۱٫ مقدمه و کارهای مرتبط
در سالهای اخیر، بسیاری از پروکسیهای امیدوارکننده حرکت انسان، مانند تلفنهای همراه، اسکناسها و شبکههای اجتماعی مختلف آنلاین کشف شدهاند. علاوه بر این، ارتباطات انسانی مدرن در چند دهه گذشته دستخوش تغییرات ساختاری عظیمی شده است ([ ۱ ] Michele et al., 2014)، که نمونه هایی از پایگاه داده های داده های ارتباطی شخصی، مانند سوابق تماس تلفن همراه را تولید کرده است ([ ۲ ] Liu). و همکاران، ۲۰۱۴). هم داده های تحرک و هم داده های ارتباطی شخصی می توانند تعامل بین مناطق فضایی با وضوح فضایی بالا را منعکس کنند ([ ۳ ] لی و همکاران، ۲۰۱۴).
استفاده از الگوریتمهای خوشهبندی فضایی در مقیاس بزرگ مجموعه دادههای تعامل فضایی از پروکسیهای انسانی در حال ظهور برای کشف نقطه گرم/سرد فضایی شهری، ایده جدیدی است که در ادبیات ارائه شده است. مطالعات کنونی معمولاً برای مسیرهای جمع آوری شده به روش های مختلف مانند تلفن های همراه، اسکناس ها و شبکه های اجتماعی مختلف آنلاین طراحی می شوند. هان و همکاران ([ ۴ ]، ۲۰۱۲) نقاط داغ RTA را از طریق یک الگوریتم خوشه بندی تعیین کرد. ژو چینگ و همکاران ([ ۵ ]، ۲۰۱۶) از روش تشخیص الگوی تجمع فضایی برای استخراج نقاط داغ شهری از مسیرهای تاکسی استفاده کرد. جانکه و همکاران ([ ۶]، ۲۰۱۶) با استفاده از روش خوشهبندی فضایی DBSCAN و فناوری مؤلفه وب، تعامل بصری آنلاین مناطق تاکسی نقطه داغ در شانگهای را تحقق بخشید. علاوه بر این، ژائو پنگ شیانگ و همکاران. ([ ۷ ]، ۲۰۱۶) یک روش خوشهبندی مسیر را بر اساس نمودار تصمیمگیری و میدان داده برای تجزیه و تحلیل دادههای مسیر تاکسی پیشنهاد کرد. درلی و همکاران ([ ۸ ]، ۲۰۱۷)، بر اساس روش آماری فضایی مبتنی بر مدل، یک مدل توصیفی برای تعیین مکان و زمان نقاط داغ تصادفات رانندگی ایجاد کرد تا تعداد تصادفات کاهش یابد. شو ژانیا و همکاران ([ ۹ ]، ۲۰۱۸) از الگوریتم ناکس برای مطالعه دادههای بررسی میکروبلاگ استفاده کرد و نقاط داغ فضایی و زمانی و تعامل مکانی-زمانی مناطق شهری پکن را تجزیه و تحلیل کرد. کین کان و همکاران ([ ۱۰]، ۲۰۱۸) از خوشه بندی مکانی-زمانی برای تجزیه و تحلیل همبستگی مکانی-زمانی داده های مسیر رفتاری به دست آمده توسط GNSS خودرو و گوشی های هوشمند استفاده کرد. لی یونگپان و همکاران ([ ۱۱ ]، ۲۰۱۸) از داده های مکانی-زمانی به دست آمده از AIS کشتی برای انجام تجزیه و تحلیل خوشه بندی مکانی-زمانی ویژگی های ترافیک دریایی استفاده کرد. یو ژئوسونگ و همکاران ([ ۱۲ ]، ۲۰۱۸) شبکه را از طریق دادههای بررسی رسانههای اجتماعی ساخت و جوامع نقاط سرد و گرم را از طریق الگوریتم استخراج جامعه وزندار جغرافیایی مورد مطالعه قرار داد. گونگ و همکاران ([ ۱۳ ]، ۲۰۲۰) از چارچوب دو لایه خوشه بندی مکانی-زمانی استفاده کرد. برای استخراج الگوهای فعالیت داده های مسیر تاکسی از احتمال بیزی و شبیه سازی مونت کارلو استفاده شد. لیانگ ژولینگ و همکاران ([ ۱۴]، ۲۰۲۱) مناطق داغ سفر کاربران شهری را از طریق الگوریتم استخراج منطقه داغ، که مبتنی بر خوشهبندی طیفی بهبودیافته است، شناسایی کرد. وانگ یان و همکاران ([ ۱۵ ]، ۲۰۲۱) از روش خوشهبندی طیفی برای خوشهبندی سریع دادههای مسیر ترافیک وسایل نقلیه الکتریکی استفاده کرد و به طور منطقی ایستگاه شارژ شهری را برای به حداقل رساندن هزینه اقتصادی سالانه آن برنامهریزی کرد. گو نایکون و همکاران ([ ۱۶ ]، ۲۰۲۱) از الگوریتم خوشهبندی DBSCAN برای خوشهبندی دادههای مسیر کشتی در زمان و مکان استفاده کرد تا پایهای برای پیشبینی بعدی الگوهای رفتاری کشتی ایجاد کند.
با این حال، مطالعاتی مانند آنچه در بالا توضیح داده شد معمولاً برای مجموعه دادههایی با محدودیت مجاورت فضا-زمان طراحی میشوند. به طور خاص، پارامترهای آستانه فاصله فضایی مورد استفاده در روشهای خوشهبندی محدود هستند و نمیتوانند خیلی بزرگ باشند، که باعث میشود مناطق گرم/سرد کشفشده معمولاً در فضا بسته شوند. در سوابق ارتباطی انسانی، فاصله بین دو منطقه فضایی که به صورت تعاملی توسط یک رکورد تلفن به هم متصل شده اند ممکن است بسیار زیاد باشد. به عبارت دیگر، مناطق فضایی دور از هم ممکن است یک نقطه گرم یا سرد را تشکیل دهند که با روشهای تشخیص موجود نمیتوان آنها را کشف کرد.
بنابراین، نویسندگان یک روش تشخیص نقطه گرم/سرد فضایی را برای سوابق ارتباط انسانی با همبستگی خودکار مقادیر PageRank ([ ۱۷ ] Zhu، ۲۰۲۱) شبکههای تعامل فضایی ساختهشده از سوابق پیشنهاد میکنند. بقیه مقاله به صورت زیر مرتب شده است ([ ۱۸ ] Chen et al., 2020): منطقه مورد مطالعه و داده ها در بخش ۲ توضیح داده شده است. بخش ۳ روش پیشنهادی را شرح می دهد. بخش ۴ نتایج و بحث ها را ارائه می کند. در نهایت، نتیجه گیری در بخش ۵ ارائه شده است.
۲٫ منطقه مطالعه و داده ها
۲٫۱٫ منطقه مطالعه
این مطالعه در میلان انجام شد که دومین شهر بزرگ ایتالیا و یک کلان شهر بین المللی در جهان است. این شهر در شمال ایتالیا در دشت لمباردی (پایتخت منطقه لمباردی و شهر میلان) با جمعیت دائمی حدود ۱٫۴۷ میلیون نفر و مساحتی در حدود ۱۸۱ کیلومتر مربع واقع شده است. تولید ناخالص داخلی منطقه شهری میلان ۴٫۸ درصد از تولید ناخالص داخلی ایتالیا را تشکیل می دهد. علاوه بر این، این شهر پرجمعیت ترین و توسعه یافته ترین منطقه در اروپا است. شکل ۱ جغرافیای منطقه مورد مطالعه را نشان می دهد. نویسندگان از دو نوع مجموعه داده تجربی استفاده کردند: مجموعه داده تلفن و مجموعه داده ویژگی های جغرافیایی مرتبط.
۲٫۲٫ مجموعه داده تلفن
مجموعه داده تلفن توسط اولین نسخه چالش بزرگ داده ارائه شده است که توسط Telecom Italia راه اندازی شد ( https://dandelion.eu/datamine/open-big-data/ ، ۱۸ نوامبر ۲۰۱۹). مجموعه دادههای آزمایشی تلفن در طول یک هفته (۱ تا ۷ نوامبر ۲۰۰۷) جمعآوری شد و از نظر فضایی در یک مجموعه فضایی غیر همپوشانی با ۱۰۰۰۰ شبکه، هر شبکه با ابعاد ۲۳۵ متر در ۲۳۵ متر جمعآوری شد. نقشه همپوشانی بین شبکه ها و منطقه مورد مطالعه در شکل ۲ نشان داده شده است .
علاوه بر این، مجموعه داده های تلفن در یک دوره ۱۰ دقیقه ای جمع آوری شدند. در نهایت، از طریق تجمع مکانی و تجمع زمانی مجموعه دادههای تلفن، تعامل مکانی را میتوان در عرض ۱۰ دقیقه برای هر جفت شبکه فضایی به دست آورد. جدول ۱ نمونه هایی از داده های تعاملی فضایی را نشان می دهد.
در جدول، Square Id1 و Square Id2 به ترتیب شناسه های شبکه منبع تعاملی و شبکه هدف هستند. برای بازههای زمانی، زمان شروع بازه به صورت تعداد میلیثانیههایی بیان میشود که از دوره یونیکس UTC در ۱ ژانویه ۱۹۷۰ گذشته است، و پایان بازه را میتوان با افزودن ۶۰۰۰۰۰ میلیثانیه (۱۰ دقیقه) به آن به دست آورد. ارزش. قدرت برهمکنش جهتی نشان دهنده قدرت برهمکنش جهتی بین Square Id1 و Square Id2 است. این مقدار متناسب با تعداد تماس های رد و بدل شده بین تماس گیرندگان در مربع Id1 و گیرندگان در Square Id2 است.. به طور کلی، مجموعه داده تلفن در ۶۴۰۴۴۸۷۲۹۷ رکورد تعامل فضایی بین ۱۰۰۰۰ شبکه جمع شد.
۲٫۳٫ مجموعه داده ویژگی های جغرافیایی
مجموعه داده ویژگی های جغرافیایی مورد استفاده در این مطالعه عمدتاً شامل مجموعه داده کاربری زمین و مجموعه داده نقطه مورد علاقه (POI) است ([ ۱۹ ] وو و همکاران، ۲۰۱۸؛ [ ۲۰ ] لی و همکاران، ۲۰۱۹). مجموعه داده استفاده از زمین توسط ماهواره های رصد زمین جمع آوری شد و با مشاهدات شبکه حسگر سطح زمین در سال ۲۰۱۲ ترکیب شد. کوپرنیک یک برنامه اروپایی برای نظارت بر زمین است ( https://land.copernicus.eu/local/urban-atlas/ urban-atlas-2012?tab=download , ۱۲ ژانویه ۲۰۲۱). مجموعه داده کاربری زمین شامل ۲۱ نوع کاربری زمین است که در شکل ۳ نشان داده شده است .
مجموعه داده نقطه مورد علاقه (POI) از OSM مشتق شده است ( https://github.com/openstreetmap ، ۱۲ ژانویه ۲۰۲۱). می توان آن را به هشت دسته تقسیم کرد: خدمات حمل و نقل ، اوقات فراغت ، کسب و کار ، خدمات عمومی ، پذیرایی و اقامت ، ارگان های مهمانی و دولتی ، گشت و گذار و خرید . نقشه همپوشانی بین مجموعه داده POI و شبکه ها در شکل ۴ نشان داده شده است .
۳٫ روش تحقیق
روش پیشنهادی شامل چهار مرحله است: ما از مجموعه داده تلفنی تجمیع شده برای ساخت یک شبکه تعامل فضایی استفاده کردیم و سپس مقدار PageRank هر گره از شبکه تعامل فضایی ساخته شده را محاسبه کردیم. ثانیاً، ما تشخیص نقطه گرم/سرد را با مقدار PageRank گرههای همبسته خودکار انجام دادیم. و در نهایت ما روی نقشه های سرد و گرم شناسایی شده با مجموعه ویژگی زمین و مجموعه داده POI، همپوشانی و تحلیل آماری را انجام دادیم.
۳٫۱٫ ساخت شبکه تعامل فضایی
شبکه تعامل فضایی از سوابق تعامل فضایی، که از مجموعه داده تلفن جمع آوری شده است، ساخته شده است. گره های شبکه نشان دهنده شبکه ها هستند و لبه ها جریان های فراخوانی بین جفت شبکه ها را رمزگذاری می کنند. لبه جهت و وزن دارد و وزن یال متناسب با قدرت اندرکنش جهتی بین گره مربوط به شبکه مبدا و گره مربوط به شبکه مقصد است. علاوه بر این، لبه های حلقه از مکان ها به خودشان نیز در نظر گرفته می شوند. این فرآیند شامل دو تعریف اساسی است.
تعریف ۱٫
با توجه به تسلط فضایی غیر همپوشانی G r i ds = {g1،g2،g3, … ,gn}، جایی که gمن, ۱ ≤ i ≤ nنشان دهنده یک شبکه است، یک رکورد تعامل فضایی به صورت تعریف شده است اسمن= ( یا من _ گ _من d _، دe s _ gمن d _, i n t e r v a l , i n t e n s i t y ); o r i _ gمن d _، دe s _ gمن d _∈ G r i dسنشان دهنده شبکه مبدا و شبکه مقصد تعامل فضایی است، i n t e r v a lنشان دهنده فاصله زمانی تجمع مجموعه داده تلفن بین دو شبکه است و شدتقدرت برهمکنش جهتی بین دو شبکه را نشان می دهد.
تعریف ۲٫
با توجه به مجموعه ای از رکوردهای تعامل فضایی اسمنs = { sمن۱، سمن۲، سمن۳, … , sمنn}و یک تسلیت فضایی غیر همپوشانی G r i ds = {g1،g2،g3, … ,gمتر}، اسمنن= { V، ای}به عنوان یک شبکه تعامل فضایی تعریف می شود که در آن V= {v1،v2, … ,vس} ،vمن⋅ گرممن d _∈ G r i ds , ۱ ≤ i ≤ s; یعنی برای هر گره vمن∈ V، یک شبکه مربوطه وجود دارد vمن⋅ گرممن d _∈ G r i dس; E= {ه۱،ه۲, … ,هتی} ,۱≤j≤ ( m ∗ ( m − ۱ ) ) ، و شرط برای هر لبه جهت دار برآورده می شود e = {vo،vپ} ∈E، یک رکورد تعامل فضایی وجود دارد s i ∈ Sمنس، s i ⋅ یا r i gمن d _=vo⋅ گرممن d _و s i ⋅ de s gمن d _=vپ⋅ گرممن d _.
به عنوان مثال، در شکل ۵ ، ۱۱ رکورد تعامل فضایی در یک مجموعه فضایی غیر همپوشانی با ۷ شبکه وجود دارد. شبکه تعامل فضایی استخراج شده مربوطه در شکل ۶ نشان داده شده است .
۳٫۲٫ محاسبه مقدار PageRank
مقدار PageRank برای ارزیابی اهمیت رتبه بندی بین صفحات وب ایجاد شده است. به طور خاص، اهمیت یک صفحه با تعداد صفحات پیوند داده شده به آن مشخص می شود. صفحه ای با لینک های بیشتر از اهمیت بالاتری برخوردار خواهد بود، یعنی ارزش پیج رنک بالاتری دارد. در این مطالعه، ما از مقادیر PageRank گرهها در شبکه تعامل فضایی برای به دست آوردن تعامل بین مناطق با فاصله فضایی زیاد استفاده کردیم. برخلاف ویژگیهای شبکه ساده، مانند درجه و درجه، مقدار PageRank میتواند تعامل بین مناطق با فاصله فضایی زیاد را منعکس کند زیرا این مقدار رابطه اتصال چند سطحی گرههای شبکه را ثبت میکند. با توجه به یک شبکه تعامل فضایی SIN = { V، ای}، فرمول محاسبه مقدار PageRank برای گره vمن∈ V است:
جایی که مvمن مجموعه ای از گره های همسایه را نشان می دهد که مستقیماً به گره متصل هستند vمن; L (vj) مجموعه ای از گره های همسایه را نشان می دهد که مستقیماً از گره متصل هستند vj; پR (vj) مقدار PageRank گره را نشان می دهد vj; nتعداد کل گره های موجود در آن است V; و 𝛼 نشان دهنده ضریب میرایی است که به طور کلی ۰٫۸۵ در نظر گرفته می شود.
از آنجایی که رکوردهای داده های تعاملی فضایی تجربی (حدود ۶٫۴ میلیارد رکورد) بزرگ هستند، تولید شبکه فضایی و محاسبه مقدار PageRank را می توان تحت پلت فرم محاسباتی کلان داده، مانند پلت فرم جرقه ([ ۲۱ ] Zhang et al., 2020) پیاده سازی کرد. ). کد خاص به شرح زیر است:
۳٫۳٫ تشخیص نقاط گرم/سرد
ایده تشخیص نقطه گرم/سرد، همبستگی خودکار مقادیر PageRank گرههای شبکه تعامل فضایی ساخته شده از سوابق است. این فرآیند شامل تعریف به شرح زیر است.
تعریف ۳٫
با توجه به یک شبکه تعامل فضایی اسمنن= { V، ای}، V= {v1،v2, … ,vn} ،و مجموعه مقادیر PageRank از V پیک گرمe R a n k s = { PR (v1) ،پR (v2) ،…،پR (vn) }، مقدار گرم/سرد گره zمنمحاسبه می شود جی∗ آماری ([ ۲۲ ] وانگ و همکاران، ۲۰۱۸؛ [ ۲۳ ] فنگ و همکاران، ۲۰۱۸). فرمول این است:
جایی که پR (vمن)مقدار PageRank گره را نشان می دهد vمن; ایکس¯= ∑nk = ۱پR (vک)nکه نشان دهنده میانگین مقادیر PageRank در است پیک گرمe R a n k s; اس۲=۱n∑ni = ۱( صR (vمن) –ایکس¯)۲نشان دهنده واریانس مقادیر PageRank در است پیک گرمe R a n k s; متر نشان دهنده تعداد گره های همسایه است که مستقیماً از گره متصل شده اند vمن; پR (vj)مقدار PageRank گره همسایه را نشان می دهد vj; و wمن ، جوزن فضایی بین گره را نشان می دهد vمنو گره مجاور آن vj.
اگر zمن< ۰، شبکه مربوط به گره vمنیک منطقه سردسیر را تعیین می کند. اگر zمن> ۰، شبکه مربوط به گره vمنیک منطقه نقطه داغ را قرار می دهد. علاوه بر این، اگر zمن= ۰، مقدار PageRank گره vمنیک مقدار تصادفی است و شبکه مربوط به گره است vمننه یک نقطه سرد است و نه یک نقطه گرم.
به طور معمول، نقاط گرم / سرد معمولا به سه دسته با توجه به سطح اطمینان تقسیم می شوند zمن[ ۲۴ ] ژو، ۲۰۱۹). سطح (+۳، -۳)، (+۲، -۲)، و (+۱، -۱) نقاط گرم و نقاط سرد را به ترتیب با اطمینان ۹۹٪، ۹۵٪، ۹۰٪ نشان می دهد [ ۲۵ ] Wen. ، ۲۰۱۸).
در نهایت، نویسندگان می توانند مجموعه ای از نقاط گرم/سرد را به دست آورند سیاچ= {ج۱،ج۲, … ,جn}، جمن= { (z1، گهo1) ، (z2، گهo2) ,…, (zn، گهon) }،۱≤i≤n،جایی که gهonبه عنوان محل شبکه که در آن گره تعریف می شود vمنواقع شده است. شکل ۷ نمونه ای از تقسیم نقاط گرم/سرد را نشان می دهد که در آن سیاچ= {ج۱،ج۲،ج۳،ج۴،ج۵،ج۶،ج۷} ، ج۱= ( – ۳ ، gهo1) ، ج۲= ( – ۲ ، gهo2) ، ج۳= ( – ۱ ، gهo3) ، ج۴= ( ۰ ، gهo4) ، ج۵= ( ۱ ، gهo5) ، ج۶= ( ۲ ، gهo6) ، ج۷= ( ۳ , gهo7).
۳٫۴٫ پوشش نقشه و تجزیه و تحلیل آماری
از طریق همپوشانی نقشه و تجزیه و تحلیل آماری، می توانیم تصمیم بگیریم که آیا تقسیم نقاط سرد و گرم معقول است یا خیر. به طور خاص، مناطق گرم و سرد باید دارای انواع کاملاً متفاوت از اشیاء و مشخصات توزیع آماری باشند. داده های نوع زمین و داده های POI دو نوع داده ویژگی معمولی هستند که ارتباط نزدیکی با فعالیت های انسانی دارند. بنابراین، در این مطالعه، این دو نوع داده عناصر جغرافیایی و شبکه فضایی را برای همپوشانی و تحلیل داده ها انتخاب می کنیم.
همپوشانی نقشه و تجزیه و تحلیل آماری داده های مکانی یک تابع اساسی از GIS است. با توجه به نوع هندسی داده های مکانی، روش های پیاده سازی متفاوتی وجود خواهد داشت. در این مقاله، نویسندگان از دو تابع چند ضلعی و نقاط برای همپوشانی استفاده کردند. به طور خاص، نویسندگان از عملیات همپوشانی چند ضلعی برای تجزیه و تحلیل نوع و کمیت مجموعه داده کاربری زمین که با شبکههای نقاط گرم/سرد تلاقی میکنند، استفاده میکنند و نوع و تعداد مجموعه دادههای POI موجود در شبکههای مربوط به گرم/گرم را محاسبه میکنند. نقاط سرد با استفاده از عملیات نقطه ای در یک چند ضلعی. این فرآیند شامل چهار تعریف اساسی است.
تعریف ۴٫
برای مجموعه ای از انواع کاربری زمین L a n dتیyp e s = { lتی۱، لتی۲، لتی۳، … ، لتیn}، G D = { gد۰، گد۱، گد۲, … , gدn}به عنوان یک مجموعه داده کاربری زمین تعریف می شود که در آن gدمن= ( گرمهoمن، یک تیتیمن) ،۰≤i≤nبه عنوان تعریف شده است منعنصر ام در مجموعه داده جغرافیایی، gهoمننشان دهنده منطقه ای است که در آن قطعه زمین است gدمن واقع شده است، و یک تیتیمننشان دهنده نوع کاربری زمین قطعه زمین است gدمن. برای مثال، شکل ۸ شامل پنج نوع کاربری زمین است: a r a b l e l a n d , r o a ds ، gr e n u r b a n a r e a s ، u r b a n f _ a b r i c ، i n dتو s t r i a lو مجموعه داده کاربری زمین G D = { gد۰، گد۱، گد۲، گد۳، گد۴، گد۵، گد۶}، جایی که، gد۰= ( گرمهo0, a r a b l e l a n d ) ،gد۱= ( گرمهo1، گr e e n u r b a n a r e a s ) ،gد۲= ( گرمهo2، من n du s t r i a l ) ،gد۳= ( گرمهo3, r o a ds ) ،gد۴= ( گرمهo4, r o a ds ) ،gد۵= ( گرمهo5, u r b a n f r a b i c ) ،and gد۶= ( گرمهo6, a r a b l e l a n d ).
تعریف ۵٫
با توجه به مجموعه داده کاربری G D = { gد۱، گد۲, … , gدn}و مجموعه ای از نقاط گرم/سرد سیاچ= {ج۱،ج۲, … ,جمتر}، جایی که جمن= { (z1، گهo1) ، (z2، گهo2) ,…, (zس، گهoتی) }،۱≤i≤m، عملیات همپوشانی بین سیاچو جی دیرا می توان به صورت زیر تعریف کرد: سیاچجی دی= { oل۱، oل۲، oل۳, … , oلمتر}، جایی که oلمن= {جمن, p o l ygo n _ o v e r l a y(جمن⋅ گرمe o ، gد۱. ge o ) ،polygo n _ o v e r l a y(جمن⋅ گرممن d _، گد۲. ge o ) ,…,polygo n _ o v e r l a y( c ⋅ ge o ، gدn. ge o ) }،۱≤i≤m. اگر رابطه توپولوژیکی متقاطع برآورده شود، پی و یا _go n _ o v e r l a yتابع ناحیه ای را که در آن قرار دارد برمی گرداند جمن⋅ گرمe o ⋅قطع می کند gدj. ge o ، ۱ ≤ j ≤ nو نوع کاربری زمین gدj. l t.
برای نقاط گرم/سرد در شکل ۷ ، آنها با مجموعه داده کاربری زمین در شکل ۸ همپوشانی دارند و نتیجه همپوشانی نقشه در شکل ۹ نشان داده شده است ، جایی که سیاچجی دی=⎧⎩⎨⎪⎪( ( – ۳ ، gهo0) ،arablelanد ) , ( ( – ۲ , gهo1) ،gr e n u r b a n a r e a s ) ، _( ( – ۳ ، gهo2) ،indu s t r i a l , ( ( ۰ , g _هo3) ،roads ) , ( ( ۳ , gهo4) ،roadس )( ( ۲ , gهo5) ،urbanf r a b i c , ( ۱ , g _ _هo6) ،arablelanد )⎫⎭⎬⎪⎪.
تعریف ۶٫
برای مجموعه ای از انواع POI پای منتیyp e s = { pتی۱، صتی۲، صتی۳، … ، صتیn}، پای مندa t a = { pد۱، صد۲، صد۳، … ، صدمتر}به عنوان یک مجموعه داده POI تعریف می شود که در آن پدمن= ( گرمe o , p t ) ,۰≤i≤m,pt∈Pای منتیyp e sنشان دهنده یک POI، و ge oنشان دهنده موقعیتی است که POI در آن قرار دارد.
به عنوان مثال، مجموعه داده POI در شکل ۹ را در نظر بگیرید که شامل هفت نوع POI است: خرید , تفریح , گشت و گذار , پذیرایی , کسب و کار , اقامت , خدمات عمومی . مجموعه داده POI مربوطه عبارتند از: پOمندa t a = { pد۰، صد۱، صد۲، صد۳، صد۴، ، صد۵، صد۶}، جایی که پد۰= { ( گرمهo0، c a t e r i n g) } ، صد۱= { ( گرمهo1c a t e r i n g) ، ( گهo1, p u b l i c s e r v i c e ) },pد۲= { ( gهo2، s i gh t s e e i n g) ، ( گهo2, a c c o m m od a t i o n ) },pد۳={ ( gهo3, r e c a t i o n ) , ( gهo3, a c o m m o d _یک نفر ) ، ( _ _ _ gهo3, بی تو ) , ( _ _ _ _ _ _ gهo3، s h o p p i n g) } ، صد۴= { ( gهo4, a c o m m _ od یک نفر ) ، ( _ _ _ gهo4، s h o p p i n g) }،صد۵= { ( گرمهo5، c a t e r i n g ) } ،صد۶= {( gهo6، c a t e r in g) ، ( گهo6، s h o p p i n g) }.
تعریف ۷٫
با توجه به مجموعه داده POI پOمنD a t a = { pد۱، صد۲، صد۳، … ، صدn}و مجموعه ای از نقاط گرم/سرد سیاچ= {ج۱،ج۲, … ,جمتر} ، جایی که جمن= { (z1، گهo1) ، (z2، گهo2) ,…, (zس، گهoتی) }،۱≤i≤m،همپوشانی نقشه بین سیاچو پOمنD a t aرا می توان به عنوان تعریف کرد سیاچپای من= { oل۱، oل۲, … , oلمتر}، جایی که oلمن= {جمن, p o i n t _ i n _ p o l ygo n (جمن⋅ge o ، pد۱.ge o ) ،point_in_pol ygo n (جمن⋅گرمe o ، pد۲.ge o ) ,…,point_in_pol ygo n (جمن⋅ گرمe o ، pدn. ge o ) }،۱≤i≤m. اگر نقطه در رابطه توپولوژیکی چند ضلعی ارضا شود، p o i n t _ i n _ p o l ygo nتابع نوع POI را برمی گرداند پدj. l t , ۱ ≤ j ≤ n.
برای طبقه بندی نقاط گرم/سرد در شکل ۷ ، آنها با مجموعه داده POI در شکل ۱۰ همپوشانی دارند و نتیجه همپوشانی نقشه به صورت شکل ۱۱ نشان داده شده است .سیاچپای من است
۴٫ آزمایش ها و بحث ها
رکوردهای تعامل فضایی آزمایشی از ۱ تا ۷ نوامبر ۲۰۱۳ جمعآوری شد و یک شبکه تجمیع شامل ۱۰۰۰۰ گره و ۱۱۶۹۴۷۵۴۰۲ یال ساخته شد. برای هر گره در شبکه، نویسندگان از الگوریتم ۱ برای محاسبه مقدار PageRank آن استفاده کردند. بر اساس شبکه های مربوط به گره ها، نقشه موضوعی گره ها، مقادیر PageRank به دست آمد، همانطور که در شکل ۱۲ نشان داده شده است.
| الگوریتم ۱ NetworkGen_PageRank ( SIFile ، ref Graph) |
| ورودی: SIFile فایل رکوردهای تعامل فضایی را نشان می دهد. |
| خروجی: نمودار نشان دهنده شبکه تعامل فضایی ایجاد شده است. |
| (۱) val phonedata = sc.textFile (مسیر + داده رکورد) |
| (۲) val edges:RDD[Edge[Int]] = نقشه داده تلفن { |
| خط ≥ |
| ردیف val = تقسیم خط “\t” |
| Edge(row(1).toInt، row(2).toInt,1) |
| } |
| (۳) val egograph: Graph[Int,Int] = Graph.fromEdges(Edges,1) |
| (۴) val uniqueInputGraph = egograph.groupEdges((e1, e2) ⇒ e1 + e2) |
| (۵) val ranks = uniqueInputGraph.pageRank(0.1). رگه ها |
خط ۱ داده های تلفنی ارتباطی را می خواند. خطوط ۲-۳ به طور مقدماتی برای به دست آوردن egograph شبکه خام تشکیل شده است. ایگوگراف خط ۴ لبه های مشابه گره شبکه خروجی و گره شبکه دسترسی را در تمام رکوردهای داده ترکیب می کند و وزن ها را برای به دست آوردن شبکه ساخته شده منحصر به فرد InputGraph اضافه می کند. خط ۵ مقادیر PageRank همه گره ها را بدست می آورد.
همانطور که از شکل ۱۲ مشاهده می شود ، عمدتاً سه رنگ در یک منطقه بزرگ توزیع شده اند: سبز، زرد و صورتی. رنگ سبز مقدار PageRank پایین را نشان میدهد که نشاندهنده ناحیه تعامل دادههای ارتباطی در فاصله نزدیک است. در مقابل، صورتی نشاندهنده مقدار PageRank بالا است که نشاندهنده منطقه تعامل داده ارتباطی از راه دور است. در همین حال، ناحیه زرد بین سبز و صورتی است.
علاوه بر این، نویسندگان از روش تشخیص پیشنهادی در این مقاله برای تشخیص نقاط گرم/سرد استفاده کردند و توزیع فضایی نقاط گرم/سرد در شکل ۱۳ نشان داده شده است . از شکل ۱۳ می توان دید که مناطق گرم/سرد شناسایی شده به وضوح با توزیع فضایی آنها متمایز می شوند. به طور خاص، نقاط گرم عمدتا در جنوب غربی پراکنده هستند، در حالی که نقاط سرد به طور گسترده پراکنده هستند. علاوه بر این، برخی از شبکهها با فاصله فضایی طولانی (یعنی مناطق صورتی که با دو دایره بنفش در شکل ۱۲ مشخص شدهاند.) نیز در همان سطح از نقاط داغ (یعنی مناطق مشخص شده توسط دو دایره سبز) دسته بندی می شوند. سهم اصلی روش پیشنهادی یافتن نواحی دارای برهمکنش دوردست و سپس استفاده از روش خوشهبندی برای خوشهبندی مناطق دارای تعامل دوردست به نقاط سرد و گرم در یک سطح است. سپس، نویسندگان استدلال کردند که این نتایج می تواند اثربخشی روش پیشنهادی را اثبات کند.
- (۱)
-
مقایسه توزیع فضایی مجموعه داده های ویژگی های جغرافیایی حاوی نقاط گرم / سرد شناسایی شده است.
نویسندگان از همپوشانی نقشه و روش آماری پیشنهادی در این مقاله استفاده کردند تا بررسی کنند که آیا نقاط گرم/سرد شناسایی شده با وضعیت واقعی منطقه مورد مطالعه مطابقت دارند یا خیر.
نویسندگان از پوشش نقشه برای شناسایی نقاط گرم/سرد با مجموعه داده تجربی کاربری زمین و مجموعه داده POI استفاده کردند و نتایج در شکل ۱۴ و شکل ۱۵ نشان داده شده است. نویسندگان از طریق تفسیر بصری، همانطور که در شکل ۱۴ نشان داده شده است، دریافتند که مناطق داغ شامل دو نوع کاربری اصلی زمین، یعنی زمین زراعی (محصولات سالانه) و جاده های دیگر است ، در حالی که مناطق سردسیر عمدتاً شامل زمین های زراعی هستند. (محصولات یکساله). علاوه بر این، همانطور که در شکل ۱۵ نشان داده شده استنویسندگان دریافتند که مناطق داغ حاوی انواع و مقادیر کمی از POI، به عنوان مثال، پذیرایی، اقامت و امکانات حمل و نقل هستند، در حالی که مناطق سرد حاوی انواع و مقادیر بیشتری از POI هستند. نتایج تجربی با وضعیت واقعی منطقه مورد مطالعه مطابقت دارد، یعنی میلان به عنوان شهری که بر توسعه حمل و نقل تمرکز دارد، دارای یک شبکه حمل و نقل بین شهری در مقیاس بزرگ است. بنابراین، مناطق داغ عمدتاً شامل سایر راهها و امکانات حملونقل هستند و هم زمینهای صنعتی و هم مناطق شهری با تراکم جمعیت بالا به حملونقل متکی هستند. بنابراین، POI ها در نزدیکی خطوط حمل و نقل پراکنده هستند.
با این حال، رابطه از طریق تجزیه و تحلیل تجسم فضایی بین مناطق گرم/سرد و ویژگیهای جغرافیایی بهدستآمده به اندازه کافی دقیق نبود، بنابراین نویسندگان بیشتر یک تحلیل آماری کمی انجام دادند. تجزیه و تحلیل آماری کمی شامل دو مقایسه بود: مقایسه توزیع کمی و مقایسه توزیع نسبت.
- (۲)
-
مقایسه توزیع کمی مجموعه دادههای ویژگیهای جغرافیایی حاوی نقاط گرم/سرد شناساییشده.
نویسندگان مقایسه توزیع کمی مجموعه داده استفاده از زمین حاوی نقاط گرم/سرد شناسایی شده از شبکه تعامل فضایی ساخته شده از سوابق تلفن در شهر میلان را انجام دادند. نتیجه در شکل ۱۶ نشان داده شده است .
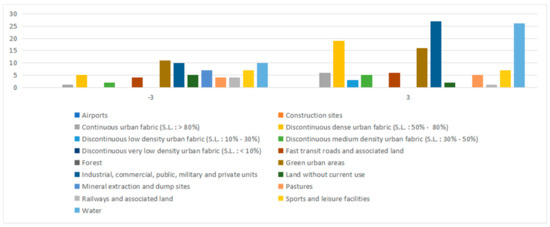
همانطور که از شکل ۱۶ مشاهده می شود ، چه یک نقطه سرد باشد و چه یک نقطه گرم، دو نوع داده کاربری زمین، زمین زراعی (محصولات سالانه) و سایر جاده ها و زمین های مرتبط ، دارای تعداد شبکه بزرگی هستند. دلیل آن این است که بخش جنوبی شهر میلان بر توسعه کشاورزی و سیستم های حمل و نقل تمرکز دارد. سپس، برای تحلیل دقیقتر، نویسندگان این دو نوع مجموعه داده کاربری زمین را حذف کردند و تنها انواع دیگر مجموعه دادههای کاربری زمین را در سردترین/گرمترین مناطق مقایسه کردند. نتایج در شکل ۱۷ نشان داده شده است.
نویسندگان می توانند از شکل ۱۷ ببینند که انواع بیشتری از مجموعه داده های کاربری زمین در مناطق سردسیر نسبت به مناطق داغ وجود دارد، اما در مناطق داغ، تعداد شبکه ای از مجموعه داده های کاربری زمین (به عنوان مثال، بافت شهری متراکم ناپیوسته (SL: 50-80%) ؛ واحدهای صنعتی ، تجاری ، عمومی ، نظامی و خصوصی ، مناطق سبز شهری ، آب ) به طور قابل توجهی بیشتر از تعداد شبکه در مناطق سردسیر است. علاوه بر این، نویسندگان مقایسه توزیع کمی مجموعه داده POI موجود در نقاط گرم/سرد شناسایی شده را انجام دادند و نتیجه در شکل ۱۸ نشان داده شده است.. از شکل ۱۸ می توان دریافت که انواع و تعداد مجموعه داده POI در نقاط داغ به طور قابل توجهی بیشتر از نقاط سرد است. بنابراین، نتایج تجربی با وضعیت واقعی سازگار است. در مقایسه با مناطق سردسیر، مناطق گرم به دلیل فعالیت های انسانی فشرده به خدمات زیرساخت بیشتری نیاز دارند. یعنی داده های کاربری زمین و داده های POI بیشتری باید گنجانده شود.
استفاده از تعداد شبکه ها برای ارائه نتایج واضح تر خواهد بود، اما اگر تعداد شبکه ها در هر دسته متفاوت باشد، برای مقایسه تعداد مناسب نیست، بنابراین از نسبت برای ارائه نتایج استفاده می کنیم.
- (۳)
-
مقایسه توزیع نسبت دادههای ویژگیهای جغرافیایی حاوی نقاط گرم/سرد شناساییشده.
از آنجایی که تعداد ویژگیهای جغرافیایی موجود به مساحت مناطق گرم/سرد بستگی دارد، نویسندگان بیشتر آزمایش کردند تا نسبتهای انواع ویژگیهای جغرافیایی موجود در مناطق گرم/سرد را مقایسه کنند. آنتروپی نسبی، همچنین به عنوان واگرایی Kullback Leibler یا واگرایی اطلاعات شناخته می شود، یک اندازه گیری نامتقارن از تفاوت بین دو توزیع احتمال است. در نظریه اطلاعات، آنتروپی نسبی معادل تفاوت آنتروپی اطلاعات دو توزیع احتمال است. برای بیان واضح تفاوت بین نقاط گرم و سرد، این مطالعه از روش آنتروپی نسبی استفاده می کند. فرمول خاص به شرح زیر است:
مقایسه نسبت مجموعه داده استفاده از زمین حاوی نقاط گرم/سرد شناسایی شده در شکل ۱۹ نشان داده شده است .
نویسندگان مقادیر آنتروپی نسبی را بین -۳ و ۳، -۲ و ۲، -۱ و ۱ محاسبه کردند و نتایج به ترتیب ۱٫۰۱۹، ۱٫۰۳۵ و ۱٫۰۳۳ است. این مقادیر نشان می دهد که مقادیر نسبت مجموعه داده استفاده از زمین موجود در نقاط گرم و نقاط سرد کمی متفاوت است. دلیل آن این است که مقادیر نسبت زمین های زراعی (محصولات سالانه) و سایر جاده ها و زمین های مرتبط بسیار بیشتر از ارزش های دیگر است. بنابراین، برای اطمینان از اثربخشی تجزیه و تحلیل داده ها، نویسندگان این دو نوع مقدار را حذف کردند و نتایج در شکل ۲۰ نشان داده شده است.
همانطور که در شکل ۲۰ مشاهده می شود ، واحدهای صنعتی ، تجاری ، عمومی ، نظامی و خصوصی نسبت بیشتری از سطوح مختلف نقاط سرد و گرم را به خود اختصاص می دهند و این نسبت در مناطق گرم از مناطق سرد بزرگتر است. منطقه نقطه ای مقادیر آنتروپی نسبی بین -۳ و ۳، -۲ و ۲، -۱ و ۱ به ترتیب ۰٫۵۹۵، ۰٫۶۰۹ و ۰٫۶۳۸ است، که بیشتر تأیید می کند که منطقه نوع زمین در منطقه سرد و منطقه گرم به طور قابل توجهی متفاوت است. .
به طور مشابه، نویسندگان بیشتر آزمایش کردند تا نسبت انواع مجموعه داده POI موجود در مناطق گرم/سرد را مقایسه کنند. نتایج در شکل ۲۱ نشان داده شده است. نویسندگان می توانند آن را برای دایرکتوری خرید و امور تجاری ببینندنسبت نقاط گرم به طور قابل توجهی بیشتر از نقاط سرد است، در حالی که برای اوقات فراغت، ورزش و خدمات عمومی برعکس است. آنتروپی نسبی به ترتیب ۰٫۹۵۹، ۰٫۹۲۵ و ۰٫۹۷۳ است. مشاهده می شود که در ناحیه توزیع POI تفاوت هایی بین منطقه سرد و منطقه گرم وجود دارد. نسبت توزیع POI در ناحیه نقطه سرد نسبتاً ثابت است، در حالی که نسبت توزیع POI در منطقه نقطه داغ تا حدی نوسان دارد. نسبت POI در ناحیه نقطه داغ نیز کمی بیشتر از ناحیه نقطه سرد است. بنابراین، نتایج تجربی با وضعیت واقعی مطابقت دارد که مردم عمدتاً در مناطق گرم به فعالیتهای صنعتی و تجاری مشغول هستند، در حالی که مردم در مناطق سردسیر عمدتاً به فعالیتهای تفریحی و سرگرمی مشغول هستند.
۵٫ نتیجه گیری ها
از آنجایی که روشهای موجود برای تشخیص نقطه گرم/سرد نمیتوانند مجموعه دادهها (به عنوان مثال، سوابق ارتباط انسانی) را که از تعاملات بین مناطق فضایی بزرگتر ایجاد میشوند، اعمال کنند، نویسندگان روش جدیدی را پیشنهاد کردند. این روش نقاط گرم/سرد فضایی را با همبستگی خودکار مقادیر PageRank شبکههای تعامل فضایی ساخته شده از سوابق شناسایی میکند. نویسندگان آزمایشهای گستردهای را برای تأیید روش پیشنهادی انجام دادند. نویسندگان میلان، ایتالیا را به عنوان منطقه مورد مطالعه، و سوابق تعامل فضایی منعکس شده توسط تماس های تلفنی، مجموعه داده کاربری زمین، و مجموعه داده POI را به عنوان مجموعه داده تجربی انتخاب کردند. نتایج تجربی موارد زیر را نشان می دهد. (۱) روش تشخیص نقطه گرم/سرد پیشنهادی میتواند برای دادههای ضبط تعاملی فضایی در فواصل طولانی اعمال شود. به طور مشخص، برخی از شبکهها با فاصله فضایی طولانی نیز در همان سطح از نقاط سرد یا نقاط گرم خوشهبندی شدند. (۲) مناطق گرم/سرد شناسایی شده به وضوح با توزیع آماری (یعنی توزیع فضایی، توزیع کمیت و توزیع نسبت) مجموعه داده استفاده از زمین و مجموعه داده POI متمایز می شوند. به طور خاص، از نظر توزیع فضایی: نقاط گرم عمدتا در جنوب غربی شهر میلان توزیع شده اند، در حالی که نقاط سرد به طور گسترده توزیع شده اند. علاوه بر این، از نظر توزیع کمی و توزیع نسبت: تعداد شبکه نقاط گرم بیشتر از تعداد شبکه نقاط سرد بود. (۳) این تفاوت های توزیع نقاط گرم/سرد مطابق با وضعیت واقعی منطقه مورد مطالعه، با توجه به تفسیر و تجزیه و تحلیل، به ویژه، تفاوت های توزیع آماری (یعنی، توزیع فضایی، توزیع کمیت و توزیع نسبت) مجموعه داده استفاده از زمین و مجموعه داده POI در نقاط گرم/سرد. به طور خلاصه، نتایج تجربی جامع صحت روش پیشنهادی ما را اثبات می کند.
مشارکت های نویسنده
مفهوم سازی: هایتائو ژانگ. سرپرستی داده ها: هایتائو ژانگ، هویکسیان شن. تحلیل رسمی: Haitao Zhang، Huixian Shen. جذب سرمایه: هایتائو ژانگ، کانگ جی. تحقیق: هایتائو ژانگ. روش: Haitao Zhang، Huixian Shen. مدیریت پروژه: هایتائو ژانگ. منابع: هایتائو ژانگ. نرم افزار: Kang Ji, Rui Song. نظارت: هایتائو ژانگ. اعتبار سنجی: Huixian Shen. تجسم: Haitao Zhang، Huixian Shen. نگارش-بررسی و ویرایش: Huixian Shen، Jinyuan Liu، Yuxin Yang. همه نویسندگان نسخه منتشر شده نسخه خطی را خوانده و با آن موافقت کرده اند.
منابع مالی
بورسیه دولتی جیانگ سو برای مطالعات خارج از کشور، بنیاد علوم طبیعی چین تحت شماره کمک مالی ۴۱۲۰۱۴۶۵ و بنیاد علوم طبیعی استان جیانگ سو با شماره کمک مالی BK2012439، BE2016774.
تضاد علاقه
نویسندگان هیچ تضاد منافع را اعلام نمی کنند.
منابع
- تیزونی، م. باجردی، پ. Decuyper، A. کن کام کینگ، جی. اشنایدر، سی ام. بلوندل، وی. اسموردا، ز. گونزالس، ام سی؛ Colizza, V. در مورد استفاده از پروکسی های تحرک انسانی برای مدل سازی اپیدمی ها. محاسبات PLoS. Biol. ۲۰۱۴ ، ۱۰ ، e1003716. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لیو، ی. کانگ، سی جی; وانگ، FH تحقیق در مورد مدل و مدل تحرک انسان مبتنی بر داده های بزرگ. Geomat. Inf. علمی دانشگاه ووهان ۲۰۱۴ ، ۳۹ ، ۶۶۰-۶۶۶٫ [ Google Scholar ]
- لی، تی. پی، تی. یوان، YC; آهنگ، سی. وانگ، وای؛ Yang, GG مروری بر طبقه بندی، الگوی و کاربرد مسیرهای فعالیت انسانی. Prog. Geogr. ۲۰۱۴ ، ۳۳ ، ۹۳۸-۹۴۸٫ [ Google Scholar ]
- هان، JW; کمبر، م. Pei, J. طبقه بندی: روش های پیشرفته. داده کاوی ، ویرایش سوم. سری مورگان کافمن در سیستم های مدیریت داده؛ مورگان کافمن: سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، ۲۰۱۲; صص ۳۹۳-۴۴۲٫ [ Google Scholar ]
- ژو، Q. کوین، ک. چن، YX; Li، ZQ تاکسی روش تشخیص نقطه داغ را بر اساس میدان داده ردیابی می کند. Geogr. Geo-Inf. علمی ۲۰۱۶ ، ۳۲ ، ۵۱-۵۶٫ [ Google Scholar ]
- جانکه، م. دینگ، ال. کرجا، ک. وانگ، اس. شناسایی نقاط کانونی مبدا/مقصد در دادههای شناور خودرو برای تحلیل بصری رفتار سفر. در حال پیشرفت در خدمات مبتنی بر مکان . Gartner, G., Huang, H., Eds. انتشارات بین المللی Springer: برلین، آلمان، ۲۰۱۶; صص ۲۵۳-۲۶۹٫ [ Google Scholar ]
- ژائو، پی ایکس؛ Qin، K. بله، XY; Wang, YL یک رویکرد خوشهبندی مسیر مبتنی بر نمودار تصمیمگیری و میدان داده برای شناسایی نقاط داغ. بین المللی جی. جئوگر. Inf. علمی ۲۰۱۶ ، ۳۱ ، ۱۱۰۱-۱۱۲۷٫ [ Google Scholar ] [ CrossRef ]
- درلی، MA; اردوغان، اس. مدلی جدید برای تعیین نقاط سیاه تصادفات رانندگی با استفاده از روشهای آماری فضایی به کمک GIS. ترانسپ Res. بخش A سیاست سیاست. ۲۰۱۷ ، ۱۰۳ ، ۱۰۶-۱۱۷٫ [ Google Scholar ] [ CrossRef ]
- Xu، ZY; Xiong، Y. گائو، RG استخراج نقطه کانونی زمانی و مکانی دادههای بررسی میکروبلاگ – مطالعه موردی پکن. مهندس Surv. نقشه ۲۰۱۸ ، ۲۷ ، ۱۰-۱۶٫ [ Google Scholar ]
- Qin، K. وانگ، ی.ال. ژائو، پی ایکس؛ Xu، WT; Xu، YQ خوشه بندی فضایی و زمانی و تجزیه و تحلیل مسیرهای رفتار. چانه. جی. نات. ۲۰۱۸ ، ۴۰ ، ۱۷۷-۱۸۲٫ [ Google Scholar ]
- لی، YP; لیو، ZJ; Zheng، ZY تحقیق در مورد روش تجزیه و تحلیل خوشهبندی دادههای AIS کشتیبرد بر اساس چگالی مکانی-زمانی. J. Chongqing Jiaotong Univ. نات. علمی ۲۰۱۸ ، ۳۷ ، ۱۱۷-۱۲۲٫ [ Google Scholar ]
- یو، XS; جیا، تی. تجزیه و تحلیل رایگان و کانونی شبکههای فضایی و جوامع آنها بر اساس دادههای ورود به شبکههای اجتماعی. علم چین ۲۰۱۸ ، ۱۳ ، ۱۷۹۷-۱۸۰۴٫ [ Google Scholar ]
- گونگ، SH. کارتلیج، جی. بای، RB; Yue, Y. استخراج الگوهای فعالیت از داده های مسیر تاکسی: یک چارچوب دو لایه با استفاده از خوشه بندی فضایی-زمانی، احتمال بیزی و شبیه سازی مونت کارلو. بین المللی جی. جئوگر. Inf. علمی ۲۰۲۰ ، ۳۴ ، ۱۲۱۰-۱۲۳۴٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لیانگ، ZL; یوان، کالیفرنیا؛ Qin، X. هان، اس جی. روش استخراج منطقه داغ فن، YQ بر اساس خوشهبندی طیفی بهبودیافته. J. دانشگاه چونگ کینگ. تکنولوژی نات. علمی ۲۰۲۱ ، ۳۵ ، ۱۲۹-۱۳۷٫ [ Google Scholar ]
- وانگ، ی. وو، CS; Gao, S. بهینه سازی انتخاب سایت ایستگاه شارژ بر اساس خوشه بندی سریع داده های رانندگی خودروهای الکتریکی. Power DSM ۲۰۲۱ ، ۲۳ ، ۸-۱۲٫ [ Google Scholar ]
- گوا، NK; چن، ام جی. چن، R. الگوریتم خوشهبندی DBSCAN برای مسیر کشتی با در نظر گرفتن ویژگیهای زمانی. مهندس Surv. نقشه ۲۰۲۱ ، ۳۰ ، ۵۱-۵۸٫ [ Google Scholar ]
- زو، تحلیل WH گره های مهم در شبکه پیچیده بورس شانگهای ۵۰ مؤلفه بر اساس رتبه صفحه و الگوریتم لووین. جلو. اقتصاد مدیریت ۲۰۲۱ ، ۲ ، ۱۳۲-۱۳۹٫ [ Google Scholar ]
- چن، جی ال. ژو، ز. لی، ال. سلام.؛ ژان، پی. Zhao, SW طرحی طراحی بهینه سازی شبکه توزیع توان ASON بر اساس الگوریتم PageRank. محاسبه کنید. تکنولوژی خودکار ۲۰۲۰ ، ۳۹ ، ۱۲۴-۱۲۷٫ [ Google Scholar ]
- وو، سی. بله، XY; رن، اف. Du، QY رفتار ورود و شور و نشاط مکانی-زمانی: یک تحلیل اکتشافی در شنژن، چین. شهرها ۲۰۱۸ ، ۷۷ ، ۲۷–۶۵٫ [ Google Scholar ] [ CrossRef ]
- لی، جی جی; لی، جی دبلیو. یوان، YZ؛ لی، GF ویژگی های توزیع فضایی و زمانی و تجزیه و تحلیل مکانیسم تراکم جمعیت شهری: موردی از شیان، شانشی، چین. شهرها ۲۰۱۹ ، ۸۶ ، ۴۵–۶۷٫ [ Google Scholar ] [ CrossRef ]
- ژانگ، اچ تی. یو، سی جی; Yan, J. یک روش جدید برای طبقه بندی عملکرد مناطق فضایی بر اساس دو مجموعه از ویژگی های نشان داده شده توسط مسیرها. بین المللی J. Data Warehous. حداقل ۲۰۲۰ ، ۱۶ ، ۱-۱۹٫ [ Google Scholar ] [ CrossRef ]
- وانگ، WF; نیو، ال. لیو، ی. یو، YT; Ma، LB تحقیق در مورد روش خوشه بندی فضایی چند متغیره مصرف برق منطقه ای بر اساس آمار Getis-OrdGi*. Inner Monglia Electr. Power ۲۰۱۸ ، ۳۶ ، ۱۵-۲۰٫ [ Google Scholar ]
- فنگ، YJ; چن، XJ; گائو، اف. لیو، ی. تأثیرات تغییر مقیاس بر نقاط داغ Getis-Ord Gi* CPUE: مطالعه موردی ماهی مرکب پرنده نئونی ( Ommastrephes bartramii ) در شمال غربی اقیانوس آرام. Acta Oceanol. گناه ۲۰۱۸ ، ۳۷ ، ۶۷-۷۶٫ [ Google Scholar ] [ CrossRef ]
- Zhou، H. تحلیل همبستگی فضایی مرکزیت گره شبکه های جغرافیایی وزن دار جهت دار در میلان، ایتالیا. پایان نامه کارشناسی ارشد، دانشگاه پست و مخابرات نانجینگ، نانجینگ، چین، ۲۰۱۹، منتشر نشده است. [ Google Scholar ]
- دونگ، W. ویژگی های توزیع فضایی عفونت های انسانی A (H7N9) در چین بین سال های ۲۰۱۳ و ۲۰۱۴٫ Assoc. محاسبه کنید. ماخ ۲۰۱۸ ، ۵ ، ۲۳۸-۲۴۲٫ [ Google Scholar ]