۱٫ مقدمه
امضاهای مکانی-زمانی برای زمان و مکان ارتکاب جنایات وابسته به دسته بندی جرم متفاوت است [ ۱ ، ۲ ]. تعدادی از مطالعات قوانین تجربی را برای دزدی ها تأیید کرده اند [ ۳ ، ۴ ، ۵ ]، و نشان می دهد که به محض سرقت از خانه، خطر سرقت مجدد افزایش می یابد، نه تنها برای قربانی (تکرار) بلکه برای همسایگان آنها (نزدیک تکرار کنید) [ ۳ ، ۶ ، ۷ ، ۸ ].
محققان و همچنین سازمانهای مجری قانون، الگوهایی را در مقیاسهای زمانی مختلف (مانند ساعتها، روزها، هفتهها و سالها) و سطوح مکانی (مثلاً ملت، منطقه، جامعه، و محله تا سطح خیابان) شناسایی کردهاند. یافتن الگوهای مکانی-زمانی به توسعه یک درک جامع و متمایز در مقایسه با تجزیه و تحلیل جرایم به صورت مجزا کمک می کند [ ۹ ]، که ممکن است به پیش بینی مکان های جرم در آینده کمک کند [ ۱۰ ]. با این حال، تحقیقات اخیر همچنین سوالاتی را در مورد قابلیت استفاده از مفروضات تکرار قربانی شدن در پیشگیری از جرم مطرح کرده است. به عنوان مثال، در یک مطالعه مبتنی بر نیوزیلند، حداقل نیمی از سرقتها (تکرار و تقریباً تکراری) در خارج از نقاط داغ قرار داشتند [ ۱۱ ].
به منظور غنیسازی توصیف، و همچنین بهطور بالقوه برای افزایش شانس پیوند جنایات مجرمان، تجزیه و تحلیل مکانی-زمانی میتواند با شواهد فیزیکی مانند DNA یا اثر انگشت تکمیل شود. متأسفانه، چنین شواهدی همیشه در صحنههای جرم وجود ندارد و برای دستههای جرم خاص بیشتر از سایرین در دسترس است [ ۱۲ ]. پردازش شواهد فیزیکی نیز بسیار پرهزینه و زمان بر است. بنابراین، برای سازمان های مجری قانون رسیدگی به مقادیر زیادی از شواهد فیزیکی از دسته های جرایم با حجم بالا [ ۱۳ ]، مانند دزدی، دشوار است.
رویکرد تکمیلی دیگر به جنبه مکانی-زمانی جرم، تمرکز بر «شواهد نرم» مرتبط با شیوههای عمل مجرمین (MO)، یعنی عادات، تکنیکها و ویژگیهای رفتاری هنگام ارتکاب یک جرم، مانند استفاده از یک جرم خاص است. ورودی یا ابزاری خاص هنگام نفوذ به ساختمان [ ۲ ، ۱۴]. به عنوان مثال، اگر مجرم از رفتارهای تکراری (مستمر) یا متفاوت (خاص) از نظر ابزار یا نقطه دسترسی به خانه/آپارتمان استفاده کند، چنین نشانه هایی ممکن است برجسته شود. این نوع شواهد ممکن است به نوبه خود به ویژگی های محیط بستگی داشته باشد و بنابراین بین دزدی ها متفاوت است. اگر از روش های طراحی شده کافی برای بررسی صحنه جرم استفاده شود، اغلب شواهد برای جمع آوری در دسترس است. هر گونه داده جمع آوری شده صحنه جرم ممکن است با استفاده از نمایه های رفتاری و جنایی [ ۱۵ ، ۱۶ ، ۱۷ ] به گونه ای تفسیر شود که بازتاب شناخت مرتکب [ ۱۸ ]، درجه ریسک پذیری و برنامه ریزی [ ۱۹ ، ۲۰ ] باشد.]، و بنابراین توصیف غنی تری از اقدامات مجرم ارائه می دهد که به پیش بینی زمان و مکان دوباره ارتکاب جنایت کمک بیشتری می کند. با این حال، در واقعیت، چنین تحلیلهایی اغلب با استفاده از افسران مجری قانون انجام میشوند و به ندرت با استفاده از مقایسههای سیستماتیک مبتنی بر دادهها در بین موارد، شهرها و مناطق انجام میشوند.
با این حال، نمونههایی از مطالعات وجود دارد که به طور مشترک MO یا متغیرهای خانگی را با جنبههای مکانی-زمانی (تکرار/تقریباً تکرار) تحلیل میکنند. این استثناها شامل مطالعه Bowers و Johnson [ ۲۱ ] است که در آن نقطه ورود و روش ورود در ۳۵۶۲ مورد تجزیه و تحلیل شد و در Vandeviver و همکاران. [ ۲۰ ]، مطالعه ای که در آن ۶۵۰ مورد با ویژگی های مسکن مجاور (۵۰۰۰۰۰ ملک مسکونی) مقایسه شد. با این حال، اگرچه تحقیقات قبلی از این دیدگاه حمایت می کند که مجرمان مجرد ممکن است به احتمال زیاد به همان صحنه سرقت برگردند [ ۵ ]]، منطق تکرار جرم را می توان بر این اساس زیر سوال برد که امضاهای MO ممکن است نتیجه یک مجرم واحد نباشد. دزدیها اغلب در گروههای کوچکی انجام میشوند که مجرمان ممکن است با هم تعامل داشته باشند و سرریز دانش ایجاد کنند (به Glaeser et al. [ ۲۲ ] مراجعه کنید). بنابراین، ارتکاب جرایم به صورت گروهی، MO خاص یک فرد را محو می کند، زیرا جرم به MO های جمع شده بستگی دارد. بنابراین، “اجتماعی” دزدی ها بر دیدگاه متفاوتی از کاربرد MO در مکان و زمان تأکید می کند. یک امضای MO محدود فضایی-زمانی به تفکیک تکرار جرایم غیر تکراری، صرف نظر از اینکه مجرم به تنهایی یا در یک گروه کار میکند، کمک میکند.
بنابراین، تجزیه و تحلیل توزیع زمانی و مکانی دزدی ها، همراه با ویژگی هایی که این جرایم را مشخص می کند و به طور بالقوه تبعیض می کند، می تواند توصیفی غنی از محل نگهداری مجرم ارائه دهد. این می تواند پیامدهای سیاستی مهمی از نظر رویه های پیشگیرانه احتمالی برای چگونگی اجتناب از جرایم و همچنین نحوه استفاده استراتژیک و کارآمد از منابع کمیاب نیروی پلیس داشته باشد [ ۲۳ ].
به طور خاص، در این مطالعه، توزیع مکانی-زمانی (از نظر تقریباً تکراری/تکرار) سرقتها را در ۱۰ شهر سوئد بررسی کردیم و بررسی کردیم که آیا تفاوتهایی در MO بین سرقتهای تقریباً تکراری/تکرار در مقابل سرقتهای غیر تکراری وجود دارد یا خیر. آیا میتوان بر اساس ویژگیهای صحنه جرم و MOهای مجرمان، احتمال اینکه صحنه جنایت بخشی از زنجیره تکرار (تکرار یا تکرار) باشد، تخمین زد. ما همچنین بررسی کردیم که چگونه ویژگی های نشان دهنده جنایات تقریباً تکراری در شهرهای مختلف متفاوت است. این تحقیقات بر اساس دادههای مربوط به سرقتهای مسکونی در شهرهای سوئد بین سالهای ۲۰۱۲ تا ۲۰۱۶ بود.
۲٫ پیشینه نظری
۲٫۱٫ نظریه های رفتار مجرمانه
جرم درباره یک بازیگر، محیط و تعامل بین این دو است [ ۲۴ ]. پیش از این، و از دیدگاه اقتصادی منطقی، رفتار مجرمانه شامل ارزیابی سیستماتیک منافع در برابر خطر بالقوه مجازات در صورت دستگیری می شود [ ۲۵ ]. اگرچه ممکن است به دست آوردن اطلاعات کامل در مورد یک هدف بالقوه دشوار باشد، اما تحقیقات اخیر از دیدگاه مشورت منطقی سارقان در انتخاب هدف حمایت می کند [ ۲۰ ]. برخلاف مدل انتخاب منطقی افراد مرتکب جرم، طرفداران نظریه فعالیت های معمولی فرض می کنند که رفتار مجرمانه قربانی محور، عادتی است و مستلزم یک اقدام بسیار کمتر عمدی توسط مجرم است [ ۲۶ ،۲۷ ]. تئوری فعالیت معمول بیشتر نشان می دهد که انتخاب هدف مجرمان با فعالیت مجرمانه موفق شکل می گیرد [ ۲۸ ]. بنابراین، در عبارات کلی، در حالی که نظریه انتخاب عقلانی بر مشورت یک مجرم فردی متمرکز است، نظریه فعالیت معمول بر عوامل تعیینکننده جمعی و زمینهای قربانی شدن تمرکز دارد.
علیرغم دلایل متفاوت برای ارتکاب جرم در تئوری انتخاب منطقی و فعالیت معمول، این دو جریان تحقیقاتی مکمل یکدیگر در توصیف الگوهای پشتوانه جرم در زمان و مکان هستند و مفروضاتی را برجسته میکنند که زیربنای الگوهای تکرار و تقریباً تکرار هستند. در راستای تئوری انتخاب عقلانی، اگر ارزیابی سودمندی محاسباتی را با مجازات کم ارائه دهد، در نتیجه ممکن است مرتکب صحنه جرم را بازبینی کند، در صورتی که تخمین خطر در حساب کم نگه داشته شود. گزارش های مشابهی نیز برای مثال در نظریه جستجوی بهینه [ ۲۱ و ۲۹ ] ارائه شده است.]، که ارزیابی بازده فوری را در رابطه با ریسک و تلاش برای جستجوی احتمالات جدید برجسته میکند، و حساب تقویتی، که بیان میکند که بازگشت به صحنه جرم به موفقیت قبلی بستگی دارد [ ۲۱ ]، مانند داشتن بازده بالا. تئوری فعالیت معمول [ ۲۶ ] دلالت بر این دارد که الگوهای تکرار شونده از موقعیت قربانیان آسیب پذیری را آشکار می کند و در نتیجه مرتکبین را تشویق می کند تا اولین جنایت را مرتکب شوند، اما همچنین به دلیل سهولت در دسترس بودن، به طور معمول صحنه جرم را بازبینی کنند. علاوه بر این، تحقیقات نشان میدهد که اگر مجرمان قبلاً جرمی را در نزدیکی مرتکب شده باشند، تمایل دارند به منطقهای بازگردند، اگر نوع جرم مشابه باشد، هر چه اخیر جرم قبلی رخ داده باشد، یا با افزایش تعداد جرایم قبلی، احتمال افزایش آن افزایش مییابد. ۵، ۳۰ ]. بنابراین، این نظریهها به مطالعه ما کمک میکنند، زیرا به توضیح دلیل جرایم تکراری و تقریباً تکراری کمک میکنند، تا زمانی که فرض شود این جنایت همان مرتکب جرم است.
با این حال، جرایم تکراری و تقریباً تکراری لزوماً توسط یک فرد انجام نمی شود. تحقیقات اجتماعی-اقتصادی نشان می دهد که جرایم کم شدت یک فعالیت “اجتماعی” است که در آن اثرات مسری رخ می دهد [ ۳۱ ، ۳۲ ]. این جرایم کوچک (مانند سرقت خودرو) و جرایم متوسط (مانند سرقت از منزل) به ویژه در مقایسه با جرایم خشن تر مانند تجاوز جنسی یا قتل در معرض درجات بالاتری از تعامل اجتماعی بین مجرمان هستند [ ۲۲ ].]. بنابراین، برای توسعه درک بیشتر از الگوهای جرم، و همچنین اینکه چه چیزی و مجرمان ممکن است در مورد و چه زمانی در تعامل باشند، تأثیر نسبی عوامل خارجی، مانند ویژگیهای مسکن، و ویژگیهای MO، مانند وسایل ورود، نیاز به به طور مشترک در مکان و زمان تحلیل شوند. همانطور که در زیر توضیح داده خواهد شد، مطالعات قبلی بر مجموعههای محدودی از دادهها، چه از نظر ویژگیها، یا تعداد موارد مورد تجزیه و تحلیل، تکیه کردهاند. بنابراین، در مرحله بعد، قوانین تجربی جنایات توزیعشده مکانی-زمانی را همراه با ویژگیهای خاص، مانند MO، که این سرقتها را مشخص میکند، مرور میکنیم.
۲٫۲٫ قاعدهمندیهای تجربی جنبههای زمانی، مکانی و تکراری جرم
همانطور که قبلاً توضیح داده شد، دزدیها در مکان و زمان دستهبندی میشوند و احتمال میدهد خانوادهها دوباره قربانی شوند (یا خانوادههای مجاور قربانی شوند). تحقیقات اولیه توسط [ ۳۳ ] نشان داد که الگوهای قربانی شدن مکرر حجم قابل توجهی از جنایات را در انگلستان و ولز نشان می دهد. تحقیقات جدیدتر نشان داد که دزدی ها در شهرها (در چندین کشور مختلف) بسیار متمرکز است. برای مثال، در مطالعات [ ۳۴ ، ۳۵ ] در ونکوور و اتاوا، درصد بالایی از تماسها با خدمات پلیس در مورد سرقت از تعداد بسیار کمی از آدرسها بوده است. نتایج مشابهی در [ ۳۶ ] نشان داده شد]، مطالعه ای در تل آویو یافا، اسرائیل، که امکان تعمیم در مورد تمرکز جرم در فضا را افزایش می دهد.
با توجه به ویژگیهای مورد استفاده برای تجزیه و تحلیل سرقتهای خانگی، دهه گذشته افزایشی در مطالعات متمرکز بر مسائل مربوط به مکان و زمان ایجاد کرده است. تجزیه و تحلیل نقطه داغ روشی است که معمولاً برای گروه بندی پرونده ها بر اساس اطلاعات مکانی با هدف پیش بینی جنایات آینده استفاده می شود [ ۱۲ ، ۳۷ ، ۳۸ ، ۳۹ ، ۴۰ ، ۴۱ ، ۴۲ ]. این مطالعات نشان دادهاند که مناطقی که قبلاً سرقت شدهاند با خطر سرقت مجدد روبرو هستند [ ۲۱ ، ۳۳ ].
علاوه بر این، نه تنها مکان، بلکه جنبه های مسکن نیز اهمیت دارد. به عنوان مثال، در مطالعهای در هلند، خانههای تراسدار، خانههای بدون گاراژ، خانههایی که مجهز به سیستم گرمایش مرکزی و/یا تهویه مطبوع نبودند، و خانههای نزدیک به محل سکونت سارقان، بیشتر مورد سرقت قرار میگرفتند. [ ۲۰ ]. علاوه بر این، نزدیکی خانوارهای استرالیایی با درجه بالایی از همگنی مسکن با سطح مشابهی از خطر بالا به خطر موقت مرتبط با قربانی شدن مرتبط است [ ۳۲ ].]. در مطالعه دیگری که بر تکرارهای (نزدیک) در بلو هوریزونته در برزیل متمرکز بود، مناطقی با مسکن ناهمگن، مانند حصار محیطی، افزایش حفاظ ها، مسکن های نامنظم و خودساخته، درجه کمتری از تکرار (نزدیک) را نشان دادند. نسبت به مسکن غربی [ ۶ ]. به عبارت دیگر، به نظر میرسد که تنوع در ساختار فیزیکی از مرتکب جنایات تکراری (تقریباً) محافظت میکند.
با توجه به روابط زمانی، خانوادههای مورد آزار و اذیت احتمالاً دوباره مورد ضرب و شتم قرار خواهند گرفت [ ۵ ]. یک مطالعه بزرگ که سرقتهای پنج کشور مختلف را با هم مقایسه کرد، نشان داد که خانههایی که در فاصله ۲۰۰ متری خانه سرقتشده قرار دارند، با خطر بالای سرقت در دو هفته آینده مواجه هستند [ ۴ ]. علاوه بر این، دوره زمانی تکرارها (تکرار مجدد در عرض هفت روز) نیز در همان زمان/روز هفته با رویداد پیشین رخ میدهد [ ۴۳ ، ۴۴ ]. پهنای باند زمانی که برای ارزیابی تکرارهای نزدیک استفاده شده است معمولاً بین ۱ تا ۱۴ روز متغیر است [ ۶ ].
بررسی جنبه های مکانی- زمانی سرقت های خانگی از سطوح مختلف تحلیل استفاده کرده است. جرم شناسی فضایی با تغییر وضوح از تحلیل کلان، از طریق محله به سطح خیابان، افزایش می یابد. با استفاده از الگوهای نقطه فضایی، Ref. [ ۲ ] دریافت که الگوهای جرم عمومی در چندین مقیاس فضایی مشابه هستند، اما تجزیه و تحلیل در سطوح ظریف (مانند بخش های خیابان) تغییرات قابل توجهی را در واحدهای بزرگتر نشان داد، که نشان می دهد جرم یک پدیده کاملاً محلی است. علاوه بر این، در بدنه تحقیقاتی که مسائل مربوط به فضا و زمان را بررسی میکند، مطالعاتی که بر MOs مجرم تمرکز دارند نیز یافت میشوند. نویسندگان [ ۷] سازگاری قابل توجهی در رفتار مجرمان در پارامترهای مربوط به جنایات نزدیک به فضا پیدا کرد، حتی زمانی که جدایی در طول زمان وجود داشت. چنین یافتههایی نشانههای خاصی از مجرمان را نشان میدهد، اما نه اینکه این امضاها معمولاً شبیه آن هستند. تحقیقات اولیه توسط [ ۲۱ ] تکرارهای نزدیک و رویدادهای سرقت غیرمرتبط را برجسته کرد، و نشان داد که “وسایل ورود” و “نقطه ورود” به طور قابل توجهی برای جنایات تقریباً تکراری همخوانی دارند. این که آیا این نتیجه همگنی مسکن یا سازگاری مجرم است، بررسی نشد. بعداً، ر. [ ۴۵ ] MO را در پیوند جرم مورد بررسی قرار داد و با تجزیه و تحلیل تا ۷۹ ویژگی جرایم برای ۱۶۰ جفت جرم (۸۰ مرتبط در مقابل ۸۰ غیر مرتبط) تعداد ویژگیهایی را که باید برای کشف الگوهای MO مورد استفاده قرار گیرند افزایش داد. نویسندگان [ ۴۵] هیچ الگوی در MO ها که جنایات تقریباً تکراری را پیش بینی می کردند، پیدا نکرد. با این حال، در حالی که [ ۲۱ ] از چند ویژگی مرتبط با MO استفاده می کرد، Ref. [ ۴۵ ] از یک نمونه نسبتاً کوچک از یک منطقه استفاده کرد و طبقهبندی ویژگیها بر اساس گزارشهای پلیس متن آزاد بود.
در مجموع، این مشاهدات ارزشمند است که بیشتر بررسی کنیم که آیا ویژگیهای سرقتهای مکرر (نزدیک) با جرایم غیر تکراری متفاوت است، و اگر چنین است، تکرارهای نزدیک در شهرهای خاص چگونه مشخص میشوند؟
۲٫۳٫ سوالات تحقیق
بهطور شگفتانگیزی، مطالعات کمی بررسی کردهاند که چگونه MO مجرمان (از جمله جنبههای زمینهای، مانند ویژگیهای فیزیکی محل) با جنایات تقریباً تکراری مرتبط هستند. بنابراین سؤالات تحقیق در این پژوهش عبارت بودند از:
- ۱٫
-
آیا ویژگی های مشخصه ای در جرایم نزدیک به تکرار وجود دارد که با جرایم غیر تکراری متفاوت است؟
- ۲٫
-
تا چه حد می توان جرایم تقریباً تکراری را بر اساس ویژگی های صحنه جرم و MOهای مجرم (ها) پیش بینی کرد؟
- ۳٫
-
آیا امضاهای مشخصه برای جنایات تقریباً تکراری بسته به موقعیت مکانی متفاوت است؟
۳٫ روش شناسی
۳٫۱٫ داده ها
بین سالهای ۲۰۱۲ و ۲۰۱۶، مجری قانون سوئد چندین هزار گزارش صحنه جرم را با استفاده از یک رویکرد سیستماتیک و ساختار یافته جمعآوری کرد. گزارش های صحنه جرم از مناطق مختلف سوئد، اما در درجه اول از جنوب سوئد و منطقه استکهلم جمع آوری شده است. لازم به ذکر است که اسامی اصلی شهرهای مورد استفاده در این تحقیق با نام شهرهای مجموعه کتاب آواز یخ و آتش [ ۴۶ ] بینام شده است. برای هر صحنه جرم، افسران مجری قانون فرمی را پر کردند که جزئیات مکان و دادههای زمانی، اما همچنین اطلاعاتی را که نمایانگر ویژگیهای MO بود، از جمله: ویژگیهای مسکونی (خانه یا آپارتمان، روستایی یا شهری، چند همسایه، و غیره)، رفتار ورودی پر کردند.(در بالکن سوراخ شده، پنجره شکسته و غیره)، رفتار قربانی (پارک شده در فرودگاه، غیبت برنامه ریزی شده، شخصی در خانه، شرکت ثبت شده و غیره)، آثار فیزیکی (DNA، اثر انگشت، اثر کفش) باقی مانده در صحنه، یا نوع کالای مسروقه (حجم یا غیر حجیم، طلا، پول نقد، لوازم الکترونیکی، عطر و غیره). این زیرگروههای MO بر اساس [ ۴۷ ] بودند و ویژگیها با کمک افسران اجرای قانون برای گروهها ترسیم شدند. داده ها به عنوان چک باکس (داده های باینری) جمع آوری شد، اما، در صورت لزوم، می توان از متن برای روشن شدن استفاده کرد. اطلاعات جمع آوری شده با جزئیات بیشتر در جدول ۱ توضیح داده شده است. طراحی فرم توسط گروهی از کارشناسان حوزه مجری قانون تصمیم گیری شد و تقریباً هر ۱۸ ماه یکبار به روز می شود. برای هر نسخه از فرم، بررسیهای نرمافزاری برای الزامات نحوه استفاده از فرم وجود داشت (مثلاً پرش از بخشهای فرم مجاز نبود. با این حال، غیر قابل اجرا یا سایر برای بخشهای خاصی در دسترس بود).
به عنوان یک نتیجه از روش جمع آوری، مقایسه بین صحنه های جرم به راحتی انجام شد، زیرا اطلاعات قابل مقایسه از همه صحنه های جرم جمع آوری شد. مقایسه زوجی بین جنایات را می توان با استفاده از شاخص جاکارد [ ۱۶ ، ۱۷ ] تحلیل کرد. مقایسههای زوجی همچنین میتواند بر روی زیر گروههای ویژگیها انجام شود تا با تقسیم طبیعی دادهها مطابقت داشته باشد – یک رویکرد رایج پذیرفته شده در تحقیقات مرتبط [ ۱۶ ، ۱۷ ]. در این مطالعه، زیرگروه های ویژگی های شرح داده شده در پاراگراف بالا، و همچنین ترکیبی از همه زیرگروه ها (با علامت MO) مورد استفاده قرار گرفت.
مجموعه دادهها شامل ۵۷۴۴ حادثه سرقت از منازل مسکونی بود که در ۱۰ شهر سوئد جمعآوری شد، با ۱۳۷ متغیر مربوط به MO، دو متغیر نشان دهنده طول و عرض جغرافیایی، پنج متغیر تاریخ و زمان وقوع جرم، و سه متغیر دیگر (یعنی یادداشتها، تاریخ). جمع آوری شده، جمع آوری شده توسط)، همانطور که در جدول ۱ نشان داده شده است. یک مقایسه زوجی از هر صحنه جرم برای اندازهگیری فاصله مکانی و فاصله زمانی انجام شد تا مشخص شود آیا صحنه جرم تقریباً تکراری است یا خیر.
جرم تکراری جایی است که مجرم در یک بازه زمانی خاص دو بار به همان صحنه جرم باز می گردد. جنایت تقریباً تکراری در سطح محله تعریف میشود که در آن دو مورد از صحنه جرم دیگری که در یک پنجره زمانی ۱۴ روزه رخ داده است بیش از ۲۰۰ متر فاصله نداشته باشند [ ۶ ]. در نتیجه، از آنجایی که بازگشت به همان صحنه جرم، تعریف جنایت تقریباً تکراری را نیز برآورده میکند، جرایم تکراری نیز در کلاس تقریباً تکرار قرار گرفتند. تغییرات در تعریف، چه با توجه به جنبه های مکانی یا زمانی، بر نتایج تأثیر می گذارد [ ۶ ]. تعریف مورد استفاده در این مطالعه گسترده ترین تعاریفی است که توسط Chainey و Silva [ ۶ ] استفاده شده است، اما همچنین تعریفی است که در مطالعات دیگر پذیرفته شده است.
مقایسههای زوجی بین تمام جرایم انجام شد. جرایمی که معیارهای نزدیک به تکرار را برآورده میکردند، به این ترتیب برچسبگذاری شدند، یعنی هر دو جنایت در یک جفت که نزدیک به تکرار در نظر گرفته میشدند برچسبی را دریافت کردند که نشان دهنده این است. این برچسب بعداً به عنوان یک متغیر وابسته استفاده شد. توزیع تقریباً تکرارها در هر شهر، با تقریبی، به جای شناسایی دقیق، اندازه شهر (بر حسب جمعیت)، به دلایل ناشناس بودن استفاده شد و در جدول ۲ قابل مشاهده است. شهرها به سه دسته تقسیم شدند: شهرهای کوچک با جمعیت کمتر از ۷۰ هزار نفر، شهرهای متوسط با ۷۰ تا ۲۰۰ هزار نفر جمعیت و شهرهای بزرگ با بیش از ۲۰۰ هزار نفر جمعیت.
بر اساس مقادیر باینری در یازده بخش از فرم سرقت، امکان محاسبه اقدامات شباهت زوجی بین موارد وجود داشت. با توجه به دو مورد و محاسبه شاخص ژاکارد حاصل با مقایسه ویژگی ها، یعنی مقادیر چک باکس، بین دو حالت مطابق با معادله ( ۱ ) امکان پذیر بود. توجه داشته باشید که از آنجایی که داده ها با استفاده از یک مقدار باینری نمایش داده شده اند، از معادله محاسبه شباهت بین ویژگی های نامتقارن باینری به جای شاخص سنتی جاکارد استفاده شده است.
در معادله ( ۱ ) نشان دهنده ویژگی هایی است که در هر دو مورد بررسی می شوند، به عنوان مثال، مقدار ۱ داده می شود و . و نشان دهنده ویژگی هایی است که بررسی می شوند اما نه در ، و بالعکس. با محاسبه شباهت ژاکارد به صورت جفتی، امکان مقایسه موارد سرقت با توجه به متغیرهای جمع آوری شده وجود داشت. برای هر جفت جرم، شاخص جاکارد برای MO کلی (یعنی همه ویژگی ها) و برای زیر گروه های مختلف MO محاسبه شد [ ۱۶ ، ۱۷ ]. زیر گروه ها قبلا در این بخش توضیح داده شد.
آزمون جمع رتبه ویلکاکسون برای تشخیص تفاوت بین دو نوع صحنه جرم استفاده شد [ ۴۸ ]. این یک آزمون ناپارامتریک برای مقایسه اینکه آیا دو مجموعه از یک توزیع هستند یا خیر است. از آنجایی که نمیتوانیم فرض کنیم که دادههای ما به طور معمول توزیع شدهاند، به جای آزمون T از یک آزمون ناپارامتریک استفاده شد [ ۴۸ ]. آزمونها بر روی مقایسه زوجی جنایات با استفاده از دادههای کامل MO و همچنین بر روی زیر گروههای MO انجام شد. به این ترتیب، از این آزمون برای تعیین اینکه آیا تفاوتی در شباهت جفت جرم با توجه به جنایات نزدیک به تکرار در مقابل جرایم غیر تکراری وجود دارد استفاده شد. اندازه های اثر ( r) نیز محاسبه شدند. با این حال، باید توجه داشت که، به دلیل عدم تعادل کلاسی عظیم هنگام مقایسه زوجی، از مجموعه دادههای تصادفی، نمونهبرداری پایین برای تجزیه و تحلیل استفاده شد. عدم تعادل کلاس، در این وضعیت، به این معنی است که با مقایسه زوجی، تعداد جفتهایی که به عنوان تکراری در نظر گرفته میشوند، بسیار بیشتر از تعداد جفتهایی است که تقریباً تکرار میشوند. برای روشن شدن اینکه چرا این یک مشکل است، هنگام آموزش یک مدل با مجموعه داده نامتعادل، این شانس وجود دارد که مدل یاد بگیرد همیشه کلاس اکثریت را حدس بزند.
اندازه اثر با استفاده از فرمول Wendt محاسبه شد. ، جایی که و حجم نمونه برای دو کلاس [ ۴۹ ] است. اندازه اثر می تواند بین ۰ و ۱ باشد. با توجه به [ ۵۰ ] اندازه اثر را می توان کوچک در نظر گرفت اگر ، متوسط اگر و بزرگ اگر .
۳٫۲٫ تنظیم آزمایش
برای تمایز بین طبقات و تخمین برچسب طبقه (یعنی اگر احتمال دارد که جرم به عنوان بخشی از یک زنجیره تقریباً تکرار در نظر گرفته شود یا خیر)، از رگرسیون لجستیک استفاده شد [ ۱۶ ، ۱۷ ].
مدلهای لجستیک از ویژگیهای MO استفاده کردند تا یاد بگیرند که چگونه کلاس را برای یک جفت جرم پیشبینی کنند، کلاس تقریباً تکراری یا غیر تکراری است. ویژگی های ارائه شده در جدول ۱ به عنوان متغیرهای مستقل استفاده شد. مدل ها برای هر شهر آموزش و آزمایش شدند. این به این دلیل است که مطالعات اولیه نشان میدهد که ایجاد یک مدل برای کل منطقه جغرافیایی غیرممکن است. مدلهای رگرسیون لجستیک با استفاده از اعتبارسنجی متقاطع ۱۰ برابر طبقهبندی شده ۱۰ بار آموزش و آزمایش شدند. اعتبار سنجی متقاطع داده ها را به طور تصادفی به k برابر بزرگ تقسیم می کند [ ۵۱]. یک مدل در همه به جز یک لایه آموزش داده می شود و سپس با استفاده از آخرین تا به عنوان داده های آزمایشی ارزیابی می شود. سپس بخش تست یک مرحله چرخانده میشود و مدل جدیدی بر روی دادههای آموزشی آموزش داده میشود و در قسمت تست ارزیابی میشود. به این ترتیب، مدلها بر روی همه دادهها آموزش داده شده و آزمایش میشوند و این فرآیند به احتمال زیاد هر شانسی را در تقسیم قطار/آزمایش که در غیر این صورت ممکن است رخ دهد، از بین میبرد. برای حذف بیشتر شانس از تقسیم داده های قطار/آزمایش، این کار ۱۰ بار تکرار شد. به این ترتیب، ۱۰۰ مدل بر روی داده های همپوشانی، اما متفاوت، آموزش و ارزیابی شدند. جنایات تقریباً تکراری کمتر از جرایم غیر تکراری بود و باعث ایجاد عدم تعادل طبقاتی شد. این می تواند هنگام آموزش یک مدل با مجموعه داده نامتعادل مشکل ساز باشد، زیرا این احتمال وجود دارد که مدل یاد بگیرد همیشه کلاس اکثریت را حدس بزند. برای رسیدگی به این موضوع،
به منظور بررسی بیشتر تفاوت بین شهرها، مهم ترین ویژگی ها در هر طبقه برای هر شهر استخراج و با یکدیگر مقایسه شد. انتخاب ویژگی برای کاهش تعداد ویژگی های موجود در یک مجموعه داده به منظور افزایش طبقه بندی و/یا عملکرد محاسباتی استفاده می شود [ ۵۲ ]. نشان داده شده است که دقت طبقه بندی هنگام کاهش تعداد ویژگی ها با استفاده از الگوریتم های انتخاب ویژگی بهبود یافته است [ ۵۳ ]. علاوه بر این، انتخاب ویژگی می تواند برای کاوش داده ها و ارائه دانش اضافی در مورد مجموعه داده استفاده شود [ ۵۴]. انتخاب ویژگی در این تحقیق به منظور اکتشاف داده ها استفاده شد. انتخاب ویژگی با نشان دادن ویژگی هایی انجام شد که احتمال می رفت در فرآیند طبقه بندی کمک کنند.
برای هر مدل، ویژگی ها به همراه ضرایب ویژگی مدل استخراج شد. به این ترتیب، میتوان دید که چگونه مدلها به اهمیت ویژگیهای مختلف وزن میدهند. علاوه بر این، هر مدل رگرسیون لجستیک اهمیت هر ویژگی را در برابر طبقات ارزیابی میکند. در نتیجه، امکان استفاده از مدل های آموزش دیده برای کشف دانش در مورد ویژگی ها وجود داشت. برای هر مدل آموزش داده شده، ضریب، T-value و p -value جمع آوری شد. این ما را قادر ساخت تا دانش بیشتری در مورد جنبه های مهم در مورد اینکه آیا صحنه جرم ممکن است نشانگر تقریباً تکرار باشد ارائه دهیم. برای هر شهر، ضرایب و مقادیر T به عنوان میانگین و p -values در هر ویژگی ارائه شده است. پ– مقادیر با استفاده از آزمون احتمال ترکیبی فیشر و میانگین هارمونیک p-value [ ۵۵ ، ۵۶ ] ترکیب شدند. علاوه بر این، میانگین p -values ارائه شده است، به طور مشابه نشان می دهد که آیا یک ویژگی در فرآیند طبقه بندی مهم بوده است یا خیر. در نهایت، با توجه به مجموعه وسیعی از ویژگیهای ممکن، تنها شاخصترین (رتبهبندی شده بر اساس T-value) از بین ویژگیها (بالا و پایین ۲۰ درصد) انتخاب شدند. هر یک از ویژگی ها را می توان نشانه ای از تکرارهای نزدیک یا عدم تکرار نزدیک در نظر گرفت.
۳٫۳٫ معیارهای ارزیابی
عملکرد مدل با استفاده از دقت F اندازهگیری شد -score و AUC. دقت به صورت زیر تعریف می شود:
که در آن مثبت واقعی (TP) صحنه های جنایی هستند که به درستی به عنوان تکرارهای نزدیک طبقه بندی شده اند و منفی واقعی (TN) صحنه های جنایی هستند که به درستی به عنوان غیر تکراری طبقه بندی می شوند [ ۵۷ ]. امتیازی بین ۰ (برای عدم طبقه بندی صحیح) و ۱ (زمانی که همه طبقه بندی ها صحیح هستند) ارائه می دهد.
اف امتیاز اغلب به عنوان یک معیار ارزیابی جایگزین برای دقت پیشنهاد می شود زیرا TN را در نظر نمی گیرد. اف -امتیاز در معادله ( ۳ ) تعریف شده است، جایی که دقت و یادآوری به ترتیب در معادلات ( ۴ ) و ( ۵ ) تعریف شده است. این متریک امتیازی بین ۰ تا ۱ ارائه میکند، مشابه متریک دقت [ ۵۱ ].
امتیاز AUC (منطقه زیر منحنی عملکرد گیرنده)، یا شاخص C، احتمال این است که مدل یک نمونه تصادفی از کلاس مثبت (یعنی صحنه جنایت تقریباً تکراری) را بالاتر از یک نمونه تصادفی از کلاس منفی قرار دهد. به عنوان مثال، صحنه جنایت تقریباً تکرار نمی شود) [ ۵۸ ، ۵۹ ]. AUC امتیازی بین ۰ تا ۱ است که در آن نمره بالاتر بهتر است. هدف و محاسبه AUC توسط [ ۶۰ ] بیشتر توضیح داده شده است. دو ویژگی مهم متریک AUC این است که به توزیع کلاس برابر یا هزینه های طبقه بندی نادرست بستگی ندارد [ ۶۰ ].
۴٫ نتایج
نتایج به دو بخش تقسیم می شود. ابتدا، مقایسه ای از توزیع داده ها بین جنایات تقریباً تکراری و غیر تکراری ارائه شده است. در مرحله دوم، عملکرد پیش بینی طبقه بندی ارائه شده است.
۴٫۱٫ مقایسه توزیع
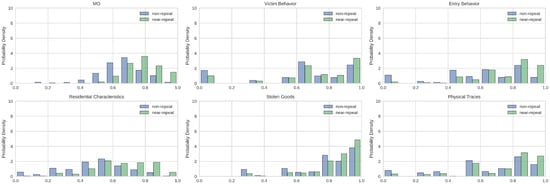
پس از نمونه برداری پایین بدون جایگزینی، شاخص ژاکارد جفتی برای جنایات تقریباً تکراری و غیر تکراری به عنوان هیستوگرام در شکل ۱ ترسیم شد . توزیع شاخص جاکارد برای MO، و همچنین زیر گروه های مختلف MO، برای هر دو جنایات تقریباً تکراری و غیر تکراری قابل مشاهده است. همانطور که در بخش ۳ بیان شد ، شاخص جاکارد با استفاده از یک مقایسه زوجی بین صحنه های جرم برای هر دو گروه MO و زیر گروه های مختلف محاسبه می شود. در شکل ۱، جرایم تقریباً تکراری اغلب دارای امتیاز تشابه بالاتری نسبت به موارد غیر تکراری هستند. این تفاوت امتیاز در توزیع بین تکرارهای نزدیک و غیر تکراری بیشتر توسط نتایج تست Wilcoxon پشتیبانی می شود. آزمون مجموع رتبه ویلکاکسون نشان داد که برای MO کلی تفاوت معنی داری بین جرایم نزدیک به تکرار و غیر تکراری وجود دارد. ، ) . علاوه بر این، تفاوتهایی بین رفتار قربانی برای جنایات تقریباً تکراری و سایر جنایات یافت شد. ، ، ) رفتار مجرم در هنگام ورود به محل سکونت برای تکرار تقریباً در مقابل سایر جرایم غیر تکراری ( ، ، ) نوع اقامت مورد نظر برای جنایات تقریباً تکراری و غیر تکراری متفاوت است ( ، ، ) نوع کالای سرقت شده از صحنه های تکرار جرم در مقابل صحنه های غیر تکراری ( ، ، و در نهایت نیز مشخص شد که نوع آثار باقی مانده در صحنه جرم برای دو طبقه متفاوت است ( ، ، ). در نتیجه، نتایج نشاندهنده تفاوت توزیعها و امکانسنجی استفاده از ویژگیها به عنوان شاخص کلاسها است. نتایج برای یک مجموعه داده نامتعادل را می توان در پیوست A مشاهده کرد.
۴٫۲٫ پیشبینی تقریباً تکراری
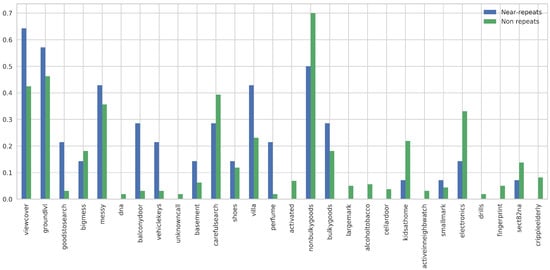
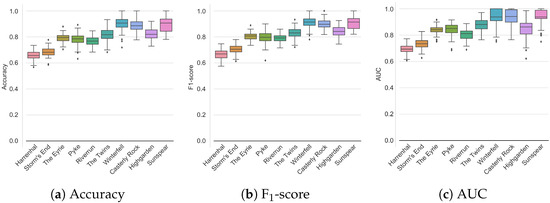
آزمایشها بر اساس هر شهر انجام شد، زیرا آزمایشهای اولیه در کل منطقه جغرافیایی ناموفق بودند (متوسط AUC حدود ۰٫۵۵)، که کمی بهتر از شانس بود. نتایج آزمایش های ارائه شده در جدول ۳ دارای میانگین F بود -امتیاز از بر تمام شهرها با نگاهی به شهرها، F -امتیاز از (هارنهال) به (Sunpear). با مقایسه عملکرد پیشبینی با اندازه شهر، به نظر میرسد که شهر بزرگتر با عملکرد پیشبینی پایینتر مطابقت دارد. این تا حدی به این دلیل است که برای شهرهای کوچکتر نقاط داده کمتری در دسترس بود، اما همچنین به این دلیل که متغیرهای جمعیتی و محیطی در شهرهای بزرگتر بسیار بزرگتر هستند. تغییرات متغیر محیطی بین شهرها توسط شکل ۲ پشتیبانی می شود ، که نشان می دهد تنها چند ویژگی انتخاب شده برای هر برچسب بین شهرها همپوشانی دارند (و نه لزوماً ویژگی های یکسان).
علاوه بر این، معیارها بین یکدیگر تفاوت چندانی ندارند. با مشاهده شکل ۳ ، نمودارهای جعبه فشرده هستند. اندازه نمودارهای جعبه در مواردی که مجموعه داده کوچکتر است تا حدودی افزایش می یابد (به ویژه در مورد Winterfell، The Twins، و Highgarden برای AUC. و همچنین Sunspear برای F. -نمره). به طور کلی، طرحهای جعبهای (و همچنین امتیازات جدول ۳ ) نشان میدهد که مدلها میتوانند بین جنایات تقریباً تکراری و جرایم غیر تکراری تمایز قائل شوند.
۴٫۳٫ مقایسه شهر
به منظور مقایسه شهرها، مقایسه زوجی ویژگیهای بین شهرها انجام شد و شاخص شباهت بین هر شهر محاسبه شد. به این ترتیب، تعداد مشترک ویژگیها بین شهرها نشان داده میشود. نتایج در شکل ۲ ارائه شده است. شکل ۲۵ ویژگی برتر را نشان می دهد که نشان دهنده تکرارهای نزدیک ( شکل ۲ الف) یا غیر تکراری ( شکل ۲) است.ب). از ۲۵ ویژگی ممکن، حداکثر ۱۰ مورد بین شهرها به اشتراک گذاشته شد. اغلب ۶-۷ ویژگی بین شهرها به اشتراک گذاشته می شد. برترین ویژگیهای مشترک در همه شهرها، که نشاندهنده تکرار نشدن آنها است، عبارت بودند از: پنجرهها باز/تهویهکننده (به اشتراک گذاشته شده در ۷ شهر از ۹ شهر)، خدمات خانگی (۶)، ورود از درب انبار (۵)، وسایل الکترونیکی به سرقت رفته (۵) ، اثر انگشت جمع آوری شده (۵)، علامت اندازه متوسط باقی مانده در هنگام نفوذ (۵)، لباس دزدیده شده (۵)، <5 علامت باقی مانده هنگام شکستن (۵)، زنگ هشدار فعال (۴)، کالاهای غیر حجیم به سرقت رفته (۴) ، کالاهای حجیم دزدیده شده (۴)، چیزی دزدیده نشده (۴)، تجارت اعلام شده/تبلیغ شده توسط قربانی (۴)، اطلاعات قربانی N/A (4)، کلید خودرو دزدیده شده (۴)، سایر کالاهای دزدیده شده (۴)، دزدگیر خراب شده است. (۴)، از در (۴) وارد شده است، پنجره را می شکند تا وارد شود (۴)، پنجره سه جداره در محل اقامت (۴).
به طور مشابه، ویژگیهای برتر نشاندهنده تکرارهای نزدیک عبارت بودند از: متفرقه. اطلاعات در دسترس نیست (۷)، استاندارد معمولی (۶)، نمای پوشش هنگام ورود (۵)، دستکش استفاده شده، (۵)، ساکنان فعال در ساعت محله (۵)، زنگ هشدار غیر فعال (۵)، خانه شهری (۵)، نامرتب جستجو در هنگام سرقت (۵)، غیبت برنامه ریزی شده (۴)، ساکنان خانه در هنگام جرم (۴)، ساکن در ثبت شرکت (۴)، نکات موجود (۴)، آشفتگی بزرگ در حین سرقت (۴)، جستجوی دقیق در حین سرقت (۴) ، کالاهای قابل جستجو به سرقت رفته (۴)، ورود از زیرزمین (۴)، شاهد وجود دارد (۴)، ورود از طریق درب آینه / پاسیو (۴)، ورود در سطح زمین (۳)، پول نقد سرقت شده (۳).
علاوه بر این، توزیع زمانی و مکانی جرایم تکراری و نزدیک به تکرار برای شهرها در شکل ۴ قابل مشاهده است.. شکل، تعداد جرایم تقریباً تکراری را برای مقادیر احتمالی فاصله زمانی (۰-۱۴ روز) و فاصله مکانی (۰-۲۰۰ متر) نشان می دهد. این نشان می دهد که توزیع زمانی جرایم واقعاً بین شهرها سازگار نبوده است. در حالی که برخی از شهرها جرایم بسیار کمی دارند که نمی توان از آنها نتیجه گیری کرد، برخی دیگر نشان دهنده تفاوت بین شهرها هستند. یکی از نمونههای دومی بین The Eyrie و Harrenhall است، جایی که Harrenhall دو قله زمانی در حدود ۶ و ۸ روز دارد، چیزی که The Eyrie ندارد. به طور مشابه، برای مقایسه فضایی، ایری افزایش کمتری از جنایات در حدود ۱۰۰ متر دارد، که برای هارنهال یا استورمز اند قابل مشاهده نیست. در عوض، به نظر می رسد که توزیع فضایی برای Storms End و Harrenhall (و در واقع همه شهرها) افزایش یا کاهش جزئی در توزیع فضایی پس از جنایات تکراری داشته باشد. با این حال، در حالی که تفاوت ها جزئی هستند، آنها هنوز وجود دارند و هیچ شهری مشابه شهر دیگری نیست. اما نکته جالب این است که اولین نقطه فضایی بعد از ۰ است، یعنی از چه فاصله ای تکرارهای نزدیک شروع می شوند؟ این در بین شهرها بسیار متفاوت بود. در مورد The Eyrie، تقریبا ۲۰ متر بود، اما برای مثال، هارنهال به ۱۰ متر نزدیکتر بود.
۵٫ تحلیل دو شهر
در این بخش، نتایج برای دو شهر خاص که به طور تصادفی انتخاب شده اند ارائه و بررسی می شود. علاوه بر این، ویژگی های مهم با جزئیات بیشتری بررسی می شود.
۵٫۱٫ مورد: سانسپیر
شکل ۲ نشان میدهد که تعداد ویژگیهای مشترک که نشاندهنده تکرارهای نزدیک یا غیرتکرار هستند بین شهرها بسیار کم است. از ۲۵ ویژگی برتر برای هر کلاس، میانگین تعداد ویژگی های مشترک تقریباً بود . در نتیجه، نتیجه گیری کلی در مورد اینکه چه ویژگی هایی بر جنایات تقریباً تکراری تأثیر می گذارد دشوار است. با این حال، با توجه به عملکرد هر شهر (همانطور که در شکل ۳ مشاهده می شود )، ممکن است نتیجه گیری های محلی یافت شود. این ادعا را تقویت می کند که دزدی ها به صورت محلی با الگوهای خاص خوشه ای هستند. به این ترتیب، یکی از بهترین شهرها، Sunspear، انتخاب شد تا بیشتر این ادعا را نشان دهد.
۵٫۱٫۱٫ مقایسه توزیع
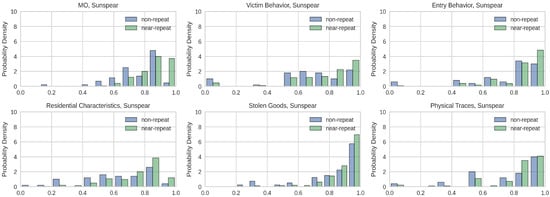
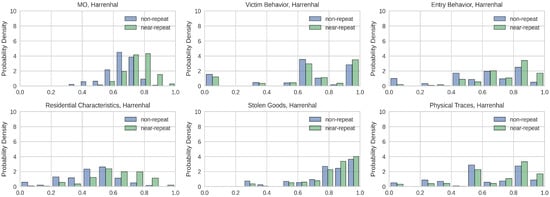
مشابه شکل ۱ ، شاخص ژاکارد جفتی برای جنایات تقریباً تکراری و غیر تکراری برای شهر انتخاب شده ترسیم شده است و در شکل ۵ قابل مشاهده است. توزیع شاخص جاکارد برای انواع مختلف رفتار MO قابل مشاهده است، با جرایم تقریباً تکراری که اغلب دارای امتیاز شباهت بالاتری نسبت به موارد غیر تکراری هستند. این تفاوت امتیاز در توزیع بین تکرارهای نزدیک و غیر تکراری بیشتر توسط نتایج تست Wilcoxon پشتیبانی می شود. آزمون مجموع رتبه ویلکاکسون نشان داد که برای MO کلی، تفاوت معنی داری بین جرایم تقریباً تکراری و غیر تکراری وجود دارد. ، ) . علاوه بر این، تفاوتهایی بین رفتار قربانی برای جنایات تقریباً تکراری و سایر جنایات یافت شد. ، ، ) رفتار مجرم در هنگام ورود به محل سکونت برای تکرار تقریباً در مقابل سایر جرایم غیر تکراری ( ، ، ) نوع اقامت مورد نظر برای جنایات تقریباً تکراری و غیر تکراری متفاوت است ( ، ، ) نوع کالای سرقت شده از صحنه های تکرار جرم در مقابل صحنه های غیر تکراری ( ، ، و در نهایت نیز مشخص شد که نوع آثار باقی مانده در صحنه جرم برای دو طبقه متفاوت است ( ، ، ). در نتیجه، نتایج نشاندهنده تفاوت توزیعها و امکانسنجی استفاده از ویژگیها به عنوان نشاندهنده کلاسها را تایید میکند.
۵٫۱٫۲٫ پیشبینی تقریباً تکراری
علاوه بر این، ویژگی های Sunspear بر روی آنها متمرکز شد. برای هر کلاس، میانگین ضرایب، میانگین T-value و انحراف معیار مربوطه محاسبه شد و ویژگی ها بر اساس T-value رتبه بندی شدند. سپس ۲۰ درصد پایین و بالای ویژگی ها استخراج شد و در جدول ۴ قابل مشاهده است.
ویژگی هایی که نشان دهنده تکرار تقریباً (به ترتیب) بودند عبارت بودند از: عطر دزدیده شده، هدف ویلا، چاپ کفش در صحنه، جستجوی دقیق هنگام سرقت، ورود از زیرزمین، تماس ناشناس قبل از سرقت، کلید خودرو به سرقت رفته، ورود از در بالکن، DNA رها شدن در صحنه، جستجوی نامرتب محل سکونت، بازرسی بسیار نامرتب از سرقت، اجناس مسروقه قابل جستجو هستند، آپارتمان مورد نظر در سطح همکف است، یا مجرم هنگام ورود به محل سکونت دارای پوششی بوده است. علاوه بر دزدیده شدن کلیدهای تماس گیرنده و وسیله نقلیه ناشناس، به نظر می رسد این ویژگی ها نشان می دهد که جنایات تقریباً تکراری، خانه های ثروتمندتری را هدف قرار می دهند که سارق می تواند وقت خود را برای جمع آوری کالاها صرف کند.
به نظر میرسد وجه مشترک ویژگیهای تقریباً تکرار، جرایم فرصتطلبانه با پاداش بالا (و احتمالاً خطر کم استنباط شده توسط مرتکب)، با سرقت کالاهای با ارزش (اما دشوار)، و کالاهای دارای علامت DNA یا سایر کالاهای قابل جستجو، عطر است. ، یا کلیدهای وسیله نقلیه که هدف خاصی از کالا را نشان می دهد. همچنین به نظر می رسد که محل اقامت و ورود هدف نشان دهنده گزینش پذیری بالاتر است. ویلاهایی که مجرم از درب بالکن یا زیرزمین وارد می شود، اغلب با منظره پوشیده. علاوه بر این، محل سکونت به طور کامل (اما بی نظم) جستجو می شود.
با این حال، به نظر می رسد وجه مشترک ویژگی های تکرار نشدن، جرایم سریع است. ورودیهای آسان، غالباً سریعاً در جایی که به نظر میرسد متخلف رفتاری نسبتاً پرخطر دارد (و احتمالاً دانش ابتدایی در مورد محل شاکی دارد) گرفته میشود.
۵٫۲٫ مورد: هارنهال
از آنجایی که یک شهر کوچکتر با جزئیات مورد بررسی قرار گرفت، جالب است که بررسی کنیم که آیا یک شهر بزرگتر ویژگی های مشابهی دارد یا خیر. تحقیقات نشان می دهد که احتمالاً چنین نیست [ ۲ ]، چیزی که توسط شکل ۲ تأیید می شود . با توجه به اینکه هارنهال یکی از شهرهایی است که بدترین عملکرد را دارد (همانطور که در شکل ۳ مشاهده می شود )، نتیجه گیری های محلی ممکن است امکان پذیر باشد.
۵٫۲٫۱٫ مقایسه توزیع
مشابه شکل ۱ ، شاخص ژاکارد جفتی برای جنایات تقریباً تکراری و غیر تکراری برای شهر انتخاب شده ترسیم شده است و در شکل ۶ قابل مشاهده است. توزیع شاخص جاکارد برای انواع مختلف رفتار MO قابل مشاهده است، با جرایم غیر تکراری که اغلب دارای امتیاز شباهت بالاتری نسبت به موارد نزدیک به تکرار هستند. این تفاوت امتیاز در توزیع بین تکرارهای نزدیک و غیر تکراری بیشتر توسط نتایج تست Wilcoxon پشتیبانی می شود. آزمون مجموع رتبه ویلکاکسون نشان داد که برای MO کلی تفاوت معنی داری بین جرایم نزدیک به تکرار و غیر تکراری وجود دارد. ، ) . علاوه بر این، تفاوتهایی بین رفتار قربانی برای جنایات تقریباً تکراری و سایر جنایات یافت شد. ، ، ) رفتار مجرم در هنگام ورود به محل سکونت برای تکرار تقریباً در مقابل سایر جرایم غیر تکراری ( ، ، ) نوع اقامت مورد نظر برای جنایات تقریباً تکراری و غیر تکراری متفاوت است ( ، ، ) نوع کالای سرقت شده از صحنه های تکرار جرم در مقابل صحنه های غیر تکراری ( ، ، و در نهایت نیز مشخص شد که نوع آثار باقی مانده در صحنه جرم برای دو طبقه متفاوت است ( ، ، ). در نتیجه، نتایج نشاندهنده تفاوت توزیعها و امکانسنجی استفاده از ویژگیها به عنوان نشاندهنده کلاسها را تایید میکند.
۵٫۲٫۲٫ پیشبینی تقریباً تکراری
ویژگی های هارنهال نیز بر روی آنها متمرکز شده است. برای هر کلاس، میانگین ضرایب، میانگین T-value و انحراف معیار مربوطه محاسبه شد و ویژگی ها بر اساس T-value رتبه بندی شدند. سپس ۲۰ درصد پایین و بالای ویژگی ها استخراج شد و در جدول ۵ قابل مشاهده است.
به نظر می رسد وجه مشترک ویژگی های تقریباً تکرار، جرایم فرصت طلبانه با پاداش بالا (و احتمالاً خطر کم استنباط شده توسط مرتکب) باشد، از جمله: مته های استفاده شده برای ورود، دزدیده شدن الکل یا تنباکو، قربانی در ثبت شرکت، چاپ دستکش در محل. ، قربانی از خدمات خانگی استفاده می کند، انعام دریافت می کند، کالاهای غیر حجیم دزدیده شده، پاسپورت یا شناسنامه به سرقت رفته، علف یا برف نگهداری می شود، کالاهای حجیم دزدیده شده، فعال در محل نگه داری، آثار ابزار باقی مانده است. به نظر می رسد کالاهای با ارزش تر (اما سخت) به سرقت رفته اند: گذرنامه یا شناسنامه به سرقت رفته، یا الکل یا دخانیات به سرقت رفته است. همچنین به نظر میرسد که اقامتگاهها و ورودیهای هدف نشاندهنده درجه بالاتری از برنامهریزی است: چاپ دستکشهایی که در محل باقی ماندهاند، متههایی که برای ورود استفاده میشود، کالاهای حجیم و غیر حجیم به سرقت رفتهاند. علاوه بر این، ویژگیها نشاندهنده استاندارد بالاتر اقامتگاهها یا قربانیان است:
لازم به ذکر است که دو ویژگی اضافی برای تکرارهای نزدیک در جدول ۵ گنجانده شده است ، اما با میانگین p-value بیشتر از : استاندارد پایین سکونت و آپارتمان اجاره ای. در حالی که آنها مقادیر T بالایی داشتند، ضرایب منفی داشتند که نشان دهنده همبستگی منفی با تکرارهای نزدیک است. با این حال، از ۱۰۰ اندازه گیری، برای سکونت و آپارتمان اجاره ای با استاندارد پایین، ۱۸ و ۱۳ مورد به ترتیب دارای ضریب کمتر از ۰ بودند و به میانگین افراطی کمک کردند. برای ویژگیهای سکونت و آپارتمان اجارهای با استاندارد پایین، ابزار هارمونیک ( https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.hmean.html ، دسترسی به ۱۹ فوریه ۲۰۲۲) و ، به ترتیب.
مشابه ویژگیهایی که در Sunspear ( جدول ۴ ) مشاهده میشود، به نظر میرسد وجه مشترک ویژگیهای تکرار نشدن جرایم سریع/تکانشی است: ورود آسان، اغلب گرفتن سریع در جایی که به نظر میرسد مجرم نسبتاً پرخطر رفتار میکند (و احتمالاً دارای برخی از جرایم است. دانش ابتدایی در مورد محل شاکیان).
۶٫ بحث
با بازگشت به اولین سوال تحقیق – اینکه آیا ویژگی های متفاوتی از جنایات تقریباً تکراری وجود دارد یا خیر – می توان نتیجه گرفت که وجود دارد. از تحلیل ها مشخص می شود که جرایم نزدیک به تکرار با جرایم غیر تکراری یکسان نیستند. به عبارت دیگر، آنها نظم های تجربی متفاوتی را نشان می دهند. آزمون جمع رتبه ویلکاکسون نشان داد که بین جنایات تقریباً تکراری و غیر تکراری برای مثال، ویژگیهای کلی MO تفاوت معنیداری وجود دارد. ، ) .
سوال دوم تحقیق مربوط به این بود که تا چه حد می توان جرایم نزدیک به تکرار را بر اساس ویژگی های صحنه جرم و MO مجرمان پیش بینی کرد. نتایج نشان میدهد که میتوان بر اساس ویژگیهای مشخصکننده، احتمال اینکه صحنه جرم بخشی از زنجیره جرم تقریباً تکراری است، بهطور قابل اعتماد تخمین زد، بهعنوان مثال، جنایت دیگری در ۵۰۰ متری و در عرض ۱۴ روز اتفاق میافتد. مدل های رگرسیون لجستیک آموزش دیده قادر به تخمین صحیح طبقات در بیش از ۸۰ درصد موارد بودند.
در نهایت، سومین سوال تحقیق بررسی کرد که آیا مشخصههای مشخصه برای جنایات تقریباً تکراری بسته به موقعیت مکانی متفاوت است یا خیر. نتایج نشان می دهد که هیچ مجموعه ای از ویژگی های کلی وجود ندارد که نشان دهنده تکرار جرایم در شهرها باشد. در عوض، مجموعه ای ناهمگون از ویژگی ها وجود دارد که با مکان های خاص (شهرها) همبستگی دارند. به عبارت دیگر، به نظر می رسد امضاهای MO به جای تعمیم در شهرها، محلی سازی شده اند. این را می توان در شکل ۲ مشاهده کرد ، جایی که به طور متوسط ۶٫۵ (از ۲۵) ویژگی بین شهرها به اشتراک گذاشته شده است.
۶٫۱٫ مشارکت ها
سهم این مطالعه چندین است. اولاً، از نظر روش شناختی، تعداد سرقت های مشاهده شده بیشتر از بسیاری از مطالعات قبلی بود. علاوه بر این، مجموعه داده با وضوح بالا، شامل ۱۳۷ ویژگی برای هر جرم مشاهده شده، حاوی داده های محیطی و MO بود. به عنوان مثال، در مطالعات مربوط به سرقت های مسکونی [ ۴۵ ] از ۱۶۰ جفت، حاوی ۷۹ ویژگی، هنگام بررسی ارتباط جرم استفاده شد. نویسندگان [ ۶۱ ] ارتباط خودکار جرم را در مقابل ارتباط جرایم دستی با استفاده از ۳۸ جفت جرم مورد بررسی قرار دادند، که تنها ۸ مورد مرتبط بودند. . علاوه بر این، Ref. [ ۴۷] ۶۵۰ جنایت مرتبط انجام شده توسط ۵۷ مجرم مختلف را مورد بررسی قرار داد. بنابراین، ۶۸۵ جنایات تقریباً تکراری و ۵۰۵۹ جنایات غیر تکراری همراه با ۱۳۷ ویژگی برای هر نمونه، یک مجموعه داده با وضوح بالا را ارائه می دهند که به نوبه خود، رویکرد دقیق تری نسبت به آنچه قبلاً تولید شده بود، فراهم می کند. لازم به ذکر است که اکثر تحقیقات قبلی در یک محیط آنگلوساکسونی انجام شده است در حالی که نتایج این مطالعه نشان می دهد که یافته ها در زمینه سوئدی نیز قابل اجرا هستند.
دوم، این مطالعه به تجزیه و تحلیل در یک شهر محدود نمی شد، بلکه چندین شهر را در یک کشور واحد در بر می گرفت. نویسندگان [ ۲ ] دریافتند که الگوهای جرم عمومی در چندین مقیاس فضایی مشابه هستند، اما تجزیه و تحلیل در سطوح ظریف تر (مانند بخش های خیابان) تغییرات قابل توجهی را در واحدهای بزرگتر نشان داد، که نشان می دهد جرم یک پدیده نسبتاً محلی است. علاوه بر این، Ref. [ ۷] سازگاری قابلتوجهی در رفتار مجرمان در پارامترهای مربوط به جنایات نزدیک به فضا، حتی زمانی که جدایی در بازههای زمانی وجود داشت، یافت. نتایج این مطالعه نتایج مشابهی را پیشنهاد میکند، با اصلاحات مهم، به عنوان مثال، امکان پیشبینی جرایم تکراری در مقیاس فضایی بالاتر (مثلاً در سطح شهر) وجود دارد، اما ما همچنین دریافتیم که بین شهرها تفاوتهایی وجود دارد. تحقیقات قبلی نشان داده است که انتخاب هدف مجرمان بر اساس آگاهی موجود (و در حال تکامل) از فضای محلی [ ۲۴ ] است که از تفاوتها در MO بین شهرها پشتیبانی میکند. به این ترتیب، مجرمان بیشتر درگیر دزدی در محیطها و اهدافی هستند که تا حدودی با آن آشنا یا راحت هستند. نتایج نیز تا حدودی توسط [ ۲۰ ] پشتیبانی میشوند]، نشان داد که متغیرهای محیطی خاصی ممکن است احتمال وقوع جرم را نشان دهند و ویژگی های محیطی ممکن است بین شهرها نیز متفاوت باشد. یافتن مقیاس فضایی صحیح هنگام ساخت مدل ها مهم است، اما چیزی است که در اینجا مورد بررسی قرار نمی گیرد. با این حال، بررسی اولیه پهنای باند مکانی-زمانی توسط Chainey و Silva [ ۶ ] انجام شده است.
ویژگیهایی که توسط مدلها انتخاب شده است نشان میدهد که صحنههای تکرار جرم جنایتهایی هستند که مجرم میتواند به آن دسترسی پیدا کند و سپس اقلام گرانقیمت را به سرعت به دست آورد. این امر نیاز به نظریه پردازی در مورد رفتار مجرمانه به عنوان یک فرد (یا افراد) در یک زمینه مکانی-زمانی را به جای تمرکز بر فرد یا زمینه، برجسته می کند. دسترسی آسان و رواج اقلام گران قیمت به احتمال زیاد یک حساب کم خطر ایجاد می کند (ر.ک. [ ۲۵ ]) و مطابق با گزارش های منطقی و نیمه منطقی رفتار مجرمانه است [ ۲۷ ، ۶۲ ].]. با این حال، عملکرد درونی مجرمان را فقط می توان از طریق نحوه تفسیر مجرم از نشانه های زمینه ای که در زمان ارتکاب جرم وجود دارد استنباط کرد (در غیر این صورت نمی توان چنین محاسبه کم خطری ایجاد کرد). در نتیجه، تمرکز بر نشانههای زمینهای، همسو با تئوری فعالیتهای معمول [ ۲۶ ، ۲۷ ]، مانند مکان، زمان، ویژگیهای مسکن، یا حضور نگهبانان، به همان اندازه برای مبارزه با جرم مهم است. بنابراین، برای جلوگیری از تکرار جرایم، اولین قدم این است که فرصت سرقت آسان منازل را از بین ببریم. این را میتوان راحتتر گفت تا انجام، اما ویژگیهای نشاندهنده جنایات تقریباً تکراری نیز شاخصهایی هستند که با نحوه بهبود امنیت در خانههایی که در غیر این صورت ممکن است کاندیدای جرایم تکراری باشند همپوشانی دارند.
با توجه به امکان پیش بینی اینکه آیا جنایتی به زودی جنایت دیگری در این نزدیکی به دنبال خواهد داشت یا خیر، به مجریان قانون اجازه می دهد منابع را بر این اساس تنظیم کند. اگر دادههای صحنه جرم نشان میدهد که احتمال وقوع جنایت دیگری در این نزدیکی وجود دارد، میتوان حضور پلیس را در محله افزایش داد یا برای افزایش هوشیاری محلی، مراقبهای محله را مطلع کرد. به این ترتیب، این امکان وجود دارد که با منابع موجود در حال حاضر از تعداد بیشتری از سرقت های مسکونی جلوگیری شود.
در حال حاضر، سازمانهای مجری قانون سوئد دستورالعملهای خاصی برای کاهش سرقتهای مسکونی در هنگام سفر ارائه میکنند (Bostadsinbrott-skydda dig، https://polisen.se/Utsatt-for-brott/Skydda-dig-mot-brott/Stold- och-inbrott/Bostadsinbrott/ ، قابل دسترسی در ۱۹ فوریه ۲۰۲۲). این توصیه این است که مثلاً یک علامت سگ یا سگ داشته باشید (در حال حاضر طبق آخرین دسترسی حذف شده است) یا ساکنان ماشین خود را در خیابان پارک کنند. همچنین توصیههایی وجود دارد که مربوط به ویژگیهایی است که نشاندهنده جنایات تقریباً تکراری است که از نظر آماری معنیدار نیستند، به عنوان مثال، از همسایه بخواهید چمنها را قطع کند، یا اگر برای مدت طولانی سفر میکنید، برف را حذف کنید. ، از نور خارجی استفاده کنید ( به عنوان مثال، “چراغ ها را به طور معمول و به طور تصادفی در خارج از خانه روشن و خاموش کنید”، از شخصی بخواهید نامه را خالی کند ( ). اینها توصیه هایی هستند که در ویژگی های شاخص جرایم تکراری وجود دارند که اگرچه برای مدل قابل توجه نیستند، اما احتمال تکرار جرم را افزایش می دهند.
آیا این بدان معنی است که این توصیه بدی است؟ احتمالا نه. با این حال، این توصیه با عمل رایج مخالف است. با توجه به بررسی ویژگیهای صحنههای جنایت تکراری و صحنههای غیر تکراری جرم، احتمالاً توصیهها باید با سایر اقدامات پیشگیرانه از جرم ترکیب شود تا تأثیر مطلوب داشته باشد. همچنین لازم به ذکر است که نورپردازی بیرونی ( ، علائم هشدار دهنده ( ) (میانگین p-value معنی دار نیست) و کالاهای دارای علامت DNA ( ) شاخص های تکرار نشدن صحنه های جنایت هستند. این سه ویژگی همچنین در نکات اجرای قانون برای کاهش احتمال سرقت منزل گنجانده شده است. در حالی که آنها ممکن است شانس سرقت های مسکونی را کاهش ندهند (این را نمی توان از این داده ها استنباط کرد)، به نظر می رسد احتمال وقوع صحنه های جرم تقریباً تکراری را کاهش می دهند. بنابراین، توصیه در مورد چگونگی جلوگیری از تکرار و تکرار جرم معمولاً نباید از یک نوع توصیه پیروی کند.
در نهایت، روش توصیف شده در این مقاله را می توان در یک سیستم پشتیبانی تصمیم برای اجرای قانون با اهداف چندگانه استفاده کرد. اولاً، می توان از آن برای تسهیل مدیریت منابع استفاده کرد. همانطور که در بالا توضیح داده شد، استفاده از این روش به مکان یابی مناطقی که مجری قانون باید منابع را در هنگام مبارزه با سرقت متمرکز کند، کمک می کند. در ترکیب با تجزیه و تحلیل نقطه داغ یا تجزیه و تحلیل زمانی (به عنوان مثال، تجزیه و تحلیل آئوریستی [ ۶۳])، افزایش تمرکز مکانی و زمانی ممکن است حاصل شود. دوم، دستورالعملهای بهروز برای گروههای نگهبان محله و سایر سازمانهای محلی ممکن است صادر شود. این می تواند در برنامه ریزی شهری یا مشاوره در مورد نحوه رفتار مالکان مسکونی در نظر گرفته شود. سوم، تحلیل روند رفتار مجرمان را می توان به روشی بسیار دقیق تر از قبل، با تمرکز بر ویژگی های MO تحلیل کرد. تجزیه و تحلیل روند را می توان برای تشخیص تفاوت ها در MO در یک منطقه جغرافیایی ملی، منطقه ای یا خاص، اما همچنین با تقسیم بندی های زمانی مختلف، به عنوان مثال، چگونگی تفاوت روندها از سال به سال یا در فصول مختلف انجام داد.
۶٫۲٫ خیابان ها برای تحقیقات آینده
در این مطالعه ترتیب زمانی مورد ارزیابی قرار نگرفت، یعنی مدل رگرسیون لجستیک ترتیب جرایم را در نظر نگرفت. با این حال، ممکن است تعجب کنید که آیا تفاوت هایی بین صحنه جنایت اول و دوم در مجموعه ای از تکرارهای نزدیک وجود دارد؟ ممکن است ترتیب جنایات بتواند ویژگی هایی را برجسته کند که ممکن است نشان دهنده تکرار تقریباً باشد. یا آیا می توان ویژگی های صحنه های جرم غیر تکراری را در اقامتگاه های تقریباً تکراری تقلید کرد تا از تکرار نزدیک جلوگیری شود؟ یعنی با توجه به یافتههای مربوط به ویژگیهای تکرار نشدنی، آیا محلهها میتوانند ویژگیهای خاصی را تقلید کنند تا خطر وقوع جنایات نزدیک به تکرار در آینده را کاهش دهند؟ توصیه هایی برای جلوگیری از سرقت از قبل در دسترس است، اما ممکن است در سطح بسیار کلی باشد. یکی دیگر از راه های جالب برای تحقیقات آینده، پیش بینی این است که آیا (ناهمسانی) در مسکن، جرایم تقریباً تکراری و غیر تکراری را پیش بینی می کند یا خیر. یک MO خاص ممکن است نتیجه یکنواختی مسکن خاص باشد تا نتیجه تاکتیک های متخلفان.
همچنین در این مطالعه تفاوت های زمانی و مکانی حاکی از تکرار جرایم ثابت شد. تحقیقات آینده می تواند به مناسب بودن چارچوب مکانی و زمانی تکرارهای نزدیک بپردازد. در واقع، تحقیقات اولیه قبلاً توسط [ ۶ ] انجام شده است. پهنای باند مکانی و زمانی، همانطور که با [ ۶ ] نشان داده می شود، ممکن است از کشوری به کشور دیگر، اما همچنین بین مناطق یک کشور، به عنوان مثال، بین محیط های شهری و روستایی متفاوت باشد. برای مثال، پهنای باند فضایی در سوئد ممکن است بین لاپلند (بخش شمالی و کم جمعیت سوئد)، استکهلم و اسکنه (پرتراکم تر) متفاوت باشد. علاوه بر این، پهنای باند مکانی و زمانی ممکن است بین سوئد متفاوت باشد (تراکم جمعیت نفر در هر کیلومتر ، تراکم جمعیت اواسط سال ۲۰۱۶ بر اساس اداره سرشماری ایالات متحده، https://www.census.gov/programs-surveys/international-programs/data/tools/international-data-base.html ، قابل دسترسی در ۱۹ فوریه ۲۰۲۲) و هلند (تراکم جمعیت از نفر در هر کیلومتر ).
همچنین بررسی اینکه آیا ویژگیهای MO نشاندهنده جنایات تقریباً تکراری است که توسط همان مجرم انجام شده است یا اینکه مجرم در رفتار خود توسط مجرم قبلی تحت تأثیر قرار گرفته است (یعنی آیا رفتار مجرمانه مسری است؟) جالب خواهد بود. برای انجام این کار، لازم است مجموعه داده با داده های مربوط به محکومیت های کیفری و اطلاعات مجرم ادغام شود.
۷٫ نتیجه گیری
با استفاده از دادههای ۵۷۴۴ سرقت مسکونی با ۱۳۷ ویژگی که MO را به تصویر میکشد، تفاوت بین جرایم تقریباً تکراری و غیر تکراری بررسی شد. مدل های رگرسیون در مورد جرایم از ۱۰ شهر مختلف در سوئد آموزش دیدند. نتایج حاکی از امکان تخمین این است که آیا جرم جزئی از جنایت تقریباً تکراری بوده یا خیر با میانگین F -امتیاز از ( ). همچنین با استفاده از مدلهای رگرسیون لجستیک، ویژگیهای نشاندهنده دو کلاس (تقریباً تکراری و غیر تکراری) استخراج شد. در نتیجه، افسران مجری قانون میتوانند با استفاده از این مدل، احتمال این که صحنه جرم بخشی از زنجیره تقریباً تکرار است را تخمین بزنند و حضور مجری قانون را در مناطقی که احتمالاً دارای پروفایل خطر جنایات تقریباً تکراری هستند، افزایش دهند.
علاوه بر این، یافتهها پیامدهای سیاستی دارند، به این صورت که تکرارهای نزدیک و سایر انواع سرقت لزوماً نباید از همان نوع توصیهها در مورد اقدامات متقابل بالقوه پیروی کنند، به عنوان مثال، در حالی که نتایج نشان میدهد که تقریباً تکرارها را میتوان در شهرها پیشبینی کرد، MO که نشان میدهد اینها بین شهرها متفاوت است و ارائه مدل های کلی و مشاوره را دشوار می کند.
همانطور که در بخش ۶٫۲ بحث شد ، کار آینده می تواند شامل بررسی پهنای باند پویا در مناطق مختلف باشد. ترتیب زمانی بین زوجهای جرم ممکن است نشان دهد که ویژگیهای خاصی نشاندهنده جنایات تقریباً تکراری اولیه هستند، به عنوان مثال، اگر ویژگیهای خاصی وجود داشته باشد که با شروع یک منطقه جرم تقریباً تکراری مرتبط باشد، یا ویژگیهایی وجود داشته باشد که نشاندهنده آخرین جنایات نزدیک به تکرار باشد. تکرار. در نهایت، جالب است که بررسی کنیم در چه اندازه شهر شروع به تقسیم بندی به بخش هایی از یک شهر مفید است.