
خلاصه
در حالی که توییتر به عنوان یک منبع برجسته اطلاعات به روز در مورد رویدادهای خطرناک معرفی شده است، قابل اعتماد بودن توییت ها هنوز یک نگرانی است. نشریه قبلی ما توییت های مرتبطی را استخراج کرد که حاوی اطلاعاتی درباره رویداد سیل سال ۲۰۱۳ کلرادو و تأثیرات آن بود. این تحقیق با استفاده از توییتهای مربوطه، قابلیت اطمینان (دقت و صحت) توییتها را با بررسی محتوای متن و تصویر و مقایسه آنها با سایر منابع دادهای در دسترس عموم، بیشتر بررسی کرد. هم شناسایی دستی اطلاعات متنی و هم استخراج خودکار تصاویر (Google Cloud Vision، رابط برنامه نویسی برنامه (API)) برای متعادل کردن تأیید دقیق اطلاعات و زمان پردازش کارآمد اجرا شد. نتایج نشان داد که هم متن و هم تصاویر حاوی اطلاعات مفیدی در مورد جاده ها/خیابان های آسیب دیده/آب گرفتگی هستند. این اطلاعات به تلاشهای هماهنگی واکنش اضطراری و تخصیص آگاهانه منابع کمک میکند، زمانی که توییتهای کافی حاوی مختصات جغرافیایی یا نام مکان/محل برگزاری باشد. این تحقیق اطلاعات ریسک جمع سپاری قابل اعتماد را برای تسهیل پاسخ اضطراری در زمان واقعی از طریق استفاده بهتر از پلتفرم های ارتباطی ریسک جمع سپاری شناسایی می کند.
کلید واژه ها:
توییتر ؛ قابلیت اطمینان داده ها ؛ ارتباط ریسک ؛ داده کاوی ; Google Cloud Vision API
۱٫ معرفی
افزایش فراوانی و شدت خطرات مرتبط با آب و هوا (به عنوان مثال، سیل، آتشسوزی، طوفان و گرما بافته) و خطرات انسانی (مانند تیراندازی جمعی، اپیدمیها) چالشهای بیسابقهای را برای ملتها و افراد در سراسر جهان به ارمغان آورده است [ ۱ ]. ارتباط ریسک و بحران در مورد بلایا در کمک به مردم برای آماده شدن و واکنش به حوادث شدید با ارائه اطلاعات ضروری برای برنامه ریزی و کاهش خسارات احتمالی به جان و اموال بسیار مهم است [ ۲ , ۳ ].]. گسترش فناوری اطلاعات و وب ۲٫۰ نحوه ارتباط افراد و سازمان ها و تعامل با دیگران را در سراسر جهان تغییر داده است. به عنوان مثال، طبق مرکز تحقیقاتی پیو، حدود ۳۰ درصد از آمریکایی ها اغلب به رسانه های اجتماعی و سایت های شبکه های اجتماعی (به عنوان مثال، فیس بوک، توییتر و غیره) برای اخبار یا اطلاعات خود در مورد رویدادهای خاص وابسته هستند [ ۴ ]. در نتیجه، رسانه های جریان اصلی سنتی استراتژی های جدیدی را برای گسترش حضور خود، توزیع محتوا و تعامل با مصرف کنندگان در رسانه های اجتماعی اتخاذ کرده اند [ ۵ ].]. به طور مشابه، محتوای آنلاین ایجاد شده توسط اعضای عمومی در پلتفرمهای رسانههای اجتماعی مختلف (مثلا توییتر) مصرف و به اشتراک گذاشته میشود، در نتیجه ارتباطات سنتی را غنیتر و به چالش میکشد، به ویژه در مراحل مدیریت اضطراری [ ۶ ]. از دیدگاه روانشناختی اجتماعی، دلایلی که عموماً افراد را به اشتراک گذاری اطلاعات در رسانه های اجتماعی سوق می دهد، خودکارآمدی، خودشکوفایی، نوع دوستی، مشارکت اجتماعی، رفتار متقابل و شهرت است [ ۷ ، ۸ ]. در نتیجه، پلتفرمهای رسانههای اجتماعی در طول بلایا برای صدور هشدار به مردم، گزارش خسارات، تعامل با ذینفعان و کمک به سازماندهی تلاشهای امدادی استفاده شده است [ ۹ ، ۱۰ ، ۱۱ ، ۱۲ ،۱۳ ].
پلتفرم های مبتنی بر علم شهروندی (به عنوان مثال، iCoast، Tweet Earthquake Dispatch، CitizenScience.gov) به شهروندان اجازه می دهد تا با دانشمندان در جمع آوری و تجزیه و تحلیل داده ها، گزارش مشاهدات و انتشار نتایج در مورد مشکلات علمی همکاری کنند [ ۱۴ ]. پلتفرمهای جمعسپاری، مانند توییتر و فیسبوک، رسانههای اجتماعی و سایتهای شبکههای اجتماعی هستند که به افراد غیرمتخصص اجازه میدهند دانش و مجموعه دادههای جدیدی تولید کنند [ ۱۵ ، ۱۶ ]. اگرچه هم علم شهروندی و هم جمعسپاری، شهروندان اجتماعی-فرهنگی متنوع و پراکنده جغرافیایی را در ایجاد/جمعآوری دادهها و دانش درگیر میکنند، اما هر کدام تفاوتهای ظریفی دارند [ ۱۷ ، ۱۸ ]]. در حالی که جمعسپاری یک رویکرد نامشخص است که از شبکههای بزرگی از مردم استفاده میکند، علم شهروندی تنها از دانشمندان، داوطلبان، و افراد عادی با علایق و دانش در مورد یک موضوع خاص استفاده میکند [ ۱۹ ]. از آنجایی که توییتها از طریق جمعسپاری تولید میشوند و معمولا حاوی شایعات و فریبکاری هستند، ما توئیتها را نادرست فرض کردیم و یک رویکرد سلسله مراتبی برای تأیید اعتبار و مرتبط بودن توییتها با استفاده از دادههای مشتقشده و تأیید شده علمی اجرا کردیم.
علیرغم اهمیت رسانه های اجتماعی در ارتباطات ریسک، چالش هایی وجود دارد که باید مورد توجه قرار گیرد. اول، اضافه بار اطلاعات به دلیل حجم انبوه محتوای تولید شده توسط کاربر می تواند کاربرانی را که در تلاش برای به دست آوردن اطلاعات مرتبط هستند، تحت فشار قرار دهد [ ۲۰ ]. دوم، دادههای رسانههای اجتماعی جمعسپاری شده اغلب فاقد ابردادههایی هستند که اطلاعاتی درباره سازنده، زمان، تاریخ، دستگاه مورد استفاده برای تولید دادهها، هدف و استاندارد ارائه میدهند که باعث میشود اعتبار کمتری داشته باشد [ ۲۱ ، ۲۲ ، ۲۳ ]. سوم، ظهور حسابهای رسانههای اجتماعی تحت کنترل ربات، هرزنامه تجاری، و هرزنامه/اطلاعات نادرست توجه جمعی در رسانههای اجتماعی [ ۲۴ ، ۲۵ ]] همچنین می تواند کیفیت داده های جمع سپاری را مختل کند. در نهایت، اکتشافی نقش مهمی در تصمیم گیری برای به اشتراک گذاشتن اطلاعات در رسانه های اجتماعی دارد. این امر در شرایط بحرانی پیچیده و پیشبینی نشده تأثیرگذار شده است و از این طریق به امکان معرفی خطاها و قضاوتهای مغرضانه به اطلاعات ریسک مشترک کمک میکند [ ۲۶ ]. این چالشها در پلتفرمهای جمعسپاری بارزتر است.
حتی زمانی که مسائل فوق کنترل می شوند، ارتباط اطلاعات، قابلیت استفاده از اطلاعات بحران رسانه های اجتماعی را تعیین می کند. بنابراین، ارزیابی ارتباط محتوای رسانه های اجتماعی بسیار مهم است [ ۱۰ ]، و از این رو ارزیابی کیفیت و قابل اعتماد بودن داده ها برای اطمینان از صحت و درستی اطلاعات به اشتراک گذاشته شده برای تصمیم گیری و مصرف عمومی در طول یک بحران بسیار مهم است. هدف این تحقیق استخراج اطلاعات ریسک از توییتها در طول سیل سال ۲۰۱۳ کلرادو و ارزیابی قابلیت اطمینان (دقت و صحت) این اطلاعات است. این کار با بررسی محتوای متن و تصویر و مقایسه محتوا با اطلاعات در دسترس عموم از دولتهای فدرال، ایالتی و محلی و سازمانهای مدیریت اضطراری انجام شد.
۲٫ بررسی ادبیات
ارتباط ریسک، عنصر اصلی مدیریت اضطراری، به عنوان «فرایند تبادل اطلاعات بین طرفهای ذینفع در مورد ماهیت، بزرگی، اهمیت یا کنترل یک خطر» تعریف میشود [ ۲۷ ]. ارتباط ریسک برای دولتها، سازمانها، مشاغل و افراد از اهمیت بالایی برخوردار است، زیرا اطلاعاتی در مورد بلایای / بحرانهای احتمالی، اثرات / آسیبهای احتمالی و اقدامات متقابل ارائه میکند. رویکردهای مبتنی بر رسانههای اجتماعی با ارتباطات مشارکتی، مشارکتی و چند جهته مشخص میشوند که به جمعیت تحت تأثیر و علاقهمند اجازه میدهد تا اطلاعات نامحدودی درباره یک خطر، صرف نظر از موقعیت جغرافیایی و زمان آن به اشتراک بگذارند [ ۲۸ ].]. به عنوان مثال، سایتهای شبکههای اجتماعی (مانند فیسبوک) و سرویسهای وبلاگ کوتاه (مثلا توییتر) به طور گسترده در طول طوفان هاروی ۲۰۱۷ [ ۲۹ ]، طوفان ماریا ۲۰۱۷ [ ۳۰ ]، آتشسوزیهای کالیفرنیا در سال ۲۰۱۸ [ ۱۲ ، ۱۳ ] و همه گیری COVID-19 [ ۳۱ ، ۳۲ ].
قابلیت اطمینان داده ها را می توان به عنوان “دقت و کامل بودن داده ها، با توجه به کاربردهایی که برای آنها در نظر گرفته شده است” تعریف کرد [ ۳۳ ]. تحقیقات موجود که قابلیت اطمینان دادههای جمعسپاری را ارزیابی میکنند، تمایل دارند بر ارزیابی کیفیت محتوا (به عنوان مثال، وجود فراداده [ ۲۱ ]، تشخیص شایعات [ ۲۴ ])، و توسعه الگوریتمها یا مدلهای یادگیری ماشین برای ارزیابی قابلیت اطمینان دادهها [ ۳۴ ، ۳۵ ، ۳۶ ] تمرکز کنند. ]. دانشمندان شهروندی و کارشناسان موضوع نیز در اعتبار سنجی قابلیت اطمینان برای تمایز و توجیه “حوادث واقعی” درک شده استفاده می شوند [ ۳۷ ، ۳۸]. بر اساس این نیاز، محققان بیشتری آمازون مکانیکال ترک را برای تأیید اثربخشی و قابلیت اطمینان دادههای جمعسپاری، علاوه بر سایر روشهای شناسایی دستی، اتخاذ کردهاند [ ۳۹ ، ۴۰ ، ۴۱ ، ۴۲ ، ۴۳ ].
علیرغم فراوانی روشهای ارزیابی موجود، برخی از مطالعات مبتنی بر الگوریتم به ندرت منابع دادههای خارجی مرتبط بالقوه را در زمینه تحقیق، مانند دادههای هواشناسی و مکانی در مطالعات سیل [ ۴۴ ] و مدلهای رقومی ارتفاع (DEM) در مطالعات زلزله یا زمین لغزش ترکیب میکنند. ۴۵ ]. در نتیجه، این مطالعات ممکن است در جمع آوری تمام اطلاعات لازم برای اعتبارسنجی قابلیت اطمینان ناکام باشند. بنابراین، این تحقیق یک گردش کار برای کار نزدیک با اسناد مرجع برای استخراج اطلاعات ریسک قابل اعتماد طراحی کرد.
پایایی در این تحقیق به «دقت اطلاعات و میزان واقعی بودن دادهها» اشاره دارد. با استفاده از این تعریف، یک گردش کار برای ارزیابی قابلیت اطمینان اطلاعات خطر استخراج شده از توییت های مربوطه که برای رویداد سیل سال ۲۰۱۳ کلرادو به دست آمده بود، ایجاد شد. با استفاده از گردش کار، متن و تصاویر توییت را بررسی کردیم که از هوش انسانی و رابط برنامه نویسی برنامه Google Cloud Vision (GCV) (API) بهره می برد. توییتهای مربوطه از طریق چندین تکنیک دادهکاوی استخراج شدهاند و میتوان آنها را در یک نشریه قبلی یافت [ ۱۰ ]. GCV API امکان شناسایی خودکار محتوای تصویر، برچسبگذاری تصاویر، و تطبیق خودکار اطلاعات آنلاین را فراهم کرد [ ۴۶ ، ۴۷ ].
۳٫ مواد و روشها
۳٫۱٫ سایت مطالعه
سیل سال ۲۰۱۳ کلرادو به شدت فرانت رینج، شهرستان ال پاسو، شهرستان بولدر و بخشی از منطقه شهری دنور را تحت تاثیر قرار داد. سیل شدید ناشی از بارندگی های شدید چند روزه از ۹ تا ۱۸ شهریور خسارات قابل توجهی به منطقه وارد کرد. شهرستان بولدر، سایت مورد مطالعه، تنها در ۱۲ سپتامبر ۹٫۴ اینچ بارندگی دریافت کرد که معادل میانگین بارندگی سالانه این شهرستان بود [ ۴۸ ]. سایر شهرستان ها از ۹ سپتامبر تا ۱۵ سپتامبر بارندگی نسبتاً کمتر اما افزایشی داشتند.
۳٫۲٫ مجموعه داده ها و پردازش
مجموعه دادههای مورد استفاده در این مطالعه شامل توییتهای تاریخی، مجموعه دادههای جغرافیایی مربوط به رویداد سیل و مکان مورد مطالعه (به عنوان مثال، نقشه وسعت سیل بولدر، نقشه خیابان بولدر)، و اسناد مرجع شامل مقالات خبری و گزارشهای آژانس از سرویس هواشناسی ملی، ایالتی است. ، و سازمان های دولتی محلی. بحث در مورد مراحل پردازش داده ها و رویکردهای تحلیلی در زیر ارائه شده است.
۳٫۲٫۱٫ توییت های سیل سال ۲۰۱۳ کلرادو
توییتهای تاریخی با استفاده از دو نوع کلیدواژه از شرکت توییتر شناسایی و خریداری شدند: (۱) نام مکان (کلرادو، بولدر، محدوده فرانت رنج، شهرستان ال پاسو و شهرستان بولدر، مترو دنور)، و (۲) رویداد/تأثیر خطر ( سیل ناگهانی، سیل، باران ۲۰۱۳، اضطراری، ضربه، پل ها و جاده های آسیب دیده، خانه های آسیب دیده، خسارات مالی، تخلیه و تخلیه). هر توییتی که حاوی نام مکان یا رویداد/تأثیر خطر باشد در تجزیه و تحلیل گنجانده شده است. این توییتها یک مدت ۱۰ روزه از ۹ تا ۱۸ سپتامبر را پوشش میداد و همه رویدادهای سیل را به تصویر میکشید. از ۱ میلیون توییت، ما ۵۲۰۲ (۰٫۴۴٪) توییت انگلیسی را استخراج کردیم که در مکانی در کلرادو برچسب جغرافیایی داشتند. مطالعه قبلی ما ۷۲۰ (۱۴ درصد از توییتهای دارای برچسب جغرافیایی و ۰) را استخراج کرد.۱۰ ، ۴۹ ]. توییتهای مربوطه حاوی اطلاعات قابلتوجهی مرتبط با سیل با امتیاز ارتباط آستانه ۱٫۳ [ ۱۰ ] بود.
۳٫۲٫۲٫ داده های GIS
برای درک توزیع فضایی توییت ها با توجه به منطقه تحت تاثیر سیل، مجموعه داده وسعت سیل از شهر بولدر [ ۵۰ ] به دست آمد. این مجموعه داده با استفاده از نظرسنجیهای میدانی، تصاویر ماهوارهای Digital Globe Worldview و ورودی عمومی از برنامههای کاربردی آنلاین جمعسپاری بولدر تولید شده است. دادههای شبکه خیابان از شهر بولدر برای ارزیابی قابلیت اطمینان توییتها با توجه به خسارات وارده به جادهها و خیابانهای سیلزده استفاده شد [ ۵۱ ].
۳٫۲٫۳٫ پیام های هشدار/هشدار سازمان ملی اقیانوسی و جوی (NOAA).
پیام های اخطار/هشدار ارسال شده توسط سرویس ملی هواشناسی در طول رویداد سیل سال ۲۰۱۳ کلرادو از دفتر پیش بینی آب و هوا NOAA در بولدر [ ۵۲ ] به دست آمد. این پیام ها حاوی پیش بینی های هواشناسی، مشاهدات، نظارت های عمومی، هشدارها، توصیه ها و مناطقی بود که ممکن است در طول رویداد سیل تحت تاثیر قرار گیرند. این پیامهای هشدار/اخطار بهعنوان اطلاعات مرجع رسمی در ارزیابی قابلیت اطمینان توییتها استفاده شد.
۳٫۲٫۴٫ اسناد مرجع
گزارشهای ارزیابی خسارت در مورد رویداد سیل کلرادو از دولتهای فدرال، ایالتی و محلی و آژانسهای مدیریت اضطراری از وبسایت مربوطه آنها بازیابی شد. اسناد شامل “گزارش آگاهی موقعیت” [ ۵۳ ]، گزارش ارزیابی بارندگی [ ۵۴ ]، و گزارش ارزیابی خسارت [ ۵۵ ] است. این گزارش ها آگاهی موقعیتی در مورد علت سیل، گستردگی و شدت سیل و همچنین خسارات وارده به اموال و زیرساخت ها در مناطق آسیب دیده ارائه می دهد. علاوه بر این، مقالات روزنامهای که حوادث و/یا حقایق (یعنی آسیب به جادههای خاص) را تأیید میکردند نیز بهعنوان اسناد مرجع استفاده شدند [ ۵۶ ، ۵۷ ].
۳٫۳٫ تحلیل ها و تکنیک ها
این بخش مراحل مورد استفاده برای ارزیابی قابلیت اطمینان توییتهای مربوطه را ارائه میکند. در زمینه ارتباطات ریسک، اطلاعات مربوطه ممکن است قابل اعتماد نباشد، به عنوان مثال، ذکر زمان و/یا مکان رویداد نمی تواند قابل اعتماد تلقی شود مگر اینکه صحت و درستی اطلاعات مربوطه تایید شود. بر اساس این منطق، این تحقیق ابتدا توییت های مرتبط را به صورت متوالی استخراج کرد و سپس قابلیت اطمینان آنها را ارزیابی کرد ( شکل ۱).). به طور خاص، مدل کیسه کلمات در توییتهای دارای برچسب جغرافیایی برای استخراج توییتهای مرتبط فرض شده اعمال شد. استخراج کیسهای از کلمات از عبارات جستجوی موضوعی خاص و کلمات/هشتگهای پرتکرار برای اندازهگیری ارتباط یک سند (یعنی توییتها) با عبارات جستجو و استخراج اسناد مرتبط فرضی استفاده میکرد. ابتدا ارتباط این توییت ها مشخص شد و پس از آن قابلیت اطمینان آن ها مورد ارزیابی قرار گرفت.
تجزیه و تحلیل متن شامل چند مرحله متوالی است. اولین قدم جستجوی اطلاعات واضح از اسناد مرجع، به ویژه پیامهای هشدار/هشدار آبوهوا از سوی سرویس ملی هواشناسی و سازمانهای مدیریت اضطراری محلی و ایالتی بود. علاوه بر این، رویدادها، نام جادهها و خیابانهای آسیبدیده و زمان ارسال هر توییت بهصورت دستی شناسایی شدند [ ۵۸ ]] از توییت های مربوطه و سپس به عنوان کلمات کلیدی برای جستجوی اطلاعات مرتبط در اسناد مرجع استفاده می شود. اگر چنین اطلاعاتی یافت نشد، موضوع، زمان ارسال و مکان توییتها برای استفاده بیشتر مستند شد. گام بعدی ارزیابی کلی بود که آیا توییتهای تایید نشده مستند با سایر توییتها بر اساس موضوع، زمان ارسال یا مکان ارتباط داشتند یا خیر. در نهایت، اطلاعات خبری در صورت وجود، به عنوان منبع مرجع مکمل نیز مورد استفاده قرار گرفت. اگر شواهدی از اسناد مرجع یا توییتهای کافی از چندین کاربر توییتر یافت میشد که با زمینه خطر در توییتهای مربوطه مطابقت داشت، توییتهای مورد مطالعه قابل اعتماد تلقی میشدند.
در فرآیند تحلیل تصویر، ۳۰۸ تصویر از ۷۲۰ توییت مرتبط دانلود شد. تصاویر در صورتی قابل اعتماد در نظر گرفته میشوند که یکی از دو شرط زیر را داشته باشند: (۱) به دست آوردن شواهد از منابع معتبر، یا (۲) اثبات متقابل یکدیگر. هر دو روش ارزیابی دستی و خودکار برای تجزیه و تحلیل ۳۰۸ تصاویر پیادهسازی شدند. در رویکرد دستی، تصاویر بهصورت دستی از نظر جادهها/خیابانها و آسیبهای اموال و همچنین محتوای متن توییت مربوطه آنها مورد بررسی قرار گرفتند. سپس محتوای تصویر، موقعیت جغرافیایی و محتوای متن با اسناد مرجع مقایسه شد. در رویکرد خودکار/هوش مصنوعی (AI)، تصاویر Google Cloud Vision API 308 در Google Cloud’s Vision API (رابط برنامه نویسی برنامه) آپلود شدند [ ۵۹]، و با استفاده از مدلهای یادگیری ماشینی از قبل آموزشدیدهشده Google، طبقهبندی و برچسبهای طبقهبندی شدند. هدف این رویکرد استفاده از ابزار AI (هوش مصنوعی) موجود برای بهبود کارایی استخراج ویژگیهای مرتبط با سیل برای تسهیل فرآیند ارزیابی قابلیت اطمینان توییتها است.
۴٫ نتایج و بحث
۴٫۱٫ ارزیابی محتوای متن
سه نویسنده این مقاله روی ارزیابی دستی متن توییت کار کردند و هر توییت توسط حداقل دو نویسنده برای به حداقل رساندن خطای انسانی یا سوگیری ارزیابی شد. در نتیجه، ۵۸۴ توئیت از ۷۲۰ توییت مربوطه برای داشتن اطلاعات قابل اعتماد تأیید شد. نمونههایی از توییتهای تأیید نشده شامل توییتهایی است که صرفاً درباره احساسات یا توییتهایی حاوی اطلاعاتی هستند که بر اساس معیارهای ارزیابی ما تأیید نمیشوند. جدول ۱ نشان میدهد که چگونه نام جادهها/خیابانهای آسیبدیده، زمان ارسال توییت و اطلاعات ریسک مرتبط به صورت دستی استخراج شده است. مکان توییت های نشان داده شده در جدول ۱ در شکل ۲ با استفاده از شماره شناسه آنها مشخص شده است. شرح مفصلی از فرآیند ما برای ارزیابی قابلیت اطمینان هر توییت در زیر ارائه شده است.
با استفاده از عبارت کلیدی «غرب برادوی»، یک پیام هشدار/هشدار مرتبط NOAA از توییت شماره ۱ در جدول ۱ یافت شد : «شدت بارندگی ساعتی در ایستگاه Sugarloaf RAWS 6 مایلی. غرب بولدر در مقایسه با ارتفاع گیج در بولدر کریک در بولدر ( غرب برادوی ). اولین اوج سیل از نزدیک به دنبال بارش شدید باران قبل از نیمه شب ۱۱ تا ۱۲ سپتامبر بود ، زمانی که ۳٫۵ اینچ در ۶ ساعت سقوط کرد. (داده ها: بارندگی: RAWS از طریق WRCC؛ و جریان: کلرادو DWR؛ ترسیم شده توسط جف لوکاس، WWA)”.
پیام بالا به ارتفاع سنج در بولدر کریک در غرب برادوی پس از اوج سیل که ناشی از بارندگی شدید قبل از نیمه شب ۱۱ سپتامبر بود اشاره کرد. این با توییت شماره ۱ مطابقت دارد و توضیح می دهد که چرا «بولدر کریک در حال ریختن کرانه خود در غرب برادوی» در ساعت ۳:۰۲ بامداد ۱۲ سپتامبر است. بنابراین، توییت شماره ۱ در جدول ۱ از نظر مکان، زمان و محتوا قابل اعتماد در نظر گرفته شد.
هنگام جستجوی «برادوی» و «خیابان آراپاهو»، هیچ مدرک مستقیمی در توییت شماره ۲ یافت نشد، که ممکن است به این دلیل باشد که خیابان آراپاهو یک جاده شهرستانی است و به طور کلی آنقدر خاص است که در گزارشهای هشدار یا ارزیابی خسارت رسمی ذکر شود. با این حال، همانطور که در نماد شماره ۲ در شکل ۲ نشان داده شده است ، بولدر کریک گذرگاه برادوی و خیابان آراپاهو را سیل کرد و به ناظر این امکان را داد که در عرض ۱۰ دقیقه افزایش سطح آب ۲٫۵ فوتی را تشخیص دهد. علاوه بر این، زمان ارسال توییت (۵:۳۰ صبح) در دوره زمانی بود که بولدر کریک رسماً شناسایی شد که انباشتگی سریع بارندگی را تجربه کرده است (به بخش ۳٫۱ مراجعه کنید ).
تقاطع خیابان ۸ و مارین (نماد شماره ۳ در شکل ۲ ) در مجاورت و توسط گریگوری کانیون کریک قرار داشت که با توییت شماره ۳ مطابقت دارد ( جدول ۱ را ببینید ) که نشان می دهد زهکشی در گریگوری کانیون خیابان هشتم را زیر آب گرفته است. بر اساس زمان، توییت شماره ۲ افزایش سریع سطح آب را در بولدر کریک در ساعت ۵:۳۰ صبح شناسایی کرد و ۲۰ دقیقه بعد، این توییت آبگرفتگی جادهها را به دلیل سیل گریگوری کانیون کریک در نزدیکی بولدر کریک گزارش کرد. این تأیید می کند که اطلاعات ریسک در توییت شماره ۳ بر اساس محتوا، زمان و مکان های جغرافیایی قابل اعتماد است.
تقاطع خیابان ۲۸ و خیابان کلرادو (نماد شماره ۴ در شکل ۲ ) بین بولدر کریک و اسکانک کریک است، و توییت شماره ۴ در اوج سیل زمانی که آب از نهرها سرازیر شد پست شد. بارندگی مداوم چند روزه باعث آبگرفتگی بیشتر شاخهها و پس از آن بیشتر جادههای شهر بولدر سیتی شد. برآورد خسارت جاده در گزارش ارزیابی خسارت رسمی [ ۵۵ ] یافت شد: “مقامات تخمین می زنند که سیل تقریباً ۴۸۵ مایل از جاده ها و ۵۰ پل را در شهرستان های آسیب دیده آسیب دیده یا ویران کرده است.” این توییت از جادههای سیلآلود با «آب تا زانو» خبر میدهد و درست پس از بارندگی شدید مداوم پست شده است. بنابراین، به عنوان یک توییت قابل اعتماد در نظر گرفته شد.
توییت شماره ۵ در جدول ۱ در زمینه ای مشابه با توییت شماره ۴ پست شد و به نظر می رسید کاربر شاهد خیابان های محله سیل زده بود. از آنجایی که این توییت قابل اعتماد بود، خیابان پانزدهم (جایی که توییت پست شده بود) را می توان به عنوان غرق در آب علامت گذاری کرد تا دیگران بتوانند از این جاده اجتناب کنند.
بزرگراه ایالتی ۳۶ چندین بار در توییت های #۶، #۱۰، #۱۱ و #۱۲ ذکر شد ( جدول ۱ ). اولین مورد در ۱۲ سپتامبر بود که بارندگی بیش از حد ادامه یافت و وضعیت سیل را تشدید کرد. این توئیت ها همچنین جزئیات دیگری را درباره بزرگراه ۳۶، مانند «باران و بارندگی»، «سیلاب بیش از ۳ فوتی آب» و «بسته شدن متعاقب آن» فاش کردند. شواهدی از این نیز در گزارش رسمی ارزیابی خسارت یافت شد [ ۵۵]: «بر اساس اطلاعات آژانس مدیریت اضطراری فدرال (FEMA)، سیل بیش از ۳۵۰ خانه را ویران کرد و بیش از ۱۹۰۰۰ خانه و ساختمان تجاری آسیب دیدند که دسترسی به بسیاری از آنها جز با پای پیاده غیرممکن بود. سیل در مجموع به ۴۸۵ مایل جاده آسیب رساند، ۳۰ پل بزرگراه ایالتی را ویران کرد و ۲۰ پل دیگر را به شدت آسیب دید. در اوج سیل، مقامات مجبور به بستن ۳۶ بزرگراه ایالتی شدند. برخی از بزرگراه ها را نمی توان هفته ها یا حتی ماه ها تعمیر کرد. این ارزیابی ها قابل اعتماد بودن توییت ها را تایید کرد.
توییت های شماره ۶، ۱۰ و ۱۲ نیز در امتداد بزرگراه ۳۶ موقعیت جغرافیایی داشتند، اما توییت شماره ۱۱ فراتر از محدوده شهر بولدر پست شد. از آنجایی که این توییت از مکانی ارسال شده است که دورتر از مکان آسیبدیده است، اثبات قابلیت اطمینان آن بدون مراجعه به توییتهایی که بزرگراه ۳۶ را نیز ذکر کردهاند، دشوار بود. این توییت قابل اعتماد در نظر گرفته شد. در نتیجه، کلیدواژههایی که تأیید شدهاند مرتبط با حوادث/مکانهای مهم هستند، مانند بزرگراه ۳۶، میتوانند برای استخراج توییتهایی استفاده شوند که فراتر از محدوده فضایی منطقه مورد مطالعه هستند یا هیچ اطلاعات موقعیت جغرافیایی ندارند. این رویکرد حجم بیشتری از توییتهای مرتبط را به دست میدهد.
توییت شماره ۷ ارسال شده در ساعت ۳:۲۲ بامداد ۱۳ سپتامبر اشاره کرد که بخشی از خیابان ۸ بین دانشگاه کلرادو بولدر و خیابان مارین (نماد شماره ۷ در شکل ۲ ) بارندگی شدیدی را تجربه کرده است. با توجه به اینکه سایت در نزدیکی بولدر کریک، سان شاین کانیون کریک، و تقاطع گرگوری کانیون کریک قرار داشت، خیابان هشتم در آن زمان به احتمال زیاد دچار سیل شده بود. یک خبر توسط هافینگتون پست گزارش داد که “حدود ۸۰ ساختمان در محوطه دانشگاه به نوعی آسیب دیدند، پلیس CU بولدر توییت کرد، و فاضلاب خام از یک لوله در یک منطقه جاری بود” [ ۵۶ ] این توییت را تایید کرد. گزارش ارزیابی خسارت دانشگاه [ ۵۷] همچنین اشاره کرد که «۸۰ ساختمان از ۳۰۰ سازه در پردیس بولدر آسیب دیده اند. این آسیب به عنوان “گسترده” توصیف شده است اما شدید نیست.” این دو مقاله خبری قابل اعتماد بودن توییت را تایید کردند.
توییتهای ۸ و ۹ در امتداد نهر سیلزده اسکانک قرار گرفتند (نمادهای ۸ و ۹ در شکل ۲ ). در حالی که خیابان ۳۰ در حال سیل بود، خیابان کلرادو مجاور از قبل بسته شده بود. هر دو خیابان در منطقه Foothills هستند که در خلاصه گزارش ارزیابی خسارت گزارش شده است که به طور جدی تحت تأثیر سیل قرار گرفته است: “کوهپایه های اطراف بولدر نیز شاهد سیل شدید و جریان های آوار بودند” [ ۵۴ ].
۴٫۲٫ ارزیابی محتوای تصویر
تحویل تعاملی اطلاعات (داستانها) از طریق تصاویر جذابتر است زیرا راهی مؤثر برای تجسم اطلاعات است و مغز را قادر میسازد تا اطلاعات را پردازش و سازماندهی کند. از طریق تصاویر، مردم می توانند درک عمیقی در مورد شدت و اهمیت مسائل مرتبط با یک فاجعه ایجاد کنند [ ۶۰ ]. با این حال، مطالعات قبلی نشان داده است که حدود ۴٪ از توییت ها هرزنامه هستند [ ۶۱ ]، و تصاویر جعلی تمایل دارند از طریق وب منتشر شوند، به ویژه در طول بحران [ ۶۲ ]. علیرغم تحقیقات فراوان در مورد فیلتر کردن هرزنامه ها یا توییت های فیشینگ [ ۶۳ ]، مطالعاتی که بر انتشار تصاویر جعلی متمرکز شده اند بسیار پراکنده هستند [ ۶۲ ]]. با توجه به این محدودیت، ۳۰۸ تصویر از توییت های مربوطه دانلود شد و دو استراتژی برای ارزیابی قابلیت اطمینان آن تصاویر اجرا شد. نتایج نشان داد که رویکرد دستی ۶۰ (۱۹٪) تصویر قابل اعتماد را در مقایسه با رویکرد هوش مصنوعی که تنها ۳۴ (۱۱٪) را شناسایی کرد، شناسایی کرد. بخش زیر نتایج هر دو رویکرد را ارائه می دهد.
۴٫۲٫۱٫ رویکرد دستی
این بخش روش سازماندهی تصاویر بر اساس مکان، زمان، عکاس را نشان می دهد. علاوه بر این، تصاویر مشابه به منظور مقایسه و روشن کردن مضامین یا موضوعات برجسته در گروههای تصویر با هم گروهبندی شدند. شکل ۳ ، شکل ۴ و شکل ۵ ، و شکل ۶ ، ۲۴ تصویر از ۳۰۸ تصویر را نشان می دهد که در مضامین مختلف شناسایی و گروه بندی شده اند. تمام تصاویر در شکل ۳ شرایط سیل بولدر کریک را در نقاط زمانی، چشم اندازها و زوایای مختلف نشان می دهند. شکل ۴ شامل تصاویری در مورد زمین زیر آب در خیابان ها و تقاطع های مختلف است. برخی از خیابان ها در ۴٫۱٫۲ و ۴٫۱٫۴ ذکر شده است.
تصاویر نشان داده شده در شکل ۵ در یک مکان توسط افراد مختلف، در زمان های مختلف و از زوایای مختلف گرفته شده است. آب سیل که از روی پل می ریزد آبشاری غیرعادی ایجاد کرد و مردم را به عکس گرفتن برای گزارش شدت و نادر بودن سیل جذب کرد. سه تصویر پایین در شکل ۵ افزایش سطح آب را در بولدر کریک در زیر پل برادوی ثبت کردند که به وضوح تغییر زمانی در شدت سیل را نشان می دهد. این یافته برای ارتباطات ریسک مبتنی بر جمع سپاری بسیار مهم است زیرا تعداد زیادی از تصاویر می توانند به رغم کمبود اطلاعات خارجی یکدیگر را تأیید کنند.
تصاویر در شکل ۶ توسط یک خبرنگار خبری محلی ارسال شده است که به طور مداوم وضعیت سیل در چندین مکان را همراه با تصاویر در توییتر گزارش می کند. مکان هایی که گزارشگر به آنها اشاره کرد عبارتند از: خیابان کلرادو، حیاط خلوت دبیرستان بولدر، استادیوم فولسوم فیلد، خیابان ۲۸ و خیابان آراپاهو. متن و تصاویر ارسال شده توسط خبرنگار می تواند قابل اعتماد باشد.
۴٫۲٫۲٫ رویکرد هوش مصنوعی
این بخش رویکرد هوش مصنوعی را برای تشخیص ویژگیهای مرتبط با سیل با استفاده از GCV API نشان میدهد و نتیجه تشخیص خودکار را ارائه میدهد. GCV API دو نوع تشخیص خودکار را ارائه کرد: تشخیص تصویر و وب [ ۵۹ ]. برای هر تصویری که به API داده میشود، مدلهای یادگیری ماشینی از قبل آموزشدیده آن، نتایج تشخیص تصویر و تشخیص وب را تولید میکنند. نتایج تشخیص تصویر شامل تصاویر حاشیه نویسی شده با تشخیص ویژگی های تصاویر است. تشخیص وب از محتوای تصویر و فراداده آن برای خزیدن در وب و شناسایی اطلاعات مرتبط از اینترنت استفاده می کند. دقت تشخیص تصویر بر اساس در دسترس بودن داده های آموزشی و الگوریتم تشخیص است. دقت تشخیص وب بر اساس محتوای تصویر، ابرداده و در دسترس بودن اطلاعات مرتبط در وب است.
در میان ۳۴ تصویر شناسایی شده توسط GCV API مرتبط با سیل سال ۲۰۱۳ کلرادو، تشخیص وب بهتر از نتایج تشخیص تصویر بود، که یک نمونه از آن را می توان در شکل ۷ یافت . مطابق شکل ۷ ، تشخیص وب به طور دقیق صحنه را به عنوان سیل سال ۲۰۱۳ کلرادو شناسایی کرد، در حالی که تشخیص تصویر فقط ویژگی آب را در تصویر تشخیص داد. از سوی دیگر، شکل ۸نشان می دهد که هر دو حالت تشخیص نتوانستند وضعیت آبگرفتگی پارکینگ را شناسایی کنند، زیرا اکثر خودروها فقط از بالا قابل مشاهده هستند. GCV API فقط میتواند نوع یا اندازه خودروها را تشخیص دهد، بهعنوان مثال، «ماشین خانوادگی» یا «وسیله نقلیه لوکس»، عمدتاً به این دلیل که تصاویر نمونه مورد استفاده برای آموزش مدلهای زیربنایی شامل صحنههای آبگرفتگی پارکینگ نمیشوند. از یک طرف، این نشان دهنده محدودیت های فعلی پردازش تصویر مبتنی بر هوش مصنوعی است. از سوی دیگر، همچنین بیانگر این است که استفاده از تصاویر به تنهایی باعث فقدان اطلاعات زمینه ای برای کمک به درک و استفاده کامل از تصاویر می شود.
۴٫۳٫ استخراج توییت های اضافه شده با استفاده از کلمات کلیدی تایید شده
بخش ۴٫۱ و بخش ۴٫۲ ۵۸۴ توییت قابل اعتماد و ۶۰ تصویر قابل اعتماد را شناسایی کردند که به ترتیب ۱۱% و ۱% از ۵۲۰۲ توییت دارای برچسب جغرافیایی و ۰٫۰۵% و ۰٫۰۱% از کل ۱,۱۹۵,۱۸۳ توییت خریداری شده را تشکیل می دهند. برای استفاده بهتر از این منبع داده، گروهی از کلیدواژه ها/موقعیت ها (به عنوان مثال، بزرگراه ۳۶) را از توییت های قابل اعتماد تأیید شده که در بخش ۴٫۱ و بخش ۴٫۲ بحث شده است، انتخاب کردیم.و از اینها برای استخراج توییت های بیشتری که هیچ اطلاعات موقعیت جغرافیایی نداشتند استفاده کرد. ما معتقد بودیم که انجام این کار حجم بیشتری از توییتهای مرتبط را به دست میآورد که به دلیل کمبود اطلاعات جغرافیایی کنار گذاشته شدند. علیرغم عدم وجود موقعیت جغرافیایی، بازه زمانی (۹ تا ۱۸ سپتامبر ۲۰۱۳) و کلمات کلیدی (الف. نام مکان: کلرادو، بولدر، و غیره، و ب. رویداد/تأثیر خطر: سیل، باران و غیره) برای دانلود استفاده شده است. آن توییتها ارتباط آن توییتها را تضمین میکرد. کلمات کلیدی که استفاده کردیم از جدول ۱ بودندکه شامل: غرب برادوی، برادوی، خیابان آراپاهو، خیابان مارین، خیابان ۲۸، خیابان کلرادو، بولدر کریک، بزرگراه ۳۶/US-36، و اسکانک کریک بود. با استفاده از این کلمات کلیدی، ما ۲۴۷۲ توییت غیر تکراری، مرتبط و قابل اعتماد اضافی و ۷۵۲ تصویر قابل اعتماد پیدا کردیم که به ترتیب ۰٫۲٪ و ۰٫۰۶٪ از کل ۱،۱۹۵،۱۸۳ توییت خام را تشکیل می دهند. این یک پیشرفت بزرگ نسبت به استفاده از توییت های دارای برچسب جغرافیایی به تنهایی برای این گردش کار تحقیقاتی است.
۵٫ بحث، پیامدهای ارتباط ریسک و تحقیقات آینده
هدف از این تحقیق استفاده از یک گردش کار یکپارچه برای استخراج و ارزیابی اطلاعات ریسک قابل اعتماد برای تسهیل ارتباطات ریسک، افزایش آگاهی موقعیتی و ارتقای پاسخ عمومی به مخاطرات طبیعی بود. اگر ارزیابیهای مربوط و قابلیت اطمینان برای کاهش یا حذف مشکلات کیفیت دادهها به درستی انجام شود، ارتباطات ریسک جمعسپاری میتواند اطلاعات ریسک ارزشمندی را ارائه دهد.
در این مطالعه، تجزیه و تحلیل محتوای متن و تصویر را برای استخراج و ارزیابی قابلیت اطمینان توییت اجرا کردیم. تحقیقات قبلی با استفاده از تجزیه و تحلیل تصویر و متن در تحقیقات سیل مبتنی بر توییتر نسبتا نادر بود، اکثر تحقیقات قبلی تنها بر روی متن توییتر متمرکز بودند. دلیل دیگر استفاده از این رویکرد این است که اطلاعات استخراج شده از متن و تصاویر اغلب مکمل یکدیگر هستند، بنابراین گنجاندن هر دو می تواند اطلاعات بیشتری را نسبت به استفاده از متن یا تصاویر استخراج کند.
نقاط قوت این تحقیق عبارتند از: (۱) داده های بارش برای توضیح علت سیل استفاده شد، (۲) از داده های مکانی برای درک وسعت مکانی سیل استفاده شد، (۳) اسناد رسمی مربوطه به دقت ارجاع شد، و (۴) ) هر دو رویکرد دستی و هوش مصنوعی در تجزیه و تحلیل محتوای تصویر برای اطمینان از دقت و زمان پردازش کارآمد پیادهسازی شدند. رویکردهای دستی و هوش مصنوعی مزایای هوش انسانی و کارایی محاسباتی را با هم ترکیب کردند. در حالی که استفاده از هوش انسانی برای اعتبارسنجی محتوای متنی توییت ها در تحقیقات متن کاوی توییتر جدید نیست، اما سهم منحصر به فردی در تحقیقات سیل به ارمغان آورد. به طور خاص، امکان شناسایی سناریوهای مختلف و اطلاعات پردازش شده را فراتر از متن ساده (به عنوان مثال، رویدادها را در تصاویر مختلف مرتبط کنید یا رویدادها را بر اساس نزدیکی آنها به رویدادهای مناطق اطراف با مشخص کردن آنها بر روی نقشه ها مرتبط کنید)، که دستیابی به رویکردهای هوش مصنوعی فعلی غیرممکن است. با توجه به اینکه شبکههای عصبی فعلی (مانند ResNet، UNet) که برای موقعیتهای فاجعهبار استفاده میشوند، نیازمند هوش انسانی برای جمعآوری و برچسبگذاری مقدار قابلتوجهی از تصاویر آموزشی هستند، رویکرد دستی ما مکمل رویکرد هوش مصنوعی است. GCV API را می توان با سایر الگوریتم های هوش مصنوعی جایگزین کرد. با این حال، گردش کار تحقیقاتی ما میتواند توسط محققان علاقهمند به طراحی سیستمهای خودکار یا نیمه خودکار برای استخراج دادهها و اطلاعات قابل اعتماد و مرتبط از جریانهای رسانههای اجتماعی که در جستجوی واکنش به بلایا هستند، استفاده شود. که دستیابی به رویکردهای فعلی هوش مصنوعی غیرممکن است. با توجه به اینکه شبکههای عصبی فعلی (مانند ResNet، UNet) که برای موقعیتهای فاجعهبار استفاده میشوند، نیازمند هوش انسانی برای جمعآوری و برچسبگذاری مقدار قابلتوجهی از تصاویر آموزشی هستند، رویکرد دستی ما مکمل رویکرد هوش مصنوعی است. GCV API را می توان با سایر الگوریتم های هوش مصنوعی جایگزین کرد. با این حال، گردش کار تحقیقاتی ما میتواند توسط محققان علاقهمند به طراحی سیستمهای خودکار یا نیمه خودکار برای استخراج دادهها و اطلاعات قابل اعتماد و مرتبط از جریانهای رسانههای اجتماعی که در جستجوی واکنش به بلایا هستند، استفاده شود. که دستیابی به رویکردهای فعلی هوش مصنوعی غیرممکن است. با توجه به اینکه شبکههای عصبی فعلی (مانند ResNet، UNet) که برای موقعیتهای فاجعهبار استفاده میشوند، نیازمند هوش انسانی برای جمعآوری و برچسبگذاری مقدار قابلتوجهی از تصاویر آموزشی هستند، رویکرد دستی ما مکمل رویکرد هوش مصنوعی است. GCV API را می توان با سایر الگوریتم های هوش مصنوعی جایگزین کرد. با این حال، گردش کار تحقیقاتی ما میتواند توسط محققان علاقهمند به طراحی سیستمهای خودکار یا نیمه خودکار برای استخراج دادهها و اطلاعات قابل اعتماد و مرتبط از جریانهای رسانههای اجتماعی که در جستجوی واکنش به بلایا هستند، استفاده شود. GCV API را می توان با سایر الگوریتم های هوش مصنوعی جایگزین کرد. با این حال، گردش کار تحقیقاتی ما میتواند توسط محققان علاقهمند به طراحی سیستمهای خودکار یا نیمه خودکار برای استخراج دادهها و اطلاعات قابل اعتماد و مرتبط از جریانهای رسانههای اجتماعی که در جستجوی واکنش به بلایا هستند، استفاده شود. GCV API را می توان با سایر الگوریتم های هوش مصنوعی جایگزین کرد. با این حال، گردش کار تحقیقاتی ما میتواند توسط محققان علاقهمند به طراحی سیستمهای خودکار یا نیمه خودکار برای استخراج دادهها و اطلاعات قابل اعتماد و مرتبط از جریانهای رسانههای اجتماعی که در جستجوی واکنش به بلایا هستند، استفاده شود.
علیرغم مزایا، هر دو رویکرد دستی و هوش مصنوعی از نظر قابلیت استفاده و پیاده سازی محدودیت های خاصی دارند. اول، با توجه به ماهیت زمانبر و پرهزینه رویکرد دستی پیشنهادی، اجرای آن ممکن است به تیمی از متخصصان نیاز داشته باشد تا تلاشهای زیادی را برای استخراج اطلاعات مربوط به ریسک مرتبط و قابل اعتماد در شرایط اضطراری اختصاص دهند. یکی از پدیدههای امیدوارکننده برای مقابله با این محدودیت، ظهور شهروندان داوطلب داوطلبی است که با ارائه داوطلبانه پشتیبانی فنی یا اطلاعات پردازش برای تسهیل تلاشهای بشردوستانه در بلایای اخیر، خود را در فعالیتهای واکنش به بلایا درگیر میکنند [ ۶۴ ، ۶۵ ]. به عنوان مثال، CitizenScience.gov، تلاش های علوم شهروندی توسط سازمان زمین شناسی ایالات متحده (https://www.usgs.gov/topic/citizen-science) و تلاشهای جمعسپاری و دانش شهروندی FEMA به شهروندان این امکان را داده است که در مدیریت اضطراری و تلاشهای واکنش برای تکمیل فعالیتهای در دست اقدام تصمیمگیرندگان شرکت کنند. با مشارکت این انساندوستان دیجیتال، ما معتقدیم که گردش کار مشخص شده در تحقیق ما میتواند تا حدی یا به طور کامل در واکنشهای بلایا به کار گرفته شود. علاوه بر این، رویکرد هوش مصنوعی قادر به تشخیص اطلاعات قابل اعتماد برای ۱۱٪ از تصاویر است که کمتر از درصد به دست آمده در رویکرد دستی (۱۹٪) است و بیشتر تصاویر شناسایی شده با رویکرد هوش مصنوعی نیز با رویکرد دستی شناسایی شدند. هوش مصنوعی دقت پایینی دارد زیرا برای تشخیص و درک تصویر با هدف کلی توسعه یافته است، اما برای یادگیری سیل/فاجعه طراحی نشده است. اگر از تصاویر بیشتری برای آموزش مدل هوش مصنوعی استفاده شود، این پتانسیل را دارد که به طور قابل توجهی دقت خود را بهبود بخشد. این رویکرد به سرمایهگذاری نیروی انسانی کمتری نیاز دارد، بنابراین مکمل رویکرد دستی است و زمانی سودمند است که تعداد قابل توجهی توییت در دسترس باشد. در نهایت، خطاهای انسانی و سوگیری اکتشافی ممکن است در رویکردهای دستی معرفی شوند، حتی اگر چندین نویسنده نتایج را بررسی کرده باشند.
با توجه به محدودیت این گردش کار تحقیقاتی، تحقیقات آینده بر سادهسازی فرآیند و خودکارسازی کل گردش کار ارزیابی ارتباط و قابلیت اطمینان دادههای توییتر تمرکز خواهد کرد. علاوه بر این، ادغام تلاشهای ارزیابی قابلیت اطمینان به رهبری شهروندان به دنبال پروتکلهای آگاهانه، سودمندی این گردش کار تحقیقاتی را تا حد زیادی افزایش میدهد. از تصاویر فضا و هوا نیز می توان برای ارزیابی قابلیت اطمینان توییت ها استفاده کرد. در حالی که محققان در تلاش برای به حداکثر رساندن میزان اطلاعات خطر از توییتر هستند، برای آژانسهای مدیریت اضطراری ضروری است که استانداردهایی با قابلیت پیروی آسان برای کاربران توییتر ایجاد کنند تا انتشار اطلاعات مربوط به بحران را تشویق کنند تا استفاده از آنها برای فعالیتهای واکنش تسهیل شود.
۶٫ نتیجه گیری
این تحقیق یک گردش کار یکپارچه را برای استخراج و ارزیابی اطلاعات ریسک قابل اعتماد از توییت ها برای تسهیل ارتباطات ریسک، افزایش آگاهی موقعیتی و ارتقای پاسخ عمومی به خطرات طبیعی اجرا کرد. هر دو روش دستی و خودکار برای ترکیب مزایای هوش انسانی و کارایی محاسباتی مورد استفاده قرار گرفتند. ما دریافتیم که هم متن توییت و هم تصاویر حاوی اطلاعات مفید و قابل اعتمادی در مورد جاده ها/خیابان های آسیب دیده/سیل زده است. این اطلاعات می تواند به تلاش های هماهنگی واکنش اضطراری و تخصیص آگاهانه منابع کمک کند. با کمک تلاشهای دانشمندان شهروند و سیستمهای خوب طراحی شده برای سادهسازی این گردش کار،
منابع
- هانا، آر. مکس، آر. بلایای طبیعی. در دسترس آنلاین: https://ourworldindata.org/natural-disasters (در ۵ فوریه ۲۰۲۰ قابل دسترسی است).
- نیول، BR; راکو، تی. یچیام، ای. سامبور، ام. اطلاعات بلایای نادر می تواند ریسک پذیری را افزایش دهد. نات. صعود چانگ. ۲۰۱۶ ، ۶ ، ۱۵۸-۱۶۱٫ [ Google Scholar ] [ CrossRef ]
- بردلی، دی.تی. مک فارلند، ام. کلارک، ام. اثربخشی ارتباط خطر فاجعه: مروری سیستماتیک از مطالعات مداخله. در ارتباط موثر در هنگام بلایا ; انتشارات دانشگاهی اپل: وارتاون، نیوجرسی، ایالات متحده آمریکا، ۲۰۱۶؛ صص ۸۱-۱۲۰٫ [ Google Scholar ]
- الیسا، اس. گريكو، اي. آمريكايي ها نسبت به نقش سايت هاي رسانه هاي اجتماعي در ارائه اخبار محتاط هستند . مرکز تحقیقات پیو: واشنگتن، دی سی، ایالات متحده آمریکا، ۲۰۱۹٫ [ Google Scholar ]
- ریچاردز، دی. جریان اصلی رسانه در مقابل رسانه های اجتماعی: آینده چه چیزی را رقم می زند؟ در دسترس آنلاین: https://tuckerhall.com/mainstream-media-vs-social-media-future-hold/2017 (در ۵ سپتامبر ۲۰۲۰ قابل دسترسی است).
- امبر، اس. استفاده از رسانه های اجتماعی در ارتباطات بحران. در ارتباط با ریسک و تاب آوری جامعه ; Routledge: لندن، بریتانیا، ۲۰۱۹؛ ص ۲۶۷-۲۸۲٫ [ Google Scholar ]
- مون، جی. چرا مردم به اشتراک می گذارند: روانشناسی اشتراک گذاری اجتماعی. در دسترس آنلاین: https://coschedule.com/blog/why-people-share/ (در ۱ مه ۲۰۱۹ قابل دسترسی است).
- اوه، اس. Syn، SY انگیزهها برای اشتراکگذاری اطلاعات و پشتیبانی اجتماعی در رسانههای اجتماعی: تحلیل مقایسهای فیسبوک، توییتر، Delicious، YouTube و Flickr. J. Assoc. Inf. علمی تکنولوژی ۲۰۱۵ ، ۶۶ ، ۲۰۴۵–۲۰۶۰٫ [ Google Scholar ] [ CrossRef ]
- Starbird، K. بررسی اکوسیستم رسانه های جایگزین از طریق تولید روایت های جایگزین از رویدادهای تیراندازی جمعی در توییتر. در مجموعه مقالات یازدهمین کنفرانس بین المللی AAAI در وب و رسانه های اجتماعی ۲۰۱۷، مونترال، QC، کانادا، ۱۵ تا ۱۸ مه ۲۰۱۷٫ [ Google Scholar ]
- لیو، ایکس. کار، بی. ژانگ، سی. کوکران، DM ارزیابی ارتباط توییتها برای ارتباط ریسک. بین المللی جی دیجیت. زمین ۲۰۱۸ ، ۱۲ ، ۷۸۱–۸۰۱٫ [ Google Scholar ] [ CrossRef ]
- بولتون، کالیفرنیا؛ شاتون، اچ. ویلیامز، اچ تی استفاده از رسانه های اجتماعی برای شناسایی و مکان یابی آتش سوزی های جنگلی. در مجموعه مقالات دهمین کنفرانس بین المللی AAAI در وب و رسانه های اجتماعی ۲۰۱۶، کلن، آلمان، ۱۷ تا ۲۰ مه ۲۰۱۶٫ [ Google Scholar ]
- برنگارت، LB; Mujkic، E. WEB 2.0: چگونه برنامه های کاربردی رسانه های اجتماعی از پاسخ های غیرانتفاعی در طول بحران آتش سوزی استفاده می کنند. محاسبه کنید. هوم رفتار ۲۰۱۶ ، ۵۴ ، ۵۸۹-۵۹۶٫ [ Google Scholar ] [ CrossRef ]
- ساچدوا، اس. McCaffrey, S. استفاده از رسانه های اجتماعی برای پیش بینی آلودگی هوا در طول آتش سوزی های کالیفرنیا. در مجموعه مقالات نهمین کنفرانس بین المللی رسانه های اجتماعی و جامعه ۲۰۱۸، کپنهاگ، دانمارک، ۱۸ تا ۲۰ ژوئیه ۲۰۱۸٫ [ Google Scholar ]
- Bonney, R. ‘علم شهروندی: یک سنت آزمایشگاهی’ [در] پرنده زنده: برای مطالعه و حفاظت از پرندگان. حفاظت از مطالعه پرندگان زنده. پرندگان ۱۹۹۶ ، ۱۵ ، ۷-۱۵٫ [ Google Scholar ]
- گرینگارد، اس. به دنبال جمعیت. اشتراک. ACM ۲۰۱۱ ، ۵۴ ، ۲۰-۲۲٫ [ Google Scholar ] [ CrossRef ]
- Hetmank، L. مؤلفه ها و توابع سیستم های جمع سپاری – مروری بر ادبیات سیستماتیک. Wirtschaftsinformatik ۲۰۱۳ ، ۴ ، ۲۰۱۳٫ [ Google Scholar ]
- اونسرود، ح. کامارا، جی. کمپبل، جی. چاکروارتی، NS مشترکات عمومی داده های جغرافیایی: چالش های تحقیق و توسعه. در مجموعه مقالات کنفرانس بین المللی علم اطلاعات جغرافیایی ۲۰۰۴، ادلفی، MD، ایالات متحده آمریکا، ۲۰ تا ۲۳ اکتبر ۲۰۰۴٫ [ Google Scholar ]
- اونسرود، ح. کمپبل، جی. فرصت های بزرگ در دسترسی به داده های “علوم کوچک”. اطلاعات علمی J. ۲۰۰۷ ، ۶ ، OD58–OD66. [ Google Scholar ] [ CrossRef ]
- ویگینز، ای. کروستون، ک. از حفاظت تا جمعسپاری: گونهشناسی علم شهروندی. در مجموعه مقالات چهل و چهارمین کنفرانس بین المللی هاوایی در سال ۲۰۱۱ در علوم سیستمی ۲۰۱۱، Kauai، HI، ایالات متحده آمریکا، ۴ تا ۷ ژانویه ۲۰۱۱٫ [ Google Scholar ]
- ساتون، JN; پالن، ال. Shklovski, I. کانال های پشتی در خط مقدم: استفاده های اضطراری از رسانه های اجتماعی در آتش سوزی های کالیفرنیای جنوبی ۲۰۰۷٫ در مجموعه مقالات پنجمین کنفرانس بین المللی ISCRAM، واشنگتن دی سی، ایالات متحده آمریکا، ۴ تا ۷ مه ۲۰۰۸٫ [ Google Scholar ]
- میک، اس. جکسون، ام جی; Leibovici، DG چارچوبی انعطافپذیر برای ارزیابی کیفیت دادههای جمعسپاری شده. در مجموعه مقالات AGILE’2014، Castellón، اسپانیا، ۳-۶ ژوئن ۲۰۱۴٫ [ Google Scholar ]
- کاستیو، سی. مندوزا، م. Poblete، B. اعتبار اطلاعات در توییتر. در مجموعه مقالات بیستمین کنفرانس بین المللی وب جهانی ۲۰۱۱، حیدرآباد، هند، ۲۸ مارس ۲۰۱۱٫ [ Google Scholar ]
- لیو، جی. لی، جی. لی، دبلیو. Wu, J. بازاندیشی کلان داده: مروری بر کیفیت داده ها و مسائل استفاده. ISPRS J. Photogramm. Remote Sens. ۲۰۱۶ ، ۱۱۵ ، ۱۳۴-۱۴۲٫ [ Google Scholar ] [ CrossRef ]
- تره فرنگی.؛ کاورلی، جی. Pu, C. هرزنامه های اجتماعی، کمپین ها، اطلاعات نادرست و شلوغی. در مجموعه مقالات بیست و سومین کنفرانس بین المللی وب جهانی ۲۰۱۴، سئول، کره، ۸ آوریل ۲۰۱۴٫ [ Google Scholar ]
- استاربرد، ک. مدوک، جی. اوراند، م. آچترمن، پی. میسون، شایعات RM، پرچم های دروغین، و هوشیاران دیجیتال: اطلاعات نادرست در توییتر پس از بمب گذاری ماراتن بوستون در سال ۲۰۱۳٫ ICConference 2014 Proc. ۲۰۱۴ . [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- دیل، اس. اکتشافی و سوگیری ها: علم تصمیم گیری. اتوبوس. Inf. Rev. ۲۰۱۵ , ۳۲ , ۹۳-۹۹٫ [ Google Scholar ] [ CrossRef ]
- Covello، ارتباط خطر VT: یک حوزه در حال ظهور از تحقیقات ارتباطات سلامت. ان بین المللی اشتراک. دانشیار ۱۹۹۲ ، ۱۵ ، ۳۵۹-۳۷۳٫ [ Google Scholar ] [ CrossRef ]
- کار، ب. علم شهروندی در ارتباطات ریسک در عصر فناوری اطلاعات و ارتباطات. موافق محاسبه کنید. تمرین کنید. انقضا ۲۰۱۶ ، ۲۸ ، ۲۰۰۵–۲۰۱۳٫ [ Google Scholar ] [ CrossRef ]
- گرینهالگ، ای. رسانه های اجتماعی پر از درخواست های نجات در طول طوفان هاروی. پروژههای حرفهای از کالج روزنامهنگاری و ارتباطات جمعی: ۲۰۱۸٫ در دسترس آنلاین: https://digitalcommons.unl.edu/journalismprojects/19/ (دسترسی در ۵ سپتامبر ۲۰۲۰).
- کیشور، ن. مارکز، دی. محمود، ع. کیانگ، ام وی؛ رودریگز، آی. فولر، آ. ابنر، پی. راسی، اف. سورنسن، سی. ماس، ال. و همکاران مرگ و میر در پورتوریکو پس از طوفان ماریا. N. Engl. جی. مد. ۲۰۱۸ ، ۳۷۹ ، ۱۶۲-۱۷۰٫ [ Google Scholar ]
- جهانبین، ک. رحمانیان، وی. استفاده از توییتر و استخراج اخبار وب برای پیش بینی شیوع کووید-۱۹٫ پیمان آسیایی جی تروپ. پزشکی ۲۰۲۰ ، ۱۳ . [ Google Scholar ] [ CrossRef ]
- روزنبرگ، اچ. سید، س. رضایی، س. همهگیری توییتر: نقش حیاتی توییتر در انتشار اطلاعات پزشکی و اطلاعات نادرست در طول همهگیری COVID-19. می توان. J. Emerg. پزشکی ۲۰۲۰ ، ۱-۷٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- دفتر پاسخگویی دولت تحقیق کاربردی و روش ها: ارزیابی قابلیت اطمینان داده های پردازش شده توسط کامپیوتر (GAO-09-680G). در دسترس آنلاین: https://www.gao.gov/assets/80/77213.pdf (در ۱۰ مارس ۲۰۲۰ قابل دسترسی است).
- رسچ، بی. اوسلندر، اف. هاواس، سی. ترکیب مدلهای موضوعی یادگیری ماشینی و تحلیل مکانی-زمانی دادههای رسانههای اجتماعی برای ارزیابی ردپای بلایا و آسیب. کارتوگر. Geogr. Inf. علمی ۲۰۱۸ ، ۴۵ ، ۳۶۲-۳۷۶٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ویویانی، م. پاسی، جی. اعتبار در رسانه های اجتماعی: نظرات، اخبار و اطلاعات بهداشتی – نظرسنجی. حداقل داده سیم دانستن کشف کنید. ۲۰۱۷ ، ۷ ، e1209. [ Google Scholar ]
- شیانگ، ز. دو، س. ممکن است.؛ فن، دبلیو. ارزیابی قابلیت اطمینان دادههای رسانههای اجتماعی: درسهایی از استخراج نظرات هتلهای TripAdvisor. در مجموعه مقالات فناوری اطلاعات و ارتباطات در گردشگری ۲۰۱۷، رم، ایتالیا، ۲۴ تا ۲۶ ژانویه ۲۰۱۷٫ [ Google Scholar ]
- آلونسو، او. مارشال، سی سی; ناجورک، MA یک چارچوب انسان محور برای اطمینان از قابلیت اطمینان در وظایف برچسبگذاری جمعسپاری. در مجموعه مقالات اولین کنفرانس AAAI در مورد محاسبات انسانی و جمع سپاری ۲۰۱۳، پالم اسپرینگز، کالیفرنیا، ایالات متحده آمریکا، ۷ تا ۹ نوامبر ۲۰۱۳٫ [ Google Scholar ]
- اوه، او. آگراوال، م. رائو، سرویسهای اطلاعاتی و رسانههای اجتماعی جامعه منابع انسانی: تحلیل نظری شایعه توییتها در طول بحرانهای اجتماعی. Mis Q. ۲۰۱۳ , ۴۰۷–۴۲۶٫ [ Google Scholar ] [ CrossRef ]
- گوبرمن، جی. اشمیتز، سی. Hemphill, L. کمیت سمیت و خشونت کلامی در توییتر. در مجموعه مقالات نوزدهمین کنفرانس ACM در زمینه کار تعاونی و محاسبات اجتماعی با پشتیبانی رایانه ۲۰۱۶، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، ۲۷ فوریه ۲۰۱۶٫ [ Google Scholar ]
- مک کورمیک، تی. لی، اچ. سزار، ن. شجاعی، ع. Spiro، ES استفاده از توییتر برای تحقیقات جمعیت شناختی و علوم اجتماعی: ابزارهایی برای جمع آوری و پردازش داده ها. اجتماعی روشها Res. ۲۰۱۷ ، ۴۶ ، ۳۹۰-۴۲۱٫ [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ویلیامز، جی. داگلی، سی. شناسایی زبانها و گویشهای مشابه در توییتر بدون حقیقت پایه. در مجموعه مقالات چهارمین کارگاه آموزشی NLP برای زبانها، انواع و گویشهای مشابه (VarDial) 2017، والنسیا، اسپانیا، ۳ آوریل ۲۰۱۷؛ (دسترسی در ۵ سپتامبر ۲۰۲۰). [ Google Scholar ]
- لیو، دبلیو. روث، دی. نام چیست؟ استفاده از نام کوچک به عنوان ویژگی برای استنتاج جنسیت در توییتر. در مجموعه مقالات مجموعه سمپوزیوم بهار ۲۰۱۳ AAAI 2013، پالو آلتو، کالیفرنیا، ایالات متحده آمریکا، ۲۵ تا ۲۷ مارس ۲۰۱۳٫ [ Google Scholar ]
- برگر، جی دی. هندرسون، جی. کیم، جی. زارلا، جی. تبعیض جنسیتی در توییتر. در مجموعه مقالات کنفرانس روشهای تجربی در پردازش زبان طبیعی ۲۰۱۱، اسکاتلند، انگلستان، ۲۷ تا ۳۱ ژوئیه ۲۰۱۱٫ [ Google Scholar ]
- دنیس، LAS؛ پالن، ال. اندرسون، KM تسلط بر رسانه های اجتماعی: تجزیه و تحلیل ارتباطات شهرستان جفرسون در طول سیل ۲۰۱۳ کلرادو. در مجموعه مقالات یازدهمین کنفرانس بین المللی ISCRAM، پارک دانشگاه، PA، ایالات متحده آمریکا، ۱۸ تا ۲۱ مه ۲۰۱۴٫ [ Google Scholar ]
- Caragea، C.; مک نیس، ن. جیسوال، ا. تریلر، جی. کیم، HW; میترا، پ. وو، دی. تاپیا، ق. گیلز، ال. ین، جی. و همکاران طبقه بندی پیام های متنی برای زلزله هائیتی. در مجموعه مقالات هشتمین کنفرانس بین المللی ISCRAM، لیسبون، پرتغال، ۸ تا ۱۱ مه ۲۰۱۱٫ [ Google Scholar ]
- چن، S.-H.; چن، ی.-اچ. یک روش بازیابی تصویر مبتنی بر محتوا بر اساس api google cloud vision و wordnet. در مجموعه مقالات کنفرانس آسیایی اطلاعات هوشمند و سیستم های پایگاه داده، کانازاوا، ژاپن، ۳ تا ۵ آوریل ۲۰۱۷٫ [ Google Scholar ]
- d’Andrea، سی. Mintz، A. مطالعه گردش بین پلتفرمی زنده تصاویر با Computer Vision API: آزمایشی بر اساس یک رویداد رسانه ورزشی. بین المللی J. Commun. ۲۰۱۹ ، ۱۳ ، ۲۱٫ [ Google Scholar ]
- مرکز آب و هوای کلرادو بارش انباشته سیل ۲۰۱۳ کلرادو. در دسترس آنلاین: https://www.ncdc.noaa.gov/news/visualizing-september-2013-colorado-flood (در ۵ ژوئیه ۲۰۱۶ قابل دسترسی است).
- لیو، ایکس. ارزیابی ارتباط و قابلیت اطمینان دادههای توییتر برای ارتباط ریسک . ProQuest Dissertations Publishing, 2017. موجود به صورت آنلاین: https://aquila.usm.edu/dissertations/1415/ (دسترسی در ۵ سپتامبر ۲۰۲۰).
- شهر بولدر. نقشه وسعت سیل بولدر ۲۰۱۳٫ در دسترس آنلاین: https://bouldercolorado.gov/open-data/city-of-boulder-september-2013-flood-extents (در ۱۰ ژوئیه ۲۰۱۶ قابل دسترسی است).
- شهر بولدر. نقشه راه ها و خیابان های اصلی. در دسترس آنلاین: https://bouldercolorado.gov/maps (در ۱۵ ژوئیه ۲۰۱۶ قابل دسترسی است).
- NOAA. هشدار/هشدار NOAA. در دسترس آنلاین: https://alerts.weather.gov/cap/co.php?x=1 (در ۱۸ ژوئیه ۲۰۱۶ قابل دسترسی است).
- FEMA. کاهش تلفات از طریق استانداردهای بالاتر نظارتی. در دسترس آنلاین: https://www.fema.gov/media-library-data/1429759760513-f96124536d2c3ccc07b3db4a4f8c35b5/FEMA_CO_RegulatoryLAS.pdf (در ۲۴ ژوئیه ۲۰۱۶ قابل دسترسی است).
- سیل شدید در محدوده کلرادو – سپتامبر ۲۰۱۳٫ در دسترس آنلاین: https://wwa.colorado.edu/resources/front-range-floods/assessment.pdf (در ۳ اوت ۲۰۱۶ در دسترس است).
- NOAA. رکورد دامنه جبهه و سیل شرق کلرادو از ۱۱ تا ۱۷ سپتامبر . NOAA: Silver Spring، MD، ایالات متحده آمریکا، ۲۰۱۴٫
- دانشجویان دانشگاه کینگکید، تی . Huffpost: نیویورک، نیویورک، ایالات متحده آمریکا، ۲۰۱۳٫ [ Google Scholar ]
- وزارت آموزش عالی. سیل ۲۰۱۳ کلرادو: تأثیرات دانشگاه ; وزارت آموزش عالی: لیتل راک، AR، ایالات متحده، ۲۰۱۳٫ در دسترس آنلاین: https://highered.colorado.gov/campusflooding.pdf (در ۲۵ ژوئیه ۲۰۱۶ قابل دسترسی است).
- دی چودوری، ام. دیاکوپولوس، ن. Naaman, M. آشکار شدن چشم انداز رویداد در توییتر: طبقه بندی و کاوش دسته های کاربران. در مجموعه مقالات کنفرانس ACM 2012 در مورد کار تعاونی با پشتیبانی رایانه ۲۰۱۲، Bellevue، WA، ایالات متحده آمریکا، ۱۱-۱۵ فوریه ۲۰۱۲٫ [ Google Scholar ]
- گوگل. Google Vision API. در دسترس آنلاین: https://cloud.google.com/vision (در ۵ آوریل ۲۰۲۰ قابل دسترسی است).
- ویس، اف. فاکنر، اس. پری، ک. مانوخینا، ی. Evans, L. Twitpic-ing the Riots: Analysing Images Share on Twitter in the 2011 UK Riots. در توییتر و جامعه ؛ Weller, K., Bruns, A., Burgess, J., Mahrt, M., Puschmann, C., Eds. پیتر لانگ: نیویورک، نیویورک، ایالات متحده آمریکا، ۲۰۱۳; صص ۳۸۵-۳۹۸٫ [ Google Scholar ]
- کلی، R. مطالعه توییتر نتایج جالبی را در مورد استفاده نشان می دهد. در دسترس آنلاین: https://www.blogomator.com/blog/tweets-are-pointless-twitter-study-reveals-interesting-results-about-usage-pear-analytics/ (در ۱ اوت ۲۰۱۶ قابل دسترسی است).
- گوپتا، ا. لامبا، اچ. کوماراگورو، پ. Joshi, A. Faking sandy: مشخص کردن و شناسایی تصاویر جعلی در توییتر در طول طوفان سندی. در مجموعه مقالات بیست و دومین کنفرانس بین المللی وب جهانی ۲۰۱۳، ریودوژانیرو، برزیل، ۱۳ تا ۱۷ مه ۲۰۱۳٫ [ Google Scholar ]
- Benevenuto، F. مگنو، جی. رودریگز، تی. Almeida، V. شناسایی هرزنامهها در توییتر. در مجموعه مقالات کنفرانس، پیام های الکترونیکی، ضد سوء استفاده و هرزنامه (CEAS) 2010، واشنگتن، دی سی، ایالات متحده آمریکا، ۱۳ تا ۱۴ ژوئیه ۲۰۱۰٫ [ Google Scholar ]
- هوریتا، FEA؛ دگروسی، ال سی. de Assis، LFG; Zipf، A.; د آلبوکرک، JP استفاده از اطلاعات جغرافیایی داوطلبانه (VGI) و جمع سپاری در مدیریت بلایا: مروری بر ادبیات سیستماتیک. در مجموعه مقالات نوزدهمین کنفرانس آمریکا در مورد سیستم های اطلاعاتی، شیکاگو، IL، ایالات متحده آمریکا، ۱۵-۱۷ اوت ۲۰۱۳٫ [ Google Scholar ]
- کلونر، سی. مارکس، اس. یوسون، تی. د پورتو آلبوکرک، جی. Höfle, B. داوطلبانه اطلاعات جغرافیایی در تجزیه و تحلیل خطرات طبیعی: مروری بر ادبیات سیستماتیک رویکردهای فعلی با تمرکز بر آمادگی و کاهش. ISPRS Int. J. Geo-Inf. ۲۰۱۶ ، ۵ ، ۱۰۳٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
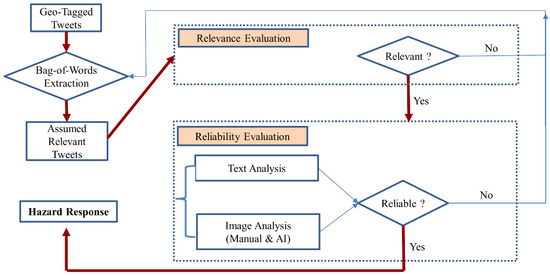
شکل ۱٫ گردش کار ارزیابی قابلیت اطمینان.
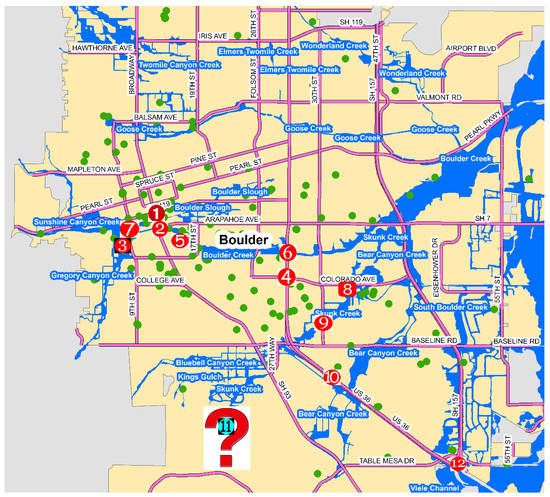
شکل ۲٫ نمونه ای از جاده ها/خیابان های شناسایی شده.

شکل ۳٫ تصاویر بولدر کریک.

شکل ۴٫ تصاویر خیابان های سیل زده.

شکل ۵٫ تصاویر متقابلا یکدیگر را ثابت می کنند.

شکل ۶٫ تصاویر گرفته شده توسط یک گزارشگر خبری محلی.

شکل ۷٫ تشخیص وب بهتر عمل کرد.

شکل ۸٫ تشخیص تصویر و وب نادرست بود.


بدون دیدگاه