
فن آوری های معنایی ارتباط خود را در تسهیل تفسیر داده های رصد زمین (EO) از طریق قالب هایی مانند RDF و مدل های قابل استفاده مجدد، به ویژه برای نمایش فضا و زمان، ثابت کرده اند. در حالی که شطرنجی ها قالب داده های معمولی برای نتایج الگوریتم های پردازش تصویر هستند، یک مشکل تکراری انتقال مقادیر پیکسل این شطرنج ها به ویژگی هایی است که مناطق مورد نظر روی زمین را معنا می کند، بنابراین تفسیر محتوای آنها را تسهیل می کند. این مقاله به این موضوع از طریق یک فرآیند یکپارچه سازی داده های معنایی بر اساس ویژگی های مکانی و زمانی می پردازد. ما (من) یک مدل معنایی مدولار و عمومی برای نمایش همگن دادههایی که یک منطقه جغرافیایی مورد علاقه را به لطف واحدهای سرزمینی واجد شرایط میکنند، پیشنهاد میکنیم.(قطعه زمین، واحدهای اداری، مناطق جنگلی، و غیره) که ما به عنوان تقسیمات یک قلمرو بزرگتر بر اساس معیارهای مرتبط با فعالیت های انسانی تعریف می کنیم. و (ب) فرآیند استخراج معنایی، تبدیل و بارگذاری (ETL) که بر اساس مدل و دادههای استخراجشده از رستر است و دادههای جمعآوری شده را به مناطق واحد مربوطه نگاشت میکند. ما رویکرد خود را از نظر (i) سازگاری مدل و خط لوله پیشنهادی برای تطبیق موارد استفاده مختلف (نظارت بر گسترش باغهای انگور و شهری)، (ب) ارزش افزوده مجموعه دادههای تولید شده برای کمک به تصمیمگیری، و (iii) ارزیابی میکنیم. مقیاس پذیری رویکرد
کلید واژه ها:
رصد زمین ؛ ادغام داده های معنایی ; داده های مکانی و زمانی ؛ تشخیص تغییر ؛ پوشش زمین ؛ NDVI
۱٫ مقدمه
رصد زمین (EO) زمینهای است که در سالهای اخیر به لطف برنامههای نظارت بر زمین در مقیاس بزرگ، مانند برنامه Landsat ایالات متحده ( https://www.usgs.gov/land-resources/nli/landsat ، قابل دسترسی ) تکامل یافته است. تاریخ: ۲۳ دسامبر ۲۰۲۱) و برنامه کوپرنیک اتحادیه اروپا ( http://www.copernicus.eu/en)، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱). به طور خاص، با برنامه کوپرنیک که توسط آژانس فضایی اروپا (ESA) پرتاب شد، ماهوارههای EO دادههایی را جمعآوری میکنند که با دادههای مشاهداتی از شبکههای حسگر روی سطح زمین ترکیب میشوند. امروزه دو نوع ماهواره در حال تولید هستند، Sentinel-1 و Sentinel-2، با چندین نوع دیگر که تا سال ۲۰۳۰ پیش بینی می شود. از سال ۲۰۱۵، این ماهواره ها تصاویر با کیفیتی از زمین ارائه می دهند (تخمین زده شده بین ۸-۱۰TB داده در روز). ، داده ها و متادیتاهای تصویر زمین را رایگان، قابل اعتماد و به روز در اختیار کاربران قرار می دهد. در دسترس بودن این منابع داده، راه را برای پشتیبانی بهتر از برنامههای کاربردی خاص دامنه موجود و ظهور موارد جدید، از کشاورزی گرفته تا جنگلداری، پایش محیطزیست گرفته تا برنامهریزی شهری، مطالعات آب و هوا و پایش بلایا هموار کرده است. این منابع داده،
یکی از فرمت های رایج داده در پردازش تصاویر ماهواره ای، شطرنجی است. یک شطرنجی پدیده های جغرافیایی را به عنوان یک سطح منظم مدل می کند که در آن هر سلول (یا پیکسل) با یک نشانگر (مثلاً NDVI یا نشانگر تغییر) یا یک مقدار پدیده با توجه به کدگذاری یا طبقه بندی از پیش تعریف شده (مثلاً طبقه بندی پوشش زمین یا سطح کدگذاری تغییر). چندین شطرنجی را می توان برای یک منطقه جغرافیایی ارائه کرد تا یک پدیده مشابه را در تاریخ های مختلف یا پدیده های مختلف نظارت کند. می توان آنها را با هم مقایسه یا ترکیب کرد تا یک مورد جدید تولید کند [ ۱]. با این حال، از منظر تصمیمگیری، تفسیر محتوای آنها به دادههای سطح بالاتر یا بازنماییهای دانش مرتبط با ویژگیهایی نیاز دارد که به برخی از مناطق مورد علاقه روی زمین معنا میبخشد.
این مقاله با ادغام داده های محاسبه شده از رسترها به عنوان راهی برای واجد شرایط بودن مناطق مورد علاقه بر اساس ویژگی های مکانی و زمانی آنها سروکار دارد. برای این منظور از مفهوم واحد سرزمینی استفاده می کنیم که آن را به عنوان بخشی از یک قلمرو بزرگتر تعریف می کنیم که در آن قلمرو بر اساس معیاری که به فعالیت های انسانی مرتبط است (اداره، قانون، اقتصاد، کشاورزی و غیره) تقسیم شده و عادی می شود. در نامگذاری های قانونی تعریف شده و پذیرفته شده. سپس، فرض میکنیم که مناطق مورد علاقه با برخی از واحدهای سرزمینی انتخاب شده برای ارتباط آنها (از نظر جزئیات یا معنی) برای کار در دست مطابقت دارد. بنابراین، مناطق مورد علاقه می توانند واحدهای اداری (به عنوان مثال، بخش ها، شهرستان ها) همانطور که در NUTS تعریف شده باشد (https://ec.europa.eu/eurostat/web/nuts/ ، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱) نامگذاری، واحدهای اقتصادی (به عنوان مثال، بسته های کشاورزی)، یا واحدهای فرهنگی (به عنوان مثال، محله، مناطق زبان). مناطق مورد علاقه معمولاً به عنوان ویژگی های جغرافیایی در قالب برداری نمایش داده می شوند. ما علاقه مند به مطالعه هستیم (i) چه نوع هستی شناسی برای پشتیبانی از استخراج دانش از داده های EO و توصیف نتایج تجزیه و تحلیل متفاوت (ویژگی ها یا شاخص های مشاهده شده) ارائه شده توسط رسترها مورد نیاز است. (ii) چگونه می توان داده های غنی EO را به لطف پردازش تصویر و سایر انواع EO مرتبط در دسترس و قابل استفاده کرد. و (iii) نحوه فعال کردن قابلیت ردیابی داده ها (منابع داده، محاسبه شطرنجی، فرآیند معنایی) برای بهبود اطمینان کاربر و بهره برداری از داده ها.
آثار اصلی این مقاله را می توان به شرح زیر خلاصه کرد:
-
یک مدل معنایی عمومی که به توصیف معنایی و همگن داده های مکانی-زمانی اجازه می دهد تا مناطق از پیش تعریف شده را واجد شرایط کند و منشأ آنها را پیگیری کند. این مدل برای رسیدگی به هر نوع خاصیت EO مشاهده شده قابل گسترش است و در چندین مورد استفاده شده است.
-
یک فرآیند استخراج، تبدیل و بارگذاری معنایی قابل تنظیم و تکرار (ETL) (فرایند به عنوان یک تصویر داکر کپسوله شده است، قابل دسترسی در https://hub.docker.com/r/h2020candela/triplification ، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱)، بر اساس مدل پیشنهادی ما مجموعه ای از توابع تبدیل را برای پر کردن مدل معنایی با داده ها و به دست آوردن یک نمایش داده معنایی همگن تعریف کرده ایم. یکی از ویژگی های این فرآیند استخراج و تجمیع داده ها از رسترها به همراه داده های سایر منابع است. تجمیع در مناطق واحدهای سرزمینی صورت می گیرد.
-
یک اکوسیستم EO Sentinel که امکان بهره برداری از تصاویر Sentinel را فراهم می کند، زیرا ما می توانیم ویژگی های مختلف را از تصاویر Sentinel نمایش و محاسبه کنیم (مثلاً، NDVI، تغییر) یا مجموعه داده های شطرنجی را از منابع خارجی (به عنوان مثال، داده های پوشش زمین) وارد کنیم.
ما رویکرد خود را از نظر سازگاری مدل پیشنهادی برای رسیدگی به موارد استفاده مختلف (نظارت بر گسترش باغهای انگور و شهری)، سازگاری خط لوله، و ارزش افزوده مجموعه دادههای تولید شده برای کمک به تصمیمگیری ارزیابی میکنیم. ما همچنین در مورد مقیاس پذیری رویکرد و رابطه بین وضوح تصویر و اندازه واحدهای سرزمینی مرجع بحث می کنیم. این مقاله [ ۲ ] را در دو جهت گسترش میدهد: (۱) مدلهای معنایی پیشنهادی را به تفصیل شرح میدهیم و (۲) بحث را در مورد موارد استفاده که در آن مدلها و خط لوله ما اعمال شدهاند، گسترش میدهیم.
این کار در محدوده پروژه اروپایی CANDELA ( http://www.candela-h2020.eu/ ، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱) توسعه یافته است، که هدف آن ایجاد پلت فرمی است که بلوک های ساختمانی و خدماتی را ارائه می دهد که به کاربران اجازه می دهد داده های کوپرنیک و همچنین مجموعه داده های باز بزرگ را به سرعت استفاده، دستکاری، کاوش و پردازش کنید. ما با پیشنهاد یکپارچگی داده های معنایی گرا، همانطور که در این مقاله ارائه شده است، و یک ماژول جستجوی معنایی بر روی داده های یکپارچه، در این پروژه مشارکت می کنیم.
ادامه این مقاله به شرح زیر سازماندهی شده است. بخش ۲ کارهای کلیدی مرتبط را مورد بحث قرار می دهد. بخش ۳ مدل معنایی ما را برای ادغام مناطق جغرافیایی و داده های استخراج شده از رسترها از طریق ابعاد مکانی و زمانی آنها ارائه می دهد. بخش ۴ جزئیات فرآیند یکپارچه سازی داده های معنایی را شرح می دهد. بخش ۵ ارزیابی تجربی رویکرد ما را شرح می دهد. در نهایت، بخش ۶ مقاله را پایان میدهد و چشماندازهایی را برای کار آینده ارائه میکند.
۲٫ کارهای مرتبط
پیشنهاد ما به دو زمینه اصلی مربوط می شود: فرآیندهای استخراج معنایی، تبدیل، و بارگذاری (ETL) برای یکپارچه سازی داده ها. و پردازش داده های شطرنجی، همانطور که در ادامه توضیح داده شده است.
۲٫۱٫ ETL معنایی برای یکپارچه سازی داده های EO
تبدیل و ادغام داده های EO (باز) را می توان به عنوان یک فرآیند ETL معنایی مورد خطاب قرار داد، جایی که فرآیند ETL توسط یک مدل معنایی هدایت می شود. این مدل باید به طور همگن منابع داده را نشان دهد. در [ ۳ ]، نویسندگان به لطف هستی شناسی W3C RDF Data Cube (QB) تصاویر EO را به عنوان یک مکعب داده با مکان و زمان خاص مدل می کنند [ ۴ ]. مکعب داده RDF واژگان استانداردی مانند واژگان شبکه حسگر (SSN) ( https://www.w3.org/TR/vocab-ssn/ ، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱)، OWL-Time (برای مفاهیم زمانی) را ترکیب می کند. [ ۵ ]، سیستم سازماندهی دانش ساده (SKOS) ( https://www.w3.org/TR/skos-reference/، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱) برای مدیریت برچسب های مفهومی، و PROV-O ( https://www.w3.org/TR/prov-o/ ، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱) (هستی شناسی برای نشان دادن منشأ داده های تولید شده توسط فرآیند یکپارچه سازی). در [ ۶ ]، QB برای انتشار دادههای سری زمانی جدولی و ساختار آنها به برشهایی که از نماهای متعدد روی دادهها پشتیبانی میکنند، استفاده شد. مکعب داده های مکانی-زمانی دیگر، مکعب داده های EO معنایی است که توسط [ ۷ ] پیشنهاد شده است: این مکعب حاوی داده های EO است که در آن هر مشاهده حداقل به یک تفسیر اسمی (یعنی طبقه بندی) مرتبط است. به دنبال یک رویکرد ETL معنایی همراه با دسترسی به داده های مبتنی بر هستی شناسی (OBDA)، کار از [ ۸] پیشنهاد می کند Data Cube، GeoSPARQL (یک هستی شناسی OWL و زبان جستجوی RDF برای داده های مکانی) [ ۹ ])، و OWL-Timein به منظور ارائه دسترسی به اطلاعات خدمات کوپرنیک گسترش یابد. در اینجا، SOSA (هستی شناسی هسته ای سبک وزن اما مستقل از SSN [ ۱۰ ]) برای نمایش مجموعه های مشاهده پذیرفته شده است، اما ترازهایی بین واژگان SOSA و QB وجود دارد تا آنها را به عنوان داده های چند بعدی بر اساس مدل «مکعب داده» توصیف کند.
نزدیکتر به ما، کار [ ۱۱ ] یک فرآیند ETL را برای یکپارچهسازی تصویر EO و منابع داده خارجی، مانند پوشش Corine Land، Urban Atlas، و Geonames تعریف کرد. این فرآیند بر اساس هستی شناسی SAR آنها انجام می شود. کار نزدیک دیگر از نظر مجموعه داده ها از [ ۱۲ ] است، که در آن داده ها یکپارچه شده و به عنوان داده های باز پیوندی (LOD) بر اساس یک هستی شناسی منتشر می شوند که proDataMarket نامیده می شود. سه منبع داده، سیستم شناسایی بسته زمینی اسپانیا، ماهواره Sentinel-2 و پروازهای LiDAR یکپارچه شده اند. در [ ۱۳]، تصاویر ماهوارهای طبقهبندی شده و با دادههای معنایی اضافی غنیسازی میشوند تا پرسشهایی را درباره آنچه میتوان در یک مکان خاص یافت، فعال کرد. در رویکرد ما، بهره برداری از داده های یکپارچه ما جستجوی تصویر را تسهیل می کند.
در نهایت، در حالی که ما به طور کامل به مقیاس پذیری رویکرد خود نمی پردازیم، چندین کار با مدیریت حجم زیادی از داده های EO سروکار دارند. در [ ۱۴ ]، یک چارچوب به یکپارچهسازی و پردازش دادههای بزرگ ناهمگن در مقیاس بزرگ که از منابع متعدد برای پشتیبانی از تصمیمگیری برای جلوگیری از بلایای طبیعی تولید شدهاند، کمک میکند. ادغام معنایی دادههای EO و غیرEO بر اساس هستیشناسی مدولار MEMON است که از BFO (Basic Formal Ontology ( https://basic-formal-ontology.org/ ، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱))، SSN، استفاده مجدد میکند. و هستی شناسی های ENVO (Environmental Ontology ( https://sites.google.com/site/environmentontology ، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱)).
در حالی که هدف بسیاری از رویکردها تولید مجموعه دادههای پیوندی باز است، برخی دیگر بر جنبههای روششناختی پیوند دادههای ناهمگن تمرکز دارند. به عنوان مثال، برای مدیریت محصولات داده های حسگر ناهمگن، رجوع کنید. [ ۱۵ ] از چندین هستی شناسی مرتبط استفاده می کند که واژگان توصیف ماهواره INSAT-3D را تشکیل می دهد. در [ ۱۶ ]، خدمات زیست محیطی به طور گسترده از داده ها و داده های IOT از سازمان های دولتی، ملی و اروپایی استفاده می کنند. مطالعه ما در اینجا به این رویکردها نزدیک است به این معنا که ما فرآیند یکپارچه سازی را در بالای یک هستی شناسی با استفاده مجدد از استانداردهای موجود هدایت می کنیم.
۲٫۲٫ پردازش داده های شطرنجی در یک چارچوب معنایی
داده های شطرنجی را می توان به دو صورت نشان داد: یا با در نظر گرفتن کل شبکه شطرنجی به عنوان پوشش یا با ارائه روش هایی برای استخراج اشیاء برداری از ماتریس شطرنجی. رویکرد اول بر ساختن نمایش معنایی پیکسلهای شطرنجی متکی است به طوری که هر ویژگی پیکسل (هندسه، مقادیر) حفظ شود. در [ ۱۷ ]، هستی شناسی پوشش RDF Grid طوری طراحی شده است که امکان ادغام بومی پوشش در سه فروشگاه RDF را فراهم می کند. ساختار شبکه ای داده ها حفظ می شود و می توان با استفاده از SPARQL پرس و جو کرد. اخیراً برنامه افزودنی Ontop-Spatial [ ۱۸ ] برای پردازش داده های شطرنجی و ایجاد نماهای RDF مکانی مجازی بالای آن توسعه یافته است.
رویکرد دوم شامل استخراج موجودیت ها از رسترها و نمایش آنها به عنوان ویژگی های هستی شناختی است. این موجودیتها مجموعهای از عناصر شطرنجی (یعنی مجموعهای از پیکسلها) هستند که با یک تعریف وابسته به زمینه خاص مطابقت دارند. در [ ۱۹ ]، این رویکرد داده های برداری علمی و شطرنجی را از مخازن LOD با استفاده از برداری و ابزارهای ریاضی برای پردازش جغرافیایی، ادغام و پردازش می کند. اول، جعبه های محدود کننده برای رستر ورودی برای پرس و جو از نقاط انتهایی LOD برای موجودیت های مربوط به یک مفهوم خاص استفاده می شود. موجودیت های بازگشتی همراه با هندسه آنها در مرحله بعدی برای انتخاب پیکسل های شطرنجی برای آموزش نظارت شده بر اساس توصیفگرهای مبتنی بر محتوا استفاده می شود. در نهایت، نتایج را می توان بردار کرد و دوباره در مخزن اصلی قرار داد. در [ ۱۱]، این رویکرد تغییر ساختار تصاویر را در وصله هایی که اندازه ثابتی دارند، که اطلاعات خارجی بر روی آنها مرتبط است، پیشنهاد می کند. هر وصله مستقیماً به یک ویژگی مبتنی بر هستی شناسی تبدیل می شود. کار از [ ۲۰ ] استانداردهای فعلی را برای نمایش داده های جغرافیایی شطرنجی گسترش می دهد. یک منطقه مورد علاقه (ROI) ابتدا چند ضلعی می شود، و سپس، داده ها با استفاده از قوانین نگاشت R2RML به یک نمایش معنایی تبدیل می شوند. این راه حل مسلماً راه حل کاملی برای نمایش فایل های شطرنجی در RDF نیست، زیرا منبع هندسی اصلی داده ها حفظ نشده است [ ۲۱ ]. در اینجا، مناطق مورد علاقه از پیش تعریف شده است. از این رو، هندسه ها (چند ضلعی ها) شناخته شده اند.
کار نزدیک دیگر از [ ۲۲ ] است، جایی که یک شطرنجی اجازه می دهد تا پدیده های جغرافیایی را به عنوان یک سطح منظم مدل سازی کند که در آن هر سلول (یا پیکسل) با یک مقدار پدیده مرتبط است. هر مقدار مرتبط با یک پیکسل مربوط به یک مشاهده است در حالی که ما مقادیر یک منطقه را جمع می کنیم. در حالی که مدل سازی آنها از نظر واژگان استفاده مجدد به ما نزدیک است، آنها ابرداده و منشأ را نشان نمی دهند و از تصاویر سنتینل سوء استفاده نمی کنند. کار ما با آنچه در [ ۲۳ و ۲۴ ارائه شده است، تطبیق می دهد] به چندین روش، با تمرکز متفاوت بر خط لوله ای که داده های RDF را از رسترهای EO و سایر منابع داده تولید می کند. علاوه بر این، ما نیازی به در نظر گرفتن نسخههای واحدهای اداری نداریم و صریحاً به تصاویر ماهوارهای اشاره میکنیم که به لطف آن میتوانیم شاخصهای جدیدی را محاسبه کنیم (در [ ۲۳ ] فقط پوشش زمین در نظر گرفته شد)، و منشأ آنها را پیگیری میکنیم.
در نهایت، با توجه به کار [ ۲۵ ، ۲۶ ]، ما بیشتر به حوزه های مورد علاقه شناسایی شده علاقه مند هستیم، در حالی که این نویسندگان به دنبال شناسایی مناطق مورد علاقه (ROI) هستند که تحت تأثیر تغییرات قابل توجه قرار گرفته اند و دانش زمینه ای را با این موارد مرتبط می کنند. ROI برای حاشیه نویسی تغییرات. رویکرد آنها برای تشخیص آتش استفاده شده است.
۳٫ مدل معنایی
ما یک مدل معنایی را برای نشان دادن دادههای شطرنجی پیشنهاد میکنیم که ویژگیهای مشاهدهشده یک منطقه مورد علاقه تقسیم شده به واحدهای سرزمینی (قطعه زمین، واحد اداری، جنگل، و غیره) را همراه با ابعاد مکانی-زمانی آنها ارائه میدهد. این مدل همچنین به ما اجازه می دهد تا داده ها و ابرداده های یکپارچه را پیگیری کنیم.
ما این مدل را با پیروی از روش NeOn [ ۲۷ ] توسعه دادیم که یک روش منعطف است که چندین سناریو را پیشنهاد می کند. به طور خاص، سناریوی استفاده مجدد از منابع هستیشناختی [ ۲۸] با هدف انتخاب مناسب ترین مجموعه منابع هستی شناسی با الزامات هستی شناسی است. این سناریو شامل فعالیتهای مختلفی است، مانند جستجوی منابع هستیشناختی نامزدی که نیازمندیها را برآورده میکنند و ارزیابی آنها برای بررسی اینکه آیا آنها نیازهای توسعهدهنده را برآورده میکنند، که با فعالیت انتخاب دنبال میشود. در مورد ما، مجموعهای از الزامات را تعریف کردیم و هستیشناسیهایی را جستوجو کردیم که بتوانند: (الف) مفاهیم فراداده را نشان دهند. (ب) فایل های شطرنجی مورد استفاده به عنوان ورودی فرآیند ETL را پیگیری کنید. و (ج) نشان دهنده انواع مختلف داده ها (واحدهای سرزمینی، داده های زمانی و مکانی).
در نتیجه این جستجو، ما منابع موجود زیر را شناسایی و به صورت دستی ارزیابی کردیم که در این حوزه به خوبی شناخته شده اند: استانداردهای OGC مانند GeoSPARQL (برای نمایش داده های مکانی) و توصیه های W3C مانند OWL-Time (برای نمایش داده های زمانی). SOSA (برای مشاهدات زمین)، DCAT ( https://www.w3.org/TR/vocab-dcat-2/ ، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱) (واژگان فراداده برای فهرست نویسی مجموعه داده ها)، و PROV-O (برای منشأ داده های تولید شده توسط فرآیند یکپارچه سازی). از این رو، مدل ما بر این مدل های انتخاب شده تکیه دارد.
ما مدلی متشکل از چندین مدل فرعی به هم پیوسته را پیشنهاد میکنیم که انواع مختلف دادهها را توصیف میکند. ما این مدلهای فرعی را در بخشهای زیر شرح میدهیم: tom ، یک مدل مشاهده سرزمینی برای نمایش واحدهای سرزمینی و مشاهدات آنها (گرفته شده در فایلهای شطرنجی). eom ، یک مدل EO برای نمایش ابرداده تصویر سنتینل. و eoam ، یک مدل تجزیه و تحلیل EO برای نمایش رسترهای تولید شده توسط پردازش تصویر یا بردارها.
۳٫۱٫ مدل مشاهده سرزمینی (تام)
مدل مشاهده سرزمینی (تام) ( شکل ۱ ) هر خروجی فعالیت های تجزیه و تحلیل EO را – تا زمانی که در قالب شطرنجی ارائه می شود – به عنوان مجموعه ای از مشاهدات جمع آوری شده در منطقه یک واحد سرزمینی نشان می دهد. کلاس tom:GeoFeatureObservationCollection ( کلاس sosa:ObservationCollection یک فرمت است که در پیش نویس کاری فعلی SOSA پیشنهاد شده است— https://www.w3.org/TR/2020/WD-vocab-ssn-ext-20200116/ ، تاریخ دسترسی : ۲۳ دسامبر ۲۰۲۱) مجموعهای از مشاهدات (از نوع tom:GeoFeatureObservation ) را نشان میدهد، که هر یک از آنها یک ویژگی معین ( sosa:ObservableProperty ) را در یک واحد سرزمینی مشاهده میکنند.
واحدهای سرزمینی که ردپایی روی زمین دارند، با استفاده از کلاس tom:GeoFeature که در کلاسهای sosa:FeatureOfInterest و geo:Feature تخصص دارد، نشان داده میشوند . آنها به یک نوع ( tom:GeoFeatureType )، مانند یک واحد اداری (کمون، شهرستان)، یک قطعه کاداستری، یک قطعه کشاورزی، یک جنگل، یا یک شبکه داده های مکانی (مانند کاشی های سنتینل) تعلق دارند. با استفاده از خاصیت sosa:hasSimpleResult ، هر مشاهده به مقدار درصد تحت پوشش دارایی در میان تمام ویژگی های مشاهده شده در مجموعه ای که به آن تعلق دارد، مرتبط می شود. به عنوان مثال، مشاهدات روی یک واحد سرزمینی می تواند نشان دهد که ۴۰٪ جنگل مختلط و ۶۰٪ جنگل مخروطی پوشیده شده است. راکلاس prov-o:Entity به ما اجازه می دهد تا (با استفاده از ویژگی prov-o:wasDerivedFrom ) از یک طرف فایل شطرنجی که برای ایجاد مجموعه مشاهدات استفاده می شود و از طرف دیگر فایل برداری که برای ایجاد منطقه استفاده می شود، ردیابی کنیم. واحدها (با کلاس هایی از ماژول eoam که در زیر توضیح داده شده است).
فایل OWL این مدل در melodi.irit.fr/ontologies/tom/ موجود است ، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱ و در WebVOWL در http://melodi.irit.fr/ontologies/tom/webvowl/index قابل مشاهده است. .html ، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱٫
۳٫۲٫ فراداده تصاویر Sentinel (eom)
فراداده تصویر سنتینل (eom) مدل فرعی است که به نمایش فراداده تصویر سنتینل اختصاص دارد. عمدتاً محصول (یک تصویر) را به عنوان نتیجه یک sosa:Observation توصیف می کند. هر مشاهده با یک اطلاعات زمانی مرتبط است، یعنی تاریخ ثبت ( sosa:phenomenomTime ) و یک اطلاعات مکانی، یعنی منطقه گرفته شده (یا توسط ویژگی هندسی eom:Product یا توسط رابطه sosa:hasFeatureOfInterest ). برای کاهش هزینه نمایه سازی تصویر، فرض می کنیم که هر تصویر Sentinel-2 به یک کاشی نگاشت شده است. بنابراین، مدل کلاسی را برای نشان دادن کاشیها به عنوان موجودیتهای فضایی پیشنهاد میکند ( geo:Feature). این مدل به گونه ای طراحی شده است که هم فراداده تصویر Sentinel-1 و هم Sentinel-2 را در شکل ۲ در نظر بگیرد.
فایل OWL این مدل در melodi.irit.fr/ontologies/eom/ موجود است ، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱ و در WebVOWL در http://melodi.irit.fr/ontologies/eom/webvowl/index قابل مشاهده است. .html ، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱٫
۳٫۳٫ مدل تجزیه و تحلیل EO (eoam)
در مدل تجزیه و تحلیل EO (eoam)، تصاویر Sentinel در انواع مختلفی از آنالیزها مصرف میشوند، مانند الگوریتمهای یادگیری ماشینی که تغییرات بین دو تصویر را شناسایی میکنند. Eoam اطلاعاتی در مورد نتایج (مجموعه دادههای شطرنجی) این فعالیتها ارائه میکند، زیرا آنها توسط فرآیند یکپارچهسازی معنایی مصرف میشوند یا خواهند شد. به لطف واژگان PROV-O، این امکان وجود دارد که بدانید از کدام تصاویر Sentinel ( eom:Product ) به عنوان ورودی یک فرآیند ( eoam:EOAnalysis ) استفاده شده است و کدام عامل ( prov-o:wasAssociatedWith ) آن را متوجه شده است. DCAT برای نمایش ابرداده های کاتالوگ مجموعه داده های شطرنجی و برداری استفاده می شود. بنابراین، هم فایل های شطرنجی ( eoam:RasterFile ) و هم فایل های برداری ( eoam:GeoFeatureFile) به عنوان توزیع این مجموعه داده ها در نظر گرفته می شوند. یک توزیع شطرنجی با ویژگی هایی که از واژگان DCAT می آیند توصیف می شود: پوشش زمانی ( dct:temporal )، ویژگی های فضایی ( dct:Location ) و وضوح مکانی ( dcat:spatialResolutionInMeter ). یک توزیع برداری با ویژگی های اصلی فایل مانند اندازه فایل ( dcat:byteSize )، قالب فایل ( dct:format )، یا سیستم مرجع مختصات (CRS) مورد استفاده ( dct:conformsTo ) توصیف می شود. شکل ۳ .
فایل OWL این مدل در melodi.irit.fr/ontologies/eoam/ موجود است ، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱ و در WebVOWL در http://melodi.irit.fr/ontologies/eoam/webvowl/index قابل مشاهده است. .html ، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱٫
۴٫ فرآیند تجزیه و تحلیل داده های EO
قبل از توضیح جزئیات فرآیند EO ETL، معماری معنایی کلی پیشنهاد خود را ارائه میکنیم.
۴٫۱٫ معماری
معماری خط لوله تجزیه و تحلیل داده های EO در شکل ۴ نشان داده شده است . این خط لوله از سه وظیفه اصلی تشکیل شده است:
-
پردازش و تجزیه و تحلیل تصاویر ماهوارهای: این کار شامل پردازش و تجزیه و تحلیل تصاویر ماهوارهای است که از یک DIAS (سرویسهای دسترسی به دادهها و اطلاعات) (در پروژه ما، CreoDias ( https://creodias.eu/ ، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱)) . تحلیلهای ممکن میتوانند از موارد ساده مانند محاسبه NDVI تا تحلیلهای پیچیدهتر مانند تشخیص تغییر در سریهای زمانی یا حاشیهنویسی پوشش زمین متغیر باشند. وظیفه فایل های شطرنجی را به عنوان خروجی تولید می کند.
-
یکپارچهسازی دادههای معنایی: این وظیفه با استفاده از فایلهای برداری که حاوی واحدهای سرزمینی هستند، دادهها را از فایلهای شطرنجی استخراج میکند. منابع برداری می توانند از مخازن داده های باز یا از پایگاه داده معنایی ما از طریق جستجوی معنایی آمده باشند.
-
جستجوی معنایی: هدف این کار تجزیه و تحلیل داده های یکپارچه با پرس و جو از پایگاه داده معنایی است. نتایج پرس و جو SPARQL را می توان برای انجام یک بار دیگر دو کار اول برای تجزیه و تحلیل بیشتر، یا به عنوان پارامترهایی برای هدایت فرآیند یا به عنوان داده های ورودی استفاده کرد. نتایج همچنین می تواند توسط برنامه های تخصصی GIS برای تجزیه و تحلیل دقیق کل داده های یکپارچه استفاده شود.
۴٫۲٫ فرآیند معنایی ETL
فرآیند معنایی به چند مرحله تقسیم می شود: (۱) استخراج داده ها از فایل های شطرنجی و برداری. (II) تبدیل داده ها. و (iii) بارگذاری داده ها در triplestore. به طور کلی، با شناسایی بخشهایی از طرحهای منبع داده که به مدلهای داده معنایی مرتبط هستند، بر تعریف نگاشت معنایی تکیه میکند و از فرآیند استخراج پشتیبانی میکند. و در مورد تعریف توابع تبدیل برای پر کردن مدل های داده. مراحل فرآیند در پاراگراف های زیر توضیح داده شده است.
۴٫۲٫۱٫ استخراج داده ها از فایل های رستری و وکتور
هدف این مرحله استخراج و ساختاردهی داده ها بر اساس اهداف مختلف است. این فرآیند به دو منبع نیاز دارد: یک بردار و یک رستر. ابتدا، ابرداده ها (مثلاً تاریخ صدور، قالب، CRS یا وسعت فضایی) استخراج می شوند. در مرحله بعد، فایل برداری پردازش می شود تا اطلاعات مربوط به واحدهای سرزمینی از یک نوع معین، از جمله هندسه آنها (یک چند ضلعی) استخراج شود، که به مختصات WGS84 CRS (CRS پیش فرض در GeoSPARQL) پیش بینی می شود. آنها کلاس tom:GeoFeature را پر می کنند . رستر همچنین برای واجد شرایط بودن هر واحد سرزمینی موجود در فایل برداری پردازش می شود.
در حال حاضر، بسته به نوع مقادیر پیکسل آنها، دو نوع فایل شطرنجی را تشخیص می دهیم:
-
رسترهای طبقه بندی شده (در مورد پوشش زمین): در این نوع شطرنجی، مقدار پیکسل کدی است که یک کلاس را نشان می دهد. بنابراین، اطلاعات اضافی برای رمزگشایی آن مورد نیاز است. به عنوان مثال، در یک رستر CESBIO، مقادیر پیکسل یک نوع پوشش زمین را رمزگذاری می کند. مقدار ۱۵ به عنوان یک تاکستان رمزگشایی می شود.
-
شطرنجهای پیوسته (مانند شاخصهای NDVI یا تغییر): یک مقدار پیکسل پردازش میشود تا به طور خودکار به یک سطح (یا کلاس) مانند خیلی کم، پایین، متوسط، زیاد یا خیلی زیاد طبقهبندی شود.
به منظور واجد شرایط بودن یک واحد سرزمینی از یک شطرنجی، یا ویژگیهای جدید (مثلاً مقادیر میانگین) با تجمع پیکسل استخراج میشوند، یا ماسکهای فضایی برای حذف مناطق نامطلوب ایجاد میشوند (یعنی فقط ناحیه داخل ردپای واحد حفظ میشود). به عنوان مثال، پوشش زمین یک قطعه ثبت زمین از یک رستر در سه مرحله محاسبه می شود: (۱) طرح ریزی قطعه و پوشش زمین شطرنجی بر روی یک سیستم مرجع مختصات. (۲) اعمال هندسه بسته به عنوان ماسک بر روی فایل تصویر شطرنجی پوشش زمین. و (iii) محاسبه درصد هر طبقه پوشش زمین که قطعه را اشغال می کند. به عنوان مثال، بسته ارائه شده در شکل ۵۱۶ پیکسل را پوشش می دهد: ۱۴ مورد از آنها به عنوان باغ انگور (کد ۱۵) حاشیه نویسی شده است و دو مورد دیگر علفزار (کد ۱۳) هستند. از این رو، ۸۷٫۵ درصد از زمین را تاکستان و ۱۲٫۵ درصد را مرتع تشکیل می دهد.
این فرآیند به چهار پارامتر نیاز دارد:
-
دوره یا تاریخ اعتبار داده های شطرنجی: این اطلاعات با استفاده از ویژگی sosa:phenomenonTime به صورت time:TemporalEntity مرتبط با هر tom:GeoFeatureObservationCollection (یکی در هر واحد سرزمینی) نشان داده می شود.
-
نوع شطرنجی: این اطلاعات، به عنوان مثال، پوشش زمین خاص، NDVI، یا تغییر، که به عنوان نمونه ای از tom:GeoFeatureObservablePropertyType نشان داده می شود، به هر tom:GeoFeatureObservationCollection پیوند داده می شود .
-
شناسه تصاویر ماهواره ای مورد استفاده برای تولید شطرنجی. این شناسه به عنوان نمونه ای از eom:Product نشان داده می شود.
-
عاملی که رستر را تولید کرده است، به عبارت دیگر، که فرآیند تجزیه و تحلیل EO را انجام می دهد. این اطلاعات به نمونه ای از prov-o:Agent تبدیل می شود.
مقادیر استخراج شده از منابع داده در قالب محوری (JSON) نشان داده می شود.
۴٫۲٫۲٫ تبدیل داده ها
هدف این مرحله تبدیل داده های پردازش شده به معنایی است. الگوهایی که نگاشت بین داده های استخراج شده (در JSON) و هستی شناسی ها را تعریف می کنند به عنوان پایه در این فرآیند استفاده می شوند. قالب ها معمولا با دست نوشته می شوند. اگرچه ابزارهای مختلف ترجمه داده وجود دارد، مانند D2RQ ( http://d2rq.org/ ، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱)، Ultrawrap ( https://capsenta.com/ultrawrap/ ، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱)، Morph ( http://mayor2.dia.fi.upm.es/oeg-upm/index.php/en/technologies/315-morph-rdb/ ، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱)، Ontop ( http://ontop. inf.unibz.it/ ، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱)، یا GeoTriples ( http://geotriples.di.uoa.gr/، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱)، ما انتخاب کردیم که الگوی نقشه برداری و مکانیسم پردازش شرح داده شده در [ ۲۹ ] را تطبیق دهیم. انگیزه این انتخاب این است که شامل عملکردهایی است که به انجام عملیات پیچیده تر، به ویژه پوشش ویژگی کمک می کند. خروجی این مرحله مجموعه ای از فایل های RDF است.
۴٫۲٫۳٫ بارگذاری داده ها
مرحله نهایی وارد کردن فایلهای RDF به فروشگاه سهگانه، با پیروی از رویکرد مادیسازی است. منابع داده به نمودارهای RDF تبدیل می شوند که سپس در یک فروشگاه سه گانه بارگذاری می شوند و از طریق موتور جستجوی SPARQL قابل دسترسی هستند. مزیت چنین رویکردی تسهیل پردازش، تجزیه و تحلیل یا استدلال در آینده بر روی داده های RDF تحقق یافته است. به طور دقیق تر، این انتخاب با انگیزه سه دلیل است:
-
انجام نگاشت بر حسب تقاضا آسان نیست، زیرا منابع داده ای که در نظر گرفتیم (در زیر ارائه شده است) در فرمت های مختلف (JSON، GeoTIFF، shapefile یا حتی فایل های فشرده از راه دور) موجود هستند (به بخش ۵٫۱ مراجعه کنید )، که نیاز به یک برنامه قبلی دارد. مرحله پردازش
-
یک تریپل استور جغرافیایی می تواند به عنوان یک انبار برای ذخیره داده های معنایی برای انجام غنی سازی و پیوند داده ها استفاده شود.
-
مجموعه داده های مختلف ممکن است توسط چندین نقطه پایانی ارائه شود که به مکانیزم فدراسیون نیاز دارند. با این حال، در حال حاضر هیچ موتور پرس و جو به اندازه کافی برای پاسخ دادن به جستارهای GeoSPARQL در چنین فدراسیونی وجود ندارد [ ۸ ]. با توجه به اینکه ما یک جستار GeoSPARQL را برای بررسی واحدهای سرزمینی ذخیره شده در سه فروشگاه مختلف ارسال می کنیم، مقایسه مکانی در حال پرواز امکان پذیر نیست.
در ادامه، نمونه ای از پرس و جوی SPARQL را در سه فروشگاه به دست آمده ارائه می کنیم. این جستار همه واحدهای قلمروی (شناسه، نوع و هندسه آنها) واقع در یک ناحیه، تعریف شده توسط [zoneWKT] را بازیابی می کند (به عنوان مثال، POLYGON (-0.457 45.125، ۰٫۹۳۶ ۴۵٫۰۸۵، ۰٫۸۶۹ ۴۴٫۰۹۱-۴۴٫۰۹۱، ۴٫۵-۴٫۵) مربوط به منطقه مورد استفاده Vineyard ما (به زیر مراجعه کنید)، دارای خواص قابل مشاهده با مقادیر بیشتر از ۰٫۵، در یک بازه زمانی معین که توسط [startDate] و [endDate] تعریف شده است (به عنوان مثال، ۲۰۱۷-۰۴-۰۱T00:00:00 و ۲۰۱۷-۰۵-۰۱T00:00:00).
پیشوند rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
پیشوند sosa: <http://www.w3.org/ns/sosa/>
پیشوند tom: <http://melodi.irit.fr/ontologies/tom.owl#>
PREFIX provo: <http://www.w3.org/TR/prov-o/>
پیشوند eoam: <http://melodi.irit.fr/ontologies/eoam.owl#>
پیشوند dcat: <https://www.w3.org/TR/vocab-dcat-2/>
پیشوند جغرافیایی: <http://www.opengis.net/ont/geosparql#>
پیشوند جغرافیایی: <http://www.opengis.net/def/function/geosparql/>
زمان پیشوند: <http://www.w3.org/2006/time#>
پیشوند xsd: <http://www.w3.org/2001/XMLSchema#>
SELECT ?geofeature ?type_name ?wkt ?dti1 ?dti2 ?value
جایی که
{
?obsv a tom:GFObservation.
?obsv sosa:observedProperty ?prop.
?obsv sosa:hasSimpleResult ?value.
FILTER(?value>=0.5).
?obsvCol sosa:hasMember ?obsv.
?obsvCol sosa:hasFeatureOfInterest ?geofeature.
?geofeature geo:hasGeometry/geo:asWKT ?wkt.
FILTER(geof:sfContains("[zoneWKT]"^^geo:wktLiteral، ?wkt)).
?obsvCol sosa:phenomenonTime ?timeInterval.
?timeInterval time:hasBeginning/time:inXSDDateTime ?dti1.
?timeInterval time:hasEnd/time:inXSDDateTime ?dti2.
FILTER((?dti1 <="[endDate]"^^xsd:dateTime &&
?dti2>="[startDate]"^^xsd:dateTime))).
?geofeature tom:hasType/tom:name ?type_name.
}
محدود ۱۰۰
کل فرآیند ETL معنایی با استفاده از فناوری docker پیادهسازی شده و در دسترس عموم است ( https://hub.docker.com/r/h2020candela/triplification )، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱٫
۵٫ ارزیابی تجربی
ارزیابی بر روی دو مورد استفاده که انواع مختلف خواص EO یک واحد سرزمینی را توصیف میکنند، انجام شد. از آنجایی که فرآیند یکپارچه سازی توسط کاربران بر اساس هدف آنها انجام می شود، پایگاه داده یکپارچه با توجه به این موارد استفاده ساخته می شود.
داده های معنایی تولید شده برای این موارد استفاده در یک پایگاه داده ذخیره می شود که می تواند از طریق یک رابط جستجوی معنایی در معرض دید قرار گیرد یا از طریق یک نقطه پایانی SPARQL ( http://melodi.irit.fr/tom/ ) قابل دسترسی باشد، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱٫
ما رویکرد را از نظر (من) سازگاری مدل پیشنهادی با دو مورد استفاده ارزیابی کردیم. (۲) سازگاری خط لوله با هر مورد استفاده. و (iii) ارزش افزوده مجموعه داده های تولید شده برای کمک به تصمیم گیری. ما همچنین در مورد مقیاس پذیری رویکرد بحث می کنیم.
۵٫۱٫ موارد استفاده
دو مورد استفاده از پروژه CANDELA برای نمایش انتخاب شد:
-
مورد استفاده از تاکستان: هدف از این مورد استفاده بازیابی تغییرات در تاکستان هایی است که در اثر خطرات طبیعی مانند سرمازدگی یا تگرگ آسیب دیده اند. این رویدادهای اقلیمی می تواند باعث خسارات قابل توجهی در باغ های انگور و کاهش تولید شراب شود. دوره های آنها برای کاربری که تصاویر مربوطه را انتخاب می کند شناخته شده است. منطقه مورد مطالعه در منطقه آکیتن فرانسه واقع شده است. تاکستان های این منطقه در تاریخ ۲۰ آوریل ۲۰۱۷ به دلیل سرمازدگی به شدت آسیب دیده بودند. ما روستای سنت امیلیون (کد INSEE: 33394) را برای انجام مطالعه انتخاب کردیم. سنت امیلیون یک دهکده کوچک قرون وسطایی است که به خوبی حفظ شده است که به دلیل شراب قرمز معتبر خود معروف است که Grands Crus Classés نامیده می شود .
-
مورد کاربری گسترش شهری: هدف کاربری مطالعه تغییرات مرتبط با گسترش شهری در مناطق کشاورزی است. این نوع مطالعه می تواند به مدیران زمین در برنامه ریزی خود کمک کند. ما تغییرات روستاها را بین سالهای ۲۰۱۷ و ۲۰۲۰ در اطراف شهر بوردو، یکی از بزرگترین شهرهای فرانسه، که توسط مناطق کشاورزی احاطه شده است، بررسی کردیم.
علیرغم تفاوت ماهیت آنها، هر دو مورد استفاده مجموعه مشترکی از انواع شطرنجی دارند:
-
نشانگر تغییر: دو شریک پروژه، Thales Alenia Space France و Thales Alenia Space Italy، هر کدام یک برنامه تشخیص تغییر برای شناسایی انواع مختلف تغییرات بین دو تصویر Sentinel توسعه دادهاند. این ابزارها رتبهبندیهای شاخص تغییر را تولید میکنند که احتمال تغییرات بین ۰ و ۱ را نشان میدهند.
-
NDVI: اطلاعات NDVI با پردازش حسگرهای مادون قرمز نزدیک و قرمز تصاویر Sentinel به دست می آید. خروجی محاسبه ماتریسی از مقادیر بین -۱ و ۱ است که NDVI هر پیکسل را مشخص می کند. از آنجایی که مقادیر بین ۱- و ۰ نشان دهنده عناصر تشکیل شده از آب است، این مقادیر روی ۰ تنظیم می شوند به طوری که شطرنجی ها فقط حاوی مقادیر بین ۰ و ۱ هستند.
-
پوشش زمین: مجموعه داده ها اطلاعاتی در مورد پوشش زمین یک منطقه روی زمین ارائه می دهند. مجموعه دادههای پوشش زمین CESBIO ( http://osr-CESBIO.ups-tlse.fr/~oso/ ، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱) برای موارد استفاده ما استفاده میشود. آنها قلمرو فرانسه را با وضوح فضایی ۱۰ متر مربع پوشش می دهند .
با توجه به واحدهای سرزمینی (مجموعه داده های برداری)، از داده های ثبت زمین برای اولین مورد استفاده می شود، در حالی که مورد دوم از داده های واحد اداری بهره برداری می کند.
-
ثبت زمین: دادههای ثبت زمین از وبسایت دادههای دولت فرانسه ( https://cadastre.data.gouv.fr/datasets/cadastre-etalab ، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱) در قالب GeoJSON یا shapefiles موجود است.
-
داده های واحد اداری: اطلاعات روستاهای داخل یک منطقه مورد علاقه را می توان از مجموعه داده های مبتنی بر OpenStreetMap که در وب سایت دولت فرانسه منتشر شده است ( https://www.data.gouv.fr/en/datasets/decoupage-administratif-communal ) به دست آورد. -francais-issu-d-openstreetmap ، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱). مجموعه داده ها در شکل فایل ها موجود هستند و سالانه به روز می شوند.
۵٫۲٫ سازگاری مدل
سازگاری (یا عمومی بودن) مدل پیشنهادی برای تطبیق دو مورد استفاده (هر مورد استفاده از داده های خاص خود استفاده می کند که انواع مختلفی از ویژگی های EO یک واحد سرزمینی را توصیف می کند) با حقایق زیر ثابت می شود:
-
این مدل با تمام مجموعه دادههای شطرنجی و نسخههای آنها به یک شکل رفتار میکند، تا زمانی که در قالب درست وجود داشته باشند. آنها می توانند حاوی اطلاعات تغییر، NDVI یا پوشش زمین باشند.
-
برای مشاهده یک نوع ویژگی EO می توان از طبقه بندی های مختلف استفاده کرد. به عنوان مثال، مشاهدات پوشش زمین می تواند از Corine Land Cover، Global Land Cover Share، CESBIO یا سایر منابع باز باشد.
-
این سیستم میتواند هر منبع برداری را که تقسیمبندیهای سرزمینی را توصیف میکند، مصرف کند، مانند قطعات کشاورزی، قطعههای ثبت زمین، واحدهای اداری، کاشیهای سنتینل یا واحدهای جنگلی.
۵٫۳٫ سازگاری خط لوله
از آنجایی که اجزای خط لوله به عنوان خدمات سازماندهی شده اند، کاربران می توانند خط لوله را با انتخاب و زنجیر کردن هر تعداد سرویس که می خواهند سفارشی کنند.
-
مورد استفاده از تاکستان: (i) ابتدا تمام قطعات روستای Saint-Emilion را از دادههای کاداستر و رستر پوشش زمین CESBIO برای سال ۲۰۱۷ بهدست میآوریم. سپس از ادغام دادههای معنایی برای ادغام اطلاعات پوشش زمین و قطعات استفاده میشود. (ii) قطعات تاکستان در روستاها از طریق جستجوی معنایی بازیابی می شوند. (iii) تصاویر Sentinel-2 مناسب برای محاسبه NDVI استفاده می شود. (IV) این تصاویر همچنین برای تشخیص تغییر استفاده می شوند. (v) رسترهای تولید شده از مراحل ۳ و ۴ به همراه بردار مرحله ۲ در پایگاه داده معنایی ادغام می شوند. (vi) در نهایت، جستجوی معنایی می تواند برای تجزیه و تحلیل تمام اطلاعات یکپارچه مربوط به تاکستان مورد علاقه استفاده شود.
-
مورد استفاده توسعه شهری: (i) ابتدا تصاویر سنتینل تطبیقی را انتخاب کرده و محاسبه NDVI را اجرا می کنیم. (ii) این تصاویر همچنین برای تشخیص تغییر استفاده می شود. (iii) ما داده های برداری تمام روستاهای بخش Gironde (کد INSEE: 33) را از مجموعه داده های واحد اداری باز به دست می آوریم. ادغام داده های معنایی در مرحله بعدی با استفاده از رستر تولید شده از مرحله قبل و فایل های برداری به دست آمده راه اندازی می شود. (IV) در نهایت، ما می توانیم جستجوی معنایی را برای تجزیه و تحلیل داده های یکپارچه مربوط به روستاهای مورد علاقه انجام دهیم.
همانطور که در بخش ۴٫۲٫۱ ذکر شد ، ادغام داده های معنایی با مجموعه ای از چهار پارامتر قابل تنظیم است. این پارامترها را می توان به عنوان ابرداده شطرنجی یا به عنوان پارامترهای تابع ارائه کرد. کاربران همچنین میتوانند آستانههای سفارشی را برای طبقهبندی کلاسها ارائه کنند، زیرا نتایج پردازش و تجزیه و تحلیل تصویر میتواند به شدت به سناریو وابسته باشد. به عنوان مثال، در مورد استفاده از تاکستان، می توان آستانه های سفارشی را برای طبقه بندی شاخص های تغییر تنظیم کرد. مقادیر زیر ۰٫۱ را می توان به جای کمتر از ۰٫۲ به عنوان تغییر بسیار کم ترجمه کرد. این نوع پارامترها باید به صراحت در زمان اجرا تنظیم شوند.
۵٫۴٫ ارزش افزوده مجموعه داده های تولید شده در کمک به تصمیم گیری
ما مزایای استفاده از دادههای یکپارچه را برای کمک به کارهایی مانند نظارت بر زمین و بررسی متقاطع دادهها ارزیابی میکنیم و در ادامه درباره آنها بحث میکنیم.
۵٫۴٫۱٫ بهبود نظارت بر زمین به لطف یکپارچه سازی داده ها
شکل ۶ نمونه ای از رابط وب مورد استفاده برای بازیابی مشاهدات مورد استفاده در تاکستان را نشان می دهد. این برنامه از سه فیلتر پشتیبانی می کند که هر کدام مربوط به یک بعد هستند: زمانی (کاربر باید یک دوره زمانی را تعریف کند)، معنایی (کاربر باید یک ویژگی ObservableProperty را انتخاب کند.از سه نمای)، و فضایی (کاربر باید یک منطقه مورد علاقه را روی نقشه ترسیم کند). جستارهای GeoSPARQL بر اساس پارامترهای ورودی فرموله می شوند و سپس به نقطه پایانی ارسال می شوند. واحدهای سرزمینی که محدودیت ها را برآورده می کنند بر روی نقشه نمایش داده می شوند (در این مثال، چند ضلعی های نمایش داده شده قطعاتی هستند که در اطراف روستای لنگون با تاکستان به عنوان پوشش زمین در آوریل ۲۰۱۷ واقع شده اند). تمام مشاهدات موجود در یک واحد سرزمینی انتخاب شده به صورت جدولی در سمت راست نمایش داده می شود. برای ساده کردن نمای، هر خط از جدول فقط اطلاعاتی در مورد ویژگی مشاهده شده، دوره، مقدار (در درصد)، یک تصویر کوچک از رستر اصلی (یا منبع داده) و تصاویر Sentinel مورد استفاده برای تولید شطرنجی را ارائه می دهد.
در این سناریو، داده های یکپارچه می توانند برای نظارت بر قلمرو مورد سوء استفاده قرار گیرند. پایگاه دانش اطلاعات دقیقی در مورد واحدهای سرزمینی (قطعه ها) منطقه داده شده ارائه می دهد. یکی از کاربردهای این نوع تحلیل، پایش پوشش زمین در طول زمان است. این را می توان با بررسی تمام مشاهدات انجام شده در این واحدهای سرزمینی انجام داد. شکل ۶ نشان می دهد که تاکستان پوشش اصلی زمین (۸۰٪ از CESBIO و ۱۰۰٪ از Corine) قطعه انتخابی (به عنوان مثال، قطعه ۳۳۱۶۴۰۰۰۰D0523) در سال ۲۰۱۷ بود. این قطعه دارای NDVI پایین بود و در طول دوره یخبندان کمی تغییر کرد (با داشتن تغییرات بسیار کم و سطوح تغییر کم).
۵٫۴٫۲٫ تأیید متقاطع داده ها به لطف یکپارچه سازی داده ها
برنامه دیگر بررسی اطلاعات از منابع مختلف، از جمله نتایج ارائه شده توسط شرکای ما است. ما از مجموعه داده حاشیه نویسی پوشش زمین به دست آمده توسط الگوریتم های داده کاوی تعاملی بر روی تصاویر ماهواره ای [ ۳۰ ] که توسط DLR (مرکز هوافضای آلمان) توسعه یافته است، استفاده کردیم. به عنوان مثال، می توان اطلاعات پوشش زمین CESBIO را با پوشش زمین مشروح شده توسط DLR مقایسه کرد یا نتیجه تشخیص تغییر را بر اساس تغییر پوشش زمین توجیه کرد. از شکل ۶ ، چندین نکته از مقایسه این دو مشاهدات ناشی می شود:
-
این بسته توسط کاربر ابزار DLR به درستی حاشیه نویسی نشده است، زیرا او آن را به عنوان یک منطقه شهری مختلط (ملاک LC_DM) شناسایی کرده است.
-
CESBIO (مالکیت LC_CESBIO17) و کورین (مالکیت LC_Corine) به درستی پوشش زمین را در سطح قطعه شناسایی می کنند. در واقع، تفاوت های مشاهده شده بین دو پوشش زمین از قدرت تفکیک فضایی شطرنج ها (که در دقت تأثیر دارد) ناشی می شود. در حالی که بهترین وضوح برای منطقه فرانسه توسط CESBIO ارائه شده است، برچسب های داده کاوی DLR توسط کاربر با دانش محدود دامنه ارائه می شود.
-
بسته با استفاده از الگوریتم یادگیری عمیق توسط TAS (ویژگی Change_Opt) دارای تغییرات کم بود. در واقع در این مدت حدود ۵ درصد تغییر در سطوح NDVI (مخصوص NDVI) وجود دارد.
۵٫۴٫۳٫ استفاده از تجزیه و تحلیل موارد
ما خروجی خط لوله ارائه شده در بخش ۵٫۳ را ارزیابی می کنیم ، زیرا می دانیم که به شدت به دقت الگوریتم های ارائه شده توسط شرکای ما بستگی دارد.
-
مورد استفاده از تاکستان: دو تصویر Sentinel-2 جمع آوری شده روی کاشی T30TYQ برای تشخیص تغییر و محاسبه NDVI استفاده می شود. تاریخ آنها به ترتیب ۱۹ آوریل ۲۰۱۷ و ۲۹ آوریل ۲۰۱۷ است: ما این تصاویر را انتخاب کردیم زیرا پوشش ابری بسیار کمی دارند (۰% و ۱۵%) و فاصله بین این مشاهدات شامل دوره مطالعه است.شکل ۷ نمای کلی از سطوح تغییر شناسایی شده و تخریب NDVI بین دو تاریخ را نشان می دهد (NDVI بعد از پدیده کمتر از قبل است، یعنی پوشش گیاهی کمتری نسبت به قبل وجود دارد). سطح تغییر بسیار پایین حذف شده است، زیرا چندان مرتبط نیست. شاخص تخریب NDVI نشان دهنده درصد تخریب کل پنج سطح NDVI است. ما همچنین بسته هایی با کمتر از ۲۰ درصد تخریب NDVI را حذف کردیم.در نهایت، ۸۵۸ بسته بهعنوان تغییر یافته، ۷۵۶ بسته با تخریب NDVI بالای ۲۰ درصد و ۵۱۰ بسته در هر دو مورد شناسایی شدهاند.
-
مورد استفاده توسعه شهری: برای محاسبه NDVI و تشخیص تغییر، توصیه می شود تصاویر را در همان دوره و در تابستان جمع آوری کنید تا پوشش ابر و تأثیر رشد گیاهی محدود شود. بنابراین، دو تصویر Sentinel-2 در ۲ آگوست ۲۰۱۷ و ۶ اوت ۲۰۲۰ جمع آوری شد و دارای ۰٪ پوشش ابری است. شکل ۸(راست) نمای کلی از سطوح تغییر شناسایی شده و سطوح NDVI کاهش یافته بین این دو تاریخ را به همراه (سمت چپ) تصاویر سنتینل منبع نشان می دهد. ما می توانیم مشاهده کنیم که (من) سطوح تغییر شناسایی شده به خوبی با NDVI تخریب شده به دلیل شهرنشینی مطابقت دارد. (ii) هر چه روستا به شهر نزدیکتر میشود، بیشتر اصلاح میشود. تحلیل بعدی می تواند اطلاعات مربوط به تغییر، NDVI و پوشش زمین را در سطح قطعه برای روستاهای خاص مقایسه کند.
۵٫۵٫ مقیاس پذیری رویکرد
از نظر سهگانهفروشی، ما در ابتدا Strabon ( http://strabon.di.uoa.gr/ تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱) را برای مزایای اصلی آن انتخاب کردیم: (i) این فروشگاه سهگانه Sesame را با قابلیت ذخیرهسازی RDF فضایی گسترش میدهد. داده ها در PostgreSQL DBMS با PostGIS افزایش یافته است. به دلیل تکنیکهای بهینهسازی خاص که به عملیات فضایی اجازه میدهد به جای تکیه بر کتابخانههای خارجی، از قابلیت PostGIS بهرهمند شوند، عملکرد کلی خوبی دارد [ ۳۱ ]. برای کاربردهای پیچیده که شامل اتصالات فضایی یا تجمعات فضایی است، Strabon یک فروشگاه RDF است که عملکرد خوبی دارد [ ۳۲]. (ii) یک نقطه پایانی SPARQL را فراهم می کند که امکان دسترسی به محتوای تریپلاستور را فراهم می کند. این رابط همچنین قابلیت بیشتری برای مدیریت پایگاه دانش فراهم می کند، به عنوان مثال قابلیت های ذخیره سازی و به روز رسانی با SPARQL Update.
در حالی که استرابون هنگام در نظر گرفتن تعداد کمی از سه گانه در ذخیره داده عملکرد خوبی داشت، زمانی که تعداد سه گانه افزایش یافت، با مشکلات مقیاس پذیری مواجه شدیم. در واقع، همین نتیجه در [ ۳۳ ] گزارش شده است. بنابراین، به این دلایل، ما به رویکردهای فدراسیون پرس و جو که در آن داده ها در سه فروشگاه های مختلف ذخیره می شوند، نگاه کردیم. در مورد ما، Strabon فقط برای داده های مکانی و GraphDB استفاده می شود ( https://graphdb.ontotext.com/، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱) (پایگاه داده گراف معنایی مطابق با استانداردهای W3C) برای سایر انواع داده. آزمایشهای اولیه دو مزیت اصلی این گزینه را نشان دادهاند: (۱) زمان پاسخدهی سریعتر برای پرسوجوهای غیرمکانی، و (ب) مقیاسپذیر و قوی چون نتیجه را بدون توجه به مقدار دادههای یکپارچه تضمین میکند. با توجه به اندازه مجموعه داده های RDF تولید شده، ما ۰٫۵ M موجودیت ویژگی های جغرافیایی (حدود ۲٫۵ M سه برابر) در Strabon و ۴ M مشاهدات (۹۷٫۵ M سه برابر) در GraphDB را پر کردیم.
۶٫ نتیجه گیری
در این مقاله، ما رویکردی را برای یکپارچهسازی دادههای محاسبهشده از رسترها بهعنوان راهی برای واجد شرایط کردن واحدهای سرزمینی (که بهعنوان بردار نشان داده میشوند)، بر اساس ویژگیهای مکانی-زمانی آنها ارائه کردیم. اولین مشارکت یک مدل معنایی عمومی است که به توصیف همگن داده های مکانی-زمانی اجازه می دهد تا مناطق از پیش تعریف شده را واجد شرایط کند. ما از این مدل برای توصیف معنایی دادهها از موارد استفاده مختلف استفاده کردیم. سهم دوم یک فرآیند معنایی Extract Transform and Load (ETL) قابل تنظیم بر اساس آن واژگان عمومی است. ما از این فرآیند برای استخراج داده ها از رسترها و پیوند مشاهدات به واحدهای سرزمینی از طریق ابعاد مکانی-زمانی آنها استفاده کردیم. آخرین اما نه کماهمیت، ما پایگاههای داده معنایی را تولید کردیم که میتوانند بیشتر برای اهداف جدید مورد سوء استفاده قرار گیرند.
به عنوان کار آینده، ما قصد داریم از سناریوهای کلان داده با مدیریت مناطق Natura 2000 بهره برداری کنیم ( https://www.eea.europa.eu/data-and-maps/data/natura-11 ، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱) (تکامل پوشش زمین و تشخیص تغییر در مناطق حفاظت شده). همچنین قصد داریم رویکرد پیشنهادی را برای رسیدگی به دادههای فایلهای CSV، به ویژه مشاهدات آب و هوا از ECAD ( https://www.ecad.eu/ ، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱) یا Meteo France ( http://www ) گسترش دهیم. .meteofrance.com/ ، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱). میتوانیم رویکرد شاخص مکان (Loc-I) ارائه شده در [ ۳۴ ] را اعمال کنیم] برای افزایش عملکرد برنامه ما. در نهایت، با در نظر گرفتن مکعب های داده به عنوان آرایه های داده چند بعدی که اغلب برای مدیریت داده های مکانی، از جمله رسترها استفاده می شوند، مدیریت این نوع ساختار را در خط لوله ETL در نظر می گیریم.
منابع
- ویلگاس، جی. سانچز پاستور، اچ. هرنانز، ال. چکا، م. رومن، دی. امکان استفاده از دادههای Sentinel-2 و LiDAR برای تخصیص وجوه سیاست مشترک کشاورزی. بین المللی J. Geo-Inf. ۲۰۱۷ ، ۶ ، ۲۵۵٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- Tran، BH; آسناک ژیل، ن. کامپاروت، سی. تروجان، سی. ادغام معنایی داده های رستری برای مشاهده زمین در واحدهای سرزمینی. در مجموعه مقالات چهارمین کارگاه بین المللی در مورد داده های پیوندی جغرافیایی (GeoLD ۲۰۲۱@ESWC ۲۰۲۱)، هراکلیون، یونان، ۶ تا ۱۰ ژوئن ۲۰۲۱؛ هالر، ا.، یامان، ب.، شریف، MA، نگومو، ACN، ویرایش. محمد احمد شریف؛ بیضا یامان; آرمین هالر; Axel-Cyrille Ngonga Ngomo: Hersonissos، یونان، ۲۰۲۱؛ صص ۱-۱۲٫ [ Google Scholar ]
- زینکه، سی. Ngomo، ACN کشف و پیوند داده های بزرگ پیوندی فضایی-زمانی. در مجموعه مقالات IGARSS 2018-2018 IEEE بین المللی زمین شناسی و سمپوزیوم سنجش از دور، والنسیا، اسپانیا، ۲۲ تا ۲۷ ژوئیه ۲۰۱۸؛ ص ۴۱۱-۴۱۴٫ [ Google Scholar ]
- بریژینف، دی. تویر، اس. تیلور، ک. Zhang، Z. انتشار و استفاده از داده های رصد زمین با مکعب داده RDF و سیستم شبکه جهانی گسسته. گزارش فنی؛ W3C و OGC. ۲۰۱۷٫ در دسترس آنلاین: https://www.w3.org/TR/eo-qb/ (در ۲۳ دسامبر ۲۰۲۱ قابل دسترسی است).
- هابز، جی آر. Pan, F. هستی شناسی زمان برای وب معنایی. ACM Trans. زبان آسیایی Inf. روند. ۲۰۰۴ ، ۳ ، ۶۶-۸۵٫ [ Google Scholar ] [ CrossRef ]
- لفور، ال. بابروک، جی. هالر، ا. تیلور، ک. وولف، ای. در مجموعه مقالات پنجمین کنفرانس بین المللی شبکه های حسگر معنایی، SSN’12، بوستون، MA، ایالات متحده آمریکا، ۱۲ نوامبر ۲۰۱۲; CEUR-WS.org: آخن، آلمان، ۲۰۱۲; جلد ۹۰۴، ص ۱-۱۶٫ [ Google Scholar ]
- آگوستین، اچ. سودمنز، ام. تاید، دی. لانگ، اس. بارالدی، ا.مکعب های داده های مشاهده معنایی زمین. دادهها ۲۰۱۹ ، ۴ ، ۱۰۲٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- برتا، ک. کومونت، اچ. دانیلز، یو. گور، ای. کوباراکیس، م. پانتازی، DA; استامولیس، جی. اوبلز، اس. زهره، V. Wahyudi، F. پروژه آزمایشگاه برنامه کوپرنیک: دسترسی آسان به داده های کوپرنیک. در مجموعه مقالات بیست و دومین کنفرانس بین المللی گسترش فناوری پایگاه داده (EDBT)، لیسبون، پرتغال، ۲۶ تا ۲۹ مارس ۲۰۱۹٫ [ Google Scholar ]
- کولاس، دی. پری، م. Herring, J. شروع به کار با GeoSPARQL . گزارش فنی؛ OGC: Rockville, MD, USA, 2013. [ Google Scholar ]
- یانوویچ، ک. هالر، ا. کاکس، اس جی. Phuoc، DL؛ Lefrançois, M. SOSA: یک هستی شناسی سبک برای حسگرها، مشاهدات، نمونه ها و عملگرها. J. وب سمنت. ۲۰۱۹ ، ۵۶ ، ۱-۱۰٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- اسپینوزا-مولینا، دی. نیکولائو، سی. دومیترو، CO. برتا، ک. کوباراکیس، م. شوارتز، جی. Datcu، M. تصاویر SAR با وضوح بسیار بالا و تجزیه و تحلیل داده های باز پیوندی بر اساس هستی شناسی ها. IEEE J. Sel. بالا. Appl. زمین Obs. Remote Sens. ۲۰۱۵ ، ۸ ، ۱۶۹۶-۱۷۰۸٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- سوخوبوک، دی. سانچز، اچ. استرادا، جی. رومن، دی. داده های مرتبط برای سیاست کشاورزی مشترک: فعال کردن پرس و جو معنایی بر روی داده های Sentinel-2 و LiDAR. در مجموعه مقالات ISWC 2017 پوسترها و نمایش ها و آهنگ های صنعتی (ISWC-PD-Industry)، وین، اتریش، ۲۳ تا ۲۵ اکتبر ۲۰۱۷؛ Nikitina, N., Song, D., Fokoue, A., Haase, P., Eds. شماره ۱۹۶۳ در مجموعه مقالات کارگاه CEUR. ۲۰۱۷٫ [ Google Scholar ]
- علیرضایی، م. کیسلف، آ. لنگکویست، ام. کلوگل، اف. Loutfi, A. یک چارچوب استدلال مبتنی بر هستی شناسی برای جستجوی تصاویر ماهواره ای برای نظارت بر بلایا. Sensors ۲۰۱۷ , ۱۷ , ۲۵۴۵٫ [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- مسمودی، م. تکتک، ح. بن عبدالله بن لمینه، س. بوکادی، ک. Karray، MH; بازاوی زغال، ح. ارشمید، بی. مریسا، م. Guegan، CG PREDICAT: یک پلت فرم خدمات گرا معنایی برای قابلیت همکاری داده ها و پیوند در رصد زمین و پیش بینی بلایا. در مجموعه مقالات یازدهمین کنفرانس IEEE 2018 در محاسبات و برنامه های کاربردی سرویس گرا (SOCA)، پاریس، فرانسه، ۲۰ تا ۲۲ نوامبر ۲۰۱۸؛ صص ۱۹۴-۲۰۱٫ [ Google Scholar ]
- ابورو، س. دوبی، ن. نایاک، MR; Golla، S. یک روش مبتنی بر هستی شناسی برای قابلیت تعامل معنایی داده های ماهواره ای. Adv. برق محاسبه کنید. مهندس ۲۰۱۵ ، ۱۵ ، ۱۰۵-۱۱۰٫ [ Google Scholar ] [ CrossRef ]
- بلوور، جی. گونسالوز، پی. کومونت، اچ. کوباراکیس، م. پرکینز، ب. بهرهبرداری از دادههای محیطی باز با استفاده از دادههای پیوندی و محاسبات ابری: پروژه ملودی. در مجموعه مقالات کنفرانس مجمع عمومی EGU، وین، اتریش، ۱۲-۱۷ آوریل ۲۰۱۵٫ پ. ۱۵۶۲۴٫ [ Google Scholar ]
- آندریف، آ. میسف، دی. باومن، پی. Risch، T. پردازش داده های شبکه بندی شده مکانی-زمانی در وب معنایی. در مجموعه مقالات کنفرانس بین المللی IEEE 2015 در علم داده و سیستم های فشرده داده، سیدنی، استرالیا، ۱۱ تا ۱۳ دسامبر ۲۰۱۵٫ صص ۳۸-۴۵٫ [ Google Scholar ] [ CrossRef ]
- برتا، ک. شیائو، جی. Koubarakis، M. Ontop-Spatial: Ontop of Geospatial Database. J. وب سمنت. ۲۰۱۹ ، ۵۸ ، ۱۰۰۵۱۴٫ [ Google Scholar ] [ CrossRef ]
- آروسنا، جی. لوزانو، جی. کوارتولی، م. اولایزولا، آی. Bermudez, J. داده های باز پیوند داده شده برای پردازش اطلاعات جغرافیایی شطرنجی و برداری. در مجموعه مقالات سمپوزیوم بین المللی علوم زمین و سنجش از دور IEEE 2015 (IGARSS)، میلان، ایتالیا، ۲۶ تا ۳۱ ژوئیه ۲۰۱۵٫ ص ۵۰۲۳–۵۰۲۶٫ [ Google Scholar ]
- هامبورگ، تی. پرودوم، سی. Würriehausen، F. کارماچاریا، ا. بوچس، اف. روکسین، ا. کروز، سی. تفسیر دادههای جغرافیایی ناهمگن با استفاده از فناوریهای وب معنایی. در مجموعه مقالات علوم محاسباتی و کاربردهای آن-ICCSA 2016، پکن، چین، ۵ تا ۸ ژوئیه ۲۰۱۶٫ Gervasi, O., Murgante, B., Misra, S., Rocha, AMA, Torre, CM, Taniar, D., Apduhan, BO, Stankova, E., Wang, S., Eds. انتشارات بین المللی اسپرینگر: چم، سوئیس، ۲۰۱۶; ص ۲۴۰-۲۵۵٫ [ Google Scholar ]
- نیشانبایف، آی. قهرمان، ای. Mcmeekin, D. A Survey of Geospatial Semantic Web for Cultural Heritage. Heritage ۲۰۱۹ , ۲ , ۱۴۷۱–۱۴۹۸٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- دینگ، ال. شیائو، جی. کالوانیز، دی. Meng, L. چارچوبی که یکپارچگی داده های جغرافیایی مبتنی بر هستی شناسی و تجزیه و تحلیل ژئوویژوال را متحد می کند. ISPRS Int. J. Geo-Inf. ۲۰۲۰ ، ۹ ، ۴۷۴٫ [ Google Scholar ] [ CrossRef ]
- Tran، BH; آسناک ژیل، ن. کامپاروت، سی. تروجان، سی. ادغام معنایی دادههای شطرنجی برای مشاهده زمین: مجموعه دادههای RDF از نسخههای واحد سرزمینی با پوشش زمین آنها. ISPRS Int. J. Geo-Inf. ۲۰۲۰ ، ۹ ، ۵۰۳٫ [ Google Scholar ] [ CrossRef ]
- تران، بی. آسناک ژیل، ن. کامپاروت، سی. تروجان، سی. رویکردی برای ادغام مشاهده زمین، تشخیص تغییر و داده های متنی برای جستجوی معنایی. در مجموعه مقالات سمپوزیوم بین المللی علوم زمین و سنجش از دور IEEE، IGARSS 2020، Waikoloa، HI، ایالات متحده آمریکا، ۲۶ سپتامبر تا ۲ اکتبر ۲۰۲۰٫ [ Google Scholar ] [ CrossRef ]
- دورن، جی. آسناک ژیل، ن. کامپاروت، سی. تروجان، سی. Hugues, R. معنی دادن به رسترهای تشخیص تغییر EO بدون نظارت: یک رویکرد مبتنی بر معنایی. در مجموعه مقالات BIGSPATIAL ’20: مجموعه مقالات نهمین کارگاه بین المللی ACM SIGSPATIAL در تجزیه و تحلیل برای داده های بزرگ جغرافیایی، BigSpatial@SIGSPATIAL ۲۰۲۰، سیاتل، WA، ایالات متحده آمریکا، ۳ نوامبر ۲۰۲۰؛ Chandola, V., Vatsavai, RR, Shashidharan, A., Eds. ACM: نیویورک، نیویورک، ایالات متحده آمریکا، ۲۰۲۰؛ صص ۱-۱۰٫ [ Google Scholar ] [ CrossRef ]
- دورن، جی. آسناک ژیل، ن. کامپاروت، سی. هیوگ، آر. Trojahn, C. از رسترهای تغییر EO تا نمودارهای دانش: رویکردی بر اساس مناطق مورد علاقه. در مجموعه مقالات چهارمین کارگاه بینالمللی دادههای پیوندی جغرافیایی (GeoLD 2021) که با هجدهمین کنفرانس وب معنایی توسعهیافته (ESWC 2021) برگزار شد (GeoLD ۲۰۲۱@ESWC ۲۰۲۱)، کرت، یونان، ۶ تا ۱۱۲ ژوئن؛ Yaman, B., Sherif, MA, Ngomo, ACN, Haller, A., Eds. بیضا یامان; محمد احمد شریف؛ اکسل-سیریل نگونگا نگومو; آرمین هالر: هرسونیسوس، یونان، ۲۰۲۱؛ جلد ۲۹۷۷، ص ۷۶-۷۹٫ [ Google Scholar ]
- سوارز-فیگوئروآ، ام سی; گومز-پرز، آ. فرناندز-لوپز، ام. روش نئون برای مهندسی هستی شناسی. در مهندسی هستی شناسی در دنیای شبکه ای ؛ سوارز-فیگوئروآ، ام سی، گومز-پرز، آ.، موتا، ای.، گنگمی، آ.، ویرایش. Springer: برلین/هایدلبرگ، آلمان، ۲۰۱۲; صص ۹-۳۴٫ [ Google Scholar ]
- سوارز-فیگوئروآ، ام سی; گومز-پرز، آ. فرناندز-لوپز، ام. چارچوب روش شناسی نئون: روش شناسی مبتنی بر سناریو برای توسعه هستی شناسی. Appl. اونتول. ۲۰۱۵ ، ۱۰ ، ۱۰۷-۱۴۵٫ [ Google Scholar ] [ CrossRef ]
- آرناس، اچ. آسناک ژیل، ن. کامپاروت، سی. تروجان، سی. ادغام معنایی داده های مکانی از مشاهدات زمین. در مجموعه مقالات بیستمین کنفرانس بین المللی مهندسی دانش و مدیریت دانش، بولونیا، ایتالیا، ۱۹ تا ۲۳ نوامبر ۲۰۱۶٫ صص ۹۷-۱۰۰٫ [ Google Scholar ]
- دومیترو، CO. شوارتز، جی. Pulak-Siwiec، A.; کولاویک، بی. لورنزو، جی. Datcu، M. داده کاوی مشاهده زمین: مورد استفاده برای نظارت بر جنگل. در مجموعه مقالات IGARSS 2019-2019 IEEE بین المللی زمین شناسی و سمپوزیوم سنجش از دور، یوکوهاما، ژاپن، ۲۸ ژوئیه تا ۲ اوت ۲۰۱۹؛ صص ۵۳۵۹–۵۳۶۲٫ [ Google Scholar ]
- پاترومپاس، ک. جیانوپولوس، جی. Athanasiou، S. Towards GeoSpatial Semantic Data Management: نقاط قوت، ضعف ها و چالش های پیش رو. در مجموعه مقالات بیست و دومین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، دالاس، تگزاس، ایالات متحده آمریکا، ۴-۷ نوامبر ۲۰۱۴٫ ACM: نیویورک، نیویورک، ایالات متحده آمریکا، ۲۰۱۴; صص ۳۰۱-۳۱۰٫ [ Google Scholar ]
- Ioannidis، T. گاربیس، جی. کیزیراکوس، ک. برتا، ک. Koubarakis، M. ارزیابی ذخیرههای RDF جغرافیایی با استفاده از معیار جغرافیایی ۲٫ J. Data Semant. ۲۰۲۱ ، ۱۰ ، ۱۸۹-۲۲۸٫ [ Google Scholar ] [ CrossRef ]
- Quoc، HNM؛ سرانو، م. مائو، HN; برسلین، جی جی. Le-Phuoc, D. A مطالعه عملکرد ذخیرههای RDF برای دادههای حسگر مرتبط . IOS Press: آمستردام، هلند، ۲۰۱۹٫ [ Google Scholar ]
- ماشین، نیوجرسی؛ Bastrakova، I. LDR: نسل دوم، سیستم ملی GeoLD. در مجموعه مقالات چهارمین کارگاه بین المللی در مورد داده های پیوندی جغرافیایی، GeoLD 2021، رویداد مجازی، ۶ تا ۱۰ ژوئن ۲۰۲۱؛ صص ۴۲-۵۰٫ [ Google Scholar ]
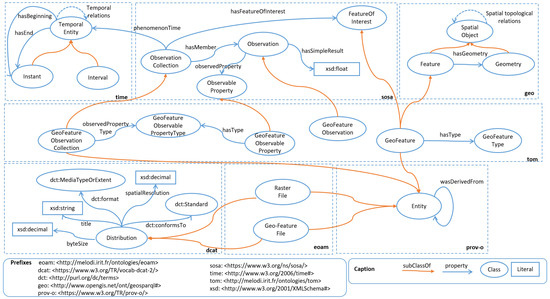
شکل ۱٫ مدل مشاهده سرزمینی (tom) نشان دهنده مقادیر دارایی مناطق محاسبه شده از رسترهای EO است.
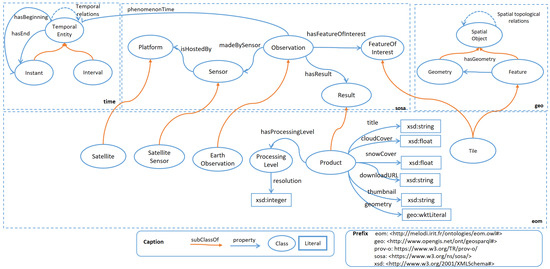
شکل ۲٫ فراداده تصویر نگهبان (eom) که بر مفهوم کاشی برای جمعآوری توصیفات تصاویر دارای ردپای یکسان متکی است.
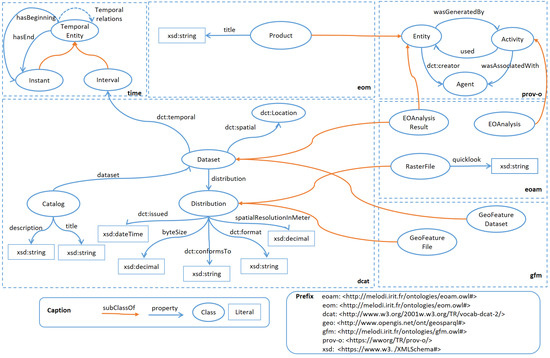
شکل ۳٫ مدل تجزیه و تحلیل EO (eoam) اطلاعاتی در مورد نتایج تجزیه و تحلیل شطرنجی (به عنوان مثال، تصاویر سنتینل) ارائه می دهد.
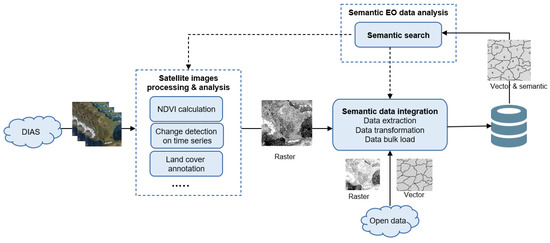
شکل ۴٫ معماری کلی رویکرد پیشنهادی.
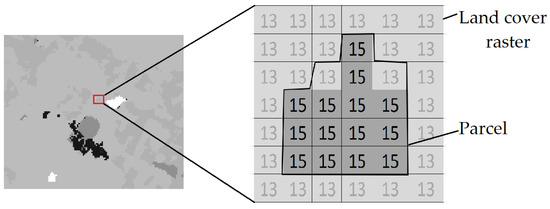
شکل ۵٫ نمونه ای از ماسک ویژگی (۱۵: تاکستان، ۱۳: علفزار).
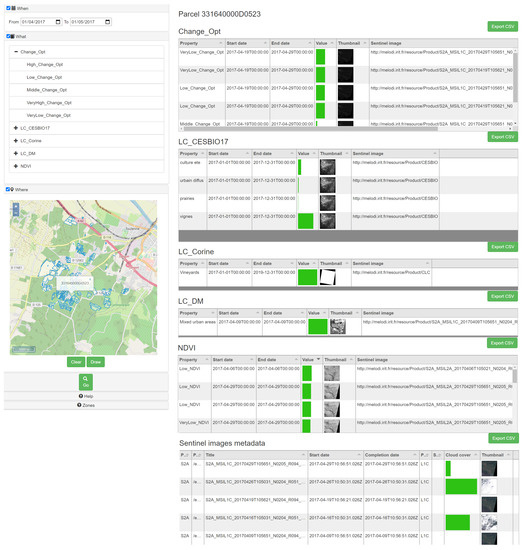
شکل ۶٫ رابط جستجوی معنایی – برنامه کاربردی در مورد استفاده از تاکستان (موجود در melodi.irit.fr/semantic-search/ )، تاریخ دسترسی: ۲۳ دسامبر ۲۰۲۱٫
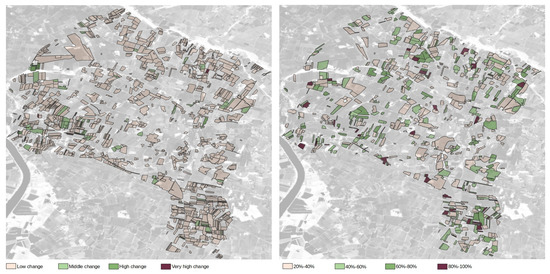
شکل ۷٫ تجزیه و تحلیل بر روی تاکستان ها در طول دوره ۱۹-۲۹ آوریل ۲۰۱۷٫ ( سمت چپ ): سطح تغییر شناسایی شده. ( راست ): تخریب NDVI.
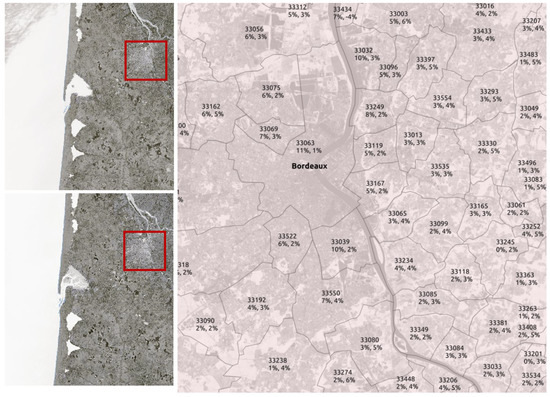
شکل ۸٫ تحلیل گسترش شهری (۲۰۱۷-۲۰۲۰) در سطح روستا. ( سمت چپ ) (تصاویر نگهبان). ( سمت راست ): کد INSEE روستا، نشانگرهای تغییر و NDVI.


بدون دیدگاه