
کلید واژه ها:
جمعیت مصنوعی ; تخصیص فضایی ؛ تولید تقاضا مبتنی بر فعالیت ; واگذاری محل کار
۱٫ مقدمه
۱٫۱٫ زمینه و انگیزه
۱٫۲٫ بررسی ادبیات
۱٫۳٫ ساختار کاغذ
۲٫ مواد و روشها
اول، وزن برای کلاس های سلولی مختلف به صورت زیر تعریف می شود:
جایی که gایکسوزن کلاس X = { L,H,C,I,E,O } است که به صورت زیر تعریف میشود: مسکونی کم ( L )، بسیار مسکونی ( H )، تجاری ( C )، صنعتی ( I )، تحصیلات ( E ) و زمین باز ( O). سلول ها ممکن است بر اساس مطالعه موردی در دست تعریف شوند و منعکس کننده توزیع های مختلف الگوهای کاداستر باشند. اگر ابعاد سلول ها بسیار متفاوت است، توصیه می شود که منطقه اشغال شده را در محاسبه وزن سلول اضافه کنید. فرمول زیر در عوض برای سلول هایی با ابعاد مساوی (بدون توجه به بعد واقعی) تصور شد. سپس، وزن سلول ها در هر زیرمنطقه (یعنی سطح ناحیه دوم اداری) با توجه به:
جایی که i سلول ها را نمایه می کند، s زیرمنطقه ها را نمایه می کند و سیسمجموعه ای از سلول ها در زیر ناحیه s است. با وزن دهی سلول ها در برابر کل در هر زیرمنطقه، این روش برای هر تعداد و نوع کلاس های کاداستر قابل استفاده می شود. تعداد محل کار در هر سلول در یک زیرمنطقه، نکار کردنمن ، س، سپس با ضرب وزن نرمال شده در تعداد کل کارگران در یک زیرمنطقه محاسبه می شود نکار کردنس:
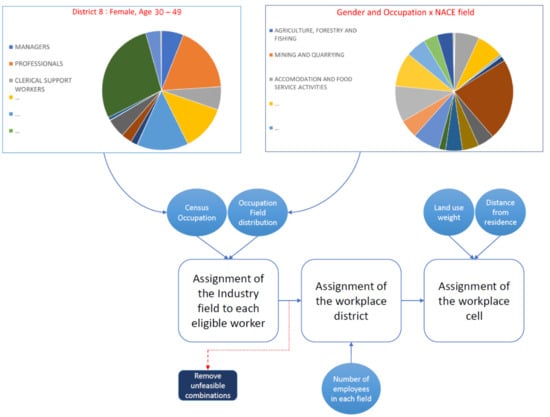
۲٫۱٫ واگذاری زمینه های NACE به جمعیت
۲٫۲٫ واگذاری زیرمنطقه
در صورتی که هیچ تناقضی بین مجموعه دادهها شناسایی نشود، منطقه حاوی محل کار برای هر فرد اختصاص داده میشود تا مجموع در هر فیلد NACE برآورده شود. تخصیص با استخراج نمونههای تصادفی بر اساس میدان NACE توزیع احتمال در هر منطقه کار انجام میشود. فیلد NACE بر اساس سن، جنسیت و محل سکونت از طریق توزیع شغل اختصاص داده می شود. بنابراین، پیوند قویتری بین این متغیرها و ناحیه کاری در مقایسه با پیوندی که صرفاً با بهرهبرداری از مجموعها برای استخراج توزیع در حالی که با مجموع حاشیههای کارکنان مطابقت دارد، به دست میآید. در ادامه، الگوریتم ۱ این مرحله اول را خلاصه می کند. فهرست احتمالات ۱توزیع مشاغل را بر اساس حاشیه سرشماری نشان می دهد در حالی که فهرست احتمالات ۲ پل مشاغل را با زمینه های NACE نشان می دهد. در مورد دوم، تمام فیلدهای NACE که ناهماهنگ هستند در زیر «سایر» دسته بندی می شوند. تابع نمونه R ( https://www.rdocumentation.org/packages/base/versions/3.6.2/topics/sample در ۲۸ دسامبر ۲۰۲۱ قابل دسترسی است) برای اعمال توزیع های مختلف بر اساس سن (A)، جنسیت (G) مورد سوء استفاده قرار می گیرد. منطقه محل سکونت (DoR) و وضعیت دانشجویی (S)؛ * مقادیر ترکیب های مختلفی از ویژگی های فردی را نشان می دهد که مربوط به توزیع های مختلف است.
| الگوریتم ۱ تخصیص NACE (فردی، توزیع شغلی {A، G، DoR، S}، توزیع NACE {G، O}) |
| ۱: حلقه: فردی i <- جمعیت |
| ۲: اگر ({A i , G i , DoR i , S i } == {A, G, DoR, S} و شغل == NA |
| ۳: شغل<-نمونه(فهرست مشاغل، اندازه = ۱، فهرست احتمالات ۱ ) |
| ۴: NACE<-sample(لیست فیلدهای NACE، اندازه = ۱، فهرست احتمالات ۲ ) |
| ۵: در غیر این صورت |
| ۶: تکلیف NACE (فردی، توزیع شغلی {A*، G*، DoR*، S*}، |
| ۷: توزیع NACE {G*، O*} |
برای خوشه «سایر»، ابتدا فاصله بین هر سلول محل اقامت و زیرمنطقه دیگر را محاسبه می کنیم. دمن – s) سپس اولین کشش گرانشی زیرمنطقه، یعنی تعداد کارمندانی که قبلاً به یک میدان NACE دیگر اختصاص داده نشده اند، در نظر گرفته می شود و احتمال کار هر فرد در یکی از مناطق. پjبه صورت زیر محاسبه می شود:
جایی که j ناحیه کاری است، wستعداد کارمندان منطقه مذکور است و من سلول محل اقامت است.
۲٫۳٫ آخرین مایل تکلیف
هنگامی که منطقه اختصاص داده شد، ما به هر فرد طبقه سلولی را که محل کار در آن قرار دارد اختصاص می دهیم. این مرحله اساسا تضمین می کند که توزیع کاربری زمین توسط تخصیص مبتنی بر مدل گرانشی که به عنوان آخرین مرحله انجام می شود، منحرف نمی شود. احتمال کار برای هر فردی که محل کار او در منطقه مورد نظر است در یکی از طبقات سلولی برابر است با:
جایی که gمن جوزن (محاسبه بر اساس مقصد استفاده از زمین رایج در هر سلول، همانطور که در دادههای کاداستر ثبت شده است)، i کلاس (بسیار مسکونی، کم مسکونی، نوع مشاغل و خدمات، و نوع تولیدی)، j ناحیه مورد نظر است، و X تعداد سلول های ناحیه است. هنگامی که کلاس سلول و زیرمنطقه کاری به یک فرد اختصاص داده می شود، سلول کاری صرفاً بر اساس فاصله از سلول محل سکونت اختصاص داده می شود. دn m:
که در آن n سلول محل اقامت و m یکی از سلول های کلاس تعریف شده در ناحیه j است.
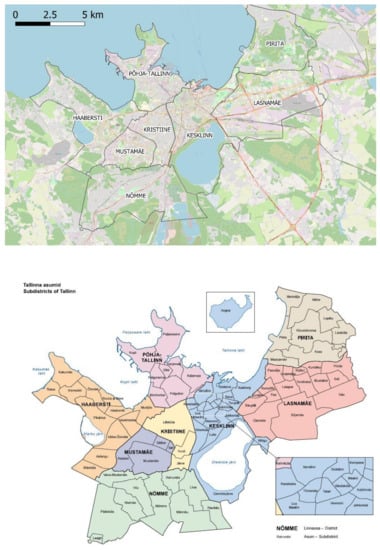
۳٫ تخصیص فضایی: مطالعه موردی تالین
۳٫۱٫ توضیحات عمومی و در دسترس بودن داده ها
۳٫۲٫ توضیحات عمومی و در دسترس بودن داده ها
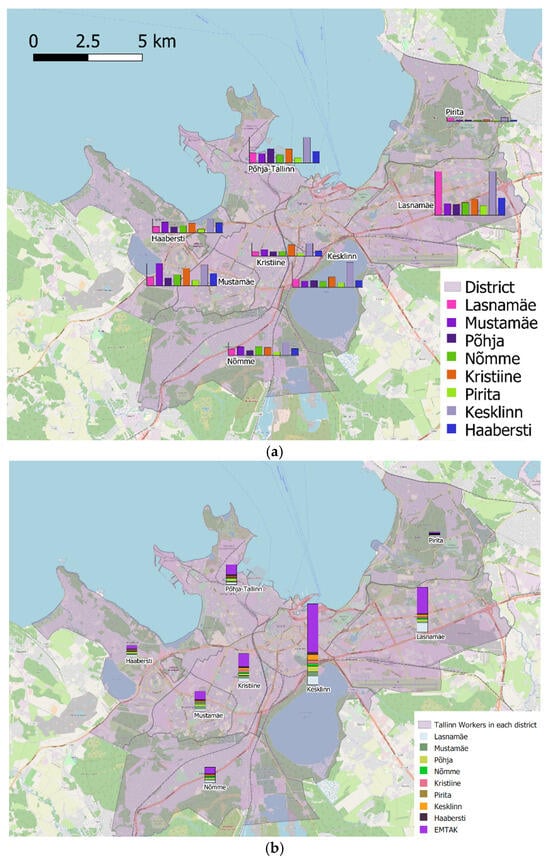
۳٫۳٫ تخصیص فضایی – محل کار
-
ابتدا، وزنهایی بر اساس کلاس هر سلول تخصیص داده میشود، که امکان محاسبه وزن کل برای تمام سلولهای هر ناحیه را نیز فراهم میکند.
-
سپس نسبت i بین وزن هر سلول و مجموع وزنهای ناحیه مطابق رابطه (۲) محاسبه میشود.
-
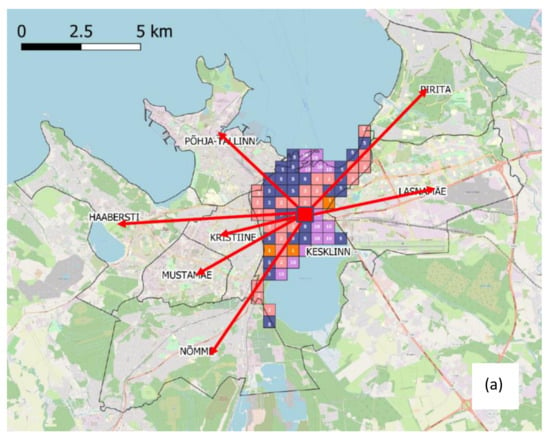
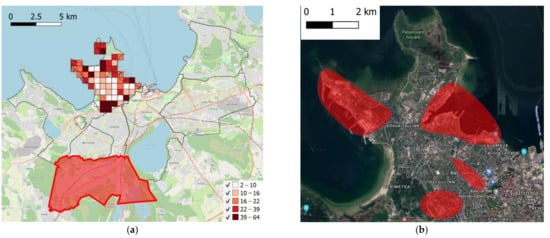
فاصله بین هر سلول محل سکونت و هر منطقه، که به عنوان میانگین بین تمام فواصل بین سلول در دست و آنهایی که در منطقه گنجانده شده است، محاسبه می شود (نمونه ای در شکل ۸ a را ببینید).
-
برای هر جفت سلول (یکی محل سکونت، دیگری محل کار واجد شرایط)، نسبت بین فاصله آنها و میانگین فاصله بین سلول های محل سکونت و تمام سلول های دیگر در منطقه محاسبه می شود.
-
هر منطقه کشش گرانشی خود را دارد که بر اساس تعداد کارمندان در میدان های باقی مانده (“سایر”) محاسبه می شود. در این حالت، احتمال کار در یک منطقه از طریق رابطه (۴) محاسبه می شود. حتی اگر نویز خاصی به تعداد کل مشاغل در زمینه “دیگر” اضافه شود، یکپارچگی فضایی حفظ می شود (مناطق دور شانس کمتری برای انتخاب دارند). علاوه بر این، نشان داده خواهد شد که چگونه تعداد کل کارکنان “سایر” در هر منطقه کاملاً ثابت است.
-
کلاس سلول محل کار بر اساس توزیع طبقات سلولی در منطقه از طریق رابطه (۵) محاسبه می شود.
-
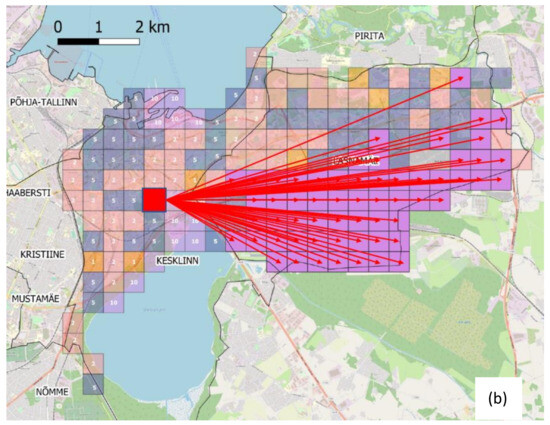
هنگامی که هم ناحیه و هم کلاس برای محل کار تخصیص یافتند، تخصیص سلول نهایی به سادگی از طریق معادله (۶) انجام می شود. شکل ۸ ب نشان می دهد که چگونه تخصیص سلول نهایی در هر کلاس انجام می شود.
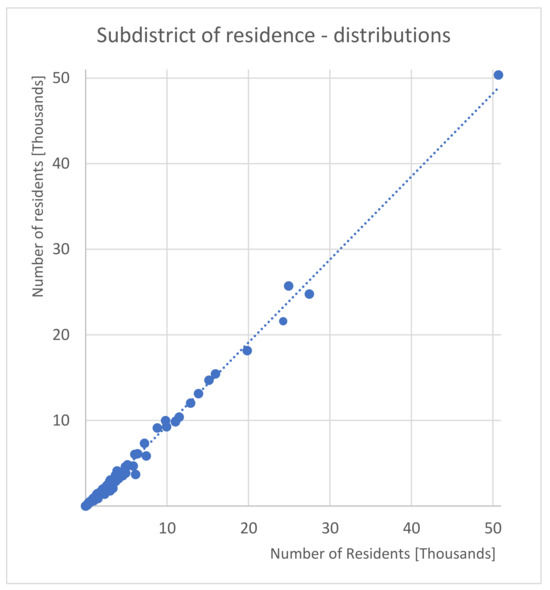
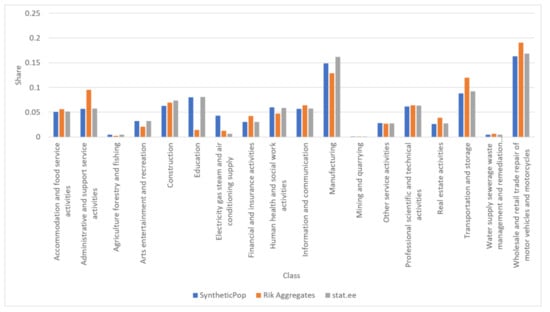
۴٫ نتایج
-
در این مطالعه، وزن فاصله باید برای محل کار در مجاورت محل سکونت بیشتر باشد. این یک الگوی غیرخطی را در ارتباط فاصله منعکس می کند. این فاصله بیش از سایر عوامل (کاربری زمین و میدان های EMTAK) برای سلول های اطراف محل سکونت وزن بیشتری دارد.
-
در [ ۳۷ ]، محل های کار به عنوان متداول ترین شناسه سلولی ثبت شده بین ساعت ۱۱:۰۰ و ۱۶:۰۰ در طول روزهای کاری شناسایی می شوند. مواردی که این شناسه های سلولی مشابه محل سکونت باشد، مستثنی هستند. در حالی که این فیلتر کردن احتمالاً اکثر کارمندان خانه، افراد بازنشسته و افراد با برنامه کاری متفاوت را تحت تأثیر قرار می دهد (رویکرد مشابه مطالعات دیگر مانند [ ۳۸ ] است)، ممکن است در شناسایی برخی موارد دور از دسترس (مانند والدین در خانه بمانند) شکست بخورد. با یک برنامه ورزشی روتین). این امر منجر به برآورد بیش از حد افراد شاغل و ساکن در همان منطقه می شود.
۵٫ بحث
۶٫ نتیجه گیری
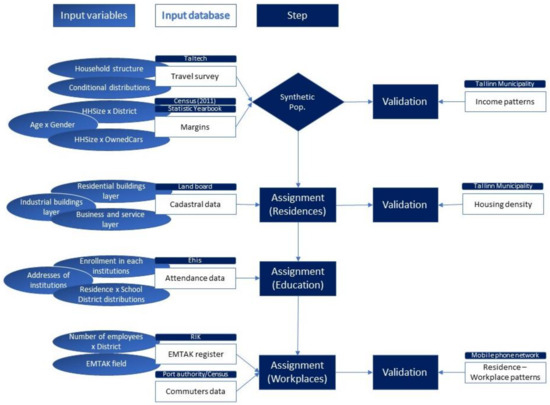
پیوست اول
| داده ها | نوع داده | منبع | استفاده | عمومی خصوصی |
| ساختار خانوار | داده های نظرسنجی | نظرسنجی از TalTech | جمعیت مصنوعی | خصوصی |
| توزیع سن × جنسیت | حاشیه آماری | سالنامه آماری تالین | جمعیت مصنوعی | عمومی |
| اندازه خانوار × توزیع منطقه | حاشیه آماری | سالنامه آماری تالین | جمعیت مصنوعی | عمومی |
| جمعیت × ناحیه فرعی | حاشیه آماری | سالنامه آماری تالین | جمعیت مصنوعی | عمومی |
| مالکیت خودرو × اندازه خانوار | توزیع احتمال | نظرسنجی از TalTech | جمعیت مصنوعی | خصوصی |
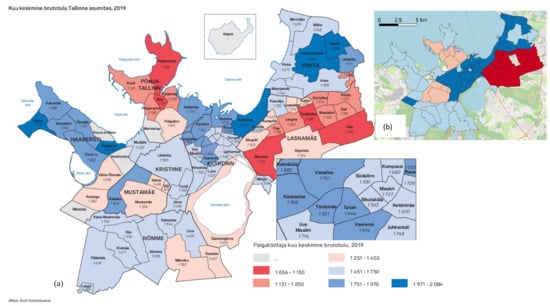
| درآمد هر عضو خانواده × ناحیه فرعی | توزیع | شهرداری تالین | اعتبار سنجی | در صورت درخواست |
| ساختمانهای مسکونی × سلول (متر مربع ) | کاربری زمین | ژئوپورتال تالین | تعیین وزن | عمومی |
| ساختمان های تولیدی و صنعتی × سلول (متر مربع ) | کاربری زمین | ژئوپورتال تالین | تعیین وزن | عمومی |
| ساختمانهای خدماتی و اداری × سلول (متر مربع ) | کاربری زمین | ژئوپورتال تالین | تعیین وزن | عمومی |
| ثبت نام × ساختمان آموزشی | وظیفه | پایگاه داده EHIS ( https://enda.ehis.ee/avalik/avalik/oppeasutus/OppeasutusOtsi.faces: پایگاه داده موسسات آموزشی و آمار ثبت نام؛ قابل دسترسی در ۱۰ دسامبر ۲۰۲۰) | تخصیص فضایی | عمومی |
| محل هر ساختمان آموزشی | وظیفه | پایگاه داده EHIS | تخصیص فضایی | عمومی |
| طبقه بندی هر ساختمان آموزشی | وظیفه | پایگاه داده EHIS | تخصیص فضایی | عمومی |
| منطقه محل سکونت × ثبت نام در هر منطقه | وظیفه | پایگاه داده EHIS | تخصیص فضایی | در صورت درخواست |
| تعداد کارمندان × منطقه × فیلد EMTAK | وظیفه | RIK | تخصیص فضایی | با پرداخت هزینه به صورت عمومی در دسترس است |
| جنسیت، سن و منطقه محل سکونت × شغل | وظیفه | سرشماری | تخصیص فضایی | عمومی |
| شغل × فیلد EMTAK | وظیفه | سرشماری | تخصیص فضایی | عمومی |
| ساختار خانوار | داده های نظرسنجی | نظرسنجی از TalTech | جمعیت مصنوعی | خصوصی |
| توزیع سن × جنسیت | حاشیه آماری | سالنامه آماری تالین | جمعیت مصنوعی | عمومی |
| اندازه خانوار × توزیع منطقه | حاشیه آماری | سالنامه آماری تالین | جمعیت مصنوعی | عمومی |
منابع
- شرانک، دی. آیزل، بی. Lomax, T. گزارش تحرک شهری ۲۰۱۹٫ در دسترس آنلاین: https://mobility.tamu.edu/umr/report/#methodology (در ۲۳ ژوئیه ۲۰۲۱ قابل دسترسی است).
- برانیگان، سی. بیدکا، م. هیچکاک، جی. مطالعه در مورد تحرک شهری – ارزیابی و بهبود دسترسی مناطق شهری گزارش نهایی و پیشنهادات خط مشی. در دسترس آنلاین: https://ec.europa.eu/transport/themes/urban/news/2017-04-07-study-urban-mobility-%E2%80%93-assessing-and-improving-accessibility-urban_en ( قابل دسترسی در ۲۳ ژوئیه ۲۰۲۱).
- لوزی، جی. مارکوچی، ای. گاتا، وی. رودریگز، ام. تئوه، تی. راموس، سی. Jonkers، E. حمل و نقل شهری پایدار و هوشمند. دپارتمان پالیسی اداره سیاست های ساختاری و انسجام – اداره کل سیاست های داخلی PE. در دسترس به صورت آنلاین: https://www.europarl.europa.eu/RegData/etudes/STUD/2020/652211/IPOL_STU(2020)652211_EN.pdf (در ۲۳ ژوئیه ۲۰۲۱ قابل دسترسی است).
- اداره امور اقتصادی و اجتماعی سازمان ملل متحد، بخش مردمی. شهرهای جهان در سال ۲۰۱۸٫ در دسترس آنلاین: https://digitallibrary.un.org/record/3799524 (در ۲۳ ژوئیه ۲۰۲۱ قابل دسترسی است).
- Benevolo، C. دامری، ر.پ. D’Auria، B. تحرک هوشمند در شهر هوشمند: طبقه بندی اقدام، شدت فناوری اطلاعات و ارتباطات و منافع عمومی. در توانمندسازی سازمان ها ; یادداشت های سخنرانی در سیستم های اطلاعاتی و سازمان. Springer: Cham, Switzerland, 2016; جلد ۱۱٫ [ Google Scholar ]
- کاغو، برو؛ بالاک، م. Axhausen، مدل های مبتنی بر عامل KW در برنامه ریزی حمل و نقل: وضعیت فعلی، مسائل و انتظارات. Procedia Comput. علمی ۲۰۲۰ ، ۱۷۰ ، ۷۲۶-۷۳۲٫ [ Google Scholar ] [ CrossRef ]
- نهمیاس بیران، ب.ح. اوکی، جی بی. کومار، ن. لیما آزودو، سی. Ben-Akiva، M. ارزیابی تأثیرات خدمات تحرک خودکار مشترک بر اساس تقاضا: یک رویکرد دسترسی مبتنی بر فعالیت. حمل و نقل ۲۰۲۰ ، ۴۸ ، ۱۶۱۳-۱۶۳۸٫ [ Google Scholar ] [ CrossRef ]
- مورنو، AT; Moeckel، R. ترکیب جمعیت دست زدن به سه قطعنامه جغرافیایی. ISPRS Int. J. Geo-Inf. ۲۰۱۸ ، ۷ ، ۱۷۴٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- حافظی، م.ح. حبیب، MA سنتز جمعیت برای مدلهای حملونقل یکپارچه مبتنی بر ریزشبیهسازی با استفاده از دادههای خرد آتلانتیک کانادا. Procedia Comput. علمی ۲۰۱۴ ، ۳۷ ، ۴۱۰-۴۱۵٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- تمپل، ام. مایندل، بی. کواریک، ع. Dupriez, O. شبیه سازی داده های پیچیده مصنوعی: بسته R simPop. J. Stat. نرم افزار ۲۰۱۷ ، ۷۹ ، ۱-۳۸٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- زو، ی. Ferreira، J. تولید جمعیت مصنوعی در مقیاس های فضایی تفکیک شده برای استفاده از زمین و میکروشبیه سازی حمل و نقل. ترانسپ Res. ضبط ۲۰۱۴ ، ۲۴۲۹ ، ۱۶۸-۱۷۷٫ [ Google Scholar ] [ CrossRef ]
- کندوری، KC; شما، دی. گاریکاپاتی، VM; Pendyala، مولد جمعیت مصنوعی پیشرفته RM که متغیرهای کنترلی را در وضوحهای جغرافیایی چندگانه در خود جای میدهد. ترانسپ Res. ضبط ۲۰۱۶ ، ۲۵۶۳ ، ۴۰-۵۰٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Yaméogo، BF; گاستینو، پ. هانکاچ، پ. وندانجون، ص. مقایسه روشهای تولید یک جمعیت مصنوعی دو لایه. ترانسپ Res. ضبط ۲۰۲۱ ، ۲۶۷۵ ، ۱۳۶-۱۴۷٫ [ Google Scholar ] [ CrossRef ]
- لنورمند، م. Deffuant، G. ایجاد یک جمعیت مصنوعی از افراد در خانواده ها: روش های بدون نمونه در مقابل روش های مبتنی بر نمونه. جی آرتیف. Soc. Soc. شبیه سازی ۲۰۱۳ ، ۱۶ ، ۱۲٫ [ Google Scholar ] [ CrossRef ]
- مک براید، EC; دیویس، AW; لی، جی اچ. گولیاس، KG گنجاندن استفاده از زمین در روش های تولید جمعیت مصنوعی و انتقال داده های رفتاری. ترانسپ Res. ضبط ۲۰۱۷ ، ۲۶۶۸ ، ۱۱-۲۰٫ [ Google Scholar ] [ CrossRef ]
- Cajka، JC; کولی، رایانه شخصی؛ ویتون، تعیین ویژگی WD به یک جمعیت مصنوعی در حمایت از مدلسازی بیماری مبتنی بر عامل. Methods Rep. RTI Press ۲۰۱۰ , ۱۹ , ۱-۱۴٫ [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- Le، DT; سرنیکیارو، جی. زگراس، سی. فریرا، جی. ساخت یک جمعیت مصنوعی از تأسیسات برای پلتفرم میکروشبیهسازی Simmobility. ترانسپ Res. Procedia ۲۰۱۶ ، ۱۹ ، ۸۱-۹۳٫ [ Google Scholar ] [ CrossRef ]
- ارث، آل. Fourie, PJ; سان، ال. ویتینز، بی جی; آتیزاز، ع. ون اگرموند، MAB; Ordóñez Medina، SA MATSim سنگاپور جمعیت مصنوعی و محل کار. در مجموعه مقالات سمپوزیوم تجزیه و تحلیل برنامه ریزی سازمان بازسازی شهری (URA)، سنگاپور، ۳ مه ۲۰۱۶٫ [ Google Scholar ]
- اوکی، جی. آکینپالی، آ. چن، اس. زی، ی. ابوطالب، YM; لیما آزودو، سی. زگراس، سی. فریرا، جی. بن آکیوا، م. شاهین، س. و همکاران ارزیابی اثرات سیستمیک خدمات خودکار بر اساس تقاضا از طریق شبیهسازی مبتنی بر عامل در مقیاس بزرگ شهرهای نمونه اولیه وابسته به خودکار ترانسپ Res. بخش A سیاست سیاست. ۲۰۲۰ ، ۱۴۰ ، ۹۸-۱۲۶٫ [ Google Scholar ] [ CrossRef ]
- اورتوزار، جی. Willumsen، LG Trip Distribution Modelling. در مدلسازی حمل و نقل ، ویرایش چهارم. جان وایلی و پسران: هوبوکن، نیوجرسی، ایالات متحده آمریکا، ۲۰۱۱٫ [ Google Scholar ]
- گالاگر، اس. ریچاردسون، LF; Ventura, SL; Eddy, W. SPEW: Synthetic Populations and Ecosystems of the World. جی. کامپیوتر. نمودار. آمار ۲۰۱۸ ، ۲۷ ، ۷۷۳-۷۸۴٫ [ Google Scholar ] [ CrossRef ]
- Ge، Y. منگ، آر. کائو، ز. کیو، ایکس. Huang، K. Virtual City: یک محیط دیجیتال مبتنی بر فردی برای تحرک انسان و رفتار تعاملی. SIMULATION ۲۰۱۴ ، ۹۰ ، ۹۱۷-۹۳۵٫ [ Google Scholar ] [ CrossRef ]
- Bodenmann, BR; وچی، آی. سانچز، بی. بود، جی. زیلر، ا. Axhausen، KW پیاده سازی یک جمعیت مصنوعی برای سوئیس. IVT، ETH زوریخ. ۲۰۱۷٫ در دسترس آنلاین: https://www.research-collection.ethz.ch/handle/20.500.11850/104334 (در ۲۸ دسامبر ۲۰۲۱ قابل دسترسی است).
- وانگ، ال. وادل، پی. Outwater، ML ادغام افزایشی استفاده از زمین و مدلسازی سفر مبتنی بر فعالیت: انتخابهای محل کار و تقاضای سفر. ترانسپ Res. ضبط ۲۰۱۱ ، ۲۲۵۵ ، ۱-۱۰٫ [ Google Scholar ] [ CrossRef ]
- فورنیه، ن. کریستوفا، ای. Akkinepally، AP; Azevedo، CL ترکیب یکپارچه جمعیت و تخصیص محل کار با استفاده از روش تطبیق فرد-خانوار مبتنی بر بهینهسازی کارآمد. حمل و نقل ۲۰۲۱ ، ۴۸ ، ۱۰۶۱-۱۰۸۷٫ [ Google Scholar ] [ CrossRef ]
- بالاک، م. Hörl، S. جمعیت مصنوعی برای ایالت کالیفرنیا بر اساس دادههای باز: نمونههایی از منطقه خلیج سانفرانسیسکو و شهرستان سن دیگو. در مجموعه مقالات صدمین نشست سالانه هیئت تحقیقات حمل و نقل، واشنگتن دی سی، ایالات متحده آمریکا، ۲۱ تا ۲۹ ژانویه ۲۰۲۱٫ [ Google Scholar ]
- ویتون، WD; Cajka، JC; Chasteen، BM; Wagener، DK; کولی، رایانه شخصی؛ گاناپاتی، ال. رابرتز، دی جی؛ Allpress، JL پایگاه های داده های ترکیبی جمعیت: پایگاه داده های جغرافیایی ایالات متحده برای مدل های مبتنی بر عامل. Methods Rep. RTI Press ۲۰۰۹ ، ۲۰۰۹ ، ۹۰۵٫ [ Google Scholar ]
- وانگ، اچ. زنگ، دبلیو. کائو، آر. شبیه سازی مشاغل شهری – انتخاب مکان مسکن و رابطه فضایی با استفاده از رویکرد چند عاملی. ISPRS Int. J. Geo-Inf. ۲۰۲۱ ، ۱۰ ، ۱۶٫ [ Google Scholar ] [ CrossRef ]
- هورل، اس. Balac, M. Synthetic جمعیت و تقاضای سفر برای پاریس و ایل دوفرانس بر اساس دادههای باز و در دسترس عموم. ترانسپ Res. قسمت C Emerg. تکنولوژی ۲۰۲۱ ، ۱۳۰ ، ۱۰۳۲۹۱٫ [ Google Scholar ] [ CrossRef ]
- سالارد، ا. بالاچ، م. Hörl، S. یک جمعیت مصنوعی برای منطقه بزرگ سائوپائولو.IVT، ETH زوریخ. ۲۰۲۰٫ در دسترس آنلاین: https://www.research-collection.ethz.ch/handle/20.500.11850/429951 (در ۲۸ دسامبر ۲۰۲۱ قابل دسترسی است).
- زیمکه، دی. کدورا، من. Nagel، K. سناریوی برلین باز MATSim: یک سناریوی شبیهسازی حمل و نقل مبتنی بر عامل چندوجهی بر اساس مدلسازی تقاضای مصنوعی و دادههای باز. Procedia Comput. علمی ۲۰۱۹ ، ۱۵۱ ، ۸۷۰–۸۷۷٫ [ Google Scholar ] [ CrossRef ]
- مک براید، EC; دیویس، AW; گولیاس، KG یک تحلیل نمایه پنهان فضایی برای طبقهبندی کاربریهای زمین برای روشهای ترکیب جمعیت در پیشبینی تقاضای سفر. ترانسپ Res. ضبط ۲۰۱۸ ، ۲۶۷۲ ، ۱۵۸-۱۷۰٫ [ Google Scholar ] [ CrossRef ]
- Triinu، O. Liikumisviiside Uuring Elektrisõidukite ja Säästva Transpordi Kasutamise Arendamiseks ، تالین، استونی. ۲۰۱۵٫
- دولت شهر تالین Tallinn Arvudes 2015. سالنامه آماری تالین ; دفتر شهر تالین: تالین، استونی، ۲۰۱۵٫ [ Google Scholar ]
- خاچمان، م. مورنسی، سی. Ciari، F. تاثیر قطعنامه جغرافیایی بر کیفیت سنتز جمعیت. ISPRS Int. J. Geo-Inf. ۲۰۲۱ ، ۱۰ ، ۷۹۰٫ [ Google Scholar ] [ CrossRef ]
- Cavoli، C. CREATE—گزارش شهر تالین، استونی. در دسترس آنلاین: http://www.create-mobility.eu/create/resources/general/download/CITY-REPORT-Tallinn-WSWE-AV3MMA (در ۲۳ ژوئیه ۲۰۲۱ قابل دسترسی است).
- حداچی، ع. پورمرادناصری، م. خوشخواه، ک. رونمایی از الگوهای رفت و آمد در مقیاس بزرگ بر اساس داده های شبکه تلفن همراه تلفن همراه. J. Transp. Geogr. ۲۰۲۰ , ۸۹ , ۱۰۲۸۷۱٫ [ Google Scholar ] [ CrossRef ]
- ژانگ، ایکس. گائو، اف. لیائو، اس. ژو، اف. کای، جی. لی، اس. به تصویر کشیدن مشاغل شهروندان و ارزیابی ترکیب مشاغل شهری با داده های تلفن همراه: یک چارچوب تحلیلی جدید فضایی-زمانی. ISPRS Int. J. Geo-Inf. ۲۰۲۱ ، ۱۰ ، ۳۹۲٫ [ Google Scholar ] [ CrossRef ]






بدون دیدگاه