۱٫ مقدمه
با توجه به فن آوری های تبلیغاتی و اهداف برای تولید تبلیغات هدفمند، شخصی سازی و سفارشی سازی وب سایت ها و خدمات به هنجار جدید در جامعه ما تبدیل شده است. نیاز به شخصی سازی توسط افزایش داده ها و اطلاعات موجود ایجاد شده است. اضافه بار اطلاعات، که یافتن اطلاعات مرتبط را چالش برانگیز می کند، یک پدیده در دو دهه گذشته بوده است. به عنوان مثال، یک مطالعه در سال ۲۰۰۳ نشان داد که ایجاد اطلاعات منحصر به فرد بین ۱ تا ۲ اگزابایت تخمین زده می شود. این بدان معناست که هر انسان باید ۲۵۰ مگابایت اطلاعات را پردازش کند. تقریباً ۲۰ سال بعد، این نشان دهنده نیاز روزافزون به سیستم های توصیه کاربر کارآمد و دقیق برای کمک به یافتن داده ها و اطلاعات مربوطه است. تحویل محتوای شخصی شده به هر مجموعه ای از کاربران ممکن است از چند جنبه تشکیل شود.
عاملی که در بیشتر رابط های وب شخصی سازی شده نقش حیاتی دارد، تعامل و ماهیت «کاربر پسند» رابط کاربری (UI) است. هر کاربر وب، خواه یک تازه کار باشد یا یک متخصص، می خواهد که رابط کاربری محتوای معنی داری ارائه دهد که بدون داشتن تخصص قبلی در مورد عملکرد آن، ارائه شود. این فرآیند از دیدگاه یک توسعهدهنده وب مستلزم کار زیادی است، اما باید برای کاربر نهایی نامرئی و بدون درز باشد. بنابراین، ابزارها و تکنیک های مختلفی برای جمع آوری ضمنی داده ها از کاربران ایجاد شده است. جمعآوری دادههای ضمنی، به عبارت سادهتر، فقط جمعآوری دادههای کاربر از طریق «تعاملات رابط» است بدون اینکه کاربر مجبور باشد دادهها را به شیوهای خاص ارائه کند. سپس از داده ها برای تعیین علایق و ارائه توصیه ها استفاده می شود. همزمان،
چنین سیستمهای توصیهکننده به طور گسترده در بسیاری از حوزههای مصرفکننده، مانند خرید آنلاین، مستقر هستند، اگرچه تحقیقات ما بر توصیههای املاک و مستغلات تمرکز دارد. توصیه املاک و مستغلات اغلب در مورد مکان یک مورد ملک است، بنابراین ما تعاملات نقشه آنلاین را به عنوان ابزاری برای درک علایق کاربر گنجانده ایم. این مقاله چهار رویکرد توصیه اصلی را برای شناسایی مؤثر اقلام دارایی در پورتال املاک و مستغلات ما ارائه میکند. (۱) تجزیه و تحلیل و اجرای فیلترینگ مبتنی بر محتوا برای پیشنهاد اقلام املاک و مستغلات. (۲) رویکرد فیلتر مشارکتی با پیشنهاد موارد مشابه به گروه مشابهی از کاربران، هزینه محاسباتی را کاهش می دهد. (۳) رویکرد مبتنی بر مکان برای پیش بینی منطقه مورد علاقه کاربر بر اساس موقعیت جغرافیایی و ترجیحات کاربر. (۴) ساخت یک مدل پیش بینی قیمت برای کمک به کاربران در تصمیم گیری آگاهانه. دلیل انتخاب دو رویکرد اول بر این واقعیت استوار است که ویژگی های پایگاه داده املاک و مستغلات شباهت زیادی به پایگاه داده فیلم دارد. ثابت شده است که هر دو فیلتر مبتنی بر محتوا و فیلتر مشارکتی توصیه های دقیقی را به کاربران ارائه می دهند [۱ ]. معرفی یک رویکرد مبتنی بر مکان ضروری است زیرا اقلام دارای یک جنبه مکان ذاتی هستند.
ما از دادههای پورتال نقشه Estatech استفاده کردهایم: https://www.the-estatech.com (در ۱۵ سپتامبر ۲۰۲۱ در دسترس قرار گرفته است) برای بخش توصیهای این مطالعه. ما همچنین داده ها را در قالب های صریح و ضمنی به دست آوردیم. علاوه بر این، دادههای تاریخی املاک و فهرست قیمتها از Zameen.com (در ۱۵ سپتامبر ۲۰۲۱) که یک پورتال املاک و مستغلات برای لیست املاک آنلاین است، بهدست آمد. تکنیکها و روشهای مورد استفاده برای الگوریتمهای توصیه، فرآیندهای درخت امتیاز، TF-IDF و K-نزدیکترین همسایهها بودند. برای پیشبینی خانه، ما دو تکنیک، یعنی رگرسیون خطی چندگانه و رگرسیون کراس بر اساس شبکههای عصبی را با هم مقایسه کردیم.
بقیه مقاله به شرح زیر سازماندهی شده است: بخش ۲ مرور ادبیات مرتبط را ارائه می کند. رویکرد روش شناختی در بخش ۳ آورده شده است. بخش ۴ یک بحث و نتایج را ارائه می دهد، در حالی که بخش ۵ مطالعه را به پایان می رساند و توصیه های آینده را ارائه می دهد.
۲٫ کارهای مرتبط
موتورهای توصیه مدرن امروزی از حوزه فیلتر کردن اطلاعات پدید آمده اند، اصطلاحی که توسط [ ۲ ] ایجاد شده است، یک راه حل را برای مسئله بازیابی اطلاعات صحیح در برابر مجموعه ای از داده های آنلاین عظیم، به نام فیلتر محتوا، تشریح می کند. برای اطمینان از انتخاب کاربر به درستی، ابزارهای تجسمی متعددی نیز برای تشخیص دقیق علایق و تمایلات کاربر ایجاد شده است. این ابزارها را می توان نوعی فیلتر محتوا نیز در نظر گرفت. این دامنه از آن زمان تاکنون در حال پیشرفت بوده است. [ ۳] گزینه های مختلفی را برای ادغام یک موتور توصیه در سفر کاربر پورتال املاک و مستغلات نشان می دهد. علاوه بر این، به همان شیوه، کار تأیید کرد که چگونه جزئیات بیشتر املاک و مستغلات میتوانند نتایج توصیههای دقیقتری را هنگام ادغام در مدل پیشنهادی ماشینهای یادگیری عمیق و فاکتورسازی ارائه دهند.
مطالعه دیگری توسط [ ۴ ] با هدف تعیین اینکه آیا وفاداری مصرف کننده به سیستم توصیه کننده کمک می کند تا دقیق تر باشد یا خیر. سایر تکنیک های پیاده سازی شده توسط [ ۵] مانند استفاده از روشهای تحلیل هوشمند دادهها برای ایجاد چارچوب توصیهگر برای حل مشکل توصیه مناسبترین مؤلفهها برای هر کاربر در هر زمان معین. آنها بیشتر به مشکل تبدیل یک مجموعه داده اصلی از یک برنامه کاربردی مبتنی بر مؤلفه واقعی به یک مجموعه داده بهینه شده پرداخته اند. پس از جمعآوری دادههای تعامل و توسعه یک مجموعه داده برای تولید نتایج پیشنهادی بهینه، الگوریتمهای یادگیری ماشین با استفاده از تکنیکهای مهندسی ویژگی و روشهای انتخاب ویژگی نیز استفاده شدند. کاربران و توسعه دهندگان به طور یکسان می خواهند پردازش اطلاعات و نمایش آن سریع باشد. سیستم توسعه یافته توسط [ ۶ ] بر اساس یک سیستم پروفایل ضمنی برای ردیابی علایق کاربر از طریق حرکات ماوس است.
یک رویکرد تحلیل شکاف توسط [ ۷ ]، تفاوتهای بین نظریه و واقعیت را در ارائه اطلاعات در مورد انتخاب مکان با توسعه ابزار طبقهبندی هفت عاملی برای ارزیابی وبسایتهای دارایی شناسایی میکند. برای به تصویر کشیدن روابط بین بردارهای ویژگی پنهان اقلام مستغلات، Ref. [ ۸ ] از اصطلاحات منظمسازی جغرافیایی مبتنی بر میانگین و فردی استفاده کرد. هر دو اصطلاح با چارچوب فاکتورسازی ماتریس منظم وزن دار ادغام شده اند تا رفتارهای بازخورد ضمنی کاربران را مدل کنند تا توصیه های دارایی شخصی شده را به آنها ارائه دهند.
یک مدل احتمالی برای فیلتر مشارکتی توسط [ ۹ ] مقادیر پیشبینیشده برای آیتمها را در مقابل کاربران فعال محاسبه میکند، با توجه به اینکه اطلاعات از قبل در مورد آن کاربران فعال موجود است. همین تحقیق روشهای فیلتر مشارکتی را به دو ماژول اصلی تقسیم میکند، فیلتر مشارکتی مبتنی بر حافظه و فیلتر مشارکتی مبتنی بر مدل. رویکردهای احتمالی اضافی ارائه شده است، برخی پیچیده تر از دیگران، از جمله کار [ ۱۰ ]. روش توصیه شده به عنوان یک فرآیند تصمیم گیری متوالی در نظر گرفته می شود و استفاده از زنجیره های تصمیم مارکوف برای ایجاد یک مدل پیشنهاد شده است. با این حال، آنها هیچ دقت بهبود یافته ای را نسبت به مدل های پیش بینی شده Breese بیان نمی کنند. سیستم توصیه دیگری توسط [ ۱۱] از فیلتر مبتنی بر محتوا، یک تکنیک فازی برای شناسایی محتوای مشابه و متفاوت و یک الگوریتم پیشبینی برای شناسایی مجموعه مناسب محتوای فیلم برای کاربر استفاده میکند. در همان زمان، ر. [ ۱۲ ] الگوریتمهای محوری از آیتم به مورد را توسعه داد. این برای ارائه نتایج بهبود یافته نسبت به الگوریتمهای مبتنی بر کاربر با مقایسه رویکرد با K-نزدیکترین همسایه انجام شده است.
در حوزه GIS، یک سیستم شخصی سازی نقشه کامل توسط [ ۱۳ ] توسعه داده می شود که در آن علایق کاربران به طور ضمنی ثبت می شود و بر اساس معیارهای مشخصی که بر اساس کلیک ها یا حرکات ماوس کاربر برآورده می شوند، رتبه بندی های خاصی داده می شود. همانطور که قبلا ذکر شد، شخصی سازی نقشه به یک منطقه مورد علاقه تبدیل شده است، زیرا اضافه بار داده ها به یک سناریوی رایج در سیستم های اطلاعات مکانی تبدیل شده است. در مدل توسعه یافته توسط [ ۱۴ ]، تمام تمرکز بر درک الگوهای استفاده از نقشه کاربران نهایی است. هدف دوباره بر توسعه نقشه های شخصی سازی شده برای کاربران در یک رابط وب متمرکز شده است. کار بر روی خطوط مشابه، RecoMap [ ۱۳]، یک پلتفرم مبتنی بر وب است که از طریق آن هر کاربر توصیه های فضایی سفارشی را بر اساس علاقه خود دریافت می کند. نتایج در یک رابط نقشه ارائه شده است که توصیه های فضایی شخصی کاربر را برجسته می کند. نقشه تطبیقی همچنین ترجیحات کاربر و زمینه ای که در آن استفاده می شود را نشان می دهد. یک رویکرد متفاوت توسط [ ۱۵ ]، ساختن یک سیستم توصیه و رابط نقشه است که در قالبی شخصیسازی شده برای کاربر نمایش داده میشود تا نتایج سریع به دست آورد. استنباط های بیشتر با مطالعه رفتار کاربر برای بهبود سیستم انجام می شود.
یکی دیگر از سیستم های توصیه گر طراحی شده توسط [ ۱۶ ] برای کاربران املاک و مستغلات است که پروفایل کاربری برای هیچ پورتال املاک و مستغلات ندارند. تعامل مبتنی بر جلسه کاربر با استفاده از زمینه جستجوی کاربر و معیارهای رتبهبندی برای هر آیتم دارایی مناسب مؤثرتر میشود. پورتالی که توسط [ ۸ ] به طور خاص برای املاک و مستغلات طراحی شده است، از دو رویکرد اساسی برای نمایه سازی کاربر، ساختار هستی شناختی و استدلال مبتنی بر مورد استفاده می کند. هدف نجات کاربر نهایی از استرس جستجوی گسترده آنلاین و ارائه نتایجی است که در آن کاربر توصیه های سریعی را بر اساس علایق خود دریافت می کند. یک سیستم توصیه که توسط وب سایت املاک و مستغلات مستقر در ایالات متحده “Trulia” استفاده می شود، از “روش شمارش مربع” استفاده می کند [ ۱۷ ]] این روش با مجموعه دادههای مقیاس بزرگ به خوبی کار میکند و نتایج سریعی را بر اساس ترجیحات کاربر بر اساس تنظیمات لبه عشق و نفرت ارائه میدهد.
در دوران کووید-۱۹، اوضاع به طور قابل توجهی در صنعت املاک و مستغلات تغییر کرده است. در برخی مناطق، قیمت مسکن با از دست دادن معیشت مردم، نشانه هایی از رکود و حتی در برخی موارد روند کاهشی را نشان داده است. این شرایط مردم را ترغیب کرده است که هنگام سرمایه گذاری در این بخش با دقت بیشتری قدم بردارند. در چنین سناریویی، یک مدل پیش بینی قیمت می تواند به کاربران در تصمیم گیری آگاهانه کمک کند. روشی توسط [ ۱۸ ] برای پیشبینی قیمت مسکن از تخمینگر میانگینگیری مدل Mallows استفاده میکند که از نظر وابستگی مکانی قوی است. مطالعه دیگری بر روی مدلهای ML برای پیشبینی قیمت خانه نتیجهگیری میکند که مدل رگرسیون تصادفی جنگل بهترین نتایج را در بین همه مدلهای مقایسه شده دیگر مانند رگرسیون خطی، درخت تصمیم، رگرسیون k-means ارائه میکند [ ۱۹ ].]. مطالعه مشابه دیگری که توسط [ ۲۰ ] انجام شد، رگرسیون را به عنوان یک مدل پیش بینی کننده اعمال می کند. آنها از MSE، MAE و RMSE به عنوان معیارهای ارزیابی خود برای دقت مدل خود استفاده می کنند. مطالعه جالب دیگری توسط [ ۲۱ ] از تحلیل رگرسیون چندگانه (MRA) برای تخمین قیمت ملک برای ارزیابی انبوه استفاده کرد. کیفیت ساختاری و موقعیت ملک به عنوان دو عامل خرد اولیه قیمت گذاری خانه در نظر گرفته شد. MRA برای تعیین ویژگیهای ساختاری و ویژگیهای مکانی که از نظر آماری بر قیمت خانه تأثیر میگذارند با استفاده از نمونهای از ۱۰۶ معامله فروش خانه از سال ۲۰۱۱ تا ۲۰۱۵ استفاده شد. یک رویکرد جایگزین توسط [ ۲۲] بر راهحلهای سنتی مبتنی بر روشها و رویههای شناخته شده و ایمان به خطاناپذیری و عینیت انسانی در تحلیل بازار املاک و مستغلات تمرکز دارد. از آنجایی که فناوری های مدرن نیز جسورانه وارد عرصه می شوند. از این رو، تمرکز اصلی این مطالعه این است که سازمان ها باید از مشاهده راه حل های خودکار (مانند AVM، CAMA و AAVM) به عنوان عملکردی در تقابل با رویکردهای سنتی خودداری کنند و در عوض آنها را به عنوان ابزار تکمیلی بپذیرند.
کار قبلی ما در شخصیسازی نقشه، مفهوم اولیه شخصیسازی را با استفاده از تحلیلهای املاک و مستغلات مورد بحث قرار میدهد [ ۲۳]. همچنین تحقیقات پسزمینه مربوط به بلوکهای ساختمانی را که منجر به یک موتور توصیه برای تجزیه و تحلیل بلادرنگ میشوند، ارزیابی میکند. تحقیقات گسترده در این زمینه شکاف هایی را بین تجزیه و تحلیل املاک و شخصی سازی، توصیه و پیش بینی مبتنی بر نقشه نشان داده است. بنابراین، ما سعی کرده ایم این شکاف را در کار تحقیق و توسعه اولیه خود پر کنیم. ما همچنین انگیزه ای برای مطالعه و توسعه متعاقب آن پیدا کردیم زیرا درگاه های املاک شخصی سازی شده مبتنی بر نقشه به طور گسترده در بازار آنلاین املاک وجود ندارد. نیاز به غربال کردن تعداد زیادی از داده های آنلاین دیگر برای اکثر کاربران مناسب نیست و شخصی سازی به یک مفهوم کلیدی در هر جنبه ای از جستجوی داده تبدیل شده است. در سناریوی ما، کاربران تست املاک و مستغلات با یک پورتال املاک، “Estatech Maps” برای جستجو و ارسال اقلام دارایی در تعامل بوده اند. سیستم توصیه ما بر اساس سه تکنیک است. این شامل محتوا، همکاری و فیلتر مبتنی بر مکان است. تعامل کاربران از طریق رابط مبتنی بر نقشه برنامه املاک و مستغلات، Estatech Maps گرفته شده و در یک پایگاه داده ذخیره می شود. بر اساس این داده ها و تجزیه و تحلیل، کاربر توصیه هایی را بر اساس حوزه مورد علاقه خود دریافت می کند. همراه با آن، ما یک ماژول مبتنی بر تکنیکهای رگرسیون سنتی و Keras API برای پیشبینی روند قیمتهای آینده اقلام دارایی گنجاندهایم. کاربر توصیه هایی را بر اساس حوزه مورد علاقه خود دریافت می کند. همراه با آن، ما یک ماژول مبتنی بر تکنیکهای رگرسیون سنتی و Keras API برای پیشبینی روند قیمتهای آینده اقلام دارایی گنجاندهایم. کاربر توصیه هایی را بر اساس حوزه مورد علاقه خود دریافت می کند. همراه با آن، ما یک ماژول مبتنی بر تکنیکهای رگرسیون سنتی و Keras API برای پیشبینی روند قیمتهای آینده اقلام دارایی گنجاندهایم.
بخش بعدی بینش دقیق فرآیند تحقیق در مورد جمع آوری داده ها، پیش پردازش آن، ایجاد محیط زمان اجرا و مفهوم مدل را مورد بحث قرار می دهد. در نهایت، این بخش در مورد زمینه های حیاتی زیر در فرآیند تحقیق به تفصیل بحث خواهد کرد. (۱) جمع آوری داده ها و فناوری. (۲) توصیه املاک. (۳) مدل پیش بینی قیمت.
۳٫ روش شناسی
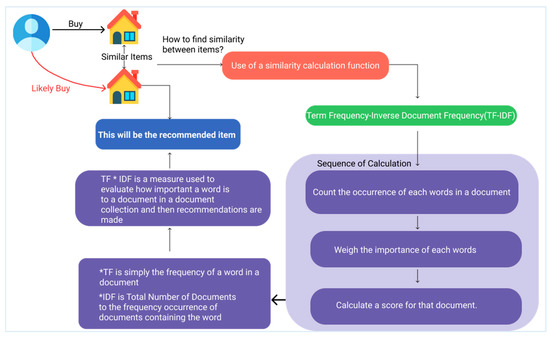
تمرکز اصلی “Estatech Maps” ارائه لیست املاک و مستغلات شخصی شده به کاربران خود در یک رابط مبتنی بر نقشه با ارائه توصیه های دقیق و ارائه بینش در مورد روند قیمت در منطقه مورد علاقه کاربر است. توصیه و پیشبینی قیمت محورهای اصلی برای ارائه شخصیسازی مبتنی بر نقشه به کاربران بود. در مرحله اول، مطالعه دقیقی بر روی تفسیر ریاضی الگوریتم های توصیه انجام شد. مرحله دوم بر روی طرح های الگوریتم متمرکز بود و در مرحله سوم توسعه بر اساس آن الگوریتم ها انجام شد و مدل ها پیاده سازی شدند. اعتبار سنجی و آزمایش این مدل ها در مرحله نهایی تحقیق انجام شد. توالی مطالعه در شکل ۱ نشان داده شده است .
در خصوص پیشبینی قیمت، پس از تحقیق در تکنیکهای مختلف پیشبینی، دو مدل انتخاب شدند. یکی مبتنی بر تکنیک رگرسیون کلاسیک است و دیگری بر شبکه های عصبی متکی است.
۳٫۱٫ جمع آوری داده ها و فناوری
دادههای تعامل کاربر در طول یک سال (مه ۲۰۲۰ تا مارس ۲۰۲۱) از پورتال استخراج شد. داده ها با فرمت JSON از پایگاه داده MongoDB استخراج شد که به فرمت CSV تبدیل شد. این شامل ۱۶۰۰ تعامل کاربر ثبت شده با پورتال بود. دادههای پیشبینی قیمت مسکن از یک پورتال مستغلات Zameen.com مستقر در پاکستان (در ۱۵ سپتامبر ۲۰۲۱) برای دو سال بین ۲۰۱۹-۲۰۲۰ برای شهر اسلامآباد بهدست آمد.
هر دو مجموعه داده از نقشه های Estatech و Zameen.com (در ۱۵ سپتامبر ۲۰۲۱ در دسترس قرار گرفت) به مجموعه داده های آزمایشی و آموزشی تبدیل شدند. دادههای Zameen.com (در ۱۵ سپتامبر ۲۰۲۱ در دسترس قرار گرفت) که برای مدل پیشبینی قیمت مسکن استفاده میشد، بیشتر به مجموعه داده اعتبار سنجی تبدیل شد. دادهها شامل چندین فایل بود: اطلاعات ورود کاربر (دموگرافیک کاربر)، دادههای تعامل (لیست ویژگیهای پربازدید) و دادههای مورد (ویژگیها).
TuriCreate برای ساخت موتور توصیه برای فیلتر کردن مبتنی بر محتوا و مشارکتی استفاده شد، در حالی که یک تکنیک خوشهبندی K-means برای توصیه مبتنی بر مکان استفاده شد. TuriCreate یک جعبه ابزار منبع باز برای ساخت مدل های Core ML برای کارهایی مانند تشخیص تصویر، تشخیص اشیا، انتقال سبک و تولید توصیه و غیره است.
Tensor Flow و Keras API بهعنوان فناوریهای پایه برای ساخت مدل پیشبینی قیمت مسکن و اعتبارسنجی مناسب برای از دست دادن مدل و دقت مدل استفاده شدند که از طریق تکنیکهای ارزیابی MSE، MAE و RMSE انجام شد. TensorFlow یک کتابخانه نرم افزار یادگیری ماشینی است که رایگان و منبع باز است. می توان از آن برای فعالیت های مختلف استفاده کرد، اما بر آموزش شبکه عصبی عمیق و استنتاج تمرکز دارد. تیم Google Brain TensorFlow را برای استفاده داخلی گوگل ایجاد کرد. در سال ۲۰۱۵ تحت مجوز آپاچی ۲٫۰ منتشر شد. دلیل استفاده از TensorFlow این است که یک کتابخانه هوش مصنوعی منبع باز است که مدل هایی را با استفاده از نمودارهای جریان داده می سازد. برنامه نویسان را قادر می سازد تا شبکه های عصبی در مقیاس بزرگ با چندین لایه ایجاد کنند. Keras یک API یادگیری عمیق است که در پایتون نوشته شده است که در بالای سیستم یادگیری ماشینی TensorFlow اجرا می شود. این با هدف امکان آزمایش سریع ساخته شده است.
۳٫۲٫ توصیه املاک
سه حوزه تمرکز موتور توصیه به تفصیل در هر یک از بخش های زیر مورد بحث قرار گرفته است.
۳٫۲٫۱٫ فیلترینگ مبتنی بر محتوا
مفهوم سیستم های توصیه گر، تجزیه و تحلیل داده ها است. این امر میتواند با الگوریتمهای مبتنی بر امتیاز یا با پیشنهاد دادن آیتمهای برتر در فهرست N-امین آرایه آیتمها، به دست آید. در سناریوی ما، سیستم توصیهکننده ما برای پیشنهاد اقلام دارایی فهرستشده برای فروش یا اجاره طراحی شده است. اگر شخصی با یک رابط مبتنی بر نقشه با یک آیتم دارایی تعامل داشته است، در ناحیه “A” با آرایه ویژگی “X” بگویید. سیستم توصیه گر می تواند موارد مشابه را به صورت لحظه ای و دقیق برای کاربر نمایش دهد.
در فیلترینگ مبتنی بر محتوا، زاویه بین پروفایل کاربر و موارد مورد علاقه کاربر مشخص می شود. این زاویه کسینوس تعیین می کند که بردارها چقدر در فضا به یکدیگر نزدیک هستند و شباهت کسینوس نیز نامیده می شود. هر چه نزدیکتر باشند، بیشتر شبیه به هم در نظر گرفته می شوند. اجازه دهید یک بردار ” U ” از کاربران {user1, user2, user3….} و یک بردار ” P ” از اقلام ویژگی {p1, p2, p3, p4……} را در نظر بگیریم. شباهت بین این دو بردار را می توان به صورت زیر محاسبه کرد:
مقدار کسینوس یا شباهت در معادله (۱) می تواند بین ۱- و ۱ باشد. بر اساس این مقدار، مقالات به ترتیب نزولی سازماندهی می شوند و توصیه های برتر به کاربر ارائه می شود.
رویکرد فیلترینگ مبتنی بر محتوا در شکل ۲ بیشتر توضیح داده شده است، که نشان می دهد یک معیار درختی برای انتخاب آیتم چگونه کار می کند. این مفهوم بر اساس میزان تعامل کاربر با یک مورد یا دسته خاص است. نسبت های بهره بین دسته های مربوطه بر اساس “افزایش مقدار فرکانس” محاسبه می شود. به عنوان مثال، تعامل خریداران با اجاره یا دسته های خرید، نسبت بهره بین دو دسته را مشخص می کند. جریان تابعی که محاسبه فرکانس را انجام می دهد در شکل ۳ توضیح داده شده است ، که جزئیات دیگری از فرآیند فیلترینگ مبتنی بر محتوا، یعنی TF – IDF را نشان می دهد.. به عنوان مثال، فرض کنید کاربری در گوگل به دنبال عبارت «ظهور تجزیه و تحلیل» است. در آن صورت، اجتناب ناپذیر است که کلمه “the” بیشتر از “تجزیه و تحلیل” رخ دهد، اما اهمیت نسبی تجزیه و تحلیل بیشتر از دیدگاه جستجوی جستجو است. در چنین مواردی، وزن دهی TF – IDF تأثیر کلمات با بسامد بالا در تعیین اهمیت یک آیتم (سند) را نفی می کند.
TF ( t ) به سادگی فراوانی یک کلمه در یک سند است، در حالی که IDF ( t ) نشان دهنده نادر بودن کلمه است، بنابراین اگر کلمه ای که در سند وجود دارد کمتر باشد، مقدار IDF افزایش می یابد. در معادله (۴)، پارامتر log برای کاهش اثر کلمات با بسامد بالا استفاده می شود. ما از هر دو فرآیند درخت امتیاز و رویکردهای TF-IDF در فرمولبندی الگوریتم فیلترینگ مبتنی بر محتوا استفاده کردهایم. در ابتدا، شباهت کاربر- کاربر و شباهت آیتم- آیتم در قالب آرایه به دست می آید. گام بعدی در این فرآیند ایجاد ماتریس شباهت آیتم-کاربر بود.
۳٫۲٫۲٫ رویکرد فیلترینگ مشارکتی
در رویکرد ما نسبت به توسعه یک فیلتر مشترک برای پورتال، کاربران آزمایشی بر اساس ترجیحاتشان به بخشهایی تقسیم شدند و موارد بر اساس انتخاب متقابل کاربران متعلق به آن بخش توصیه شد. هر چه کاربر بیشتر با موارد نمایش داده شده تعامل داشته باشد و به آنها امتیاز دهد، سیستم با دقت بیشتری می تواند موارد مناسب را پیشنهاد دهد. الگوریتم های طراحی شده برای فیلتر کردن مشارکتی بیشتر مبتنی بر یافتن شباهت های بین کاربران بر اساس رتبه یا رتبه ای است که به موارد قبلی داده اند. بنابراین، برای پیشبینی هر آیتم برای کاربر ” u “، محاسباتی برای محاسبه مجموع وزنی کاربر ” u ” دادهشده توسط کاربران به آیتم ” i ” انجام میشود. پیش بینی سپس به صورت زیر محاسبه می شود:
عبارت پیش بینی کاربر ‘ u ‘ در برابر یک مورد ” i ” است.
عبارت پیشبینی کاربر « u » در برابر یک مورد « i » است. تعاملی است که کاربر می گویند ” v “. با یک آیتم ” i ” شباهت بین دو کاربر، یعنی کاربر “ u ” است. و کاربر ” v “.
مطابق جدول ۱ ، تعاملات بین کاربران و ویژگیها ثبت میشود و پیشنهادهایی به کاربر جدید “u1” تولید میشود. در همان زمان، نماد “x” نشان دهنده هرگونه تعامل بین یک کاربر و یک آیتم دارایی است. بدیهی است که بین کاربر ۱ و کاربر ۲ شباهت بیشتری نسبت به کاربر ۳ وجود دارد. بر این اساس، کاربر ۱ و کاربر ۲ برای توصیه های بعدی با هم گروه بندی می شوند. الگوریتم ۱ یک الگوریتم تعمیم یافته را نشان می دهد که برای گروه بندی کاربر ۱ و کاربر ۲ با هم طراحی شده است تا ویژگی های یکسان به آنها توصیه شود.
| الگوریتم ۱ الگوریتم توصیه مشترک برای کاربر جدید “U1” |
| ۱: ورودی: Properties Dataset → all properties |
| ۲: همسایه ها برای رتبه بندی → K |
| ۳: کاربر جدید برای توصیه → U1 |
| ۴: توصیه های فعلی برای کاربر جدید U1 → ∅ |
| ۵: تاریخچه موقعیت مکانی کاربران → L |
| ۶: رتبه = ۰ |
| ۷: خروجی : N مورد توصیه می شود |
| ۸: برای هر → خاصیت ∈ همه خواص انجام می دهند |
| ۹: اگر (کاربران برای P1==کاربران برای P2) سپس |
| ۱۰: رتبه ++ |
| ۱۱: گروه بر اساس نزدیکترین همسایه در شباهت (K، ویژگی، کاربر، L) = کاربران برای P1 و & کاربر برای P2 |
| ۱۲: توصیهها [U1] → [P3] |
| ۱۳: رتبه نزولی . مرتب سازی (خواص) |
| ۱۴: توصیه های بازگشت [] |
۳٫۲٫۳٫ فیلتر بر اساس مکان
هدف از یک سیستم توصیه مبتنی بر مکان، توصیه موارد بر اساس موقعیت جغرافیایی یک کاربر است. در این سناریو، توصیههایی را میتوان برای یک کاربر جدید نیز ممکن کرد (مشکل شروع سرد) که در آن موارد بر اساس کاربران مکانهای اطراف که ممکن است بر اساس پارامترهای دیگر مانند سن یا جنسیت و غیره با کاربر جدید هماهنگ شوند، توصیه میشوند. توصیههای مبتنی بر آن میتوانند در صرفهجویی در زمان و هزینههای سفر، زمانی که بهطور مؤثر از طریق یک رابط تعاملی نمایش داده میشوند، بسیار سودمند باشند.
معادله (۴) احتمال تعامل یک کاربر را با یک مورد “i” محاسبه می کند که بر اساس فاصله از تمام تعاملات قبلی کاربر، که در مورد ما، سایر موارد دارایی هستند، ایجاد شده است. در حالی که در الگوریتم ۲ الگوریتم برای کاربر آزمایشی ۱ مشخص شده است.
در الگوریتم ۲، یک الگوریتم تعمیم یافته برای محاسبه توصیه های مبتنی بر مکان برای کاربران ارائه شده است. حداقل ۵۰ کاربر را در یک خوشه برای محاسبه امتیاز شباهت در نظر می گیرد.
| الگوریتم ۲ الگوریتم توصیه مبتنی بر مکان برای کاربر جدید “U1” |
| ۱: ورودی: یک کاربر |
| ۲: مجموعه کاربران → U |
| ۳: تاریخچه مکان کاربران → L |
| ۴: ماتریس شباهت بین کاربران → M |
| ۵: توصیه های فعلی برای کاربر جدید بر اساس مکان → ∅ |
| ۶: تعداد = ۰ |
| ۷: خروجی: برترین توصیه های دارایی مبتنی بر مکان N بر اساس شباهت ها و ترجیحات کاربران |
| ۸: M = مقادیر ماتریس شباهت |
| ۹: تعداد کاربران نزدیک که برای شباهت انتخاب شده اند |
| ۱۰: محاسبه امتیاز ≤ ۵۰ |
| ۱۱: برای هر → کاربر ∈ U do |
| ۱۲: LOC = کشف مکان // سطح سلسله مراتب یا دانه بندی مکان |
| ۱۳: امتیاز فاصله شباهت را محاسبه کنید |
| ۱۴: محاسبه فاصله از کاربران نزدیک |
| ۱۵: امتیاز شباهت آخرین x ویژگی های متقابل کاربر U1 == امتیاز شباهت امتیاز شباهت کاربر نزدیک |
| ۱۶: خصوصیات را بر اساس تعداد مرتب کنید |
| ۱۷: N امتیاز برتر را انتخاب کنید |
| ۱۸: N خواص برتر را انتخاب کنید |
| ۱۹: N توصیه ها را برگردانید |
۳٫۳٫ مدل پیش بینی قیمت
جنبه مهمی که در مدل پیشبینی قیمت باید به آن توجه کرد این است که دادههای مورد استفاده برای این تحلیل «مجموعه قیمتهای پیشنهادی» توسط پورتال املاک Zameen.com (در ۱۵ سپتامبر ۲۰۲۱) است. این قیمتها میتوانند با توجه به تغییرات بازار یا هر افزونگی در بخش املاک و مستغلات تغییر کنند.
برای جنبه پیشبینی و تحلیل، دو تکنیک رگرسیون، یعنی (۱) رگرسیون خطی چندگانه و (۲) رگرسیون کراس انتخاب شدند. مقایسه متقابل و اعتبار سنجی این تکنیک ها انجام شد. مدلی که از نظر امتیاز واریانس عملکرد بهتری داشت به عنوان مدل نهایی برای تجسم قیمت مسکن انتخاب شد.
۳٫۳٫۱٫ رگرسیون خطی چندگانه
این یک نوع رگرسیون خطی است که در آن فرض بر این است که متغیر مستقل y و متغیر وابسته x یک رابطه خطی یا مستقیم دارند. ما از کتابخانه Sklearn برای وارد کردن ماژول رگرسیون خطی استفاده کردیم. همانطور که قبلاً ذکر شد، مجموعه داده ما به یک مجموعه آزمایشی و یک مجموعه قطار تقسیم شد.
۳٫۳٫۲٫ رگرسیون کراس
ما از تکنیک های رگرسیون برای پیش بینی متغیر مستقل y که قیمت است استفاده می کنیم. ما ۱۴ ویژگی داریم (شناسه_ملاک، شناسه_موقعیت، نوع_ملاک، قیمت بر حسب pkr، قیمت به دلار، مکان، شهر، استان، اتاق خواب، حمام، هدف منطقه، تاریخ اضافه شدن به پورتال، منطقه در مارلا، مساحت در فوت مربع،) ; بنابراین ما ۱۴ نورون را به عنوان خط پایه به همراه یک خروجی و یک لایه ورودی برای مدل انتخاب کردیم. ۴ لایه مخفی وجود دارد.
این مدل برای ۴۰۰ دوره آموزش داده شد و دقت آموزش و اعتبارسنجی در طول هر چرخه ثبت شد. در نهایت، مدل بر روی نتایج قطار و آزمایش اجرا شد، با عملکرد تلفات در هر دوره اندازهگیری شد تا میزان عملکرد مدل را پیگیری کند.
۴٫ نتایج و بحث
۴٫۱٫ ساخت مدل فیلترینگ مبتنی بر محتوا و مشارکتی
ما کتابخانه Sklearn را بهعنوان یک ماژول به نام فاصله زوجی انتخاب کردیم که هر دو مورد را که ویژگیهای مشابهی دارند یا هر دو کاربر که علایق مشابهی دارند را شناسایی میکند. برای اعمال چنین فاصله ای، تابعی را تعریف کردیم که پارامترهای برهمکنش ها، شباهت و نوعی را که در آن شباهت را به دست می آوریم، برمی گرداند. الگوریتم پیشنهادهایی را بر اساس مشخصات کاربر (مدل فیلتر مشارکتی) برای مورد اول ایجاد می کند. برای مورد دوم، پیشنهادات بر اساس ویژگی های مورد (فیلتر مبتنی بر محتوا) است. در پایان، ما توانستیم هم برای کاربران و هم برای آیتم ها توصیه هایی را به دست آوریم. در جدول ۲ و جدول ۳مشاهده میشود که برای همه کاربران، امتیازات «S» به ترتیب نزولی بهدست میآید که بیشترین شباهتها در بالاست.
در جدول ۴ و جدول ۵ مشاهده می شود که نمرات به دست آمده در برابر هر کاربر به راحتی قابل تفسیر نیست. مشخص نیست که کاربر در برابر کدام شناسه دارایی موارد مورد علاقه پیشنهادی را دریافت می کند. برای شفافتر کردن نتایج، از کتابخانه Turicreate استفاده کردهایم. این باعث شد که نتایج به دست آمده برای درک آسان تر شود. جدول ۴ نتایج مدل توصیه مبتنی بر محتوا را نشان می دهد. این مدل برای پنج کاربر پورتال ارزیابی شد و توصیه هایی برای آنها ایجاد شد.
در جدول ۴ ، مجموعه ۵ کاربر، همان ۵ مورد دارایی را به دلیل محبوبیت آن آیتم ها به عنوان بیشترین تعامل با آنها، توصیه می کند.
جدول ۵ ویژگی های توصیه شده به کاربران را بر اساس گروه بندی با سایر کاربران دارای علایق مشابه نشان می دهد. شناسه های دارایی دارای امتیاز بالاتر در رتبه های بالاتری قرار می گیرند. به هر کاربر مجموعهای از ویژگیها توصیه میشود، که به وضوح نشان میدهد که شخصیسازی برای هر کاربر وجود دارد.
۴٫۲٫ ساخت مدل توصیه مبتنی بر مکان از طریق خوشه بندی K-Means
خوشهبندی K-means تعداد «k» مرکزها را در یک مجموعه داده مشخص میکند. پس از آن، هر نقطه داده را با نزدیکترین خوشه اختصاص می دهد. این نقاط داده در نهایت در خوشه ای با نزدیک ترین میانگین قرار می گیرند. در رویکرد ما، هدف از اعمال خوشهبندی K-Means گروهبندی کاربران مشابه بر اساس مکانهای مربوطه است. همانطور که کاربران خوشهبندی میشوند، بالاترین مورد جستجو یا تعامل در میان آن گروه کاربری شروع به توصیه به هر کاربر میکند. شکل ۴مکان های ایجاد شده خودکار را برای کاربران از مکان های مختلف اسلام آباد به همراه شناسه های خوشه مربوطه نشان می دهد. هنگامی که ماوس روی هر خوشه ای قرار می گیرد، بیشترین مورد جستجو شده در آن خوشه را نشان می دهد که به کاربران آن خوشه توصیه می شود. به عنوان مثال، در یکی از خوشهها، تعداد اموال جستجو شده ID 689 بالاترین است. از آنجایی که برابر با بالاترین تعداد برای آن خوشه است، همه کاربرانی که در آن خوشه قرار می گیرند، شناسه ویژگی ۶۸۹ را به عنوان ویژگی توصیه شده برای مشاهده دریافت خواهند کرد.
۴٫۳٫ اعتبار سنجی سیستم توصیه کننده
برای اعتبارسنجی توصیهها، میتوان رفتار کاربر را شبیهسازی کرد و رتبهبندیهای احتمالی یا گمشده یا، در مورد ما، تعاملاتی که ممکن است یک کاربر با هر مورد دارایی احتمالی داشته باشد را پر کرد. سپس مقادیر شبیهسازی شده را میتوان با معیارهای خطا مانند میانگین مربعات خطا برای تعیین انحراف مقادیر پیشبینیشده نسبت به مقادیر مشاهدهشده ارزیابی کرد. خطای کلی این مقادیر می تواند یک نمای کلی از دقت مدل ما ارائه دهد.
جدول ۶ ماتریس تولید شده را برای تعاملاتی که کاربر احتمالاً با اقلام دارایی دارد و محاسبه MSE برای ماتریس کلی نشان می دهد. روشهای دیگر اعتبارسنجی مدل را میتوان از طریق فراخوانی و دقت انجام داد. هر دو بسیار مفید هستند، زیرا نشان میدهند که توصیهها چقدر دقیق هستند. با این حال، مشکل یادآوری و دقت این است که پس از اعمال این معیارها، موارد توصیه شده بر اساس ارزش وزنی آنها مرتب نمی شوند.
MAP@k (میانگین دقت در k) یک معیار ارزیابی است که ترتیب موارد توصیه شده را نیز در نظر می گیرد. در مورد ما، ما ۵ مورد را به مجموعه ۵ کاربر توصیه کرده ایم، بنابراین در مورد ما k = 5. ما یک محیط آزمایشی را برای گروه پنج کاربر پورتال خود تنظیم کردیم. لیستی از موارد توصیه شده به ترتیب ایجاد شده توسط موتور توصیه گر ما به آنها ارائه شد. کاربران با موارد خاصی تعامل داشتند و بازخورد شفاهی در مورد اینکه آیا توصیههای تولید شده مورد علاقه هستند یا خیر ارائه کردند. به عنوان مثال، دقت آماری موتور توصیه برای یک کاربر معین ۱ به شرح زیر است.
-
[۱، ۱، ۱، ۰، ۰] که در آن ۱ مخفف یک توصیه صحیح است به طوری که کاربر با آن تعامل داشته است و ۰ مخفف توصیه ای است که کاربر با آن تعامل نداشته است.
-
[۱/۱، ۲/۲، ۳/۳، ۲/۳، ۱/۳] دقت در k است.
-
(۱/۵) [۱/۱ + ۲/۲ + ۳/۳ + ۲/۳ + ۱/۳] = ۰٫۷۹۹۹ دقت متوسط در k است.
دقت برای سه مورد اول که با آنها تعامل داشت بیشتر است، اما برای دو مورد آخر که کاربر با آنها تعامل نداشت، دقت کاهش می یابد. بنابراین، برای کاربر ۱، میانگین دقت تقریبا ۸۰٪ است. در حالی که برای همه مجموعههای کاربران، این میانگین دقت متوسط خواهد بود و میتوان آن را با گرفتن میانگین دقت محاسبه کرد.
۴٫۴٫ House Prize Perdiiction Modell
همانطور که قبلا ذکر شد، ما دو مدل پیشبینی قیمت ملک (۱) رگرسیون خطی چندگانه (۲) رگرسیون کراس را مقایسه و اعتبارسنجی کردهایم. MLR مبتنی بر تکنیکهای رگرسیون سنتی است، در حالی که Keras اساس خود را در شبکههای عصبی دارد. ما هر دو رویکرد را در یک محیط پایتون زمان اجرا آزمایش کردیم. شکل ۵ توصیف سطح بالایی از روش اتخاذ شده برای مدل را ارائه می دهد. هر دو مدل با داده ها و پارامترهای داده شده به خوبی عمل کردند. با این حال، مدل با نرخ خطای کمتر و امتیاز واریانس بهتر یا ضریب تعیین به عنوان مدل نهایی برای استقرار انتخاب شد.
۴٫۴٫۱٫ رگرسیون خطی چندگانه
پس از اجرای اولین مدل رگرسیون خطی چندگانه، شکل ۶ ویژگی های برتر توصیه شده را بر اساس توصیه های مکان در مناطق مختلف شهر اسلام آباد نشان می دهد، در حالی که شکل ۷ نمایانگر تجسم پیش بینی قیمت است. قیمت واقعی همان قیمتی است که قبلاً در داده های آزمایشی وجود داشت، در حالی که قیمت پیش بینی شده پس از اجرای مدل بر روی داده های قطار به دست آمد. جدول ۷ خطاهای MAE، MSE و RMSE این پیش بینی ها را نشان می دهد. همچنین می توانیم امتیاز واریانس را تقریباً ۰٫۷۰۳۹۷ ببینیم.
۴٫۴٫۲٫ رگرسیون کراس
امتیاز واریانس رگرسیون کراس تقریباً ۸۰۲۸/۰ است. این عملکرد بهتر از رویکرد رگرسیون خطی چندگانه است. علاوه بر این، همانطور که در جدول ۸ و جدول ۹ نشان داده شده است، خطاهای عددی برای RMSE در مورد Keras نیز کاهش یافته است . بنابراین، پیشبینیهای ما در این سناریو به قیمت واقعی نزدیکتر است.
شکل ۸ و شکل ۹ نشان دهنده روش های مختلف تغییر قیمت ها در شهر اسلام آباد است. در شکل ۸ ، میانگین قیمت های بخش (منطقه محله) مشخص شده است. این تجسم نمای کلی روشنی از اینکه چه مناطقی می توانند تغییرات شدید قیمت را نشان دهند و چه مناطقی راکد باقی می مانند ارائه می دهد. این داده ها در ۲ سال گذشته تجزیه و تحلیل شده است و پیش بینی ها نشان می دهد که چگونه قیمت ها در سال های آینده تغییر می کنند یا ثابت می مانند. ناحیه آبی در شکل نشان میدهد که چگونه قیمتها در سالهای آینده در آن محلهها افزایش قابل توجهی داشته است. در مقابل، نواحی قرمز نشاندهنده رکود قیمتها هستند و تصویر واضحتری را برای کمک به تصمیمگیری در اختیار کاربر قرار میدهند.
۵٫ نتیجه گیری ها
سه الگوریتم پیشنهادی مختلف برای پورتال املاک و مستغلات “Estatech Maps” به همراه دو مدل مختلف برای پیشبینی قیمت مسکن توسعه داده شد. ابتدا، ما اهداف خود را تجزیه و تحلیل و پیاده سازی فیلتر مبتنی بر محتوا برای پیشنهاد اقلام املاک و مستغلات تعیین کردیم. رویکرد فیلتر مشارکتی برای کاهش هزینه محاسباتی با پیشنهاد موارد مشابه به گروه مشابهی از کاربران استفاده شد. سپس، رویکرد مبتنی بر مکان را برای پیشبینی مناطق مورد علاقه کاربر بر اساس موقعیت جغرافیایی کاربر اعمال کردیم. همه اینها با حداقل دقت ۷۹ درصد به دست آمد. مدلهای پیشبینی ایجاد شد و نتایج با افزایش، کاهش یا رکود قیمت در بخشهای مختلف شهر اسلامآباد برای کمک بهتر به افرادی که برای خرید داراییهای زمین در آینده برنامهریزی میکنند، مشاهده شد. مدل ما قادر به پیشبینی دقیق تغییرات در روند قیمت مسکن با حداقل دقت ۸۰ درصد بود که از طریق مدل پیشبینی مبتنی بر شبکه عصبی ما بود. این کار می تواند به طور موثر در هر دامنه خرید و فروش املاک و مستغلات مورد استفاده قرار گیرد و تجربه کلی کاربر از پورتال های املاک و مستغلات را بهبود بخشد. این ثابت می کند که سیستم مبتنی بر نقشه ما در ارائه داده ها و توصیه هایی به کاربران بر اساس محبوبیت یک آیتم، شباهت کاربر و موقعیت جغرافیایی.
در حالی که امروزه توصیهها و تحلیلهای پیشبینی در حال تبدیل شدن به یک روند رایج حتی در کوچکترین کسبوکارها هستند، در پاکستان، صنعت املاک و مستغلات در اجرای این تکنیکها نه تنها از نظر رابط مبتنی بر نقشه، بلکه از نظر ارائه نیز کم است. این آیتم ها را به نحوی موثر در اختیار کاربر قرار می دهد. بنابراین، رویکرد ما برای نمایش یک آیتم مورد علاقه کاربر بر روی یک رابط مبتنی بر نقشه یکی از پیشگامان پورتال املاک و مستغلات در پاکستان خواهد بود.
ما در این تحقیق از مدل های متوالی NN برای توصیه و پیش بینی خود استفاده کرده ایم. یکی از زمینههای بهبود و مبنای کار آینده میتواند کاوش و پیادهسازی این مدلها به عنوان مدلهای موازی برای بهبود زمان پاسخ و کارایی باشد. رویکرد دیگر می تواند ترکیب تکنیک های متعدد برای ایجاد یک مدل ترکیبی باشد. از همین رویکرد در این مطالعه استفاده شد که در آن مدلهای کاب-داگلاس و رگرسیون خطی برای تشکیل یک مدل ریاضی [ ۲۴ ] ترکیب شدند. GIS ابزار اضافی برای سازماندهی داده های منطقه ای منطقه مورد مطالعه بود. به نوبه خود، این می تواند طیف وسیع تری از رفتارهای کاربران را پوشش دهد و از هزینه های محاسباتی بالا در انتهای سرور جلوگیری کند.