کلید واژه ها:
موقعیت یابی اثر انگشت ؛ موقعیت یابی داخلی ؛ درجه همپوشانی فاصله ارزش های افراطی ؛ رگرسیون فرآیند گاوسی
۱٫ مقدمه
۲٫ کارهای مرتبط
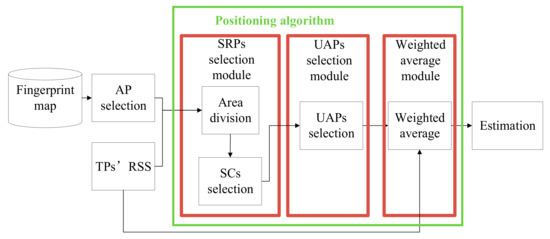
۳٫ مقدمات و چارچوب الگوریتم پیشنهادی
۳٫۱٫ شرح مسئله فرعی
مکان واقعی TP به صورت بیان می شود و نقشه اثر انگشت شامل مکان های RP و RSS مربوطه است. فرض کنید که M AP و N RP وجود دارد. مکان RP ها را می توان به عنوان ذخیره کرد . نشان دهنده محل است . RSS جمع آوری شده در به صورت زیر بیان می شود:
جایی که . نشان دهنده RSS از در در نمونه گیری تی ام T نشان دهنده تعداد نمونه برداری است.
نقشه اثر انگشت را می توان به صورت زیر بیان کرد:
برای راحتی بیان، فرض کنید که فقط یک نمونه در TP دریافت شده است . RSS جمع آوری شده در TP به صورت زیر بیان می شود:
مسئله موقعیت یابی را می توان به صورت زیر فرموله کرد:
جایی که مکان تخمین زده شده TP با استفاده از نقشه رابطه است .
۳٫۲٫ آزمایش مقدماتی
۳٫۳٫ چارچوب
۴٫ الگوریتم ها
۴٫۱٫ الگوریتم انتخاب AP
۴٫۱٫۱٫ الگوریتم IOD
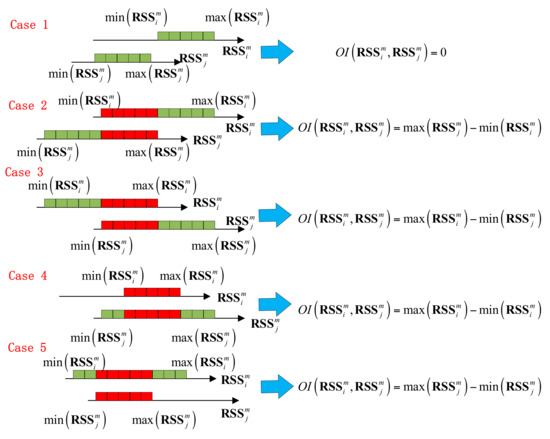
این بخش به طور خلاصه الگوریتم اولیه IOD [ ۳۰ ] را بررسی می کند. فرض کنید که و می تواند تشخیص دهد . داده های نمونه گیری RSS از جمع آوری شده در و به صورت زیر بیان می شود:
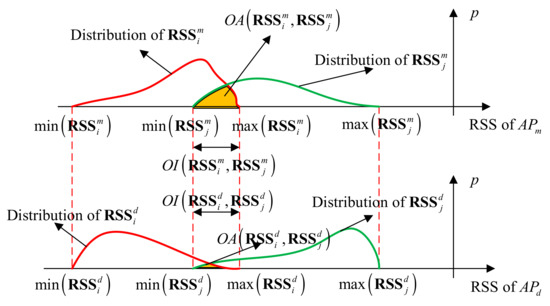
بنابراین، فواصل و را می توان به عنوان نشان داد و ، به ترتیب. الگوریتم IOD [ ۳۰ ] ابتدا OI بین را محاسبه می کند و ، که طول بازه قرمز در شکل ۴ است و سپس آن را عادی می کند برای بدست آوردن ارزش ، یعنی
جایی که و نشان دهنده طول و ، به ترتیب، یعنی
۴٫۱٫۲٫ بیانیه شماره الگوریتم IOD
با این حال، در شکل ۵ ، روابط زیر وجود دارد.
بنابراین الگوریتم IOD معادله زیر را دارد.
۴٫۱٫۳٫ الگوریتم DIOD پیشنهادی
الگوریتم IOD [ ۳۰ ] فقط همپوشانی بازه RSS یک بعدی را در نظر می گیرد که ویژگی های توزیع را نادیده می گیرد. ما الگوریتم IOD را با گسترش طول همپوشانی بازهای یک بعدی به ناحیه همپوشانی دو بعدی (OA) بهبود میبخشیم. همانطور که در شکل ۵ نشان داده شده است ، زمانی که ناحیه OA بزرگتر باشد، اهمیت AP کمتر است. در غیر این صورت اهمیت AP بیشتر است. مساحت قسمت همپوشانی دو بعدی با احتمال p همبستگی مثبت دارد . بر اساس OA، برای ارزیابی اهمیت پیشنهاد شده است . را به صورت زیر محاسبه می شود:
جایی که و به صورت زیر محاسبه می شوند:
جایی که تعداد دفعات مقدار RSS را نشان می دهد در واقع در فاصله همپوشانی بین و .
در شکل ۵ ، و . بنابراین بر اساس معادلات (۱۴)–(۱۶) نابرابری زیر را داریم.
چون N RP وجود دارد ، ترکیبات RP را می توان در همه به دست آورد. اجازه دهید ارزش نهایی برای ارزیابی اهمیت باشد . می توان آن را به صورت زیر محاسبه کرد:
۴٫۲٫ الگوریتم موقعیت یابی
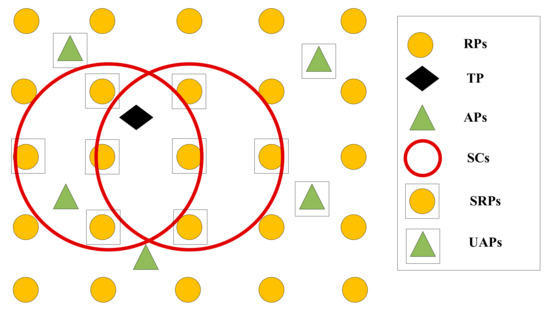
۴٫۲٫۱٫ ماژول انتخاب SRPs
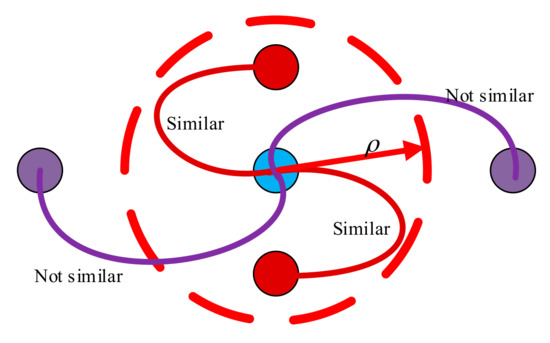
بر اساس مشخصه فوق می گیریم و به عنوان مثالی برای نشان دادن قوانین تعیین AP های بدون تغییر هر دایره. RSS از _ دریافت شده در TP در زمان کوتاه یک متغیر تصادفی است. حداقل و حداکثر مقادیر این متغیر تصادفی به صورت نمایش داده می شود و ، به ترتیب. از این رو، . فاصله RSS از دریافت شده در RP در را می توان به صورت بیان کرد ، جایی که به صورت زیر بیان می شود:
جایی که تعداد کل RP ها را نشان می دهد .
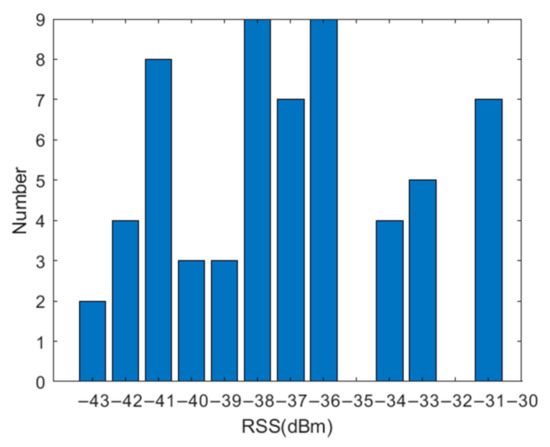
مقادیر شدید RSS جمع آوری شده در RP در یک دایره
الگوریتم استاندارد GPR فرض می کند که متغیر مستقل از توزیع گاوسی پیروی می کند. میانگین و واریانس امتیازهای جمع آوری نشده بر اساس فرضیه توزیع نرمال مشترک با آموزش RP های جمع آوری شده تخمین زده می شود . مدل مشاهده RSS زیر را در نظر بگیرید دریافت شده در .
جایی که نویز مشاهده را نشان می دهد و برآورده می کند . رابطه بین یک مشاهده و مشاهده دیگر فقط تابع کوواریانس است که می تواند به صورت زیر بیان شود:
جایی که واریانس است و پارامتر طول است. آنها هر دو پارامتر هایپر هستند. ۲-هنجار با نشان داده می شود ، که نشان دهنده فاصله اقلیدسی بین دو بردار است.
RSS پیش بینی شده برای یک موقعیت ناشناخته را می توان به صورت زیر محاسبه کرد:
جایی که بردار کوواریانس بین مکانهای RP و مکان ناشناخته، K ماتریس کوواریانس مکانهای RP ، Z بردار مقادیر مشاهدات RSS و I ماتریس هویت است.
GPR بهبودیافته که مدل انتشار سیگنال Wi-Fi [ ۴۱ ] و GPR استاندارد را ترکیب می کند، می تواند RSS واقعی را با دقت بیشتری تقریب بزند . RSS ناشناخته از در را می توان به صورت زیر محاسبه کرد:
جایی که . فاصله از است به .
بر اساس مقادیر تقریبی RSS محاسبه شده توسط GPR بهبودیافته و مقادیر RSS جمع آوری شده RPs ، کل مقادیر شدید که در را می توان به صورت بیان کرد ، جایی که:
معیار انتخاب SRPs
از آنجا که فاصله RSS از در TP است ، باید در دایره ای قرار گیرد که حاوی TP در فضای اقلیدسی است. فرض کنید این دایره است ، بنابراین رابطه فاصله RSS بین TP و معادله زیر را برآورده می کند.
از آنجایی که بدست آوردن مقدار α و β به دلیل نمونهبرداری کوتاه در TP دشوار است ، معادله (۲۶) به صورت معادله زیر ساده شده است. .
۴٫۲٫۲٫ ماژول انتخاب UAPs
بدون از دست دادن کلیت، فرض کنید که F SC با بیشترین تعداد APهای بدون تغییر q وجود دارد. q AP های بدون تغییر هر SC به عنوان یک مجموعه مستقل در نظر گرفته می شوند و عملیات تقاطع را روی مجموعه های مستقل F انجام می دهند تا UAP ها را بدست آورند . UAP ها را می توان به صورت زیر بیان کرد:
یک مثال برای نشان دادن واضح ماژول انتخاب UAPs استفاده می شود. فرض کنید که ، ۶ SC وجود دارد با بیشترین تعداد AP های بدون تغییر ، و هر SC دارای APهای بدون تغییر جدول ۲ شش AP بدون تغییر خاص هر SC را نشان می دهد . مشاهده می شود که اگرچه این SC ها تعداد AP های بدون تغییر یکسانی دارند ، اما ممکن است دارای AP های بدون تغییر متفاوت باشند . برای نگه داشتن UAPها به عنوان AP های بدون تغییر متعلق به همه SCها، AP های بدون تغییر موجود در هر SC به عنوان یک مجموعه مستقل در نظر گرفته می شوند و سپس محل تلاقی همه مجموعه ها گرفته می شود. AP های موجود در تقاطع، UAP های انتخاب شده هستند که می تواند به صورت زیر بیان شود:
۴٫۲٫۳٫ ماژول میانگین وزنی
برخی از الگوریتمهای سنتی [ ۱۹ ، ۲۰ ] از فاصله اقلیدسی RSS برای محاسبه شباهت بین SRP و TP استفاده میکنند و از متقابل فاصله اقلیدسی به عنوان وزن SRP استفاده میکنند. می توان آن را به صورت زیر بیان کرد:
جایی که ، نشان دهنده i امین SRP است.
بر اساس رابطه (۲۴) مشاهده می شود که وقتی RSS به تدریج کوچکتر می شود، مقدار مطلق شیب آن به تدریج کوچکتر می شود که عدم تقارن را نشان می دهد. و . به طور کلی تر، قانون اساسی این است که بر AP های نزدیک تر با مقادیر RSS قوی تر تأکید کنید. با این حال، معیار فاصله اقلیدسی سنتی [ ۲۰ ] این ویژگی انتشار را در نظر نمی گیرد. بر اساس UAP های انتخاب شده، ما یک الگوریتم وزن جدید برای حل این مسئله پیشنهاد می کنیم، به عنوان مثال،
که در آن S تعداد UAP ها و نشان دهنده j th UAP است.
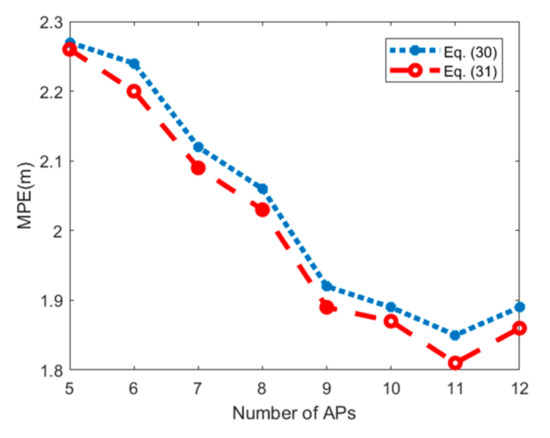
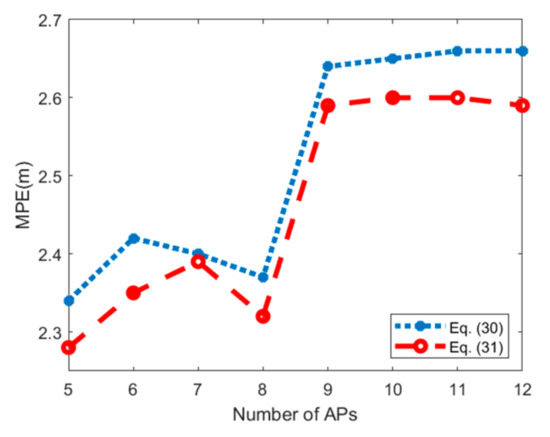
در مقایسه با معادله (۳۰)، معادله (۳۱) به RSS بزرگتر (مقدار مطلق کوچکتر است) اجازه می دهد تا هنگام محاسبه شباهت RSS بین TP و SRP وزن بیشتری داشته باشد. در نهایت، بر اساس مختصات SRP و وزن، تخمین TP را می توان به صورت زیر محاسبه کرد:
که در آن R تعداد SRP ها را نشان می دهد.
۵٫ آزمایشات
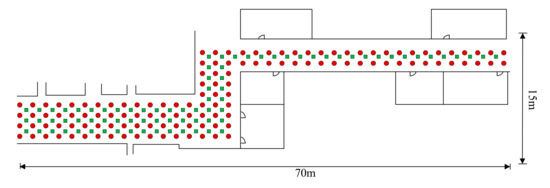
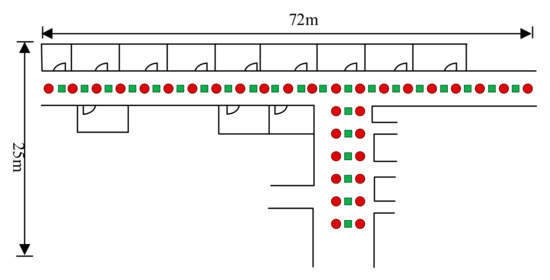
۵٫۱٫ تنظیمات آزمایشی
۵٫۲٫ الگوریتم های مقایسه و متریک عملکرد
علاوه بر این، مجموعهای از معیارهای عملکرد برای ارزیابی نتایج آزمایشها اتخاذ میشوند. این معیارهای عملکرد عبارتند از: خطای موقعیت یابی ( PE )، میانگین خطای موقعیت یابی ( MPE ) و تابع توزیع تجمعی ( CDF ). تعاریف این شاخص ها به صورت زیر بیان می شود:
که در آن G تعداد TP ها را نشان می دهد ، و نشان دهنده احتمال است.
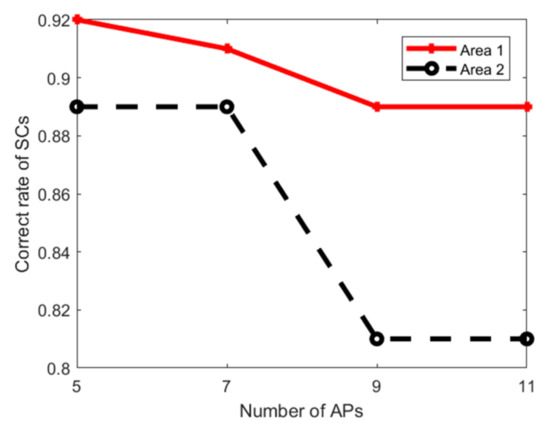
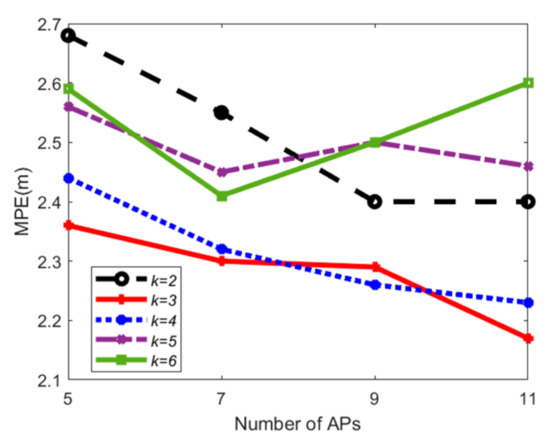
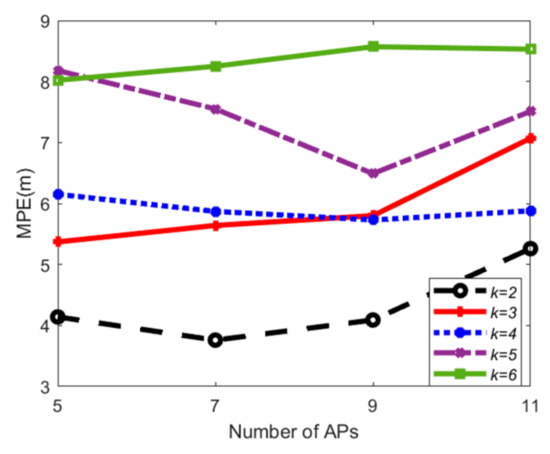
۵٫۳٫ ارزیابی امکان سنجی
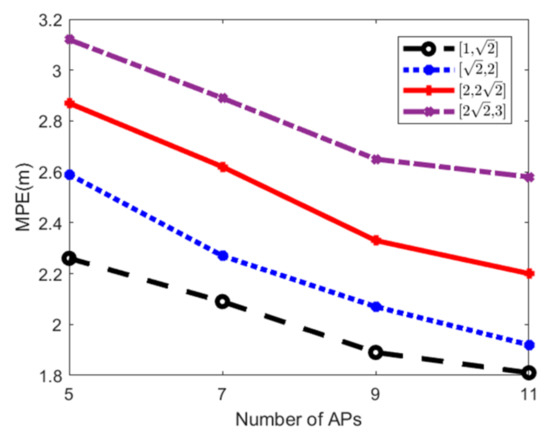
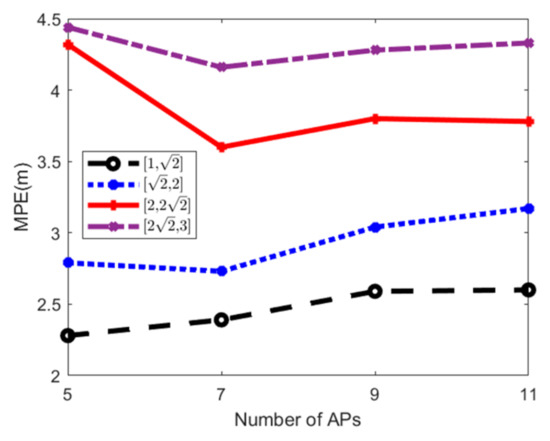
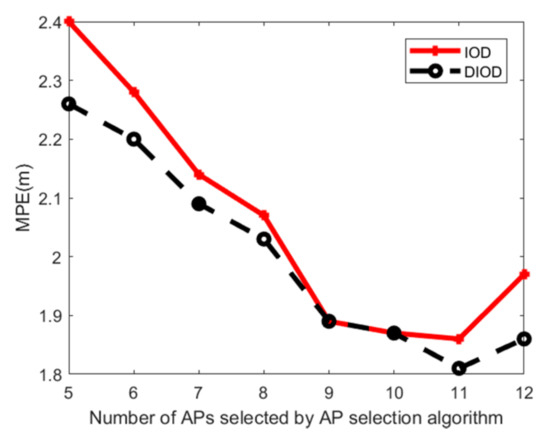
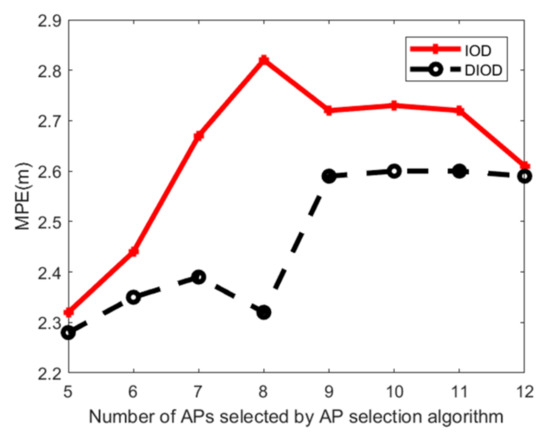
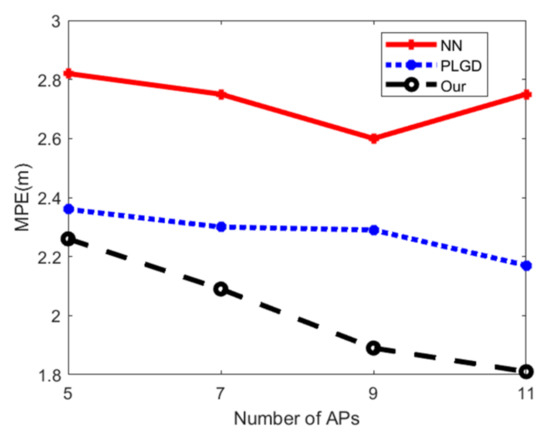
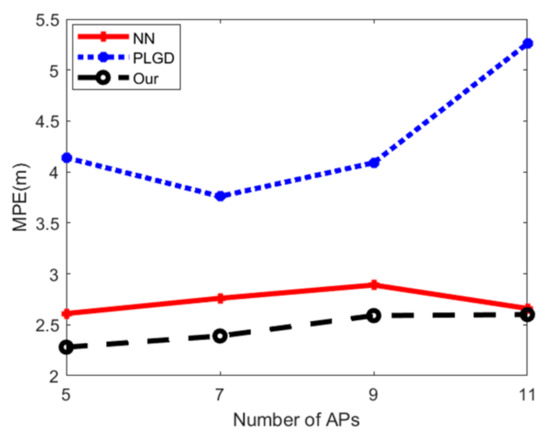
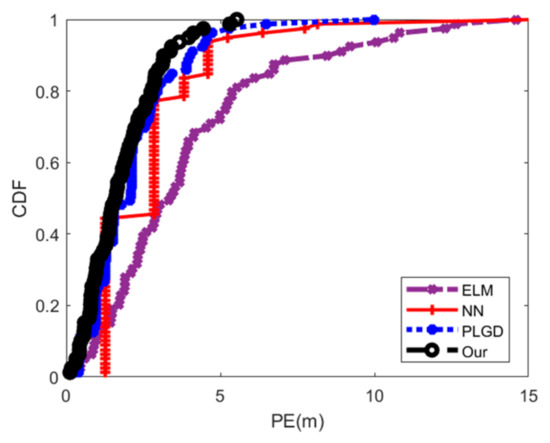
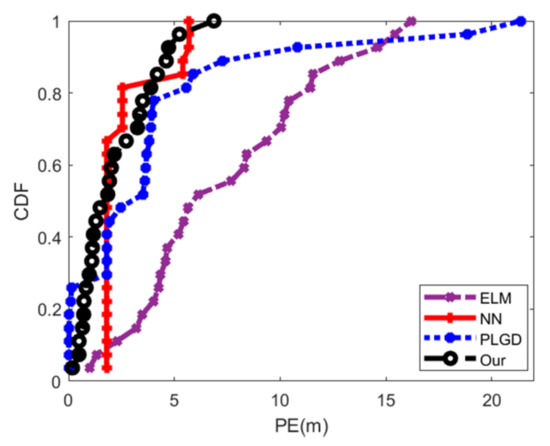
۵٫۴٫ ارزیابی دقت موقعیت
۵٫۵٫ هزینه زمانی الگوریتم تعیین موقعیت پیشنهادی
۶٫ بحث های بیشتر
۷٫ نتیجه گیری
منابع
- کائو، اچ. وانگ، ی. بی، جی. سان، م. چی، اچ. Xu، S. روش تعیین موقعیت اثر انگشت برای Wi-Fi دو باند بر اساس رگرسیون فرآیند گاوسی و K-نزدیکترین همسایه. ISPRS Int. J. Geo-Inf. ۲۰۲۱ ، ۱۰ ، ۷۰۶٫ [ Google Scholar ] [ CrossRef ]
- بی، جی. هوانگ، ال. کائو، اچ. یائو، جی. سانگ، دبلیو. ژن، جی. لیو، ی. روش محلیسازی اثرانگشت داخلی با استفاده از الگوریتم خوشهبندی و جبران پویا. ISPRS Int. J. Geo-Inf. ۲۰۲۱ ، ۱۰ ، ۶۱۳٫ [ Google Scholar ] [ CrossRef ]
- Farrell, J. Aided Navigation: GPS با سنسورهای نرخ بالا . McGraw-Hill: نیویورک، نیویورک، ایالات متحده آمریکا، ۲۰۰۸٫ [ Google Scholar ]
- کوک، م. هول، جی. شون، تی. موقعیت یابی داخلی با استفاده از اندازه گیری های باند فراعرض و اینرسی. IEEE Trans. وه تکنولوژی ۲۰۱۵ ، ۶۴ ، ۱۲۹۳-۱۳۰۳٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- او هست.؛ چان، اس. موقعیت یابی داخلی بر اساس اثر انگشت Wi-Fi: پیشرفت ها و مقایسه های اخیر. IEEE Commun. Surv. معلم خصوصی ۲۰۱۶ ، ۱۸ ، ۴۶۶-۴۹۰٫ [ Google Scholar ] [ CrossRef ]
- بندرا، U. هاسگاوا، م. اینو، ام. موریکاوا، اچ. Aoyama, T. طراحی و اجرای یک سیستم سنجش موقعیت مبتنی بر قدرت سیگنال بلوتوث. در مجموعه مقالات کنفرانس رادیویی و بی سیم IEEE 2004، آتلانتا، GA، ایالات متحده آمریکا، ۲۲ سپتامبر ۲۰۰۴٫ صص ۳۱۹-۳۲۲٫ [ Google Scholar ]
- کو، ی. پاننوتو، پی. Dutta, P. Demo: Luxapose: موقعیت یابی داخلی با تلفن های همراه و نور مرئی. در مجموعه مقالات بیستمین کنفرانس بین المللی سالانه محاسبات و شبکه های موبایل، مائوئی، HI، ایالات متحده آمریکا، ۷ تا ۱۱ سپتامبر ۲۰۱۴٫ ACM: نیویورک، نیویورک، ایالات متحده آمریکا؛ ص ۲۹۹-۳۰۲٫ [ Google Scholar ]
- تائو، ی. Zhao, L. یک سیستم جدید برای تطبیق خودکار نقشه رادیویی وای فای و موقعیت یابی داخلی. IEEE Trans. وه تکنولوژی ۲۰۱۸ ، ۶۷ ، ۱۰۶۸۳–۱۰۶۹۲٫ [ Google Scholar ] [ CrossRef ]
- چن، ال. یانگ، ک. Wang, X. بومی سازی فضای داخلی مبتنی بر اثر انگشت Wi-Fi تعاونی قوی. IEEE Internet Things J. ۲۰۱۶ ، ۳ ، ۱۴۰۶-۱۴۱۷٫ [ Google Scholar ] [ CrossRef ]
- یوسف، م. Agrawala، A. سیستم تعیین مکان هوروس. سیم. شبکه ۲۰۰۸ ، ۱۴ ، ۳۵۷-۳۷۴٫ [ Google Scholar ] [ CrossRef ]
- تائو، ی. Zhao، L. محلیسازی اثر انگشت با جستجوی منطقه تطبیقی. IEEE Commun. Lett. ۲۰۲۰ ، ۲۴ ، ۱۴۴۶-۱۴۵۰٫ [ Google Scholar ] [ CrossRef ]
- جون، ج. او، ال. گو، ی. جیانگ، دبلیو. کوشواها، ج. ویپین، ا. چنگ، ال. لیو، سی. Zhu, T. اثر انگشت وای فای کم سربار. IEEE Trans. اوباش محاسبه کنید. ۲۰۱۸ ، ۱۷ ، ۵۹۰-۶۰۳٫ [ Google Scholar ] [ CrossRef ]
- چن، پی. شانگ، جی. Gu, F. یادگیری ویژگی RSSI از طریق مدل رتبهبندی برای محلیسازی اثر انگشت Wi-Fi. IEEE Trans. وه تکنولوژی ۲۰۲۰ ، ۶۹ ، ۱۶۹۵-۱۷۰۵٫ [ Google Scholar ] [ CrossRef ]
- ظفری، ف. گکلیاس، ع. Leung, K. بررسی سیستمها و فناوریهای محلیسازی داخلی. IEEE Commun. Surv. معلم خصوصی ۲۰۱۹ ، ۲۱ ، ۲۵۶۸–۲۵۹۹٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Tang, L. مقایسه روشهای موقعیتیابی داخلی مبتنی بر WiFi. در مجموعه مقالات سیزدهمین کنفرانس بین المللی ۲۰۱۹ در مورد پردازش سیگنال و سیستم های ارتباطی (ICSPCS)، ساحل طلایی، QLD، استرالیا، ۱۶ تا ۱۸ دسامبر ۲۰۱۹؛ صص ۱-۶٫ [ Google Scholar ]
- او هست.؛ لین، دبلیو. Chan، S. محلیسازی داخلی و بهروزرسانی خودکار اثر انگشت با سیگنالهای AP تغییر یافته. IEEE Trans. اوباش محاسبه کنید. ۲۰۱۷ ، ۱۶ ، ۱۸۹۷-۱۹۱۰٫ [ Google Scholar ] [ CrossRef ]
- ژو، ام. سان، دبلیو. Yu, H. با بهبود مدل محلی سازی داخلی مبتنی بر WiFi، دستگاه تلفن همراه را تعیین مکان کنید. IEEE Internet Things J. ۲۰۱۹ ، ۶ ، ۸۷۹۲–۸۸۰۳٫ [ Google Scholar ] [ CrossRef ]
- باهل، ص. Padmanabhan، V. RADAR: یک سیستم ردیابی و مکان یابی کاربر مبتنی بر RF در ساختمان. در مجموعه مقالات IEEE INFOCOM 2000، تل آویو، اسرائیل، ۲۶-۳۰ مارس ۲۰۰۰٫ صص ۷۷۵-۷۸۴٫ [ Google Scholar ]
- یین، جی. یانگ، کیو. Ni, L. یادگیری نقشه های رادیویی زمانی تطبیقی برای تخمین مکان مبتنی بر قدرت سیگنال. IEEE Trans. اوباش محاسبه کنید. ۲۰۰۸ ، ۷ ، ۸۶۹-۸۸۳٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هو، جی. لیو، دی. یان، ز. لیو، اچ. تجزیه و تحلیل تجربی بر روی موقعیت یابی اثر انگشت زانوترین همسایه داخلی. IEEE Internet Things J. ۲۰۱۹ ، ۶ ، ۸۹۱–۸۹۷٫ [ Google Scholar ] [ CrossRef ]
- شو، دبلیو. یو، ک. هوآ، ایکس. لی، کیو. کیو، دبلیو. ژو، بی. خوشه بندی نقاط مرجع مبتنی بر موقعیت های مجازی و وزن دهی مبتنی بر فاصله فیزیکی برای موقعیت یابی Wi-Fi داخلی. IEEE Internet Things J. ۲۰۱۸ , ۵ , ۳۰۳۱–۳۰۴۲٫ [ Google Scholar ] [ CrossRef ]
- شرستا، س. تالویتی، جی. Lohan, E. محلیسازی داخلی مبتنی بر دکانولوشن با سیگنالهای WLAN و مکانهای نقطه دسترسی ناشناخته. در مجموعه مقالات IEEE ICL-GNSS، تورین، ایتالیا، ۲۵-۲۷ ژوئن ۲۰۱۳٫ [ Google Scholar ]
- کراماریوک، آ. هاتونن، اچ. لوهان، E. مزایای خوشه بندی در موقعیت یابی وای فای موبایل محور در ساختمان های چند طبقه. در مجموعه مقالات کنفرانس بین المللی محلی سازی و GNSS (ICL-GNSS)، بارسلون، اسپانیا، ۲۸-۳۰ ژوئن ۲۰۱۶٫ صص ۱-۶٫ [ Google Scholar ]
- رضوی، ع. والکاما، م. لوهان، ES K-Means خوشهبندی اثر انگشت برای تخمین کف با پیچیدگی کم در محلیسازی موبایل داخلی. در مجموعه مقالات کارگاه های آموزشی IEEE Globecom 2015 (GC Wkshps)، سن دیگو، کالیفرنیا، ایالات متحده آمریکا، ۶ تا ۱۰ دسامبر ۲۰۱۵؛ صص ۱-۷٫ [ Google Scholar ]
- هو، ایکس. شانگ، جی. گو، اف. هان، کیو. بهبود موقعیتیابی Wi-Fi در فضای داخلی از طریق AP، شباهت و خوشهبندی انتشار قرابت نیمه نظارت شده را تنظیم میکند. بین المللی J. Distrib. Sens. Netw. ۲۰۱۵ ، ۲۰۱۵ ، ۱۰۹۶۴۲٫ [ Google Scholar ] [ CrossRef ]
- وانگ، بی. لیو، ایکس. یو، بی. جیا، آر. Gan, X. یک روش موقعیتیابی WiFi بهبود یافته بر اساس خوشهبندی اثر انگشت و فاصله اقلیدسی وزندار سیگنال. Sensors ۲۰۱۹ , ۱۹ , ۲۳۰۰٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- عباس، م. الهامشاری، م. ریزک، اچ. ترکی، م. Youssef, M. WiDeep: سیستم محلی سازی دقیق و قوی مبتنی بر WiFi با استفاده از یادگیری عمیق. در مجموعه مقالات کنفرانس بین المللی IEEE 2019 در مورد محاسبات و ارتباطات فراگیر (PerCom)، کیوتو، ژاپن، ۱۱ تا ۱۵ مارس ۲۰۱۹؛ صص ۱-۱۰٫ [ Google Scholar ]
- کوئیکه-آکینو، تی. وانگ، پی. پایوویچ، م. سان، اچ. Orlik، محلیسازی فضای داخلی مبتنی بر اثرانگشت PV با WiFi تجاری MMWave: یک رویکرد یادگیری عمیق. دسترسی IEEE ۲۰۲۰ ، ۸ ، ۸۴۸۷۹–۸۴۸۹۲٫ [ Google Scholar ] [ CrossRef ]
- لو، ایکس. زو، اچ. ژو، اچ. زی، ال. هوانگ، جی.-بی. ماشین یادگیری فوق العاده قوی با کاربرد آن در موقعیت یابی داخلی. IEEE Trans. سایبرن. ۲۰۱۶ ، ۴۶ ، ۱۹۴-۲۰۵٫ [ Google Scholar ] [ CrossRef ]
- وو، بی. ما، ز. پوسلاد، اس. Zhang, W. یک الگوریتم انتخاب نقطه دسترسی بیسیم کارآمد برای تعیین مکان بر اساس تعیین درجه همپوشانی فاصله زمانی RSSI. در مجموعه مقالات سمپوزیوم ارتباطات بی سیم ۲۰۱۸ (WTS)، فینیکس، AZ، ایالات متحده آمریکا، ۱۷ تا ۲۰ آوریل ۲۰۱۸؛ صص ۱-۸٫ [ Google Scholar ]
- یوسف، م. آگراوالا، ا. Udaya Shankar، A. تعیین مکان WLAN از طریق خوشهبندی و توزیعهای احتمال. در مجموعه مقالات اولین کنفرانس بین المللی IEEE در مورد محاسبات و ارتباطات فراگیر ۲۰۰۳ (PerCom 2003)، فورت ورث، TX، ایالات متحده آمریکا، ۲۶ مارس ۲۰۰۳; صص ۱۴۳-۱۵۰٫ [ Google Scholar ]
- ژانگ، دبلیو. یو، ک. وانگ، دبلیو. Li, X. الگوریتم انتخاب AP خود تطبیقی بر اساس بهینه سازی چند هدفه برای موقعیت یابی وای فای داخلی. IEEE Internet Things J. ۲۰۲۱ ، ۸ ، ۱۴۰۶-۱۴۱۶٫ [ Google Scholar ] [ CrossRef ]
- چن، ی. یانگ، کیو. یین، جی. Chai، X. انتخاب نقطه دسترسی کم مصرف برای تخمین مکان داخلی. IEEE Trans. بدانید. مهندسی داده ۲۰۱۶ ، ۱۸ ، ۸۷۷-۸۸۸٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- او هست.؛ Chan, S. Tilejunction: کاهش نویز سیگنال برای محلی سازی داخلی بر اساس اثر انگشت. IEEE Trans. اوباش محاسبه کنید. ۲۰۱۶ ، ۱۵ ، ۱۵۵۴-۱۵۶۸٫ [ Google Scholar ] [ CrossRef ]
- لین، تی.-ن. Fang, S.-H.; Tseng، W.-H.; لی، سی.- دبلیو. هسیه، J.-W. انتخاب نقطه دسترسی مبتنی بر تبعیض گروهی برای محلی سازی اثر انگشت WLAN. IEEE Trans. وه تکنولوژی ۲۰۱۴ ، ۶۳ ، ۳۹۶۷-۳۹۷۶٫ [ Google Scholar ] [ CrossRef ]
- زو، اچ. جین، م. جیانگ، اچ. زی، ال. Spanos، CJ WinIPS: سیستم موقعیت یابی داخلی غیر نفوذی مبتنی بر WiFi با ساخت و انطباق نقشه رادیویی آنلاین. IEEE Trans. سیم. اشتراک. ۲۰۱۷ ، ۱۶ ، ۸۱۱۸-۸۱۳۰٫ [ Google Scholar ] [ CrossRef ]
- هوانگ، بی. خو، ز. جیا، بی. Mao, G. طرح بهروزرسانی نقشه رادیویی آنلاین برای محلیسازی مبتنی بر اثر انگشت WiFi. IEEE Internet Things J. ۲۰۱۹ ، ۶ ، ۶۹۰۹–۶۹۱۸٫ [ Google Scholar ] [ CrossRef ]
- وو، سی. یانگ، ز. Xiao, C. تطبیق نقشه رادیویی خودکار برای محلی سازی فضای داخلی با استفاده از تلفن های هوشمند. IEEE Trans. اوباش محاسبه کنید. ۲۰۱۸ ، ۱۷ ، ۵۱۷-۵۲۸٫ [ Google Scholar ] [ CrossRef ]
- گلادی، پ. کوالسکی، ب. رگرسیون حداقل مربعات جزئی: یک آموزش. مقعدی چیم. Acta ۱۹۸۶ ، ۱۸۵ ، ۱-۱۷٫ [ Google Scholar ] [ CrossRef ]
- کونتی، ا. درداری، د. گوئرا، م. موچی، ال. Win، MZ توصیف تجربی ناوبری تنوع. سیستم IEEE J. ۲۰۱۴ ، ۸ ، ۱۱۵-۱۲۴٫ [ Google Scholar ] [ CrossRef ]
- لیو، ز. دای، دبلیو. Win, M. Mercury: یک سیستم بدون زیرساخت برای محلی سازی و ناوبری شبکه. IEEE Trans. اوباش محاسبه کنید. ۲۰۱۸ ، ۱۷ ، ۱۱۱۹–۱۱۳۳٫ [ Google Scholar ] [ CrossRef ]
- رای، ا. چینتالاپودی، KK; Padmanabhan، VN; سن، R. Zee: جمع سپاری صفر تلاش برای محلی سازی داخلی. در مجموعه مقالات هجدهمین کنفرانس بین المللی سالانه ACM در محاسبات و شبکه موبایل، استانبول، ترکیه، ۲۲ تا ۲۶ اوت ۲۰۱۲٫ صص ۲۹۳-۳۰۴٫ [ Google Scholar ]
- سان، دبلیو. لیو، جی. وو، سی. یانگ، ز. ژانگ، ایکس. لیو، Y. MoLoc: در مورد تشخیص دوقلوهای اثر انگشت. در مجموعه مقالات سی و سومین کنفرانس بین المللی IEEE در مورد سیستم های محاسباتی توزیع شده، فیلادلفیا، PA، ایالات متحده آمریکا، ۸ تا ۱۱ ژوئیه ۲۰۱۳٫ ص ۲۲۶-۲۳۵٫ [ Google Scholar ]
- زو، ن. ژائو، اچ. فنگ، دبلیو. Wang, Z. رویکرد فیلتر ذرات جدید برای موقعیتیابی داخل ساختمان با ترکیب حسگرهای WiFi و اینرسی. چانه. جی. هوانورد. ۲۰۱۵ ، ۲۸ ، ۱۷۲۵-۱۷۳۴٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- یانگ، اس. دسای، پ. ورما، م. Gerla، M. FreeLoc: محلیسازی فضای داخلی جمعسپاری بدون کالیبراسیون. در مجموعه مقالات IEEE INFOCOM 2013، تورین، ایتالیا، ۱۴-۱۹ آوریل ۲۰۱۳٫ ص ۲۴۸۱-۲۴۸۹٫ [ Google Scholar ]
- شو، دبلیو. کیو، دبلیو. هوآ، ایکس. Yu, K. بهبود اندازه گیری RSSI Wi-Fi برای محلی سازی داخل ساختمان. IEEE Sens. J. ۲۰۱۷ ، ۱۷ ، ۲۲۲۴–۲۲۳۰٫ [ Google Scholar ] [ CrossRef ]
- Rappaport، TS Wireless Communications: Principles and Practice ; Prentice-Hall: Englewood Cliffs, NJ, USA, 1996; جلد ۲٫ [ Google Scholar ]
- تائو، ی. ژائو، ال. محلیسازی اثر انگشت با مرز دایرهای. IEEE Commun. Lett. ۲۰۲۱ ، ۲۵ ، ۲۹۲۸-۲۹۳۲٫ [ Google Scholar ] [ CrossRef ]