
کیفیت دادههای مکانی
همانطور که در بخش ۲-۱ مورد بحث قرار گرفت، دادههای مکانی بازنماییهای تعمیم یافته و ساده شده از پدیدههای دنیای واقعی بر اساس روش خاصی که در آن فضای جغرافیایی مفهوم سازی میشود، هستند. آنها همچنین معمولاً مشاهده ای هستند و تحت شرایط غیر کنترل شده جمع آوری میشوند. بنابراین، دادههای مکانی ممکن است حاوی خطاهای ذاتی باشند که در مقیاسهای نقشه خاص و برای برخی کاربردها ناچیز هستند، اما در مقیاسهای دیگر نقشه و برای سایر کاربردها قابل توجه هستند (موریس ۲۰۰۸). برای اینکه دادههای مکانی مفید باشند، کیفیت آنها باید با کاربردهای مورد نظر آنها سازگار باشد. به عنوان مثال، یک مدل ارتفاع دیجیتال با وضوح ۳۰ متر برای مدلسازی هیدرولوژیکی در یک حوضه بزرگ به اندازه کافی خوب است، اما برای پیشبینی سیل ساحلی در زمینهای هموار کیفیت پایینی دارد.
کیفیت دادهها به وضعیت صحت، دقت، کامل بودن، سازگاری و به موقع بودن دادهها اشاره دارد که آنها را برای استفاده خاصی مناسب میکند. برای حل موفقیتآمیز مشکلات زیستمحیطی، دادههای مکانی باید دقیق و مطابق با دنیای واقعی باشند که در مقیاسهای معینی نشان میدهند، باید کامل، سازگار و دقیق با حداقل سطح قابل قبول عدم قطعیت باشند، و باید به اندازه کافی جاری یا به موقع برای استفاده مورد نظر باشند.
اندازه گیری کیفیت دادههای مکانی
کیفیت دادههای مکانی تا حد زیادی توسط دقت، دقت، کامل بودن و سازگاری اندازه گیری شده برای هر یک از اجزای مکانی، ویژگی و زمانی دادههای مکانی تعیین میشود ( ورگین، ۲۰۰۵). با این حال در مدلهای دادههای مکانی مرسوم، به صراحت به زمان پرداخته نمیشود. بحث در این بخش بر ارزیابی کیفیت اجزای مکان و ویژگی متمرکز است.
دقت
دقت اندازه گیری نزدیکی مقادیر داده به مقادیر واقعی یا مقادیری است که به عنوان واقعی پذیرفته شده اند. تفاوت بین مقادیر مشاهده شده و واقعی خطا است. به عبارت دیگر، دقت اندازه گیری درجه ای است که یک مقدار داده عاری از خطا است. خطاها ممکن است انحرافات منفرد و تصادفی از واقعیت باشند یا ممکن است انحرافات گسترده و سیستماتیک در سراسر مجموعه داده باشند. غیرممکن است که دادههای مکانی ۱۰۰ درصد دقیق باشند، اما امکان داشتن دادههایی با دقت در محدوده تحمل مشخص وجود ندارد. برای مثال، یک مختصات نقطه نمونه ممکن است تا ۵± متر دقیق باشد. بنابراین، دقت همیشه معیاری نسبت به مشخصات است.
دقت موقعیتی معیاری است که نشان میدهد توصیف مختصات ویژگیهای ارائه شده در دادهها تا چه اندازه با موقعیت واقعی آنها مقایسه میشود. اندازه گیری دقت موقعیت بستگی به ابعاد دارد ( ورگین، ۲۰۰۵). دقت موقعیت یک ویژگی نقطه واحد به عنوان فاصله بین مکان کدگذاری شده و مکان واقعی تعریف میشود که معمولاً از دقت افقی و عمودی تشکیل شده است. فرض کنید مکان واقعی یک نقطه (x, y, z) و مکان رمزگذاری شده آن (x’, y’, z’) باشد. دقت افقی آن برابر با محاسبه میشود، یعنی فاصله افقی بین مکانهای واقعی و کدگذاری شده. دقت عمودی آن اختلاف ارتفاع است، برای ارزیابی دقت موقعیتی مجموعه ای از نقاط در لایه داده، اغلب از RMSE استفاده میشود.
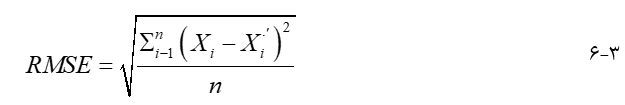
در اینجا RMSE به عنوان جذر میانگین مجذور اختلاف بین هر مقدار داده و مقدار واقعی متناظر آن تعریف میشود. معادله کلی برای محاسبه RMSE را میتوان به صورت زیر بیان کرد: در جایی که X’i مقدار داده ای i است، Xi مقدار واقعی متناظر آن و n تعداد مقادیر داده است. هر چه RMSE به صفر نزدیکتر باشد، دادهها دقیق تر هستند. برای n نقطه که مختصات واقعی آنها (x1، y1، z1)، (x2، y2، z2)، است. . .، (xn، yn، zn)، و مختصات کدگذاری شده آن (x’1، y’1، z’1)، (x’2، y’2، z’2)، . . .، (x′n، y′n، z′n)، RMSE موقعیتهای افقی آنها برابر است با :
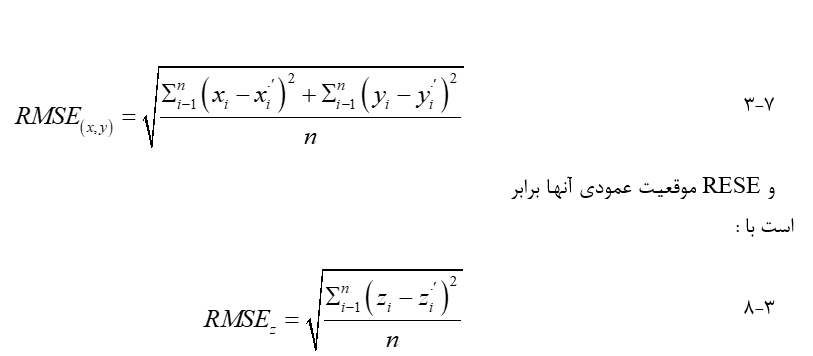
ارزیابی دقت موقعیت یک ویژگی خط یا چند ضلعی پیچیده تر است، زیرا خطا ترکیبی از خطای موقعیت (خطا در مکان یابی نقاط در امتداد خط یا چند ضلعی) و خطای تعمیم (خطا در انتخاب نقاط برای نشان دادن خط یا چند ضلعی) است. روشهای مختلفی برای اندازه گیری دقت موقعیتی ویژگیهای خط یا چندضلعی وجود دارد. یکی از روشها اندازهگیری فاصلههای مساوی عمود بر خط کدگذاری شده یا ویژگی چندضلعی تا تقاطع آنها با خط واقعی یا چندضلعی، و سپس محاسبه RMSE است (شکل ۳٫۲۱). این روش توسط استاندارد دقت افقی نقشه و دادههای مکانی استرالیا که توسط کمیته بین دولتی نقشه برداری و نقشه برداری ایجاد شده است توصیه میشود. روشهای دیگر عبارتند از فاصله Hausdorff، باند اپسیلون، پوشش تک بافر و پوشش بافر دوگانه (Ariza-López and Mozas-Calvache 2012).

شکل ۳-۲۱ اندازه گیری دقت موقعیت افقی خط

جدول ۳-۳ ماتریس خطا برای لایه پوشش زمین
در عمل، دقت موقعیتی مجموعه ای از داده آزمایشی در برابر مجموعه ای از داده مستقل با دقت بالاتر با مقایسه مختصات مکانهای نمونه در مجموعه داده آزمایشی با مختصات مکانهای مرجع که میتوان فرض کرد در منبع مستقل یکسان هستند، ارزیابی میشود. منابع احتمالی برای اطلاعات با دقت بالاتر شامل بررسیهای زمینی زمینشناسی، بررسیهای زمینی GPS، بررسیهای فتوگرامتری و پایگاههای داده مکانی با دقت بسیار بالاتر است. علاوه بر این حداقل بیست مکان نمونه باید برای ارزیابی انتخاب شود، که باید به طور مساوی در منطقه جغرافیایی مورد علاقه توزیع شده و منعکس کننده توزیع خطا در مجموعه داده باشد.
دقت مشخصه معیاری است که نشان میدهد مقادیر مشخصه ویژگیهای نمایش داده شده در دادهها با مقادیر واقعی آنها چقدر نزدیک است. به اندازه دقت موقعیت مهم است. بسته به ماهیت داده ها، دقت ویژگی ممکن است به روشهای مختلفی اندازه گیری شود. برای ویژگیهای عددی مانند ارتفاع، بارش و دما، دقت ممکن است بر حسب خطای اندازهگیری (به عنوان مثال، بارش با دقت ۱ میلیمتر) یا RMSE اندازهگیری شود. برای ویژگیهای طبقهبندی مانند کاربری زمین و انواع خاک، دقت معمولاً با استفاده از ماتریسهای خطای طبقهبندی ارزیابی میشود. ماتریس خطای طبقهبندی که به عنوان ماتریس خطا یا ماتریس سردرگمی نیز شناخته میشود، جدولبندی متقابلی از کلاسهای کدگذاری شده و واقعی در مکانهای نمونه است. در عمل، ماتریسهای خطا، رابطه بین دادههای مرجع شناختهشده از یک منبع مستقل با دقت بالاتر و دادههای آزمون را بر اساس دسته به دسته مقایسه میکنند. به عنوان مثال فرض کنید لایه داده پوشش زمین حاوی پنج نوع پوشش زمین داریم: تالاب، جنگل، مرتع، یخچال/برف و خشک. با مقایسه انواع پوشش زمین طبقه بندی شده در لایه داده با دادههای مرجع شناخته شده با دقت بالاتر در ۱۰۵۶ مکان نمونه، یک ماتریس خطا همانطور که در جدول ۳-۳ نشان داده شده است تولید میشود. عنصر در ردیف i و ستون j ماتریس تعداد مکانهای نمونه اختصاص داده شده به کلاس i است اما در واقع متعلق به کلاس j است. مجموع ردیف i تعداد کل امتیازهای نمونه اختصاص داده شده به کلاس i است. مجموع ستون j تعداد کل نقاط نمونه در واقع متعلق به کلاس j است.
چهار معیار برای ارزیابی دقت ویژگی بر اساس یک ماتریس خطا ایجاد شده است: دقت کلی، دقت تولیدکننده، دقت کاربر و شاخص کاپا توافق. دقت کلی به عنوان مجموع مقادیر مورب تقسیم بر تعداد مکانهای نمونه تعریف میشود. برای مثال بالا، دقت کلی برای این مجموعه داده پوشش زمین (۷۴ + ۳۹۸ + ۶۵ + ۳۰۰ + ۲۹) / ۱۰۵۶ = ۸۲ درصد است. این نشان میدهد که به طور کلی، ۸۲ درصد از مکانهای نمونه به درستی طبقه بندی شده اند.
دقت تولیدکننده نشان میدهد که مکانهای نمونه کلاس مشخص چقدر در مجموعه داده طبقهبندی شدهاند. با تقسیم تعداد مکانهای نمونه بهدرستی طبقهبندیشده در هر دسته (در مورب اصلی) بر تعداد مکانهای نمونه که واقعاً به آن دسته تعلق دارند (کل ستون) محاسبه میشود. به عنوان مثال دقت تولید کننده از جنگل ۸۷ درصد است. این بدان معنی است که ۱۳ درصد از مکانهای جنگلی به اشتباه طبقه بندی شده اند، یعنی گم شده اند. بنابراین دقت تولیدکننده معیاری برای خطای حذف است.
احتمال اینکه یک مکان نمونه واقعاً در یک دسته بندی خاص طبقه بندی شود نشان دهنده آن دسته در زمین است. دقت کاربر با تقسیم تعداد پیکسلهای طبقه بندی شده صحیح در هر دسته بر تعداد مکانهای نمونه طبقه بندی شده برای آن دسته (مجموع ردیف) محاسبه میشود. به عنوان مثال، دقت کاربر در جنگل ۸۲ درصد است. این بدان معناست که ۸۲ درصد از مکانهای نمونه طبقهبندیشده بهعنوان جنگل، در واقع مکانهای جنگلی هستند، اما ۲۵ درصد از مکانهای نمونه طبقهبندیشده بهعنوان جنگل، مکانهای جنگلی روی زمین نیستند – آنها به اشتباه طبقهبندی شده و به عنوان جنگل درج شدهاند. شاخص توافق کاپا یا به سادگی کاپا، آماری است که توافق در طبقه بندی را با در نظر گرفتن توافق اتفاقی اندازه گیری میکند. این نسبت مکانهایی است که به درستی طبقه بندی شدهاند پس از محاسبه احتمال توافق تصادفی. آمار کاپا یک ماتریس خطا، به صورت زیر محاسبه میشود:
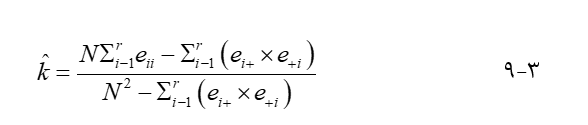
جایی که r تعداد سطرهای ماتریس است، eii عنصر سطر i و ستون i، xi+ و x+i به ترتیب مجموع سطرها و ستونهای سطر i و ستون i هستند و N تعداد کل مکانهای نمونه است. . این آمار قدرت نسبی توافق را با استفاده از مقیاس نشان داده شده در جدول ۳٫۴ توصیف میکند.
برای ماتریس خطا فهرست شده در جدول ۳٫۳، آمار کاپا آن ۰٫۷۴ محاسبه شده است که نشان دهنده توافق قابل توجه است. در حالی که دقت کلی فقط از دادهها در امتداد مورب ماتریس خطا استفاده میکند و خطاهای حذف و اشتباه را حذف میکند، کاپا عناصر غیر قطری را در خود جای میدهد.
به عنوان دستورالعمل کلی حداقل پنجاه مکان نمونه برای هر دسته باید در یک ماتریس خطا گنجانده شود. یک منطقه بزرگ با تعداد زیادی دسته به مکانهای نمونه بیشتری نیاز دارد. در ارزیابی دقت، مکانهای نمونه بیشتری باید به دستههای مهمتر یا متغیرتر (به عنوان مثال، مکانهای نمونه بیشتر برای تالابها و کمتر برای آبهای آزاد) اختصاص داده شود.