموعه داده خروجی است که شامل یک منطقه (یا مناطق) با عرض مشخص در اطراف یک ویژگی ورودی میباشد. در مورد مجموعه دادههای رستری، این عوارض ورودی بهعنوان یک سلول شبکه یا گروهی از سلولهای شبکه که مقدار یکنواختی دارند (مثلاً همه سلولهایی که مقدار آنها ۱ است) تعریف میشوند تا بافر شوند. بافرها بهویژه برای تعیین ناحیه نفوذ در اطراف ویژگیهای مورد نظر مناسب هستند. در حالی که بافرهای برداری معمولاً منطقهای دقیق در فاصله مشخص از ویژگی هدف ایجاد میکنند، بافرهای رستری معمولاً بهصورت تقریبی محاسبه میشوند و سلولهایی را نشان میدهند که در محدوده فاصله مشخصشده از هدف قرار دارند (شکل ۸٫۲ “بافر رستری در اطراف یک سلول هدف”).
اکثر برنامههای سیستم اطلاعات جغرافیایی (GIS) بافرهای رستری را با ایجاد شبکهای از مقادیر فاصله از مرکز سلولهای هدف به مرکز سلولهای همسایه محاسبه میکنند و سپس این فواصل را طبقهبندی مجدد میکنند. بهطور معمول، “۱” نشاندهنده سلولهایی است که با هدف اصلی همپوشانی دارند، “۲” نشاندهنده سلولهایی است که در منطقه بافر تعریفشده توسط کاربر قرار دارند و “۰” نشاندهنده سلولهایی است که خارج از هدف و مناطق بافر قرار دارند. این سلولها همچنین میتوانند برای نمایش بافرهای حلقهای متعدد با گنجاندن مقادیر «۳»، «۴»، «۵» و غیره طبقهبندی شوند تا فواصل متحدالمرکز اطراف سلولهای هدف را نشان دهند.
شکل ۸٫۲ بافر رستر در اطراف سلول(های) هدف
 تجزیه و تحلیل چند لایه
تجزیه و تحلیل چند لایه
 تجزیه و تحلیل چند لایه
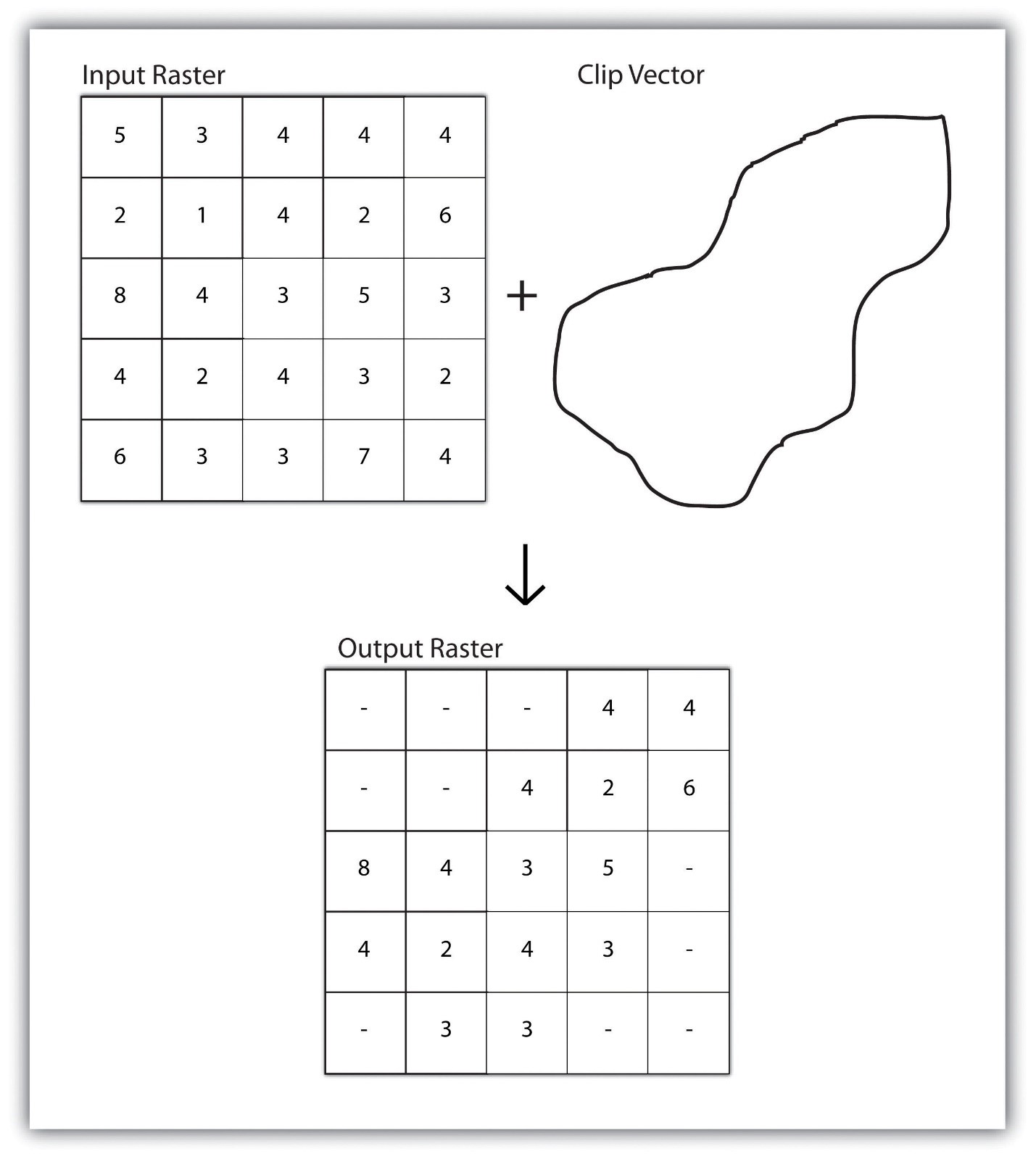
تجزیه و تحلیل چند لایهیک مجموعه داده رستری همچنین میتواند مشابه یک مجموعه داده برداری برش داده شود (شکل ۸٫۳ “برش یک رستر به لایه چند ضلعی برداری”). در این حالت، رستری ورودی توسط یک لایه کلیپ چند ضلعی برداری پوشانده میشود. فرآیند برش رستری منجر به ایجاد یک رستری جدید میشود که مشابه رستری ورودی است، اما تنها در وسعت لایه کلیپ چند ضلعی مشترک قرار دارد.
شکل ۸٫۳ برش یک رستر به یک لایه چند ضلعی برداری
پوششهای رستری در مقایسه با نمونههای برداری خود نسبتاً ساده هستند و به توان محاسباتی بسیار کمتری نیاز دارند (Burroughs, 1983). باروز، ۱۹۸۳٫ سیستمهای اطلاعات جغرافیایی برای ارزیابی منابع طبیعی. نیویورک: انتشارات دانشگاه آکسفورد. علیرغم سادگی، مهم است که اطمینان حاصل شود که تمام رستری های همپوشانی به درستی ثبت شدهاند (یعنی از نظر فضایی تراز شدهاند)، مناطق یکسانی را پوشش میدهند و وضوح یکسانی (یعنی اندازه سلولها) را حفظ میکنند. اگر این مفروضات نقض شوند، تحلیل دچار مشکل خواهد شد یا لایه خروجی تولید شده دارای نقص خواهد بود. با توجه به این نکات، چندین روش مختلف برای اجرای همپوشانی رستری وجود دارد (Chrisman, 2002). کریسمن، ن. ۲۰۰۲٫ کاوش در سیستمهای اطلاعات جغرافیایی. ویرایش دوم. نیویورک: جان وایلی و پسران.
پوشش رستری ریاضی رایجترین روش همپوشانی است. اعداد درون سلولهای تراز شده شبکههای ورودی میتوانند هر نوع تبدیل ریاضی که توسط کاربر مشخص شده است را انجام دهند. پس از محاسبه، یک رستر خروجی تولید میشود که حاوی مقدار جدیدی برای هر سلول است (شکل ۸٫۴ “همپوشانی رستر ریاضی”). همانطور که میتوان تصور کرد، کاربردهای زیادی برای چنین عملکردی وجود دارد. به طور خاص، پوشش رستری اغلب در مطالعات ارزیابی ریسک استفاده میشود، جایی که لایههای مختلف برای تولید نقشهای که مناطق با ریسک یا پاداش بالا را نشان میدهد، ترکیب میشوند.
شکل ۸٫۴ روکش رستری ریاضی
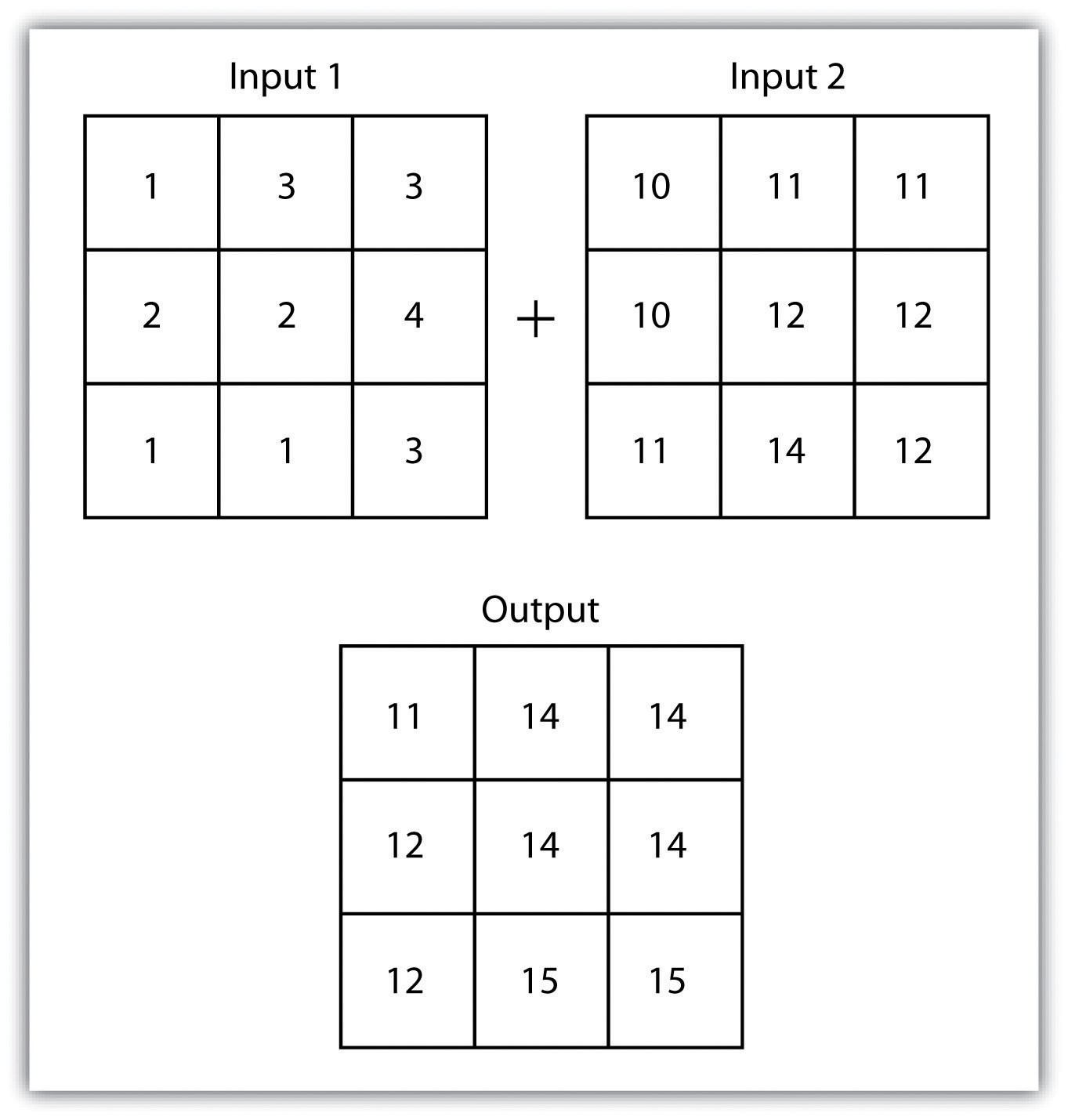
دو لایه رستری ورودی برای تولید یک رستر خروجی با مقادیر سلول جمع شده روی هم قرار گرفته اند.
روش پوشش رستری بولی دومین تکنیک قدرتمند را در تجزیه و تحلیل دادههای رستری معرفی میکند. همانطور که دربجش “ویژگیها و تجزیه و تحلیل دادهها” بحث شد، عملگرهای بولی AND، OR و XOR میتوانند برای ترکیب اطلاعات دو مجموعه داده رستری ورودی به یک رستر خروجی استفاده شوند. به طور مشابه، روش همپوشانی رستری از عملگرهای رابطهای (<، <=، =، <>، >، و =>) برای ارزیابی شرایط مجموعه دادههای شطرنجی ورودی بهره میبرد. در هر دو روش همپوشانی بولی و رابطهای، سلولهایی که معیارهای ارزیابی را برآورده میکنند معمولاً با کد ۱ در لایه رستری خروجی نمایش داده میشوند، در حالی که سلولهایی که نادرست ارزیابی میشوند، مقدار ۰ را دریافت میکنند.
با این حال، سادگی این روشها میتواند منجر به خطاهایی در تفسیر شود، به ویژه اگر روکش به درستی طراحی نشده باشد. فرض کنید که یک مدیر منابع طبیعی دو مجموعه داده رستری ورودی دارد که قصد دارد بر روی آنها عملیات همپوشانی انجام دهد. یکی از این مجموعه دادهها مکان درختان را نشان میدهد (با مقادیر «۰» برای بدون درخت و «۱» برای درخت)، و دیگری مکان مناطق شهری را نشان میدهد (با مقادیر «۰» برای غیرشهری و «۱» برای شهری). اگر او قصد داشته باشد مکان درختان را در مناطق شهری پیدا کند، یک عملیات ریاضی ساده از این مجموعه دادهها مقدار «۲» را در تمام پیکسلهای حاوی درخت در مناطق شهری تولید میکند. به طور مشابه، اگر او بخواهد مناطق بدون درخت (یا «غیر درختی» و غیرشهری) را شناسایی کند، میتواند رستر خروجی حاصل از جمعزدن این دادهها را برای همه ورودیهای «۰» بررسی کند. در نهایت، اگر او بخواهد مناطق شهری و بدون درخت را پیدا کند، میتواند تمام سلولهای حاوی «۱» را جستجو کند. با این حال، مقدار «۱» در هر پیکسل، برای سلولهای درختی غیرشهری نیز کدگذاری میشود. در واقع، انتخاب مقادیر پیکسلهای ورودی و معادله همپوشانی در این مثال نتایج گیجکنندهای ایجاد میکند که ناشی از طرح ضعیف همپوشانی است.
خوراکی های کلیدی
- فرآیندهای همپوشانی دو یا چند نقشه موضوعی را روی هم قرار می دهند تا یک نقشه جدید را تشکیل دهند.
- عملیات همپوشانی موجود برای استفاده با داده های برداری شامل مدل های نقطه در چند ضلعی، خط در چند ضلعی یا چند ضلعی در چند ضلعی است.
- اتحاد، تقاطع، تفاوت متقارن و هویت عملیات رایجی هستند که برای ترکیب اطلاعات از مجموعه دادههای مختلف استفاده میشوند.
- عملیات پوشش رستری می تواند از عملگرهای قوی ریاضی، بولی یا رابطه ای برای ایجاد مجموعه داده های خروجی جدید استفاده کند.
تمرینات
- از حوزه مطالعاتی خود، سه لایه داده نظری را توصیف کنید که میتوانند برای ایجاد یک نقشه خروجی جدید که به یک سؤال فضایی پیچیده پاسخ میدهد، روی هم قرار گیرند، مانند “بهترین مکان برای قرار دادن یک مرکز خرید کجاست؟”
- آنلاین شوید و مجموعه داده های برداری یا رستری مرتبط با سوالی را که مطرح کردید پیدا کنید.