
خلاصه
کلید واژه ها:
تحلیل فضایی ; تشکیل الگو ؛ مدل سازی شهری ; الگوی استقرار ; سنجش از دور
۱٫ معرفی
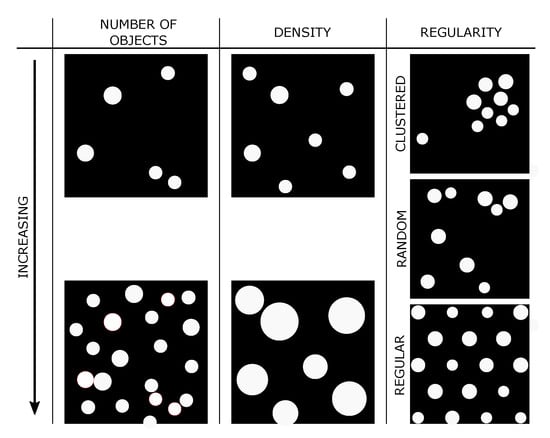
۲٫ چارچوب مفهومی
- (من)
-
تعداد اشیاء مورد بررسی؛
- (II)
-
تراکم اجسام در منطقه مورد بررسی؛ و
- (iii)
-
نظم، که ما آن را با یک مقدار مشخصه خاص کمیت می کنیم.
۳٫ داده ها و روش ها
۳٫۱٫ داده ها
۳٫۲٫ روش
ما تراکم را به عنوان ضریب منطقه پرجمعیت تعریف می کنیم آساختن-بالاو منطقه A را مورد بررسی قرار داد :
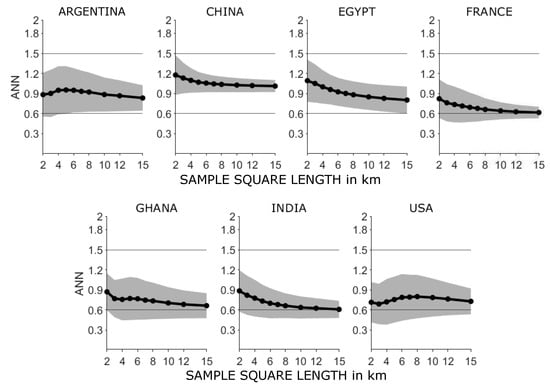
این ANN[ ۳۴ ] معمولاً برای اندازه گیری توزیع سکونتگاه ها در تحقیقات جغرافیایی استفاده می شود [ ۱۵ ، ۱۶ ]. این الگوهای خوشه ای، تصادفی و منظم را که توسط نشان داده شده اند متمایز می کند ANNمقادیر نزدیک به ۰، ۱ یا ۲٫۱۵، به ترتیب. هنگام محاسبه ANN، میانگین حسابی r¯آاز فاصله rمنبین هر نقطه داده من∈[۱،ن]و از نزدیکترین همسایه آن در ناحیه مورد بررسی A استفاده شده است. این فاصله با فاصله مقایسه می شود r¯E=0.5∗آ/ننقاط داده در یک توزیع تصادفی [ ۳۴ ]:
به منظور کمی کردن قابلیت اطمینان طبقه بندی الگو به عنوان انحراف از توزیع منظم، مقدار z برای ANNمحاسبه می شود. این احتمال را نشان می دهد که با آن فرضیه توزیع نقطه تصادفی می تواند به درستی رد شود. یک مقدار z <1.96یا >1.96فاصله اطمینان ۹۰% را تشکیل می دهد و مقدار به صورت تعریف می شود
۴٫ تجزیه و تحلیل
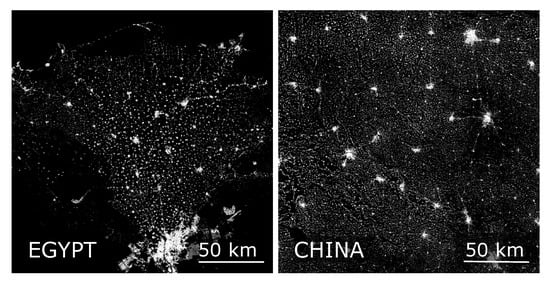
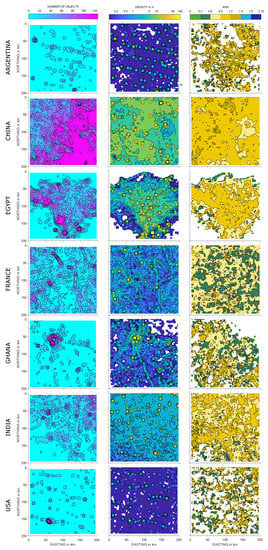
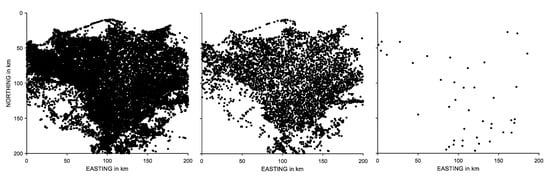
۴٫۱٫ ترتیب تسویه حساب
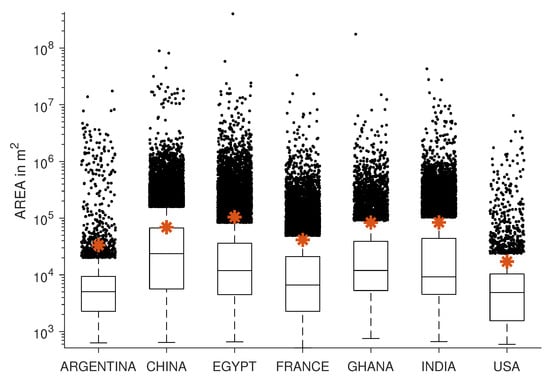
۴٫۲٫ توزیع اندازه
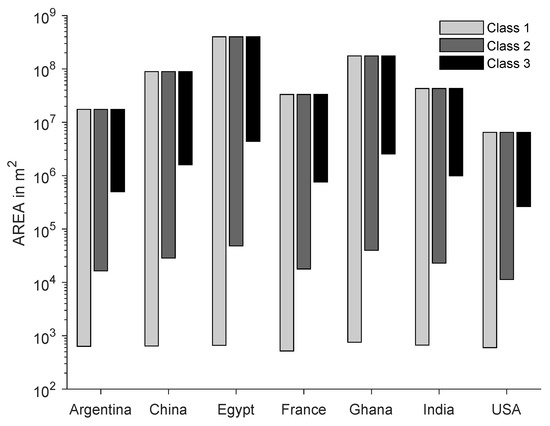
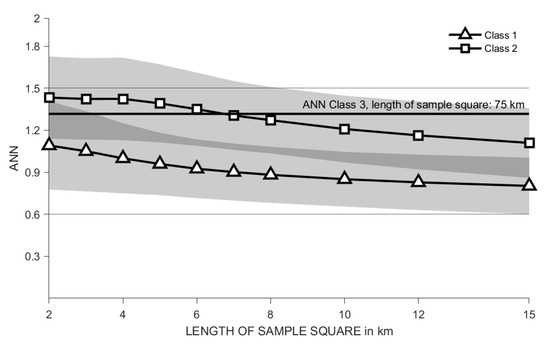
۴٫۳٫ کلاس ها
۴٫۴٫ ساختارهای تسویه حساب منظم
۵٫ بحث
۶٫ نتیجه گیری
اختصارات
در این نسخه از اختصارات زیر استفاده شده است.
| ANN | شاخص میانگین نزدیکترین همسایه |
| CPT | نظریه مکان مرکزی |
| DLR | مرکز هوافضای آلمان |
| GUF | ردپای جهانی شهری |
| ss | مربع نمونه |
پیوست A. اطلاعات بیشتر

منابع
- رتیف، اف. باند، ا. پاپ، جی. موریسون-ساندرز، ای. کینگ، ن. مگاترندهای جهانی و پیامدهای آنها برای ارزیابی زیست محیطی. محیط زیست ارزیابی تاثیر Rev. ۲۰۱۶ , ۶۱ , ۵۲-۶۰٫ [ Google Scholar ] [ CrossRef ]
- زو، ز. ژو، ی. Seto، KC; استوکس، EC; دنگ، سی. پیکت، ST; Taubenböck، H. درک یک سیاره شهری: جهت گیری های استراتژیک برای سنجش از دور. از راه دور. حس محیط. ۲۰۱۹ ، ۲۲۸ ، ۱۶۴-۱۸۲٫ [ Google Scholar ] [ CrossRef ]
- Batty, M. The New Science of Cities ; انتشارات MIT: کمبریج، MA، ایالات متحده آمریکا، ۲۰۱۳٫ [ Google Scholar ]
- باتی، ام. ساخت علم شهرها. شهرها ۲۰۱۲ ، ۲۹ ، S9–S16. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پرتغالی، ج. پیچیدگی، شناخت و شهر . پیچیدگی اسپرینگر، اسپرینگر: برلین/هایدلبرگ، آلمان؛ نیویورک، نیویورک، ایالات متحده آمریکا، ۲۰۱۱٫ [ Google Scholar ]
- تاوبن باک، اچ. دبری، اچ. کیو، سی. اشمیت، ام. وانگ، ی. Zhu، X. هفت نوع شهر که نمایانگر پیکربندی مورفولوژیکی شهرها در سراسر جهان هستند. Cities ۲۰۲۰ , ۱۰۵ , ۱۰۲۸۱۴٫ [ Google Scholar ] [ CrossRef ]
- بننسون، آی. Torrens, PM Geosimulation: مدلسازی خودکار پدیدههای شهری . جان وایلی و پسران: هوبوکن، نیوجرسی، ایالات متحده آمریکا، ۲۰۰۴٫ [ Google Scholar ]
- لیو، ی. باتی، م. وانگ، اس. Corcoran، J. مدلسازی تغییرات شهری با اتوماتای سلولی: مسائل معاصر و جهتگیریهای تحقیقاتی آینده. Prog. هوم Geogr. ۲۰۱۹ . [ Google Scholar ] [ CrossRef ]
- راتور، MM; احمد، ع. پل، آ. Rho, S. برنامه ریزی شهری و ساخت شهرهای هوشمند مبتنی بر اینترنت اشیا با استفاده از تجزیه و تحلیل داده های بزرگ. محاسبه کنید. شبکه ۲۰۱۶ ، ۱۰۱ ، ۶۳-۸۰٫ [ Google Scholar ] [ CrossRef ]
- وو، ن. راهکارهای هوش مصنوعی سیلوا، EA برای پویایی زمین شهری: بررسی جی. پلان. روشن شد ۲۰۱۰ ، ۲۴ ، ۲۴۶-۲۶۵٫ [ Google Scholar ]
- ژائو، ک. تارکوما، اس. لیو، اس. Vo, H. داده کاوی تحرک انسانی شهری: یک مرور کلی. در مجموعه مقالات کنفرانس بین المللی IEEE در سال ۲۰۱۶ درباره داده های بزرگ (داده های بزرگ)، واشنگتن، دی سی، ایالات متحده آمریکا، ۵ تا ۸ دسامبر ۲۰۱۶؛ IEEE: Piscataway, NJ, USA, 2016; صفحات ۱۹۱۱-۱۹۲۰٫ [ Google Scholar ]
- هیلی، کی. فاک نوانس. اجتماعی نظریه ۲۰۱۷ ، ۳۵ ، ۱۱۸-۱۲۷٫ [ Google Scholar ] [ CrossRef ]
- Christaller, W. Die Zentralen Orte در Süddeutschland: Eine Ökonomisch-Geographische Untersuchung Über die Gesetzmässigkeit der Verbreitung und Entwicklung der Siedlungen mit Städtischen Funktionen ; Wissenschaftliche Buchgesellschaft: دارمشتات، آلمان، ۱۹۳۳٫ [ Google Scholar ]
- آلن، PM؛ Sanglier, M. یک مدل پویا از رشد در یک سیستم مکان مرکزی. Geogr. مقعدی ۱۹۷۹ ، ۱۱ ، ۲۵۶-۲۷۲٫ [ Google Scholar ] [ CrossRef ]
- AbouKorin، AA تحلیل فضایی سیستم شهری در دره نیل مصر. مهندس عین شمس J. ۲۰۱۸ ، ۹ ، ۱۸۱۹-۱۸۲۹٫ [ Google Scholar ] [ CrossRef ]
- یانگ، آر. خو، Q. طولانی، H. ویژگی های توزیع فضایی و تجزیه و تحلیل بازسازی بهینه سکونتگاه های روستایی چین در طول فرآیند شهرنشینی سریع. J. Rural Stud. ۲۰۱۶ ، ۴۷ ، ۴۱۳-۴۲۴٫ [ Google Scholar ] [ CrossRef ]
- کروگمن، پی. اقتصاد خودسازماندهی ؛ شماره ۳۳۸٫۹ KRU 1996; CIMMYT: مکزیکو سیتی، مکزیک، ۱۹۹۶٫ [ Google Scholar ]
- کراس، MC; هوهنبرگ، تشکیل الگوی PC خارج از تعادل. Rev. Mod. فیزیک ۱۹۹۳ ، ۶۵ ، ۸۵۱٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- پورویس، بی. مائو، ی. رابینسون، دی. آنتروپی و کاربرد آن در سیستم های شهری. Entropy ۲۰۱۹ ، ۲۱ ، ۵۶٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- لواشوا، ن. سیدوروا، آ. سمینا، ع. Ni، M. یک مدل موج خودکار فضایی-زمانی توسعه قلمرو شانگهای. پایداری ۲۰۱۹ ، ۱۱ ، ۳۶۵۸٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- مددا، اف. Nijkamp، P. Rietveld, P. A Perspective Morphogenetic on Spatial Complexity. در پیچیدگی و شبکه های فضایی ; Reggiani, A., Nijkamp, P., Eds. Springer: برلین/ هایدلبرگ، آلمان، ۲۰۰۹; صص ۵۱-۶۰٫ [ Google Scholar ]
- پلز، PF; فریزن، جی. هارتیگ، جی. اندازه مشابه محله های فقیر نشین ناشی از بی ثباتی تورینگ در رفتار مهاجرت. فیزیک Rev. ۲۰۱۹ , ۹۹ . [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بارینگتون-لی، سی. Millard-Ball, A. یک قرن گسترش در ایالات متحده. Proc. Natl. آکادمی علمی ایالات متحده آمریکا ۲۰۱۵ ، ۱۱۲ ، ۸۲۴۴–۸۲۴۹٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- اوربیتا، پی. فرناندز، ای. راموس، ال. مندز مارتینز، جی. Bento، R. یک شاخص پراکندگی شهری مبتنی بر پوشش زمین مناسب برای مناطق بسیار پراکنده و مصنوعی شده ناپیوسته: مورد پرتغال قاره ای. سیاست کاربری زمین ۲۰۱۹ ، ۸۵ ، ۹۲-۱۰۳٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- رومانو، بی. زولو، اف. فیورینی، ال. سیابو، اس. Marucci، A. Sprinkling: رویکردی برای توصیف پویایی شهرنشینی در ایتالیا. پایداری ۲۰۱۷ ، ۹ ، ۹۷٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- ساگانیتی، ال. فاواله، ا. پیلوگالو، ا. اسکورزا، اف. مورگانته، ب. ارزیابی تکه تکه شدن شهری در مقیاس منطقه ای با استفاده از شاخص های آبپاشی. Sustainability ۲۰۱۸ , ۱۰ , ۳۲۷۴٫ [ Google Scholar ] [ CrossRef ][ Green Version ]
- یوینگ، ویژگی های RH، علل و اثرات پراکندگی: مروری بر ادبیات. در اکولوژی شهری: دیدگاهی بین المللی در مورد تعامل بین انسان و طبیعت . Marzluff, JM, Shulenberger, E., Endlicher, W., Alberti, M., Bradley, G., Ryan, C., Simon, U., ZumBrunnen, C., Eds.; Springer: Boston, MA, USA, 2008; صص ۵۱۹-۵۳۵٫ [ Google Scholar ]
- کوندو، اس. میورا، تی. مدل واکنش- انتشار به عنوان چارچوبی برای درک تشکیل الگوی بیولوژیکی. Science ۲۰۱۰ , ۳۲۹ , ۱۶۱۶-۱۶۲۰٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- اش، تی. هلدنز، دبلیو. هیرنر، آ. کیل، م. مارکونچینی، ام. راث، ا. زیدلر، جی. دچ، اس. Strano، E. ایجاد زمینه جدید در نقشه برداری سکونتگاه های انسانی از فضا – ردپای جهانی شهری. Isprs J. Photogramm. از راه دور. Sens. ۲۰۱۷ , ۱۳۴ , ۳۰-۴۲٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- اش، تی. باکوفر، اف. هلدنز، دبلیو. هیرنر، آ. مارکونچینی، ام. پالاسیوس لوپز، دی. راث، ا. اورین، اس. زیدلر، جی. دچ، اس. و همکاران جایی که ما زندگی می کنیم – خلاصه ای از دستاوردها و تکامل برنامه ریزی شده ردپای شهری جهانی. Remote Sens. ۲۰۱۸ , ۱۰ , ۸۹۵٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- اش، تی. شنک، ا. اولمان، تی. تیل، م. راث، ا. Dech, S. خصوصیات انواع پوشش زمین در تصاویر TerraSAR-X با تجزیه و تحلیل ترکیبی آمار لکه و اطلاعات شدت. IEEE Trans. Geosci. از راه دور. Sens. ۲۰۱۱ , ۴۹ , ۱۹۱۱-۱۹۲۵٫ [ Google Scholar ] [ CrossRef ]
- هادسون، JC یک نظریه مکان برای سکونتگاه روستایی. ان دانشیار صبح. Geogr. ۱۹۶۹ ، ۵۹ ، ۳۶۵-۳۸۱٫ [ Google Scholar ] [ CrossRef ]
- فریزن، جی. هارتیگ، جی. هن، ک. پلز، PF جمعیت شناسی مبتنی بر انتشار – مدل تورینگ به عنوان مفهومی برای ظهور کم تحرکی. arXiv ۲۰۲۰ ، arXiv:2005.05107. [ Google Scholar ]
- کلارک، جی پی؛ ایوانز، فاصله CF تا نزدیکترین همسایه به عنوان معیاری از روابط فضایی در جمعیت ها. اکولوژی ۱۹۵۴ ، ۳۵ ، ۴۴۵-۴۵۳٫ [ Google Scholar ] [ CrossRef ]
- فریزن، جی. تاوبنبوک، اچ. ورم، م. Pelz, PF اندازه مشابه محله های فقیر نشین. Habitat Int. ۲۰۱۸ ، ۷۳ ، ۷۹-۸۸٫ [ Google Scholar ] [ CrossRef ]
- فریزن، جی. تاوبنبوک، اچ. ورم، م. توزیع اندازه Pelz، PF زاغهها در سراسر جهان با استفاده از دادهها و روشهای طبقهبندی مختلف. یورو J. Remote Sens. ۲۰۱۹ ، ۵۲ ، ۹۹–۱۱۱٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کلوتز، ام. کمپر، تی. گیس، سی. اش، تی. Taubenböck, H. نقشه چقدر خوب است؟ یک چارچوب مقایسه متقابل چند مقیاسی برای لایههای اسکان جهانی: شواهدی از اروپای مرکزی سنسور از راه دور محیط. ۲۰۱۶ ، ۱۷۸ ، ۱۹۱-۲۱۲٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Siksna، A. اثرات اندازه بلوک و شکل در مراکز شهرهای آمریکای شمالی و استرالیا. مورفول شهری. ۱۹۹۷ ، ۱ ، ۱۹-۳۳٫ [ Google Scholar ]
- گودال، DW; West, NE مقایسه تکنیکهای ارزیابی الگوهای پراکندگی. Vegetatio ۱۹۷۹ ، ۴۰ ، ۱۵-۲۷٫ [ Google Scholar ] [ CrossRef ]
- رودی، SH; برونتون، اس ال. پروکتور، جی ال. کوتز، JN کشف معادلات دیفرانسیل جزئی مبتنی بر داده. علمی Adv. ۲۰۱۷ , ۳ , e1602614. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- ژائو، اچ. طبقه، BD; براتز، RD; بازانت، MZ یادگیری فیزیک تشکیل الگو از تصاویر. فیزیک کشیش لِت ۲۰۲۰ , ۱۲۴ , ۰۶۰۲۰۱٫ [ Google Scholar ] [ CrossRef ] [ PubMed ]





بدون دیدگاه