
کلید واژه ها:
VideoGIS ; فضایی و زمانی هوش مصنوعی جغرافیایی ; محدودیت های فضایی ؛ یادگیری عمیق
۱٫ مقدمه
۲٫ بررسی ادبیات
۲٫۱٫ تشخیص ناهنجاری جمعیت
۲٫۲٫ محلی سازی ناهنجاری جمعیت
۳٫ مواد و روشها
۳٫۱٫ بررسی اجمالی
۳٫۲٫ بیانیه های مشکل
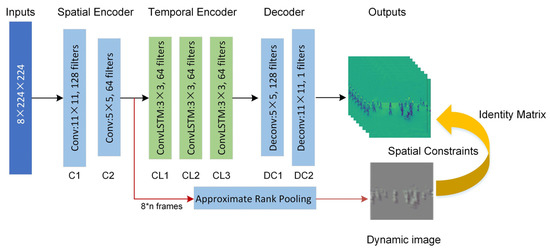
۳٫۳٫ رمزگذار خودکار فضایی و زمانی با تقریب نقشه پویا
۳٫۳٫۱٫ مفاهیم اساسی
۳٫۳٫۲٫ رمزگذار خودکار فضایی و زمانی
برخلاف ساختار مکعبی، رمزگذار زمانی نمایش پنهان ویژگی های ظاهری را تولید می کند که به عنوان نمایش نهفته در نظر گرفته می شود. با توجه به داده های آموزشی x ، مدل های رمزگذار و رمزگشا توسط دو شبکه فرعی پارامتری می شوند. پθ( x | z)و qΦ( z| x )جایی که θو Φپارامترهای شبکه هستند و zیک متغیر پنهان جمعی را نشان می دهد. بنابراین، نمایش پنهان را می توان از طریق زیر به دست آورد:
از دیدگاه ساختار رمزگذار-رمزگشا، ما فرض میکنیم که رمزگذارهای خودکار نمایشهای پنهان را تولید میکنند:
جایی که ساعتآمنو ساعتمترمنبه ترتیب نمایش های پنهانی برای ظاهر و حرکت هستند. پارامترها (دبلیوآ،دبلیومتر،بآ،بمتر)برای یک مجموعه داده آموزشی داده شده یاد می گیرند. پس از آن، مدل نگاشتهایی را از بازنمایی ذاتی مکانی/زمانی به رمزگذار خودکار مکانی-زمانی مییابد. ماتریس وزن و شرایط بایاس نگاشت توسط پارامتر بندی می شوند دبلیونو بن، تابع نگاشت عبارت است از:
بر اساس به دست آمده ساعتآمنو ساعتمترمن، بهینه سازی شبکه عصبی در رمزگذار خودکار مکانی-زمانی یادگیری تابع نگاشت با به حداقل رساندن موارد زیر است:
۳٫۳٫۳٫ تقریب تصویر پویا
با انگیزه [ ۲۰ ، ۵۱ ]، ما یک رویکرد کارآمد را پیشنهاد می کنیم که در آن یک تصویر واحد فریم های ویدئو را خلاصه می کند. تفاوت این است که ما فقط از نقشه پویا به عنوان یک ماسک یا محدودیت های فضایی برای فریم های بازسازی شده استفاده می کنیم. اجازه دهید ψ (منتی) ∈آردیک بردار استخراج شده از یک فریم ویدیویی جداگانه باشد منتی; ما تصویر پویا را با فشرده سازی دنباله ویدیو در بردار پارامترهای d * به کار می بریم :
جایی که ρ ( ⋅ )تابع نقشه است که یک توالی ویدیو را به یک بردار نگاشت می کند و d* نیز می تواند به عنوان یک تصویر در نظر گرفته شود. به طور متفاوت، ما این اصطلاح را حذف کردیم ψبه عنوان ورودی به تقریب از قبل در نقشه های ویژگی است. همچنین می توانیم d* را به صورت زیر در نظر بگیریم:
جایی که اس( ق| د ) =⟨د،Vتی⟩امتیاز رتبه بندی مربوط به هر بار t و استVتی=۱تی∑تیr = ۱ψ (منr)میانگین زمانی این فریم های ویدئویی تا زمان t است. ویژگی ها منعکس کننده ترتیب فریم ها در ظاهر هستند، تکامل پویا در حوزه های مکانی و زمانی قابل ثبت است.
برای ایجاد یک مرز فضایی، محاسبه تصاویر پویا با درجه بالایی از دقت ممکن است ضروری نباشد. بنابراین، ما از یک تقریب برای رتبه بندی ادغام مانند [ ۵۱ ] برای بهینه سازی معادله (۷) استفاده می کنیم، که سریعتر است و در عمل به خوبی کار می کند:
جایی که αتینشان دهنده ضریب داده شده توسط αتی= ۲ ( T− t + ۱ ) − ( T + ۱ ) (اچتی–اچt – ۱). به عبارت دیگر، میتوانیم تقریبکننده نقشه پویا را بهعنوان یک لایه برای ترکیب کردن ظاهر و حرکت اجسام بازسازی کنیم.
ما یک ماتریس هویت ابداع کردیم منمبرای تعریف مرزهای فضایی برای تشخیص ناهنجاری ( شکل ۳ را ببینید ). هدف ماتریس شناسایی مناطقی از یک تصویر است که برای تولید ضرر بازسازی استفاده میشوند. به طور رسمی، اجازه دهید منبه هر پیکسل مرتبط شود تودر تصویر پویا دبا مقدار اسکالر m ( u ). از این رو، منمیک ماتریس m × n مشابه تصویر پویا است د. می توان آن را محاسبه کرد:
۳٫۴٫ تشخیص ناهنجاری
استفاده از نمونهگیری خطی در یک دنباله ویدئویی، محاسبات را در مقایسه با یک طرح غیرنمونهبرداری کاهش میدهد. پس از آموزش، خطای بازسازی با توجه به تفاوت بین قاب ورودی و قاب بازسازی شده با محدودیت های مکانی محاسبه می شود. ما امتیاز نظم را به صورت زیر تعریف کردیم:
جایی که ایکس¯¯¯قاب بازسازی شده از است ایکس، φ ( ⋅ )تابع خطای پیکسل است، نمجموع اعداد فریم است، wعرض است، ساعتارتفاع فریم ویدیو است و منایکسماتریس هویت مرتبط است. توجه داشته باشید که ۱۶ فریم مربوط به یک ماتریس هویت در کار ما است.
با بررسی دادههای جایی که مدل تمایل به خطا دارد، امتیازهای ناهنجاری را محاسبه میکنیم اسآ( تی )، نمرات نظم اسr( تی )، و سپس خطای بازسازی را به [۰، ۱] نرمال کنید. روش محاسبه امتیاز نظم به شرح زیر است:
فرض کنید هیچ رویداد غیرعادی در یک سکانس ویدیو وجود ندارد. در آن صورت، به دلیل عدم وجود الگوهای نامنظم در حین تمرین، امتیاز خطای بازسازی مربوطه بالاتر از توالی ویدیویی غیرعادی است. بنابراین، تعیین یک آستانه برای امتیاز نظم میتواند ارزیابی کند که آیا یک رویداد غیرعادی در یک فریم ویدیو رخ داده است یا خیر. در این کار، ما آستانه را به عنوان تغییرات تطبیقی در نظر می گیریم که به صورت زیر محاسبه می شود:
جایی که اسr( تی )نشان دهنده امتیاز نظم و پارامتر تنظیم است آاز طریق آموزش به دست می آید.
| الگوریتم ۱٫ الگوریتم تشخیص ناهنجاری جمعیت |
| ورودی : { منتی}دسته ای از فریم های ویدئویی خام در زمان t است خروجی : فریم های ویدئویی ناهنجار ۱: تغییر اندازه {منتی}تا ۲۲۴ × ۲۲۴ پیکسل در بلوک ورودی ۲: برای هر فریم ویدیو منمنکه در {منتی}انجام ۳: فریم ویدیو را به جلو پخش کنید منمناز طریق بلوک رمزگذار فضایی ۴: نقشه های ویژگی SF را از لایه C2 از بلوک رمزگذار مکانی ۵ انتخاب کنید: انتشار SF به جلو از طریق بلوک ۶ رمزگذار زمانی : در صورت تولید SFs = 16 ایجاد تصویر پویا از طریق بلوک تقریبی محاسبه ماتریس هویت منمتیاز تصویر پویا (معادله (۹)) پایان تصویر پویا را آغاز کنید اگر ۷: انتشار SF به جلو از طریق بلوک رمزگذار موقتی ۸: نقشه های ویژگی TF را از لایه CL3 بلوک رمزگذار موقت ۹ انتخاب کنید: انتشار TF به جلو از طریق بلوک رسیور ۱۰: انتخاب کنید فریم RF بازسازی شده از لایه DC2 از بلوک انکودر ۱۱: پایان برای ۱۲: برای شاخص RF = 1 تا ۱۶، ۱۳ را انجام دهید : محاسبه امتیاز نظم برای هر RF (معادلات (۱۰)-(۱۴)) اگر امتیاز نظم < آستانه خروجی پایان RF اگر ۱۴: پایان برای |
۳٫۵٫ تجسم ناهنجاری و محلی سازی
برخلاف مطالعات موجود، روش پیشنهادی نیازی به شبکه اضافی ندارد که بسیار سریعتر است و در نظارت تصویری به خوبی کار می کند. به طور رسمی، اجازه دهید هتفسیری از نقشه برجسته تصویر ورودی باشد. سپس نقشه برجستگی به صورت زیر تعریف می شود:
جایی که ایکستصویر ورودی است، m∈ _[ ۰ ، ۱ ]۱ × H× Wماسک است، rنشان دهنده تصویر مرجع و Φعملگر اغتشاش است.
با توجه به سابقه نظارت زمانبر چنین بازسازیهایی، هدف ما تعیین مینیاتوریترین اشیاء غیرعادی است، بازسازی که به ما امکان میدهد خط مشی زیربنایی محاسبه احتمالات خطا را شناسایی کنیم. از این نظر، ما یک ویژگی مهم ماده فعال را که ذاتی آشفتگی ویژگیهای مکانی-زمانی است در نظر میگیریم. به طور دقیق، خطای بازسازی در مکان پیکسل ( x ، y ) در قاب t به صورت زیر محاسبه می شود:
جایی که سخطای بازسازی پیکسل است، fدبلیو( ⋅ )رمزگذار خودکار ذکر شده در بالا است، منمقدار شدت پیکسل نرمال شده است و منمماتریس هویت برای ارائه محدودیت های فضایی است. علاوه بر این، تعریف مبتنی بر ماسک از یک توضیح با خطاهای بازسازی پیکسل، یک نقشه تفسیر را تشکیل می دهد.
۴٫ آزمایش و نتایج
۴٫۱٫ مجموعه داده
۴٫۲٫ جزئیات پیاده سازی
۴٫۳٫ نتایج و تجزیه و تحلیل
۴٫۳٫۱٫ ارزیابی دقت
۴٫۳٫۲٫ ارزیابی زمان – هزینه
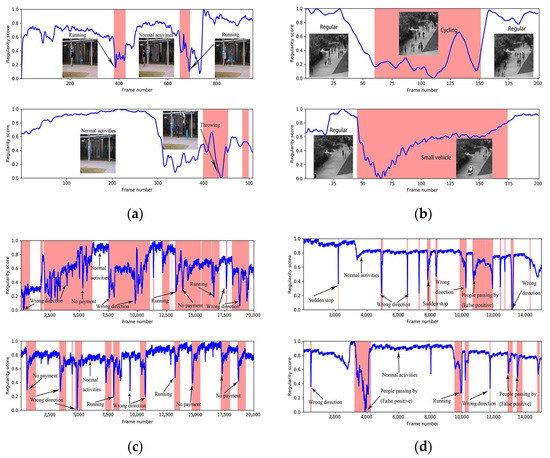
۴٫۳٫۳٫ تحلیل کیفی
۴٫۳٫۴٫ توضیحات بصری با اغتشاش معنی دار
۴٫۳٫۵٫ تحلیل و بررسی
۵٫ نتیجه گیری ها
منابع
- ژو، ی. کین، ام. وانگ، ایکس. Zhang, C. تجزیه و تحلیل وضعیت جمعیت منطقه ای بر اساس GeoVideo و همکاری داده های چند رسانه ای. در مجموعه مقالات چهارمین کنفرانس مدیریت اطلاعات پیشرفته، ارتباطات، کنترل الکترونیک و اتوماسیون IEEE 2021 (IMCEC)، چونگ کینگ، چین، ۱۸ تا ۲۰ ژوئن ۲۰۲۱؛ ص ۱۲۷۸–۱۲۸۲٫ [ Google Scholar ]
- پیدهورسکی، اس. المحسن، ر. دورتو، جی. تشخیص تازگی احتمالی با رمزگذارهای خودکار متخاصم. در مجموعه مقالات سی و دومین کنفرانس سیستم های پردازش اطلاعات عصبی (NeurIPS 2018)، مونترال، QC، کانادا، ۳ تا ۸ دسامبر ۲۰۱۸؛ جلد ۳۱، ص ۶۸۲۲–۶۸۳۳٫ [ Google Scholar ]
- فن، اس. Meng, F. الگوریتم پیشبینی ویدیویی و تشخیص ناهنجاری مبتنی بر تمایز دوگانه. در مجموعه مقالات پنجمین کنفرانس بین المللی ۲۰۲۰ در زمینه هوش محاسباتی و کاربردها (ICCIA)، پکن، چین، ۱۹ تا ۲۱ ژوئن ۲۰۲۰؛ صص ۱۲۳-۱۲۷٫ [ Google Scholar ]
- وانگ، تی. کیائو، م. لین، ز. لی، سی. سنوسی، ح. لیو، ز. چوی، سی. شبکه های عصبی مولد برای تشخیص ناهنجاری در صحنه های شلوغ. IEEE Trans. Inf. پزشکی قانونی امن. ۲۰۱۸ ، ۱۴ ، ۱۳۹۰–۱۳۹۹٫ [ Google Scholar ] [ CrossRef ]
- گونگ، دی. لیو، ال. لی، وی. سها، بی. منصور، آقا؛ ونکاتش، س. هنگل، AVD به خاطر سپردن نرمال بودن برای تشخیص ناهنجاری: رمزگذار خودکار عمیق تقویت شده با حافظه برای تشخیص ناهنجاری بدون نظارت. در مجموعه مقالات کنفرانس بین المللی IEEE/CVF در بینایی کامپیوتر، سئول، کره، ۲۷ اکتبر تا ۲ نوامبر ۲۰۱۹؛ صفحات ۱۷۰۵-۱۷۱۴٫ [ Google Scholar ]
- وو، اچ. نگوین، تی دی؛ تراورس، ا. ونکاتش، س. Phung, D. تشخیص ناهنجاری موضعی مبتنی بر انرژی در نظارت تصویری. در کنفرانس اقیانوس آرام-آسیا در مورد کشف دانش و داده کاوی ؛ Springer: Cham، آلمان، ۲۰۱۷; صص ۶۴۱-۶۵۳٫ [ Google Scholar ]
- لیو، دبلیو. لو، دبلیو. لیان، دی. گائو، اس. پیشبینی قاب آینده برای تشخیص ناهنجاری-یک پایه جدید. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو، سالت لیک سیتی، UT، ایالات متحده آمریکا، ۱۸ تا ۲۳ ژوئن ۲۰۱۸؛ صص ۶۵۳۶–۶۵۴۵٫ [ Google Scholar ]
- بابایی زاده، م. فین، سی. ایرهان، د. کمپبل، RH; لوین، اس. پیش بینی ویدئویی تغییرات تصادفی. arXiv ۲۰۱۷ , arXiv:1710.11252. [ Google Scholar ]
- کاسترجون، ال. بالاس، ن. Courville، A. VRNN های شرطی بهبود یافته برای پیش بینی ویدیو. در مجموعه مقالات کنفرانس بین المللی IEEE/CVF در بینایی کامپیوتر، سئول، کره، ۲۷ اکتبر تا ۲ نوامبر ۲۰۱۹؛ ص ۷۶۰۸-۷۶۱۷٫ [ Google Scholar ]
- دوست خوب، من. پوگت ابادی، ج. میرزا، م. خو، بی. وارد-فارلی، دی. اوزایر، س. کورویل، آ. Bengio، Y. شبکه های متخاصم مولد. در مجموعه مقالات بیست و هفتمین کنفرانس بین المللی سیستم های پردازش اطلاعات عصبی (NeurIPS 2014)، مونترال، QC، کانادا، ۸ تا ۱۳ دسامبر ۲۰۱۴٫ جلد ۲، ص ۲۶۷۲–۲۶۸۰٫ [ Google Scholar ]
- گوسیخا، دی. ابیرمی، س. Baskaran, R. تجزیه و تحلیل خودکار رفتار انسان از فیلم های نظارتی: یک نظرسنجی. آرتیف. هوشمند Rev. ۲۰۱۴ , ۴۲ , ۷۴۷-۷۶۵٫ [ Google Scholar ] [ CrossRef ]
- اوجه، س. Sakhare, S. تکنیک های پردازش تصویر برای ردیابی اشیا در نظارت تصویری – یک بررسی. در مجموعه مقالات کنفرانس بین المللی ۲۰۱۵ در محاسبات فراگیر (ICPC)، پونا، هند، ۸ تا ۱۰ ژانویه ۲۰۱۵٫ صص ۱-۶٫ [ Google Scholar ]
- کیران، BR; توماس، دی.م. Parakkal, R. مروری بر روش های مبتنی بر یادگیری عمیق برای تشخیص ناهنجاری بدون نظارت و نیمه نظارت در فیلم ها. J. Imaging ۲۰۱۸ ، ۴ ، ۳۶٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- کنگ، ی. یوان، جی. لیو، جی. هزینه بازسازی پراکنده برای تشخیص رویدادهای غیرعادی. در مجموعه مقالات کنفرانس IEEE 2011 در مورد دید کامپیوتری و تشخیص الگو (CVPR)، کلرادو اسپرینگز، CO، ایالات متحده آمریکا، ۲۰-۲۵ ژوئن ۲۰۱۱٫ صص ۳۴۴۹–۳۴۵۶٫ [ Google Scholar ]
- لیو، سی. غسال، س. جیانگ، ز. سرکار، اس. یک رویکرد مدلسازی گرافیکی فضایی-زمانی بدون نظارت برای تشخیص ناهنجاری در CPS توزیع شده. در مجموعه مقالات هفتمین کنفرانس بین المللی ACM/IEEE 2016 در مورد سیستم های فیزیکی-سایبری (ICCPS)، وین، اتریش، ۱۱ تا ۱۴ آوریل ۲۰۱۶؛ صص ۱-۱۰٫ [ Google Scholar ]
- ژو، اس. شن، دبلیو. زنگ، دی. نیش، م. وی، ی. Zhang، Z. شبکه های عصبی کانولوشنال مکانی-زمانی برای تشخیص ناهنجاری و محلی سازی در صحنه های شلوغ. فرآیند سیگنال اشتراک تصویر. ۲۰۱۶ ، ۴۷ ، ۳۵۸-۳۶۸٫ [ Google Scholar ] [ CrossRef ]
- کنگ، ی. یوان، جی. Tang, Y. جستجوی ناهنجاری ویدیویی در صحنههای شلوغ از طریق زمینه حرکت مکانی-زمانی. IEEE Trans. Inf. پزشکی قانونی امن. ۲۰۱۳ ، ۸ ، ۱۵۹۰-۱۵۹۹٫ [ Google Scholar ] [ CrossRef ]
- یوان، ی. وانگ، دی. وانگ، Q. تشخیص ناهنجاری در صحنه های ترافیکی از طریق بازسازی حرکت آگاهانه فضایی. IEEE Trans. هوشمند ترانسپ سیستم ۲۰۱۶ ، ۱۸ ، ۱۱۹۸-۱۲۰۹٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- چو، دبلیو. ژو، اچ. یائو، سی. Cai, D. آموزش ویژگی مکانی-زمانی هدایت شده کدگذاری پراکنده برای تشخیص رویدادهای غیرعادی در ویدیوهای بزرگ. IEEE Trans. چند رسانه ای ۲۰۱۹ ، ۲۱ ، ۲۴۶-۲۵۵٫ [ Google Scholar ] [ CrossRef ]
- ژو، JT; دو، ج. زو، اچ. پنگ، ایکس. لیو، ی. Goh، RSM AnomalyNet: یک شبکه تشخیص ناهنجاری برای نظارت تصویری. IEEE Trans. Inf. پزشکی قانونی امن. ۲۰۱۹ ، ۱۴ ، ۲۵۳۷–۲۵۵۰٫ [ Google Scholar ] [ CrossRef ]
- یوان، ی. فنگ، ی. لو، ایکس. آشکارساز فرضیه آماری برای تشخیص رویدادهای غیرعادی در صحنه های شلوغ. IEEE Trans. سایبرن. ۲۰۱۷ ، ۴۷ ، ۳۵۹۷-۳۶۰۸٫ [ Google Scholar ] [ CrossRef ]
- حسن، م. چوی، جی. نویمان، جی. روی-چودری، AK; دیویس، LS نظم زمانی یادگیری در توالی های ویدیویی. در مجموعه مقالات کنفرانس IEEE در مورد دید کامپیوتری و تشخیص الگو (CVPR)، لاس وگاس، NV، ایالات متحده، ۲۷-۳۰ ژوئن ۲۰۱۶٫ صص ۷۳۳-۷۴۲٫ [ Google Scholar ]
- تودور یونسکو، آر. اسموریانو، اس. الکس، بی. پوپسکو، ام. افشای نقاب از رویدادهای غیرعادی در ویدئو. در مجموعه مقالات کنفرانس بین المللی IEEE در بینایی کامپیوتر، ونیز، ایتالیا، ۲۲ تا ۲۹ اکتبر ۲۰۱۷؛ صص ۲۹۱۴–۲۹۲۲٫ [ Google Scholar ]
- خو، دی. یان، ی. ریچی، ای. Sebe, N. تشخیص رویدادهای غیرعادی در ویدیوها با یادگیری بازنمایی عمیق ظاهر و حرکت. محاسبه کنید. Vis. تصویر زیر. ۲۰۱۷ ، ۱۵۶ ، ۱۱۷-۱۲۷٫ [ Google Scholar ] [ CrossRef ]
- لو، دبلیو. لیو، دبلیو. گائو، اس. یادآوری تاریخ با LSTM کانولوشن برای تشخیص ناهنجاری. در مجموعه مقالات کنفرانس بین المللی IEEE 2017 در چند رسانه و نمایشگاه (ICME)، هنگ کنگ، چین، ۱۰ تا ۱۴ ژوئیه ۲۰۱۷؛ صص ۴۳۹-۴۴۴٫ [ Google Scholar ]
- وانگ، ال. ژو، اف. لی، ز. زو، دبلیو. Tan, H. تشخیص رویداد غیرعادی در ویدیوها با استفاده از رمزگذار خودکار مکانی-زمانی ترکیبی. در مجموعه مقالات بیست و پنجمین کنفرانس بین المللی IEEE در مورد پردازش تصویر (ICIP)، آتن، یونان، ۷ تا ۱۰ اکتبر ۲۰۱۸؛ ص ۲۲۷۶-۲۲۸۰٫ [ Google Scholar ]
- پیپی، ز. چینگهای، دی. هایبو، ال. Xinglin، H. تشخیص ناهنجاری و مکان در فیلمهای نظارت شلوغ. Acta Opt. گناه ۲۰۱۸ ، ۳۸ ، ۹۷-۱۰۵٫ [ Google Scholar ]
- لی، ایکس. چن، ام. وانگ، کیو. کمی سازی و تشخیص حرکت جمعی در صحنه های جمعی. IEEE Trans. فرآیند تصویر ۲۰۲۰ ، ۲۹ ، ۵۵۷۱-۵۵۸۳٫ [ Google Scholar ] [ CrossRef ] [ PubMed ]
- لیو، ی. هان، ز. ژونگ، جی. لی، سی. Liu, Z. تشخیص ناهنجاری عمومی مولفههای پشتیبانی زنجیرهای بر اساس شبکههای متخاصم مولد. IEEE Trans. ساز. Meas. ۲۰۱۹ ، ۶۹ ، ۲۴۳۹–۲۴۴۸٫ [ Google Scholar ] [ CrossRef ]
- وانگ، سی. یائو، ی. یائو، اچ. روش تشخیص ناهنجاری ویدیویی بر اساس پیشبینی فریم آینده و مکانیسم توجه. در مجموعه مقالات یازدهمین کارگاه و کنفرانس سالانه محاسبات و ارتباطات (CCWC) 2021 IEEE، به صورت آنلاین. ۲۷–۳۰ ژانویه ۲۰۲۱؛ ص ۴۰۵-۴۰۷٫ [ Google Scholar ]
- سابکرو، م. فیاض، م. فتحی، م. مؤید، ز. Klette, R. Deep-anomaly: شبکه عصبی کاملاً کانولوشن برای تشخیص سریع ناهنجاری در صحنه های شلوغ. محاسبه کنید. Vis. تصویر زیر. ۲۰۱۸ ، ۱۷۲ ، ۸۸-۹۷٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- یان، اس. اسمیت، جی اس. لو، دبلیو. Zhang، B. تشخیص رویداد غیرعادی از ویدیوها با استفاده از رمزگذار خودکار متغیر متغیر دو جریانی. IEEE Trans. شناخت. توسعه دهنده سیستم ۲۰۲۰ ، ۱۲ ، ۳۰-۴۲٫ [ Google Scholar ] [ CrossRef ]
- پراویرو، اچ. پنگ، جی دبلیو. پان، TY; تشخیص رویداد غیرعادی Hu، MC در ویدیوهای نظارتی با استفاده از رمزگشای دو جریانی. در مجموعه مقالات کنفرانس بین المللی IEEE 2020 در کارگاه های آموزشی چند رسانه ای و نمایشگاهی (ICMEW)، لندن، بریتانیا، ۶ تا ۱۰ ژوئیه ۲۰۲۰؛ صص ۱-۶٫ [ Google Scholar ]
- ناواراتنه، آر. الهاکون، د. دی سیلوا، دی. Yu, X. تشخیص ناهنجاری فضایی-زمانی با استفاده از یادگیری عمیق برای نظارت تصویری در زمان واقعی. IEEE Trans. Ind. اطلاع رسانی. ۲۰۲۰ ، ۱۶ ، ۳۹۳-۴۰۲٫ [ Google Scholar ] [ CrossRef ]
- طارق، س. فاروق، ح. جلیل، ع. Wasif، تشخیص ناهنجاری SM با فیلتر ذرات برای نظارت تصویری آنلاین. دسترسی IEEE ۲۰۲۱ ، ۹ ، ۱۹۴۵۷-۱۹۴۶۸٫ [ Google Scholar ]
- زو، ی. Newsam، ویژگی S. Motion-aware برای بهبود تشخیص ناهنجاری ویدیویی. arXiv ۲۰۱۹ ، arXiv:1907.10211. [ Google Scholar ]
- سابکرو، م. فیاض، م. فتحی، م. Klette، R. Deep-Cascade: شبکه های عصبی عمیق سه بعدی آبشاری برای تشخیص سریع ناهنجاری و محلی سازی در صحنه های شلوغ. IEEE Trans. فرآیند تصویر ۲۰۱۷ ، ۲۶ ، ۱۹۹۲-۲۰۰۴٫ [ Google Scholar ] [ CrossRef ]
- Lv، H.; ژو، سی. کوی، ز. خو، سی. لی، ی. یانگ، جی. محلیسازی ناهنجاریها از ویدیوهای دارای برچسب ضعیف. IEEE Trans. فرآیند تصویر ۲۰۲۱ ، ۳۰ ، ۴۵۰۵-۴۵۱۵٫ [ Google Scholar ] [ CrossRef ] [ PubMed ]
- احمد، ع. ساجان، ک.اس. سریواستاوا، ا. Wu, Y. تشخیص ناهنجاری، محلیسازی و طبقهبندی با استفاده از جریانهای داده Synchrophasor Drifting. IEEE Trans. شبکه هوشمند. ۲۰۲۱ ، ۱۲ ، ۳۵۷۰-۳۵۸۰٫ [ Google Scholar ] [ CrossRef ]
- گانوکراتانا، تی. آرامویت، س. Sebe, N. تشخیص ناهنجاری بدون نظارت و محلی سازی بر اساس شبکه ترجمه عمیق فضایی-زمانی. دسترسی IEEE ۲۰۲۰ ، ۸ ، ۵۰۳۱۲–۵۰۳۲۹٫ [ Google Scholar ] [ CrossRef ]
- محمد، ک. احمد، ج. Lv، Z. بلاویستا، پ. یانگ، پی. Baik، SW Efficient Deep Deep-based CNN-Fire Detection and Localization در برنامه های نظارت تصویری. IEEE Trans. سیستم مرد سایبرن. سیستم ۲۰۱۹ ، ۴۹ ، ۱۴۱۹-۱۴۳۴٫ [ Google Scholar ] [ CrossRef ]
- کویل، دی. Weller, A. «تبیین» یادگیری ماشینی چالشهای خطمشی را آشکار میکند. Science ۲۰۲۰ ، ۳۶۸ ، ۱۴۳۳-۱۴۳۴٫ [ Google Scholar ] [ CrossRef ]
- هو، بی جی; ژو، یادگیری ZH با ساختار قابل تفسیر از Gated RNN. IEEE Trans. شبکه عصبی فرا گرفتن. سیستم ۲۰۲۰ ، ۳۱ ، ۲۲۶۷-۲۲۷۹٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- سلواراجو، آر.آر. کگزول، ام. داس، ا. ودانتام، ر. پریخ، د. Batra, D. Grad-cam: توضیحات بصری از شبکه های عمیق از طریق محلی سازی مبتنی بر گرادیان. در مجموعه مقالات کنفرانس بین المللی IEEE در بینایی کامپیوتر، ونیز، ایتالیا، ۲۲ تا ۲۹ اکتبر ۲۰۱۷؛ صص ۶۱۸-۶۲۶٫ [ Google Scholar ]
- جیانگ، PT; ژانگ، CB; هو، کیو. چنگ، MM; Wei, Y. LayerCAM: بررسی نقشههای فعالسازی کلاس سلسله مراتبی برای محلیسازی. IEEE Trans. فرآیند تصویر ۲۰۲۱ ، ۳۰ ، ۵۸۷۵-۵۸۸۸٫ [ Google Scholar ] [ CrossRef ]
- وانگ، اچ. وانگ، ز. دو، م. یانگ، اف. ژانگ، ز. دینگ، اس. مردزیل، پ. Hu, X. Score-CAM: توضیحات بصری با وزن برای شبکه های عصبی کانولوشن. در مجموعه مقالات کنفرانس IEEE/CVF در کارگاه های آموزشی بینایی رایانه و تشخیص الگو، سیاتل، WA، ایالات متحده آمریکا، ۱۴ تا ۱۹ ژوئن ۲۰۲۰؛ ص ۲۴-۲۵٫ [ Google Scholar ]
- چن، جی. لی، SE; تومیزوکا، ام. رانندگی خودکار شهری سرتاسر قابل تفسیر با یادگیری تقویتی عمیق نهفته. IEEE Trans. هوشمند ترانسپ سیستم ۲۰۲۱ ، ۱-۱۱٫ [ Google Scholar ] [ CrossRef ]
- لیپتون، ZC افسانه های تفسیرپذیری مدل. اشتراک. ACM ۲۰۱۶ ، ۶۱ ، ۳۶-۴۳٫ [ Google Scholar ] [ CrossRef ]
- باو، دی. ژو، بی. خسلا، ع. اولیوا، ا. Torralba، A. تشریح شبکه: کمیت تفسیرپذیری بازنماییهای بصری عمیق. در مجموعه مقالات کنفرانس IEEE در مورد دید رایانه و تشخیص الگو، هونولولو، HI، ایالات متحده آمریکا، ۲۱ تا ۲۶ ژوئیه ۲۰۱۷؛ صص ۶۵۴۱–۶۵۴۹٫ [ Google Scholar ]
- فن، م. وی، دبلیو. Xie، X. لیو، ی. گوان، ایکس. لیو، تی. آیا میتوانیم به توضیحات شما اعتماد کنیم؟ بررسی سلامت برای مترجمان در تجزیه و تحلیل بدافزار اندروید. IEEE Trans. Inf. امنیت پزشکی قانونی ۲۰۲۱ ، ۱۶ ، ۸۳۸-۸۵۳٫ [ Google Scholar ] [ CrossRef ]
- بیلن، اچ. فرناندو، بی. گاووس، ای. Vedaldi، A. Action Recognition with Dynamic Image Network. IEEE Trans. الگوی مقعدی ۲۰۱۸ ، ۴۰ ، ۲۷۹۹–۲۸۱۳٫ [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- Fong، RC; ودالدی، ا. توضیحات قابل تفسیر جعبههای سیاه با اغتشاش معنادار. در مجموعه مقالات کنفرانس بین المللی IEEE در بینایی کامپیوتر، ونیز، ایتالیا، ۲۲ تا ۲۹ اکتبر ۲۰۱۷؛ صص ۳۴۲۹–۳۴۳۷٫ [ Google Scholar ]
- دابکوفسکی، پ. Gal, Y. برجسته بودن تصویر در زمان واقعی برای طبقهبندیکنندههای جعبه سیاه. در مجموعه مقالات سی و یکمین کنفرانس سیستم های پردازش اطلاعات عصبی (NIPS 2017)، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، ۴ تا ۹ دسامبر ۲۰۱۷؛ پ. ۳۰٫ [ Google Scholar ]
- واگنر، جی. کوهلر، جی.ام. گیندل، تی. هتزل، ال. Wiedemer, JT; Behnke, S. توضیحات بصری قابل تفسیر و ریز برای شبکه های عصبی کانولوشن. در مجموعه مقالات کنفرانس IEEE/CVF در مورد دید کامپیوتری و تشخیص الگو، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، ۱۵ تا ۲۰ ژوئن ۲۰۱۹؛ ص ۹۰۹۷–۹۱۰۷٫ [ Google Scholar ]
- رائو، ز. او، م. Zhu, Z. ورودی-آشفتگی-حساسیت برای تجزیه و تحلیل عملکرد CNNS در تشخیص تصویر. در مجموعه مقالات کنفرانس بین المللی IEEE 2019 در مورد پردازش تصویر (ICIP)، تایپه، تایوان، ۲۲ تا ۲۵ سپتامبر ۲۰۱۹؛ ص ۲۴۹۶–۲۵۰۰٫ [ Google Scholar ]
- لو، سی. شی، ج. Jia, J. تشخیص رویداد غیرعادی با سرعت ۱۵۰ فریم در ثانیه در متلب. در مجموعه مقالات کنفرانس بین المللی IEEE در بینایی کامپیوتر، سیدنی، NSW، استرالیا، ۱-۸ دسامبر ۲۰۱۳٫ صص ۲۷۲۰–۲۷۲۷٫ [ Google Scholar ]
- آدم، ا. ریولین، ای. شیمشونی، آی. Reinitz، D. شناسایی رویدادهای غیرمعمول در زمان واقعی با استفاده از مانیتورهای چندگانه مکان ثابت. IEEE Trans. الگوی مقعدی ۲۰۰۸ ، ۳۰ ، ۵۵۵-۵۶۰٫ [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ماهادوان، وی. لی، دبلیو. بالودیا، وی. Vasconcelos، N. تشخیص ناهنجاری در صحنه های شلوغ. در مجموعه مقالات کنفرانس IEEE Computer Society در سال ۲۰۱۰ در مورد دید رایانه و تشخیص الگو، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، ۱۳ تا ۱۸ ژوئن ۲۰۱۰٫ صفحات ۱۹۷۵-۱۹۸۱٫ [ Google Scholar ]
- سینگ، دی. Mohan، CK Deep Spatio-Temporal Representation برای تشخیص تصادفات جاده ای با استفاده از رمزگذار خودکار پشته ای. IEEE Trans. هوشمند ترانسپ ۲۰۱۹ ، ۲۰ ، ۸۷۹–۸۸۷٫ [ Google Scholar ] [ CrossRef ]






بدون دیدگاه