۱٫ معرفی
برنامههای کاربردی بلادرنگ مانند وظایف تجسم چندسطحی، الزامات بسیار بالایی را برای عملکرد زمانبندی دادههای مکانی-زمانی در مقیاس بزرگ مطرح میکنند [ ۱ ]. کارایی تجسم دینامیکی بلادرنگ وظایف چند دانه ای کاربر همه جا حاضر در محیط ابری به کیفیت الگوریتم زمان بندی بستگی دارد. زمانبندی دادههای مکانی-زمانی یک استراتژی است که برای تخصیص معقول منابع فیزیکی با توجه به الزامات دادهای وظایف تجسم چند سطحی و برای تسریع سرعت انتقال داده از منبع داده به یک موتور رندر بصری استفاده میشود. این یک فرآیند بسیار پیچیده است، از رندر بصری سمت سرویس گیرنده تا کش سمت مشتری، سپس به کش کردن سرور، و در نهایت به پرس و جو از پایگاه داده سمت سرور [ ۲ , ۳ ]]. هر بخش روش های شتاب گیری متفاوتی دارد. در سالهای اخیر، روشهای زمانبندی دادههای مکانی-زمانی برای نمایش و تحلیل تجسم کارآمد به طور گسترده در زمینه علم اطلاعات جغرافیایی (GIS) مورد مطالعه قرار گرفتهاند، و یک سری روشهای زمانبندی بهینهسازی دادههای مکانی-زمانی پدیدار شدهاند، مانند پردازش دادههای خام ساده شده [ ۴ , ۵ ، پیش بارگذاری داده در سمت کلاینت [ ۶ ، ۷ ]، زمانبندی چند رشتهای در سمت سرور [ ۸ ، ۹ ]، و یک استراتژی کش چندسطحی [ ۱۰ ، ۱۱ ]. در حال حاضر، با استقرار تدریجی مراکز داده GIS در فضای ابری [ ۱۲]، چگونگی برآوردن نیازهای زمانبندی مختلف وظایف تجسم چندسطحی و تحقق بهینهسازی جهانی جریان دادههای مکانی-زمانی در ابر [ ۱۳ ، ۱۴ ] به مسائل اصلی تبدیل شدهاند که کارایی ساخت و ساز و تعامل بلادرنگ صحنه سهبعدی وظیفهگرا را محدود میکنند. گرفتار.
زمانبندی دادههای مکانی-زمانی بهینهشده در سمت مشتری عمدتاً استراتژی پردازش ساده دادههای خام، بارگذاری دینامیکی مبتنی بر نقطه نظر و واکشی اولیه را اتخاذ میکند [ ۱۵ ، ۱۶ ]. الگوریتمهای سادهسازی دادههای اصلی موجود، دادهها را به سطوح جزئیات (LOD) تبدیل میکنند، مانند پنج LOD متوالی تعریفشده توسط CityGML [ ۴ ]. با افزایش LOD ها، اشیاء به طور فزاینده ای پیچیده می شوند، که می تواند نه تنها مدل بلوک ساده، غیر توپولوژیکی و غیر معنایی مناطق شهری بزرگ را بیان کند، بلکه می تواند مدل ظریف چند مقیاسی را با توپولوژی و معناشناسی مناطق محلی نیز بیان کند. ۱۷ ].]. سپس، از طریق استراتژی رندر گرافیکی سمت مشتری، همراه با ترجیحات کاربر، فاصله از مکان دیدگاه، بارگذاری دینامیکی و نمایش سطوح مختلف دادههای مکانی-زمانی، دادههای ریز دانه را میتوان با دقت بالا بارگذاری کرد. نزدیکترین نقطه دید، واقعیت تجسم صحنه سه بعدی را می توان بهبود بخشید، داده های درشت دانه را می توان با دقت کم در دورترین نقطه بارگذاری کرد، و مقدار داده های کشیده شده در سمت مشتری را می توان کاهش داد [ ۱۸ ، ۱۹ ]. استاندارد جامعه ۳D Tiles OGC در حال حاضر تأثیر قوی دارد و در کاربردهای متعددی استفاده می شود [ ۲۰]. برای مثال، استراتژی زمانبندی کاشیهای سهبعدی در سزیوم، الگوریتم زمانبندی دادههای سمت مشتری معمولی است که میتواند کارایی رندر مشتری را بهبود بخشد [ ۲۱ ]. با این حال، این روش معمولاً برای مدلهای سهبعدی و ابرهای نقطه سهبعدی با تطبیقپذیری ضعیف طراحی میشود و نمیتوان آن را برای زمانبندی بهینهسازی دادههای پایش دسترسی بلادرنگ شبکه حسگر اینترنت اشیا، دادههای ردیابی حرکت انسان و وسایل نقلیه و ارتباط اجتماعی اعمال کرد. داده ها. [ ۲۰ ، ۲۲]. در عین حال، روش زمانبندی بهینهسازی سمت کلاینت تنها تعیین میکند که چه دادههایی از منبع داده سمت سرور درخواست میشوند. اگرچه کارایی پردازش سمت مشتری را تسریع میکند، اما توان عملیاتی سرویس داده کل سیستم را بهبود نمیبخشد.
از طریق یک مکانیسم کش کارآمد، تاخیر پرس و جو داده و انتقال شبکه ناشی از وظایف با همزمانی بالا قابل حل است [ ۲۳ ]. سیستم GIS موجود عمدتاً از یک معماری کش چندسطحی، از جمله کش حافظه سمت سرور، کش فایل سمت سرویس گیرنده و کش حافظه سمت سرویس گیرنده استفاده می کند [ ۲ ]. داده های مکانی-زمانی که ممکن است به آنها دسترسی داشته باشد به طور موقت در فضای کش ذخیره می شود و سپس از طریق همکاری مؤثر بین سرور و کلاینت، حافظه و ذخیره سازی دیسک، فشار دسترسی روی پایگاه داده سرور کاهش می یابد [ ۲۴ ] و مشکل تاخیر داده هایی که به موتور تجسم می رسند اجتناب می شود [ ۹]. برای بهبود کارایی زمانبندی دادهها برای کارهای با همزمانی بالا، برخی از الگوریتمهای جایگزین حافظه پنهان برای جایگزینی دادههای موقت بیفایده حافظه پنهان برای بهبود نرخ ضربه دادهها استفاده میشوند. LRU (کمترین استفاده اخیر) و LFU (کمترین استفاده از آن) دو الگوریتم جایگزین حافظه پنهان هستند که به طور گسترده مورد استفاده قرار می گیرند، و همچنین به طور گسترده در GIS استفاده می شوند [ ۲۵ ، ۲۶ ]. الگوریتم LRU به تغییر ویژگی های دسترسی حساس است اما ویژگی های کلی دسترسی به داده ها را در نظر نمی گیرد، در حالی که الگوریتم LFU برعکس است [ ۲۷ ، ۲۸ ]. علاوه بر این، با توجه به شباهت دسترسی داده های مجاورت مکانی [ ۲۹]، الگوریتمهای جایگزینی کش مختلف برای بهینهسازی فرآیند زمانبندی دادههای مکانی-زمانی، جلوگیری از دسترسی مکرر به پایگاه داده سرور، کاهش مقدار دادههای ارسال شده توسط شبکه و بهبود قابل توجهی توانایی دسترسی همزمان و توانایی زمانبندی دادههای مکانی-زمانی مشتق شدهاند. با این حال، معماری کش چندسطحی با اندازه فضای کش و نرخ ضربه کش محدود می شود. هنگامی که نرخ ضربه کش داده کم است، همچنان باید به توان عملیاتی داده سمت سرور برای برآوردن نیازهای زمانبندی داده سمت سرویس گیرنده تکیه کند.
عملکرد زمانبندی دادههای سمت سرور در محیط ابری، قابلیت خدمات کل سیستم دادههای مکانی و زمانی را تعیین میکند [ ۳۰ ، ۳۱ ]. داده های مکانی-زمانی معمولاً در خوشه پایگاه داده یا سیستم فایل توزیع شده در محیط ابری ذخیره می شوند [ ۳۲ ]. روشهای موجود عمدتاً یک استخر رشته و اتصال ایجاد میکنند، بر اساس زمانبندی چند رشتهای و استراتژی متعادلسازی بار، برای حل دسترسی به دادههای همزمانی بالا در سمت سرور [ ۳۳]. این استراتژی دسترسی و زمانبندی هیچ تفاوتی در انواع دادهها ندارد و پیکربندی ماکت داده و تخصیص منابع ذخیرهسازی در محیط ابری ثابت است. بنابراین، نمی تواند به طور انعطاف پذیر با تغییرات پویا در الزامات کار تجسم سازگار شود [ ۳۴ ، ۳۵ ]. از یک طرف، روشهای پیکربندی نامعقول داده منجر به زمان انتقال بیش از حد داده میشود [ ۳۶ ]. از سوی دیگر، توان عملیاتی داده مرکز داده ابری کاهش می یابد [ ۳۷]. در محیط ابری، منابع ذخیره سازی و شبکه به طور کامل مورد استفاده قرار می گیرد، پیکربندی و روش زمان بندی منبع داده سمت سرور بهینه شده است، ظرفیت عملیاتی سرویس داده ابری گسترش می یابد، و توانایی عرضه هر نوع داده مکانی-زمانی برای برآورده کردن خواسته های وظیفه تضمین شده است، که برای زمان بندی داده های مکانی-زمانی بسیار مهم است [ ۳۸ ]. فناوری کانتینر روشی برای بسته بندی یک برنامه کاربردی است تا بتوان آن را با وابستگی هایش از سایر فرآیندها جدا کرد [ ۳۹ ]]. با ظهور فناوری کانتینر و مجازی سازی، کانتینرسازی پایگاه داده در محیط ابری سرور را قادر می سازد تا به صورت پویا تعداد کپی های داده را مطابق با الزامات دسترسی به داده پیکربندی کند و تخصیص منابع سخت افزاری و نرم افزاری کانتینر را کنترل کند [ ۴۰ ]. بر این اساس، یک روش زمانبندی داده دقیقتر برای وظایف تجسم چندسطحی میتواند برای بهینهسازی قابلیت سرویس داده در محیط ابری و به حداکثر رساندن استفاده از منابع نرمافزاری و سختافزاری شکل بگیرد.
چگونگی درک بهتر وظایف بلادرنگ و پویا و پاسخگویی به نیازهای خدماتی کاربران یک چالش است و کیفیت الگوریتم زمان بندی نقش اساسی در آن دارد. Ramkumar و Gunasekaran (2019) یک الگوریتم زمانبندی را برای تجمیع سرور اول (FCFS) عناصر برتر پیشنهاد کردند که عملکرد سیستم را بهبود می بخشد و مصرف زمان را کاهش می دهد [ ۴۱ ]]. با این حال، در واقع، وظایف multigranularity از کاربران مختلف می آیند و اولویت های متفاوتی دارند. الگوریتم FCFS ممکن است باعث شود که برخی از وظایف فوری برای مدت طولانی در صف منتظر بمانند و نتوانند تحت درخواستهای فوری فوری کار به خوبی کار کنند. یکی دیگر از الگوریتمهای زمانبندی اولویت (PSA) باید اولویت وظایف را قبل از زمانبندی مشخص کند. با این حال، قبل از فرآیند زمانبندی، اولویت محاسبه سیستم ثابت است، که باعث میشود سیستم نتواند با موقعیتهای پیچیده مقابله کند [ ۴۲ ]. بر اساس PSA، در سال ۲۰۱۱، لی، یینگ و ون استراتژی جدیدی را پیشنهاد کردند که متشکل از یک الگوریتم زمانبندی اولویت پویا (DPSA) است و نشان داد که DPSA کارایی بهتری دارد و امکانپذیرتر از PSA است [ ۴۳ ].]. با این حال، DPSA نیاز به محاسبه مجدد و تنظیم اولویت هر کار قبل از هر زمانبندی جدید دارد. هنگام رویارویی با وظایف در مقیاس بزرگ و چند دانه ای، تنظیم دقیق زمان صف کار را افزایش می دهد، که اغلب نمی تواند نیازهای تعداد زیادی از وظایف پویا بلادرنگ را برآورده کند.
با توجه به چالشهای زمانبندی فوق، این مقاله یک روش زمانبندی دادههای مکانی-زمانی بهینه را بر اساس جریان حداکثری پیشنهاد میکند که فرآیند زمانبندی دادههای مکانی-زمانی چندگانه را برای ساخت مدل حداکثر جریان ترسیم میکند. مشارکت های زیر توسط این کار ارائه شده است:
-
تعریف یک کار تجسم چندسطحی و اولویت دادههای آن و طراحی چارچوب زمانبندی دادههای مکانی-زمانی با توجه به ساختار ذخیرهسازی و زمانبندی دادههای مکانی-زمانی در یک محیط ابری.
-
نگاشت توپولوژی شبکه زمانبندی منابع داده به مدل حداکثر جریان و ایجاد یک مدل زمانبندی جریان حداکثر از دادههای مکانی-زمانی میتواند به وضوح توانایی سرویسهای داده مکانی-زمانی چندمنبعی و چند دانهای را کمیت کند.
-
طراحی دو روش تنظیم دینامیکی وظیفه محور پارامترهای مدل حداکثر جریان: گره کش و تخصیص ظرفیت گره ذخیره سازی. این روش میتواند اندازه جریان دادههای مکانی-زمانی چندگانه را کنترل کند و در عین حال بهینهسازی جریان دادههای جهانی را حفظ کند و به طور انعطافپذیری با نیازهای وظایف تحت منابع سختافزار محدود در محیط ابری سازگار شود.
بقیه این مقاله به شرح زیر سازماندهی شده است: بخش ۲ طراحی چارچوب زمانبندی داده های مکانی-زمانی را ارائه می دهد. بخش ۳ ساخت یک مدل زمانبندی دادههای مکانی-زمانی را بر اساس حداکثر جریان نشان میدهد. بخش ۴ روش تنظیم حداکثر جریان مبتنی بر وظیفه را برای بهینه سازی جریان داده توضیح می دهد. یک سیستم نمونه اولیه برای زمانبندی دادههای مکانی-زمانی و یک رابط تنظیم پارامتر مبتنی بر وب کاربر پسند توسعه داده شده است، و یک تحلیل تجربی در بخش ۵ پیادهسازی شده است . در نهایت، نتیجه گیری و بحث در بخش ۶ مورد بررسی قرار می گیرد.
۲٫ چارچوب زمانبندی داده های مکانی-زمانی برای وظایف تجسم چند سطحی
روش زمانبندی دادههای مکانی-زمانی برای وظایف تجسم چندسطحی نیاز دارد که نه تنها ویژگیهای دادههای مکانی-زمانی، بلکه الزامات زمانبندی مختلف وظایف تجسم چند سطحی را نیز با جزئیات در نظر بگیرد. برای ایجاد یک مکانیسم زمانبندی دادههای مکانی-زمانی کارآمد که با تغییرات پیچیده در وظایف تجسم صحنه سهبعدی سازگار میشود، بخش ۲٫۱ ابتدا الزامات زمانبندی وظایف تجسم چند سطحی را تحلیل میکند. سپس، بخش ۲٫۲ یک چارچوب زمانبندی دادههای مکانی-زمانی برای وظایف تجسم چندسطحی طراحی میکند.
۲٫۱٫ وظایف تجسم چند سطحی و اولویت های داده
داده های فضایی-زمانی چندوجهی توسط الزامات وظایف تجسم چندسطحی هدایت می شوند. تجسم داده ها و ساخت صحنه ها به ابزارهای مهمی برای نمایش، شناخت و کنترل فضای سایبری-فیزیکی-اجتماعی تبدیل شده است. در کاربرد تجسم دادههای مکانی-زمانی، مشتریان متنوع در مقیاس بزرگ به سرویس تجسم دادههای مکانی-زمانی در زمان واقعی دسترسی پیدا میکنند و این مشتریان سطوح مختلفی از وظایف تجسم را دارند که در نتیجه نیازمندیهای متفاوتی برای محتوای دادههای مکانی-زمانی هستند. با توجه به مقیاس ارائه داده ها، ظرافت ساخت صحنه سه بعدی و اهداف کاربردی، سه نوع کار تجسم مربوط به محتوای صحنه های مختلف و اولویت های زمان بندی داده در زیر خلاصه شده است [ ۴۴ ، ۴۵ ،۴۶ ، ۴۷ ].
کار تجسم نمایش: این کار بر نمایش تطبیقی دادههای مکانی-زمانی در صحنههای گسسته-پیوسته، پویا-ایستا، واقعی-انتزاعی و ریز-درشت و همچنین تجسم مشارکتی که به شدت با صحنههای واقعی ادغام میشود، تمرکز دارد. به عنوان مثال، الگوهای شهری (زمین، ساختمان ها و جاده ها) به طور پویا با زمان تغییر می کنند، و اگرچه دامنه دید و عناصر قابل پیش بینی است، حجم داده ها زیاد است، بنابراین خروجی پرس و جو پایگاه داده وظیفه اصلی است. هدف برنامهریزی I/O کارآمد و رندر صحنه با عملکرد بالا در زمان واقعی است.
کار تجسم تحلیلی: این کار ویژگی های پنهان و اطلاعات همبستگی را در داده های مکانی-زمانی به دست آمده توسط تحلیل محاسباتی پیچیده برجسته می کند. کاربردهای معمولی شامل تجسم پویا از محاسبات بلادرنگ، نتایج شبیهسازی زمان واقعی، و تجسم یکپارچه نمادسازی و صحنههای واقعی است. این کار عمدتاً مبتنی بر تحلیل داده ها و محاسبات شبیه سازی است و نیاز به همکاری روش های زمان بندی برای سرعت بخشیدن به کارایی فرآیند تجزیه و تحلیل و تولید پویا نتایج دارد.
وظیفه تجسم اکتشافی: از طریق عملیات تنظیم اکتشافی تمرکز، تغییر شکل و برجسته سازی اشیاء خاص در صحنه واقعیت افزوده، جفت ارگانیک داده ها، مغز انسان، هوش ماشین و صحنه های کاربردی برای پشتیبانی از تجسم تجزیه و تحلیل تداعی عمیق تحقق می یابد. مانند تأیید فرضیه، استقراء دانش و استدلال. به عنوان مثال، تعامل چند رایانه ای و چند کاربره مشترک در یک محیط پیچیده عمدتاً مبتنی بر تعامل واقعیت است، با تمرکز بر زنجیره تحلیل تعاملی و تجسم زمان واقعی، در حالی که نتایج تحلیل پویا بلادرنگ و محتوای تعاملی را یکپارچه می کند. بنابراین، الزامات بالاتری برای زمانبندی دادههای مکانی-زمانی مطرح میشود.
۲٫۲٫ چارچوب زمانبندی داده های مکانی-زمانی
همانطور که در شکل ۱ نشان داده شده است ، چارچوب زمانبندی داده های مکانی-زمانی از سه بخش تشکیل شده است: سرور ابری، وظایف تجسم چند سطحی و برنامه های کاربردی متنوع.
در شکل ۱ ، سه نوع از کاربردهای تجسم در زمان واقعی فهرست شده است: بررسی صحنه، تجزیه و تحلیل شبیه سازی و مدیریت تعامل. الزامات دادهها و اهداف کاربردی برنامههای تجسم متنوع در نهایت تعداد زیادی از وظایف تجسم را تشکیل میدهند، که مطابق با مفهوم وظایف، همانطور که در بخش ۲٫۱ قبلی توضیح داده شد، به سه دسته تقسیم میشوند . سطوح مختلف وظایف تجسم نیازمندیهای متفاوتی برای زمانبندی دادههای مکانی-زمانی دارند. بنابراین، سرویس زمانبندی دادههای مکانی-زمانی در فضای ابری برای پاسخگویی پویا به دسترسی دادههای برنامههای کاربردی متنوع مورد نیاز است.
در شکل ۱، سرور ابری داده های خام چندمنبعی و چند دانه ای را ذخیره می کند، ذخیره می کند، ذخیره می کند، و داده های خام چندمنظوره و چند دانه ای را در وظایف تجسم هدف قرار می دهد و خدمات داده های مکانی-زمانی انعطاف پذیر و مقیاس پذیر را برای برنامه های کاربردی متنوع ارائه می دهد. پس از ورود داده های خام به سیستم ذخیره سازی ابری، داده ها از طریق کانتینر مجازی سازی و فناوری خوشه در سرورهای پایگاه داده مختلف مستقر می شوند. سپس، با توجه به ویژگی های دسترسی به داده ها، سرور کش الگوریتم کش مناسب را برای ذخیره داده هات اسپات و بهبود کارایی خدمات داده برای به اشتراک گذاشتن فشار دسترسی به پایگاه داده باطن تغییر می دهد. هنگامی که سیستم در حال اجرا است، از طریق تخصیص منابع ذخیره سازی و منابع پهنای باند هر نوع کانتینر پایگاه داده و سوئیچینگ استراتژی حافظه پنهان، تخصیص پویا جریان داده های مکانی-زمانی محقق می شود.
۳٫ مدل زمانبندی داده های مکانی-زمانی بر اساس حداکثر جریان
این بخش مفهوم و ساختار مدل زمانبندی حداکثر جریان پیشنهادی (MFS) را برای دادههای مکانی-زمانی توصیف میکند. بخش ۳٫۱ ساخت مدل MFS را معرفی می کند. بخش ۳٫۲ پیکربندی اولیه گره و ظرفیت لبه مدل MFS را ارائه می دهد. در نهایت، یک روش محاسبه برای مدل MFS در بخش ۳٫۳ معرفی شده است .
۳٫۱٫ ساخت مدل حداکثر جریان برای زمانبندی دادههای مکانی-زمانی
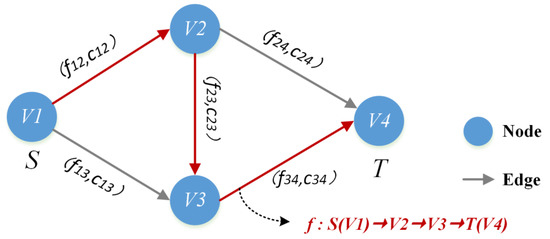
مدل حداکثر جریان یک گراف متصل جهت دار پیچیده است که می تواند به صورت بیان شود جی=(V، E)با مجموعه گره Vو ست لبه E. V={vمن|من∈ز+}مجموعه ای از تمام گره های گراف و E={(vمن،vj)|من∈ز+،j∈ز+،من≠j}مجموعه ای از تمام لبه های نمودار است. در شکل ۲ ، v1گره شروع جریان مدل است جی، همچنین به عنوان گره منبع شناخته می شود اس، و v4گره همگرایی جریان مدل است جی، همچنین به عنوان گره سینک شناخته می شود تی. هر لبه دارای دو پارامتر است، جمنjو fمنj، جایی که جمنjحداکثر جریانی است که لبه می تواند حمل کند که ظرفیت نیز نامیده می شود. fمنjجریان انتقال واقعی است، و fمنj≤جمنj. هر گره به جز S و T در مدل G از اصل بقای جریان ورودی و خروجی پیروی می کند که می تواند به صورت بیان شود. f+(vمن)=f-(vمن)( f+جریان ورودی به گره است vمن، f-جریان خروجی از است vمن). یک جریان قابل اجرا f. در مدل جیمقدار جریان عبوری از گره را نشان می دهد اسبه گره تی. حداکثر مقدار جریان های امکان پذیر fمترآایکسحداکثر جریان نامیده می شود. توپولوژی شبکه انتقال داده های مکانی-زمانی (در شکل ۱ ) را می توان به مدل حداکثر جریان نگاشت کرد که در آن سرور یا سرور کش به مدل گره V نگاشت می شود که دارای دو ویژگی است: نوع داده و حجم داده. اتصال شبکه به مدل لبه E نگاشت شده است که دارای ویژگی های پهنای باند محدود برای هر نوع داده است.
مفهوم اصلی مدل حداکثر جریان، حفظ جریان است، اما یک کپی داده می تواند به طور مداوم خدمات داده را ارائه دهد. بنابراین، این مقاله یک تبدیل انتزاعی از چارچوب زمانبندی دادههای مکانی-زمانی سمت سرور (نشان داده شده در شکل ۱ ) به دست میآورد و گرههای کمکی مربوطه را برای مدل MFS اضافه میکند ( شکل ۳ ). از طریق این تبدیل، حفظ جریان هر مرحله زمانبندی دادههای مکانی-زمانی تحقق مییابد که با مدل جریان حداکثر مطابقت دارد و ظرفیت سرویس هر مجموعه دادههای مکانی-زمانی قابل محاسبه است. گره ها از چپ به راست عبارتند از گره منبع S ، گره داده D ، گره ذخیره سازی d ، داده های حافظه پنهان/ترانزیت R., حداکثر جریان داده گره MD و سینک گره T در شکل ۳ . گره منبع S در مدل منبع داده مکانی-زمانی را نشان می دهد و گره سینک T وظیفه تجسم چندسطحی را نشان می دهد. برای نگاشت توپولوژی زمانبندی دادههای چندگانه مستقیماً به مدل حداکثر جریان، برخی از گرههای داده کمکی Dو حداکثر گره های جریان داده مDاضافه می شوند. در میان آنها، D={Dک|ک=۱،۲،۳،…q}مجموعه منابع هر نوع داده مکانی-زمانی را نشان می دهد. مD={مDک|ک=۱،۲،۳،…،q}حداکثر جریان هر نوع داده مکانی-زمانی را نشان می دهد Dک، همچنین به عنوان حداکثر قابلیت سرویس داده ای که سیستم می تواند به وظایف تجسم ارائه دهد نیز شناخته می شود که با حل مدل MFS به دست می آید.
علاوه بر این، گره های ذخیره سازی د={دکn|ک=۱،۲،۳،…q، n=1،۲،۳…،پ}، که در آن k نشان دهنده نوع داده و n نشان دهنده تعداد کپی ها است، پایگاه های داده کانتینری هستند که فضای دیسک را برای ذخیره داده های مکانی-زمانی از انواع، دانه بندی ها و حجم های مختلف در سرور ماشین مجازی VM اختصاص داده اند. گره های کش
آر={آرم|م=۱،۲،۳،…،متر}در پایگاه داده های حافظه ای گنجانده شده اند که می توانند فشار دسترسی پایگاه داده سمت سرور را به اشتراک بگذارند. فرض کنید در شرایط ایده آل، تمام درخواست های داده در حافظه پنهان از دست می روند و گره کش به عنوان یک گره انتقال در نظر گرفته می شود. گره ترانزیت نیز از قوانین حفظ جریان پیروی می کند و جریان داده ارسالی از سرور را به گره MD به طور کامل انتقال می دهد. حداکثر جریان از Dکبه عنوان ثبت می شود ز۱(مDک). اگر درخواستی در کش وجود داشته باشد، داده ها مستقیماً از گره کش به گره منتقل می شوند MDگره اگر همه درخواستها در حافظه پنهان وارد شوند، حداکثر جریان Dکبه عنوان ثبت می شود ز۲(مDک)و مدل MFS در این مورد همانطور که در شکل ۴ نشان داده شده است. با این حال، در یک حالت عملی، محدوده حداکثر جریان از Dکباید راضی کند ز(مDک)∈(ز۱(مDک)،ز۲(مDک)); بدین ترتیب، ز۱(مDک)حد پایین نامیده می شود و ز۲(مDک)حد بالایی نامیده می شود.
۳٫۲٫ تنظیمات اولیه گره و ظرفیت لبه
فناوری کانتینر مجازی سازی بسیار قابل حمل، سبک وزن و ایمن تر است که می تواند تحمل خطا در ذخیره سازی داده ها را بهبود بخشد و در دسترس بودن بالا را به همراه داشته باشد. بنابراین، این مقاله از فناوری کانتینر مجازی سازی برای استقرار خوشه های پایگاه داده در سرورهای مختلف استفاده می کند. قرار دادن نامتعادل داده ها در سرور منجر به زمان انتقال داده بیش از حد می شود و توان عملیاتی داده سرویس داده ابری را کاهش می دهد. بنابراین، این مقاله یک استراتژی چند تکراری را برای استقرار چندین کپی از داده های مشابه در سرورهای مختلف اتخاذ می کند. علاوه بر این، ما باید وابستگی بین داده ها را در نظر بگیریم. به عنوان مثال، اگر هر دو داده Dکو Dک+منباید در مرحله ساخت صحنه برنامه ریزی شود، آنها را می توان بسیار وابسته و برای قرار دادن در همان سرور مناسب در نظر گرفت. در غیر این صورت باعث رقابت در منابع سرور می شوند.
دو نوع گره در مدل ذخیره سازی داده های مکانی-زمانی را امکان پذیر می کند: گره ذخیره سازی d و گره کش .آر. در میان آنها، پیکربندی مقداردهی اولیه d تعیین می کند که چه تعداد تکرار و در کدام سرور داده ها قرار گیرد. Dک. پیکربندی اولیه از آرالگوریتم جایگزینی حافظه پنهان اولیه را برای ذخیره داده های هات اسپات انتخاب می کند. به طور کلی، تنظیمات اولیه هر دو دو آربه تجربه متخصص تکیه کنید در شکل ۳ و شکل ۴ ، ظرفیت و جریان لبه در مدل MFS هر نوع داده به صورت بیان شده است. fمنj(fمنj1،…،fمنjک،…،fمنjq)/جمنj(جمنj1،…،جمنjک،…،جمنjq)، جایی که fمنj است را جمع داده ها جریاناز لبه و fمنjکجریان هر یک است Dک، fمنj=∑ک=۱qfمنjک. جمنjمجموع ظرفیت انتقال لبه است و جمنjکظرفیت انتقال هر کدام است Dک، جمنj=∑ک=۱qجمنjک. پیکربندی اولیه ظرفیت لبه به تفصیل در زیر توضیح داده شده است:
این حاشیه، غیرمتمرکز(Dک،Vم)در شکل ۳ ارتباط بین گره های داده های کمکی و گره ذخیره سازی است حاشیه، غیرمتمرکز (Dک،آرم)در شکل ۴ ارتباط بین گره های داده کمکی و گره کش است. جمنjاز حاشیه، غیرمتمرکز(Dک،Vم)و حاشیه، غیرمتمرکز (Dک،آرم)به عنوان مقدار داده ای که واقعاً روی سرور مستقر شده است تعریف می شود Vمو سرور کش R به ترتیب و جمنjکمقدار هر نوع داده ای است که واقعاً مستقر شده است.
ظرفیت انتقال داده از حاشیه، غیرمتمرکز (Vم،آرم)در شکل ۳ بین گره ذخیره سازی و گره کش به وضوح تحت تاثیر پهنای باند و مقدار داده های ذخیره شده است. در معادله (۱) ب(Vم، آرم)پهنای باند شبکه بین دو گره است Vمو آرم، دآتیآاسمنzه(دکn)مقدار داده گره ذخیره سازی را نشان می دهد دکn، α یک ثابت است که از پهنای باند و مقدار داده محاسبه می شود و t زمان انتقال است. تحت همان پهنای باند شبکه، مقدار بیشتری از داده ها در سرور ذخیره می شود Vم، زمان بیشتری برای تکمیل تمام انتقال داده ها صرف می شود. بنابراین، این مقاله تعریف می کند جمنjاز حاشیه، غیرمتمرکز(Vم،آرم)به این ترتیب که با مقدار داده های ذخیره شده توسط سرور نسبت معکوس دارد Vم، و جمنjکاز حاشیه، غیرمتمرکز(Vم،آرم)با تخصیص حداکثر ظرفیت انتقال محاسبه می شود جمنjبا توجه به نسبت Dکبه مقدار کل داده، همانطور که در رابطه (۲) نشان داده شده است.
ظرفیت انتقال داده از حاشیه، غیرمتمرکز(آرم، مDک)همچنین تحت تأثیر پهنای باند و مقدار داده های ذخیره شده است. تنظیم پهنای باند بین گره ها آرمو مDکمانند ب(آرم، مDک)، بلوک های کش r ={rکل|ک=۱،۲،۳…،q، ل=۱،۲،۳،…،y}چند نوع داده مکانی-زمانی در گره کش ذخیره می شود آر، جایی که rکلl-امین بلوک کش است Dک. مشابه تعریف از جمنjکاز حاشیه، غیرمتمرکز(Vم، آرم)، جمنjکاز حاشیه، غیرمتمرکز(آرم، مDک)همانطور که در رابطه (۳) نشان داده شده است، تعریف می شود.
ارتباط بین گره حداکثر جریان داده کمکی و گره سینک به صورت ثبت می شود حاشیه، غیرمتمرکز(مDک،تی)، که مسیر عرضه هر نوع جریان داده به سمت مشتری در سرویس زمانبندی است. این جمنjکاز حاشیه، غیرمتمرکز(مDک،تی)حداکثر جریان است Dک، توسط مدل MFS محاسبه شده است.
علاوه بر این، حاشیه، غیرمتمرکز(vمن،vj)برای مطابقت با دو محدودیت در مدل MFS ضروری است.
محدودیت ظرفیت: برای برآوردن محدودیت جریان کل انواع داده ها ضروری است. محدودیت ظرفیت هر نوع داده Dک، ۰≤∑ک=۱qfمنjک≤جمنjو fمنjک≤جمنjک, k = ۱,۲,۳, …, q ;
حفاظت جریان: همه گره ها باید از قوانین حفاظت جریان پیروی کنند، از جمله کل جریان داده ای که باید حفظ شود و هر نوع جریان داده ای که باید حفظ شود. ∑ک=۱qf+(vمن)=∑ک=۱qf-(vمن)و f+(vمن)=f-(vمن), k = ۱,۲,۳, …, q ;
بر اساس تحلیل های فوق، تابع هدف و محدودیت های مدل MFS برای داده های مکانی-زمانی در معادلات (۴) و (۵) نشان داده شده است. ∑کqfمنjکحداکثر مقدار جریان های امکان پذیر همه داده ها در مدل MFS است.
۳٫۳٫ الگوریتم حداکثر جریان
هدف از بهینهسازی جهانی جریان دادههای مکانی-زمانی، به حداکثر رساندن جریان امکانپذیر همه دادهها در مدل است. پس از مقداردهی اولیه مدل جریان، حد پایین و بالای حداکثر جریان داده جریان می یابد ز۱(مDک)،ز۲(مDک)بر اساس الگوریتم حداکثر جریان بهبود یافته Dinic [ ۴۸ ] حل می شوند، که می تواند به طور موثر حداکثر مقدار جریان داده های چندگانه را حل کند. ایده اصلی الگوریتم استفاده از استراتژی BFS (عرض-اول-جستجو) برای لایه بندی و عبور از گره های شبکه باقی مانده است. جیfکاز مدل G، بنابراین شبکه باقیمانده لایه ای به دست می آید جیfک”و استفاده از DFS (depth-first-search) برای یافتن مسیر افزایشی و مقدار جیfک”[ ۴۹ ]. مسیر افزایش یک مسیر از گره s به گره T در مدل G = (V, E) است که در طول آن جریان بیشتری می تواند منتقل شود [ ۵۰ ]. مراحل دقیق الگوریتم Dinic به شرح زیر است و نمودار جریان الگوریتم در شکل ۵ نشان داده شده است .
-
وارد کردن جریان داده از Dکاز ۰ در مدل جی=(V،E);
-
شبکه باقی مانده را بسازید جیfکاز مدل جی=(V،E)و از استراتژی BFS برای یافتن شبکه باقیمانده لایه ای استفاده کنید جیfک”مدل زمانبندی؛ اگر گره سینک داخل نباشد جیfک”، به (۶) بروید
-
از استراتژی DFS برای یافتن مسیر افزایش استفاده کنید. اگر جیfک”یک مسیر افزایشی از گره منبع S به گره غرق T دارد، به (۴) بروید. اگر نه، به (۵) بروید؛
-
با توجه به مسیر افزایش یافت شده و مقدار افزوده، ویژگی لبه هدایت شده شبکه باقیمانده لایه ای را تقویت و اصلاح کنید. جیfک”، سپس به (۳) بروید؛
-
جیfک”هیچ مسیر افزایشی در دسترس نیست. رفتن به (۲)؛
-
جریان امکان پذیر حاصل حداکثر جریان است ز(مDک)از Dک;
-
برای شروع افزایش جریان Dک+۱، مراحل (۲) تا (۶) را تا k = q تکرار کنید.
در نهایت حد پایین و بالایی حداکثر جریان داده طبق رابطه (۶) به دست می آید.
۴٫ روش تخصیص حداکثر جریان مبتنی بر وظیفه برای دادههای مکانی و زمانی
در سرویس ابری، با تنظیم پارامترهای مدل حداکثر جریان برای تغییر پایین تر ز۱(مDک)و بالا ز۲(مDک)محدودیت یک داده مکانی-زمانی خاص، حداکثر جریان کلی تمام خدمات داده را می توان حفظ کرد تا به صورت پویا نیازهای دسترسی مختلف وظایف تجسم چند سطحی را برآورده کند. بخش ۴٫۱ روش تنظیم جریان را بر اساس گره کش معرفی می کند و بخش ۴٫۲ روش تنظیم جریان را بر اساس گره ذخیره سازی معرفی می کند.
۴٫۱٫ تخصیص ظرفیت گره کش
حافظه نهان در مقایسه با کانتینر پایگاه داده خارجی که برای بهبود توانایی دسترسی به داده های سیستم استفاده می شود، به خواندن سریع داده و عملکرد بالا دست می یابد. تخصیص ظرفیت انتقال گره کش را می توان با انتخاب یک الگوریتم و خط مشی کش خاص تغییر داد. با گذشت زمان، انواع داده های بیشتری به گره کش اضافه می شود. اگر گره کش پر باشد، از الگوریتم جایگزین تطبیقی برای حذف داده های سرد و آماده سازی فضای ذخیره سازی برای داده های جدید استفاده می شود. از آنجایی که سطوح مختلف وظایف تجسم اولویت آشکاری برای دادههای مکانی-زمانی دارند، اگر گره کش فعلی نتواند درخواست دادههای پشت سر هم را در حالت در حال اجرا برآورده کند، الگوریتم گره کش میتواند به طور موقت تغییر کند تا محتوای دادههای ذخیره شده در گره کش را تغییر دهد. برای انطباق با نیازهای تغییرات پویا. از این رو، یک الگوریتم کش ترکیبی وظیفه محور برای بهبود جریان داده بر اساس اندازه کش، نرخ ضربه و فرکانس دسترسی طراحی شده است. به عنوان مثال، اگر وظیفه مشتری اولویت داده آشکاری نداشته باشد، می توان از الگوریتم جایگزینی LRU یا LFU با در نظر گرفتن LOD استفاده کرد. بر اساس LRU یا LFU، ابتدا می توان اشیاء با LOD بالا را حذف کرد، که نه تنها می تواند مقدار داده های کش را به حداقل برساند، بلکه اطمینان حاصل می کند که تا آنجا که ممکن است اشیاء در حافظه پنهان باقی می مانند و به طور قابل توجهی نرخ ضربه مشتری را بهبود می بخشد. حافظه پنهان اگر وظیفه مشتری ترجیح داده آشکاری داشته باشد، استراتژی پیش بارگیری فعال، به جای بارگیری بر اساس تقاضا، می تواند اتخاذ شود، که در آن داده های هدف ابتدا در حافظه پنهان می شوند و سپس توانایی سرویس داده بهبود می یابد. در عین حال، به دلیل نزدیکی فضایی دسترسی شیء فضایی، اشیاء در مجاورت فضایی فرکانس دسترسی مشابهی دارند. از این رو، الگوریتم جایگزینی حافظه پنهان مبتنی بر مجاورت فضایی را می توان اضافه کرد.
همانطور که در شکل ۶ نشان داده شده است ، الگوریتم کش وضعیت پیکربندی داده ها را در گره کش تنظیم می کند و تغییر در مقدار داده باعث می شود ظرفیت انتقال لبه تغییر کند. همانطور که در بخش ۳٫۲ توضیح داده شد ، هنگامی که نسبت بلوک های داده هات اسپات در گره کش افزایش می یابد، حداکثر ظرفیت انتقال آن جمنjکنیز به نسبت افزایش می یابد. به طور خلاصه، الگوریتم کش ترکیبی وظیفه محور نقش مهمی در افزایش ظرفیت انتقال جریان داده هات اسپات در سرویس زمان بندی ایفا می کند.
۴٫۲٫ تخصیص ظرفیت گره ذخیره سازی
هنگامی که اولویتهای دسترسی به دادهها با وظایف همزمانی بالا تغییر میکنند، با تغییر الگوریتم ذخیره ترکیبی، میتوان جریان دادههای ترجیحی را بهبود بخشید، اما تنظیم الگوریتم کش ترکیبی تنها به هدف افزایش حد بالای داده ترجیحی میرسد. حداکثر جریان ز۲(مDک); حد پایین جریان هنوز تغییر نکرده است. جریان داده های عملی همچنان می تواند نزدیک به حد پایین باشد. بنابراین، راه دیگری برای افزایش جامع حداکثر جریان ترجیحی داده ها، تنظیم تخصیص ظرفیت لبه سرور زیرینی است که گره ذخیره سازی در آن قرار دارد.
با توجه به اولویتهای دسترسی به دادهها در وظایف تجسم، این دو نوع استراتژی تنظیم میتوانند اندازه جریان هر نوع داده مکانی-زمانی را برای برآوردن نیازهای کار تغییر دهند. در میان آنها، روش تنظیم الگوریتم گره کش هیبریدی تغییرات را سریعتر و انعطاف پذیرتر می کند، در حالی که روش تخصیص ظرفیت لبه اتصال سرور می تواند حداکثر جریان داده های مکانی-زمانی را به دقت تخصیص دهد و پهنای باند جریان داده های مکانی-زمانی را از پایین بهبود می بخشد. موثرتر. در یک پروژه واقعی، استراتژی تنظیم جریان داده مکانی-زمانی را می توان با توجه به تغییرات کار انتخاب کرد تا با کمترین هزینه نیازهای جریان داده وظایف تجسم چند سطحی را برآورده کند.
۵٫ تجزیه و تحلیل تجربی
برای تأیید اثربخشی روش MFS پیشنهادی در تجسم دادههای مکانی-زمانی وظیفهمحور، آزمایشهای زمانبندی دادههای مکانی-زمانی مربوط به سه سطح کار تجسم، با شش نوع داده مکانی-زمانی معمولی، از جمله DEM، مدل ساختمان، DSM، مسیر، رابطه و داده های خط لوله، که به طور مفصل در جدول ۱ توضیح داده شده است . روش MFS را با دو استراتژی مهم مقایسه کرد، یعنی اولین خدمت (FCFS) [ ۴۱ ] و الگوریتم زمانبندی اولویت (PSA) [ ۵۱ ]، با شبیه سازی و تجزیه و تحلیل تغییرات عملیات داده واقعی، و امکان سنجی روش MFS
۵٫۱٫ محیط تجربی و داده ها
آزمایش زمانبندی دادههای مکانی-زمانی با جاوا نسخه ۱٫۸ پیادهسازی شده است و یک رابط مبتنی بر وب برای پیکربندی پارامتر و نظارت بر جریان داده توسعه داده شده است. گره های ذخیره سازی توسط MongoDB مبتنی بر کانتینر نسخه ۴٫۰٫۱۲ و گره های کش توسط Redis نسخه ۵٫۰٫۵ مبتنی بر کانتینر پیاده سازی می شوند. کل سیستم آزمایشی بر روی هفت ماشین مجازی مستقر شده است که هر کدام با سیستم عامل CentOS 7 نصب شده اند و دارای پردازنده دو هسته ای، ۴ گیگابایت رم و ۵۰ گیگابایت حجم هارد دیسک هستند. چهار تا از ماشین های مجازی به عنوان گره های ذخیره سازی، دو تا به عنوان گره های کش و یکی به عنوان سرویس زمان بندی داده ها استفاده می شوند.
همانطور که در جدول ۱ نشان داده شده است، شش نوع داده مکانی-زمانی معمولی در آزمایش تهیه شده است ، که در آن وظایف تجسم صحنه نمایش بر اساس مدل DEM و ساختمان، وظایف تجسم تحلیلی صحنه بر اساس DSM و مسیر و داده های رابطه است [ ۵۲ ، ۵۳ ]، و کارهای تجسم صحنه اکتشافی از داده های خط لوله استفاده می کنند. برای ارزیابی دقت روش MFS پیشنهادی ما، از مجموعه داده های باز (ساخت مجموعه داده های مدل) برای نیویورک ( http://maps.nyc.gov/download/3dmodel/DA_WISE_GML.zip ) استفاده کردیم. صحنه های کاربردی معمولی از سه نوع کار تجسم در شکل ۷ نشان داده شده است. شکل ۷a مدل شهر را توصیف می کند که به وظیفه تجسم نمایش تعلق دارد. شکل ۷ b بهترین مسیر فرار از زلزله را از طریق تجزیه و تحلیل شبیه سازی به دست می آورد و شکل ۷ c نمایش دانش روابط اجتماعی در محوطه دانشگاه را نشان می دهد که هر دو به وظیفه تجسم تحلیلی تعلق دارند. شکل ۷ d عیب یابی دقیق خطای خط لوله را در محیط واقعیت افزوده تعاملی، که به وظیفه تجسم اکتشافی تعلق دارد، توضیح می دهد.
۵٫۲٫ نتایج تجربی و تجزیه و تحلیل
۵٫۲٫۱٫ محاسبه حداکثر جریان داده در حالت اولیه
با توجه به الزامات وظایف تجسم چند سطحی، سرویس ذخیره سازی داده های مکانی-زمانی ساخته می شود و پارامترهای زمان بندی پیکربندی می شوند. مدل MFS داده های مکانی-زمانی تجربی در شکل ۸ ساخته شده است. وضعیت پیکربندی گره و ظرفیت انتقال داده هر لبه در جدول ۲ نشان داده شده است که با معادلات (۱) – (۳) محاسبه شده است. ب(Vم،آرم)=ب(آرم، مDک)=ب. حد پایین و بالای هر نوع داده مکانی و زمانی ز۱(مDک)و ز۲(مDک)همانطور که در جدول ۳ نشان داده شده است، می توان تحت حالت اولیه توسط الگوریتم Dinic به دست آورد .
۵٫۲٫۲٫ تنظیم مدل MFS
رابط مدیریت حداکثر جریان داده های مکانی-زمانی مبتنی بر وب در شکل ۹ نشان داده شده است ، و عناصر نمودار با Echarts [ ۵۴ ] پیاده سازی شده اند. رابط مدیریت را می توان برای تنظیم پارامترهای ظرفیت برای برآوردن نیازهای مختلف سطوح مختلف وظایف تجسم برای داده های مکانی-زمانی استفاده کرد. با کشیدن سرور و نوار لغزنده حافظه نهان، پارامترهای ظرفیت لبه تغییر میکند و در نتیجه توانایی سرویس هر نوع داده مکانی-زمانی در محیط ابری تغییر میکند. با شبیه سازی درخواست ها برای سه نوع کار تجسمی همانطور که در شکل ۷ توضیح داده شده است: نمایش وظیفه تجسم: مدل شهر; کار تجسم تحلیلی: راه فرار از زلزله و روابط اجتماعی دانشجویان در محوطه دانشگاه. کار تجسم اکتشافی: عیب یابی خط لوله. همانطور که در نمودار پایین سمت چپ نشان داده شده است، توان عملیاتی واقعی هر نوع داده را می توان در زمان واقعی نظارت کرد. علاوه بر این، تحت تنظیمات پارامتر فعلی، مقادیر حد بالا و پایین هر نوع داده مکانی-زمانی محاسبه شده بر اساس روش در این مقاله در نمودار پایین سمت راست نشان داده شده است.
روش آزمون مورد استفاده در آزمایش زمانبندی دادهها، تمام دادههای مکانی-زمانی را از طریق پیمایش متوالی درخواست و زمانبندی میکند. علاوه بر این، قسمت ابتدایی هر نوع توالی داده های مکانی-زمانی در گره کش ذخیره می شود. بنابراین، در طول آزمایش، درخواست ها در حافظه قرار می گیرند و سپس از طریق سرور باطن پردازش می شوند. از طریق این روش تست ویژه، زمانی که مدل MFS در حالت های حد بالا و پایین است، می توانیم توان عملیاتی داده های سیستم را آزمایش کنیم. در مرحله بعد، ما اثربخشی این روش را از طریق دو مورد خاص تجسم چند سطحی تأیید میکنیم.
مورد A: هنگامی که تعداد زیادی از وظایف نمایشگر به سیستم زمانبندی متصل می شوند، دسترسی به داده ها ترجیح داده می شود D1و D2و منبع سرویس داده با نرخ دسترسی کم را می توان به سرویس داده با نرخ دسترسی فشرده برای بهبود سرعت پاسخ سیستم و استفاده از منابع اختصاص داد. بنابراین، نوار لغزنده در رابط مدیریت جریان حداکثر کشیده می شود، پارامترهای ظرفیت تنظیم می شوند و قابلیت سرویس دهی D1و D2بهبود یافته است. حدود بالا ز۲(مDک)و حدود پایین تر ز۱(مDک)همانطور که در جدول ۴ نشان داده شده است، از هر نوع داده مکانی-زمانی در مورد A می توان با الگوریتم Dinic به دست آورد . در مقابل جدول ۳ ، هر دو حد پایین و حد بالایی از D1و D2پس از تنظیم افزایش می یابد. در همان زمان، حداکثر مقدار جریان از D3– D6کاهش می یابد.
با تغییر در پارامترهای مدل، خروجی داده های واقعی از D1و D2نیز تغییر می کنند. منحنی های نظارت بر توان زمان واقعی از D1و D2در شکل ۱۰ نشان داده شده است. بخش قبلی منحنی های توان عملیاتی D1و D2بالاتر هستند زیرا داده های مورد نیاز کار در گره کش قرار می گیرند. در این زمان، مقادیر توان عملیاتی نظارت شده واقعی با حد بالایی مدل MFS مطابقت دارد. در حالی که بخش دوم مقادیر توان کاهش مییابد زیرا دادههای مورد نیاز کار ضربه نمیخورد، در این زمان، مقادیر توان عملیاتی نظارت شده واقعی با حد پایین مدل MFS مطابقت دارد. زمان بندی داده های D1قبل از آن تکمیل می شود D2; بنابراین، توان عملیاتی تحت نظارت واقعی بعدی D1به ۰ کاهش می یابد.
در شکل ۱۰ a، توان عملیاتی D1در ابتدا در ۶۱٫۴۸ مگابایت بر ثانیه نگهداری می شود و سپس به ۵۱٫۹۶ مگابایت بر ثانیه کاهش می یابد و توان عملیاتی D2در ابتدا در ۹۱٫۸۰ مگابایت بر ثانیه حفظ می شود و سپس در حالت اولیه به ۴۶٫۹۵ مگابایت بر ثانیه کاهش می یابد. پس از تنظیم مدل، مقادیر توان عملیاتی واقعی از D1و D2در مورد A همانطور که در شکل ۱۰ ب نشان داده شده است. توان عملیاتی D1در ابتدا در ۷۴٫۶۱ مگابایت بر ثانیه نگهداری می شود و سپس به ۷۰٫۵۵ مگابایت بر ثانیه کاهش می یابد و توان عملیاتی D2در ابتدا در ۱۰۹٫۸ مگابایت بر ثانیه حفظ می شود و سپس به ۵۳٫۳۴ مگابایت بر ثانیه کاهش می یابد. با مقایسه شکل ۱۰ a,b، متوجه می شویم که توان عملیاتی واقعی D1در بخش اول ۲۱٫۳۶% و قسمت دوم ۳۵٫۷۸% افزایش یافته است. توان عملیاتی واقعی D2در بخش اول ۱۹٫۶۱ درصد و قسمت دوم ۱۳٫۶۱ درصد افزایش یافته است. در نتیجه، با تنظیم پارامترهای مدل MFS، توان عملیاتی واقعی دادههای ترجیحی وظیفه نمایش بهبود مییابد، و توانایی سرویس دادههای مکانی-زمانی تحت شرایط یک کار نمایش فشرده بهبود مییابد.
حالت ب: هنگامی که تعداد زیادی از وظایف تحلیلی به سیستم زمان بندی متصل می شوند، دسترسی به داده ها ترجیح داده می شود. D3، D4و D5. مشابه مورد A، برای بهبود قابلیت سرویس دهی سیستم، باید منابع بیشتری به آن تخصیص داده شود D3، D4و D5. حدود بالا و حد پایین هر نوع داده مکانی-زمانی در مورد B را می توان با الگوریتم Dinic به دست آورد، همانطور که در جدول ۵ نشان داده شده است. در مقایسه با جدول ۳ ، حدود پایین و حد بالایی از D3، D4و D5پس از تنظیم افزایش می یابد. در همان زمان، مقادیر حداکثر جریان از D1و D2کاهش می یابد زیرا منابع کمتری به آنها اختصاص می یابد.
با تغییر در پارامترهای مدل، خروجی داده های واقعی از D3، D4و D5نیز تغییر می کنند. منحنی های نظارت بر توان زمان واقعی از D3، D4و D5در شکل ۱۱ نشان داده شده است. بخش قبلی منحنیهای توان عملیاتی بالاتر است زیرا دادههای مورد نیاز کار در گره حافظه پنهان قرار میگیرند. در این زمان، مقادیر توان عملیاتی نظارت شده واقعی با حد بالایی مدل MFS مطابقت دارد. در حالی که بخش دوم مقادیر توان کاهش مییابد زیرا دادههای مورد نیاز کار ضربه نمیخورد، در این زمان، مقادیر توان عملیاتی نظارت شده واقعی با حد پایین مدل MFS مطابقت دارد.
در شکل ۱۱ a، توان عملیاتی D3در ابتدا در ۴۷٫۳۸ مگابایت بر ثانیه حفظ می شود و سپس به ۲۲٫۶۵ مگابایت بر ثانیه کاهش می یابد. D4ابتدا در ۵۸٫۷۹ مگابایت بر ثانیه حفظ می شود و سپس به ۱۷٫۷۹ مگابایت بر ثانیه کاهش می یابد و توان عملیاتی D5در ابتدا در ۱۴٫۷۵ مگابایت بر ثانیه حفظ می شود و سپس در حالت اولیه به ۱۰٫۲۸ مگابایت بر ثانیه کاهش می یابد. پس از تنظیم مدل، توان عملیاتی از D3در ابتدا در ۶۶٫۴۱ مگابایت بر ثانیه حفظ می شود و سپس به ۳۰٫۰۱ مگابایت بر ثانیه کاهش می یابد. D4ابتدا در سرعت ۷۰٫۳۰ مگابایت بر ثانیه حفظ می شود و سپس به ۲۷٫۴۶ مگابایت بر ثانیه کاهش می یابد و توان عملیاتی D5در ابتدا در ۱۷٫۴۴ مگابایت بر ثانیه نگهداری می شود و سپس در شکل ۱۱ ب به ۱۳٫۰۰ مگابایت بر ثانیه کاهش می یابد. با مقایسه شکل ۱۱ a,b، توان عملیاتی واقعی D3در بخش اول ۴۰٫۱۶% و در قسمت دوم ۳۲٫۴۹% افزایش یافته است. توان عملیاتی واقعی D4در بخش اول ۱۹٫۵۸% و در قسمت دوم ۵۴٫۳۶% افزایش یافته است. و توان عملیاتی واقعی D5در بخش اول ۱۸٫۲۴ درصد افزایش یافته است در حالی که در بخش دوم ۲۶٫۴۶ درصد افزایش یافته است. در نتیجه، با تنظیم پارامترهای مدل MFS، توان عملیاتی واقعی دادههای اولویت کار تحلیلی بهبود مییابد و توانایی سرویس دادههای مکانی-زمانی تحت شرایط یک کار تحلیلی فشرده بهبود مییابد.
تنظیم پارامترهای هر داده مکانی-زمانی در مدل MFS منجر به تغییرات در توان داده مربوطه می شود. رابطه بین آنها در شکل ۱۲ a,b نشان داده شده است. در شکل ۱۲ الف DکUحد بالایی است ز۲(مDک)و DکLحد پایینی بالایی است ز۱(مDک). در شکل ۱۲ ب DکLو DکUقسمت اول و قسمت دوم توان عملیاتی واقعی است. این نشان میدهد که وقتی دادههای نقطه اتصال اولویت وظیفه تغییر میکنند، توان عملیاتی داده نظارت با پارامترهای مدل مربوطه تغییر میکند و جهت افزایش و کاهش این دو یکسان است. بنابراین، روش MFS می تواند به طور انعطاف پذیری هر نوع جریان داده های مکانی-زمانی را در صورت نیاز تنظیم کند و بهینه سازی جهانی جریان داده های مکانی-زمانی را تحت منابع سخت افزاری محدود در محیط ابری تحقق بخشد.
۵٫۲٫۳٫ تحلیل میانگین توان عملیاتی
یک الگوریتم زمانبندی دادههای مکانی-زمانی وظیفهگرا در یک محیط ابری نه تنها باید به طور موثر از منابع پهنای باند شبکه استفاده کند، بلکه باید با اولویتهای دسترسی به دادهها در رابطه با وظایف تجسم چند سطحی سازگار شود. با در نظر گرفتن میانگین توان به عنوان شاخص برای ارزیابی عملکرد الگوریتم زمانبندی، آزمایشهای مقایسهای با روش FCFS، PSA و MFS در این مقاله انجام میشود. این دو الگوریتم جهانی هستند و ویژگی های متمایز دارند. FCFS شامل دسترسی سفارشی به وظایف است که مزیت انصاف و معایب عدم در نظر گرفتن رضایت از زمانبندی را دارد. PSA ابتدا وظایف را با اولویت بالا اجرا می کند، بنابراین از مزیت در نظر گرفتن فوریت یک کار و ضرر افزایش هزینه محاسبات برخوردار است. مقایسه MFS با FCFS و PSA ثابت میکند که MFS میتواند با اولویت دسترسی به دادههای وظایف تجسم چندسطحی از دو جنبه زمانبندی تمایز نیافته و زمانبندی اولویت سازگار شود. برای اطمینان از قابلیت اطمینان نتایج آزمایشی، به هر الگوریتم در مجموعه ای از آزمون های زمان بندی یک رده وظیفه اختصاص داده شد و میزان داده های مورد دسترسی توسط کارها برابر بود.شکل ۱۳ میانگین توان عملیاتی شش نوع داده مکانی-زمانی را با استفاده از روش FCFS، PSA و MFS ارائه شده در این مقاله نشان می دهد. و میانگین توان عملیاتی در موارد A و B معادل مقدار کل داده های برگشتی تقسیم بر زمان اجرای کار است.
در شکل ۱۳ الف، زمانی که تقاضا برای داده های مکانی و زمانی D1و D2درخواست شده توسط وظایف نمایش افزایش می یابد، میانگین توان عملیاتی داده های D1 و D2 با استفاده از روش MFS بهتر از روش های FCFS و PSA است و نتایج تجربی FCFS و PSA مشابه هستند. در شکل ۱۳ ب، میانگین توان عملیاتی D3، D4و D5با روش زمانبندی حداکثر جریان بهتر از روشهای FCFS و PSA است و نتایج تجربی FCFS و PSA مشابه است. ویژگی های روش زمان بندی برای تعیین دلایل به دست آوردن نتایج تجربی مورد تجزیه و تحلیل قرار گرفت. قابل ذکر است، روش MFS وظیفه محور است. هنگامی که ویژگی های داده تعداد زیادی درخواست کار تغییر می کند، منابع با پهنای باند محدود را می توان مجدداً تخصیص داد، و پهنای باند بیشتری به داده های اولویت کار داده می شود، در حالی که سایر داده ها در این زمان منابع پهنای باند کمتری را تخصیص می دهند. به عنوان مثال میانگین توان عملیاتی دادههای D3، D4 و D6 با استفاده از روش MFS از FCFS و PSA در مورد A کوچکتر است و میانگین توان عملیاتی دادههای D6 با استفاده از روش MFS کمتر از FCFS و PSA در مورد B است. روشهای FCFS و PSA این مکانیسم تنظیم را ندارند،
به طور خلاصه، روش MFS پیشنهاد شده در این مقاله میتواند با اولویتهای دسترسی به دادههای وظایف تجسم چند سطحی سازگار شود و توان عملیاتی دادههای هدف را بهبود بخشد. اگرچه PSA اولویت وظایف را در زمانبندی در نظر میگیرد، نقش آن در بهبود کارایی زمانبندی دادههای هدف به خوبی روش MFS نیست. علاوه بر این، به دلیل اصل انصاف FCFS برای همه وظایف، برای زمانبندی دادهها که شامل وظایف تجسم چندسطحی است، نامناسب است.
۶٫ نتیجه گیری
یک روش زمانبندی دادههای انعطافپذیر و کارآمد، کلید تحقق ساخت و ساز بلادرنگ و تعامل تصویرسازی صحنه سهبعدی است. در این مقاله، چارچوب زمانبندی دادههای مکانی-زمانی برای وظایف تجسم چندسطحی ارائه شده است. سپس مدل زمانبندی دادههای مکانی-زمانی مبتنی بر جریان حداکثر به تفصیل معرفی میشود. بر این اساس، روش تخصیص حداکثر جریان مبتنی بر وظیفه برای دادههای مکانی-زمانی معرفی میشود. یک سیستم نمونه اولیه مبتنی بر کانتینر مجازی سازی برای زمان بندی داده ها و یک رابط تنظیم پارامتر مبتنی بر وب کاربر پسند توسعه داده شده است. نتایج تجربی نشان میدهد که روش MFS مورد بررسی در این مقاله میتواند از تنظیم انعطافپذیر و بهینه جریانهای دادههای مکانی-زمانی متعدد مورد نیاز کارهای تجسم پشتیبانی کند.
ابتدا، تعاریف یک کار تجسم چندسطحی و اولویت داده آن ارائه شده است. سپس با توجه به ساختار ذخیرهسازی و زمانبندی دادههای مکانی-زمانی در یک محیط ابری، چارچوب زمانبندی دادههای مکانی-زمانی طراحی میشود که مبنای نظری را برای زمانبندی بهینه دادهها بهبود میبخشد.
دوم، ساختار شبکه توپولوژیکی برنامهریزی دادههای مکانی-زمانی به مدل حداکثر جریان نگاشت شده و روش پیکربندی پارامتر گره و لبه و روش محاسبه دقیق جریان حداکثری دادههای مکانی-زمانی چندگانه معرفی میشوند. سپس، دو روش تنظیم وظیفه محور برای پارامترهای مدل حداکثر جریان، که پشتیبانی فنی را برای برنامهریزی بهینه دادههای مکانی-زمانی ریز دانه بهبود میبخشد، ارائه میشود.
سوم، یک سیستم نمونه اولیه مبتنی بر فناوری کانتینر مجازیسازی، که یک رابط کاربرپسند برای تنظیم پارامتر و محاسبه مدل فراهم میکند و از نظارت و نمایش بیدرنگ و نمایش جریان دادههای فضایی-زمانی چندنوعی پشتیبانی میکند، توسعه یافته است. سیستم ما از کنترل بهینهسازی جریان دادههای فضایی-زمانی کارآمد و انعطافپذیر پشتیبانی میکند و الگوی خوبی برای زمانبندی دادههای مکانی-زمانی بعدی در محیط ابری ارائه میدهد.
تحقیقات آینده بر روشهای زمانبندی دادههای مکانی-زمانی تحت معماریهای چندتکرار و متفرقه، مانند محیطهای ابری، محاسبات لبه و مشتریان متنوع تمرکز خواهد کرد. در همین حال، ما توانایی تنظیم تطبیقی سرویس زمانبندی دادههای مکانی-زمانی را با توجه به نیازهای مختلف کار مشتری بهبود خواهیم داد.