
یک روش تشخیص شی سبک وزن در تصاویر هوایی بر اساس شبکه تجمع مسیر همجوشی متراکم
توسط

۱،۲ ،
،
۱،۲،
۱،۲،
۱،۲، *،
۱،۲و
۱،۲
چکیده
:
ماژول استفاده مجدد از ویژگی ; بلوک متراکم باقیمانده همجوشی ویژگی متراکم ; سنجش از دور
۱٫ مقدمه
-
تصاویر هوایی عموماً اندازه بزرگی دارند و به این نتیجه میرسند که اندازه اهداف نسبت به تصاویر کوچک است که به راحتی میتوان از دست رفته تشخیص داد.
-
RSI ها اغلب با دلایل خارجی، مانند سایه ها، نمونه های مشابه و پس زمینه های پیچیده تداخل دارند، که تشخیص قوانین بافت بین اشیا و اشیاء نادرست را دشوار می کند.
-
هنگامی که برخی از نمونهها در RSI کنار هم قرار میگیرند، Non-Maximum Suppression (NMS) جعبههای مرزی اشیاء مختلف را فیلتر میکند و در نتیجه تشخیص از دست رفته است.
-
این مقاله یک روش تشخیص شی برای تصاویر هوایی پیشنهاد میکند. این روش نه تنها سبک وزن است، بلکه می تواند کار تشخیص دقیق و کارآمد را در RSI انجام دهد.
-
به منظور تقویت توانایی مدل برای تشخیص اشیاء کوچک و متوسط، اطلاعات معنایی و مکان در نقشه های ویژگی توسط ماژول استفاده مجدد از ویژگی (FRM) ترکیب شده است، که می تواند اطلاعات ویژگی استخراج شده از ستون فقرات را غنی کند.
-
یک شبکه تجمیع مسیر ترکیبی متراکم (DFF-PANet) با استفاده از بلوک متراکم باقیمانده متقاطع (CSRDB) طراحی شده است تا مشکل تداخل خارجی ناشی از RSI های پیچیده و قابل تغییر را بهتر مدیریت کند.
-
این مطالعه از مجموعه دادههای DOTA و HRSC2016 برای آزمایشها استفاده میکند تا مدلی را که ما ارائه کردهایم تأیید کند و سپس اثرات هر بهبودی را که از طریق یک سری آزمایشهای مقایسهای و فرسایشی پیشنهاد کردهایم تجزیه و تحلیل میکند.
۲٫ آثار مرتبط
۲٫۱٫ الگوریتم های تشخیص اشیا
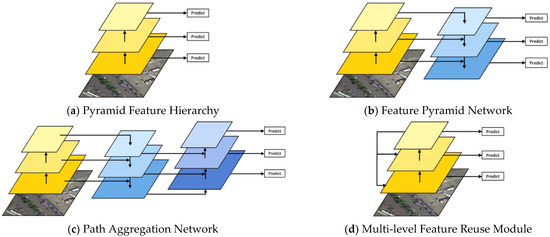
۲٫۲٫ ویژگی هرم
۳٫ روش
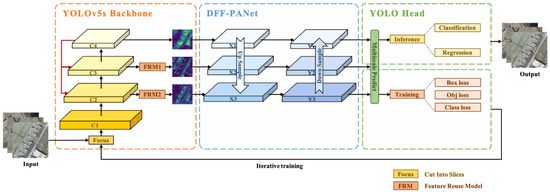
۳٫۱٫ ساختار کلی شبکه
۳٫۲٫ ستون فقرات YOLOv5s
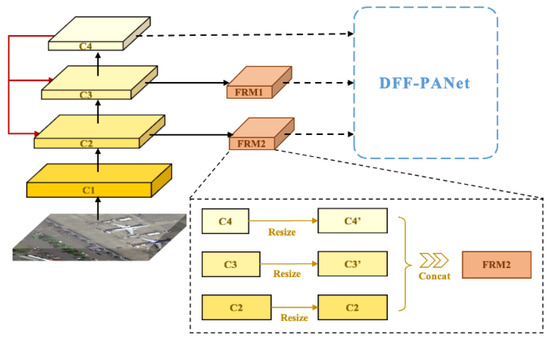
با این حال، از آنجایی که نقشههای ویژگی سطح پایین و سطح متوسط حاوی اطلاعات معنایی کمتری هستند، این نقشههای ویژگی پردازش اطلاعات ممکن است بر عملکرد تشخیص اشیاء کوچک و متوسط تأثیر بگذارد. ارتقای دقت تشخیص اشیاء کوچک و متوسط برای اطمینان از تعادل اطلاعات معنایی بین نقشههای ویژگی سطح پایین و سطح بالا اهمیت زیادی دارد. با الهام از مرجع [ ۲۱ ]، ما از ماژول استفاده مجدد از ویژگی (FRM) در ستون فقرات استفاده کردیم که مکانیزم استفاده مجدد کارآمد را برای ستون فقرات فراهم می کند. FRM در شکل ۴ نشان داده شده است . بیان ریاضی FRM را می توان به صورت زیر بیان کرد:
جایی که ایکسنشان دهنده سی۱نقشه ویژگی در ستون فقرات پس از فوکوس. اسنشان دهنده نقشه های ویژگی برای استفاده مجدد در ستون فقرات ( سی۲و سی۳به ترتیب) که لایه منبع نامیده می شود. تیمننشان دهنده عملیات تبدیلی است که لایه منبع را به همان وضوح تبدیل می کند. ψتیبرای استفاده مجدد از لایه منبع پس از تبدیل وضوح استفاده می شود و یک لایه جدید ایجاد می کند افآرمتی. yمننقشه ویژگی هرم بعدی را نشان می دهد. ψrبه عنوان تلفیقی از نقشه ویژگی هرم لایه قبلی استفاده می شود yمن – ۱و افآرمتی.
-
استراتژی تبدیل تیمن: ابتدا از لایه کانولوشنال ۱ × ۱ برای کاهش ابعاد هر لایه منبع استفاده می شود. در مرحله بعد، با استفاده از درون یابی دوخطی، مقیاس به مقیاسی هم اندازه با کانولوشن برای ذوب شدن تبدیل می شود، بنابراین لایه منبع با وضوح تبدیل شده تولید می شود. سی۲“و سی۳“، به ترتیب). شایان ذکر است که نرمال سازی BatchNorm [ ۳۱ ] و تابع فعال سازی ReLU [ ۳۲ ] به هر لایه کانولوشنی conv1 × ۱ اضافه می شود تا مشکل ناپدید شدن گرادیان و انفجار گرادیان در طول انتشار پس از انتشار را مدیریت کند.
-
استفاده مجدد از ویژگی ψتی: پس از فرآیند تبدیل استراتژی T i ، نقشه های ویژگی جدید تولید می شوند ( سی۲“و سی۳“، به ترتیب). برای استفاده مجدد، دو روش جداگانه برای ادغام نقشههای ویژگی جدید وجود دارد سی۱، الحاق و عملیات جمع عناصر. عملیات الحاق اغلب برای تشخیص تصویر استفاده می شود، که می تواند ویژگی های کانولوشن استخراج شده را ترکیب کند و اطلاعات را حفظ کند و در عین حال ابعاد را افزایش دهد. عملیات جمع عناصر اغلب برای طبقه بندی تصویر استفاده می شود که می تواند اطلاعات تصویر را افزایش دهد و در عین حال افزایش اطلاعات را حفظ کند. بنابراین، ما از عملیات الحاق برای استفاده مجدد از اطلاعات ویژگی ستون فقرات استفاده می کنیم تا ویژگی های استفاده مجدد به عنوان ورودی DFF-PANet استفاده شوند.
-
ادغام ویژگی ψr: بعد از افآرمتیایجاد می شود، با نقشه ویژگی هرمی لایه قبلی به DFF-PANet ارسال می شود (در بخش ۳٫۳ معرفی خواهد شد ).yمن – ۱برای ادغام ویژگی، و نقشه ویژگی های هرم بعدی yمنتولید می شود.
۳٫۳٫ شبکه تجمیع مسیر ترکیبی متراکم (DFF-PANet)
-
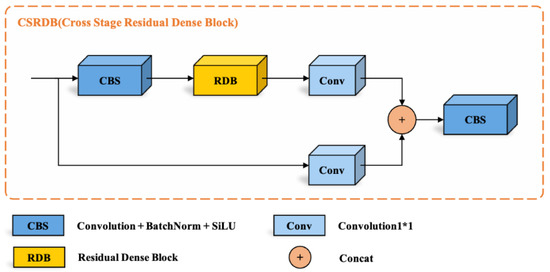
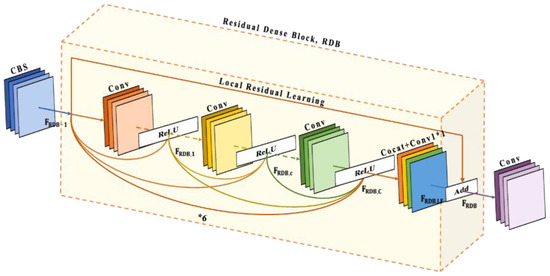
لایه اتصال متراکم: در این ماژول، لایه اتصال متراکم از ۶ لایه کانولوشن برای اتصال متراکم با نرخ رشد ۳۲ تشکیل شده است. FRDB,1خروجی کانولوشن اول را نشان می دهد. FRDB,cخروجی هر پیچیدگی میانی را نشان می دهد. در این مقاله، c∈{۲,۳,۴,۵}. FRDB,cخروجی آخرین پیچیدگی را نشان می دهد. در این مقاله، C= ۶. با در نظر گرفتن هر کانولوشن میانی به عنوان مثال، خروجی کانولوشن توسط لایه قبلی RDB و تمام پیچیدگی ها در RDB به هم متصل می شود، سپس توسط لایه کانولوشن و تابع فعال سازی ReLU محاسبه می شود، در نهایت خروجی به دست می آید. قابل ذکر است که تمامی کانولوشن ها در RDB به کانولوشن های کانولوشن اول تا کانولوشن قبلی این کانولوشن اشاره دارد. بیان ریاضی آن را می توان به صورت زیر نشان داد:
افR D B , C= σ(دبلیوR D B , C[افR D B – ۱،افR D B ، ۱, … ,افR D B ، ج – ۱] )جایی که σنشان دهنده تابع فعال سازی ReLU است. دبلیوR D B , Cنشان دهنده وزن جلایه کانولوشن. لایه اتصال متراکم باعث می شود که CBS و خروجی هر لایه به طور مستقیم به تمام لایه های بعدی متصل شود، که نه تنها ویژگی های پیشخور را حفظ می کند بلکه ویژگی های متراکم محلی را نیز استخراج می کند.
-
ترکیب ویژگی های محلی: همه ویژگی ها در RDB به صورت محلی با الحاق ترکیب می شوند. علاوه بر این، لایه کانولوشنال ۱ × ۱ برای کاهش ابعاد و کنترل تطبیقی اطلاعات خروجی معرفی شده است. بیان ریاضی آن را می توان به صورت زیر بیان کرد:
افR D B ، L F=اچR D BL Fاف( [افR D B – ۱،افR D B ، ۱, … ,افR D B ، ج – ۱،افR D B ، C] )جایی که اچR D BL Fافلایه کانولوشنال ۱×۱ را در RDB نشان می دهد. ادغام ویژگی های محلی می تواند به طور تطبیقی ویژگی های کانولوشنال قبلی و همه ویژگی های کانولوشنال در RDB فعلی را ترکیب کند.
-
یادگیری باقی مانده محلی: یادگیری باقی مانده محلی می تواند جریان اطلاعات بین اطلاعات ویژگی قبل از RDB و ویژگی های متراکم محلی پردازش شده توسط RDB را ارتقا دهد. بیان ریاضی خروجی نهایی RDB را می توان به صورت زیر بیان کرد:
افR D B=افR D B – ۱+افR D B ، L Fجایی که افR D B ، L Fنشان دهنده اطلاعات ویژگی پس از ادغام ویژگی محلی است. یادگیری باقیمانده محلی نه تنها شامل ویژگی های قبل از RDB بلکه ویژگی های متراکم محلی بعد از RDB است.
۳٫۴٫ سر یولو
۳٫۴٫۱٫ استنتاج
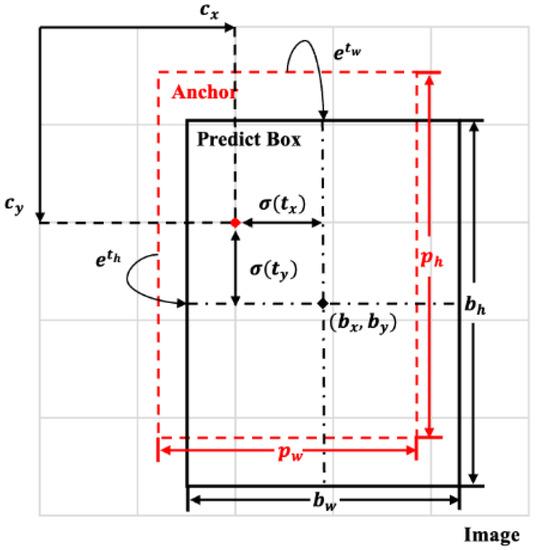
پس از ترکیب ویژگی ها در DFF-PANet، ویژگی ها برای شناسایی به YOLO Head ارسال می شوند. در این پایان نامه، ما از سه مقیاس تشخیص مختلف برای شناسایی نمونه هایی با اندازه های مختلف استفاده می کنیم. ۳۲ × ۳۲، ۱۶ × ۱۶و ۸ × ۸، به ترتیب. گرفتن ۸ × ۸مقیاس تشخیص به عنوان مثال، شبکه تصویر ورودی را به تقسیم می کند ۸ × ۸شبکهها، هر نقطه شبکه با سه لنگر باکس با اندازههای مختلف از پیش تنظیم شده است. اگر مرکز یک شی در شبکه بیفتد، شبکه مسئول شیء است. هر شبکه سه جعبه مرزی را پیشبینی میکند، هر جعبه مرزی شامل پنج پارامتر است. ایکس-هماهنگ كردن، y-به ترتیب مختصات، عرض، ارتفاع و اطمینان نقطه مرکزی جسم. سپس، شبکه به طور مکرر مقدار تلفات را از طریق انتشار به عقب محاسبه می کند، به طور مداوم ویژگی های لنگر باکس را تنظیم می کند و در نهایت انکر باکس های اضافی را توسط NMS فیلتر می کند. مختصات جعبه مرزی پیش بینی شده را می توان به صورت زیر بیان کرد:
جایی که بایکسو بyهستند ایکسو y– مختصات نقطه مرکزی جعبه پیش بینی. بwو بساعتعرض و ارتفاع جعبه پیش بینی هستند. بایکس، بy، بwو بساعتمختصات جعبه پیش بینی را تعیین کنید. تیایکسو تیyانحراف نقطه مرکز شی نسبت به گوشه سمت چپ بالای شبکه که نقطه در آن قرار دارد. تیwو تیساعتعرض و ارتفاع جعبه مرزی پیش بینی شده است. تیایکس، تیy، تیwو تیساعتپارامترهایی هستند که از طریق یادگیری تکراری به دست می آیند. جایکسو جyانحراف شبکه ای هستند که نقطه مرکز شی نسبت به گوشه سمت چپ بالای تصویر قرار دارد. پwو پساعتعرض و ارتفاع انکر باکس هستند. σ( x )تابع برای کنترل افست مرکز شی در واحد شبکه مربوطه معرفی شده است. نمودار تولید جعبه پیش بینی در شکل ۷ نشان داده شده است .
۳٫۴٫۲٫ آموزش
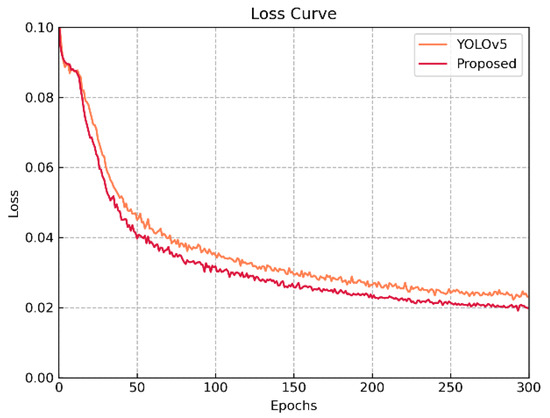
برای شبکه پیشنهادی در این پایان نامه، تابع ضرر کلی را می توان به صورت زیر بیان کرد:
جایی که LB o x، LO b jو Lسیl sبه ترتیب تابع از دست دادن رگرسیون جعبه مرزی، تابع از دست دادن اطمینان و تابع از دست دادن طبقه بندی را نشان می دهد. فراپارامترها λ۱، λ۲و λ۳تنظیمات پیش فرض هستند { ۱ , ۱ , ۱ }. تابع تلفات رگرسیون جعبه مرزی توسط Complete Intersection over Union (CIoU) محاسبه می شود، تابع از دست دادن اطمینان و تابع از دست دادن طبقه بندی توسط Binary Cross Entropy With Logits Loss (BCEWithLogitsLoss) [ ۳۴ ] محاسبه می شود. فرمول BCEWithLogitsLoss به شرح زیر است:
جایی که Nتعداد بردارهای ورودی است. xi∗و xبردار پیش بینی و بردار واقعی مربوطه هستند. σ(x)تابع سیگموئید است.
- (۱)
-
تابع از دست دادن رگرسیون جعبه مرزی
CIoU Loss [ ۳۵ ] برای محاسبه افت موقعیت جعبه پیش بینی و جعبه حقیقت زمینی معرفی شده است. بیان ریاضی آن را می توان به صورت بیان کرد
CIoU=IoU−ρ۲(Pbox,Tbox)c2−ava=v1−IoU+vv =۴π۲( a r c t a nwgتیساعتgتی− a r c t a nwساعت)۲LB o x= ۱ – Io U+ρ۲(پb o x،تیb o x)ج۲+ a vجایی که wو ساعتعرض و ارتفاع جعبه پیش بینی هستند پb o x∈آرنتی× (ایکسج، yج, w , h )، به ترتیب. wgتیهستند ساعتgتیعرض و ارتفاع جعبه حقیقت زمین است تیb o x∈آرنتی× (ایکسج، yج, w , h )، به ترتیب. N t تعداد اشیاء است. آضریب وزنی است. vفاصله نسبت ابعاد بین جعبه پیش بینی و جعبه حقیقت زمین است.
- (۲)
-
عملکرد از دست دادن اعتماد به نفس
LO b j=∑مننپB CEدبلیوi t h L o gمن خیلی زود ( _ _ _ _پo b j،تیo b j)جایی که نپتعداد کانال های لایه پیش بینی است، پیش فرض ۳ است. پo b j∈آرنپ×wمن×ساعتمنبردار پیش بینی است. تیo b j∈آرنپ×wمن×ساعتمنبردار واقعی است. wمن( i = ۱ , ۲ , ۳ )عرض لایه پیش بینی است. ساعتمن( i = ۱ , ۲ , ۳ )ارتفاع لایه پیش بینی است.
- (۳)
-
تابع از دست دادن طبقه بندی
Lسیls=∑iNpBCEWithLogitsLoss(Pcls,Tcls)جایی که Npشماره کانال لایه پیش بینی است، پیش فرض ۳ است. Pcls∈RNt×Ncتوزیع احتمال پیش بینی هر دسته است. Tcls∈RNt×Ncتوزیع احتمال واقعی هر دسته است. Ntتعداد اشیا است. Ncتعداد دسته ها است.
۳٫۵٫ شبه کد ساختار شبکه
شبه کد روش پیشنهادی ما در الگوریتم ۱ نشان داده شده است.
| الگوریتم ۱: یک روش تشخیص سبک وزن. | |
| ورودی: | Input∈R3×۲۵۶×۲۵۶، Inputبه تصویر ورودی اشاره دارد. |
| مرحله ۱: | x=Focus(Input),x∈R32×۱۲۸×۱۲۸، xبرای به دست آوردن نقشه های ویژگی به ستون فقرات ارسال می شود X={x1,x2,x3,x4}. |
| گام ۲: | F={}، Fبه نقشه های ویژگی اشاره دارد که برای ترکیب ویژگی ها به DFF-PANet ارسال می شوند. برای k در محدوده (۱،۴) اگر k=1 سپس ادامه دهید : if k=2: افک⇐ افR M(ایکسک، ایکسk + ۱، ایکسk + ۲) اگر k = ۳ : افک⇐ افR M(ایکسک، ایکسk + ۱) اگر k = ۴ : افک⇐ افR M(ایکسک) پایان اگر اف= اف. a p p e n d(افک) پایان برای |
| مرحله ۳: | افبه DFF-PANet ارسال می شود، سه نقشه ویژگی با اندازه های مختلف ز= {z1،z2،z3}تولید می شوند. |
| خروجی: | احساس رضایت ⇐ سی _ _ _ _ _l a s s i fi c a t i o n ( ) & R e g r e s s i o n ( ) برگشت رای ست _ _ _ _ _ |
۴٫ آزمایشات
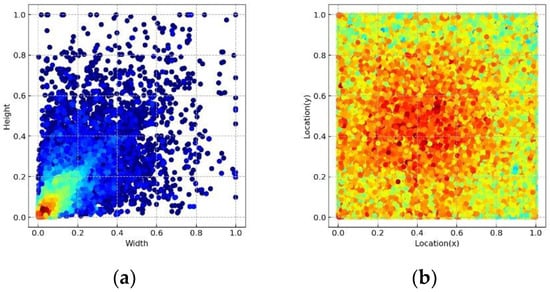
۴٫۱٫ مجموعه داده
۴٫۱٫۱٫ مجموعه داده DOTA
۴٫۱٫۲٫ مجموعه داده HRSC2016
۴٫۲٫ آموزش شبکه
۴٫۲٫۱٫ تنظیم پارامتر
۴٫۲٫۲٫ معیارهای ارزیابی
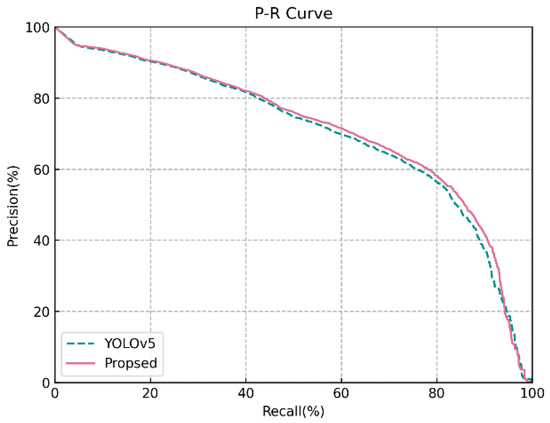
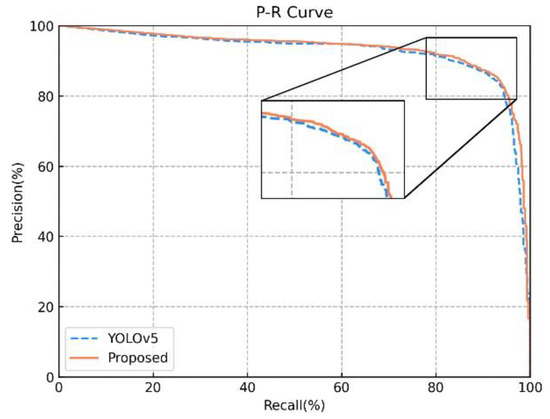
دقت، درستی پ, Recall R , Average Precision A P، به معنای دقت متوسط m A Pو اف۱ – اسc o r eبرای ارزیابی کمی توانایی تشخیص روش پیشنهادی ما انتخاب شدهاند. فرمول P ، R و A Pبه شرح زیر است:
جایی که تیپمثبت واقعی است. نمونه های مثبت به عنوان نمونه های مثبت پیش بینی می شوند. افپمثبت کاذب است. نمونه های منفی به عنوان نمونه های مثبت پیش بینی می شوند. FN منفی کاذب است. نمونه های مثبت به عنوان نمونه های منفی پیش بینی می شوند. A Pدقت متوسط است، یعنی ناحیه اطراف منحنی دقت-یادآوری (منحنی PR)، که برای جلوگیری از عدم تعادل بین دقت و یادآوری استفاده می شود. A Pمقدار بین ۰ و ۱ است. هر چه ناحیه محصور شده توسط منحنی PR بزرگتر باشد، عملکرد مدل بهتر است. را m A Pمیانگین است A Pاز همه دسته ها در مجموعه داده فرمول به شرح زیر است:
جایی که کتعداد کل کلاس ها است. آرnفراخوانی یک کلاس مشخص است n. پn(آرn)دقت در هنگام فراخوانی کلاس است آرn.
ما همچنین از شاخص اندازه گیری استفاده می کنیم اف۱ – اسc o r eبرای متعادل کردن رابطه بین دقت و یادآوری بهتر. هر چه مقدار بزرگتر باشد، عملکرد مدل بهتر است. فرمول به شرح زیر است:
۴٫۳٫ نتایج تجربی
۴٫۳٫۱٫ نتایج تجربی در مجموعه داده DOTA
۴٫۳٫۲٫ نتایج تجربی در مجموعه داده HRSC2016
۴٫۴٫ نتایج تجسم
۴٫۵٫ مطالعه فرسایش
-
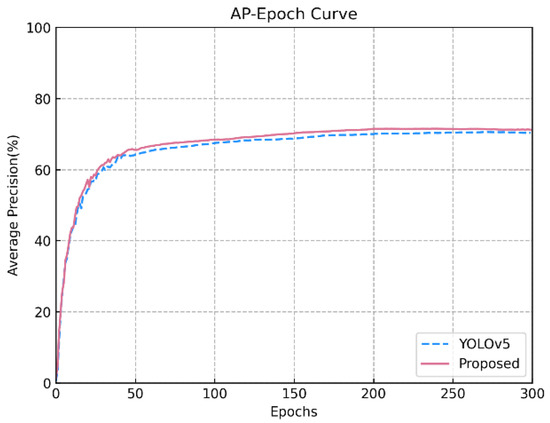
ماژول استفاده مجدد از ویژگی (FRM): برای نشان دادن اعتبار FRM، ما FRM را بر اساس خط پایه اضافه کردیم. با کمک FRM، شبکه به ۷۰٫۸ درصد mAP رسید که ۰٫۴ درصد بیشتر از خط پایه بود. علاوه بر این، نتایج تجربی بالاتر از نتایج بدون FRM بود. به این دلیل است که قبل از استفاده از FRM، نقشههای ویژگی سطح پایین فاقد اطلاعات معنایی غنی هستند که منجر به توانایی تشخیص ناکافی نمونههای کوچک میشود. در حین افزودن FRM، اطلاعات موقعیت در نقشههای ویژگی سطح پایین میتواند به طور کامل با اطلاعات معنایی در نقشههای سطح بالا ترکیب شود، در نتیجه توانایی استفاده مجدد از ویژگی ستون فقرات برای ترویج مشکل توانایی استخراج ویژگی ناکافی شبکه را افزایش میدهد.
-
شبکه تجمیع مسیر ترکیبی متراکم (DFF-PANet): برای تأیید اعتبار DFF-PANet، گردن خط پایه با DFF-PANet جایگزین شد. همانطور که ظاهراً در جدول نشان داده شده است، شبکه به ۷۱٫۳% mAP رسید که پس از افزودن DFF-PANet، ۰٫۹% بیشتر از خط پایه بود. این به دلیل قابلیت همجوشی ویژگی قوی بلوک های متراکم باقیمانده در DFF-PANet است. پس از به دست آوردن ویژگی های متراکم محلی، اطلاعات ویژگی انباشته شده را از طریق ترکیب ویژگی های جهانی برای بهبود عملکرد شبکه حفظ می کند.
-
روش پیشنهادی: وقتی FRM و DFF-PANet هر دو به مدل اضافه شدند، روشی که ما ارائه کردیم به دست آمد. ما به ۷۱٫۵ درصد mAP رسیدیم که ۱٫۱ درصد بیشتر از خط پایه بود. روش بهبود یافته ما همچنین به بالاترین امتیاز F1 رسید. نشان می دهد که FRM و DFF-PANet هر دو ماژول های موثری برای بهبود عملکرد شبکه هستند. آنها هر دو تا حدی توانایی تشخیص مدل را افزایش می دهند.
۵٫ بحث
-
روش مدل: ما مدل پیشنهادی خود را با نسخههای مختلف مدلهای YOLOv5 در مجموعه دادههای DOTA، یعنی YOLOv5n (نانو)، YOLOv5s (کوچک) و YOLOv5m (متوسط) مقایسه کردیم. نتایج تجربی در جدول ۹ نشان داده شده است. همانطور که از جدول ۹ مشاهده می شود ، روش پیشنهادی ما دارای پیشرفت های خاصی در نسخه های مختلف مدل های YOLOv5 است که به ترتیب ۱٫۶٪، ۱٫۱٪ و ۰٫۹٪ افزایش یافته است.
-
مدل سبک وزن: در حال حاضر، طراحی ساختار شبکه ای که بتواند دقت تشخیص و پارامترهای مدل را به طور همزمان متعادل کند، جهت اصلی در الگوریتم های تشخیص اشیا است. اگرچه اکثر ساختارهای شبکه به دقت بالایی دست می یابند، اما معمولاً به مقدار زیادی محاسبات نیاز دارند و دستیابی به عملکرد تشخیص خوب با مقدار کمی محاسبه دشوار است. در این مطالعه، مدل YOLOv5s مورد استفاده ما به تعادلی بین دقت تشخیص و پارامترهای مدل دست مییابد. پارامترهای مدل فقط ۹٫۲ M و زمان استنتاج ۴٫۶ ms است که الزامات تشخیص بلادرنگ را برآورده می کند (بیش از ۳۰ فریم؛ یعنی زمان استنتاج کمتر از ۳۳٫۳ میلی ثانیه است). بنابراین، میتوان آن را در دستگاههای فرانتاند، مانند پایانههای موبایل [ ۵۲ ] مستقر کرد. جدول ۹نشان می دهد که تعداد پارامترها در YOLOv5s نزدیک به ۱۳ M کمتر از YOLOv5m است، که تا حد زیادی پارامترهای مدل را کاهش می دهد. در مقایسه با YOLOv5n، اگرچه پارامترهای مدل ۶٫۱ M بیشتر از آن است، دقت تشخیص ۳٪ بهبود یافته است. بنابراین، در مقایسه با YOLOv5n، افزایش تعداد پارامترها قابل قبول است.
-
دقت مدل: تجزیه و تحلیل مقایسهای مجموعه داده و آزمایشهای فرسایشی که در بالا ذکر شد نشان میدهد که روش پیشنهادی ما عملکرد عالی برای نمونههایی با اندازههای مختلف یا با بسیاری از عوامل تداخل خارجی دارد. با این حال، همانطور که از داده های جدول ۵ مشاهده می شود، دقت تشخیص اشیا مانند زمین پیست زمینی (GTF)، زمین بسکتبال (BC) و زمین توپ فوتبال (SBF) هنوز از رتبه اول عقب است. روش ما هنگام برخورد با چنین اشیایی به نتیجه رضایت بخشی نمی رسد. ممکن است به این دلیل باشد که چنین اشیایی گاهی در یک پسزمینه قرار دارند و اطلاعات بافت آنها مشابه است. اطلاعات ویژگی را نمی توان به وضوح توسط مدل شناسایی کرد، که منجر به عملکرد تشخیص پایین اشیا می شود. در کارهای آینده، امیدواریم که مدل را از این جنبه بهبود ببخشیم.
۶٫ نتیجه گیری
- (۱)
-
اول، ما از ماژول استفاده مجدد از ویژگی (FRM) برای استفاده مجدد از نقشه های ویژگی در ستون فقرات استفاده می کنیم. این ماژول می تواند توانایی تشخیص شبکه را برای اهداف کوچک و متوسط از طریق ترکیب اطلاعات معنایی و اطلاعات مکان افزایش دهد.
- (۲)
-
پس از آن، شبکه تجمیع مسیر ترکیبی متراکم (DFF-PANet) را طراحی کردیم تا بتوانیم مسئله عوامل تداخل خارجی را در RSIها بهتر مدیریت کنیم.
مشارکت های نویسنده
منابع مالی
بیانیه هیئت بررسی نهادی
بیانیه رضایت آگاهانه
بیانیه در دسترس بودن داده ها
قدردانی
تضاد علاقه
اختصارات
اختصارات استفاده شده در این پایان نامه به شرح زیر است:
| یک ۲ S-Det | انتخاب لنگر خود تطبیقی |
| AFANet | شبکه تجمیع ویژگی های تطبیقی |
| BCEWithLogitsLoss | آنتروپی متقاطع باینری با از دست دادن لجیت |
| CF2PN | شبکه هرمی فیوژن ویژگی متقابل |
| CIoU | تقاطع کامل بر روی اتحادیه |
| CNN ها | شبکه های عصبی کانولوشنال |
| CSPDarknet53 | Cross Stage Partial Darknet 53 |
| CSRDB | بلوک متراکم باقیمانده متقاطع |
| DFF-PANet | شبکه تجمیع مسیر ترکیبی متراکم |
| DOTA | مجموعه داده های تشخیص شی در تصاویر هوایی |
| DPM | مدل قطعات قابل تغییر شکل |
| فلاپ ها | عملیات نقطه شناور |
| FRM | ماژول استفاده مجدد از ویژگی |
| HOG | هیستوگرام گرادیان های جهت دار |
| ICN | آبشار تصویر و شبکه هرمی ویژگی |
| IoU | تقاطع روی اتحادیه |
| M2Det | آشکارساز چند سطحی و چند مقیاسی |
| MFPNet | شبکه هرمی چند ویژگی |
| ام اس کوکو | اشیاء مشترک مایکروسافت در زمینه |
| MSE-DenseNet | چند مقیاسی SELU DenseNet |
| NMS | سرکوب غیر حداکثری |
| پاسکال VOC | کلاس های شیء بصری پاسکال |
| منحنی روابط عمومی | منحنی دقیق-یادآوری |
| R-CNN | شبکه عصبی کانولوشنال منطقه ای |
| R-DFPN | شبکه هرمی با ویژگی چرخشی متراکم |
| RDB | بلوک متراکم باقیمانده |
| RoI | منطقه مورد نظر |
| RoI Trans. | ترانسفورماتور RoI |
| RRPN | شبکه های پیشنهادی منطقه چرخشی |
| RPN | شبکه های پیشنهادی منطقه |
| RSI ها | تصاویر سنجش از راه دور |
| SGD | نزول گرادیان تصادفی |
| SSD | آشکارساز مولتی باکس تک شات |
| SVM | ماشین بردار پشتیبانی |
| یولو | شما فقط یک بار نگاه می کنید |
منابع
- فو، جی. لیو، سی جی; ژو، آر. سان، تی. Zhang، طبقهبندی QJ برای تصاویر سنجش از دور با وضوح بالا با استفاده از یک شبکه کاملاً کانولوشن. Remote Sens. ۲۰۱۷ , ۹ , ۴۹۸٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ماگیوری، ای. تارابالکا، ی. چارپیات، جی. Alliez، P. شبکه های عصبی کانولوشن برای طبقه بندی تصاویر سنجش از دور در مقیاس بزرگ. IEEE Trans. Geosci. Remote Sens. ۲۰۱۷ , ۵۵ , ۶۴۵–۶۵۷٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژو، جی. نیش، LY; غمیسی، ص. شبکه های عصبی کانولوشن تغییر شکل پذیر برای طبقه بندی تصاویر فراطیفی. IEEE Geosci. سنسور از راه دور Lett. ۲۰۱۸ ، ۱۵ ، ۱۲۵۴-۱۲۵۸٫ [ Google Scholar ] [ CrossRef ]
- وو، XW; سهو، د. Hoi, SCH پیشرفت های اخیر در یادگیری عمیق برای تشخیص اشیا. محاسبات عصبی ۲۰۲۰ ، ۳۹۶ ، ۳۹-۶۴٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- چنگ، جی. ژو، رایانه شخصی؛ هان، JW یادگیری شبکه های عصبی کانولوشنال چرخش ثابت برای تشخیص اشیاء در تصاویر سنجش از دور نوری VHR. IEEE Trans. Geosci. Remote Sens. ۲۰۱۶ , ۵۴ , ۷۴۰۵–۷۴۱۵٫ [ Google Scholar ] [ CrossRef ]
- Qu، Z. زو، اف. Qi، C. تشخیص هدف تصویر سنجش از دور: بهبود مدل YOLOv3 با شبکه های کمکی. Remote Sens. ۲۰۲۱ , ۱۳ , ۳۹۰۸٫ [ Google Scholar ] [ CrossRef ]
- ژانگ، جی.ام. جین، XK; سان، ج. وانگ، جی. Sangaiah، AK ویژگیهای کانولوشنال فضایی و معنایی برای ردیابی شیء بصری قوی. چندتایی. ابزارهای کاربردی ۲۰۲۰ ، ۷۹ ، ۱۵۰۹۵-۱۵۱۱۵٫ [ Google Scholar ] [ CrossRef ]
- لی، ایکس. هو، WM; شن، CH; ژانگ، ZF; دیک، ا. Van den Hengel، A. بررسی مدلهای ظاهری در ردیابی اشیاء بصری. ACM Trans. هوشمند سیستم تکنولوژی ۲۰۱۳ ، ۴ ، ۱-۴۸٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کائو، سی. وو، جی. زنگ، ایکس. فنگ، ز. Huang, Z. تحقیق در مورد هواپیما و کشتی تشخیص تصاویر سنجش از دور هوایی بر اساس شبکه عصبی کانولوشن. Sensors ۲۰۲۰ , ۲۰ , ۴۶۹۶٫ [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ردمون، جی. دیووالا، س. گیرشیک، آر. فرهادی، الف. شما فقط یک بار نگاه می کنید: یکپارچه، تشخیص شی در زمان واقعی. در مجموعه مقالات کنفرانس IEEE در مورد دید کامپیوتری و تشخیص الگو، لاس وگاس، NV، ایالات متحده، ۲۷-۳۰ ژوئن ۲۰۱۶٫ IEEE: Piscataway Township، NJ، ایالات متحده، ۲۰۱۶٫ [ Google Scholar ]
- ردمون، جی. فرهادی، A. YOLO9000: بهتر، سریعتر، قوی تر. در مجموعه مقالات کنفرانس IEEE در مورد دید رایانه و تشخیص الگو، هونولولو، HI، ایالات متحده آمریکا، ۲۱ تا ۲۶ ژوئیه ۲۰۱۷٫ [ Google Scholar ]
- ردمون، جی. فرهادی، A. YOLOv3: یک پیشرفت افزایشی. arXiv ۲۰۱۸ , arXiv:1804.02767. [ Google Scholar ]
- بوچکوفسکی، آ. وانگ، سی. لیائو، H. YOLOv4: سرعت و دقت بهینه تشخیص اشیا. arXiv ۲۰۲۰ ، arXiv:2004.10934. [ Google Scholar ]
- اورینگهام، ام. اسلامی، س. گول، LV; ویلیامز، سی. وین، جی. زیسرمن، آ. چالش کلاسهای شیء بصری پاسکال: گذشتهنگر. بین المللی جی. کامپیوتر. Vis. ۲۰۱۵ ، ۱۱۱ ، ۹۸-۱۳۶٫ [ Google Scholar ] [ CrossRef ]
- لین، TY; مایر، م. بلنگی، اس. هیز، جی. Zitnick، CL مایکروسافت COCO: اشیاء مشترک در زمینه ؛ Springer International Publishing: Cham, Switzerland, 2014. [ Google Scholar ]
- یوان، ز. لیو، ز. زو، سی. چی، جی. Zhao، D. تشخیص شیء در تصاویر سنجش از راه دور از طریق شبکه هرمی چند ویژگی با بلوک میدان پذیرنده. Remote Sens. ۲۰۲۱ , ۱۳ , ۸۶۲٫ [ Google Scholar ] [ CrossRef ]
- هوانگ، دبلیو. لی، جی. چن، کیو. جو، م. Qu, J. CF2PN: تشخیص هدف شبکه هرمی ترکیبی مبتنی بر سنجش از دور. Remote Sens. ۲۰۲۱ , ۱۳ , ۸۴۷٫ [ Google Scholar ] [ CrossRef ]
- زو، اچ. ژانگ، پی. وانگ، ال. ژانگ، ایکس. Jiao, L. یک رویکرد تشخیص شی چند مقیاسی برای تصاویر سنجش از راه دور بر اساس MSE-DenseNet و تخصیص لنگر پویا. سنسور از راه دور Lett. ۲۰۱۹ ، ۱۰ ، ۹۵۹–۹۶۷٫ [ Google Scholar ] [ CrossRef ]
- ژانگ، اچ. وو، جی. لیو، ی. Yu, J. VaryBlock: رویکردی جدید برای تشخیص اشیاء در تصاویر سنجش از دور. Sensors ۲۰۱۹ , ۱۹ , ۵۲۸۴٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژانگ، تی. ژانگ، جی. گوا، سی. چن، اچ. ژو، دی. وانگ، ی. Xu, A. بررسی الگوریتم تشخیص شیء تصویر بر اساس یادگیری عمیق. مخابرات علمی ۲۰۲۰ ، ۳۶ ، ۹۲-۱۰۶٫ [ Google Scholar ]
- وی، ال. کوی، دبلیو. هو، ز. سان، اچ. Hou, S. یک ویژگی چند سطحی تک شات که از شبکه عصبی مجدد برای تشخیص اشیا استفاده می شود. Vis. محاسبه کنید. ۲۰۲۱ ، ۳۷ ، ۱۳۳-۱۴۲٫ [ Google Scholar ] [ CrossRef ]
- لیو، دبلیو. آنگلوف، دی. ایرهان، د. سگدی، سی. رید، اس. فو، سی. Berg، AC SSD: آشکارساز MultiBox تک شات . Springer: Cham، Switzerland، ۲۰۱۶٫ [ Google Scholar ]
- لین، TY; دلار، P. گیرشیک، آر. او، ک. حریهاران، بی. Belongie, S. ویژگی شبکه های هرمی برای تشخیص اشیا. در مجموعه مقالات کنفرانس IEEE 2017 در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، لندن، بریتانیا، ۱ ژوئیه ۲۰۱۷٫ [ Google Scholar ]
- لیو، اس. چی، ال. کین، اچ. شی، ج. جیا، J. شبکه تجمیع مسیر برای تقسیمبندی نمونه. در مجموعه مقالات کنفرانس IEEE/CVF 2018 در مورد دید رایانه و تشخیص الگو (CVPR)، سالت لیک سیتی، UT، ایالات متحده آمریکا، ۱۸ تا ۲۳ ژوئن ۲۰۱۸٫ [ Google Scholar ]
- لین، TY; گویال، پ. گیرشیک، آر. او، K. P Dollár از دست دادن کانونی برای تشخیص شی متراکم. در مجموعه مقالات معاملات IEEE در تحلیل الگو و هوش ماشینی، ونیز، ایتالیا، ۲۲ تا ۲۹ اکتبر ۲۰۱۷؛ صفحات ۲۹۹۹-۳۰۰۷٫ [ Google Scholar ]
- گیرشیک، آر. دوناهو، جی. دارل، تی. Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. در مجموعه مقالات انجمن کامپیوتر IEEE، کلمبوس، OH، ایالات متحده، ۲۳ تا ۲۸ ژوئن ۲۰۱۴٫ [ Google Scholar ]
- Girshick, R. Fast R-CNN. در مجموعه مقالات کنفرانس بین المللی IEEE 2015 در بینایی رایانه (ICCV)، سانتیاگو، شیلی، ۷ تا ۱۳ دسامبر ۲۰۱۵٫ [ Google Scholar ]
- رن، اس. او، ک. گیرشیک، آر. Sun, J. Faster R-CNN: Towards towards realtime object detection with region proposal networks. IEEE Trans. الگوی مقعدی ماخ هوشمند ۲۰۱۷ ، ۳۹ ، ۱۱۳۷-۱۱۴۹٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- قانون، اچ. Deng, J. CornerNet: تشخیص اشیاء به عنوان نقاط کلیدی جفت شده. بین المللی جی. کامپیوتر. Vis. ۲۰۲۰ ، ۱۲۸ ، ۶۴۲-۶۵۶٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- تیان، ز. شن، سی. چن، اچ. او، T. Fcos: تشخیص شی یک مرحله ای کاملاً کانولوشن. در مجموعه مقالات کنفرانس بین المللی IEEE/CVF در بینایی کامپیوتر، سئول، کره، ۲۷ تا ۲۸ اکتبر ۲۰۱۹٫ [ Google Scholar ]
- آیوف، اس. Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. در مجموعه مقالات سی و دومین کنفرانس بین المللی یادگیری ماشین، لیل، فرانسه، ۶ تا ۱۱ ژوئیه ۲۰۱۵؛ Francis, B., David, B., Eds. Microtome Publishing: Brookline, MA, USA; صص ۴۴۸-۴۵۶٫
- گلوروت، ایکس. بوردس، آ. Bengio، Y. شبکه های عصبی یکسو کننده پراکنده عمیق. در مجموعه مقالات چهاردهمین کنفرانس بین المللی هوش مصنوعی و آمار، Ft. Lauderdale، FL، ایالات متحده آمریکا، ۱۱-۱۳ آوریل ۲۰۱۱; جفری، جی، دیوید، دی.، میروسلاو، د.، ویرایش. Microtome Publishing: Brookline, MA, USA; صص ۳۱۵-۳۲۳٫
- ژانگ، ی. تیان، ی. کنگ، ی. ژونگ، بی. Fu، Y. شبکه متراکم باقیمانده برای وضوح تصویر فوق العاده. در مجموعه مقالات کنفرانس IEEE/CVF 2018 درباره بینایی کامپیوتری و تشخیص الگو، سالت لیک سیتی، UT، ایالات متحده آمریکا، ۱۸ تا ۲۳ ژوئن ۲۰۱۸٫ [ Google Scholar ]
- سان، ز. لنگ، X. لی، ی. شیونگ، بی. جی، ک. Kuang، G. BiFA-YOLO: یک روش جدید مبتنی بر YOLO برای تشخیص کشتی دلخواه در تصاویر SAR با وضوح بالا. Remote Sens. ۲۰۲۱ , ۱۳ , ۴۲۰۹٫ [ Google Scholar ] [ CrossRef ]
- ژنگ، ز. وانگ، پی. لیو، دبلیو. لی، جی. بله، آر. Ren, D. Distance-IoU loss: یادگیری سریعتر و بهتر برای رگرسیون جعبه مرزی. در مجموعه مقالات کنفرانس AAAI در مورد هوش مصنوعی، نیویورک، نیویورک، ایالات متحده آمریکا، ۷ تا ۱۲ فوریه ۲۰۲۰٫ [ Google Scholar ]
- دینگ، جی. زو، ن. Xia، GS; بای، ایکس. یانگ، دبلیو. یانگ، من؛ بلنگی، اس. لو، جی. داتکو، ام. Pelillo، M. تشخیص شیء در تصاویر هوایی: معیار و چالشهای مقیاس بزرگ. arXiv ۲۰۲۱ ، arXiv:2102.12219. [ Google Scholar ]
- لیو، ز. یوان، ال. ونگ، ال. Yang, Y. مجموعه داده های تصویری ماهواره ای نوری با وضوح بالا برای تشخیص کشتی و برخی خطوط پایه جدید. در مجموعه مقالات کنفرانس بین المللی کاربردها و روش های تشخیص الگو، پورتو، پرتغال، ۲۴ تا ۲۶ فوریه ۲۰۱۷٫ SciTePress: پکن، چین، ۲۰۱۷٫ [ Google Scholar ]
- سان، دبلیو. ژانگ، ایکس. ژانگ، تی. زو، پی. گائو، ال. تانگ، ایکس. لیو، بی. شبکه تجمیع ویژگی تطبیقی برای تشخیص اشیا در تصاویر سنجش از دور. در مجموعه مقالات سمپوزیوم بین المللی زمین شناسی و سنجش از دور IGARSS 2020-2020 IEEE، Waikoloa، HI، ایالات متحده آمریکا، ۲۶ سپتامبر تا ۲ اکتبر ۲۰۲۰؛ IEEE: Piscataway Township، NJ، ایالات متحده آمریکا، ۲۰۲۰٫ [ Google Scholar ]
- شیائو، ز. وانگ، ک. وان، س. تان، ایکس. خو، سی. Xia، F. A2S-Det: تطبیق لنگر کارایی در تشخیص اشیاء با تصویر هوایی Remote Sens. ۲۰۲۱ ، ۱۳ ، ۷۳٫ [ Google Scholar ] [ CrossRef ]
- یانگ، ایکس. سان، اچ. فو، ک. یانگ، جی. سان، ایکس. یان، م. Guo, Z. تشخیص خودکار کشتی در تصاویر سنجش از راه دور از Google Earth از صحنه های پیچیده بر اساس چرخش چند مقیاسی شبکه های هرمی ویژگی متراکم. Remote Sens. ۲۰۱۸ , ۱۰ , ۱۳۲٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ما، جی. شائو، دبلیو. بله، اچ. وانگ، ال. وانگ، اچ. ژنگ، ی. Xue, X. تشخیص متن صحنه دلخواه از طریق پیشنهادات چرخشی. IEEE Trans. چندتایی. ۲۰۱۸ ، ۲۰ ، ۳۱۱۱–۳۱۲۲٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- عظیمی، س.م. ویگ، ای. بهمنیار، ر. کورنر، ام. Reinartz، P. به سمت تشخیص شی چند کلاسه در تصاویر سنجش از دور نامحدود. در کامپیوتر ویژن-ACCV 2018 ؛ Springer International Publishing: Cham، سوئیس، ۲۰۱۹٫ [ Google Scholar ]
- دینگ، جی. زو، ن. لانگ، ی. Xia، GS; Lu, Q. ترانسفورماتور RoI یادگیری برای تشخیص اجسام جهت دار در تصاویر هوایی. arXiv ۲۰۱۸ , arXiv:1812.00155. [ Google Scholar ]
- ژانگ، ی. شنگ، دبلیو. جیانگ، جی. جینگ، ن. Mao, Z. شاخه های اولویت برای تشخیص کشتی در تصاویر سنجش از دور نوری. Remote Sens. ۲۰۲۰ , ۱۲ , ۱۱۹۶٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژانگ، ز. گوو، دبلیو. زو، اس. Yu, W. به سوی تشخیص کشتی دلخواه با پیشنهاد منطقه چرخشی و شبکه های تبعیض. IEEE Geosci. سنسور از راه دور Lett. ۲۰۱۸ ، ۱۵ ، ۱۷۴۵-۱۷۴۹٫ [ Google Scholar ] [ CrossRef ]
- یانگ، ایکس. هو، ال. ژو، ی. وانگ، دبلیو. Yan, J. برچسب متراکم برای تشخیص چرخش آزاد ناپیوستگی مرز. در مجموعه مقالات کنفرانس IEEE/CVF در مورد دید رایانه و تشخیص الگو، نشویل، TN، ایالات متحده، ۲۰-۲۵ ژوئن ۲۰۲۱٫ [ Google Scholar ]
- لیائو، م. زو، ز. شی، بی. شیا، جی. Bai, X. رگرسیون حساس به چرخش برای تشخیص متن صحنه جهت دار. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو، سالت لیک سیتی، UT، ایالات متحده آمریکا، ۱۸ تا ۲۳ ژوئن ۲۰۱۸٫ [ Google Scholar ]
- کیان، دبلیو. یانگ، ایکس. پنگ، اس. گوا، ی. Yan, J. یادگیری از دست دادن مدوله شده برای تشخیص شی چرخانده شده. arXiv ۲۰۱۹ ، arXiv:1911.08299. [ Google Scholar ]
- مینگ، کیو. ژو، ز. میائو، ال. ژانگ، اچ. لی، ال. یادگیری لنگر پویا برای تشخیص شی دلخواه گرا. arXiv ۲۰۲۰ ، arXiv:2012.04150. [ Google Scholar ]
- یانگ، ایکس. لیو، کیو. یان، جی. لی، ا. ژانگ، ز. Yu, G. R3det: آشکارساز تک مرحله ای تصفیه شده با ویژگی اصلاح شده برای جسم در حال چرخش. arXiv ۲۰۱۹ ، arXiv:1908.05612. [ Google Scholar ]
- کینگ، ی. لیو، دبلیو. فنگ، ال. Gao, W. بهبود شبکه Yolo برای تشخیص هدف سنجش از راه دور با زاویه آزاد. Remote Sens. ۲۰۲۱ , ۱۳ , ۲۱۷۱٫ [ Google Scholar ] [ CrossRef ]
- لو، آر. چن، ال. زینگ، جی. یوان، ز. Wang, J. یک روش تشخیص سریع هواپیما برای تصاویر SAR بر اساس شبکه توجه جمعشده مسیر دو جهته کارآمد. Remote Sens. ۲۰۲۱ , ۱۳ , ۲۹۴۰٫ [ Google Scholar ] [ CrossRef ]






بدون دیدگاه