
خلاصه
:
طبقه بندی ; تقسیم بندی معنایی ; میراث فرهنگی دیجیتال ; ابرهای نقطه ای ; یادگیری ماشینی ؛ یادگیری عمیق
۱٫ معرفی
سوالات تحقیق و ساختار مقاله
- RQ1
-
آیا میتوان دستورالعملهایی را برای تقسیمبندی خودکار ابرهای نقطه در حوزه CH به جامعه تحقیقاتی ارائه کرد؟
- RQ2
-
کدام الگوریتم های ML و DL برای تقسیم بندی معنایی ابر نقطه سه بعدی میراث بهتر عمل می کنند؟
- RQ3
-
آیا راه حلی برنده بین ML و DL در حوزه CH وجود دارد؟
- RQ4
-
آیا مقایسه نتایج عملکرد الگوریتمهای ML و DL با یک خط لوله درست است؟
۲٫ آثار مرتبط
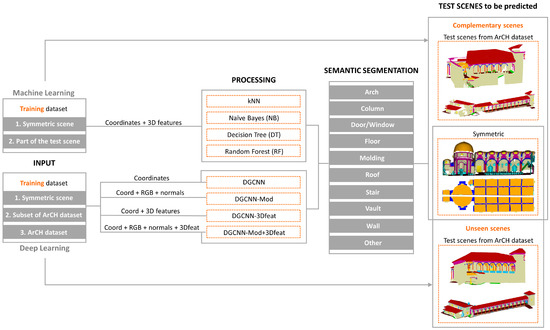
۳٫ مواد و روشها
۳٫۱٫ معیار برای تقسیم بندی معنایی ابر نقطه ای
۳٫۲٫ طبقهبندیکنندههای یادگیری ماشین برای تقسیمبندی معنایی ابر نقطهای
انتخاب ویژگی ها
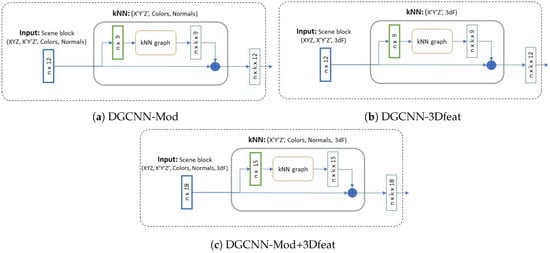
۳٫۳٫ یادگیری عمیق برای تقسیم بندی معنایی ابر نقطه ای
جایی که μ�میانگین نمونه های آموزشی و σ�انحراف معیار نمونه های آموزشی است. در عوض، Scaler2 ویژگیها را با استفاده از آماری که نسبت به موارد پرت قوی هستند، مقیاسبندی میکند. این مرحله پیش پردازش، میانه را حذف می کند و داده ها را با توجه به محدوده چندک (IQR: InterQuartile Range) مقیاس می کند. IQR محدوده بین چارک ۱ (چک ۲۵) و چارک سوم (چرک ۷۵) است. با محاسبه آمار مربوطه بر روی نمونه ها در مجموعه آموزشی، مرکز و مقیاس بندی به طور مستقل در هر ویژگی اتفاق می افتد. سپس محدوده میانی و بین چارکی ذخیره می شود تا در مجموعه آزمایش و اعتبارسنجی استفاده شود. علاوه بر این، شبکه اصلی DGCNN از تلفات آنتروپی متقاطع استفاده می کند. از آنجایی که ما از مجموعه دادههای واقعا نامتعادل استفاده میکنیم، تصمیم میگیریم افت کانونی [ ۵۰ ] را آزمایش کنیم] همچنین. این تابع خاص فقط برای حل مسائل عدم تعادل پیاده سازی شده است.
۳٫۴٫ معیارهای ارزیابی عملکرد
۴٫ نتایج
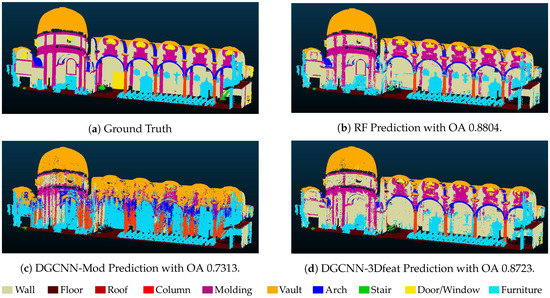
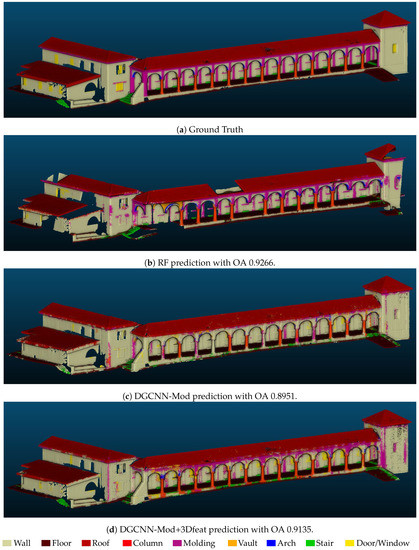
۴٫۱٫ آزمایش اول – بخش بندی یک صحنه جزئی مشروح
۴٫۲٫ آزمایش دوم – بخشبندی یک صحنه نادیده، Sacro Monte Varallo (SMV)
-
از دست دادن کانونی برای DGCNN-Mod.
-
پیش پردازش Scaler1 برای DGCNN-3Dfeat.
-
از دست دادن کانونی و پیش پردازش Scaler2 برای DGCNN-Mod+3Dfeat.
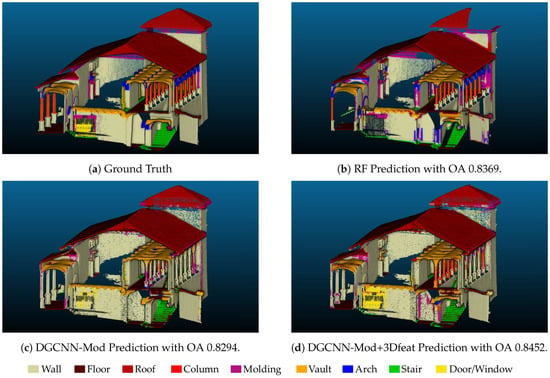
۴٫۳٫ آزمایش سوم – بخش بندی یک صحنه نادیده، Sacro Monte Ghiffa (SMG)
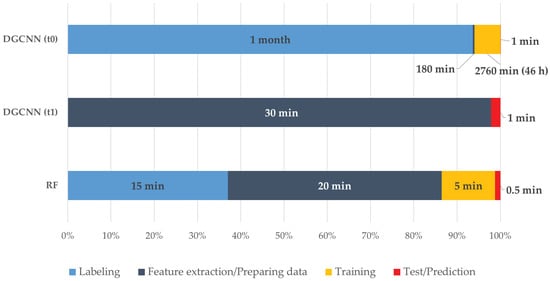
۴٫۴٫ تجزیه و تحلیل نتایج
۵٫ بحث و گفتگو
۶٫ نتیجه گیری و کارهای آینده
مشارکت های نویسنده
منابع مالی
قدردانی
تضاد علاقه
پیوست اول

منابع
- یو، اچ. یانگ، ز. تان، ال. وانگ، ی. سان، دبلیو. سان، م. تانگ، ی. روشها و مجموعههای داده در بخشبندی معنایی: مروری. محاسبات عصبی ۲۰۱۸ ، ۳۰۴ ، ۸۲-۱۰۳ . [ Google Scholar ] [ CrossRef ]
- ژانگ، ک. هائو، ام. وانگ، جی. د سیلوا، CW; فو، سی. گراف پویا پیوندی CNN: یادگیری در ابر نقطه از طریق پیوند دادن ویژگی های سلسله مراتبی. arXiv ۲۰۱۹ ، arXiv:1904.10014. [ Google Scholar ]
- زی، ی. تیان، جی. Zhu, X. مروری بر تقسیم بندی معنایی ابر نقطه ای. IEEE Geosci. سنسور از راه دور Mag. (GRSM) ۲۰۲۰ . [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لاماس، ج. ام لرونز، پی. مدینه، ر. زالاما، ای. Gómez-García-Bermejo, J. طبقه بندی تصاویر میراث معماری با استفاده از تکنیک های یادگیری عمیق. Appl. علمی ۲۰۱۷ ، ۷ ، ۹۹۲٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- گریلی، ای. اوزدمیر، ای. Remondino، F. کاربرد استراتژیهای یادگیری ماشینی و عمیق برای طبقهبندی ابرهای نقطه میراث. بین المللی قوس. فتوگرام حسگر از راه دور اسپات. Inf. علمی ۲۰۱۹ ، XLII-4/W18 ، ۴۴۷–۴۵۴٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گریلی، ای. Remondino، F. طبقه بندی میراث دیجیتال سه بعدی. Remote Sens. ۲۰۱۹ , ۱۱ , ۸۴۷٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- مالینورنی، ای. پیردیکا، آر. پائولانتی، م. مارتینی، م. مربیدونی، سی. ماترون، اف. Lingua، A. یادگیری عمیق برای تقسیم معنایی ابر نقطه سه بعدی. بین المللی قوس. فتوگرام حسگر از راه دور اسپات. Inf. علمی ۲۰۱۹ ، XLII-2/W15 ، ۷۳۵–۷۴۲٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پیردیکا، آر. ماملی، م. Malinverni، ES; پائولانتی، م. Frontoni، E. تولید خودکار مجموعه داده های مصنوعی ابر نقطه ای برای بازنمایی ساختمان های تاریخی. در مجموعه مقالات کنفرانس بین المللی واقعیت افزوده، واقعیت مجازی و گرافیک کامپیوتری، سانتا ماریا آل باگنو، ایتالیا، ۲۴ تا ۲۷ ژوئن ۲۰۱۹؛ ص ۲۰۳-۲۱۹٫ [ Google Scholar ]
- LeCun، Y.; بنژیو، ی. هینتون، جی. یادگیری عمیق. طبیعت ۲۰۱۵ ، ۵۲۱ ، ۴۳۶-۴۴۴٫ [ Google Scholar ] [ CrossRef ]
- کلوکوف، آر. Lempitsky، V. فرار از سلول ها: شبکه های عمیق kd برای تشخیص مدل های ابر نقطه سه بعدی. در مجموعه مقالات کنفرانس بین المللی IEEE در بینایی کامپیوتر، ونیز، ایتالیا، ۲۲ تا ۲۹ اکتبر ۲۰۱۷؛ صص ۸۶۳-۸۷۲٫ [ Google Scholar ]
- زی، اس. لیو، اس. چن، ز. Tu, Z. shapecontextnet توجهی برای تشخیص ابر نقطه. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو، سالت لیک سیتی، UT، ایالات متحده آمریکا، ۱۸ تا ۲۳ ژوئن ۲۰۱۸؛ صص ۴۶۰۶-۴۶۱۵٫ [ Google Scholar ]
- آلتمن، NS مقدمه ای بر رگرسیون ناپارامتریک هسته و نزدیکترین همسایه. صبح. آمار ۱۹۹۲ ، ۴۶ ، ۱۷۵-۱۸۵٫ [ Google Scholar ]
- ژانگ، اچ. بررسی شرایط برای بهینه بودن بیز ساده. بین المللی ج. تشخیص الگو. آرتیف. هوشمند ۲۰۰۵ ، ۱۹ ، ۱۸۳-۱۹۸٫ [ Google Scholar ] [ CrossRef ]
- بریمن، ال. فریدمن، جی. استون، سی جی; اولشن، RA طبقه بندی و رگرسیون درختان ; CRC Press: Boca Raton، FL، USA، ۱۹۸۴٫ [ Google Scholar ]
- بریمن، L. جنگل های تصادفی. ماخ فرا گرفتن. ۲۰۰۱ ، ۴۵ ، ۵-۳۲٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- وانگ، ی. سان، ی. لیو، ز. Sarma, SE; برونشتاین، MM; Solomon، JM Dynamic graph cnn برای یادگیری روی ابرهای نقطه ای. ACM Trans. نمودار (TOG) ۲۰۱۹ ، ۳۸ ، ۱-۱۲٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ماترون، اف. لینگوا، ا. پیردیکا، آر. Malinverni، ES; پائولانتی، م. گریلی، ای. رموندینو، اف. مورتیوسو، ا. Landes، T. معیاری برای تقسیمبندی معنایی ابر نقاط میراث در مقیاس بزرگ. ISPRS Int. قوس. فتوگرام حسگر از راه دور اسپات. Inf. علمی ۲۰۲۰ ، XLIII-B2 ، ۱۴۱۹-۱۴۲۶٫ [ Google Scholar ] [ CrossRef ]
- پیردیکا، آر. پائولانتی، م. ماترون، اف. مارتینی، م. مربیدونی، سی. Malinverni، ES; فروتونی، ای. Lingua، AM Point Cloud Semantic Segmentation با استفاده از چارچوب یادگیری عمیق برای میراث فرهنگی. Remote Sens. ۲۰۲۰ , ۱۲ , ۱۰۰۵٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- اوسس، ن. دورنایکا، اف. مجاهد، ع. ترسیم و طبقه بندی بر اساس تصویر بنایی میراثی ساخته شده. Remote Sens. ۲۰۱۴ ، ۶ ، ۱۸۶۳-۱۸۸۹٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ریویرو، بی. لورنسو، PB; اولیویرا، دی وی؛ گونزالس-خورخه، اچ. Arias, P. تجزیه و تحلیل مورفولوژیکی خودکار دیوارهای بنایی شبه دوره ای از LiDAR. محاسبه کنید. کمک مدنی زیرساخت. مهندس ۲۰۱۶ ، ۳۱ ، ۳۰۵-۳۱۹٫ [ Google Scholar ] [ CrossRef ]
- بارسانتی، اس جی; گوئیدی، جی. De Luca, L. بخش بندی مدل های سه بعدی برای تجزیه و تحلیل ساختاری میراث فرهنگی – برخی از مسائل مهم. ISPRS Ann. فتوگرام Remote Sens. Spatial Inf. علمی ۲۰۱۷ ، ۴ ، ۱۱۵٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- پوکس، اف. نوویل، آر. هالوت، پی. Billen، R. طبقهبندی ابر نقطهای از تسرها از دادههای لیزر زمینی همراه با تطبیق تصویر متراکم برای استخراج اطلاعات باستانشناسی. بین المللی J. Adv. زندگی علمی. ۲۰۱۷ ، ۴ ، ۲۰۳-۲۱۱٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گریلی، ای. دینینو، دی. مارسیکانو، ال. پتروچی، جی. Remondino، F. نظارت بر تقسیم بندی میراث فرهنگی سه بعدی. در مجموعه مقالات سومین کنگره بین المللی میراث دیجیتال ۲۰۱۸ (DigitalHERITAGE) که به طور مشترک با بیست و چهارمین کنفرانس بین المللی سیستم های مجازی و چند رسانه ای ۲۰۱۸ (VSMM 2018)، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، ۲۶ تا ۳۰ اکتبر ۲۰۱۸ برگزار شد. صص ۱-۸٫ [ Google Scholar ]
- گریلی، ای. فارلا، ای. ترسانی، ع. Remondino، F. تجزیه و تحلیل ویژگی های هندسی برای طبقه بندی ابرهای نقطه میراث فرهنگی. بین المللی قوس. فتوگرام Remote Sens. Spatial Inf. علمی ۲۰۱۹ ، XLII-2/W15 ، ۵۴۱–۵۴۸٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گریلی، ای. Remondino، F. تعمیم یادگیری ماشین در میراث مختلف معماری سه بعدی. ISPRS Int. J. Geo-Inf. ۲۰۲۰ ، ۹ ، ۳۷۹٫ [ Google Scholar ] [ CrossRef ]
- مورتیوسو، ا. گرسن مایر، ص. جداسازی مجازی بناهای تاریخی: آزمایشها و ارزیابیهای یک رویکرد خودکار برای طبقهبندی ابرهای نقطهای چند مقیاسی به عناصر معماری. Sensors ۲۰۲۰ , ۲۰ , ۲۱۶۱٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژانگ، جی. ژائو، ایکس. چن، ز. Lu, Z. مروری بر تقسیمبندی معنایی مبتنی بر یادگیری عمیق برای Point Cloud (نوامبر ۲۰۱۹). دسترسی IEEE ۲۰۱۹ ، ۷ ، ۱۷۹۱۱۸–۱۷۹۱۳۳٫ [ Google Scholar ] [ CrossRef ]
- گریفیث، دی. Boehm, J. SynthCity: یک ابر نقطه مصنوعی در مقیاس بزرگ. arXiv ۲۰۱۹ ، arXiv:1907.04758. [ Google Scholar ]
- Qi، CR; سو، اچ. مو، ک. Guibas، LJ Pointnet: یادگیری عمیق در مجموعه های نقطه برای طبقه بندی و تقسیم بندی سه بعدی. در مجموعه مقالات کنفرانس IEEE در مورد دید رایانه و تشخیص الگو، هونولولو، HI، ایالات متحده آمریکا، ۲۱ تا ۲۶ ژوئیه ۲۰۱۷؛ صص ۶۵۲-۶۶۰٫ [ Google Scholar ]
- Qi، CR; یی، ال. سو، اچ. Guibas، LJ Pointnet++: یادگیری ویژگی های سلسله مراتبی عمیق در مجموعه های نقطه در یک فضای متریک. در مجموعه مقالات سی و یکمین کنفرانس سیستم های پردازش اطلاعات عصبی (NIPS 2017)، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، ۴ تا ۹ دسامبر ۲۰۱۷؛ ص ۵۰۹۹-۵۱۰۸٫ [ Google Scholar ]
- آتزمون، م. مارون، اچ. لیپمن، Y. شبکه های عصبی کانولوشنال نقطه ای توسط اپراتورهای توسعه. arXiv ۲۰۱۸ ، arXiv:1803.10091. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- دی دیوژ، ام. کوادروس، ا. هونگ، سی. Douillard, B. یادگیری ویژگی های بدون نظارت برای طبقه بندی اسکن های سه بعدی در فضای باز. در مجموعه مقالات کنفرانس استرالیایی در مورد روبیتیک و اتوماسیون، سیدنی، NSW، استرالیا، ۲-۴ دسامبر ۲۰۱۳٫ جلد ۲، ص. ۱٫ [ Google Scholar ]
- ارمنی، من. سنر، او. ضمیر، ع. جیانگ، اچ. بریلاکیس، آی. فیشر، ام. Savarese, S. تجزیه معنایی سه بعدی فضاهای داخلی در مقیاس بزرگ. در مجموعه مقالات کنفرانس IEEE در مورد دید کامپیوتری و تشخیص الگو، لاس وگاس، NV، ایالات متحده، ۲۷-۳۰ ژوئن ۲۰۱۶٫ صص ۱۵۳۴-۱۵۴۳٫ [ Google Scholar ]
- گایگر، ا. لنز، پی. استیلر، سی. Urtasun, R. Vision ملاقات با روباتیک: مجموعه داده کیتی. بین المللی ربات جی. Res. ۲۰۱۳ ، ۳۲ ، ۱۲۳۱-۱۲۳۷٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هاکل، تی. ساوینوف، ن. لدیکی، ال. Wegner، JD; شیندلر، ک. Pollefeys, M. Semantic3d. net: یک معیار جدید طبقه بندی ابر نقطه ای در مقیاس بزرگ. arXiv ۲۰۱۷ , arXiv:1704.03847. [ Google Scholar ]
- چن، بی. شی، س. گونگ، دبلیو. ژانگ، کیو. یانگ، جی. دو، ال. سان، ج. ژانگ، ز. آهنگ، S. طبقه بندی ابر نقطه چند طیفی LiDAR: یک رویکرد دو مرحله ای. Remote Sens. ۲۰۱۷ , ۹ , ۳۷۳٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژانگ، جی. لین، ایکس. Ning، X. طبقهبندی مبتنی بر SVM ابرهای نقطهای LiDAR در هوا در مناطق شهری. Remote Sens. ۲۰۱۳ , ۵ , ۳۷۴۹–۳۷۷۵٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Laube، P. فرانتس، MO; Umlauf, G. ارزیابی ویژگی ها برای طبقه بندی مبتنی بر SVM از اولیه های هندسی در ابرهای نقطه ای. در مجموعه مقالات پانزدهمین کنفرانس بین المللی IEEE 2017 IAPR در مورد کاربردهای بینایی ماشین (MVA)، ناگویا، ژاپن، ۸ تا ۱۲ مه ۲۰۱۷؛ صص ۵۹-۶۲٫ [ Google Scholar ]
- باباحاجیانی، پ. فن، ال. گابوج، م. تشخیص اشیاء در ابر نقطه سه بعدی صحنه خیابان شهری. در مجموعه مقالات کنفرانس آسیایی بینایی کامپیوتر، سنگاپور، ۱ تا ۲ نوامبر ۲۰۱۴٫ صص ۱۷۷-۱۹۰٫ [ Google Scholar ]
- لی، ز. ژانگ، ال. تانگ، ایکس. دو، بی. وانگ، ی. ژانگ، ال. ژانگ، ز. لیو، اچ. می، جی. زینگ، ایکس. و همکاران یک رویکرد سه مرحله ای برای طبقه بندی ابر نقطه TLS. IEEE Trans. Geosci. Remote Sens. ۲۰۱۶ , ۵۴ , ۵۴۱۲–۵۴۲۴٫ [ Google Scholar ] [ CrossRef ]
- Lodha، SK; فیتزپاتریک، دی.م. طبقهبندی دادههای هلمبولد، DP Aerial lidar با استفاده از adaboost. در مجموعه مقالات ششمین کنفرانس بین المللی IEEE در مورد تصویربرداری و مدل سازی دیجیتال سه بعدی (۳DIM 2007)، مونترال، QC، کانادا، ۲۱-۲۳ اوت ۲۰۰۷٫ ص ۴۳۵-۴۴۲٫ [ Google Scholar ]
- لیو، ی. الکساندروف، م. زلاتانوا، اس. ژانگ، جی. مو، اف. چن، X. طبقه بندی ابرهای نقطه تاسیسات نیرو از وسایل نقلیه هوایی بدون سرنشین بر اساس محدودیت های adaboost و توپولوژیکی. Sensors ۲۰۱۹ , ۱۹ , ۴۷۱۷٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کانگ، ز. یانگ، جی. ژونگ، آر. روش طبقهبندی مبتنی بر شبکه بیزی که دادههای لیدار هوابرد را با تصاویر نوری یکپارچه میکند. IEEE J. Sel. بالا. Appl. زمین Obs. Remote Sens. ۲۰۱۶ ، ۱۰ ، ۱۶۵۱–۱۶۶۱٫ [ Google Scholar ] [ CrossRef ]
- تامپسون، DR. Hochberg، EJ; آسنر، GP; گرین، RO؛ Knapp، DE; گائو، پیش از میلاد؛ گارسیا، آر. گیراچ، ام. لی، ز. ماریتورنا، اس. و همکاران نقشه برداری هوابرد طیف بازتاب اعماق دریا با مخلوط های خطی بیزی سنسور از راه دور محیط. ۲۰۱۷ ، ۲۰۰ ، ۱۸-۳۰٫ [ Google Scholar ] [ CrossRef ]
- بلژیک، م. Drăguţ، L. جنگل تصادفی در سنجش از دور: بررسی برنامهها و جهتهای آینده. ISPRS J. Photogramm. Remote Sens. ۲۰۱۶ ، ۱۱۴ ، ۲۴–۳۱٫ [ Google Scholar ] [ CrossRef ]
- پدرگوسا، اف. واروکو، جی. گرامفورت، آ. میشل، وی. تیریون، بی. گریزل، او. بلوندل، م. پرتنهوفر، پی. ویس، آر. دوبورگ، وی. و همکاران Scikit-learn: یادگیری ماشینی در پایتون. جی. ماخ. فرا گرفتن. Res. ۲۰۱۱ ، ۱۲ ، ۲۸۲۵-۲۸۳۰٫ [ Google Scholar ]
- جان، جی اچ. Langley, P. تخمین توزیع پیوسته در طبقه بندی کننده های بیزی. arXiv ۲۰۱۳ ، arXiv:1302.4964. [ Google Scholar ]
- چهاتا، ن. گوا، ال. مالت، سی. انتخاب ویژگی لیدار هوابرد برای طبقهبندی شهری با استفاده از جنگلهای تصادفی. اسکن لیزری ۲۰۰۹ IAPRS ۲۰۰۹ ، XXXVIII-3/W8 ، ۲۰۷-۲۱۲٫ [ Google Scholar ]
- واینمن، ام. جوتزی، بی. هینز، اس. Mallet, C. تفسیر ابر نقطه معنایی بر اساس همسایگی های بهینه، ویژگی های مرتبط و طبقه بندی کننده های کارآمد. ISPRS J. Photogramm. Remote Sens. ۲۰۱۵ ، ۱۰۵ ، ۲۸۶-۳۰۴٫ [ Google Scholar ] [ CrossRef ]
- لین، TY; گویال، پ. گیرشیک، آر. او، ک. Dollár, P. از دست دادن کانونی برای تشخیص اجسام متراکم. در مجموعه مقالات کنفرانس بین المللی IEEE در بینایی کامپیوتر، ونیز، ایتالیا، ۲۲ تا ۲۹ اکتبر ۲۰۱۷؛ صفحات ۲۹۸۰-۲۹۸۸٫ [ Google Scholar ]







بدون دیدگاه