
خلاصه
کلید واژه ها:
توصیه مکان ؛ فرآیند گاوسی ؛ مکانی – زمانی – معنایی ; شبکه های اجتماعی مبتنی بر مکان ؛ توصیه top -N
۱٫ معرفی
۲٫ کارهای مرتبط
۲٫۱٫ نفوذ جغرافیایی
۲٫۲٫ نفوذ زمانی
۲٫۳٫ تأثیر معنایی
۲٫۴٫ رفتارهای ورود ناهمگون
۳٫ بررسی تجزیه و تحلیل داده ها
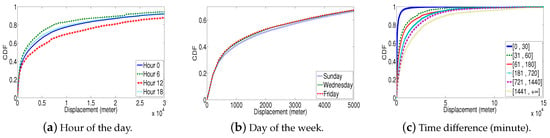
۳٫۱٫ الگوهای حرکتی ناهمگن
۳٫۲٫ نفوذ زمانی
۴٫ STS: توصیه مکان مکانی – زمانی – معنایی
۴٫۱٫ پیش بینی جابجایی
هدف از مدل مبتنی بر فرآیند گاوسی ما یادگیری یک تابع نهفته است fتوکه اطلاعات زمانی کاربر را ترسیم می کندتیتوبه بردار جابجایی او Dتو:
به منظور در نظر گرفتن نویز، که در عمل رایج است (مثلاً مختصات GPS کاملاً دقیق نیستند)، یک نویز گاوسی مستقل و مستقل را فرض میکنیم. ϵ، با واریانس σ۲:
توزیع مشترک جابجایی های مشاهده شده fتوو مقادیر تابعی که باید پیش بینی شود fتو”با توجه به این تئوری که مقادیر تابعی که باید آموخته شود از توزیع گاوسی چند متغیره تبعیت می کند، به دست می آید:
جایی که من ماتریس هویت هستم، μ()تابع میانگین است و ک()ماتریس کوواریانس است. این (r،ج)عنصر ام از ک(تیتو،تیتو)نشان دهنده کوواریانس محاسبه شده در اطلاعات زمانی ۴ بعدی r و c درتیتو. بر این اساس، عناصر ک(تیتو”،تیتو)، ک(تیتو،تیتو”)و ک(تیتو”،تیتو”)نشان دهنده کوواریانس های محاسبه شده در تمام جفت های اطلاعات زمانی ۴ بعدی در ( تیتو”، تیتو)، ( تیتو، تیتو”) و تیتو”، به ترتیب. شکل ۴ نمونه ای از ماتریس کوواریانس را نشان می دهد ک(تیتو،تیتو”).
با شرطی کردن توزیع قبلی گاوسی مشترک بر روی اطلاعات زمانی مشاهده شده، احتمال fتو”:
ما می توانیم تابع نهفته تخمین زده شده را بدست آوریم fتو”یعنی جابجایی های آینده پیش بینی شده بر اساس توزیع آن:
فرآیند گاوسی همچنین واریانس توزیع را تولید می کند که می تواند برای اندازه گیری اطمینان پیش بینی استفاده شود:
۴٫۱٫۱٫ تابع میانگین و تابع کوواریانس
برای تابع میانگین، از یک فرم ساده استفاده می کنیم که میانگین جابجایی های گذشته کاربر u است:
توابع کوواریانس متعددی وجود دارد که فرآیند گاوسی را در سناریوهای مختلف کاربردی انعطاف پذیر می کند. ما با یک تابع معروف به نام تابع کوواریانس نمایی مربعی برای مدل خود شروع می کنیم:
جایی که تیمترو تیnاطلاعات زمانی ۴ بعدی مرتبط با دو جابجایی (نمایه شده توسط m و n ) کاربر u هستند. h و λفراپارامترهایی هستند که به ترتیب مقیاس (یا واریانس) خروجی تابع و مقیاس طول ورودی را کنترل می کنند. از آنجایی که چهار نوع اطلاعات زمانی ممکن است تأثیرات متفاوتی بر فعالیتهای ورود کاربران داشته باشند، ما آنها را با تعیین وزن برای هر نوع ترکیب میکنیم (به عنوان مثال، wمن، جایی که من=۱،۲،۳،۴). ما این وزن ها را با یادگیری از داده های مشاهده شده تعیین می کنیم. توجه داشته باشید که اگرچه چهار نوع اطلاعات زمانی ترکیب شده اند تا تأثیر زمانی را به صورت خطی نشان دهند، اما تأثیر متقابل بین اطلاعات زمانی هر جفت جابجایی کاربر u به صورت غیرخطی (یعنی به شکل یک ماتریس کوواریانس) مدلسازی میشود. ، به شکل ۴ مراجعه کنید )، که قادر است با دقت بیشتری تأثیر زمانی بر رفتار ورود کاربران را به تصویر بکشد.
۴٫۱٫۲٫ اتصالات مدل
طبق تعریف فرآیند گاوسی، توزیع داده های مشاهده شده از توزیع گاوسی چند متغیره تبعیت می کند:
جایی که Θتوپارامترهای مدل متشکل از فراپارامترهای تابع کوواریانس و وزن اطلاعات زمانی هستند. احتمال حاشیه ای ورود به سیستم منفی مربوطه به دست می آید:
برازش مدل به یک مسئله بهینه سازی غیرمحدب برای به حداقل رساندن احتمال حاشیه ای ورود به سیستم منفی تبدیل می شود . ما نزول گرادیان تصادفی (SGD) را برای یادگیری پارامترهای مدل اعمال می کنیم Θتو، که به طور مکرر به روز می شوند:
جایی که αمیزان یادگیری است. اگر به حداکثر تعداد تکرارهای از پیش تعریف شده رسیده باشد یا احتمال حاشیه ای ورود به سیستم منفی در یک تکرار خاص همگرا شود، روند بهینه سازی تکمیل می شود.
ما مشتقات L را با توجه به پارامترهای مدل پیدا می کنیمΘتو(هیپرپارامترهای تابع کوواریانس h , λ، σو وزن هر نوع اطلاعات زمانی wمن):
که در آن مشتق ماتریس کوواریانس است ک(تیتو،تیتو)با توجه به هر فراپارامتر کوواریانس به دست می آید (عنصر ماتریس با ردیف m و ستون n نمایه می شود ):
و
مشتق ماتریس کوواریانس ک(تیتو،تیتو)با توجه به وزن هر نوع اطلاعات زمانی wمنبه دست می آید (عنصر ماتریس با ردیف m و ستون n نمایه می شود ):
۴٫۲٫ تقویت معنایی آگاهانه
برای کاربر u ، توزیع دسته با شمارش وقوع یک دسته خاص تخمین زده می شود ψمندر زمینه زمانی داده شده تی”از بررسی های تاریخی او:
جایی که nψمن،تی”تعداد وقوع دسته است ψمنبا توجه به اطلاعات زمانی تی”، و |سیتو|تعداد بازدیدهای کاربر توسط شما است. توجه داشته باشید که توزیع احتمال دسته مشتق شده مشروط به این شرط است که ∑من=۱|Ψ|پ(ψمن|تی”)= ۱٫ بر اساس چنین توزیع دسته بندی، ما می توانیم ترجیحات کاربر را در یک بازه زمانی مشخص استنباط کنیم و از این رو دقت توصیه مکان را بهبود ببخشیم.
۴٫۳٫ یک چارچوب توصیه یکپارچه
با توجه به اطلاعات زمانی تیتو، جابجایی بعدی پیش بینی شده کاربر u را با نشان می دهیمدتو(به بخش ۴٫۱ مراجعه کنید ). برای مکان نامزد ل”، ما فاصله بین مکان فعلی کاربر u را محاسبه می کنیمل”، نشان داده شده با د”. سپس تفاوت بین را بدست می آوریم دتوو د”:
از نظر تئوری، تفاوت کمتر است Δتو، احتمال اینکه مکان بررسی شود بیشتر می شود. بر اساس چنین تفاوت فاصله جغرافیایی، احتمال اینکه محل نامزد باشد را استخراج می کنیم ل”توسط کاربر u بررسی خواهد شد .
که در آن n یک پارامتر طراحی است که خطای پیشبینی جابجایی را محدود میکند. یک n مناسب یک n معقول ایجاد می کند (یک n بسیار کوچک نمی تواند خطای پیش بینی جابجایی را محدود کند (به عنوان مثال، زمانی که n = ۱، خطاهای پیش بینی ۱۰ متر و ۱۰۰ متر به ترتیب احتمال بررسی ۰٫۱ و ۰٫۰۱ را ایجاد می کنند، که به طور منطقی قابل مقایسه نیستند. در دنیای واقعی)؛ و یک n بسیار بزرگ می سازد پتو،ل”درویکرد به ۱، که در واقع تأثیر جغرافیایی را از بین می برد.) احتمال ورود که با احتمال ورود به معنای معنایی برای توصیه ترکیب می شود. انتخاب n به مجموعه داده مورد استفاده بستگی دارد، ما در بخش ۵ مثالی برای یک LBSN واقعی خواهیم داد .
در ادامه تأثیر معنایی بر احتمال ورود را ارائه دهید. دسته بندی مکان نامزد را نشان می دهیم ل”توسط ψ”. بر اساس توزیع دسته کاربر uپتو(Ψ|تیتو)(به بخش ۴٫۲ مراجعه کنید )، ما این احتمال را به دست می آوریم که کاربر در مکانی تحت دسته بندی ثبت نام کند. ψ”:
در نهایت، ما تأثیر مکانی-زمانی و تأثیر معنایی-زمانی را با هم ترکیب میکنیم تا احتمال نهایی را بدست آوریم که کاربر u در مکان نامزد بررسی میشود.ل”:
۵٫ ارزیابی و بحث
۵٫۱٫ تنظیمات آزمایشی
۵٫۱٫۱٫ مجموعه داده ها
۵٫۱٫۲٫ خطوط پایه
۵٫۱٫۳٫ معیارهای
هدف یک مدل پیشنهاد مکان این است که با توجه به اطلاعات اعلام حضور کاربر در حال حاضر، مکانهایی را که دارای بالاترین رتبهبندیشدهترین مکانها هستند، بهطوریکه اعلام حضور بعدی وی پس از یکی از مکانهای توصیهشده انجام شود، توصیه شود . برای اندازهگیری دقت روش پیشنهاد مکان، از Precision@N استفاده کردیم که نسبت مکانهای پیشبینیشده موفقیتآمیز به توصیههای برتر N است :
جایی که Uنشاندهنده مجموعه کاربران از مجموعه داده آزمایشی است، N نشاندهنده اندازه لیست توصیهها است، Lتوrنشان دهنده لیست توصیه های برتر N است که توسط مدل توصیه برای کاربر u ارائه شده استLتونشان دهنده لیست موقعیت مکانی واقعی است که توسط کاربر u بررسی شده است. از این متریک می توان برای نشان دادن نسبت ضربه توصیه top -N استفاده کرد.
در همین حال، ما همچنین از میانگین رتبه متقابل (MRR)، یک معیار رتبهبندی محبوب برای اندازهگیری کیفیت توصیهها استفاده میکنیم، با این که بفهمیم اولین مکان با موفقیت پیشبینی شده چقدر از بالای فهرست فاصله دارد (میانگین در تمام موارد آزمایشی):
جایی که آرمنموقعیت اولین مکان پیشبینیشده با موفقیت در لیست توصیههایی است که برای کاربر من بازگردانده شده است.
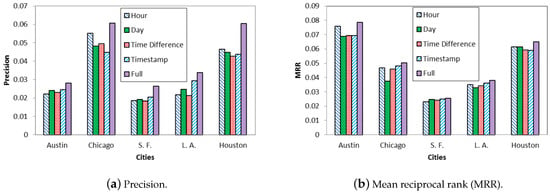
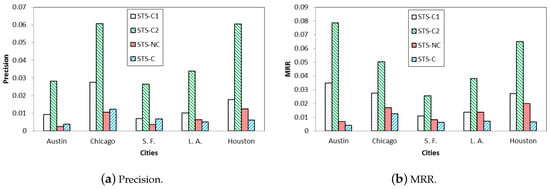
۵٫۲٫ نتایج تجربی
۵٫۲٫۱٫ اثر پراکندگی داده ها
۵٫۲٫۲٫ اثر اطلاعات زمانی
۵٫۲٫۳٫ اثر اطلاعات دسته
۵٫۲٫۴٫ مطالعات مقایسه ای
۵٫۳٫ بحث
۶٫ نتیجه گیری
منابع
- گائو، اچ. تانگ، جی. هو، ایکس. لیو، اچ. بررسی اثرات زمانی برای توصیه مکان در شبکه های اجتماعی مبتنی بر مکان. در مجموعه مقالات هفتمین کنفرانس ACM در مورد سیستم های توصیه کننده، هنگ کنگ، چین، ۱۲ تا ۱۶ اکتبر ۲۰۱۳٫ صص ۹۳-۱۰۰٫ [ Google Scholar ]
- لیو، ایکس. لیو، ی. لی، ایکس. کاوش در زمینه مکانها برای توصیههای مکان شخصیشده. در مجموعه مقالات بیست و پنجمین کنفرانس مشترک بین المللی هوش مصنوعی، نیویورک، نیویورک، ایالات متحده آمریکا، ۹ تا ۱۵ ژوئیه ۲۰۱۶؛ صص ۱۱۸۸-۱۱۹۴٫ [ Google Scholar ]
- گائو، آر. لی، جی. لی، ایکس. آهنگ، سی. چانگ، جی. لیو، دی. وانگ، سی. STSCR: بررسی تأثیر متوالی مکانی-زمانی و اطلاعات اجتماعی برای توصیه مکان. محاسبات عصبی ۲۰۱۸ ، ۳۱۹ ، ۱۱۸-۱۳۳٫ [ Google Scholar ] [ CrossRef ]
- لیو، جی. ژانگ، ز. لیو، سی. کیو، ا. ژانگ، اف. بهرهبرداری از تأثیرات اجتماعی دو بعدی جغرافیایی و ترکیبی برای توصیه مکان. ISPRS Int. J. Geo-Inf. ۲۰۲۰ ، ۹ ، ۲۸۵٫ [ Google Scholar ] [ CrossRef ]
- ژانگ، جی دی. Chow، CY iGSLR: توصیه موقعیت جغرافیایی-اجتماعی شخصی: یک رویکرد تخمین چگالی هسته. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، اورلاندو، فلوریدا، ایالات متحده آمریکا، ۵ تا ۸ نوامبر ۲۰۱۳٫ صص ۳۳۴-۳۴۳٫ [ Google Scholar ]
- یانگ، دی. ژانگ، دی. یو، ز. Wang, Z. یک سیستم توصیه موقعیت مکانی شخصی سازی شده با احساسات. در مجموعه مقالات بیست و چهارمین کنفرانس ACM در مورد فرامتن و رسانه های اجتماعی، پاریس، فرانسه، ۱-۳ مه ۲۰۱۳٫ صص ۱۱۹-۱۲۸٫ [ Google Scholar ]
- کوراشیما، تی. ایواتا، تی. هوشیده، ت. تکایا، ن. مدل موضوعی فوجیمورا، K. Geo: مدلسازی مشترک حوزه فعالیت و علایق کاربر برای توصیه مکان. در مجموعه مقالات ششمین کنفرانس بین المللی ACM در جستجوی وب و داده کاوی، رم، ایتالیا، ۴ تا ۸ فوریه ۲۰۱۳٫ صص ۳۷۵-۳۸۴٫ [ Google Scholar ]
- خزاعی، ا. علیمحمدی، ع. توصیه موقعیت مکانی گروه محور آگاه به زمینه در شبکه های اجتماعی مبتنی بر مکان. ISPRS Int. J. Geo-Inf. ۲۰۱۹ ، ۸ ، ۴۰۶٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- لو، ز. وانگ، اچ. مامولیس، ن. تو، دبلیو. Cheung، DW با جمعآوری چندین توصیهکننده در تنوع، توصیه مکان شخصیسازی کرد. GeoInformatica ۲۰۱۷ ، ۲۱ ، ۴۵۹-۴۸۴٫ [ Google Scholar ] [ CrossRef ]
- چو، ای. مایرز، SA; Leskovec, J. دوستی و تحرک: حرکت کاربر در شبکه های اجتماعی مبتنی بر مکان. در مجموعه مقالات هفدهمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، سن دیگو، کالیفرنیا، ایالات متحده آمریکا، ۲۱ تا ۲۴ اوت ۲۰۱۱٫ ص ۱۰۸۲-۱۰۹۰٫ [ Google Scholar ]
- لیان، دی. ژائو، سی. Xie، X. سان، جی. چن، ای. Rui, Y. GeoMF: مدلسازی جغرافیایی مشترک و فاکتورسازی ماتریسی برای توصیه نقطهنظر. در مجموعه مقالات بیستمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، نیویورک، نیویورک، ایالات متحده آمریکا، ۲۴ تا ۲۷ اوت ۲۰۱۴٫ صص ۸۳۱-۸۴۰٫ [ Google Scholar ]
- بله، م. یین، پی. لی، WC; لی، DL بهرهبرداری از تأثیر جغرافیایی برای توصیههای نقطهنظر مشارکتی. در مجموعه مقالات سی و چهارمین کنفرانس بین المللی ACM SIGIR در مورد تحقیق و توسعه در بازیابی اطلاعات، پکن، چین، ۲۵ تا ۲۹ ژوئیه ۲۰۱۱٫ صص ۳۲۵-۳۳۴٫ [ Google Scholar ]
- نولاس، ا. اسکلاتو، اس. لاتیا، ن. Mascolo، C. ویژگیهای تحرک کاربر استخراج برای پیشبینی مکان بعدی در خدمات مبتنی بر مکان. در مجموعه مقالات دوازدهمین کنفرانس بین المللی IEEE در مورد داده کاوی، بروکسل، بلژیک، ۱۰-۱۳ دسامبر ۲۰۱۲٫ ص ۱۰۳۸-۱۰۴۳٫ [ Google Scholar ]
- چنگ، سی. یانگ، اچ. کینگ، آی. لیو، MR فاکتورسازی ماتریس ذوب شده با نفوذ جغرافیایی و اجتماعی در شبکه های اجتماعی مبتنی بر مکان. در مجموعه مقالات بیست و ششمین کنفرانس AAAI در مورد هوش مصنوعی، تورنتو، ON، کانادا، ۲۲ تا ۲۶ ژوئیه ۲۰۱۲٫ صص ۱۷-۲۳٫ [ Google Scholar ]
- یوان، Q. کنگ، جی. ما، ز. سان، ا. Thalmann، NM توصیه نقطه مورد علاقه آگاه از زمان. در مجموعه مقالات سی و ششمین کنفرانس بین المللی ACM SIGIR در مورد تحقیق و توسعه در بازیابی اطلاعات، دوبلین، ایرلند، ۲۸ ژوئیه تا ۱ اوت ۲۰۱۳٫ صص ۳۶۳-۳۷۲٫ [ Google Scholar ]
- یان، سی. تو، ی. وانگ، ایکس. ژانگ، ی. هائو، ایکس. ژانگ، ی. Dai، Q. STAT: مکانیسم توجه مکانی-زمانی برای شرح ویدیو. IEEE Trans. چندتایی. ۲۰۱۹ ، ۲۲ ، ۲۲۹-۲۴۱٫ [ Google Scholar ] [ CrossRef ]
- هو، بی. Ester, M. مدلسازی موضوع فضایی در رسانههای اجتماعی آنلاین برای توصیه مکان. در مجموعه مقالات هفتمین کنفرانس ACM در مورد سیستم های توصیه کننده، هنگ کنگ، چین، ۱۲ تا ۱۶ اکتبر ۲۰۱۳٫ صص ۲۵-۳۲٫ [ Google Scholar ]
- لیو، بی. فو، ی. یائو، ز. Xiong, H. یادگیری ترجیحات جغرافیایی برای توصیه نقطه مورد علاقه. در مجموعه مقالات نوزدهمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، شیکاگو، IL، ایالات متحده، ۱۱-۱۴ اوت ۲۰۱۳٫ صص ۱۰۴۳-۱۰۵۱٫ [ Google Scholar ]
- ژائو، اس. ژائو، تی. کینگ، آی. Lyu, MR Geo-teaser: رتبه جاسازی متوالی جغرافیایی-زمانی برای توصیه نقطه مورد علاقه. در مجموعه مقالات بیست و ششمین کنفرانس بین المللی در مورد همنشین وب جهانی، پرت، استرالیا، ۳ تا ۷ آوریل ۲۰۱۷؛ صص ۱۵۳-۱۶۲٫ [ Google Scholar ]
- لیو، تی. لیائو، جی. وو، زی. وانگ، ی. وانگ، جی. بهرهبرداری از توجه آگاهی جغرافیایی-زمانی برای توصیههای مورد علاقه بعدی. محاسبات عصبی ۲۰۲۰ ، ۴۰۰ ، ۲۲۷-۲۳۷ . [ Google Scholar ] [ CrossRef ]
- وانگ، اچ. شن، اچ. اویانگ، دبلیو. چنگ، ایکس. بهرهبرداری از تأثیر جغرافیایی خاص POI برای توصیههای نقطهنظر. در مجموعه مقالات بیست و هفتمین کنفرانس بین المللی مشترک هوش مصنوعی، استکهلم، سوئد، ۱۳ تا ۱۹ ژوئیه ۲۰۱۸؛ صص ۳۸۷۷-۳۸۸۳٫ [ Google Scholar ]
- کای، ال. خو، جی. لیو، جی. Pei, T. ادغام زمینه های مکانی و زمانی در یک مدل فاکتورسازی برای توصیه POI. بین المللی جی. جئوگر. Inf. علمی ۲۰۱۸ ، ۳۲ ، ۵۲۴-۵۴۶٫ [ Google Scholar ]
- لی، اچ. هونگ، آر. وو، زی. جنرال الکتریک، Y. یک مدل فاکتورسازی ماتریس احتمالی مکانی-زمانی برای توصیه نقطه مورد علاقه. در مجموعه مقالات کنفرانس بین المللی SIAM 2016 در مورد داده کاوی، میامی، FL، ایالات متحده آمریکا، ۵-۷ مه ۲۰۱۶؛ صص ۱۱۷-۱۲۵٫ [ Google Scholar ]
- راسموسن، CE; ویلیامز، فرآیندهای گاوسی CKI برای یادگیری ماشینی ؛ انتشارات MIT: کمبریج، MA، ایالات متحده آمریکا، ۲۰۰۵٫ [ Google Scholar ]
- کلاوزت، ا. شالیزی، CR; نیومن، ME توزیع قانون قدرت در داده های تجربی. SIAM Rev. ۲۰۰۹ , ۵۱ , ۶۶۱-۷۰۳٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لی، ایکس. کنگ، جی. لی، XL; فام، TAN; کریشناسوامی، S. Rank-geofm: یک روش فاکتورگیری جغرافیایی مبتنی بر رتبه بندی برای توصیه نقطه مورد علاقه. در مجموعه مقالات سی و هشتمین کنفرانس بین المللی ACM SIGIR در مورد تحقیق و توسعه در بازیابی اطلاعات، سانتیاگو، شیلی، ۹ تا ۱۳ اوت ۲۰۱۵٫ صص ۴۳۳-۴۴۲٫ [ Google Scholar ]
- مک.؛ ژانگ، ی. وانگ، کیو. لیو، ایکس. توصیه نقطه مورد علاقه: بهرهبرداری از رمزگذارهای خودکار آگاه با نفوذ همسایه. در مجموعه مقالات بیست و هفتمین کنفرانس بین المللی ACM در مدیریت اطلاعات و دانش، تورینو، ایتالیا، ۲۲ تا ۲۶ اکتبر ۲۰۱۸؛ صص ۶۹۷-۷۰۶٫ [ Google Scholar ]
- یانگ، اچ. چن، ال. Xiong، Y. Wu, J. PGRank: رتبهبندی جغرافیایی شخصی برای توصیههای نقطهنظر. در مجموعه مقالات بیست و پنجمین کنفرانس بین المللی همکار در وب جهانی، مونترال، QC، کانادا، ۱۱-۱۵ آوریل ۲۰۱۶؛ صص ۱۳۷-۱۳۸٫ [ Google Scholar ]
- لیو، سی. لیو، جی. خو، اس. وانگ، جی. لیو، سی. چن، تی. جیانگ، تی. یک شبکه کانولوشنال متسع فضایی-زمانی برای توصیه نقطه مورد علاقه. ISPRS Int. J. Geo-Inf. ۲۰۲۰ ، ۹ ، ۱۱۳٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- یینگ، ی. چن، ال. Chen, G. یک سیستم توصیه POI آگاه از زمان با استفاده از تجزیه تانسور آگاه از متن و HITS وزنی. محاسبات عصبی ۲۰۱۷ ، ۲۴۲ ، ۱۹۵-۲۰۵ . [ Google Scholar ] [ CrossRef ]
- علیان نژادی، م. رافائلیدیس، دی. Crestani، F. یک مدل رتبهبندی مشترک منظم و منظم حساس به زمان دو مرحلهای مشترک برای توصیه نقطه مورد علاقه. IEEE Trans. دانستن مهندسی داده ۲۰۱۹ ، ۳۲ ، ۱۰۵۰-۱۰۶۳٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- یائو، زی. بهرهبرداری از الگوهای تحرک انسانی برای توصیههای مورد علاقه. در مجموعه مقالات یازدهمین کنفرانس بین المللی ACM در جستجوی وب و داده کاوی، مارینا دل ری، کالیفرنیا، ایالات متحده آمریکا، ۵ تا ۹ فوریه ۲۰۱۸؛ صص ۷۵۷-۷۵۸٫ [ Google Scholar ]
- چانگ، بی. پارک، ی. پارک، دی. کیم، اس. Kang, J. مدل تعبیه سلسله مراتبی نقطه مورد علاقه محتوا آگاه برای توصیه های پی در پی POI. در مجموعه مقالات بیست و هفتمین کنفرانس بین المللی مشترک هوش مصنوعی، استکهلم، سوئد، ۱۳ تا ۱۹ ژوئیه ۲۰۱۸؛ صص ۳۳۰۱–۳۳۰۷٫ [ Google Scholar ]
- لیو، بی. Xiong، H. توصیه نقطه مورد علاقه در شبکه های اجتماعی مبتنی بر مکان با آگاهی از موضوع و مکان. در مجموعه مقالات سیزدهمین کنفرانس بین المللی SIAM در مورد داده کاوی، آستین، تگزاس، ایالات متحده آمریکا، ۲ تا ۴ مه ۲۰۱۳٫ صص ۳۹۶-۴۰۴٫ [ Google Scholar ]
- یین، ز. کائو، ال. هان، جی. ژای، سی. Huang, T. کشف و مقایسه موضوع جغرافیایی. در مجموعه مقالات بیستمین کنفرانس بین المللی وب جهانی، حیدرآباد، هند، ۲۸ مارس تا ۱ آوریل ۲۰۱۱; صص ۲۴۷-۲۵۶٫ [ Google Scholar ]
- لیو، ایکس. لیو، ی. ابرر، ک. Miao, C. توصیه شخصی شده نقطه مورد علاقه توسط انتقال ترجیحی کاربران معدن. در مجموعه مقالات بیست و دومین کنفرانس بین المللی ACM در مدیریت اطلاعات و دانش، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، ۲۷ اکتبر تا ۱۰ نوامبر ۲۰۱۳٫ صص ۷۳۳-۷۳۸٫ [ Google Scholar ]
- هائو، پی. چانگ، WH; Chiang, JH جاسازی رویداد بلادرنگ برای توصیه POI. محاسبات عصبی ۲۰۱۹ ، ۳۴۹ ، ۱-۱۱٫ [ Google Scholar ] [ CrossRef ]
- لیان، دی. Ge، Y. ژانگ، اف. یوان، نیوجرسی؛ Xie، X. ژو، تی. Rui, Y. فیلتر مشارکتی مبتنی بر محتوا برای توصیه مکان. IEEE Trans. دانستن مهندسی داده ۲۰۱۸ ، ۳۰ ، ۱۱۲۲-۱۱۳۵٫ [ Google Scholar ] [ CrossRef ]
- ژانگ، جی دی. Chow، CY; Zheng, Y. ORec: یک چارچوب توصیه مبتنی بر نقطه نظر. در مجموعه مقالات بیست و چهارمین کنفرانس بین المللی ACM در مورد مدیریت اطلاعات و دانش، ملبورن، استرالیا، ۱۹ تا ۲۳ اکتبر ۲۰۱۵٫ صفحات ۱۶۴۱-۱۶۵۰٫ [ Google Scholar ]
- ژو، ایکس. ماسکولو، سی. Zhao, Z. شبکههای حافظه ارتقا یافته با موضوع برای توصیههای شخصیشده نقطهنظر. در مجموعه مقالات بیست و پنجمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، انکوریج، AK، ایالات متحده آمریکا، ۴ تا ۸ اوت ۲۰۱۹؛ صفحات ۳۰۱۸–۳۰۲۸٫ [ Google Scholar ]
- یین، اچ. وانگ، دبلیو. وانگ، اچ. چن، ال. ژو، X. یادگیری عمیق مشارکتی سلسله مراتبی آگاه به فضایی برای توصیه POI. IEEE Trans. دانستن مهندسی داده ۲۰۱۷ ، ۲۹ ، ۲۵۳۷–۲۵۵۱٫ [ Google Scholar ] [ CrossRef ]
- منیح، ع. سالخوتدینوف، فاکتورسازی ماتریس احتمالی RR. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی سیستم های پردازش اطلاعات عصبی، ونکوور، BC، کانادا، ۸-۱۱ دسامبر ۲۰۰۸٫ ص ۱۲۵۷–۱۲۶۴٫ [ Google Scholar ]
- کوی، کیو. تانگ، ی. وو، اس. وانگ، L. Distance2Pre: ترجیح فضایی شخصی برای پیشبینی نقطه مورد علاقه بعدی. در مجموعه مقالات بیست و سومین کنفرانس اقیانوس آرام-آسیا در مورد کشف دانش و داده کاوی، ماکائو، چین، ۱۴ تا ۱۷ آوریل ۲۰۱۹؛ صص ۲۸۹-۳۰۱٫ [ Google Scholar ]
- فنگ، اس. کنگ، جی. آن، ب. Chee, YM Poi2vec: نمایش نهفته جغرافیایی برای پیشبینی بازدیدکنندگان آینده. در مجموعه مقالات سی و یکمین کنفرانس AAAI در مورد هوش مصنوعی، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، ۴ تا ۱۰ فوریه ۲۰۱۷؛ ص ۱۰۲-۱۰۸٫ [ Google Scholar ]
- مسمیت، دی. وینوگراد، S. ضرب ماتریس از طریق پیشرفت های حسابی. در مجموعه مقالات نوزدهمین سمپوزیوم سالانه ACM در تئوری محاسبات، نیویورک، نیویورک، ایالات متحده آمریکا، ۲۵-۲۷ مه ۱۹۸۷٫ صص ۱-۶٫ [ Google Scholar ]
- فاکس، سی دبلیو؛ رابرتز، اس جی آموزش استنتاج بیزی متغیر. آرتیف. هوشمند Rev. ۲۰۱۲ , ۳۸ , ۸۵-۹۵٫ [ Google Scholar ] [ CrossRef ]






بدون دیدگاه