

رگرسیون وزن جغرافیایی
تجزیه و تحلیل رگرسیون مرسوم معادله رگرسیون واحد را برای نشان دادن رابطه بین یک متغیر وابسته و تعدادی متغیر مستقل بر اساس این فرض که رابطه ثابت و سازگار در کل منطقه مورد مطالعه است، ایجاد میکند. به عبارت دیگر، یک معادله رگرسیون ساده یا چندگانه معمولی یک مدل جهانی است که در آن ضرایب رگرسیون در فضا ثابت در نظر گرفته میشود. با این حال، در تجزیه و تحلیل محیطی، این پارامترها ممکن است خود تابعی از موقعیت جغرافیایی باشند، زیرا شکل و قدرت روابط بین متغیرهای محیطی میتواند در سراسر فضا متفاوت باشد. نتایج رگرسیون معمولی ماهیت واقعی روابط متغیر مکانی بین یک پدیده محیطی و عوامل تأثیرگذار را نشان نخواهد داد. GWR رگرسیون چندگانه «جهانی» را با تولید مجموعهای از تخمینهای پارامتر محلی برای هر رابطه در هر نقطه داده در یک منطقه گسترش میدهد.
اساساً معادله رگرسیون خطی را در هر مکان داده با ضرایب رگرسیون متفاوت تخمین میزند. معادله رگرسیون محلی GWR را میتوان به صورت زیر نوشت :
که در آن k تعداد متغیرهای مستقل است، y مقدار پیش بینی شده متغیر وابسته y در مکان i، ai و {bij | j =1, 2, . . . , k} ضرایب رگرسیون در مکان i و xij مقدار مشاهده شده متغیر مستقل j در مکان i است. بنابراین، معادله رگرسیون مختص محل نقطه داده i است.
یک معادله رگرسیون محلی در محل i از طریق وزن دهی به تمام مشاهدات اطراف بر اساس تابعی از فاصله i محل برآورد میشود – یعنی به هر مشاهده وزنی اختصاص داده میشود که نشان دهنده تأثیر مقدار مشاهده شده بر روی مقدار i است که باید برآورد شود. مشاهدات نزدیک به محل من وزن بیشتری نسبت به دورتر میگیرم. وزنها را میتوان با چندین روش تعیین کرد. ساده ترین راه این است که وزنها را به صورت زیر تعریف کنید :
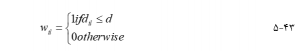
که در آن wil وزنی است که به مشاهده یا نقطه نمونه l برای تخمین معادله رگرسیون در مکان i نسبت داده میشود، dil نشان دهنده فاصله مکان i تا نقطه نمونه l است و d مقدار آستانه فاصله است.
با روش وزن دهی فوق، هر گونه مشاهده بیشتر از فاصله d از محل i هیچ تاثیری بر مکان i ندارد و از برآورد معادله رگرسیونی برای مکان i خارج میشود. همه مشاهدات درون d از محل من دارای وزن مساوی هستند. با این حال، این روش از مشکل ناپیوستگی رنج میبرد. ضرایب رگرسیون در مکانهای مختلف ممکن است بطور قابل توجهی تغییر کند، به ویژه هنگامی که تراکم نقاط نمونه در آن مکانها بسیار متفاوت باشد. یکی از راههای حل این مشکل این است که وزنها را با استفاده از یک تابع وزنی پیوسته dil، که به عنوان هسته شناخته میشود، تعریف کنیم. تابع هسته معمولی (که به عنوان هسته شعاع ثابت در ArcGIS استفاده میشود) عبارت است از :

که در آن h کمیتی است که به عنوان پهنای باند شناخته میشود. این تابع یک منحنی گاوسی را نشان میدهد. وزن در مکان i 1 است، که در آن i برابر با ۱ و dil برابر با صفر است. وزن سایر نقاط داده طبق منحنی گاوسی با افزایش فاصله بین i و l کاهش مییابد. هنگامی که دیل به فاصله معینی افزایش مییابد، وزنها تقریباً صفر میشوند و این مشاهدات را از تخمین ضرایب رگرسیون برای مکان i حذف میکند. پهنای باند در هسته در واحدهای مشابه مختصات مورد استفاده در دادهها بیان میشود. وقتی پهنای باند بسیار بزرگی انتخاب میشود ، وزنها به ۱ میرسند و مدل GWR محلی به یک مدل رگرسیون جهانی معمولی تبدیل میشود.
پهنای باند در هسته با واحدهای مشابه مختصات استفاده شده در دادهها بیان میشود. هنگامی که پهنای باند بسیار بزرگ انتخاب میشود، وزنها به ۱ نزدیک میشوند و مدل GWR محلی به یک مدل رگرسیون جهانی معمولی تبدیل میشود. هسته گاوسی بیان شده در معادله ۵-۴۴ از پهنای باند ثابت h استفاده میکند. برای استفاده زمانی مناسب است که نقاط نمونه به طور معقول و منظم در منطقه مورد مطالعه قرار گرفته باشند. با این حال، زمانی که نقاط نمونه به طور منظم فاصله ندارند، انتظار میرود که از پهنای باند نسبتاً کوچک در مناطقی که نقاط نمونه به طور متراکم توزیع شدهاند استفاده شود، و از پهنای باند نسبتاً بزرگ در جایی که نقاط نمونه به طور پراکنده توزیع شدهاند استفاده شود. یکی از راههای پیادهسازی این رویکرد پهنای باند تطبیقی این است که دقیقاً همان تعداد نقاط نمونه در پهنای باند محلی یک هسته برای تخمین در هر مکان گنجانده شود. تابع وزن دهی زیر چنین هسته تطبیقی است که به آن هسته بیسکوئر میگویند (که به عنوان یک هسته تطبیقی در ArcGIS استفاده میشود):

که در آن hi پهنای باندی است که شامل p مشاهدات نزدیک به مکان i است، با فرض اینکه p تعداد مشخصی از نقاط نمونه است که باید گنجانده شود. پهنای باند را با به حداقل رساندن مجموع اعتبار متقاطع خطاهای مربعی که به صورت زیر مشخص میشود بهینه سازی مینمایند :

که در آن yi مقدار مشاهده شده y در مکان i است، و مقدار پیش بینی شده y در مکانی است که با استفاده از مقدار خاصی از h زمانی که مشاهده i در تخمین استفاده نمیشود، ساخته شده است (برانسسدون و همکاران، ۱۹۹۸). مشاهده i از محاسبات حذف میشود تا در ناحیه مشاهدات پراکنده، مدل صرفاً بر اساس مشاهده i کالیبره نشود.
روش دیگر برای انتخاب پهنای باند مطلوب، به حداقل رساندن معیارهای تصحیح اطلاعات Akaike (AICc) است (هورویچ و همکاران ۱۹۹۸). شکل ریاضی آن برای GWR پیچیده است، بنابراین ما بر تفسیر آن تمرکز میکنیم. AICc اساساً یک معیار انتخاب مدل است. این اندازه گیری از کیفیت نسبی مدل، در اینجا معادله رگرسیون، برای مجموعه اطلاعات ارائه شده را ارائه میدهد. مدل با مقدار AICc کوچکتر بهتر است – یعنی با دادههای مشاهده شده تناسب بهتری را فراهم میکند. در اینجا، پهنای باند با کمترین AICc مقدار بهینه است.
هستههایی غیر از موارد ذکر شده در بالا میتوانند در GWR استفاده شوند و در بستههای نرم افزاری مختلف پیاده سازی شده اند. هنگامی که هسته یا تابع وزنی انتخاب شد و پهنای باند بهینه به دست آمد، همه مشاهدات نسبت به مکان i وزن داده میشوند و سپس از مشاهدات وزنی برای تخمین رگرسیون خطی در مکان بر اساس اصل حداقل مربعات استفاده میشود و سپس واضح است که تخمینهای ضریب رگرسیون میتواند براساس مکانها متفاوت باشد و ناهمگونی مکانی را منعکس کند. برای جزئیات بیشتر به ( فودرینگ هام و همکاران، ۲۰۰۲) مراجعه کنید. کادر ۵-۱۰ نحوه پیاده سازی GWR و تفسیر نتایج را در ArcGIS نشان میدهد. کادر ۵-۱۱ نمونه ای از استفاده از GWR برای مدل سازی روابط پشههای نابالغ و تراکم انسان با بروز دنگی در تایوان را ارائه میدهد.