
خلاصه
کلید واژه ها:
تشخیص شباهت کاربر مشکل شروع سرد ؛ آگاهی از زمینه (CA) ؛ سیستم توصیه (RS) ; دستگاه های هوشمند ؛ کلونی زنبورهای مصنوعی (ABC)، تعاملات اجتماعی ؛ فیلتر مشارکتی (CF)
۱٫ معرفی
-
پیشنهاد یک موتور جدید تشخیص شباهت کاربر (USDE) که میتواند شباهتهای بین کاربران را با در نظر گرفتن تعاملات اجتماعی ایجاد شده در دنیای واقعی یا بهطور مجازی از طریق SNs مدلسازی کند.
-
ادغام پتانسیل دستگاه های هوشمند شخصی کاربران با RS ها برای گرفتن طیف گسترده ای از اطلاعات متنی در مورد کاربران و در نتیجه ارائه توصیه های شخصی تر.
-
تجهیز USDE پیشنهادی به یک الگوریتم خوشهبندی کاربر برای فعال کردن RS پیشنهادی برای مواجهه با چالشبرانگیزترین موقعیتهای شروع سرد که برای آنها سایر RSها، از جمله RSهای مبتنی بر مکان، در ارائه توصیههای شخصیشده شکست میخورند.
۲٫ بررسی ادبیات
-
اگرچه استفاده از منابع داده اضافی مانند تنظیمات برگزیده کاربران می تواند به CSP رسیدگی کند، درخواست از کاربران برای ارائه دستی چنین اطلاعاتی همیشه امکان پذیر نیست. علاوه بر این، این اطلاعات در طول زمان در حال تغییر هستند. به عنوان مثال، ژانرهای موسیقی یا فیلم مورد علاقه کاربران می تواند در طول زمان تغییر کند. درخواست از کاربران برای به روز رسانی منظم تنظیمات برگزیده خود، محدودیت برخی از RS هایی است که اخیراً توسعه یافته اند. با رشد فوق العاده دستگاه های هوشمند، ما دیگر محدود به تعداد محدودی از ارائه دهندگان زمینه مانند گوشی های هوشمند و تبلت ها نیستیم. بنابراین، در این تحقیق، ما به طور خودکار مشخصات کاربر را بر اساس دستگاه های هوشمند شخصی وی به روز می کنیم.
-
تکیه بر SN ها برای شناسایی کاربران مشابه اجتماعی، محدودیت جدیدی را برای RS ها تحمیل می کند (یعنی کاربران باید عضو یک SN باشند). علاوه بر این، RS ها هنوز از CSP رنج می برند زمانی که هیچ اطلاعاتی وجود ندارد که به طور صریح یا ضمنی تعامل اجتماعی کاربر را در SN ها بیان کند. در مطالعات قبلی، تنها تعاملات مجازی از SNها برای شناسایی کاربران مرتبط با اجتماعی استخراج شد [ ۱۲ ]. با این حال، در این تحقیق، تعاملات اجتماعی در دنیای واقعی استخراج شده از دستگاه های هوشمند کاربران به USDE ما اضافه شده است. این تعاملات اجتماعی در دنیای واقعی نقش مهمی را به عنوان منبع داده اضافی برای شناسایی شباهت بین کاربران ایفا می کند.
-
معیارهای شباهت همبستگی کسینوس و پیرسون را می توان به عنوان گسترده ترین معیارهای شباهت استفاده شده [ ۳۰ ، ۳۷ ] در RS های مبتنی بر CF ذکر کرد. اقدامات مشابهی که پیشنهاد شده است، استفاده بسیار کم را در شرایط سخت CSP نشان می دهد. در مقایسه با معیارهای شباهت کاربردی، یک معیار تشابه مبتنی بر اعتماد جدید در این تحقیق پیشنهاد شده است. در این مطالعه، یک تکنیک خوشهبندی مبتنی بر ازدحام در USDE استفاده میشود تا RS پیشنهادی برای رسیدگی به CSP قدرتمندتر شود. به عبارت دیگر، USDE پیشنهادی توسط یک الگوریتم خوشهبندی برای شناسایی کاربران مشابه بر اساس تعاملات اجتماعی در دنیای واقعی و اطلاعات متنی موجود در نمایههایشان توانمند است.
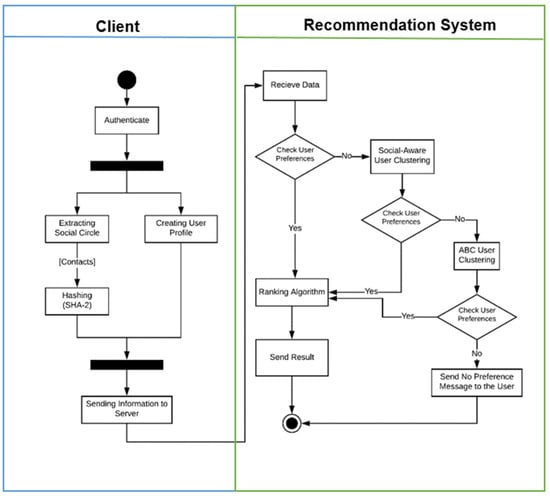
۳٫ به روز رسانی نمایه کاربر با استفاده از دستگاه های هوشمند
۴٫ موتور تشخیص شباهت کاربر
۴٫۱٫ طبقه بندی تعامل اجتماعی
در این مقاله فرض شده است که شباهت بین کاربر هدف و کاربران دارای PSI بیشتر از شباهت کاربران با SSI است. بدیهی است که توصیه های ارائه شده توسط افرادی که در گروه کاربران مشابه با PSI هستند قابل اعتمادتر از توصیه های ارائه شده توسط گروه کاربران مشابه با SSI در نظر گرفته می شوند. بر اساس این فرض، ما اعتماد به توصیههای ارائه شده توسط گروه کاربران مشابه دارای PSI را دو برابر بیشتر از گروه کاربران مشابه دارای SSI در نظر میگیریم. با این حال، اگر تعداد قابل توجهی (یعنی ۳۰ [ ۴۹ ]) از افراد در حلقه اجتماعی نداشته باشیم، از روش خوشهبندی کاربر استفاده میشود و وزن اعتماد دوباره ۱ در نظر گرفته میشود. از این رو، اوزان اعتماد به شرح زیر در نظر گرفته می شود:
۴٫۲٫ خوشه بندی پروفایل کاربر
-
هر الگو باید به یک خوشه کاربری اختصاص داده شود، به عنوان مثال، ∪کj = ۱جj= ز∪�=۱���=�.
-
هر خوشه کاربری حداقل یک الگوی زمینه دارد که به آن اختصاص داده شده است، به عنوان مثال، جک≠ ۰ ، k = ۱ ، … ، K ��≠۰, �=۱, …,�.
-
هر الگوی زمینه به یک و تنها یک خوشه کاربری اختصاص داده می شود، به عنوان مثال، جک∩ c j = ۰ ، w h e r e k ≠ j ��∩��=۰, �ℎ��� �≠�.
خوشهبندی فرآیند شناسایی خوشههای کاربران در دادههای نمایه کاربر چند بعدی (زمینهها) بر اساس فضای ویژگی (یعنی موارد نمایه کاربر) از طریق اندازهگیری شباهت است. محبوب ترین راه برای ارزیابی یک اندازه گیری شباهت از طریق استفاده از اندازه گیری های فاصله است [ ۵۱ ]. پرکاربردترین اندازه گیری فاصله، فاصله اقلیدسی است که به صورت زیر تعریف می شود:
۵٫ الگوریتم پیشنهادی پیشنهادی
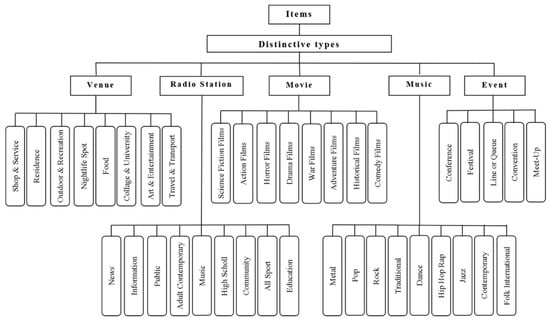
برای الگوریتم پیشنهادی پیشنهادی، ما پنج زیر مجموعه مختلف ناهمگن از آیتمها را در مجموعه آیتمهای اصلی شامل فیلمها، مکانها، رویدادها، موسیقی و ایستگاههای رادیویی در نظر میگیریم. بنابراین ترکیب تمامی زیر مجموعه ها به صورت زیر بیان می شود:
که در آن، i ∈ { ۱ , ۲ , … , ۵ }�∈{۱, ۲, …,۵}و منمن��همه موارد را با یک برچسب خاص تعریف کنید من�مانند فیلم، مکان، موسیقی، رویداد و مجموعه ایستگاه های رادیویی. علاوه بر این، متر�تعداد آیتم ها را در یک زیر مجموعه خاص مشخص می کند. اگر سرویس پیشنهادی اقلام فیلم را در نظر بگیریم، همه متر�آیتم های قرار داده شده در مجموعه فیلم بر اساس ژانرهایشان در هشت دسته مختلف طبقه بندی می شوند که در شکل ۴ نشان داده شده است. اگر به صراحت ژانر فیلمی را که برای کاربر هدف جالب است تشخیص دهیم، از الگوریتم توصیهکننده CF برای توصیه به کاربر هدف استفاده میشود. ک�-فیلم های با رتبه بالا در ژانر مورد نظر. اجازه دهید این را در نظر بگیریم ک�-لیست با رتبه بالا از فیلم های پیشنهادی به عنوان ماتریس، آرk × ۱��×۱. با توجه به افرادی که در حلقه اجتماعی کاربر هدف قرار دارند من�به عنوان مجموعه ای که توسط نمن= {توjمن∣∣ j = ۱ , ۲ , … , l ; i ≠ j a n d توj∈ U}��={���| �=۱,۲,…,�;�≠� ��� ��∈�}. با استفاده از رتبه بندی آنها برای آیتم ک�، یک ماتریس رتبه بندی همسایه به صورت زیر تعریف می شود:
بدیهی است که توصیه های ارائه شده توسط افرادی که در گروه کاربران مشابه با PSI هستند قابل اعتمادتر از توصیه های ارائه شده توسط گروه کاربران مشابه با SSI در نظر گرفته می شوند. بر اساس وزن اعتماد (۱)، رتبه بندی میانگین بر اساس اعتماد برای آیتم ک�تعریف شده است r“ک��′مانند:
جایی که ωj��وزن اعتماد برای کاربر است j�بر اساس (۱). پس از محاسبه میانگین رتبه برای همه موارد، موارد ترجیحی مرتب می شوند. توصیه موارد تکراری که کاربران قبلاً با آنها تعامل داشته اند، توصیه های ناکارآمد در نظر گرفته می شود [ ۵۹ ]. به عنوان مثال، اگر کاربر مورد نظر قبلاً فیلمی را تماشا کرده باشد، توصیه کردن همان فیلم بی اثر است. برای غلبه بر این مشکل، یک مکانیسم پس پردازش مبتنی بر اطلاعات تاریخی را برای حذف موارد تکراری در نظر می گیریم. اگر کاربر قبلاً فیلمی را تماشا کرده باشد، این اطلاعات در پایگاه داده ذخیره می شود. پس از آماده سازی ک�-توصیه های با رتبه بالا، ما لیست توصیه ها را با اطلاعات تاریخی موجود در پایگاه داده مقایسه می کنیم. برای مورد تکراری، آن را با توصیه با رتبه بالا جایگزین می کنیم.
نمونه هایی از سناریوهای چالش برانگیز
در سناریوی اول، وضعیتی را در نظر بگیرید که کاربر هیچ اولویت صریحی در رابطه با ژانرهای فیلم ندارد یا کاربر برای اولین بار در RS ما ثبت نام می کند. این بدان معناست که دادههای جمعآوریشده توسط شبکه شخصی کاربر بهصراحت ترجیحات کاربر را بیان نمیکند. این مشکل به طور گسترده ای به نام CSP شناخته می شود. در این شرایط به جای تکیه بر ترجیحات صریح کاربر، محتمل ترین گزینه ترجیحی از حلقه اجتماعی کاربر استخراج می شود. شایان ذکر است که عملکرد RS های پیشنهادی ما تنها به داده های استخراج شده از SN ها بستگی ندارد. تعاملات اجتماعی بین کاربران را می توان از تعامل اجتماعی آنها در SN (یعنی کاربران دارای SSI) یا تعاملات اجتماعی در دنیای واقعی آنها (یعنی کاربران با PSI) استخراج کرد. هدف ما این است که میانگین ترجیحات حلقه اجتماعی کاربر هدف برای هر دسته از ژانرهای فیلم را پیدا کنیم. اگر دایره اجتماعی کاربر هدف من�به صورت نشان داده شده است نمن��، ترجیحات شخصی آنها از نمایه های پویا استخراج می شود. همانطور که در شکل ۴ مشاهده می شود ، هشت ژانر مختلف فیلم وجود دارد. بنابراین، ماتریس ترجیح کاربر را تعریف می کنیم پنمن���به شرح زیر است:
که در آن g= { ۱ , ۲ , … , ۸ }�={۱, ۲,…, ۸}تعداد ژانرهای فیلم از جمله فیلم های اکشن، ترسناک، جنگی، درام، ماجراجویی، کمدی و تاریخی را مشخص می کند. توجه داشته باشید که پمنj���یک شاخص عددی است که نشان می دهد آیا کاربر j�به ژانر فیلم علاقه مند است من�یا نه. با در نظر گرفتن هر دو گروه کاربران مشابه با PSI و SSI، میتوانیم معیار اعتماد مشابهی را برای محاسبه ترجیح میانگین وزنی به صورت زیر اعمال کنیم:
۶٫ آزمایش ها و نتایج
۶٫۱٫ به روز رسانی نمایه کاربر
۶٫۱٫۱٫ مجموعه داده های مرتبط با زمینه
۶٫۱٫۲٫ مجموعه داده های متا
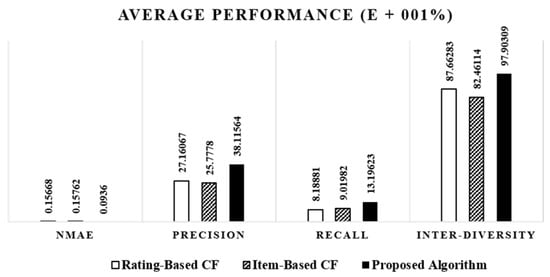
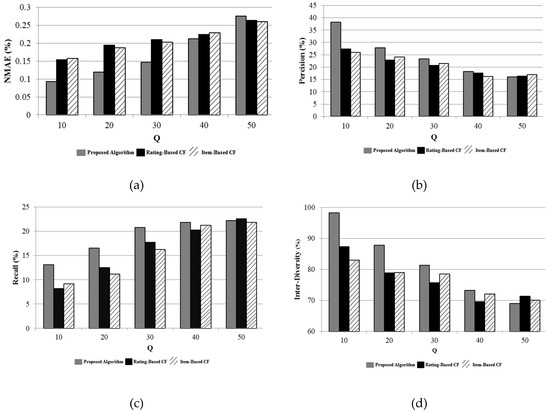
۶٫۲٫ ارزیابی سیستم پیشنهادی پیشنهادی
۶٫۳٫ ارزیابی USDE پیشنهادی تحت CSP
۷٫ نتیجه گیری و کار آینده
منابع
- روپا، م. پاتار، اس. بویا، ر. Venugopal، KR; آیینگار، س. Patnaik، L. اینترنت اجتماعی اشیاء (SIoT): مبانی، حوزه های رانش، بررسی سیستماتیک و جهت گیری های آینده. محاسبه کنید. اشتراک. ۲۰۱۹ ، ۱۳۹ ، ۳۲-۵۷٫ [ Google Scholar ]
- ملک، ام.آر. فرانک، AU یک رویکرد محاسباتی سیار برای اهداف ناوبری. در سمپوزیوم بین المللی وب و سیستم های اطلاعات جغرافیایی بی سیم ; Springer: برلین/هایدلبرگ، آلمان، ۲۰۰۶; صص ۱۲۳-۱۳۴٫ [ Google Scholar ]
- محمدی، ن. Malek، M. VGI و تطابق داده های مرجع بر اساس توصیفگر چرخشی مکان یابی و تطبیق بخش. ترانس. GIS ۲۰۱۵ ، ۱۹ ، ۶۱۹-۶۳۹٫ [ Google Scholar ] [ CrossRef ]
- اورسینو، دی. ویرجیلی، L. انسانی کردن اینترنت اشیا: تعریف نمایه و قابلیت اطمینان یک چیز در یک سناریوی چند اینترنت اشیاء. به سوی اینترنت اجتماعی اشیاء (SIoT): فناوریها، معماریها و برنامههای کاربردی توانمند . Springer: Cham، سوئیس، ۲۰۲۰؛ صص ۵۱-۷۶٫ [ Google Scholar ]
- بائو، جی. ژنگ، ی. ویلکی، دی. موکبل، ام. توصیههایی در شبکههای اجتماعی مبتنی بر مکان: یک نظرسنجی. GeoInformatica ۲۰۱۵ ، ۱۹ ، ۵۲۵-۵۶۵٫ [ Google Scholar ] [ CrossRef ]
- Erdeniz، SP; منیچتاس، ا. Maglogiannis، I. فلفرنیگ، آ. سیستمهای Tran، TNT Recommender برای IoT که برنامههای کاربردی خود کمی را فعال میکنند. تکامل. سیستم ۲۰۱۹ ، ۱۱ ، ۲۹۱-۳۰۴٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Raghuwanshi، SK; Pateriya, R. Recommendation Systems: Techniques, Challenges, Application, and Evaluation. در محاسبات نرم برای حل مسئله ; Springer: سنگاپور، ۲۰۱۹؛ صص ۱۵۱-۱۶۴٫ [ Google Scholar ]
- شائو، ی. Xie، Y.-H. تحقیق در مورد مشکل شروع سرد الگوریتم فیلتر مشارکتی در مجموعه مقالات سومین کنفرانس بین المللی ۲۰۱۹ در تحقیقات کلان داده، پاریس، فرانسه، ۲۷-۲۹ نوامبر ۲۰۱۹؛ صص ۶۷-۷۱٫ [ Google Scholar ]
- روداس-سیلوا، جی. گالیندو، جی. گارسیا گوتیرز، جی. Benavides، DJIA انتخاب اجزای پیادهسازی خط محصول نرمافزار با استفاده از سیستمهای توصیهگر: برنامهای برای وردپرس. دسترسی IEEE ۲۰۱۹ ، ۷ ، ۶۹۲۲۶–۶۹۲۴۵٫ [ Google Scholar ] [ CrossRef ]
- یانگ، دی. ژانگ، دی. یو، ز. Yu, Z. جستجوی مکان با آگاهی از اولویتهای ریز با استفاده از ردپای دیجیتال جمعسپاری شده از LBSN. در مجموعه مقالات کنفرانس مشترک بین المللی ACM 2013 در محاسبات فراگیر و فراگیر، زوریخ، سوئیس، ۸ تا ۱۲ سپتامبر ۲۰۱۳٫ ص ۴۷۹-۴۸۸٫ [ Google Scholar ]
- Serrat, O. تجزیه و تحلیل شبکه های اجتماعی. در راه حل های دانش ; Springer: سنگاپور، ۲۰۱۷; صص ۳۹-۴۳٫ [ Google Scholar ]
- ژانگ، ی. شی، ز. زو، دبلیو. یو، ال. لیانگ، اس. زنجیره های مارکوف شخصی سازی شده مشترک Li، XJN با تعبیه شبکه اجتماعی برای توصیه شروع سرد. محاسبات عصبی ۲۰۱۹ ، ۳۸۶ ، ۲۰۸-۲۲۰ . [ Google Scholar ] [ CrossRef ]
- ژانگ، جی. پنگ، کیو. سان، اس. لیو، سی. الگوریتم توصیه فیلتر مشارکتی بر اساس اولویت کاربر که از ویژگیهای دامنه مورد مشتق شده است. فیزیک یک آمار مکانیک. Appl. ۲۰۱۴ ، ۳۹۶ ، ۶۶-۷۶٫ [ Google Scholar ] [ CrossRef ]
- ژانگ، اس. Lv، Q. پیشبینی مشارکت گروهی مبتنی بر EGU در شبکههای اجتماعی مبتنی بر رویداد. دانستن سیستم مبتنی بر ۲۰۱۸ ، ۱۴۳ ، ۱۹-۲۹٫ [ Google Scholar ] [ CrossRef ]
- خروف، ح. توصیه رویداد Troncy، R. Hybrid با استفاده از دادههای مرتبط و تنوع کاربر. در مجموعه مقالات هفتمین کنفرانس ACM در مورد سیستم های توصیه کننده، هنگ کنگ، چین، ۱۲ تا ۱۶ اکتبر ۲۰۱۳٫ ص ۱۸۵-۱۹۲٫ [ Google Scholar ]
- رامیرز-گارسیا، ایکس. García-Valdez, M. پس فیلترینگ برای یک سیستم توصیهکننده آگاه از زمینه رستوران. در پیشرفت های اخیر در رویکردهای ترکیبی برای طراحی سیستم های هوشمند . Springer: Cham, Switzerland, 2014; صص ۶۹۵-۷۰۷٫ [ Google Scholar ]
- خو، ام. لیو، اس. فیلتر مشارکتی ترکیبی مبتنی بر معنایی و متن آگاه برای توصیه رویداد در شبکههای اجتماعی مبتنی بر رویداد. دسترسی IEEE ۲۰۱۹ ، ۷ ، ۱۷۴۹۳–۱۷۵۰۲٫ [ Google Scholar ] [ CrossRef ]
- اوجاغ، س. ملک، ام.آر. سعیدی، س. لیانگ، اس. یک سیستم توصیهگر جهتگیری آگاه مبتنی بر مکان با استفاده از دستگاههای هوشمند اینترنت اشیا و شبکههای اجتماعی. ژنرال آینده. محاسبه کنید. سیستم ۲۰۲۰ ، ۱۰۸ ، ۹۷-۱۱۸٫ [ Google Scholar ] [ CrossRef ]
- حسین پور، م. ملک، ام.آر. کلارامونت، سی. به حداکثر رساندن تأثیر اجتماعی – فضایی در شبکه های اجتماعی مبتنی بر مکان. ژنرال آینده. محاسبه کنید. سیستم ۲۰۱۹ ، ۱۰۱ ، ۳۰۴–۳۱۴٫ [ Google Scholar ] [ CrossRef ]
- توریخوس، اس. Bellogín، A.; سانچز، پی. کشف کاربران مرتبط در شبکه های اجتماعی مبتنی بر مکان. در مجموعه مقالات مدل سازی، انطباق و شخصی سازی کاربر – بیست و هشتمین کنفرانس بین المللی، UMAP، جنوا، ایتالیا، ۱۲ تا ۱۸ ژوئیه ۲۰۲۰؛ ص ۱۲-۱۸٫ [ Google Scholar ]
- راوی، ال. سوبرامانیاسوامی، وی. ویجایاکومار، وی. چن، اس. کارمل، ا. Devarajan, M. سیستم توصیهکننده مبتنی بر مکان هیبریدی برای برنامهریزی حرکت و سفر. اوباش شبکه Appl. ۲۰۱۹ ، ۲۴ ، ۱۲۲۶-۱۲۳۹٫ [ Google Scholar ] [ CrossRef ]
- براونهوفر، ام. Ricci، F. سیستمهای توصیهگر متنآگاه، فیلتر کردن اطلاعات و برنامههای کاربردی پشتیبانی تصمیم هستند که با بهرهبرداری از دادههای ترجیحی کاربر وابسته به زمینه، توصیههایی را تولید میکنند، مانند رتبهبندیهایی که با توصیف موقعیت زمینهای که هنگام تجربه کاربر مورد شناسایی میشوند، تقویت میشوند. در واقع، بسیاری از عوامل زمینه ای (به عنوان مثال، آب و هوا، فصل، خلق و خوی یا همنشین) ممکن است به طور بالقوه بر روی آن تأثیر بگذارند. Inf. تکنولوژی تور. ۲۰۱۷ ، ۱۷ ، ۱۰۱-۱۱۹٫ [ Google Scholar ]
- وو، دبلیو. ژائو، جی. ژانگ، سی. منگ، اف. ژانگ، ز. ژانگ، ی. Sun، Q. بهبود عملکرد توصیهکنندههای متنآگاه مبتنی بر تانسور با استفاده از Factorization Tensor Bias با رمزگذاری خودکار ویژگی زمینه. دانستن سیستم مبتنی بر ۲۰۱۷ ، ۱۲۸ ، ۷۱-۷۷٫ [ Google Scholar ] [ CrossRef ]
- Panniello، U. توژیلین، ا. Gorgoglione، M. مقایسه سیستمهای توصیهگر آگاه از زمینه از نظر دقت و تنوع. مدل سازی کاربر UserAdapt. تعامل داشتن. ۲۰۱۴ ، ۲۴ ، ۳۵-۶۵٫ [ Google Scholar ] [ CrossRef ]
- آدوماویسیوس، جی. Tuzhilin، A. سیستم های توصیه گر زمینه آگاه. در Recommender Systems Handbook ; Springer: Boston, MA, USA, 2011; ص ۲۱۷-۲۵۳٫ [ Google Scholar ]
- Colombo-Mendoza، LO; والنسیا-گارسیا، آر. رودریگز-گونزالس، آ. آلور-هرناندز، جی. Samper-Zapater، JJ RecomMetz: یک سیستم توصیهکننده موبایل مبتنی بر دانش مبتنی بر زمینه برای زمانهای نمایش فیلم. سیستم خبره Appl. ۲۰۱۵ ، ۴۲ ، ۱۲۰۲-۱۲۲۲٫ [ Google Scholar ] [ CrossRef ]
- ایریناکی، م. گائو، جی. وارلامیس، آی. Tserpes, K. Recommender Systems for Large-Scale Social Networks: A Review of Challenges and Solutions . الزویر: آمستردام، هلند، ۲۰۱۸٫ [ Google Scholar ]
- لیو، ال. محاسبات خدمات: از خدمات ابری، خدمات تلفن همراه تا اینترنت خدمات. IEEE Trans. خدمت محاسبه کنید. ۲۰۱۶ ، ۹ ، ۶۶۱-۶۶۳٫ [ Google Scholar ] [ CrossRef ]
- کوی، ز. خو، X. ژو، اف. کای، ایکس. کائو، ی. ژانگ، دبلیو. Chen, J. سیستم توصیه شخصی مبتنی بر فیلتر مشارکتی برای سناریوهای اینترنت اشیا. IEEE Trans. خدمت محاسبه کنید. ۲۰۲۰ ، ۱۳ ، ۶۸۵-۶۹۵٫ [ Google Scholar ] [ CrossRef ]
- Ahn, HJ یک معیار تشابه جدید برای فیلتر مشترک برای کاهش مشکل شروع سرد کاربر جدید. Inf. علمی ۲۰۰۸ ، ۱۷۸ ، ۳۷-۵۱٫ [ Google Scholar ] [ CrossRef ]
- فرناندز-توبیاس، آی. کانتادور، آی. تومئو، پی. آنیلی، فولکس واگن؛ دی نویا، تی. پرداختن به شروع سرد کاربر با فیلتر مشترک بین دامنهای: بهرهبرداری از فراداده مورد در فاکتورسازی ماتریس. مدل سازی کاربر UserAdapt. تعامل داشتن. ۲۰۱۹ ، ۲۹ ، ۴۴۳-۴۸۶٫ [ Google Scholar ] [ CrossRef ]
- آکاما، اس. کودو، ی. مورای، تی. انتخاب همسایه برای فیلتر مشارکتی مبتنی بر کاربر با استفاده از مجموعههای خشن مبتنی بر پوشش. در مباحث در نظریه مجموعه های خشن ; Springer: Cham، سوئیس، ۲۰۲۰؛ صص ۱۴۱-۱۵۹٫ [ Google Scholar ]
- ژو، اف. او، X. وانگ، ایکس. خو، جی. لیو، ک. Hong, R. فیلتر مشارکتی مبتنی بر آیتم برای توصیه top-n. ACM Trans. Inf. سیستم (TOIS) ۲۰۱۹ ، ۳۷ ، ۱-۲۵٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- آماتو، اف. Moscato، V. پیکاریلو، ا. Piccialli، F. SOS: یک سیستم توصیه کننده چند رسانه ای برای شبکه های اجتماعی آنلاین. ژنرال آینده. محاسبه کنید. سیستم ۲۰۱۷ ، ۹۳ ، ۹۱۴-۹۲۲۳٫ [ Google Scholar ] [ CrossRef ]
- د کاروالیو، ال سی; رودریگز، اف. اولیویرا، پی. یک الگوریتم توصیه ترکیبی برای رسیدگی به مشکل شروع سرد. در مجموعه مقالات کنفرانس بین المللی سیستم های هوشمند هیبریدی ; Springer: Cham, Switzerland, 2018; ص ۲۶۰-۲۷۱٫ [ Google Scholar ]
- Allioui، YE یک رویکرد جدید برای حل مشکل شروع سرد کاربر جدید در سیستم های توصیه گر با استفاده از فیلتر مشترک. بین المللی J. Sci. مهندس Res. ۲۰۱۷ ، ۸ ، ۲۷۳-۲۸۱٫ [ Google Scholar ]
- Chatzidimitris، T. گاوالاس، دی. کاساپاکیس، وی. کنستانتوپولوس، سی. کیپریادیس، دی. پانتزیو، جی. زارولیاگیس، CJP; Computing, U. A Location History-Aware Recommender System for Smart Retail Environments ; محاسبات شخصی و همه جا حاضر: لندن، بریتانیا، ۲۰۲۰؛ صص ۱-۱۲٫ [ Google Scholar ]
- هرلوکر، جی ال. کنستان، ج.ا. تروین، ال جی؛ Riedl, JT ارزیابی سیستم های توصیه کننده فیلتر مشترک. ACM Trans. Inf. سیستم (TOIS) ۲۰۰۴ ، ۲۲ ، ۵-۵۳٫ [ Google Scholar ] [ CrossRef ]
- هارپر، اف ام؛ Konstan، JA مجموعه داده های MovieLens: تاریخچه و زمینه. ACM Trans. تعامل داشتن. هوشمند سیستم ۲۰۱۵ ، ۵ ، ۱-۱۹٫ [ Google Scholar ] [ CrossRef ]
- یو، ایکس. پان، ا. تانگ، L.-A. لی، ز. Han, J. Geo-friends توصیه در شبکه اجتماعی سایبری فیزیکی مبتنی بر GPS. در مجموعه مقالات کنفرانس بین المللی ۲۰۱۱ در مورد پیشرفت در تجزیه و تحلیل شبکه های اجتماعی و استخراج، Kaohsiung، تایوان، ۲۵-۲۷ ژوئیه ۲۰۱۱; صص ۳۶۱-۳۶۸٫ [ Google Scholar ]
- شیائو، ایکس. ژنگ، ی. لو، کیو. Xie، X. استنباط روابط اجتماعی بین کاربران با تاریخچه مکان انسانی. J. هوش محیطی. اومانیز. محاسبه کنید. ۲۰۱۴ ، ۵ ، ۳-۱۹٫ [ Google Scholar ] [ CrossRef ]
- آدوماویسیوس، جی. سانکارانارایانان، ر. سن، اس. Tuzhilin، A. ترکیب اطلاعات زمینه ای در سیستم های توصیه گر با استفاده از یک رویکرد چند بعدی. ACM Trans. Inf. سیستم (TOIS) ۲۰۰۵ ، ۲۳ ، ۱۰۳-۱۴۵٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- سعیدی، س. موسی، ع. El-Sheimy، N. ناوبری شخصی با آگاهی از زمینه با استفاده از ترکیب حسگر تعبیه شده در گوشی های هوشمند. Sensors ۲۰۱۴ , ۱۴ , ۵۷۴۲-۵۷۶۷٫ [ Google Scholar ] [ CrossRef ]
- آلفرد، وی. الگوریتمهایی برای یافتن الگوها در رشتهها. مجموعه الگوریتم ها ۲۰۱۴ ، ۱ ، ۲۵۵٫ [ Google Scholar ]
- نصرت بولوش، ح. اوزون، ای. Doruk, A. مقایسه الگوریتم های تطبیق رشته ها در اسناد وب. در مجموعه مقالات علمی بین المللی ۲۰۱۷، گابروو، بلغارستان، ۱۷-۱۸ نوامبر ۲۰۱۷؛ جلد ۲، ص ۲۷۹-۲۸۲٫ [ Google Scholar ]
- پاندیسلوام، پ. ماریموتو، تی. لاورنس، آر. مطالعه تطبیقی روی الگوریتم تطبیق رشتههای توالیهای زیستی. در مجموعه مقالات کنفرانس بین المللی محاسبات هوشمند، تایوان، چین، ۳ تا ۶ اوت ۲۰۱۴٫ [ Google Scholar ]
- احتشام الحق، م. اعظم، م. نعیم، یو. امین، ی. Loo, J. احراز هویت مداوم کاربران تلفن هوشمند بر اساس تشخیص الگوی فعالیت با استفاده از سنجش غیرفعال تلفن همراه. J. Netw. محاسبه کنید. Appl. ۲۰۱۸ ، ۱۰۹ ، ۲۴-۳۵٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- السسر، ک. Peplau, LA پارتیشن شیشه ای: موانع دوستی های متقابل در محل کار. هوم مرتبط. ۲۰۰۶ ، ۵۹ ، ۱۰۷۷-۱۱۰۰٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کار، اس اس; Ramalingam، A. آیا ۳۰ عدد جادویی است؟ مسائل مربوط به تخمین حجم نمونه Natl. J. Community Med. ۲۰۱۳ ، ۴ ، ۱۷۵-۱۷۹٫ [ Google Scholar ]
- کامشواران، ک. ملارویزی، ک. بررسی تکنیک های خوشه بندی در داده کاوی. بین المللی جی. کامپیوتر. علمی Inf. تکنولوژی ۲۰۱۴ ، ۵ ، ۲۲۷۲-۲۲۷۶٫ [ Google Scholar ]
- ابراهیم، ع. گروسان، سی. Ramos, V. Swarm Intelligence in Data Mining (مطالعات در هوش محاسباتی) ; Springer: برلین/هایدلبرگ، آلمان، ۲۰۰۶; جلد ۳۴٫ [ Google Scholar ]
- سیستم توصیه کننده فیلم کاتاریا، آر. با زنبور مصنوعی فراابتکاری. محاسبات عصبی Appl. ۲۰۱۸ ، ۳۰ ، ۱۹۸۳-۱۹۹۰٫ [ Google Scholar ] [ CrossRef ]
- سعیدی، س. صمدزادگان، ف. El-Sheimy، N. استخراج شیء از دادههای لیدار با استفاده از الگوریتم خوشهبندی کلونی ازدحام زنبور عسل مصنوعی. CMRT09 IAPRS ۲۰۰۹ ، ۳۸ ، ۱۳۳-۱۳۸٫ [ Google Scholar ]
- Zhongzhi, S. الگوریتم خوشه بندی مبتنی بر هوش ازدحام. در مجموعه مقالات فناوری اطلاعات و شبکه اطلاعات، ۲۰۰۱٫ ICII 2001-Beijing. ۲۰۰۱ کنفرانس های بین المللی، پکن، چین، ۲۹ اکتبر تا ۰۱ نوامبر ۲۰۰۱٫ صص ۵۸-۶۶٫ [ Google Scholar ]
- فام، دی.تی. قنبرزاده، ع. کوچ، ای. اوتری، اس. رحیم، س. زیدی، ام. الگوریتم زنبورها-ابزاری جدید برای مسائل پیچیده بهینهسازی. در سیستم های ماشین های تولید هوشمند ; الزویر: آمستردام، هلند، ۲۰۰۶; ص ۴۵۴-۴۵۹٫ [ Google Scholar ]
- پاترلینی، اس. کرینک، تی. تکامل دیفرانسیل و بهینه سازی ازدحام ذرات در خوشه بندی پارتیشنی. محاسبه کنید. آمار داده آنال. ۲۰۰۶ ، ۵۰ ، ۱۲۲۰-۱۲۴۷٫ [ Google Scholar ] [ CrossRef ]
- روی، ا. توانا، م. بانرجی، اس. Caprio, DD یک سیستم توصیهکننده گردشگری با آگاهی از زمینه ایمن با استفاده از کلنی زنبورهای مصنوعی و بازپخت شبیهسازی شده. بین المللی J. Appl. مدیریت علمی ۲۰۱۶ ، ۸ ، ۹۳-۱۱۳٫ [ Google Scholar ] [ CrossRef ]
- Gao, W. الگوریتم خوشهبندی کلونی مورچهها و مطالعه عملکرد آن بهبود یافته است. محاسبه کنید. هوشمند نوروسک. ۲۰۱۶ ، ۲۰۱۶ ، ۱-۱۴٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژو، تی. سو، آر کیو؛ لیو، آر آر. جیانگ، LL; وانگ، BH; Zhang، YC توصیه های دقیق و متنوع از طریق حذف همبستگی های اضافی. جدید جی. فیزیک. ۲۰۰۹ ، ۱۱ ، ۱۲۳۰۰۸٫ [ Google Scholar ] [ CrossRef ]
- هان، جی. پی، جی. کامبر، ام. داده کاوی: مفاهیم و تکنیک ها . الزویر: آمستردام، هلند، ۲۰۱۱٫ [ Google Scholar ]
- فیس بوک. Facebook for Developers، Graph API. در دسترس آنلاین: https://developers.facebook.com/docs/graph-api/overview (در ۱ مارس ۲۰۲۰ قابل دسترسی است).
- IMDB. مجموعه داده های IMBD در دسترس آنلاین: https://www.imdb.com/interfaces/ (در ۱ ژوئن ۲۰۲۰ قابل دسترسی است).
- گلدبرگ، ک. رودر، تی. گوپتا، دی. Perkins, C. Eigentaste: یک الگوریتم فیلتر مشترک زمان ثابت. Inf. Retr. ۲۰۰۱ ، ۴ ، ۱۳۳-۱۵۱٫ [ Google Scholar ] [ CrossRef ]
- سلام پاتروس، ز. نجفی، س. ارزیابی دقت پیشبینی الگوریتمهای فیلتر مشارکتی در سیستمهای توصیهکننده . موسسه سلطنتی فناوری KTH: استکهلم، سوئد، ۲۰۱۶٫ [ Google Scholar ]
- رفائیل زاده، پ. تانگ، ال. لیو، اچ. اعتبارسنجی متقابل. در دایره المعارف سیستم های پایگاه داده ; Springer: New York, NY, USA, 2009; صص ۵۳۲-۵۳۸٫ [ Google Scholar ]
- ایگناتوف، دی. پولمنز، جی. ددن، جی. Viaene, S. یک تکنیک اعتبارسنجی متقابل جدید برای ارزیابی کیفیت سیستمهای توصیهگر. در ادراک و هوش ماشینی ؛ Springer: برلین/هایدلبرگ، آلمان، ۲۰۱۲; صص ۱۹۵-۲۰۲٫ [ Google Scholar ]
- Au، MH; لیانگ، ک. لیو، جی کی. لو، آر. Ning, J. عملیات دادههای شخصی حفظ حریم خصوصی در ابر تلفن همراه – شانسها و چالشها در برابر تهدید مداوم پیشرفته. ژنرال آینده. محاسبه کنید. سیستم ۲۰۱۸ ، ۷۹ ، ۳۳۷-۳۴۹٫ [ Google Scholar ] [ CrossRef ]






بدون دیدگاه