

آزمون اهمیت رگرسیون ساده
پایایی یا اهمیت آماری رابطه خطی نشان داده شده توسط یک معادله رگرسیون و ضرایب رگرسیون برآورد شده نیاز به آزمایش دارد زیرا احتمالاً تحت تأثیر خطاهای نمونه گیری قرار میگیرند.
پایایی یا اهمیت کلی معادله رگرسیون با استفاده از آماره آزمون F مورد آزمایش قرار میگیرد. از آزمون F برای مقایسه تغییرات در دو نمونه و آزمایش اینکه آیا اختلاف بین دو واریانس نمونه به طور تصادفی بوجود آمده است یا خیر استفاده میشود. در اینجا برای آزمایش اینکه آیا معادله رگرسیون میتواند بخش قابل توجهی از تغییرات y را با فرضیه صفر H0 توضیح دهد استفاده میشود که کسری از تغییرات در y با x توضیح داده شده است. واریانس در y که با رگرسیون توضیح داده میشود، واریانس رگرسیون نامیده میشود:

در اینجا k تعداد متغیرهای مستقل است. برای رگرسیون ساده، k = 1 است. واریانس y که توسط رگرسیون توضیح داده نشده است، واریانس باقی مانده نامیده میشود :

آمار آزمون F برای رگرسیون به شرح زیر است :

هنگامی که بخش بزرگی از واریانس کل با واریانس رگرسیون همراه است، نسبت F بالا به دست میآید که نشان میدهد معادله رگرسیون پیش بینی یا تخمین خوبی از y ارائه میدهد. برعکس ، یک واریانس باقیمانده بزرگ ممکن است به F پایینی منجر شود ، که نشان میدهد معادله رگرسیون ممکن است غیرقابل اعتماد باشد زیرا سایر متغیرهایی که در معادله ذکر نشدهاند ممکن است نقش مهمی در توضیح تغییرات y داشته باشند. بنابراین، مقدار آماره آزمون F به تعیین اینکه آیا مقدار تغییرپذیری در y محاسبه شده توسط معادله رگرسیون در مقایسه با مقادیر مرتبط با باقیماندهها یا خطاها معنادار است یا خیر کمک میکند. ابزارهای تحلیل رگرسیون در GIS مقدار p را برای نسبت F محاسبه شده ارائه میدهند. اگر مقدار p برابر یا کمتر از سطح معنی داری α باشد ، H0 رد میشود و معادله رگرسیون منفی میشود. در کل قابل توجه بنابراین ، مقدار p مرتبط با نسبت F معمولاً به عنوان معیاری برای مناسب بودن معادله رگرسیون با دادههای نمونه استفاده میشود.
اهمیت ضرایب رگرسیون با استفاده از آماره آزمون t مورد آزمایش قرار میگیرد. فرضیه صفر H0 این است که مقدار واقعی ضریب رگرسیون صفر است. بنابراین، اگر آزمون t برای b نتواند H0 را رد کند، متغیر مستقل x تأثیر قابل توجهی بر متغیر وابسته y ندارد، بنابراین x در درک y مهم نیست.
اگر آزمون t برای a نتواند H0 را رد کند، میتوانیم نتیجه بگیریم که یک حاصل از دادههای نمونه نتیجه تصادف یا خطای نمونهگیری است، بنابراین مقدار y پیشبینیشده توسط معادله رگرسیون قابل اعتماد نیست. از خطاهای استاندارد a و b برای انجام آزمون t استفاده میشود. فرمولهای ریاضی برای محاسبه آمار آزمون t برای a و b را میتوان در راجرسون (۲۰۱۵) یافت. میتوانیم از مقادیر p مرتبط با نمرات آزمون t برای تصمیمگیری در مورد رد یا عدم رد H0 استفاده کنیم.
رگرسیون چندگانه
بسیاری از مشکلات زیست محیطی دارای ماهیت چند متغیره هستند. به عنوان مثال غلظت سم قارچی در آجیل در محلهای رشد بستگی به بارندگی، دما و سرعت باد دارد. شدت بارندگی به دمای سطح دریا، فشار سطح دریا، سرعت باد و سایر عوامل محیطی مربوط میشود. رگرسیون چندگانه برای پرداختن به مشکلات چند متغیره، گسترشی برای رگرسیون ساده ارائه میدهد. این یک رابطه خطی بین یک متغیر وابسته y و دو یا چند متغیر مستقل ایجاد میکند (x1 ، x2 ، x3 ، … xk). شکل کلی معادله رگرسیون چندگانه عبارت است از :
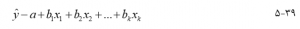
که در آن k تعداد متغیرهای مستقل، y مقدار پیش بینی شده متغیر وابسته y، و a و {bi | i =1, 2, . . . , k} ضرایب رگرسیون تخمین زده شده از دادههای نمونه هستند. همانند رگرسیون ساده، ضرایب رگرسیون با به حداقل رساندن مجموع مجذور باقیماندهها به دست میآید. اینکه چگونه رگرسیون چندگانه با دادههای نمونه تناسب دارد، با ضریب تعیین چندگانه، اندازه گیری میشود، که نسبت تغییرات توضیح داده شده و تغییرات کل در y است، که از نظر مفهومی با در رگرسیون ساده یکسان است. با این حال، با گنجاندن متغیرهای بیشتر افزایش مییابد، در حالی که بهترین معادله رگرسیون چندگانه لزوماً از همه متغیرهای موجود استفاده نمیکند. برای رفع این نقص، با توجه به تعداد متغیرهای مستقل و حجم نمونه به صورت زیر تنظیم میشود :
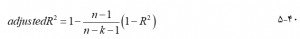
که در آن n حجم نمونه است. و تنظیم شده به همان روش تفسیر میشوند.
از آزمونهای F و t نیز برای ارزیابی اهمیت آماری معادله رگرسیون چندگانه و ضرایب رگرسیون فردی استفاده میشود. pvalue برای تعیین اهمیت آماری با توجه به سطح معناداری α استفاده میشود.
هر دو رگرسیون ساده و رگرسیون چندگانه فرض میکنند که دادهها عددی هستند. رابطه بین متغیرهای وابسته و مستقل خطی است ، اما فقط به روابط جزئی پرداخته میشود ، نه روابط ریاضی دقیق ، و باقیماندهها دارای توزیع نرمال هستند و بدون هیچ همبستگی خودکار از یکدیگر مستقل هستند. رگرسیون چندگانه نیز فرض میکند که متغیرهای مستقل ارتباط معناداری با یکدیگر ندارند، یعنی چند خطی بین متغیرهای مستقل وجود ندارد. در صورت وجود چند خطی قابل توجه، واریانس ضرایب رگرسیون برآورد شده متورم میشود که ممکن است متغیرهای مستقل ناچیز را معنی دار نشان دهد. شدت چند خطی را میتوان با استفاده از ضریب تورم واریانس (VIF) تعیین کرد.

که در آن در واقع برای متغیر مستقل است و ضریب تعیین چندگانه مرتبط با رگرسیون (به عنوان متغیر وابسته) روی همه متغیرهای مستقل دیگر است. به عنوان یک قاعده کلی، یک VIF بیشتر از ۷-۵ نشان دهنده چند خطی بودن بالا، نشانه ای از مشکلات بالقوه چند خطی است. جذر VIF همچنین نشان میدهد که خطای استاندارد چقدر بزرگتر است،
در صورتی که این متغیر با سایر متغیرهای مستقل ارتباطی نداشته باشد ، چقدر بزرگتر خواهد بود.
اینکه آیا بقایای مدل رگرسیون به طور عادی توزیع میشوند یا خیر، با استفاده از آمار آزمون جارکیو-برآ (جارکیو و برآ، ۱۹۸۷) آزمایش میشود. فرضیه صفر برای این آزمون این است که باقیماندهها به طور معمول توزیع میشوند. هنگامی که مقدار p برای آزمون کمتر از سطح اهمیت باشد، H0 رد میشود و باقی ماندهها معمولا توزیع نمیشوند که نشان میدهد مدل رگرسیون مغرضانه است. اگر باقیماندهها نیز از لحاظ مکانی به هم وابسته باشند، تکرار ممکن است ناشی از حذف یک یا چند متغیر مستقل کلیدی باشد. همبستگی مکانی باقیمانده را میتوان با استفاده از مورن اول جهانی آزمایش کرد.
مشکل محیطی چند متغیره ممکن است شامل تعداد زیادی متغیر باشد. لازم نیست همه متغیرهای ممکن در یک معادله رگرسیون چندگانه گنجانده شوند. اینکه کدام متغیرها باید شامل یا حذف شوند عمدتا بر اساس دانش حوزه، ملاحظات عملی و گاهی عقل سلیم تصمیم گیری میشود. تعیین بهترین معادله رگرسیون چندگانه مبتنی بر ارزیابی اهمیت آماری معادله رگرسیون و ضرایب فردی، ، VIF تعدیل شده و برخی معیارهای آماری دیگر است. به طور کلی معادله رگرسیون زمانی میتواند انتخاب شود که اهمیت کلی آن با مقدار p تعیین شود. برای تعداد معینی از متغیرهای مستقل، معادله با بیشترین مقدار تعدیل شده باید انتخاب شود. متغیرهای ناچیز و متغیرهایی با چند خطی بالا (VIF > 7.5) باید حذف شوند. بنابراین، یک معادله رگرسیون چندگانه را میتوان گام به گام، با آزمایش متغیر مستقل در یک زمان و گنجاندن آن در مدل رگرسیون در صورت معنادار بودن آماری، یا با گنجاندن همه متغیرهای مستقل بالقوه در معادله و حذف آنهایی که معنی دار هستند، ساخت. از نظر آماری معنی دار کادر ۵-۹ استفاده از این اصول را برای یافتن معادله رگرسیونی برای مدل سازی رابطه میانگین دمای سالانه، ارتفاع و جنبه با ArcGIS نشان میدهد.
| کادر ۵-۹ تحلیل رگرسیون در ArcGIS |
کاربردی |
| برای پیروی از این مثال، ArcMap را راه اندازی کنید و شکل فایل گیج را از مسیر زیر بارگیری کنید. |
| C:\Databases\GIS4EnvSci\VirtualCatchment\Shapefiles\. |
| در این مثال شما قرار است روابط بین میانگین دمای سالانه (متغیر وابسته)، ارتفاع و جنبه (متغیرهای مستقل) را با استفاده از رگرسیون چندگانه بررسی کنید. دادههای مشاهده شده برای سه متغیر در هر ایستگاه هواشناسی در فیلدهای دما، ارتفاع و جنبه در جدول ویژگی سنجها ذخیره میشود. |
رگرسیون دما بر ارتفاع و جهت |
| ۱) ArcToolBox را باز کنید. به قسمت Spatial Statistics Tools > Modeling Spatial Relationships بروید و روی Least Squares Ordinary دوبار کلیک کنید. |
| ۲. در کادر محاوره ای Ordinary Least Squares : |
| الف) gauges را به عنوان کلاس ویژگی ورودی انتخاب کنید. |
| ب) Id را به عنوان فیلد شناسه یکتا انتخاب کنید. |
| ج) به دایرکتوری خروجی خود بروید و نام کلاس ویژگی خروجی را وارد کنید. |
| د) temp را به عنوان متغیر وابسته انتخاب کنید. |
| ه) ارتفاع و جنبه به عنوان متغیرهای توضیحی (مستقل) هستند. |
| و) به دایرکتوری خروجی خود بروید و نام فایل گزارش خروجی را وارد کنید. |
| ز) روی گزینههای اضافی کلیک کنید. |
| ح) به دایرکتوری خروجی خود بروید و نام جدول خروجی ضریب را وارد کنید. |
| ت) به دایرکتوری خروجی خود بروید و نام جدول خروجی تشخیصی را وارد کنید. |
| ی) روی OK کلیک کنید. صبر کنید تا فرآیند کامل شود. کلاس ویژگی خروجی، گزارش و جداول ایجاد میشود. کلاس ویژگی خروجی مقادیر دمای برآورد شده توسط رگرسیون و باقیماندهها را ذخیره میکند. در نمای داده به عنوان یک نقشه باقیمانده نشان داده شده است، که تخمینهای بیش از حد و کمتر در هر مشاهده توسط مدل رگرسیون را نشان میدهد. |
| ۳) همانطور که در شکل ۵-۲۰a نشان داده شده است، جدول خروجی ضریب را اضافه کرده و باز کنید. |
| ۴) همانطور که در شکل ۵-۲۰b نشان داده شده است، جدول خروجی تشخیصی را اضافه کرده و باز کنید. |
| ۵) فایل PDF گزارش خروجی را باز کنید. |
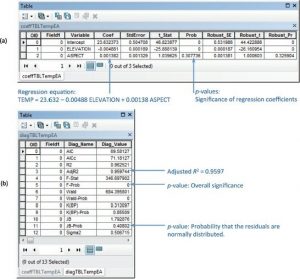
شکل ۵-۲۰ جداول خروجی رگرسیون: (الف) جدول ضریب و (ب) جدول تشخیصی
تفسیر |
| تحلیل کامل نتایج رگرسیون ممکن است شامل عناصر مهم دیگری باشد، اما بحث در اینجا به مؤلفههای زیر محدود میشود: معادله رگرسیون، تعدیلشده، اهمیت کلی، اهمیت متغیرهای رگرسیون فردی، چند خطی بودن و توزیع باقیماندهها. آنها در سطح ۰۵/۰= α ارزیابی میشوند. با استفاده از مقادیر فهرست شده در زیر عنوان Coef در جدول خروجی ضریب در شکل ۵-۲۰ a، میتوانیم معادله رگرسیون را به صورت زیر بیان کنیم : |
| که در آن y میانگین دمای تخمینی، ارتفاع، و جنبه است. مقدار در جدول خروجی تشخیصی در شکل ۵-۲۰ b نشان میدهد که ۹۷/۹۵ درصد از تغییرات دما را میتوان با ارتفاع و جنبه توضیح داد. مقدار p اندازه گیری اهمیت کلی معادله رگرسیون ذکر شده در جدول خروجی تشخیصی صفر است، نشان میدهد که معادله رگرسیون اهمیت کلی بسیار خوبی دارد و برای پیش بینی یا برآورد دما قابل اعتماد است. از گزارش pdf، برای ارتفاع و برای جنبه هر دو ۰۵۱۶/۱ است که کمتر از ۵/۷ است. بنابراین چند خطی کمی بین دو متغیر مستقل وجود دارد. مقدار p برای آزمون جارکیو-برآ که در جدول خروجی تشخیصی ذکر شده است ۴۰۸/۰ بیشتر از α است که نشان میدهد باقی ماندهها به طور معمول توزیع شده اند. مقادیر p که اهمیت ضرایب رگرسیون فردی را اندازهگیری میکنند، تحت عنوان Prob در جدول خروجی ضریب فهرست شدهاند. p-value برای elevation صفر است، اما p-value برای جنبه ۳۰۷۷/۰ است که بیشتر از α است. بنابراین، جنبه مهم نیست و باید حذف شود. |
رگرسیون دما بر ارتفاع |
| ۶) در ArcToolBox به مسیر Spatial Statistics Tools > Modeling Spatial Relationships بروید و بر روی Ordinary Least Squares دوبار کلیک کنید. |
| ۷) در کادر محاوره ای Ordinary Least Squares : |
| الف) سنجها را به عنوان کلاس ویژگی ورودی انتخاب کنید. |
| ب) شناسه را به عنوان فیلد شناسه یکتا انتخاب کنید. |
| ج) به دایرکتوری خروجی خود بروید و نام کلاس ویژگی خروجی را وارد کنید. |
| د) temp را به عنوان متغیر وابسته انتخاب کنید. |
| ه) ارتفاع تیک به عنوان متغیر توضیحی. |
| و) به دایرکتوری خروجی خود بروید و نام فایل گزارش خروجی را وارد کنید. |
| ز) روی گزینههای اضافی کلیک کنید. |
| ح) به فهرست خروجی خود بروید و نام جدول خروجی ضریب را وارد کنید. |
| ت) به دایرکتوری خروجی خود بروید و نام جدول خروجی تشخیصی را وارد کنید. |
| ۸) روی OK کلیک کنید. صبر کنید تا فرآیند کامل شود. |
| ۹) نتایج را تفسیر کنید. با توجه به جداول خروجی ضریب و تشخیصی، معادله رگرسیون ساده را میتوان به صورت زیر نوشت : |
| مقدار تعدیل شده ۹۵۹۶/۰ است، تقریباً همان چیزی است که توسط معادله رگرسیون چندگانه در بالا ایجاد شده است. مقدار p برای اهمیت کلی معادله رگرسیون و آن برای ارتفاع همگی صفر هستند، که نشان میدهد هم معادله رگرسیون ساده و هم متغیر مستقل بسیار معنی دار هستند. آزمون جارکیو-برآ ناچیز است و نشان میدهد که باقی ماندهها دارای توزیع نرمال هستند. به نظر میرسد معادله رگرسیون ساده به اندازه معادله رگرسیون چندگانه خوب است، اما فقط به متغیر مستقل نیاز دارد. میتوانید از معادله رگرسیون ساده برای پیش بینی یا تخمین قابل اعتماد دما با استفاده از مقادیر ارتفاع استفاده کنید. |

{kind=link}
بدون دیدگاه