
خلاصه
کلید واژه ها:
OpenStreetMap ; نقشه برداری LULC ; کیفیت داده ها ؛ ارزیابی کیفیت ذاتی ; کامل بودن ؛ تنوع
۱٫ معرفی
- (۱)
-
ارزیابی کیفیت ذاتی یک مجموعه داده LULC مبتنی بر OSM انجام شده است. در مقابل، بیشتر مطالعات گذشته از مجموعه داده مرجع LULC برای ارزیابی کیفیت استفاده کردهاند. روش تحلیلی ما را می توان برای مناطق دیگر، به ویژه مناطقی که مجموعه داده مرجع LULC رایگان برای آنها در دسترس نیست، اعمال کرد.
- (۲)
-
هم کامل بودن و هم الگوهای تنوع کل یک کشور (چین) نقشه برداری و تجزیه و تحلیل شد، و نتایج نشان می دهد که معیار تنوع ممکن است به عنوان مکملی برای ارزیابی کیفیت ذاتی استفاده شود.
۲٫ منطقه مطالعه و داده ها
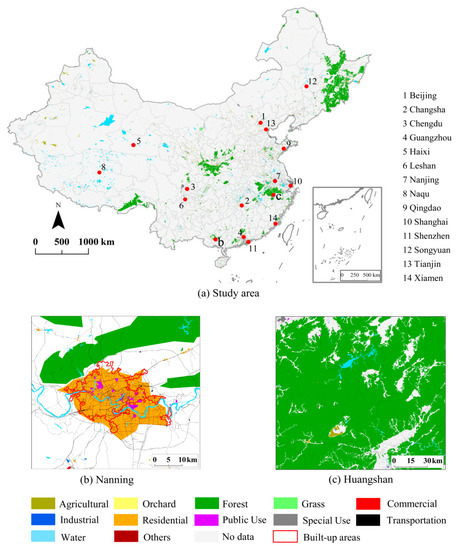
۲٫۱٫ منطقه مطالعه
۲٫۲٫ داده ها
۳٫ روش ها
۳٫۱٫ تولید و اعتبار سنجی مجموعه داده LULC مبتنی بر OSM
۳٫۱٫۱٫ تولید
-
مرحله ۱: ویژگی های خط را به ویژگی های چند ضلعی تبدیل کنید. به گفته ژو و همکاران. [ ۱۷ ]، تبدیل یک ویژگی خط به یک ویژگی چند ضلعی از طریق بافر امکان پذیر است، یعنی ایجاد یک منطقه بافر در اطراف ویژگی خط، پس از آن، منطقه بافر را می توان به عنوان یک ویژگی چند ضلعی مشاهده کرد. چالش در اینجا تعیین شعاع بافر مناسب برای انواع مختلف OSM است زیرا اشیاء خط OSM ممکن است با مقادیر مشخصه های مختلف برچسب گذاری شوند (به عنوان مثال، بزرگراه ها = اولیه، بزرگراه ها = ثانویه، و بزرگراه ها = مسکونی). چنین شعاع مناسبی توسط ژو و همکاران تعیین شد. [ ۱۷] از طریق مقایسه با مجموعه داده LULC مرجع مربوطه (GMESUA). با این حال، چنین مجموعه داده مرجع برای منطقه مورد مطالعه ما در دسترس نبود، و بنابراین شعاع های بافر مختلف (از ۴٫۵ تا ۱۰ متر) برای انواع مختلف OSM به صورت دستی با مراجعه به استاندارد فنی مهندسی بزرگراه چین و تصاویر مربوطه تعیین شد. Google Earth ( جدول ۱ ). شعاع بافر به طور کلی با اهمیت یک نوع جاده OSM همبستگی مثبت داشت.
-
مرحله ۲: اشیاء OSM را به کلاس های مرجع مربوطه طبقه بندی کنید. به دلیل عدم وجود محصول مرجع LULC، ما به صورت دستی تمام اشیاء OSM را (با توجه به برچسب های آنها) به ۱۲ کلاس LULC طبقه بندی کردیم: کشاورزی، باغ، جنگل، چمن، تجاری، صنعتی، مسکونی، استفاده عمومی، استفاده ویژه، حمل و نقل، آب. ، و زمین های دیگر ( جدول ۲ ). تمام این کلاسهای LULC از سطح اول استانداردهای طبقهبندی ملی کاربری زمین چین بهدست آمدند.
-
مرحله ۳: چندین کلاس (یا لایه) LULC را در یک لایه ادغام کنید. این یک مرحله ضروری است زیرا برخی از اشیاء چند ضلعی در OSM ممکن است همپوشانی داشته باشند اما با کلاس های مختلف LULC مطابقت دارند. بنابراین ممکن است تعیین یک کلاس LULC منحصر به فرد برای همان منطقه جغرافیایی دشوار باشد. راه حل این است که (۱۲) کلاس های LULC با توجه به مساحت متوسط آنها از کوچک به بزرگ همپوشانی داشته باشند [ ۱۷ ]. به طور خاص، مشخصه یا کلاسی با کمترین مساحت متوسط در بالا و آن با بیشترین مساحت متوسط در پایین قرار گرفت. پس از این فرآیند، تمام کلاس ها (یا لایه ها) LULC بیشتر در یک لایه ادغام شدند.
۳٫۱٫۲٫ اعتبار سنجی
دقت اندازه گیری می کند که مجموعه داده LULC مبتنی بر OSM چقدر با محصول مرجع LULC مربوطه مطابقت دارد. این مطالعه از راهبرد نمونه گیری طبقه ای استفاده کرد. تعدادی از نقاط نمونه ابتدا به طور تصادفی برای هر کلاس LULC انتخاب شد و سپس با درصد مساحت هر کلاس در مجموعه داده OSM همبستگی مثبت داشت. کلاس LULC واقعی هر نقطه نمونه به صورت دستی و مستقل توسط دو نفر با مراجعه به Google Earth علامت گذاری شد. هنگامی که هر نقطه توسط دو نفر به طور متفاوت مشخص می شد، نفر سوم در تحلیل شرکت می کرد و تصمیم نهایی با رای گیری گرفته می شد. تمام نقاط نمونه به عنوان مرجع برای ارزیابی دقت مجموعه داده LULC مبتنی بر OSM استفاده شد. بر اساس تمام امتیازات (در مجموع ۳۴۶۴) چندین معیار دقت با مقایسه هر جفت کلاس LULC در مجموعه داده مبتنی بر OSM با موارد موجود در مرجع محاسبه شد. سه معیار رایج – دقت کلی (OA)، دقت کاربر (UA) و دقت تولیدکننده (PA) – محاسبه شد:
که در آن N تعداد نقاط در کل، n نشان دهنده تعداد کلاس های LULC ( n= 12) پمن(oسمتر)و پمن(rهf)تعداد نقاط طبقه بندی شده به عنوان متعلق به کلاس LULC – i را در مجموعه داده های مبتنی بر OSM و در مرجع به ترتیب نشان می دهد، و پمنتعداد نقاط طبقه بندی شده به عنوان متعلق به کلاس LULC -i در هر دو مجموعه داده را نشان می دهد.
۳٫۲٫ نقشه برداری و تحلیل الگوهای کامل بودن و تنوع
۳٫۲٫۱٫ معیارهای کامل بودن و تنوع
یک نقشه/مجموعه داده LULC ممکن است با تعدادی کلاس LULC نیز مشخص شود (مثلاً ۱۲). تعاریف مختلفی از تنوع ارائه شده است [ ۳۴ ]، که در میان آنها شاخص تنوع شانون یا آنتروپی شانون [ ۳۵ ] بیشتر در ادبیات استفاده می شود. شاخص تنوع شانون را می توان برای اندازه گیری انواع کلاس های LULC در یک منطقه مورد استفاده قرار داد و بنابراین در مطالعه ما استفاده شد. به این معنا که،
جایی که S نشان دهنده شاخص تنوع شانون از مجموعه داده LULC مبتنی بر OSM است، پمننشاندهنده درصد مساحت کلاس LULC i در یک واحد جغرافیایی، و n نشاندهنده تعداد کلاسهای LULC است. در مطالعه ما، n = ۱۲، و بنابراین اسمی تواند از صفر (به معنی فقط یک کلاس LULC) تا ۲٫۴۸ (یعنی همه ۱۲ کلاس دارای درصد یکسانی هستند، یعنی ۸٫۳۳٪) متفاوت باشد.
۳٫۲٫۲٫ نقشه برداری و تحلیل
-
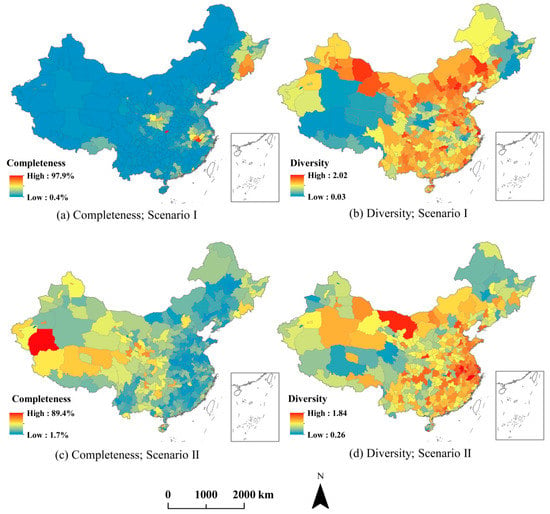
هر دو الگوهای کامل و تنوع به صورت بصری تجزیه و تحلیل شدند. تعدادی سوال در نظر گرفته شد. به عنوان مثال، کدام مناطق دارای ارزش کامل بودن و تنوع نسبتاً بالا یا پایین بودند؟ آیا تفاوتی بین الگوهای کامل و تنوع، از نظر سناریوهای I و II وجود داشت؟ آیا بین کامل بودن و تنوع الگوهای یک سناریو همبستگی وجود داشت؟
-
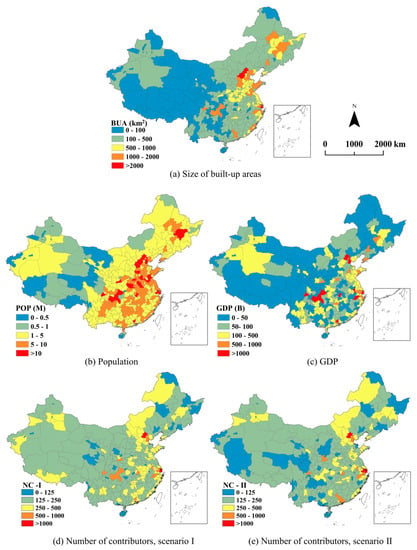
برای ارزیابی کمی، تعدادی از عوامل برای شناسایی عواملی که میتوانستند الگوهای کامل و تنوع را تحت تأثیر قرار دهند، مورد استفاده قرار گرفتند. ابتدا سه عامل اجتماعی-اقتصادی [اندازه مناطق ساخته شده، جمعیت آنها و تولید ناخالص داخلی (GDP)] در نظر گرفته شد. داده های مربوطه در سال ۲۰۱۹ از اداره ملی آمار چین ( http://www.stats.gov.cn ) به دست آمده است. این عوامل به این دلیل انتخاب شدند که مطالعات نشان دادهاند که کامل بودن دادههای OSM در شهرداریهایی با تراکم جمعیت بالا بیشتر است [ ۲۷ ]. کامل بودن نیز با تولید ناخالص داخلی همبستگی مثبت دارد [ ۲۵]. بنابراین، بررسی اینکه آیا این عوامل هنوز هم می توانند با الگوهای کامل و تنوع مجموعه داده LULC مبتنی بر OSM چین همبستگی مثبت داشته باشند مفید است. علاوه بر این، تعداد مشارکتکنندگان (که دادههای OSM را ویرایش کرده بودند) بر اساس تجزیه و تحلیل دادههای تاریخچه OSM محاسبه شد ( https://planet.openstreetmap.org/planet/full-history/ ، در ژانویه ۲۰۱۹ مشاهده شد). این عدد بر حسب هر بخش در سطح استان (برای سناریوی I) و مناطق ساخته شده از هر بخش در سطح استان (برای سناریوی II) محاسبه شد تا مشخص شود که آیا تعداد مشارکت کنندگان با کامل بودن و/همبستگی مثبت دارد یا خیر. یا الگوهای تنوع
۴٫ نتایج و تجزیه و تحلیل
۴٫۱٫ تولید و اعتبار سنجی مجموعه داده LULC مبتنی بر OSM
۴٫۲٫ نقشه برداری و تحلیل الگوهای کامل بودن و تنوع
۵٫ ترکیبی از کامل بودن و الگوهای تنوع
-
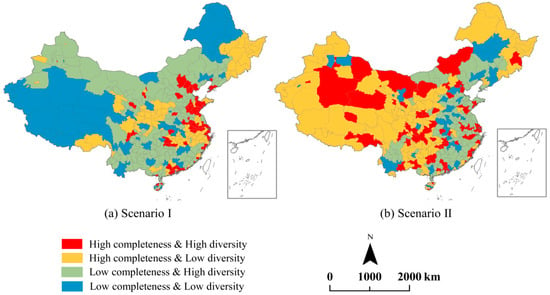
گروه I (کامل بالا و تنوع بالا): کامل بودن بالاتر از یک آستانه معین بود ( آج، همانطور که تنوع بود ( آد).
-
گروه دوم (تنوع بالا و تنوع کم): کامل بودن بالاتر از آج، اما تنوع کمتر از آد.
-
گروه III (کامل کم و تنوع بالا): کامل بودن کمتر از آج، اما تنوع بالاتر از آد;
-
گروه چهارم (کمیت کم و تنوع کم): کامل بودن کمتر از آج، و تنوع کمتر از آد.
-
گروه I: برای هر دو سناریو I و II، بیشتر بخشهای سطح استان شهرداریها بودند، به عنوان مثال، پکن ( شکل ۶ الف)، شانگهای، و تیانجین، شهرهای پایتخت، مانند گوانگژو، نانجینگ، چنگدو، و چانگشا، و نسبتاً توسعهیافته شهرها (شنژن، چینگدائو و شیامن)، و مناطقی در ساحل شرقی. این بخشها احتمالاً توجه بیشتری را از جانب داوطلبان به خود جلب کردند، و بنابراین ارزشهای کامل و تنوع آنها نسبتاً بالا بود.
-
گروه دوم: تقسیمات این گروه در سطح استان در سناریوها متفاوت بود. در سناریوی اول، بیشتر بخشها در شرق، مرکز و شمال شرقی چین قرار داشتند که به دلیل داشتن درصد وسیعی از جنگل است. در سناریوی دوم، آنها در جنوب غربی، شمال غربی و شمال شرقی چین قرار داشتند که به دلیل داشتن درصد مساحت زیادی از زمین های مسکونی بود. این تقریباً با آنچه در شکل ۲ a,c نشان داده شده است مطابقت داشت.
-
گروههای III و IV: تقسیمبندیهای سطح استان این گروهها به چند دلیل ارزش کاملی پایینی داشتند: برخی از بخشها (مانند Haixi و Naqu) با مساحت زمین بزرگ مشخص میشدند، و بنابراین داوطلبان به زمان و تلاش بیشتری نیاز داشتند. این تقسیمات را به خوبی ترسیم کنید. بعلاوه، برخی از بخش ها (مثلاً لشان ( شکل ۶ ب) و سونگ یوان ( شکل ۶ ج)) کمتر شناخته شده بودند، به ویژه در مقایسه با گروه I، و بنابراین احتمالاً داوطلبان کمتر مورد توجه قرار می گرفتند. علاوه بر این، اکثر بخشها مقدار تنوع نسبتاً بالایی را نشان دادند، که نشان میدهد در بیشتر موارد کلاس LULC غالبی نبود. با این حال، برخی از بخش ها (به عنوان مثال، شکل ۶ج) درصد مساحت نسبتاً بزرگی از آب (۷۹٫۳٪ برای نمودار سمت چپ در شکل ۶ ج) یا زمین های مسکونی (۸۵٫۶٪ برای نمودار سمت راست در شکل ۶ c) را نشان می دهد، که منجر به ارزش تنوع پایین می شود.
۶٫ بحث
۶٫۱٫ معیارهای کیفیت
۶٫۲٫ برنامه های کاربردی
۶٫۳٫ محدودیت ها
۷٫ نتیجه گیری
- (۱)
-
OA مجموعه داده LULC مبتنی بر OSM در چین به اندازه ۸۲٫۲٪ بود که نشان می دهد مجموعه داده های LULC تولید شده برای کشور موثر بوده و قابل مقایسه با داده های مربوط به مناطق مطالعاتی اروپایی در کار گذشته است.
- (۲)
-
الگوهای کامل و تنوع هر دو با تقسیم بندی در سطح استان متفاوت بود. علاوه بر این، الگوهای کامل به طور قابل توجهی با الگوهای تنوع مربوطه متفاوت بود. بهویژه در مقیاس مناطق ساختهشده، تقسیمبندیهایی با مقادیر کامل بودن بالا ممکن است به دلیل ارزش تنوع پایین به خوبی ترسیم نشده باشند.
- (۳)
-
همبستگی بین الگوهای تنوع و هر یک از سه عامل اجتماعی-اقتصادی و تعداد مشارکت کنندگان نه تنها بیشتر از آنهایی بود که برای الگوهای کامل در نظر گرفته می شد، بلکه به طور قابل توجهی مثبت بود. بنابراین، الگوی تنوع بازتاب بهتری از عوامل اجتماعی-اقتصادی و الگوی فضایی مشارکتکنندگان است.
- (۴)
-
هر دو الگوی کامل و تنوع را می توان در گروه های مختلف (کاملیت زیاد و تنوع زیاد، کامل بودن زیاد و تنوع کم، کامل بودن کم و تنوع زیاد، و کامل بودن کم و تنوع کم) ترکیب کرد. الگوهای ترکیبی هم به کاربران OSM و هم برای داوطلبان سود میرسانند که درک بهتری از مجموعه دادههای LULC مبتنی بر OSM ارائه میدهند.
منابع
- جونز، دی. هانسن، ای جی; بلی، ک. دوهرتی، ک. Verschuyl، JP; پاو، جی. کارل، آر. داستان، SJ نظارت بر استفاده از زمین و پوشش اطراف پارک ها: یک رویکرد مفهومی. سنسور از راه دور محیط. ۲۰۰۹ ، ۱۱۳ ، ۱۳۴۶-۱۳۵۶٫ [ Google Scholar ] [ CrossRef ]
- لیانگ، جی. ژونگ، ام. زنگ، جی. چن، جی. هوآ، اس. لی، ایکس. یوان، ی. وو، اچ. گائو، X. مدیریت ریسک برای برنامهریزی استفاده بهینه از زمین که ارزشهای خدمات اکوسیستم را یکپارچه میکند: مطالعه موردی در چانگشا، چین میانه. علمی کل محیط. ۲۰۱۷ ، ۵۷۹ ، ۱۶۷۵-۱۶۸۲٫ [ Google Scholar ] [ CrossRef ] [ PubMed ]
- مصدقی، ر. وارنکن، جی. تاملینسون، آر. میرفندرسسک، اچ. مقایسه AHP فازی و AHP در یک مدل تصمیمگیری چند معیاره فضایی برای برنامهریزی کاربری اراضی شهری. محاسبه کنید. محیط زیست سیستم شهری ۲۰۱۵ ، ۴۹ ، ۵۴-۶۵٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- رییسی، م. بله، ال. رجبی فرد، ع. Ngo، T. برنامه ریزی کاربری زمین: مفاهیم برای پایداری حمل و نقل. سیاست کاربری زمین ۲۰۱۶ ، ۵۰ ، ۲۵۲-۲۶۱٫ [ Google Scholar ] [ CrossRef ]
- Hegazy, IR; Kaloop، MR نظارت بر رشد شهری و تشخیص تغییر کاربری زمین با GIS و تکنیکهای سنجش از دور در استان دقاهلیه مصر. بین المللی J. Sustain. محیط ساخته شده ۲۰۱۵ ، ۴۴ ، ۱۱۷-۱۲۴٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ریمال، بی. ژانگ، ال. کشتکار، ح. هک، BN; رجال، س. Zhang، P. پویایی کاربری/پوشش زمین و مدلسازی گسترش زمین شهری با ادغام اتوماتای سلولی و زنجیره مارکوف. بین المللی J. Geo-Inf. ۲۰۱۸ ، ۷۷ ، ۱۵۴٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- زنگ، سی. لیو، ی. Stein، AL; جیائو، ال. خصوصیات و مدلسازی فضایی پراکندگی شهری در منطقه شهری ووهان، چین. بین المللی J. Appl. زمین Obs. Geoinf. ۲۰۱۵ ، ۳۴ ، ۱۰-۲۴٫ [ Google Scholar ] [ CrossRef ]
- چن، جی. چن، جی. لیائو، ا. کائو، ایکس. چن، ال. چن، ایکس. او، سی. آویزان شدن.؛ پنگ، اس. لو، ام. و همکاران نقشه برداری جهانی پوشش زمین با وضوح ۳۰ متر: یک رویکرد عملیاتی مبتنی بر POK ISPRS J. Photogramm. Remote Sens. ۲۰۱۵ ، ۱۰۳ ، ۷-۲۷٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گرکوسیس، جی. مونتراکیس، جی. Kavouras, M. مروری بر ۲۱ محصول جهانی و ۴۳ منطقه ای نقشه برداری پوشش زمین. بین المللی J. Remote Sens. ۲۰۱۵ ، ۳۶ ، ۵۳۰۹-۵۳۳۵٫ [ Google Scholar ] [ CrossRef ]
- فریتز، اس. ببینید، L. پرگر، سی. مک کالوم، آی. شیل، سی. شپاچنکو، دی. دوراور، ام. کارنر، ام. درزل، سی. Laso-Bayas، JC; و همکاران مجموعه داده جهانی از دادههای مرجع پوشش زمین و کاربری زمین جمعسپاری شده. علمی داده ۲۰۱۷ ، ۴ ، ۱۷۰۰۷۵٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- هو، ی. Han, Y. شناسایی مناطق عملکردی شهری بر اساس دادههای POI: مطالعه موردی منطقه توسعه اقتصادی و فناوری گوانگژو. پایداری ۲۰۱۹ ، ۱۱ ، ۱۳۸۵٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- کانگ، جی. کورنر، ام. وانگ، ی. تاوبنبوک، اچ. طبقهبندی نمونه ساختمان Zhu، XX با استفاده از تصاویر نمای خیابان. ISPRS J. Photogramm. Remote Sens. ۲۰۱۸ , ۱۴۵ , ۴۴–۵۹٫ [ Google Scholar ] [ CrossRef ]
- پی، تی. سوبولفسکی، اس. راتی، سی. شاو، اس. لی، تی. ژو، سی. بینشی جدید در طبقه بندی کاربری زمین بر اساس داده های تلفن همراه جمع آوری شده است. بین المللی جی. جئوگر. Inf. علمی ۲۰۱۴ ، ۲۸ ، ۱۹۸۸-۲۰۰۷٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Goodchild، M. شهروندان به عنوان حسگرها: دنیای جغرافیای داوطلبانه. ژئوژورنال ۲۰۰۷ ، ۶۹ ، ۲۱۱-۲۲۱٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ارسنجانی، ج. هلبیچ، ام. باکیالله، م. Hagenauer, J. به سمت نقشه برداری الگوهای کاربری زمین از اطلاعات جغرافیایی داوطلبانه. بین المللی جی. جئوگر. Inf. علمی ۲۰۱۳ ، ۲۷ ، ۲۲۶۴-۲۲۷۸٫ [ Google Scholar ] [ CrossRef ]
- شولتز، ام. ووس، ج. اور، ام. کارتر، اس. Zipf، A. پوشش زمین را از OpenStreetMap و سنجش از راه دور باز کنید. بین المللی J. Appl. زمین Obs. Geoinf. ۲۰۱۷ ، ۶۳ ، ۲۰۶-۲۱۳٫ [ Google Scholar ] [ CrossRef ]
- ژو، Q. جیا، ایکس. Lin, H. رویکردی برای ایجاد مکاتبات بین OpenStreetMap و مجموعه داده های مرجع برای استفاده از زمین و نقشه برداری پوشش زمین. ترانس. GIS ۲۰۱۹ ، ۲۳ ، ۱۱۷۷–۱۴۶۴٫ [ Google Scholar ] [ CrossRef ]
- شن، جی. یانگ، اس. زنگ، ک. ژو، جی. فن، اچ. مائو، بی. نظر جمعیت مشارکت کننده برای OpenStreetMap: نظرسنجی در چین. بین المللی قوس. فتوگرام حسگر از راه دور اسپات. Inf. علمی ۲۰۱۸ ، ۴۲ ، ۱۵۲۵-۱۵۳۱٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ارسنجانی، ج. Vaz, E. ارزیابی یک رویکرد نقشه برداری مشترک برای کاوش الگوهای کاربری زمین برای چندین کلانشهر اروپایی. بین المللی J. Appl. زمین Obs. Geoinf. ۲۰۱۵ ، ۳۵ ، ۳۲۹-۳۳۷٫ [ Google Scholar ] [ CrossRef ]
- ویانا، سی ام؛ انکالادا، ال. Rocha, J. ارزش مشارکتهای تاریخی OpenStreetMap به عنوان منبع دادههای نمونهگیری برای نقشههای کاربری/پوشش زمین چندزمانی. بین المللی J. Geo-Inf. ۲۰۱۹ ، ۸ ، ۱۱۶٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- Haklay, M. اطلاعات جغرافیایی داوطلبانه چقدر خوب است؟ مطالعه تطبیقی مجموعه دادههای OpenStreetMap و Ordnance Survey. محیط زیست طرح. B طرح. دس ۲۰۱۰ ، ۳۷ ، ۶۸۲-۷۰۳٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گیرس، جی اف. Touya, G. ارزیابی کیفیت مجموعه داده OpenStreetMap فرانسه. ترانس. GIS ۲۰۱۰ ، ۱۴ ، ۴۳۵-۴۵۹٫ [ Google Scholar ] [ CrossRef ]
- ژانگ، ی. لی، ایکس. وانگ، آ. بائو، تی. تیان، اس. تراکم و تنوع شبکههای جادهای OpenStreetMap در چین. J. Urban Manag. ۲۰۱۵ ، ۴۴ ، ۱۳۵-۱۴۶٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژو، Q. بررسی رابطه بین تراکم و کامل بودن داده های ساختمان شهری در OpenStreetMap برای تخمین کیفیت. بین المللی جی. جئوگر. Inf. علمی ۲۰۱۸ ، ۳۲ ، ۲۵۷-۲۸۱٫ [ Google Scholar ] [ CrossRef ]
- تیان، ی. ژو، Q. Fu، X. تجزیه و تحلیل تکامل، کامل بودن و الگوهای فضایی داده های ساختمانی OpenStreetMap در چین. ISPRS Int. J. Geo-Inf. ۲۰۱۹ ، ۸۸ ، ۳۵٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- استیما، ج. Painho، M. بررسی پتانسیل OpenStreetMap برای استفاده از زمین / تولید پوشش زمین: مطالعه موردی برای پرتغال قاره. در OpenStreetMap در GIScience, Lecture Notes in Geoinformation and Cartography . جوکار ارسنجانی، ج.، زیپف، ع.، مونی، پ.، هلبیچ، م.، ویرایش. Springer International Publishing: Cham, Switzerland, 2015. [ Google Scholar ]
- دورن، اچ. تورنروس، تی. Zipf، A. ارزیابی کیفیت VGI با استفاده از دادههای معتبر – مقایسه با دادههای کاربری زمین در جنوب آلمان. ISPRS Int. J. Geo-Inf. ۲۰۱۵ ، ۴ ، ۱۶۵۷-۱۶۷۱٫ [ Google Scholar ] [ CrossRef ]
- ببینید، L. کامبر، ا. سالک، سی. فریتز، اس. ولده، م. پرگر، سی. شیل، سی. مک کالوم، آی. کراکسنر، اف. Obsersteiner, M. مقایسه کیفیت داده های جمع سپاری ارائه شده توسط متخصص و غیر متخصص. PLoS ONE ۲۰۱۳ ، ۸۸ ، e69958. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کامبر، ا. ببینید، L. فریتز، اس. ولده، م. پرگر، سی. فودی، جی. استفاده از داده های کنترلی برای تعیین قابلیت اطمینان اطلاعات جغرافیایی داوطلبانه در مورد پوشش زمین. بین المللی J. Appl. زمین Obs. Geoinf. ۲۰۱۳ ، ۲۳ ، ۳۷-۴۸٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژو، Q. Tian، YJ استفاده از شاخصهای هندسی برای تخمین کامل بودن کمی بلوکهای خیابان در OpenStreetMap. ترانس. GIS ۲۰۱۸ ، ۲۲ ، ۱۵۵۰-۱۵۷۲٫ [ Google Scholar ] [ CrossRef ]
- هریستوا، دی. ویلیامز، ام. موصلی، م. پانزاراسا، پ. ماسکولو، سی. اندازه گیری تنوع اجتماعی شهری با استفاده از شبکه های به هم پیوسته جغرافیایی اجتماعی. در مجموعه مقالات بیست و پنجمین کنفرانس بین المللی وب جهانی، مونترال، QC، کانادا، ۱۱ تا ۱۵ آوریل ۲۰۱۶٫ [ Google Scholar ]
- Vogiatzakis، LN; Manolaki, P. بررسی تنوع و تنوع مناظر مدیترانه شرقی. Land ۲۰۱۷ , ۶۶ , ۷۱٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ولاسکوز، جی. گوتیرز، جی. هرناندو، ا. گارسیا-آبریل، آ. مارتین، MA; Irastorza، P. اندازه گیری تنوع موزاییک بر اساس نقشه کاربری اراضی در منطقه مادرید، اسپانیا. سیاست کاربری زمین ۲۰۱۸ ، ۷۱ ، ۳۲۹-۳۳۴٫ [ Google Scholar ] [ CrossRef ]
- Nagendra، H. روندهای مخالف در پاسخ به شاخص های شانون و سیمپسون تنوع چشم انداز. Appl. Geogr. ۲۰۰۲ ، ۲۲ ، ۱۷۵-۱۸۶٫ [ Google Scholar ] [ CrossRef ]
- شانون، م. ویور، دبلیو . نظریه ریاضی ارتباطات . انتشارات دانشگاه ایلینوی: Champaign, IL, USA, 1949. [ Google Scholar ]
- نیس، پ. زیلسترا، دی. Zipf، A. مقایسه مشارکت داوطلبانه اطلاعات جغرافیایی و توسعه جامعه برای مناطق منتخب جهان. اینترنت آینده ۲۰۱۳ ، ۵ ، ۲۸۲-۳۰۰٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Fonte, CC; مارتینهو، ن. ارزیابی کاربرد دادههای OpenStreetMap برای کمک به اعتبارسنجی نقشههای کاربری/پوشش زمین. بین المللی جی. جئوگر. Inf. علمی ۲۰۱۷ ، ۳۱ ، ۲۳۸۲-۲۴۰۰٫ [ Google Scholar ] [ CrossRef ]
- جانسون، کارشناسی; لیزوکا، ک. ادغام دادههای جمعسپاری OpenStreetMap و تصاویر سریهای زمانی Landsat برای نقشهبرداری سریع استفاده از زمین/پوشش زمین (LULC): مطالعه موردی منطقه خلیج لاگونا فیلیپین. Appl. Geogr. ۲۰۱۶ ، ۶۷ ، ۱۴۰-۱۴۹٫ [ Google Scholar ] [ CrossRef ]
- لیو، ایکس. Long, Y. شناسایی و خصوصیات خودکار بسته ها با OpenStreetMap و نقاط مورد علاقه. محیط زیست طرح. B طرح. دس ۲۰۱۶ ، ۴۳ ، ۳۴۱-۳۶۰٫ [ Google Scholar ] [ CrossRef ]
- سریواستاوا، اس. لوبری، اس. تویا، دی. Vargas-Muñoz، J. خصوصیات کاربری زمین با استفاده از تصاویر Google Street View و OpenStreetMap. در مجموعه مقالات کنفرانس انجمن آزمایشگاههای اطلاعات جغرافیایی در اروپا (AGILE)، لوند، سوئد، ۱۲ تا ۱۵ ژوئن ۲۰۱۸٫ [ Google Scholar ]




بدون دیدگاه