
با افزایش سریع قیمت مسکن در هلند، نیاز فزاینده ای به پیش بینی های ارزش محلی بیشتر برای وثیقه های وام مسکن در بخش مالی وجود دارد. بسیاری از مطالعات موجود بر مدل سازی قیمت خانه برای یک شهر خاص تمرکز دارند. با این حال، این مدل ها اغلب برای وام دهندگان وام مسکن با دارایی های گسترده در سراسر کشور جالب نیستند. به همین دلیل است که با فراوانی مجموعه دادههای ملی ملی، این مقاله سه مدل قیمتگذاری لذتگرا (رگرسیون خطی، رگرسیون وزندار جغرافیایی، و افزایش گرادیان شدید-XGBoost) را برای مدلسازی ارزشهای ارزیابی املاک برای پنج شهرداری بزرگ در بخشهای مختلف پیادهسازی و مقایسه میکند. از هلند مقادیر ارزیابی مورد استفاده برای آموزش مدل توسط Stater NV ارائه شده است. که بزرگترین ارائه دهنده خدمات وام مسکن در هلند است. از بین سه مدل اجرا شده، مدل XGBoost بالاترین دقت را دارد. XGBoost می تواند ۸۳ درصد از واریانس را با RMSE 65312 یورو، MAE 43625 یورو و MAPE 6.35 درصد در پنج شهرداری توضیح دهد. دو متغیر مهم در مدل، کل مساحت زندگی و ارزش مالیات هستند که از مجموعه دادههای در دسترس عموم گرفته شدهاند. علاوه بر این، مقایسه ای بین نمایه سازی و XGBoost انجام شده است که نشان می دهد مدل XGBoost قادر است مقادیر ارزیابی انواع مختلف خانه ها را با دقت بیشتری پیش بینی کند. واریانس غیرقابل توضیح باقی مانده به احتمال زیاد ناشی از عدم وجود شاخص های خوب برای وضعیت خانه است. به طور کلی، این مقاله مزایای مجموعه دادههای مکانی باز را برای ایجاد یک مدل ملی ارزیابی املاک و مستغلات برجسته میکند.
کلید واژه ها:
مدل سازی ارزش املاک و مستغلات ; بازار مسکن ; قیمت مسکن ؛ ارزیابی املاک و مستغلات ; مدل لذت جویانه ; افزایش شیب شدید رگرسیون وزنی جغرافیایی ; هلند
۱٫ مقدمه
در هلند، دریافت ارزیابی توسط یک ارزیاب خبره هنگام گرفتن وام مسکن، همانطور که توسط مرجع بازارهای مالی (AFM) اجباری شده است [ ۱ ]. این ارزیابی ها نقش مهمی در درخواست وام مسکن دارند. در اعطای وام مسکن، نسبت بین مبلغ وام گرفته شده و ارزش وثیقه را Loan-to-Value می نامند. وام به ارزش و وام به درآمد دو عامل مهم تعیین کننده میزان وام گرفتن هستند. آنها به عنوان یک شاخص خوب برای ریسک وام دهنده [ ۲ ] عمل می کنند و از مردم در برابر گرفتن وام مسکنی که توانایی پرداخت آن را ندارند محافظت می کنند.
ارزیابی ها می تواند اشتباه باشد. به عنوان مثال، در سال ۲۰۱۸، DNB، بانک مرکزی هلند، گزارش انتقادی در مورد کیفیت و استقلال ارزیابی مسکن هلند منتشر کرد [ ۳ ]. آنها به این نتیجه رسیدند که ارزشی بیش از حد ساختاری توسط ارزیابان وجود دارد، بر این اساس که ۹۵٪ از تمام ارزیابی ها برابر یا بالاتر از قیمت فروش (در دوره مشاهده شده) هستند. تلاش برای ارزیابی دقیق نه تنها برای مدیریت ریسک ذکر شده، بلکه برای ایجاد اعتماد بین خریدار مسکن و بخش مالی که برای جامعه مفید است، مهم است.
ما می توانیم بین ارزیابی های سنتی و ارزیابی های مبتنی بر مدل تمایز قائل شویم. با ارزیابی های سنتی، یک ارزیاب برای ارزیابی وضعیت خانه به خانه مراجعه می کند. ویژگی های ذاتی خانه بخش بزرگی از قیمت آن را تعیین می کند. نمونه ها شامل تعداد اتاق خواب، مقدار فضای نشیمن، وجود باغ یا گاراژ و وجود پنل های خورشیدی است. ارزیابان این عوامل را وزن می کنند و قیمت فروش خانه هایی با ویژگی های مشابه را مقایسه می کنند. در نهایت، ارزیاب تلاش می کند تا یک برآورد عینی از ارزش ملک انجام دهد. ارزیابی های سنتی دقیق اما زمان بر و در نتیجه گران هستند.
در مقابل، ارزیابیهای مبتنی بر مدل، با استفاده از دادههای خانههای مشابهی که قبلاً فروخته شدهاند، یک تخمین خودکار مبتنی بر مدل از قیمت یک خانه خاص انجام میدهند. یکی از مزایای ارزیابی های مبتنی بر مدل نسبت به ارزیابی های سنتی این است که ارزان تر هستند. با این حال، دقت ارزیابیهای مبتنی بر مدل بستگی به مقدار دادههای خانههای مشابه دارد که میتوانند به عنوان مرجع استفاده شوند.
مدلهای قیمتگذاری لذتگرا، که قیمت مسکن را با استفاده از دادههای کمی در مورد ویژگیهای خانه، مکان و عرضه در مقابل تقاضا تخمین میزنند، میتوانند برای بهبود ارزیابیهای مبتنی بر مدل استفاده شوند. ادبیات نشان داده است که برای بسیاری از شهرها، به عنوان مثال، لندن [ ۴ ]، روتردام [ ۵ ]، لایپزیگ [ ۶ ] و سنگاپور [ ۷ ]، قیمت خانه را می توان با استفاده از این نوع مدل ها تخمین زد. با این حال، بسیاری از این مدل ها بر روی یک شهر واحد در یک کشور تمرکز دارند.
برآوردهای مبتنی بر مدل مبتنی بر مدلهای قیمتگذاری لذتگرا در حال حاضر در عمل به عنوان جایگزینی برای ارزیاب سنتی استفاده میشوند. در هلند، یک نمونه بدنام WOZ-waarde است که یک ارزش مالیاتی است که توسط دولت ایجاد شده است. در هسته خود، WOZ-waarde از تطبیق قیمتهای فروش خانههایی با ویژگیهای مشابه میآید [ ۸ ]. مشابه مدل لذتگرا، از ویژگیها و مکان خانه برای پیشبینی استفاده میکند. این داده ها از ثبت رسمی از Kadaster، که یک نهاد اداری مستقل در هلند برای نگهداری دفاتر ثبت املاک، مانند ثبت پایگاه آدرس ها و ساختمان ها (BAG) است، می آیند. ۹ ] به دست می آید.]. در واقع، این مدل پیچیدهتر از مدل قیمت لذتبخش است. از بسیاری از لایه های اضافی برای بهبود و اعتبارسنجی دقت مدل استفاده می کند. به عنوان مثال، آنها برای اطمینان از اعتبار، نمونههایی از ارزیابیهای فیزیکی را برای خانههای بسیار منحصربهفرد انجام میدهند. علاوه بر این، از تصاویر ماهواره ای برای بررسی اینکه آیا خانه ها دارای ویژگی های فیزیکی ثبت شده هستند یا خیر استفاده می شود (به عنوان مثال، مالک خانه ممکن است یک پسوند خانه یا استخر شنا ساخته باشد که ارزش ملک را افزایش می دهد). یک صاحب خانه می تواند گزارشی در مورد WOZ-waarde خانه خود دریافت کند. این گزارش شامل خانه هایی شبیه به خانه صاحب خانه است که برای استخراج WOZ-waarde استفاده می شود.
WOZ-waarde به عنوان نشانه ای از ارزش ملک است که توسط شهرداری برای مالیات استفاده می شود. برای شهرداری ها غیرممکن است که تک تک خانه ها را از طریق بازرسی خانه ها به صورت سالانه ارزیابی کنند. بسیاری از شرکت های بیمه و وام دهندگان وام مسکن در یک قایق هستند: هزینه های انجام یک ارزیابی سنتی برای هر خانه در مجموعه آنها بسیار زیاد است. با این حال، محدودیتی در استفاده از WOZ-waarde وجود دارد، زیرا این داده ها را نمی توان به صورت انبوه برای هر خانه جداگانه، بدون دلایل قانونی کافی درخواست کرد. بنابراین، بسیاری از وام دهندگان وام مسکن و شرکت های بیمه ترجیح می دهند ارزش مسکن موجود در پرتفوی خود را با شاخص های ملی برای ارزیابی مجدد قیمت مسکن تنظیم کنند. اشکال شاخصسازی این است که عوامل مختلفی را که ارزش خانه را تعیین میکنند به یک شاخص واحد تعمیم میدهد. در نتیجه، خانهها همچنان میتوانند بیش از حد یا کمتر از ارزشگذاری شوند، برای مثال اگر نرخ رشد قیمت برای مناطق مختلف، ویژگیهای مکان یا نوع خانه متفاوت باشد.
یک مثال تجاری از مدل قیمت خانه (هدونیک) Calcasa [ ۱۰ ] است. Calcasa، یک شرکت فینتک، خود را با مدل ارزشگذاری املاک خود وارد بازار میکند که توسط دفاتر رتبهبندی مانند Moody’s، Fitch Ratings و Standard & Poor’s تایید شده است. آنها شرکت های بیمه و ارائه دهندگان وام مسکن را برای ارائه ارزیابی های مبتنی بر مدل برای پرتفوی خود هدف قرار می دهند. متأسفانه، از آنجایی که این مدل کسب و کار آنهاست، مشخص نیست که دقیقاً چه مدلی را اجرا می کنند. با این حال، Calcasa از ویژگیهای مسکن همراه با دادههای فروش تاریخی برای مدل خود استفاده میکند، که شبیه به آنچه مدل WOZ-waarde استفاده میکند.
در مجموع از این نمونه ها می توان دریافت که قطعاً بازاری برای مدل های قیمت خانه در هلند وجود دارد. به نظر میرسد همه این مدلها بر سیستمهایی تکیه دارند که سعی میکنند قیمتهای فروش خانههای مشابه را بر اساس ویژگیهایشان مطابقت دهند. این داده های فروش نقطه شروع کلیدی برای همه مدل ها هستند. اگر دادههای فروش کافی وجود داشته باشد، دشوارترین چالش جمعآوری اطلاعات دقیق در مورد یک خانه است. ویژگیهای فیزیکی اصلی، و همچنین ویژگیهای محله، به ترتیب از طریق Kadaster هلند و آژانس مرکزی آمار (CBS) در دسترس عموم هستند. در پایان، هر کسی که دادههای بیشتری و در عین حال دقیق داشته باشد، در نهایت میتواند بهترین پیشبینی را انجام دهد.
تا آنجا که ما می دانیم، در حال حاضر هیچ مدل قیمت گذاری لذت جویانه ای وجود ندارد که بتواند تخمین قیمت مسکن را در شهرهای مختلف انجام دهد. هدف این مقاله بررسی ارزیابی مبتنی بر مدل املاک و مستغلات با استفاده از قیمتگذاری لذتگرا در شهرها و دادههای در دسترس عموم است. ما میخواهیم روشهای مختلف یادگیری ماشین (ML) را برای تولید مدلهای قیمتگذاری لذتبخش مقایسه کنیم و آنها را بر اساس دقت، هزینه، سرعت و نیازهای داده ارزیابی کنیم.
سوالات پژوهشی که برای دستیابی به این هدف مطرح می کنیم به شرح زیر است:
-
کدام رویکردهای ML در حال حاضر برای قیمتگذاری لذتگرا استفاده میشوند و چگونه عمل میکنند؟
-
کدام عوامل برای تفاوت قیمت خانه ها در شهرها مهم است؟
-
کدام اطلاعات در مورد این عوامل در دسترس است؟
-
چگونه می توانیم با استفاده از بینش های به دست آمده، روشی برای قیمت گذاری لذت جویانه در شهرهای مختلف بسازیم؟
-
نتایج اعمال این روش با مجموعه داده واقعی چیست؟
بقیه این مقاله به شرح زیر سازماندهی شده است: بخش ۲ یک نمای کلی از شاخصسازی قیمت سنتی و چهار مدل قیمتگذاری لذتگرا برای ارزیابی املاک ارائه میکند: (۱) رگرسیون خطی، (۲) رگرسیون وزندار جغرافیایی (GWR)، (۳) چندگانه مقیاس GWR (MGWR)، (۴) افزایش گرادیان شدید (XGBoost)، و همچنین متغیرهایی که معمولا در این مدل ها استفاده می شود. بخش ۳ منابع داده و معیارهای مدل مورد استفاده در این مقاله برای ساخت مدل ها را معرفی می کند. بخش ۴ مدل ها و اشکالات آنها را ارزیابی می کند و همچنین عملکرد آنها را در برابر نمایه سازی سنتی مقایسه می کند. بخش ۵ پیامدهای نتایج مدل را مورد بحث قرار می دهد. سرانجام، بخش ۶نتیجه گیری را به سؤالات تحقیق و زمینه های تحقیق بیشتر ارائه می دهد.
۲٫ پس زمینه
در این بخش مزایا و محدودیتهای دو رویکرد برای برآورد قیمت مسکن مورد بحث قرار میگیرد: شاخصهای قیمت و مدلهای قیمتگذاری لذتگرا. به طور همزمان، شاخص قیمت و سایر شاخصهای قیمت مسکن هلند برای نشان دادن تحولات بازار مسکن هلند بررسی میشوند. علاوه بر این، این بخش هر دو مدل عملی و همچنین چهار مدل پیشرفته را که معمولاً در ادبیات برای مدلهای قیمت لذتبخش استفاده میشوند، ارزیابی میکند: رگرسیون خطی (LR)، رگرسیون وزندار جغرافیایی (GWR)، GWR چند مقیاسی (MGWR). ، و افزایش گرادیان شدید (XGBoost). در نهایت، یک مرور کلی از ویژگی های مشترک برای چنین مدل های قیمت لذت بخش ارائه شده است. این نمای کلی به سه دسته تقسیم می شود: ویژگی های بازار، ویژگی های مکان و ویژگی های ذاتی خانه.
۲٫۱٫ شاخص های قیمت خانه هلندی و مدل تکراری فروش
شاخص سازی قیمت روشی برای محاسبه میانگین افزایش قیمت نرمال شده برای انواع مختلف کالاها است. چهار روش رایج برای محاسبه یک شاخص به شرح زیر است: (۱) شاخص Paasche، (۲) شاخص Laspeyres، (۳) شاخص Lowe، و (۴) شاخص فیشر. هدف هر شاخصی ارائه یک نشانه خوب برای تغییر قیمت در یک بازه زمانی خاص است. یک شاخص قیمت اغلب برای تخمین ارزش فعلی با استفاده از یک مقدار شناخته شده تاریخی استفاده می شود. این فرآیند را نمایه سازی می نامند. در مورد قیمت مسکن، ارزش فعلی یک خانه را می توان با استفاده از قیمت فروش از گذشته و نمایه سازی آن با استفاده از شاخص قیمت مسکن، تخمین زد.
برای هلند، شاخص قیمت مسکن قابل توجه توسط Kadaster محاسبه می شود. Kadaster آژانس ثبت زمین و نقشه برداری هلند است. ثبت رسمی املاک و مالکیت زمین در هلند را حفظ می کند. این رجیستری آدرس ها و ساختمان های پایگاه ثبت (BAG) نامیده می شود. شاخص قیمت مسکن به همراه سایر آمارهای مربوط به بازار مسکن هلند در داشبوردی در دسترس عموم ارائه شده است که هر ماه به روز می شود.
شاخص Kadaster با استفاده از مدل وزنی تکرار فروش محاسبه می شود [ ۱۱ ]. چهار روش فوق الذکر برای محاسبه شاخص های قیمت مستلزم فروش چندگانه یک کالا در بازه زمانی مورد نظر برای یک شاخص دقیق است. این به معنای فروش چندگانه یک کالا در سال برای یک شاخص سالانه است. با این حال، این مورد برای خانههایی نیست که اغلب برای چندین دهه معامله نمیشوند. مدل فروش تکراری برای دور زدن این موضوع به طور خاص توسعه داده شده است.
مدل تکرار فروش میانگین تغییر در قیمت فروش برای یک کالا را بین دو لحظه مختلف در زمان میدهد [ ۱۲ ]. در مورد قیمت مسکن، میانگین تغییر قیمت همان خانه ای که در سال های جداگانه فروخته شده است را نشان می دهد. به طور اجتناب ناپذیر، پیش نیاز این مدل نیاز به حداقل دو تاریخ فروش جداگانه برای هر خانه منحصر به فرد است. مدل فروش تکراری نه تنها برای محاسبه قیمت مسکن، بلکه سایر کالاهای غیرمعمول مانند کلکسیون (مثلاً آثار هنری) مورد استفاده قرار می گیرد. مدل فروش تکراری وزنی این مدل را گسترش میدهد، زیرا خانههایی که اغلب معامله میشوند کمتر از خانههایی که در بازه زمانی طولانیتر معامله میشوند، به میانگین کل کمک میکنند. این امر از تعصب نسبت به خانه هایی که اغلب معامله می شوند جلوگیری می کند.
علاوه بر این، شاخص قیمت خانه Kadaster از دو سطح اصلاح منحصر به فرد تشکیل شده است: یکی برای استان های مختلف هلند ( جدول A1 )، دیگری برای شش نوع مختلف مسکن ( جدول A2 ). هر دو شاخص بر اساس تمام معاملات املاک و مستغلات در بیست سال گذشته (۲۰۰۰-۲۰۲۰) با سال ۲۰۱۵ به عنوان سال پایه است. در حالی که قیمت مسکن از روند یکسانی پیروی می کند، تفاوت های کوچک در طی سالیان متمادی منجر به تفاوت های قابل توجهی در طول زمان می شود [ ۱۱ ]. بیشترین افزایش در Noord-Holland مشاهده می شود، جایی که قیمت ها تا ۷۶٫۷۰٪ افزایش یافته است که دو برابر بیشتر از ۳۸٫۱۶٪ در لیمبورگ است (همانطور که در مشاهده می شود جدول A1 مشاهده می شود.). برای انواع مختلف خانه ها، این تفاوت از نظر آماری نیز معنادار است، همانطور که در [ ۱۱ ] ثابت شده است]. با توجه به این واقعیت ها، می توان نتیجه گرفت که برای مدل سازی قیمت مسکن در مقیاس محلی تر برای بازار مسکن هلند، به عوامل بیشتری نیاز است.
در پایان، شاخصسازی تخمین معقولی برای قیمت مسکن ارائه میکند، اما فقط در مقیاس جهانی. در یک مدل محلی، زمانی که کسی میخواهد ارزش فعلی یک خانه خاص را تخمین بزند، یک شاخص احتمالاً تخمین “به اندازه کافی خوب” را ارائه می دهد. برای یک خانه تکی، یک شاخص نمی تواند تغییر قیمت دقیق را تعیین کند، زیرا بر اساس میانگین تغییر قیمت یک نمونه بزرگتر است. گنجاندن عوامل مختلف برای ایجاد شاخص های بیشتر دقت را بهبود می بخشد. با وجود این، بزرگترین نقطه ضعف هنوز باقی است. شاخص ها به نمونه های بزرگی از کل معاملات متکی هستند تا قابل اعتماد باشند. با استفاده از رگرسیون، مدلهای قیمت لذتگرا یک جایگزین معتبر زمانی که یک نمونه داده بزرگ در دسترس نیست، هستند.
۲٫۲٫ مدل های قیمت لذت بخش
قیمتگذاری لذتگرا بیان میکند که قیمت یک محصول تجمیع قیمتهایی است که خریدار مایل است برای ویژگیهای فردی محصول خرج کند. برای یک خانه، این ویژگیها از ویژگیهای ذاتی (مثلاً تعداد اتاقها) تا مشخصه مکان (مثلاً دسترسی به امکانات رفاهی) و همچنین ویژگیهای بازار (مثلاً عرضه خانهها در منطقه) را شامل میشود [ ۱۳ ]. به همین ترتیب، قیمت مسکن منعکس کننده تغییرات کلان اقتصادی در خواسته ها و ارزش های جامعه است. به این ترتیب، قیمت خانه نقش همه جانبه ای در تعیین کمیت قیمت کالاهای نامشهود مانند هوای پاک [ ۴ ]، وجود فضای سبز [۴] دارد. ۱۴ ] دارد.] و زیرساخت های قابل دسترس. مدلهای قیمت لذتگرا از انواع مختلفی از مدلهای رگرسیونی برای تخمین قیمت و وزن هر مشخصه استفاده میکنند. چهار نوع مدل رگرسیون مورد استفاده در تحقیقات اخیر برای برآورد قیمت خانه لذتبخش عبارتند از: رگرسیون خطی (چند)، رگرسیون وزندار جغرافیایی (GWR)، GWR چند مقیاسی (MGWR) – بهبودی بر GWR – و افزایش گرادیان شدید (XGBoost) .
۲٫۳٫ رگرسیون خطی (LR)
رگرسیون خطی (LR) تغییر در یک متغیر وابسته را بر اساس یک رابطه خطی به یک یا چند متغیر مستقل مدل می کند. با استفاده از حداقل مربعات معمولی، تأثیر هر ویژگی با یک ضریب منفرد توصیف می شود. تحقیقات با موفقیت نشان می دهد که روابط خطی بین قیمت خانه و مساحت سطح زندگی یک خانه وجود دارد [ ۱۵ ]. علاوه بر این، بسیاری از ویژگی های ذاتی دیگر مانند تعداد اتاق خواب ها [ ۱۶ ] و میزان فضای باغ [۱۶] ۱۴ ]] یک سهم خطی اساسی را در قیمت یک خانه نشان می دهد. مزیت مدل رگرسیون خطی در سادگی آن برای داشتن پاسخ یکسان برای تمام نقاط داده است. در نتیجه، مدلهای رگرسیون خطی معمولاً کمتر مستعد برازش بیش از حد مجموعه دادهها هستند.
برعکس، سادگی مدلهای رگرسیون خطی نیز در مدلسازی پدیدههای پیچیدهتر مانند قیمت مسکن، افت آنها است. در عمل، بسیاری از عوامل دیگر که در قیمت مسکن نقش دارند نیز روابط غیرخطی را نشان می دهند [ ۵ ]. به عنوان مثال، یک اتاق اضافی تأثیر بیشتری بر ارزش یک آپارتمان نسبت به یک خانه مستقل دارد. این را می توان با شکستن رابطه غیر خطی به یک رابطه خطی با گنجاندن یک ویژگی دیگر، در این مورد نوع خانه، حل کرد. با این حال، اغلب اتفاق میافتد که روابط غیرخطی را نمیتوان از طریق گنجاندن ویژگیهای اضافی به روابط خطی تجزیه کرد.
در نهایت، مدلهای رگرسیون خطی به دلیل عدم مدلسازی یک مؤلفه فضایی، تخمینگر خوبی برای قیمت مسکن نیستند [ ۱۶ ]. قیمت خانه برای همان نوع خانه در آمستردام بسیار متفاوت از قیمت خانه در گرونینگن است [ ۱۷ ]. هم در سطح ملی و هم در سطح شهر، قیمت یک خانه اغلب متفاوت است. این به دلیل ناهمگونی فضایی است، به این معنی که مقدار یک متغیر در فضا متفاوت است. در نظر نگرفتن ناهمگونی فضایی در مدل باعث عدم ایستایی فضایی می شود. ناایستایی فضایی نام [ ۱۸ ] برای وضعیتی است که در آن یک مدل جهانی، مانند رگرسیون خطی، به دلیل نقش ایفای مکان، قادر به پیشبینی دقیق نتیجه نیست.
یکی از راه های کاهش مشکل عدم ایستایی فضایی، گروه بندی مشاهدات از طریق استفاده از یک متغیر ساختگی، مانند گنجاندن کدهای پستی [ ۱۹ ] یا فاصله تا مرکز شهر [ ۲۰ ] است. علاوه بر این، استدلال می شود که از طریق کمی کردن ویژگی های کافی، می توان مناطق را تشخیص داد [ ۲۱]. با این وجود، اشکال کمی کردن ویژگیهای بیشتر این است که برای ایجاد تمایزات قابل اعتماد، داده بسیار فشرده است. با وجود همه اینها، این مدل هنوز وابستگی فضایی خانه های واقع در نزدیکی را نادیده می گیرد، که ثابت شده است که از نظر آماری مربوط به مدل سازی قیمت خانه است. در مجموع، فقدان مولفه فضایی و متعاقب آن کاهش دقت مدل نمی تواند با نگاه کردن به ویژگی های فردی خانه ها در یک محله یا شهر قابل توجه باشد.
۲٫۴٫ رگرسیون وزنی جغرافیایی (GWR)
رگرسیون وزندار جغرافیایی (GWR) یک مدل پارامتری مبتنی بر رگرسیون خطی سنتی است، اما ناهمگونی فضایی را نیز برای جلوگیری از مشکل عدم ایستایی فضایی در نظر میگیرد. مشابه رگرسیون خطی، GWR به هر متغیر مستقل یک ضریب تخمینی می دهد. با این حال، ضریب از نظر مکانی بسته به نقاط داده نزدیک [ ۱۸ ] متفاوت است. کدام نقاط به اندازه کافی نزدیک در نظر گرفته می شوند و وزنی که هر نقطه به آن اختصاص می یابد از طریق یک تابع هسته تعریف می شود. GWR برای دقت بهتر بر اساس ویژگیهای ذاتی [ ۵ ] و ویژگیهای مکان [ ۶ ] مفید است.
برای تجزیه و تحلیل فضایی مانند GWR، دانستن در مورد خودهمبستگی فضایی مهم است. خودهمبستگی فضایی در نقل قولی از توبلر که به قانون اول جغرافیا نیز معروف است، مشهورتر توصیف شده است: “همه چیز به هر چیز دیگری مربوط است، اما چیزهای نزدیک بیشتر از چیزهای دور مرتبط هستند” [ ۲۲ ]. به طور رسمی تر، خودهمبستگی فضایی همبستگی بین نقاط داده مکان های مجاور در فضا است. آمارهای متداول برای تعیین خودهمبستگی های فضایی، آمار آزمون موران I و جیری است. خودهمبستگی مکانی می تواند نشانه ای از گم شدن یک متغیر وابسته باشد. به نوبه خود، این بدان معنی است که مدل به اشتباه مشخص شده است، که منجر به نتایجی می شود که می توانند از نظر آماری نامعتبر باشند.
تابع هسته نقش مهمی در نحوه وزن دهی مدل به هر یک از ضرایب ایفا می کند. دو نوع اصلی از توابع هسته وجود دارد: (۱) ثابت، که نقاط داده را در یک شعاع ثابت در نظر می گیرد، و (۲) تطبیقی، که مقدار ثابتی از همسایگان را در نظر می گیرد. یک تابع تطبیقی به طور خودکار پهنای باند خود را طوری تنظیم می کند که همیشه تعداد نقاط داده یکسانی را شامل شود. این باعث می شود آن را برای مجموعه داده های فضایی، که به طور یکنواخت از نظر مکانی توزیع نشده اند، ایده آل کند. متداولترین تابع هسته مورد استفاده در ادبیات شناسایی شده در قیمتگذاری املاک، هسته گاوسی تطبیقی است که همه مشاهدات را در نظر میگیرد اما وزن هر چه دورتر از یک مشاهده باشد به سمت صفر میرود. ۵ ، ۶ ، ۷ ، ۲۳ ].]. عملکرد هسته مدل GWR را می توان با استفاده از روش جستجوی طلایی و اعتبارسنجی متقابل بهینه کرد. مرحله بهینه سازی تابع هسته بسیار مهم است، زیرا یک تابع هسته به طور تصادفی انتخاب شده دقت مدل را کاهش می دهد.
نقطه ضعف مدل GWR این واقعیت است که تابع هسته مجبور است برای همه متغیرها پهنای باند یکسانی داشته باشد. پهنای باند مقدار نقاط داده ای است که در تابع هسته وزن می شود. متغیرهای مختلف ممکن است بر مناطق بزرگتر یا کوچکتر تأثیر بگذارند. در این حالت، فرض ثابت بودن پهنای باند اشتباه است. برخی از اثرات فقط می توانند به تأثیرات خانه های دیگر در همان محله مرتبط باشند، در حالی که برخی دیگر در سطح جهانی تحت تأثیر همه نقاط داده در شهر هستند. این سادهسازی واقعیت جرقهای ایجاد یک تغییر جدید در GWR شد که شامل پهنای باند متغیر است که رگرسیون وزندار جغرافیایی چند مقیاسی نامیده میشود.
۲٫۵٫ رگرسیون وزنی جغرافیایی چند مقیاسی (MGWR)
رگرسیون وزنی جغرافیایی چند مقیاسی (MGWR) پهنای باند متغیر را برای هر یک از ضرایب معرفی می کند [ ۲۴ ]. علیرغم اولین انتشار در سال ۲۰۱۷، این مدل مطالعات کمتری نسبت به GWR داشته است، هم در کل و هم در زمینه تخمین قیمت مسکن. این می تواند به دلیل این واقعیت باشد که ابزارهای رایج تجزیه و تحلیل فضایی، مانند ArcGis، هنوز یک تجزیه و تحلیل MGWR داخلی ندارند، فقط برای GWR. انتشار اخیر همراه با عدم پشتیبانی عمده از ابزارهای تحلیل فضایی به این معنی است که تحقیقات کمتری در مورد MGWR در مقایسه با GWR انجام شده است.
با این وجود، تحقیقات نشان داده است که MGWR اغلب نسبت به GWR بهبود می یابد [ ۲۴ ]. با این حال، بهبودهای توصیف شده در مطالعات مختلف متفاوت است. این تفاوت ها گاهی خیلی کوچک هستند که از نظر آماری قابل توجه نیستند. همانطور که در [ ۲۵ ] دیده می شود، واریانس توضیح داده شده ( ) افزایش جزئی ۰٫۰۵ (۱۰٪ بهبود) را هنگام تغییر از GWR به MGWR نشان می دهد. علاوه بر این، یک مطالعه اخیر در مورد قیمتهای اجاره AirBnB نیز با استفاده از MGWR در مقابل GWR 0.10 بهبود داشت [ ۲۶ ]. به طور کلی، تحقیقات [ ۲۵ ، ۲۶ ] موافق هستند که تأثیرات مختلف محلی و جهانی متغیرها مزیت اصلی MGWR نسبت به GWR است.
۲٫۶٫ درختان رگرسیون و تقویت گرادیان شدید (XGBoost)
اگرچه با (M)GWR، ضرایب میتوانند از نظر فضایی برای مدلسازی تأثیرات مثبت در یک مکان و همچنین تأثیرات منفی در مکان دیگر متفاوت باشند، آنها هنوز بر روابط خطی برای انجام تحلیل رگرسیون متکی هستند. یک جایگزین برای این مدل درخت تصمیم است که قادر به مدل سازی رفتار غیر خطی است. درخت تصمیم که معمولاً برای طبقه بندی استفاده می شود، می تواند برای رگرسیون نیز استفاده شود که در آن سناریو اغلب درختان رگرسیون نامیده می شوند. تقویت گرادیان تکنیکی است که از یادگیری گروهی بسیاری از مدلهای پیشبینی ضعیف برای پیشبینی بهتر از استفاده از یک درخت استفاده میکند. در نهایت، افزایش گرادیان شدید (XGBoost) کتابخانه ای است که این افزایش گرادیان را برای مدل های درختی به روشی سریع و کارآمد پیاده سازی می کند.
XGBoost همچنین دارای برنامه هایی برای پیش بینی قیمت خانه است. برای مدلسازی مجموعه داده مسکن بوستون با میانگین درصد مطلق خطای کمتر از ۵% استفاده شده است [ ۲۷ ]. این مجموعه داده یک مجموعه داده محبوب برای مسابقات Kaggle برای مقایسه عملکرد مدل های مختلف یادگیری ماشین است. مشابه مجموعه داده بوستون، بیشتر کاربردهای دیگر XGBoost نیز بر مدل سازی قیمت خانه بر اساس ویژگی های ذاتی خود خانه تمرکز دارند [ ۲۸ ]. به طور کلی، این XGBoost را یکی دیگر از کاندیدای اصلی برای مدل قیمتگذاری لذتگرا میکند که میتواند روابط غیرخطی را نیز ثبت کند.
۲٫۷٫ ویژگی های تخمین قیمت خانه
بر اساس مطالعات تحلیل شده و کاربردهای عملی برای مدلهای قیمتگذاری لذتگرا، فهرستی از ویژگیها شناسایی و به سه دسته ویژگیهای بازار، ویژگیهای مکان و ویژگیهای ذاتی خانه تقسیم میشود. دو مقوله مهم، ویژگیهای ذاتی و موقعیت مکانی خانه هستند، زیرا ویژگیهای بازار تأثیرات جهانی هستند که بر همه خانهها تأثیر میگذارند. با این وجود، ویژگی های بازار به منظور کامل بودن درج شده است. این بررسی اجمالی بر اساس مروری بر متغیرهای مدل لذتگرای ژو و همکاران است. [ ۱۶ ]. با این حال، این بررسی اجمالی عمدتاً بر متغیرهایی متمرکز است که در مدلهای رگرسیون وزندار جغرافیایی نیز گنجانده شدهاند.
ویژگی های بازار به عنوان تأثیرات جهانی بر کل بازار مسکن شناسایی می شوند. یکی از تأثیرات بزرگ بازار، سیاست های ملی است، مانند لغو اخیر (ژانویه ۲۰۲۱) مالیات نقل و انتقال برای مبتدیان در بازار مسکن هلند. این سیاستهای ملی اغلب تأثیر یکسانی بر تمام قیمتهای مسکن دارند. ۲۱]. یکی دیگر از تأثیرات جهانی نرخ بهره وام مسکن است. نرخ بهره کمتر باعث می شود خریدار خانه پول بیشتری برای خرج کردن داشته باشد. در نتیجه، این اغلب باعث افزایش قیمت خانه می شود. از آنجایی که ویژگی های بازار تأثیرات جهانی هستند، واریانس مکانی قیمت مسکن را توضیح نمی دهد. به این ترتیب، این متغیرها در یک مدل رگرسیون وزندار جغرافیایی تعلق ندارند. با این وجود، آنها نقش مهمی در توضیح تفاوت زمانی قیمتهای مسکن دارند، زیرا در نگاهی به رشد قیمت مسکن به صورت سالانه نقشی را ایفا میکنند.
در مقابل، ویژگی های ذاتی بزرگترین عوامل متمایزکننده قیمت مسکن هستند [ ۴ ، ۲۹ ، ۳۰ ]. به این ترتیب، آنها همچنین بیشترین استفاده را برای مدلهای قیمتگذاری لذتگرا دارند [ ۱۶ ]. نه تنها در ادبیات، بلکه در کاربردهای عملی، مانند مدل مالیات هلند، این متغیرها نقش غالب را ایفا می کنند. بزرگترین تأثیرات منطقه زندگی و حجم [ ۱۶] که معمولاً با مقدار فضای باغ دنبال می شود. امکاناتی مانند گاراژ و حمام های متعدد نیز به افزایش قیمت خانه کمک می کند. سال ساخت می تواند به عنوان یک شاخص متوسط از بهره وری انرژی و وضعیت نگهداری باشد. با این حال، همیشه وضعیت واقعی خانه را نشان نمی دهد. خانه های قدیمی احتمالاً یک بار در طول عمر خود بازسازی می شوند، بنابراین ویژگی های دیگری مانند برچسب انرژی مورد نیاز است. علاوه بر این، ساختمانهای قدیمیتر نیز میتوانند میراث فرهنگی باشند، که میتواند منجر به قیمتهای بالاتر برای ساختمانهای قدیمیتر به دلیل ارزش تاریخی قابل توجه آنها شود که در [ ۵ ] بیان شد. نمای کلی همه متغیرها در جدول ۱ آورده شده است.
بزرگترین نقطه ضعف ویژگی های ذاتی این است که داده های باز در مورد این ویژگی ها به سختی به دست می آیند. بیشتر داده های آژانس های املاک یا محافظت می شوند یا فقط قابل خرید هستند. با وجود این، منابع ملی عمومی خوب برای ویژگی های خانه در هلند وجود دارد. Kadaster اطلاعات اولیه در مورد هر خانه از جمله سال ساخت و منطقه زندگی را ارائه می دهد.
در ادبیات، اکثر مدلهای GWR برای قیمتگذاری خانه تنها بر مدلسازی ویژگیهای ذاتی بر اساس دادههای جمعآوریشده از بازارهای املاک و مستغلات یا آژانسهای املاک تمرکز دارند [ ۵ ، ۳۱ ، ۳۲ ، ۳۳ ]. با این حال، تحقیقات [ ۴ ، ۷ ] همچنین نشان میدهد که ویژگیهای مربوط به مکان/همسایگی خانه نیز به قیمت خانه کمک میکند. طبق [ ۴ ]، مکان/محله ۱۵ تا ۵۰ درصد کل قیمت خانه را تشکیل می دهد. به این ترتیب، حتی زمانی که اطلاعات کمی در مورد هر خانه خاص در دسترس باشد، باز هم می توان با استفاده از ویژگی های مکان، تخمین محلی تری انجام داد.
در این مقاله، ویژگی های مکان به ویژگی های ناشی از نوع محله و وجود ساختمان های مجاور اشاره دارد. برای مثال، دسترسی نزدیک به فروشگاههای رفاه، تفریحات و پارکها همگی تأثیرات مثبتی بر قیمت خانه دارند [ ۱۹ ]. این با تئوری اجاره پیشنهادی موافق است، که بیان میکند هر چه خانه به منطقه تجاری مرکزی نزدیکتر باشد، اجاره مسکن بالاتر میرود.
به همین ترتیب، دسترسی نقش دیگری در قیمت خانه ایفا می کند. زمان سفر به مکان های خاص مانند منطقه تجاری مرکزی می تواند شاخص بهتری نسبت به مسافت باشد. با این حال، همه اشکال حمل و نقل تأثیر مثبتی ندارند. نزدیکی بزرگراه تأثیر مخرب بیشتری دارد. تأثیر اغتشاش صوتی بیشتر از تأثیر آن بر دسترسی بهتر شهرهای دیگر است. دیدگاه ها نیز نقش دارند. چشم انداز رودخانه، دریاچه یا دریا می تواند تأثیرات مثبتی داشته باشد، در حالی که آسیاب های بادی و ساختمان های بلند اثرات مضری دارند.
در نهایت، شاخص های اجتماعی-اقتصادی برای یک محله وجود دارد که به قیمت مسکن نیز مربوط می شود. متوسط درآمد خانوار بیشتر در مناطقی با مسکن گرانتر دیده میشود. نرخ جرم و جنایت اغلب تأثیر منفی بر قیمت مسکن دارد. هنگام تحقیق در مورد این روابط، مهم است که کشف کنید آیا واقعاً یک همبستگی اتفاقی وجود دارد یا خیر. به طور کلی، ویژگی های مکان تأثیر کمتری نسبت به خصوصیات ذاتی دارند، زیرا ارزش مرتبط با هر یک از آنها بر اساس شخصی متفاوت است، با این حال آنها هنوز هم می توانند بینش بزرگی در مورد اینکه چرا خانه های خاص قیمت خانه های بالاتری نسبت به سایرین دارند ارائه دهند. خلاصه ای از متغیرهای مکان در جدول ۲ آورده شده است.
۳٫ داده ها و روش ها
در این مطالعه، ما سه مدل قیمتگذاری لذتگرا را برای پیشبینی ارزشهای ارزیابی خانهها در هلند بر اساس مدلها و متغیرهای مورد بحث در بخش قبل ایجاد میکنیم. مدل های انتخاب شده (۱) LR، (۲) GWR و (۳) XGBoost هستند. هر مدل برای داده های ارزیابی دنیای واقعی ارائه شده توسط Stater NV، که بزرگترین ارائه دهنده خدمات وام مسکن در هلند است، اعمال می شود. این مدلها از دادههای سالهای ۲۰۱۸ و ۲۰۲۰ برای پنج شهرداری بزرگ منتخب در سراسر هلند، یعنی روتردام، آمستردام، آیندهوون، آمرسفورت و گرونینگن استفاده میکنند. فرض بر این است که این مجموعه داده تنوع کافی را برای آموزش مدل برای هر شهر خاص در هلند فراهم می کند. در نهایت، این بخش با مروری بر متغیرهای توضیحی و پارامترهای مدل که بهینه شده اند به پایان می رسد.
۳٫۱٫ معیارهای مدل
هدف نهایی این است که کشف کنیم آیا ویژگیهای خانه و مکان امکان پیشبینی منطقی ارزیابیها را فراهم میکند یا خیر، و آیا این رویکرد بهتر از نمایهسازی سنتی است. این سه مدل با استفاده از معیارهای کمی و کیفی ارزیابی می شوند.
۳٫۱٫۱٫ معیارهای کمی
معیارهای کمی بر اساس معیارهای عملکرد دقت رایج برای مدلهای یادگیری ماشینی است. اول، به عنوان معیاری برای خوبی تناسب عمل می کند. ثانیاً، خطای پیشبینی با ریشه میانگین مربعات خطا یا RMSE تعیین میشود. RMSE خطاهای بزرگ را با مجذور کردن آنها بیشتر از خطاهای کوچکتر وزن می کند. این معیاری است که اغلب برای بهینه سازی مدل های رگرسیون استفاده می شود. علاوه بر این، MAE محاسبه می شود که میانگین مطلق خطای میانگین است. MAE همیشه کمتر یا برابر با RMSE است، زیرا وزن بیشتری برای خطاهای مطلق بزرگتر ایجاد نمی کند. در نهایت، میانگین درصد مطلق خطا یا MAPE، خطای نسبی را می دهد. این مفید است، زیرا قیمت خانه از ۱۵۰۰۰۰ یورو تا بیش از یک میلیون متغیر است و به همین دلیل، خانههای گرانتر با خطاهای بزرگتر دقت مدل را مختل نمیکند.
۳٫۱٫۲٫ معیارهای کیفی
یک مدل کمی دقیقتر لزوماً بهتر نیست اگر قابلیت نگهداری مدل هزینههای بسیار بالاتری داشته باشد. هدف معیارهای کیفی ارائه بینش بهتر در مورد هزینه های عملیاتی برای پیاده سازی مدل و به روز نگه داشتن مدل است. دو معیار اصلی در اینجا عبارتند از (۱) زمان اجرای مدل: چقدر زمان/تلاش لازم است تا مدل فعلی جایگزین شود، (۲) نگهداری مدل: چه مقدار زمان برای به روز نگه داشتن مدل باید صرف شود و در حال اجرا (بارگیری داده های جدید و آموزش مدل).
۳٫۲٫ کاوش در متغیر پاسخ
هر درخواست وام مسکن در هلند نیاز به ارزیابی رسمی توسط یک ارزیاب معتبر دارد. ارزش ارزیابی، بیان شده در یورو، چیزی است که به عنوان نشانه ای از ارزش دارایی استفاده می شود. این به عنوان متغیر پاسخ برای مدل ها استفاده می شود. تعداد کل ارزیابی های املاک در سال در شکل ۱ الف آورده شده است. این نشان می دهد که میزان کل ارزیابی ها در سال متفاوت است. به عنوان مثال، در حوالی بحران مالی ۲۰۰۷-۲۰۰۸، درخواست های وام مسکن بسیار کمتری وجود داشت. از سوی دیگر، در سال های اخیر به دلیل افزایش تقاضا در بازار مسکن هلند، درخواست های وام مسکن بیشتر شده است.
علاوه بر این، شکل ۱ ب نشان می دهد که تعداد ارزیابی ها در هر شهرداری متفاوت است. به نظر می رسد که این تقریباً با تراکم جمعیت هلند مرتبط است، جایی که شهرداری های بزرگتر ارزیابی های بیشتری دارند. شکل A1در ضمیمه نشان می دهد که این توزیع در طول سال ها مشابه است. در سالهایی که درخواستهای وام مسکن کمی دارند، مانند سال ۲۰۰۸، بسیاری از شهرداریهای کوچکتر فقط حدود ۳۰۰ ارزیابی دارند که تنها بخش کوچکی از کل خانههایشان است. برای این مناطق، پیش بینی دقیق دشوارتر است. در عوض، ما بر روی پنج شهرداری بزرگ، یعنی روتردام، آمستردام، آیندهوون، آمرسفورت و گرونینگن تمرکز می کنیم. اگر مدلها پیشبینیهایی را با دقت خوبی برای این پنج منطقه انجام دهند، در این صورت درصد زیادی از مجموعه داده Stater را پوشش میدهند.
میانگین قیمت خانه ها در سراسر هلند متفاوت است. به طور مشابه، میانگین ارزش ارزیابی مجموعه داده نیز در هر شهرداری و همچنین در زمان متفاوت است. برای ارزش های ارزیابی ۲۰۰۰ و ۲۰۲۰، افزایش در تعداد و میانگین ارزش ارزیابی بین سال های ۲۰۰۰ و ۲۰۲۰ مشاهده می شود. شکل ۱).ج). این بدان معناست که یک مدل پیشبینی کامل برای مقادیر ارزیابی باید تفاوتها را هم در زمان و هم در مکان منطقهای تشخیص دهد. با این حال، هدف این مقاله توضیح تفاوتهای بین سالها و پیشبینی قیمتهای ارزیابی آینده برای خانهها نیست، که کار دشوارتری است که نیازمند رویکردی متفاوت است. برای خدمات وام مسکن، ارزش فعلی وثیقه وام مسکن بیشترین اهمیت را دارد. به این ترتیب، فقط آموزش مدل ها برای یک سال خاص مشکلی نیست. در این مقاله، مدلها بر روی دادههای سالهای ۲۰۱۸ و ۲۰۲۰ آموزش داده میشوند. سال ۲۰۲۰ انتخاب شده است، زیرا این آخرین سال کامل است. علاوه بر این، سال ۲۰۱۸ برای اعتبارسنجی مدل برای یک سال متفاوت با ارزیابی های کمتر انتخاب شده است. برای سال ۲۰۱۸، تعداد ارزیابی ها برای این ۵ شهرداری در جدول ۳ خلاصه شده است.
۳٫۳٫ کاوش در متغیرهای توضیحی
مجموعه داده ارزیابی شامل داده های اضافی در مورد نوع خانه (آپارتمان یا خانه خانوادگی) و وجود گاراژ یا فضای پارکینگ است. این متغیرهای طبقهبندی با استفاده از رمزگذاری یکطرفه تبدیل میشوند، زیرا مدلها فقط میتوانند دادههای عددی را بپذیرند. علاوه بر این، از چهار مجموعه داده برای جمع آوری اطلاعات بیشتر در مورد خانه ها و مکان آنها استفاده می شود. آنها از سه حزب می آیند: ثبت کاداستر هلند (Kadaster)، اداره مرکزی آمار هلند (CBS)، و آژانس تصدی هلند (RVO). جدول ۴ را ببینید .
همانطور که در بخش ۲ ذکر شد ، Kadaster ثبت مرکزی مربوط به مالکیت زمین در هلند را حفظ می کند. پایگاه ثبت آدرسها و ساختمانها (BAG) [ ۹ ] مختصات جغرافیایی برای هر آدرس معتبر در هلند و همچنین کل منطقه زندگی و سال ساخت خانه را ارائه میکند. دادههای BAG از طریق آدرس – ترکیبی از کد پستی، نام خیابان و شماره خانه – از مجموعه دادههای ارزیابی به هم متصل میشوند.
علاوه بر اطلاعات در مورد خانه های واقعی، Kadaster همچنین اطلاعاتی در مورد مرزهای تمام زمین ها در هلند دارد که در DKK ذخیره می شوند [ ۳۸ ]. همانطور که ادبیات نشان داده است، مساحت زمین نسبت به منطقه زندگی اهمیت کمتری دارد، اما همچنان بر قیمت خانه تاثیر می گذارد. به خصوص در مراکز شهر، فضای باغ بیشتر ارزشمند است. برای این تحقیق، Kadaster جدول “Location Cadastral Object” (LKO) را ارائه کرده است که زمین های زیادی را از DKK به ساختمان ها از BAG مرتبط می کند. داده های زمین با استفاده از شناسه ساختمانی که در BAG موجود است به هم متصل می شوند.
در مجموع، پس از پیوستن و محاسبه سطح ترکیبی همه زمینها، به طور متوسط ۶۹٫۳ درصد از خانههای خانوادگی دارای یک مساحت زمین مرتبط هستند. برای تمام آپارتمان هایی که زمین ندارند، یک صفر پر می شود، زیرا آپارتمان ها عموماً زمین ندارند. نمودار پراکندگی متغیرهای Kadaster در شکل A2 a آورده شده است که یک رابطه قوی بین ارزش ارزیابی هم برای منطقه مسکونی و هم برای مساحت زمین نشان می دهد. در نهایت، درصد کلی رکوردهای از دست رفته برای این متغیر در جدول ۵ در زیر “مساحت زمین” خلاصه شده است.
مجموعه داده بعدی به اصطلاح «آمار مربع» از CBS است [ ۳۹ ]. CBS متغیرهای جامعه شناختی و جمعیتی زیادی را در مورد کل هلند منتشر می کند. آنها این داده ها را برای سطوح مختلف وضوح منتشر می کنند. از بالاترین وضوح تا کمترین وضوح، مجموعه های زیر منتشر می شود: کد پستی کامل (PC6)، کاشی های ۱۰۰ × ۱۰۰ متر، کاشی های ۵۰۰ × ۵۰۰ متر، کد پستی ۴ کاراکتری (PC4) و محله ها و بلوک های شهر. محله ها و حتی شهرداری ها می توانند ادغام شوند، تقسیم شوند یا مرزها را تغییر دهند. در این مقاله از مجموعه داده های ۱۰۰×۱۰۰ متر و ۵۰۰×۵۰۰ متر استفاده شده است. یکی از مزایای اصلی مجموعه داده کاشی این است که اندازه و موقعیت جغرافیایی آنها در طول سال ها ثابت می ماند. شکل ۲مثالی از سه متغیر برای Amersfoort (2018) ارائه می دهد.
پیوستن به مجموعه داده کاشی با استفاده از مختصات جغرافیایی از BAG امکان پذیر است. با این حال، هر خانه ای در یک کاشی قرار ندارد. دلیل اصلی این است که کاشیهای کمتر از ۵ خانوار به دلایل حفظ حریم خصوصی ارزششان سانسور شده است. این مشکل عمدتاً مربوط به متغیرهای جمعیت شناختی بود، مانند تعداد افراد ۰-۱۴ ساله، ۱۵-۲۴ سال و غیره و میانگین ارزش مالیات (WOZ-waarde). ترکیب و جایگزینی کاشی های ۱۰۰ متری با کاشی های ۵۰۰ متری برای مقادیر مطلق، مانند تعداد افراد ۰ تا ۱۴ سال، امکان پذیر نیست. از طرف دیگر، اگر مقدار متوسط باشد، می توان از کاشی های ۵۰۰ متری استفاده کرد، زیرا کاشی های ۵۰۰ متری فقط میانگین تعمیم یافته تری از نمونه بزرگتر را ارائه می دهند. برای میانگین درآمد و میانگین ارزش مالیاتی، جدول ۶مقدار زیرمجموعه دادههایی که مقادیر گمشده کاشیهای ۱۰۰ متری با کاشیهای ۵۰۰ متری جایگزین شدهاند، چقدر است. این به طور متوسط ۵٪ از کل تعداد مشاهدات است.
علاوه بر این، در داخل مجموعه داده CBS، متغیرهای زیادی وجود دارد که فاصله تا نزدیکترین «X» یا مقدار «Y» را در شعاع خاصی از کاشی فهرست میکنند. اینها به ترتیب با «AFS» و «AV##» (که در آن ## شعاع را بر حسب کیلومتر مشخص میکند) مخفف شدهاند. X و Y به امکاناتی مانند فروشگاه های مواد غذایی، کافه ها، استخرها، بیمارستان ها، سینماها و غیره اشاره دارد. متغیرهای «فاصله تا» و «مقدار در شعاع» که نوع یک ساختمان را توصیف میکنند، در نهایت همبستگی بالایی دارند. به این ترتیب، فقط متغیرهای “فاصله تا …” گنجانده شده است. به طور خلاصه، نمای کلی متغیرهای جدول A4 در ضمیمه، توصیف همه متغیرها و مجموعه کاشی هایی را که آنها استفاده می کنند (نام متغیرها که به _۱۰۰ یا _۵۰۰ ختم می شوند) فهرست می کند.
علاوه بر این، بر اساس مختصات جغرافیایی از BAG، امکان محاسبه فاصله تا مرکز شهر برای هر خانه وجود دارد. مختصات مراکز شهر به صورت دستی با استفاده از نقشه های گوگل تعیین می شود. برای پنج شهرداری در این تحقیق، این هنوز با دست قابل انجام است. با این حال، برای کل هلند، راه حل متفاوتی باید پیدا شود. متغیر به دست آمده ‘dist_centre’ نامیده می شود. در پایان، فاصله تا متغیر مرکز شهر نیز با متغیرهای فاصله CBS همبستگی دارد. به عنوان مثال، همانطور که در شکل ۲ ج مشاهده می شود، بین فاصله تا کافه و فاصله تا مرکز شهر آمرسفورت رابطه وجود دارد. برای رگرسیون خطی، متغیرهای همبسته باید حذف شوند. در غیر این صورت، مدل می تواند ناپایدار شود.
علیرغم حذف متغیرهای “مقدار در شعاع”، هنوز یک مسئله همبستگی وجود دارد. برخی از متغیرهای “فاصله تا” و همچنین فاصله مرکز شهر با یکدیگر همبستگی دارند. نمودار همبستگی را در شکل ۳ ببینید. کادرهایی که با رنگ قرمز مشخص شده اند، ضریب همبستگی ۰٫۷۵ یا بالاتر را نشان می دهند (همبستگی قوی). بقیه همبستگی های غیر معنی دار خط خورده اند. به این ترتیب، متغیرهای زیر حذف می شوند: فاصله تا نیازهای روزانه (به نفع فاصله تا سوپرمارکت)، فاصله تا سینما، موزه و سکو (به نفع فاصله تا نزدیکترین ایستگاه قطار)، فاصله تا بیمارستان و داروخانه (به نفع فاصله تا پزشک عمومی)، فاصله تا کافه تریا (به نفع فاصله تا کافه)، و در نهایت، همانطور که در پاراگراف قبل ذکر شد، فاصله تا مرکز شهر.
در نهایت، RVO مجموعه داده ای را منتشر می کند که شامل تمام ثبت های رسمی برچسب انرژی در هلند است [ ۴۰ ]. این داده ها را می توان با استفاده از شناسه از BAG به مجموعه داده موجود پیوست. این مجموعه داده محدودیتهای خود را نیز دارد، زیرا هر خانهای دارای برچسب انرژی رسمی نیست. در گذشته داشتن برچسب انرژی هنگام فروش خانه اجباری نبود. مجموعه داده RVO فقط شامل ثبت است، بنابراین هر خانه در این مجموعه داده وجود ندارد. علاوه بر برچسب انرژی، مجموعه داده همچنین حاوی اطلاعات دقیق تری در مورد نوع خانه و مصرف انرژی است. با این حال، به دلیل اینکه بسیاری از خانه ها در این مجموعه داده وجود ندارند، از نوع خانه موجود از Stater و همچنین میانگین مصرف انرژی از CBS استفاده می شود. در نهایت برچسب انرژی برای ۷۰ درصد خانه ها موجود است (جدول ۵ )؛ برای توزیع نمونه، شکل A2 ب را ببینید.
مجموعه کامل متغیرها در جدول A4 خلاصه شده است. با این حال، هنوز متغیرهایی وجود دارند که مقادیر گم شده ای دارند. همانطور که قبلا اشاره شد، تعداد مقادیر از دست رفته در جدول ۵ خلاصه شده است. در اینجا، «فاصله» به متغیرهای فاصله مجموعه داده CBS اشاره دارد. متغیرهایی که در این نمای کلی گنجانده نشده اند ۱۰۰٪ کامل هستند. برای CBS، تعداد زیادی از متغیرهای گمشده با شامل کردن کاشیهای ۵۰۰×۵۰۰ متر نیز حل شد. تعداد رکوردهایی که از مقادیر مجموعه داده ۵۰۰ × ۵۰۰ متر استفاده می کنند در جدول ۶ خلاصه شده است.
یک مسئله کوچک اضافی مربوط به این واقعیت است که همه متغیرها برای سال ۲۰۲۰ در دسترس نیستند. جدیدترین سال کاملاً کامل، ۲۰۱۸ است. برای سال ۲۰۲۰، برخی از متغیرهای مربوط به درآمد و “فاصله تا …” هنوز در دسترس نیستند. با این حال، میتوان فرض کرد که اکثر این متغیرها در دو سال گذشته فقط اندکی تغییر کردهاند. به این ترتیب، برای سال ۲۰۲۰، متغیرهای گمشده را با مقادیر ۲۰۱۸ جایگزین می کنیم.
حذف تمام رکوردهای دارای مقادیر از دست رفته یک گزینه نیست، زیرا بخش بزرگی از رکوردها حداقل یک یا دو متغیر از دست داده اند. نتیجه یک مجموعه داده خواهد بود که فقط از چند صد رکورد در هر شهرداری تشکیل شده است. در عوض، مقادیر مجهول از رکوردهای مشابه منتسب می شوند. این کار با استفاده از “ک-نزدیکترین همسایه” با ۷ همسایه انجام می شود. تعداد همسایگان بر اساس این واقعیت است که گزارش های ارزیابی معمولاً از حدود ۵ خانه به عنوان خانه های مرجع استفاده می کنند. قبل از وارد کردن مقادیر، ابتدا ستونهای متغیر از کمترین مقادیر به بیشترین مقادیر از دست رفته مرتبسازی میشوند تا تضمین شود که متغیرهایی که کمترین متغیرهای گمشده را دارند ابتدا وارد میشوند.
در نتیجه، از چهار منبع داده خارجی از Kadaster، CBS و RVO برای جمع آوری ۳۱ متغیر قابل استفاده استفاده می شود. نمای کلی متغیرها در جدول A4 در پیوست ارائه شده است. Kadaster عمدتا ویژگی های ذاتی خانه را ارائه می دهد، در حالی که CBS ویژگی های مکان را در مورد محله ارائه می دهد. علاوه بر این، RVO همچنین برچسب های انرژی را برای درصد زیادی از تمام خانه ها ارائه می دهد. با این حال، از همه متغیرهای موجود استفاده نمی شود. جدول A5 ۲۲ متغیری را خلاصه می کند که به دلیل همبستگی زیاد با سایر متغیرها یا استفاده برای استخراج متغیرهای دیگر، شامل نمی شوند. در نهایت، همان طور که در جدول ۵ نشان داده شده است، مسئله کمبود مقادیر وجود دارد. دو متغیر بزرگ با مقادیر گمشده، مساحت زمین و برچسب انرژی هستند که تا ۳۰ درصد مقادیر گمشده دارند. مقادیر گمشده با استفاده از “k-nearest همسایه” با ۷ همسایه برای جلوگیری از دور ریختن اکثر رکوردها نسبت داده می شوند. این مجموعه داده کامل برای تحقق سه مدل پیشبینی استفاده میشود.
۳٫۴٫ بهینه سازی Hyper-Parameter با استفاده از CV
برخلاف LR، GWR و XGBoost پارامترهای مدلی دارند که میتوان آنها را بهینه کرد. این با استفاده از N بار مکرر k-folds اعتبار متقاطع انجام می شود. در این مقاله، ۴ برابر (k = 4) 10 بار (N = 10) به دلیل حجم نمونه کوچک (~۱k نمونه آموزشی) در هر شهرداری تکرار شده است. بنابراین، هر چین تقریباً ۷۵۰ نمونه برای تنظیم پارامترها و ۲۵۰ نمونه برای ارزیابی است. استفاده از اعتبارسنجی متقاطع k-folds (تکرار) باعث کاهش بیش از حد برازش می شود و تصویر بهتری از عملکرد واقعی ایجاد می کند. در این مقاله، مدلها با استفاده از R پیادهسازی میشوند. به طور خاص، با استفاده از بستههای R به نامهای «lm»، «GWmodel» و «xgboost» که با روشهای اعتبارسنجی متقابل داخلی ارائه میشوند.
برای GWR، سه پارامتر مربوط به تابع هسته وجود دارد که به خوبی تنظیم شده اند. خود تابع هسته، پهنای باند هسته و تنظیمات “تطبیقی”. تابع کرنل شکل کرنل را تعیین می کند. Gaussian، boxcar و bi-square معمولاً در ادبیات استفاده میشوند [ ۲۶ ، ۴۱ ]. در پایان، هسته گاوسی تطبیقی برای هر پنج شهرداری بهترین عملکرد را داشت. جدول A3 پهنای باند استفاده شده توسط هر شهرداری را خلاصه می کند.
در نهایت، برای XGBoost، نرخ یادگیری (eta) و حداکثر عمق درخت را بهینه میکنیم. نرخ یادگیری بالاتر به این معنی است که مدل گام های بزرگ تری به سمت حداقل تابع ضرر بردارد. نرخ یادگیری بهینه بین ۰٫۱۳ و ۰٫۱۷ برای پنج شهرداری است، بنابراین میانگین آنها به ۰٫۱۵ رسید، زیرا هدف نهایی ایجاد یک مدل واحد برای کل هلند است. این تأثیر ناچیزی بر RMSE داشت. مشابه عمق درخت، ۴ مدل از ۵ مدل با عمق درخت ۷ بهترین عملکرد را داشتند. با این حال، این تنها آزمون RMSE را اندکی بهبود بخشید و در عین حال مجموعه آموزشی RMSE را تا حد زیادی بهبود بخشید. به این ترتیب، برای جلوگیری از نصب بیش از حد، عمق درخت کمی کمتر از ۶ انتخاب می شود.
۴٫ نتایج
این بخش نتایج مدل های LR، GWR و XGBoost نهایی را که آموزش داده شده اند، خلاصه می کند. هر یک از مدل ها بر اساس معیارهای کمی و کیفی از بخش ۳٫۱ ارزیابی می شوند. اول، مدلهای منحصربهفرد برای هر شهرداری برای سالهای ۲۰۱۸ و ۲۰۲۰ ارزیابی میشوند. دوم، یک مدل XGBoost ارزیابی میشود که در هر پنج شهرداری آموزش داده شده است. در نهایت، مقایسهای بین شاخصسازی و پنج مدل منحصربهفرد انجام میشود که در آن ارزشهای ارزیابی فعلی وثیقه متعلق به وامهای مسکن از سال ۲۰۰۰ را پیشبینی میکنند.
برای مدل LR، مدل اولیه برازش ضعیفی را عمدتاً به دلیل واریانس بالای مقادیر ارزیابی بالا ارائه کرد. ما مقادیر پرت بالای ۷۵۰۰۰۰ یورو را فیلتر می کنیم، که اکثر ارزیابی ها را حفظ می کند و در عین حال بهبود قابل توجهی در مدل ایجاد می کند. این در مقایسه نمودارهای چندک – چندک در شکل ۴ نشان داده شده است. ارزش های ارزیابی بالا به احتمال زیاد نماینده خوبی برای کل جمعیت خانه ها نیستند. بنابراین، آنها حذف می شوند زیرا تأثیر زیادی بر دقت پیش بینی دارند.
علاوه بر این، به عنوان یک رویکرد جایگزین دیگر، مقادیر ارزیابی برای مدلسازی تأثیر رو به کاهش فضای زندگی ثبت شد. متأسفانه، هر دو مدل ورود به سیستم خطی با مقادیر ارزیابی ثبت شده و مدل لاگ خطی با فضاهای زندگی ثبت شده دقت مدل را بهبود نمیبخشند. در نهایت، بهترین مدل LR مدلی است که دارای مقادیر ارزیابی فیلتر شده است. همانطور که در جدول ۷ خلاصه شده است، مدل LR دارای RMSE 85.628 یورو است و از ۰٫۷۸۵، که در کل یک تناسب کافی است. از آنجایی که مقادیر ارزیابی به شدت از ۵۰۰۰۰ یورو تا ۷۵۰۰۰۰ یورو متفاوت است، باید به میانگین درصد مطلق خطا (MAPE) و صرفاً میانگین میانگین خطا (MAE) توجه کرد. اینها به ترتیب با میانگین خطای ۹٫۶۱ درصد و ۵۶۲۱۹ یورو مطابقت دارند.
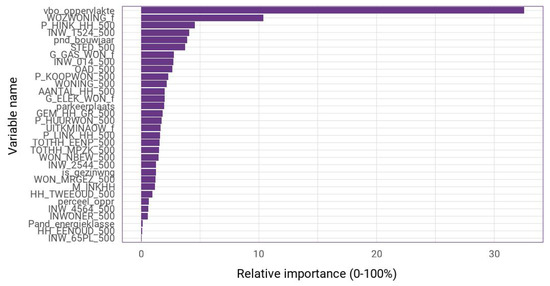
عملکرد LR در بهترین حالت کافی است. بسیاری از متغیرهای CBS یک رابطه خطی قوی با ارزش ارزیابی نشان نمی دهند. با این حال، به دلیل گنجاندن منطقه نشیمن (نام متغیر: perceel_oppr) و WOZ-waarde، هنوز هم می توان یک مدل مناسب با انحراف کمتر از ۱۰٪ برای Amersfoort ایجاد کرد. شکل A3 نشان می دهد که این دو متغیر تا حد زیادی دو عامل مهم هستند، که پس از آن متغیری که درآمد بالا (P_HINK_HH)، افراد ۱۵ تا ۲۴ ساله و سال ساخت را توصیف می کند، قرار می گیرد.
رگرسیون وزندار جغرافیایی (GWR) برازش بهتری نسبت به مدل LR فراهم میکند، همانطور که در نمای کلی عملکرد GWR در جدول ۸ خلاصه شده است. همانطور که در بخش ۳٫۴ اشاره شد، GWR با استفاده از یک تابع هسته گاوسی تطبیقی با پهنای باند متفاوت در هر شهرداری آموزش داده شده است. برای Amersfoort، ۱۰ متغیر مهم و نمونه ای از تأثیرات فضایی منطقه زندگی در شکل ۵ ترسیم شده است.
مهم ترین متغیر، دوباره، منطقه نشیمن است، که پس از آن WOZ-waarde است. نمودار اهمیت متغیر به نظر می رسد شکلی مشابه با رگرسیون خطی داشته باشد ( شکل A3 ). این بار نیز برخی از متغیرهای فاصله مانند فاصله تا نزدیکترین سوپرمارکت و کافه نمایان می شود. در حالی که تأثیر متغیرهای دیگر جزئی به نظر می رسد، بدون گنجاندن آنها، ۰٫۰۹ کاهش می یابد، که منجر به تناسب کمتر خوب با MAPE دوباره ۱۰٪ می شود. GWR نهایی موفق به مدل سازی مقادیر ارزیابی تنها با ۷٫۶۷% انحراف به طور متوسط می شود. مهمتر کاهش بیشتر است و RMSE، نشان دهنده نقاط پرت کمتر است. بدترین عملکرد شهرداری گرونینگن است که احتمالاً به دلیل داشتن کمترین نمونه است. از سوی دیگر، روتردام عملکرد خوبی دارد، که شاید به دلیل درصد بیشتری از آپارتمان ها در این مجموعه داده باشد. به طور متوسط، آپارتمان ها خطای پیش بینی کمتری (۶٫۹۸٪) نسبت به خانه های خانوادگی (۷٫۴۱٪) دارند. این را می توان به دلیل پایین بودن میانگین ارزش ارزیابی آپارتمان ها و ارزیابی های پایین تر دارای نقاط مرجع بیشتر نسبت داد. نتایج برای سال ۲۰۲۰ در جدول A6 در پیوست خلاصه شده است. آنها کاهش جزئی در دقت پیشبینی را نشان میدهند اما نه قابل توجه.
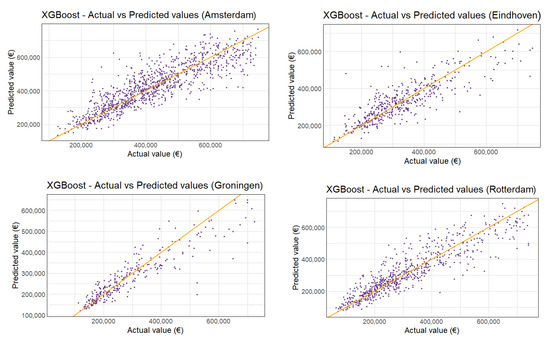
مدل نهایی مدل XGBoost است، با تنظیمات پارامترهای eta = 0.15، عمق درخت = ۶، برای هر یک از پنج شهرداری. پس از ۳۹ دور تقویت به طور متوسط، هیچ پیشرفت عمده ای ایجاد نمی شود، و پس از ۱۵۹ دور، عملکرد شروع به کمی بدتر شدن می کند. تناسب مدل XGBoost بهترین تناسب کلی را دارد ( = ۰٫۸۴۸) با کمترین امتیاز RMSE (58,374 یورو). خلاصه ای از معیارهای عملکرد در جدول ۹ آورده شده است. شکل ۶ مقادیر ارزیابی پیش بینی شده در مقابل واقعی را برای Amersfoort 2018 نشان می دهد. سایر شهرداری ها در شکل A4 نشان داده شده اند . همانطور که در شکل A5 مشاهده می شود، منطقه نشیمن و WOZ-waarde دوباره مهم ترین متغیرها هستند . حتی با حذف ارزیابیهای بالای ۷۵۰۰۰۰ یورو، اختلاف کمی بیشتر در ارزشهای ارزیابی بالا وجود دارد. به طور کلی، مدل XGBoost پیش بینی های دقیقی را با تنها ۵ درصد انحراف به طور متوسط ارائه می دهد. جدول ۱۰ میانگین عملکرد هر مدل را برای هر یک از پنج شهرداری خلاصه می کند.
در نهایت، از آنجایی که XGBoost بهترین مدل است، یک مدل XGBoost برای هر پنج شهرداری با استفاده از تنظیمات پارامتر یکسان آموزش داده شده است ( جدول ۱۱ ). این مدل شامل نام شهرداری به عنوان یک متغیر اضافی است. خطای پیشبینی مدل کمی به ۶ درصد افزایش مییابد. علاوه بر این، RMSE به طور قابلتوجهی بیشتر از MAE افزایش مییابد، که نشان میدهد در حالی که عملکرد کلی فقط اندکی کاهش یافته است، مدل در گرفتن موارد پرت بدتر است. نام شهرداری در نهایت به سومین متغیر مهم تبدیل می شود. در حالی که عملکرد مدل کمی بدتر است، اما همچنان از مدلهای GWR که به صورت جداگانه آموزش دیدهاند بهتر عمل میکند.
در مجموع، وقتی به معیارهای عملکرد کمی نگاه میکنیم، مدلهای XGBoost بهتر از مدلهای رگرسیون خطی و GWR عمل میکنند. معیارهای کیفی نهایی، زمان اجرا و نگهداری مدل است. در این تحقیق بیشترین تلاش برای جمع آوری تمامی متغیرها و تهیه مجموعه داده ها انجام شد. به این ترتیب، در عمل، انتظار می رود این نیز به بیشترین تعمیر و نگهداری نیاز داشته باشد. BAG را می توان به طور معمول با استفاده از درخواست API به روز کرد. با این حال، مجموعه دادههای RVO و CBS هر دو از عصارهای استفاده میکنند که نقطه پایانی API ندارد. در مجموع، آمادهسازی دادهها برای مدل نیازمند کارهای دستی است که به راحتی نمیتوان آن را خودکار کرد.
علاوه بر این، زمان آموزش نیز در نظر گرفته می شود. LR ساده و سریع است. برای میلیونها رکورد، این مشکل در رایانههای مدرن به ندرت پیش میآید. از سوی دیگر، GWR رگرسیون ها را برای یک شبکه محاسبه می کند. در مورد شهرداری آمرسفورت، یک شبکه کاشی ۱۰۰ × ۱۰۰ متر برای آمرسفورت (تقریباً ۱۰ کیلومتر × ۱۰ کیلومتر) برابر با ۱۰۰ × ۱۰۰ کاشی = ۱۰ هزار کاشی = ۱۰ هزار رگرسیون منحصر به فرد محاسبه شده است. در سخت افزار مدرن، این کمتر از ۵ دقیقه طول می کشد. برای مقیاس ملی، شبکه باید در هر دو بعد بسیار بزرگتر باشد. بنابراین، قدرت محاسباتی مورد نیاز به صورت تصاعدی افزایش می یابد. تطبیق رگرسیون برای کل هلند احتمالا به جای چند دقیقه یک روز طول می کشد.
برخلاف GWR، XGBoost دارای یک GPU نیز است. در این مقاله، اندازههای نمونه برای یک سال به ازای هر شهرداری نسبتاً کوچک بود، بنابراین حتی استفاده از تنها CPU منجر به تناسب خوب در کمتر از ۱۰ دقیقه با استفاده از XGBoost شد. با استفاده از GPU، XGboost سریعتر از مدل GWR هنگام آموزش برای کل هلند است. زمان آموزش مدل چیزی است که زمان زیادی برای یک کارمند هزینه نمی کند. در پایان، جمعآوری دادهها و ایجاد مجموعه داده فعالترین کار وقتگیر است که برای هر سه مدل تلاش یکسانی میطلبد.
در نهایت، رویکرد فعلی در استاتر از شاخص قیمت مسکن منطقهای Kadaster ( جدول A1 ) برای شاخصسازی ارزیابیها استفاده میکند. هر دو روش با کم کردن مقدار نمایه شده از مقدار پیش بینی شده XGBoost، همانطور که در شکل ۷ نشان داده شده است، مقایسه می شوند. این دو نمودار بر اساس نوع مسکن از هم جدا شدهاند و پیشبینیها را برای همه خانههای خانوادگی و برای همه آپارتمانها فهرست میکنند. در هر دو مورد، XGBoost ارزشهای ارزیابی بالاتری را نسبت به روش نمایهسازی پیشبینی میکند، به طور متوسط ۳۴۶۷۸ یورو برای آپارتمانها (+۱۷٫۳۱ درصد بالاتر از شاخص) و ۲۸۵۶۶ یورو (۱۱٫۱۲ درصد).
دو مشاهدات را می توان از شکل ۷ انجام داد. اول، پیشبینیهای XGBoost برای آپارتمانها انحراف کمتری از شاخص را در مقایسه با پیشبینیهای خانههای خانوادگی نشان میدهند. یک توضیح برای این موضوع، واریانس بالاتر در ارزش های ارزیابی خانه های خانوادگی در مقایسه با آپارتمان ها است. این مدل به احتمال زیاد پیشبینی ضعیفی برای یک خانه خانوادگی نسبت به یک آپارتمان دارد، همانطور که با مقادیر پرت بزرگتر نشان داده میشود (به ندرت تفاوت بزرگ +۲۵۰k €).
دوم، تفاوت بین آپارتمانها و خانههای خانوادگی با دیگر شاخص Kadaster برای انواع مسکن مطابقت دارد ( جدول A2). از این شاخص می توان دریافت که آپارتمان ها تقریباً ۲۰ درصد بیشتر از خانه های خانوادگی در کل هلند (۲۰۰۰-۲۰۲۰) افزایش یافته است. مدل XGBoost قادر به توضیح این موضوع است، در حالی که شاخص منطقه ای چنین نیست. این نتیجه گیری اصلی را تایید می کند که مدل XGBoost می تواند جایگزین بهتری برای نمایه سازی قیمت باشد. یک شاخص ایده آل برای Kadaster هم منطقه و هم نوع خانه را تشخیص می دهد. این می تواند یک پیشرفت نسبتا ساده نسبت به روش فعلی نمایه سازی باشد. در مجموع، این پشتیبانی اضافی برای این نتیجه گیری فراهم می کند که رویکرد مدل می تواند نسبت به شاخص سازی بهبود یابد، زیرا می تواند نوع مسکن را در نظر بگیرد.
۵٫ بحث
در نهایت مدل XGBoost قادر است زیر مجموعه بزرگی از خانه ها را با دقت بهتری نسبت به نمایه سازی مدل سازی کند. این مدل فقط از ارزشهای ارزیابی زیر ۷۵۰۰۰۰ یورو استفاده میکند، زیرا بالاترین ارزیابیها (گرانترین خانهها) به دلیل تأثیر قویتر ترجیحات فردی خریداران باعث افزایش زیادی در واریانس شدند. این فقط ۴٫۲۴٪ از تمام ارزیابی ها را حذف می کند. به این ترتیب، چالش مدل سازی ارزش های ارزیابی برای گران ترین خانه ها باقی می ماند.
در مدل XGBoost، منطقه زندگی و ارزش مالیات (WOZ-waarde) 70٪ از واریانس توضیح داده شده را تشکیل می دهند، در حالی که سایر متغیرها در مجموع واریانس توضیح داده شده را ۷٪ افزایش می دهند. یک اشکال این است که WOZ-waarde منحصر به فرد هلند است. ما استدلال می کنیم که نتایج مشابه برای کشورهای دیگر قابل دستیابی است، زیرا WOZ-waarde نیز تحت تأثیر متغیرهایی مانند منطقه زندگی است. به هر حال، WOZ-waarde یک ارزیابی تقریبی از سوی دولت است. بدون گنجاندن آن، منطقه نشیمن احتمالاً نقش بزرگتری ایفا می کند. در مجموع، مدل نتایج پیشبینی بهتری برای هلند با درج ارزش مالیات (متوسط) دارد. همانطور که در مقایسه بین نمایه سازی و XGBoost نشان داده شده است، XGBoost نسبت به نمایه سازی برتری دارد، زیرا مدل انواع مختلفی از خانه ها را در نظر می گیرد.شکل ۷ ). واریانس غیرقابل توضیح باقی مانده ۱۷٪ احتمالاً به دلیل یک متغیر گمشده است که کیفیت خانه را توضیح می دهد. اطلاعات مربوط به خانه از گزارش های رسمی ارزیابی می تواند به کاهش این اختلاف کمک کند، زیرا آنها حاوی اطلاعات بیشتری در مورد خود خانه هستند.
علاوه بر این که XGBoost دارای دقت بالاتری نسبت به LR و GWR است (از نظر معیارهای کمی، ، RMSE و MAPE)، همچنین از نظر عملکرد زمان تمرین در مقایسه با GWR عملکرد خوبی دارد. XGBoost دارای این مزیت است که می تواند بر روی GPU اجرا شود، در حالی که GWR به CPU متصل است، که هنگام محاسبه رگرسیون برای شبکه های بزرگ کل کشورها با مشکلات عملکردی مواجه می شود. بنابراین، زمان آموزش XGBoost در هنگام آموزش مدلها برای همه ارزشهای ارزیابی مسئلهای نیست. بیشترین زمان مصرف در مقایسه با نمایه سازی، در به روز نگه داشتن داده های مدل است که برای هر سه مدل به یک اندازه زمان بر است. فقط داده های Kadaster از طریق API های مختلف به راحتی قابل دسترسی هستند. مجموعه داده های CBS و RVO باید به صورت دستی دانلود شوند.
نقاط ضعف مدل XGBoost، پرتهای بزرگتر در مقایسه با شاخصسازی محافظهکارانه است، و همچنین این واقعیت که مدل در حال حاضر یک سال کامل را پیشبینی میکند و تغییرات ماهانه را در نظر نمیگیرد. این می تواند تا حدی با اطمینان از اینکه مدل هر ماه دوباره آموزش می بیند، و جایگزینی ارزیابی های قدیمی ترین ماه با ماه جدید کاهش می یابد. در نهایت، برای به روز نگه داشتن داده های مدل ها تلاش بیشتری لازم است. با این حال، در ازای این تلاش اضافی، XGBoost میتواند پیشبینیهای محلیتر برای کل هلند برای ارزیابی وثیقههای وام مسکن انجام دهد.
۶٫ نتیجه گیری
این مقاله ارزیابی مبتنی بر مدل املاک و مستغلات را با استفاده از قیمتگذاری لذتگرا در شهرها بررسی میکند. ما رویکردهای مختلف یادگیری ماشینی (ML) را برای تولید مدلهای قیمتگذاری لذتگرا مقایسه میکنیم و آنها را بر اساس دقت، هزینه، سرعت و نیازهای داده ارزیابی میکنیم. برای دستیابی به این هدف، پنج سوال تحقیقی را مطرح کردیم که برای آنها به نتایج زیر رسیدیم.
کدام رویکردهای ML در حال حاضر برای قیمتگذاری لذتگرا استفاده میشوند و چگونه عمل میکنند؟
چهار مدل قیمتگذاری لذتگرا از ادبیات، و همچنین متغیرهای مورد استفاده در مدلسازی ارزش املاک و مستغلات تحلیل میشوند. از این رو، ما سه مدل قیمتگذاری لذتگرا را با استفاده از رگرسیون خطی (LR)، رگرسیون وزندار جغرافیایی (GWR)، و افزایش گرادیان شدید (XGBoost) پیادهسازی کردیم. آنها ارزش های ارزیابی را برای پنج شهرداری در بخش های مختلف هلند مدل می کنند: آمستردام، آمرسفورت، آیندهوون، گرونینگن، و روتردام. نتایج کمی برای هر مدل در جدول ۱۰ ارائه شده است. این مدلها روی ارزشهای ارزیابی زیر ۷۵۰۰۰۰ یورو آزمایش میشوند، زیرا بالاترین ارزیابیها (گرانترین خانهها) به دلیل تأثیر قویتر ترجیحات فردی خریداران، افزایش زیادی در واریانس ایجاد کردند.
برای سال ۲۰۲۰، XGBoost به بهترین وجه واریانس مقادیر ارزیابی را با میانگین توضیح می دهد. از ۰٫۸۵۲٫ این یک پیشرفت آماری قابل توجه نسبت به GWR ( = ۰٫۸۰۹) و LR ( = ۰٫۷۳۴). برای XGBoost، میانگین RMSE در پنج شهرداری ۶۱۰۲۸ یورو و MAE 35451 یورو است. ارزشهای ارزیابی بالاتر واریانس بیشتری نسبت به ارزشهای ارزیابی پایینتر دارند. بنابراین، در پیشبینیهای انجامشده، برخی موارد پرت وجود دارد. به طور متوسط، میانگین درصد خطای مطلق (MAPE) 5.89٪ است. در سال ۲۰۲۰، برای یک ارزیابی متوسط ۴۵۰۰۰۰ یورو (در سال ۲۰۱۸)، این معادل با خطای حدود ۲۷۰۰۰ یورو است. بنابراین، XGBoost به طور کلی روش خوبی برای مدلسازی ارزشهای ارزیابی است.
کدام عوامل برای تفاوت قیمت خانه ها در شهرها مهم است؟ کدام اطلاعات در مورد این عوامل در دسترس است؟
دو متغیر مهم در هر سه نوع مدل عبارتند از: مساحت کل زندگی (vbo_oppervlakte، از Kadaster) و میانگین ارزش مالیات تمام خانه های مجاور در یک منطقه ۵۰۰ × ۵۰۰ متر (WOZ-waarde، از CBS). علاوه بر این، متغیرهای مهم دیگر در مدل XGBoost شامل عرض جغرافیایی خانه، درصد درآمد متعلق به ۲۰٪ بالاترین درآمد در هلند، مصرف برق و در نهایت فاصله تا نزدیکترین کافه است. بخش غربی هلند به طور کلی دارای ارزش های ارزیابی بالاتری است. علاوه بر این، افراد ثروتمند معمولا در محله های گران تری زندگی می کنند. فاصله تا نزدیکترین کافه احتمالا به فاصله تا مرکز شهر مربوط می شود. سایر متغیرها، مانند برچسب های انرژی، تأثیر کمی دارند زیرا بیشترین مقادیر گم شده را دارند.
چگونه می توانیم با استفاده از بینش های به دست آمده، روشی برای قیمت گذاری لذت جویانه در شهرهای مختلف بسازیم؟ نتایج اعمال این روش با مجموعه داده واقعی چیست؟
هدف نهایی یک مدل ارزیابی ملی برای هلند است. این پنج شهرداری بهطور خاص انتخاب شدند، زیرا استانهای منحصربهفردی را در بخشهای مختلف هلند نشان میدهند. علاوه بر این، این شهرداریها دارای بیشترین جمعیت هستند. به این ترتیب، ما معتقدیم که آنها یک نمونه ترکیبی خوب برای یک مدل ملی ارائه می دهند. مدل تک XGBoost که برای هر پنج شهرداری آموزش داده شده است، میتواند ۸۳ درصد واریانس را با RMSE 65312 یورو، MAE 43625 یورو و MAPE 6.35 درصد توضیح دهد ( جدول ۱۱ ). در مجموع، این مدل XGBoost تنها به میزان اندکی بدتر از پنج مدل آموزشدیده فردی عمل میکند و تنها ۰.۰۲ کاهش برای و افزایش ۰٫۴۸ درصدی برای MAPE. بنابراین، می توان نتیجه گرفت که به احتمال زیاد XGBoost قادر به مدل سازی ارزش های ارزیابی برای همه شهرداری ها است.
در نهایت، یک مقایسه کمی بین XGBoost و نمایه سازی با مقایسه پیش بینی های هر دو روش برای ارزش های ارزیابی از سال ۲۰۰۰ انجام شده است. پیش بینی ها در دو دسته تشخیص داده می شوند: آپارتمان ها و خانه های خانوادگی. در هر دو مورد، مدل XGBoost پیش بینی های بالاتری نسبت به شاخص انجام می دهد: +۱۷٫۱۴٪ برای آپارتمان ها و +۱۱٫۱۲٪ برای خانه های خانوادگی ( شکل ۷ ). بدیهی است که این شاخص با در نظر گرفتن میانگین بسیاری از قیمتهای املاک، تخمین محافظهکارانهتری از افزایش قیمت است. پیشبینیهای مدل XGBoost نیز با شاخص نوع مسکن مطابقت دارد ( جدول A2). این شاخص نشان دهنده افزایش ۷۰ درصدی قیمت آپارتمان در مقایسه با تنها ۵۰ درصدی خانه های خانوادگی است. این نشان میدهد که مدل XGBoost میتواند تفاوتها در توسعه قیمت آپارتمانها و خانههای خانوادگی را توضیح دهد. در نهایت، لازم به ذکر است که مدل XGBoost در پیشبینیهای خود برای خانههای خانوادگی نیز دارای چند نقطه پرت است. با این حال، بر اساس نتایج آموزش برای سال ۲۰۱۸، می توان نتیجه گرفت که مدل XGBoost می تواند برای اکثر ارزیابی ها، به استثنای گران ترین ارزیابی ها، قابل اعتمادتر از نمایه سازی باشد.
بر اساس نتایج قبلی، ما به توصیههای زیر برای تحقیقات آینده با محوریت مدلسازی ارزش املاک با استفاده از دادههای باز و XGBoost میرسیم:
- –
-
عدم وجود ویژگی برای مدل سازی کیفیت خانه. واریانس غیرقابل توضیح باقی مانده ۱۷ درصد احتمالاً به دلیل یک متغیر گمشده است که کیفیت خود خانه یا سایر ویژگی های مکان را توضیح می دهد. یک گزارش ارزیابی رسمی حاوی اطلاعات دقیق تری در مورد وضعیت یک خانه است. این می تواند به ترسیم تصویر بهتری از خود خانه کمک کند.
- –
-
به عنوان مثال، نقشه غرق زمین از TU Delft یک مورد استفاده جالب برای بررسی عوامل خطر سبد املاک و مستغلات ارائه می دهد. غرق شدن زمین یک مشکل واقعی در هلند، به ویژه در گرونینگن است. در نتیجه بهره برداری از گاز، ارزش ملک در منطقه به شدت کاهش می یابد. این یک خطر آشکار برای صاحب وام مسکن و وام دهنده است. مشکل دیگر برای بسیاری از خانه ها پوسیدگی پایه است. شاید بتوان مناطق خطر را با ترکیب داده های غرق با ترکیبات زمین شناسایی کرد.
اختصارات
در این نسخه از اختصارات زیر استفاده شده است:
| LR | رگرسیون خطی |
| (M)GWR | (چند مقیاسی) رگرسیون وزنی جغرافیایی |
| XGBoost | افزایش شیب شدید |
| سی بی اس | “Centraal Bureau voor de Statistiek” (ENG: آژانس مرکزی آمار) |
| کیسه | “Basisregistratie adressen & gebouwen” (ENG: آدرسها و ساختمانهای ثبت پایه) |
| DKK | ‘Digitale kadastrale kaart’ (ENG: نقشه کاداستر دیجیتال) |
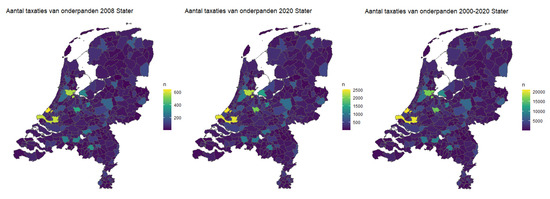
شکل A1. تعداد ارزیابیهای املاک و مستغلات استاتر، ( سمت چپ ) ۲۰۰۸، ( وسط ) ۲۰۲۰، ( راست ) ژانویه ۲۰۰۰ تا ژانویه ۲۰۲۱٫
شکل A2. کاوش متغیرهای خارجی از Kadaster & CBS (Amersfoort، ۲۰۱۸). ( الف ) Kadaster – اندازه زمین ( ) و مساحت کل ( ). ( ب ) RVO-برچسبهای انرژی.
شکل A3. اهمیت متغیر برای مدل LR آمرسفورت (۲۰۱۸). هر ۵ شهرداری نتایج مشابهی دارند.
شکل A4. مناسب مدل مدل های XGBoost برای آمستردام، آیندهوون، روتردام، گرونینینگن (۲۰۱۸)، (خط نارنجی y = x است).
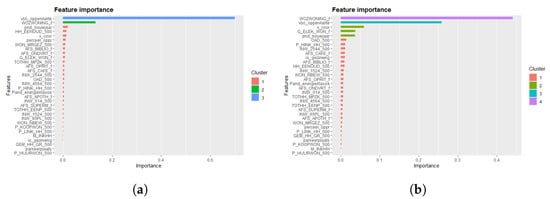
شکل A5. اهمیت متغیر XGBoost Amersfoort & Amsterdam (2018). ( الف ) آمرسفورت. ( ب ) آمستردام.
منابع
- AFM. Hypotheek در Relatie tot Waarde Huis (LTV). در دسترس آنلاین: https://afm.nl/nl-nl/consumenten/themas/producten/hypotheek/hoeveel-lenen/maximale-hypotheek (در ۲ فوریه ۲۰۲۱ قابل دسترسی است).
- لوزج، م. Rannenberg، A. اثرات کلان اقتصادی نسبت LTV و LTI در ایرلند. Appl. اقتصاد Lett. ۲۰۱۸ ، ۲۵ ، ۱۵۰۷-۱۵۱۱٫ [ Google Scholar ] [ CrossRef ]
- بانک De Nederlandsche. کیفیت و یکپارچگی ارزیابی املاک مسکونی ; مطالعات گاه به گاه؛ De Nederlandsche Bank: آمستردام، هلند، ۲۰۱۹٫ [ Google Scholar ]
- برندر، LM; Koetse، MJ ارزش فضای باز شهری: متاآنالیزهای ارزیابی احتمالی و نتایج قیمتگذاری لذتگرا. جی. محیط زیست. مدیریت ۲۰۱۱ ، ۹۲ ، ۲۷۶۳-۲۷۷۳٫ [ Google Scholar ] [ CrossRef ] [ PubMed ]
- پوتراوا، مدل قیمت گذاری لذت بخش برای بازار مسکن روتردام. پایان نامه کارشناسی ارشد، TU Delft، دلفت، هلند، ۲۰۲۰٫ [ Google Scholar ]
- لیبلت، وی. بارتکه، اس. شوارتز، N. تجزیه و تحلیل قیمت گذاری لذت بخش از تأثیر فضاهای سبز شهری بر قیمت های مسکونی: مورد لایپزیگ، آلمان. یورو طرح. گل میخ. ۲۰۱۸ ، ۲۶ ، ۱۳۳-۱۵۷٫ [ Google Scholar ] [ CrossRef ]
- کائو، ک. دیائو، م. وو، بی. مدل رگرسیون وزندار جغرافیایی مبتنی بر دادههای بزرگ برای قیمت مسکن عمومی: مطالعه موردی در سنگاپور. ان صبح. دانشیار Geogr. ۲۰۱۹ ، ۱۰۹ ، ۱۷۳-۱۸۶٫ [ Google Scholar ] [ CrossRef ]
- واردرینگ اسکامر. Hoe de WOZ-Waarde tot Stand Komt. در دسترس آنلاین: https://waarderingskamer.nl/klopt-mijn-woz-waarde/totstandkoming-woz-waarde/ (در ۱ مارس ۲۰۲۱ قابل دسترسی است).
- کاداستر. BAG، آدرس ها و ثبت کلید ساختمان ها. در دسترس آنلاین: https://kadaster.nl/zakelijk/registraties/basisregistraties/bag (در ۱۵ ژانویه ۲۰۲۱ قابل دسترسی است).
- کالکاسا WOX-Waarde. در دسترس آنلاین: https://calcasa.nl/wox-online (در ۲ مارس ۲۰۲۱ قابل دسترسی است).
- یانسن، اس. د وریس، پی. کولن، اچ. لامین، سی. Boelhouwer, P. توسعه شاخص قیمت مسکن برای هلند: کاربرد عملی فروش تکراری وزنی. جی. امور مالی املاک و مستغلات. اقتصاد ۲۰۰۸ ، ۳۷ ، ۱۶۳-۱۸۶٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هاردینگ، جی پی؛ روزنتال، اس اس; سیرمنز، ج. کاهش ارزش سرمایه مسکن، نگهداری و تورم قیمت مسکن: برآوردها از مدل فروش تکراری. J. شهری اقتصاد. ۲۰۰۷ ، ۶۱ ، ۱۹۳-۲۱۷٫ [ Google Scholar ] [ CrossRef ]
- قیمت گودمن، AC Hedonic، شاخص های قیمت و بازار مسکن. J. شهری اقتصاد. ۱۹۷۸ ، ۵ ، ۴۷۱-۴۸۴٫ [ Google Scholar ] [ CrossRef ]
- Luttik, J. ارزش درختان، آب و فضای باز که توسط قیمت خانه در هلند منعکس شده است. Landsc. طرح شهری. ۲۰۰۰ ، ۴۸ ، ۱۶۱-۱۶۷٫ [ Google Scholar ] [ CrossRef ]
- فاربر، اس. ییتس، ام. مقایسه مدلهای رگرسیون محلی در زمینه قیمت خانه لذتبخش. می توان. J. Reg. علمی ۲۰۰۶ ، ۲۹ ، ۴۰۵-۴۲۰٫ [ Google Scholar ]
- ژو، جی. ژانگ، اچ. گو، ی. Pantelous، AA سطوح مقرون به صرفه قیمت مسکن با استفاده از تحلیل رگرسیون خطی فازی: مورد شانگهای. محاسبات نرم. ۲۰۱۸ ، ۲۲ ، ۵۴۰۷–۵۴۱۸٫ [ Google Scholar ] [ CrossRef ]
- سی بی اس. Prijzen Koopwoningen. در دسترس آنلاین: https://cbs.nl/nl-nl/reeksen/prijzen-koopwoningen (در ۱۶ ژانویه ۲۰۲۱ قابل دسترسی است).
- فاثرینگهام، ای. براندون، سی. چارلتون، ام. رگرسیون وزندار جغرافیایی: تحلیل روابط متغیر فضایی . جان وایلی و پسران: هوبوکن، نیوجرسی، ایالات متحده آمریکا، ۲۰۰۲; جلد ۱۳٫ [ Google Scholar ] [ CrossRef ]
- Gong, Y. بعد فضایی قیمت خانه. A+ BE| Archit. محیط ساخته شده ۲۰۱۷ ، ۴ ، ۱-۱۸۶٫ [ Google Scholar ]
- مک میلن، DP بازگشت تمرکز به شیکاگو: استفاده از فروش تکراری برای شناسایی تغییرات در شیب فاصله قیمت مسکن. Reg. علمی اقتصاد شهری ۲۰۰۳ ، ۳۳ ، ۲۸۷-۳۰۴٫ [ Google Scholar ] [ CrossRef ]
- تومال، ام. مدل سازی اجاره مسکن با استفاده از رگرسیون وزنی جغرافیایی خودرگرسیون فضایی: مطالعه موردی در کراکوف، لهستان. ISPRS Int. J. Geo-Inf. ۲۰۲۰ ، ۹ ، ۳۴۶٫ [ Google Scholar ] [ CrossRef ]
- Tobler, WR یک فیلم کامپیوتری شبیه سازی رشد شهری در منطقه دیترویت. اقتصاد Geogr. ۱۹۷۰ ، ۴۶ ، ۲۳۴-۲۴۰٫ [ Google Scholar ] [ CrossRef ]
- سیمز، اس. دنت، پی. Oskrochi، GR مدلسازی تاثیر مزارع بادی بر قیمت خانه در بریتانیا. بین المللی جی. استراتژی. پروپ. ۲۰۰۸ ، ۱۲ ، ۲۵۱-۲۶۹٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- وو، سی. رن، اف. هو، دبلیو. Du، Q. رگرسیون وزندار جغرافیایی و زمانی چند مقیاسی: بررسی عوامل تعیینکننده مکانی-زمانی قیمت مسکن. بین المللی جی. جئوگر. Inf. علمی ۲۰۱۸ ، ۳۳ ، ۴۸۹-۵۱۱٫ [ Google Scholar ] [ CrossRef ]
- ژانگ، اس. وانگ، ال. لو، اف. بررسی اجاره مسکن با رگرسیون ترکیبی وزندار جغرافیایی: مطالعه موردی در نانجینگ. ISPRS Int. J. Geo-Inf. ۲۰۱۹ ، ۸ ، ۴۳۱٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- شبینا، ز. بویوکلیوا، بی. Ng، پلت فرم اجاره کوتاه مدت MKM در زمینه گردشگری شهری: رویکردهای رگرسیون وزنی جغرافیایی (GWR) و چند مقیاسی GWR (MGWR). Geogr. مقعدی ۲۰۲۱ ، ۵۳ ، ۶۸۶-۷۰۷٫ [ Google Scholar ] [ CrossRef ]
- شاهحسینی، م. در آغوش گرفتن.؛ فام، اچ. بهینهسازی وزنهای مجموعه برای مدلهای یادگیری ماشین: مطالعه موردی برای پیشبینی قیمت مسکن. در سیستم های خدمات هوشمند، مدیریت عملیات و تجزیه و تحلیل ؛ Yang, H., Qiu, R., Chen, W., Eds. انتشارات بین المللی Springer: Cham، سوئیس، ۲۰۲۰; صص ۸۷-۹۷٫ [ Google Scholar ]
- Avanijaa, J. پیشبینی قیمت خانه با استفاده از الگوریتم رگرسیون XGBoost. ترک. جی. کامپیوتر. ریاضی. آموزش. (TURCOMAT) ۲۰۲۱ ، ۱۲ ، ۲۱۵۱-۲۱۵۵٫ [ Google Scholar ] [ CrossRef ]
- بنابراین، HM; Tse، RY; گانسان، اس. برآورد تأثیر حمل و نقل بر قیمت خانه: شواهدی از هنگ کنگ. J. Prop. Valuat. سرمایه گذاری. ۱۹۹۷ ، ۱۵ ، ۴۰-۴۷٫ [ Google Scholar ] [ CrossRef ]
- امری، س. Tularam، GA عملکرد رگرسیون خطی چندگانه و شبکههای عصبی غیرخطی و تکنیکهای منطق فازی در مدلسازی قیمت مسکن. جی. ریاضی. آمار ۲۰۱۲ ، ۸ ، ۴۱۹-۴۳۴٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- براندون، سی. کورکوران، جی. هیگز، جی. تجسم فضا و زمان در الگوهای جرم: مقایسه روشها. محاسبه کنید. محیط زیست سیستم شهری ۲۰۰۷ ، ۳۱ ، ۵۲-۷۵٫ [ Google Scholar ] [ CrossRef ]
- de Wit، ER; انگلوند، پی. فرانک، MK قیمت و حجم معاملات در بازار مسکن هلند. Reg. علمی اقتصاد شهری ۲۰۱۳ ، ۴۳ ، ۲۲۰-۲۴۱٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ویلر، دی سی؛ Páez, A. رگرسیون وزنی جغرافیایی. در کتابچه راهنمای تحلیل فضایی کاربردی: ابزارها، روش ها و کاربردهای نرم افزاری ; Springer: برلین/هایدلبرگ، آلمان، ۲۰۱۰; صص ۴۶۱-۴۸۶٫ [ Google Scholar ] [ CrossRef ]
- مک کلاسکی، جی جی. Rausser، GC سایت های زباله خطرناک و نرخ های قدردانی مسکن. جی. محیط زیست. اقتصاد مدیریت ۲۰۰۳ ، ۴۵ ، ۱۶۶-۱۷۶٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- آمبروز، بی. آیکهولتز، پی. Lindenthal, T. قیمت ها و مبانی خانه: ۳۵۵ سال شواهد. جی. اعتبار پول. بانک. ۲۰۱۲ ، ۴۵ ، ۴۷۷-۴۹۱٫ [ Google Scholar ] [ CrossRef ]
- فیورست، اف. مک آلیستر، پی. ناندا، ا. Wyatt, P. آیا بهره وری انرژی برای خریداران خانه اهمیت دارد؟ بررسی رتبه بندی EPC و قیمت معاملات در انگلستان. اقتصاد انرژی ۲۰۱۵ ، ۴۸ ، ۱۴۵-۱۵۶٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- د گروت، اچ. de Vor, F. تاثیر سایت های صنعتی بر ارزش املاک مسکونی: تحلیل قیمت گذاری لذت جو از هلند. Reg. گل میخ. ۲۰۱۱ ، ۴۵ ، ۶۰۹-۶۲۳٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Kadaster/ESRI Nederland. DKK: مجموعه داده زمین. در دسترس آنلاین: https://arcgis.com/home/group.html?id=eb452ccc59e0431c8b42b06c7e7a6fee#overview (دسترسی در ۵ مارس ۲۰۲۱).
- سی بی اس. آمار ۱۰۰ × ۱۰۰ متر مربع. در دسترس آنلاین: https://cbs.nl/nl-nl/dossier/nederland-regionaal/geografische-data/kaart-van-100-meter-bij-100-meter-met-statistieken (دسترسی در ۱ مارس ۲۰۲۱).
- RVO. مجموعه داده برچسب های انرژی در دسترس آنلاین: https://www.ep-online.nl/ (در ۱ مارس ۲۰۲۱ قابل دسترسی است).
- فاثرینگهام، ای. یانگ، دبلیو. کانگ، دبلیو. رگرسیون جغرافیایی وزن دار چند مقیاسی (MGWR). ان صبح. دانشیار Geogr. ۲۰۱۷ ، ۱۰۷ ، ۱۲۴۷-۱۲۶۵٫ [ Google Scholar ] [ CrossRef ]
- کاداستر. داشبورد Vastgoed، Prijsindex. در دسترس آنلاین: https://kadaster.nl/zakelijk/vastgoedinformatie/vastgoedcijfers/vastgoeddashboard/prijsindex (در ۱۵ فوریه ۲۰۲۱ قابل دسترسی است).
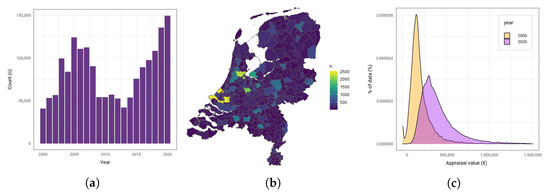
شکل ۱٫ کاوش مجموعه داده های ارزیابی املاک مسکونی Stater NV ( a ) ارزیابی ها در سال (۲۰۰۰-۲۰۲۰). ( ب ) سوابق به ازای هر شهرداری (۲۰۲۰). ( ج ) افزایش میانگین ارزش ارزیابی، (Amersfoort، ۲۰۰۰ و ۲۰۲۰).
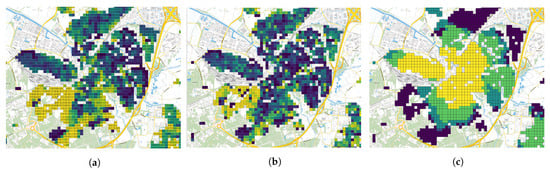
شکل ۲٫ آمارهای مختلف CBS 100 × ۱۰۰ متر (Amersfoort، ۲۰۱۸). ( الف ) ارزش مالیاتی (WOZ-waarde) (1k €). ( ب ) مصرف برق (کیلووات ساعت). ( ج ) نزدیکترین کافه (کیلومتر).
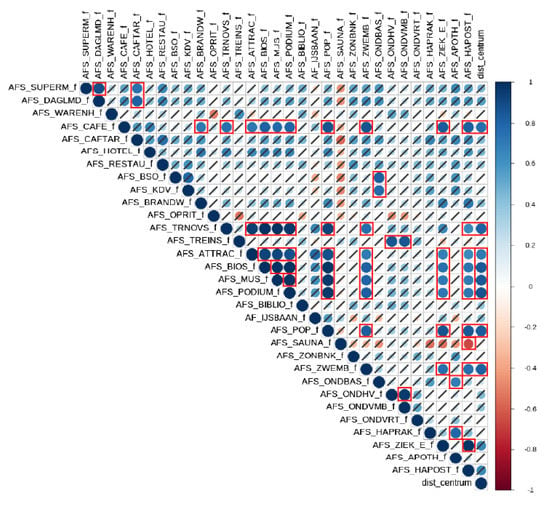
شکل ۳٫ نمودار همبستگی متغیرهای “فاصله تا نزدیکترین…” CBS (Amersfoort، ۲۰۱۸).
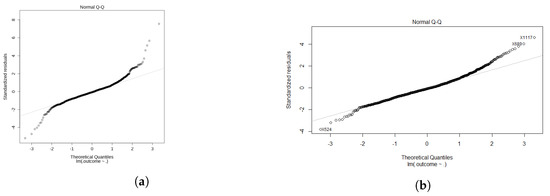
شکل ۴٫ نمودار Q-Q که تأثیر بر تناسب کلی را برای شامل همه ارزیابیها نشان میدهد (Amersfoort، ۲۰۱۸). ( الف ) همه ارزیابیها، تناسب ضعیف. ( ب ) ارزیابیها <750000 یورو، تناسب کافی.
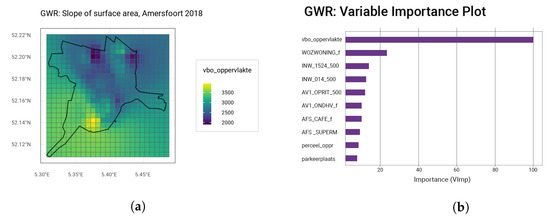
شکل ۵٫ نمودارهایی که مدل GWR را توصیف می کنند (Amersfoort، ۲۰۱۸). ( الف ) تأثیر منطقه زندگی. ( ب ) اهمیت متغیر.
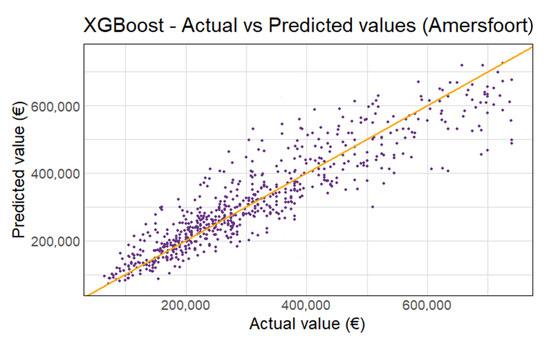
شکل ۶٫ XGBoost پیش بینی شده در مقابل مقادیر واقعی (Amersfoort، ۲۰۱۸).
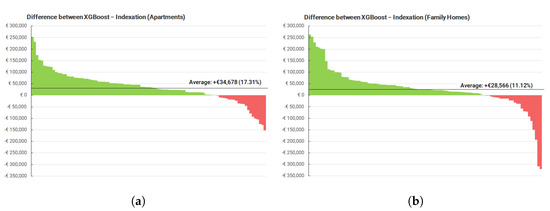
شکل ۷٫ تفاوت بین پیش بینی XGBoost و نمایه سازی با استفاده از شاخص قیمت منطقه ای (سبز = XGBoost بالاتر را پیش بینی می کند). ( الف ) برای آپارتمان ها، XGBoost 17.31 درصد بالاتر را پیش بینی می کند. ( ب ) برای خانه های خانوادگی، XGBoost 11.12 درصد بالاتر را پیش بینی می کند.