۱٫ مقدمه
نظارت تصویری بیدرنگ نقش مهمی را در پیشگیری از جرم، کنترل ترافیک، نظارت بر محیطزیست، تهدیدات تروریستی و مدیریت شهر ایفا میکند [ ۱ ]. نظارت تصویری ابزاری مؤثر برای نظارت در زمان واقعی ۲۴ هکتار در روز است [ ۲ ]، و دوربین ها اندام های بصری شهرهای هوشمند هستند [ ۳ ]. این دوربین ها حجم زیادی از داده های ویدئویی را جمع آوری می کنند و استخراج اطلاعات مفید از داده های انبوه ضروری است. بینایی کامپیوتری جایگزین چشم انسان برای تشخیص بصری، ردیابی و اندازهگیری اشیاء ویدئویی میشود [ ۴ ]]. در سال های اخیر، تشخیص و ردیابی اشیا به کانون تحقیقاتی و مرزی در زمینه بینایی کامپیوتر تبدیل شده است. با این حال، به دلیل تأثیر بسیاری از عوامل، مانند انسداد، تاری حرکت، تغییر روشنایی، تغییر مقیاس و غیره، تشخیص اشتباه و تطبیق اشتباه همچنان در ردیابی چند شی رخ می دهد. علاوه بر این، سیستمهای نظارت تصویری هر دوربین را به یک مانیتور مربوطه در مرکز کنترل متصل میکنند که نمیتواند رابطه فضایی بین دوربینهای مختلف را در صحنه جغرافیایی منعکس کند. بنابراین، ناظران ویدئویی باید منطقه نظارت را درک کنند تا تصاویر روی هر مانیتور را به صورت ذهنی به منطقه مربوطه در دنیای واقعی نگاشت کنند [ ۵ ]]. وقتی دوربین های کافی وجود داشته باشد، شکی نیست که یک چالش قابل توجه است. در عین حال، با توسعه سریع فناوری نقشه برداری و نقشه برداری، مردم الزامات بالاتری را برای بیان موجودات جغرافیایی فضایی مطرح می کنند. عناصر کاربردی و خلاقانهتر مانند نمای خیابان، تصاویر سنجش از دور و مدلهای سهبعدی در نقشهسازی ادغام میشوند و بیان بصری نقشه را افزایش میدهند. با این حال، اطلاعات جغرافیایی کنونی هنوز عمدتاً توسط اشیاء ایستا نشان داده می شود. داده های اصلی اطلاعات جغرافیایی باید از قبل اندازه گیری شده و در پایگاه داده ذخیره شوند، که با دقت بالا، چارچوب مختصات یکپارچه و عملکرد در زمان واقعی ضعیف مشخص می شود.
بر اساس تجزیه و تحلیل فوق، داده های ویدئویی بصری، آموزنده و بسیار زائد هستند، اما می توانند حرکت اجسام متحرک، مانند وسایل نقلیه و عابران پیاده را در زمان واقعی ضبط کنند. با این حال، اطلاعات جغرافیایی فقط میتواند فضای استاتیک جغرافیایی را در ویدیوی نظارتی بیان کند. نحوه توصیف اجسام متحرک در یک ویدیوی نظارتی در یک چارچوب جغرافیایی ثابت موضوعی است که ارزش مطالعه دارد. GIS به عنوان یک چارچوب مرجع کلی پیشنهاد شد که همه دوربینها را میتوان به آن نقشهبرداری کرد [ ۶]. این چارچوب نه تنها یک مرجع فضایی یکپارچه ارائه میکند، بلکه اطلاعات معنایی غنی را نیز ارائه میکند که همکاری چند دوربینی و ردیابی شی را تسهیل میکند. ادغام اطلاعات جغرافیایی استاتیک و ویدیوی پویا، بیان اجسام متحرک را در یک ویدیوی نظارتی تحت یک چارچوب با دقت بالا و یکپارچه امکان پذیر می کند. ادغام این دو نه تنها پشتیبانی از داده ها و تضمینی برای صنایع (زمینه ها) بیشتر، مقیاس های بزرگتر (فضا و زمان) و ابعاد بیشتر تحقیقات یادگیری عمیق را فراهم می کند، بلکه این کلان داده ها با یک پایه زمانی یکپارچه و چارچوب مرجع جغرافیایی و رابطه منطقی ذاتی، بدون شک تأثیر عمیقی در توسعه نقشه برداری و نقشه برداری خواهد داشت.
برخی از محققان و دست اندرکاران صنعت در داخل و خارج از کشور تحقیقاتی در این زمینه انجام داده اند، اما هنوز مشکلاتی وجود دارد. از نظر ژئوفضایی سازی ویدئویی، بسیاری از مطالعات تحقیقاتی بر اساس فرض یک زمین مسطح در فضای جغرافیایی است. رابطه نقشه برداری بین تصاویر و دنیای واقعی از طریق یک ماتریس هموگرافی [ ۷ ، ۸ ]، یعنی از یک تصویر دو بعدی به فضای دو بعدی برقرار می شود. روش مبتنی بر ماتریس هموگرافی برای صحنه های بزرگ مقیاس یا صحنه هایی با زمین پیچیده مناسب نیست. در جنبه همجوشی، تحقیق نسبتاً پراکنده است، زیرا برای ردیابی اشیاء چند دوربینی [ ۹ ]، جستجوی مسیر [ ۱۰ ]، مدیریت دادههای قطعه ویدیویی [ ۱۱ ] استفاده میشود.]، خلاصه های ویدئویی [ ۱۲ ]، جمعیت شماری [ ۱۳ ] و غیره. دنیای واقعی کنونی به سرعت در حال توسعه و تغییر است و نحوه بیان و تشخیص کامل آن بسیار مهم است. مدل واقعی شهر سه بعدی (۳DCM) به کانون تحقیقات فعلی نقشه برداری و نقشه برداری تبدیل شده است. صحنه جغرافیایی سه بعدی تقاضای توسعه اطلاعات جغرافیایی در حال حاضر است. واضح است که ادغام اجسام متحرک و صحنه های جغرافیایی ایستا دوبعدی نمی تواند پاسخگوی این تقاضا باشد. بررسی ادغام موثر اجسام متحرک در یک ویدیوی نظارتی و یک صحنه جغرافیایی ایستا سه بعدی به مشکلی تبدیل شده است که در حال حاضر قابل حل است.
در این کار، تحقیق ما عمدتاً شامل سه بخش است. در مرحله اول، ما اشیاء را بر اساس یادگیری عمیق شناسایی و ردیابی می کنیم تا اطلاعات شی را در تصویر بدست آوریم. دوم، ما به مدل سطح دیجیتال با دقت بالا (DSM) برای ایجاد مدل نقشه برداری بین ویدیوی نظارتی و فضای جغرافیایی سه بعدی، یعنی از تصاویر دو بعدی تا فضای سه بعدی، تکیه می کنیم. ثالثاً، بر اساس مدل نقشه برداری، اطلاعات مکانی – زمانی اشیاء متحرک در یک مدل سه بعدی تجسم می شود. آزمایش ها نشان می دهد که روش های پیشنهادی به نتایج خوبی دست می یابند. روشهای پیشنهادی برای درک سریع و کارآمد فعالیتهای اجسام متحرک در یک صحنه جغرافیایی برای کاربران مفید است که به کاربران اجازه میدهد آنها را شخصاً احساس کنند.
ادامه این مقاله به شرح زیر سازماندهی شده است: بخش ۲ آثار مرتبط را معرفی می کند. بخش ۳ چارچوب تلفیقی از اطلاعات جغرافیایی سه بعدی و اجسام متحرک را در ویدیوهای نظارتی ارائه می کند. بخش ۴ اصول و روش های اتخاذ شده در این مقاله را از چهار جنبه نشان می دهد: مدل تصویربرداری دوربین، تقاطع پرتو با DSM، تشخیص و ردیابی عابر پیاده، و کسب اطلاعات مکانی – زمانی اشیا. بخش ۵ آزمایش را انجام و تجزیه و تحلیل می کند. بخش ۶ مسیر حرکت اجسام متحرک را در مدل سه بعدی ارائه می کند. بخش ۷ مطالعه را خلاصه و نتیجه گیری می کند.
۲٫ کارهای مرتبط
داده های ویدئویی نظارتی دارای مزایایی مانند غنا، شهود و به موقع بودن اطلاعات است. با این حال، چالش های متعددی نیز وجود دارد، مانند حجم عظیم داده ها، کمیاب بودن اطلاعات جغرافیایی، و پراکندگی اطلاعات با ارزش بالا. استخراج اجسام متحرک از فیلم های نظارتی و ژئوفضایی سازی تصاویر ویدئویی ضروری است. در این بخش به معرفی آثار مرتبط در چهار جنبه می پردازیم: کالیبراسیون دوربین، فضای جغرافیایی ویدئو، تشخیص و ردیابی اشیا، و ادغام فیلم های نظارتی و اطلاعات جغرافیایی.
۲٫۱٫ کالیبراسیون دوربین
کالیبراسیون دوربین یک موضوع اساسی در زمینه بینایی کامپیوتر است و در بسیاری از کاربردها مانند نظارت تصویری، بازسازی سه بعدی، ناوبری ربات و … ضروری است و با این کار می توان به پارامترهای درونی و بیرونی دوربین دست یافت. پارامترهای ذاتی شامل فاصله کانونی، نقطه اصلی، ضرایب انحراف و ضرایب اعوجاج است که ویژگی ذاتی دوربین است. ژانگ [ ۱۴ ] یک تکنیک انعطافپذیر برای کالیبره کردن دوربین با مشاهده یک الگوی مسطح نشاندادهشده در چند جهت مختلف پیشنهاد کرد که استفاده از آن آسان است و دقت بالایی دارد. روش هارتلی [ ۱۵] با تجزیه و تحلیل تطابق نقطه بین حداقل سه تصویر گرفته شده از یک نقطه فضایی با جهت های مختلف دوربین انجام شد که بر اساس چرخش خالص دوربین بدون اطلاع از جهت گیری آن بود. Triggs [ ۱۶ ] ابتدا چهارگانه مطلق را به یک میدان خود کالیبراسیون معرفی کرد، روشی که حداقل به سه تصویر گرفته شده توسط یک دوربین متحرک با پارامترهای ذاتی ثابت اما ناشناخته نیاز دارد. کالیبراسیون پارامترهای ذاتی دوربین به خوبی در ادبیات توضیح داده شده است. پارامترهای بیرونی موقعیت و جهت گیری دوربین را در جهان تعیین می کنند. آنها را می توان با دستگاه های بیرونی (GPS و IMU) یا مشکل Perspective-n-Point (PnP) [ ۱۷ ] در بینایی کامپیوتر به دست آورد. برخی از محققان مسئله PnP را مطالعه کرده اند. لپتیت [ ۱۸] یک راه حل غیر تکراری از n تناظر نقطه ۳ بعدی به ۲ بعدی ارائه کرد که برای همه قابل اجرا بود n≥۴و پیکربندی های مسطح و غیر مسطح را به درستی مدیریت کرد. راهحل لی [ ۱۹ ] برای مسئله PnP نیز غیر تکراری بود و میتوانست بهینه را قویاً بازیابی کند. هنگامی که هیچ نقطه مرجع اضافی وجود نداشت، نتایج آن بهتر از الگوریتم تکراری بود.
۲٫۲٫ ژئوفضایی سازی ویدیویی
ژئوفضایی سازی ویدیویی رابطه نگاشت بین نقاط تصویر و نقاط فضایی را مطالعه می کند. دو روش اصلی ژئوفضایی سازی ویدیویی وجود دارد: روش مبتنی بر ماتریس هموگرافی [ ۷ ، ۸ ] و روش مبتنی بر تقاطع بین پرتو تصویربرداری و مدل زمین [ ۲۰ ].]. اولی فرض می کند که زمین در فضا مسطح است، و به طور کلی ارتفاع آن را ۰ نسبت می دهد. ماتریس هموگرافی را می توان با چهار یا چند مختصات تصویری مربوط به مختصات جهان تعیین کرد. اگرچه محاسبه کوچک است، اما برای صحنه های توپوگرافی بزرگ یا پیچیده مناسب نیست. مورد دوم مستلزم ساخت پرتوهای تصویربرداری و جستجوی پیمایش در مدل زمین است. در نتیجه، این روش تحت تأثیر توپوگرافی قرار نمی گیرد. با این وجود، به مقدار زیادی محاسبات و یک مدل زمین با دقت بالا نیاز دارد. در سال های اخیر، روش های دیگر نقشه برداری ظهور کرده است. Milosavljević [ ۲۱ ] یک فرآیند معکوس را با بازتاب دادن اشیاء تعیین شده با موقعیت بر روی تصویر ویدیویی اتخاذ کرد. در سال ۲۰۱۷، میلوساولیویچ [ ۲۲] ارجاع جغرافیایی نظارت را با جفت کردن مختصات تصویر با مکانهای جغرافیایی سه بعدی آنها تخمین زد، که میتوان از آن برای ارجاع جغرافیایی دوربینهای مداربسته ثابت و PTZ استفاده کرد.
۲٫۳٫ تشخیص و ردیابی شی
ردیابی اشیاء یک میدان دید کامپیوتری است که هدف آن حفظ هویت اشیاء است. Tracking-by-Detection یک چارچوب ردیابی پرکاربرد است که در آن اجسام ابتدا شناسایی می شوند و سپس به مسیرها متصل می شوند. تشخیص شی مستلزم حل دو مسئله است: شی کجاست و شی چیست. در سال ۲۰۱۴، Girshick [ ۲۳ ] برای اولین بار R-CNN را پیشنهاد کرد، که می تواند در مدل های تشخیص اشیاء استفاده شود، و شروع به افزایش در تشخیص اشیا مبتنی بر یادگیری عمیق کرد. اگرچه Fast R-CNN [ ۲۴ ] متعهد به کاهش زمان اجرای یک شبکه تشخیص اشیا بود، اما همچنان با تنگنای محاسبات پیشنهادی منطقه مواجه بود. برای حل مشکل، رن [ ۲۵] یک شبکه پیشنهاد منطقه (RPN) را برای تولید پیشنهاد منطقه معرفی کرد که ویژگی های کانولوشنال تصویر کامل را با Fast R-CNN به اشتراک می گذاشت. او [ ۲۶ ] Mask R-CNN را پیشنهاد کرد، که فقط یک سربار کوچک به سریعتر R-CNN اضافه کرد و میتوانست اشیاء را به طور موثر تشخیص دهد و همزمان یک ماسک تقسیمبندی با کیفیت بالا به دست آورد. آشکارسازهای بالا همه مدلهای دو مرحلهای چارچوبهای تشخیص شی هستند. بر اساس رگرسیون، ردمون [ ۲۷ ] برای اولین بار مدل تشخیص شی فقط یک بار نگاه می کنید (YOLO) را ارائه کرد. از آنجایی که فقط یک شبکه آموزشی دارد، YOLO از نظر سرعت اجرا مزیت زیادی دارد. با توجه به کمبود YOLO در تشخیص اشیاء کوچک، SSD [ ۲۸مدل ] ایده رگرسیون مورد استفاده در YOLO را اتخاذ کرد و به مکانیسم لنگر پیشنهادی در Faster R-CNN اشاره کرد. YOLOv2، YOLOv3، YOLOv4 و SSD مربوط به مدل های تک مرحله ای هستند. ردیابی شی برای تعیین مکان شی و ثبت مسیر و پارامترهای شی مورد نظر استفاده می شود. تطبیق تراکلت ها برای ایجاد یک مسیر جهانی کامل یک مشکل است. Huang [ ۲۹ ] ابتدا الگوریتم تداعی سلسله مراتبی را پیشنهاد کرد، که پاسخهای تشخیص را به trackletها مرتبط میکرد، و سپس این مسیرهای بسیار تکه تکه شده در هر سطح از سلسله مراتب بیشتر برای ایجاد مسیر طولانی نهایی مرتبط شدند. او [ ۳۰] الگوریتم فاکتورسازی ماتریس غیرمنفی محدود (RNMF) را برای حل مشکل تطبیق ردیاب با کاهش خطاهای ردیابی در tracklets پیشنهاد کرد. Xu [ ۳۱ ] یک روش شهودی اما آسان برای پیاده سازی به نام گروه ویژگی پیشنهاد کرد که کاهش دقت را به دلیل انسداد کاهش داد. Wang [ ۳۲ ] اجازه داد که تشخیص شی و تعبیه ظاهر در یک مدل مشترک، که اولین سیستم MOT بلادرنگ (تقریباً) بود، با سرعت اجرای ۲۲ تا ۴۰ FPS و دقت ردیابی بالا، آموخته شود. هنگامی که رابطه توپولوژیکی دوربین ها ناشناخته است، مشکل ردیابی چند دوربین را می توان در یک مشکل شناسایی مجدد (شناسه مجدد) شخص انتزاع کرد. ریستانی [ ۳۳] از تلفات سه گانه وزنی و یک تکنیک استخراج هویت سخت برای به دست آوردن ویژگی های ظاهری استفاده کرد که در تشخیص شی و شناسایی مجدد عملکرد خوبی داشت. ژانگ [ ۳۴ ] از R-CNN سریعتر برای شناسایی اشیا و مدل شناسایی مجدد شخص برای استخراج ویژگی های ظاهری ابتدا استفاده کرد و سپس با خوشه بندی سلسله مراتبی مسیرها را ادغام کرد. تاگور [ ۳۵ ] یک رویکرد شناسایی مجدد سلسله مراتبی کارآمد، ابتدا از طریق هیستوگرام رنگی و سپس از طریق مقایسه عمیق مبتنی بر ویژگی، که بر روی شش مجموعه داده ارزیابی شد، پیشنهاد کرد.
۲٫۴٫ ادغام فیلم های نظارتی و اطلاعات جغرافیایی
Katkere [ ۳۶ ] GIS و ویدئو را برای اولین بار با استفاده از جریان های داده های ویدئویی متعدد برای ایجاد محیط های مجازی فراگیر یکپارچه کرد. Takehara [ ۳۷ ] دوربینهای ثابت و جریانهای داده ضبطشده در زمان واقعی را یکپارچه کرد، که میتوانست نماهای سه بعدی بسازد و حرکت افراد را در فضا به روشی قابل درک نشان دهد. Zhang [ ۳۸ ] فرض کرد که چرخش دوربین صفر است و سپس ماتریس تبدیل را برای تحقق یکپارچگی GIS دو بعدی و نظارت تصویری محاسبه کرد. یانگ [ ۳۹ ] نظارت چند نما را اتخاذ کرد و نماهای سه بعدی قابل هدایت از اشیاء ردیابی شده را بر روی یک بازنمایی سایت سه بعدی بازسازی شده ارائه کرد، که در هنگام وقوع رویداد، دیدگاههایی را در اختیار کاربران قرار داد. زی [ ۸] ادغام GIS و اجسام متحرک در ویدئوهای نظارتی را مورد بحث قرار داد و مدل یکپارچهسازی را پیشنهاد کرد که در آن دادههای ویدئویی توسط یک دوربین واحد جمعآوری میشد. در سال ۲۰۱۹، Xie [ ۷ ] در مورد ادغام اجسام متحرک ویدئویی چند دوربینی (MCVO) و GIS بحث کرد. سناریوهای کاربردی هر دو مقاله محدود به موقعیتی است که در آن ناحیه ویدیو صاف است.
۳٫ چارچوب اطلاعات جغرافیایی سه بعدی و اجسام متحرک
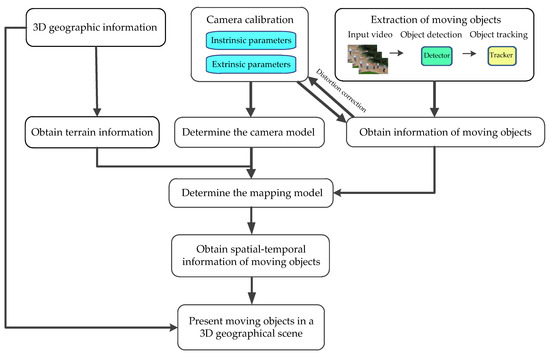
اطلاعات ویدیویی را می توان توسط دوربین ها از مکان های جغرافیایی مختلف جمع آوری کرد که دنباله ای از تصاویر (فریم ها) است. اگر اپراتورهای امنیتی با منطقه مانیتورینگ آشنا نباشند، نمی توانند محل اشیاء را از این تصاویر بدست آورند. ادغام یک ویدیو و GIS می تواند اشیایی را که آنها به آنها علاقه مند هستند یکسان کند. با انجام این کار، اطلاعات مکانی – زمانی اشیاء متحرک را می توان در یک مدل جغرافیایی سه بعدی نمایش داد که می تواند به پیاده سازی اندازه گیری اشیاء و افزایش کیفیت کمک کند. نمایش چند بعدی بصری GIS چارچوب ترکیبی اطلاعات جغرافیایی سه بعدی و اجسام متحرک در ویدئوی نظارتی در شکل ۱ نشان داده شده است .
در چارچوب خود، ادغام اطلاعات جغرافیایی سه بعدی و اجسام متحرک در ویدیوی نظارتی را به چندین بخش تقسیم میکنیم:
-
کالیبراسیون دوربین هدف کالیبراسیون دوربین به دست آوردن پارامترهای درونی و بیرونی است که می تواند مدل دوربین را تعیین کند.
-
استخراج اجسام متحرک آشکارسازهای اشیاء و ردیابها میتوانند اطلاعات اجسام متحرک را در یک ویدیو استخراج کنند که در مورد موقعیتهای مکانی-زمانی در یک تصویر است. این موقعیت ها خیلی دقیق نیستند و حاوی خطا هستند. آنها نیاز به اصلاح اعوجاج دارند.
-
مدل نقشه برداری در فرآیند تصویربرداری دوربین، اطلاعات عمق از بین می رود. برای بازیابی موقعیت جسم در فضا، به اطلاعات زمین که توسط یک مدل جغرافیایی سه بعدی به دست آمده است نیاز داریم. با توجه به یک دوربین مدرج و یک پیکسل تصویر، یک پرتو تصویربرداری (X0,Y0,Z0)+k(U,V,W)ساخته شده است. پرتو تصویربرداری زمین را در نقطه ای که جسم در آن قرار دارد قطع می کند.
-
اطلاعات مکانی – زمانی در فضای سه بعدی علاوه بر اطلاعات موقعیت سه بعدی، عرض و ارتفاع جسم را نیز می توان با محاسبه هندسی به دست آورد.
-
تجسم. اشیاء متحرک را در یک صحنه جغرافیایی سه بعدی ارائه دهید.
به طور خلاصه، کالیبراسیون دوربین و استخراج اجسام متحرک اساس همجوشی است. مدل نقشه برداری پلی از فضای تصویر به دنیای واقعی است. اطلاعات مکانی – زمانی در فضای سه بعدی داده های حیاتی همجوشی هستند. و تجسم نتیجه ادغام است. بدیهی است که ادغام اطلاعات جغرافیایی سه بعدی و اجسام متحرک در ویدئوهای نظارتی با هدف ارائه یک چارچوب یکپارچه و ایجاد مزایای این دو مکمل است.
۴٫ اصول و روشها
بخش ۳ چارچوب ادغام را نشان داده و یک توصیف کلی ارائه کرده است. این چارچوب به الگوریتمهای خاصی برای مدل دوربین، استخراج شی یا مدل نگاشت متکی نیست. در بخش ۴ ، اصول و روشهای این موضوعات اصلی را در این مقاله توضیح خواهیم داد.
۴٫۱٫ مدل تصویربرداری دوربین
دوربین نقشه برداری بین دنیای سه بعدی (فضای شی) و یک تصویر دو بعدی است. به عبارت دیگر، میتوانیم نقاط موجود در فضا را با مختصات سهبعدی به نقاطی در صفحه تصویر زیر مدل دوربین نگاشت کنیم. تخصصی ترین و ساده ترین مدل دوربین، دوربین پین هول است. مدل تصویربرداری در معادله (۱) فهرست شده است:
جایی که λدر رابطه (۱) ضریب مقیاس است. [uv]Tیک نقطه در صفحه تصویر است. [u0v0]Tمختصات نقطه اصلی O هستند. fxو fyنشان دهنده فاصله کانونی دوربین بر حسب ابعاد پیکسل در uو vجهت، به ترتیب؛ پارامتر sپارامتر چولگی است. و [XWYWZW]Tنقطه ای در فضا است پارامترهای موجود در K را پارامترهای ذاتی می نامند. پارامترهای موجود در [R|t]که جهت و موقعیت دوربین را به یک سیستم مختصات جهانی مرتبط می کند، پارامترهای بیرونی نامیده می شوند. Kو [R|t]را می توان با روش های کالیبراسیون به دست آورد.
مدل تصویربرداری دوربین ارائه شده ایده آل است و اعوجاج لنز را در نظر نمی گیرد. بنابراین، از مدلهای اعوجاج شعاعی و اعوجاج مماسی برای نمایش دقیق یک دوربین واقعی استفاده میشود:
(۱) مدل اعوجاج شعاعی:
جایی که k1، k2و k3پارامترهای مدل اعوجاج شعاعی هستند. r2=x2+y2. (xdistorted,ydistorted)و (x,y)مختصات تصویر نرمال شده هستند.
(۲) مدل اعوجاج مماسی:
جایی که p1و p2پارامترهای مدل اعوجاج مماسی هستند. با ترکیب معادلات (۲) و (۳) می توان نتیجه گرفت که:
بنابراین، برای هر نقطه پ، موقعیت صحیح این نقطه است ( u , v )در صفحه پیکسل را می توان از طریق پنج ضریب اعوجاج یافت (ک۱،ک۲،ک۳،پ۱،پ۲).
۴٫۲٫ تقاطع پرتو با DSM
با توجه به رابطه (۱)، هنگامی که یک دوربین کالیبره می شود، C تعیین می شود. بنابراین، ما می توانیم نقاط را ترسیم کنیم (ایکسدبلیو،Yدبلیو،زدبلیو)در فضا به نقاط ( u , v )در صفحه تصویر زیر مدل دوربین. برعکس، نمیتوانیم مختصات سهبعدی را از پیکسلهای تصویر محاسبه کنیم، زیرا اطلاعات عمق در طول فرآیند تصویربرداری از بین میرود. یعنی نمی توانیم ۳ بعدی را از ۲ بعدی بازیابی کنیم. بنابراین استفاده از اطلاعات توپوگرافی ضروری است. DSM یک مدل دیجیتال توپوگرافی است که نقش برجسته و وضعیت را در سطح توصیف می کند. از مدل دیجیتالی زمین تشکیل شده و سطح زمین، از جمله تمام اجسام روی آن را نشان می دهد.
مدل راه حل محلی سازی مبتنی بر DSM در شکل ۲ نشان داده شده است ، که در آن O نقطه مرکزی دوربین، A نقطه شیء است، و منحنی L نشان دهنده زمینی است که از A عبور می کند. همه نقاط روی پرتو تصویربرداری OA در یک تصویر گرفته می شوند. نقطه روی صفحه تصویر بنابراین، نقاط روی پرتو تصویربرداری را می توان جستجو کرد و با مدل DSM مطابقت داد. مراحل محاسبه خاص به شرح زیر است:
- (۱)
-
ساخت یک پرتو تصویربرداری، (ایکس۰،Y0،ز۰) +k ( U، V، دبلیو)، جایی که (ایکس۰،Y0،ز۰)مکان دوربین در فضا است، k ≥ ۰فاصله دلخواه است و ( U، V، دبلیو)یک بردار واحد است که جهت پرتو تصویربرداری از دوربین را نشان می دهد. همانطور که در شکل ۲ الف نشان داده شده است، فرض کنید که محل نقطه A در تصویر است (توآ،vآ)، و مختصات پیکسل هر نقطه B در پرتو تصویربرداری OA نیز هستند (توآ،vآ). جایگزین λ(یک ثابت) به معادله (۱) برای به دست آوردن ب (ایکسب،Yب،زب). این می دهد:
- (۲)
-
جستجو برای نقاط شی از نقطه دوربین شروع کنید و در جهت پرتو تصویربرداری OA جستجو کنید. مرحله جستجو فاصله شبکه است Δ داز DSM. مختصات از ننقطه جستجو عبارتند از:
جایگزین (ایکسن،Yن)به DSM برای جستجو و مطابقت. ثبت ارتفاع در (ایکسن،Yن)در DSM به عنوان الف (ایکسن،Yن). ارتفاعات چهار نقطه گوشه شبکه که در آن (ایکسن،Yن)واقع شده است ز۱، ز۲، ز۳و ز۴، به ترتیب. سپس،
چه زمانی الف (ایکسن،Yن) ≥زنبرای اولین بار ظاهر می شود، نشان می دهد که شی A عبور کرده است:
- ①
-
اگر الف (ایکسن،Yن) =زن، (ایکسن،Yن،زن)مختصات جهان جسم A است.
- ②
-
اگر الف (ایکسن،Yن) >زن، به این معنی است که نقطه شی بین نقطه جستجو قرار دارد نو ن– ۱. الف (ایکسن،Yن)مخفف شده است Eن. با درون یابی، تخمین مکان دقیق تری را می توان به دست آورد. فرآیند درونیابی در شکل ۲ ب نشان داده شده است. با توجه به رابطه نسبت مثلث، وجود دارد:
مختصات جهان جسم A عبارتند از:
۴٫۳٫ تشخیص و ردیابی عابر پیاده
برای فیلم های نظارتی در صحنه های ثابت، مردم بدون توجه به اطلاعات پس زمینه به اشیاء متحرک توجه بیشتری می کنند. بنابراین، اجسام متحرک نیز در تجزیه و تحلیل هوشمند ویدئویی تاکید دارند.
You Only Look Once (YOLO) خانواده ای از مدل های معروف به دلیل عملکرد بسیار بالا و در عین حال فوق العاده کوچک است. YOLOv5 سبک وزن است و در تشخیص اجسام کوچک با در نظر گرفتن دقت و سرعت مزایای خوبی دارد. علاوه بر این، فرآیند انتخاب جعبه لنگر در YOLOv5 یکپارچه شده است. بنابراین، بدون در نظر گرفتن هیچ یک از مجموعه داده ها به عنوان ورودی، به طور خودکار “یاد می گیرد” که بهترین جعبه های لنگر را برای آن مجموعه داده ارائه کند و از آنها در طول آموزش استفاده کند. شکل ۳معماری شبکه YOLOv5 را نشان می دهد. از سه بلوک اصلی معماری تشکیل شده است: (۱) ستون فقرات، (۲) گردن، و (iii) سر. ساختار فوکوس در ستون فقرات اضافه شده و دو ساختار CSP طراحی شده است. ساختار CSP1-x در DarkNet گنجانده شده است و CSPDarknet را ایجاد می کند که ستون فقرات Yolov5 است. CSPDarknet ویژگی هایی را از تصاویر متشکل از شبکه های CSP1-x استخراج می کند. CSP مشکلات گرادیان تکراری را در ستون فقرات در مقیاس بزرگ حل می کند که منجر به پارامترهای کمتر و FLOPS کمتر (عملیات ممیز شناور در ثانیه) می شود. به نوبه خود، سرعت و دقت استنتاج را تضمین می کند و اندازه مدل را کاهش می دهد. قسمت گردن از PANet برای ایجاد یک شبکه هرم ویژگی برای انجام تجمیع ویژگی ها و ارسال آن به Head برای پیش بینی استفاده می کند. ساختار CSP2-X مورد استفاده در گردن، قابلیت ترکیب ویژگی های شبکه را تقویت می کند. سر Yolov5 سه اندازه مختلف از نقشه های ویژگی را برای پیش بینی چند مقیاسی تولید می کند. نتایج تشخیص شامل کلاس، امتیاز، مکان و اندازه است.
روش SORT عمیق [ ۴۰ ] از فیلتر کالمن بازگشتی و ارتباط فریم به فریم داده برای تحقق ردیابی شی استفاده می کند. فاصله Mahalanobis برای ترکیب اطلاعات حرکت و کوچکترین فاصله کسینوس برای مرتبط کردن اطلاعات ظاهری اجسام استفاده می شود. با استفاده از یک جمع وزنی مطابق با معادله (۱۱)، دو معیار متریک بالا برای تأیید متریک نهایی و خروجی اطلاعات ردیابی شی از طریق الگوریتم مجارستانی برای دستیابی به تطابق ترکیب می شوند:
جایی که د( ۱ )(i,j)فاصله ماهالانوبیس (مربع) است، d(2)(i,j)فاصله کسینوس و λیک هایپرپارامتر است.
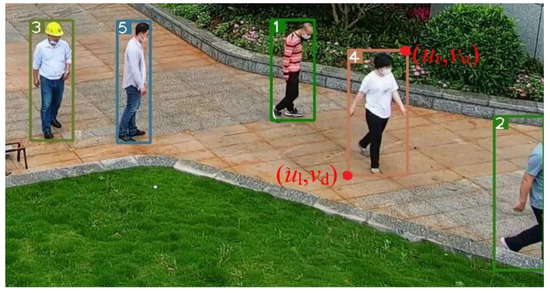
ما YOLOv5 را برای فیلتر کردن هر تشخیصی که یک شخص نیست استفاده می کنیم و سپس از یک الگوریتم SORT عمیق برای ردیابی افرادی که توسط YOLOv5 شناسایی می شوند استفاده می کنیم. این به این دلیل است که متریک ارتباط عمیق بر روی یک مجموعه داده فقط برای شخص آموزش داده شده است. نتایج خروجی شامل (شناسه فریم، ul، vu، ur، vd) ( شکل ۴ ). ( ul، vu، ur، vd) اندازه و موقعیت جعبه مرزی را توصیف کنید.
از آنجایی که این مقاله با تقاطع پرتوهای تصویربرداری و DSM مکان اشیاء را تعیین می کند، انتخاب نقطه مرکزی موقعیت ایستاده روی هر دو پا منطقی است. عابران پیاده بیشتر اوقات در حال حرکت هستند. بسیاری از قاب های اشیا برای اندازه گیری موقعیت نقطه مرکزی هر دو پا استفاده می شود. منطقی است که بر اساس معادله زیر محاسبه شود:
نتایج ردیابی شی را مطابق با معادله (۱۲) بدست آورید و آنها را مطابق مدل تصحیح اعوجاج دوربین تصحیح کنید. سپس، نتایج تصحیح اعوجاج به مدل نقشه برداری منتقل می شود تا مسیرهای جغرافیایی اشیاء به دست آید.
۴٫۴٫ اکتساب اطلاعات مکانی – زمانی اشیاء
با فرض اینکه عابر پیاده بر زمین عمود باشد و مختصات جهانی نقطه تماس مرکز پاها باشد. (Xa,Ya,Za)، (Xa,Ya)بنابراین محل سر عابر پیاده است. موقعیت سر نقطه مرکزی لبه بالایی جعبه مرزی است که به صورت حذف شده است. (ut,vt). با جایگزینی مدل تصویربرداری دوربین (معادله (۱))، ارتفاع سر به صورت حل می شود Zt. بنابراین ارتفاع عابر پیاده برابر است با:
عرض بدنه جسم با عرض جعبه مرزی محاسبه می شود. دو نقطه ای که خط افقی حاوی نقطه مرکزی هر دو پا با کادر محدود کننده جسم ملاقات می کند، هستند (ul,vf)و (ur,vf)، به ترتیب. (ul,vf)، (ur,vf)و ارتفاع Zaدر مدل تصویربرداری دوربین جایگزین می شوند، که مختصات جهان مربوطه را می توان به عنوان به دست آورد (Xl,Yl,Za)و (Xr,Yr,Za). عرض جسم برابر است با:
با استفاده از شناسه شی بهعنوان شناسه منحصربهفرد، اطلاعات مکانی-زمانی اشیا، مانند مختصات جغرافیایی سه بعدی، ارتفاع شی، عرض، و شناسه قاب ذخیره میشوند.
۵٫ آزمایش ها و نتایج
۵٫۱٫ محیط تجربی
ما ابتدا یک چارچوب ترکیبی کلی از اطلاعات جغرافیایی سه بعدی و اجسام متحرک را در ویدئوی نظارتی پیشنهاد کردیم. تمرکز ما این است که اطلاعات مکانی-زمانی سه بعدی اجسام متحرک را بدست آوریم و مسیر حرکت آنها را در مدل سه بعدی نمایش دهیم. تا آنجا که می دانیم، هیچ مجموعه داده ای در دسترس عموم برای این موضوع تحقیقاتی وجود ندارد. ما نمی توانیم نتایج خود را با آخرین هنر مقایسه کنیم. برای تأیید آزمایش خود، گوشه ای از یک پارک اداری را انتخاب کردیم که به مناطق چپ و راست تقسیم شده است که با پله ها محدود شده است. اگرچه هر دو ناحیه راست و چپ نسبتاً مسطح هستند، اما این دو ناحیه در یک صفحه نیستند. اختلاف ارتفاع بین دو منطقه بین ۵۰ تا ۶۰ سانتی متر است. منطقه مناسب برای آزمایش انتخاب شد. شکاف های کاشی بسیار واضح در ناحیه مناسب وجود دارد، که برای اندازه گیری مقدار واقعی مسیرهای جسم متحرک و مقایسه مسیرهای موقعیت یابی جسم با مسیرهای واقعی مناسب هستند. در عین حال، برای خوانندگان راحت تر است که نتایج تجسم کامل را ببینند و به طور مستقیم در مورد اثرات موقعیت یابی قضاوت کنند.
در این آزمایش، از یک دوربین گنبدی نور سفید هوشمند با سرعت بالا (Dahua) با هسته شبکه ۲۰۰ W مدل DH-SD-6C3230U-HN-D2 استفاده شد. وضوح تصویر آن ۱۹۲۰ × ۱۰۸۰ و نرخ فریم آن ۲۵ فریم بر ثانیه بود. یک ویدیوی نظارتی ۳۶ ثانیه با مجموع ۹۰۰ فریم گرفته شد. مدل سه بعدی با فتوگرامتری به دست آمد. سیستم مختصات مورد استفاده، سیستم مختصات ژئودتیک چین ۲۰۰۰ و سیستم ارتفاعی، ارتفاع ژئودتیک GPS بود که یک چارچوب مرجع ارائه می کرد. مختصات جغرافیایی منطقه مورد مطالعه بزرگ و نمودارها مختصر و خوانا نبودند. در عین حال، با توجه به محرمانه بودن نتایج بررسی، داده های مورد استفاده در این مقاله ترجمه و چرخش شدند.
۵٫۲٫ پارامترهای ذاتی
همانطور که در شکل ۵ نشان داده شده است ، از هواپیمای مدل آلومینا با آرایه ۹×۱۲، طول ضلع مربع ۴۰ میلی متر و دقت ۰٫۰۱ میلی متر استفاده شده است. با حرکت هواپیما چند عکس از هواپیمای مدل در جهت های مختلف گرفته شد. ما از این تصاویر برای کالیبره کردن این دوربین با روش کالیبراسیون Zhang Zhengyou استفاده کردیم [ ۱۴ ]. برای به دست آوردن دقت کالیبراسیون بالاتر، تصاویر با میانگین خطاهای بازپرداخت بزرگ حذف شدند. در نهایت ۱۵ تصویر برای کالیبراسیون انتخاب شدند. نتایج کالیبراسیون به شرح زیر است:
ماتریس ذاتی توسط: K=⎡⎣⎢۱۵۸۱.۵۷۶۶۰۰−۰٫۵۲۳۰۱۵۸۱.۱۸۵۱۰۱۰۱۲.۴۳۹۸۵۵۹.۷۰۲۳۱⎤⎦⎥.
اعوجاج شعاعی است [۰٫۰۳۱۴۰٫۰۳۵۸۰٫۲۷۲۵]. اعوجاج مماسی است [۰٫۰۰۰۴−۰٫۰۰۰۲]و خطای بازپرداخت ۰٫۱۳ پیکسل است.
۵٫۳٫ پارامترهای بیرونی
پنج نقطه نقطه عطف به طور مساوی در محدوده دید دوربین توزیع شدند و یک ایستگاه کل برای اندازه گیری مختصات سه بعدی پنج نقطه عطف استفاده شد. به دلیل اعوجاج دوربین، برخی از خطاها را به پارامترهای بیرونی وارد می کند. در نتیجه، ابتدا تصحیح اعوجاج کامل شد و سپس مختصات پیکسل پنج نقطه مشخص جمع آوری شد که در شکل ۶ نشان داده شده است. از طریق پنج جفت نقطه، روش EPNP [ ۱۸ ] برای محاسبه ماتریس پارامترهای بیرونی دوربین ثابت شد. جفت نقطه مربوطه در جدول ۱ نشان داده شده است.
مختصات دوربین مدرج در سیستم مختصات جهانی (۳۹٫۳۱۴، ۸۴٫۲۶۷، ۹۲٫۵۱۲) می باشد. ماتریس چرخش و ماتریس ترجمه به شرح زیر است:
تا حالا، K، R، t، و (k1,k2,k3,p1,p2)به دست آمده و مدل تصویربرداری دوربین مشخص شده است.
۵٫۴٫ ردیابی اشیا
روش پیشنهادی برای شناسایی و ردیابی عابران پیاده در فیلم نظارتی اتخاذ شد و برخی از فریمهای اصلی و فریمهای ردیابی انتخاب شدند ( شکل ۷ ). همانطور که از شکل ۷ مشاهده می شود ، هیچ خطای تطبیقی برای پنج جسم متحرک وجود ندارد و نتایج ردیابی خوب است.
۵٫۵٫ تخمین مکان شی
هر مکان با پرتاب یک پرتو تصویربرداری سه بعدی از مرکز دوربین و نقطه مرکزی هر دو پا در صفحه تصویر به داخل صحنه و تعیین محل تلاقی آن با زمین به دست می آید. DSM واقعی ترین نمایش توپوگرافی را نشان می دهد که از طریق مدل سه بعدی به دست می آید. شبکه DSM 5 سانتی متر × ۵ سانتی متر با دقت ۶٫۵ سانتی متر است (فقط زمین). از آنجایی که فاصله شبکه DSM کمتر از دقت ارتفاع آن است، مکانهای اشیا با استفاده از Elev(XN,YN)≥ZNبه عنوان شرط تصمیم، بدون پردازش درون یابی در این آزمایش.
شکل ۸ مسیر مسطح اجسام متحرک را در سیستم مختصات جهان نشان می دهد. اگرچه برخی از لرزش ها وجود دارد، اما آنها حرکت واقعی اجسام متحرک را به عنوان یک کل منعکس می کنند. شکل ۹ مسیرهای ارتفاعی را نشان می دهد. در شکل ۹a ارتفاع اجسام اول، سوم، چهارم و پنجم ملایم است و نوسان شدیدی ندارد. با این حال، ارتفاع جسم دوم تکان میخورد. جسم دوم به تخت گل نزدیک می شود. تحت تأثیر خطاها، نقاط مرکزی پاها در برخی فریم ها به نقاط روی تخت گل نگاشت می شوند، نه روی زمین، که منطقی نیست. برای انعکاس دقیق اطلاعات ارتفاع اجسام متحرک، فیلتر میانه اتخاذ شده است. ارتفاعات با فیلتر میانه با اندازه پنجره ۲۵ فیلتر می شوند. میخ های شکل ۹ ب را می توان با فیلتر میانه فیلتر کرد. سپس، مسیرها توسط یک چند جمله ای مکعبی در شکل ۹ برازش می شوندج نتایج رضایت بخشی در اعمال چند جمله ای مکعبی برای برازش مسیرهای ارتفاعی بر اساس اصل محاسبه روش حداقل مربعات به دست آمده است. مسیرهای سه بعدی اجسام متحرک در یک نمودار ( شکل ۱۰ ) ارائه شده است که در آن ارتفاعات ابتدا با فیلتر میانه فیلتر شده و سپس توسط یک چند جمله ای مکعبی برازش می شوند.
۵٫۶٫ تخمین عرض و ارتفاع جسم
در بخش ۵٫۵ ، ما مکان های اشیا را در هر فریم دنباله می شناسیم. در همین حال، ما همچنین می خواهیم عرض و ارتفاع شی را بدانیم. معادلات (۱۳) و (۱۴) روشی را برای محاسبه عرض و ارتفاع جسم ارائه می دهند. به دلیل تأثیر وضعیت های راه رفتن، نتایج محاسبه عرض و ارتفاع جسم ثابت نخواهد شد. بنابراین، فیلتر میانه با اندازه پنجره ۲۵ نیز در اینجا برای فیلتر کردن عرض و ارتفاع شی استفاده می شود.
شکل ۱۱ و شکل ۱۲ به ترتیب عرض و ارتفاع اجسام متحرک را نشان می دهند. پس از حذف ناهنجاری ها با فیلتر میانه، میانگین عرض و ارتفاع در رابطه (۱۵) محاسبه می شود:
جایی که xiعرض/ارتفاع شی پس از فیلتر در هر فریم است و nتعداد فریم است. میانگین عرض و ارتفاع اجسام متحرک در جدول ۲ نشان داده شده است.
۵٫۷٫ اطلاعات مکانی – زمانی اجسام متحرک
ما اطلاعات مکانی-زمانی اشیاء متحرک، از جمله مختصات جهان سه بعدی، عرض و ارتفاع را به دست آورده ایم. جدول ۳ بخشی از اطلاعات مکانی- زمانی شی چهارم را نشان می دهد که مکان، عرض و ارتفاع جسم چهارم را در صحنه جغرافیایی از قاب ۳۶۸ تا فریم ۳۸۴ نشان می دهد.
۵٫۸٫ آمار زمان آزمایشی
ما آزمایشهایی را به ترتیب در محیطهای سختافزاری CPU و GPU انجام دادیم. مدت زمان فیلم نظارتی مورد استفاده در آزمایش ها ۳۶ ثانیه با ۲۵ فریم در ثانیه و در مجموع ۹۰۰ فریم است. نتایج تجربی در جدول ۴ نشان داده شده است. در طراحی آزمایشی فعلی، عملیاتی مانند استخراج فریم کلیدی را روی ویدیو انجام ندادیم و این قسمت در ادامه بررسی خواهد شد.
۵٫۹٫ تجزیه و تحلیل نتایج تجربی
مسیرهای پیاده روی عابران پیاده توسط یک ایستگاه کل اندازه گیری شد تا صحت نتایج تجربی را تأیید کند، که به عنوان مقدار واقعی مسیرها استفاده شد. مقایسه و تجزیه و تحلیل مسیرهای اندازه گیری شده و نقشه برداری شده در شکل ۱۳ نشان داده شده است.
فاصله عمودی بین نقطه نقشه برداری و مسیر اندازه گیری شده به عنوان استاندارد برای ارزیابی خطای موقعیت مسطح در نظر گرفته می شود. حداکثر خطا (ME) و ریشه میانگین مربعات خطا (RMSE) موقعیت شی پویا عبارتند از:
جایی که diفاصله عمودی بین iنقطه نقشه برداری و مسیر اندازه گیری شده، و nتعداد نقاط نقشه برداری است. ME و RMSE موقعیت مسطح و ارتفاع به ترتیب در جدول ۵ و جدول ۶ نشان داده شده است.
همانطور که از شکل ۱۳ مشاهده می شود ، موقعیت های مسطح پنج جسم همگی ارتعاش دارند. به این دلیل است که یک فرد بدن سفت و سختی نیست. در فرآیند حرکت، جعبه مرزی به دلیل تأثیر چرخش بازو، گام برداشتن و چرخش پا و غیره نوسان خواهد داشت. به ویژه، جسم چهارم به طور مکرر در نزدیکی موقعیت شروع به دور خود می چرخد و باعث لرزش شدید در نزدیکی قسمت شروع می شود. در همین حال، اشیاء دوم و چهارم نیز نوسانات زیادی را در سمت راست شکل ۱۳ نشان می دهند. دلیل آن این است که اشیای دوم و چهارم در حال دور شدن از میدان دید دوربین و مسدود شدن توسط تخت گل نزدیک است. جعبه مرزی دقیق نیست. ME جسم دوم و چهارم ۴۰ سانتی متر و ۴۸ سانتی متر است ( جدول ۵) به ترتیب بزرگتر از اجسام اول، سوم و پنجم است. در موقعیت های دیگر، ME جسم دوم و چهارم به ترتیب ۲۵ سانتی متر و ۲۸ سانتی متر است. RMSE پنج جسم نسبتا کوچک است و کمتر از ۱۰ سانتی متر است. به طور کلی، در صورتی که جعبه مرزی بتواند کل جسم را به طور کامل ترسیم کند، رویکرد پیشنهادی در این مقاله می تواند موقعیت یابی اجسام متحرک را با دقت بالا مشخص کند و ME موقعیت مسطح را می توان در ۳۱ سانتی متر کنترل کرد و RMSE در ۱۰ سانتی متر
همانطور که در شکل ۱۴ نشان داده شده است ، با افزایش تعداد فریم ها، تمام خطاهای ارتفاعی روند کاهشی را نشان می دهند که عمدتاً تحت تأثیر دقت DSM است. منطقه مانیتورینگ بین دو ساختمان بلند قرار دارد و اشیا از وسط دو ساختمان بلند به سمت محوطه باز بیرون در حال حرکت هستند. تحت تأثیر سیگنالهای ماهوارهای، دقت جمعآوری دادههای مدل سهبعدی در ناحیه میانی ضعیف و در ناحیه باز بیرونی بهتر است و در نتیجه دقت DSM ناهموار است. داده های شکل ۱۴ برای به دست آوردن ME و RMSE هر شیء مورد تجزیه و تحلیل آماری قرار گرفته اند ( جدول ۶ ). از جدول ۶ قابل مشاهده استکه ME پنج جسم در ارتفاع همگی در ۱۰ سانتی متر و RMSE همه در ۳ سانتی متر هستند که دقت ارتفاع بالایی دارد.
ما مسیر حرکت اجسام متحرک را ارزیابی کرده ایم. روش ارائه شده در این مقاله نتایج خوبی را هم در دقت مسطح و هم در دقت ارتفاع به دست آورده است. در مرحله بعد، اطلاعات هندسی اجسام متحرک را ارزیابی می کنیم. اولین قدم اندازهگیری پهنترین حالت بدن با باز کردن پاها به اندازه عرض شانه و بازوهای آویزان طبیعی است. سپس، نتایج اندازه گیری شده به عنوان مقدار واقعی عرض شی در نظر گرفته می شود. مقدار واقعی ارتفاع جسم به روش معمول به دست می آید. صاف بایستید و پاشنه ها را کنار هم قرار دهید و ارتفاع را از پاشنه تا بالای سر اندازه بگیرید. ما عرض و ارتفاع محاسبه شده را با مقدار واقعی در جدول ۷ مقایسه کردیم wو hنتایج محاسبه شده از جدول ۲ هستند و w˜و h˜به ترتیب مقادیر واقعی عرض و ارتفاع هستند. خطا برابر است با مقدار محاسبه شده منهای مقدار واقعی. از نتایج مقایسه، خطاهای ارتفاع همگی کوچک هستند (در عرض ۲ سانتی متر). خطاهای عرض کمی بزرگتر از خطاهای ارتفاع (در عرض ۵ سانتی متر) است.
۶٫ تجسم
ما اشیاء متحرک در ویدیوی نظارتی را به فضای جغرافیایی سه بعدی نگاشت کردیم، که نه تنها می تواند بر مضرات افزونگی ویدیو غلبه کند، بلکه برای مدیران مفید است تا به طور شهودی اشیاء را نظارت کنند و درک اندازه گیری، آمار و تجزیه و تحلیل را تسهیل کند. اشیاء. مدل اطلاعات جغرافیایی سه بعدی مورد استفاده در این مقاله با فتوگرامتری وسیله نقلیه هوایی بدون سرنشین داجیانگ به دست آمد. ریشه میانگین مربعات خطای موقعیت مسطح و ارزیابی به عنوان استاندارد دقت استفاده می شود. معادلات مربوطه عبارتند از:
جایی که ( xi، yi، zi) مختصات در مدل سه بعدی هستند، ( x˜i، y˜i، z˜i) مختصاتی هستند که در میدان اندازه گیری می شوند و n تعداد نقاط است. معادله (۱۸) معادله محاسبه خطای مسطح و معادله (۱۹) معادله محاسبه خطای ارزیابی است. بدون در نظر گرفتن تخت گل، درختان، خانه ها و موقعیت های دیگر، ۶۶ نقطه روی زمین توسط یک ایستگاه کل در مزرعه اندازه گیری شد و مختصات نقطه مربوطه از مدل سه بعدی در دفتر گرفته شد. پس از محاسبه، دقت مسطح مدل سه بعدی ۳٫۷ سانتی متر و دقت ارزیابی ۶٫۵ سانتی متر بود. مدل سه بعدی دقت بالایی دارد.
همانطور که در شکل ۱۵ نشان داده شده است، مسیر حرکت اجسام متحرک در ویدئوی نظارتی در مدل سه بعدی ظاهر شد . ما مسیر اجسام در مدل سه بعدی را از نمای جانبی، نمای بالا و نزدیک به جهت دوربین ارائه کردیم.
در شکل ۱۵ ، به طور شهودی میتوانیم ببینیم که تمام پنج شیء در امتداد شکافهای میان کاشیهای کف راه میروند. جسم اول و چهارم دو چرخش با زاویه راست ایجاد می کنند. اجسام دوم، سوم و پنجم همگی مستقیم راه می روند. همانطور که در شکل ۱۵ ب، ج نشان داده شده است، مسیرهای پنج شی با مسیرهای پیاده روی واقعی یکسان است. در شکل ۱۵ الف، مسیرهای اجسام را می توان یافت که روی زمین نشسته اند، و هیچ تعلیقی وجود ندارد، که نشان می دهد خطای ارتفاع کم است. شکل ۱۵سازگاری بین مسیرهای نگاشت شده و مسیرهای واقعی را نشان می دهد، که به طور کامل نشان می دهد که روش در این مقاله می تواند اطلاعات مکانی – زمانی اشیاء را استخراج کند و دقت موقعیت یابی بالایی دارد.
۷٫ نتیجه گیری
هدف این مقاله تحقق بخشیدن به ادغام اطلاعات جغرافیایی سه بعدی و اجسام متحرک بود. این همجوشی راه را برای فرصت های جدید، نه تنها برای بینایی کامپیوتر، بلکه برای ژئوماتیک هموار می کند. این می تواند به کاربران کمک کند تا یک ویدیو را در یک چارچوب جغرافیایی یکپارچه درک کنند. توانایی به دست آوردن موقعیت جغرافیایی هر جسم متحرک در ویدئو به کیفیت مدل نقشه برداری بستگی دارد که ارتباط نزدیکی با مدل دوربین، مختصات پیکسل شی و دقت DSM دارد. در این مقاله، مدل دوربین با کالیبراسیون دوربین تعیین شد، استخراج اجسام متحرک توسط YOLOv5 و SORT عمیق و DSM توسط یک مدل جغرافیایی سه بعدی به دست آمد. پس از تصحیح اعوجاج، مختصات پیکسلی اجسام متحرک به مدل نگاشت ارسال شد. ما اجسام متحرک را با اطلاعات مکانی شناختیم و سپس عرض و ارتفاع جسم را محاسبه کردیم. در نهایت، مسیر حرکت اجسام در یک صحنه جغرافیایی سه بعدی ارائه شد. برای بررسی اثربخشی روش پیشنهادی، نتایج تجربی با مقادیر واقعی مقایسه شد. نتایج مقایسه نشان می دهد که روش پیشنهادی به دقت بسیار خوبی در موقعیت جغرافیایی و اندازه گیری هندسی اجسام متحرک در ویدئوهای نظارتی دست یافته است.
چارچوب پیشنهادی در این مقاله از اهمیت بالایی برخوردار است و ایده هایی برای تحقیقات مرتبط ارائه می دهد. ما مختصات پیکسلها را به مختصات جغرافیایی سهبعدی تجزیه کردیم تا به موقعیتیابی و اندازهگیری دقیق اشیاء نظارتی دست یابیم، که پشتیبانی فنی مطلوبی را برای امنیت شهری، از جمله تجزیه و تحلیل مکانی-زمانی اشیاء، جستجوی اشیا، هشدارهای غیرعادی، و آمار اشیا فراهم میکند. در عین حال، آن نیز یک موضوع فرعی از برنامه ۳DCM است. برخی از محققان با اندازه گیری سرعت راه رفتن افراد شروع به مطالعه امید به زندگی کرده اند. شکی نیست که داده های مکانی- زمانی که ما به دست آوردیم می تواند داده های تحلیلی را برای این محققان فراهم کند. بر اساس اهمیت موضوع تحقیق، ادغام بیان چند دوربین و چند شی را در یک صحنه جغرافیایی سه بعدی یکپارچه مطالعه خواهیم کرد.