

طبقه بندی بدون نظارت
برخلاف طبقه بندی تحت نظارت ، طبقه بندی بدون نظارت نیازی به تحلیلگر تصویر ندارد که کلاسهای پوشش زمین را مشخص کرده و مجموعههای آموزشی را قبل از طبقه بندی ارائه دهد. بلکه به طور خودکار خوشههای طیفی پیکسلها را بر اساس مقادیر DN در تصویر با استفاده از یک الگوریتم خوشه بندی خاص گروه بندی میکند. سپس تحلیلگر تصویر آنها را با کلاسهای پوشش زمین مقایسه میکند.
الگوریتمهای خوشه بندی زیادی برای طبقه بندی بدون نظارت موجود است. تکنیکهای موسوم به خوشه بندی k-means (Hartigan and Wong 1979) و ISODATA (Iterative Self-Organizing Data Analysis Techniques؛ Tou and Gonzalez 1974) دو روش پرکاربرد هستند. هر دو شامل روشهای تکراری هستند و از تحلیلگر تصویر میخواهد تعداد کلاسهای مورد انتظار در تصویر را مشخص کند. الگوریتم k-means به دنبال یافتن مراکز خوشهها در فضای اندازه گیری چند بعدی نوارهای ورودی است که فاصله پیکسلها تا خوشه ای که به آن تعلق دارند را به حداقل میرساند. شامل مراحل زیر است:
- به طور تصادفی تعداد مراکز خوشه ای مشخص شده توسط کاربر را در فضای اندازه گیری چند بعدی قرار دهید و میانگین بردارهای آنها را محاسبه کنید.
- بردار اندازه گیری هر پیکسل را با میانگین بردار هر خوشه مقایسه کنید و هر پیکسل را به خوشه ای که میانگین بردار آنها نزدیکتر است اختصاص دهید.
- محاسبه بردارهای میانگین خوشه جدید برای هر یک از خوشهها با تمام پیکسلهای اختصاص داده شده به خوشه.
- مراحل ۲ و ۳ را تا زمانی که تغییر قابل توجهی در محل بردارهای میانگین خوشه بین تکرارهای پی در پی ایجاد نشود، تکرار کنید. «تغییر» را میتوان با فاصله از بردار میانگین خوشه تا بردار اندازهگیری پیکسل عضو آن که از یک تکرار به تکرار دیگر تغییر کرده است، یا با درصد پیکسلهای درون خوشه که بین تکرارها تغییر کرده است اندازهگیری شد.
ISODATA گونه ای از روش k-means است. روش k-means را با تقسیم و ادغام خوشهها اصلاح میکند. در هر تکرار، بردارهای میانگین خوشه دوباره محاسبه میشوند و پیکسلها با توجه به بردارهای میانگین جدید طبقهبندی میشوند. همه پیکسلها به نزدیکترین خوشه طبقه بندی میشوند مگر اینکه انحراف استاندارد یا آستانه فاصله توسط تحلیلگر تصویر مشخص شده باشد، در این صورت ممکن است برخی از پیکسلها در صورتی که معیارهای انتخاب شده را نداشته باشند، طبقه بندی نشده باشند. اگر تعداد پیکسلهای عضو در یک خوشه از آستانه تعیین شده توسط تحلیلگر کوچکتر باشد یا مراکز خوشهها از آستانه فاصله تعیین شده توسط تحلیلگر نزدیکتر باشند، خوشهها ادغام میشوند. اگر انحراف استاندارد خوشه از مقدار تعیین شده توسط تحلیلگر بیشتر شود و تعداد پیکسلهای عضو دو برابر آستانه برای حداقل تعداد اعضا باشد، خوشهها به دو خوشه مختلف تقسیم میشوند. بنابراین، تقسیم خوشه تکراری، ادغام و حذف بر اساس پارامترهای آستانه ورودی مشخص شده توسط تحلیلگر انجام میشود. این روند تا زمانی ادامه مییابد که تعداد پیکسلها در هر کلاس کمتر از آستانه تغییر پیکسل انتخاب شده تغییر کند یا به حداکثر تعداد تکرار برسد. ISODATA تعداد خوشههای مختلف را مجاز میکند، در حالی که k به معنای فرض میشود که تعداد خوشهها از قبل مشخص است. کادر ۶-۱۲ نحوه انجام یک طبقه بندی بدون نظارت را با روش ISODATA در ArcGIS نشان میدهد.
کادر ۶-۱۲ طبقه بندی بدون نظارت در ArcGIS |
کاربردی |
| برای پیروی از این مثال، ArcMap را راه اندازی کنید، وchapter6_mlc.mxd را باز کنید که در کادر ۶-۱۱ ذخیره شده است. |
طبقه بندی تصویر |
| ۱) در نوار ابزار طبقه بندی تصویر، روی Classification > Iso Cluster Unsupervised Classification کلیک کنید. در محاوره Unsupervised Classification Iso Cluster : |
| الف)wy00ar.tif را به عنوان باندهای رستری ورودی انتخاب کنید. |
| ب) عدد ۶ را به عنوان تعداد کلاسها وارد کنید. (توجه داشته باشید که تعداد طبقات طیفی به پیچیدگی منطقه مورد مطالعه بستگی دارد. از آنجایی که هر طبقه پوشش زمین ممکن است دارای انواع الگوهای پاسخ طیفی باشد، تعداد طبقات طیفی تنظیم شده برای طبقه بندی بدون نظارت معمولاً از تعداد مورد انتظار طبقات کاربری زمین بیشتر میشود). |
| ج) C:\Databases\GIS4EnvSci\WooriYallock\wylc_iso را به عنوان رستر طبقه بندی شده خروجی وارد کنید. |
| د) مقادیر پیش فرض را برای سایر پارامترها بپذیرید. |
| ه) روی OK کلیک کنید. wylc_iso ایجاد و در نمای داده نمایش داده میشود که مشابه شکل ۶-۲۷ است. |
| ۲) wylc_iso را با wylc مقایسه کنید و انواع کاربری زمین را برای هر یک از شش خوشه یا باند طیفی در wylc_iso شناسایی کنید. این را میتوان با استفاده از ابزار Swipe به شرح زیر تسهیل کرد: |
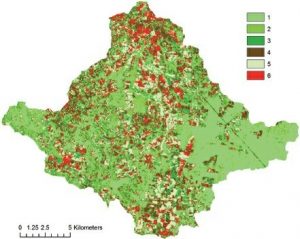
شکل ۶-۲۷ تصویر طبقه بندی شده با ISODATA
| الف) در فهرست مطالب، تیک wylc_iso و wylc را بزنید و تیک سایر لایهها را بردارید. wylc را زیر wylc_iso قرار دهید. |
| ب) روی Customize > Toolbars > Effects در منوی اصلی ArcMap کلیک کنید. |
| ج) در نوار ابزار Effects، wylc_iso را در لیست لایهها انتخاب کنید. |
| د) در نوار ابزار Effects، روی ابزار Swipe کلیک کنید تا لایه انتخاب شده wylc_iso به صورت تعاملی جدا شود و wylc زیر آن شش طبقه را باید ببینید : ۱) جنگل، ۲)جنگل (با گونههای متفاوت از کلاس ۱)، ۳) علفزار، ۴) خاک/مسکونی، ۵) زمین زراعی / علفزار و ۶) مسکونی / خاک. حجم آب در حوضه آبریز عموماً کوچک است. آنها در کلاس ۱ گروه بندی میشوند. نتایج نشان میدهد که چندین کلاس پوشش زمین از نظر طیفی مشابه هستند و نمیتوان آنها را در مجموعه دادههای تصویر چند طیفی با الگوریتم طبقه بندی بدون نظارت متمایز کرد. این یکی از پیامدهای نامطلوب احتمالی طبقه بندی بدون نظارت است. |
| ۳) مراحل ۱ و ۲ را تکرار کنید تا ابزار Iso Cluster Unsupervised Classification را چندین بار با تعداد کلاسهای طیفی مختلف اجرا کنید و نتایج را با wylc و wy00ar.tif مقایسه کنید تا ببینید که آیا تعداد کلاسهای طیفی باید بیشتر یا کمتر باشد. |
تصویر طبقه بندی شده را صاف کنید |
| در تصویر طبقه بندی شده، تعداد زیادی پیکسل طبقه بندی شده اشتباه یا تکههای کوچک پیکسل وجود دارد. این پیکسلهای جدا شده را میتوان از طریق یک عملیات صاف کردن حذف کرد. برای دستیابی به این هدف میتوان از فیلتر اکثریت، که مقادیر پیکسل را با مقدار اکثریت در همسایگیهای مجاور آنها جایگزین میکند، استفاده کرد. |
| ۴) ArcToolBox را باز کنید. در پنجره ArcToolBox، به Spatial Analyst Tools > Generalization بروید و روی Majority Filter دوبار کلیک کنید. |
| ۵) در گفتگوی Majority Filter : |
| الف) wylc_iso را به عنوان رستر ورودی انتخاب کنید. |
| ب) C:\Databases\GIS4 EnvSci\WooriYallock\wylc_iso_sرا به عنوان رستر خروجی وارد کنید. |
| ج) تعداد محلهها را به هشت تغییر دهید. |
| د) HALF را به عنوان آستانه جایگزینی تنظیم کنید (یعنی نیمی از پیکسلهای داخل همسایگی باید مقدار یکسانی داشته باشند و به هم پیوسته باشند). |
| ه) روی OK کلیک کنید. wylc_iso_s ایجاد شده و در نمای داده نمایش داده میشود. شکل ۶-۲۸ قسمت مرکزی تصویر صاف شده را در مقایسه با تصویر طبقه بندی شده قبل از صاف کردن نشان میدهد. |

شکل ۶-۲۸ تصاویر طبقه بندی شده قبل و بعد از صاف شدن: (الف) قبل از صاف کردن و (ب) پس از صاف شدن
پوشههای حاصل از طبقه بندی بدون نظارت، طبقات طیفی هستند که بر اساس گروه بندی طبیعی مقادیر DN در یک تصویر شناسایی میشوند. این کلاسها ممکن است با کلاسهای مورد علاقه زمین مطابقت داشته باشند یا ندهند. تحلیلگر تصویر باید با استفاده از دانش شخصی و برخی از اشکال دادههای مرجع، مانند نقشههای بزرگ مقیاس و عکسهای هوایی، انواع پوشش زمین را به هر طبقه طیفی تعیین و اختصاص دهد.
طبقهبندی بدون نظارت اغلب کلاسهای پوشش زمین بیش از حد تولید میکند، که ممکن است نیاز به ترکیب برای ایجاد یک نقشه پوشش زمین معنیدار باشد. در موارد دیگر، طبقهبندی ممکن است منجر به کلاسهای طیفی شود که ممکن است بیمعنی باشند، زیرا ترکیبی از انواع پوششهای مختلف را نشان میدهند، همانطور که در نتایج تولید شده در کادر ۶-۱۲ نشان داده شده است. طبقهبندی بدون نظارت اغلب زمانی استفاده میشود که شواهد مشاهدهای و دانش کافی در مورد ماهیت انواع پوشش زمین برای منطقه تحت پوشش تصویر وجود نداشته باشد، یا جایی که تحلیلگر نمیتواند مجموعههای آموزشی از انواع پوشش شناختهشده را با دقت و اطمینان انتخاب کند. همچنین میتواند به عنوان یک مرحله اولیه قبل از طبقه بندی تحت نظارت مورد استفاده قرار گیرد. در این نوع طبقهبندی ترکیبی، طبقهبندی بدون نظارت برای تعیین ترکیب طبقه طیفی تصویر استفاده میشود تا به تحلیلگر تصویر کمک کند مجموعههای آموزشی را انتخاب کند که به اندازه کافی تنوع طیفی هر کلاس را برای طبقهبندی نظارت شده نشان دهد. برخی از برنامههای طبقه بندی بدون نظارت امضاء کلاس را برای همه خوشههای شناسایی شده خروجی میدهند. پس از استفاده تحلیلگر از دادههای مرجع برای مرتبط کردن طبقات طیفی با پوششهای مورد نظر ،
هر دو طبقه بندی تحت نظارت و بدون نظارت که در این بخش مورد بحث قرار گرفته است، بر اساس پیکسل به پیکسل است. آنها فرض میکنند که بردارهای اندازه گیری مرتبط با پیکسلهای مختلف مستقل هستند، در حالی که آنها در واقع از لحاظ مکانی همبستگی دارند. به عنوان مثال، پیکسلی که به عنوان مرتع طبقه بندی میشود احتمالاً توسط همان کلاس پیکسل احاطه شده است. با توجه به این فرض “استقلال”، طبقه بندی تصویر اغلب باعث ایجاد پیکسلهای جدا از طبقه بندی نادرست در فضای داخلی کلاس میشود که معمولاً به آنها لکهها گفته میشود. همانطور که در تصویر نشان داده شده است، ممکن است ظاهر نمک و فلفل ایجاد شود. شکل ۶-۲۷ و ۶-۲۸ a در عمل، طبقه بندی تصویر معمولاً با صاف کردن پس از طبقه بندی به منظور حذف لکهها و بهبود کیفیت تصویر طبقه بندی شده دنبال میشود، همانطور که در کادر ۶-۱۲ نشان داده شده است.
اطلاعات پوشش زمین برای درک الگوها و ویژگیهای چشم انداز، تخمین تبادل کربن، آب و انرژی بین زمین و جو، و برای مدل سازی محیطی، نظارت و تصمیم گیری اساسی است. سنجش از دور ابزار عمده ای برای به دست آوردن اطلاعات پوشش زمین در گذشته و حال فراهم میکند. کادر ۶-۱ و مطالعات موردی ۱ ، ۵ و ۱۲ درفصل ۱۰ نمونههایی از استفاده از دادههای سنجش از دور برای استخراج اطلاعات پوشش زمین برای ارزیابی تأثیر زلزله بر روی زیستگاه پانداهای غولپیکر، مدلسازی رواناب بارندگی، ارزیابی زمین و ارزیابی اقتصادی خدمات اکوسیستم ارائه میکند.