
خلاصه
برنامه ریزی و مدیریت مدرن فضاهای شهری یک موضوع ضروری برای شهرهای هوشمند است و به اطلاعات به روز و قابل اعتماد در مورد کاربری زمین و نقش های عملکردی مکان هایی که مناطق شهری را یکپارچه می کنند بستگی دارد. در چند سال گذشته، به دلیل افزایش دسترسی به دادههای ارجاعشده جغرافیایی از رسانههای اجتماعی، حسگرهای تعبیهشده، و تصاویر سنجش از راه دور، تکنیکهای مختلفی برای تجزیه و تحلیل کاربری زمین رایج شدهاند. در این مقاله، ابتدا انواع دادهها و روشهای متفاوتی که معمولاً در این زمینه اتخاذ میشوند، و همچنین اهداف آنها را برجسته و مورد بحث قرار میدهیم. سپس، بر اساس یک مطالعه سیستماتیک پیشرفته، ما بر کاوش پتانسیل نقاط مورد علاقه (POIs) برای طبقهبندی کاربری زمین، به عنوان یکی از رایجترین دستههای دادههای جمعسپاری متمرکز شدیم. ما یک برنامه کاربردی برای جمع آوری خودکار POI برای منطقه مورد مطالعه ایجاد کردیم، و مجموعه داده ای را ایجاد کردیم که برای تولید تعداد زیادی ویژگی استفاده شد. ما از یک تکنیک رتبهبندی برای انتخاب مناسبترین ویژگیها برای طبقهبندی کاربری زمین استفاده کردیم. به عنوان داده های حقیقت زمینی، ما از CORINE Land Cover (CLC) استفاده کردیم که یک مجموعه داده محکم و قابل اعتماد برای کل قلمرو اروپا در دسترس است. از یک شبکه عصبی مصنوعی (ANN) در سناریوهای مختلف استفاده شد و نتایج ما مقادیر بیش از ۹۰ درصد را برای دقت و امتیاز F در یک آزمایش انجامشده نشان میدهد. تحلیل ما نشان میدهد که دادههای POI پتانسیل امیدوارکنندهای برای توصیف فضاهای جغرافیایی دارند. هدف کار شرح داده شده در اینجا ارائه جایگزینی برای روش های فعلی برای طبقه بندی کاربری و پوشش زمین (LULC) است.
کلید واژه ها:
داده کاوی ; یادگیری ماشینی ؛ طبقه بندی کاربری زمین ; نقاط مورد علاقه ؛ شهرهای هوشمند
۱٫ معرفی
با توسعه اخیر و سریع شهرها، نگرانی های پایداری حوزه جدیدی را برای یک زمینه ضروری در مطالعات اخیر، یعنی رشد هوشمند، گشوده است. به طور کلی رشد هوشمند تلاشی است برای مدیریت بهتر منابع طبیعی از طریق کاهش و کنترل مصرف آنها [ ۱ ]. به همین دلیل، نیاز به برنامه ریزی کاربری اراضی شهری و مدیریت کارآمد مناطق شهری به وضوح اهمیت یافته است [ ۲ ]. این نقاط به طور مستقیم با طراحی و توسعه شهرهای هوشمند مرتبط هستند و به یک هدف مشترک که تلاش برای ایجاد کیفیت زندگی بالا برای مردم در دنیایی پایدارتر است، همگرا می شوند. با توجه به فضاهای شهری، تحلیل کاربری زمین به موضوعی ضروری در این زمینه تبدیل می شود.
در حال حاضر، فضاهای شهری نیز به دلیل مسائلی مانند گسترش شهری، کنترل ترافیک، رفاه، نظارت بر فعالیت جمعیت، پروژه های ساختمانی، حفظ محیط زیست، تجزیه و تحلیل خطرات و آلودگی و تجزیه و تحلیل اقتصادی، علاوه بر مراقبت های بهداشتی عمومی و سایر خدمات ضروری، مورد توجه قرار گرفته اند. که همگی مربوط به رشد هوشمند و شهرهای هوشمند است. کار در این موضوعات اغلب نیازمند طراحی و مدیریت نقشه های ریزدانه است [ ۲ ، ۳ ]. با این حال، با تغییر مناطق شهری، به روز نگه داشتن نقشه ها و اطلاعات مربوط به زیرساخت ها و مناطق عملکردی چالشی است که محققان و ادارات دولتی با توجه به پیچیدگی سیستم های شهری مدرن روزانه با آن مواجه هستند [۳، ۴ ] .].
در این زمینه، سه مفهوم اساسی وجود دارد که باید روی آنها تمرکز کرد، یعنی: (۱) کاربری زمین، (۲) پوشش زمین، و (۳) مناطق عملکردی. استفاده از زمین بسیار با نحوه استفاده مردم از زمین مرتبط است – به عنوان مثال، برای حفاظت، توسعه، یا استفاده مختلط [ ۵]. از نظر پوشش زمین، یک فضای معین را می توان به عنوان جنگل، کشاورزی، سطوح غیرقابل نفوذ، تالاب و حتی انواع آب طبقه بندی کرد که شامل آب های آزاد یا تالاب می شود. علاوه بر این، مفهوم مناطق عملکردی به فضاهایی اطلاق می شود که در آن فعالیت های انسانی رخ می دهد. همان منطقه عملکردی بسته به نوع کاربری زمین می تواند عملکردهای مختلفی را پشتیبانی کند. این انواع شامل کاربری مسکونی، تجاری یا صنعتی، تجاری و غیره است. علاوه بر این، از همان منطقه عملکردی می توان برای فعالیت های مختلف انسانی مانند زندگی، خرید، غذا خوردن و تفریح و غیره استفاده کرد [۶ ]]. برای تجزیه و تحلیل پوشش زمین (LC)، بسیاری از نویسندگان به طور کلی روش هایی را بر اساس تفسیر تصاویر سنجش از دور و استخراج اطلاعات از اشیاء تصویر، که اجزای صحنه یا موجودیت های معنادار در یک تصویر معین هستند، اتخاذ می کنند [۷] (به عنوان مثال، درخت، خانه ، پارکینگ ماشین یا وسیله نقلیه).
درک چگونگی استفاده و تعامل مردم با مناطق عملکردی و چگونگی تغییر این مناطق معمولاً برای تجزیه و تحلیل کاربری زمین ضروری شده است [ ۳ ، ۶ ، ۸ ]. از آنجایی که بیشتر محققان به جای مناطق عملکردی در مقیاس بزرگ بر روی اشیاء پوشش زمین تمرکز می کنند، نقشه های این نوع واحدهای شهری به طور گسترده در دسترس نیست. گذشته از اینکه یک منطقه کاربردی از نظر فضایی بزرگتر از یک شی است، اولی از نظر معنایی نیز با دومی متفاوت است. به عنوان مثال، در حالی که یک منطقه مسکونی یک منطقه کاربردی است، یک ساختمان متعلق به اشیاء پوشش زمین است. از آنجا که این دو نوع واحد در لایههای معنایی متفاوتی قرار دارند، روشهای مبتنی بر شیء سنتی نمیتوانند مناطق عملکردی را طبقهبندی کنند [ ۴]]. با این وجود، مطالعات زیادی بر اساس تصاویر سنجش از دور برای ارائه طبقهبندی مناطق شهری از طریق تجزیه و تحلیل مورفولوژیکی، استخراج ویژگیهای طیفی و بافتی برای نمایش اطلاعات برای یک منطقه معین وجود دارد [۹ ] . این رویکرد در سال های اخیر به طور قابل توجهی در حال تحول بوده است، زیرا به ما اجازه می دهد تا به نحوی اطلاعاتی در مورد پوشش زمین مربوط به مورفولوژی منطقه، با توجه به حضور، شکل، اندازه و حتی توزیع فضایی ساختمان ها، از جمله فضاهای باز [ ۱۰ ، ۱۱ ، ۱۲]. با این حال، رابطه بین مناظر شهری و نحوه استفاده مردم از آنها برای شناسایی مناطق عملکردی ضروری است، با توجه به اینکه الگوهای کاربری زمین نیز تحت تأثیر سبک زندگی داخلی و سایر عوامل نیز قرار دارند [ ۹ ، ۱۳ ]. از آنجایی که تصاویر سنجش از دور ویژگیهای معنایی سطح بالایی را ارائه نمیدهند، لازم است منابع داده دیگری را برای ارائه آنها جمع آوری کنیم.
استفاده از مدلهای سنجش از دور سنتی نیز طبقهبندی کاربری زمین با ویژگیهای موضوعی معمولی را دشوار میکند [ ۴ ]. با توجه به این نگرانی، بسیاری از نویسندگان استفاده از ترکیبی از انواع داده ها و روش های مختلف را پیشنهاد می کنند [ ۲ ، ۱۴ ]. علاوه بر این، با توسعه سریع فناوری در سالهای اخیر، روشهای متعددی بر اساس قابلیتهای جدید اضافه شده توسط پیشرفتها در سیستمهای اطلاعات جغرافیایی (GIS) و دادههای بزرگ جغرافیایی پدید آمده است [۱۳] .]. به عنوان پیشنهادی برای طبقهبندی بهتر مناظر شهری، برخی از نویسندگان استفاده از دادهها، مانند اطلاعات اجتماعی، ویژگیهای اجتماعی-اقتصادی، نقاط مورد علاقه (POI) یا دادههای شبکه اجتماعی مبتنی بر مکان (LSBN) را همراه با تصاویر سنجش از دور پیشنهاد کردهاند. ساخت مدل های قوی تر [ ۲ ، ۳ ، ۶ ، ۹ ].
هدف اصلی این مقاله ارائه رویکردی برای طبقهبندی کاربری زمین بر اساس ویژگیهای استخراجشده از POI، به عنوان یکی از رایجترین انواع دادههای جمعسپاری است. برای بایگانی کردن این هدف، ما یک نظرسنجی را برای جمعآوری مقالات مرتبط با خصوصیات فضاهای جغرافیایی انجام دادیم، که به ما امکان میدهد تا تحلیل سیستماتیک ارائه شده را انجام دهیم، که به عنوان پسزمینه برای توسعه رویکرد پیشنهادی ما استفاده میشود. علاوه بر این، ما روشی را برای جمعآوری خودکار دادههای ورودی به صورت رایگان، در یک منطقه بزرگ، و استفاده از مجموعه داده CORINE Land Cover (CLC) به عنوان حقیقت اصلی، که منبعی است که توسط جامعه اروپایی ایجاد شده است، از طریق یک روش سخت و زمانبر پیشنهاد میکنیم. روند. در آینده، ما معتقدیم که یک رویکرد خودکار مانند ما می تواند به طور خودکار ایجاد شود، یا حداقل به ایجاد آن کمک کند. علاوه بر این، به منظور بررسی پتانسیل دادههای POI برای شناسایی استفاده و پوشش فضاهای جغرافیایی، آزمایشهای مختلفی را انجام میدهیم و دقت بیش از ۹۰ درصد را در یکی از موارد بایگانی میکنیم. مجموعه دادههایی که استفاده میکنیم و همچنین کد منبع برنامهای که برای جمعآوری POI توسعه دادهایم، در دسترس عموم قرار گرفتهاند و میتوان آنها را از طریق پیوند موجود در دانلود کرد.بخش مواد تکمیلی
ساختار باقیمانده این مقاله به شرح زیر است: بخش ۲ یک توصیف پیشرفته، شامل تجزیه و تحلیل مقایسه ای داده ها و روش های مورد استفاده برای طبقه بندی کاربری اراضی را ارائه می دهد. بخش ۳ رویکردی را که ما برای توصیف مناطق جغرافیایی، از جمله جمعآوری و پیش پردازش دادهها پیشنهاد کردیم، توضیح میدهد. در بخش ۴ ، نتایجی را که از طریق کاری که انجام دادهایم بر اساس سناریوهای مختلفی که برنامهریزی کردهایم، ارائه و مورد بحث قرار میدهیم. در نهایت، در بخش ۵ ، نتیجهگیری و پیشنهادات خود را برای کار آینده ارائه میکنیم.
۲٫ وضعیت هنر
با توجه به اهمیت به روز بودن اطلاعات مربوط به LULC و مناطق عملکردی شهری، اخیراً تلاش های زیادی در این زمینه صورت گرفته است و محبوبیت انواع داده ها و روش های مختلف برای کشف دانش در زمینه تحلیل کاربری اراضی افزایش یافته است. در این بخش، رایجترین دستهبندی دادهها و متداولترین روشهای بهکار گرفته شده توسط نویسندگان در این موضوع را مورد بحث قرار میدهیم.
۲٫۱٫ داده ها
بسیاری از تکنیک ها را می توان برای تجزیه و تحلیل کاربری زمین، بر اساس انواع داده های مختلف استفاده کرد. یک وظیفه مهم برای محققان بهبود دقت نتایج حاصل از این تکنیک ها است. ادغام ویژگی های استخراج شده از انواع داده های مختلف، تا حدی می تواند نتایج بهتری را نشان دهد. در این بخش، انواع دادههای اصلی را که اغلب برای استخراج منطقه عملکردی شهری و طبقهبندی LULC استفاده میشوند، ارائه میکنیم. انواع داده های ارائه شده در این بخش فرعی حداقل در دو مطالعه در میان مجموعه آثاری که در طول بررسی ما مورد تجزیه و تحلیل قرار گرفتند، استفاده شد.
۲٫۱٫۱٫ تصاویر سنجش از راه دور
چندین روش، که برای به روز رسانی نقشه های LC استفاده می شود، بر اساس تفسیر عکس های هوایی و بررسی های میدانی است که زمان بر و دشوار است. با توجه به توسعه اخیر فناوری های سنجش از دور، تعداد زیادی از تصاویر سنجش از دور از طریق حسگرهای نصب شده در هواپیما یا ماهواره ها در دسترس هستند [ ۱۵ ]. علاوه بر این، تصاویر سنجش از دور در مجموعه داده های علمی وجود دارد که در برخی موارد توسط دانشگاه ها [ ۱۶ ]، مراکز تحقیقاتی [ ۳ ] و سازمان های دولتی [ ۱۷] ارائه شده است.]، در میان سایر سازمان ها. تصاویر سنجش از دور اغلب برای استخراج اطلاعات LC مفید هستند و در ترکیب با سایر انواع داده ها، عموماً امکان شناسایی قطعات زمین مورد استفاده برای اهداف مختلف (مثلاً مسکونی، تجاری یا صنعتی) را فراهم می کنند. این شناسایی معمولاً بر اساس خصوصیات فیزیکی اشیاء، با ویژگی های مختلف، مانند توزیع فضایی، رنگ، بافت، شکل و غیره است [ ۲ ، ۱۵ ].
برای تحلیل کاربری زمین و منطقه عملکردی، هنگام بحث در مورد تصاویر سنجش از دور، ویژگیهای معنایی سطح پایین را میتوان به عنوان اطلاعاتی که با دادهها همراه است، مانند ویژگیهای فیزیکی (مانند رنگ و بافت) توصیف کرد و ویژگیهای معنایی سطح بالا مستقیماً به هم مرتبط هستند. به “دانش” خاص برای هر کاربر و برنامه کاربردی [ ۲ ، ۴]. شکاف معنایی معمولاً به نابرابری ویژگی های شناسایی شده بین ویژگی های معنایی سطح پایین و سطح بالا اشاره دارد. استفاده از ویژگیهای معنایی سطح پایین احتمالاً دقت کمتری دارد زیرا اشیاء مختلف ممکن است ویژگیهای فیزیکی یکسانی داشته باشند و اشیاء یکسان ممکن است ویژگیهای متفاوتی داشته باشند. در طبقهبندی، افزودن ویژگیهای معنایی سطح بالا، ارجاع به ویژگیهای مختلف شی دادهشده توسط کاربر انسانی احتمالاً به نتایج بهتری دست خواهد یافت. به عنوان مثال، مجموعه ای از تصاویر سنجش از دور که در آن اشیاء پوشش زمین (به عنوان مثال، ساختمان ها) را می توان بر اساس یک توصیف سطح پایین تشخیص داد. در این مورد، اطلاعات سطح بالا ویژگی های خوبی را برای طبقه بندی مناطق عملکردی، مانند مناطق مسکونی، تجاری، یا صنعتی فراهم می کند [ ۲]]. افزودن ویژگی های معنایی سطح بالا توسط بسیاری از نویسندگان پیشنهاد شده است – به عنوان مثال، ژونگ و همکاران. [ ۱۸ ]، تا امکان دستیابی به نتایج بهتر برای طبقه بندی کاربری اراضی فراهم شود.
۲٫۱٫۲٫ داده های جمع سپاری شده
دادههای جمعسپاری بهطور داوطلبانه توسط کاربران، عمدتاً با استفاده از برنامههای کاربردی تلفن همراه، ایجاد میشوند تا دادههای مفیدی را برای دامنههای مختلف و انواع مختلف ارائه دهند، بهویژه زمانی که دادهها فرصتطلبانه هستند، بر اساس زمینه کاربر، مانند POI، دادههای رسانههای اجتماعی، مسیرهای تاکسی، تلفن همراه. استفاده، فعالیتهای ورود از شبکههای اجتماعی مبتنی بر مکان (LBSNs)، و حتی پیامهای متنی [ ۹ ، ۱۹ ]. در سرتاسر جهان، هر روز ۷۰۰۰ میلیون چک در Foursquare وجود دارد، ۵۰۰ میلیون توییت پست میشود و بیش از ۸۰ میلیون عکس در اینستاگرام آپلود میشود [ ۲۰]]. این منابع غنی و متنوع داده به طور بالقوه اطلاعاتی را در مورد فعالیت های انسانی و اطلاعات اجتماعی-اقتصادی ارائه می دهند که ایده اصلی بسیاری از مطالعات برای نشان دادن عملکردهای شهری بوده است [ ۹ ]. در میان دستههای مختلف دادههای جمعسپاری، بیشترین استفاده از آنها موارد زیر است:
نقاط مورد علاقه (POI)
عملکردهای شهری خاص توسط توزیع های فضایی و تعاملات انواع مختلف POI منعکس می شوند [ ۶ ]. برای انواع مختلف فعالیت ها (مانند کار، مطالعه، غذاخوری، خرید یا استراحت)، افراد معمولاً به POI های خاصی مراجعه می کنند. به همین دلیل، بسیاری از مطالعات علمی (به عنوان مثال، [ ۶ ، ۱۳ ، ۱۹ ، ۲۱ ، ۲۲ ]) بر استخراج ویژگی ها از POI متمرکز شده اند، که اغلب با تصاویر سنجش از دور ترکیب می شوند. POI ها را می توان از منابع مختلف جمع آوری کرد و اغلب به صورت رایگان از طریق رابط های برنامه نویسی برنامه های کاربردی شبکه های اجتماعی (API) و ارائه دهندگان خدمات نقشه آنلاین در دسترس هستند. برای مثال، گونگ و همکاران. [ ۱۱ ] و ژای و همکاران. [۱۹ ] از POIهای استخراج شده از طریق APIهای ارائه شده توسط Baidu Map Services استفاده کرد، در حالی که لیو و همکاران. [ ۲۲ ] آنها را از http://www.dianping.com ، یکی از بزرگترین شرکتهای آنلاین تا آفلاین چین، https://www.fang.com ، یکی از بزرگترین ارائهدهندگان خدمات اطلاعات خانه آنلاین در چین، و همچنین نقشههای Baidu به دست آورد.
پیام های متنی
دادههای جمعسپاری معمولاً حاوی مقادیر بسیار زیادی پیامهای متنی هستند که میتوانند برای تولید ویژگیهای اجتماعی-اقتصادی مورد سوء استفاده قرار گیرند [ ۹ ]. از جمله نمونههای رایج این نوع دادههای جمعسپاری، توییتها (یا پیامهای توییتر) هستند که در [ ۹ ، ۱۹ ، ۲۰ ، ۲۳ ، ۲۴ ] استفاده میشوند. علاوه بر این، سرویسهای دیگری نیز برای همین منظور مورد استفاده قرار میگیرند، مانند برنامه Sina Weibo [ ۲۳ ]، زیرا دارای ساختار کاربری متقارن توییتر است، که در آن کاربر میتواند بدون نیاز به ایجاد دوستی، شخص دیگری را دنبال کند. دسته دیگری از داده های متنی که می تواند در طبقه بندی کاربری زمین در نظر گرفته شود، برچسب های مرتبط با هر عکس در فلیکر [ ۸] است.]. به طور کلی، کاربران میتوانند مختصات جغرافیایی را به پیامها و عکسها متصل کنند، که تمرکز شبکههای اجتماعی مبتنی بر مکان (LSBN) است، که اغلب APIهای باز را برای دانلود رایگان این محتوا ارائه میدهند.
فعالیتهای ورود از LBSN
با در نظر گرفتن مکان فیزیکی کاربران، چندین LBSN آثاری از تعاملات اجتماعی ایجاد کرده اند. به طور کلی، در این شبکه های اجتماعی، کاربران می توانند در یک مکان بررسی کنند، به آن امتیاز دهند و نظرات یا نکات خود را به اشتراک بگذارند [ ۶ ]. برخی از نمونههای LBSN عبارتند از Gowalla، Foursquare و Facebook Places که با افزایش ابعاد این خدمات، به طور فزایندهای مورد سوء استفاده قرار میگیرند. فلیکر را نیز می توان در این دسته در نظر گرفت [ ۸ ]، زیرا یک عکس در یک مکان خاص شاهد حضور کاربر در آن زمان است. برخی از مطالعات (به عنوان مثال، در [ ۲۵ ]) جنبه های مکانی، زمانی، اجتماعی و متنی مرتبط با صدها میلیون فعالیت ورود کاربر محور را تجزیه و تحلیل کرده اند. دیگران (به عنوان مثال، در [ ۲۰]) فعالیت های ثبت نام LBSN را به عنوان یک عامل محبوبیت برای POI بررسی کرده اند. استفاده از چنین داده هایی توسط زینگ و همکاران تشویق شد. [ ۹ ] برای بهبود نتایج زمانی که دسته های دیگر داده ها اطلاعات مفیدی را ارائه نمی دهند.
۲٫۱٫۳٫ مجموعه داده های OpenStreetMap (OSM).
در مقایسه با منابع اختصاصی، برای بسیاری از مناطق توسعهیافته، مجموعه دادههای OSM تقریباً همیشه کامل هستند، طبق تحلیل اخیر در شبکههای خیابانی آنها [ ۲۶]]. مجموعه ای از رابط های کاربر پسند برای داوطلبان در دسترس است. این رابطها برخی از قابلیتهای ویرایش نقشه را ارائه میکنند که به کاربر اجازه میدهد نمایش هندسی ویژگیها یا مناطق مورد علاقه را بر اساس تصاویر سنجش از دور ارائه شده توسط طیف وسیعی از کتابخانههای تصویری موجود برای پروژههای مبتنی بر علم شهروندی مشخص کند. علاوه بر این، ویژگی های فردی را می توان به ویژگی های نقشه برداری شده اضافه کرد تا آنها را غنی کند. ایجاد این نوع خدمات به لطف فناوری دقیق مبتنی بر GPS موجود در دستگاه های تلفن همراه، پیشرفت هایی را در نقشه های دیجیتال ارائه کرده است که ممکن است تجربه نقشه جدید و کامل تری را ایجاد کند. در نتیجه، محتوای دیجیتال به طور قابل توجهی متنوع شده است و به لطف داوطلبان، اطلاعات فضایی بسیار بیشتری را به ارمغان می آورد. به دلیل تعداد زیاد کاربران، مجموعه های بسیار بزرگتری از محتوا و اطلاعات دیجیتال برای استفاده جامعه رایگان است. در این زمینه، OSM یک نمونه ایده آل از یک پروژه مشارکتی است. به عنوان مثال، مجموعه داده های آن توسط لیو و همکاران استفاده می شود. [۲ ] و ژانگ و همکاران. [ ۳ ] در مطالعات خود.
۲٫۱٫۴٫ مسیرهای تاکسی
فراتر از دسته بندی های ذکر شده داده ها، بسیاری از آثار نیز با مقداری فرکانس از مسیرهای تاکسی استفاده کرده اند [ ۲۲ ، ۲۷ ]. مسیرهای تاکسی می توانند به راحتی نقاط سوار و تحویل، طول سفر و زمان هر سفر را ارائه دهند. با این حال، این نقاط اغلب نشان دهنده مکان های دقیقی نیستند که کاربران در آن فعالیت های خود را انجام می دهند [ ۲۸]. در بیشتر موارد، مسافران از تاکسی خود بسیار دور از مقصد نهایی خارج می شوند. علاوه بر این، از آنجایی که اطلاعات ارائه شده توسط مسیرهای تاکسی حاوی نشانه دقیقی از اهداف مسافر برای فعالیت هایشان نیست، پرداختن به این نوع اطلاعات چالش برانگیز است. این دلیل اصلی است که چرا دادههای مسیر تاکسی معمولاً با انواع دادههای دیگر (مثلاً بلوکهای ساختمان یا اطلاعات کاربر LBSN) ترکیب میشوند تا نتایج بهتری ارائه دهند.
۲٫۱٫۵٫ بلوک های ساختمان
بلوکهای ساختمانی اغلب بهعنوان «بلوکهای خیابانی» شناخته میشوند، و اگرچه برای مثال، مقولهای متفاوت از مسیرهای تاکسی را نشان میدهند، اغلب به عنوان اطلاعات تکمیلی در بسیاری از مطالعات استفاده میشوند. اطلاعات بلوک های ساختمانی معمولاً توسط ادارات محلی [ ۱۴ ] ارائه می شود، اما استخراج این نوع داده ها از تصاویر سنجش از راه دور امکان پذیر است. این تکنیک برای مثال توسط لیو و همکاران استفاده شد. [ ۲۲ ]، و بلوکهای ساختمانی بهدستآمده با سوابق شبکههای اجتماعی، مسیرهای تاکسی و POI برای مشخص کردن ساختمانهای با کاربری مختلط ترکیب شدند. کار دیگری که توسط هوانگ و همکاران انجام شده است. [ ۱۵ ]، همچنین از بلوک های ساختمانی همراه با تصاویر سنجش از دور برای نقشه برداری کاربری زمین شهری استفاده کرد.
۲٫۲٫ مواد و روش ها
با پیشرفت در منابع محاسباتی، در دسترس بودن داده های جغرافیایی مرجع و ابزارهای مدرن ارائه شده توسط برنامه های GIS، تکنیک های مختلف برای تجزیه و تحلیل کاربری زمین محبوب شده اند. در این بخش، رایجترین روشهایی که اغلب در این زمینه اتخاذ میشوند را برجسته میکنیم. روشهای تحت پوشش این بخش فرعی حداقل در دو مطالعه علمی در میان مجموعهای از آثار مورد تجزیه و تحلیل در نظرسنجی ما استفاده شدهاند.
۲٫۲٫۱٫ طبقه بندی شی گرا (OOC)
اصطلاحاتی مانند “شی گرا” و “شی خاص” به عنوان تجزیه و تحلیل تصویر مبتنی بر شی (OBIA) نیز نامیده می شود. این حوزه علمی پس از اولین نرم افزار تجاری که به طور خاص برای طراحی و تجزیه و تحلیل «اشیاء تصویری» به جای پیکسل های منفرد، بر اساس تصاویر سنجش از دور طراحی شده بود، پدیدار شد [۷] .]. با این مفاهیم، اجزای صحنه یا موجودیت ها اشیاء قابل تشخیص در یک تصویر مشخص هستند (به عنوان مثال، یک درخت، خانه، یا وسیله نقلیه). با استفاده از یک رویکرد شی گرا، طبق تعریف کاربر خاص، تصاویر مبتنی بر پیکسل به اشیا تقسیم می شوند. در هر شیء تصویر، همگنی تعریف شده توسط کاربر در طول فرآیند تقسیم بندی به دست می آید. برای جلوگیری از رشد زیاد ناهمگونی ایجاد شده توسط کاربر، یک جفت شیء مجاور در هر مرحله از فرآیند ادغام می شوند. اگر رشد کوچکتر از پارامتر مقیاس [ ۱۰ ] تجاوز کند، فرآیند قطع می شود . در حال حاضر، این یکی از محبوب ترین روش ها برای استخراج الگوهای کاربری زمین از طریق ویژگی های فیزیکی اشیاء زمین از تصاویر است [ ۱۳ ].]. اگرچه بسیاری از مطالعات از این روش استفاده کردهاند، طبقهبندی شیگرا فقط میتواند اطلاعات پوشش زمین را بر اساس ویژگیهای معنایی سطح پایین نشان دهد، جایی که روابط فضایی بین اشیاء زمینی در نظر گرفته نمیشود.
۲٫۲٫۲٫ تخصیص دیریکله نهفته (LDA)
هنگام تجزیه و تحلیل توصیفات متنی فراوان برای کشف ویژگیهای موضوعی و ساختارهای مربوط به آنها، تعداد زیادی از مطالعات از مدلهای موضوع احتمالی استفاده کردند و در میان آنها، رایجترین آنها LDA [ ۶ ] بود. یک مدل LDA اغلب برای استخراج اطلاعات اجتماعی-اقتصادی از دادههای جمعسپاری استفاده میشود و توصیفهای صریحی از فعالیتهای انسانی ارائه میکند، مانند آنچه که توسط Xing و همکارانش اجرا شده است. [ ۹ ]. علاوه بر این، از آن برای استخراج موضوعات از توضیحات متنی عکسهای فلیکر به منظور ایجاد ویژگیهایی برای مدل طبقهبندی کاربری زمین استفاده شده است [ ۸]]. LDA یک مدل بدون نظارت است که به روش مولد و احتمالی کار می کند و یک رویکرد کیسه ای از کلمات را پیاده سازی می کند، به این معنی که ترتیب کلمات در سند قابل اجرا نیست. در LDA، ایده اصلی این است که اسناد را به عنوان احتمال توزیع شده موضوعات پنهان نشان دهیم، که در آن هر موضوع توزیعی از کلمات است. برای ساده کردن مفهوم، مدل موضوع احتمالی، از جمله LDA، می تواند به طور کلی به عنوان “ترکیبی تصادفی از موضوعات” توصیف شود [ ۱۸ ].
۲٫۲٫۳٫ K-Means
در میان بسیاری از الگوریتم های خوشه بندی، K-means یکی از رایج ترین الگوریتم ها در داده کاوی است [ ۱۸ ]. بهعنوان یک نوع یادگیری بدون نظارت، خوشهبندی K-means برای دادههای بدون برچسب استفاده میشود – یعنی زمانی که دستهها تعریف نشده باشند. این الگوریتم با مکان یابی گروه ها در داده ها با استفاده از پارامتر k که تعداد گروه ها را نشان می دهد کار می کند. فرآیند خوشهبندی تکراری است و در هر تکرار، نقاط داده بر اساس ویژگیهایشان به یکی از گروههای k اختصاص داده میشوند. یک مثال از کاربرد K-means توسط Trevino [ ۲۹ ] ارائه شده است، که در آن شباهت ویژگی برای خوشه بندی نقاط داده استفاده می شود. علاوه بر این، تکنیک های خوشه بندی با موفقیت توسط بسیاری از نویسندگان برای پیشنهادات مختلف، مانند تعریف مناطق یا مناطق [ ۳۰] به کار گرفته شده است.]، طبقه بندی ویژگی های استخراج شده از داده های رسانه های اجتماعی [ ۲ ]، تجزیه و تحلیل همبستگی بین نقاط مورد علاقه و مناطق [ ۱۳ ]، و جمع آوری مناطق رسمی مشابه از نظر توزیع موضوع منطقه [ ۲۱ ].
۲٫۲٫۴٫ شناخت معنایی سلسله مراتبی (HSC)
HSC یک روش بیزی از پایین به بالا با ساختار سلسله مراتبی است که برای طبقه بندی مناطق عملکردی شهری استفاده می شود [ ۴ ، ۱۴]]. از چهار سطح معنایی تشکیل شده است: مناطق عملکردی، الگوهای اشیاء فضایی، دسته بندی اشیاء، و ویژگی های بصری. در این مدل با استفاده از احتمالات شرطی، هر سطح رابطه بین دو لایه معنایی را مشخص می کند. بنابراین، سطح اول می تواند برای مثال، رابطه بین مناطق عملکردی و الگوهای اشیاء فضایی را مدل کند. به طور معمول، اشیاء مختلف به طور کلی دارای توزیعهای متفاوتی از ویژگیهای بصری در یک الگوی شی فضایی مشابه هستند، در حالی که در یک نوع شیء مشابه، الگوهای متفاوتی از اشیاء فضایی ممکن است وجود داشته باشد و تفاوتهای کوچکی در رابطه با توزیع ویژگیهای بصری آنها داشته باشد. HSC برای طبقه بندی LULC و منطقه عملکردی با استفاده از داده هایی مانند تصاویر سنجش از راه دور، POI ها و بلوک های جاده استفاده می شود.
۲٫۲٫۵٫ جنگل تصادفی (RF)
RF یک الگوریتم یادگیری مجموعه کیسهای است که با ساختن درختهای تصمیمگیری چندگانه کار میکند، جایی که هر یک بر اساس یک نمونه فرعی تصادفی از مجموعه داده آموزشی [ ۳ ] است. این مدل نتایج خود را بر اساس کلاسی که بیشترین درخت رای داده است ارائه می دهد. به عنوان یک روش مجموعه مبتنی بر درخت، این طبقهبندیکننده میتواند دقت بالاتری نسبت به درختهای تصمیم منفرد، مانند درختهای طبقهبندی و رگرسیون (CART) یا C4.5 ارائه دهد. علاوه بر این، در بسیاری از موارد، بدون نیاز به تنظیم پارامترهای متعدد، RF بر مدل های محبوب مانند ماشین های بردار پشتیبانی غلبه می کند. در این زمینه، RF به خوبی در ادبیات تثبیت شده است و به طور گسترده برای طبقه بندی کاربری زمین و منطقه عملکردی استفاده می شود [ ۴ ، ۸ ، ۱۹ ].
۲٫۲٫۶٫ ماشین بردار پشتیبانی (SVM)
بهطور کلی، ماشینهای بردار پشتیبان را میتوان به عنوان یک روش یادگیری تحت نظارت توصیف کرد که به عنوان یک طبقهبندی متمایز کار میکند. این روش یک ابر صفحه یا مجموعهای از ابرصفحهها ایجاد میکند که امکان طبقهبندی ورودیها را در فضایی با ابعاد بالا با جدا کردن آنها فراهم میکند. الگوریتم بر اساس داده های آموزشی، یک ابر صفحه بهینه را خروجی می دهد. این ابر صفحه یک فضای N بعدی است که در آن “N” تعداد ویژگی های مورد استفاده برای آموزش است. به عنوان مثال، یک ابر صفحه ایجاد شده برای یک فضای دو بعدی، خطی است که آن را به دو قسمت مختلف تقسیم می کند [ ۳۱ ]. این مدلی مبتنی بر اصل به حداقل رساندن ریسک ساختاری است [ ۳۲]. این روش، به عنوان مثال، به عنوان یک طبقه بندی در طبقه بندی صحنه، برای پیش بینی برچسب صحنه استفاده می شود. ایده اصلی این تکنیک آموزش یک طبقهبندی کننده یادگیری خطی در فضای هسته با در نظر گرفتن تعمیم و بهینهسازی عملکرد است که منجر به غلبه بر مشکل طبقهبندی الگو میشود [ ۱۸ ]. SVM برای مثال توسط لیو و همکاران انتخاب شد. [ ۲ ] برای شناسایی انواع کاربری اراضی شهری. نویسندگان SVM را اتخاذ کردند زیرا در مطالعات قبلی پیشنهاد شده بود (به عنوان مثال، در [ ۳۳ ، ۳۴ ]) که، هنگام کار با ویژگی های با ابعاد بالا، این روش دارای سطح کارایی بالایی به عنوان یک طبقه بندی است.
۲٫۲٫۷٫ شبکه عصبی پیچیده عمیق (DCNN)
یک رویکرد رایج برای طبقهبندی LULC استفاده از روشهایی در هر فیلد برای استخراج یا طبقهبندی مستقیم ویژگیهای سطح پایین ویژگیهای فیزیکی تصاویر است. این روشها میتوانند مزایایی نسبت به روشهای مبتنی بر هر پیکسل یا شی اضافه کنند. با این حال، تکنیکهای طبقهبندی پوشش زمین و مبتنی بر شیء مبتنی بر هر پیکسل و تکنیکهای طبقهبندی پوشش زمین بر اساس توصیفگرهای دستی ویژگی و معماریهای کم عمق هستند و نمیتوانند با تصاویر پیچیده کاربری زمین برای ثبت ویژگیهای خوب کار کنند [۱۵ ]]. از آنجایی که این تصاویر برای تعمیم استفاده می شوند، هیچ یک از این روش ها به سطح دقتی که عموماً برای کاربردهای عملی لازم است، نمی رسد. کاربری زمین را می توان در سطوح مختلفی در طرح LULC توصیف کرد، از جمله شدت پیکسل ها، لبه ها، اشیاء، بخش هایی از اشیاء و قطعات زمین. معماری های عمیق می توانند به طور موثر همه این سطوح را نشان دهند. از طریق یک فرآیند یادگیری عمیق، گروهی از الگوریتمهای یادگیری ماشین با به کارگیری معماریهای عمیق، که ترکیبی از تبدیلهای غیرخطی متعدد هستند، قصد مدلسازی انتزاعات سطح بالا را دارند. مدلهای یادگیری عمیق یک رویکرد بسیار امیدوارکننده برای رسیدگی به مشکلات طبقهبندی LULC شهری هستند، زیرا میتوانند نمایشهای سلسله مراتبی ویژگیهایی را که طرحهای LULC شهری را توصیف میکنند، مدل کنند.۳۵ ]. در میان بسیاری از روشهای یادگیری عمیق، تکنیک DCNN به سطح بالایی از عملکرد در طبقهبندی کاربری زمین، بر اساس تصاویر سنجش از دور دست یافته است.
۲٫۳٫ تحلیل مقایسه ای
با توجه به اطلاعات ارائه شده در جدول ۱ ، POIها از رایج ترین انواع داده های جمع سپاری هستند که در مطالعاتی که ما تجزیه و تحلیل کردیم مشاهده شده است. بسیاری از نویسندگان آنها را اتخاذ میکنند، عمدتاً به دلیل ارتباط مستقیمی که با رفتار انسانی دارند، که تا حدودی امکان آشکار کردن روشهای استفاده افراد از فضاها را فراهم میکند. علاوه بر این، POI ها اغلب با فعالیت های کاربر LBSN مرتبط هستند، و به همین دلیل، این دو نوع داده اغلب برای طبقه بندی کاربری زمین ترکیب می شوند [ ۲ ، ۳]]. با مشاهده جدول، همچنین می توان به استفاده از انواع مختلف داده های جمع سپاری تولید شده توسط داوطلبان در کارهای روزمره آنها اشاره کرد. در بسیاری از کشورها، دادههای جمعسپاری شده بهطور گسترده در دسترس هستند، و استفاده از آنها را در مواردی تشویق میکنند که سایر مجموعههای داده (مانند دادههای برنامهریزی شهری یا دادههای GPS) در دسترس نیستند.
با توجه به روشها، به دلیل عدم وجود دادههای صحت زمین برای اعتبارسنجی نتایج، بسیاری از محققین از تکنیکهای بدون نظارت استفاده میکنند که در میان آنها روشهای خوشهبندی، از جمله خوشهبندی طیفی و K-نزدیکترین همسایه (KNN) رایج هستند. با این حال، با توجه به مطالعاتی که ما تحلیل کردیم، متداولترین تکنیک در این دسته K-means است، با توجه به سادگی و کارایی آن برای کارهایی مانند گروهبندی POI، مناطق عملکردی یا فضاهای جغرافیایی. برخی از نمونههای آثاری که در آنها از K-means استفاده شده است عبارتند از [ ۲ ، ۱۶ ]. در [ ۲ ]، نویسندگان به این نتیجه رسیدند که استفاده از این روش همراه با روش های دیگر منجر به نتایج رضایت بخشی برای طبقه بندی کاربری اراضی می شود.
در طول بررسی خود، موارد مختلفی را مشاهده کردیم که در آن دادههای حقیقت پایه در دسترس بود، که نویسندگان را به سمت اتخاذ تکنیکهای نظارت شده سوق داد. در میان تکنیکهای تحت نظارت، RF یکی از رایجترین تکنیکها بود، با توجه به اثربخشی آن بهعنوان یک طبقهبندی، با در نظر گرفتن تعادل بین مصرف منابع و عملکرد برای موضوعاتی مانند طبقهبندی کاربری زمین و مناطق عملکردی. با این حال، دلایل دیگری وجود دارد که چرا RF اغلب انتخاب می شود، به عنوان مثال، در [ ۴ ، ۳۶ ]. با در نظر گرفتن مورد خاص مورد دوم، نویسندگان ذکر کردند که آنها این الگوریتم را اتخاذ کردند زیرا آن را به عنوان یک روش مقیاس پذیر و قدرتمند برای مقابله با مجموعه داده های حاوی تعداد زیادی ویژگی می دیدند.
به طور کلی روش های مختلفی مشاهده شد. همانطور که در جدول ۱ می بینیم ، تکنیک های مورد استفاده شامل بیز ساده (NB)، ماشین های یادگیری افراطی (EML)، Word2Vec، تجزیه مبتنی بر اسکلت، تقسیم بندی چند وضوح، Place2Vec، یادگیری عمیق مشترک (JDL) و بسیاری دیگر است. اگرچه مواردی وجود دارد که روش های مختلفی برای اهداف مشابه انتخاب شده است، مجموعه داده های مورد استفاده اغلب متفاوت بوده و مقایسه نتایج و نتیجه گیری ها را دشوار می کند.
۳٫ رویکرد پیشنهادی
با توجه به تحقیقات قبلی ما، همانطور که در مطالعه پیشرفته ارائه شد، بسیاری از رویکردهای مختلف برای طبقه بندی کاربری اراضی مشاهده شد. در حالی که بسیاری از آنها بر اساس تفسیر تصویر هستند، یک نگرانی بزرگ از این به دلیل هزینه های مربوطه ناشی می شود. علاوه بر زمانبر بودن این تکنیکها، گران هستند. اگرچه برخی از دانشمندان از داده های جمع سپاری در تحلیل های خود استفاده کرده اند، استفاده از این نوع داده ها معمولاً به عنوان مکملی برای تکنیک های تفسیر تصویر به کار گرفته می شود. با توجه به این نگرانی، ما رویکردی را بر اساس تنها دادههای POI آزمایش کردیم. به عنوان حقیقت اصلی، ما از یک مجموعه داده LULC در دسترس برای کل قلمرو اروپا استفاده کردیم.
۳٫۱٫ منطقه مطالعه
برای این مورد مطالعه، منطقه شهری لیسبون (LMA) انتخاب شد. LMA منطقه ای در پرتغال است که مرکز آن لیسبون، پایتخت و بزرگترین شهر این کشور است. LMA در ۳۰۱۵ کیلومتر مربع پراکنده است و حدود ۲٫۸ میلیون نفر جمعیت دارد که ۲۷ درصد از جمعیت پرتغال را تشکیل می دهد. تراکم جمعیت در این منطقه تقریباً ۹۳۲ اینچ در هر کیلومتر مربع است که بالاترین میزان در کشور است که حدود هشت برابر بیشتر از میانگین کشوری است. با پوشش ۱۸ شهرداری، همچنین بزرگترین منطقه شهری در کشور (دهمین منطقه بزرگ در اتحادیه اروپا) است.
۳٫۲٫ استخراج POI
همانطور که توسط سایر نویسندگان ذکر شده است، POI ها به صورت رایگان و به طور گسترده به صورت آنلاین در دسترس هستند، یا از طریق API ها یا خدمات دانلودی که توسط جوامع داده جمع آوری شده تامین می شوند. همچنین امکان دریافت داده های POI از LBSN وجود دارد. یک مثال، سرویسی است که توسط Facebook API ارائه میشود، که در آن میتوان جستجو را با توجه به مختصات مرکز و شعاع انجام داد. این شبکه اجتماعی گزینههای مختلفی از کیتهای توسعه نرمافزار (SDK) را برای تسهیل توسعه برنامههایی که میتوانند با سرویسهای API برای دریافت دادهها تعامل داشته باشند، فراهم میکند. کاربران می توانند حساب های خود را به عنوان توسعه دهندگان ثبت کنند و به آنها اجازه می دهد این نوع برنامه ها را ایجاد کنند.
برای این مطالعه، ما استفاده از دادههای POI موجود از مکانهای Facebook را انتخاب کردیم. هنگامی که یک شرکت صفحه ای در فیس بوک ایجاد می کند، LBSN به آن اجازه می دهد مختصاتی را اضافه کند که نشان دهنده موقعیت جغرافیایی آن است. اگر چنین مکانی اضافه شود، صفحه به عنوان یک POI با نام Facebook Place در دسترس خواهد بود. این نوع از POI از طریق یک سرویس API ارائه شده توسط شبکه اجتماعی نیز قابل دسترسی هستند.
برای دریافت خودکار داده های POI موجود در Facebook Places، نرم افزاری را توسعه دادیم. برای استفاده از API فیس بوک، ابتدا لازم بود مختصاتی را که در حین جستجو استفاده می شود، تعریف کنیم. نرم افزاری که ما توسعه دادیم برای محاسبه این نقاط با در نظر گرفتن چهار مختصات داده شده توسط کاربر استفاده شد که نشان دهنده حدود یک مستطیل پیش بینی شده بر روی منطقه ای است که جستجو انجام شده است. در مورد خاص LMA، جعبه مرزی اتخاذ شده از مختصات زیر تشکیل شده است:
-
شمال:
- ○
-
غرب: ۳۹٫۰۶۴۷۱۸۳۸, −۹٫۵۰۰۵۲۶۶۱
- ○
-
شرق: ۳۹٫۰۶۴۷۱۸۳۸, −۸٫۴۹۰۹۷۲۱۳
-
جنوب:
- ○
-
غرب: ۳۸٫۴۰۹۰۷۴۴۲، −۹٫۵۰۰۵۲۶۶۱
- ○
-
شرق: ۳۸٫۴۰۹۰۷۴۴۲, −۸٫۴۹۰۹۷۲۱۳
پس از ایجاد مجموعه مختصات، نقاط خارج از محدوده جغرافیایی منطقه مورد مطالعه را دور انداختیم. این را می توان با استفاده از یک GIS یا یک پایگاه داده مکانی انجام داد. با این حال، همانطور که در شکل ۱ نشان داده شده است، با توجه به محدودیت های این نوع جستجو، مختصات نیاز به رعایت فاصله از پیش تعریف شده دارند که منجر به مشکل همپوشانی شعاع ها می شود. در عمل، این بدان معنی است که در طول جستجو، همان POI می تواند در نتیجه درخواست های مختلف بازگردانده شود. ما این مشکل را با فیلتر کردن مجموعه داده نهایی با استفاده از شناسه منحصربفرد ارائه شده توسط Facebook برای هر POI حل کردیم.
نرم افزار ما مختصات تولید شده را در جدول پایگاه داده ذخیره می کند. شکل ۲ مراحل مربوط به فیلتر کردن این نقاط را نشان می دهد تا آنها را برای پردازش آماده کند. در ابتدا، مجموعه مختصات تولید شده با توجه به چهار پارامتر ارائه شده توسط کاربر، کل منطقه را پوشش می دهد. این را می توان در هنگام ایجاد یک لایه در نرم افزار GIS با استفاده از این نقاط مشاهده کرد. در این مطالعه، ما یک پرس و جوی ویژه را مستقیماً در پایگاه داده، بر اساس یک چند ضلعی ذخیره شده در یک جدول انجام دادیم که حاوی اطلاعات مربوط به محدوده جغرافیایی منطقه مورد مطالعه است. در نتیجه فقط امتیازات در محدوده حفظ شدند. اگرچه ما تصمیم گرفتیم که داده ها را مستقیماً با SQL دستکاری کنیم، اما ممکن است با انجام یک تقاطع از طریق یک برنامه GIS به راحتی به همین هدف دست پیدا کنیم.
پس از تولید مختصات جغرافیایی، برنامه توسعهیافته آنها را با جستجو از طریق سرویسی به نام «API جستجوی مکانها برای وب» پردازش کرد [ ۴۳ ، ۴۴]، ارائه شده توسط فیس بوک، برای جمع آوری داده ها. برای هر مختصات، Facebook API همه POI ها را در شعاع داده شده برگرداند. پس از بازگشت، داده های POI به دست آمده در یک جدول پایگاه داده ذخیره شدند. از آنجایی که هر درخواست چند ثانیه طول می کشد، زمان لازم برای جمع آوری داده ها به اندازه منطقه و در نتیجه تعداد مختصاتی که باید پردازش شوند بستگی دارد. پس از اتمام، لازم است مجموعه داده نهایی فیلتر شود تا POI های مکرر حذف شوند. یک بار دیگر، در این مورد، این کار با دستکاری جدول به طور مستقیم در پایگاه داده انجام شد. برای حل این مشکل خاص، ما فکر می کنیم با توجه به سادگی و کارایی آن، این بهترین رویکرد است.
داده های مورد استفاده در این کار در محدوده پروژه دیگری جمع آوری شد و به همین دلیل ابتدا برای کل کشور به دست آمد. با این حال، همانطور که قبلا توضیح داده شد، در تجربه ای که در اینجا ارائه می کنیم، تمرکز ما LMA بود. با استفاده از نرم افزاری که توسعه دادیم، ۱۷۱۱۷۷ POI توزیع شده در امتداد قاره پرتغال جمع آوری کردیم که از این تعداد ۱۷۷۷۷ در LMA قرار داشتند. با توجه به اینکه هر POI می تواند به بیش از یک دسته تعلق داشته باشد، مجموعه داده جمع آوری شده در مجموع ۲۴۱۴۴ نمونه را در منطقه مورد مطالعه ارائه می دهد که برای استخراج ویژگی ها برای آموزش مدل ها استفاده شده است.
آخرین مرحله در فرآیند جمع آوری POI، دریافت طبقه بندی مکان های فیس بوک است. ما این کار را از طریق API انجام دادیم، زیرا ساده و سریع بود. اگرچه هر POI جمعآوریشده دارای یک ویژگی است که حاوی فهرستی از همه دستههایی است که به آنها تعلق دارد، برخی عملیات باید انجام شود تا آن را به طبقهبندی بهدستآمده جداگانه پیوند دهیم. ما برخی دستکاری ها را با استفاده از SQL به منظور ایجاد این اتصالات انجام دادیم. این مرحله اختیاری است. با این حال، به شدت توصیه میشود زیرا فهرست دستههایی که با هر POI بازگردانده میشوند به خودی خود ساختار سلسله مراتبی ندارند، و به همین دلیل، زمانی که این طبقهبندی ناشناخته باشد، نتیجه تحلیل نهایی ممکن است چندان ارزشمند نباشد.
۳٫۳٫ داده های حقیقت پایه
پوشش زمین CORINE (CLC) [ ۴۵ ، ۴۶ ] اساساً مجموعه داده ای است که استفاده و پوشش مناطق جغرافیایی در اروپا را نشان می دهد. این به عنوان ابتکار آژانس محیط زیست اروپا، در مشارکت با کشورهای عضو ایجاد شد. به عنوان یک کارتوگرافی موضوعی، دادههای CLC عمدتاً با تفسیر تصویر، اغلب با استفاده از راهحلهای خودکار یا نیمه خودکار موجود در برنامههای GIS تولید میشوند. مجموعه داده را می توان در قالب شطرنجی یا برداری با حداقل واحد نقشه برداری (MMU) 25 هکتار (هکتار) برای پدیده های منطقه و حداقل عرض ۱۰۰ متر برای پدیده های خطی بارگیری کرد. با توجه به نامگذاری رسمی آن [ ۴۷]، داده های CLC در ۴۴ کلاس در سه سطح سلسله مراتبی تقسیم می شوند. برای اولین بار در سال ۱۹۹۰ منتشر شد و در سال های ۲۰۰۰، ۲۰۰۶، ۲۰۱۲ و ۲۰۱۸ به روز شد. برای تجزیه و تحلیل خود، ما از آخرین نسخه در قالب داده های برداری استفاده کردیم.
آماده سازی داده ها
ما یک روش مبتنی بر شبکه [ ۴۸ ] را برای نشان دادن قطعات زمین برای طبقه بندی اتخاذ کردیم. این روش شامل ایجاد سلول هایی است که به طور یکنواخت در منطقه مورد مطالعه توزیع شده اند. با استفاده از یک برنامه GIS، شبکه ای که در آن هر سلول ۲۵۰ متر طول و ۲۵۰ متر عرض دارد، به طور خودکار ساخته شد، همانطور که در شکل ۳ نشان داده شده است . هنگام ایجاد، شبکه یک مربع است که توسط چند ضلعی با اندازه انتخاب شده تشکیل شده است. برای اینکه فقط سلول ها در داخل منطقه مورد مطالعه باقی بمانند، عملیات تقاطع را انجام دادیم. شبکه به دست آمده در یک جدول پایگاه داده ذخیره شد. برای هر سلول، یک ویژگی فضایی که نشان دهنده مرکز آن است گنجانده شده است. این ویژگی هنگام ایجاد ویژگیها برای آموزش مدل پیشبینی ضروری است.
پس از ایجاد شبکه، کلاس LULC را برای هر سلول بر اساس داده های CORINE استخراج کردیم. فرض بر این بود که در هر قطعه زمین فقط یک طبقه وجود دارد. به عنوان مثال، اگر در یک سلول معین ۲۰٪ زمین تحت پوشش کلاس “۱۱۱” وجود داشته باشد. بافت شهری پیوسته» و در ۸۰ درصد باقیمانده، طبقه غالب «۱۱۲٫ بافت شهری ناپیوسته» را در نظر می گیریم که بیشتر فضا را نشان می دهد – یعنی آخرین. با این حال، قبل از استخراج کلاس غالب برای هر سلول، ساختار کلاس داده را سازماندهی کردیم، دو سطح را حفظ کردیم و امکان طبقهبندی آسان واحدها را بعداً فراهم کردیم. جدول ۲ساختار کلاس جدید را نشان می دهد. این عملیات با استفاده از ابزار “انحلال” موجود در تقریباً هر برنامه مدرن GIS انجام شد که امکان ادغام چند ضلعی ها از داده های برداری را فراهم می کند.
با توجه به ۱۵ کلاس به دست آمده از فرآیند سازماندهی مجدد که اعمال کردیم، پس از آماده سازی شبکه، ۸۱۲۳۸ سلول برای منطقه مورد مطالعه به دست آوردیم. هر سلول برای استخراج ویژگی ها در دسترس است تا به عنوان داده های آموزشی برای مدل ها استفاده شود. تعداد دقیق نمونه های مورد استفاده در هر سناریو در بخش ۴ توضیح داده شده است .
۳٫۴٫ استخراج ویژگی
ما چهار نوع مشخص از ویژگیها را بر اساس دستههای POI جمعآوریشده و سطوح مربوط به آنها استخراج کردیم که در طبقهبندی مکانهای فیسبوک از ۱ تا ۶ متغیر است [ ۴۹ ]. از طریق یک تحلیل اکتشافی، ما تصمیم گرفتیم بر روی تمام دستههای متعلق به سطوح ۲، ۳، ۴ و ۵ تمرکز کنیم، با توجه به اینکه سطح ۱ بسیار عمومی و سطح ۶ بسیار خاص است و فقط دستههای خدمات رستوران را ارائه میکند. جدول ۳ گروه های ویژگی استخراج شده را نشان می دهد.
به عنوان فاصله شعاع بهینه، ما ۲۵۰۰، ۵۰۰۰ و ۱۰۰۰۰ متر را مورد تجزیه و تحلیل قرار دادیم، جایی که آخرین مورد نشان داد که قادر به تولید بهترین مدل ها است. برای یافتن نسبت POI، این با محاسبه زیر برای هر دسته محاسبه شد: مقدار نقاط داخل شعاع، تقسیم بر مجموع POI های متعلق به دسته. با در نظر گرفتن تمام مجموعه ویژگی ها، برای همه سطوح، در مجموع ۵۹۲۸ ویژگی استخراج کردیم که ۵۰۰ مورد از آنها به گروه ۱، ۱۸۰۸ به گروه ۲، ۲۸۸۸ به گروه ۳، و ۷۳۲ مورد باقی مانده به گروه ۴ تعلق داشتند.
۳٫۵٫ انتخاب ویژگی
پس از استخراج ویژگی های POI، ابتدا از یک ماتریس همبستگی برای تجزیه و تحلیل ارتباط هر نوع ویژگی استفاده کردیم. ما متوجه شدیم که ویژگی های متعلق به گروه ۲ همبستگی بسیار پایینی با کلاس های LULC نشان می دهند. به همین دلیل، ما این ویژگی ها را کنار گذاشتیم. با توجه به ویژگیهای گروه ۴، تأیید کردیم که آنها تقریباً مشابه ویژگیهای متعلق به گروه ۳ هستند. از آنجایی که نسبت POI نیاز به توان محاسباتی بیشتری برای محاسبه دارد، در مقایسه با مقدار آنها در یک شعاع سلول معین، تصمیم گرفتیم برای حفظ گروه ۳ به جای ۴٫
همانطور که قصد داشتیم پتانسیل معیارهای استخراج شده از داده های POI برای طبقه بندی LULC را بررسی کنیم، با در نظر گرفتن ۳۳۸۸ ویژگی باقیمانده، برای هر سناریو، از یک روش رتبه بندی [ ۵۰ ] برای انتخاب با ارزش ترین مجموعه ویژگی استفاده کردیم. معیارهای مختلفی از جمله بهره اطلاعات، نسبت سود و شاخص جینی در این فرآیند مورد آزمایش قرار گرفتند. ما این رویکرد را انتخاب کردیم زیرا در مقایسه با روشهای دیگر معمولاً سریعتر است و منابع کمتری مصرف میکند. با استفاده از این تکنیک، مجموعههای ویژگیهای مختلفی را انتخاب کردیم که برای آزمونهای طبقهبندی به کار گرفته شدند. تعداد مشخصه های انتخاب شده در هر سناریو در بخش ۴ ارائه شده است . فهرستی از مجموعههای ویژگیهای مورد استفاده بهصورت آنلاین در http://tiny.cc/9eq8rz موجود است .
۳٫۶٫ طبقه بندی
همانطور که در بخش پیشرفته ارائه شد، در میان بسیاری از مطالعات علمی مختلف که مورد تجزیه و تحلیل قرار دادیم، استفاده از تکنیک های مختلف مشاهده شد. برخی از آنها برای آماده سازی و پیش پردازش داده ها و برخی دیگر برای کارهای طبقه بندی استفاده می شوند. با این حال، برای ایجاد یک مدل قادر به طبقهبندی کاربری زمین با استفاده از ویژگیهای عددی، ما معتقدیم که میتوان با موفقیت از یک روش قدرتمند استفاده کرد که معمولاً در این زمینه دیده نمیشود، یعنی یک شبکه عصبی مصنوعی (ANN). ما سناریوهای مختلف را با استفاده از ANN آزمایش کردیم، همانطور که در بخش بعدی ارائه شد. جزئیات پارامترسازی در جدول ۴ نشان داده شده است. به عنوان معیارهای ارزیابی، موارد زیر اتخاذ شد: دقت، امتیاز F، کاپا، دقت و یادآوری. برای آموزش مدلها، ما یک تکنیک اعتبارسنجی متقاطع ۱۰ برابری را اتخاذ کردیم. RapidMiner Studio [ ۵۱ ] برای تستهای طبقهبندی که ما انجام دادیم مورد استفاده قرار گرفت و جزئیات پیادهسازی الگوریتم ANN در این نرمافزار را میتوان در مستندات رسمی مشاهده کرد [ ۵۲ ].
۴٫ نتایج و بحث
همانطور که در یک تحلیل اکتشافی که قبلا انجام شده بود متوجه شدیم، یک الگوی مجاورت جغرافیایی بین کلاسهای «۲٫ مناطق کشاورزی»، «۳٫ مناطق جنگلی و نیمه طبیعی» و «۱۱۲٫ به نظر می رسد بافت شهری ناپیوسته وجود داشته باشد. با توجه به این شواهد، برخی آزمایشهای اولیه انجام شد (در اینجا ارائه نشده است)، که در آنها متوجه شدیم که مدلهای تولید شده در هنگام استفاده از این سه کلاس با هم تمایل به ارائه عملکرد پایین دارند. به همین دلیل، در اکثر آزمایشهایی که در زیر به آنها پرداخته میشود، تصمیم گرفتیم این کلاسها را جداگانه در نظر بگیریم.
در اولین آزمون طبقه بندی، از یک مجموعه داده حاوی ۱۴۴ ویژگی استفاده کردیم. جدول ۵ نتایج ارزیابی مدل را نشان می دهد. برای این تجربه، ما چهار کلاس مجزا را به عنوان هدف نهایی برای طبقهبندی انتخاب کردیم: (۱) «۲٫ مناطق کشاورزی»؛ (۲) «۱۱۱٫ بافت شهری پیوسته»؛ (۳) «۱۱۲٫ بافت شهری ناپیوسته»؛ (۴) «۱۲۱٫ واحدهای صنعتی یا تجاری و تأسیسات عمومی». این آموزش با استفاده از ۲۶۶۷ مثال از کلاس ۱۲۱ و ۳۰۰۰ مثال برای هر یک از موارد باقی مانده ساخته شده است. همانطور که مشاهده می شود، دقت و فراخوانی کلاس ۱۱۲ هر دو در مقایسه با سایرین پایین تر است، در حالی که به نظر می رسد مدل قادر به تشخیص بهتر کلاس ۲ در بین همه آنها باشد.
همانند آزمایش قبلی، آزمایشی را نیز بر اساس مدلی که با استفاده از چهار کلاس آموزش داده شده بود، انجام دادیم. با این حال، در این آزمون از کلاس «۳» استفاده کردیم. مناطق جنگلی و نیمه طبیعی» به جای کلاس «۲». از طریق روش انتخاب خودکار که قبلا توضیح داده شد، ما ۱۵۷ ویژگی را انتخاب کردیم. نتایج به دست آمده در جدول ۶ قابل مشاهده است . آنها نشان می دهند که به طور کلی، مدل تقریباً هیچ تفاوتی در مقایسه با مدل ایجاد شده در آزمون قبلی نشان نمی دهد، اگرچه ما از همان ۳۰۰۰ مثال از هر کلاس استفاده کردیم، به جز کلاس ۱۲۱، که برای آن از ۲۶۶۷ مثال استفاده کردیم.
در آزمایش سوم که انجام شد، از کلاسهای ۱۱۱ و ۱۲۱ نیز استفاده کردیم. به منظور بررسی اینکه یک مدل تا چه اندازه میتواند جنگلها، مناطق نیمه طبیعی و زمینهای کشاورزی را از فضاهای شهری متراکم و مناطق صنعتی متمایز کند، تصمیم گرفتیم کلاسهای ۲ را در نظر بگیریم. و ۳ برای آموزش مدل. همانند آزمایشهایی که قبلاً انجام شد، مجموعهای از دادههای متشکل از ۱۱۶۶۷ نمونه را نیز به کار بردیم، اگرچه حاوی ۱۴۲ ویژگی است – یعنی ۱۵ مورد کمتر از قبل. با توجه به اطلاعات موجود در جدول ۷ ، ارزیابی مدل نشان می دهد که در مناطق شهری متراکم، طبقه بندی کننده به نتایج بهتری نسبت به سایر طبقات می رسد.
با جایگزینی کلاس ۱۲۱ با کلاس ۱۱۲، ما یک مدل جدید را آموزش دادیم، که به یک نمونه فرعی متشکل از ۴۰۰۰ نمونه از هر کلاس تکرار میشود، به جز یکی که نشان دهنده بستههای بافت شهری پیوسته است، که فقط ۳۰۴۳ نمونه برای آن موجود بود. مجموعه داده مذکور دارای ۱۵۸ ویژگی است و از طریق ارزیابی مدل به نتایج مندرج در جدول ۸ دست یافتیم .
به منظور تکمیل آزمایشهای ارائهشده، در یک سناریوی جدید با در نظر گرفتن ۲۲۱ ویژگی، مدلی را آزمایش کردیم که با استفاده از سه کلاس که معتقد بودیم برای طبقهبندی کاربری زمین بسیار ارزشمند است، آموزش داده شد: (۱) «۲٫ مناطق کشاورزی»؛ (۲) «۱۱۱٫ بافت شهری پیوسته»؛ (۳) «واحدهای صنعتی یا تجاری و تأسیسات عمومی». نتایج را می توان در جدول ۹ مشاهده کرد . برای این تست خاص، از ۴۰۰۰ مثال از کلاس ۲، ۳۰۴۳ از کلاس ۱۱۱ و ۲۶۶۷ از کلاس ۱۲۱ استفاده کردیم.
با توجه به اینکه کلاس های ۱۱۱ و ۱۱۲ هر دو از کلاس “۱٫۱” هستند. بافت شهری»، مدلی ایجاد کردیم که نمونههای این کلاسها را ادغام میکند. با استفاده از مجموعه داده ای حاوی ۹۶ ویژگی و ۴۰۰۰ نمونه از کلاس جدید، علاوه بر ۳۰۴۳ مورد دیگر از کلاس ۱۱۱ و ۲۶۶۷ از ۱۲۱، نتایج ارائه شده در جدول ۱۰ را به دست آوردیم .
آخرین آزمایش ما بر اساس یک مجموعه داده حاوی ۹۳ ویژگی بود. این مدل با ۴۰۰۰ نمونه از کلاس های ۱۱۱ و ۱۱۲ با هم آموزش داده شد. ۴۰۰۰ نمونه دیگر از کلاسهای ۲ و ۳ به یک کلاس جدید و ۲۶۶۷ نمونه، طبق معمول، از کلاس ۱۲۱ نگاشت شدند. ما تصمیم گرفتیم نمونههایی را که جنگلها و مناطق نیمه طبیعی را نشان میدهند به آنهایی که مناطق کشاورزی را محدود میکنند، به دلیل شباهت مشاهده شده بین اینها بپیوندیم. دو کلاس از طریق یک تحلیل اکتشافی که ما انجام دادیم. نتایج به دست آمده در جدول ۱۱ ارائه شده است .
هنگام تجزیه و تحلیل نتایج به دست آمده، می توان برخی از مشاهدات را مورد بحث قرار داد. با در نظر گرفتن امتیاز F به ازای هر کلاس، میتوانیم ببینیم که، به طور کلی، مدلها تمایل به نشان دادن نتایج پایینتری برای طبقهبندی نمونههایی دارند که مناطق شهری ناپیوسته را نشان میدهند. در واقع، ما میتوانیم این را با بررسی یک ماتریس سردرگمی تأیید کنیم، جایی که این قطعات زمین اغلب به اشتباه طبقهبندی میشوند. همانطور که در جدول ۱۲ ارائه شده استمدل اغلب تمایل دارد کلاس ۱۱۲ را به عنوان ۲ یا ۱۱۱ پیش بینی کند، در حالی که نمونه های زیادی از قطعات کشاورزی را نیز به عنوان مناطق شهری ناپیوسته طبقه بندی می کند. با این حال، هنگام تجزیه و تحلیل نتایج حاصل از ارزیابی مدل سناریوی ۳، می توان مشاهده کرد که هنگام استفاده از کلاس های ۲، ۳، ۱۱۱ و ۱۲۱، زمین های کشاورزی و قطعات جنگلی آنهایی هستند که کمترین امتیاز F را ارائه می دهند. با بررسی ماتریس های سردرگمی تولید شده برای هر سناریو، متوجه شدیم که این کلاس ها اغلب با یکدیگر اشتباه گرفته می شوند.
برای تلاش برای یافتن دلیل اصلی طبقه بندی نادرست جنگل ها، زمین های کشاورزی و مناطق شهری ناپیوسته در بین خود، یک تحلیل اکتشافی انجام دادیم. همانطور که در شکل ۴نشان می دهد که نزدیکی جغرافیایی بین این طبقات وجود دارد. با توجه به اینکه ویژگی های استفاده شده در برخی موارد نشان دهنده فاصله بین هر مرکز و نزدیکترین نقطه نقطه هر دسته و در موارد دیگر، میزان نقاط هر دسته در شعاع هر مرکز سلولی است، می توان مشکوک شد که از آنجایی که بسیاری از مقولهها اغلب در مناطق شهری متراکم قرار دارند، فاصله از سلولهایی که این سه کلاس و POI را نشان میدهند نیز میتواند مشابه باشد. به عبارت دیگر، این بدان معناست که سلولهایی که این سه کلاس را نشان میدهند، اغلب دور از بسیاری از دستههای POI دیگر قرار دارند. به دنبال این ایده، ما همچنین فکر میکنیم که میزان POI از اکثر دستهها میتواند در این زمینهها کمتر باشد، و تمایز بین آنها را با استفاده از ویژگیهایی که در اینجا انتخاب شدهاند دشوار میسازد.
۵٫ نتیجه گیری و کار آینده
در ابتدا در این کار به منظور بررسی مجموعه ای از آثار مرتبط با تحلیل فضای جغرافیایی، نظرسنجی انجام دادیم. از طریق تجزیه و تحلیل سیستماتیک، انواع داده ها و روش های اصلی و همچنین استفاده از آنها در این زمینه را برجسته و مورد بحث قرار داده ایم. از تجزیه و تحلیل پیشرفته، ما پتانسیل نوع خاصی از داده های جمع سپاری را برای طبقه بندی کاربری زمین، یعنی POI ها، بررسی کردیم. ما منابع موجود این اطلاعات را به دقت مطالعه کردیم تا تصمیم بگیریم که کدام یک برای تحلیل ما مناسبتر است. بر اساس سرویسی که به صورت آنلاین در دسترس است، ما یک برنامه کاربردی برای جمع آوری خودکار POI برای منطقه مورد مطالعه خود ایجاد کردیم. علاوه بر این، برای آماده کردن دادهها برای آزمایشهای خود، برخی از درمانهای داده را اعمال کردیم.
بر اساس دادههای POI، ما انواع مختلفی از ویژگیها را استخراج و تجزیه و تحلیل کردیم تا آنهایی را انتخاب کنیم که ارتباط بیشتری برای استفاده داشته باشند. با توجه به این واقعیت که ما تعداد زیادی ویژگی داشتیم، تکنیکی را به کار گرفتیم که در ادبیات به خوبی تثبیت شده بود تا به طور خودکار مناسب ترین آنها را برای هر آزمایشی که انجام دادیم رتبه بندی کنیم. برای طبقه بندی کاربری زمین، ما یک روش مبتنی بر شبکه را بر اساس یک مجموعه داده حقیقت زمینی بسیار قابل اعتماد انتخاب کردیم. ما سناریوهای مختلفی را برای تست های خود تعریف کردیم و یک الگوریتم قدرتمند برای تجزیه و تحلیل طبقه بندی در هنگام استفاده از ویژگی های عددی برای همه آنها اتخاذ کردیم.
اگرچه روش مبتنی بر شبکه ای که ما به عنوان بخشی از روشی که برای تهیه داده ها استفاده کردیم، قبلاً در ادبیات پیشنهاد شده بود، می توان تأکید کرد که در مطالعه ما، تفاوت هایی با تکنیک اصلی وجود دارد. اول، کار ما بر اساس داده های برداری بود به جای داده های شطرنجی. ما معتقدیم که دادههای برداری برای راهحلهای خودکار یا نیمه خودکار اعمال شده برای تحلیل جغرافیایی کارآمدتر هستند، زیرا میتوانند اطلاعات بیشتری مربوط به هر قطعه زمین را جمعآوری کنند و همچنین میتوانند به راحتی مستقیماً در یک پایگاه داده ذخیره و دستکاری شوند. علاوه بر این، ویژگیهایی که ما اتخاذ کردیم تا حدی با ویژگیهایی که در زمان پیشنهاد روش استفاده میشد متفاوت است. کار ما شواهد محکمی را ارائه می دهد که این روش شناسی به خوبی کار می کند، و ما این تفاوت هایی را که اجرا کرده ایم به عنوان سهم خود در پیشرفت هنر می بینیم.
با استفاده از یک شبکه عصبی مصنوعی و دادههای مبتنی بر POI، از طریق سناریوهای طبقهبندی مختلف، به مقادیر بیش از ۹۰ درصد برای دقت و امتیاز F در موفقترین مورد در اینجا دست یافتیم. به طور کلی، برای اکثر تجربیات، مقادیر این معیارها نزدیک به ۸۰٪ است که ثابت می کند POI ها پتانسیل پیشنهاد به عنوان یک نوع داده برای طبقه بندی کاربری زمین را دارند. به عنوان یکی از رایجترین انواع دادههای جمعسپاری، آنها بهطور گسترده و رایگان برای بسیاری از کشورها در دسترس هستند و میتوانند به تنهایی یا در صورت ترکیب با انواع دادههای دیگر، کمکهای مرتبطی را ارائه دهند، در نتیجه نتایج در مطالعات مربوط به توصیف فضاهای جغرافیایی را بهبود بخشند.
در مورد مهندسی ویژگی، در این کار، چهار گروه مختلف از ویژگی ها را استخراج و تحلیل کردیم. تأیید شد که تنها دو مورد از آنها برای طبقه بندی کاربری اراضی مفید هستند. اگرچه ما تعداد قابل توجهی از ویژگی ها را ایجاد کردیم، آنها معیارهای خاصی را نشان می دهند که از داده های POI استخراج شده است. بنابراین، بهعنوان پیشنهادی برای کار آینده، ما توصیه میکنیم پتانسیل معیارهای جدید – به عنوان مثال، شباهت معنایی بین POIها – را با توجه به توصیفهای متنی آنها، که میتواند به عنوان ویژگیهایی برای آموزش مدلها اضافه شود، تجزیه و تحلیل کنید، در نتیجه احتمالاً نتایج بهتری ارائه میشود. استفاده از شبکه های عصبی عمیق برای پردازش زبان طبیعی (NLP) به عنوان یک ابزار قدرتمند برای استخراج ویژگی ها از متون نشان داده شده است [ ۱۳ ، ۱۹]]. اتخاذ چنین شبکه های عصبی عمیق در رویکرد ما می تواند عملکرد طبقه بندی کاربری زمین را بهبود بخشد.
همانطور که در تحلیل های پیشرفته بیان شد، داده های POI، به عنوان یکی از رایج ترین انواع داده های جمع سپاری، به طور گسترده در سرویس های API و مخازن آنلاین در دسترس هستند. با این حال، مانند بسیاری از مجموعه داده های تولید شده توسط تعداد زیادی از کاربران یا داوطلبان، یافتن نویز زیادی در این مجموعه داده ها بسیار رایج است. به همین دلیل، ما همچنین به عنوان کار آینده، ارزیابی کیفیت دادههای POI جمعسپاری شده از منابع مختلف را پیشنهاد میکنیم. ما متوجه شده ایم که استفاده از مجموعه داده های قابل اعتماد کلید دستیابی به نتایج خوب در بسیاری از موارد است.
در این کار، ما پتانسیل دادههای POI را برای توصیف فضاهای جغرافیایی-یعنی طبقهبندی LULC- بررسی کردیم. در تجزیه و تحلیلی که انجام دادیم، تنها یک منبع را برای این نوع مجموعه دادهها انتخاب کردیم. بنابراین، برای کار آینده، ما همچنین بررسی تکنیکهایی را پیشنهاد میکنیم که میتوانند برای ادغام POIهای جمعآوریشده از منابع مختلف به منظور غنیسازی دادههای اضافی اتخاذ شوند. ما بر این باوریم که استفاده از مجموعهای از دادهها تا حد امکان کامل میتواند به ایجاد مدلهای کارآمد کمک کند.
منابع
- سوسنتی، ر. سوتومو، اس. بوچوری، آی. بروتوسوناریو، رشد هوشمند PM، شهر هوشمند و تراکم: در جستجوی شاخص مناسب برای تراکم مسکونی در اندونزی. Procedia-Soc. رفتار علمی ۲۰۱۶ ، ۲۲۷ ، ۱۹۴-۲۰۱٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لیو، ایکس. او، جی. یائو، ی. ژانگ، جی. لیانگ، اچ. وانگ، اچ. Hong, Y. طبقه بندی کاربری زمین شهری با ادغام داده های سنجش از دور و رسانه های اجتماعی. بین المللی جی. جئوگر. Inf. علمی ۲۰۱۷ ، ۳۱ ، ۱۶۷۵-۱۶۹۶٫ [ Google Scholar ] [ CrossRef ]
- ژانگ، ی. لی، کیو. هوانگ، اچ. وو، دبلیو. دو، X. وانگ، اچ. استفاده ترکیبی از سنجش از دور و داده های سنجش اجتماعی در نقشه برداری کاربری زمین شهری با دانه بندی ریز: مطالعه موردی در پکن، چین. Remote Sens. ۲۰۱۷ , ۹ , ۸۶۵٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژانگ، ایکس. دو، اس. وانگ، Q. شناخت معنایی سلسله مراتبی برای مناطق عملکردی شهری با تصاویر ماهواره ای VHR و داده های POI. ISPRS J. Photogramm. Remote Sens. ۲۰۱۷ ، ۱۳۲ ، ۱۷۰-۱۸۴٫ [ Google Scholar ] [ CrossRef ]
- NOAA. وب سایت خدمات ملی اقیانوس. تفاوت بین پوشش زمین و کاربری زمین چیست؟ ۲۰۱۸٫ در دسترس آنلاین: https://oceanservice.noaa.gov/facts/lclu.html (در ۱۳ مارس ۲۰۱۹ قابل دسترسی است).
- گائو، اس. یانوویچ، ک. کوکللیس، اچ. استخراج مناطق عملکردی شهری از نقاط مورد علاقه و فعالیت های انسانی در شبکه های اجتماعی مبتنی بر مکان. ترانس. GIS ۲۰۱۷ ، ۲۱ ، ۴۴۶-۴۶۷٫ [ Google Scholar ] [ CrossRef ]
- بلاشکه، تی. هی، GJ; کلی، NM; لانگ، اس. هافمن، پی. آدینک، EA؛ فیتوسا، RQ; ون در میر، اف. ون در ورف، اچ. ون کویلی، اف. و همکاران تجزیه و تحلیل تصویر مبتنی بر شی جغرافیایی – به سوی یک الگوی جدید. ISPRS J. Photogramm. Remote Sens. ۲۰۱۴ ، ۸۷ ، ۱۸۰-۱۹۱٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Terroso-Saenz، F. Muñoz، A. کشف کاربری زمین بر اساس طبقه بندی اطلاعات جغرافیایی داوطلبانه. سیستم خبره Appl. ۲۰۲۰ , ۱۴۰ , ۱۱۲۸۹۲٫ [ Google Scholar ] [ CrossRef ]
- زینگ، اچ. Meng, Y. ادغام معیارهای چشم انداز و ویژگی های اجتماعی-اقتصادی برای طبقه بندی منطقه عملکردی شهری. محاسبه کنید. محیط زیست سیستم شهری ۲۰۱۸ ، ۷۲ ، ۱۳۴-۱۴۵٫ [ Google Scholar ] [ CrossRef ]
- برنان، آر. Webster، TL طبقه بندی پوشش زمین شی گرا سطوح مشتق شده از لیدار. می توان. J. Remote Sens. ۲۰۰۶ ، ۳۲ ، ۱۶۲-۱۷۲٫ [ Google Scholar ] [ CrossRef ]
- گونگ، بی. من، جی. Mountrakis، G. یک رویکرد شبکه ایمنی مصنوعی برای طبقهبندی کاربری زمین/پوشش زمین با چند حسگر. سنسور از راه دور محیط. ۲۰۱۱ ، ۱۱۵ ، ۶۰۰-۶۱۴٫ [ Google Scholar ] [ CrossRef ]
- چی، ز. بله، پیش از این؛ لی، ایکس. Lin, Z. یک الگوریتم جدید برای طبقه بندی کاربری و پوشش زمین با استفاده از داده های SAR قطبی RADARSAT-2. سنسور از راه دور محیط. ۲۰۱۲ ، ۱۱۸ ، ۲۱-۳۹٫ [ Google Scholar ] [ CrossRef ]
- یائو، ی. لی، ایکس. لیو، ایکس. لیو، پی. لیانگ، ز. ژانگ، جی. Mai، K. سنجش توزیع فضایی کاربری زمین شهری با ادغام نقاط مورد علاقه و مدل Google Word2Vec. بین المللی جی. جئوگر. Inf. علمی ۲۰۱۷ ، ۳۱ ، ۸۲۵-۸۴۸٫ [ Google Scholar ] [ CrossRef ]
- ژانگ، ایکس. دو، اس. وانگ، کیو. یکپارچهسازی طبقهبندی از پایین به بالا و بازخورد از بالا به پایین برای بهبود نقشهبرداری پوشش زمین شهری و منطقه عملکردی. سنسور از راه دور محیط. ۲۰۱۸ ، ۲۱۲ ، ۲۳۱-۲۴۸٫ [ Google Scholar ] [ CrossRef ]
- هوانگ، بی. ژائو، بی. Song، Y. نقشهبرداری کاربری زمین شهری با استفاده از یک شبکه عصبی پیچیده عمیق با تصاویر سنجش از دور چندطیفی با وضوح فضایی بالا. سنسور از راه دور محیط. ۲۰۱۸ ، ۲۱۴ ، ۷۳-۸۶٫ [ Google Scholar ] [ CrossRef ]
- Durduran، SS طبقه بندی خودکار پوشش زمین با وضوح بالا با استفاده از یک روش وزن دهی داده جدید: ترکیبی از الگوریتم خوشه بندی k-means و اقدامات گرایش مرکزی (KMC-CTM). Appl. محاسبات نرم. J. ۲۰۱۵ ، ۳۵ ، ۱۳۶-۱۵۰٫ [ Google Scholar ] [ CrossRef ]
- دنگ، ز. زو، ایکس. او، س. Tang, L. طبقه بندی کاربری/پوشش زمین با استفاده از تصاویر سری زمانی Landsat 8 در یک منطقه به شدت شهری. Adv. Sp. Res. ۲۰۱۹ ، ۶۳ ، ۲۱۴۴-۲۱۵۴٫ [ Google Scholar ] [ CrossRef ]
- ژونگ، ی. زو، س. Zhang، L. طبقه بندی صحنه بر اساس مدل موضوع احتمالی ترکیب چند ویژگی برای تصاویر سنجش از دور با وضوح فضایی بالا. IEEE Trans. Geosci. Remote Sens. ۲۰۱۵ , ۵۳ , ۶۲۰۷–۶۲۲۲٫ [ Google Scholar ] [ CrossRef ]
- ژای، دبلیو. بای، ایکس. شی، ی. هان، ی. پنگ، Z.-R. Gu, C. Beyond Word2vec: رویکردی برای استخراج و شناسایی منطقه عملکردی شهری با ترکیب Place2vec و POI. محاسبه کنید. محیط زیست سیستم شهری ۲۰۱۹ ، ۷۴ ، ۱-۱۲٫ [ Google Scholar ] [ CrossRef ]
- García-Palomares, JC; Salas-Olmedo، MH; مویا گومز، بی. Condeço-Melhorado، A. گوتیرز، جی. پویایی شهر از طریق توییتر: روابط بین کاربری زمین و جمعیت شناسی مکانی و زمانی. شهرها ۲۰۱۸ ، ۷۲ ، ۳۱۰–۳۱۹٫ [ Google Scholar ] [ CrossRef ]
- یوان، جی. ژنگ، ی. Xie, X. کشف مناطقی از عملکردهای مختلف در یک شهر با استفاده از تحرک انسان و POI. SIGKDD بین المللی Conf. بدانید. کشف کنید. حداقل داده ۲۰۱۲ . [ Google Scholar ] [ CrossRef ]
- لیو، ایکس. نیو، ن. لیو، XJ; جین، اچ. او، جی پی؛ جیائو، ال.ام. Liu, YL مشخص کردن ساختمانهای با کاربری مختلط بر اساس دادههای بزرگ چند منبعی. بین المللی جی. جئوگر. Inf. علمی ۲۰۱۸ ، ۳۲ ، ۷۳۸-۷۵۶٫ [ Google Scholar ]
- جندرایک، ام. بالز، تی. مک کلور، SC; لیائو، ام. قرار دادن مردم در تصویر: ترکیب دادههای رسانههای اجتماعی بزرگ مبتنی بر مکان و تصاویر سنجش از راه دور برای بهبود اطلاعات شهری بافتی در شانگهای. محاسبه کنید. محیط زیست سیستم شهری ۲۰۱۷ ، ۶۲ ، ۹۹-۱۱۲٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لنسلی، جی. Longley، PA جغرافیای موضوعات توییتر در لندن. محاسبه کنید. محیط زیست سیستم شهری ۲۰۱۶ ، ۵۸ ، ۸۵-۹۶٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- چنگ، ز. کاورلی، جی. تره فرنگی.؛ Sui، DZ میلیونها ردپا را در خدمات اشتراکگذاری مکان کاوش میکند. بین المللی Conf. وبلاگ ها Soc. رسانه ۲۰۱۱ ، ۲۰۱۰ ، ۸۱-۸۸٫ [ Google Scholar ]
- ارسنجانیا، جی جی; Vaz, E. ارزیابی یک رویکرد نقشه برداری مشترک برای کاوش الگوهای کاربری زمین برای چندین کلانشهر اروپایی. بین المللی J. Appl. زمین Obs. Geoinf. ۲۰۱۵ ، ۳۵ ، ۳۲۹-۳۳۷٫ [ Google Scholar ] [ CrossRef ]
- یوان، نیوجرسی؛ ژنگ، ی. Xie، X. وانگ، ی. ژنگ، ک. Xiong، H. کشف مناطق عملکردی شهری با استفاده از مسیرهای فعالیت نهفته. IEEE Trans. بدانید. مهندسی داده ۲۰۱۵ ، ۲۷ ، ۷۱۲-۷۲۵٫ [ Google Scholar ] [ CrossRef ]
- گونگ، ال. لیو، ایکس. وو، ال. لیو، ی. استنباط اهداف سفر و کشف الگوهای سفر از دادههای مسیر تاکسی. کارتوگر. Geogr. Inf. علمی ۲۰۱۶ ، ۴۳ ، ۱۰۳-۱۱۴٫ [ Google Scholar ] [ CrossRef ]
- Trevino، A. مقدمه ای بر K-Means Clustering. Oracle + DataScience.com. ۲۰۱۶٫ در دسترس آنلاین: https://www.datascience.com/blog/k-means-clustering (در ۲۰ مارس ۲۰۱۹ قابل دسترسی است).
- جیانگ، اس. آلوز، آ. رودریگز، اف. فریرا، جی. Pereira، FC داده های نقطه مورد علاقه استخراج از شبکه های اجتماعی برای طبقه بندی و تفکیک کاربری زمین شهری. محاسبه کنید. محیط زیست سیستم شهری ۲۰۱۵ ، ۵۳ ، ۳۶-۴۶٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پاتل، اس. فصل ۲: SVM (ماشین بردار پشتیبانی) – نظریه. Machine Learning 101. 2017. موجود به صورت آنلاین: https://medium.com/machine-learning-101/chapter-2-svm-support-vector-machine-theory-f0812effc72 (در ۱۰ ژوئن ۲۰۱۹ قابل دسترسی است).
- Sotiropoulos، DN; Tsihrintzis، پارادایم های یادگیری ماشین GA. در پارادایم های یادگیری ماشینی: سیستم های ایمنی مصنوعی و کاربردهای آنها در شخصی سازی نرم افزار . انتشارات بین المللی اسپرینگر: چم، سوئیس، ۲۰۱۷; صص ۱۰۷-۱۲۹٫ [ Google Scholar ]
- ژانگ، ایکس. Du، S. یک مدل مخلوط دیریکله خطی برای تجزیه صحنه ها: کاربرد برای تجزیه و تحلیل منطقه بندی های عملکردی شهری. سنسور از راه دور محیط. ۲۰۱۵ ، ۱۶۹ ، ۳۷-۴۹٫ [ Google Scholar ] [ CrossRef ]
- لیلبرگ، جی. زو، ی. Zhang، Y. از ماشینهای برداری و word2vec برای طبقهبندی متن با ویژگیهای معنایی پشتیبانی کنید. در مجموعه مقالات چهاردهمین کنفرانس بین المللی IEEE 2015 در زمینه انفورماتیک شناختی و محاسبات شناختی (ICCI*CC)، پکن، چین، ۶ تا ۸ ژوئیه ۲۰۱۵؛ صص ۱۳۶-۱۴۰٫ [ Google Scholar ]
- ژانگ، ال. ژانگ، ال. Du, B. یادگیری عمیق برای داده های سنجش از راه دور: یک آموزش فنی در مورد وضعیت هنر. IEEE Geosci. سنسور از راه دور Mag. ۲۰۱۶ ، ۴ ، ۲۲-۴۰٫ [ Google Scholar ] [ CrossRef ]
- ژان، ایکس. اوکوسوری، اس وی؛ Zhu, F. استنباط کاربری زمین شهری با استفاده از دادههای ورود به شبکه اجتماعی در مقیاس بزرگ. شبکه تف کردن اقتصاد ۲۰۱۴ ، ۱۴ ، ۶۴۷-۶۶۷٫ [ Google Scholar ] [ CrossRef ]
- فریاس مارتینز، وی. فریاس مارتینز، E. خوشه بندی طیفی برای سنجش کاربری زمین شهری با استفاده از فعالیت توییتر. مهندس Appl. آرتیف. هوشمند ۲۰۱۴ ، ۳۵ ، ۲۳۷-۲۴۵٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- یائو، ی. لیانگ، اچ. لی، ایکس. ژانگ، جی. او، جی. با ادغام Google Tensorflow و مدلهای طبقهبندی صحنه، الگوهای کاربری زمین شهری را حس میکند. بین المللی قوس. فتوگرام حسگر از راه دور اسپات. Inf. Sci.-ISPRS Arch. ۲۰۱۷ ، ۴۲ ، ۹۸۱-۹۸۸٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- آهنگ، جی. لین، تی. لی، ایکس. پریشچپوف، نقشه برداری AV مناطق عملکردی شهری با ادغام تصاویر سنجش از دور با وضوح بسیار بالا و نقاط مورد علاقه: مطالعه موردی Xiamen، چین. Remote Sens. ۲۰۱۸ ، ۱۰ ، ۱۷۳۷٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- ژانگ، سی. سارجنت، آی. پان، X. لی، اچ. گاردینر، آ. هار، جی. اتکینسون، پی. یک شبکه عصبی کانولوشنال مبتنی بر شی (OCNN) برای طبقهبندی کاربری زمین شهری. سنسور از راه دور محیط. ۲۰۱۸ ، ۲۱۶ ، ۵۷-۷۰٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- فلورس، ای. زرتیا، م. Scharcanski, J. دیکشنری های ویژگی های عمیق برای طبقه بندی صحنه استفاده از زمین تصاویر با وضوح فضایی بسیار بالا. تشخیص الگو ۲۰۱۹ ، ۸۹ ، ۳۲-۴۴٫ [ Google Scholar ] [ CrossRef ]
- ژانگ، سی. سارجنت، آی. پان، X. لی، اچ. گاردینر، آ. هار، جی. اتکینسون، پی. یادگیری عمیق مشترک برای طبقه بندی پوشش زمین و کاربری زمین. سنسور از راه دور محیط. ۲۰۱۹ ، ۲۲۱ ، ۱۷۳-۱۸۷٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- فیس بوک. API جستجوی مکانها برای وب. در دسترس آنلاین: https://developers.facebook.com/docs/places/web/search/ (در ۸ ژوئیه ۲۰۲۰ قابل دسترسی است).
- فیس بوک. اطلاعات مکان در دسترس آنلاین: https://developers.facebook.com/docs/graph-api/reference/place-information (در ۸ ژوئیه ۲۰۲۰ قابل دسترسی است).
- کوپرنیک. پوشش زمین CORINE. در دسترس آنلاین: https://land.copernicus.eu/pan-european/corine-land-cover (در ۲ مارس ۲۰۲۰ قابل دسترسی است).
- کوپرنیک. CLC 2018. در دسترس آنلاین: https://land.copernicus.eu/pan-european/corine-land-cover/clc2018?tab=metadata (در ۸ ژوئیه ۲۰۲۰ قابل دسترسی است).
- کوزترا، بی. بوتنر، جی. هازو، جی. آرنولد، اس. دستورالعمل های نامگذاری مصور CLC را به روز کرد. ۲۰۱۹٫ [ Google Scholar ]
- Calegari، GR; کارلینو، ای. پرونی، دی. Celino، I. استخراج کاربری زمین شهری از دادههای مکانی باز مرتبط. ISPRS Int. J. Geo-Inf. ۲۰۱۵ ، ۴ ، ۲۱۰۹-۲۱۳۰٫ [ Google Scholar ] [ CrossRef ]
- فیس بوک. همه دسته بندی ها. در دسترس آنلاین: https://www.facebook.com/pages/category/ (در ۱۶ دسامبر ۲۰۱۹ قابل دسترسی است).
- نواکوویچ، جی. Strbac، P. Bulatović، D. به سوی انتخاب ویژگی بهینه با استفاده از روش های رتبه بندی و الگوریتم های طبقه بندی. یوگسل. جی. اوپر. Res. ۲۰۱۱ ، ۲۱ ، ۱۱۹-۱۳۵٫ [ Google Scholar ] [ CrossRef ]
- RapidMiner. RapidMiner | پلتفرم علم داده و یادگیری ماشین ۲۰۲۰٫ در دسترس آنلاین: https://rapidminer.com/ (دسترسی در ۱۸ ژوئن ۲۰۱۹).
- RapidMiner. شبکه عصبی در دسترس آنلاین: https://docs.rapidminer.com/latest/studio/operators/modeling/predictive/neural_nets/neural_net.html (در ۸ ژوئیه ۲۰۲۰ قابل دسترسی است).
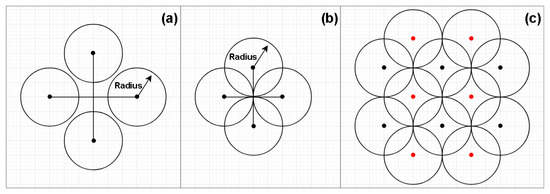
شکل ۱٫ تولید مختصات. همانطور که در ( a ) مشاهده می شود، اگر فواصل بین نقاط خیلی زیاد باشد، برنامه نمی تواند کل منطقه را پوشش دهد، بنابراین، معقول ترین پیکربندی ممکن است در ( b ) باشد. با اتخاذ این پیکربندی، الگوی نهایی در ( c ) نشان داده میشود، جایی که میتوان دید که نقاط قرمز در مقایسه با نقاط سیاه کمی جابهجا میشوند. این پیکربندی به نرم افزار اجازه می دهد تا منطقه بیشتری را با مناطق کمتری با هم تداخل داشته باشد.
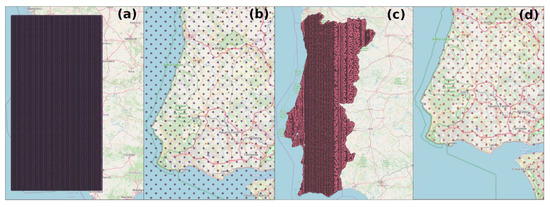
شکل ۲٫ مجموعه ای از مختصات تولید شده برای انجام جستجو. همانطور که در ( الف ) مشاهده می شود، نقاط در ابتدا در کل منطقه در داخل مربع بر اساس محدودیت های داده شده توسط کاربر توزیع شدند. ب ) نقاط خارج از محدوده جغرافیایی کشور را نشان می دهد. ( c ، d ) موقعیت مختصات نهایی را پس از فیلتر کردن نشان می دهد.
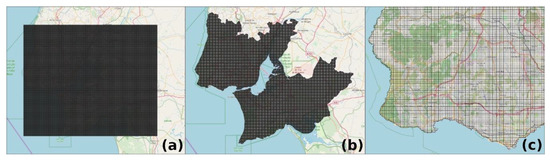
شکل ۳٫ شبکه ای که در آن هر سلول نشان دهنده یک واحد زمین است که باید طبقه بندی شود. هنگامی که ایجاد می شود، شبکه مانند ( a ) به نظر می رسد؛ همانطور که در ( b , c ) می بینیم، پس از تقاطع، تنها سلول های داخل محدوده جغرافیایی منطقه مورد مطالعه نگهداری شدند .
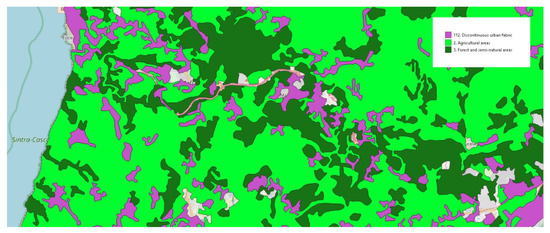
شکل ۴٫ مجاورت جغرافیایی بین جنگل ها، زمین های کشاورزی و مناطق شهری ناپیوسته.