کلید واژه ها:
مناطق عملکردی شهری ; داده های جمع آوری موبایل ; تاب خوردگی زمان پویا ; SOM
۱٫ مقدمه
۲٫ منطقه مطالعه و مجموعه داده ها
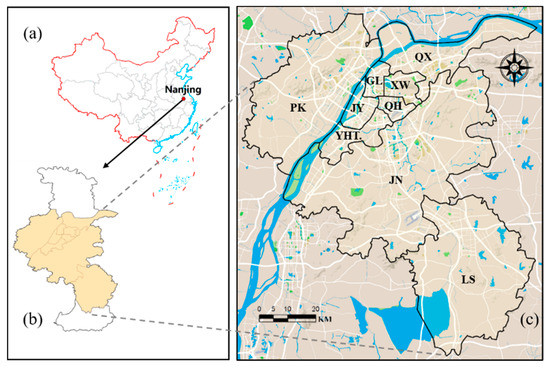
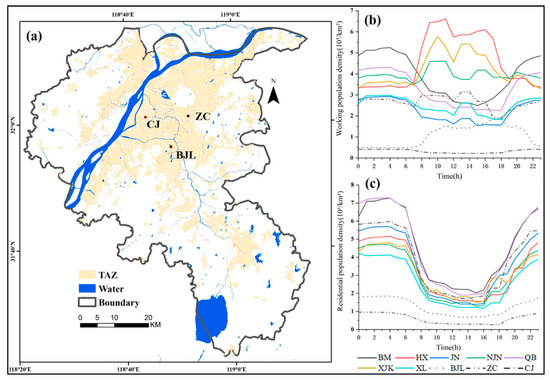
۲٫۱٫ منطقه مطالعه
۲٫۲٫ داده ها
-
داده های مشترکین موبایل داده های مشترکین تلفن همراه که نه منطقه در نانجینگ را پوشش می دهد ( شکل ۱ج) از شرکت موبایل جیانگ سو خریداری و از ۱۸ تا ۲۴ فوریه ۲۰۱۹ خریداری شد. با وضوح زمانی ساعتی و وضوح فضایی شبکه ۱۵۰ × ۱۵۰ متر. هر زمان که یک تلفن همراه با یک ایستگاه پایه ارتباط برقرار کند (مانند دریافت تماس، ارسال و دریافت پیامک، بهروزرسانی موقعیت مکانی)، ایستگاه پایه به طور خودکار دادههای سیگنالی حاوی اطلاعات مکان ایستگاه پایه را ضبط و تولید میکند. دادههای مشترک تلفن همراه خریداریشده با ویژگیهای کار و محل سکونت کاربران همراه است. ویژگی های کاربر بر اساس محدوده دوره های زمانی و مدت زمانی که کاربر در منطقه تحت پوشش ایستگاه پایه می ماند، مورد قضاوت قرار می گیرد. روش تبعیض خاص به شرح زیر است: هنگامی که کاربر بیش از ۷ روز در ماه در منطقه تحت پوشش ایستگاه پایه ظاهر می شود و زمان حضور از ۱۰:۰۰ تا ۱۷ است: ۰۰، ویژگی کار به کاربر اختصاص داده می شود. هنگامی که کاربری که بیش از ۷ روز در منطقه تحت پوشش ایستگاه پایه ظاهر می شود و زمان حضور از ساعت ۰:۰۰ تا ۶:۰۰ یا ۲۱:۰۰ تا ۲۳:۰۰ باشد، ویژگی اقامت به کاربر اختصاص داده می شود. تعداد کاربران تلفن همراه، کاربران ویژگی های مسکونی و کاربران ویژگی کار در هر منطقه ایستگاه پایه در هر ساعت به صورت آماری به دست می آید و داده های جمعیتی این سه ویژگی در یک شبکه ۱۵۰ × ۱۵۰ متر درون یابی می شوند. هر شبکه شامل شناسه شبکه، زمان (که در آن سال ۲۰۱۹ نشان دهنده سال است، ۰۲۱۸ نشان دهنده ۱۸ فوریه، و ۰۱۰۰ نشان دهنده ساعت ۱:۰۰ صبح)، طول و عرض جغرافیایی و تعداد افراد با ویژگی های مختلف است. ۰۰ یا ۲۱:۰۰ تا ۲۳:۰۰، ویژگی اقامت به کاربر اختصاص داده می شود. تعداد کاربران تلفن همراه، کاربران ویژگی های مسکونی و کاربران ویژگی کار در هر منطقه ایستگاه پایه در هر ساعت به صورت آماری به دست می آید و داده های جمعیتی این سه ویژگی در یک شبکه ۱۵۰ × ۱۵۰ متر درون یابی می شوند. هر شبکه شامل شناسه شبکه، زمان (که در آن سال ۲۰۱۹ نشان دهنده سال است، ۰۲۱۸ نشان دهنده ۱۸ فوریه، و ۰۱۰۰ نشان دهنده ساعت ۱:۰۰ صبح)، طول و عرض جغرافیایی و تعداد افراد با ویژگی های مختلف است. ۰۰ یا ۲۱:۰۰ تا ۲۳:۰۰، ویژگی اقامت به کاربر اختصاص داده می شود. تعداد کاربران تلفن همراه، کاربران ویژگی های مسکونی و کاربران ویژگی کار در هر منطقه ایستگاه پایه در هر ساعت به صورت آماری به دست می آید و داده های جمعیتی این سه ویژگی در یک شبکه ۱۵۰ × ۱۵۰ متر درون یابی می شوند. هر شبکه شامل شناسه شبکه، زمان (که در آن سال ۲۰۱۹ نشان دهنده سال است، ۰۲۱۸ نشان دهنده ۱۸ فوریه، و ۰۱۰۰ نشان دهنده ساعت ۱:۰۰ صبح)، طول و عرض جغرافیایی و تعداد افراد با ویژگی های مختلف است.جدول ۱ ).
-
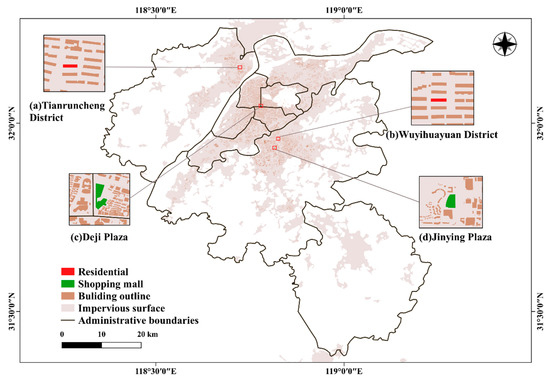
داده های ساختمان داده های برداری ساختمان ها در منطقه اصلی شهری نانجینگ عمدتاً با بارگیری از پلت فرم BIGEMAP ( http://www.bigemap.com/ ، دسترسی به ۱۸ نوامبر ۲۰۲۱) به دست آمده است. دادههای ساختمانی از دست رفته در اطراف حومهها با همپوشانی با تصاویر شهری GF-2 بهدست آمدند و سپس به صورت بصری تفسیر شدند. تصاویر GF-2-شهری پس از رهگیری تصویر GF-2 با توزیع سطح غیرقابل نفوذ در نانجینگ (از وب سایت http://data.ess.tsinghua.edu.cn/ ، مشاهده شده در ۱۸ نوامبر ۲۰۲۱) به دست آمد. منطقه ساخته شده [ ۴۱]. دادههای سطح غیرقابل نفوذ به سطوحی مانند سقفها، روسازیهای آسفالتی یا روسازیهای بتنی اشاره دارد و در این مطالعه، ما از سطوح غیرقابل نفوذ ۲۰۱۸ استخراجشده از تصاویر Landsat با استفاده از چارچوب «exclude and شامل» [ ۴۲ ] برای نشان دادن وسعت ساختشده استفاده میکنیم. بالای منطقه نانجینگ دادههای GF-2 از پلتفرم سرویس دادههای ماهوارهای رصد زمین ( http://36.112.130.153:7777/DSSPlatform/index.html ، قابل دسترسی در ۱۸ نوامبر ۲۰۲۱) در ۲۳ مه ۲۰۱۹ دانلود شدند. دادههای GF-2 حاوی پانکروماتیک (PAN) هستند. ) تصاویر با وضوح ۰٫۸۹ متر و تصاویر چند طیفی (MSS) با وضوح ۳٫۲ متر. دادههای MSS تحت تصحیح RPC [ 43 ]، کالیبراسیون رادیومتری و تصحیح جوی FLAASH [ ۴۳ ] قرار گرفتند. ۴۴ ] قرار گرفتند.]، و داده ها با داده های PAN اصلاح شده با RPC با استفاده از روش انتشار نزدیکترین همسایه [ ۴۵ ] ترکیب شدند. در نهایت، ۱۲۲۵۴۴ چند ضلعی ساختمانی در منطقه ساخته شده نانجینگ وجود داشت ( شکل ۲ )، که به عنوان واحدهای تحلیل پایه برای خوشه بندی بعدی مناطق عملکردی شهری استفاده شد.
-
داده های POI دادههای POI سرویس نقشه Gaode که منطقه مورد مطالعه را پوشش میدهد در دسامبر ۲۰۱۸ به دست آمد و از Gaode ( https://lbs.amap.com ، دسترسی به ۱۸ نوامبر ۲۰۲۱)، یکی از بزرگترین ارائهدهندگان خدمات نقشهبرداری وب در چین، خریداری شد. POI میتواند همه مکانهای دارای موقعیت مکانی را نشان دهد که دارای وسعت فضایی بزرگ یا کوچک و تشخیص زیاد یا کم هستند، اما همه POI نمیتوانند اطلاعات مؤثری برای حدسزنی عملکرد ساختمان ارائه دهند، یا حتی باعث تداخل شوند، بنابراین نقاط با دانهبندی فضایی کوچک و تشخیص عمومی کم، مانند توالت های عمومی، ایستگاه های اتوبوس، دکه های روزنامه فروشی و غیره، ابتدا باید از داده های اصلی حذف شوند [ ۴۶ ]]. سپس، با مراجعه به گونگ و همکاران، نقاط POI باقیمانده با توجه به نوع عملکرد ساختمان طبقهبندی شدند. (۲۰۱۹) برای معیارهای طبقه بندی کاربری زمین شهری در چین [ ۴۷ ، ۴۸ ]. دادههای POI بهدستآمده در نه دسته، یعنی: مسکونی، گروهبندی شدند. کسب و کار؛ مراکز خرید؛ صنعتی؛ اداری؛ پزشکی؛ پارک ها و فضای سبز؛ آموزشی; و امکانات عمومی ( جدول ۲). با توجه به ویژگی داده ها و منطقه مورد مطالعه، دسته بندی های POI ما کمی با سیستم طبقه بندی متفاوت است. برای مثال، مقوله تجاری به مراکز خرید و تجارت تقسیم میشود، زیرا دادههای ما میتواند فعالیتهای افرادی را با ویژگیهای شغلی و مسکونی به خوبی نشان دهد، و آموزش به طور جداگانه از امکانات عمومی متمایز شد زیرا نانجینگ از نظر منابع آموزشی غنی است. از آنجایی که تعداد دستههای POI مختلف بسیار متفاوت است و توزیع فضایی انواع کاربریهای زمین یکسان ناهموار است، دادههای POI اصلی باید بازسازی شوند تا سوگیری دادهها حذف شود. روش های بازسازی عمدتاً شامل موارد زیر است: (۱) در پاسخ به مشکل علامت گذاری مکرر POI های تجاری، ما POI های تجاری با فاصله کمتر از ۱۰ متر را حذف کردیم. (۲) از آنجایی که تعداد POIهای صنعتی و مسکونی دست کم گرفته شده بود، POIهای صنعتی و مسکونی طبق روش پیشنهادی ژانگ و همکاران اضافه شدند. [۴۹ ]; و (۳) برای رده عمومی، POIها با تفسیر بصری به دلیل دقت طبقه بندی نسبتا پایین تر از طریق روش فوق، بر روی ساختمان ها اضافه شدند. مقدار داده های بازسازی شده توسط POI به طور قابل توجهی افزایش یافت ( جدول ۲ )، و انواع مختلف کاربری زمین به طور مساوی در فضا توزیع شدند. روش بازسازی داده های POI و توزیع فضایی داده های POI بازسازی شده ارجاع داده شده است [ ۴۱ ]. داده های ساخته شده توسط POI برای حاشیه نویسی انواع عملکردی ساختمان استفاده می شود.
-
منطقه تحلیل ترافیک منطقه تحلیل ترافیک با همپوشانی بافرهای شبکه جاده ای OSM با داده های سطح غیرقابل نفوذ شهر نانجینگ ایجاد می شود. در این مطالعه، داده های شبکه جاده ای OSM شهر نانجینگ برای دسامبر ۲۰۱۸ از OpenStreetMap ( https://www.openstreetmap.org ، دسترسی به ۱۸ نوامبر ۲۰۲۱) دانلود شد. OSM به هفت کلاس تقسیم شد و شعاع های بافر مختلفی را تنظیم کرد که با شمارش شعاع واقعی جاده به دست آمد. به عنوان مثال، اولیه روی ۴۴ متر، ثانویه روی ۳۴٫۸ متر، ثالث روی ۳۰٫۴ متر، مسکونی به ۲۱٫۵ متر، بزرگراه ها به ۴۲ متر، تنه به ۶۰٫۵ متر و راه آهن به ۷٫۷ تنظیم شد. m، همانطور که در [ ۴۱] توضیح داده شده است. پس از همپوشانی، ۸۲۰۹ منطقه تجزیه و تحلیل ترافیک نهایی (TAZ) به دست آمد.
-
FROM-GLC10. FROM-GLC10 اولین نقشه جهانی پوشش زمین با وضوح ۱۰ متر در جهان است [ ۵۰ ]، و می توان آن را به صورت رایگان از این وب سایت دانلود کرد ( http://data.ess.tsinghua.edu.cn/ ، در ۱۸ نوامبر ۲۰۲۱ مشاهده شد) . در این مطالعه، دادههای FROM-GLC10 با مرزهای منطقه مورد مطالعه برای به دست آوردن انواع پوشش زمین در نانجینگ، از جمله بدنههای آبی، مراتع، زمینهای خشک و جنگلها رهگیری شدند.
۳٫ روش
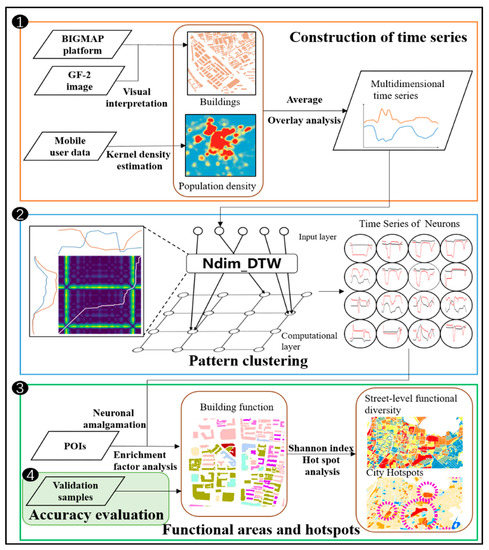
۳٫۱٫ مجموعه داده تراکم کاربر تلفن همراه با ویژگی ها
ابتدا، برای اطمینان از اینکه اطلاعات جمعی در هر ساختمان گرفته می شود، داده های شبکه گسسته با استفاده از تخمین تراکم هسته (KDE) به داده های شطرنجی چگالی کاربر پیوسته تبدیل می شوند، که یک روش ناپارامتریک برای تخمین توابع چگالی احتمالی برای محاسبه چگالی عناصر در آنها است. محله های اطراف [ ۵۱ ]. معادله KDE را می توان به صورت زیر بیان کرد:
جایی که تابع هسته است. h پهنای باند یا شعاع جستجو است. n تعداد نقاط شناخته شده در پهنای باند است. و d ابعاد داده ها است.
۳٫۲٫ الگوریتم فاصله Ndim-DTW
تعریف ۱٫
تعریف ۲٫
برای درک بهتر روش، محاسبه فاصله Ndim-DTW با یک مثال شامل دو نوع شیء ساختمانی نشان داده شده است. و ). در این مثال، سری زمانی از و را می توان به عنوان نشان داد و ( m = n زیرا طول رکورد MUD برای تمام اشیاء ساختمان یکسان است). در تعیین فواصل DTW از و ، اولین مرحله ساخت شبکه ماتریس فاصله D از عناصر. مقادیر هر عنصر ( ) در این ماتریس می توان به صورت زیر محاسبه کرد:
جایی که نشان می دهد ارزش در ساعت در P ، نشان می دهد ارزش در ساعت در P ، نشان می دهد ارزش در ساعت در Q ، و نشان می دهد ارزش در ساعت در Q _ و نشان دهنده تفاوت بین این دو نقطه الگوریتم را می توان به یافتن یک مسیر از طریق تعدادی از نقاط شبکه در این شبکه ماتریس کاهش داد، به عنوان مثال، مسیر تاب برداشتن ( W )، با عنصر kth از W به عنوان تعریف شده است. ، نشان دهنده نگاشت P به Q است. بنابراین، W را می توان به صورت زیر بیان کرد:
میتواند تعداد نمایی از مسیرها وجود داشته باشد که محدودیتهای بالا را برآورده کند، جایی که یک مسیر بهینه با حداقل تجمع وجود دارد:
معادله فوق را می توان با معادله بازگشتی زیر به حداقل رساند:
جایی که مجموع جریان است و حداقل فاصله های تجمعی عناصر قبلی. به دست آمده نشان دهنده فاصله Ndim-DTW بین P و Q است. اطلاعات بیشتر در مورد محاسبه فواصل DTW چند بعدی را می توان در ادبیات [ ۳۵ ] یافت.
۳٫۳٫ شبکه SOM
وزن گره ها را در محله برنده به روز کنید،
جایی که یک محدودیت برای به روز رسانی است، به عنوان مثال، ضریب بزرگی به روز رسانی. وزن فعلی گره v است. میزان یادگیری است. و میانگین خطای کوانتیزاسیون، یعنی میانگین فاصله از گره های همسایه تا گره برنده است.
۳٫۴٫ مقداردهی اولیه در الگوریتم OC
۳٫۵٫ شناسایی عملکرد شهری و تشخیص نقطه اتصال
مجموعه داده POI بازسازی شده برای شناسایی عملکردهای نتایج خوشه بندی در بخش ۳٫۴ استفاده شد. ضریب غنی سازی (EF) [ ۵۶ ] برای توصیف غنای نسبی داده های POI در هر سطح ساختمان استفاده شد:
جایی که نشان دهنده غنی سازی ساختمان است در کلاس POI تعداد کلاس است POI در نزدیکی محل ساختمان i (به عنوان مثال، شعاع ۱۰ متر). تعداد کل POI های کلاس l را نشان می دهد. تعداد تمام POI ها در نزدیکی محل ساختمان است ; و تعداد کل POI در کل منطقه مورد مطالعه است. مقدار ۱ برای نشان می دهد که سطح غنی سازی کلاس POI برابر با میانگین سطح منطقه است و (یا ) نشان می دهد که غنی سازی کلاس POI بزرگتر (یا کمتر) از مقدار متوسط منطقه است. میانگین EF تمام ساختمان های هر خوشه به عنوان مقدار EF آن خوشه استفاده می شود.
برای آشکار ساختن کلان مناطق عملکردی شهری، غنای نسبی خوشه ها را می توان بیشتر در سطح TAZ جمع کرد. شاخص شانون برای توصیف تنوع عملکردی در سطح TAZ استفاده شد:
جایی که تنوع عملکردی است خیابان هفتم و نسبت ساختمان های با عملکرد است . آمار Getis-Ord G i * برای به تصویر کشیدن تجزیه و تحلیل نقاط حساس عملکردی در شهر استفاده می شود و مناطقی با مقادیر G i * بزرگتر از ۲٫۵۸ نقاط عملکردی نامیده می شوند [ ۵۷ ].
جایی که شاخص شانون خیابان است ، وزن فضایی بین خیابان ها است ، و ، n تعداد کل خیابان ها است. علاوه بر این،
۳٫۶٫ ارزیابی دقت
۴٫ نتایج
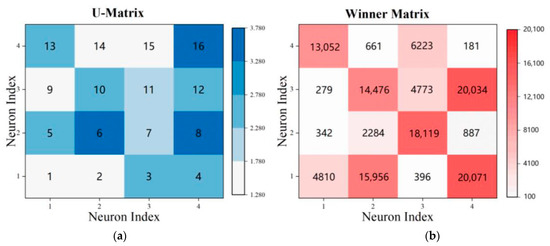
۴٫۱٫ U-Matrix و Winner Matrix
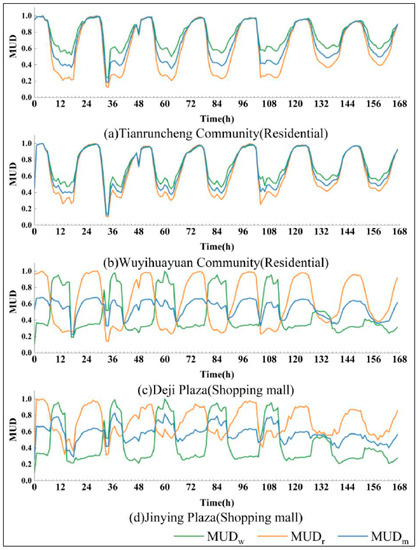
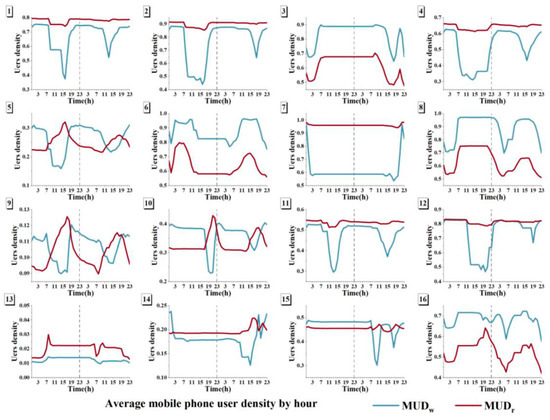
۴٫۲٫ تغییر منحنی در هر BMU
۴٫۳٫ عوامل غنی سازی
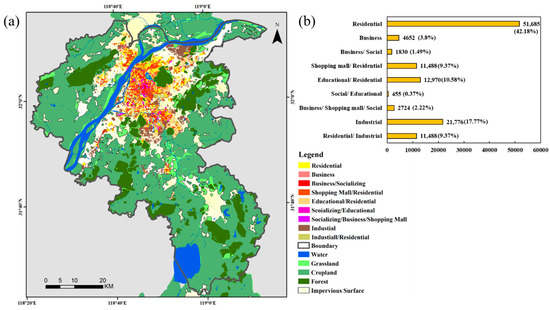
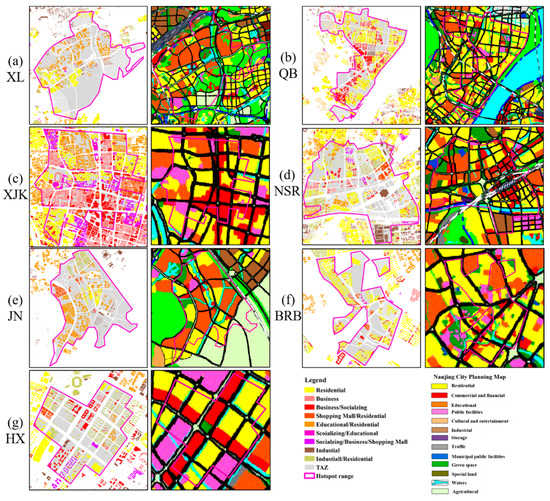
۴٫۴٫ انواع عملکرد شهری در سطح ساختمان
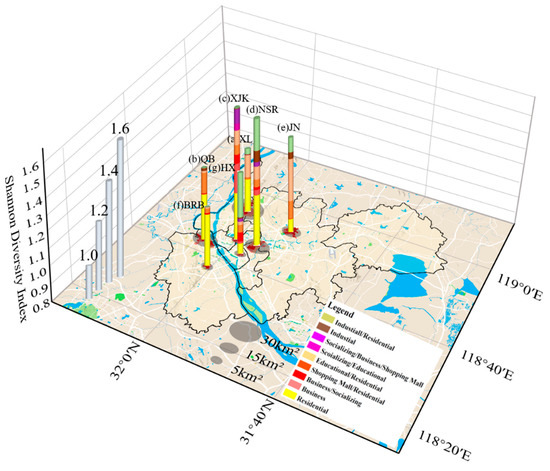
۴٫۵٫ نقاط مهم کاربردی شهری سطح TAZ
۴٫۶٫ ارزیابی دقت
۵٫ بحث
۵٫۱٫ مقایسه روش های مختلف طبقه بندی
۵٫۲٫ ویژگی های هات اسپات شهری
۶٫ نتیجه گیری
منابع
- کوربوزیه، ال. Eardley، A. منشور آتن . Grossman Publishers: New York, NY, USA, 1973. [ Google Scholar ]
- ام عزیزم.؛ فلاستی، اس. شهرسازی پست مدرن. ان دانشیار صبح. Geogr. ۱۹۹۸ ، ۸۸ ، ۵۰-۷۲٫ [ Google Scholar ] [ CrossRef ]
- بروکس، آر. ساختار و رشد محله های مسکونی در شهرهای آمریکا اثر هومر هویت. Soc. نیروهای ۱۹۴۱ ، ۱۹ ، ۴۵۳-۴۵۴٫ [ Google Scholar ] [ CrossRef ]
- Janowicz، K. مهندسی ژئوآنتولوژی مبتنی بر مشاهدات. ترانس. GIS ۲۰۱۲ ، ۱۶ ، ۳۵۱-۳۷۴٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژونگ، سی. هوانگ، ایکس. آریسونا، اس ام. اشمیت، جی. باتی، ام. استنتاج توابع ساختمان از یک مدل احتمالی با استفاده از داده های حمل و نقل عمومی. محاسبه کنید. محیط زیست سیستم شهری ۲۰۱۴ ، ۴۸ ، ۱۲۴-۱۳۷٫ [ Google Scholar ] [ CrossRef ]
- کارول، اچ. سلسله مراتب عملکردهای مرکزی در شهر. ان دانشیار صبح. Geogr. ۱۹۶۰ ، ۵۰ ، ۴۱۹-۴۳۸٫ [ Google Scholar ] [ CrossRef ]
- کاتبرت، آل. اندرسون، WP با استفاده از آمار فضایی برای بررسی الگوی توسعه زمین شهری در هالیفاکس-دارتموث. پروفسور Geogr. ۲۰۰۲ ، ۵۴ ، ۵۲۱-۵۳۲٫ [ Google Scholar ] [ CrossRef ]
- داوی، ک. پافکا، ای. ترکیب عملکردی چیست؟ یک رویکرد مجموعه ای. طرح. عمل تئوری. ۲۰۱۷ ، ۱۸ ، ۲۴۹-۲۶۷٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژانگ، ی. لی، کیو. تو، دبلیو. مای، ک. یائو، ی. چن، ی. تشخیص کاربری زمین شهری کاربردی با ادغام دادههای مکانی چند منبعی و همبستگیهای متقابل. محاسبه کنید. محیط زیست سیستم شهری ۲۰۱۹ ، ۷۸ ، ۱۰۱۳۷۴٫ [ Google Scholar ] [ CrossRef ]
- عبداللهی، س. پرادان، بی. منصور، س. شریف، مدل سازی مبتنی بر GIS ARM برای اندازه گیری و ارزیابی فضایی توسعه کاربری مخلوط برای یک شهر فشرده. GIScience Remote Sens. ۲۰۱۵ ، ۵۲ ، ۱۸-۳۹٫ [ Google Scholar ] [ CrossRef ]
- تو، دبلیو. هو، ز. لی، ال. کائو، جی. جیانگ، جی. لی، کیو. لی، کیو. به تصویر کشیدن مناطق عملکردی شهری با جفت کردن تصاویر سنجش از دور و داده های سنجش انسانی. Remote Sens. ۲۰۱۸ , ۱۰ , ۱۴۱٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- یانگ، ی. Newsam، S. کیسه کلمات بصری و الحاقات فضایی برای طبقه بندی کاربری اراضی. در مجموعه مقالات هجدهمین کنفرانس بین المللی SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، سن خوزه، کالیفرنیا، ایالات متحده آمریکا، ۳-۵ نوامبر ۲۰۱۰٫ صص ۲۷۰-۲۷۹٫ [ Google Scholar ] [ CrossRef ]
- هرولد، ام. کوکللیس، اچ. Clarke، KC نقش معیارهای فضایی در تحلیل و مدلسازی تغییر کاربری اراضی شهری. محاسبه کنید. محیط زیست سیستم شهری ۲۰۰۵ ، ۲۹ ، ۳۶۹-۳۹۹٫ [ Google Scholar ] [ CrossRef ]
- بسیار خوب، AO تشخیص خودکار ساختمان ها از تصاویر تک طیفی VHR با استفاده از اطلاعات سایه و برش های نمودار. ISPRS J. Photogramm. Remote Sens. ۲۰۱۳ ، ۸۶ ، ۲۱-۴۰٫ [ Google Scholar ] [ CrossRef ]
- ژای، دبلیو. بای، ایکس. شی، ی. هان، ی. پنگ، Z.-R. Gu, C. Beyond Word2vec: رویکردی برای استخراج و شناسایی منطقه عملکردی شهری با ترکیب Place2vec و POI. محاسبه کنید. محیط زیست سیستم شهری ۲۰۱۸ ، ۷۴ ، ۱-۱۲٫ [ Google Scholar ] [ CrossRef ]
- یائو، ی. لی، ایکس. لیو، ایکس. لیو، پی. لیانگ، ز. ژانگ، جی. Mai، K. سنجش توزیع فضایی کاربری زمین شهری با ادغام نقاط مورد علاقه و مدل Google Word2Vec. بین المللی جی. جئوگر. Inf. علمی IJGIS ۲۰۱۶ ، ۳۱ ، ۸۲۵-۸۴۸٫ [ Google Scholar ] [ CrossRef ]
- هو، تی. یانگ، جی. لی، ایکس. Gong, P. نقشه برداری کاربری زمین شهری با استفاده از تصاویر Landsat و داده های اجتماعی باز. Remote Sens. ۲۰۱۶ , ۸ , ۱۵۱٫ [ Google Scholar ] [ CrossRef ]
- گائو، اس. یانوویچ، ک. کوکللیس، اچ. استخراج مناطق عملکردی شهری از نقاط مورد علاقه و فعالیت های انسانی در شبکه های اجتماعی مبتنی بر مکان. ترانس. GIS ۲۰۱۷ ، ۲۱ ، ۴۴۶-۴۶۷٫ [ Google Scholar ] [ CrossRef ]
- تو، دبلیو. کائو، جی. یو، ی. شاو، اس.-ال. ژو، ام. وانگ، ز. چانگ، ایکس. خو، ی. لی، کیو. اتصال داده های تلفن همراه و رسانه های اجتماعی: رویکردی جدید برای درک عملکردهای شهری و الگوهای روزانه. بین المللی جی. جئوگر. Inf. علمی IJGIS ۲۰۱۷ ، ۳۱ ، ۲۳۳۱-۲۳۵۸٫ [ Google Scholar ] [ CrossRef ]
- ژونگ، سی. آریسونا، اس ام. هوانگ، ایکس. باتی، م. اشمیت، جی. تشخیص پویایی ساختار شهری از طریق تحلیل شبکه فضایی. بین المللی جی. جئوگر. Inf. علمی ۲۰۱۴ ، ۲۸ ، ۲۱۷۸-۲۱۹۹٫ [ Google Scholar ] [ CrossRef ]
- کائو، آر. ژو، جی. تو، دبلیو. لی، کیو. کائو، جی. لیو، بی. ژانگ، Q. Qiu, G. یکپارچه سازی تصاویر هوایی و نمای خیابان برای طبقه بندی کاربری زمین شهری. Remote Sens. ۲۰۱۸ ، ۱۰ ، ۱۵۵۳٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- پی، تی. سوبولفسکی، اس. راتی، سی. شاو، اس.-ال. لی، تی. ژو، سی. بینشی جدید در طبقه بندی کاربری زمین بر اساس داده های تلفن همراه جمع آوری شده است. بین المللی جی. جئوگر. Inf. علمی ۲۰۱۴ ، ۲۸ ، ۱۹۸۸-۲۰۰۷٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- یوان، نیوجرسی؛ ژنگ، ی. Xie, X. کشف مناطق عملکردی در یک شهر با استفاده از حرکات انسانی و نقاط مورد علاقه . Springer: برلین/هایدلبرگ، آلمان، ۲۰۱۷; صص ۳۳-۶۲٫ [ Google Scholar ] [ CrossRef ]
- کارلسون، سی. اولسون، ام. شناسایی مناطق عملکردی: نظریه، روش ها و کاربردها. ان Reg. علمی ۲۰۰۶ ، ۴۰ ، ۱-۱۸٫ [ Google Scholar ] [ CrossRef ]
- یوان، نیوجرسی؛ ژنگ، ی. Xie، X. وانگ، ی. ژنگ، ک. Xiong، H. کشف مناطق عملکردی شهری با استفاده از مسیرهای فعالیت پنهان. IEEE Trans. بدانید. مهندسی داده ۲۰۱۴ ، ۲۷ ، ۷۱۲-۷۲۵٫ [ Google Scholar ] [ CrossRef ]
- کالابرس، اف. دیائو، م. دی لورنزو، جی. فریرا، جی. Ratti, C. درک الگوهای تحرک فردی از داده های سنجش شهری: یک مثال ردیابی تلفن همراه. ترانسپ Res. قسمت C Emerg. تکنولوژی ۲۰۱۳ ، ۲۶ ، ۳۰۱-۳۱۳٫ [ Google Scholar ] [ CrossRef ]
- دیائو، م. زو، ی. فریرا، جی جی؛ راتی، سی. استنتاج فعالیتهای روزانه فردی از رد پای تلفن همراه: نمونه بوستون. محیط زیست طرح. B طرح. دس ۲۰۱۶ ، ۴۳ ، ۹۲۰-۹۴۰٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لیو، ز. ما، تی. دو، ی. پی، تی. یی، جی. پنگ، اچ. نقشه برداری پویایی ساعتی جمعیت شهری با استفاده از مسیرهای بازسازی شده از سوابق تلفن همراه. ترانس. GIS ۲۰۱۸ ، ۲۲ ، ۴۹۴-۵۱۳٫ [ Google Scholar ] [ CrossRef ]
- چن، سی. ما، جی. سوسیلو، ی. لیو، ی. وانگ، ام. وعده دادههای بزرگ و دادههای کوچک برای تحلیل رفتار سفر (معروف به تحرک انسان). ترانسپ Res. قسمت C Emerg. تکنولوژی ۲۰۱۶ ، ۶۸ ، ۲۸۵-۲۹۹٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژانگ، اس. یانگ، ی. ژن، اف. Lobsang، T. بررسی الگوهای فعالیت زمانی مناطق شهری با استفاده از دادههای تلفن همراه مبتنی بر شبکه: مطالعه موردی ووهو، چین. چانه. Geogr. علمی ۲۰۲۰ ، ۳۰ ، ۶۹۵-۷۰۹٫ [ Google Scholar ] [ CrossRef ]
- ژان، دی. منگ، ب. تجزیه و تحلیل خوشه بندی فضایی توزیع مسکونی و اشتغال در پکن بر اساس ویژگی های اجتماعی آنها. Acta Geogr. گناه ۲۰۱۳ ، ۶۸ ، ۱۶۰۷-۱۶۱۸٫ [ Google Scholar ]
- شیائو، ی. وانگ، ز. لی، ز. تانگ، ز. ارزیابی دسترسی به پارک شهری در شانگهای – پیامدهایی برای برابری اجتماعی در چین شهری. Landsc. طرح شهری. ۲۰۱۷ ، ۱۵۷ ، ۳۸۳-۳۹۳٫ [ Google Scholar ] [ CrossRef ]
- یوان، جی. ژنگ، ی. Xie, X. کشف مناطقی از عملکردهای مختلف در یک شهر با استفاده از تحرک انسان و POI. در مجموعه مقالات هجدهمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، پکن چین، ۱۲ تا ۱۶ اوت ۲۰۱۲٫ ص ۱۸۶-۱۹۴٫ [ Google Scholar ]
- چن، ی. لیو، ایکس. لی، ایکس. لیو، ایکس. یائو، ی. در آغوش گرفتن.؛ خو، X. Pei، F. ترسیم مناطق عملکردی شهری با دادههای رسانههای اجتماعی در سطح ساختمان: یک روش K-medoids مبتنی بر فاصله زمانی پویا (DTW). Landsc. طرح شهری. ۲۰۱۷ ، ۱۶۰ ، ۴۸-۶۰٫ [ Google Scholar ] [ CrossRef ]
- شکوهی یکتا، م. هو، بی. جین، اچ. وانگ، جی. Keogh، EJ تعمیم DTW به حالت چند بعدی نیاز به یک رویکرد تطبیقی دارد. حداقل داده بدانید. کشف کنید. ۲۰۱۷ ، ۳۱ ، ۱-۳۱٫ [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- الجلبوت، ای. گلکوف، وی. صدیقی، ی. استروبل، ام. Cremers, D. Clustering with Deep Learning: Taxonomy and New Methods. arXiv ۲۰۱۸ , arXiv:1801.07648. [ Google Scholar ]
- کائو، آر. تو، دبلیو. یانگ، سی. لی، کیو. لیو، جی. ژو، جی. ژانگ، Q. لی، کیو. کیو، جی. ادغام داده های سنجش از راه دور و اجتماعی مبتنی بر یادگیری عمیق برای تشخیص عملکرد منطقه شهری. ISPRS J. Photogramm. Remote Sens. ۲۰۲۰ , ۱۶۳ , ۸۲–۹۷٫ [ Google Scholar ] [ CrossRef ]
- روهانا، NA; یوسف، ن. Uti، MN; دین، AHM در حال کاوش الگوی موج فضایی-زمانی با استفاده از تکنیک بدون نظارت. ISPRS Int. قوس. فتوگرام حسگر از راه دور اسپات. Inf. علمی ۲۰۱۹ ، XLII-4/W16 ، ۵۴۳–۵۴۸٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Wandeto، JM; Nyongesa، HO; Dresp-Langley، B. تشخیص تغییرات ساختاری در مناطق جغرافیایی مورد علاقه با نقشه برداری خود سازماندهی شده: شهر لاس وگاس و دریاچه مید در طول سالها. arXiv ۲۰۱۸ ، arXiv:1803.11125. [ Google Scholar ]
- لوکش، اس. کومار، PM; دیوی، ام آر. پارتاساراتی، پ. Gokulnath، C. یک سیستم تشخیص خودکار گفتار تامیل با استفاده از شبکه عصبی بازگشتی دو طرفه با نقشه خودسازماندهی. محاسبات عصبی Appl. ۲۰۱۹ ، ۳۱ ، ۱۵۲۱-۱۵۳۱٫ [ Google Scholar ] [ CrossRef ]
- سان، ج. وانگ، اچ. آهنگ، ز. لو، جی. منگ، پی. Qin, S. نقشه برداری از مقوله های کاربری ضروری شهری در نانجینگ با ادغام داده های بزرگ چند منبعی. Remote Sens. ۲۰۲۰ , ۱۲ , ۲۳۸۶٫ [ Google Scholar ] [ CrossRef ]
- لی، ایکس. گونگ، پی. چارچوبی «حذف-شمول» برای استخراج سکونتگاههای انسانی در مناطق در حال توسعه سریع چین از تصاویر Landsat. سنسور از راه دور محیط. ۲۰۱۶ ، ۱۸۶ ، ۲۸۶-۲۹۶٫ [ Google Scholar ] [ CrossRef ]
- ژانگ، جی. دی رن، LI; Qin، XW; Zhu، XY تصحیح هندسی تصویر SAR فضایی با وضوح بالا بر اساس مدل RPC. J. Remote Sens. ۲۰۰۸ , ۱۲ , ۹۴۲-۹۴۸٫ [ Google Scholar ]
- یوان، جی.-جی. نیو، ز. وانگ، X.-P. تصحیح جوی تصویر فراطیفی هایپریون بر اساس FLAASH. Spectrosc. طیف مقعدی ۲۰۰۹ ، ۲۹ ، ۱۱۸۱-۱۱۸۵٫ [ Google Scholar ]
- دورادو-مونوز، ال. مسنجر، DW; Bove, D. یکپارچه سازی اطلاعات فضایی و طیفی برای افزایش ویژگی های فضایی در نقشه گوف بریتانیای کبیر. J. Cult. میراث. ۲۰۱۸ ، ۳۴ ، ۱۵۹-۱۶۵٫ [ Google Scholar ] [ CrossRef ]
- کائو، ی. لیو، جی. وانگ، ی. وانگ، ال. وو، دبلیو. Su, F. مطالعه ای در مورد روش طبقه بندی عملکردی ساختمان های شهری با استفاده از داده های POI. J. Geo-Inf. علمی ۲۰۲۰ ، ۲۲ ، ۱۳۳۹-۱۳۴۸٫ [ Google Scholar ]
- گونگ، پی. چن، بی. لی، ایکس. لیو، اچ. وانگ، جی. بای، ی. چن، جی. چن، ایکس. نیش، ال. فنگ، اس. و همکاران نقشه برداری مقوله های ضروری کاربری زمین شهری در چین (EULUC-چین): نتایج اولیه برای سال ۲۰۱۸٫ علمی. گاو نر ۲۰۲۰ ، ۶۵ ، ۱۸۲-۱۸۷٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لین، ا. سان، ایکس. وو، اچ. لو، دبلیو. وانگ، دی. ژونگ، دی. وانگ، ز. ژائو، ال. Zhu, J. شناسایی عملکرد ساختمان شهری با ادغام تصاویر سنجش از دور و داده های POI. IEEE J. Sel. بالا. Appl. زمین Obs. Remote Sens. ۲۰۲۱ , ۱۴ , ۸۸۶۴–۸۸۷۵٫ [ Google Scholar ] [ CrossRef ]
- ژانگ، ایکس. دو، اس. وانگ، Q. شناخت معنایی سلسله مراتبی برای مناطق عملکردی شهری با تصاویر ماهواره ای VHR و داده های POI. ISPRS J. Photogramm. Remote Sens. ۲۰۱۷ ، ۱۳۲ ، ۱۷۰-۱۸۴٫ [ Google Scholar ] [ CrossRef ]
- گونگ، پی. لیو، اچ. ژانگ، ام. لی، سی. وانگ، جی. هوانگ، اچ. کلینتون، ن. جی، ال. لی، دبلیو. بای، ی. و همکاران طبقه بندی پایدار با نمونه محدود: انتقال مجموعه نمونه با وضوح ۳۰ متری جمع آوری شده در سال ۲۰۱۵ به نقشه برداری پوشش زمینی با وضوح ۱۰ متری در سال ۲۰۱۷٫ علمی. گاو نر ۲۰۱۹ ، ۶۴ ، ۳۷۰-۳۷۳٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- دهناد، ک. برآورد چگالی برای آمار و تجزیه و تحلیل داده ها. Technometrics ۲۰۱۲ , ۲۹ , ۴۹۵٫ [ Google Scholar ] [ CrossRef ]
- لیو، ی. لیو، ایکس. گائو، اس. گونگ، ال. کانگ، سی. ژی، ی. چی، جی. شی، ال. حس اجتماعی: رویکردی جدید برای درک محیط های اجتماعی-اقتصادی ما. ان دانشیار صبح. Geogr. ۲۰۱۵ ، ۳ ، ۵۱۲-۵۳۰٫ [ Google Scholar ] [ CrossRef ]
- دینگ، اچ. ترایچفسکی، جی. شوئرمن، پی. وانگ، ایکس. Keogh، E. پرس و جو و استخراج داده های سری زمانی: مقایسه تجربی نمایش ها و اندازه گیری های فاصله. Proc. VLDB Enddow. ۲۰۰۸ ، ۱ ، ۱۵۴۲-۱۵۵۲٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Kohonen, T. Self-Organizing Maps , ۳rd ed.; Springer: برلین/هایدلبرگ، آلمان، ۲۰۰۱٫ [ Google Scholar ]
- آرتور، دی. Vassilvitskii, S. k-means: مزایای کاشت دقیق. Soc. Ind. Appl. ریاضی. ۲۰۰۷ ، ۱۰۲۷-۱۰۳۵٫ [ Google Scholar ]
- وربورگ، پی اچ. de Nijs، TC; ون اک، جی آر. ویسر، اچ. دی جونگ، ک. روشی برای تجزیه و تحلیل ویژگی های همسایگی الگوهای کاربری زمین. محاسبه کنید. محیط زیست سیستم شهری ۲۰۰۴ ، ۲۸ ، ۶۶۷-۶۹۰٫ [ Google Scholar ] [ CrossRef ]
- گتیس، ع. Ord, JK تجزیه و تحلیل ارتباط فضایی با استفاده از آمار فاصله. Geogr. مقعدی ۱۹۹۲ ، ۲۴ ، ۱۸۹-۲۰۶٫ [ Google Scholar ] [ CrossRef ]
- لیو، ایکس. نیو، ن. لیو، ایکس. جین، اچ. او، جی. جیائو، ال. لیو، ی. مشخص کردن ساختمانهای با کاربری مختلط بر اساس دادههای بزرگ چند منبعی. بین المللی جی. جئوگر. Inf. علمی IJGIS ۲۰۱۸ ، ۳۲ ، ۷۳۸-۷۵۶٫ [ Google Scholar ]
- ژانگ، سی. شی، س. ژو، ال. وانگ، اف. تائو، اچ. استنباط استفاده ترکیبی از ساختمانها با دادههای چند منبعی بر اساس تجزیه تانسور. ISPRS Int. J. Geo-Inf. ۲۰۲۱ ، ۱۰ ، ۱۸۵٫ [ Google Scholar ] [ CrossRef ]
- تو، دبلیو. ژانگ، ی. لی، کیو. مای، ک. کائو، جی. اثر مقیاس بر ادغام سنجش از دور و حس انسانی برای به تصویر کشیدن توابع شهری. IEEE Geosci. سنسور از راه دور Lett. ۲۰۲۰ ، ۱۸ ، ۳۸-۴۲٫ [ Google Scholar ] [ CrossRef ]
- لین، تی. سان، سی. لی، ایکس. ژائو، کیو. ژانگ، جی. جنرال الکتریک، آر. بله، اچ. هوانگ، ن. یین، ک. الگوی فضایی مناظر کاربردی شهری در امتداد شیب شهری-روستایی: مطالعه موردی در شهر Xiamen، چین. بین المللی J. Appl. زمین Obs. Geoinf. ۲۰۱۶ ، ۴۶ ، ۲۲-۳۰٫ [ Google Scholar ] [ CrossRef ]
- نمشکال، ج. اوردنیچک، ام. Pospíšilová، L. موقتی بودن فضای شهری: ریتم های روزانه یک روز معمولی هفته در منطقه شهری پراگ. J. Maps. ۲۰۲۰ ، ۱۶ ، ۳۰-۳۹٫ [ Google Scholar ] [ CrossRef ]