
خلاصه
کش ; راه اندازی حمله ؛ آدمک ها ; رهبر ; حفاظت از حریم خصوصی ؛ شهرت، آبرو
۱٫ معرفی
۱٫۱٫ بیان مشکل
۱٫۲٫ انگیزه
۱٫۳٫ مشارکت
-
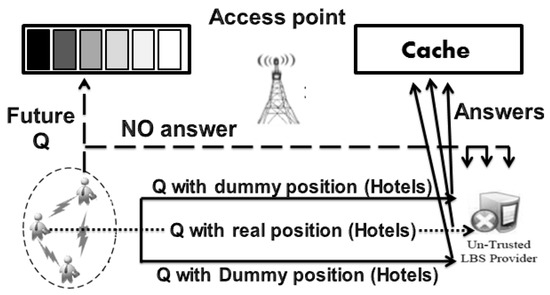
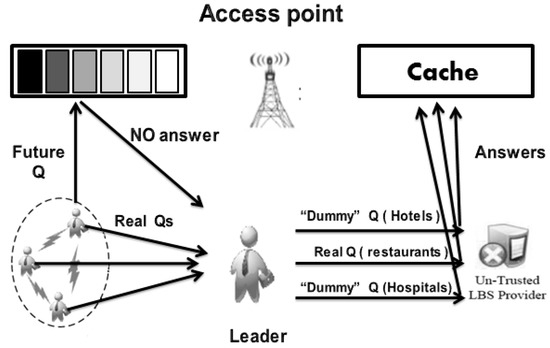
این مقاله یک رویکرد رهبر پیشنهاد میکند تا به طور کامل از اتصال کاربران LBS (اعضای یک خوشه) به طرف غیرقابل اعتماد (سرور LBS) جلوگیری کند. یک رابطه همزیستی برای تشکیل پایه اعتماد بین اعضای خوشه و رهبر آنها استفاده می شود. در نتیجه، رهبر یک TTP قوی در نظر گرفته می شود.
-
این مقاله راه حلی را برای مشکل تولید ساختگی معرفی می کند که به عنوان یک مشکل گران و باز برای دستیابی به حفاظت از حریم خصوصی جامع (یعنی حفاظت از حریم خصوصی مکان و پرس و جو) در نظر گرفته می شود.
-
بسته به آنتروپی مکان، یک معیار حریم خصوصی جدید ارائه شده است. برای اندازه گیری نزدیکی مهاجم به لحظه شروع حمله استفاده می شود.
-
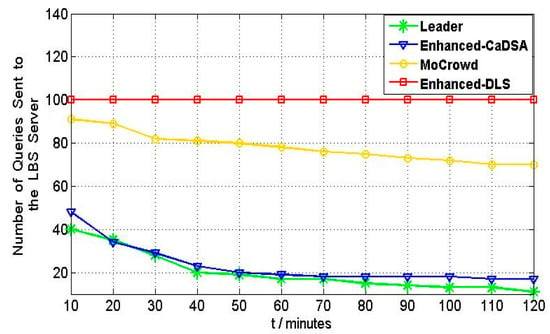
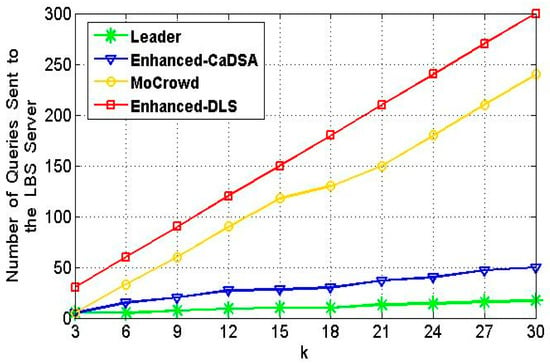
برای نشان دادن استحکام رویکرد پیشنهادی از نظر هزینه ارتباط، مقاومت در برابر حملات استنتاج، و نسبت ضربه حافظه پنهان، سه رویکرد معروف، یعنی بهبود یافته-DLS [ ۳۴ ]، پنهان شدن در یک جمعیت موبایل [ ۳۸ ]، و بهبود یافته- CaDSA [ ۴۰ ] مورد مطالعه و مقایسه قرار می گیرد.
۲٫ کارهای مرتبط
۲٫۱٫ گروه اول: بیشتر بار در سمت سرور
۲٫۲٫ گروه دوم: بیشترین بار در سمت کاربر
۲٫۳٫ گروه سوم: تعادل بار
۳٫ رویکرد حفاظت از حریم خصوصی پیشنهادی
۳٫۱٫ رویکرد پیشنهادی (رهبر)
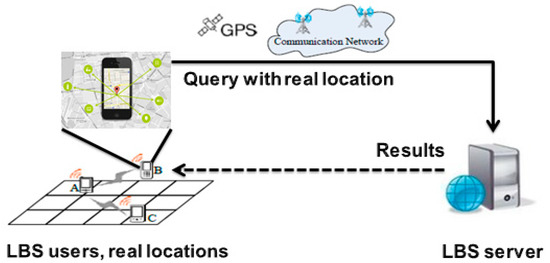
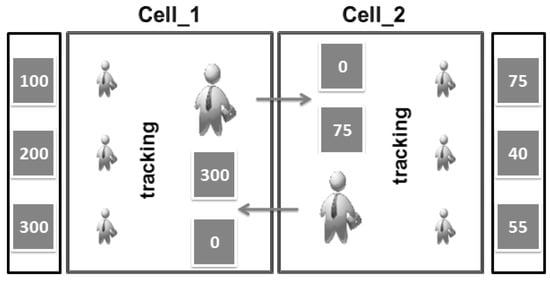
اجازه دهید S مجموعه ای از اتصالات بین کاربران LBS و سرور قبلی را نشان دهد (همانطور که در شکل ۱ نشان داده شده است ).
جایی که سیپآستی(Uمن)تعداد اتصالات به سرور LBS نامعتبر مربوط به است توسهrمن، سیپآستی(Uمن+۱)تعداد اتصالات مربوط به سرور LBS نامعتبر است توسهrمن+۱، و سیپآستی(Ug)تعداد اتصالات به سرور LBS نامعتبر مربوط به است توسهrg.
معیارهای انتخاب رهبر بر اساس حداکثر تعداد اتصالات به سرور LBS خواهد بود. بنابراین، رهبر، کاربری خواهد بود که شرایط زیر را برآورده کند:
۳٫۲٫ اعتماد به رهبر
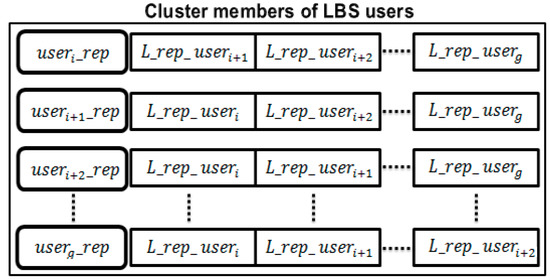
به طور کلی، اجازه دهید تیLمن(vآلتوه⃛)نشان دهنده مقدار سطح اعتماد a است توسهrمن، جایی که در آن واقع شده است توسهrمن+۱٫ اگر پاسخ دریافتی درست باشد، پس تیLمن(vآلتوه⃛)=تیLمن(vآلتوه⃛+۱). اگر پاسخ دریافتی جعلی است، پس تیLمن(vآلتوه⃛)=تیLمن(vآلتوه⃛-۱). مقدار جدید حاصل شهرت محلی نامیده می شود (توسهr_L_rهپ)مربوط به توسهrمنکه توسهrمن+۱درباره او ساخته شده است. با اعمال هر یک از اعضای خوشه این فرآیند بر روی بقیه، می توان شهرت محلی را به دست آورد. به عبارت دیگر، هر کاربری که در خوشه گنجانده شده است، دارای جفت مجموعه اندازه خواهد بود (g-1)در مورد شهرت محلی مربوط به هر یک از باقیمانده ها، و این شهرت محلی می تواند بسته به اعتبار پاسخ پرسش آزمایشی افزایش یا کاهش یابد. در نتیجه جفت های زیر را بدست می آوریم:
جایی که توسهrمن_L_rهپشهرت محلی ساخته شده در مورد است توسهrمنبا هر دو توسهrمن+۱و توسهrg، توسهrمن+۱_L_rهپشهرت محلی ساخته شده در مورد است توسهrمن+۱با هر دو توسهrمنو توسهrg، و توسهrg_L_rهپشهرت محلی ساخته شده در مورد است توسهrgبا هر دو توسهrمنو توسهrمن+۱٫
بر اساس نمایش در فرمول (۱)، هر یک توسهr_rهپ(vآل˜توه)تعداد معینی از اتصالات سرور LBS در گذشته مربوط به هر یک از اعضای خوشه را به شرح زیر مطابقت می دهد:
با ضرب دو جزء مربوط به هر کاربر در (۴)، شهرت عمومی جی_rهپهر کاربر به صورت زیر محاسبه می شود:
در نتیجه معیارهای جدید انتخاب رهبری عبارتند از:
شایان ذکر است که یک مورد خاص ممکن است زمانی رخ دهد که حداکثر شهرت عمومی برای دو کاربر یا بیشتر یکسان باشد. در این صورت رهبر بر اساس همین معیارها به صورت تصادفی انتخاب می شود. پس از انتخاب رهبر بر اساس معیارهای جدید، همه اعضای خوشه برای دریافت پاسخ های واقعی به پرسش های خود که توسط رهبر خودشان به سرور LBS ارسال شده است، مورد اعتماد خواهند بود. شبه کد مربوطه برای انتخاب رهبر در الگوریتم ۱ گنجانده شده است.
| الگوریتم ۱: الگوریتم انتخاب رهبر |
| ورودی: n×n(تعداد سلول ها یا خوشه ها)، g(تعداد کاربران LBS در یک سلول یا خوشه)، سیپآستی_تو(تعداد اتصالات به سرور LBS در گذشته برای کاربر تو) اچآسساعتتیآبله(کهy=توسهr،vآل=جیrهپ). |
| خروجی: جیLهآدهrسی(شهرت عمومی رهبر در سلول ج) |
 |
الگوریتم ۲ شبه کد را برای محاسبه شهرت محلی نشان می دهد.
| الگوریتم ۲: محاسبه شهرت محلی ( محلیهرزه) |
| تابع محلیهرزه(ریکاوری کننده تو.فرستنده من) |
| ورودی: تیساس،آتیساس |
| خروجی: لoجآلrهپ |
| ۱: پاسخها reciever_u = تست i (TQ S ,u) |
| ۲: (نآرآ)=تعداد تطبیق (آnسwهrسrهجمنهvهr_تو،آتیساس) |
| ۳: ( NWA ) = تعداد ( TQ S ) – NRA |
| ۴: جدید (تیLrهجمنهvهr_تو)= قدیمی (تیLrهجمنهvهr_تو)+نآرآ-ندبلیوآ |
| ۵: لoجآلrهپ= جدید (تیLrهجمنهvهr_تو) |
| ۶: بازگشت لoجآلrهپ |
جایی که تیساسپرس و جوهای آزمایشی است، آتیساسپاسخ به سوالات آزمون است، (نآرآ)تعداد پاسخ های درست است، (ندبلیوآ)تعداد پاسخ های اشتباه است و تیLسطح اعتماد گیرنده است.
۴٫ معیارهای حریم خصوصی استفاده شده
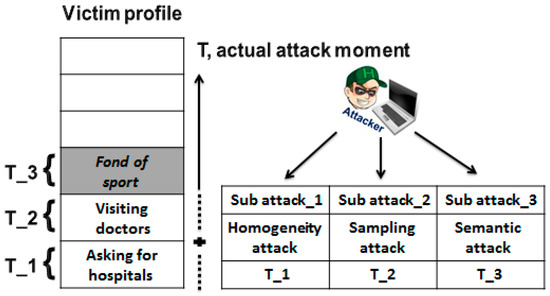
۴٫۱٫ حملات استنتاج
۴٫۲٫ انواع معیارهای حریم خصوصی استفاده شده
۴٫۲٫۱٫ متریک حریم خصوصی رهبر
از آنجایی که پرس و جوهای واقعی برای رهبر ارسال می شود که به عنوان آدمک در سمت او عمل می کنند، مفهوم ک-آnonyمترمنتیyبه طور خودکار برای محافظت از حریم خصوصی رهبر به دست می آید. اجازه دهید کنشان دادن به ک-آnonyمترمنتیyدر سطح τلحظه). اجازه دهید پمن(من=۱،۲،…،ک)نشان دهنده احتمال تشخیص است منتیساعتمکان به عنوان یک مکان واقعی در میان (ک-۱)آدمک، و اجازه دهید qمناحتمال پرس و جو را نشان می دهد منتیساعتمکان به شرح زیر
بنابراین، آنتروپی مکان در τلحظه را می توان به صورت زیر ارائه کرد:
وقتی همه کمکان های ممکن احتمال پرس و جو یکسانی دارند، E(τ)به حداکثر مقدار می رسد. در این حالت، آنتروپی مکان به صورت زیر خواهد بود:
با توجه به شکل ۱۰ ، مشخص است که مقدار آنتروپی مکان متفاوت است، از آبه ب، Eنشان دهنده میزان حفاظت از حریم خصوصی در سمت رهبر، و (ب-آ-E)نشان دهنده نزدیکی مهاجم به حمله او علیه رهبر است. در نتیجه، معیار حریم خصوصی جدید را می توان به صورت زیر ارائه کرد:
جایی که τ∈Γ.
۴٫۲٫۲٫ متریک حریم خصوصی سیستم
به طور کلی، کاربرانی که پاسخهای پرس و جو خود را در حافظه پنهان پیدا میکنند، تحت هر معیار حریم خصوصی به ارزش کامل حریم خصوصی دست مییابند، زیرا از برخورد با سرورهای LBS غیرقابل اعتماد از طریق Leader جلوگیری میکنند و هیچ اطلاعاتی در مورد موقعیتهای واقعی و هم نمیتوان استنباط کرد. پرس و جوهای واقعی ما از معیار حریم خصوصی پیشنهاد شده در [ ۴۰ ] به نام نسبت ضربه حافظه پنهان (CHR) استفاده کردیم که پرس و جوهای پاسخ داده شده توسط کش را به نسبت تعداد کل پرس و جوهای درگیر در سیستم به صورت زیر اندازه گیری می کند:
۵٫ نتایج تجربی و ارزیابی
۵٫۱٫ ارزیابی نتایج هزینه ارتباطات
۵٫۲٫ ارزیابی نتایج مقاومت در برابر حملات استنتاج
۵٫۳٫ ارزیابی نتایج نسبت ضربه حافظه پنهان
۶٫ نتیجه گیری
منابع
- چن، ال. تامبر، اس. جاروینن، ک. سیمونا، LE; آلن ساویککو، آ. لپاکوسکی، اچ. Bhuiyan، MZH; بو پاشا، س. فرارا، جی.ان. هونکالا، اس. و همکاران استحکام، امنیت و حریم خصوصی در خدمات مبتنی بر مکان برای اینترنت اشیاء آینده: یک نظرسنجی. IEEE Access ۲۰۱۷ ، ۵ ، ۸۹۵۶–۸۹۷۷٫ [ Google Scholar ] [ CrossRef ]
- Elmisery، AM; رو، اس. بوتویچ، دی. یک میان افزار مبتنی بر مه برای انطباق خودکار با اصول حفظ حریم خصوصی OECD در اینترنت چیزهای مراقبت بهداشتی. دسترسی IEEE ۲۰۱۶ ، ۴ ، ۸۴۱۸–۸۴۴۱٫ [ Google Scholar ] [ CrossRef ]
- ژو، جی. کائو، ز. دونگ، ایکس. Vasilakos، AV امنیت و حریم خصوصی برای IoT مبتنی بر ابر: چالش ها. IEEE Commun. Mag. ۲۰۱۷ ، ۵۵ ، ۲۶-۳۳٫ [ Google Scholar ]
- سان، جی. چانگ، وی. راماچاندران، م. سان، ز. لی، جی. یو، اچ. لیائو، دی. الگوریتم حریم خصوصی مکان کارآمد برای سرویسها و برنامههای کاربردی اینترنت اشیا (IoT). J. Netw. محاسبه کنید. Appl. ۲۰۱۷ ، ۸۹ ، ۳-۱۳٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- الله، من. شاه، MA مدلی جدید برای حفظ حریم خصوصی مکان در اینترنت اشیا. در مجموعه مقالات بیست و دومین کنفرانس بین المللی اتوماسیون و محاسبات ۲۰۱۶ (ICAC)، کولچستر، انگلستان، ۷ تا ۸ سپتامبر ۲۰۱۶؛ IEEE: Piscataway, NJ, USA, 2016. [ Google Scholar ]
- عبدالموتی، ا. Alrayes، F. به سوی درک آگاهی از حریم خصوصی مکان در شبکه های جغرافیایی-اجتماعی. ISPRS Int. J. Geo-Inf. ۲۰۱۷ ، ۶ ، ۱۰۹٫ [ Google Scholar ] [ CrossRef ]
- پاگالو، U. دورانته، ام. Monteleone, S. اینترنت اشیا در حریم خصوصی و حفاظت از داده ها چه چیز جدیدی دارد؟ چهار چالش قانونی در اشتراک گذاری و کنترل در اینترنت اشیا در حفاظت از داده ها و حریم خصوصی: (در) Visibilities و Infrastructures ; انتشارات بین المللی اسپرینگر: چم، سوئیس، ۲۰۱۷; صص ۵۹-۷۸٫ [ Google Scholar ]
- حسن، ASM; Qu، Q. لی، سی. چن، ال. Jiang, Q. یک معماری حریم خصوصی موثر برای حفظ مسیرهای کاربر در برنامه های LBS مبتنی بر پاداش. ISPRS Int. J. Geo-Inf. ۲۰۱۸ ، ۷ ، ۵۳٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- الرویس، ع. الحوتیلی، ع. هو، سی. چنگ، ایکس. محاسبات مه برای اینترنت اشیا: مسائل امنیتی و حریم خصوصی. محاسبات اینترنتی IEEE. ۲۰۱۷ ، ۲۱ ، ۳۴-۴۲٫ [ Google Scholar ] [ CrossRef ]
- ممکن است.؛ وانگ، ی. یانگ، جی. میائو، ی. لی، دبلیو. سیستم کاربردی بزرگ سلامت مبتنی بر اینترنت اشیا و داده های بزرگ سلامت. IEEE Access ۲۰۱۷ ، ۵ ، ۷۸۸۵–۷۸۹۷٫ [ Google Scholar ] [ CrossRef ]
- سامره، س. Zamil، MGA; الارود، AF; راوشده، م. الحمید، م.ف. Alamri، A. چارچوب تشخیص فعالیت کارآمد: به سمت سنجش داده های سلامت حساس به حریم خصوصی. دسترسی IEEE ۲۰۱۷ ، ۵ ، ۳۸۴۸–۳۸۵۹٫ [ Google Scholar ] [ CrossRef ]
- درداری، د. کلوزاس، پی. Djuric، PM ردیابی داخلی: تئوری، روشها و فناوریها. IEEE Trans. وه تکنولوژی ۲۰۱۵ ، ۶۴ ، ۱۲۶۳-۱۲۷۸٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژانگ، ال. لیو، ک. جیانگ، ی. لی، X.-Y. لیو، ی. یانگ، پی. لی، ز. یانگ، پی مونتاژ: ترکیب فریم ها با تداوم حرکت برای ردیابی چند کاربره بلادرنگ. IEEE Trans. اوباش محاسبه کنید. ۲۰۱۷ ، ۱۶ ، ۱۰۱۹–۱۰۳۱٫ [ Google Scholar ] [ CrossRef ]
- Shin، KG; جو، ایکس. چن، ز. Hu, X. حفاظت از حریم خصوصی برای کاربران خدمات مبتنی بر مکان. IEEE Wirel. اشتراک. ۲۰۱۲ ، ۱۹ ، ۳۰-۳۹٫ [ Google Scholar ] [ CrossRef ]
- ورنک، م. اسکورتسوف، پ. دور، اف. Rothermel, K. طبقه بندی حملات و رویکردهای حریم خصوصی مکان. پارس محاسبات همه جا حاضر. ۲۰۱۴ ، ۱۸ ، ۱۶۳-۱۷۵٫ [ Google Scholar ] [ CrossRef ]
- فنگ، دبلیو. یان، ز. Xie, H. احراز هویت ناشناس در اعتماد در شبکه های اجتماعی فراگیر بر اساس امضای گروهی. IEEE Access ۲۰۱۷ ، ۵ ، ۶۲۳۶–۶۲۴۶٫ [ Google Scholar ] [ CrossRef ]
- یو، آر. بای، ز. یانگ، ال. وانگ، پی. حرکت، OA؛ Liu, Y. الگوریتم پنهانسازی مکان براساس بهینهسازی ترکیبی برای سرویسهای مبتنی بر مکان در شبکههای ۵G. دسترسی IEEE ۲۰۱۶ ، ۴ ، ۶۵۱۵–۶۵۲۷٫ [ Google Scholar ] [ CrossRef ]
- گدیک، بی. لیو، ال. حفاظت از حریم خصوصی مکان با K-Anonymity شخصی شده: معماری و الگوریتم ها. IEEE Trans. اوباش محاسبه کنید. ۲۰۰۸ ، ۷ ، ۱-۱۸٫ [ Google Scholar ] [ CrossRef ]
- گروتسر، م. Grunwald، D. استفاده ناشناس از خدمات مبتنی بر مکان از طریق پنهان کاری مکانی و زمانی. در MobiSys ’03: مجموعه مقالات اولین کنفرانس بین المللی سیستم های تلفن همراه، برنامه ها و خدمات . ACM: نیویورک، نیویورک، ایالات متحده آمریکا، ۲۰۰۳٫ [ Google Scholar ]
- موکبل، MF; Chow, C.-Y.; Aref, WG The New Casper: Query Processing for Location Services Without Computing Privacy. در مجموعه مقالات VLDB ’06، سئول، کره، ۱۲-۱۵ سپتامبر ۲۰۰۶٫ ACM: نیویورک، نیویورک، ایالات متحده آمریکا، ۲۰۰۶; صص ۷۶۳-۷۷۴٫ [ Google Scholar ]
- برسفورد، آ. Stajano, F. حریم خصوصی مکان در محاسبات فراگیر. محاسبات فراگیر IEEE ۲۰۰۳ ، ۲ ، ۴۶-۵۵٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هو، بی. Gruteser، M. حفاظت از حریم خصوصی مکان از طریق سردرگمی مسیر. در مجموعه مقالات اولین کنفرانس بین المللی امنیت و حریم خصوصی برای مناطق در حال ظهور در شبکه های ارتباطی (SECURECOMM’05)، آتن، یونان، ۵-۹ سپتامبر ۲۰۰۵٫ صص ۱۹۴-۲۰۵٫ [ Google Scholar ]
- میروویتز، جی. روی Choudhury، R. پنهان کردن ستاره ها با آتش بازی: حریم خصوصی مکان از طریق استتار. در مجموعه مقالات پانزدهمین کنفرانس بین المللی سالانه محاسبات موبایلی و شبکه، پکن، چین، ۲۰-۲۵ سپتامبر ۲۰۰۹٫ صص ۳۴۵-۳۵۶٫ [ Google Scholar ]
- خو، تی. Cai, Y. حفاظت از حریم خصوصی موقعیت مکانی مبتنی بر احساس برای خدمات مبتنی بر مکان. در مجموعه مقالات کنفرانس ACM 2009 در مورد امنیت رایانه و ارتباطات، CCS 2009، شیکاگو، IL، ایالات متحده آمریکا، ۹ تا ۱۳ نوامبر ۲۰۱۹؛ ACM: نیویورک، نیویورک، ایالات متحده آمریکا، ۲۰۰۹; صص ۳۴۸-۳۵۷٫ [ Google Scholar ]
- پینگلی، ا. یو، دبلیو. ژانگ، ن. فو، ایکس. Zhao، W. Cap: یک سیستم حفاظت از حریم خصوصی آگاه از زمینه برای خدمات مبتنی بر مکان. در مجموعه مقالات بیست و نهمین کنفرانس بین المللی IEEE در سال ۲۰۰۹ در مورد سیستم های محاسباتی توزیع شده، مونترال، QC، کانادا، ۲۲ تا ۲۶ ژوئن ۲۰۰۹٫ صص ۴۹-۵۷٫ [ Google Scholar ]
- هونگ، اس. لیو، سی. رن، بی. هوانگ، ی. Chen, J. چارچوب حفاظت از حریم خصوصی شخصی مبتنی بر فناوری پنهان برای تلفن های هوشمند. IEEE Access ۲۰۱۷ ، ۵ ، ۶۵۱۵–۶۵۲۶٫ [ Google Scholar ] [ CrossRef ]
- مانویلر، جی. اسکودلاری، آر. کاکس، LP Smile: اعتماد مبتنی بر برخورد برای خدمات اجتماعی موبایل. در مجموعه مقالات CCS ’09، شیکاگو، IL، ایالات متحده آمریکا، ۹-۱۳ نوامبر ۲۰۰۹٫ ACM: نیویورک، نیویورک، ایالات متحده آمریکا، ۲۰۰۹; ص ۲۴۶-۲۵۵٫ [ Google Scholar ]
- متعجب.؛ Xu, J. ناشناس بودن مکان بدون قرار گرفتن در معرض. در مجموعه مقالات بیست و پنجمین کنفرانس بین المللی مهندسی داده IEEE 2009، شانگهای، چین، ۲۹ مارس تا ۲ آوریل ۲۰۰۹٫ صص ۱۱۲۰–۱۱۳۱٫ [ Google Scholar ]
- Chen, Z. جمع آوری و انتشار اطلاعات کارآمد انرژی در شبکه های حسگر بی سیم. Ph.D. پایان نامه، دانشگاه میشیگان، آن آربر، MI، ایالات متحده آمریکا، ۲۰۰۹٫ [ Google Scholar ]
- آرداگنا، سی. کرمونینی، ام. دامیانی، ای. دی کاپیتانی دی ویمرکاتی، اس. Samarati, P. حفاظت از حریم خصوصی مکان از طریق تکنیک های مبهم سازی. در مجموعه مقالات بیست و یکمین کنفرانس سالانه IFIP WG 11.3 در مورد امنیت داده ها و برنامه ها، ردوندو بیچ، کالیفرنیا، ایالات متحده آمریکا، ۸ تا ۱۱ ژوئیه ۲۰۰۷٫ صص ۴۷-۶۰٫ [ Google Scholar ]
- Gutscher، A. تحول هماهنگ – راه حلی برای مشکل حریم خصوصی خدمات مبتنی بر مکان؟ در مجموعه مقالات بیستمین کنفرانس بین المللی پردازش موازی و توزیع شده (IPDPS ’06)، جزیره رودز، یونان، ۲۵-۲۹ آوریل ۲۰۰۶; پ. ۳۵۴٫ [ Google Scholar ]
- کیدو، اچ. یاناگیساوا، ی. Satoh, T. یک تکنیک ارتباطی ناشناس با استفاده از Dummies برای خدمات مبتنی بر مکان. در مجموعه مقالات ICPS ’05. اقدامات. کنفرانس بین المللی خدمات فراگیر ۲۰۰۵، سانتورینی، یونان، ۱۱ تا ۱۴ ژوئیه ۲۰۰۵٫ [ Google Scholar ]
- پینگلی، ا. ژانگ، ن. فو، ایکس. چوی، H.-A.; سوبرامانیام، اس. ژائو، دبلیو. حفاظت از حریم خصوصی جستجو برای خدمات مستمر مبتنی بر مکان. در مجموعه مقالات ۲۰۱۱ IEEE INFOCOM، شانگهای، چین، ۱۰-۱۵ آوریل ۲۰۱۱٫ [ Google Scholar ]
- نیو، بی. لی، کیو. زو، ایکس. کائو، جی. لی، اچ. دستیابی به K-ناشناس بودن در خدمات مبتنی بر مکان آگاه از حریم خصوصی. در مجموعه مقالات کنفرانس IEEE INFOCOM 2014-IEEE در زمینه ارتباطات کامپیوتری، تورنتو، ON، کانادا، ۲۷ آوریل تا ۲ مه ۲۰۱۴٫ [ Google Scholar ]
- هارا، ت. سوزوکی، آ. ایواتا، م. آراسه، ی. Xie، X. ناشناس سازی موقعیت مکانی کاربر مبتنی بر ساختگی تحت محدودیت های دنیای واقعی. IEEE Access ۲۰۱۶ ، ۴ ، ۶۷۳-۶۸۷٫ [ Google Scholar ] [ CrossRef ]
- سان، دبلیو. چن، سی. ژنگ، بی. چن، سی. لیو، پی. یک شاخص هوایی برای پردازش پرس و جو فضایی در شبکه های جاده ای. IEEE Trans. بدانید. مهندسی داده ۲۰۱۵ ، ۲۷ ، ۳۸۲-۳۹۵٫ [ Google Scholar ] [ CrossRef ]
- دوری، ر. Thurimella, R. بهره برداری از شباهت سرویس برای حفظ حریم خصوصی در جستارهای جستجوی مبتنی بر مکان. IEEE Trans. توزیع موازی سیستم ۲۰۱۴ ، ۲۵ ، ۳۷۴-۳۸۳٫ [ Google Scholar ] [ CrossRef ]
- شکری، ر. تئودوراکوپولوس، جی. پاپادیمیتراتوس، پ. کاظمی، ا. هوباکس، جی.-پی. پنهان شدن در جمعیت موبایل: حریم خصوصی موقعیت مکانی از طریق همکاری. IEEE Trans. ایمن قابل اعتماد محاسبه کنید. ۲۰۱۴ ، ۱۱ ، ۲۶۶-۲۷۹٫ [ Google Scholar ]
- زو، ایکس. چی، اچ. نیو، بی. ژانگ، دبلیو. لی، ز. Li, H. Mobicache: وقتی k-anonymity با حافظه پنهان روبرو می شود. در مجموعه مقالات کنفرانس ارتباطات جهانی IEEE 2013 (GLOBECOM)، آتلانتا، GA، ایالات متحده آمریکا، ۹ تا ۱۳ دسامبر ۲۰۱۳٫ [ Google Scholar ]
- نیو، بی. لی، کیو. زو، ایکس. کائو، جی. لی، اچ. Ben, N. افزایش حریم خصوصی از طریق ذخیره سازی در سرویس های مبتنی بر مکان. در مجموعه مقالات کنفرانس IEEE 2015 در زمینه ارتباطات رایانه ای (INFOCOM)، هنگ کنگ، چین، ۲۶ آوریل تا ۱ مه ۲۰۱۵٫ [ Google Scholar ]
- جورجیادو، ی. de By, RA; Urania، K. حریم خصوصی موقعیت مکانی در پی GDPR. ISPRS Int. J. Geo-Inf. ۲۰۱۹ ، ۸ ، ۱۵۷٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- پان، X. چن، دبلیو. وو، ال. پیائو، سی. Hu, Z. حفاظت از حریم خصوصی شخصی شده در برابر حملات همگن حساسیت بر روی شبکه های جاده ای در خدمات تلفن همراه. جلو. محاسبه کنید. علمی ۲۰۱۶ ، ۱۰ ، ۳۷۰-۳۸۶٫ [ Google Scholar ] [ CrossRef ]
- لین، سی. وو، جی. Yu, CW حفاظت از حریم خصوصی مکان و حریم خصوصی پرس و جو: یک رویکرد خوشه بندی ترکیبی. موافق محاسبه کنید. تمرین کنید. انقضا ۲۰۱۵ ، ۲۷ ، ۳۰۲۱-۳۰۴۳٫ [ Google Scholar ] [ CrossRef ]
- سراوانان، س. راماکریشنان، BS حفظ حریم خصوصی در زمینه خدمات مبتنی بر مکان از طریق مکان یابی در گردشگری سیار. Inf. تکنولوژی تور. ۲۰۱۶ ، ۱۶ ، ۲۲۹-۲۴۸٫ [ Google Scholar ] [ CrossRef ]
- لی، ی. یوان، ی. وانگ، جی. چن، ال. لی، جی. حفظ حریم خصوصی موقعیت مکانی آگاه در شبکه های جاده ای. در کنفرانس بین المللی سیستم های پایگاه داده برای کاربردهای پیشرفته ; Springer International Publishing: Cham, Switzerland, 2016. [ Google Scholar ]
- لی، بی. اوه، جی. یو، اچ. Kim, J. حفاظت از حریم خصوصی مکان با استفاده از معنای مکانی. در مجموعه مقالات هفدهمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی ; ACM: نیویورک، نیویورک، ایالات متحده آمریکا، ۲۰۱۱٫ [ Google Scholar ]






بدون دیدگاه