
کلید واژه ها:
تعمیم خودکار نقشه ; چارچوب دانش محور ; کمیت شباهت هندسی ; فضای نقشه چند مقیاسی ; ترسیم منطقه شهری
۱٫ مقدمه
۲٫ روش شناسی
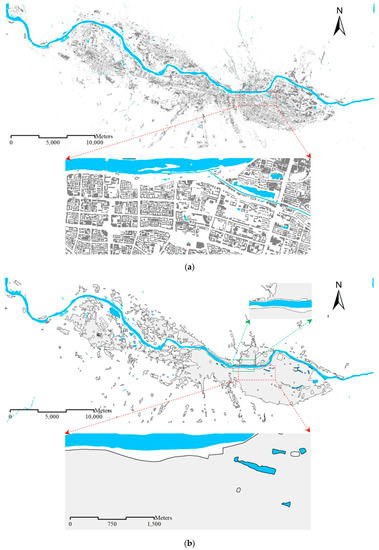
۲٫۱٫ داده های تجربی
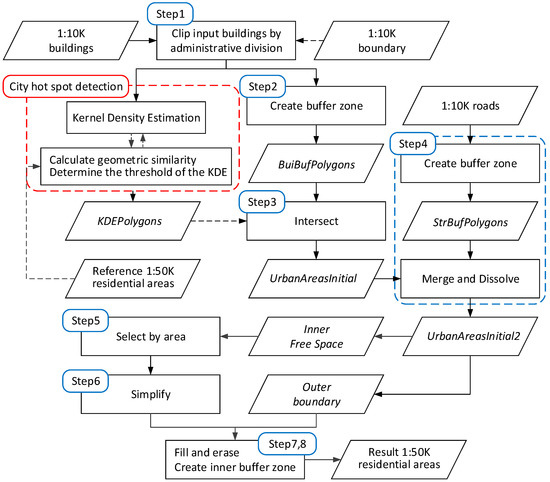
۲٫۲٫ روش تعمیم مناطق مسکونی از چارچوب دانش محور پیروی می کند
۲٫۲٫۱٫ شناسایی ساختار و شناسایی فرآیند بر اساس تحلیل نقشه
-
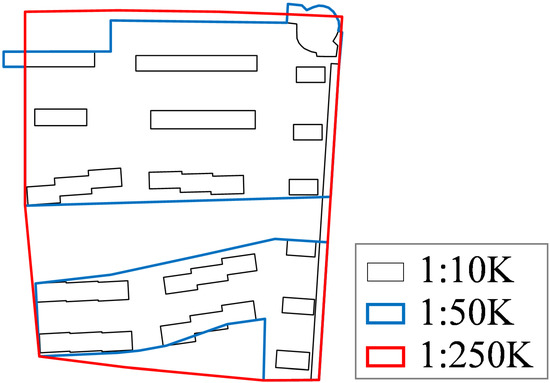
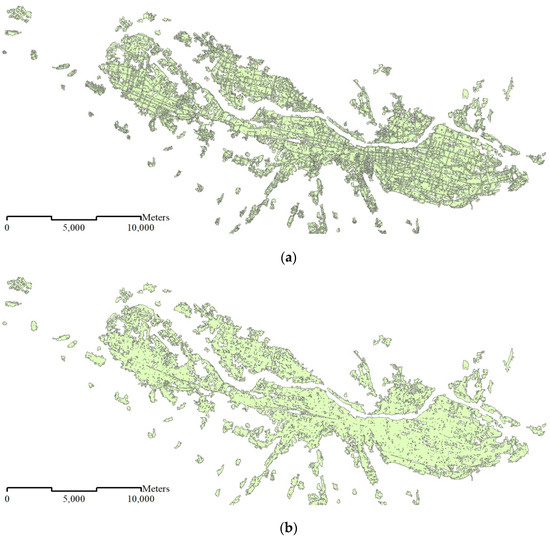
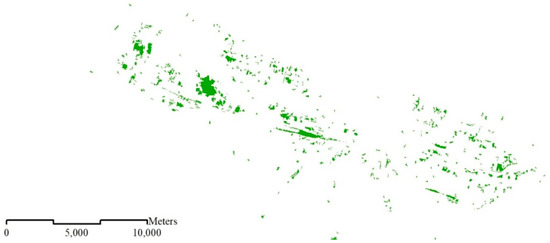
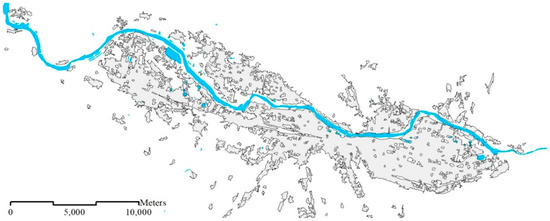
در مجموعه داده ۱:۱۰K، مناطق مسکونی به عنوان ساختمان نشان داده می شوند ( شکل ۱ a).
-
در مجموعه داده ۱:۵۰K، مناطق مسکونی با استفاده از گروهها و بلوکهای ساختمان [ ۹ ] نشان داده میشوند ( شکل ۱ ب) در مقیاس ۱:۵۰K، جادهها نشان داده نمیشوند، بنابراین مناطق مسکونی را میتوان به بلوکها تقسیم کرد.
-
در مجموعه داده ۱:۲۵۰K، مناطق مسکونی کل سکونتگاه های شهری را به تصویر می کشند ( شکل ۲ a).
-
در مجموعه داده ۱:۱M، فقط شهرهای بزرگ (یعنی مناطق مسکونی) ظاهر می شوند ( شکل ۲ ب).
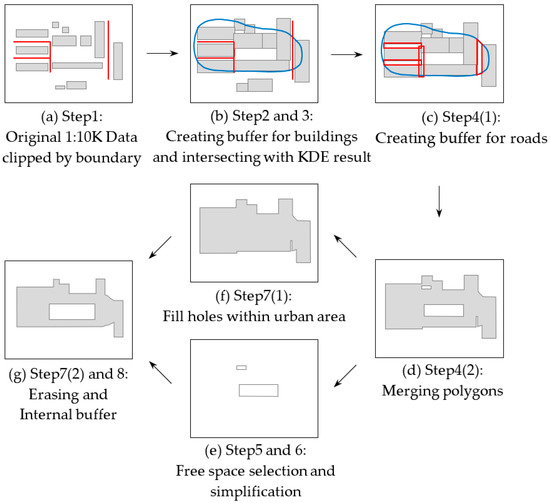
۲٫۲٫۲٫ مدلسازی فرآیند
-
فاصله بافر
-
آستانه انتخاب
-
آستانه KDE
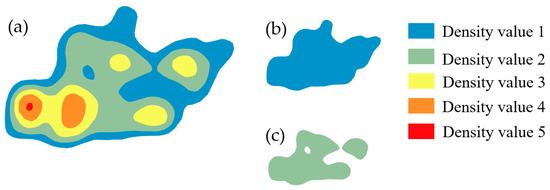
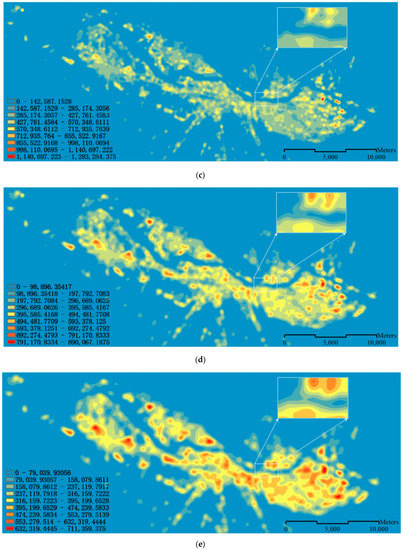
(۱) KDE برای تشخیص نقاط داغ توزیع ساختمان های ۱:۱۰K استفاده می شود. ابزار تراکم هسته در ArcGIS (V10.2) برای محاسبه چگالی ویژگی در همسایگی اطراف آن ویژگی ها استفاده می شود. فرمول محاسبه چگالی هسته [ ۴۲ ] است:
جایی که Density(x,y)چگالی پیش بینی شده در یک مکان جدید است (x,y); radiusشعاع جستجو از نقطه است (x,y); i=1,…,nنقاط داخل هستند (x,y)فاصله شعاع؛ و popiمقدار فیلد جمعیت است. و distiنشان دهنده فاصله بین سلول و ithنقطه ای در محله دایره ای شکل
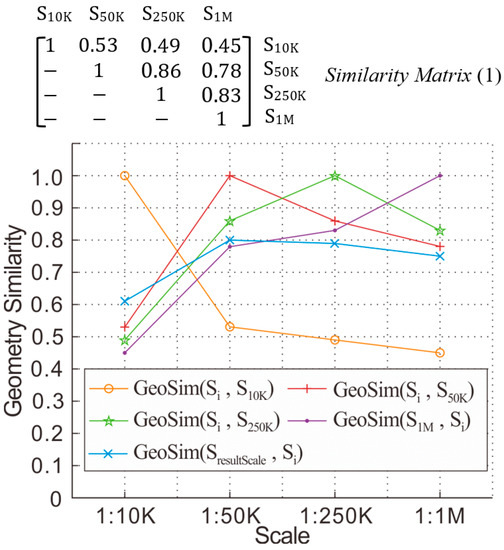
تابع تطبیق مدل نسبت Tversky به صورت زیر است:
جایی که GeoSim(ObjD,RefD)درجه تشابه بین داده های شی و داده های مرجع است. کارکرد fمساحت مناطق خاص را اندازه گیری می کند. ObjD∩RefDمناطق مشترک متعلق به داده های شی و داده های مرجع را نشان می دهد. ObjD−RefDمناطقی را نشان می دهد که به داده های شی تعلق دارند اما نه به داده های مرجع. و R efD−ObjDمناطقی هستند که به داده های مرجع تعلق دارند اما به داده های شی تعلق ندارند.
۲٫۲٫۳٫ فرآیند تعمیم تفصیلی
۳٫ آزمایش ها و نتایج
۳٫۱٫ نتایج و تجزیه و تحلیل
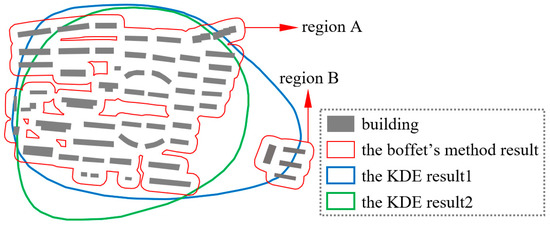
۳٫۱٫۱٫ نتایج و تجزیه و تحلیل تشابه هندسی
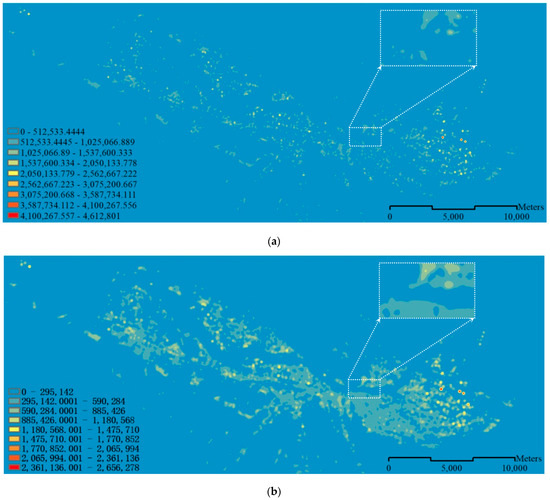
۳٫۱٫۲٫ نتایج KDE با مقادیر آستانه متفاوت و بازرسی دستی
۳٫۱٫۳٫ اندازه گیری تشابه و تعیین آستانه
۳٫۱٫۴٫ نتایج تعمیم
۳٫۲٫ ارزیابی
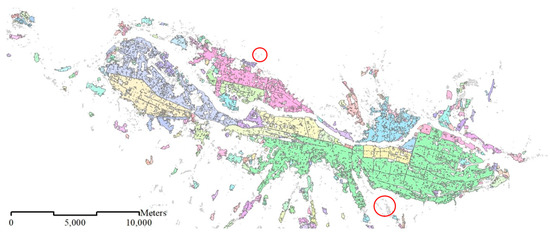
۳٫۲٫۱٫ مقایسه بصری با داده های مرجع ۱:۵۰K
۳٫۲٫۲٫ ارزیابی کمی
۳٫۲٫۳٫ ارضای نیازها در عمل
۴٫ بحث
۵٫ نتیجه گیری و کار آینده
منابع
- رواس، الف. خودکارسازی تعمیم داده های جغرافیایی: سن بلوغ؟ در مجموعه مقالات بیستمین کنفرانس بین المللی کارتوگرافی، پکن، چین، ۶ اوت ۲۰۰۱٫ [ Google Scholar ]
- لی، دی. هاردی، پی. تعمیم خودکار – ابزارها و مدل ها. در مجموعه مقالات بیست و دوم کنفرانس بین المللی کارتوگرافی، لاکرونیا، اسپانیا، ۱۱ تا ۱۶ ژوئیه ۲۰۰۵٫ [ Google Scholar ]
- دوچن، سی. رواس، ع. Cambier, C. مدل CartACom: تبدیل ویژگی های نقشه برداری به عوامل ارتباطی برای تعمیم نقشه برداری. بین المللی جی. جئوگر. Inf. علمی ۲۰۱۲ ، ۲۶ ، ۱۵۳۳-۱۵۶۲٫ [ Google Scholar ] [ CrossRef ]
- یانگ، م. آی، تی. یان، ایکس. چن، ی. Zhang، X. یک روش مبتنی بر نقشه-جبر برای تشخیص خودکار تغییرات و بهروزرسانی دادههای مکانی در مقیاسهای چندگانه. ترانس. GIS ۲۰۱۸ ، ۲۲ ، ۴۳۵-۴۵۴٫ [ Google Scholar ] [ CrossRef ]
- یو، دبلیو. ژانگ، ی. Chen, Z. تعمیم خودکار نقاط مورد علاقه تسهیلات با تعیین حدود منطقه خدمات. دسترسی IEEE ۲۰۱۹ ، ۷ ، ۶۳۹۲۱–۶۳۹۳۵٫ [ Google Scholar ] [ CrossRef ]
- یان، اچ. Li, J. روابط شباهت فضایی در فضاهای نقشه چند مقیاسی . Springer International Publishing: Cham, Switzerland, 2015. [ Google Scholar ]
- ویبل، آر. کلر، اس. Reichenbacher, T. غلبه بر گلوگاه کسب دانش در تعمیم نقشه: نقش سیستم های تعاملی و هوش محاسباتی. در مجموعه مقالات دومین کنفرانس بین المللی نظریه اطلاعات فضایی (COSIT 95)، Semmering، اتریش، ۲۱ سپتامبر ۱۹۹۵٫ [ Google Scholar ]
- Kilpeläinen، T. کسب دانش برای قوانین تعمیم. کارتوگر. Geogr. Inf. علمی ۲۰۰۰ ، ۲۷ ، ۴۱-۵۰٫ [ Google Scholar ] [ CrossRef ]
- Mustiere، S. تعمیم نقشه برداری جاده ها در یک رویکرد محلی و تطبیقی: یک مشکل کسب دانش. بین المللی جی. جئوگر. Inf. علمی ۲۰۰۵ ، ۱۹ ، ۹۳۷-۹۵۵٫ [ Google Scholar ] [ CrossRef ]
- داگلاس، دی اچ. الگوریتم های Peucker، TK برای کاهش تعداد نقاط مورد نیاز برای نمایش یک خط دیجیتالی یا کاریکاتور آن. می توان. کارتوگر. J. ۱۹۷۳ , ۱۰ , ۱۱۲-۱۲۲٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- رگنولد، ن. ادواردز، آ. Barrault, M. استراتژیها در تعمیم ساختمان: مدلسازی دنباله، محدود کردن انتخاب. در مجموعه مقالات نوزدهمین کارگاه ICC در مورد پیشرفت و توسعه در تعمیم خودکار نقشه، اتاوا، ON، کانادا، ۱۴ تا ۲۱ اوت ۱۹۹۹٫ [ Google Scholar ]
- Sester, M. بهینه سازی رویکردها برای تعمیم و انتزاع داده ها. بین المللی جی. جئوگر. Inf. علمی ۲۰۰۵ ، ۱۹ ، ۸۷۱-۸۹۷٫ [ Google Scholar ] [ CrossRef ]
- Bayer, T. ساده سازی خودکار ساختمان با استفاده از رویکرد بازگشتی. در کارتوگرافی در اروپای مرکزی و شرقی ; Gartner, G., Ortag, F., Eds. Springer: برلین/هایدلبرگ، آلمان، ۲۰۰۹; صص ۱۲۱-۱۴۶٫ [ Google Scholar ]
- یان، ایکس. آی، تی. Zhang، X. روش تطبیق و سادهسازی الگو برای ساخت ویژگیها بر اساس شناخت شکل. بین المللی J. Geo-Inf. ۲۰۱۷ ، ۶ ، ۲۵۰٫ [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- یانگ، م. یوان، تی. یان، ایکس. آی، تی. جیانگ، سی. یک رویکرد ترکیبی برای ساده سازی ساختمان با یک ارزیاب از یک شبکه عصبی پس انتشار. بین المللی جی. جئوگر. Inf. علمی ۲۰۲۱ ، ۵ ، ۱-۳۰٫ [ Google Scholar ] [ CrossRef ]
- زیر.؛ لی، ز. مدلهای جبری Lodwick، G. Jean-Claude Muller برای تجمیع ویژگیهای ناحیه بر اساس عملگرهای مورفولوژیکی. بین المللی جی. جئوگر. Inf. علمی ۱۹۹۷ ، ۱۱ ، ۲۳۳-۲۴۶٫ [ Google Scholar ] [ CrossRef ]
- لی، ز. یان، اچ. آی، تی. چن، جی. تعمیم خودکار ساختمان بر اساس مورفولوژی شهری و نظریه گشتالت. بین المللی جی. جئوگر. Inf. علمی ۲۰۰۴ ، ۱۸ ، ۵۱۳-۵۳۴٫ [ Google Scholar ] [ CrossRef ]
- QI، H.; لی، زی. رویکردی به گروه بندی ساختمان بر اساس محدودیت های سلسله مراتبی. در آرشیو بین المللی فتوگرامتری، سنجش از دور و علوم اطلاعات فضایی. جلد ⅩⅩⅩⅤⅠⅠ. قسمت B2 (ص ۴۴۹-۴۵۴). در دسترس آنلاین: http://www.isprs.org/proceedings/XXXVII/congress/2_pdf/3_WG-II-3/13.pdf (دسترسی در ۱۰ اکتبر ۲۰۲۱).
- بادر، ام. روشهای کمینه سازی انرژی برای جابجایی ویژگی در تعمیم نقشه. Ph.D. Thesis, Universität Zürich, Zürich, Switzerland, 2001. [ Google Scholar ]
- آی، تی. ژانگ، ایکس. ژو، Q. یانگ، ام. یک مدل میدان برداری برای مدیریت جابجایی تضادهای متعدد در تعمیم ساختمان. بین المللی جی. جئوگر. Inf. علمی ۲۰۱۵ ، ۲۹ ، ۱۳۱۰-۱۳۳۱٫ [ Google Scholar ] [ CrossRef ]
- پیله فروشها، پ. کریمی، م. منصوریان، ع. یک مدل جدید ترکیبی از جابجایی بلوک های ساختمانی و کاهش مساحت بلوک های ساختمانی برای حل تعارضات فضایی. ترانس. GIS ۲۰۲۱ , ۲۵ , ۱۳۶۶–۱۳۹۵٫ [ Google Scholar ] [ CrossRef ]
- براسل، ک. Weibel, R. مرور و چارچوب مفهومی تعمیم خودکار نقشه. بین المللی جی. جئوگر. Inf. سیستم ۱۹۸۸ ، ۲ ، ۲۲۹-۲۴۴٫ [ Google Scholar ] [ CrossRef ]
- مک مستر، RB; شی، تعمیم KS در کارتوگرافی دیجیتال . انجمن جغرافیدانان آمریکایی: واشنگتن، دی سی، ایالات متحده آمریکا، ۱۹۹۲٫ [ Google Scholar ]
- گالاندا، ام. تعمیم خودکار چندضلعی در یک سیستم چند عاملی. Ph.D. Thesis, Universität Zürich, Zürich, Switzerland, 2003. [ Google Scholar ]
- سارجاکوسکی، مدلهای مفهومی تعمیم و بازنمایی چندگانه LT. در تعمیم اطلاعات جغرافیایی: مدلسازی نقشه برداری و کاربردها ; Mackaness, W., Ruas, A., Sarjakoski, LT, Eds. الزویر: آکسفورد، انگلستان، ۲۰۰۷; صص ۱۱-۳۶٫ [ Google Scholar ]
- اوکیف، جی. داستروفسکی، جی. هیپوکامپ به عنوان یک نقشه فضایی: شواهد اولیه از فعالیت واحد در موش صحرایی با حرکت آزادانه. Brain Res. ۱۹۷۱ ، ۳۴ ، ۱۷۱-۱۷۵٫ [ Google Scholar ] [ CrossRef ]
- اوکیف، جی. نادل، ال . هیپوکامپ به عنوان یک نقشه شناختی . کلارندون: آکسفورد، بریتانیا، ۱۹۷۸٫ [ Google Scholar ]
- هفتینگ، تی. فاین، م. مولدن، اس. موزر، م. موزر، E. ریزساختار یک نقشه فضایی در قشر آنتورینال. طبیعت ۲۰۰۵ ، ۴۳۶ ، ۸۰۱-۸۰۶٫ [ Google Scholar ] [ CrossRef ] [ PubMed ]
- یان، ایکس. آی، تی. یانگ، م. تانگ، ایکس. لیو، کیو. رویکرد یادگیری عمیق نموداری برای گروهبندی ساختمانهای شهری. Geocarto Int. ۲۰۲۰ ، ۸ ، ۱-۲۴٫ [ Google Scholar ] [ CrossRef ]
- لی، ز. Huang, P. اقدامات کمی برای اطلاعات مکانی نقشه ها. بین المللی جی. جئوگر. Inf. علمی ۲۰۰۲ ، ۱۶ ، ۶۹۹-۷۰۹٫ [ Google Scholar ] [ CrossRef ]
- Mackaness، WA; بورگارد، دی. Duchêne, C. تعمیم نقشه. در دایره المعارف بین المللی جغرافیا: مردم، زمین، محیط زیست و فناوری ؛ Richardson, D., Castree, N., Goodchild, MF, Kobayashi, A., Liu, W., Marston, RA, Eds. John Wiley & Sons Ltd.: Hoboken, NJ, USA, 2017. [ Google Scholar ] [ CrossRef ]
- بوفه، ا. Serra, SR شناسایی ساختارهای فضایی در بلوک های شهری برای توصیف شهر. در مجموعه مقالات بیستمین کنفرانس بین المللی کارتوگرافی، پکن، چین، ۶ اوت ۲۰۰۱; صفحات ۱۹۷۴-۱۹۸۳٫ [ Google Scholar ]
- چودری، او. Mackaness، W. شناسایی خودکار مرزهای سکونتگاه شهری برای پایگاههای اطلاعاتی چندگانه. محاسبه کنید. محیط زیست سیستم شهری ۲۰۰۸ ، ۳۲ ، ۹۵-۱۰۹٫ [ Google Scholar ] [ CrossRef ]
- لیو، ی. مارتین، ام. مننو جان، ک. مدل ارزیابی تشابه معنایی در تعمیم پایگاه داده طبقهای. در مجموعه مقالات سمپوزیوم نظریه جغرافیایی، پردازش و کاربردها، اتاوا، ON، کانادا، ۹ تا ۱۲ ژوئیه ۲۰۰۲٫ [ Google Scholar ]
- ژو، Q. مطالعه تطبیقی رویکردها برای تعیین مناطق ساخته شده با استفاده از داده های شبکه راه. ترانس. GIS ۲۰۱۵ ، ۱۹ ، ۸۴۸-۸۷۶٫ [ Google Scholar ] [ CrossRef ]
- لی، ی. سان، س. جی، ایکس. خو، ال. لو، سی. ژائو، ی. تعریف مرزهای منطقه ساخته شده شهری بر اساس مسیرهای تاکسی: مطالعه موردی پکن. J. Geovisualization Spat. مقعدی ۲۰۲۰ ، ۴ ، ۸٫ [ Google Scholar ] [ CrossRef ]
- بورگارد، دی. اشتاینیگر، اس. استفاده از تحلیل مؤلفه اصلی در فرآیند تعمیم خودکار. در مجموعه مقالات بیست و دومین کنفرانس بین المللی کارتوگرافی، لاکرونیا، اسپانیا، ۹ تا ۱۶ ژوئیه ۲۰۰۵; انجمن بین المللی کارتوگرافی (ICA): لاکرونیا، اسپانیا، ۲۰۰۵٫ [ Google Scholar ]
- دو، اس. لو، ال. کائو، ک. Shu, M. استخراج الگوهای ساختمان با پارتیشن نمودار چندسطحی و گروه بندی ساختمان. Isprs J. Photogramm. Remote Sens. ۲۰۱۶ ، ۱۲۲ ، ۸۱-۹۶٫ [ Google Scholar ] [ CrossRef ]
- چودری، او. Mackaness، W. تجسم سکونتگاه ها در مورد تغییرات بزرگ در مقیاس. در مجموعه مقالات هشتمین کارگاه ICA در مورد تعمیم و بازنمایی چندگانه، لاکرونیا، اسپانیا، ۹ تا ۱۶ ژوئیه ۲۰۰۵٫ [ Google Scholar ]
- جیانگ، بی. لیو، ایکس. مقیاسبندی فضای جغرافیایی از دیدگاه بلوکهای شهری و میدانی و استفاده از اطلاعات جغرافیایی داوطلبانه. بین المللی جی. جئوگر. Inf. علمی ۲۰۱۲ ، ۲۶ ، ۲۱۵-۲۲۹٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- اسمیت، ب. در مورد ترسیم خطوط روی نقشه. در نظریه اطلاعات فضایی، مجموعه مقالات COSIT ’95 برلین/هایدلبرگ/وین/نیویورک/لندن/توکیو، وین، اتریش، ۲۱-۲۳ سپتامبر ۱۹۹۵ . Frank, AU, Kuhn, W., Mark, D., Eds. Springer: برلین/هایدلبرگ، آلمان، ۱۹۹۵; صص ۴۷۵-۴۸۴٫ [ Google Scholar ]
- سیلورمن، تخمین چگالی BW برای آمار و تجزیه و تحلیل داده ها . چپمن و هال: نیویورک، نیویورک، ایالات متحده آمریکا، ۱۹۸۶٫ [ Google Scholar ]
- Thurstain-Goodwin، MT; Unwin, D. تعریف و ترسیم نواحی مرکزی شهرها برای پایش آماری با استفاده از نمایش های سطحی پیوسته. ترانس. GIS ۲۰۰۰ , ۴ , ۳۰۵-۳۱۷٫ [ Google Scholar ] [ CrossRef ]
- بوروسو، جی. تراکم شبکه و تعیین حدود مناطق شهری. ترانس. GIS ۲۰۰۳ ، ۷ ، ۱۷۷-۱۹۱٫ [ Google Scholar ] [ CrossRef ]
- Borruso، G. برآورد تراکم شبکه: یک رویکرد GIS برای تجزیه و تحلیل الگوهای نقطه در فضای شبکه. ترانس. GIS ۲۰۱۰ ، ۱۲ ، ۳۷۷-۴۰۲٫ [ Google Scholar ] [ CrossRef ]
- جیا، تی. جیانگ، بی. اندازه گیری پراکندگی شهری بر اساس گره های عظیم خیابان ها و مفهوم بدیع شهرهای طبیعی. arXiv ۲۰۱۱ ، arXiv:1010.0541. سند WWW. در دسترس آنلاین: https://arxiv.org/ftp/arxiv/papers/1010/1010.0541.pdf (دسترسی در ۱۰ اکتبر ۲۰۲۱).
- Tversky، A. ویژگی های مشابهت. روانی Rev. ۱۹۷۷ , ۸۴ , ۳۲۷-۳۵۲٫ [ Google Scholar ] [ CrossRef ]
- هولت، الف. تشابه فضایی و GIS: گروه بندی انواع فضایی. در مجموعه مقالات یازدهمین کنفرانس سالانه مرکز تحقیقات اطلاعات فضایی، داندین، نیوزلند، ۱۳ تا ۱۵ دسامبر ۱۹۹۹٫ [ Google Scholar ]
- پوپر، KR منطق کشف علمی ; هاچینسون: لندن، بریتانیا، ۱۹۷۲; ۴۸۰p [ Google Scholar ]
- آی، تی. که، اس. یانگ، م. Li, J. تولید پاکت و سادهسازی چند خطوط با استفاده از مثلثسازی Delaunay. بین المللی جی. جئوگر. Inf. علمی ۲۰۱۷ ، ۳۱ ، ۲۹۷-۳۱۹٫ [ Google Scholar ] [ CrossRef ]
- آرکین، ای.ام. جویدن، LP; Huttenlocher، DP; Kedem، K. میچل، JSB یک متریک قابل محاسبه کارآمد برای مقایسه اشکال چند ضلعی. IEEE Trans. الگوی مقعدی ماخ هوشمند ۱۹۹۱ ، ۱۳ ، ۲۰۹-۲۱۶٫ [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- سمال، ع. ست، اس. Cueto، K. یک رویکرد مبتنی بر ویژگی برای ترکیب منبع جغرافیایی. بین المللی جی. جئوگر. Inf. علمی ۲۰۰۴ ، ۱۸ ، ۴۵۹-۴۸۹٫ [ Google Scholar ] [ CrossRef ]
- فرانک، آر. استر، M. اندازه گیری شباهت کمی برای نقشه ها. در حال پیشرفت در مدیریت داده های مکانی ; Riedl, A., Kainz, W., Elmes, GA, Eds. Springer: برلین، آلمان، ۲۰۰۶; صص ۴۳۵-۴۵۰٫ [ Google Scholar ]
- Goodchild، MF; Hunter، GJ یک اندازه گیری دقت موقعیتی ساده برای ویژگی های خطی. بین المللی جی. جئوگر. Inf. علمی ۱۹۹۷ ، ۱۱ ، ۲۹۹-۳۰۶٫ [ Google Scholar ] [ CrossRef ]
- Winecoff، AA; Brasoveanu، F. Casavant، B. کاربران در حلقه: یک رویکرد آگاهانه روانشناختی برای بازیابی موارد مشابه. در مجموعه مقالات سیزدهمین کنفرانس ACM در مورد سیستمهای توصیهکننده، کپنهاگ، دانمارک، ۱۶ تا ۲۰ سپتامبر ۲۰۱۹٫ [ Google Scholar ]
- وانگ، ز. مولر، جی.-سی. تعمیم خط بر اساس تجزیه و تحلیل ویژگی های شکل. کارتوگر. Geogr. Inf. سیستم ۱۹۹۸ ، ۲۵ ، ۳-۱۵٫ [ Google Scholar ] [ CrossRef ]
- رودریگز، MA ارزیابی تشابه معنایی در بین کلاسهای موجودیت فضایی. Ph.D. پایان نامه، دانشگاه مین، اورونو، ME، ایالات متحده آمریکا، ۲۰۰۰٫ [ Google Scholar ]



بدون دیدگاه