
خلاصه
فنآوریهای معنایی در هسته یکپارچهسازی دادههای رصد زمین (EO)، با ارائه زیرساختی مبتنی بر نمایش RDF و هستیشناسی قرار دارند. از آنجایی که بسیاری از دادههای EO در فایلهای شطرنجی میآیند، این مقاله به ادغام دادههای محاسبهشده از رسترها به عنوان راهی برای واجد شرایط کردن واحدهای جغرافیایی از طریق ویژگیهای مکانی-زمانی آنها میپردازد. ما (من) یک هستیشناسی مدولار را پیشنهاد میکنیم که به توصیف معنایی و همگن دادههای مکانی-زمانی کمک میکند تا مناطق از پیش تعریفشده را واجد شرایط کند. (ii) یک فرآیند استخراج معنایی، تبدیل و بارگذاری (ETL)، که به ما امکان میدهد دادهها را از رستر استخراج کنیم و آنها را به واحدها و ویژگیهای مکانی-زمانی مربوطه پیوند دهیم. و (iii) یک مجموعه داده حاصل که به عنوان یک فروشگاه سه گانه RDF منتشر می شود، از طریق یک نقطه پایانی SPARQL در معرض دید قرار می گیرد و توسط یک رابط معنایی مورد سوء استفاده قرار می گیرد. ما فرآیند ادغام را با فایلهای شطرنجی نشان میدهیم که پوشش زمین یک منطقه جغرافیایی کارخانه شرابسازی فرانسوی، واحدهای اداری آن و ثبتهای زمین آنها را در دورههای مختلف ارائه میدهد. نتایج با توجه به سه مورد استفاده از این دادههای EO مورد ارزیابی قرار گرفتهاند: ادغام مشاهدات سری زمانی. راهنمای فرآیند EO؛ و مقایسه متقابل داده ها
کلید واژه ها:
رصد زمین ؛ ادغام معنایی ; پوشش زمین ؛ RDF
۱٫ معرفی
رصد زمین (EO) دامنهای است که در سالهای گذشته به لطف برنامههای نظارت بر زمین در مقیاس بزرگ، مانند برنامه Landsat ایالات متحده ( https://www.usgs.gov/land-resources/nli/landsat ) پیشرفت زیادی کرده است. و برنامه کوپرنیک اتحادیه اروپا ( http://www.copernicus.eu/en). به طور خاص، با برنامه کوپرنیک که توسط آژانس فضایی اروپا (ESA) راه اندازی شد، داده ها توسط ماهواره ها جمع آوری شده و با داده های مشاهداتی از شبکه های حسگر در سطح زمین ترکیب می شوند. امروزه دو نوع ماهواره سنتینل در حال تولید هستند که چندین نوع دیگر تا سال ۲۰۳۰ پیش بینی می شود. از سال ۲۰۱۵، Sentinel-1 و Sentinel-2 تصاویری با کیفیت بالا از زمین ارائه می دهند (تخمینی بین ۸ ترابایت تا ۱۰ ترابایت داده در روز) و به کاربران ارائه می دهند. دادهها و ابردادههای تصویر زمین رایگان، قابل اعتماد و بهروز. در دسترس بودن این منابع داده فرصتهایی را برای پشتیبانی بهتر از برنامههای کاربردی حوزهمحور موجود و تقویت برنامههای نوظهور جدید، از کشاورزی گرفته تا جنگلداری، نظارت بر محیطزیست گرفته تا برنامهریزی شهری، مطالعات آب و هوا و پایش بلایای طبیعی باز کرد. این منابع داده،
یکی از راه های رایج نمایش نتایج الگوریتم های پردازش تصویر، شطرنجی است. شطرنجی یک شبکه مستطیلی از پیکسل ها را نشان می دهد و از یک کدگذاری یا طبقه بندی از پیش تعریف شده که به یک تحلیل یا نیاز خاص اختصاص داده شده است (به عنوان مثال، طبقه بندی پوشش زمین) تولید می شود. در این تنظیم، هر پیکسل حاوی مقداری برای مشخص کردن منطقه مربوطه است (به عنوان مثال، پوشش زمین نماینده آن). چنین نمایش هایی ممکن است به طور خودکار توسط الگوریتم های مختلف از جمله یادگیری ماشین ساخته شوند. بسیاری از رسترها را می توان برای یک منطقه جغرافیایی (به عنوان مثال، یک کاشی سنتینل-۲) ارائه کرد: می توان آنها را با هم مقایسه کرد، ترکیب کرد یا برای ایجاد یک مورد جدید استفاده کرد [ ۱]. با این حال، شطرنجی ها برای انسان قابل خواندن نیستند. تفسیر محتوای آنها، چه توسط کاربران ابزارهای نرم افزاری پشتیبانی تصمیم، نیاز به توضیحات سطح بالاتر، بر اساس نمایش ویژگی های مکانی و زمانی دارد.
در زمینه EO، یک نوع اساسی از داده ها، پوشش سطح زمین یا پوشش زمین (به عنوان مثال، آب، زمین های زراعی، یا شهری) است. در بسیاری از موارد، اطلاعات پوشش زمین به صورت شطرنجی به یک فایل متنی حاوی قرارداد نامگذاری طبقات پوشش زمین ارائه می شود. هر پیکسل در فایل رستر با یکی از این کلاس ها مرتبط است. این رسترها ممکن است در فرمت های مختلف باشند. آنها توسط سرویس های مختلف در نتیجه پردازش عظیم تصویر سری زمانی تحت وضوح های مختلف تولید می شوند [ ۲]. نمونه هایی از طبقه بندی پوشش زمین عبارتند از: سهم پوشش زمین جهانی (GLC-SHARE)، پوشش زمین کورین اروپایی (CLC) و پوشش زمین CESBIO فرانسه (CESBIO-LC). گام بعدی برای استفاده از پوشش زمین، محاسبه درصد هر نوع پوشش زمین در یک منطقه معین (یعنی قطعه کشاورزی)، برای شناسایی پوشش اصلی زمین در این منطقه است. سپس دادههای پوشش زمین میتواند برای مطالعه تکامل محصول، پیشرفت مناطق شهری یا تأثیر مخاطرات طبیعی مفید باشد. علاوه بر این، نمایش معنایی دادههای پوشش زمین برای حاشیهنویسی تصویر که جستجوی معنایی را بهبود میبخشد مورد بهرهبرداری قرار گرفته است [ ۳ ، ۴ ].
این مقاله به ادغام داده های محاسبه شده از رسترها به عنوان راهی برای واجد شرایط بودن واحدهای جغرافیایی، بر اساس ویژگی های مکانی-زمانی آنها می پردازد. ما علاقه مند به مطالعه (i) نوع هستی شناسی مورد نیاز برای پشتیبانی از استخراج دانش از داده های EO هستیم، تا بتوانیم نتایج تجزیه و تحلیل متفاوت (ویژگی ها یا شاخص های مشاهده شده) را که توسط شطرنجی ها توصیف شده است، توصیف کنیم. (ii) چگونه می توان داده های EO غنی را که به لطف پردازش تصویر و انواع دیگر داده های EO مرتبط گرفته شده است، در دسترس و قابل استفاده قرار داد. و (iii) نحوه پیگیری منشأ هر داده تولید شده (منابع داده، محاسبه شطرنجی، فرآیند معنایی). مشارکت های ارائه شده در این مقاله به هر یک از این چالش ها می پردازد.
-
به عنوان اولین مشارکت، ما یک واژگان عمومی را پیشنهاد میکنیم که به توصیف معنایی و همگن دادههای مکانی-زمانی اجازه میدهد تا مناطق از پیش تعریفشده را همراه با منشأ آنها واجد شرایط کند. این مدل برای مقابله با هر نوع خاصیت EO مشاهده شده قابل گسترش است.
-
به عنوان کمک دوم، ما یک فرآیند استخراج معنایی قابل تنظیم، تبدیل، و بار (ETL) را بر اساس مدل پیشنهادی تعریف کردیم. همانطور که در [ ۵]، فرآیند استخراج با پیوند دادن بخش هایی از طرحواره منابع داده با مفاهیم و ویژگی های مدل داده آغاز می شود. از این رو، ما مجموعهای از توابع تبدیل را برای پر کردن مدل معنایی با دادهها (که به عنوان مقادیر نشان داده میشوند) تعریف کردیم و یک نمایش داده معنایی همگن به دست آوردیم. یکی از ویژگی های فرآیند یکپارچه سازی استخراج و تجمیع داده ها از رستر همراه با داده های منابع دیگر است. سپس دادههای استخراجشده را به مفاهیم مدل معنایی پیوند میدهد و به آن ابعاد مکانی-زمانی اختصاص میدهد که به لطف آن میتوان همه دادهها را پیوند داد و پرس و جو کرد. این فرآیند قابل تکرار است، زیرا از طریق یک تصویر داکر قابل دسترسی است ( https://hub.docker.com/r/h2020candela/triplification ).
-
سهم سوم مجموعه داده حاصل از فرآیند یکپارچه سازی سه منبع مختلف است که ما برای اعتبار سنجی تجربی استفاده کردیم: داده های پوشش زمین یک منطقه جغرافیایی کارخانه شراب سازی فرانسوی، واحدهای اداری آن، و ثبت زمین آنها. ذخیره و منتشر شده به عنوان یک فروشگاه سه گانه RDF، از طریق یک نقطه پایانی SPARQL در معرض دید قرار می گیرد و توسط یک رابط پرس و جو معنایی مورد سوء استفاده قرار می گیرد. با توجه به یک دوره و نام روستا یا منطقه جغرافیایی که با هندسه آن تعریف شده است، میتوان ثبتهای اراضی این منطقه و سیر تحول پوشش اراضی آنها در این دوره را بازیابی کرد. این داده ها به عنوان پایه ای برای سه سناریو عمل می کنند: ادغام مشاهدات سری زمانی. راهنمای فرآیند EO؛ و مقایسه متقابل داده ها
این کار کار در [ ۶ ] را با (الف) نشان دادن ابرداده و منشأ منابع داده با استفاده از واژگان DCAT و PROV-O و خود داده ها با گسترش واژگان SOSA گسترش می دهد. (ب) در نظر گرفتن دادههای استخراجشده از شطرنجیها بهعنوان ویژگیهای قابل مشاهده، که باعث میشود مدل به اندازه کافی عمومی برای تطبیق هر نوع خاصیت (مانند پوشش زمین، شاخص تغییر یا شاخص پوشش گیاهی) تا زمانی که در قالب شطرنجی در دسترس باشند.
این کار در چارچوب پروژه CANDELA ( http://www.candela-h2020.eu/ ) انجام می شود که هدف آن ارائه بلوک های ساختمانی و خدماتی است که به کاربران اجازه می دهد به سرعت از داده های Copernicus استفاده، دستکاری، کاوش و پردازش کنند. مجموعه بزرگی از داده های باز یکی از انگیزههای ساخت چنین پلتفرمی این است که جستجوی تصاویر تنها با استفاده از متا داده اصلی آنها، عمدتاً با استفاده از نوع حسگر، تاریخ ضبط و مکان برای یافتن تصاویر مرتبط برای یک هدف خاص کافی نیست. اطلاعات متنی، که از منابع داده ناهمگون مختلف، مانند رسترها، به دست میآیند، ممکن است مانند یک ماژول جستجوی معنایی مفید باشند.
مقاله بصورت زیر مرتب شده است. بخش ۲ کار اصلی مرتبط را مورد بحث قرار می دهد. بخش ۳ مدل معنایی را برای ادغام داده های استخراج شده از شطرنجی با داده های جغرافیایی، از طریق ابعاد مکانی و زمانی ارائه می دهد. بخش ۴ منابع داده انتخابی و فرآیند یکپارچه سازی داده های معنایی را شرح می دهد. بخش ۵ نتایج و بحثی را از نظر کاربرد مجموعه داده حاصل در موارد استفاده مختلف ارائه میکند. در نهایت، بخش ۶ مقاله را با دیدگاه هایی برای کار آینده به پایان می رساند.
۲٫ کارهای مرتبط
۲٫۱٫ مدلهای معنایی و فرآیندهای ETL معنایی برای یکپارچهسازی دادههای EO
پیشنهادهای معنایی مختلف ETL به تبدیل و ادغام دادههای EO (باز) به دادههای باز پیوندی (LOD) پرداختهاند. همانطور که قبلاً معرفی شد، این فرآیند به طور کلی توسط یک مدل معنایی هدایت می شود تا یک نمایش داده همگن به دست آورد. بیشتر این مدلها از واژگان استاندارد وب معنایی مجدداً استفاده میکنند و اخیراً از مدیریت دادههای چند بعدی مانند مکعبهای داده نتیجه میگیرند. در [ ۷ ]، نویسندگان تصاویر EO را به عنوان یک مکعب داده با یک مکان و زمان خاص به عنوان ابعاد مدل میکنند – یک پیشرفت مهم برای شبکه مکانی-زمانی داده [ ۷ ]. برای این منظور، در سال ۲۰۱۷، W3C هستی شناسی RDF Data Cube (QB) را پیشنهاد کرد [ ۸]] که در بسیاری از پیشنهادات به تصویب رسیده است. QB واژگان استانداردی مانند شبکه حسگر (SSN)، OWL-Time، سیستم سازماندهی دانش ساده (SKOS) و PROV-O را ترکیب می کند. در [ ۹ ]، QB برای انتشار دادههای سری زمانی جدولی و برای ساختاربندی آن به برشها برای پشتیبانی از چندین نما روی دادهها استفاده شده است. به روشی شبیه به یک مکعب داده های مکانی-زمانی، مکعب داده های EO معنایی [ ۱۰ ] حاوی داده های EO است که در آن برای هر مشاهده حداقل یک تفسیر اسمی (به عنوان مثال، طبقه بندی) در دسترس است. نزدیک به کار ما اما با رویکرد دسترسی به داده مبتنی بر هستی شناسی (OBDA)، مدل مورد استفاده در [ ۱۱] سه هستی شناسی، یعنی Data Cube، GeoSPARQL و OWL-Time را برای ارائه دسترسی به خدمات کوپرنیک گسترش می دهد. در عوض، ما SOSA را برای نمایش مجموعههای مشاهداتی انتخاب کردهایم، اما همترازیهایی ( https://www.w3.org/TR/vocab-ssn/ ) بین واژگان SOSA و QB وجود دارد تا مشاهدات را بهعنوان دادههای چند بعدی مطابق با مدل مکعب داده توصیف کند. .
در حالی که هدف برخی از رویکردها تولید مجموعههای داده پیوندی باز است، روشهای دیگر بر جنبههای روششناختی پیوند دادههای ناهمگن، همانطور که در [۱۲] بحث شد، برای محصولات دادههای حسگر تمرکز میکنند . چندین هستی شناسی برای ایجاد واژگان ماهواره ای INSAT-3D به هم مرتبط شده اند. در [ ۱۳ ]، خدمات زیست محیطی فشرده داده بر اساس داده های EO و داده های پایگاه های داده دولتی، آژانس های ملی و اروپایی پیشنهاد شده است.
رویکرد ما در اینجا به این مطالعات نزدیک است به این معنا که ما فرآیند یکپارچه سازی را در بالای یک هستی شناسی با استفاده مجدد از استانداردهای موجود هدایت می کنیم. یکی دیگر از پیشنهادهای نزدیک، پیشنهادی از [ ۳ ] است که یک فرآیند ETL را برای ادغام تصویر EO و منابع داده خارجی، مانند CLC، Urban Atlas، و Geonames انجام می دهد. این فرآیند به هستی شناسی SAR آنها متکی است. کار مشابه دیگری از نظر مجموعه داده ها از [ ۱۴ ] است که در آن داده ها یکپارچه شده و به عنوان LOD بر اساس هستی شناسی به نام proDataMarket منتشر می شوند. سه منبع داده، سیستم شناسایی بسته زمینی اسپانیا، ماهواره Sentinel-2 و پروازهای LiDAR یکپارچه شده اند. در [ ۱۵]، تصاویر ماهوارهای طبقهبندی شده و با دادههای معنایی غنی میشوند تا پرسشهایی را درباره آنچه میتوان در یک مکان خاص یافت، فعال کرد. کار ما راه حل مشابهی برای رسیدن به یک هدف با انواع مختلف داده ها به اشتراک می گذارد.
چندین کار به موضوع مدیریت حجم زیادی از داده های EO می پردازد. برای مثال، در [ ۱۶ ] یک چارچوب به یکپارچهسازی و پردازش دادههای ناهمگن در مقیاس بزرگ که از منابع متعدد تولید میشود برای حمایت از تصمیمهایی که از بلایای طبیعی جلوگیری میکنند کمک میکند. ادغام معنایی دادههای EO و غیر EO بر اساس هستیشناسی مدولار MEMON است که از هستیشناسیهای BFO، CCO، SSN و ENVO دوباره استفاده میکند.
۲٫۲٫ پردازش داده های شطرنجی در یک چارچوب معنایی
ما میتوانیم دو رویکرد را برای نمایش دادههای شطرنجی متمایز کنیم که با دو روش سنتی پردازش دادههای شطرنجی مطابقت دارند: پردازش کل شبکه شطرنجی به عنوان پوشش یا ارائه روشهایی برای استخراج اشیاء برداری از ماتریس شطرنجی. گزینه اول بر نمایش معنایی پیکسل های شطرنجی متکی است به طوری که هر ویژگی پیکسل (هندسه، مقادیر) حفظ شود. [ ۱۷ ] هستی شناسی پوشش RDF Grid را برای پشتیبانی از یکپارچگی بومی پوشش در سه فروشگاه RDF طراحی کرد. ساختار شبکه ای داده ها حفظ می شود و می توان با استفاده از SciSPARQL پرس و جو کرد. اخیراً پسوند فضایی Ontop [ ۱۸] می تواند داده های شطرنجی را پردازش کند و نماهای RDF جغرافیایی مجازی بالای آنها ایجاد کند. این ابزار به لطف اعلام نقشه و تابع تخلیه چند ضلعی PostGIS به طور خودکار هر پیکسل شطرنجی را به یک ویژگی تبدیل می کند. در نتیجه رستر باید قبل از پردازش به پایگاه داده PostGIS وارد شود. در این رویکرد، تبدیل تمام پیکسلهای شطرنجی به RDF به میزان قابل توجهی تعداد سهگانهها را افزایش میدهد که در نهایت ممکن است باعث مشکلات عملکرد شود.
رویکرد دوم شامل استخراج موجودیت ها از فایل های شطرنجی و نمایش آنها به عنوان ویژگی های هستی شناختی است. این موجودیتها مجموعهای از عناصر شطرنجی (یعنی مجموعهای از پیکسلها) هستند که با یک تعریف وابسته به زمینه خاص مطابقت دارند. یک نمونه اولیه در [ ۱۹ ] برای یکپارچه سازی و پردازش داده های برداری علمی و شطرنجی از مخازن LOD با استفاده از برداری و ابزارهای ریاضی برای پردازش جغرافیایی ارائه شده است. اول، جعبه های محدود کننده از رستر برای پرس و جو از نقاط انتهایی LOD برای ویژگی های جغرافیایی استفاده می شود. سپس، از ویژگیهای جغرافیایی بازگشتی برای انتخاب پیکسلهای شطرنجی برای آموزش نظارتشده بر اساس توصیفگرهای مبتنی بر محتوا استفاده میشود. در نهایت، نتایج را می توان بردار، تبدیل، و در triplestore درج کرد. در [ ۳]، این رویکرد پیشنهاد میکند که تصاویر را به صورت تکههایی با اندازه ثابت، که اطلاعات متنی به آنها مرتبط است، بازسازی کند. در پایان، هر پچ مستقیماً بر اساس هستی شناسی خود به یک ویژگی تبدیل می شود. راه حل مشابهی در [ ۲۰] پیاده سازی شده است] که در آن ویژگی های هستی شناختی بخش های جاده هستند. با نگاشت جعبه های مرزی آنها (۱ متر در اطراف بخش) به داده های شطرنجی، مقدار پیکسل در این ناحیه با یک آستانه مقایسه می شود و مقدار یک ویژگی معنایی بخش جاده را تعیین می کند. نویسندگان همچنین پیشنهاد میکنند که زبان پرس و جو SPARQL را به گونهای گسترش دهیم که توابع هندسی استاندارد را هم در فایلهای شطرنجی و هم در فایلهای برداری مدیریت کند. برای این کار، ناحیه مورد نظر شطرنجی را چند ضلعی می کنند. این راه حل مسلماً راه حل کاملی برای نمایش فایل های شطرنجی در RDF نیست زیرا منبع هندسی اصلی داده ها حفظ نشده است [ ۲۱ ]. در رویکرد ما، مناطق مورد علاقه از پیش تعریف شده اند، از این رو هندسه ها (چند ضلعی ها) شناخته شده اند.
۲٫۳٫ تعیین موقعیت مشارکت ما
در جدول ۱ ، مدل خود را با نزدیکترین مدلهای پیشرفته برای نمایش یا یکپارچهسازی دادههای EO مقایسه میکنیم. ما یک مدل را زمانی منتشر میکنیم که در دسترس عموم باشد یا در یک سند همراه (مقاله یا وبسایت) یا با کمک ابردادههای غنی به خوبی توضیح داده شود. گفته می شود این مدل زمانی قابل استفاده مجدد است که به اندازه کافی عمومی باشد تا در سناریوها یا سیستم های دیگر مورد استفاده قرار گیرد. در جدول مقایسه، ویژگیهای هر مدل را که شامل ما میشود، گزارش کردیم. مدل ما تمام نیازهای مورد نیاز برای یک مدل غنی تر و بازتر را برآورده می کند. منتشر شده، قابل استفاده مجدد است و از بعد زمانی و همچنین ابرداده منبع پشتیبانی می کند. علاوه بر این، یکی از معدود مدل هایی است که می تواند داده های شطرنجی را نشان دهد.
جدول ۲ مقایسه ای از پیشنهاد ما را با نزدیکترین موارد در ادبیات برای ادغام یا نمایش شطرنجی ارائه می دهد. مشابه ترین رویکردی که از ورودی برداری (شامل ویژگی های جغرافیایی) استفاده می کند [ ۱۹ ] است. اما این کار تکمیل نشده و مدل آن منتشر نشده است.
در جدول ۲ما دو روش برای انجام یکپارچهسازی دادههای معنایی متمایز میکنیم: یا یک واسطه برای سیستمهای مجازی ساخته میشود (نقشهبرداری بر اساس تقاضا) یا تحقق دادهها برای سیستمهای پایدار انجام میشود (مادیسازی دادهها). اینها جنبه های مهم فرآیند ETL هستند. برای نگاشت بر اساس تقاضا، داده ها در منبع خود باقی می مانند، در نتیجه پرس و جوهای SPARQL باید در مرحله ارزیابی پرس و جو بازنویسی شوند. این رویکرد در زمینه مجموعه داده های بسیار بزرگی که به دلیل محدودیت منابع به سختی از متمرکزسازی پشتیبانی می کنند، مناسب است. برای تحقق داده ها، مانند رویکردهای انبار، منابع داده به نمودارهای RDF تبدیل می شوند که پس از آن در یک فروشگاه سه گانه بارگذاری می شوند و از طریق موتور جستجوی SPARQL قابل دسترسی هستند. پیشنهاد ما رویکرد تحقق را اعمال می کند. مزیت اصلی این رویکرد تسهیل پردازش، تحلیل یا استدلال بیشتر بر روی داده های RDF تحقق یافته است. به طور خاص، این انتخاب به دلایل زیر انجام می شود: (۱) اجرای نقشه بر اساس تقاضا آسان نیست زیرا منابع داده ای که در نظر گرفتیم (در زیر ارائه شده است) در قالب های مختلف (JSON/GeoJSON، تصویر GeoTIFF، shapefile) موجود هستند. یا حتی فایل های فشرده از راه دور)، که نیاز به یک مرحله پیش پردازش تبدیل دارد. (۲) سهگانههای زمینفضایی را میتوان به عنوان انباری برای ذخیره دادههای معنایی در نظر گرفت تا غنیسازی و پیوند دادهها انجام شود. و (iii) مجموعه داده های مختلف ممکن است توسط نقاط پایانی متفاوتی ارائه شوند که به مکانیزم های فدراسیون نیاز دارند، با این حال، در حال حاضر هیچ موتور پرس و جو به اندازه کافی بالغ برای پاسخگویی به جستارهای GeoSPARQL در چنین فدراسیونی وجود ندارد [ یا استدلال بر روی داده های RDF تحقق یافته. به طور خاص، این انتخاب به دلایل زیر انجام می شود: (۱) اجرای نقشه بر اساس تقاضا آسان نیست زیرا منابع داده ای که در نظر گرفتیم (در زیر ارائه شده است) در قالب های مختلف (JSON/GeoJSON، تصویر GeoTIFF، shapefile) موجود هستند. یا حتی فایل های فشرده از راه دور)، که نیاز به یک مرحله پیش پردازش تبدیل دارد. (۲) سهگانههای زمینفضایی را میتوان به عنوان انباری برای ذخیره دادههای معنایی در نظر گرفت تا غنیسازی و پیوند دادهها انجام شود. و (iii) مجموعه داده های مختلف ممکن است توسط نقاط پایانی متفاوتی ارائه شوند که به مکانیزم های فدراسیون نیاز دارند، با این حال، در حال حاضر هیچ موتور پرس و جو به اندازه کافی بالغ برای پاسخگویی به جستارهای GeoSPARQL در چنین فدراسیونی وجود ندارد [ یا استدلال بر روی داده های RDF تحقق یافته. به طور خاص، این انتخاب به دلایل زیر انجام می شود: (۱) اجرای نقشه بر اساس تقاضا آسان نیست زیرا منابع داده ای که در نظر گرفتیم (در زیر ارائه شده است) در قالب های مختلف (JSON/GeoJSON، تصویر GeoTIFF، shapefile) موجود هستند. یا حتی فایل های فشرده از راه دور)، که نیاز به یک مرحله پیش پردازش تبدیل دارد. (۲) سهگانههای زمینفضایی را میتوان به عنوان انباری برای ذخیره دادههای معنایی در نظر گرفت تا غنیسازی و پیوند دادهها انجام شود. و (iii) مجموعه داده های مختلف ممکن است توسط نقاط پایانی متفاوتی ارائه شوند که به مکانیزم های فدراسیون نیاز دارند، با این حال، در حال حاضر هیچ موتور پرس و جو به اندازه کافی بالغ برای پاسخگویی به جستارهای GeoSPARQL در چنین فدراسیونی وجود ندارد [ (i) اجرای نقشه بر اساس تقاضا آسان نیست زیرا منابع داده ای که در نظر گرفتیم (در زیر ارائه شده است) در قالب های مختلف (JSON/GeoJSON، تصویر GeoTIFF، shapefile یا حتی فایل های فشرده از راه دور) در دسترس هستند، که به یک پیش نیاز نیاز دارد. مرحله پردازش تبدیل؛ (۲) سهگانههای زمینفضایی را میتوان به عنوان انباری برای ذخیره دادههای معنایی در نظر گرفت تا غنیسازی و پیوند دادهها انجام شود. و (iii) مجموعه داده های مختلف ممکن است توسط نقاط پایانی متفاوتی ارائه شوند که به مکانیزم های فدراسیون نیاز دارند، با این حال، در حال حاضر هیچ موتور پرس و جو به اندازه کافی بالغ برای پاسخگویی به جستارهای GeoSPARQL در چنین فدراسیونی وجود ندارد [ (i) اجرای نقشه بر اساس تقاضا آسان نیست زیرا منابع داده ای که در نظر گرفتیم (در زیر ارائه شده است) در قالب های مختلف (JSON/GeoJSON، تصویر GeoTIFF، shapefile یا حتی فایل های فشرده از راه دور) در دسترس هستند، که به یک پیش نیاز نیاز دارد. مرحله پردازش تبدیل؛ (۲) سهگانههای زمینفضایی را میتوان به عنوان انباری برای ذخیره دادههای معنایی در نظر گرفت تا غنیسازی و پیوند دادهها انجام شود. و (iii) مجموعه داده های مختلف ممکن است توسط نقاط پایانی متفاوتی ارائه شوند که به مکانیزم های فدراسیون نیاز دارند، با این حال، در حال حاضر هیچ موتور پرس و جو به اندازه کافی بالغ برای پاسخگویی به جستارهای GeoSPARQL در چنین فدراسیونی وجود ندارد [ (۲) سهگانههای زمینفضایی را میتوان به عنوان انباری برای ذخیره دادههای معنایی در نظر گرفت تا غنیسازی و پیوند دادهها انجام شود. و (iii) مجموعه داده های مختلف ممکن است توسط نقاط پایانی متفاوتی ارائه شوند که به مکانیزم های فدراسیون نیاز دارند، با این حال، در حال حاضر هیچ موتور پرس و جو به اندازه کافی بالغ برای پاسخگویی به جستارهای GeoSPARQL در چنین فدراسیونی وجود ندارد [ (۲) سهگانههای زمینفضایی را میتوان به عنوان انباری برای ذخیره دادههای معنایی در نظر گرفت تا غنیسازی و پیوند دادهها انجام شود. و (iii) مجموعه داده های مختلف ممکن است توسط نقاط پایانی متفاوتی ارائه شوند که به مکانیزم های فدراسیون نیاز دارند، با این حال، در حال حاضر هیچ موتور پرس و جو به اندازه کافی بالغ برای پاسخگویی به جستارهای GeoSPARQL در چنین فدراسیونی وجود ندارد [۱۱ ]. از آنجایی که ما یک جستار GeoSPARQL را برای بررسی ویژگیهای جغرافیایی ذخیره شده در مکانهای مختلف ارسال میکنیم، مقایسه فضایی در پرواز امکانپذیر نیست.
۳٫ مدل های معنایی برای یکپارچه سازی داده های EO
هدف ما ادغام منابع داده با استفاده از ابعاد مکانی-زمانی آنهاست. به عبارت دیگر، با توجه به مناطق مورد علاقه، مانند واحدهای سرزمینی یا قطعات کشاورزی، و منابع داده، میخواهیم یک نمودار دانش بسازیم که دادههای مناسب را به هر واحد پیوند دهد. رویکرد ما بر یک مدل معنایی متکی است که واژگان منحصر به فردی را برای نمایش تمام داده ها و واحدهای سرزمینی ارائه می دهد. ما این مدل را به عنوان یک هستی شناسی عمومی و مدولار طراحی کردیم که از واژگان استاندارد استفاده مجدد می کند. برای ساخت اولین ماژول، به نام مدل واحد سرزمینی (TUM)، ما از هستیشناسی TSN (هستیشناسی نامگذاری آماری سرزمینی) مجددا استفاده و گسترش دادیم [ ۲۲] .] که حوزه های مورد علاقه، مانند واحدهای اداری و بسته ها را به همراه نسخه های آنها نشان می دهد. برای نمایش مشاهدات انجام شده در یک منطقه معین و برای یک دوره، ما یک ماژول دوم، هستی شناسی TUOM (هستی شناسی مدل مشاهده واحد سرزمینی) را تعریف کردیم. مشاهده را می توان به عنوان فعالیتی در نظر گرفت که ارزش ملکی محاسبه شده از مناطق را تولید می کند. قبل از ارائه مدلهای TUM و TUOM ( بخش ۳٫۲ )، واژگان پیشرفتهای را توصیف میکنیم که آنها بر آن تکیه میکنند ( بخش ۳٫۱ )، یعنی GeoSPARQL (برای دادههای مکانی)، OWL-Time (برای ویژگیهای زمانی)، DCAT. (برای ابرداده منابع داده)، PROV-O (برای منشأ منابع داده) و SOSA (برای مشاهدات).
۳٫۱٫ واژگان مورد استفاده مجدد
۳٫۱٫۱٫ واژگان استاندارد
هستی شناسی GeoSPARQL ( https://www.ogc.org/standards/geosparql ): هستی شناسی GeoSPARQL (عصاره ارائه شده در کادر بالا سمت چپ شکل ۱ )، یک استاندارد OGC، کلاس geo:SpatialObject متشکل از دو زیر کلاس اصلی را معرفی می کند. , geo:feature و geo:geometry [ ۲۳ ]. اولی یک موجودیت از دنیای واقعی را نشان می دهد در حالی که دومی تمام اشکال هندسی تعریف شده بر روی یک سیستم مرجع مختصات فضایی را نشان می دهد. یک موجودیت با رابطه geo:hasGeometry با هندسه های خود مرتبط می شود. GeoSPARQL روابط و توابع توپولوژیکی را برای پیوند اشیاء فضایی (تقاطع، لمس و غیره) فراهم می کند.
هستی شناسی OWL-Time ( https://www.w3.org/TR/owl-time/ ): هستی شناسی OWL-Time (جعبه سمت راست بالای شکل ۱ ) [ ۲۴ ] توسط W3C برای مدل سازی مفاهیم زمانی توصیه شده است. لحظه ها و فواصل) و بیان روابط توپولوژیکی که در نظریه آلن بین آنها تعریف شده است (قبل، بعد و غیره). برای توصیف ویژگی های زمانی داده ها استفاده می شود.
واژگان DCAT ( https://www.w3.org/TR/vocab-dcat-2/ ): DCAT واژگانی است که برای انتشار کاتالوگ های فراداده در وب طراحی شده است. در DCAT، کاتالوگ (dcat:Catalog) مجموعه داده ای است که در آن هر آیتم یک رکورد ابرداده است که برخی از منابع را توصیف می کند. دامنه کاتالوگ مجموعه ای از ابرداده در مورد مجموعه داده ها یا خدمات داده است. مجموعه داده (dcat:Dataset) مجموعهای از دادهها است که توسط یک عامل منتشر یا مدیریت میشود. این واژگان عناصری از واژگان دیگر مانند اصطلاحات هسته دوبلین (پیشوند dct) را ترکیب می کند: dct:temporal و dct:spatial برای توصیف پوشش مکانی و زمانی مجموعه داده استفاده می شود. نمونه ای از کلاس dcat:Distribution یک پیاده سازی مشخص از یک مجموعه داده را نشان می دهد (به عنوان مثال، شطرنجی، شکل فایل، و غیره).
هستیشناسی PROV-O ( https://www.w3.org/TR/prov-o/ ): PROV-O یک مدل داده، سریالسازی و تعاریف را برای پشتیبانی از تبادل اطلاعات منشأ در وب تعریف میکند. این یک توصیه W3C است که امکان ارزیابی کیفیت، قابلیت اطمینان یا قابل اعتماد بودن داده ها را فراهم می کند. در این واژگان، موجودیت (prov-o:Entity) چیزی است که ممکن است از موجودات دیگر مشتق شود.
هستی شناسی SOSA ( https://www.w3.org/TR/vocab-ssn/ ): هستی شناسی SOSA (حسگر، مشاهده، نمونه، و محرک) [ ۲۵] یک هستی شناسی هسته سبک وزن اما مستقل است که کلاس ها و ویژگی های اولیه هستی شناسی SSN (شبکه حسگر معنایی) را نشان می دهد. این سنسورها، مشاهدات و روشهای آنها را توصیف میکند و تا حد زیادی در طیف وسیعی از کاربردها و اخیراً در تصاویر ماهوارهای مورد استفاده قرار گرفته است. در واژگان SOSA، یک مشاهده (sosa:Observation) به عنوان فعالیتی در نظر گرفته میشود که با استفاده از یک رویه مشخص، یک تخمین ارزش دارایی را ارائه میکند. این به ما اجازه می دهد تا ویژگی مربوط به علاقه و ویژگی مشاهده شده را نیز توصیف کنیم. SOSA از OWL-Time برای تاریخ مشاهدات استفاده مجدد می کند (sosa:phenomenomTime). کلاس sosa:ObservationCollection یک برنامه افزودنی است که در یک پیش نویس فعلی پیشنهاد شده است ( https://www.w3.org/TR/2020/WD-vocab-ssn-ext-20200116/). مجموعهای از مشاهدات را نشان میدهد که مقدار مشترکی برای یک یا چند ویژگی مشاهده دارند (مانند حسگر مشابه، صحنه مشابه). چنین نمایشی از تکرار سه گانه جلوگیری می کند و در نتیجه، ذخیره سازی داده ها را بهینه می کند و زمان اجرای پرس و جو را کاهش می دهد.
۳٫۱٫۲٫ سایر واژگان
هستیشناسی TSN (هستیشناسی نامگذاری آماری سرزمینی [ ۲۲ ]، که توسط کادر بالا و میانی در شکل ۱ ارائه شده است) هر نامگذاری سرزمینی را در طول زمان توصیف میکند (یعنی نسخههایی از نامگذاریها را مجاز میسازد). هستی شناسی TSN رویکرد پردورانتیستی هستی شناسی ها را برای روان [ ۲۶ ] برای توصیف عناصر TSN که در زمان متفاوت هستند، اتخاذ می کند. با این حال، نویسندگان ترجیح می دهند از عبارت Version استفاده کنند در حالی که سایر هستی شناسی ها، برای روانی، از TimeSlice استفاده می کنند . از آنجایی که نسخههای واحد سرزمینی موجودیتهایی را نشان میدهد که در یک زمان معین مکانیابی شدهاند، هستیشناسی از هستیشناسیهای GeoSPARQL و OWL-Time دوباره استفاده میکند.
۳٫۲٫ هستی شناسی ادغام
هستی شناسی ادغام مدولار است: هر ماژول یک مدل مستقل با تعداد محدودی از روابط با مفاهیم ماژول های دیگر را تشکیل می دهد.
۳٫۲٫۱٫ مدل واحد سرزمینی (TUM)
برای نشان دادن انواع مختلف واحدهای سرزمینی، مانند واحدهای اداری و بستهها، در طول عمرشان، ما هستیشناسی مدل واحد سرزمینی (TUM) را پیشنهاد میکنیم که هستیشناسی TSN شرح داده شده در بالا را گسترش میدهد. در واقع، از آنجایی که واحدهای اداری و مجموعه داده های ثبت زمین به طور منظم به روز می شوند، امکان مدیریت نسخه های مختلف محتوای آنها وجود دارد. TUM دو کلاس tum:AdministrativeUnit و tum:Parcel را معرفی می کند. آنها tsn:Unit را گسترش می دهند تا بازه های زمانی مختلف این موجودیت ها را در طول زمان در نظر بگیرند. ما از واژگان PROV-O برای مدیریت منابع یکپارچه استفاده می کنیم. بنابراین یک نسخه نامگذاری واحد سرزمینی به عنوان یک prov-o:Entity در نظر گرفته می شود که از یک مجموعه داده (باز) مشتق شده است، به عنوان مثال، یک prov-o:Entity دیگر. این منبع (tum:NomenclatureSourceDataset) نیز به عنوان یک dcat نشان داده می شود:
۳٫۲٫۲٫ مدل مشاهده واحد سرزمینی (TUOM)
برای نمایش مشاهدات انجام شده بر روی واحدهای سرزمینی (به عنوان مثال، پوشش زمین، شاخص تغییر یا NDVI)، ما هستی شناسی TUOM (هستی شناسی مدل مشاهده واحد سرزمینی) را تعریف کرده ایم. این هستی شناسی ( شکل ۲) برای توصیف مشاهدات روی واحدها به SOSA متکی است. هر ویژگی مشاهده شده (به عنوان مثال، کلاس Water یا Vineyards CESBIO-LC) به عنوان یک tuom:GeoFeatureObservableProperty نشان داده می شود و به یک tuom:GeoFeatureObservablePropertyType تعلق دارد (به عنوان مثال، CESBIO-LC 2018). یک tuom:GeoFeatureObservationCollection همه مشاهدات جمعآوریشده برای یک نوع ویژگی از یک شطرنجی (بعد زمانی) و برای یک واحد سرزمینی (بعد مکانی) را گروهبندی میکند. به عنوان نتیجه اندازه گیری شده برای یک ویژگی مشاهده شده، یک مقدار درصد به هر مشاهده نسبت داده می شود. مثلاً ۲۵ درصد آب و ۷۵ درصد تاکستان. برای کاهش پیچیدگی پرس و جو و پردازش زمان، ویژگی غالب tuom:dominantObservedProperty مجموعه مشاهده را نیز محاسبه می کنیم.
۴٫ فرآیند ادغام معنایی
فرآیند ادغام معنایی را می توان به چندین مرحله تقسیم کرد، مانند فرآیند ETL. این فرآیند بر تعریف نگاشت های معنایی، با شناسایی بخش هایی از طرحواره منابع داده که به مدل داده های معنایی مرتبط هستند، تکیه دارد و از فرآیند استخراج پشتیبانی می کند. و در مورد تعریف توابع تبدیل برای پر کردن ماژول های داده با مقادیر همگن.
۴٫۱٫ منابع اطلاعات
ما دو نوع منبع داده را متمایز میکنیم: (من) دادههای برداری با یک جزء جغرافیایی مربوط به مناطقی که میخواهیم از دادههای شطرنجی (مثلاً واحدهای سرزمینی یا ثبتهای زمین) واجد شرایط شوند. (۲) رسترها با ابردادههایشان (تاریخ، ردپای و طبقهبندی مربوطه).
-
منابع داده برداری: منابع داده برداری حاوی ویژگی های جغرافیایی با هندسه هستند. ما دو منبع داده برداری زیر را برای تولید مجموعه داده RDF خود در نظر می گیریم.
-
واحدهای اداری: واحدهای اداری فرانسوی را می توان از مجموعه داده های باز مختلف، به ویژه مجموعه داده مبتنی بر OpenStreetMap به دست آورد ( https://www.data.gouv.fr/en/datasets/decoupage-administratif-communal-francais-issu-d- openstreetmap/ ) و مجموعه داده GeoZones ( https://www.data.gouv.fr/en/datasets/geozones/ ). دومی جزئیات بیشتری در مورد واحدهای اداری نسبت به اول ارائه می دهد، اما کمتر به روز می شود. به همین دلیل، مجموعه داده مبتنی بر OpenStreetMap را انتخاب کردیم که به صورت فایلهای شیپ موجود است.
-
ثبتهای زمین: دادههای ثبت زمین از وبسایت دادههای دولت فرانسه ( https://cadastre.data.gouv.fr/datasets/cadastre-etalab ) در قالب GeoJSON یا shapefiles در دسترس است. مجموعه داده شناسایی و مکان یابی قطعات را از ثبت زمین فراهم می کند.
-
-
منابع داده شطرنجی: یک منبع داده شطرنجی ماتریسی از سلول ها (یا پیکسل ها) را ارائه می دهد که در آن هر سلول حاوی مقداری است که نشان دهنده پدیده در نظر گرفته شده توسط منبع است. هر سلول بخشی از سطح زمین را می پوشاند. اندازه سلول ها با وضوح فضایی شطرنجی تعریف می شود. وضوح فضایی بالاتر شامل سلول های بیشتری در واحد سطح است. هنگامی که سلول ها حاوی مقادیر کلاس هستند (به عنوان مثال، کلاس پوشش زمین)، طبقه بندی باید برای رمزگشایی این مقادیر ارائه شود.رستر قالب استاندارد تبادل بین ابزارهای توسعه یافته در پروژه است، از جمله ابزارهایی برای تشخیص تغییر و طبقه بندی پوشش زمین از تصاویر Sentinel. فرمت های دیگر در توسعه بعدی در نظر گرفته خواهند شد. مجموعه داده RDF ما داده های محاسبه شده از رسترهای پوشش زمین را فراهم می کند.
-
رسترهای پوشش زمین: هر پیکسل از رسترهای پوشش زمین اطلاعاتی در مورد پوشش فیزیکی سطح زمین در این مکان ارائه می دهد. به عنوان مثال، پوشش ممکن است بیش از جنگل ها، علفزارها یا زمین های زراعی باشد. هر نوع پوشش با توجه به طبقه بندی خاص با یک عدد همراه است و مقدار پیکسل بر روی یکی از این اعداد تنظیم می شود. منابع مختلف پوشش زمین با طبقه بندی آنها وجود دارد. یک منبع در مقیاس جهانی GLC-SHARE ( http://www.fao.org/geospatial/resources/detail/en/c/1036591/ ) است که توسط فائو در سال ۲۰۱۲ ایجاد شد و در قالب شطرنجی به عنوان فایل GeoTIFF ارائه شد. مجموعه داده های CLC ( https://www.data.gouv.fr/en/datasets/corine-land-cover-occupation-des-sols-en-france ) بر اساس واژگان CLC (http://dd.eionet.europa.eu/vocabulary/landcover/clc ). دو مورد اخیر برای سالهای ۲۰۱۲ و ۲۰۱۸ منتشر شدهاند. پوشش زمین فرانسوی خاصتر مربوط به CESBIO است ( http://osr-CESBIO.ups-tlse.fr/~oso/ ). یک نسخه جدید سالانه از سال ۲۰۱۶ ارائه می شود (مجموعه داده های ۲۰۰۹، ۲۰۱۰، ۲۰۱۱ و ۲۰۱۴ نیز موجود است) در قالب شطرنجی به عنوان یک فایل GeoTIFF. به طور خاص، CESBIO-LC عمدتاً بر اساس تصاویر Sentinel-2 است که در تمام طول سال به دست میآید، در حالی که GLC-SHARE منابع مختلف EO را ترکیب میکند. علاوه بر این، در حالی که GLC-SHARE دارای پوشش جهانی است، با وضوح فضایی ۱۰۰۰ متر ۲در هر پیکسل، CESBIO-LC تنها فرانسه را با وضوح فضایی ۱۰ متر پوشش می دهد ۲٫ ما مجموعه دادههای CESBIO و طبقهبندی پوشش زمین مربوطه را به دلیل کیفیت بالای آن انتخاب کردیم.
-
۴٫۲٫ فرآیند معنایی ETL
ما یک فرآیند ETL معنایی چهار مرحله ای را برای ساختن یک فروشگاه سه گانه RDF از منابع داده ناهمگن تعریف کردیم:
-
بازیابی داده ها: در این مرحله مجموعه داده های مورد علاقه بر اساس معیارهای مکانی و زمانی شناسایی و با استفاده از مکانیسم های جستجوی اختصاصی بازیابی می شوند. این مرحله را می توان به صورت نیمه اتوماتیک و با کمک اسکریپت های اختصاصی انجام داد. به عنوان مثال، مجموعه داده حاوی اطلاعات یک روستای فرانسوی را می توان بر اساس کد INSEE و سال انتشار آن بازیابی کرد. در مورد رسترهای پوشش زمین، باید شرح مفصلی از طبقات پوشش زمین مورد استفاده برای کدگذاری رستر نیز بازیابی شود. چنین واژگانی معمولاً با یک متن (CESBIO-LC) یا فایل PDF (CLC یا GLC-SHARE) توصیف می شود.
-
استخراج داده ها: هدف این مرحله استخراج و ساختاردهی داده ها از منابع داده است. در مرحله اول، ابرداده (به عنوان مثال، تاریخ صدور، قالب، CRS، یا وسعت فضایی) استخراج می شود. هندسه موجودیت در فایل های برداری با WGS84 CRS که CRS پیش فرض GeoSPARQL است مطابقت دارد. رسترها برای واجد شرایط بودن واحدهای سرزمینی پردازش میشوند: یا ویژگیهای جدید (مثلاً مقادیر میانگین) از طریق تجمع پیکسل استخراج میشوند یا از یک ماسک فضایی برای حذف مناطق نامطلوب استفاده میشود (یعنی فقط ناحیه داخل ردپای واحد حفظ میشود). به عنوان مثال، پوشش زمین یک قطعه از یک رستر در سه مرحله محاسبه می شود:
- (آ)
-
بسته و شطرنجی پوشش زمین را روی همان CRS دوباره طرح کنید.
- (ب)
-
بسته (هندسه نسخه بسته در تاریخ معین) را به عنوان یک ماسک روی شطرنجی اعمال کنید.
- (ج)
-
درصد هر طبقه پوشش زمین که قطعه را اشغال می کند را محاسبه کنید. به عنوان مثال در شکل ۳ ، بسته چهار پیکسل را پوشش می دهد: سه تا از آنها به عنوان تاکستان (کد ۱۵) حاشیه نویسی شده اند، آخرین مورد آب است (کد ۲۳). به عبارت دیگر ۷۵ درصد زمین را تاکستان و مابقی را آب تشکیل می دهد.
نتیجه این مرحله یک ساختار موقت JSON است که برای تبدیل در مرحله بعد استفاده می شود. ما JSON را انتخاب کردیم زیرا می تواند مشاهدات و ویژگی های جغرافیایی را توصیف کند. -
تبدیل داده: هدف این مرحله تبدیل داده های پردازش شده به معنایی است. الگوهایی که نگاشت بین طرحواره منبع و هستی شناسی ها را تعریف می کنند به عنوان پایه در این فرآیند استفاده می شوند. آنها معمولاً دست نویس هستند و نگاشتها را واضح می کنند. ابزارهای ترجمه دادهها، مانند D2RQ ( http://d2rq.org/ )، Ultrawrap ( https://capsenta.com/ultrawrap/ )، Morph ( http://mayor2.dia.fi.upm.es/oeg- upm/index.php/en/technologies/315-morph-rdb/ )، Ontop ( http://ontop.inf.unibz.it/ )، یا GeoTriples ( http://geotriples.di.uoa.gr/ ) با استفاده از چنین نگاشت ها می توان استفاده کرد. با این حال، ما انتخاب کرده ایم که الگوی نقشه برداری و مکانیزم پردازش کار اخیر خود را تکامل دهیم [ ۲۷] زیرا می توان توابع بیشتری را برای انجام عملیات پیچیده تری اضافه کرد که در رویکردهای جایگزین امکان پذیر نیست. خروجی این مرحله مجموعه ای از فایل های RDF است.در این مرحله، طبقه بندی پوشش زمین (کدهای کلاس و برچسب) نیز به عنوان نمونه هایی از دو کلاس به RDF تبدیل می شود: tuom:GeoFeatureObservablePropertyType و tuom:GeoFeatureObservableProperty. فرآیند تبدیل طبقهبندی توصیفشده توسط ساختار CSV متشکل از دو ستون (کد و برچسب) را به عنوان ورودی میگیرد و میتواند به طور مستقل با ستون شطرنجی انجام شود. پیوست A نمونه ای از ساختار JSON است که در مرحله قبل استخراج شده است.پیوست B عصاره ای از الگوهای مورد استفاده برای تبدیل اطلاعات استخراج شده به فرمت RDF را ارائه می دهد. در این الگوها، تابع valueToLiteral برای تبدیل یک مقدار به literal و کلمه کلیدی $ Instance_X برای شروع خودکار نمونه ای از کلاس X با تعریف URI آن استفاده می شود. متغیرها (با $ شروع می شوند .) مقادیر نمایش JSON را نشان می دهند.ضمیمه C برخی از سه گانه RDF تولید شده از ساختار JSON ارائه شده در ضمیمه A را با استفاده از الگوهای بالا فهرست می کند.
-
بارگذاری داده: مرحله نهایی شامل وارد کردن فایلهای RDF به فروشگاه سهگانه است.
۴٫۳٫ معماری سیستم
این سیستم از طریق فناوری داکر توسعه یافته است. همانطور که در شکل ۴ توضیح داده شده است دو داکر وجود دارد : اولی شامل اسکریپت های پایتون برای بازیابی داده ها، پردازش داده ها، تبدیل داده ها، و بار انبوه سه طبقه است، دومی برای استقرار سه فضای مکانی استفاده می شود که پایگاه دانش را مدیریت می کند.
در حال حاضر، چندین فروشگاه سهگانه از ذخیرهسازی و جستجوی دادههای مکانی با استفاده از GeoSPARQL یا stSPARQL پشتیبانی میکنند. مجانی که پشتیبانی خوبی ارائه می دهند عبارتند از پارلمان ( http://parliament.semwebcentral.org/ ) [ ۲۸ ]، Strabon ( http://strabon.di.uoa.gr/ ) [ ۲۹ ] و GraphDB ( http:// graphdb.ontotext.com/ ). آنها به صراحت استاندارد هندسه جغرافیایی موجود را اتخاذ می کنند، اگرچه بسیاری از فروشگاه های سه گانه اکنون از پرس و جوهای فضایی با پیچیدگی های مختلف پشتیبانی می کنند [ ۳۰ ]. در حالی که پارلمان را آزمایش نکردهایم، برای GraphDB انجام دادیم که برای جستارهای مربوط به اتصالات فضایی ضعیف عمل کرد. از این رو Strabon در پروژه ما انتخاب شده است زیرا مزایای زیادی دارد:
-
Strabon سهگانه Sesame را با ظرفیت ذخیرهسازی دادههای RDF فضایی در DBMS PostgreSQL ارتقا یافته با PostGIS گسترش میدهد. به لطف تکنیکهای بهینهسازی خاصی که به عملیات فضایی اجازه میدهد به جای تکیه بر کتابخانههای خارجی، از قابلیت PostGIS بهره ببرند، این triplestore عملکرد کلی خوبی دارد [ ۳۱ ]. برای کاربردهای پیچیده که شامل هر دو اتصال فضایی یا تجمعات فضایی است، Strabon تنها ذخیره RDF است که عملکرد خوبی داشت [ ۳۲ ].
-
Strabon همچنین یک نقطه پایانی SPARQL را ارائه می دهد که به دسترسی به محتوای فروشگاه تریپل کمک می کند. این رابط همچنین یک امکان اضافی برای مدیریت پایگاه دانش فراهم می کند، به عنوان مثال ذخیره و به روز رسانی عملکردها با به روز رسانی SPARQL.
اولین داکر حاوی فرآیند ETL در اینجا به صورت عمومی در دسترس است ( https://hub.docker.com/r/h2020candela/triplification ). دومین داکر حاوی Strabon را میتوان به صورت آنلاین ( https://hub.docker.com/r/bde2020/strabon ) پیدا کرد.
۵٫ نتایج و بحث
نتایج با توجه به مشارکت مجموعه داده حاصل در سه مورد استفاده ارزیابی میشوند: ادغام مشاهدات سری زمانی. راهنمای فرآیند EO؛ و مقایسه داده ها مناطق مورد علاقه برای پاسخ به نیازهای داده در پروژه CANDELA انتخاب شدند که انواع مختلف تجزیه و تحلیل از تشخیص تغییر تا تکامل پوشش زمین را پشتیبانی می کند. مجموعه داده به دست آمده به کاربران اجازه می دهد تا به طور همگن از داده ها پرس و جو کنند و به وظایف بازیابی اطلاعات آنها کمک کند. ارائه موارد استفاده مختلف، سهم پیشنهاد ما را از نظر هستیشناسی مدولار تأیید میکند که میتواند انواع مختلفی از ویژگیهای EO استخراج شده از رسترها را در امتداد ابعاد مکانی و زمانی آنها در خود جای دهد.
داده های معنایی حاصل در یک پایگاه داده ذخیره شده است که می توان از طریق یک رابط جستجوی معنایی یا از طریق یک نقطه پایانی SPARQL ( http://melodi.irit.fr/tu/ ) به آن دسترسی پیدا کرد.). فروشگاه تریپل حاوی اطلاعاتی در مورد دهکده های فرانسوی و نسخه های ۲۰۱۷ و ۲۰۱۸ آنها است. از سال ۱۳۷۷، ۵۸ روستای داخل محدوده مطالعاتی (بخش های ۲۴، ۳۳ و ۴۷ فرانسه) دارای نسخه بسته بودند. کل مجموعه منجر به ۲۲۴۰۰۰ بسته (نمونه هایی از tum:ParcelVersion) در پایگاه داده می شود. اطلاعات CESBIO-LC (2017 و ۲۰۱۸) بر اساس موارد استفاده و نیاز کاربر به تجزیه و تحلیل به روز می شود. در حالی که عملکرد پرس و جو در نسخه موجود عمومی فعلی مجموعه داده RDF بهینه نیست، عملکرد و مقیاس پذیری باید در آینده مورد توجه قرار گیرد. یک نسخه توسعهیافته از مجموعه داده (شامل بستهها و واحدهای اداری از سایر بخشهای فرانسوی) بر روی پلت فرم پروژه CANDELA مستقر خواهد شد.
ما در پاراگرافهای زیر یک رابط کاربری اساسی را ارائه میکنیم که امکان پرسوجو از مجموعه دادهها را از طریق پرسوجوهای SPARQL و تجسم نتایج با کمک نقشه را فراهم میکند. کاربران نهایی مجموعه داده را از نظر محتوای آن ارزیابی کردند تا رابطی که برای پرس و جو ارائه شده بود. در حالی که موارد استفاده مورد بحث در زیر به نیازهای پروژه اختصاص دارد، مجموعه داده به طور بالقوه می تواند برای جامعه مفید باشد زیرا تمام بسته ها، واحدهای اداری و نسخه های آنها را برای یک منطقه خاص در فرانسه فهرست می کند.
۵٫۱٫ ادغام مشاهدات سری زمانی
مجموعه داده حاصل اطلاعاتی در مورد بسته ها و واحدهای اداری (روستاها) سه بخش فرانسوی ارائه می دهد. همچنین شامل جزئیات شطرنجی های پردازش شده است. کاربران می توانند از پایگاه دانش برای نظارت بر تغییر پوشش زمین در طول زمان استفاده کنند. این را می توان با بررسی تمام مشاهدات انجام شده در تمام نسخه های بسته یا واحدهای اداری انجام داد. نمونه ای از پرس و جو شامل بسته ها و نتایج آن در شکل ۵ نشان داده شده است . قابل مشاهده است که پوشش زمین قطعه ۳۳۲۲۶۰۰۰۰A0012 بین سالهای ۲۰۱۷ و ۲۰۱۸ اندکی تغییر کرده است: تاکستان از ۷۶ درصد به ۶۲ درصد کاهش یافته است در حالی که بافت شهری از ۱۵ درصد به ۲۶ درصد افزایش یافته است.
همانطور که منشأ داده و ابرداده منبع را پیگیری می کنیم، می توان جزئیات منشأ شطرنجی را که برای ایجاد یک مشاهده استفاده شده است، بازیابی کرد. شکل ۶ یک پرس و جو برای رستر را نشان می دهد که برای محاسبه مشاهدات انجام شده بر روی بسته در سال ۲۰۱۷ استفاده می شود (atuom:GeoFeatureObservationCollection). برعکس، همچنین امکان بازیابی تمام مشاهدات ایجاد شده از یک شطرنجی داده شده وجود دارد.
۵٫۲٫ راهنمای فرآیند EO
مجموعه داده همچنین می تواند در فرآیندهای مختلف تجزیه و تحلیل EO مورد سوء استفاده قرار گیرد. از یک طرف، میتوان مجموعهای از الگوریتمها را بر روی نتایج پرسوجوی برگشتی اعمال کرد که حاوی اطلاعات مکانی و زمانی (به ترتیب بستهها یا تصاویر سنتینل مرتبط؛ و دوره) هستند. از سوی دیگر، نتایج بازگشتی میتوانند با ارائه پارامترهای مکانی و زمانی دقیق، عملکرد الگوریتمها را راهنمایی و تقویت کنند (از نتایج یک پرس و جو، میدانیم که در کدام منطقه و برای چه دورهای باید تحلیل خاصی انجام شود) . سپس می توان خط لوله ای ساخت که پرس و جوی معنایی را با ماژول های دیگر مانند تشخیص تغییر یا محاسبه NDVI ترکیب کند.
به طور دقیق تر، مجموعه داده به دو مورد استفاده از پروژه CANDELA خدمت می کند:
-
تشخیص تغییر در تاکستان ها : هدف استفاده از این مورد تشخیص تغییرات در پوشش گیاهی تاکستان به دلیل خطرات طبیعی مانند سرمازدگی یا تگرگ است. پایگاه داده معنایی را می توان برای بازیابی و مکان یابی قطعات تاکستان در طول زمان استفاده کرد. شکل ۷ پرس و جو و داده های حاصل را هنگام پرس و جو از تمام قطعات تاکستان روستای بارساک (کد ۳۳۰۳۰) در سال ۲۰۱۷ نشان می دهد. بسته های تاکستان روی نقشه نمایش داده می شوند. با شناسایی پاکت های تاکستان، می توان تصاویر مربوطه را برای تجزیه و تحلیل تشخیص تغییر بازیابی کرد.
-
گسترش شهری و کشاورزی : کاربرد مطالعات موردی تأثیر گسترش شهری بر مناطق کشاورزی به دلیل توسعه مستمر سکونتگاههای انسانی. علاوه بر این، تلاش میکند تغییرات پوشش زمین کشاورزی را در طول زمان به دلیل تغییرات اقلیمی که کشاورزان را مجبور به تغییر محصولات خود برای دستیابی به بازده اقتصادی بالاتر میکند، تجزیه و تحلیل کند. سپس پایگاه دانش بهعنوان مرجعی مورد بهرهبرداری قرار میگیرد که از آن میتوان قطعات کشاورزی را که به شهری تبدیل شدهاند استعلام کرد. شکل ۸چنین پرسشی را نشان می دهد. بسته های تغییر یافته واقع در شمال غربی روستای بارساک بر روی نقشه (مناطق احاطه شده) مشخص شده اند. در حالی که این سناریو به اولین مورد استفاده نزدیک است، در اینجا با شاخصهای پوشش زمین که برای هر سال ذخیره میشوند، میتوان قطعاتی را که تحت تأثیر یک تکامل (تکامل پوشش زمین) قرار گرفتهاند شناسایی کرد.
۵٫۳٫ مقایسه متقابل داده ها
یکی دیگر از سناریوهای بهره برداری از این مجموعه داده، مقایسه متقابل اطلاعات از منابع مختلف، از جمله نتایج ارائه شده توسط شرکای پروژه است. به عنوان مثال، می توان اطلاعات CESBIO-LC را با پوشش زمین که توسط DLR، شریک پروژه، شرح داده شده است، مقایسه کرد. یا برای توضیح تشخیص تغییر از نتایج یادگیری ماشین بدون نظارت، همانطور که توسط Thalès (یکی دیگر از شرکای پروژه) ارائه شده است. برای مثال اول، در حالی که نتایج DLR هنوز در مجموعه داده گنجانده نشده است، یک مقایسه دستی از آنچه در مجموعه داده ما ذخیره شده و نقشه پوشش زمین تولید شده توسط DLR انجام شده است.
۶٫ نتیجه گیری
ما یک مدل معنایی مدولار را پیشنهاد میکنیم که میتواند ابعاد مختلف مورد نیاز برای نمایش دادههای EO را در خود جای دهد: زمان، مکان، مشاهده، ابرداده منبع، و منشأ، همراه با یک فرآیند ETL معنایی برای پر کردن این مدل. ما رویکرد خود را با ادغام دادههای پوشش زمین یک منطقه جغرافیایی خاص کارخانه شراب سازی فرانسوی، واحدهای اداری آن و ثبت زمین آن نشان دادیم. امکان سنجی رویکرد و ظرفیت سیستم در H2020 EO Big Data Hackathon نشان داده شده است ( http://www.candela-h2020.eu/content/joint-hackathon-organized-eo-2-2017-projects). در طول این رویداد، شرکتکنندگان میتوانند برای ادغام مجموعهدادههای پوشش زمین جدید به پلت فرم پروژه دسترسی داشته باشند و سپس برای بازیابی جزئیات واحدهای اداری یا قطعهها با پوشش زمین خود، از فروشگاه سهگانه پرس و جو کنند. تمام وظایف از طریق اسکریپت های پایتون تحقق می یابد.
به عنوان کار آینده، سایر مجموعه دادههای موجود مانند کاربری زمین، شاخص پوشش گیاهی و تشخیص تغییر را در نظر خواهیم گرفت. پس از فرآیند سهگانهسازی دادهها که تعریف کردیم، میتوان اطلاعات اضافی را در طول عمر بستهها به آنها متصل کرد تا در فرآیند تحلیل به آنها ارجاع داده شود. همچنین، ادغام سایر مجموعه دادههای پوشش زمین، مانند مجموعههای [ ۳۳ ] را در نظر خواهیم گرفت. در نهایت، جهت دیگر در نظر گرفتن سناریوهای کلان داده (به عنوان مثال با استفاده از داده های Natura 2000) و ارزیابی مقیاس پذیری رویکرد، از جمله امکان در نظر گرفتن معماری ترکیبی و استراتژی های ذخیره سازی (با پشتیبانی های ذخیره سازی رابطه ای، NoSQL و RDF) است.
ضمیمه A. استخراج داده ها
در مرحله استخراج داده ها، داده های شطرنجی استخراج می شوند. در زیر یک نتیجه (ساده شده) نشان دهنده مشاهدات است.
{
"نوع": "LC_CESBIO"،
"raster": "LC_CESBIO_OCS_2017_CESBIO_tile"،
"foi": "VX2017_330300000A0480"،
"تاریخ شروع": "۰۱/۰۱/۲۰۱۷"،
"تاریخ پایان": "۳۱-۱۲-۲۰۱۷",
"مشاهدات": [{
"ملک": ۱۱،
"نتیجه": ۰٫۱
}،
{
«ملک»: ۳۱،
"نتیجه": ۰٫۹
}
]
}
پیوست ب. الگوهای تبدیل داده
در مرحله تبدیل داده، از یک الگو برای تبدیل داده های استخراج شده به فرمت RDF استفاده می شود. عصاره ای از هر قالب در زیر ارائه شده است.
ضمیمه B.1. الگوی مجموعه داده واحد اداری
$ نمونه a tum:AdminUnit.
$ نمونه tum:code valueToLiteral( $ .insee، رشته).
$ نمونه tum:hasVersion $ Instance_AdminUnitVersion.
$ Instance_AdminUnitVersion a tum:AdminUnitVersion.
$ Instance_AdminUnitVersion tum:name valueToLiteral( $ .name، رشته).
$ Instance_AdminUnitVersion tum:area valueToLiteral( $ .area، float).
$ Instance_AdminUnitVersion geo:hasGeometry $ Instance_Geometry.
$ Instance_Geometry a geo:Geometry.
$Instance_Geometry geo:asWKT valueToLiteral( $ .wkt، wktLiteral).
ضمیمه B.2. الگو برای مجموعه داده بسته
$ نمونه a tum:Parcel.
$ نمونه tum:code valueToLiteral( $ .id، رشته).
$ نمونه tum:contenance valueToLiteral( $ .contenance، عدد صحیح).
$ نمونه tum:hasVersion $ Instance_ParcelVersion.
$ Instance_ParcelVersion tum:belongsTo valueToInstance( $ .village,
AdminUnitVersion)
$ Instance_ParcelVersion geo:hasGeometry $ Instance_Geometry.
$ Instance_Geometry a geo:Geometry.
$ Instance_Geometry geo:asWKT valueToLiteral( $ .wkt، wktLiteral).
ضمیمه B.3. الگو برای مجموعه داده پوشش زمین
$ نمونه a tuom:GFObservationCollection.
$ نمونه dcat:Dataset.
$ نمونه prov-o: Entity.
$ نمونه tuom:observedPropertyType valueToInstance( $ .type,
GFObservablePropertyType).
$ نمونه prov-o:wasDerivedFrom valueToInstance( $ .raster، RasterFile).
$ نمونه sosa:hasFeatureOfInterest valueToInstance( $ .foi، ParcelVersion).
$ نمونه sosa:phenomenonTime valueToInterval( $ .startDate، $ .endDate).
#حلقه
$ نمونه sosa:hasMember $ Instance_GFObservation.
$ Instance_GFObservation a tuom:GFObservation.
$ Instance_GFObservation sosa:hasSimpleResult valueToLiteral( $ .result، float).
$ Instance_GFObservation sosa:observedProperty
valueToInstance ( $ .property، GFObservableProperty).
ضمیمه C. خروجی داده های RDF
در زیر نمونه ای از داده های معنایی است که بر اساس الگوهای ارائه شده قبلی تبدیل شده اند.
ضمیمه C.1. داده های واحد اداری
:AdminUnit/33030
a tum:AdminUnit; tum:code "33030"^^xsd:string;
tum:hasVersion :AdminUnitVersion/V2017_L3_33030.
:AdminUnitVersion/V2017_L3_33030
a tum:AdminUnitVersion; tum:name "Barsac"^^xsd:string; tum:area "1451.0"
^^xsd:float;
geo:hasGeometry :Geometry/V2017_L3_33030.
:AdminUnitVersion/V2018_L3_33030
a tum:AdminUnitVersion; tum:name "Barsac"^^xsd:string; tum:area "1451.0"
^^xsd:float;
geo:hasGeometry :Geometry/V2018_L3_33030.
:Geometry/V2017_L3_33030 geo:asWKT "POLYGON ((..))".
:Geometry/V2018_L3_33030 geo:asWKT "POLYGON ((..))".
ضمیمه C.2. داده های بسته
: بسته/۳۳۰۳۰۰۰۰۰A0480
a tum:Parcel; tum:code "330300000A0480"^^xsd:string; tum:contenance
"۶۴۱۲۰"^^xsd:integer;
tum:hasVersion :ParcelVersion/VX2017_330300000A0480;
tum:hasVersion :ParcelVersion/VX2018_330300000A0480.
:ParcelVersion/VX2017_330300000A0480
a tum:ParcelVersion; tum: متعلق به :AdminUnitVersion/V2017_L3_33030;
geo:hasGeometry :Geometry/VX2017_330300000A0480.
:ParcelVersion/VX2018_330300000A0480
a tum:ParcelVersion; tum: متعلق به :AdminUnitVersion/V2018_L3_33030;
geo:hasGeometry :Geometry/VX2018_330300000A0480.
:Geometry/VX2018_330300000A0480 geo:asWKT "POLYGON ((..))". :Geometry/VX2017_330300000A0480 geo:asWKT "POLYGON ((..))".
ضمیمه C.3. داده های پوشش زمین
#مشاهدات پوشش زمین برای سال ۲۰۱۷
:GFObservationCollection/LC_CESBIO__330300000A0480_1483228800_1514678400
a tuom:GFObservationCollection; a dcat:Dataset; a prov-o:Entity;
tuom:observedPropertyType :GFObservablePropertyType/LC_CESBIO;
prov-o:wasDerivedFrom:RasterFile/LC_CESBIO_OCS_2017_CESBIO_tile.
sosa:hasFeatureOfInterest :ParcelVersion/VX2017_330300000A0480;
sosa:phenomenonTime :Interval/1483228800_1514678400;
sosa:hasMember :GFObservation/LC_CESBIO__330300000A0480_11_1483228800_
۱۵۱۴۶۷۸۴۰۰;
sosa:hasMember :GFObservation/LC_CESBIO__330300000A0480_31_1483228800_
۱۵۱۴۶۷۸۴۰۰٫
:GFObservation/LC_CESBIO__330300000A0480_11_1483228800_1514678400
a tuom:GFObservation; sosa:hasSimpleResult "0.1"^^xsd:float;
sosa:observedProperty:GFObservableProperty/LC_CESBIO_11.
:GFObservation/LC_CESBIO__330300000A0480_31_1483228800_1514678400
a tuom:GFObservation; sosa:hasSimpleResult "0.9"^^xsd:float;
sosa:observedProperty:GFObservableProperty/LC_CESBIO_31.
:GFObservableProperty/LC_CESBIO_11 tuom:name "culture ete"^^xsd:string. :GFObservableProperty/LC_CESBIO_31 tuom:name "foret feuillus"^^xsd:string.
#مشاهدات پوشش زمین برای سال ۲۰۱۸
:GFObservationCollection/LC_CESBIO18_330300000A0480_1514764800_1546214400
a tuom:GFObservationCollection; a dcat:Dataset; a prov-o:Entity;
tuom:observedPropertyType:GFObservablePropertyType/LC_CESBIO18;
prov-o:wasDerivedFrom:RasterFile/LC_CESBIO_OCS_2018_CESBIO_tile.
sosa:hasFeatureOfInterest :ParcelVersion/VX2018_330300000A0480;
sosa:phenomenonTime :Interval/1514764800_1546214400;
sosa:hasMember :GFObservation/LC_CESBIO18_330300000A0480_10_1514764800_
۱۵۴۶۲۱۴۴۰۰;
sosa:hasMember :GFObservation/LC_CESBIO18_330300000A0480_16_1514764800_
۱۵۴۶۲۱۴۴۰۰٫
:GFObservation/LC_CESBIO18_330300000A0480_10_1514764800_1546214400
a tuom:GFObservation; sosa:hasSimpleResult "0.12"^^xsd:float;
sosa:observedProperty:GFObservableProperty/LC_CESBIO18_10.
:GFObservation/LC_CESBIO18_330300000A0480_16_1514764800_1546214400
a tuom:GFObservation; sosa:hasSimpleResult "0.88"^^xsd:float;
sosa:observedProperty:GFObservableProperty/LC_CESBIO18_16.
:GFObservableProperty/LC_CESBIO18_10 tuom:name "mais"^^xsd:string. :GFObservableProperty/LC_CESBIO18_16 tuom:name "forets de feuillus"^^xsd:string.
منابع
- ویلگاس، جی. سانچز پاستور، اچ. هرنانز، ال. چکا، م. رومن، دی. امکان استفاده از دادههای Sentinel-2 و LiDAR برای تخصیص وجوه سیاست مشترک کشاورزی. بین المللی J. Geo-Inf. ۲۰۱۷ ، ۶ ، ۲۵۵٫ [ Google Scholar ]
- لامبین، ای. Geist, H. تغییر کاربری و پوشش زمین ; Springer: برلین/هایدلبرگ، آلمان، ۲۰۰۶٫ [ Google Scholar ]
- اسپینوزا-مولینا، دی. نیکولائو، سی. دومیترو، CO. برتا، ک. کوباراکیس، م. شوارتز، جی. Datcu، M. تصاویر SAR با وضوح بسیار بالا و تجزیه و تحلیل داده های باز پیوندی بر اساس هستی شناسی ها. IEEE J. Sel. بالا. Appl. زمین Obs. Remote Sens. ۲۰۱۵ ، ۸ ، ۱۶۹۶-۱۷۰۸٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- دومیترو، سی. شوارتز، جی. Datcu، M. حاشیه نویسی معنایی پوشش زمین برگرفته از تصاویر SAR با وضوح بالا. IEEE J. Sel. بالا. Appl. زمین Obs. Remote Sens. ۲۰۱۶ , ۹ , ۲۲۱۵–۲۲۳۲٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- برگماسکی، س. گوئرا، اف. اورسینی، م. سرتوری، سی. وینچینی، ام. رویکرد معنایی به فن آوری های ETL. دانستن داده ها مهندس ۲۰۱۱ ، ۷۰ ، ۷۱۷-۷۳۱٫ [ Google Scholar ] [ CrossRef ]
- Tran، BH; آسناک ژیل، ن. کامپاروت، سی. تروجان، سی. رویکردی برای ادغام مشاهده زمین، تشخیص تغییر و داده های متنی برای جستجوی معنایی. در مجموعه مقالات سمپوزیوم بین المللی علوم زمین و سنجش از دور (IGARSS)، Waikoloa، HI، ایالات متحده آمریکا، ۱۹ تا ۲۴ ژوئیه ۲۰۲۰٫ [ Google Scholar ]
- زینکه، سی. Ngomo، ACN کشف و پیوند داده های بزرگ پیوندی فضایی-زمانی. در مجموعه مقالات IGARSS 2018-2018 IEEE بین المللی زمین شناسی و سمپوزیوم سنجش از دور، والنسیا، اسپانیا، ۲۲ تا ۲۷ ژوئیه ۲۰۱۸؛ ص ۴۱۱-۴۱۴٫ [ Google Scholar ]
- بریژینف، دی. تویر، اس. تیلور، ک. Zhang, Z. انتشار و استفاده از داده های رصد زمین با مکعب داده RDF و سیستم شبکه جهانی گسسته . گزارش فنی؛ W3C و OGC: Wayland، MA، ایالات متحده آمریکا، ۲۰۱۷٫ [ Google Scholar ]
- لفورت، ال. بابروک، جی. هالر، ا. تیلور، ک. وولف، ای. در مجموعه مقالات پنجمین کارگاه بین المللی در مورد شبکه های حسگر معنایی، بوستون، MA، ایالات متحده آمریکا، ۱۲ نوامبر ۲۰۱۲; صص ۱-۱۶٫ [ Google Scholar ]
- آگوستین، اچ. سودمنز، ام. تاید، دی. لانگ، اس. بارالدی، ا.مکعب های داده های مشاهده معنایی زمین. دادهها ۲۰۱۹ ، ۴ ، ۱۰۲٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- برتا، ک. کومونت، اچ. دانیلز، یو. گور، ای. کوباراکیس، م. پانتازی، DA; استامولیس، جی. اوبلز، اس. زهره، V. Wahyudi، F. پروژه آزمایشگاه برنامه کوپرنیک: دسترسی آسان به داده های کوپرنیک. در مجموعه مقالات بیست و دومین کنفرانس بین المللی گسترش فناوری پایگاه داده (EDBT)، لیسبون، پرتغال، ۲۶ تا ۲۹ مارس ۲۰۱۹٫ [ Google Scholar ]
- ابورو، س. دوبی، ن. نایاک، MR; Golla، S. یک روش مبتنی بر هستی شناسی برای قابلیت تعامل معنایی داده های ماهواره ای. Adv. برق محاسبه کنید. مهندس ۲۰۱۵ ، ۱۵ ، ۱۰۵-۱۱۰٫ [ Google Scholar ] [ CrossRef ]
- بلوور، جی. کلیفورد، دی. گونکالوز، پی. Koubarakis, M. پروژه MELODIES: یکپارچه سازی داده های متنوع با استفاده از داده های پیوندی و محاسبات ابری. در مجموعه مقالات کنفرانس ۲۰۱۴ درباره داده های بزرگ از فضا (BiDS’14)، فراسکاتی، ایتالیا، ۱۲ تا ۱۴ نوامبر ۲۰۱۴٫ ص ۲۴۴-۲۴۷٫ [ Google Scholar ]
- سوخوبوک، دی. سانچز، اچ. استرادا، جی. رومن، دی. داده های مرتبط برای سیاست کشاورزی مشترک: فعال کردن پرس و جو معنایی بر روی داده های Sentinel-2 و LiDAR. در مجموعه مقالات پوسترها و نمایشهای ISWC 2017 و آهنگهای صنعتی همزمان با شانزدهمین کنفرانس بینالمللی وب معنایی (ISWC 2017)، وین، اتریش، ۲۳ تا ۲۵ اکتبر ۲۰۱۷؛ در دسترس آنلاین: http://ceur-ws.org/Vol-1963/##paper559 (در ۲۰ اوت ۲۰۲۰ قابل دسترسی است).
- علیرضایی، م. کیسلف، آ. لنگکویست، م. کلوگل، اف. Loutfi, A. یک چارچوب استدلال مبتنی بر هستی شناسی برای جستجوی تصاویر ماهواره ای برای نظارت بر بلایا. Sensors ۲۰۱۷ , ۱۷ , ۲۵۴۵٫ [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- مسمودی، م. تکتک، ح. بن عبدالله بن لمینه، س. بوکادی، ک. Karray، MH; بازاوی زغال، ح. ارشمید، بی. مریسا، م. Guegan، CG PREDICAT: یک پلت فرم خدمات گرا معنایی برای قابلیت همکاری داده ها و پیوند در رصد زمین و پیش بینی بلایا. در مجموعه مقالات SOCA 2018: یازدهمین کنفرانس بین المللی IEEE در مورد محاسبات و برنامه های کاربردی سرویس گرا، پاریس، فنس، ۲۰ تا ۲۲ نوامبر ۲۰۱۸٫ صص ۱۹۴-۲۰۱٫ [ Google Scholar ]
- آندریف، آ. میسف، دی. باومن، پی. Risch، T. پردازش داده های شبکه بندی شده مکانی-زمانی در وب معنایی. در مجموعه مقالات DSDIS 2015-2015 کنفرانس بین المللی IEEE در علم داده و سیستم های فشرده داده، سیدنی، استرالیا، ۱۳ تا ۱۵ دسامبر ۲۰۱۵٫ صص ۳۸-۴۵٫ [ Google Scholar ]
- برتا، ک. شیائو، جی. Koubarakis، M. Ontop-Spatial: Ontop of Geospatial Database. J. وب سمنت. ۲۰۱۹ ، ۵۸ ، ۱۰۰۵۱۴٫ [ Google Scholar ] [ CrossRef ]
- آروسنا، جی. لوزانو، جی. کوارتولی، م. اولایزولا، آی. Bermudez, J. داده های باز پیوند داده شده برای پردازش اطلاعات جغرافیایی شطرنجی و برداری. در مجموعه مقالات سمپوزیوم بین المللی علوم زمین و سنجش از دور IEEE 2015 (IGARSS)، میلان، ایتالیا، ۱۸ تا ۲۵ ژوئیه ۲۰۱۵٫ ص ۵۰۲۳–۵۰۲۶٫ [ Google Scholar ]
- هامبورگ، تی. پرودوم، سی. Würriehausen، F. کارماچاریا، ا. بوچس، اف. روکسین، ا. کروز، سی. تفسیر دادههای جغرافیایی ناهمگن با استفاده از فناوریهای وب معنایی. در مجموعه مقالات کنفرانس بین المللی علوم محاسباتی و کاربردهای آن، پکن، چین، ۴ تا ۷ ژوئیه ۲۰۱۶٫ ص ۲۴۰-۲۵۵٫ [ Google Scholar ]
- نیشانبایف، آی. قهرمان، ای. Mcmeekin, D. A Survey of Geospatial Semantic Web for Cultural Heritage. Heritage ۲۰۱۹ , ۲ , ۱۴۷۱–۱۴۹۸٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- برنارد، سی. ویلانوا-الیور، ام. جنسل، جی. دائو، اچ. تغییرات مدلسازی در پارتیشنهای سرزمینی در طول زمان: هستیشناسیهای TSN و TSN-change. در مجموعه مقالات SAC’18: سی و سومین سمپوزیوم سالانه ACM در محاسبات کاربردی، پائو، فرانسه، ۹ تا ۱۳ آوریل ۲۰۱۸٫ صص ۸۶۶-۸۷۵٫ [ Google Scholar ] [ CrossRef ]
- کولاس، دی. پری، م. Herring, J. شروع به کار با GeoSPARQL . گزارش فنی؛ OGC: Wayland، MA، ایالات متحده آمریکا، ۲۰۱۳٫ [ Google Scholar ]
- هابز، جی آر. Pan, F. هستی شناسی زمان برای وب معنایی. ACM Trans. زبان آسیایی Inf. روند. ۲۰۰۴ ، ۳ ، ۶۶-۸۵٫ [ Google Scholar ] [ CrossRef ]
- یانوویچ، ک. هالر، ا. کاکس، اس جی. Phuoc، DL؛ Lefrançois, M. SOSA: یک هستی شناسی سبک برای حسگرها، مشاهدات، نمونه ها و عملگرها. J. وب سمنت. ۲۰۱۹ ، ۵۶ ، ۱-۱۰٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ولتی، سی. Fikes، R. یک هستی شناسی قابل استفاده مجدد برای Fluents در OWL. در مجموعه مقالات FOIS 2006: چهارمین کنفرانس بین المللی هستی شناسی رسمی در سیستم های اطلاعاتی، آمستردام، NL، ایالات متحده، ۹-۱۱ نوامبر ۲۰۰۶٫ IOS Press: بالتیمور، MD، ایالات متحده؛ ص ۲۲۶-۲۳۶٫ [ Google Scholar ]
- آرناس، اچ. آسناک ژیل، ن. کامپاروت، سی. تروجان، سی. ادغام معنایی داده های مکانی از مشاهدات زمین. در مجموعه مقالات رویدادهای ماهواره ای EKAW 2016 — بیستمین کنفرانس بین المللی مهندسی دانش و مدیریت دانش، بولونیا، ایتالیا، ۱۹ تا ۲۳ نوامبر ۲۰۱۶؛ صص ۹۷-۱۰۰٫ [ Google Scholar ]
- نبرد، آر. کولاس، دی. فعال کردن وب معنایی مکانی با پارلمان و GeoSPARQL. سمنت. وب ۲۰۱۲ ، ۳ ، ۳۵۵-۳۷۰٫ [ Google Scholar ] [ CrossRef ]
- کیزیراکوس، ک. کارپاتیوتاکیس، م. Koubarakis، M. Strabon: A Semantic Geospatial Dbms. در وب معنایی ISWC 2012 ; Springer: برلین/هایدلبرگ، آلمان، ۲۰۱۲; صص ۲۹۵-۳۱۱٫ [ Google Scholar ]
- شیدر، اس. دگبلو، ا. لمنز، آر. ون الزاکر، سی. زیمرهوف، پ. کوستیچ، ن. جونز، جی. بانهاتی، جی. پرس و جوی اکتشافی نقاط پایانی SPARQL در فضا و زمان. سمنت. وب ۲۰۱۷ ، ۸ ، ۶۵-۸۶٫ [ Google Scholar ] [ CrossRef ]
- پاترومپاس، ک. جیانوپولوس، جی. Athanasiou، S. Towards GeoSpatial Semantic Data Management: نقاط قوت، ضعف ها و چالش های پیش رو. در مجموعه مقالات SIGSPATIAL’14: بیست و دومین کنفرانس بین المللی SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، دالاس، تگزاس، ایالات متحده آمریکا، ۴ تا ۷ نوامبر ۲۰۱۴٫ صص ۳۰۱-۳۱۰٫ [ Google Scholar ]
- Ioannidis، T. گاربیس، جی. کیزیراکوس، ک. برتا، ک. Koubarakis, M. Evaluating Geospatial RDF stores Using the Benchmark Geographica 2. arXiv ۲۰۱۹ , arXiv:1906.01933. [ Google Scholar ]
- دومیترو، CO. شوارتز، جی. Pulak-Siwiec، A.; کولاویک، بی. لورنزو، جی. Datcu، M. داده کاوی مشاهده زمین: مورد استفاده برای نظارت بر جنگل. در مجموعه مقالات IGARSS 2019-2019 IEEE بین المللی زمین شناسی و سمپوزیوم سنجش از دور، یوکوهاما، ژاپن، ۲۸ ژوئیه تا ۲ اوت ۲۰۱۹؛ صص ۵۳۵۹–۵۳۶۲٫ [ Google Scholar ]
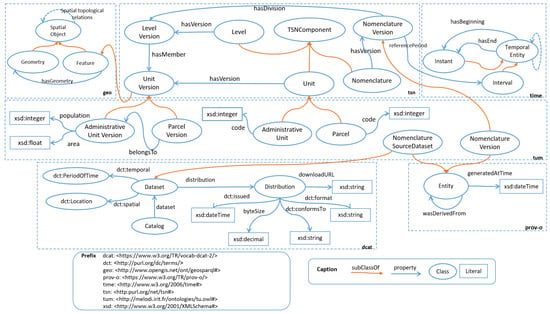
شکل ۱٫ هستی شناسی مدل واحد سرزمینی برای نشان دادن واحدهای سرزمینی (مانند واحدهای اداری فرانسه و قطعات ثبت زمین)، و تاریخچه آنها.
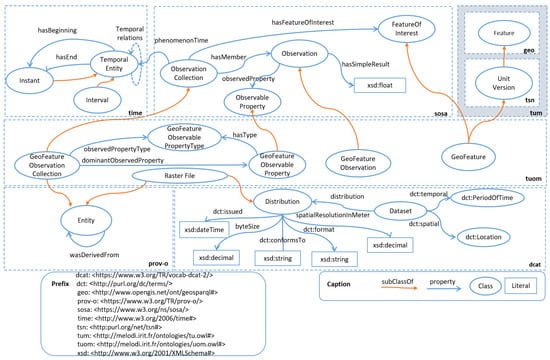
شکل ۲٫ هستی شناسی مدل مشاهده واحد سرزمینی برای نشان دادن مقادیر دارایی واحدهای سرزمینی محاسبه شده از رسترهای EO.
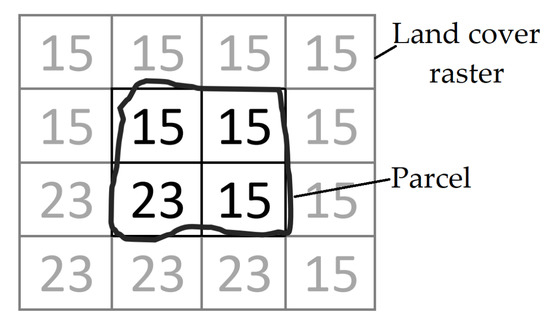
شکل ۳٫ نمونه ای از پوشش بسته (۱۵: تاکستان، ۲۳: آب).
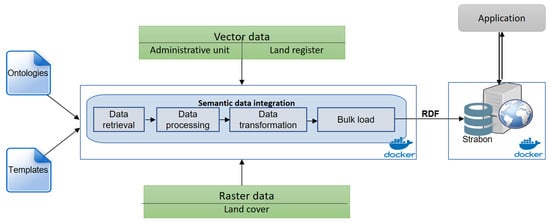
شکل ۴٫ معماری سیستم بر اساس فناوری داکر.
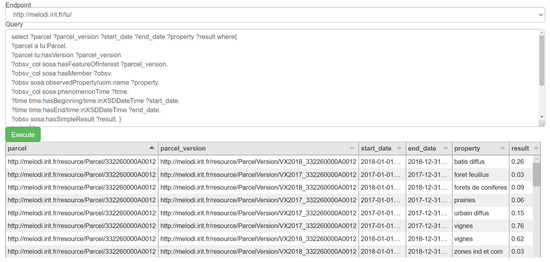
شکل ۵٫ نظارت بر تغییر پوشش زمین.

شکل ۶٫ منشأ داده و ابرداده منبع.
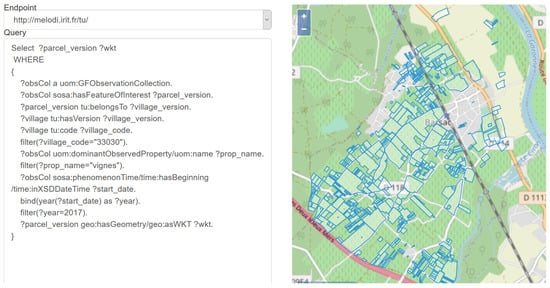
شکل ۷٫ موقعیت قطعات تاکستان (مناطق احاطه شده) روستای بارساک در سال ۲۰۱۷٫
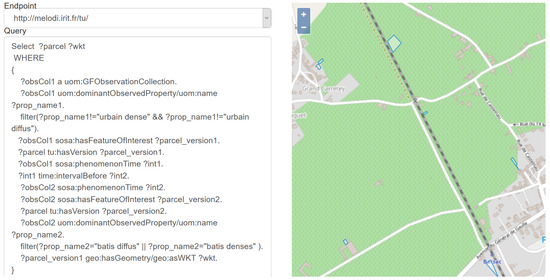
شکل ۸٫ موقعیت قطعات تغییر یافته (مناطق احاطه شده)، از زمین کشاورزی به شهری در شمال غربی روستای بارساک بین سال های ۲۰۱۷ و ۲۰۱۸٫


بدون دیدگاه