۱٫ مقدمه
شبکه های اجتماعی امروزه در جوامع مدرن نقشی حیاتی دارند. از علایق و بررسی ها گرفته تا ترجیحات و نظرات سیاسی، در زندگی روزمره ما نقش بسته است. شبکه های اجتماعی مانند اینستاگرام، فیس بوک، توییتر و Foursquare به کاربران اجازه می دهند داده های متنی را با اطلاعات مکانی-زمانی (مهر زمانی و مختصات جغرافیایی) به اشتراک بگذارند. ما از این شبکه های اجتماعی به عنوان شبکه های اجتماعی مبتنی بر مکان (LBSN) یاد می کنیم. دادههای متنی تولید شده در شبکههای اجتماعی مبتنی بر مکان، مجموعهای از رکوردها هستند که نشاندهنده «کجا»، «زمان» و «چه» هستند، که در آن «کجا» به معنای مختصات جغرافیایی طول و عرض جغرافیایی یک مکان است، «وقتی» یک مهر زمانی است. ، و “چه” محتوای متنی است.
درک الگوهای داده های متنی مکانی-زمانی تولید شده در LBSN می تواند به ما در درک الگوهای تحرک انسانی [ ۱ ، ۲ ] یا زمان و مکان فعالیت های اجتماعی محبوب [ ۳ ، ۴ ، ۵ ] در محیط های شهری کمک کند. علاوه بر این، داده های متنی مکانی-زمانی از LBSN با موفقیت برای تشخیص رویدادهای دنیای واقعی مانند زلزله [ ۶ ، ۷ ] یا برای پیش بینی رویدادهایی مانند ناآرامی های مدنی [ ۸ ] استفاده شده است.]. درک بهتر این نوع داده ها می تواند در طیف وسیعی از سناریوها مفید باشد. به عنوان مثال، مرکز STAPLES یک عرصه چند منظوره در لس آنجلس، کالیفرنیا است که فعالیتهای مختلف انسانی مانند رویدادهای ورزشی و کنسرتها را برگزار میکند. استفاده از “STAPLES Center” برای حاشیه نویسی این مکان ممکن است هدف کامل مکان را آشکار نکند. در حالی که استفاده از دادههای یک LBSN میتواند تفاوتهای ظریف مکانی-زمانی فعالیتهای انسانی را که در نقاط مورد علاقهای مانند این اتفاق میافتد، کشف کند.
یکی از چالشهای مربوط به مدلسازی این نوع داده، چندوجهی بودن آن است. مهرهای زمانی، مختصات جغرافیایی و دادههای متنی مقادیر و طرحهای نمایش متفاوتی را نشان میدهند، که ترکیب مؤثر آنها را دشوار میکند. مهرهای زمانی و مختصات جغرافیایی متغیرهای پیوسته هستند در حالی که متن دنباله ای از موارد گسسته است و معمولاً با استفاده از فضاهای برداری نمایش داده می شود.
یک چالش اضافی با نمایش فردی هر نوع متغیر همراه است. رویکردهای قبلی (به بخش ۲ مراجعه کنید ) برای مدلسازی نحوه تولید متن در یک زمینه مکانی-زمانی از یک نمایش دانهبندی واحد برای زمان یا مکان استفاده میکنند: یا با استفاده از گسستهسازیهای دستساز، مدلهای خودکار مانند الگوریتمهای خوشهبندی، یا مدلهای احتمالی. الگوهای مکانی-زمانی برای تولید دادههای متنی باید الگوهایی را در جزئیات مختلف مانند ساعتها، هفتهها، ماهها و سالها، برای زمان یا بلوکها، محلهها و شهرها، برای فضا ثبت کنند. هنگام در نظر گرفتن دادههای متنی، کارهای قبلی متن را با رویکرد مجموعهای از کلمات مدلسازی کردهاند (به بخش ۲ مراجعه کنید )، بدون توجه به ساختار متوالی متون.
سوال تحقیقی که این کار را هدایت میکند این است که آیا مدلسازی زمان و مکان در دانهبندیهای مختلف همراه با ساختار متوالی متون میتواند مدلسازی دادههای متن شرطی مکانی-زمانی را بهبود بخشد یا خیر. مشارکت های اصلی کار فعلی ما به شرح زیر است:
- ۱٫
-
یک معماری مدل زبان عصبی شرطی فضایی-زمانی پیشنهاد کنید که زمان و مکان را در دانه بندی های مختلف نشان می دهد و ساختار متوالی متون را به تصویر می کشد. با مدلسازی زمان و مکان در دانهبندیهای مختلف، معماری پیشنهادی با ویژگیهای خاص هر منبع داده سازگار است. با توجه به آزمایشهای ما بر روی دو مجموعه داده LBSN، ثابت شده است که این مهم است.
- ۲٫
-
یک تجزیه و تحلیل کیفی انجام دهید که در آن تجسمهایی را نشان میدهیم که میتواند به دستیابی به بینشهایی در مورد الگوهایی که تولید زبان را تحت شرایط مکانی-زمانی هدایت میکنند کمک کند. با مدلسازی زمان و مکان در دانهبندیهای مختلف، میتوانیم چگونگی وزن هر سطح دانهبندی را در مدل نمایشی تحلیل کنیم. برای این تجزیه و تحلیل، ما آزمایش هایی را با یک شبکه عصبی مبتنی بر ترانسفورماتور انجام دادیم. شبکههای عصبی مبتنی بر توجه مانند معماری ترانسفورماتور این مزیت را دارند که با تجسم وزنهای توجه، بینشی در مورد اهمیت اجزای بافت مکانی-زمانی ارائه میکنند.
نقشه راه
این سند به شرح زیر سازماندهی شده است. در بخش ۲ ، پیشینه ای از ادبیات مربوط به این کار را ارائه می دهیم. در بخش اول بخش، برنامههایی را توضیح میدهیم که از دادههای متنی مکانی-زمانی از LBSN استفاده میکنند. پس از آن، ما به مدل هایی می پردازیم که به طور مشترک سه متغیر را نشان می دهند و اشکالات موجود در رویکردهای قبلی را برجسته می کنیم که باید به آنها پرداخته شود. در بخش ۳ ، ابتدا پیشزمینهای در مورد مدلسازی زبان ارائه میکنیم، قبل از ارائه فرمولبندی مسئله به عنوان یک کار مدلسازی زبان شرطی مکانی-زمانی. ما پسزمینهای از شبکههای عصبی را برای مدلسازی زبان ارائه میکنیم و در نهایت معماری مدل زبان عصبی پیشنهادی را توصیف میکنیم. در بخش ۴، ما چارچوب تجربی خود را توصیف می کنیم. ما مجموعه دادههای LBSN مورد استفاده در آزمایشهای خود را ارائه میکنیم و معیار ارزیابی و آزمایشهایی را که برای درک مدلسازی زمان و مکان در دانهبندیهای مختلف انجام دادیم، توصیف میکنیم. در نهایت، در بخش ۵ ، نتایج خود را مورد بحث قرار میدهیم.
۲٫ کارهای مرتبط
در این بخش، مروری بر کار در ادبیات مربوط به این تحقیق ارائه میکنیم. ابتدا، ما کاربردهای اصلی داده های متنی مکانی-زمانی تولید شده در LBSN را توصیف می کنیم. بعداً، مدلهایی را برای دادههای متنی مکانی-زمانی که نزدیکترین به کار ما به دست آمده از این برنامههایی که قبلا ذکر شد، بررسی میکنیم. این آثار به مطالعه چگونگی تولید متن در یک زمینه مکانی-زمانی می پردازند و ما بر نحوه مدل سازی زمان و مکان به عنوان زمینه ای برای تولید زبان تمرکز می کنیم.
۲٫۱٫ برنامه های کاربردی برای داده های متنی فضایی-زمانی
همانطور که در بخش های قبلی بیان شد، منابع داده های متنی زیادی با ابعاد مکانی-زمانی وجود دارد. با این وجود، بیشتر آثار موجود در ادبیات بر حوزه LBSN تمرکز دارند. این فراوان ترین منبع داده و آسان ترین برای به دست آوردن با استفاده از API است. کاربردهای اصلی که در ادبیات شناسایی میکنیم، مدلسازی فعالیت، مدلسازی تحرک، تشخیص رویداد و پیشبینی رویداد است. در ادامه این برنامه ها را شرح می دهیم.
۲٫۱٫۱٫ مدل سازی فعالیت
مدلسازی فعالیت، فعالیتهای انسانی را در محیطهای شهری با استفاده از دادههای متنی مکانی-زمانی مرتبط با فعالیتهای انسانی مطالعه میکند. همانطور که مردم اطلاعات مربوط به فعالیت هایی را که در زندگی روزمره انجام می دهند به اشتراک می گذارند، داده های متنی مکانی-زمانی از LBSN اطلاعات مفیدی در مورد الگوهای مکانی و زمانی فعالیت های انسانی ارائه می دهد. برخلاف تجزیه و تحلیل استاتیک دادههای مکانی، دادههای متنی مکانی-زمانی میتوانند هدف بازدید از نقطهای را که میزبان انواع مختلفی از رویدادها است، کشف کنند. به عنوان مثال، مرکز STAPLES، یک عرصه چند منظوره در لس آنجلس، کالیفرنیا، رویدادهای ورزشی را به عنوان مسابقات بسکتبال برگزار می کند، اما می تواند موارد دیگری مانند کنسرت را نیز برگزار کند. افراد ممکن است برای اهداف مختلف به مرکز STAPLES مراجعه کنند. استفاده از “STAPLES Center” برای حاشیه نویسی یک رکورد موقعیت مکانی ممکن است هدف کامل مکان را آشکار نکند.
آثار در مدلسازی فعالیت بر برچسبگذاری مکان و مدلهایی تمرکز دارند که به طور مشترک متن، زمان و مکان را نشان میدهند. هر دو رویکرد مناطق شهری را با استفاده از داده های جمع آوری شده از LBSN مشخص می کنند. یک مجموعه داده شده است R = {r1, … ,rمتر}از سوابق دادههای متنی مکانی-زمانی، برچسبگذاری مکان برچسبهایی را پیدا میکند که به بهترین شکل PoIها را توصیف میکنند، چه ثابت [ ۹ ] یا در دورههای زمانی مختلف [ ۳ ]. کارهایی که به طور مشترک متن، زمان و مکان را برای مدلسازی فعالیت نشان میدهند، امکان ترکیب سه نوع داده در یک طرح نمایش منحصر به فرد را فراهم میکنند [ ۴ ، ۱۰ ].
۲٫۱٫۲٫ مدل سازی تحرک
مدلسازی تحرک با استفاده از دادههای متنی مکانی-زمانی به ما اجازه میدهد تا نه تنها جنبههای هندسی دادههای حرکتی انسان را بشناسیم، بلکه معنای آن را نیز بدانیم: یعنی رفتن از نقطه A در زمان .تی۰به نقطه B در زمان تی۱به اندازه رفتن از “خانه” در آن زمان آموزنده نیست تی۰“کار” در زمان تی۱یا از “کار” در زمان تی۲به یک “رستوران” در زمان تی۳. مطالعه الگوهای تحرک انسانی دارای کاربردهایی مانند پیشبینی/توصیه مکان [ ۲ ، ۱۱ ] برای کاربران فردی و استخراج الگوی مسیر برای درک تحرک در مناطق شهری است [ ۱ ، ۱۲ ]. این اطلاعات می تواند منجر به درک دلایل انگیزش رفتارهای حرکتی افراد، درک تفاوت های ظریف مشکلات حرکتی در محیط های شهری و سپس انجام اقدامات موثر برای حل آنها شود.
۲٫۱٫۳٫ تشخیص رویداد
روشهای تشخیص رویداد که در جریان دادههای متنی مکانی-زمانی از LBSN به کار میروند، به ما امکان میدهد رویدادهای محلیشده جغرافیایی را در زمان واقعی از خبرنگاران دست اول شناسایی کنیم. همانطور که توسط آلن و همکاران تعریف شده است. [ ۱۳ ]، رویداد چیزی است که در زمان و مکان خاصی اتفاق میافتد و بر زندگی مردم تأثیر میگذارد، مثلاً اعتراضات، بلایا، بازیهای ورزشی، کنسرتها. برخی از انواع رویدادهایی که در LBSN منعکس می شوند و می توان آنها را شناسایی کرد، زلزله [ ۶ ، ۷ ، ۱۴ ] یا تراکم ترافیک [ ۱۵ ، ۱۶ ] است.
۲٫۱٫۴٫ پیش بینی رویداد
روشهای پیشبینی رویداد، بر خلاف تشخیص رویداد، که معمولاً رویدادها را در زمان وقوع کشف میکند، وقوع رویدادها را در آینده پیشبینی میکند. رویکرد رایج استفاده از داده های LBSN در ارتباط با منابع خارجی برای ساخت مدل های پیش بینی است. برای برخی رویدادها مانند حوادث جنایی [ ۱۷ ، ۱۸ ، ۱۹ ] یا ناآرامیهای مدنی [ ۸ ، ۱۹ ]، پیشبینی مکان دقیق با زمان زیادی از قبل مهم است. یک رویکرد رایج این است که ویژگی ها را به عنوان شاخص ها و مدل های پیش بینی قطار برای مناطق فضایی تعریف کنیم [ ۱۷ ]]. برای ناآرامیهای مدنی، پیشبینی معمولاً در سطح شهر یا مناطق اداری کوچکتر است، در حالی که برای جرایم و رویدادهای ترافیکی، پیشبینی در سطح دانه ریزتری مانند محلهها یا بلوکها است. متغیر زمانی برای شناسایی الگوهای در حال تغییر که نشان دهنده وقوع یک رویداد در آینده است استفاده می شود.
۲٫۲٫ مدلهایی برای دادههای متنی مکانی-زمانی
با تجزیه و تحلیل برنامه های کاربردی قبلی، مدل سازی فعالیت را می توان وظیفه اصلی در نظر گرفت. اجازه پاسخگویی را می دهد ⟨ ساعت ⟩ _ _ _اتفاق می افتد، ⟨ ساعت ⟩ _ _ _اتفاق می افتد، و ⟨ ساعت کار ⟩ _ _ _اتفاق می افتد و می توان آن را وظیفه اساسی در نظر گرفت. به عنوان مثال الگوهای فعالیت مکانی و زمانی را می توان برای تعریف نقاط انتقال در مسیرها برای مدل های تحرک استفاده کرد. الگوهای فعالیت مکانی و زمانی به عنوان ویژگیهایی برای مدلهای پیشبینی رویداد استفاده میشوند و فعالیتهای انفجاری موضعی غیرمعمول برای شناسایی رویدادها استفاده میشود. در مرحله بعد، ما بر روی مدل های تخصصی برای مدل سازی فعالیت تمرکز می کنیم. ابتدا مدل هایی را توصیف می کنیم که موضوعات جغرافیایی را شناسایی می کنند. سپس، روشهای تعبیه چند وجهی را برای دادههای متنی مکانی-زمانی توصیف میکنیم.
۲٫۲٫۱٫ مدلسازی موضوع فضایی-زمانی
مدلسازی موضوع فضایی-زمانی موضوعات مرتبط با مناطق جغرافیایی را کشف میکند [ ۲۰ ، ۲۱ ، ۲۲ ، ۲۳ ، ۲۴ ، ۲۵ ، ۲۶ ]. می و همکاران [ ۲۰ ] یک تعمیم از مدل احتمالی نهفته معنایی نمایه سازی [ ۲۷ ] را پیشنهاد کرد، که در آن موضوعات را می توان با متن یا با ترکیب مهر زمانی و مکان تولید کرد. آیزنشتاین و همکاران [ ۲۱] یک مدل سازی موضوع آبشاری را پیشنهاد کرد. کلمات توسط یک توزیع چند جمله ای که میانگین یک مدل موضوع پنهان و یک مدل موضوع منطقه است، تولید می شوند. مناطق متغیرهای پنهانی هستند که مختصات را نیز تولید می کنند. موضوعات توسط توزیع دیریکله تولید می شوند. نواحی توسط یک توزیع چندجمله ای و مختصات توسط یک توزیع گاوسی دو متغیره تولید می شوند. هر منطقه دارای توزیع چند جمله ای بر روی موضوعات است و هر موضوع دارای توزیع چند جمله ای بر روی کلمات کلیدی است. وانگ و همکاران [ ۲۲ ] LATM را پیشنهاد کرد [ ۲۲ ]، که توسعه ای از تخصیص دیریکله پنهان (LDA) است [ ۲۸ ]] که قادر به یادگیری روابط بین مکان ها و کلمات است. در مدل، هر کلمه دارای یک مکان مرتبط است. برای تولید کلمات، مدل کلمه و همچنین مکان را تولید می کند، در هر دو مورد با توزیع چندجمله ای بسته به موضوعی که توسط توزیع دیریکله تولید می شود. علاوه بر این، Sizov [ ۲۳ ] مدلی شبیه به کار وانگ و همکاران توسعه داد. [ ۲۲ ]. آنها به جای استفاده از توزیع چندجمله ای برای تولید مکان، آن را با دو توزیع گاوسی جایگزین می کنند که طول و عرض جغرافیایی ایجاد می کند. یین و همکاران [ ۴ ] یک مدل مولد را مورد مطالعه قرار داد که در آن مناطق نهفته ای وجود دارد که از نظر جغرافیایی توسط یک گاوسی توزیع شده اند. هونگ و همکاران [ ۲۴] از یک مدل زبان پایه، یک مدل زبان وابسته به منطقه و یک مدل زبان موضوعی استفاده کنید. مختصات جغرافیایی با استفاده از الگوریتم های خوشه بندی به مناطق گسسته می شوند. مناطق توسط یک توزیع چند جمله ای بسته به کاربر و یک توزیع منطقه جهانی تولید می شوند. مختصات جغرافیایی توسط مناطق با استفاده از توزیع های گاوسی چند متغیره تولید می شوند. کلمات بسته به توزیع جهانی موضوع، کاربر و منطقه توسط موضوعات تولید می شوند. احمد و همکاران [ ۲۵] یک مدل موضوع سلسله مراتبی ایجاد کرد که هم توزیع موضوعی سند و هم منطقه خاص را مدل میکند و بهعلاوه تغییرات منطقهای موضوعات را مدل میکند. روابط بین مناطق جغرافیایی توزیع شده گاوسی با فرض یک رابطه سلسله مراتبی دقیق بین مناطق که در طول استنتاج آموخته می شود، مدل سازی می شود. در نهایت، کلینگ و همکاران. [ ۲۶ ] MGTM [ ۲۶ ] را پیشنهاد کرد ، مدلی مبتنی بر فرآیندهای چند دیریکله. نویسندگان از فرآیند دیریکله سلسله مراتبی سه سطحی با توزیع فیشر برای تشخیص خوشه های جغرافیایی، توزیع سند-موضوع چندجمله ای دیریکله و توزیع موضوع-کلمه چند جمله ای دیریکله استفاده کردند.
۲٫۲٫۲٫ روش های جاسازی
روشهای جاسازی، نمایشهای آموختهشده برای متغیرهای گسسته توزیع شدهاند. نمایش های تعبیه شده آموخته شده در پردازش زبان طبیعی [ ۲۹ ، ۳۰ ] و نمایش گره گراف [ ۳۱ ] بسیار محبوب هستند. برای دادههای متنی مکانی-زمانی، نمایشهای تعبیهشده یک نمایش مشترک برای عناصر تاپل را یاد میگیرند. ⟨ t i m e , l o c a t i o n , t e x t ⟩ .
ژانگ و همکاران [ ۱۰ ] CrossMap پیشنهادی [ ۱۰ ]. در CrossMap، اولین قدم گسسته سازی مُهرهای زمانی و مختصات با استفاده از تکنیک های تخمین تراکم هسته است. پس از آن، CrossMap از دو استراتژی مختلف برای یادگیری نمایش های تعبیه شده استفاده می کند: Recon و Graph. در Recon، مسئله به عنوان یک کار بازسازی رابطه بین عناصر تاپل مدل شده است ⟨ t i m e , l o c a t i o n , t e x t ⟩ ,در حالی که در Graph، هدف یادگیری نمایش هایی است که ساختار یک گراف از تاپل ها ساخته شده است ⟨ t i m e , l o c a t i o n , t e x t ⟩حفظ می شود. در [ ۵ ]، CrossMap برای یادگیری نمایش تعبیه شده در یک جریان گسترش یافته است. نویسندگان دو استراتژی مبتنی بر یادگیری زوال زندگی و یادگیری محدود را برای یافتن بازنمایی از دادههای جریان پیشنهاد میکنند. برخلاف CrossMap، مهرهای زمانی و مختصات جغرافیایی به جای خوشهبندی مبتنی بر تخمین تراکم هسته، به پنجرههای فضایی دستساز و سلولهای زمانی گسسته میشوند. ژانگ و همکاران [ ۱۰ ، ۳۲ ] توسعه دیگری را برای CrossMap پیشنهاد کرد، در این مورد، برای یادگیری بازنمایی از منابع متعدد. مجموعه داده اصلی مجموعه تاپل ها است ⟨ t i m e , l o c a t i o n , t e x t ⟩ .هر مجموعه داده یک گراف را تعریف می کند و نمایش ها برای حفظ ساختار نمودار یاد می گیرند. گره هایی که همان موجودیت را نشان می دهند بین گراف اصلی و گراف های ثانویه به اشتراک گذاشته می شوند. در طول آموزش، فرآیند یادگیری به طور متناوب بین یادگیری جاسازی ها برای نمودار اصلی و جاسازی ها برای مجموعه داده های ثانویه تغییر می کند.
۲٫۲٫۳٫ تجزیه و تحلیل مدل هایی که از داده های متنی مکانی-زمانی استفاده می کنند
در جدول ۱ ، خلاصه ای از کارهای مورد بحث در این بخش را ارائه می دهیم. رویکردهای موجود مبتنی بر مدلسازی موضوع یا روشهای جاسازی هستند. آثاری که از رویکرد مدلسازی موضوع پیروی میکنند بر اساس مدلهای موضوعی مانند تحلیل معنایی پنهان احتمالی [ ۳۳ ] یا تخصیص دیریکله پنهان [ ۲۸ ] است.] و با تخصیص توزیع بر روی مکان ها به موضوعات یا با معرفی مناطق جغرافیایی پنهان، مدل ها را گسترش دهید. هم مدلهای موضوعی و هم روشهای تعبیهسازی، رویکرد مجموعهای از کلمات را برای مدلسازی متن در نظر میگیرند، که ساختار متوالی متون را نادیده میگیرد. هنگام در نظر گرفتن مدلسازی زمان و مکان، هر اثر با استفاده از سلولهای فضایی دست ساز و پنجرههای زمانی یا الگوریتمهای خوشهبندی، مهرهای زمانی و مختصات جغرافیایی را در یک سطح از دانهبندی مدلسازی میکند. فقط احمد و همکاران [ ۲۵ ] سلسله مراتب را مدل می کند، اما فقط برای فضا. تا جایی که ما می دانیم، هیچ مطالعه ای در مورد اینکه چگونه نمایش زمان و مکان در سطوح مختلف دانه بندی بر مدل سازی تولید متن تحت شرایط مکانی-زمانی تأثیر می گذارد، وجود ندارد. علاوه بر این، هیچ اثری ساختار متوالی متون را مدل نمی کند.
یک مشکل اضافی در مورد مدلسازی دادههای متنی مکانی-زمانی، که ذکر آن مهم است، چارچوب ارزیابی است. ساخت یک مجموعه داده مرجع در این زمینه پیچیده است. اول، یک متغیر زمانی درگیر است: این بدان معنی است که داده ها باید برای مدت طولانی جمع آوری شوند. دوم، داده ها مربوط به یک منطقه خاص هستند: این بدان معنی است که استفاده از مدل ها در یک منطقه جدید مستلزم جمع آوری داده ها از آن منطقه است. ما می توانیم مشاهده کنیم (به ستون مجموعه داده در جدول ۱ مراجعه کنید ) که هیچ اتفاق نظری در مورد اینکه چه مجموعه داده ای به عنوان یک استاندارد برای ایجاد ارزیابی منصفانه بین رویکردهای مختلف استفاده شود وجود ندارد. به همین دلیل، ما تصمیم گرفتیم این مشکل را با استفاده از یک مجموعه داده جدید تقویت نکنیم و آزمایشهای خود را با استفاده از جدیدترین مجموعه دادهها (به بخش ۴٫۱ مراجعه کنید ) که در [ نگاه کنید] توسعه میدهیم.۵ ، ۱۰ ، ۳۲ ].
علاوه بر این، هر اثر زمان و مکان را با تکنیکهای متفاوتی مانند خوشهبندی، مدلهای احتمالی یا گسستهسازیهای دستساز مدلسازی میکند و از معیارهای ارزیابی متفاوت متناسب با مدل پیشنهادی خود استفاده میکند. به عنوان مثال، آثاری که نتایج آنها مدلهای طبقهبندی هستند با استفاده از معیارهای طبقهبندی مانند دقت، آثاری که توزیعهای احتمالی را تولید میکنند با استفاده از Perplexity و کارهایی که مدلهای رتبهبندی را پیشنهاد میکنند با استفاده از میانگین رتبه متقابل ارزیابی میشوند. همانطور که در این کار، ما یک مدل زبان عصبی شرطی فضایی-زمانی را پیشنهاد میکنیم، از Perplexity به عنوان معیار ارزیابی استفاده میکنیم که یک معیار ارزیابی مدلسازی زبان سنتی است. استفاده از Perplexity بر روی متن تولید شده، زیرا ما فقط به متن نگاه می کنیم، به ما این امکان را می دهد که معیار ارزیابی را از نحوه مدل سازی زمان و مکان جدا کنیم.
به طور کلی، میتوان نتیجه گرفت که رویکردهای موجود دو بعد مشکل را نادیده میگیرند:
- ۱٫
-
ساختار ترتیبی زبان
- ۲٫
-
مدلی یکپارچه برای نمایش زمان و مکان که از زمان و مکان در دانه بندی های مختلف به عنوان زمینه برای تولید زبان استفاده می کند.
۳٫ راه حل پیشنهادی
در این بخش راه حل پیشنهادی خود را شرح می دهیم. ابتدا، فرمول مسئله را نشان میدهیم که به عنوان یک کار مدلسازی زبان در چارچوب است. پس از آن، مدل پیشنهادی را توصیف می کنیم که قبلاً به طور مختصر معماری های مدل زبان عصبی پیشرفته را بررسی کردیم. در نهایت، گسستهسازی مهرهای زمانی و مختصات جغرافیایی و همچنین انتخاب پارامترها را نشان میدهیم.
۳٫۱٫ مدل سازی زبان
مدل سازی زبان به عنوان وظیفه اختصاص دادن یک احتمال به دنباله ای از کلمات تعریف می شود : p ( w ) = p (w0،w1⋯wj − ۱،wj). مدلهای پیشرفته برای مدلسازی زبان مبتنی بر شبکههای عصبی هستند. به طور معمول، مدلهای زبان شبکههای عصبی به عنوان مدلهای پیشبینی متمایز ساخته و آموزش داده میشوند که پیشبینی توزیع احتمال را یاد میگیرند. p (wj/w0،w1⋯wj − ۱)برای یک کلمه داده شده مشروط به کلمات قبلی در دنباله. این مدل ها بر روی مجموعه ای از اسناد آموزش داده می شوند. احتمال وجود یک دنباله از کلمات p (w0⋯wj − ۱،wj)را می توان با: ∏i = ji = ۱p (wمن/w0،w1⋯wمن – ۱).
مدل سازی زبان شرطی به عنوان وظیفه اختصاص دادن یک احتمال به دنباله ای از کلمات با زمینه c تعریف می شود : p ( w / c ) = p ( (w0،w1⋯wj − ۱،wj) /ج ). سپس، احتمال هر کلمه در دنباله به صورت محاسبه می شود p (wj/ ج ،w0،w1⋯wj − ۱). مدلهای زبان شرطی در چندین کار پردازش زبان طبیعی کاربرد دارند: به عنوان مثال، ترجمه ماشینی (تولید متن به زبان مقصد مشروط به متن در زبان مبدأ)، شرح تصویری مشروط بر تصویر، خلاصهای مشروط بر متن، پاسخ. مشروط به یک سوال و یک سند و غیره. در مورد ما، زمینه یک مُهر زمانی و مختصات خواهد بود.
۳٫۲٫ فرمول مسأله
با توجه به مجموعهای از رکوردها که توصیفات متنی یک منطقه جغرافیایی را در برهههای زمانی مختلف ارائه میکنند، هدف ما ایجاد مدلی است که بتواند این دادههای چندوجهی را نشان دهد. به دنبال فرمولبندی کار مدلسازی زبان سنتی، ما نیاز داریم که مدل حاصل با توجه به مهر زمانی و مختصات جغرافیایی مرتبط با آن متن، احتمالی را به یک متن اختصاص دهد.
به طور رسمی تر، اجازه دهید اچ= {r1, … ,rn}مجموعه ای از رکوردهای متنی حاشیه نویسی مکانی-زمانی (به عنوان مثال، یک توییت). هر یک rمنیک تاپل است ⟨تیمن،لمن،همن⟩، جایی که تیمنمهر زمانی مرتبط با است rمن، لمنیک بردار دو بعدی است که مکان مربوط به آن را نشان می دهد rمن، و همننشان دهنده متن در است rمن. با توجه به اینکه همندنباله ای از کلمات است w0⋯wn، اختصاص یک احتمال به w0⋯wnداده شده ⟨تیمن،لمن⟩را می توان به صورت نوشت p ( (w0،w1⋯ ،wn) / ⟨تیمن،لمن⟩ )، که نمونه ای از کار مدل سازی زبان شرطی ارائه شده در بخش ۳٫۱ است.
۳٫۳٫ شبکه های عصبی برای مدل سازی زبان
از آنجایی که ما یک معماری شبکه عصبی را برای مدلسازی تولید متن تحت شرایط مکانی-زمانی پیشنهاد میکنیم، در نظر میگیریم که ارائه پسزمینهای از معماریهای شبکه عصبی پیشرفته برای مدلسازی زبان مهم است. ما دو معماری شبکه عصبی را توصیف میکنیم که نتایج پیشرفتهای را در بسیاری از وظایف پردازش زبان طبیعی نشان دادهاند [ ۳۴ ]: شبکههای عصبی بازگشتی (RNN) و مدلهای خودتوجهی مبتنی بر ترانسفورماتور.
شبکههای عصبی بازگشتی [ ۳۵ ] خانوادهای از معماریهای شبکه عصبی هستند که رفتار دینامیکی زمانی را ثبت میکنند. RNN با موفقیت برای مشکلات پردازش زبان طبیعی مانند تشخیص گفتار [ ۳۶ ] و ترجمه ماشینی [ ۳۷ ، ۳۸ ، ۳۹ ] و غیره به کار گرفته شده است. در مورد داده های مکانی-زمانی، آنها بیشتر برای مدل سازی تحرک استفاده شده اند [ ۴۰ ، ۴۱ ، ۴۲ ، ۴۳ ]. در معماری پایه برای RNN، بردار h وجود دارد که نشان دهنده دنباله است. در هر مرحله زمانی t ، مدل به عنوان ورودی می گیرد ساعتt – ۱و تی – تی ساعتعنصر دنباله ایکستی; سپس، محاسبه می کند ساعتتی. برای مدل سازی زبان، در هر مرحله زمانی t ، ساعتتیبه عنوان ورودی یک شبکه فید فوروارد که توکن بعدی را پیش بینی می کند استفاده می شود ایکسt + ۱. محبوب ترین معماری های RNN، حافظه بلند مدت (LSTM) [ ۴۴ ] و واحد بازگشتی دردار (GRU) [ ۴۵ ] است. هر دو نوع مکانیسمهایی را معرفی میکنند که جریان اطلاعات را بین حالتهای پنهان نشاندهنده دنباله کنترل میکنند.
معماری های توجه به خود با چندین اثر که از این رویکرد پیروی می کنند، حوزه پردازش زبان طبیعی (NLP) را متحول کرده است. Transformer [ ۴۶ ] در ابتدا برای کار ترجمه زبان پیشنهاد شد. بعداً، مدلهای زبانی از پیش آموزش دیده [ ۴۷ ، ۴۸ ، ۴۹]، با پیروی از مدل خودتوجهی پیشنهاد شده توسط ترانسفورماتور، وضعیت پیشرفته را برای بسیاری از وظایف NLP بهبود بخشیده است. این رویکرد از رمزگذاری موقعیتی برای استفاده از موقعیت های کلمات و چندین لایه خود توجهی چند سر استفاده می کند. معماری توجه به خود مؤلفه مکرر RNN ها را که موازی سازی را محدود می کند، حذف می کند. این امکان آموزش سریعتر با کیفیت برتر را در مقایسه با مدلهای قبلی مبتنی بر شبکههای عصبی مکرر فراهم میکند.
۳٫۴٫ توضیحات مدل
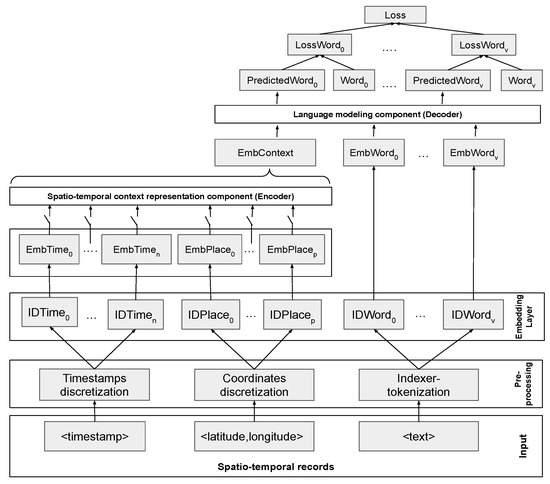
معماری پیشنهادی ما شامل یک شبکه عصبی سرتاسر برای رمزگذاری زمینههای مکانی و زمانی و رمزگشایی/تولید متن است. طراحی ما برای مدلسازی بافت مکانی-زمانی در دانهبندیهای مختلف و برای اینکه مؤلفه رمزگشایی/تولیدکننده نسبت به نحوه کدگذاری زمینههای مکانی و زمانی بیخبر باشد، هدف قرار گرفته است.
شکل ۱ معماری مدل را نشان می دهد. به منظور تغذیه مدل ما با داده های متنی مکانی-زمانی، برخی مراحل پیش پردازش مورد نیاز است. ابتدا، متن نشانه گذاری می شود، مهرهای زمانی به پنجره های زمانی گسسته می شوند، و مختصات جغرافیایی به سلول های فضایی گسسته می شوند (معادله ( ۱ )). پس از آن، مُهرهای زمانی گسسته و مختصات جغرافیایی گسسته شده از لایههای تعبیهشده عبور داده میشوند (معادله ( ۲ )). لایه جاسازی کلمات، پنجره های زمانی و سلول های فضایی را در یک نمایش متراکم طرح می کند. هر مورد با استفاده از یک جدول جستجو تعبیه شده است و برای هر نوع آیتم یک جدول جستجو وجود دارد: پنجره های زمانی، سلول های مکانی و کلمات. هر مورد با یک عدد صحیح همراه است که به عنوان یک شاخص در جدول جستجوی مربوطه استفاده می شود.
پس از مرحله گسسته سازی، مرحله بعدی ساختن زمینه مکانی-زمانی است (معادله ( ۳ )). هر مهر زمانی را می توان به n پنجره زمانی گسسته، و هر مختصات را می توان به سلول های فضایی p تفکیک کرد. را n + pپنجره های زمانی و سلول های فضایی نمایانگر زمینه مکانی-زمانی هستند. پس از آن، متن از یک لایه رمزگذار عبور داده می شود که منجر به یک تانسور بازنمایی متن (EmbContext) می شود. این تانسور بازنمایی بافت دارای ابعاد ثابت/غیر متغیر است (<1,d> که در آن d بعد نمایش است) صرف نظر از نحوه انتخاب زمینه. تانسور EmbContext به عنوان اولین عنصر به دنباله ای از جاسازی های کلمه الحاق می شود (معادله ( ۴ )). این دنباله [EmbContext، EmbWords] از طریق یک رمزگشا منتقل می شود که مدل زبان را نشان می دهد. در نهایت، ما اتلاف را برای به حداقل رساندن با استفاده از آنتروپی متقاطع بین توالی پیشبینیشده کلمات و دنباله مشاهدهشده کلمات در مثالهای آموزشی محاسبه میکنیم (معادله ( ۵)). این معماری کلی است که ما پیشنهاد می کنیم. بلوک های اصلی معماری ما (Encoder، Decoder) را می توان با استفاده از رویکردهای مختلف، مانند شبکه های عصبی بازگشتی یا بلوک های ترانسفورماتور خود توجه، پیاده سازی کرد. ما آنها را در بخش ۴ آزمایش می کنیم .
ویژگی برجسته معماری ما این است که امکان نمایش زمان و مکان در سطوح مختلف دانه بندی را فراهم می کند. این با مدلسازی بافت مکانی-زمانی به عنوان دنبالهای از نشانههای گسسته که معانی خاص هر نوع زمینه را نشان میدهد، به دست میآید. برای مثال، میتوانیم بافت زمانی را با ساعت روز (۰-۲۳)، روز هفته (یکشنبه تا دوشنبه)، هفته از ماه، و ماه سال (ژانویه تا دسامبر) و بافت مکانی نمایش دهیم. بر اساس بلوک، محله، منطقه و غیره
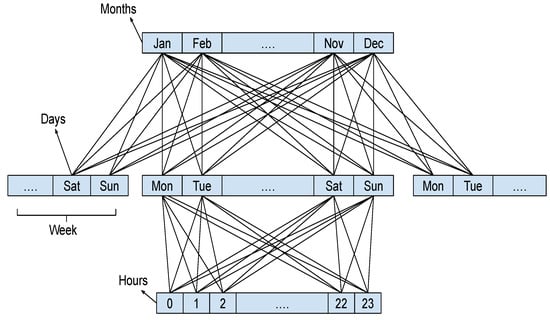
۳٫۵٫ گسسته سازی مهرهای زمانی و مختصات جغرافیایی
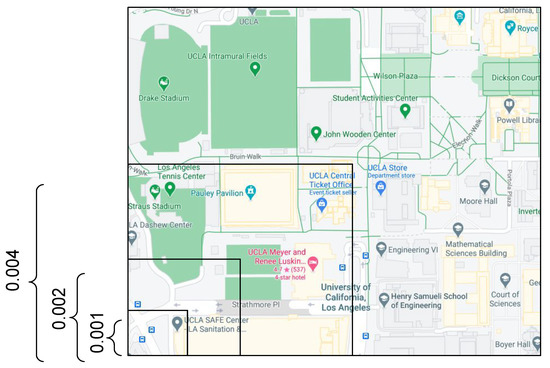
برای گسسته کردن مختصات جغرافیایی و مهرهای زمانی، از سلولهای مربعی با اندازه مساوی در مورد مختصات جغرافیایی و پنجرههای زمانی دست ساز در مورد مهرهای زمانی استفاده میکنیم. برای گسستهسازی مهر زمانی، از ترتیبات معنایی انسانی زمان استفاده میکنیم، بهویژه ساعت روز (۰-۲۳)، روز هفته (یکشنبه تا دوشنبه)، هفته ماه (هفته اول تا هفته پنجم)، و ماه سال (ژانویه تا دسامبر). شکل ۲ سلسله مراتبی را نشان می دهد که این گسسته سازی ها را توصیف می کند. برای گسسته سازی فضایی، از سلول های فضایی هم اندازه با استفاده از مختصات فضایی به عنوان فضای متریک استفاده می کنیم. شکل ۳ سلسله مراتبی را نشان می دهد که گسسته سازی های سلول مربعی را توصیف می کند.
ذکر این نکته حائز اهمیت است که رویکرد ما برای نمایش زمینه ها به عنوان دنباله های گسسته امکان کار در سطوح مختلف دانه بندی را فراهم می کند. به عنوان مثال، یک نمایش درشت می تواند زمان را با یک نشانه منفرد مربوط به ماه نشان دهد، که در آن یک رویکرد دقیق تر می تواند زمان را به صورت دنباله ای حاوی ماه، روز، ساعت و غیره رمزگذاری کند. ما استدلال می کنیم که این یک ویژگی اصلی ما است. معماری زیرا به ما اجازه می دهد تا بازنمایی بافت مکانی-زمانی را بسته به کاربرد تطبیق دهیم. به عنوان مثال، برای رویدادهای مربوط به فعالیت های روزانه (مثلاً رفتن به محل کار، صرف ناهار)، جزئیات در سطح ساعت باید کارآمدتر باشد. از سوی دیگر، برای رویدادهای مربوط به رویدادهای فصلی (به عنوان مثال، کریسمس، تعطیلات)، جزئیات در سطح ماه باید بهتر عمل کنند.
۳٫۶٫ مولفه های
در تمام آزمایشهایمان، ما از نمایش تعبیه ۱۲۸ بعدی استفاده میکنیم t i m e s t a m p، l o c a t i o n، و روزی _ _ _س. مدل ها با استفاده از نزول گرادیان کوچک دسته ای با بهینه ساز Adam [ ۵۰ ] آموزش داده می شوند. ما از ۱۲۸ مثال به عنوان اندازه دسته ای و توقف اولیه در مجموعه داده اعتبار سنجی استفاده می کنیم. ما آزمایشهایی را با شبکههای عصبی مکرر GRU چند لایه [ ۴۵ ] و شبکههای عصبی مبتنی بر ترانسفورماتور برای اجزای رمزگذار/رمزگشا معماری پیشنهادی ما توسعه میدهیم. شبکههای عصبی بازگشتی GRU از یک GRU دو لایه با اندازه لایه پنهان ۱۲۸ استفاده میکنند. در همین حال، شبکههای عصبی مبتنی بر ترانسفورماتور در همه موارد با ۲ لایه خودتوجهی، ۴ سر و اندازه برداری ۱۲۸ برای پرسوجوها استفاده میشوند. کلیدها و مقادیر (برای جزئیات بیشتر به [ ۴۶ ] مراجعه کنید).
۴٫ آزمایشات
در این بخش، چارچوب تجربی خود را شرح می دهیم. هدف این است که درک بهتری از الگوهایی که تولید زبان را در زمینههای مکانی-زمانی هدایت میکنند، به دست آوریم. به ویژه، نگاه کردن به داده های تعریف شده از تاپل ها ⟨ t i m e , l o c a t i o n , t e x t ⟩ ,مدل در یک کار مدلسازی زبان سنتی (یعنی با استفاده از متریک Perplexity) ارزیابی میشود. ابتدا مجموعه داده ها را شرح می دهیم. پس از آن، روش ارزیابی را ارائه می کنیم. سپس، نتایج تجربی را نشان میدهیم و در نهایت، مطالعات کاربردهای دنیای واقعی مدلهای مورد مطالعه را به نمایش میگذاریم.
۴٫۱٫ مجموعه داده ها
ما آزمایشهایی را با استفاده از دو مجموعه داده LBSN انجام میدهیم: یکی از توییتر و دیگری از Foursquare، هر مجموعه داده در ادامه توضیح داده میشود:
-
لس آنجلس (‘LA-TW’): این مجموعه داده [ ۱۰ ] مجموعه ای از توییت های دارای برچسب جغرافیایی از لس آنجلس، ایالات متحده است. این تعداد ۱,۵۸۴,۳۰۷ توئیت با برچسب جغرافیایی از ۰۱/۰۸/۲۰۱۴ تا ۳۰/۱۱/۲۰۱۴ است ( جدول ۲ را ببینید ).
-
(‘NY-FS’): این مجموعه داده نیز برای اولین بار در [ ۱۰ ] گزارش شد. این شامل بررسی های چهار ضلعی است که توسط کاربران در شهر نیویورک، ایالات متحده در توییتر گزارش شده است. این داده ها شامل ۴۷۹۲۹۷ ثبت ورود از تاریخ ۲۵/۰۲/۲۰۱۰ تا ۱۶/۰۸/۲۰۱۲ است ( جدول ۲ را ببینید ).
۴٫۲٫ روش ارزیابی
برای هر آزمایش، مجموعه داده را در آزمون آموزشی- اعتبارسنجی- تقسیم می کنیم، ۱۰٪ از هر مجموعه داده را به عنوان آزمون، ۱۰٪ برای اعتبار سنجی و ۸۰٪ برای آموزش نگه می داریم. با توجه به اینکه ورودی مدل ها مجموعه ای از تاپل ها به شکل زیر است: ⟨ t i m e s t a m p , c o o r di n a t es , t e x t ⟩ , _برای هر آزمایش، واژگان را روی ۱۲۲۸۸ رایج ترین کلمه در مجموعه آموزشی قرار می دهیم. تعداد سلول های فضایی و پنجره های زمانی بسته به آزمایش متغیر است. ما تاپل هایی را که تعداد کلمات در واژگان ده یا کمتر است فیلتر می کنیم و همه URL ها را به نشانه “http” کاهش می دهیم.
ارزیابی مدلسازی زبان معمولاً با استفاده از Perplexity [ ۵۱ ] انجام میشود. گیجی اندازه گیری می کند که چگونه یک مدل زبان یک نمونه آزمایشی را به خوبی پیش بینی می کند و به طور متوسط چند بیت برای نمایش نمونه آزمایشی در هر کلمه مورد نیاز است. توجه به این نکته ضروری است که در Perplexity هر چه امتیاز کمتر باشد، مدل بهتر است. گیجی، برای مجموعه آزمایشی که در آن همه جملات یکی پس از دیگری در یک دنباله از کلمات مرتب شده اند w1, … ,wتیطول T به صورت زیر تعریف می شود:
۴٫۳٫ کاوش گسسته
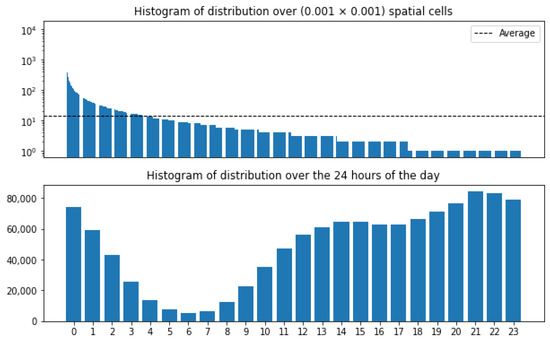
به منظور درک بهتر گسستهسازیهای مکانی-زمانی، در شکل ۴ و شکل ۵ ، ما هیستوگرامهای گسستهسازی مهرهای زمانی و مختصات جغرافیایی را برای هر دو مجموعه داده NY-FS و TW-LA نشان میدهیم. ما ۲۴ ساعت روز (۰-۲۳) و گسسته سازی مختصات جغرافیایی را توسط سلول های فضایی (۰٫۰۰۱ × ۰٫۰۰۱) نشان می دهیم.
ما میتوانیم مشاهده کنیم که برای هر دو مجموعه داده، ساعات اولیه صبح کمترین فراوانی را دارد و از بعد از ظهر تا ساعات شب افزایش مییابد. در مجموع، ۱۹۱۵۷ سلول فضایی برای مجموعه داده NY-FS و ۸۴۶۹۳ برای مجموعه داده LA-TW وجود دارد. در مورد مجموعه داده NY-FS، حدود ۸۲٪ (۱۵۷۹۶) از سلول ها کمتر از میانگین تعداد پیام در هر سلول (خط نقطه چین در شکل ۴ ) دارند، در حالی که برای LA-TW، توزیع مشابه است: حدود ۸۳% (۷۰۵۲۹) از سلول ها کمتر از میانگین تعداد پیام در هر سلول دارند (خط نقطه چین در شکل ۵)). این شباهتها در الگوهای مشاهدهشده در هیستوگرامها نشان میدهد که حتی زمانی که این مجموعه دادهها از شهرهای مختلف و در پنجرههای زمانی مختلف جمعآوری شدهاند، الگوهایی برای تولید متن تحت بافتهای زمانی- مکانی وجود دارد که مستقل از مکان و پنجره زمانی که دادهها در آنها وجود دارد، غالب هستند. جمع آوری شدند.
۴٫۴٫ تجزیه و تحلیل رمزگذار – رمزگشا
در اولین مجموعه آزمایشهای خود، گزینههای مختلف را برای مؤلفه بازنمایی بافت مکانی-زمانی (Encoder) و مؤلفه مدلسازی زبان (Decoder) ارزیابی میکنیم (به بخش ۳٫۴ مراجعه کنید ). در هر مورد، ما دو نوع را آزمایش می کنیم. برای رمزگذار، ما (۱) نمایش خروجی جاسازیهای لایه جاسازی را با یک لایه کاملاً متصل در بالا و (۲) نمایش رمزگذار خودتوجهی پیشنهاد شده در [ ۴۶ ] (بدون کدگذاری موقعیتی، زیرا ترتیب است) آزمایش میکنیم. بی ربط در توالی نشانه هایی که زمینه مکانی-زمانی را نشان می دهند) همچنین با یک لایه کاملاً متصل در بالا. برای رمزگشا، ما (۱) یک شبکه عصبی بازگشتی GRU دو لایه [ ۴۵ ] و (۲) یک نمایش رمزگذار دو لایه مبتنی بر ترانسفورماتور پیشنهاد شده در [ ۴۵] را آزمایش میکنیم.۴۶ ].
در جدول ۳ ، نتایج را برای Foursquare و در جدول ۴ نشان می دهیم، ما نتایج را برای توییتر نشان می دهیم. برای هر دو مجموعه داده، ما دو گزینه مختلف را برای زمانها و مکانها در رمزگذار آزمایش میکنیم: همه زمانها (همه زمانها)، همه مکانها (همه مکانها) و همه زمانها – مکانها (همه). ما میتوانیم ببینیم که برای هر دو مجموعه داده و برای هر گزینه زمان و مکان، فقط استفاده از جاسازیها در رمزگذار بهتر از استفاده از مؤلفه Self-Attention عمل میکند. در حالی که برای رمزگشا، مؤلفه خودتوجهی به همان اندازه بهتر از GRU در همان تحلیل عمل کرد. ترکیب رمزگذار (Embeddings)–Decoder (Self-Attention) بهترین نتایج را در همه موارد به دست آورد. تفسیر ما از این نتایج این است که مکانیسم توجه به خود در زمینه مکانی-زمانی نویز را بین واحدها در زمینه مکانی-زمانی معرفی می کند. در حالی که فقط استفاده از Embedding ها، بازنمایی واحدهای مکانی-زمانی را مستقل از یکدیگر نگه می دارد. در مورد رمزگشا، چنین موضوعی وجود ندارد: چیزی که ما در حال مدلسازی آن هستیم، ساختار متوالی متن است که میتواند با رمزگشای خودتوجهی ضبط شود. در بخش بعدی، جایی که ما جزئیات مختلف را برای زمان و مکان تجزیه و تحلیل میکنیم، از این تنظیمات رمزگذار (جاسازیها) و رمزگشا (توجه به خود) به عنوان تنظیم ارزیابی استفاده میکنیم.
۴٫۵٫ تجزیه و تحلیل دانه بندی فضایی-زمانی
در این بخش، ما مطالعه میکنیم که چگونه مدلسازی زمان و مکان در دانهبندیهای مختلف بر مدلهای زبان شرطی مکانی-زمانی تأثیر میگذارد. در جدول ۵ ، نتایج مجموعه داده توییتر را از لس آنجلس نشان می دهیم. میتوانیم ببینیم که در هر مورد، از جمله یک زمینه مکانی یا یک زمینه زمانی، نتایج Perplexity بهبود مییابد. علاوه بر این، پیشرفتها برای زمینههای زمانی در مقایسه با یک مدل زبانی که بافت مکانی-زمانی را نادیده میگیرد (ردیف اول جدول) حاشیهای بود. زمینههای مکانی در همه موارد بیش از زمینههای زمانی پیشرفتهای قابلتوجهی را نشان میدهند. هرچه سلول فضایی بزرگتر باشد، نتایج بهتری حاصل می شود.
به عنوان مکمل نتایج در جدول ۵ ، در جدول ۶ ، نتایج را با سلول های فضایی بزرگتر نشان می دهیم. می بینیم که به جای گرفتن نتایج بهتر، Perplexity بدتر می شود، که نشان می دهد نقطه شیرین برای گرفتن بهترین نتایج، سلول های فضایی بین ۰٫۰۰۸ و ۰٫۰۱۶ است.
در جدول ۷، ما نتایج را برای مجموعه داده Foursquare از نیویورک نشان می دهیم. Perplexities برای این مجموعه داده کمتر از Perplexities برای مجموعه داده Twitter از لس آنجلس است. این به دلیل این واقعیت است که بیشتر گزارش های Foursquare تولید متون عمومی هستند که توسط برنامه پیشنهاد شده است. این متون فقط در بیشتر موارد در مکانی که بررسی می شود متفاوت است، در حالی که مجموعه داده توییتر بیشتر متون رایگان است. در مورد مدلسازی مکانی-زمانی، نتایج مشابهی را با مجموعه داده توییتر مشاهده میکنیم. در همه موارد، از جمله زمینه مکانی-زمانی، گیجی را بهبود می بخشد. با زمینههای زمانی، بهبودهای حاشیهای ایجاد میشود، در حالی که بافتهای مکانی بیشترین حاشیه را در بهبودها نشان میدهند. برخلاف نتایج حاصل از مجموعه داده توییتر؛ با این مجموعه داده، اندازه سلول کوچکتر نتایج بهتری نسبت به موارد وسیعتر ایجاد می کند.
به عنوان مکمل نتایج در جدول ۷ ، در جدول ۸ ، نتایج را با سلول های فضایی کوچکتر نشان می دهیم. می بینیم که نتایج بهبود می یابند و Perplexity کمتر می شود. به دلیل محدودیت منابع نتوانستیم کاهش اندازه سلول های فضایی را ادامه دهیم. علاوه بر این، برای یافتن نقطهای که در آن Perplexity شروع به زوال میکند، باید سلولهای فضایی کوچکتر از اندازه معمولی مکانهای محبوب را که در آن فعالیتها در Foursquare گزارش میشود، آزمایش کنیم.
۴٫۶٫ تحلیل کیفی
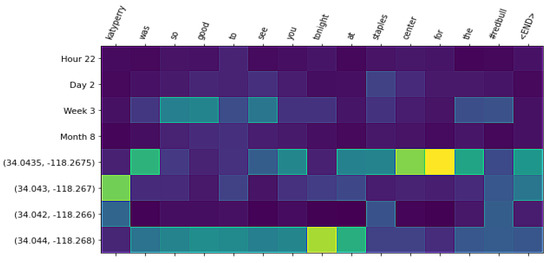
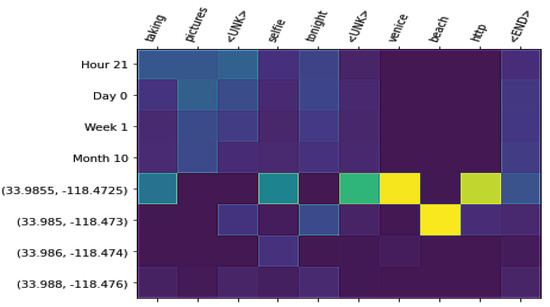
در این بخش، تحلیل کیفی تولید زبان را برای مدلهای مورد مطالعه انجام میدهیم. ابتدا، نمونههایی از متون تولید شده پس از آموزش یک مدل زبان شرطی فضایی-زمانی را با توجه به زمینه مکانی-زمانی نشان میدهیم. در نهایت، شکل ۶ ، شکل ۷ و شکل ۸ را نشان میدهیم، جایی که میتوانیم وزنهای توجهی را که مؤلفه تولید متن به عناصر در زمینه مکانی-زمانی میدهد، ببینیم. وزن توجه می تواند به ویژه برای جامعه GIS در مدل ما مفید باشد، زیرا آنها کلمات را به زمینه های مکانی و زمانی مرتبط می کنند و قابلیت تفسیر را ارائه می دهند. ما می توانیم رابطه مستقیم بین کلمات فردی و جزئیات مختلف نمایش را ببینیم.
در جدول ۹ ، نمونههایی از یک مدل زبان آموزشدیده با مجموعه داده توییتر از لس آنجلس را با تمام جزئیات گسستهسازی زمان و مکان نشان میدهیم (ردیف آخر در جدول ۵ ). ما دو مرکز را برای فعالیت های شهری در لس آنجلس انتخاب کردیم: مرکز استیپلز و ساحل ونیز. برای مرکز استیپلز، تاریخ کنسرت گروه بریتانیایی Arctic Monkeys و تاریخ یک بازی بسکتبال بین لس آنجلس لیکرز و لس آنجلس کلیپرز را انتخاب کردیم. ما می توانیم مشاهده کنیم که حتی برای یک مکان، متون تولید شده می توانند با رویدادهای مختلف مرتبط باشند. برای مثال هایی که از ساحل ونیز به عنوان زمینه استفاده می کنند، می توانیم ببینیم که متون تولید شده با فعالیت های ساحلی مرتبط هستند.
این نوع تحلیل، کاربرد مدلهای زبان شرطی مکانی-زمانی را نشان میدهد که بر روی مجموعه دادههای LBSN برای توصیف فعالیتهای انسانی در مناطق شهری آموزش داده شدهاند. شکل ۶ ، شکل ۷ و شکل ۸ نمونه هایی را نشان می دهد که مرکز Staples به عنوان زمینه ارائه شده است. در شکل ۶ ، تاریخ بازی لس آنجلس لیکرز را نشان می دهیم. ما میتوانیم ببینیم که کلمه “staples” با دانهبندی دقیقتر گسستهسازی مختصات جغرافیایی مرتبط است، در حالی که کلمه “شب” به گسستهسازی مهر زمانی به عنوان ساعت روز توجه میکند. در شکل ۶، تاریخ را از کنسرت کیتی پری نشان می دهیم. ما می توانیم ببینیم که چگونه کلمات “katyperry” و “در مرکز اصلی” با بهترین جزئیات گسسته سازی مختصات جغرافیایی مرتبط هستند. در همین حال، کلمه “امشب”، یک اصطلاح کلی تر، با درشت ترین دانه بندی همراه است. در شکل ۸ ، مثالی را با مختصات جغرافیایی ساحل ونیز به عنوان بافت فضایی نشان می دهیم. ما می توانیم مشاهده کنیم که چگونه کلمه “ونیز” با بهترین سطح گسسته سازی فضایی همراه است. در حالی که کلمه “ساحل” با دومین دانه بندی عالی همراه است، “ساحل” یک اصطلاح کلی تر از “ونیز” است، اما همچنین فقط با مناطق ساحلی در یک شهر مرتبط است.
مثالهای بالا پتانسیل مدل ما را برای تحلیلهای مکانی-زمانی نشان میدهند. از یک طرف، ما نشان میدهیم که مدلهای زبانی ما قادر به تولید جملاتی هستند که به طور کارآمد و منسجم یک زمینه مکانی-زمانی را توصیف میکنند. این می تواند به ویژه برای محققانی مفید باشد که سعی می کنند یک رویداد را با استفاده از زبان طبیعی از زمینه های مکانی-زمانی توصیف یا خلاصه کنند. علاوه بر این، وزن توجه ما یک رابطه قابل تفسیر بین متن، مکان و زمان فراهم می کند. تا جایی که ما می دانیم، این اولین کاری است که از مکانیزم توجه برای این منظور استفاده می کند. این تفاسیر ارزشمند هستند، زیرا بینش هایی را در مورد چگونگی تأثیر مکان و زمان بر آنچه مردم می گویند (چه در شبکه های اجتماعی یا هر منبع داده دیگری با این ماهیت) ارائه می دهند. اگرچه تفسیر شبکه های عصبی دشوار است، وزنهای توجه نمونهای شناختهشده از مؤلفههای قابل تفسیر هستند که بهطور گسترده در ترجمه ماشینی و زیرنویسهای ویدیویی، از جمله موارد دیگر، استفاده شده است. ما امیدواریم که نتایج ارائه شده در اینجا علاقه به استفاده از این مکانیسم را در حوزههای زمانی- مکانی افزایش دهد.
۵٫ نتیجه گیری ها
در این کار، ما مشکل مدلسازی دادههای متنی حاشیهنویسی مکانی-زمانی را بررسی کردیم. ما بررسی کردیم که چگونه دانه بندی های مختلف زمان و مکان بر تولید زبان شرطی مکانی-زمانی در شبکه های اجتماعی مبتنی بر مکان تأثیر می گذارد. ما یک معماری مدل زبان عصبی را پیشنهاد کردیم که با دانه بندی های مختلف زمان و مکان سازگار باشد. یک نتیجه قابل توجه از آزمایش های ما بر روی دو مجموعه داده از شبکه های اجتماعی توییتر (لس آنجلس) و Foursquare (نیویورک) این است که هر مجموعه داده دارای تنظیمات دانه بندی بهینه خود برای تولید زبان مکانی-زمانی است. از آنجایی که معماری پیشنهادی ما برای مدلسازی زمان و مکان در دانهبندیهای مختلف قابل انطباق است، میتواند الگوها را با توجه به هر مجموعه داده ثبت کند. این نتایج مستقیماً با نشان دادن تجربی این که تنظیم مناسب دانهبندیهای زمانی و مکانی میتواند به مدلسازی/تولید زبان فضایی-زمانی کمک کند، مستقیماً به سؤال تحقیق ما پاسخ میدهد. در ارزیابیهای کیفی خود، ابتدا نشان میدهیم که چگونه میتوان از مدل پیشنهادی برای خلاصه کردن فعالیتها در محیطهای شهری با تولید زبان طبیعی استفاده کرد. این برنامه بر اهمیت مدلسازی ساختار متوالی متون به منظور تولید توصیفات منسجم برای زمینههای مکانی-زمانی تأکید میکند. ثانیا، ما نشان میدهیم که چگونه کلمات با معنایی متمایز به سلولهای فضایی و پنجرههای زمانی مرتبط با معنایی آنها مرتبط میشوند. ما نشان می دهیم که چگونه می توان از مدل پیشنهادی برای خلاصه کردن فعالیت ها در محیط های شهری با تولید زبان طبیعی استفاده کرد. این برنامه بر اهمیت مدلسازی ساختار متوالی متون به منظور تولید توصیفات منسجم برای زمینههای مکانی-زمانی تأکید میکند. ثانیا، ما نشان میدهیم که چگونه کلمات با معنایی متمایز به سلولهای فضایی و پنجرههای زمانی مرتبط با معنایی آنها مرتبط میشوند. ما نشان می دهیم که چگونه می توان از مدل پیشنهادی برای خلاصه کردن فعالیت ها در محیط های شهری با تولید زبان طبیعی استفاده کرد. این برنامه بر اهمیت مدلسازی ساختار متوالی متون به منظور تولید توصیفات منسجم برای زمینههای مکانی-زمانی تأکید میکند. ثانیا، ما نشان میدهیم که چگونه کلمات با معنایی متمایز به سلولهای فضایی و پنجرههای زمانی مرتبط با معنایی آنها مرتبط میشوند.
ما با کار با مجموعه داده های جدیدتر و با استفاده از گسسته سازی های دست ساز فرصت های تحقیقاتی ارزشمند آینده را پیش بینی می کنیم. ما تصمیم گرفتیم آزمایشهای خود را با این مجموعه دادهها انجام دهیم تا فرآیند ارزیابی با کارهای قبلی سازگار باشد. برای گسستهسازی مهر زمانی و مختصات جغرافیایی، میخواهیم از استفاده از محدودیتهای سخت بین سلولها اجتناب کنیم، زیرا این امر میتواند منجر به تخصیص زمانها و مکانهایی شود که ممکن است به هم نزدیک باشند به سلولهای مختلف.