
خلاصه
شاخص های اجتماعی-اقتصادی کلیدی برای درک چالش های اجتماعی هستند. آنها برای به دست آوردن بینش و درک عمیق، پدیده های پیچیده را از هم جدا می کنند. زیرمجموعههای خاصی از شاخصها برای توصیف پایداری، توسعه انسانی، آسیبپذیری، ریسک، تابآوری و سازگاری با تغییرات آب و هوایی ایجاد شدهاند. با این وجود، کیفیت ناکافی و در دسترس بودن داده ها اغلب قدرت توضیحی آنها را محدود می کند. وضوح مکانی و زمانی اغلب در مقیاس مناسب برای نظارت نیست. شاخص های اقتصادی-اجتماعی بیشتر توسط نهادهای دولتی ارائه می شود و بنابراین محدود به مرزهای اداری است. علاوه بر این، رویکردهای محاسباتی روششناختی متفاوت برای یک شاخص، قابلیت مقایسه بین کشورها و مناطق را مختل میکند. OpenStreetMap (OSM) یک پایگاه داده جهانی استاندارد شده بی نظیر با وضوح مکانی و زمانی بالا ارائه می دهد. با کمال تعجب، پتانسیل OSM در این زمینه تا حد زیادی ناشناخته به نظر می رسد. در این مطالعه، ما از یادگیری ماشین برای پیشبینی چهار شاخص اقتصادی-اجتماعی نمونه برای شهرداریها بر اساس OSM استفاده کردیم. با مقایسه قدرت پیشبینی شبکههای عصبی با مدلهای رگرسیون آماری، ما منابع بیاثر OSM را برای توسعه شاخص ارزیابی کردیم. OSM چشم انداز نظارت را در سراسر مرزهای اداری، موضوعات بین رشته ای و عوامل نیمه کمی مانند انسجام اجتماعی فراهم می کند. برای مثال، برای تعیین تأثیر تفاوتهای منطقهای و بینالمللی در مشارکت کاربران بر روی خروجیها، هنوز تحقیقات بیشتری مورد نیاز است. با این وجود،
کلید واژه ها:
شاخص ها ؛ یادگیری ماشینی ؛ OpenStreetMap ; آسیب پذیری ؛ تاب آوری ; سازگاری با تغییرات آب و هوایی
۱٫ معرفی
در سیاست ها و تحقیقات فعلی در مورد سازگاری با تغییرات آب و هوایی، تاب آوری و آسیب پذیری مفاهیم کلیدی برای درک بعد انسانی استراتژی ها و اقدامات برای سازگاری با تغییرات جهانی است.
آسیب پذیری عبارت است از ناتوانی جامعه در عمل و در نتیجه تأثیرگذاری بر تأثیرات تغییرات جهانی بر رفاه مردم آن. افزایش تابآوری جوامع، کاهش خطر بلایا و در نتیجه کاهش اثرات تغییرات آب و هوایی، مستلزم توجه به جنبههای اجتماعی توسعه پایدار و مقابله با علل است، نه علائم. شاخص های اجتماعی-اقتصادی معیارهای مهمی برای ارزیابی ابعاد فضایی یا اجتماعی هستند. عواملی مانند وضعیت اقتصادی یا شغلی افراد بر انطباق و ظرفیت مقابله آنها تأثیر می گذارد [ ۱ ، ۲ ، ۳ ، ۴ ].
اگرچه دادههای رسمی اجتماعی-اقتصادی از نهادهای دولتی و غیردولتی قابل اعتماد، جامع و اغلب بهترین گزینه برای توصیف پدیدههای اجتماعی هستند، اما تنها در قطعنامههای زمانی و مکانی خاص در دسترس هستند و فاقد استانداردسازی بین سطوح اداری، حتی در داخل کشورها هستند. تلاشهای عظیم برای رسیدگی به این موضوع شامل دستورالعمل INSPIRE کمیسیون اروپا با چشمانداز به اشتراکگذاری بیسابقه دادههای مکانی است. با این حال، این ابتکار به دلیل موانع زیادی که بر سر راه اجرای آن وجود دارد، هنوز نتوانسته است به پتانسیل کامل خود برسد [ ۵ ]. تا به حال، نظرسنجی های دقیق اغلب برای ایجاد دانش در مورد روابط اجتماعی با محیط طبیعی، فرهنگی و اقتصادی ضروری بوده است.
حجم فزاینده داده ها، سیاست های داده باز و داده های جمع آوری شده منجر به افزایش در دسترس بودن و دسترسی به شاخص های اجتماعی-اقتصادی شده است. با این وجود، اندازهگیری پدیدههای چند وجهی پیچیده (مانند انعطافپذیری، آسیبپذیری، پایداری، سازگاری) هنوز به دلیل در دسترس نبودن دادهها محدود است [ ۲ ، ۴ ، ۶ ، ۷ ]. از این رو، نیاز به روشهایی که امکان استخراج شاخصها از منابع داده را فراهم میکنند، که به طور دائم در دسترس باشند و اطلاعات فضایی مقیاسپذیر را ارائه دهند، بسیار واضح شده است.
در سالهای اخیر، هوش مصنوعی و بهویژه روشهای یادگیری ماشینی در بسیاری از رشتههای علمی به منظور پیشبینی ویژگیها و ساختارهای اجتماعی با تحلیل الگوهای ضمنی در دادههای سیستمهای مشاهدهشده، توسعه و آزمایش شدهاند. جنگل تصادفی (RF) یکی از الگوریتمهای یادگیری ماشینی است که به طور گسترده برای دادههای جغرافیایی به کار میرود: به عنوان مثال، برای طبقهبندی پوشش زمین از مجموعههای دادههای زمینی [۸ ] ، نقشهبرداری از انواع مورفولوژی پوشش گیاهی [ ۹ ]، پیشبینی زیستگاه فیشر (Pekania pennanti) [ ۱۰ ]، یک رویکرد چند داده ای برای تقویت طبقه بندی محصولات [ ۱۱ ]، یا کاهش مقیاس داده های سرشماری [۱۱] ۱۲]]. یکی دیگر از الگوریتمهای یادگیری ماشینی که در بین رشتهها کاربرد دارد، شبکههای عصبی (NN) است. به عنوان مثال می توان به ارزیابی آسیب پذیری لرزه ای [ ۱۳ ]، مدل سازی سطح کف دریا [ ۱۴ ]، ارزیابی خطر سیل [ ۱۵ ] و تجزیه و تحلیل تکامل الگوی زمین [ ۱۶ ] اشاره کرد. در یادگیری ماشینی، شبکه های عصبی به دسته یادگیری عمیق تعلق دارند.
این تحقیق با هدف توسعه یک رویکرد یادگیری ماشین برای استنباط شاخصهای اجتماعی-اقتصادی از OpenStreetMap (OSM) برای شهرداریها انجام شد. فرضیه اصلی این بود که پروکسی هایی برای ویژگی های اجتماعی-اقتصادی در داده های جغرافیایی پایگاه داده OSM وجود دارد. به عنوان مثال، آیا نیمکت های پارک می توانند پیش بینی کننده ای برای جمعیت سالمند باشند؟ آیا اندازه نواحی صنعتی یا تراکم حملونقل عمومی یا زیرساختها میتواند نشانهای از نرخ بیکاری باشد؟ آیا طبیعت یا صنعت برای مهاجرت پیش بینی کننده تر است؟ با چهار شاخص (ساکنان، بیکاری، مهاجرت و سالمندان) انتخاب شده بر اساس داده های آماری رسمی، ما مناسب بودن OSM را به عنوان منبع داده آزمایش کردیم و عملکرد پیش بینی سه رویکرد را مقایسه کردیم: (۱) پیش بینی تصادفی به عنوان خط پایه با رگرسیون خطی. ; (۲) یک الگوریتم یادگیری ماشین؛ و (۳) یک الگوریتم یادگیری عمیق. ما قدرت پیشبینی هر رویکرد را با مقایسه آنها با مناطق آزمایشی که در آن از وضعیت واقعی اطلاع داریم، ارزیابی کردیم.
این مقاله تحقیقاتی بر اساس تحقیقات قبلی توسط نویسندگان [ ۱۷ ، ۱۸ ] است و یک رویکرد تصفیه شده برای تجزیه و تحلیل پایگاه داده OSM با هوش مصنوعی (AI) را نشان می دهد. بخش ۲ منطقه مورد مطالعه را معرفی می کند و روش اتخاذ شده را توسعه می دهد، از جمله شاخص های هدف و الگوریتم های یادگیری ماشین مورد استفاده قرار گرفته است. بخش ۳ نتایج پیشبینی مدلها، از جمله ارزیابی عملکرد مقایسهای را ارائه میکند. بخش ۴ یافتههای مربوط به هر شاخص و چالشهای مقطعی را در میان آنها مورد بحث قرار میدهد که منجر به فرصتهایی برای تحقیقات آینده میشود. بخش ۵با جمع بندی سوال تحقیق و نتایج اصلی به پایان می رسد.
۲٫ روش
گردش کار از روایت تحقیق پیروی می کند ( شکل ۱ ). ابتدا مجموعه داده OSM دانلود شد. ثانیاً در یک استعلام فضایی همه چیز در محدوده یک شهرداری شمارش شد. ثالثاً، در یک مرحله پردازش داده، یک تجزیه و تحلیل مؤلفه اصلی (PCA) برای کاهش تعداد ابعاد انجام شد که در نتیجه مؤلفههای اصلی نامرتبط به عنوان کاندیدای شاخص ایجاد شد. چهارم، متعاقباً از کاندیداهای شاخص برای پیشبینی چهار شاخص اقتصادی-اجتماعی (بیکاری، ساکنان، مهاجرت، سالمندان) استفاده شد. پنجم، نتایج مدل اعتبار سنجی شد و در آخر نقشه برداری شد.
در بخش زیر ابتدا مطالعه موردی و شاخص های اقتصادی-اجتماعی انتخاب شده شرح داده شده است. در مرحله دوم، OSM به عنوان منبع داده با ویژگیهای کلیدی و پیامدهای آن برای محاسبه ویژگیهای فضایی برای هر شهرداری توصیف میشود. سوم، الگوریتم های یادگیری ماشین و پیاده سازی، توابع و تنظیمات آنها مورد بحث قرار می گیرد.
۲٫۱٫ منطقه آزمایشی
به عنوان مصالحه بین منابع محاسباتی، مدیریت داده ها و پیچیدگی مدل، مقیاس منطقه ای انتخاب شد. بادن-وورتمبرگ ایالت فدرال جنوب غربی آلمان است که از غرب با فرانسه و از جنوب با سوئیس هم مرز است ( شکل ۲ ). قلمرو اداری با وسعت ۳۵۷۵۱٫۴۶ کیلومتر مربع به چهار ناحیه اداری (Regierungsbezirke) که شامل ۳۵ شهرستان (Landkreise) و نه شهر مستقل (Stadtkreise) است، تقسیم می شود. در مجموع، ۱۱۰۱ شهرداری با حدود ۱۱ میلیون نفر جمعیت وجود دارد. تراکم جمعیت ۳۱۰ نفر در هر کیلومتر مربع است که از آلمان به طور کلی که ۲۳۲ نفر در هر کیلومتر مربع است بیشتر است [ ۱۹]]. از نظر اقتصادی، بادن-وورتمبرگ یکی از قوی ترین مناطق اروپا است و از نظر قدرت خرید پس از هامبورگ و باواریا در رتبه سوم آلمان قرار دارد [ ۲۰ ]. کسب و کارهای خانوادگی برای این منطقه معمولی هستند. نرخ کلی بیکاری ۱/۳ درصد و در مناطق روستایی کمتر است [ ۲۱ ]. در سال ۲۰۱۸، میانگین سنی ۴۳٫۵ سال بود که نسبت به سال ۱۹۷۰ ۹ سال افزایش داشت. اگرچه مهاجرت قابل توجهی از جوانان وجود داشته است، اما این تعداد در سال های اخیر تغییر چندانی نکرده است [۲۲ ] . در حال حاضر ۲۹۴۰۰۰ نفر ۸۵ سال یا بیشتر سن دارند. این رقم شش برابر بیشتر از سال ۱۹۷۰ است. پیش بینی فعلی پیش بینی می کند که این تعداد تا سال ۲۰۶۰ به ۸۰۵۰۰۰ نفر افزایش یابد [ ۲۳ ].
۲٫۲٫ شاخص های اجتماعی-اقتصادی منتخب
شاخص های اقتصادی-اجتماعی انتخاب شده برای این پژوهش عبارت بودند از: (الف) ساکنان; ب) بیکاری؛ ج) سالمندان؛ و (د) مهاجرت. مقیم به تعداد ساکنان در هر شهرداری اشاره دارد. بیکاری به درصد افراد بیکار به عنوان بخشی از تعداد کل افراد شاغل گفته می شود. نسبت افراد مسن درصد افراد مسن تر از ۶۵ سال را به عنوان بخشی از کل جمعیت نشان می دهد. مهاجرت با کم کردن مهاجرت از مهاجرت محاسبه می شود. تراز مثبت به این معنی است که افراد بیشتری به شهرداری رفتند تا خارج از آن. این چهار معیار شرایط اجتماعی و اقتصادی را توضیح میدهند و مبنای مشترکی برای بسیاری از شاخصهای اقتصادی-اجتماعی و مربوط به ارزیابی و ارزیابی پدیدههای پیچیده مانند انعطافپذیری، آسیبپذیری و پایداری هستند.۶ ، ۲۴ ، ۲۵ ، ۲۶ ].
۲٫۳٫ OpenStreetMap – توسعه ویژگیهای فضایی برای شهرداریها
OSM یک پروژه رایگان و مشارکتی است که در سال ۲۰۰۴ تأسیس شد [ ۲۷ ]. هدف این پروژه ایجاد نقشه دسترسی باز از جهان است. تمام عناصر یک نقشه توپوگرافی، مانند خانه ها، خیابان ها، راه آهن ها و جنگل ها توسط داوطلبان در سراسر جهان نقشه برداری می شوند [ ۲۸ ]. دادههای جمعسپاری شده تحت مجوز پایگاه داده باز عمومی میشوند. آمار فعلی بیش از شش میلیون کاربر ثبت شده، ۵٫۷۵ میلیارد گره و ۳٫۵ میلیون تغییر نقشه در روز را نشان می دهد [ ۲۹ ].
هر عنصر در پایگاه داده با حداقل یک تگ در متن ساده توصیف می شود. تگ از یک کلید و یک مقدار تشکیل شده است. کلید می تواند اشیاء نمایش داده شده را با ویژگی های عملکردی یا سایر ویژگی ها مانند نام یا مالک توصیف کند. کلیدها منحصر به فرد و دسته بندی هستند (مثلاً کاربری زمین) و کلاس ها یا دامنه هایی را که هر شی به آن تعلق دارد را توصیف می کند. از مقادیر می توان برای مشخص کردن بیشتر ویژگی ها و توضیحات فردی استفاده کرد (به عنوان مثال، برچسب: کلید = کاربری زمین، ارزش = زمین کشاورزی).
برای هدف این مطالعه، ابتدا مجموعه داده کامل OSM را برای ایالت فدرال بادن-وورتمبرگ از وبسایت Geofabrik ( https://download.geofabrik.de ؛ اکتبر ۲۰۱۹) دانلود کردیم. سپس فایل .pbf دانلود شده با استفاده از osm2pgsql به پایگاه داده PostgreSQL با پسوند PostGIS وارد شد ( https://github.com/openstreetmap/osm2pgsql). در طول واردات، کاهش داده اولیه از طریق «سبک» وارد کردن پیشفرض مورد استفاده صورت گرفت، که کلیدهای خاص و اطلاعات اضافی را بدون ارتباط توضیحی از مجموعه داده حذف میکند. جداول هندسه و صفت PostGIS (نقطه، خط و چند ضلعی) به دست آمده حاوی ۶۰ کلید مرتبط به عنوان ستون و مقادیر مربوطه به عنوان ردیف است. در مرحله پیش پردازش بیشتر، داده های OSM با مرزهای اداری شهرداری های داخل ایالت فدرال تقاطع یافتند. در نتیجه، مجموع هندسهها (مساحت و طول) و تعداد نقاط برای هر وقوع یک جفت کلید-مقدار منحصر به فرد با SQL-پرسوجوها برای هر شهرداری محاسبه شد، که منجر به ایجاد جدولی با ۱۱۰۱ ردیف شد که هر ردیف یک نمونه را نشان میدهد. به معنی یک شهرداری ( جدول ۱ ).
مراحل قبلی منجر به سه لایه مجزا (نقاط، خطوط، چندضلعی)، با کلیدها و مقادیر و مجموع مربوط به وقوع فضایی مشاهده شده آنها (تعداد، متر مربع، کیلومتر) شد. هر خط یا نمونه برای یک ویژگی فضایی شمارش میشود، و بنابراین، تعداد نامحدودی از خطوط در هر برچسب در هر شهرداری وجود دارد. تمام مراحل زیر با استفاده از R با R Studio [ ۳۰ ، ۳۱ ] انجام شد (بستههای اضافی: “tidyr”؛ “dplyr” [ ۳۲ ، ۳۳ ]). این سه جدول از پایگاه داده PostGIS به R Studio وارد شدند (عملکرد: dbReadTable(؛ بسته: “RPostgres” [ ۳۴]). در مرحله مقدماتی پاکسازی داده ها، شش کلید (addr، name، xmas، contact، TMS، openGeoDB) حذف شدند، زیرا حاوی اطلاعات مرتبط برای کار پیش رو نبودند. علاوه بر این، فقط برچسب هایی که در ۱۰۰ شهرداری یا بیشتر ظاهر می شوند در نظر گرفته شدند. سپس ستونهای کلید و مقدار به یک ستون برچسب متصل شدند. پس از آن، تگ ها بر اساس مجموع به ازای هر شهرداری جمع شدند و در یک ستون در هر برچسب نوشته شدند (تابع: dcast(؛ بسته: “reshape2” [ ۳۵ ]). همین مراحل برای سه جدول (نقاط، خطوط، چندضلعی) انجام شد و جداول حاصل با کد شهرداری به یک جدول ملحق شدند. در مرحله بعدی، این دادههای خام برای بخش یادگیری ماشین از قبل پردازش شدند.
جمعیت شهرداری و همچنین منطقه وارد شد (تابع: read_excel(؛ بسته: “readxl” [ ۳۶ ]). مجموعه داده ها با احتیاط از طریق تولید اعداد تصادفی به ۵۰ درصد شهرداری های آزمایشی و ۵۰ درصد شهرداری های آموزشی برای آزمایش قدرت پیش بینی و افزایش تعمیم تقسیم شد. برای تنظیم اندازههای مختلف شهرداریها، پیشبینیکنندهها به ازای هر ۱۰۰۰ نفر در ارتباط بودند. داده های آموزشی استاندارد شده و PCA انجام شد (عملکرد: preProcess(؛ بسته: “caret” [ ۳۷]). پارامترهای پیش فرآیند از دادههای آموزشی نیز برای دادههای آزمون گرفته شد تا از طریق استانداردسازی کل مجموعه دادهها، اطلاعات آینده در فرآیند آموزش ترکیب نشود. PCA برای کاهش ابعاد و داشتن مجموعهای از نامزدهای شاخص غیرهمبسته برای پیشبینی چهار شاخص اجتماعی-اقتصادی استفاده شد ( پیوست A را ببینید ).
۲٫۴٫ یادگیری ماشینی برای پیش بینی شاخص های اجتماعی-اقتصادی
بخش زیر الگوریتمهای پیشبینیکننده و توابع R آنها را که برای این تجزیه و تحلیل اعمال شد، از جمله پارامترهای مدل توصیف میکند. ابتدا خط مبنا با پیشبینی تصادفی و یک مدل خطی ایجاد شد. در مرحله دوم، شبکههای عصبی تصادفی و شبکههای عصبی عمیق (DNN)به عنوان یک رویکرد یادگیری ماشین و یادگیری عمیق استفاده شدند. ثالثاً، این مدلها با حقیقت زمین مقایسه شدند و از نظر قدرت پیشبینی ارزیابی شدند.
برای پیشبینی تصادفی (RP)، مقادیر تصادفی در محدوده دادههای آزمون تولید شد. میانگین خطای مطلق (MAE) در داده های آزمون محاسبه و به عنوان خط پایه مقایسه شد. MAE برای آزمایش عملکرد مدل انتخاب شد که در جدول ۲ گزارش شده است . میانگین مربعات خطا (MSE) به دلیل تخمین بیش از حد بالقوه عملکرد مدل نادیده گرفته شد زیرا همه مقادیر نتیجه حداقل تا حداکثر برای مقایسه بین آنها نرمال شدند. از این رو، محاسبه مجذور مقادیر بین صفر و یک میتواند به مقادیر مطلق کوچکتری منجر شود و عملکرد را مبهم کند.
رگرسیون خطی (LR) به عنوان یک روش پیشبینی آماری پایه برای درک بهتر عملکرد الگوریتمهای یادگیری ماشین (تابع: lm(؛ بسته: کتابخانه پایه R) انجام شد.
جنگل تصادفی (RF) یک الگوریتم یادگیری ماشینی است که بر اساس آمار درختان تصمیم گیری است. در یک فرآیند یادگیری تصادفی، چندین درخت تصمیم گیری نامرتبط محاسبه می شود. در تنظیمات استاندارد، ۵۰۰ درخت توسط زیرمجموعههای پیشبینیکنندهها ساخته میشوند تا از تسلط یک پیشبینیکننده بسیار قوی اجتناب کنند (عملکرد: randomForest(؛ بسته: randomForest [38] ) . اهمیت ارزیابی پیشبینیکنندهها برای شناسایی پیشبینیکنندههای مربوطه درست است. ارتباط پیشبینیکنندهها با کمک آنها در کاهش خطای آزمون روی همه درختان تعیین میشود.
شبکههای عصبی مصنوعی الگوریتمهای یادگیری ماشینی هستند که عملکردی مشابه مغز انسان دارند. تعدادی لایه و گره پنهان، الگوها را در داده ها ساختار، سازماندهی و تشخیص می دهند. مدلهای متوالی متعدد با حداکثر چهار لایه پنهان و ۲۵۶ گره برای هر یک از چهار نشانگر آموزش داده میشوند (تابع: sequential(؛ بسته: “keras” [ ۳۹ ]). در نهایت، بهترین چهار DNN، یکی برای هر نشانگر، با کمترین MAE انتخاب میشوند.
در بسته keras، هنوز هیچ روشی برای ارزیابی اهمیت پیشبینیکننده و تحلیل جعبه سیاه شبکه عصبی گنجانده نشده است. مشابه ثبت جنگل تصادفی سهم در کاهش خطا، اهمیت ویژگی جایگشت (PFI) اجرا شد. در اینجا، رویکرد فیروزی (۲۰۱۸) اتخاذ شد که مبتنی بر [ ۴۰ ، ۴۱ ] است. اگرچه از لحاظ روش شناختی تعریف نشده است، روش بر روی داده های آزمون پیاده سازی شد. برای هر پیشبینیکننده، مقادیر بهطور تصادفی جابهجا میشوند و خطای شبکه عصبی محاسبه میشود. پس از آن، PFI مطلق با کم کردن خطای مدل اصلی از خطای جایگشت محاسبه شد، که منجر به یک مقدار در مورد سهم پیشبینیکننده در کاهش MAE شد.
روشی که در بالا توضیح داده شد برای هر چهار نتیجه انجام شد که به مجموعههای تست و تمرین یکسان تقسیم شد. نقشهبرداری نهایی شاخصها با اجرای یک طبقهبندی کمیت با هشت کلاس انجام شد.
۳٫ نتایج
بخش زیر با مقایسه کلی عملکرد همه الگوریتمهای یادگیری ماشین کاربردی در چهار شاخص شروع میشود. پس از آن، توزیع فضایی و عناصر پیش بینی کننده OSM برای هر شاخص ارائه شده است.
۳٫۱٫ مقایسه الگوریتم های یادگیری ماشین و عملکرد مدل
ستون اول MAE حاصل را برای پیش بینی تصادفی مقادیر برای ایجاد خط پایه برای مقایسه نشان می دهد ( جدول ۲ ). ستون های دوم، سوم و چهارم خطاهای LR، RF و DNN هستند. به طور کلی، رگرسیون خطی بهتر از پیشبینی تصادفی، RF بهتر از LR و DNN بهتر از RF بود. برای مدل DNN، تعداد ساکنان در هر شهرداری با کمترین خطا به بهترین شکل پیشبینی شد و پس از آن مهاجرت، سالمندان و بیکاری قرار گرفتند.
۳٫۲٫ ویژگی های فضایی تعداد ساکنین
تعداد ساکنان هر شهرداری به ترتیب کاهش MAE مدلسازی شده توسط تصادفی، خطی، RF و بهترین DNN بود.
مدل DNN به وضوح از مدل RF بهتر عمل کرد اما منجر به چالش درک مدل شد. با انجام شاخص عملکرد ویژگی (PFI)، چهار پیشبینیکننده مهم ساکنان عبارت بودند از ( جدول ۳ ): سیستم قطار ، زیرساخت ، خرید و فرهنگ ، و روستایی .
بیشترین خطا مربوط به مرکز ایالت اشتوتگارت بود ( شکل ۳). در واقع، اشتوتگارت بخشی از دادههای آموزشی نبود و به دلیل اندازه بینظیر آن در مجموعه آموزشی، مقدار نرمال شده بیش از دو داشت. مدل DNN نتوانست اندازه فوقالعاده سرمایه را از دادههای آموزشی برونیابی کند. این مشکل نرمال سازی حداقل تا حداکثر است، که می تواند منجر به مقادیر داده های تست شود که در داده های آموزشی دیده نمی شوند. علاوه بر این، شهر کارلسروهه به عنوان یکی از بدترین پیشبینیها ظاهر شد، که دوباره مشکلاتی را که مدل در پیشبینی شهرهای نسبتاً بزرگ در مقایسه با اکثر شهرداریهای کوچکتر دارد، نشان میدهد. Mudau و Talheim به ترتیب با ۵۰۰۹ و ۴۸۳۰ سکنه کمترین خطا را به خود اختصاص دادند. میانگین تعداد ساکنان در تمام ۱۱۰۱ شهرداری بادن-وورتمبرگ ۱۰۰۵۴ است. از این رو، این مدل در اطراف میانه خوب عمل می کند و در پیش بینی نقاط پرت عملکرد کمتری دارد. مناطق بدون ارزش (NA) وضعیت اداری قانونی شهرداری را ندارند و به همین دلیل در آمارها لحاظ نمی شوند.
۳٫۳٫ پیش بینی کننده های بیکاری
میزان بیکاری به عنوان سهمی از کل جمعیت به ازای هر شهرداری در مقایسه با سایر شاخص های اقتصادی-اجتماعی دشوارترین پیش بینی بود. علاوه بر این، تفاوت زیادی بین DNN و RF وجود نداشت. در سراسر ایالت فدرال تقریباً اشتغال کامل وجود دارد، با قهرمانان پنهان بسیاری در حومه شهر. این موضوع بیکاری کمتر مناطق روستایی را در مقایسه با کلان شهرها توضیح می دهد ( شکل ۴ ).
PCA گردشگری بالاترین امتیاز PFI را به دست آورد و پس از آن مناظر طبیعی ، روستاهای تاریخی ، سیستم قطار و مراقبت های اجتماعی قرار دارند ( جدول ۴ ). از این رو، PCA هایی که نوع شناسی شهرداری را توصیف می کنند، غالب بودند. Schluchsee، واقع در جنگل سیاه، بالاترین خطا را در بین تمام شهرداری ها نشان داد.
پیش بینی بیکاری در شهرداری را بیش از حد برآورد کرد. دومین بالاترین MAE برای Heidenheim an der Brenz گزارش شد، جایی که بیکاری واقعی دست کم گرفته شد. جالب اینجاست که در مجاورت فضایی هایدنهایم، اولم کمترین خطا را داشت و پس از آن هوخدورف، هاوزرن و آلن قرار گرفتند.
۳٫۴٫ ویژگی های پیش بینی برای نسبت افراد مسن
نسبت افراد مسن در شهرداری کمی بهتر از بیکاری مدل سازی شد. باز هم، فقط یک تفاوت حاشیه ای بین RF و DNN وجود داشت، اگرچه هر دو برتر از مدل خطی بودند ( جدول ۲ ). در سراسر بادن-وورتمبرگ، هیچ الگوی روشنی بین مناطق روستایی و شهری وجود ندارد ( شکل ۵ ). در منطقه جنگل سیاه غربی، سهم افراد مسن نسبتاً زیاد است، در حالی که در شمال اشتوتگارت و در منطقه جنوب شرقی، سهم جمعیت جوانتر بیشتر است.
ویژگیهای فضایی مربوط به جمعیت مسنتر با بالاترین امتیاز PFI در دسته تفریحات طبیعت و پس از آن زیرساختها شامل جادهها و سایر عناصر زیرساخت قرار دارند ( جدول ۵ ). سومین بعد بالاترین امتیاز یکی دیگر از جنبه های بعدی با طبیعت است و پس از آن حومه شهر و خانه سالمندان قرار دارند .
در Untermarchtal، سهم افراد مسن بر اساس OSM کمتر برآورد شد که بالاترین MAE را داشتند. علاوه بر این، Steinheim am Albuch دومین بدترین نمرات پیش بینی را داشت، زیرا نسبت افراد مسن بیش از حد برآورد شده بود. در انتهای دیگر مقیاس Wittghausen و Kappelrodeck قرار دارند که خطا نزدیک به صفر است.
۳٫۵٫ ویژگی های فضایی تعادل مهاجرت
تعادل بین مهاجرت و مهاجرت و جذابیت فضایی کلی یک شهرداری سومین مدل برتر بود. رودخانه راین در زیر فرایبورگ پس از مناطق شهری اشتوتگارت و کارلسروهه منطقه بسیار جذابی است ( شکل ۶ ).
سیستم قطار دوباره برای مدل مهم است، همانطور که قبلاً در مدل برای ساکنان مشاهده شد. همانند مدل قبلی جمعیت سالمندان، ابعاد تفریحات طبیعت و زیرساخت از اهمیت جاودانی برخوردار است ( جدول ۶ ). پس از آن منطقه شهری و صنعتی قرار دارند . مشابه تعداد ساکنان، مدل در توضیح موارد پرت در این دسته، یعنی شهرهای اشتوتگارت و مانهایم، ناکام است. در مقابل، این مدل برای Schönaich و Oberderdingen عالی عمل می کند.
۴٫ بحث
توسعه شاخصهای اجتماعی-اقتصادی پویا برای اندازهگیری توسعه یا آسیبپذیری و توصیف پدیدههای پیچیده، علیرغم رشد کلی در دسترس بودن دادهها، همچنان یک چالش است. در این مطالعه، شاخصهای اقتصادی-اجتماعی برای ساکنان، بیکاری، سالمندان و مهاجرت به صورت مکانی از دادههای OSM با الگوریتمهای یادگیری ماشین پیشبینی میشوند.
۴٫۱٫ ساکنان
مدل DNN که بهترین عملکرد را برای همه گزینهها داشت، تعداد ساکنان را با عناصر ویژگی از دستههای سیستمهای قطار ، زیرساخت ، خرید ، و روستایی فرهنگی پیشبینی کرد.. اشتوتگارت، بزرگترین تراکم شهری در مجموعه داده، به اشتباه معرفی شد، که تلاش این مدل را برای متمایز کردن مقادیر پرت از مقادیر شدید نشان میدهد. این مشکل بازتولید مقادیر شدید با الگوریتم های یادگیری ماشین و نیاز به مجموعه داده های کامل را نشان می دهد. از آنجایی که این مدلها هرچه دادهها کاملتر باشند، تخمینهای قابلاعتمادتری تولید میکنند، زمانی که تشخیص نقاط پرت و تمایز از مقادیر شدید به دلیل شباهت در اعداد غیرقابل اعتماد باشد، نقاط ضعفی را برای مقادیر شدید در مجموعههای داده باریک نشان میدهند.
۴٫۲٫ بیکاری
با نگاه عمیقتر به مدلسازی نرخهای بیکاری، دیدیم که این مدل تا حد زیادی بیکاری را با گردشگری ، مناظر طبیعی و روستایی تاریخی توضیح میدهد . این نشان دهنده ارتباط مستقیم میراث طبیعی و فرهنگی با نرخ گردشگری و اشتغال در منطقه جنگل سیاه است. اگر از دارایی های فرهنگی و طبیعی محافظت نشود، می توان نشان داد که اثرات منفی زیادی بر نرخ اشتغال دارد.
با این حال، بیکاری برای کلان شهرها بیش از حد برآورد شده است. این را می توان با چندین واقعیت توضیح داد. اولاً، این مدل اشتغال را با میراث طبیعی و فرهنگی توضیح میدهد ، که تجمعات شهری را که در آن بازار کار نزدیک به اشتغال کامل است، بازتولید نمیکند. علاوه بر این، ویژگی خاص ایالت فدرال، یک اقتصاد بسیار غیرمتمرکز با قهرمانان پنهان در حومه شهر است که مشاغل عالی را در مناطق روستایی فراهم میکنند، اما همچنین در تلاش برای به دست آوردن کارمندان بسیار ماهر است. مطالعه در منطقه اشتوتگارت روندهای مشابهی را نشان داد [ ۱۸]. برای بررسی بیشتر و نه تنها پیشبینی بیکاری، عادیسازی دادهها نیاز به کاوش دارد، که مطابق با مطالعات قبلی برای تنظیم تنوع فضایی OSM در مشارکت است [ ۱۷ ، ۱۸ ]. علاوه بر این، آموزش مدل با مجموعه دادههای بزرگتر که شهرهای بزرگتر را در خود جای داده است، بنابراین توزیع ارزش شدید را تثبیت میکند، ممکن است این مشکل را برای الگوریتمهای یادگیری ماشین حل کند.
علاوه بر این، مدل خطاهایی را در پیشبینی بیکاری برای Schluchsee و Heidenheim an der Brenz نشان داد. شهرداری Schluchsee از تعداد زیادی گزینه های تفریحی در اطراف دریاچه سود می برد. انواع گزینه های تفریحی مانند پیاده روی، غواصی، قایقرانی و شنا و در زمستان، اسکی، آن را به یک مقصد گردشگری محبوب تبدیل می کند. بنابراین، عملکرد بهتر شهرداری نسبت به منطقه تا حدی بالاتر بودن MAE را توضیح می دهد. در هایدنهایم، بیکاری ۱۲٫۶ درصد در سال گذشته افزایش یافته است، که بسیار بیشتر از بقیه منطقه است [ ۴۲ ].
با این وجود، نقطه قوت عمده روش ارائه شده با نمایش این ارزیابی فضایی اتصالات آشکار می شود. با تمرکز بر تقطیر روابط متقابل بسیار پیچیده، تصمیم گیرندگان منطقه ای می توانند روابط پیچیده بین حفاظت از میراث فرهنگی و طبیعی و اشتغال در صنعت گردشگری را بر روی نقشه مشاهده کنند. این روش این پتانسیل را دارد که در تحقیقات بیشتر برای استخراج ارتباطات ناشناخته، ترکیبی از مدیریت منطقه ای هدف گرا با کنترل موفقیت، توسعه یابد.
۴٫۳٫ مسن
برای افراد مسن، مدل DNN به شدت بر متغیرهای مرتبط با طبیعت و امکانات مراقبت تمرکز دارد. با نگاه عمیق تر به سومین شاخص سالمندان، عملکرد مدل شهرداری Untermarchtal برجسته می شود. با توجه به موقعیت منحصر به فرد Untermarchtal، با صومعه فعال خود، شامل یک خانه مراقبت ویژه و تنها ۸۹۳ نفر، این مدل نسبت بالای افراد مسن را دست کم می گیرد. مشابه یافتههای [ ۲۲ ]، مکانهای روستایی را میتوان تحت سلطه یک بازیگر اقتصادی واحد قرار داد، و این وضعیت به خوبی توسط مدلها نشان داده نمیشود. همچنین غربالگری شهرداریهایی با MAE بسیار پایین، مانند شونایخ، اوبردردینگن، ویتیهاوزن، و کاپلرودک، که به دلیل مقادیر متوسط به خوبی نشان داده شدهاند، میتواند مفید باشد.
جالب اینجاست که سومین متغیر توضیحی تحرک بود. در رابطه با سالمندان به حمل و نقل عمومی، قدرت روش ارائه شده در اینجا قابل مشاهده است. در مجموعه داده های OSM، اطلاعات مربوط به زیرساخت، طبیعت، و میراث فرهنگی، اما همچنین تحرک و اتصال را می توان به صورت عمیق ارزیابی کرد و دانشی در مورد روابط و ارتباطات جدید با الگوریتم های یادگیری ماشین به دست آورد. این مطالعه منجر به اطلاعات فضایی در مورد وابستگی سالمندان به حمل و نقل عمومی قابل اعتماد می شود. به این ترتیب، در ترکیب با تغییرات جمعیتی در حال انجام، یک تصمیم گیرنده اکنون این امکان را خواهد داشت که تقاضای آینده برای نیازهای ظرفیت تحرک را ارزیابی کند و توسعه حمل و نقل عمومی خاص برای سالمندان را با توجه به توزیع فضایی مقطر هدف قرار دهد.
۴٫۴٫ مهاجرت
علاوه بر بعد مقطعی، هر شاخص با ابعاد صریح مشخص می شود. مهاجرت را می توان با زیرساخت ، اقتصادی ، ارائه خدمات و ویژگی های طبیعی توصیف کرد .
مطابق با ساکنان و بیکاری، مدل DNN همچنین برای پیشبینی مقادیر شدید برای تعادل مهاجرت تلاش کرد. مشکل در مواردی تشدید میشد که مقادیر شدید بخشی از دادههای آزمایش بودند. برای پیشبینی تعادل مهاجرت، دو شهر بزرگ بادن-وورتمبرگ، اشتوتگارت و کارلسروهه، به خوبی بازتولید نشدند.
۴٫۵٫ مقایسه مدل
هنگام تعمیق تجزیه و تحلیل عملکردهای مدل های مختلف، دیدیم که DNN قابل اطمینان ترین عملکرد را دارد. دو MAE الگوریتم یادگیری ماشین بسیار به یکدیگر نزدیکتر بودند. با این حال، DNN در هر چهار مورد بهتر یا برابر با RF بود. این مطابق با تحقیقات فعلی است، زیرا شبکه های عصبی عمیق در مطالعات قبلی از بسیاری از مدل ها بهتر عمل کرده اند [ ۴۳ ، ۴۴ ، ۴۵ ، ۴۶ ، ۴۷ ، ۴۸ ، ۴۹٫]. علیرغم عملکرد کمی بدتر RF، شایان ذکر است که DNN به پیکربندی مدل قابل توجهی نیاز داشت، بدون آن عملکرد بسیار بدتری نسبت به هر دو روش دیگر داشت. علاوه بر این، RF برای برقراری ارتباط و درک آسان تر است. اهمیت ویژگی RF در این رویکرد پیاده سازی شد. در اینجا، DNN اغلب به عنوان یک جعبه سیاه دیده می شود که درک عوامل محرک را دشوار می کند [ ۴۹]. علاوه بر این، ثابت شد که RF قوی تر است و اجرای آن بسیار آسان تر است. بدون آموزش گسترده، ما میتوانیم بدتر شدن عملکرد مدل DNN را مشاهده کنیم، زیرا حساسیت به انتخاب دادههای آموزش و آزمون آشکار شد. RF در مقایسه با نمونهگیری تصادفی، نتایج قوی و حساستری تولید کرد. نیازهای محاسباتی برای RF نیز بسیار کمتر از DNN بود. از این رو، در مواردی که حداکثر عملکرد مدل مورد نیاز است، DNN مدل انتخابی است، در حالی که برای داده کاوی و درک، RF اغلب به نظر می رسد که عملکرد بسیار خوبی دارد.
به ترتیب فزاینده، با شروع با کمترین MAE DNN، جمعیت شاخص به بهترین وجه پیش بینی شد و پس از آن مهاجرت، افراد مسن و بیکاری. اگرچه DNN قدرت پیشبینی برتری داشت، اما این مدل در مقادیر پرت و در مقادیر شدید عملکرد بدی داشت. این امر به ویژه هنگام بازتولید تعداد ساکنان در مقیاس منطقه ای قابل مشاهده است، زیرا برآوردها برای ساکنان شهرهای بزرگتر بدتر بود. این امر عمدتاً در مورد اشتوتگارت و کارلسروهه بود. با این حال، این ممکن است با تعمیق تحقیق با مجموعه دادههای بزرگتر که شهرهای بزرگتر را در خود جای داده است، حل شود، به طوری که توزیع ارزش شدید تثبیت شود و تخمینهای قابل اعتمادتری تولید کند.
۴٫۶٫ چالش ها
بخش مهمی از شاخصهای اقتصادی-اجتماعی، قدرت توضیحی آنها در مورد پدیدههای غیرعادی یا در موقعیتهای شدید است. یادگیری ماشین، و به ویژه DNN، اغلب به عنوان یک جعبه سیاه دیده می شود که پذیرش و کاربرد آن را محدود می کند [ ۵۰ ]. با این وجود، PFI روشی بسیار فشرده برای تفسیر اهمیت ویژگی جهانی است. از آنجایی که رویکرد به خطای مدل مرتبط است، انجام آن تنها با دسترسی به نتیجه امکان پذیر است و نه برای ارزیابی یک مدل مستقل [ ۵۱] .]. با کنار گذاشتن متغیرهای توضیحی مختلف، ارزیابی سهم آنها در نتیجه کلی، پیوندهای متقابل شاخصهای اجتماعی و ویژگیهای فضایی را تقطیر میکند، که در درک مسائل توسعه منطقهای کلیدی است و به تصمیمگیری هدفمحور کمک میکند.
علاوه بر این، یکی از چالشهای اصلی که در همه شاخصها مطرح میشد، نمایش مقادیر افراطی بود. به این ترتیب، میتوان در این مطالعه نشان داد که نمایش توزیع ارزش افراطی، همانطور که در هر تلاش مدلسازی وجود دارد، یک نقص عمده در روششناسی است. این یک مشکل درهم تنیده در دسترس بودن مجموعه داده های گسترده برای آموزش مدل، فرآیند پیچیده تمایز بین مقادیر پرت و شدید، و آموزش همزمان مدل ها برای نمایش توزیع های نرمال و توزیع های ارزش شدید است.
یک محدودیت مشترک مهم دادههای OSM، سهم نامتعادل فضایی و از این رو، تغییرات در پوشش مکانی و تراکم اطلاعات، بهویژه در سطح جهانی است. آلمان، و به ویژه منطقه مورد مطالعه انتخاب شده، در میان مناطقی است که تعداد مشارکت کنندگان نسبتاً بالایی دارد و پوشش اطلاعاتی بالایی دارد، به عنوان مثال، با شاخص کامل بالای ۵۰ درصد در سال ۲۰۱۶ برای آلمان [۵۲ ] . با این وجود، کامل بودن در داخل کشور هنوز تفاوتی را بین مناطق روستایی و مناطق شهری از نظر پوشش و کیفیت داده ها نشان می دهد [ ۵۳ ، ۵۴]، که می تواند قدرت توضیحی نتایج مدل را در این مطالعه محدود کند. بنابراین، جالب است که ببینیم آیا میتوان آستانههای خاصی را برای مناطقی با پوشش پایینتر ایجاد کرد یا اینکه عدم وجود دادههای OSM میتواند در این زمینه به عنوان پیشبینیکننده استفاده شود. نقص دیگر این است که مدیریت روش کاربر پسند نیست. استفاده از تکنیکهای یادگیری ماشینی دشوار است و به مجموعه مهارتهای آماری و تحلیلی نیاز دارد. علاوه بر این، مدیریت ساختار داده OSM در مدل چندان شهودی نیست که در مجموع، استفاده از رویکرد را برای تصمیم گیرندگان دشوار می کند. با این وجود، ما موفق شدهایم نشان دهیم که مجموعه دادههای OSM حاوی مقدار زیادی دانش در مورد واقعیتهای اقتصادی-اجتماعی هستند و این اطلاعات را میتوان با یادگیری ماشین استخراج کرد.
۴٫۷٫ تحقیقات آینده
پس از آزمایش روش در منطقه کوچک مقیاس اشتوتگارت، ما این رویکرد را بیشتر توسعه دادیم. به عنوان مصالحه بین منابع محاسباتی، مدیریت داده ها و پیچیدگی مدل، مقیاس منطقه ای انتخاب شد. در تحقیقات بیشتر، پتانسیل در مقیاس جهانی و قابلیت انتقال مدلها بین مناطق باید ارزیابی شود، با توجه به تأثیر بالقوه بالای نتایج به دلیل سطوح مختلف کامل بودن دادههای OSM و/یا استفاده از دستورالعملهای مختلف برچسبگذاری (محلی). در راستای یک مجموعه داده بزرگتر، باید بر در نظر گرفتن بهتر مقادیر شدید تأکید شود. اغلب تصمیم گیرندگان عمدتاً به موارد خاص، یعنی ارزش های افراطی علاقه مند هستند. تلاشهای بیشتری برای ارائه پاسخهای پایدار به این سؤالات پیچیده در انتهای بیرونی مجموعه داده مورد نیاز است.
۵٫ نتیجه گیری ها
زندگی در جهانی در هم تنیده جهانی، به ندرت مشکلی محدود به یک نقطه خاص در مکان و زمان می شود. به این ترتیب، چالشهای بزرگ تغییرات جهانی و متعاقباً انعطافپذیری، آسیبپذیری و پایداری که با آن مواجه هستیم، ثابت نیستند.
در این پرتو، ابتدا درک و بعداً پایش پدیدههای چند وجهی نیازمند یک منبع بینرشتهای جهانی از دادهها است. OSM یک منبع ارزشمند داده است و یادگیری ماشین ابزار استنباط شاخص های بین رشته ای را فراهم می کند. OSM تجلی فیزیکی فعالیتهای انسانی را مستند میکند و این دادهها را میتوان برای انجام تحلیلهای اجتماعی-اقتصادی با استفاده از یادگیری ماشین استفاده کرد. شبکه های عصبی از نظر عملکرد مدل در مقایسه با جنگل تصادفی موفق بوده اند. در اینجا ما جذابیت این پتانسیل بکر برای تولید دانش را با ترکیب الگوریتمهای یادگیری ماشینی و عمیق با OSM برای توسعه شاخصهای اجتماعی-اقتصادی نشان دادهایم. این ارزیابی بینشهای دلگرمکنندهای در مورد تجلی ویژگیهای اجتماعی-اقتصادی در دادههای OSM ارائه کرد.
برای بهرهبرداری کامل از فرصتهای OSM از نظر پوشش فضایی، رایانههای شخصی به محدودیتهای خود در بحث دادهها دست مییابند. کاوش بیشتر در زمینه پیشبینیکنندههای جهانی و قابلیت انتقال مدلها در مناطق یا کشورها مورد نیاز است. تحلیلهای زمانی اضافی ممکن است عملکرد مدلها و قدرت پیشبینی آنها را بیشتر بهبود بخشد و به استنباط مرتبطترین پیشبینیکنندهها کمک کند.
ضمیمه A. برچسب های مرتبط با پیش بینی
| پیشگو | برچسب ها (بیشترین بارگیری) |
| تفریح در طبیعت | کاربری_جنگل; مسیر_با دوچرخه; operator_بادن-وورتمبرگ |
| زیر ساخت | سیگنال های_ترافیک بزرگراه; مسیر_قطار; بزرگراه_تقاطع_راه آهن_راه آهن |
| سیستم قطار | مسیر_مسیر؛ راه آهن_راه آهن; operator_DB Netz; مسیر_راه آهن |
| مناظر طبیعی | دیدگاه_گردشگری; عرض_۱; مرز_طبیعی; رشته_کوه_طبیعی; غذا_بله |
| گردشگری | فروشگاه_کتاب; موزه_گردشگری; قلعه_تاریخی; هتل_گردشگری |
| شهر بزرگ | مسیر_اتوبوس; یک طرفه_بله; بزرگراه_نقطه عطف |
| حومه شهر | ساختمان_گاراژ; route_power; زمین_تفریح_زمین; آبراه_زهکشی; خط قدرت |
| طبیعت | رشته_کوه_طبیعی; مکان_منطقه; مرز_طبیعی; مسیر_اسکی; سبد_پسماندهای رفاهی |
| روستایی تاریخی | بزرگراه_خیابان_زنده; تاریخی_باستان شناسی; پل_ساخته_آدمی; operator_DHL |
| صنعتی | کاربری_صنعتی; sport_multi; سطح_شن; پیست تفریحی |
| روستایی | کابل برق؛ مکان_هملت; دوچرخه_استفاده_مسیر کناری; ساختمان_عمومی |
| مراقبت اجتماعی | ساختمان_مهدکودک; آسایشگاه_سالمندان; پیست تفریحی; |
| خانه سالمندان | آسایشگاه_سالمندان عرض_۱۰; فرقه_جدید_حواری |
| خرید و فرهنگ | فروشگاه_اغذیه فروشی; مرکز_هنرهای_آرامش; فروشگاه_نوشیدنی |
منابع
- اندازه گیری آسیب پذیری در برابر خطرات طبیعی. به سوی جوامع مقاوم در برابر بلایا ، ویرایش دوم؛ Birkmann, J., Ed. انتشارات دانشگاه ملل متحد: توکیو، ژاپن؛ نیویورک، نیویورک، ایالات متحده آمریکا، ۲۰۱۳; ISBN 9789280871715. [ Google Scholar ]
- سورگ، ال. مدینه، ن. فلدمایر، دی. سانچز، آ. ووینوویچ، ز. بیرکمن، جی. مارچیز، الف. کشف پدیده های چند وجهی آسیب پذیری اجتماعی-اقتصادی. نات. خطرات ۲۰۱۸ ، ۹۲ ، ۲۵۷-۲۸۲٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- جمشد، ع. رعنا، IA; میرزا، ام. Birkmann, J. ارزیابی رابطه بین آسیب پذیری و ظرفیت: یک مطالعه تجربی در مورد سیل روستایی در پاکستان. بین المللی J. کاهش خطر بلایا. ۲۰۱۹ ، ۳۶ ، ۱۰۱۱۰۹٫ [ Google Scholar ] [ CrossRef ]
- کاتر، SL; Finch, C. تغییرات زمانی و مکانی در آسیب پذیری اجتماعی در برابر مخاطرات طبیعی. Proc. Natl. آکادمی علمی ایالات متحده آمریکا ۲۰۰۸ ، ۱۰۵ ، ۲۳۰۱-۲۳۰۶٫ [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- کوتسف، آ. مینگینی، ام. توماس، آر. سیتل، وی. لوتز، ام. از زیرساختهای دادههای مکانی تا فضاهای داده – چشمانداز فناوری در مورد تکامل SDI اروپا. ISPRS Int. J. Geo-Inf. ۲۰۲۰ ، ۹ ، ۱۷۶٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- فلدمایر، دی. وایلدن، دی. مهربان، سی. قیصر، تی. گلداشمیت، آر. دیلر، سی. Birkmann, J. Indicators for Monitoring Urban Climate Change Resilience and Adaptation. پایداری ۲۰۱۹ ، ۱۱ ، ۲۹۳۱٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- شفر، م. Thinh، NX; گریوینگ، اس. چگونه می توان انعطاف پذیری آب و هوا را اندازه گیری و تجسم کرد؟ ارزیابی یک مفهوم مبهم با استفاده از منطق فازی مبتنی بر GIS. پایداری ۲۰۲۰ ، ۱۲ ، ۶۳۵٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- لایننکوگل، پ. دک، آر. هوث، جی. اوتینگر، ام. Mack, B. پتانسیل ژئوداده باز برای طبقه بندی خودکار زمین در مقیاس بزرگ و طبقه بندی پوشش زمین. Remote Sens. ۲۰۱۹ , ۱۱ , ۲۲۴۹٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- میشا، NB; خدمه، KA نقشه برداری انواع مورفولوژی پوشش گیاهی در اکوسیستم ساوانای خشک: ادغام تجزیه و تحلیل تصویر مبتنی بر شی سلسله مراتبی با جنگل تصادفی. بین المللی J. Remote Sens. ۲۰۱۴ ، ۳۵ ، ۱۱۷۵-۱۱۹۸٫ [ Google Scholar ] [ CrossRef ]
- بلومدال، EM; تامپسون، سی ام. کین، جی آر. ون کین، آر. چرچیل، دی. Moskal, LM; Lutz، JA ساختار جنگلی پیشبینیکننده لانههای ماهیگیر ( Pekania pennanti ) در جنگل اخیراً سوخته در یوسمیت، کالیفرنیا، ایالات متحده وجود دارد. برای. Ecol. مدیریت ۲۰۱۹ ، ۴۴۴ ، ۱۷۴-۱۸۶٫ [ Google Scholar ] [ CrossRef ]
- هوت، سی. Waldhoff، G. رویکرد چند داده ای برای طبقه بندی محصولات با استفاده از داده های چند زمانی، دو قطبی TerraSAR-X و داده های جغرافیایی رسمی. یورو J. Remote Sens. ۲۰۱۸ ، ۵۱ ، ۶۲-۷۴٫ [ Google Scholar ] [ CrossRef ]
- دیویل، پی. لینارد، سی. مارتین، اس. گیلبرت، ام. استیونز، FR; Gaughan، AE; بلوندل، وی دی. Tatem، AJ نقشه برداری پویا جمعیت با استفاده از داده های تلفن همراه. Proc. Natl. آکادمی علمی ایالات متحده آمریکا ۲۰۱۴ ، ۱۱۱ ، ۱۵۸۸۸-۱۵۸۹۳٫ [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- شیخیان، ح. دلاور، م.ر. استین، A. ارزیابی آسیبپذیری لرزهای چند معیاره مبتنی بر GIS با استفاده از ادغام استخراج قانون محاسبات دانهای و شبکههای عصبی مصنوعی. ترانس. GIS ۲۰۱۷ ، ۲۱ ، ۱۲۳۷-۱۲۵۹٫ [ Google Scholar ] [ CrossRef ]
- Wlodarczyk-Sielicka، M. Lubczonek، J. استفاده از یک شبکه عصبی مصنوعی برای پردازش دادههای بزرگ هیدروگرافی در طول مدلسازی سطح. کامپیوترها ۲۰۱۹ ، ۸ ، ۲۶٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- کیم، دی.-ای. گوربسویل، پی. لیونگ، اس.-ای. غلبه بر کمبود داده در ارزیابی خطر سیل با استفاده از سنجش از دور و شبکه عصبی مصنوعی Smart Water ۲۰۱۹ ، ۴ ، ۱۸۳٫ [ Google Scholar ] [ CrossRef ]
- سیلیس، جی. Lay-Ekuakille، A. تلسکا، وی. Statuto، D.; Picuno، P. تجزیه و تحلیل تکامل یک منظر روستایی با ترکیب SAR Geodata با تکنیک های GIS. در مهندسی بیوسیستم های نوآورانه برای کشاورزی پایدار، جنگلداری و تولید مواد غذایی ؛ کاپولا، آ.، دی رنزو، جی سی، آلتیری، جی.، دی آنتونیو، پی.، ویرایش. Springer International Publishing: بازل، سوئیس، ۲۰۲۰؛ صص ۲۵۵-۲۶۳٫ شابک ۹۷۸-۳-۰۳۰-۳۹۲۹۸-۷٫ [ Google Scholar ]
- فلدمایر، دی. ساتر، اچ. Birkmann, J. یک شاخص ریسک باز با شاخصهای یادگیری از برچسبهای OSM، که توسط یادگیری ماشینی توسعه یافته و با WorldRiskIndex آموزش دیده است. بین المللی قوس. فتوگرام حسگر از راه دور اسپات. Inf. علمی ۲۰۱۹ ، XLII-4/W14 ، ۳۷–۴۴٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ساتر، اچ. فلدمایر، دی. Birkmann, J. مطالعه اکتشافی تاب آوری شهری در منطقه اشتوتگارت بر اساس OpenStreetMap و شاخص های تاب آوری ادبیات. بین المللی قوس. فتوگرام حسگر از راه دور اسپات. Inf. علمی ۲۰۱۹ ، XLII-4/W14 ، ۲۱۳–۲۲۰٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- آمار Bundesamt Bevölkerungsdichte (Einwohner je km²) در Deutschland Nach Bundesländern zum 31 دسامبر ۲۰۱۸٫ موجود به صورت آنلاین : https://de.statista.com/statistik/daten/studie/1242/umfrage/bevoelkerungsdichte-in-deutschdesschlander-n در ۵ اکتبر ۲۰۱۹).
- GfK. Kaufkraft Je Einwohner Nach Bundesländern Im Jahr 2019 Laut GfK-Kaufkraftstudie. در دسترس آنلاین: https://de.statista.com/statistik/daten/studie/168591/umfrage/kaufkraft-nach-bundeslaendern/ (دسترسی در ۴ دسامبر ۲۰۱۹).
- Bundesagentur für Arbeit. نقل قول Monatliche Arbeitslosen in Baden-Württemberg von November 2018 bis November 2019. موجود به صورت آنلاین: https://de.statista.com/statistik/daten/studie/155318/umfrage/arbeitslosenquote-in-baden-wuerttemberg/19 دسامبر (دسترسی به ۱۹ دسامبر ۲۰) ).
- Statistisches Landesamt. بادن-وورتمبرگ: Bevölkerung im Schnitt 43,5 Jahre alt: Jüngste Einwohner در Riedhausen (Landkreis Ravensburg)، älteste در Ibach (Landkreis Waldshut). در دسترس آنلاین: https://www.statistik-bw.de/Presse/Pressemitteilungen/2019211 (در ۴ دسامبر ۲۰۱۹ قابل دسترسی است).
- Statistisches Landesamt. ۲۹۴۰۰۰ Hochbetagte در Baden-Württemberg Zahl Der 85-Jährigen Und Älteren Hat Sich Seit 1970 Versechsfacht–Baden-Baden Mit Höchstem Anteil an Der Bevölkerung. در دسترس آنلاین: https://www.statistik-bw.de/Presse/Pressemitteilungen/2019254 (در ۲ اکتبر ۲۰۱۹ قابل دسترسی است).
- کاتر، SL; برتون، سی جی; شاخصهای مقاومت در برابر بلایای Emrich، CT برای محک زدن شرایط پایه. جی. هومل. امن ظهور. مدیریت ۲۰۱۰ ، ۷ . [ Google Scholar ] [ CrossRef ]
- کاتر، SL چشم انداز شاخص های انعطاف پذیری در برابر بلایا در ایالات متحده آمریکا. نات. خطرات ۲۰۱۵ ، ۸۰ ، ۷۴۱-۷۵۸٫ [ Google Scholar ] [ CrossRef ]
- سازمان ملل متحد چارچوب شاخص جهانی برای اهداف توسعه پایدار و اهداف دستور کار ۲۰۳۰ برای توسعه پایدار: شاخصهای هدف توسعه پایدار باید تفکیک شوند، در مواردی که مرتبط هستند، بر اساس درآمد، جنسیت، سن، نژاد، قومیت، وضعیت مهاجرت، معلولیت و موقعیت جغرافیایی، یا سایر ویژگیها ، مطابق با اصول بنیادی آمار رسمی. در دسترس به صورت آنلاین: https://unstats.un.org/sdgs/indicators/Global%20Indicator%20Framework%20after%202019%20refinement_Eng.pdf (در ۴ دسامبر ۲۰۱۹ قابل دسترسی است).
- مشارکت کنندگان OpenStreetMap. تخلیه سیاره. در دسترس آنلاین: https://www.openstreetmap.org (در ۲ اکتبر ۲۰۱۹ قابل دسترسی است).
- OpenStreetMap-Deutschland. سؤالات متداول: آیا OpenStreetMap بود؟ در دسترس آنلاین: https://www.openstreetmap.de/faq.html#was_ist_osm (در ۹ آوریل ۲۰۲۰ قابل دسترسی است).
- نقشه خیابان باز آمار در دسترس آنلاین: https://wiki.openstreetmap.org/wiki/Stats (در ۹ آوریل ۲۰۲۰ قابل دسترسی است).
- RStudio: توسعه یکپارچه برای R [نرم افزار کامپیوتری] ; RStudio, Inc.: Boston, MA, USA, 2016; در دسترس آنلاین: http://www.rstudio.com/ (در ۱۷ آوریل ۲۰۲۰ قابل دسترسی است).
- تیم اصلی R. زبان و محیطی برای محاسبات آماری ; بنیاد R برای محاسبات آماری: وین، اتریش، ۲۰۱۹؛ ISBN 9783900051075. [ Google Scholar ]
- ویکهام، اچ. Henry, L. Tidyr: Tidy Messy Data. بسته R نسخه ۱٫۰٫۰٫ در دسترس آنلاین: https://CRAN.R-project.org/package=tidyr (در ۵ نوامبر ۲۰۱۹ قابل دسترسی است).
- ویکهام، اچ. فرانسوا، آر. هنری، ال. مولر، ک. RStudio. Dplyr: گرامر دستکاری داده ها. بسته R نسخه ۱٫۰٫۲٫ در دسترس آنلاین: https://CRAN.R-project.org/package=dplyr (در ۵ نوامبر ۲۰۱۹ قابل دسترسی است).
- ویکهام، اچ. اوم، جی. مولر، ک. RStudio; کنسرسیوم R; Tomoaki، N. RPostgres ‘Rcpp’ Interface به ‘PostgreSQL’. بسته R نسخه ۱٫۲٫۰٫ در دسترس آنلاین: https://CRAN.R-project.org/package=RPostgres (در ۵ نوامبر ۲۰۱۹ قابل دسترسی است).
- ویکهام، اچ. تغییر شکل داده با بسته تغییر شکل. J. Stat. نرم افزار ۲۰۰۷ ، ۲۱ ، ۱-۲۰٫ [ Google Scholar ] [ CrossRef ]
- ویکهام، اچ. Bryan, J. Readxl: خواندن فایل های اکسل. بسته R نسخه ۱٫۳٫۱٫ در دسترس آنلاین: https://CRAN.R-project.org/package=readxl (در ۵ نوامبر ۲۰۱۹ قابل دسترسی است).
- کوهن، م. وینگ، جی. وستون، اس. ویلیامز، ای. کیفر، ا. انگلهارت، آ. کوپر، تی. مایر، ز. کنکل، بی. تیم اصلی R; و همکاران Caret: طبقه بندی و آموزش رگرسیون. بسته R نسخه ۶٫۰-۸۶٫ در دسترس آنلاین: https://CRAN.R-project.org/package=caret (در ۵ نوامبر ۲۰۱۹ قابل دسترسی است).
- لیاو، ا. وینر، ام. جنگل تصادفی: جنگل های تصادفی بریمن و کاتلر برای طبقه بندی و رگرسیون. بسته R نسخه ۴٫۶-۱۴٫ در دسترس آنلاین: https://CRAN.R-project.org/package=randomForest (در ۵ نوامبر ۲۰۱۹ قابل دسترسی است).
- آلر، جی جی. Chollet، F. Keras: R رابط به “Keras”. بسته R نسخه ۲٫۳٫۰٫۰٫ در دسترس آنلاین: https://CRAN.R-project.org/package=keras (در ۵ نوامبر ۲۰۱۹ قابل دسترسی است).
- بریمن، ال. جنگل های تصادفی. ماخ فرا گرفتن. ۲۰۰۱ ، ۴۵ ، ۵-۳۲٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- فیشر، ا. رودین، سی. Dominici، F. همه مدل ها اشتباه هستند، اما بسیاری از آنها مفید هستند: یادگیری اهمیت یک متغیر با مطالعه یک کلاس کامل از مدل های پیش بینی به طور همزمان. جی. ماخ. فرا گرفتن. Res. ۲۰۱۹ ، ۲۰ ، ۱-۸۱٫ [ Google Scholar ]
- Swp. Arbeitslose در استوورتمبرگ. در دسترس آنلاین: https://www.swp.de/suedwesten/staedte/gaildorf/ostwuerttemberg-arbeitslose-arbeitsmarkt-agenturfuerarbeit-statistik-38704793.html (در ۱۲ نوامبر ۲۰۱۹ قابل دسترسی است).
- میگل-هورتادو، او. مهمان، ر. استیونیج، اس وی؛ نیل، جی جی; Black, S. مقایسه طبقهبندیکنندههای یادگیری ماشین و رگرسیون خطی/لجستیک برای بررسی رابطه بین ابعاد دست و ویژگیهای جمعیتی. PLoS ONE ۲۰۱۶ , ۱۱ , e0165521. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- بلژیک، م. Drăguţ، L. جنگل تصادفی در سنجش از دور: بررسی برنامهها و جهتهای آینده. ISPRS J. Photogramm. Remote Sens. ۲۰۱۶ ، ۱۱۴ ، ۲۴–۳۱٫ [ Google Scholar ] [ CrossRef ]
- Berk, R. ارزیابی خطر یادگیری ماشین در تنظیمات عدالت کیفری . انتشارات بین المللی Springer: چم، سوئیس، ۲۰۱۹; ISBN 9783030022730. [ Google Scholar ]
- ویتن، آی اچ. فرانک، ای. هال، MA; پال، سی جی داده کاوی. In Practical Machine Learning Tools and Techniques , ۴th ed.; Morgan Kaufmann ناشر: Cambridge, MA, USA, 2017; شابک ۹۷۸-۰-۱۲-۳۷۴۸۵۶-۰٫ [ Google Scholar ]
- ای سوزا، LR; میراندا، تی. E Sousa، RL; Tinoco, J. استفاده از تکنیک های داده کاوی در ارزیابی ریسک Rockburst. مهندسی ۲۰۱۷ ، ۳ ، ۵۵۲-۵۵۸٫ [ Google Scholar ] [ CrossRef ]
- خو، پی. شی، س. چو، ایکس. ارزیابی عملکرد ابزارهای یادگیری عمیق در کانتینرهای داکر. در مجموعه مقالات سومین کنفرانس بین المللی ۲۰۱۷، چنگدو، چین، ۱۰ تا ۱۱ اوت ۲۰۱۷؛ صص ۳۹۵-۴۰۳٫ [ Google Scholar ]
- انگچوان، دبلیو. دیموپولوس، AC; تیروولاس، اس. کابالرو، FF; سانچز-نیوبو، آ. آرنت، اچ. آیوسو متئوس، جی ال. هارو، جی.ام. چاترجی، س. Panagiotakos، DB شاخصهای اجتماعی جمعیتشناختی وضعیت سلامت با استفاده از رویکرد یادگیری ماشینی و دادههای حاصل از مطالعه انگلیسی طولی پیری (ELSA). پزشکی علمی نظارت کنید. ۲۰۱۹ ، ۲۵ ، ۱۹۹۴–۲۰۰۱٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Ribeiro, M. تجسم مدل های ML با LIME. در دسترس آنلاین: https://uc-r.github.io/lime (در ۴ دسامبر ۲۰۱۹ قابل دسترسی است).
- Fioruzi، HO اجرای سرتاسری یادگیری عمیق در R با استفاده از Keras. در دسترس آنلاین: https://rstudio-pubs-static.s3.amazonaws.com/452498_2bb5b64288b94710a86982c3f70bb483.html#4_model_interpretabilitydiagnosis (در ۵ نوامبر ۲۰۱۹ قابل دسترسی است).
- ارسنجانی، ج. Fonte, C. در مورد کمک اطلاعات جغرافیایی داوطلبانه به تلاشهای نظارت بر زمین. در کتاب راهنمای اروپایی اطلاعات جغرافیایی جمعسپاری شده ; Capineri, C., Haklay, M., Huang, H., Antoniou, V., Kettunen, J., Ostermann, F., Purves, R., Eds. Ubiquity Press: لندن، انگلستان، ۲۰۱۶; ص ۲۶۹-۲۸۴٫ در دسترس آنلاین: www.jstor.org/stable/j.ctv3t5r09.24 (در ۱۷ آوریل ۲۰۲۰ قابل دسترسی است).
- زیلسترا، دی. Zipf، A. مطالعه مقایسه ای داده های جغرافیایی اختصاصی و اطلاعات جغرافیایی داوطلبانه برای آلمان. در مجموعه مقالات سیزدهمین کنفرانس بین المللی AGILE در علم اطلاعات جغرافیایی، گیماراس، پرتغال، ۱۱-۱۴ مه ۲۰۱۰٫ [ Google Scholar ]
- Haklay, M. اطلاعات جغرافیایی داوطلبانه چقدر خوب است؟ مطالعه تطبیقی مجموعه داده های نظرسنجی OpenStreetMap و مهمات. محیط زیست طرح. B طرح. دس ۲۰۱۰ ، ۳۷ ، ۶۸۲-۷۰۳٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
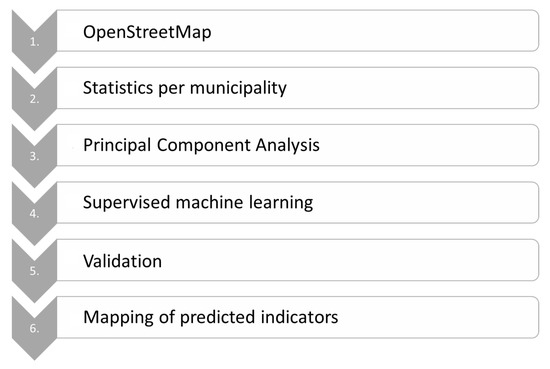
شکل ۱٫ گردش کار کلی تجزیه و تحلیل انجام شده.
شکل ۲٫ نقشه منطقه مورد مطالعه.
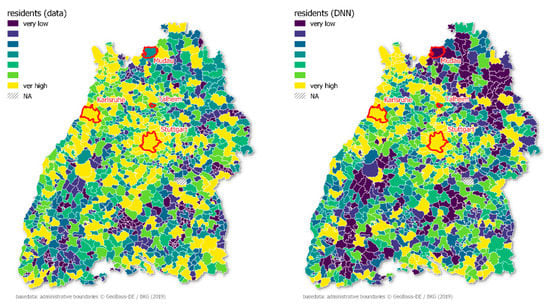
شکل ۳٫ نقشه مقادیر عادی ساکن ( سمت چپ ) و مقادیر پیش بینی شده ( راست ) شهرداری های بادن-وورتمبرگ را نشان می دهد.
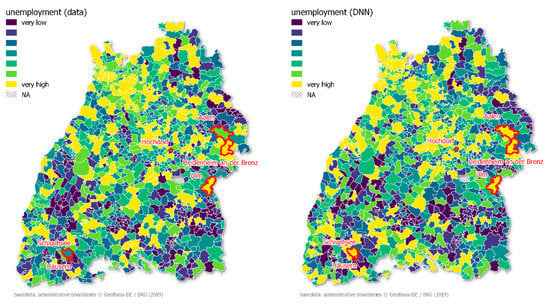
شکل ۴٫ نقشه ای که مقادیر عادی بیکاری ( چپ ) و مقادیر پیش بینی شده ( راست ) شهرداری های بادن-وورتمبرگ را نشان می دهد.

شکل ۵٫ نقشه نسبت نرمال شده افراد مسن ( چپ ) و مقادیر پیش بینی شده ( راست ) شهرداری های بادن-وورتمبرگ را نشان می دهد.
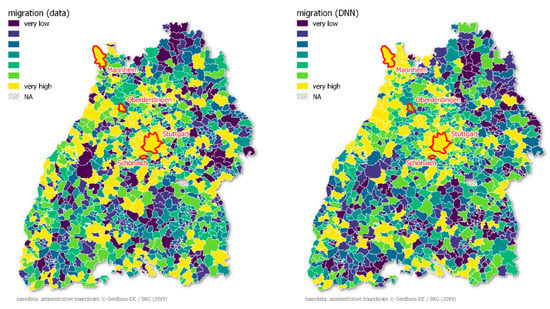
شکل ۶٫ نقشه تعادل مهاجرت عادی شده ( سمت چپ ) و مقادیر پیش بینی شده ( راست ) شهرداری های بادن-وورتمبرگ را نشان می دهد.


بدون دیدگاه