۱٫ معرفی
امروزه، نوسازی شهری به طور گسترده در سراسر جهان انجام شده است، که می تواند به طور موثر کمبود منابع زمین شهری را کاهش دهد و کارایی کاربری زمین شهری را بهبود بخشد [ ۱ ، ۲ ، ۳ ]. به عنوان مثال، نوسازی شهری در چین منجر به تخریب گسترده مناطق شهری قدیمی و کم تراکم و روستاهای شهری در چند دهه گذشته شده است [ ۲ ]. در طول فرآیند بازسازی، سایت های ساخت و ساز می توانند منبع مقادیر زیادی گرد و غبار باشند که به راحتی می تواند به هوا و آب اطراف منتقل شود و منجر به آلودگی شدید محیطی شود.
برای کاهش آلودگی گرد و غبار همراه، مالچ پلاستیکی به طور گسترده توسط دولت های محلی در چین استفاده شده است ( شکل ۱).). علاوه بر این، مالچ پلاستیکی همیشه سبز است و آن را دوستدار محیط زیست می کند. در واقع، مالچ پلاستیکی سبز معمولاً از پلی اتیلن ساخته می شود. اکثر پروژه های نوسازی شهری در چین از همان مالچ پلاستیکی سبز برای کاهش آلودگی گرد و غبار استفاده می کنند. پس از فرآیند ساخت و ساز، مالچ پلاستیکی را می توان در کارخانه های شیمیایی مربوطه بازیافت کرد. با توجه به قوانین سختگیرانه حفاظت از محیط زیست در چین، مالچ پلاستیکی سبز در پروژه های نوسازی شهری ضروری است و فرصتی برای شناسایی دقیق مکان های ساخت و ساز در طول گسترش و نوسازی شهری فراهم می کند. بنابراین، نظارت و شناسایی این پوششهای پلاستیکی سبز (GPC) که میتواند توزیع فضایی سایتهای ساخت و ساز را فراهم کند، از اهمیت بالایی برخوردار است. علاوه بر این، تشخیص GPC همچنین می تواند به بخش حفاظت از محیط زیست در کنترل دقیق گرد و غبار ساختمانی کمک کند. با این حال، تا آنجا که می دانیم، هنوز گزارشی در مورد تشخیص GPC در زمینه سنجش از راه دور وجود ندارد. بنابراین، ما بسیار انگیزه داریم تا یک روش طبقهبندی دقیق برای GPC بر اساس یادگیری عمیق (DL) از تصاویر سنجش از دور VHR پیشنهاد کنیم.
طبقه بندی دقیق GPC به دلایل زیر چالش برانگیز است. اولاً، مناظر پیچیده شهری منجر به تنوع زیاد الگوهای فضایی GPC می شود. ثانیا، دادههای برچسبگذاریشده محدود GPC میتواند به بیش از حد برازش مدل طبقهبندی مبتنی بر یادگیری عمیق منجر شود. برای مقابله با این مسائل، ابتدا از یک CNN قابل تغییر شکل چند مقیاسی برای توضیح تغییر مقیاس و شکل GPC استفاده کردیم. پس از آن، نمونههای GPC بدون برچسب را با دادههای برچسبگذاریشده در یک چارچوب یادگیری نیمهنظارتشده ادغام کردیم تا قابلیت تعمیم مدل را افزایش دهیم.
در واقع، پوشش پلاستیک سبز شهری را می توان به عنوان یک مقوله خاص پوشش زمین شهری در نظر گرفت. به دلیل دیدگاه همدیدی و مقرون به صرفه بودن، سنجش از دور به طور گسترده برای نقشه برداری کاربری زمین شهری و پوشش زمین (LULC) استفاده شده است [ ۴ ، ۵ ، ۶ ]. روشهای سنتی عمدتاً بر بازرسی بصری و برداری از تصاویر سنجش از راه دور VHR متمرکز بودند. با این حال، این هم زمان و هم کار فشرده است. بنابراین، چگونگی توسعه یک روش طبقهبندی خودکار LULC شهری به یک موضوع تحقیقاتی داغ تبدیل شده است [ ۷ ، ۸ ، ۹ ]. مطالعات اولیه [ ۱۰ ، ۱۱ ، ۱۲ ، ۱۳ ، ۱۴ ،۱۵ ] عمدتاً ویژگیهای دستساز (یعنی شاخصهای طیفی، ویژگیهای بافت) را با طبقهبندیکنندههای یادگیری ماشین ترکیب میکند تا به طور خودکار یک نوع LULC شهری خاص را استخراج کند. برای مثال، شائو و همکاران. [ ۱۰ ] استخراج سطح غیرقابل نفوذ شهری را بر اساس جنگل تصادفی (RF) از تصاویر GaoFen-1 و Sentinel-1A انجام داد. یین و همکاران [ ۱۱ ] از هر دو روش مبتنی بر زیر پیکسل و سوپر پیکسل برای توصیف فضای سبز شهری در منطقه Haidian، پکن استفاده کرد. در مطالعات قبلی، ما همچنین تجزیه و تحلیل تصادفی جنگل و بافت را برای نقشهبرداری پوشش گیاهی شهری [ ۱۲ ] و استخراج مناطق غرقشده شهری [ ۱۳ ] از دادههای سنجش از راه دور وسیله نقلیه هوایی بدون سرنشین (UAV) اتخاذ کردیم.
در همین حال، هنوز هیچ مطالعه مرتبطی در مورد نقشه برداری پوشش پلاستیک سبز شهری از داده های سنجش از دور وجود ندارد. تحقیقات مشابه عمدتاً شامل شناسایی مکانهای ساختوساز و دفن زباله شهری است. یو و همکاران [ ۱۶ ] یک روش یادگیری بدون نظارت برای طبقهبندی ساختمانهای در حال ساخت از دادههای پهپاد چند زمانی پیشنهاد کرد. سیلوستری و همکاران [ ۱۷ ] از طبقهبندیکننده حداکثر احتمال (MLC) و تصاویر IKONOS برای شناسایی مکانهای دفن زباله شهری کنترلنشده استفاده کرد. با توجه به اینکه هیچ مطالعه منتشر شده ای بر طبقه بندی پوشش پلاستیک سبز متمرکز نشده است، این مقاله می تواند اولین تلاش برای حل این موضوع مهم و چالش برانگیز باشد.
لازم به ذکر است که مطالعات فوق عمدتاً بر ویژگی های دست ساز و رویکردهای یادگیری ماشین برای طبقه بندی LULC شهری متکی هستند. با این حال، طراحی ویژگیهای دست ساز به شدت به تخصص دامنه متکی است، که ممکن است منجر به ناتوانی در کشف ویژگیهای سطح بالا و متمایز از تصاویر سنجش از دور شود. از سوی دیگر، یادگیری عمیق دارای توانایی قوی برای استخراج ویژگی های چند سطحی معرف از داده های اصلی به جای طراحی ویژگی های تجربی است و می تواند به صورت انتها به انتها کار کند، که منجر به عملکرد چشمگیر در زمینه کامپیوتر ویسون شده است. ۱۸ ، ۱۹ ، ۲۰ ، ۲۱ ، ۲۲ ]، مانند طبقه بندی تصاویر [ ۱۸ ]]، تشخیص شی [ ۱۹ ] و تقسیم بندی معنایی [ ۲۲ ]. اخیراً، یادگیری عمیق، به ویژه CNN عمیق، نیز با موفقیت در کاربردهای سنجش از دور متعدد استفاده شده است [ ۲۳ ، ۲۴ ، ۲۵ ، ۲۶ ، ۲۷ ، ۲۸ ، ۲۹ ]. به عنوان مثال، هوانگ و همکاران. [ ۲۳ ] یک CNN عمیق نیمه انتقالی برای نقشه برداری کاربری زمین شهری، بر اساس تصاویر VHR WorldView-2 پیشنهاد کرد و به دقت ۹۱٫۲۵% دست یافت. ژانگ و همکاران [ ۲۴ ] یک CNN مبتنی بر شی برای طبقه بندی کاربری زمین شهری پیشنهاد کرد و به دقت طبقه بندی و کارایی محاسباتی عالی دست یافت. دونگ و همکاران [ ۲۵] از یک رویکرد ترکیبی از جنگل تصادفی و CNN برای نقشه برداری جنگل های نیمه گرمسیری استفاده کرد و نتایج آنها نشان داد که مدل توسعه یافته می تواند منجر به بهبود استخراج اطلاعات شود. در مطالعات قبلی خود [ ۳۰ ]، یک CNN دو شاخه ای را برای نقشه برداری کاربری زمین شهری اصلاح کردیم و دریافتیم که مدل CNN پیشنهادی از الگوریتم های یادگیری ماشین سنتی مانند MLC، RF و ماشین بردار پشتیبانی (SVM) بهتر عمل می کند. علاوه بر این، ما مدل فوق را به یک نسخه چند شاخه ای برای ادغام تصاویر Sentinel-1/2 چند سنسور و چند زمانی گسترش دادیم [ ۳۱]. همه مطالعات فوق نشان دادند که CNN می تواند ابزار موثری برای طبقه بندی تصاویر سنجش از دور ارائه دهد. بنابراین، در این مطالعه، ما از یک CNN تغییر شکلپذیر چند مقیاسی جدید برای یادگیری ویژگیهای سطح بالا و نماینده طبقهبندی پوشش پلاستیکی سبز استفاده کردیم.
نمی توان انکار کرد که پیشرفت های بزرگی در نقشه برداری LULC شهری از تصاویر سنجش از دور از طریق یادگیری عمیق انجام شده است. با این حال، یادگیری عمیق به شیوهای مبتنی بر دادههای جامع کار میکند و تعداد زیادی از نمونههای برچسبگذاری شده باید به یک مدل DL وارد شوند تا از برازش بیش از حد جلوگیری شود. در همین حال، باید توجه داشت که برچسبگذاری نمونههای آموزشی عظیم، به ویژه در زمینههای سنجش از دور و علوم زمین، کار گسترده و زمانبر است. بنابراین، چگونگی ادغام نمونههای برچسبدار محدود با دادههای عظیم بدون برچسب برای بهبود قابلیت تعمیم مدل، یک سوال کلیدی است. یادگیری نیمه نظارتی دقیقاً ابزار مؤثری برای مقابله با این موضوع فراهم می کند. او و همکاران [ ۳۲] شبکه متخاصم مولد (GAN) مبتنی بر یادگیری نیمه نظارتی برای طبقه بندی تصاویر ابرطیفی (HSI) پیشنهاد کرد، در حالی که نمونه های بدون برچسب از مولد GAN بودند. فانگ و همکاران [ ۳۳ ] همچنین از یک استراتژی یادگیری نیمه نظارت شده بر اساس چندین روش انتخاب نمونه برای طبقه بندی HSI استفاده کرد. با الهام از این مطالعات، ما همچنین یک چارچوب یادگیری نیمه نظارتی را برای طبقهبندی پوششهای پلاستیکی سبز شهری بر اساس نمونههای محدود و با حاشیهنویسی معرفی کردیم.
به طور خلاصه، مشارکت های این مطالعه به شرح زیر است:
- (۱)
-
برای اولین بار، ما یک روش یادگیری عمیق را برای نقشه برداری پوشش پلاستیکی سبز شهری از داده های سنجش از دور VHR ایجاد کردیم که می تواند ابزار موثری برای نظارت بر سایت ساخت و ساز و حفاظت از محیط زیست باشد.
- (۲)
-
ما از یک CNN تغییر شکل پذیر چند مقیاسی برای مقابله با تنوع مقیاس ها و اشکال شی زمین در مناظر پیچیده شهری استفاده کردیم.
- (۳)
-
ما نمونههای برچسبگذاریشده محدود را با دادههای بدون برچسب عظیم در یک چارچوب یادگیری نیمهنظارتشده ادغام کردیم تا قابلیت تعمیم مدل طبقهبندی برای پوششهای پلاستیکی سبز را افزایش دهیم.
۲٫ منطقه مطالعه و مجموعه داده
۲٫۱٫ منطقه مطالعه
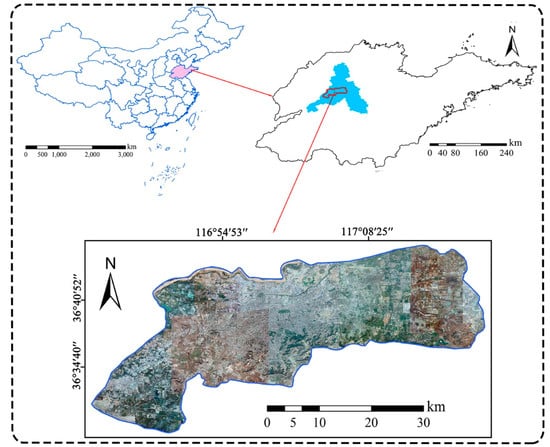
منطقه مورد مطالعه ( شکل ۲ ) مناطق ساخته شده شهری شهر جینان است که مرکز استان استان شاندونگ چین است. این شامل بخشهایی از ناحیه لیچنگ، ناحیه لیکسیا، ناحیه تیانچیائو، ناحیه هوآیین، ناحیه شیزونگ و ناحیه چانگ کینگ با مساحت تقریبی ۱۰۱۵ کیلومتر مربع است .
شهر جینان در میانه غرب استان شاندونگ، در لبه شرقی دشت شمال چین قرار دارد. مشخصه آن یک بادهای موسمی قاره ای معتدل و نیمه مرطوب با میانگین دمای سالانه ۱۳٫۸ درجه سانتی گراد، متوسط دوره بدون یخبندان ۱۷۸ روز و میانگین بارندگی سالانه تقریباً ۶۸۵ میلی متر است. اخیراً جینان شاهد گسترش و نوسازی سریع شهری بوده است. تعداد زیادی روستا در حاشیه مناطق شهری تخریب شده و برخی از ساختمان های قدیمی در مناطق شهری بازسازی شده اند. بیشتر این مناطق بازسازی شده توسط مالچ پلاستیکی سبز پوشیده شده است.
۲٫۲٫ مجموعه داده
با توجه به استفاده گسترده و در دسترس بودن داده ها، داده های سنجش از راه دور از پلت فرم Google Earth (GE) [ ۳۴ ] پذیرفته شد. به طور خاص، این تصویر از پایگاه داده تاریخ جنرال الکتریک (به دست آمده در سال ۲۰۱۹) بود و وضوح مکانی حدود ۱٫۱۹ متر بر پیکسل داشت. در واقع، تصاویر سنجش از راه دور مربوطه عمدتا توسط Maxar (یعنی شرکت DigitalGlobe، Westminster، CO، ایالات متحده آمریکا) ارائه شده است. حسگرهای نوری شامل WorldView-2، WorldView-3 و WorldView-4 بودند. اگرچه سری WorldView می تواند مشاهدات چند طیفی ارائه دهد، داده های ارائه شده توسط پلتفرم Google Earth تنها دارای سه باند (یعنی قرمز، سبز و آبی، RGB) هستند. علاوه بر این، پلتفرم Google Earth فقط داده ها را با وضوح رادیومتریک ۸ بیتی ارائه می دهد.
اندازه تصویر ۳۵۹۷۶ × ۶۳۰۵۵ پیکسل بود که مربوط به حدود ۴۳ × ۷۵ کیلومتر مربع است ( شکل ۲ ). طرح طبقه بندی در این مطالعه شامل دو نوع پوشش پلاستیکی سبز (GPC) و غیر GPC بود. هر دو نمونه آموزشی و آزمایشی مربوط به وصله های تصویری با اندازه ۲۲۴ پیکسل × ۲۲۴ پیکسل هستند. در واقع، اندازه ۲۲۴ پیکسل × ۲۲۴ پیکسل یک اندازه وصله تصویر استاندارد در زمینه کامپیوتر (CV) بوده است، جایی که شبکه های عصبی کانولوشنال محبوب (به عنوان مثال ResNet، DenseNet) یک پچ تصویر ۲۲۴ × ۲۲۴ را می گیرند و یک تصویر پیش بینی شده را خروجی می کنند. برچسب. بنابراین، برای مقایسه با این مدلهای CV، از این تنظیم نیز در این مطالعه استفاده کردیم. علاوه بر این، از آنجایی که وضوح فضایی حدود ۱٫۲ متر بر پیکسل است، وصله تصویر ۲۲۴ × ۲۲۴ با ۲۶۸ × ۲۶۸ متر مربع مطابقت دارد .. در این زمینه، وصله تصویر میتواند صحنهای را پوشش دهد که برای تشخیص ناحیه پوششدار پلاستیکی خیلی بزرگ یا خیلی کوچک نیست. شکل ۳ چندین نمونه از هر نوع پوشش زمین را نشان می دهد.
به منظور توصیف جزئیات ترکیب مواد GPC، دادههای Sentinel-2 L2A را که در ۲۸ اوت ۲۰۱۹ از آژانس فضایی اروپا (ESA) بهدستآمده بود دانلود کردیم و امضای بازتاب طیفی GPC ( شکل ۴ ) را با استفاده از باندهای ۲-۸ ترسیم کردیم. مرئی/نزدیک مادون قرمز)، باند ۸a (نزدیک مادون قرمز)، و باند ۱۱-۱۲ (مادون قرمز موج کوتاه). آنها نشان دادند که امضای بازتاب طیفی پوشش پلاستیکی سبز شبیه به زمین های ساخته شده یا لخت است، که منجر به سردرگمی طیفی در طبقه بندی تصویر می شود ( شکل ۴ )، به ویژه برای تصاویر RGB با تنها سه باند، مانند آزمایش ما.
۳٫ روش ها
۳٫۱٫ مروری بر مدل پیشنهادی
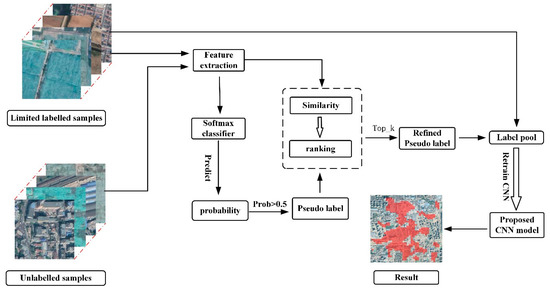
شکل ۵ نمای کلی روش پیشنهادی برای نقشه برداری پوشش پلاستیکی سبز را نشان می دهد. ورودی یک وصله تصویری با ۲۲۴ سطر و ۲۲۴ ستون است و نتیجه نهایی یک کلاس پوشش زمین پیش بینی شده است. به طور خاص، روش پیشنهادی شامل دو جزء است: (۱) استخراج ویژگی بر اساس CNN عمیق. و (۲) یادگیری نیمه نظارتی که داده های برچسب دار و بدون برچسب را ادغام می کند. در مورد اولی، ما از یک CNN قابل تغییر شکل چند مقیاسی برای یادگیری ویژگیهای فضایی در مناظر پیچیده شهری استفاده کردیم. برای دومی، CNN آموزش دیده ابتدا برای تخصیص داده های بدون برچسب با یک برچسب شبه استفاده شد. پس از آن، مطمئن ترین داده ها از طریق رتبه بندی برتر انتخاب شدند و به مجموعه آموزشی برای بازآموزی مدل CNN اضافه شدند.
۳٫۲٫ CNN قابل تغییر شکل چند مقیاسی برای نمایش ویژگی
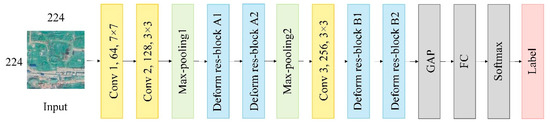
شکل ۶ و جدول ۱ ساختار دقیق CNN قابل تغییر شکل چند مقیاسی را برای نمایش ویژگی های عمیق نشان می دهد. به طور خاص، این شامل چندین لایه کانولوشن، لایههای حداکثر تجمعی، و بلوکهای باقیمانده چند مقیاسی قابل تغییر شکل است. در همین حال، برای به دست آوردن نتیجه طبقه بندی نهایی، یک ادغام میانگین جهانی (GAP)، یک لایه کاملا متصل (FC) و یک لایه Softmax آبشاری شدند.
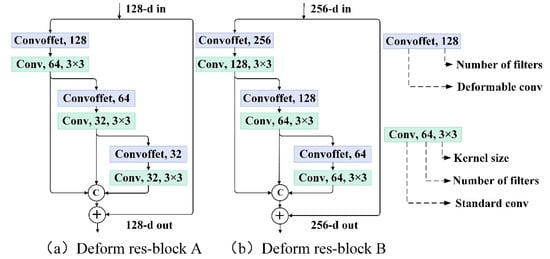
در این مطالعه، هم پیچیدگیهای تغییر شکلپذیر و هم بلوکهای باقیمانده چند مقیاسی برای نمایش ویژگیهای بهتر به مدل عمیق CNN معرفی شدند. از طریق پیچیدگی تغییر شکلپذیر، میدان پذیرنده و مکانهای نمونهگیری برای سازگاری با اشکال و مقیاسهای اجسام زمینی آموزش داده شدند که برای استخراج ویژگیهای بسیار متمایز مفید بود. در همین حال، یک بلوک باقیمانده چند مقیاسی میتواند ویژگیهای سلسله مراتبی و چند مقیاسی را استخراج کند و جریان گرادیان را همزمان بهبود بخشد. علاوه بر این، ادغام پیچشهای تغییر شکلپذیر در بلوک باقیمانده چند مقیاسی میتواند محاسن هر دو مدول را ترکیب کند و سازگاری ویژگی را با الگوهای فضایی پیچیده مناظر شهری افزایش دهد. شکل ۷پارامترهای دقیق بلوک های باقیمانده چند مقیاسی قابل تغییر شکل را نشان می دهد.
علاوه بر این، در مطالعه قبلی ما [ ۳۱ ]، CNN تغییر شکل پذیر چند مقیاسی برای یادگیری ویژگی های فضایی در یک چشم انداز تالاب ساحلی پیشنهاد شد و عملکرد خوبی را نشان داد. بنابراین، در این مطالعه با در نظر گرفتن ناهمگونی فضایی سناریوهای پیچیده شهری، آن را نیز معرفی کردیم. جزئیات بیشتر مدل فوق را می توان در [ ۳۱ ] یافت.
۳٫۳٫ انتخاب نمونه برای یادگیری نیمه نظارتی
ماهیت مبتنی بر دادههای یادگیری عمیق، تعداد زیادی نمونه برچسبدار با کیفیت بالا را برای حفظ قابلیت تعمیم مدل میطلبد. با این حال، در زمینه سنجش از دور و علوم زمین، برچسب گذاری دستی نمونه های کافی به دلیل شدت کار بالا و راندمان پایین غیرممکن است. از سوی دیگر، یادگیری نیمه نظارتی با هدف یادگیری از دادههای برچسبدار و بدون برچسب، ارائه یک استراتژی مطلوب برای رسیدگی به مسئله دادههای آموزشی ناکافی است و میتواند با استخراج تعداد زیادی از نمونههای بدون برچسب به دقت رضایتبخشی دست یابد. بنابراین، ما به یادگیری عمیق نیمه نظارتی متوسل شدیم و یک استراتژی دو مرحلهای را برای انتخاب مطمئنترین نمونههای بدون برچسب برای بازآموزی مدل پیشنهاد کردیم.
قبل از توضیح استراتژی دو مرحلهای برای انتخاب نمونههای بدون برچسب، ابتدا جزئیات دادههای برچسبگذاری شده را معرفی میکنیم. برای شروع، ما ۷۰۰ نمونه را برای هر دسته، شامل GPC و غیر GPC، حاشیه نویسی کردیم تا مخزن برچسب اولیه را بسازیم. نمونههای برچسبگذاری شده بهطور تصادفی به دو بخش ۳۰۰ برای مجموعه آموزشی و ۴۰۰ برای مجموعه تست تقسیم شدند. در همین حال، ۹۰٪ از مجموعه آموزشی برای آموزش CNN به کار گرفته شد، در حالی که ۱۰٪ باقی مانده به عنوان یک مجموعه اعتبار سنجی برای ارزیابی عملکرد در طول آموزش استفاده شد.
استراتژی دو مرحله ای پیشنهادی برای یادگیری نیمه نظارتی به شرح زیر بود. در مرحله اول، CNN آموزش دیده برای پیش بینی نمونه ها از استخر بدون برچسب برای استخراج احتمال خلفی استفاده شد. فقط نمونه های بدون برچسب با احتمال بیش از ۰٫۵ انتخاب می شوند و با یک دسته پیش بینی شده (یعنی نمونه های شبه نشاندار) تخصیص می یابند. با این حال، این نمونه های شبه برچسب ممکن است غیر قابل اعتماد باشند. اگر مستقیماً همه این نمونهها را به استخر برچسبگذاری شده اضافه کنیم تا مدل CNN را دوباره آموزش دهیم، عملکرد همیشه به دلیل نویز اضافی افزایش نمییابد.
برای اطمینان از قابلیت اطمینان نمونههای شبه برچسبگذاری شده، مرحله دوم را برای انتخاب دادههای بدون برچسب معرفی کردیم. ما شباهتهای بین هر نمونه شبه برچسبدار و همه نمونههای برچسبگذاریشده را محاسبه کردیم که با فاصله اقلیدسی اندازهگیری میشوند:
جایی که تومنتومنو لjل�به ترتیب i- امین نمونه برچسب دار و j- امین نمونه برچسب دار را مشخص کنید. s ( ⋅ )س(⋅)معیار تشابه را نشان می دهد. و f( ⋅ )�(⋅)مخفف عبارت عمیق ویژگی است. پس از آن، استخر برچسب گذاری شده را به ترتیب نزولی از شباهت های بالا مرتب کردیم. اگر نمونههای آموزشی top – k دارای همان دستهبندی با نمونه شبه برچسبگذاریشده باشند، آنگاه این نمونه شبه برچسبگذاری شده قابل اعتماد در نظر گرفته میشود و میتواند به مجموعه برچسبگذاریشده برای آموزش مجدد CNN اضافه شود [ ۲۹ ]. علاوه بر این، ما تأثیر مقدار k در top – k را بر طبقهبندی GPC تجزیه و تحلیل کردیم. نتایج در بخش ۴٫۴ نشان داده شده است.
۳٫۴٫ جزئیات آموزش شبکه
اگرچه میتوان تعداد نمونههای آموزشی را با استفاده از یادگیری نیمهنظارتی افزایش داد، اما ما همچنان از روش تقویت دادهها برای تقویت بیشتر قابلیت تعمیم و کاهش خطر بیشبرازش استفاده میکنیم. به طور خاص، تمام نمونه های برچسب گذاری شده اولیه ۹۰، ۱۸۰ یا ۲۷۰ درجه چرخانده شدند و به بالا و پایین برگشتند.
تمام وزنهای مدل CNN پیشنهادی با نرمالسازی He [ ۳۵ ] مقداردهی اولیه شدند و همه سوگیریها در ابتدا روی ۰ تنظیم شدند. برای بهینهسازی وزنها و سوگیریها برای بهبود عملکرد طبقهبندی، یک بهینهساز Adam [ ۳۶ ] با نرخ یادگیری اولیه استفاده شد. ۱۰-۴ . _ یک تکنیک توقف اولیه برای انتخاب بهترین مدل به کار گرفته شد. از دست دادن آنتروپی متقابل [ ۳۷ ] اتخاذ شد که بیان آن به شرح زیر است:
که در آن L نشان دهنده از دست دادن آنتروپی متقابل است. yˆمن�^منمخفف احتمال پیش بینی شده توسط مدل است. y i بیانگر حقیقت پایه است. و N به تعداد کلاس ها اشاره دارد.
روند آموزش شامل مراحل زیر بود:
- (۱)
-
در مرحله اول، ستون فقرات، به عنوان مثال، CNN تغییر شکل پذیر چند مقیاسی تنها با استفاده از داده های برچسب گذاری شده اولیه آموزش داده شد.
- (۲)
-
در مرحله بعد، ستون فقرات برای پیشبینی مجموعه دادههای بدون برچسب استفاده شد و تنها نمونههایی که فرآیند انتخاب دو مرحلهای را پشت سر گذاشتند به مجموعه برچسبگذاریشده با برچسبهای شبه اضافه میشوند.
- (۳)
-
ستون فقرات با نمونههایی از استخر جدید برچسبگذاری شده دوباره آموزش داده شد.
علاوه بر این، کتابخانه یادگیری عمیق مورد استفاده TensorFlow [ ۳۸ ] بود. کل چارچوب یادگیری نیمه نظارت شده بر روی سیستم عامل اوبونتو ۱۸٫۰۴ با پردازنده Intel Xeon(R) Gold 5118 و NVIDIA TITAN V با حافظه ۱۲ گیگابایتی انجام شد.
۳٫۵٫ ارزیابی های دقت
پس از آموزش مدل طبقه بندی، در مجموع از ۴۰۰ نمونه آزمایش برای محاسبه دقت کلی و ماتریس سردرگمی استفاده شد. معیارهای زیر نیز محاسبه شد: دقت تولید کننده (PA)، دقت کاربر (UA) و ضریب کاپا. در همین حال، ارزیابی بصری نیز برای بررسی خطاهای طبقه بندی آشکار درگیر شد. به طور کلی، بازرسی بصری یک روش ارزیابی ذهنی است که از طریق مقایسه نتایج نقشه برداری پوشش پلاستیکی سبز با تصاویر با وضوح بالا از Google Earth، خوب بودن یا نبودن نتیجه طبقه بندی را تعیین می کند. از آنجایی که مالچ پلاستیکی سبز رنگ را میتوان با چشم در Google Earth شناسایی کرد، ما از تصاویر تفسیر شده بصری به عنوان «استاندارد طلا» استفاده کردیم. علاوه بر این، ما بررسی های میدانی را در چندین مکان در جینان انجام دادیم تا مطمئن شویم که تصاویر تفسیر شده درست هستند.
ما همچنین یک مطالعه فرسایشی برای توجیه عملکرد استراتژی یادگیری نیمه نظارتی انجام دادیم. علاوه بر این، مقایسه ای با چندین مدل متداول CNN در زمینه بینایی کامپیوتر برای ارزیابی اثربخشی CNN تغییر شکل پذیر چند مقیاسی در این مقاله انجام شد.
۴٫ نتایج و بحث
۴٫۱٫ نتایج طبقه بندی GPC
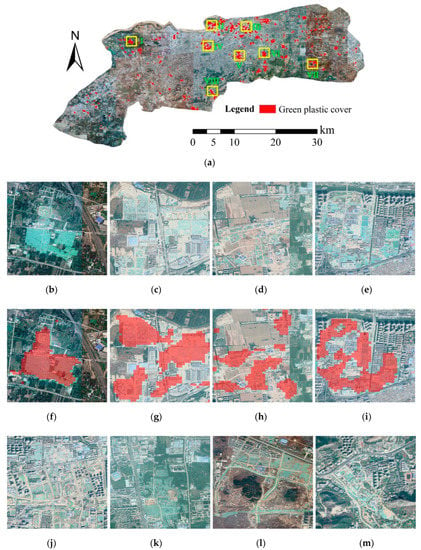
پس از روش یادگیری نیمه نظارت شده، بهترین مدل آموزش دیده برای طبقه بندی کل تصاویر سنجش از دور VHR استفاده شد. یک پنجره کشویی ۲۲۴ × ۲۲۴ برای پیشبینی پوشش پلاستیک سبز استفاده شد. شکل ۸ توزیع فضایی نتایج پیشبینی GPC را نشان میدهد. می توان مشاهده کرد که مناطق پوشیده از پلاستیک سبز عمدتاً در قسمت شرقی جینان واقع شده اند که نشان می دهد جینان در حال تجربه نوسازی شهری به سمت شرق بوده است. نتایج پایش سنجش از دور فوق مطابق با برنامهریزی شهری جینان است که اثربخشی روش پیشنهادی را در کشف اطلاعات کلیدی در مورد نوسازی شهری تأیید میکند.
شکل ۸ همچنین چندین بخش از تصاویر سنجش از راه دور اصلی و نتایج پیشبینی GPC را نشان میدهد. از مناطق فرعی می توان دریافت که منظر شهری نسبتاً پیچیده است و ناهمگونی فضایی بالایی دارد. بنابراین، تشخیص دقیق GPC یک کار چالش برانگیز است. با این حال، بازرسی دقیق بصری نشان میدهد که نتایج استخراج مناطق پوشیده از پلاستیک سبز با حقیقت زمین سازگاری خوبی دارد، که استحکام روش پیشنهادی ما را توجیه میکند.
۴٫۲٫ نتایج ارزیابی دقت
بخش ۴٫۱ عمدتاً نتایج طبقه بندی را به صورت کیفی از یک بازرسی بصری ارزیابی می کند. برای توجیه بیشتر عملکرد، این بخش یک ماتریس سردرگمی محاسبه شده از مجموعه آزمایشی را برای ارزیابی کمی دقت نقشه برداری پوشش پلاستیکی سبز شهری اتخاذ می کند. تعداد نمونه های آزمایشی برای هر کلاس ۴۰۰ عدد می باشد. جدول ۲ نتایج ارزیابی دقت را فهرست می کند.
جدول ۲ نشان می دهد که دقت کلی به ۹۱٫۶۳٪ و شاخص کاپا به ۰٫۸۳۲۵ رسیده است، که نشان می دهد روش پیشنهادی عملکرد عالی در نقشه برداری پوشش پلاستیک سبز شهری از داده های سنجش از دور VHR به دست آورده است. در همین حال، از آنجایی که ما شناسایی GPC را به عنوان یک وظیفه طبقهبندی صحنه سنجش از دور میدیدیم، طبقهبندی مبتنی بر پچ و استراتژی پنجره کشویی منجر به یک مرز دندانهدار میشود که منجر به خطاهای اضافی هنگام محاسبه کل مساحت GPC میشود. برای مقابله با این موضوع، ما می خواهیم از روش های تقسیم بندی معنایی مانند UNet [ ۳۹ ] و سری DeepLab [ ۴۰ ] بهره برداری کنیم.] در مطالعات آینده برای بازیابی مرزهای دقیق GPC. با این حال، باید توجه داشت که روشهای تقسیمبندی معنایی نیاز به بردار کردن GPC برای آمادهسازی دادههای آموزشی دارند، که نسبت به روش پیشنهادی ما نیاز به کار بیشتری دارد. در این شرایط، روش پیشنهادی میتواند به عنوان یک روش سریع، مقرونبهصرفه و در عین حال قابل اعتماد برای تشخیص GPC در نظر گرفته شود، بهویژه زمانی که مصالحه بین حجم کار و دقت در نظر گرفته میشود.
۴٫۳٫ تأثیر یادگیری نیمه نظارتی بر طبقه بندی GPC
برای توجیه سهم یادگیری نیمه نظارت شده در طبقه بندی GPC، ما یک مطالعه فرسایشی انجام دادیم. به طور خاص، تنها ۲۷۰ نمونه اولیه برچسبگذاری شده برای هر کلاس (GPC و غیر GPC) برای آموزش مدل طبقهبندی استفاده شد. دقت با استفاده از همان مجموعه تست بخش ۴٫۲ ارزیابی شد. ماتریس سردرگمی جدید به شرح زیر است.
جدول ۳ نشان می دهد که هنگام استفاده از داده های برچسب گذاری شده محدود، عملکرد طبقه بندی پایین تر از یادگیری نیمه نظارت است. OA تنها به ۸۵٫۲۵% می رسد، کاهش ۶٫۳۸%، در حالی که شاخص کاپا از ۰٫۸۳۲۵ به ۰٫۷۰۵۰ کاهش یافته است، کاهش ۰٫۱۲۷۵٫ بنابراین، معرفی یادگیری نیمه نظارت شده می تواند عملکرد طبقه بندی را بهبود بخشد. این عمدتا به دلیل قابلیت یادگیری نیمه نظارت شده برای استخراج موثر داده های عظیم بدون برچسب است. استراتژی انتخاب دو مرحلهای دادههای برچسبگذاریشده شبه در این مطالعه میتواند اطمینان حاصل کند که محرمانهترین دادهها به مجموعه برچسبگذاریشده اضافه میشوند.
۴٫۴٫ تاثیر k در Top-k بر طبقه بندی GPC
در این بخش، ما تأثیر k در top – k بر طبقهبندی GPC را تحلیل میکنیم. یک سری k از ۴۵ تا ۲۷۰ با گام ۴۵ در نظر گرفته شد. با توجه به اینکه تعداد نمونههای GPC بسیار کمتر از نمونههای غیر GPC در استخر بدون برچسب است، ابتدا تعدادی نمونه M GPC را انتخاب کردیم. پس از آن، همان تعداد نمونه M غیر GPC نیز انتخاب شد. نتایج ارزیابی دقت در جدول ۴ نشان داده شده است.
جدول ۴ نشان می دهد که تعداد نمونه های کاندید شبه برچسب دار به تدریج با افزایش k در بالای k کاهش می یابد . این قابل درک است زیرا هر چه مقدار k بیشتر باشد، آستانه اطمینان این نمونههای شبه برچسبدار بالاتر است. وقتی مقدار k خیلی زیاد است، هیچ نمونه شبه برچسبی وجود نخواهد داشت که استراتژی انتخاب را برآورده کند.
جدول ۴ همچنین نشان می دهد که دقت طبقه بندی GPC زمانی که k برابر ۹۰ باشد، بالاترین میزان است. این ممکن است به دلیل سازش بین اطلاعات اضافی و نویز معرفی شده باشد. وقتی k کمتر از مقدار بهینه باشد (۹۰ در این مطالعه)، نمونههای شبه نشاندار بیشتری به مخزن برچسبدار اضافه میشوند. با این حال، نویز بیشتری نیز معرفی خواهد شد. در همین حال، زمانی که k فراتر از مقدار بهینه افزایش مییابد، هم تعداد نمونههای شبه برچسبگذاری شده و هم به دست آوردن اطلاعات همراه کاهش مییابد که منجر به کاهش عملکرد طبقهبندی میشود.
۴٫۵٫ مقایسه با مدل های کلاسیک CNN
برای توجیه بیشتر اثربخشی مدل پیشنهادی، چندین مدل کلاسیک CNN در زمینه بینایی کامپیوتری برای مقایسه اتخاذ شد، مانند VGG [ ۴۱ ]، ResNet [ ۴۲ ] و DenseNet [ ۴۳ ]. لازم به ذکر است که تمامی مدل های فوق با استفاده از یک استراتژی یادگیری نیمه نظارتی یکسان آموزش داده شده و در یک مجموعه آزمایشی مورد ارزیابی قرار گرفته اند. نتایج مقایسه در جدول ۵ فهرست شده است.
جدول ۵ نشان می دهد که مدل CNN پیشنهادی (CNN تغییر شکل پذیر چند مقیاسی) بالاترین دقت را در بین چهار مدل یادگیری عمیق به دست آورد. به طور خاص، VGG در مقایسه با ResNet (86.88٪) و DenseNet (89.62٪) OA نسبتاً کمتری (۸۵٫۸۷٪) داشت. این عمدتا به این دلیل است که VGG از یک آبشار ساده از لایه های کانولوشن در ساخت معماری شبکه خود استفاده کرد [ ۴۱ ]]، و در استخراج ویژگی های بسیار معرف مشکل دارد. در همین حال، ResNet از مسئله ناپدید شدن گرادیان در فرآیند انتشار برگشت خطا به دلیل معرفی یادگیری باقیمانده و اتصال پرش، که منجر به دقت بالاتر شد، اجتناب کرد. همانطور که برای DenseNet، معماری شبکه آن شامل اتصالات پرش بیشتری برای تجمیع ویژگی ها بود و بهترین عملکرد را داشت. با این حال، در این مقاله CNN تغییر شکل پذیر چند مقیاسی از تمام مدل های CNN کلاسیک بهتر عمل کرد. این می تواند به این دلیل باشد که CNN پیشنهادی هنگام در نظر گرفتن تغییرات شکل و مقیاس مناظر پیچیده شهری، سازگاری بهتری دارد.
علاوه بر این، ما مدلهای CNN فوق را بدون استراتژی یادگیری نیمه نظارتی مقایسه کردیم، به عنوان مثال، تنها نمونههای برچسبدار محدود اولیه مورد استفاده قرار گرفتند. نتایج مقایسه در جدول ۶ آمده است.
مشابه جدول ۵ ، جدول ۶ نشان می دهد که مدل پیشنهادی CNN از سایر شبکه های ستون فقرات با OA 85.25% و شاخص کاپا ۰٫۷۰۵۰ عملکرد بهتری داشت. بنابراین، اثربخشی CNN پیشنهادی در طبقهبندی GPC تحت شرایط نمونههای برچسبدار محدود بیشتر تأیید شد.
۴٫۶٫ مقایسه با داده های Sentinel-2
از زمان اجرای موفقیتآمیز برنامه کوپرنیک اروپایی که توسط آژانس فضایی اروپا (ESA) آغاز شد، دادههای چند طیفی Sentinel-2 اکنون دسترسی آزاد و رایگان برای عموم دارند و بینشهای جدیدی را برای کاربردهای سنجش از دور، مانند پوشش زمین ساحلی ارائه میکنند. طبقه بندی [ ۳۱ ]، نقشه برداری محصول [ ۴۴ ]، و نظارت بر مناطق شهری [ ۴۵ ]]. برای توجیه بیشتر عملکرد روش پیشنهادی، ما از CNN پیشنهادی برای تشخیص GPC از دادههای Sentinel-2 استفاده کردیم. به طور خاص، داده های Sentinel-2 L2A در ۲۸ آگوست ۲۰۱۹ به دست آمد. در مجموع از ۱۰ باند در آزمایش استفاده شد، از جمله باندهای ۲-۴ (۱۰ متر)، باندهای ۵-۷ (۲۰ متر)، باند ۸ (۱۰ متر). ، band8a (20 متر) و باندهای ۱۱-۱۲ (۲۰ متر). در همین حال، نوارهایی با وضوح فضایی ۲۰ متر با استفاده از نرم افزار SNAP توسعه یافته توسط ESA به ۱۰ متر نمونه برداری شدند. از آنجایی که وصله تصویری داده های جنرال الکتریک استفاده شده ۲۲۴ × ۲۲۴ با وضوح فضایی ۱٫۱۹ متر بر پیکسل است، برای حفظ قابلیت مقایسه، وصله تصویری داده های Sentinel-2 روی ۲۷×۲۷ تنظیم شد. علاوه بر این، مجموعه داده های آموزشی و آزمایشی مشابهی انجام شد برای آموزش و ارزیابی مدل استفاده می شود. نتایج مقایسه دقت در جدول ۷ فهرست شده است.
جدول ۷ نشان میدهد که CNN پیشنهادی میتواند عملکرد بالایی برای دادههای Sentinel-2 و Google Earth، با OA 91.63% و ۹۰٫۸۷% داشته باشد. این بیشتر نشان داد که مدل CNN پیشنهادی ما دارای توانایی شناسایی GPC قوی برای دادههای Google Earth یا دادههای چند طیفی Sentinel-2 به عنوان ورودی شبکه است.
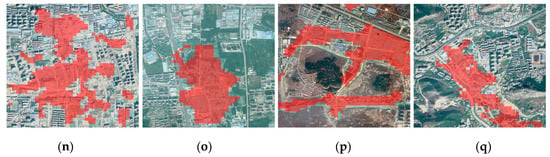
شکل ۹ توزیع فضایی نتایج پیشبینی GPC را با استفاده از دادههای Sentinel-2 نشان میدهد. از طریق مقایسه با نتایج پیشبینی GPC با استفاده از دادههای Google Earth، میتوان مشاهده کرد که نتایج پیشبینی GPC با استفاده از این دو تصویر مختلف دارای الگوهای فضایی مشابهی هستند.
اکنون که نتیجه طبقهبندی GPC از Sentinel-2 در دسترس است، میتوان از آن برای اصلاح نتیجه دادههای GE استفاده کرد. لازم به ذکر است که کل منطقه مورد مطالعه مساحت وسیعی به مساحت تقریبی ۱۰۱۵ کیلومتر مربع را شامل می شود .، پوشش کل منطقه با تصاویر VHR تک تاریخ را دشوار می کند. در واقع، منطقه مورد مطالعه توسط مجموعه داده های VHR چند تاریخه از GE پوشش داده شده است. در همین حال، اکثر GPCها در مدت کوتاهی با ساختمانهای جدید جایگزین میشوند، بنابراین، اگر کل نتایج طبقهبندی را از چند تاریخ GE توسط Sentinel-2 تکتاریخ اصلاح کنیم، خطاهایی از عدم تطابق تاریخهای مشاهده وجود خواهد داشت. در این بخش، زیرمجموعهای از دادههای GE را انتخاب کردیم که تاریخ مشاهده آن (۲۳ اوت ۲۰۱۹) نزدیک به دادههای Sentinel-2 (28 اوت ۲۰۱۹) است. سپس یک همجوشی سطح تصمیم را برای ادغام نتایج طبقهبندی GE و Sentinel-2 اعمال کردیم. فقط تقاطع نتایج طبقه بندی GE و Sentinel-2 حفظ شد تا قابلیت اطمینان تشخیص GPC افزایش یابد که در شکل ۱۰ نشان داده شده است .
۴٫۷٫ مقایسه با طبقه بندی تصادفی جنگل
جنگل تصادفی (RF)، پیشنهاد شده توسط Breiman [ ۴۶ ]، به طور گسترده ای برای نقشه برداری کاربری/پوشش زمین در زمینه سنجش از دور با دقت طبقه بندی بهبود یافته استفاده شده است [ ۱۲ ، ۱۳ ، ۴۷ ، ۴۸ ]. برای توجیه بیشتر عملکرد CNN پیشنهادی، باید آن را با RF مقایسه کرد. بنابراین، RF با همان نمونه های آموزشی و آزمایشی روش پیشنهادی برای حفظ انصاف آموزش و آزمایش شد. نتایج مقایسه دقت در جدول ۸ فهرست شده است.
جدول ۸ نشان می دهد که در مقایسه با طبقه بندی RF، CNN پیشنهادی می تواند OA را به ترتیب ۷٫۷۶% و ۵٫۸۸% برای داده های GE و S2 افزایش دهد. این عمدتا به این دلیل است که CNN می تواند ویژگی های تمایز سطح بالایی را در مقایسه با RF استخراج کند، که برای بهبود دقت طبقه بندی مفید بود.
۵٫ نتیجه گیری ها
این مطالعه یک چارچوب یادگیری عمیق نیمه نظارتی را برای نقشه برداری پوشش پلاستیکی سبز شهری از تصاویر سنجش از دور VHR پیشنهاد کرد. یک CNN تغییر شکل پذیر چند مقیاسی برای یادگیری ویژگی های متمایز در مناظر پیچیده شهری مورد بهره برداری قرار گرفت. یک استراتژی انتخاب نمونه دو مرحله ای برای یادگیری نیمه نظارت شده برای شناسایی قابل اعتمادترین نمونه از مجموعه بدون برچسب پیشنهاد شد. آزمایشها و مطالعه فرسایش برای تأیید عملکرد خوب روش پیشنهادی انجام شد.
نتایج تجربی نشان میدهد که روش پیشنهادی میتواند مناطق پوشیده از پلاستیک سبز در جینان را با عملکرد بالا طبقهبندی کند. ارزیابی دقت نشان داد که دقت کلی (OA) 91.63 درصد و شاخص کاپا ۰٫۸۳۲۵ بود. علاوه بر این، یک بازرسی دقیق بصری نشان داد که بیشتر مناطق سبز پوشیده از پلاستیک را می توان به درستی شناسایی کرد. یک مطالعه فرسایشی نشان داد که استراتژی یادگیری نیمه نظارت شده می تواند OA را تا ۶٫۳۸٪ در مقایسه با یادگیری نظارت شده افزایش دهد، که نشان می دهد استخراج محرمانه ترین داده های بدون برچسب می تواند به طور موثری دقت طبقه بندی را بهبود بخشد. در همین حال، مقایسه با چندین مدل کلاسیک CNN در زمینه بینایی کامپیوتری نشان داد که CNN تغییر شکل پذیر چند مقیاسی در این مطالعه بالاترین دقت را داشت.
علاوه بر این، این مطالعه اولین تلاش برای شناسایی پوشش پلاستیکی سبز از دادههای سنجش از دور VHR بر اساس روشهای یادگیری عمیق است که میتواند پایهای برای مطالعات مربوطه باشد. اگرچه CNN پیشنهادی در حال حاضر برای شناسایی مناطق پوشیده از پلاستیک شهری استفاده میشود، اما میتوان آن را برای کاربردهای دیگر مانند درک صحنه سنجش از دور نیز به کار برد. در کار آینده، ما کارایی مدل را بیشتر توجیه خواهیم کرد و از مدلهای تقسیمبندی معنایی برای استخراج مرزهای دقیق مناطق پوشیده از پلاستیک سبز استفاده خواهیم کرد.