۱٫ مقدمه
منابع زمین دارای ویژگی های زیر به عنوان حامل وجود و توسعه انسانی است: منابع تجدیدناپذیر، مکان ثابت و توزیع نامتعادل [ ۱ ]. با گسترش جمعیت و اقتصاد با چنین سرعتی، میزان منابع زمینی موجود به تدریج کاهش می یابد. در جامعه مدرن، ساختمان ها و جاده ها اجزای اساسی چیدمان شهری هستند و استخراج دقیق ساختمان ها و جاده ها از تصاویر ماهواره ای سنجش از دور به تحقق برنامه ریزی کلان شهر کمک می کند [ ۲ ].]. روشهای تحقیق برای تصاویر سنجش از دور را میتوان به دو بخش تقسیم کرد: روشهای محاسباتی نظری سنتی و روشهای تحلیل دادههای بزرگ هوش مصنوعی. روش محاسبه نظری سنتی استخراج ویژگیهای بافت تصویر از طریق محاسبه نظری هر پیکسل از تصویر است، به طوری که تقسیمبندی تصویر سنجش از راه دور و استخراج هدف را تحقق بخشد. اگرچه روش سنتی از نظر دقت تقسیم بندی به استاندارد خاصی رسیده است، اما نیاز به تنظیم دستی پارامترهای محاسباتی دارد که باعث مصرف منابع انسانی و منابع مادی و عدم کارایی محاسباتی می شود. برعکس، روش یادگیری عمیق در هوش مصنوعی میتواند بخشبندی تصویر سنجش از راه دور را کامل کند [ ۳ ، ۴ ]] و عملکرد قطعه بندی خودکار تصویر با دقت بالا را بدون دخالت دستی درک کنید [ ۵ ، ۶ ]. سودهای حاصل از دوران کلان داده جهشی کیفی در کارایی محاسبات ایجاد کرده است که نتیجه آن این است که راندمان محاسباتی در مقایسه با روشهای سنتی بسیار بهبود یافته است. بنابراین، استفاده از روش یادگیری عمیق در هوش مصنوعی برای دستیابی به بخش بندی معنایی تصاویر سنجش از دور اهمیت زیادی دارد.
در چند سال گذشته، کارهای زیادی در زمینه تقسیم بندی معنایی تصاویر سنجش از دور انجام شده است. به عنوان مثال، یوان و همکاران. [ ۷ ] ویژگیهای بافت و طیف تصویر را با استفاده از هیستوگرامهای طیفی محلی، ترکیب خطی ویژگیهای نماینده با استفاده از هر هیستوگرام طیفی محلی، طبقهبندی پیکسل بر اساس تخمین وزن، و در نهایت تقسیمبندی تصاویر را محاسبه کرد. این روش می تواند تا حد زیادی بعد ویژگی شبکه را از طریق طرح ریزی زیرفضا کاهش دهد و متوجه شود که بعد ورودی شبکه می تواند به صورت تطبیقی انتخاب شود. با این حال، نقطه ضعف این است که فقط از اطلاعات طیفی در فرآیند محاسبه استفاده می شود. لی و همکاران [ ۸] یک الگوریتم حوضه آبخیز برای نشانگرهای جاسازی لبه پیشنهاد کرد که برای تقسیمبندی تصاویر سنجش از دور با وضوح بالا استفاده شد. این روش منجر به بهبود در دو مرحله کلیدی تقسیمبندی (یکی استخراج برچسب و دیگری برچسبگذاری پیکسل) میشود که میتواند دقت بخشبندی لبهها را در تصاویر با وضوح بالا بهبود بخشد. علاوه بر این، این روش از یک آشکارساز تعبیه لبه برای استخراج اطلاعات لبه با اطمینان استفاده می کرد که معمولاً در موقعیت هایی با مرزهای ضعیف استفاده می شد و دقت موقعیت یابی مرزهای هدف را بهبود می بخشید. اگرچه دقت مرز تقسیمبندی بهبود یافته است، اما مشکلاتی نیز وجود دارد که اطلاعات ویژگیهای دقیق پیچیده است و عوامل تداخلی، دستیابی به اطلاعات را دشوار میکنند. فن و همکاران [ ۹] دریافت که این روش های تقسیم بندی سنجش از دور به ندرت از اطلاعات قبلی استفاده می کنند. در نتیجه، او رویکرد جدیدی را بر اساس اطلاعات قبلی پیشنهاد کرد. در این روش از الگوریتم خوشه بندی C-means فازی وزنی تکراری تک نقطه ای استفاده شد که توزیع داده ها و تأثیر اولیه سازی تصادفی مراکز خوشه را بر کیفیت خوشه بندی حل کرد. روش تقسیمبندی ویژگی فوق میتواند تصاویر سنجش از راه دور را به طور موثر تقسیم کند، اما مشکلاتی نیز وجود دارد، مانند مقاومت در برابر نویز ضعیف، سرعت پایین تقسیمبندی، طراحی پارامترهای دستی و غیره، که نمیتوان از آنها برای تقسیم خودکار مقادیر زیاد استفاده کرد. از داده ها
یادگیری عمیق فعلی هنوز در حوزه ساخت و ساز و استخراج جاده در حال توسعه است. پانبونیوئن و همکاران [ ۱۰ ] یک شبکه رمزگذاری و رمزگشایی پیچیده عمیق پیشرفته برای تقسیمبندی جاده تصاویر سنجش از راه دور، با ترکیب تابع فعالسازی ELU [ ۱۱ ] و شبکه SegNet [ ۱۲ ] برای تشکیل یک شبکه تقسیمبندی سرتاسر، و در نهایت از طریق بهینهسازی نشانگرها و حذف اشیاء کاذب جاده برای بهبود بیشتر اثر کلی. با این حال، برای این روش، کاربردهای کمتری از اطلاعات ویژگی های پیوسته هنگام استخراج جاده ها از تصاویر سنجش از دور استفاده می شود که منجر به نقشه تداخل و ناحیه شکستگی می شود. Sun et al. [۱۳ ] یک استراتژی ترکیبی جدید مبتنی بر یک شبکه کانولوشنال کامل با تقسیمبندی تصویر با وضوح فوقالعاده بالا ارائه کرد که ادغام ویژگیهای معنایی سطح عمیق و اطلاعات جزئیات سطح کم را به حداکثر رساند. با ترکیب با این مدل، مدل سطح دیجیتال موثر پیشنهاد شد و اطلاعات تصاویر سنجش از دور با وضوح بالا استخراج شد که بخشبندی دقیق شبکه کانولوشن کامل را بهبود بخشید. با این حال، در تقسیمبندی تصویر سنجش از دور، مشکلاتی وجود داشت که مقیاس تقسیمبندی هدف ناسازگار بود و مقیاس اطلاعات استخراج نشده بود. به منظور حل مشکل، لیو و همکاران. [ ۱۴] یک شبکه عصبی کانولوشن عمیق چند کانالی را برای کاهش از دست دادن ویژگیهای فضایی و مقیاس اهداف تقسیمبندی شده در تصاویر پیشنهاد کرد. چی و همکاران [ ۱۵ ] یک مکانیسم پیچیدگی و توجه چند مقیاسی را بر اساس یک مدل تقسیم بندی پیشنهاد کرد. مکانیسم توجه، از سوی دیگر، تنها می تواند میدان دریافت محلی را به تصویر بکشد. لی و همکاران [ ۱۶ ] پیشنهاد استفاده از یک شبکه مکانیزم توجه دو طرفه برای تقسیم معنایی تصاویر سنجش از دور را پیشنهاد کرد. یکی بر روی اطلاعات معنایی مکانی در نقشه ویژگی متمرکز است و دیگری بر روی اطلاعات مرتبط بین کانال ها. ترکیب اطلاعات توجه دو طرفه می تواند به طور موثری دقت بخش بندی را بهبود بخشد. لان و همکاران [ ۱۷] یک شبکه عصبی قطعهبندی خودکار جاده با زمینه جهانی برای قطعهبندی جاده تحت پسزمینه پیچیده و انسداد میدان دید پیشنهاد کرد. در شبکه، یک شبکه کانولوشنال حفره باقیمانده برای ارائه یک میدان پذیرای وسیع استفاده شد. اگرچه با اطلاعات چند مقیاسی یک میدان پذیرنده بزرگتر، برای شبکه، ارتباط لایه میانی را نمی توان نادیده گرفت. او و همکاران [ ۱۸ ] یک شبکه توجه ترکیبی مرتبه اول و مرتبه دوم را برای افزایش ارتباط اطلاعات ویژگی در وسط شبکه پیشنهاد کرد.
به طور خلاصه، برای روشهای تقسیمبندی معنایی تصویر سنجش از دور بالا [ ۷ ، ۸ ، ۹ ، ۱۰ ، ۱۱ ، ۱۲ ، ۱۳ ، ۱۴ ، ۱۵ ، ۱۶ ، ۱۷ ، ۱۸] در یادگیری عمیق، نتایج رضایت بخشی به دست آمده است. در حال حاضر، در اکثر شبکههای تقسیمبندی معنایی، نمونهبرداری پایین از شبکه عصبی کانولوشنال (CNN) برای استخراج ویژگیها استفاده میشود. نقشه های ویژگی در طول استخراج بارها فشرده می شوند که منجر به از بین رفتن جزئیات می شود. نمونهبرداری بیشتر توسط نقشههای ویژگی با ویژگیهای دقیق از دست رفته، بازیابی نقشههای ویژگی با وضوح بالا و طبقهبندی دقیق وضوح را دشوار میکند. در فرآیند استخراج ویژگی توسط شبکه های کانولوشن عمیق، میدان دریافت محدود است. اگرچه می توان با استفاده از پیچش توخالی و اهرام مشخصه میدان دریافتی بزرگتری به دست آورد، میدان دریافت هنوز محلی است، درک صحنه های دوردست نمی تواند به دست آید و پیکسل ها را نمی توان به طور دقیق طبقه بندی کرد. برای حل این مشکلات، یک شبکه استخراج معنایی ترکیبی با وضوح چندگانه و ترانسفورماتور (HMRT) در این مطالعه پیشنهاد شده است. به طور کلی، این کار سه کمک داشته است: (۱) شاخه استخراج معنایی با وضوح چندگانه ساخته شده است. در این ساختار، شاخههایی از وضوحهای مختلف ترکیب ویژگیها را انجام میدهند، که نه تنها تضمین میکند که وضوح بالا و چندگانه در طول فرآیند نمونهبرداری پایین نگه داشته میشود، بلکه تضمین میکند که اطلاعات ویژگی حفظ میشود. (۲) شبکه استخراج ویژگی دنباله ترانسفورماتور معرفی شده است. در این شبکه هر پیکسل با یک میدان گیرنده جهانی با استفاده از رمزگذاری و رمزگشایی محقق می شود و در این بین اطلاعات مکان پیکسل روی هم قرار می گیرد. می توان بر میدان پذیرای کوچک شبکه عصبی کانولوشن غلبه کرد و درک یک صحنه از راه دور را می توان بهبود بخشید.
۲٫ روش شناسی
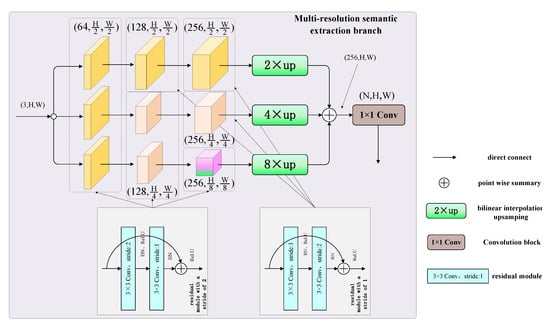
به منظور حل دو مشکل از دست دادن جزئیات ناشی از فشرده سازی مقیاس در فرآیند نمونه برداری پایین و عدم درک از راه دور به دلیل محدودیت میدان پذیرنده، این مقاله یک مفهومی ترکیبی با وضوح چندگانه و ترانسفورماتور پیشنهاد می کند. شبکه استخراج (HMRT). چارچوب کلی HMRT در شکل ۱ نشان داده شده است. چارچوب کلی HMRT پیشنهادی در این کار به دو شاخه موازی تقسیم میشود. شعبه اول نقشه های ویژگی با وضوح متفاوت را به شبکه ارائه می دهد. نقشه های ویژگی با وضوح های مختلف به ۲ بار پایین نمونه، ۴ بار پایین نمونه و ۸ بار پایین نمونه تقسیم می شوند. ۳ مرحله مختلف در فرآیند نمونه برداری پایین هر نقشه ویژگی وضوح وجود دارد. هر مرحله کانال نقشه ویژگی را ترسیم می کند و بعد را افزایش می دهد و تعداد کانال ها به ترتیب ۶۴، ۱۲۸ و ۲۵۶ می باشد. در نهایت، سه نقشه ویژگی با وضوح های مختلف به صورت متقابل ترکیب می شوند. در فرآیند تلفیق متقابل نقشه ویژگی، نقشههای ویژگی در مقیاسهای مختلف نمونهبرداری میشوند و به اندازه تصویر ورودی بازیابی میشوند، به طوری که شعبه دوم میتواند مستقیماً از این نقشههای ویژگی در هنگام ادغام ویژگیها استفاده کند. شاخه دوم عمدتاً از ترکیبی از شبکه های عصبی کانولوشن و ترانسفورماتورها برای استخراج اطلاعات معنایی از میدان دریافتی جهانی نقشه ویژگی استفاده می کند. ابتدا، اطلاعات نقشه ویژگی محلی تصویر ورودی را از طریق شبکه عصبی کانولوشن استخراج می کند و نقشه ویژگی ۱۶ بار پایین نمونه برداری شده را به دست می آورد. در مرحله بعد، برخلاف شبکه تقسیم بندی معنایی فعلی، از روش Transformer برای ادامه رمزگذاری و رمزگشایی نقشه ویژگی ۱۶ بار پایین نمونه استفاده می کند. مزیت روش رمزگذاری و رمزگشایی ترانسفورماتور این است که کل نقشه ویژگی را یک میدان دریافتی جهانی انجام می دهد، که بر محدودیت میدان گیرنده ناشی از هسته پیچشی کوچک شبکه عصبی کانولوشن غلبه می کند. علاوه بر این، اطلاعات موقعیت هر پیکسل در نقشه ویژگی در فرآیند رمزگذاری معرفی می شود، به طوری که هر پیکسل اطلاعات معنایی را در بعد موقعیت اضافه می کند. در فرآیند رمزگشایی، ماتریس نگاشت با ابعاد بالا به عنوان ماتریس پرس و جو استفاده می شود و ماتریس کلید-مقدار و ماتریس عددی از خروجی لایه رمزگذاری Transformer هستند. نمودار ساختار HMRT در نشان داده شده استشکل ۱ ، و دو تبدیل بعدی متفاوت در لایه شبکه وجود دارد. ابعاد نقشه ویژگی سه بعدی تعداد کانال ها، ارتفاع و عرض نقشه ویژگی را نشان می دهد. در نقشه ویژگی دو بعدی، N نشان دهنده تعداد دسته ها و D نشان دهنده بعد نگاشت لایه پنهان شبکه رمزگذاری و رمزگشایی ترانسفورماتور است. نیمه بالایی شکل شاخه استخراج معنایی با وضوح چندگانه و نیمه پایینی شاخه استخراج معنایی Transformer است.
۲٫۱٫ شاخه استخراج معنایی با وضوح چندگانه
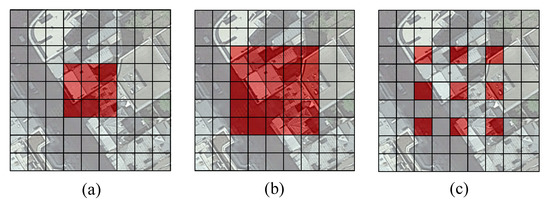
اهمیت شاخه استخراج معنایی با وضوح چندگانه این است که در فرآیند استخراج ویژگی نمونهبرداری پایین شبکه عصبی کانولوشن، حداکثر لایه ادغام یا ۳ × ۳هسته کانولوشن با گام کانولوشن کشویی ۲ معمولاً برای فشرده سازی طول و عرض نقشه ویژگی استفاده می شود. اگرچه اطلاعات معنایی غنی از این طریق به دست می آید، اما دور انداختن بسیاری از اطلاعات دقیق اجتناب ناپذیر است. به منظور درک شهودی تفاوتها در فرآیند فشردهسازی نقشه ویژگی، ما سه روش فشردهسازی ویژگی را نشان میدهیم که عبارتند از: (۱) پیچیدگی با یک ۳ × ۳هسته پیچیدگی، یک گام ۱، و یک بالشتک ۱٫ (۲) پیچیدگی با یک ۳ × ۳هسته کانولوشن، یک گام ۲، و یک بالشتک ۱٫ (۳) حداکثر ادغام با یک پنجره ۲ × ۲اندازه و گام ۲٫ جلوه های تجسم سه روش فشرده سازی ویژگی در شکل ۲ نشان داده شده است ، شکل ۲ a پیچیدگی را با گام ۱ نشان می دهد، شکل ۲ b پیچش را با گام ۲ نشان می دهد، شکل ۲ c را نشان می دهد. حداکثر ادغام با گام ۲٫ اندازه تصویر ورودی نشان داده شده در شکل ۲ برابر است با ۵۱۲ × ۵۱۲.
همانطور که در شکل ۲ نشان داده شده است ، پیچیدگی با گام ۱ برای استخراج ویژگی کافی است، تقریباً تمام جزئیات ویژگی را در تصویر اصلی حفظ می کند، و اندازه نقشه ویژگی خروجی با مشخصات تصویر ورودی مطابقت دارد. ۵۱۲ × ۵۱۲). در فرآیند استخراج ویژگی عملیات کانولوشن با گام ۲، اندازه ویژگی خروجی برابر است با ۲۵۶ × ۲۵۶، که به نصف تصویر ورودی اصلی فشرده می شود. هنگام مقایسه شکل ۲ b با شکل ۲ a، دشوار نیست که متوجه شویم شکل ۲ b اطلاعات ویژگی های کمتری نسبت به شکل ۲ a دارد. سپس، نتیجه خروجی حداکثر فشردهسازی ویژگی ادغام در شکل ۲ c را با شکل ۲ a,b مقایسه کنید، تصویر در شکل ۲ c ناهموار به نظر میرسد و از دست دادن اطلاعات ویژگی جدیتر از شکل ۲ است.ب در نهایت، نتیجه میگیریم که قابلیتهای بیان اطلاعات معنایی فشردهسازی ویژگی به شرح زیر است: پیچیدگی با گام ۱ بیشتر از پیچیدگی با گام ۲ است و پیچیدگی با گام ۲ بیشتر از حداکثر عملیات ادغام است. با گام ۲٫
در حال حاضر، اکثر شبکههای عصبی کانولوشن فعلی نیاز به استفاده از حداکثر عملیات ادغام با گام ۲ و استفاده مکرر از عملیات کانولوشن با گام ۲ در فرآیند استخراج ویژگی دارند که منجر به از دست رفتن اطلاعات دقیق در نقشه ویژگی [ ۱۹ ، ۲۰]. برای غلبه بر این مشکل، این بخش یک شاخه استخراج معنایی با وضوح چندگانه را پیشنهاد میکند تا نقشههای ویژگی با وضوح چندگانه غنی برای شبکه ارائه کند. شاخه استخراج معنایی چند رزولوشن ارائه شده در این بخش به سه شاخه تقسیم می شود. سه شاخه از ورودی یکسانی استفاده می کنند، اما تصویر ورودی در مضرب های مختلف نمونه برداری می شود تا نقشه های ویژگی با وضوح های مختلف به دست آید. سه نقشه ویژگی با وضوح های مختلف عبارتند از ۲ بار پایین نمونه، ۴ بار پایین نمونه و ۸ بار پایین نمونه.
ساختار شاخه استخراج معنایی با وضوح چندگانه در شکل ۳ نشان داده شده است ، ورودی کل شاخه تصویری از ۳ × H× Wاندازه. شاخه اول در شکل ۳ نمونه برداری ۲ بار پایین است که شامل یک ماژول باقیمانده با گام ۲ و دو ماژول باقیمانده با گام ۱ است. ماژول ها با گام ۲ و ماژول باقی مانده با گام ۱٫ شاخه سوم در شکل ۳هر شاخه از سه ماژول باقیمانده تشکیل شده است و سه ماژول باقیمانده به تدریج تعداد نگاشت کانال را در طول فرآیند نمونه برداری پایین افزایش می دهد. تعداد نگاشت کانال به ترتیب ۶۴، ۱۲۸ و ۲۵۶ است. پس از عبور سه شاخه از ماژول های باقیمانده با گام های مختلف، نقشه های ویژگی نمونه برداری پایین به ترتیب ۲ بار، ۴ بار و ۸ بار به دست می آید. در مرحله بعد، نقشه های ویژگی باید جمع آوری و ترکیب شوند. با این حال، وضوح نقشه های ویژگی متناقض است و باید در همان سطح استاندارد شود. بنابراین، نقشههای ویژگی باید نمونهبرداری شوند، و مضرب نمونهگیری بالا، تبدیل معکوس مضرب نمونهبرداری پایین است، که ۲ برابر نمونهبرداری بالا، ۴ برابر نمونهبرداری بالا هستند، و به ترتیب ۸ برابر افزایش نمونه. پس از نمونه برداری از سه شاخه، نقشه های ویژگی به اندازه تصویر ورودی بازیابی می شوند و سپس به ترتیب اضافه می شوند و در بعد کانال ذوب می شوند تا نقشه ویژگی به دست آید. ۲۵۶ × H× Wاندازه. سرانجام، ۱ × ۱کانولوشن برای ترسیم تعداد کانالهای نقشههای ویژگی اطلاعات معنایی حاوی رزولوشنهای چندگانه به تعداد دستههای N که توسط مدل قابل یادگیری است، استفاده میشود. در نتیجه، نقشه ویژگی استخراج معنایی با وضوح چندگانه ( ن× اچ× W) از اطلاعات دسته به دست می آید.
بسیاری از CNN های عالی در سال های اخیر ظاهر شده اند، از جمله ResNet [ ۲۱ ]، VGG [ ۲۲ ] و GoogLeNet [ ۲۳ ]. پس از در نظر گرفتن مقدار پارامترها و دقت شبکه، این کار ماژول پایه ResNet-18 را به عنوان بلوک باقیمانده در سه شاخه اتخاذ می کند. ساختار دو ماژول باقیمانده در شکل ۳ در شکل ۴ نشان داده شده است . این کار از ماژول های باقیمانده با دو نوع گام استفاده می کند، انتشار رو به جلو مدول باقیمانده با گام ۱ در معادله ( ۱ ) نشان داده شده است.
جایی که سیo nv3 × ۳یک پیچش ۳×۳ با گام ۱ است، βBN است، σیک تابع فعال سازی ReLU است.
انتشار رو به جلو ماژول باقیمانده با گام ۲ در معادله ( ۲ ) نشان داده شده است.
جایی که سیo nv3 × ۳هست یک ۳ × ۳پیچیدگی با گام ۲، βBN است، σیک تابع فعال سازی ReLU است، سیo nv“3 × ۳هست یک ۳ × ۳پیچیدگی با گام ۱٫
ساختار خاص شاخه استخراج معنایی با وضوح چندگانه در جدول ۱ نشان داده شده است . جدول تنظیمات پارامترهای شش مرحله (ورودی، مرحله اول، مرحله دوم، مرحله سوم، همگرایی ویژگی و خروجی) شاخه را نشان می دهد.
۲٫۲٫ شعبه استخراج معنایی ترانسفورماتور
اهمیت شاخه استخراج معنایی ترانسفورماتور این است که میدان پذیرای کوچک شبکههای عصبی کانولوشنال معمولی باعث عدم درک صحنه از راه دور میشود. اگرچه روشهای زیادی برای بهبود مشکل میدانهای ادراک کوچک وجود داشته است، مانند بزرگکردن هسته کانولوشن و استفاده از کانولوشن آتروس، اما همه آنها دارای اشکالاتی هستند. از یک طرف، پس از بزرگ شدن هسته کانولوشن، مقدار پارامترهای مدل و محاسبات مدل افزایش می یابد که باعث افزایش سربار محاسباتی زیادی می شود. در صورت کمبود زمان و منابع محاسباتی محدود، انتخاب خوبی نیست. از سوی دیگر، اگرچه استفاده از کانولوشن آتروس میتواند میدان دریافت هسته کانولوشن اصلی را بدون افزودن محاسبات اضافی گسترش دهد. پیچش آتروس با ۰ پر می شود وقتی هسته پیچیدگی گسترش می یابد و در نتیجه جزئیات داخلی از بین می رود. پیچ خوردگی آتروس برای استخراج اجسام هدف بزرگ دوستانه تر است و می تواند وابستگی اشیاء هدف بزرگ را در فواصل طولانی به تصویر بکشد، اما مزایای اجسام هدف کوچک به اندازه کافی آشکار نیست. از آنجایی که padding 0 مورد استفاده توسط هسته کانولوشن بر تداوم هسته کانولوشن در فرآیند استخراج ویژگی تأثیر می گذارد، اشیاء هدف کوچک تقسیم می شوند یا نادیده گرفته می شوند، که بر اثربخشی استخراج شی هدف کوچک تأثیر می گذارد. تغییر در اندازه میدان پذیرنده نقش زیادی در فرآیند استخراج ویژگی دارد. یک هسته کانولوشن با یک میدان پذیرنده بزرگ می تواند وابستگی طولانی مدت یک هدف بزرگ را استخراج کند. در حالی که یک هسته کانولوشن با یک میدان پذیرنده کوچک می تواند ویژگی های کامل یک شی هدف کوچک را استخراج کند. با در نظر گرفتن ابعاد عرض هسته کانولوشن به عنوان مثال، فرآیند استخراج میدان پذیرنده در معادله نشان داده شده است (۳ ).
که در آن K اندازه و عرض هسته کانولوشن است، d نرخ اتساع است، ک“اندازه میدان پذیرنده است.
به منظور انعکاس تفاوت میدانهای دریافتی به راحتی و شهودی، این کار اندازههای مختلف هستههای پیچشی و اندازههای مختلف نرخ اتساع را برای تجسم طراحی میکند. مقایسه میدان های پذیرنده با نرخ های اتساع مختلف و هسته های پیچشی در شکل ۵ نشان داده شده است .
مشاهده میشود که شبکههای تقسیمبندی معنایی کنونی دارای محدودیتهایی در زمینه دریافتی هستند، بنابراین این کار روش ترانسفورماتور را با میدانهای دریافتی جهانی [ ۲۴ ، ۲۵ ، ۲۶ ، ۲۷ ، ۲۸ ] ترکیب میکند تا عمیقاً اطلاعات معنایی نقشههای ویژگی را استخراج کند. بر این اساس، یک شبکه عصبی کانولوشن هیبریدی (ResNet-18) و یک شاخه استخراج معنایی ترانسفورماتور بر اساس رمزگذاری و رمزگشایی ترانسفورماتور ساخته شده است.
۲٫۲٫۱٫ چارچوب کلی شاخه استخراج معنایی ترانسفورماتور
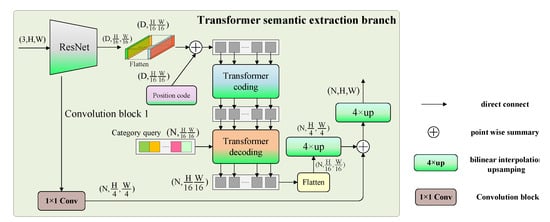
چارچوب کلی شاخه استخراج معنایی ترانسفورماتور از یک شبکه عصبی کانولوشنال ترکیبی (شبکه ستون فقرات) و ماژول های رمزگذاری و رمزگشایی ترانسفورماتور تشکیل شده است. ساختار این شاخه در شکل ۶ نشان داده شده است ، D در شکل بعد نقشه برداری است و Nتعداد دسته ها است. در مرحله اول، شبکه ستون فقرات ResNet-18 را با یک پنجره کشویی برای استخراج ویژگی ها اتخاذ می کند. ثانیاً، شبکه ستون فقرات ۱۶ بار نمونه برداری پایین انجام می دهد و نقشه ویژگی را در ابعاد عرض و ارتفاع صاف می کند تا یک نقشه ویژگی با ابعاد (D, H/16, W/16) به دست آید. سپس، نقشه ویژگی به دست آمده را به ماتریس کدگذاری موقعیت با همان اندازه اضافه می کنیم و نتیجه را برای کدگذاری سراسری در ماژول کدگذاری Transformer وارد می کنیم. تعداد دفعاتی که ماژول رمزگذاری رمزگذاری را تکرار می کند روی ۶ تنظیم می شود. رمزگشایی ترانسفورماتور مربوطه پس از رمزگذاری انجام می شود و در مجموع ۶ لایه رمزگشا تنظیم می شود. ماتریس پرس و جو اولین لایه رمزگشایی توسط ماتریس دسته ارائه می شود و ماتریس پرس و جو بعد از لایه دوم خروجی لایه رمزگشایی قبلی است. علاوه بر این، ماتریس کلید-مقدار و ماتریس عددی نیز خروجی ماتریس رمزگشایی لایه قبلی هستند. پس از رمزگذاری و رمزگشایی ترانسفورماتور، نقشه ویژگی با ابعاد (H, H/16، W/16) خروجی می شود. سپس آخرین بعد نقشه ویژگی به دو بعد مسطح می شود تا نقشه ویژگی (H, H/16, W/16) با تعداد کانال های دسته N بدست آید. بار برای بدست آوردن نقشه ویژگی با ابعاد (H, H/4, W/4). دلیل استفاده از نمونه برداری ۴ برابری این است که اندازه نقشه ویژگی با بلوک پیچشی ۱ شبکه ستون فقرات مطابقت داشته باشد. از آنجایی که نقشه ویژگی بلوک کانولوشن ۱ برای غنیسازی اطلاعات موقعیت استفاده میشود، ادغام نقشه ویژگی میتواند به بازیابی موقعیت کمک کند. سرانجام، برای دستیابی به طبقه بندی در سطح پیکسل، نقشه ویژگی باید به اندازه تصویر ورودی بازیابی شود. در فرآیند بازیابی، نقشه ویژگی ۴ بار نمونه برداری می شود تا نقشه ویژگی به دست آید.
۲٫۲٫۲٫ ویژگی استخراج شبکه ستون فقرات
شاخه استخراج معنایی ترانسفورماتور پیشنهاد شده در این بخش از یک شبکه عصبی کانولوشن به عنوان شبکه ستون فقرات برای استخراج ویژگی استفاده می کند. ResNet-18 برای استخراج اطلاعات معنایی عمیق تصویر استفاده می شود، اما ساختار ResNet-18 مورد استفاده در این مقاله کمی با ساختار مقاله اصلی متفاوت است.
همانطور که در جدول ۲ ، بعد از تصویر نشان داده شده است۵۱۲ × ۵۱۲اندازه از بلوک کانولوشن ۱، بلوک کانولوشن ۲، بلوک کانولوشن ۳ و بلوک پیچیدگی ۴ عبور می کند که با کاغذ اصلی سازگار است، نقشه ویژگی ۳۲ × ۳۲اندازه را می توان به دست آورد. در مرحله بعد، شبکه این وضوح را حفظ می کند و از کانولوشن برای عمیق کردن ویژگی های استخراج شده استفاده می کند. تعمیق کانولوشن توسط بلوک کانولوشن ۵ تکمیل می شود و بلوک کانولوشن ۵ a است ۳ × ۳پیچیدگی با گام ۱ و ۲۵۶ کانال. نقشه ویژگی خروجی نهایی ۱/۱۶ اندازه تصویر ورودی است که دو برابر اندازه خروجی شبکه اصلی اصلی است. این یک نقشه ویژگی وضوح بزرگ را حفظ می کند، که منجر به استخراج اطلاعات ویژگی های غنی تر از ویژگی های جهانی Transformer می شود. علاوه بر این، تعداد کانال های نقشه ویژگی خروجی نیز به نصف کاهش می یابد. دلیل این امر این است که ترانسفورماتور متصل به شبکه ستون فقرات، زمانی که به رمزگذاری و رمزگشایی ادامه میدهد، همچنان دارای یک کانال نقشه برداری با ابعاد بالا است. کاهش تعداد کانال ها در شبکه ستون فقرات می تواند مقدار مشخصی از پارامترها را کاهش دهد.
۲٫۲٫۳٫ رمزگذاری و رمزگشایی ترانسفورماتور
رمزگذاری و رمزگشایی ترانسفورماتور اولین بار توسط Vaswani و همکاران ارائه شد. [ ۲۹ ] برای پردازش زبان طبیعی. این روش اطلاعات کلی را از نقشه ویژگی ورودی استخراج می کند. با الهام از این نوآوری، این مقاله ترانسفورماتور را به وظیفه تقسیم بندی معنایی پیوند و تنظیم دقیق می کند تا محدودیت های میدان پذیرای شبکه عصبی کانولوشنال را هنگام انجام تقسیم بندی معنایی جبران کند. ساختار کلی ترانسفورماتور بهبود یافته در این مقاله از رمزگذاری و رمزگشایی تشکیل شده است، و ماژول های رمزگذاری و رمزگشایی از مکانیسم توجه به خود به مکانیزم توجه چند سر متصل شده اند. ساختار ترانسفورماتور در شکل ۷ نشان داده شده است .
اولاً، نقشه ویژگی ورودی، نقشه ویژگی (D، H/16، W/16) است که توسط شبکه ستون فقرات استخراج شده است. در مرحله دوم، تابع مسطح کردن دو بعد آخر را در یک بردار یک بعدی برای به دست آوردن یک نقشه ویژگی جدید (D، H/16، W/16) ترسیم می کند. سپس ماتریس کدگذاری موقعیت p ∈آر( D , H / ۱۶ , W / ۱۶ )هر پیکسل در نقشه ویژگی و نقشه ویژگی به عنوان ورودی لایه کدگذاری روی هم قرار می گیرند. لایه کدنویسی ابتدا تحت لایه نرمال سازی ویژگی قرار می گیرد تا ابعاد کانال را عادی کند و سپس از نگاشت های مختلف ماتریس عبور می کند تا ماتریس پرس و جو را به دست آورد. q∈آر( H / ۱۶ , W / ۱۶ , D )، ماتریس کلید-مقدار k ∈آر( H / ۱۶ , W / ۱۶ , D )و ماتریس عددی v ∈آر( H / ۱۶ , W / ۱۶ , D ). فرآیند محاسبه در معادلات (۴) – (۷) نشان داده شده است. ایکسمن n p u tورودی لایه کدگذاری است. Δلایه عادی سازی ویژگی را نشان می دهد. کqیک تابع نگاشت ماتریس پرس و جو لایه رمزگذاری است. ککتابع نگاشت ماتریس کلید-مقدار لایه کدگذاری است. کvتابع نگاشت ماتریس عددی لایه کدگذاری است.
پس از به دست آوردن ماتریس پرس و جو، ماتریس کلید-مقدار و ماتریس عددی، سه ماتریس برای محاسبه توجه به ماژول مکانیسم توجه چند سر وارد می شوند. ماژول مکانیسم توجه چند سر با اتصال چندین ماژول مکانیسم توجه به خود به دست می آید (این مقاله تعداد سرهای مکانیسم توجه چند سر را ۴ تنظیم می کند). مزیت توجه چند سر این است که اطلاعات ویژگی را می توان از شاخه های مختلف برای غنی سازی اطلاعات معنایی به دست آورد و شاخه های مختلف می توانند به طور مستقل ویژگی ها را استخراج کرده و سپس آنها را ادغام کنند که می تواند تنوع استخراج ویژگی را افزایش دهد. پس از ماژول مکانیسم توجه چند سر، نقشه ویژگی خروجی و نقشه ویژگی قبل از لایه عادی سازی ویژگی، اطلاعات نقشه ویژگی اصلی را از طریق اتصال پرش جمع می کنند. همانطور که در معادله نشان داده شده است (۸ ).
جایی که Γنشان دهنده ماژول مکانیسم توجه چند سر است، ایکسa t t e nخروجی مکانیزم توجه چند سر است، q , k , v به ترتیب نشان دهنده ماتریس پرس و جو، ماتریس کلید-مقدار و ماتریس عددی لایه کدگذاری است. ایکسمن n p u tورودی لایه کدگذاری است.
سپس از طریق لایه عادی سازی ویژگی و لایه کاملاً متصل، بعد ویژگی به بعد بالا نگاشت می شود. نگاشت کاملا متصل یک نقشه برداری ۴ بار است. در نهایت، نقشه ویژگی اصلی قبل از ورود به اتصال کامل نیز با اتصال پرش جمع می شود تا نقشه ویژگی خروجی لایه کدگذاری (HW,D) به دست آید. فرآیند محاسبه در معادله ( ۹ ) نشان داده شده است.
جایی که ایکسe n c o de rخروجی لایه کدنویسی است، Πنقشه برداری کاملاً متصل را نشان می دهد، Δنمایانگر لایه عادی سازی ویژگی و ایکسa t t e nخروجی مکانیسم توجه چند سر است.
ورودی لایه رمزگشایی از دو بخش تشکیل شده است: نقشه ویژگی خروجی لایه کدگذاری و نقشه ویژگی جستجوی دسته که بر اساس تعداد دسته ها ایجاد شده است. لایه ویژگی قبل از ورود به مکانیسم توجه چند سر لایه رمزگشایی نرمال می شود و سپس نقشه ویژگی خروجی لایه کدگذاری به یک ماتریس ارزش کلیدی تجزیه می شود. ک“∈آر( H / ۱۶ , W / ۱۶ , N )و یک ماتریس عددی v“∈آر( H / ۱۶ , W / ۱۶ , N )از طریق نگاشت های ماتریسی مختلف در میان آنها، N تعداد دسته ها است. فرآیند محاسبه در معادلات (۱۰) – (۱۲) نشان داده شده است.
جایی که ایکس“e n c o de rخروجی لایه عادی سازی ویژگی است، Δلایه عادی سازی ویژگی را نشان می دهد، ایکسe n c o de rخروجی لایه کدنویسی است، ک“کتابع نگاشت ماتریس کلید-مقدار را در لایه رمزگشایی نشان می دهد، ک“vتابع نگاشت ماتریس عددی را در لایه رمزگشایی نشان می دهد.
ماتریس پرس و جو لایه رمزگشایی q“∈آر( H / ۱۶ , W / ۱۶ , N )با توجه به مقدار دهی اولیه دسته و ماتریس کلید-مقدار به دست می آید ک“∈آر( H / ۱۶ , W / ۱۶ , N )و ماتریس عددی v“∈آر( H / ۱۶ , W / ۱۶ , N )از طریق نقشه برداری ماتریسی به دست می آیند. در مرحله بعد، ما آنها را به مکانیسم توجه چند سر برای رمزگشایی به طور همزمان وارد می کنیم و نتیجه رمزگشایی شده از طریق لایه عادی سازی ویژگی و نقشه برداری کاملاً متصل می رود. نگاشت کاملا متصل یک نقشه برداری ۴ بار است. سپس، اولین ویژگی لایه رمزگشایی و نقشه ویژگی قبل از لایه عادی سازی ویژگی به ترتیب با هم ترکیب می شوند. در نهایت نقشه ویژگی دسته خروجی لایه رمزگشایی و نقشه ویژگی ورودی لایه کدگذاری بعدی به دست می آید. فرآیند محاسبه در معادله ( ۱۳ ) نشان داده شده است.
جایی که ایکسدe c o de rخروجی لایه رمزگشایی است، Πنقشه برداری کاملاً متصل را نشان می دهد، Δلایه عادی سازی ویژگی را نشان می دهد، Γنشان دهنده ماژول مکانیسم توجه چند سر است، q“، ک“، v“ماتریس پرس و جو، ماتریس کلید-مقدار و ماتریس عددی لایه رمزگشایی هستند.
ساختار ماژول مکانیسم توجه چند سر در شکل ۸ نشان داده شده است . همانطور که در شکل ۸ نشان داده شده است ، ماتریس پرس و جو q ، ماتریس کلید-مقدار k ، و ماتریس عددی vوارد می شوند. فرآیند محاسبه یک مکانیسم توجه واحد به شرح زیر است: ابتدا ماتریس کلید-مقدار و جابجایی ماتریس پرس و جو ضرب می شوند. در مرحله دوم، Softmax در آخرین نتایج به دست آمده انجام می شود. در نهایت، نتیجه Softmax و ماتریس عددی برای به دست آوردن نتیجه توجه ضرب می شوند. علاوه بر این، مکانیسم توجه چند سر پیشنهاد شده در این مقاله، مکانیسم های توجه تک سر را برای به دست آوردن اطلاعات مکانیسم توجه شاخه های مختلف به هم متصل می کند.
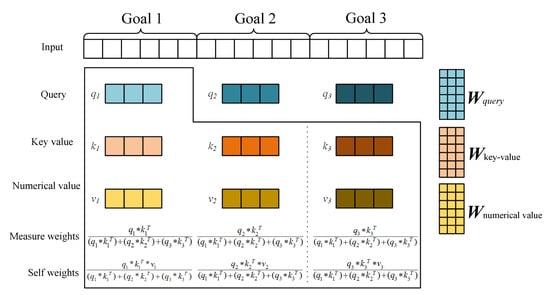
فرآیند تجزیه یک ماژول مکانیزم توجه به خود در شکل ۸ نشان داده شده است . در مورد ورودی سه هدف، سه هدف با ماتریس نگاشت ماتریس پرس و جو مربوطه آنها محاسبه می شود. دبلیوqتو هستی _ _، ماتریس نگاشت کلید-مقدار دبلیوk e y− v a l u eو ماتریس نگاشت عددی دبلیوn u m e r i c l v a l u eبرای به دست آوردن ماتریس پرس و جو مربوطه، ماتریس کلید-مقدار و ماتریس عددی ( q1،q2،q3،ک۱،ک۲،ک۳،v1،v2،v3). سپس سافت مکس وزن خود هدف و تمام اهداف را محاسبه می کند. فرآیند محاسبه وزنهای اندازهگیری در معادله ( ۱۴ ) و ساختار تجزیه فرآیند محاسبه مکانیسم توجه به خود در شکل ۹ نشان داده شده است .
جایی که دبلیوe i gh tسمنوزن های اندازه گیری هدف i است، qمننشان دهنده ماتریس پرس و جو از هدف i است، کمننشان دهنده ماتریس کلید-مقدار هدف i است.
در نهایت، وزن خود با ضرب وزن هر هدف و ماتریس عددی مربوطه به دست می آید. فرآیند محاسبه در معادله ( ۱۵ ) نشان داده شده است.
جایی که A t e n t i o _nمنوزن خود (اطلاعات توجه) هدف i است، دبلیوe i gh tسمنوزن های اندازه گیری هدف i است، vمننشان دهنده ماتریس عددی هدف i است.
۳٫ آزمایش و تجزیه و تحلیل نتایج
در این فصل، آزمایشهایی روی مجموعه دادههای تقسیمبندی تصویر هوایی (AISD) [ ۳۰ ] و مسابقه برچسبگذاری معنایی ISPRS 2D (ISPRS) [ ۳۱ ] انجام شد. مدل HMRT با بسیاری از بهترین مدل های موجود در حال حاضر FCN-8S [ ۳۲ ]، U-Net [ ۳۳ ]، PSPNet [ ۳۴ ] و DeeplabV3+ [ ۳۵ ] مقایسه شد. نرخ دقت کلی (OA)، نرخ فراخوان (Recall)، F1-Score و میانگین تقاطع بیش از اتحادیه (MIoU) به عنوان شاخص های تحلیل کمی آزمایش استفاده می شود. نتایج نشان می دهد که HMRT از مدل مقایسه در شاخص های مختلف ارزیابی بهتر است.
۳٫۱٫ مجموعه داده ها
۳٫۱٫۱٫ مجموعه داده AISD
تصاویر اصلی مجموعه داده AISD از دادههای تصویر سنجش از دور آنلاین OpenStreetMap جمعآوری شد و مجموعه دادههای تقسیمبندی معنایی تصاویر سنجش از دور با وضوح بالا با حاشیهنویسی دستی ساخته شد. AISD شامل داده های تصویری از شش منطقه بود: برلین، شیکاگو، پاریس، پوتسدام و زوریخ. این مقاله دادههای منطقهای پوتسدام را برای انجام آزمایش انتخاب کرد و مجموعه دادهها را Potsdam-A نامیدیم. ۲۴ تصویر اصلی و برچسب با اندازه متوسط ۳۰۰۰ × ۳۰۰۰ در Potsdam-A وجود دارد. نمونه تصویر و برچسب اصلی در شکل ۱۰ نشان داده شده است .
از آنجایی که تصویر اصلی خیلی بزرگ بود که نمیتوان مستقیماً وارد آموزش مدل شود، ما از پایتون برای برش عکس استفاده کردیم. ۳۰۰۰ × ۳۰۰۰به تصویر از ۵۱۲ × ۵۱۲و در نهایت در مجموع ۱۷۲۸ عکس به دست آورد. در مورد مقدار کمی داده، اثر تعمیم ضعیف و توانایی یادگیری ویژگی مدل ضعیف بود. بنابراین، برای اطمینان از اینکه مدل قابلیت یادگیری قابل اعتمادی دارد، به افزایش داده ها نیاز بود. مجموعه داده های اصلی به طور تصادفی به صورت افقی، عمودی برگردانده شد و ۹۰ درجه چرخید تا به ۴۳۰۷ عکس افزایش یابد.
۳٫۱٫۲٫ مجموعه داده ISPRS
مجموعه داده مسابقه برچسبگذاری معنایی ISPRS 2D یک مجموعه داده تصویر هوایی با وضوح بالا با برچسبگذاری معنایی کامل است که توسط انجمن بینالمللی فتوگرامسنجی و سنجش از دور (ISPRS) منتشر شده است. به طور مشابه، منطقه پوتسدام را در ISPRS برای تأیید عملکرد تعمیم مدل انتخاب کردیم و مجموعه داده را Potsdam-B نامگذاری کردیم. Potsdam-B از ۳۸ تصویر با برچسب دقیق و پنج پیش زمینه تشکیل شده بود: سطوح غیر قابل نفوذ، ساختمان ها، پوشش گیاهی کم، درخت و ماشین. نمونه تصویر و برچسب اصلی در شکل ۱۱ نشان داده شده است .
ما همان استراتژی برش مجموعه داده Potsdam-A را در مجموعه داده Potsdam-B اتخاذ کردیم تا ۵۱۸۴ عکس از ۵۱۲ × ۵۱۲اندازه.
۳٫۲٫ جزئیات پیاده سازی
در این آزمایش، ما پنج شاخص ارزیابی شامل نرخ دقت کلی ( OA )، نرخ فراخوان ( Recall )، امتیاز F ۱ و تقاطع روی اتحاد ( IoU ) را انتخاب کردیم. آنها به شرح زیر است:
تابع تلفات متقاطع آنتروپی (CEloss) برای محاسبه مقدار تفاوت بین مقدار واقعی و مقدار پیشبینی شده اعمال شد. مدل پس انتشار را انجام داد و بهترین پارامترها را تحت هدایت مقدار تفاوت آموخت. فرآیند استخراج اتلاف CE در معادله ( ۲۱ ) نشان داده شده است:
که در آن m تعداد نمونه ها است، n نشان دهنده تعداد دسته ها است، p (ایکسمن ج)یک متغیر است (اگر دسته j با نمونه i یکی باشد، ۱ است، در غیر این صورت ۰ است) q(ایکسمن ج)نمونه احتمال است، i کلاس j پیشبینی میشود .
همه آزمایشها روی Ubuntu16.04 LTS با پردازنده Intel(R)Core(TM)i7-8750F @2.20 گیگاهرتز، ۱۶ G حافظه (RAM) و NVIDIA GeForce RTX1060 (8 گیگابایت) انجام شد. پایتون ۳٫۸ استفاده شد و مدل با استفاده از Pytorch1.0.1 ساخته شد. همه مدل ها برای ۳۰۰ دوره با اندازه دسته ای ۴ آموزش داده شدند و نرخ یادگیری اولیه ۰٫۰۰۱ بود.
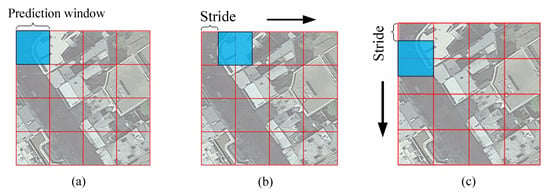
این مقاله پردازش پس از پیشبینی مدل را بهبود میبخشد. روش پیشبینی مدل، اتصال چند مقیاسی و کشویی پنجره را اضافه میکند که میتواند نتایج پیشبینی را به طور قابل توجهی بهبود بخشد. روش اجرای استراتژی چند مقیاسی به این صورت است که تصویر را بر اساس تصویر پیشبینیشده اصلی به میزان ۱٫۰، ۱٫۲۵، ۱٫۵، ۱٫۷۵، ۲٫۰ برابر بزرگنمایی میکنیم و سپس پیشبینی میکنیم. پس از به دست آمدن نتیجه پیش بینی، اندازه تصویر به اندازه تصویر اصلی کاهش می یابد و برای به دست آوردن نتیجه پیش بینی نهایی اضافه می شود. استراتژی اتصال پنجره کشویی این است که پنجره کشویی گام را برای پیش بینی تصویر مطابق قانون از چپ به راست و از بالا به پایین در گوشه سمت چپ بالای تصویر پیش بینی شده تنظیم کنید. نمودار شماتیک استراتژی پیش بینی اتصال پنجره کشویی در نشان داده شده استشکل ۱۲ . شکل ۱۲ a اندازه پنجره پیش بینی را نشان می دهد، شکل ۱۲ b نشان دهنده گام برای لغزش به سمت راست، شکل ۱۲ c نشان دهنده گام برای لغزش به پایین است. در فرآیند پاننگ، به منظور اطمینان از اینکه کل تصویر را می توان توسط مدل پیش بینی کرد و خروجی را به دست آورد، گام پانینگ را کمتر یا مساوی با اندازه پنجره پیش بینی تنظیم می کنیم. اگر گام کوچکتر از پنجره پیش بینی باشد، قسمت های پیش بینی مکرر ظاهر می شود. بنابراین، ما از روش جمع کلی برای تحقق پیشبینی برای قسمتهای پیشبینی مکرر استفاده میکنیم.
۳٫۳٫ تجزیه و تحلیل نتایج
۳٫۳٫۱٫ معیارهای ارزیابی و اثر پیش بینی
- (۱)
-
آزمایش اصلی
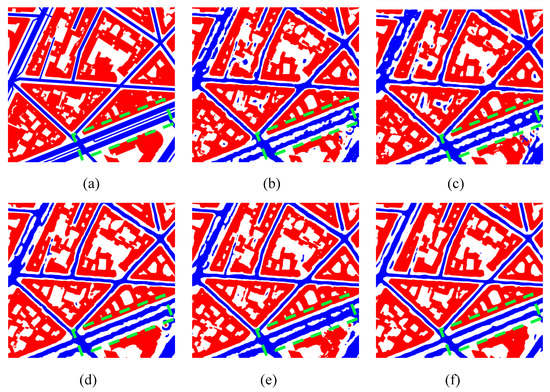
به منظور آزمایش ماژول HMRT پیشنهادی، آزمایشهای جامعی بر روی مجموعه داده Potsdam-A انجام شد. معیارهای ارزیابی در جدول ۳ نشان داده شده است و مقایسه نتایج پیش بینی در شکل ۱۳ نشان داده شده است . علاوه بر این، آزمایشهای فرسایش برای تأیید اثربخشی شاخه استخراج معنایی با وضوح چندگانه انجام شد. شبکه بدون ماژول شاخه استخراج معنایی با وضوح چندگانه آزمایش شد و HMRT-1 نامگذاری شد.
در جدول ۳ ، یادآوری، F1، OA و MIoU HMRT به ترتیب ۸۵٫۳۲، ۸۴٫۸۸، ۸۵٫۹۹ درصد و ۷۴٫۱۹ درصد به دست آمد. هر چهار شاخص بهتر از شبکه های مقایسه بودند [ ۳۲ ، ۳۳ ، ۳۴ ، ۳۵ ]. در این میان، OA به ۸۵٫۹۹% رسید که ۰٫۹۲ بیشتر از DeeplabV3+ بود و MioU به ۷۴٫۱۹ رسید که ۱٫۳۷ بالاتر از DeeplabV3+ بود.
IOU هر مدل در مجموعه تست Potsdam-A در جدول ۴ نشان داده شده است. شاخص های IOU HMRT به ترتیب ۶۵٫۲۱٪، ۷۳٫۱۵٪ و ۸۴٫۲۱٪ بود که از چهار شبکه مقایسه بیشتر بود [ ۳۲ ، ۳۳ ، ۳۴ ، ۳۵ ]. نتایج IOU نشان داد که HMRT دارای مزایای مطلق در دقت تقسیم بندی است.
- (۲)
-
تعمیم تجربی
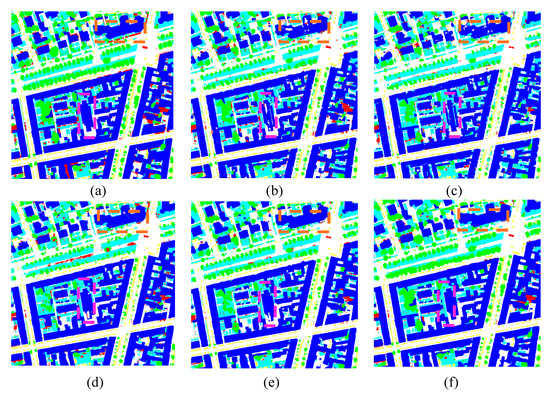
برای تأیید عملکرد تعمیم مدلهای پیشنهادی در این مقاله، از مجموعه دادههای Potsdam-B برای آزمایش بیشتر استفاده شد. معیارهای ارزیابی در جدول ۵ نشان داده شده است. در جدول ۵ ، فراخوان، F1، OA و MIoU HMRT به ترتیب به ۹۱٫۲۹، ۹۰٫۴۱، ۹۱٫۳۲ و ۸۴٫۰۰ درصد رسید. همه شاخص ها در بالاترین سطح خود قرار داشتند که می تواند ثابت کند که مدل پیشنهادی در این مقاله نه تنها موثر است، بلکه عملکرد تعمیم خوبی دارد.
علاوه بر این، این مقاله نتایج پیشبینی هر مدل را به تصویر میکشد. مقایسه نتایج پیش بینی در شکل ۱۴ نشان داده شده است . شکل ۱۴ a برچسب واقعی است، شکل ۱۴ b–f به ترتیب با نتایج پیشبینی FCN-8S، U-Net، PSPNet، DeeplabV3+ و HMRT مطابقت دارد. از طریق مقایسه، میتوان دریافت که مدل HMRT پیشنهادی در این مقاله دارای یک میدان پذیرای جهانی است و دقت تقسیمبندی بالاتر از مدل مقایسه است. کادر چین دار در شکل، ناحیه ای را که اثر تقسیم بندی آشکار است، برجسته می کند.
۳٫۳٫۲٫ تحلیل کمی استراتژی ارتقای نتایج پیشبینی مدل
این کار از دو روش پس پردازش، همجوشی چند مقیاسی و دوخت کشویی برای بهبود دقت پیشبینی استفاده کرد. استراتژی همجوشی چند مقیاسی، سازگاری با اهداف اندازه های مختلف در تصاویر سنجش از دور است، و پارامترهای تجربی این است که تصویر پیش بینی شده به ترتیب با ۱٫۰، ۱٫۲۵، ۱٫۵، ۱٫۷۵، ۲٫۰ برابر بزرگنمایی میشود. استراتژی دوخت کشویی برای کاهش مشکل لبه های ناهموار زمانی که تصاویر به طور مستقیم دوخته می شوند، است، پارامتر آزمایشی این است که اندازه گام نصف پنجره کشویی است (۵۱۲ × ۵۱۲). در نهایت، ما از روش متغیر کنترلشده برای آزمایش بر روی دو استراتژی پس پردازش استفاده کردیم و هر شبکه ۴ مجموعه از نتایج تجربی را بهدست آورد. نتایج آزمایش تحلیل کمی در جدول ۶ نشان داده شده است.
از جدول ۶ نتیجه میگیریم که دو استراتژی همجوشی چند مقیاسی و هم پیوندی لغزشی میتوانند دقت پیشبینی را تا حدی بهبود بخشند و دقت پیشبینی زمانی به بالاترین حد خود میرسد که از دو استراتژی همجوشی چند مقیاسی و اتصال کشویی استفاده شود. همزمان. به منظور نشان دادن بصری اثربخشی استراتژی پس پردازش، شکل ۱۵ مقایسه بین نتیجه پیش بینی شده بدون استفاده از استراتژی های پس پردازش و نتیجه پیش بینی شده با استفاده از دو استراتژی پس از پردازش را نشان می دهد. از مقایسه شکل ۱۵ب، ج، می توان دید که استراتژی های پس از پردازش، آثار دوخت تصاویر پیوند را کاهش می دهد و خطوط کلی ساختمان ها و جاده های هدف پیش زمینه در تصویر واضح تر است.
۴٫ نتیجه گیری
این مقاله HMRT را برای استخراج ساختمانها و جادهها از تصاویر سنجش از دور با وضوح بالا پیشنهاد میکند. در مقایسه با شبکههای کنونی، HMRT دارای سه مزیت است: (۱) شاخه استخراج معنایی با وضوح چندگانه برای استفاده از شاخههایی با وضوحهای مختلف برای ترکیب ویژگیها ساخته شده است، که تضمین میکند که وضوح بالا و وضوح چندگانه همیشه میتوانند در طول پایین نگه داشته شوند. -فرایند نمونه برداری و اطلاعات ویژگی به طور کامل حفظ می شود. این مشکل را حل می کند که فشرده سازی نقشه ویژگی منجر به از دست دادن جزئیات می شود و شبکه عصبی کانولوشن فاقد درک صحنه از راه دور است، زمانی که الگوریتم تقسیم بندی معنایی فعلی از یک شبکه عصبی کانولوشن (CNN) برای استخراج ویژگی های تصویر استفاده می کند. (۲) شبکه استخراج ویژگی دنباله ترانسفورماتور معرفی شده است که از طریق آن می توان میدان پذیرای جهانی نقشه ویژگی را به دست آورد، وابستگی طولانی مدت هدف تقسیم بندی بهبود می یابد و موضوع کاهش وضوح حل می شود که ناشی از آن است. فشرده سازی نقشه ویژگی در طول استفاده از استخراج ویژگی کانولوشنال. (۳) این مدل دارای مزایای زیر است، مانند بالاترین شاخص دقت، برتری مطلق در دقت تقسیم بندی، و عملکرد قوی کافی.
با این حال، هنوز کاستی هایی در تقسیم بندی ساختمان ها و جاده ها وجود دارد: (۱) استفاده از میدان گیرنده جهانی ترانسفورماتور برای استخراج ویژگی ها هنوز در مرحله توسعه است، بنابراین فضای توسعه در دقت تقسیم بندی لبه ساختمان ها وجود دارد. و جاده ها و ساختار مدل. (۲) پیچیدگی پارامترهای رمزگذار و رمزگشای ترانسفورماتور زیاد است. (۳) هنگامی که تصویر سنجش از راه دور حاوی نویز زیادی باشد، دقت تقسیم بندی کاهش می یابد. در نتیجه، HMRT را برای بهبود دقت بخشبندی و غلبه بر مشکل کاهش دقت قطعهبندی در صورت نویز زیاد در تصاویر سنجش از دور بهینهسازی میکنیم.