


طبقه بندی داده ها
هدف یادگیری
هدف این بحث توصیف روشهای موجود برای تجزیه و تحلیل دادهها به کلاسهای مختلف جهت نمایش بصری در نقشه است.
فرآیند طبقهبندی دادهها، دادههای خام را در کلاسهای از پیش تعریفشده یا binها گروهبندی میکند. این کلاسها ممکن است در نقشه با استفاده از نمادهای منحصر به فرد یا، در مورد نقشههای choropleth، با یک رنگ یا طیف رنگی ویژه نمایش داده شوند (برای اطلاعات بیشتر در مورد رنگها، به پست “تحلیل جغرافیایی II: دادههای رستری”). نقشههای choropleth نقشههای موضوعی هستند که با رنگهای مدرج سایهدار میشوند تا برخی از متغیرهای آماری مورد نظر را نشان دهند. اگرچه این فرآیند به نظر ساده میرسد، چندین روش طبقهبندی مختلف در دسترس نقشهسازان است. این روشها مقادیر ویژگیها را در بازههای مختلف تجزیه میکنند. Monmonier (1991) اشاره کرده است که روشهای طبقهبندی مختلف میتوانند تأثیر زیادی بر قابلیت تفسیر یک نقشه خاص داشته باشند، زیرا الگوی بصری نمایش دادهشده به راحتی با تغییر فاصلههای بازهای خاص تحریف میشود. علاوه بر روش انتخابی، تعداد کلاسهایی که برای نمایش ویژگیهای مورد نظر انتخاب میشوند نیز میتواند تأثیر قابلتوجهی بر توانایی بیننده برای تفسیر اطلاعات نقشه بگذارد. افزودن تعداد زیاد کلاسها ممکن است نقشه را پیچیده و مبهم کند. از سوی دیگر، انتخاب تعداد کم کلاسها ممکن است نقشه را سادهسازی کرده و روندهای مهم دادهها را پنهان سازد. در بیشتر موارد، طبقهبندی مؤثر از چهار تا شش کلاس مجزا استفاده میکند.
اگرچه ممکن است مشکلاتی در هر تکنیک طبقهبندی وجود داشته باشد، یک choropleth طراحیشده بهخوبی میتواند قابلیت تفسیر نقشه را بهطور چشمگیری افزایش دهد. در بخش بعدی، روشهای طبقهبندی معمولاً موجود در بستههای نرمافزاری سیستمهای اطلاعات جغرافیایی (GIS) شرح داده میشوند. در این مثالها، از دادههای جمعیتی اداره سرشماری ایالات متحده برای شهرستانهای ایالات متحده در سال ۱۹۹۷ استفاده خواهد شد. این دادهها به صورت رایگان در وبسایت سرشماری ایالات متحده (http://www.census.gov) در دسترس هستند.
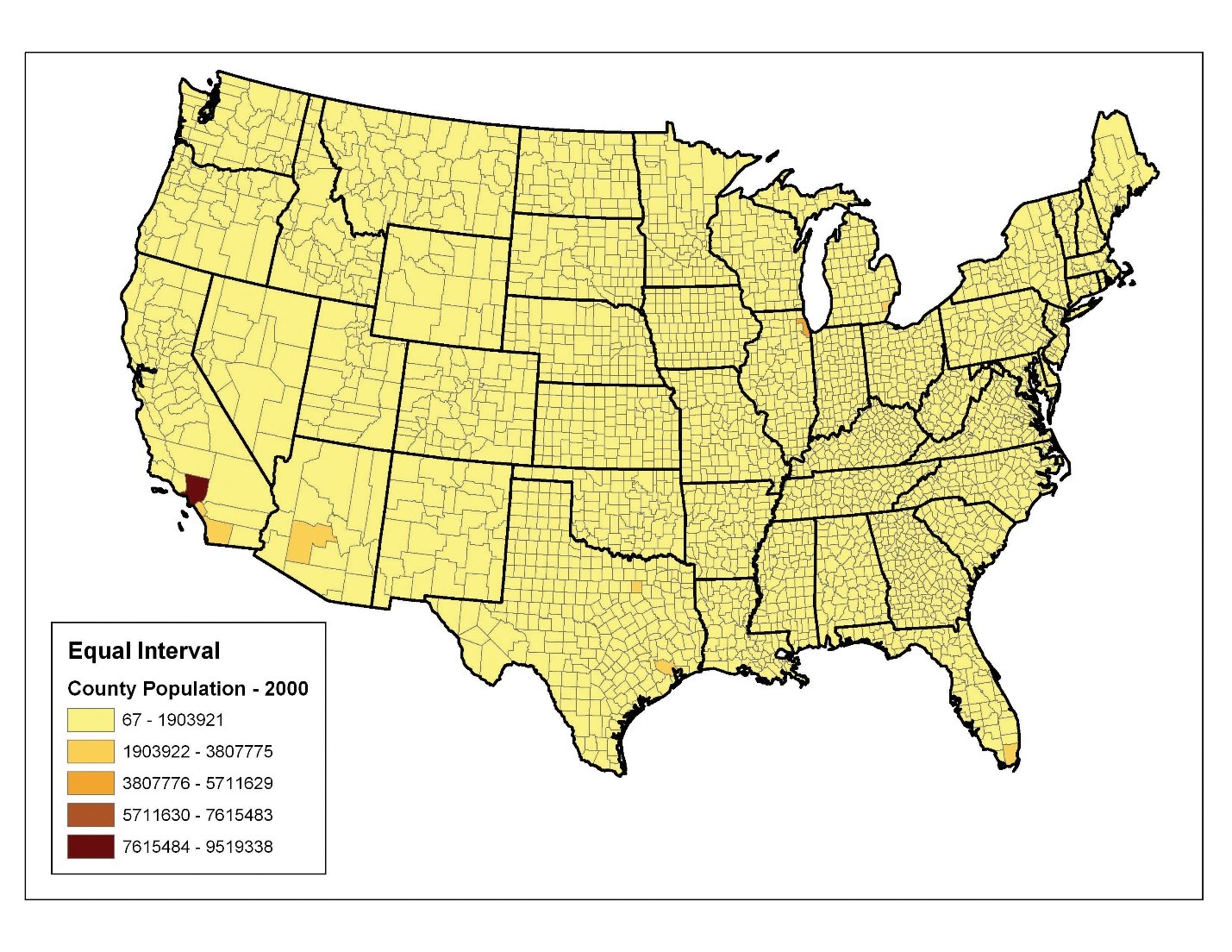
روش طبقهبندی بازه مساوی (یا گام مساوی) مقادیر ویژگیها را به کلاسهایی با اندازه برابر تقسیم میکند. تعداد کلاسها توسط کاربر تعیین میشود. این روش بهویژه برای دادههای پیوسته مانند بارش یا دما مناسب است. در دادههای اداره سرشماری ۱۹۹۷، مقادیر جمعیت شهرستانها در ایالات متحده از ۴۰ (شهرستان پارک ملی یلوستون، MO) تا ۹،۱۸۴،۷۷۰ (شهرستان لسآنجلس، کالیفرنیا) متغیر است، که محدوده آن ۹،۱۸۴،۷۷۰ – ۴۰ = ۹،۱۸۴،۷۳۰ است. اگر تصمیم بگیریم این دادهها را به ۵ کلاس بازهای مساوی طبقهبندی کنیم، دامنه هر طبقه بهطور میانگین ۹،۱۸۴،۷۳۰ / ۵ = ۱،۸۳۶،۹۴۶ خواهد بود (شکل ۶٫۱۹ “طبقهبندی فاصله مساوی برای دادههای جمعیت شهرستانهای ایالات متحده در سال ۱۹۹۷”).
مزیت روش طبقهبندی فاصله مساوی این است که افسانهای ساده میسازد که تفسیر و ارائه آن برای مخاطبان غیر فنی آسان است. نقطه ضعف اصلی این است که در برخی مجموعه دادهها، بیشتر مقادیر در یک یا دو کلاس قرار میگیرند، در حالی که سایر کلاسها مقادیر کمی دارند یا هیچ مقداری را شامل نمیشوند. همانطور که در شکل ۶٫۱۹ “طبقهبندی بازههای مساوی برای دادههای جمعیت شهرستانهای ایالات متحده در سال ۱۹۹۷” مشاهده میشود، تقریباً تمام شهرستانها به اولین سطل (زرد) اختصاص داده شدهاند.
شکل ۶٫۱۹ طبقه بندی بازه های مساوی برای داده های جمعیت شهرستان ایالات متحده در سال ۱۹۹۷
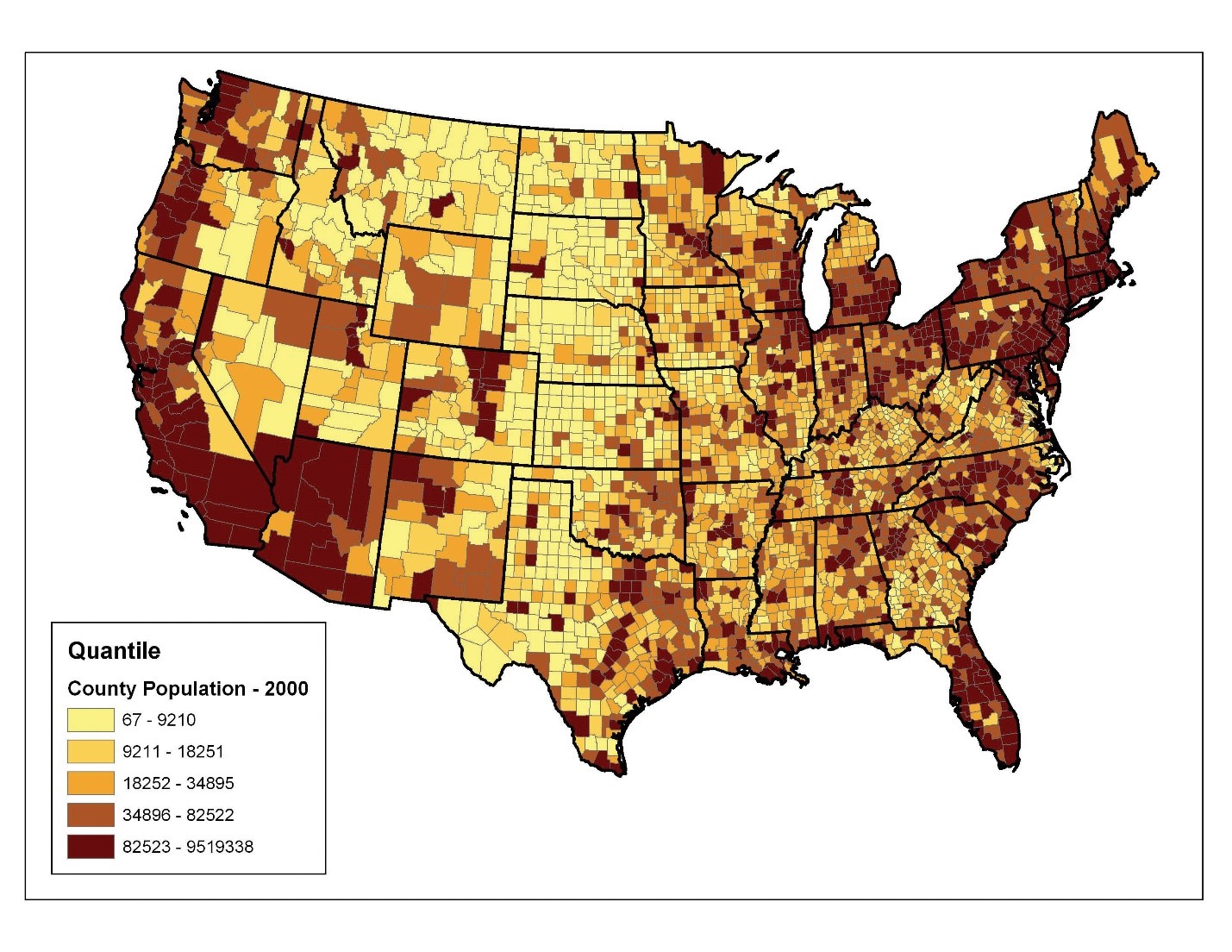
روش طبقهبندی چندک (Quantile Classification) تعداد مشاهدات مساوی را در هر کلاس قرار میدهد. این روش برای دادههایی که به طور یکنواخت در محدوده آن توزیع شدهاند، بهترین کارایی را دارد. شکل ۶٫۲۰ “کوانتیلها” روش طبقهبندی چندک را با پنج کلاس نشان میدهد. از آنجایی که در ایالات متحده ۳۱۴۰ شهرستان وجود دارد، هر کلاس در این روش شامل ۳۱۴۰ / ۵ = ۶۲۸ شهرستان خواهد بود.
مزیت این روش این است که معمولاً بر تأکید بر موقعیت نسبی مقادیر دادهها برتری دارد (یعنی تعیین اینکه کدام شهرستانها شامل ۲۰ درصد از جمعیت ایالات متحده هستند). نقطه ضعف اصلی روش طبقهبندی چندک این است که ویژگیهایی که در یک کلاس قرار میگیرند ممکن است مقادیر بسیار متفاوتی داشته باشند، به ویژه اگر دادهها به طور مساوی در محدوده آن توزیع نشده باشند. علاوه بر این، امکان دارد مقادیر با تفاوتهای محدودهای کوچک در کلاسهای مختلف قرار بگیرند که میتواند تفاوتهای بزرگتری در دادهها نسبت به آنچه که واقعاً وجود دارد، نشان دهد.
شکل ۶٫۲۰ چندک
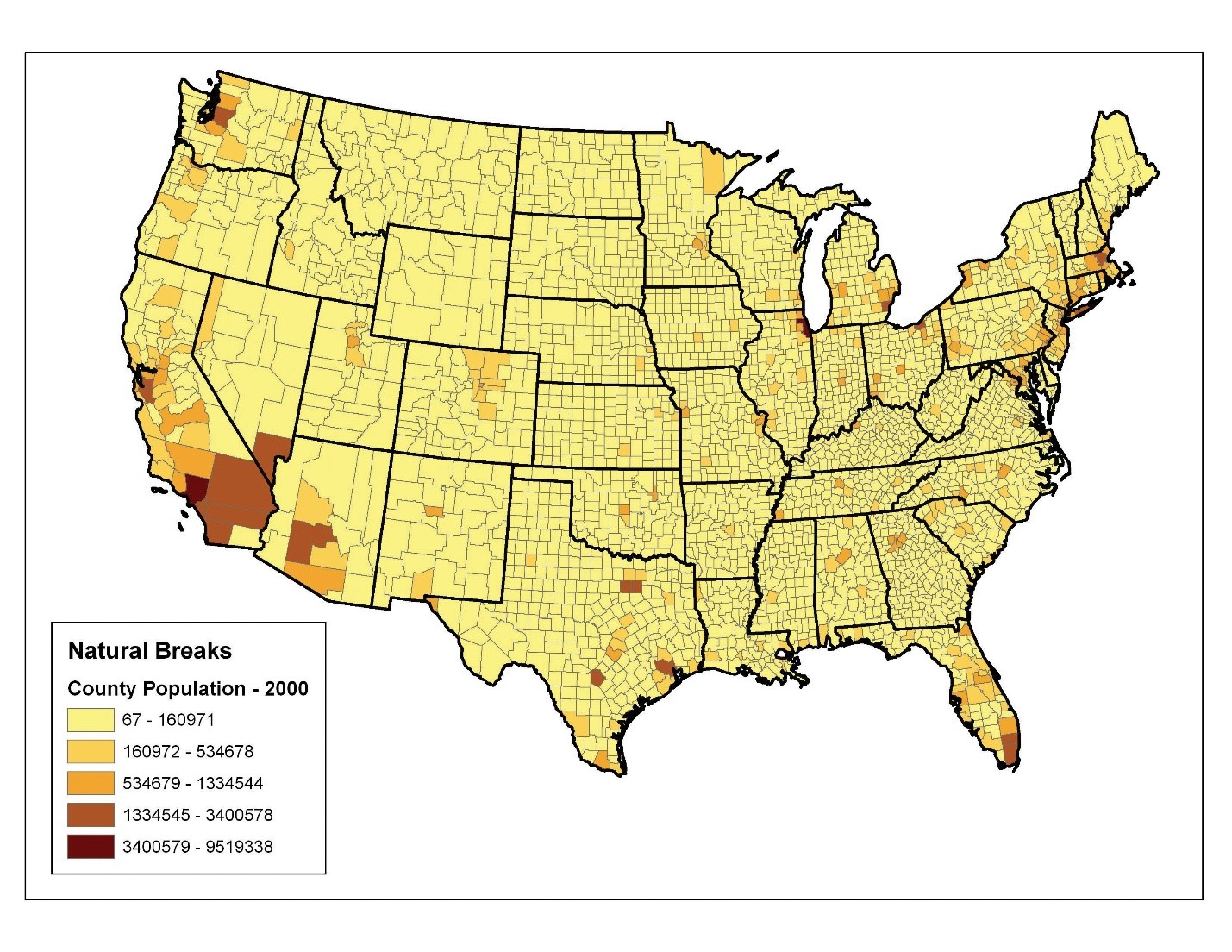
روش طبقهبندی شکستهای طبیعی (یا جنکس) از یک الگوریتم برای گروهبندی مقادیر به کلاسهایی استفاده میکند که با نقاط شکست مجزا از هم جدا شدهاند. این روش بهترین عملکرد را برای دادههایی دارد که به طور ناموزون توزیع شدهاند، اما به سمت هر دو انتهای توزیع منحرف نمیشوند. شکل ۶٫۲۱ “وقفههای طبیعی” طبقهبندی شکستهای طبیعی برای دادههای تراکم جمعیت شهرستانهای ایالات متحده در سال ۱۹۹۷ را نشان میدهد.
یکی از معایب احتمالی این روش این است که میتواند کلاسهایی ایجاد کند که دارای محدودههای عددی بسیار متفاوتی باشند. به عنوان مثال، کلاس ۱ ممکن است با محدودهای کمی بیش از ۱۵۰,۰۰۰ مشخص شود، در حالی که کلاس ۵ با محدودهای بیش از ۶,۰۰۰,۰۰۰ مشخص خواهد شد. در چنین مواردی، ممکن است مفید باشد که کلاسها را بعد از تلاش طبقهبندی تغییر داده یا برچسبها را به مقیاسهای ترتیبی مانند “کوچک”، “متوسط” یا “بزرگ” تغییر دهید. این روش به ویژه میتواند نقشهای تولید کند که برای بیننده قابل درکتر باشد.
نقطه ضعف دیگر این روش این است که مقایسه دو یا چند نقشه که با استفاده از طبقهبندی شکستهای طبیعی ایجاد شدهاند، دشوار است؛ زیرا محدوده کلاسها برای هر مجموعه داده خاص است.
شکل ۶٫۲۱ شکست های طبیعی
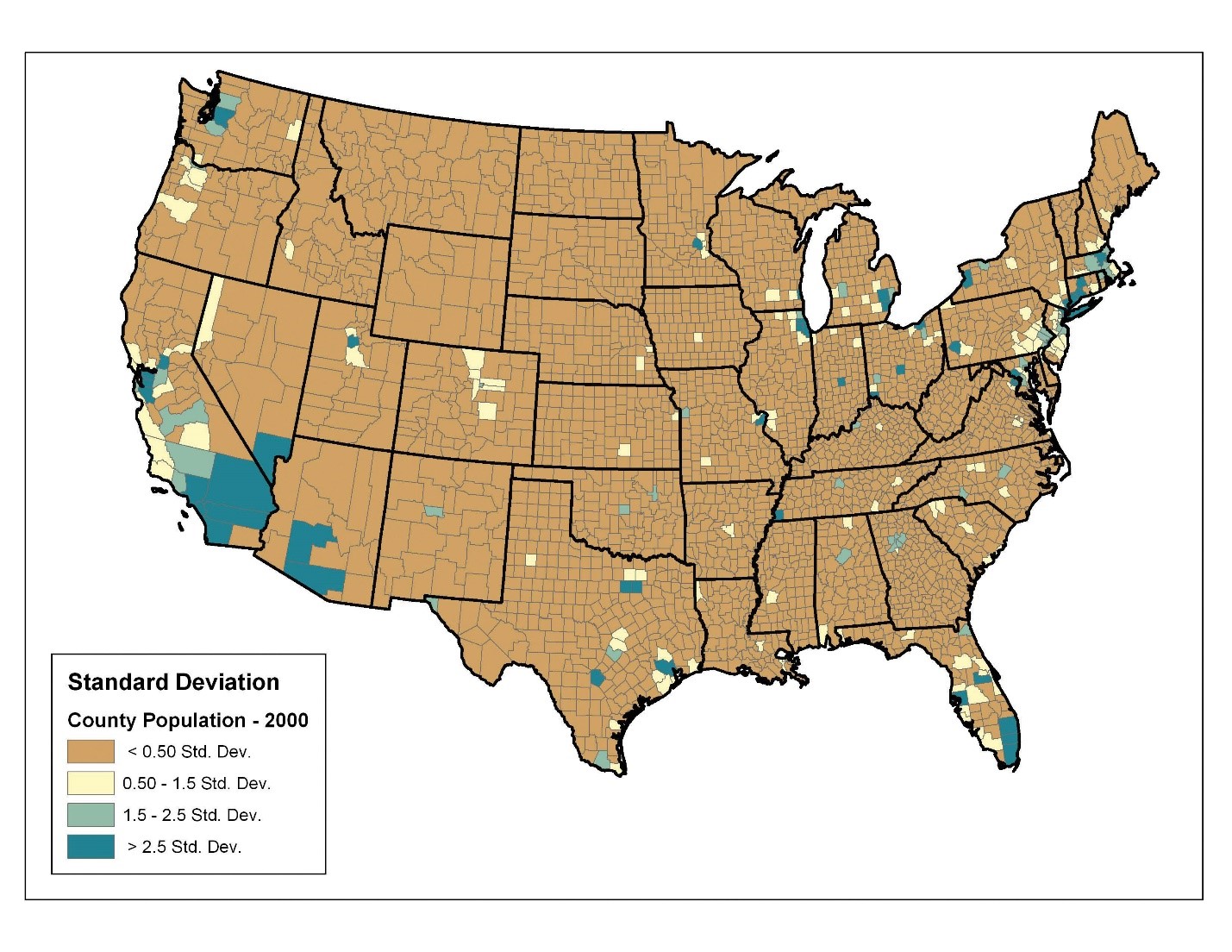
در نهایت، روش طبقهبندی انحراف استاندارد، هر کلاس را با اضافه کردن و کم کردن انحراف استاندارد از میانگین مجموعه دادهها تشکیل میدهد. این روش برای دادههایی که توزیع نرمال دارند، مناسبتر است. برای نمونه، در دادههای جمعیت شهرستان، میانگین برابر با ۸۵,۱۰۸ و انحراف معیار ۲۷۷,۰۸۰ است. بنابراین، همانطور که در افسانه شکل ۶٫۲۲ “انحراف استاندارد” مشاهده میشود، کلاس مرکزی شامل مقادیری است که در فاصله ۰٫۵ انحراف استاندارد از میانگین قرار دارند، در حالی که کلاسهای بالاتر و پایینتر شامل مقادیری هستند که ۰٫۵ یا بیشتر انحراف استاندارد بالاتر یا پایینتر از میانگین قرار دارند.
شکل ۶٫۲۲ انحراف معیار
در نتیجه، چندین روش طبقهبندی دادهها وجود دارد که میتوانند برای نقشههای choropleth اعمال شوند. اگرچه روشهای دیگری نیز در دسترس هستند (مانند مساحت مساوی یا بهینهسازی)، آنهایی که در اینجا بیان شدهاند، رایجترین و قابلدسترسترین روشها را نشان میدهند. هر یک از این روشها دادهها را به شیوهای متفاوت نمایش میدهند و جنبههای مختلف روند در مجموعه دادهها را برجسته میکنند. در حقیقت، روش طبقهبندی و همچنین تعداد کلاسهای مورد استفاده میتواند به تفاسیر متفاوتی از مجموعه دادهها منجر شود. این بر عهده شما، نقشهبردار است که روشی را انتخاب کنید که به بهترین شکل با نیازهای مطالعهتان مطابقت داشته باشد و دادهها را تا حد ممکن بهطور معنادار و شفاف ارائه نمایید.
خوراکی های کلیدی
- نقشههای کروپلث نقشههای موضوعی هستند که با رنگهای مدرج سایهدار میشوند تا برخی از متغیرهای آماری مورد علاقه را نشان دهند.
- چهار روش برای طبقه بندی داده های ارائه شده در اینجا شامل فواصل مساوی، چارک، شکست های طبیعی و انحراف معیار است. این روش ها مزایا و معایب خاصی را هنگام تجسم یک متغیر مورد علاقه نشان می دهند.
تمرینات
- با توجه به نقشه های choropleth ارائه شده در این پست، به نظر شما کدام مجموعه داده را بهتر نشان می دهد؟چرا؟
- آنلاین شوید و دو روش دیگر طبقه بندی داده ها را که برای کاربران GIS در دسترس است شرح دهید.
- برای جدول سی مقدار داده ایجاد شده درمبحث«توضیحات و خلاصهها» ، تمرین ۱، محدوده دادهها را برای هر کلاس مشخص کنید، به گونهای که گویی در حال ایجاد طرحهای طبقهبندی فاصله و کمیت یکسان هستید.